Spaces:
Sleeping

title: AxiomForgeAI Environment Server
emoji: 🌌
colorFrom: indigo
colorTo: pink
sdk: docker
pinned: false
app_port: 7860
tags:
- openenv
AxiomForgeAI
A self-improving math environment where a model practices on verified problems, generates new challenges when ready, and learns from solution attempts whose reasoning steps and final answers agree.
The Problem
Math reasoning models can fail in two different ways. Sometimes the setup, arithmetic, and algebraic steps look reasonable, but the final answer is wrong. Sometimes the final answer is right, but the reasoning that produced it is incomplete, inconsistent, or hard to trust.
For a math user, both failures matter. Checking only the final answer misses where the solution went off track. Checking only the steps misses whether the work actually reaches the right result. The useful signal is the agreement between the reasoning path and the final answer.
This project builds a practice loop around that signal. The model first works on problems with known answers, gets feedback on both the chain of reasoning and the final result, and only then starts generating new challenges for itself. The constraint is intentionally small: a 1.5B math model.
The Environment
The environment is a practice loop for math reasoning. Each training group starts with one problem, asks the model for multiple solution attempts, scores those attempts from several angles, and uses GRPO to reinforce the attempts that are stronger than the rest of the group.

The environment has two task sources:
- Grounded source: A dataset problem from GSM8K / MATH comes with a known final answer. This gives the environment a reliable anchor for checking whether the model actually reached the right result.
- Self-play source: The curriculum selects a target skill and difficulty. The model writes a new question, then samples multiple solutions to that question. This adds practice beyond static datasets, but only after the grounded signal is stable enough.
Both sources feed the same scoring and update loop. For every selected problem, the model samples K candidate solutions. The environment checks final-answer correctness when a gold answer exists, scores reasoning quality with a PRM, checks chain consistency and symbolic arithmetic where possible, checks answer formatting, and scores self-generated questions for clarity, novelty, difficulty fit, and solvability.
GRPO then compares the K attempts against each other. The model is not rewarded for a solution in isolation; the strongest attempt in the group becomes the direction for learning. Training starts grounded-only, gradually mixes in self-play groups, and falls back to grounded practice if generated-question quality or answer correctness drops.
How Self-Improvement Works
Self-improvement comes from turning each problem into a small comparison. The model does not produce one solution and move on; the environment samples several attempts, scores each attempt, and asks which reasoning path was strongest.
GRPO uses that within-group comparison as the learning signal. Attempts with correct answers, stronger reasoning chains, and cleaner final-answer format are reinforced. Attempts with broken chains or unsupported answers become weaker examples.
practice -> sample attempts -> verify steps and answer -> compare -> reinforce -> adjust difficulty
Reward System
The reward is designed to avoid a common math-training failure: optimizing for either the final answer or the reasoning trace alone. A good solution should reach the right answer, explain the path clearly, and keep the final result consistent with the steps that produced it.
| Signal | What it checks | Why it matters |
|---|---|---|
| Final answer | Matches the gold answer when one exists | Keeps grounded problems tied to objective correctness |
| Process score | PRM score over the reasoning steps | Rewards clear mathematical progress, not just the last line |
| Chain consistency | Correct-prefix and step-answer consistency signals | Gives partial learning signal when a solution goes wrong midway |
| Format | Parseable final answer and clean response structure | Makes automatic grading reliable |
| Question quality | Topic fit, difficulty fit, clarity, novelty, and solvability | Keeps self-play from generating vague or useless practice tasks |
Grounded problems use the gold answer as the anchor. Self-play problems add a question-quality score before the solution reward is trusted. Both paths produce one combined score for each sampled attempt, and GRPO uses those scores only in comparison with the other attempts from the same problem.
grounded: answer correctness + process score + chain consistency + format
self-play: question quality + solution quality
both -> one combined score per attempt -> GRPO compares attempts within the group
Training Phases
Training follows a simple three-phase schedule. It starts with grounded-only practice so the model learns to keep answers and reasoning stable on problems with known solutions. Self-play is then introduced gradually, while grounded questions remain as an anchor. Once both are stable, training continues with a mixed task source and falls back to grounded-only batches if answer quality drops.

Training Script
The GRPO training loop is available in two forms:
scripts/launch_grpo.sh— the primary launch script; sets CUDA/threading env vars, verifies Flash-Attention, and callsrun_grpo_training.pywith the full parameter set.bash scripts/launch_grpo.shtrain_grpo.ipynb— notebook version with the same parameters, structured aroundenv.reset / env.step / env.state / env.closefor interactive inspection.
Logs
Each training run writes the following logs for verification:
logs/metrics.jsonl— per-iteration metrics: reward, accuracy, step quality, LCCP, training phase, and self-play statslogs/grpo/<run_id>/console_output.log— full console output with run config, GPU info, and per-iteration progresslogs/grpo/<run_id>/metrics.csv— same metrics in CSV format for quick inspectionlogs/grpo/<run_id>/config.json— exact hyperparameters used for the run
Results
These plots come from a single GPU training run and focus on the core question: did the model get better at making its reasoning and final answer agree?
Evaluation Quality Over Training
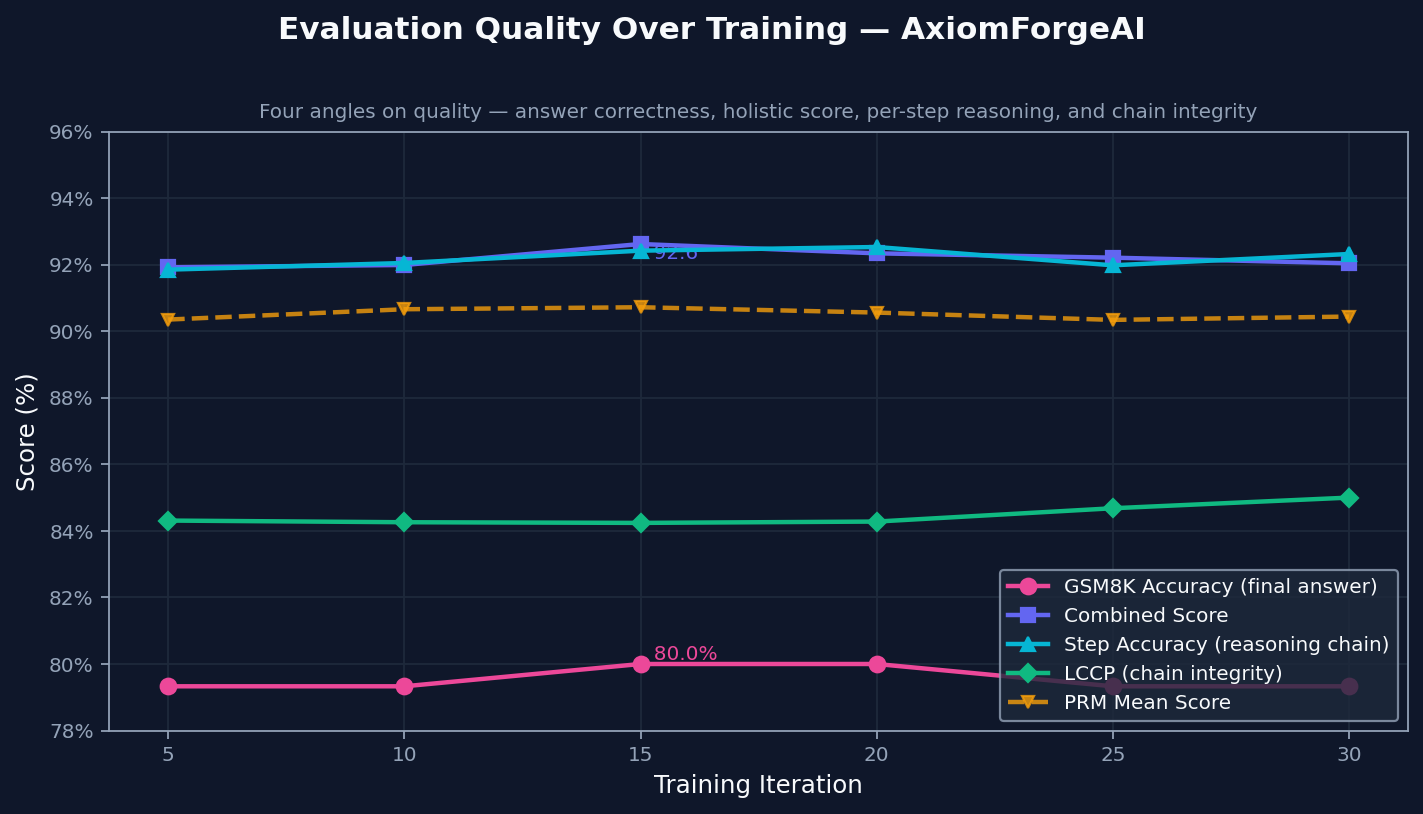
The environment tracks final correctness, solution quality, step validity, and how long the reasoning chain stays correct. All four move upward together, which suggests the model is not just finding better final answers. It is also producing reasoning that holds up longer.
Training Journey
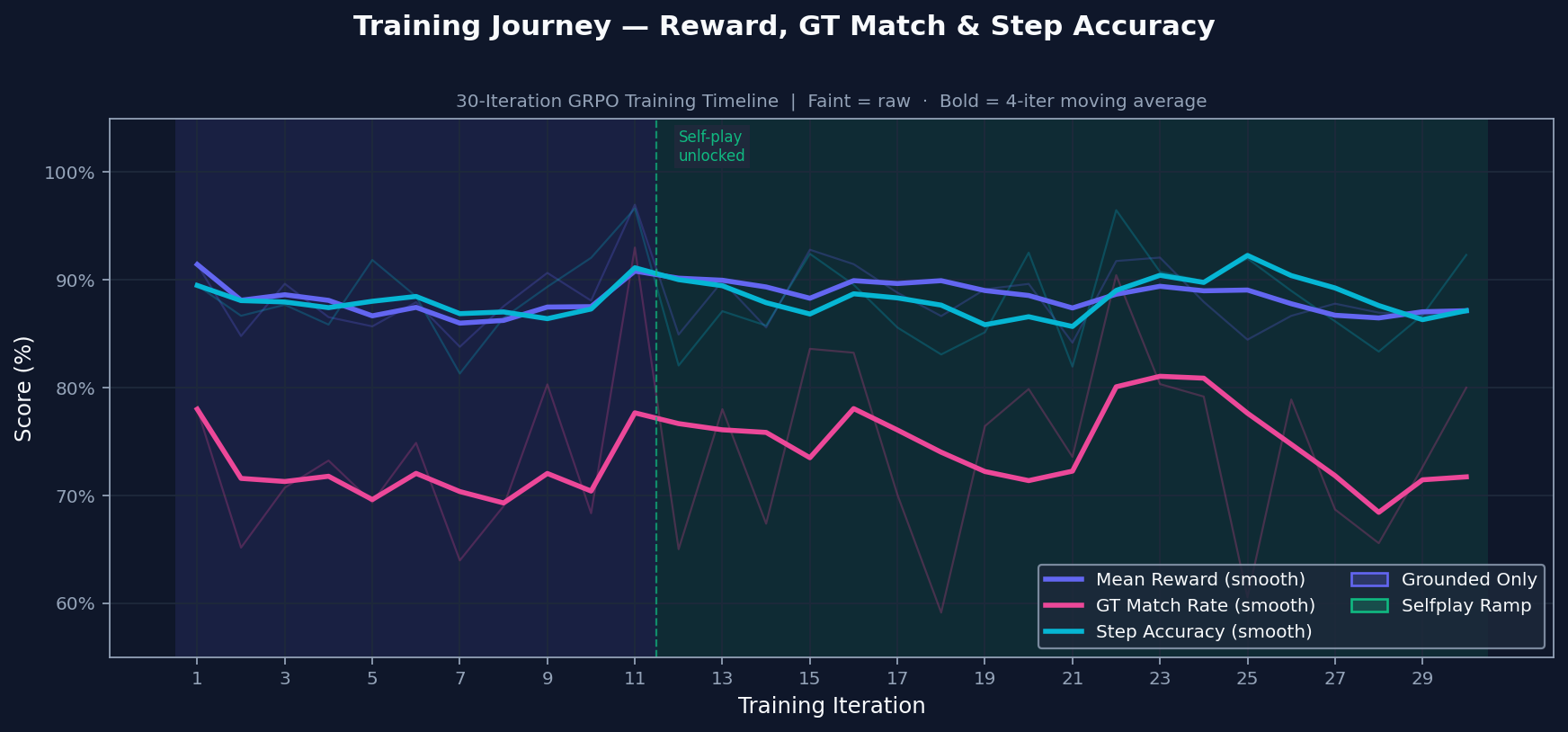
Training starts with grounded practice on problems with known answers. Self-play is introduced only after the grounded signal is stable, so the model does not train on its own generated problems too early. The transition is conditional, not just a timer.
Self-Play Curriculum
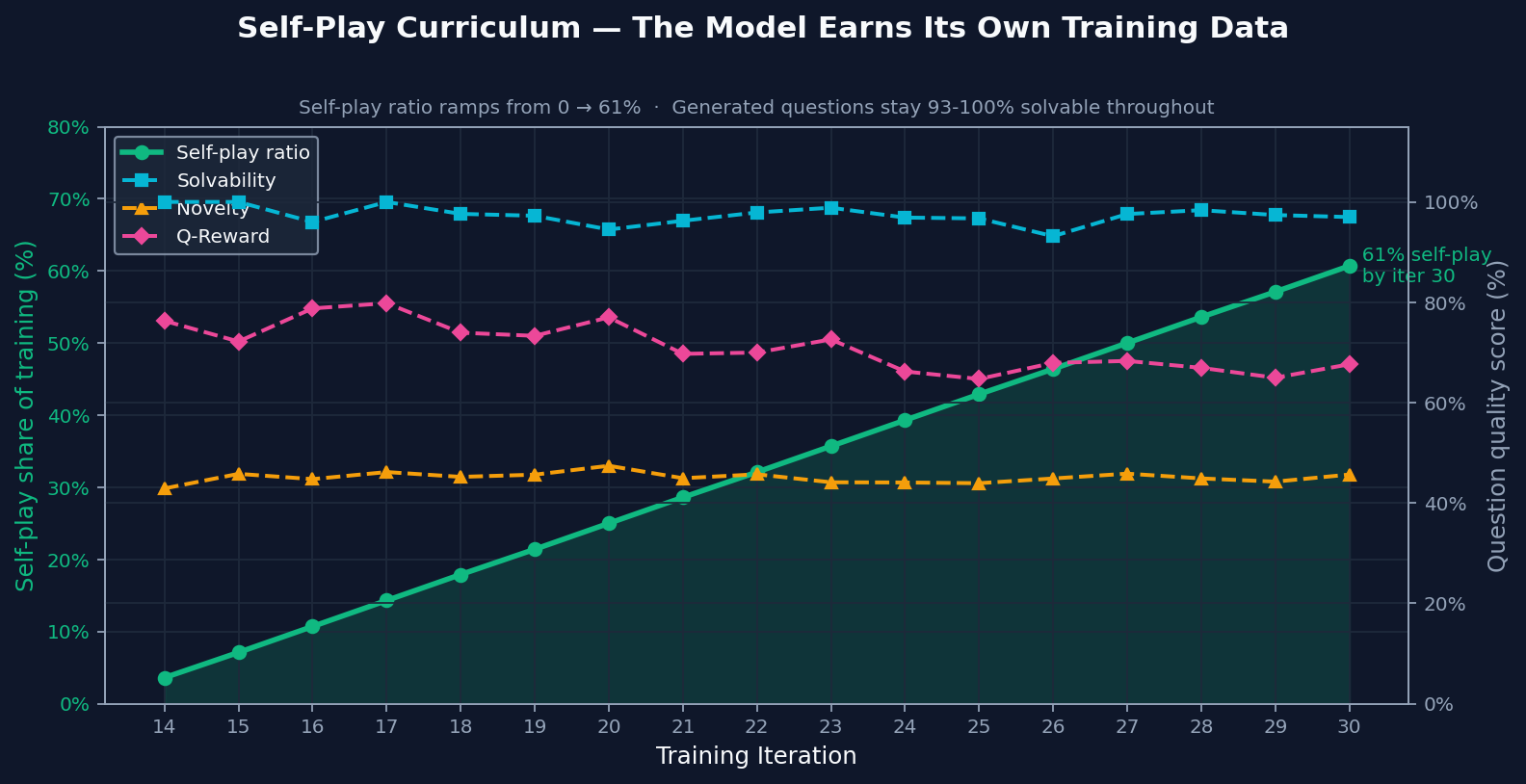
By the end of training, most practice came from self-play. The important part is that generated problems stayed solvable and novel even after self-play became a larger share of training. That makes the ramp meaningful: self-play added useful practice instead of recycled noise.
Reward Confidence
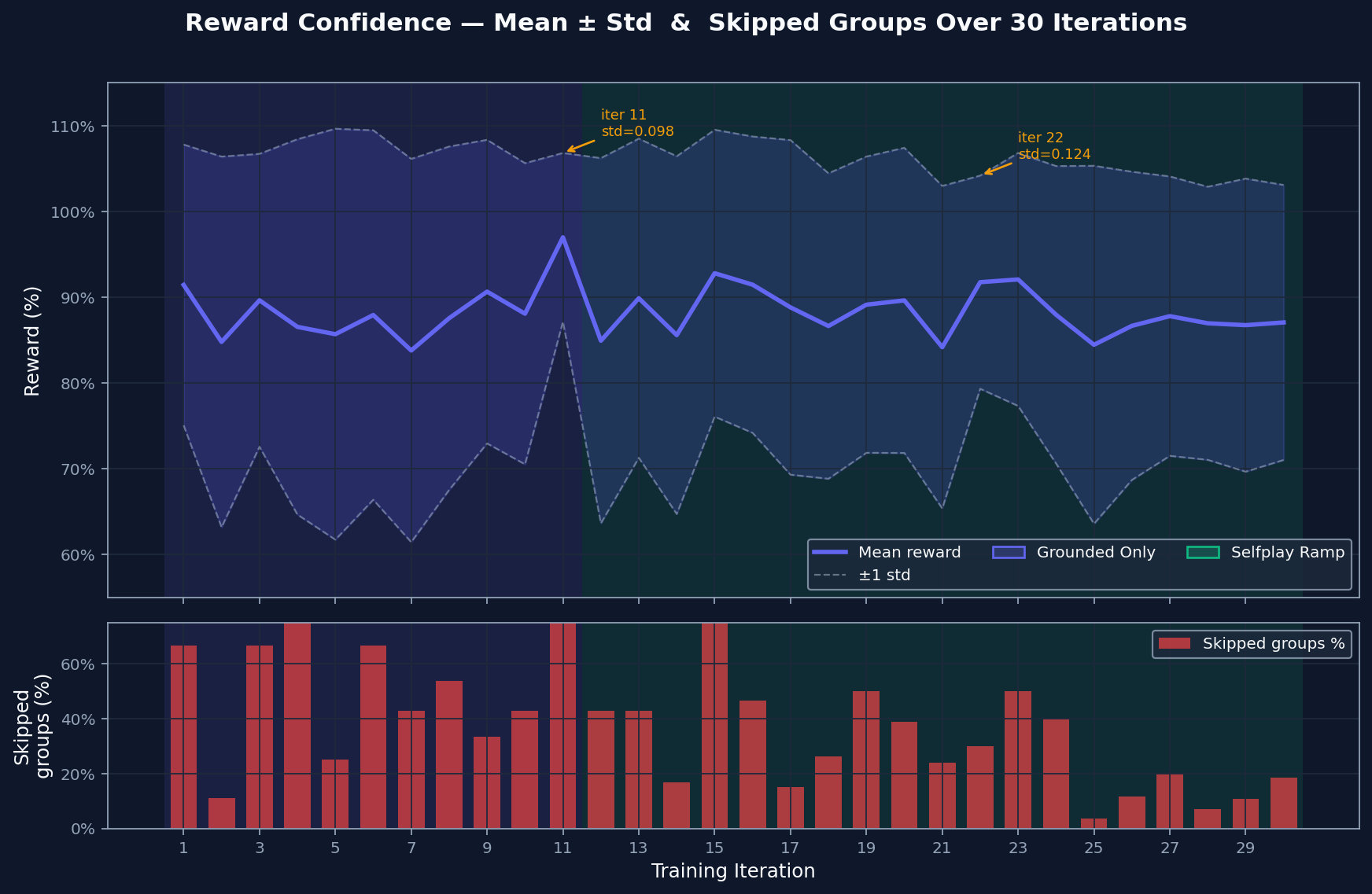
The reward spread shows how much contrast exists between the model's best and worst attempts. Wide spread gives GRPO something to learn from. Skipped groups are cases where attempts are too similar to compare usefully. That rate falls as harder material enters the curriculum, which suggests the comparison signal stays useful.
Step-Level Reasoning Quality
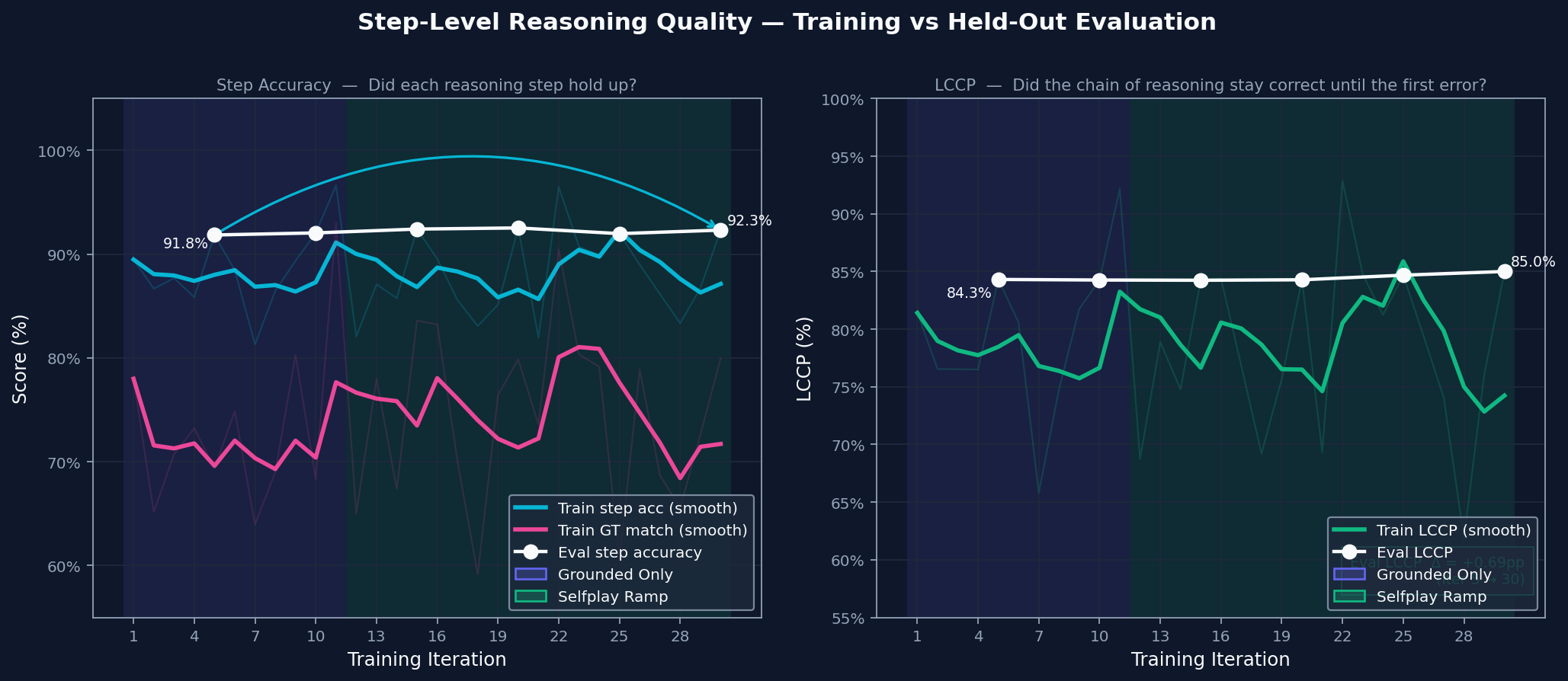
Step accuracy checks whether each line of reasoning is valid. Chain integrity checks whether those valid steps form an unbroken path to the answer. Both improve together, which means the model is building solutions that hold together more often instead of only producing better-looking outputs.
Why It Matters
Reliable math reasoning needs more than fluent explanations or lucky final answers. A system that can separate correct reasoning from unsupported answers gives the model a better training target: not just "get the number," but build a chain of logic that reaches the number.
AxiomForgeAI matters because it turns that target into an environment. The same pattern can extend beyond math to other verifiable domains where attempts can be checked, compared, and improved: code, logic, structured data transformations, and scientific problem solving.
Engineered for the OpenEnv Hackathon India 2026