Spaces:
Sleeping

Sleeping
Commit ·
3ba37b2
1
Parent(s): efc106e
Sync README from main: add HF links, Logs section, fix image URLs
Browse files
README.md
CHANGED
|
@@ -16,6 +16,10 @@ tags:
|
|
| 16 |
|
| 17 |
*A self-improving math environment where a model practices on verified problems, generates new challenges when ready, and learns from solution attempts whose reasoning steps and final answers agree.*
|
| 18 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
## The Problem
|
| 20 |
|
| 21 |
Math reasoning models can fail in two different ways. Sometimes the setup, arithmetic, and algebraic steps look reasonable, but the final answer is wrong. Sometimes the final answer is right, but the reasoning that produced it is incomplete, inconsistent, or hard to trust.
|
|
@@ -28,7 +32,7 @@ This project builds a practice loop around that signal. The model first works on
|
|
| 28 |
|
| 29 |
The environment is a practice loop for math reasoning. Each training group starts with one problem, asks the model for multiple solution attempts, scores those attempts from several angles, and uses GRPO to reinforce the attempts that are stronger than the rest of the group.
|
| 30 |
|
| 31 |
-

|
| 32 |
|
| 33 |
The environment has two task sources:
|
| 34 |
|
|
@@ -73,7 +77,7 @@ both -> one combined score per attempt -> GRPO compares attempts within the grou
|
|
| 73 |
|
| 74 |
Training follows a simple three-phase schedule. It starts with grounded-only practice so the model learns to keep answers and reasoning stable on problems with known solutions. Self-play is then introduced gradually, while grounded questions remain as an anchor. Once both are stable, training continues with a mixed task source and falls back to grounded-only batches if answer quality drops.
|
| 75 |
|
| 76 |
-

|
| 77 |
|
| 78 |
## Training Script
|
| 79 |
|
|
@@ -87,37 +91,46 @@ The GRPO training loop is available in two forms:
|
|
| 87 |
- [`train_grpo.ipynb`](train_grpo.ipynb) — notebook version with the same parameters, structured around `env.reset / env.step / env.state / env.close` for interactive inspection.
|
| 88 |
|
| 89 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 90 |
## Results
|
| 91 |
|
| 92 |
These plots come from a single GPU training run and focus on the core question: did the model get better at making its reasoning and final answer agree?
|
| 93 |
|
| 94 |
### Evaluation Quality Over Training
|
| 95 |
|
| 96 |
-

|
| 97 |
|
| 98 |
The environment tracks final correctness, solution quality, step validity, and how long the reasoning chain stays correct. All four move upward together, which suggests the model is not just finding better final answers. It is also producing reasoning that holds up longer.
|
| 99 |
|
| 100 |
### Training Journey
|
| 101 |
|
| 102 |
-

|
| 103 |
|
| 104 |
Training starts with grounded practice on problems with known answers. Self-play is introduced only after the grounded signal is stable, so the model does not train on its own generated problems too early. The transition is conditional, not just a timer.
|
| 105 |
|
| 106 |
### Self-Play Curriculum
|
| 107 |
|
| 108 |
-

|
| 109 |
|
| 110 |
By the end of training, most practice came from self-play. The important part is that generated problems stayed solvable and novel even after self-play became a larger share of training. That makes the ramp meaningful: self-play added useful practice instead of recycled noise.
|
| 111 |
|
| 112 |
### Reward Confidence
|
| 113 |
|
| 114 |
-

|
| 115 |
|
| 116 |
The reward spread shows how much contrast exists between the model's best and worst attempts. Wide spread gives GRPO something to learn from. Skipped groups are cases where attempts are too similar to compare usefully. That rate falls as harder material enters the curriculum, which suggests the comparison signal stays useful.
|
| 117 |
|
| 118 |
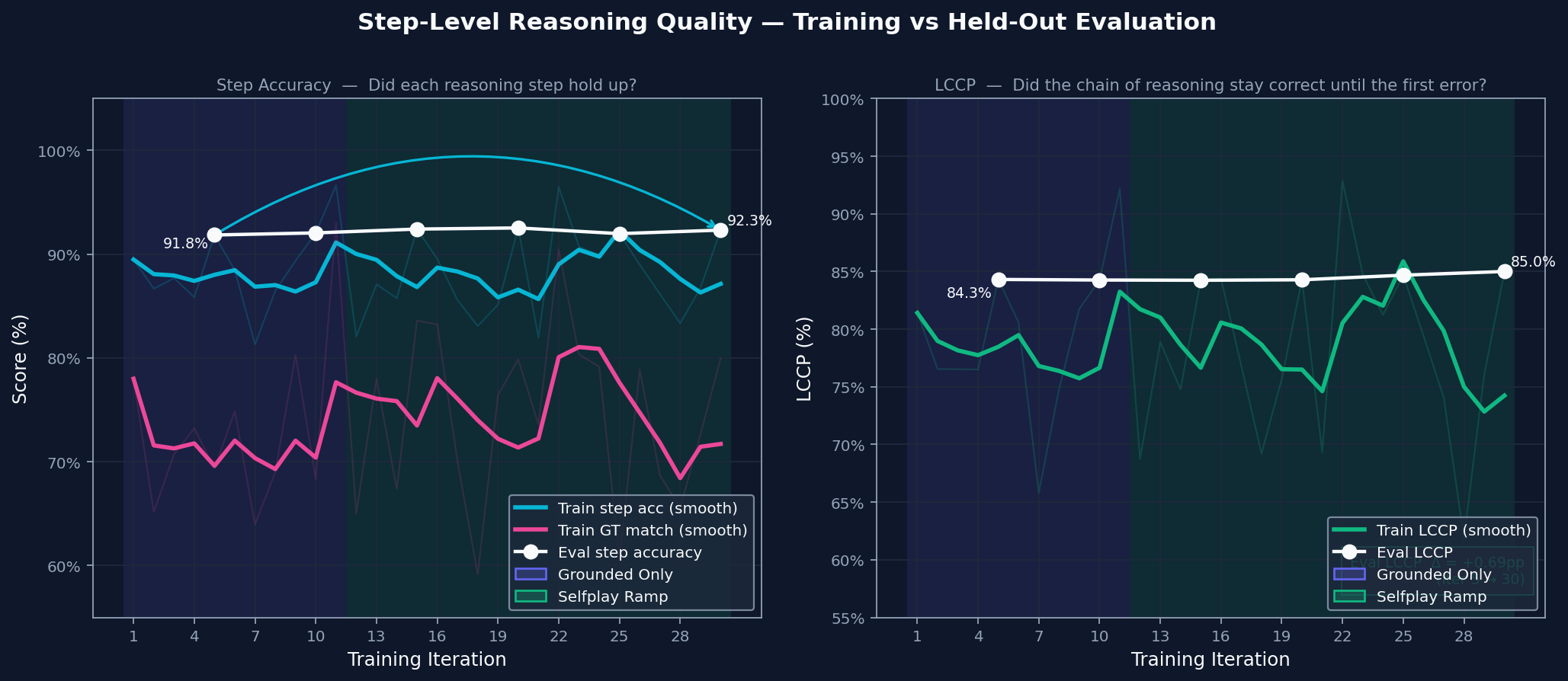
### Step-Level Reasoning Quality
|
| 119 |
|
| 120 |
-

|
| 121 |
|
| 122 |
Step accuracy checks whether each line of reasoning is valid. Chain integrity checks whether those valid steps form an unbroken path to the answer. Both improve together, which means the model is building solutions that hold together more often instead of only producing better-looking outputs.
|
| 123 |
|
|
|
|
| 16 |
|
| 17 |
*A self-improving math environment where a model practices on verified problems, generates new challenges when ready, and learns from solution attempts whose reasoning steps and final answers agree.*
|
| 18 |
|
| 19 |
+
[Hugging Face Space](https://huggingface.co/spaces/jampuramprem/AxiomForgeAI)
|
| 20 |
+
|
| 21 |
+
[Hugging Face Blog](https://huggingface.co/spaces/jampuramprem/AxiomForgeAI/blob/main/blog.md)
|
| 22 |
+
|
| 23 |
## The Problem
|
| 24 |
|
| 25 |
Math reasoning models can fail in two different ways. Sometimes the setup, arithmetic, and algebraic steps look reasonable, but the final answer is wrong. Sometimes the final answer is right, but the reasoning that produced it is incomplete, inconsistent, or hard to trust.
|
|
|
|
| 32 |
|
| 33 |
The environment is a practice loop for math reasoning. Each training group starts with one problem, asks the model for multiple solution attempts, scores those attempts from several angles, and uses GRPO to reinforce the attempts that are stronger than the rest of the group.
|
| 34 |
|
| 35 |
+

|
| 36 |
|
| 37 |
The environment has two task sources:
|
| 38 |
|
|
|
|
| 77 |
|
| 78 |
Training follows a simple three-phase schedule. It starts with grounded-only practice so the model learns to keep answers and reasoning stable on problems with known solutions. Self-play is then introduced gradually, while grounded questions remain as an anchor. Once both are stable, training continues with a mixed task source and falls back to grounded-only batches if answer quality drops.
|
| 79 |
|
| 80 |
+

|
| 81 |
|
| 82 |
## Training Script
|
| 83 |
|
|
|
|
| 91 |
- [`train_grpo.ipynb`](train_grpo.ipynb) — notebook version with the same parameters, structured around `env.reset / env.step / env.state / env.close` for interactive inspection.
|
| 92 |
|
| 93 |
|
| 94 |
+
## Logs
|
| 95 |
+
|
| 96 |
+
Each training run writes the following logs for verification:
|
| 97 |
+
|
| 98 |
+
- `logs/metrics.jsonl` — per-iteration metrics: reward, accuracy, step quality, LCCP, training phase, and self-play stats
|
| 99 |
+
- `logs/grpo/<run_id>/console_output.log` — full console output with run config, GPU info, and per-iteration progress
|
| 100 |
+
- `logs/grpo/<run_id>/metrics.csv` — same metrics in CSV format for quick inspection
|
| 101 |
+
- `logs/grpo/<run_id>/config.json` — exact hyperparameters used for the run
|
| 102 |
+
|
| 103 |
## Results
|
| 104 |
|
| 105 |
These plots come from a single GPU training run and focus on the core question: did the model get better at making its reasoning and final answer agree?
|
| 106 |
|
| 107 |
### Evaluation Quality Over Training
|
| 108 |
|
| 109 |
+
|
| 110 |
|
| 111 |
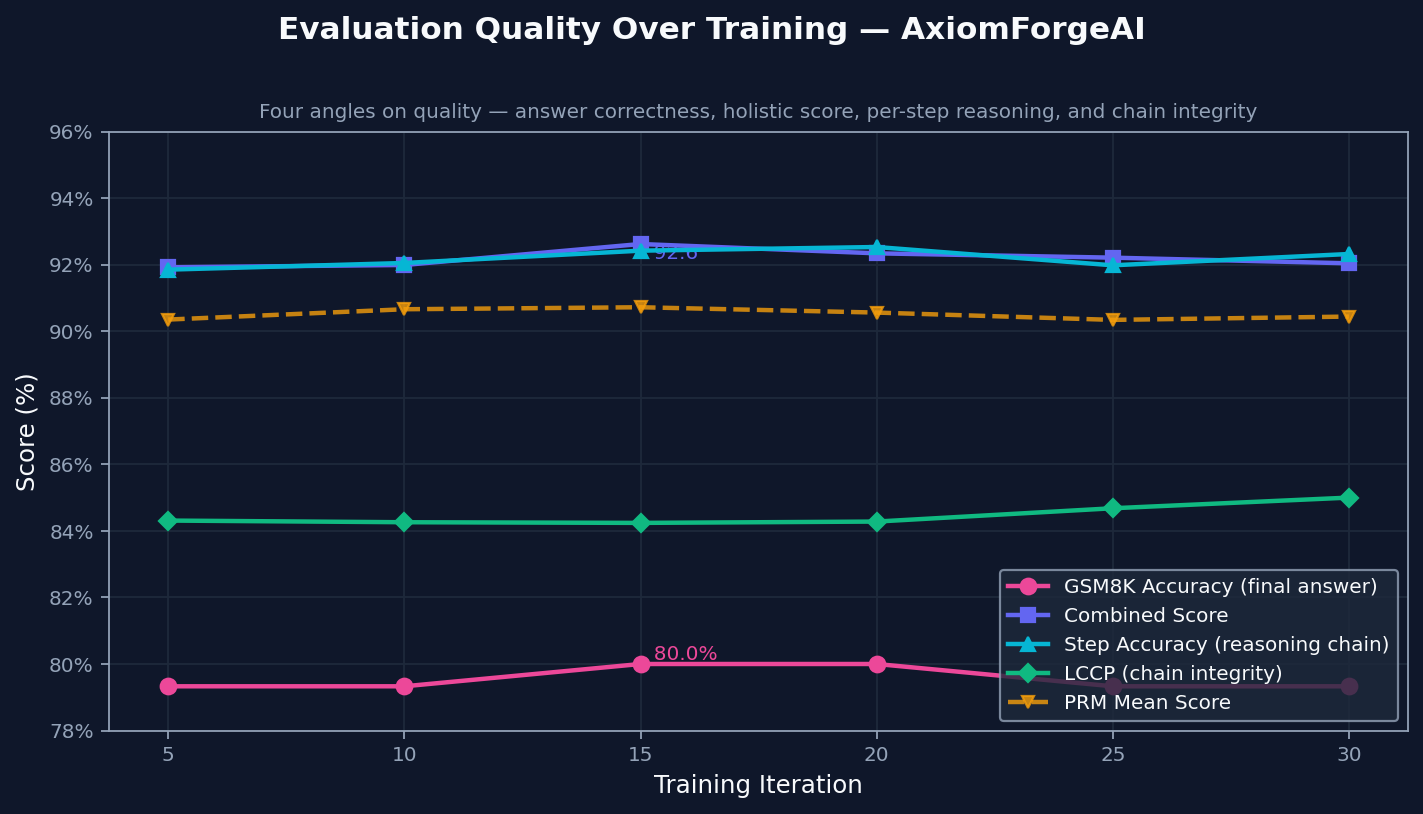
The environment tracks final correctness, solution quality, step validity, and how long the reasoning chain stays correct. All four move upward together, which suggests the model is not just finding better final answers. It is also producing reasoning that holds up longer.
|
| 112 |
|
| 113 |
### Training Journey
|
| 114 |
|
| 115 |
+
|
| 116 |
|
| 117 |
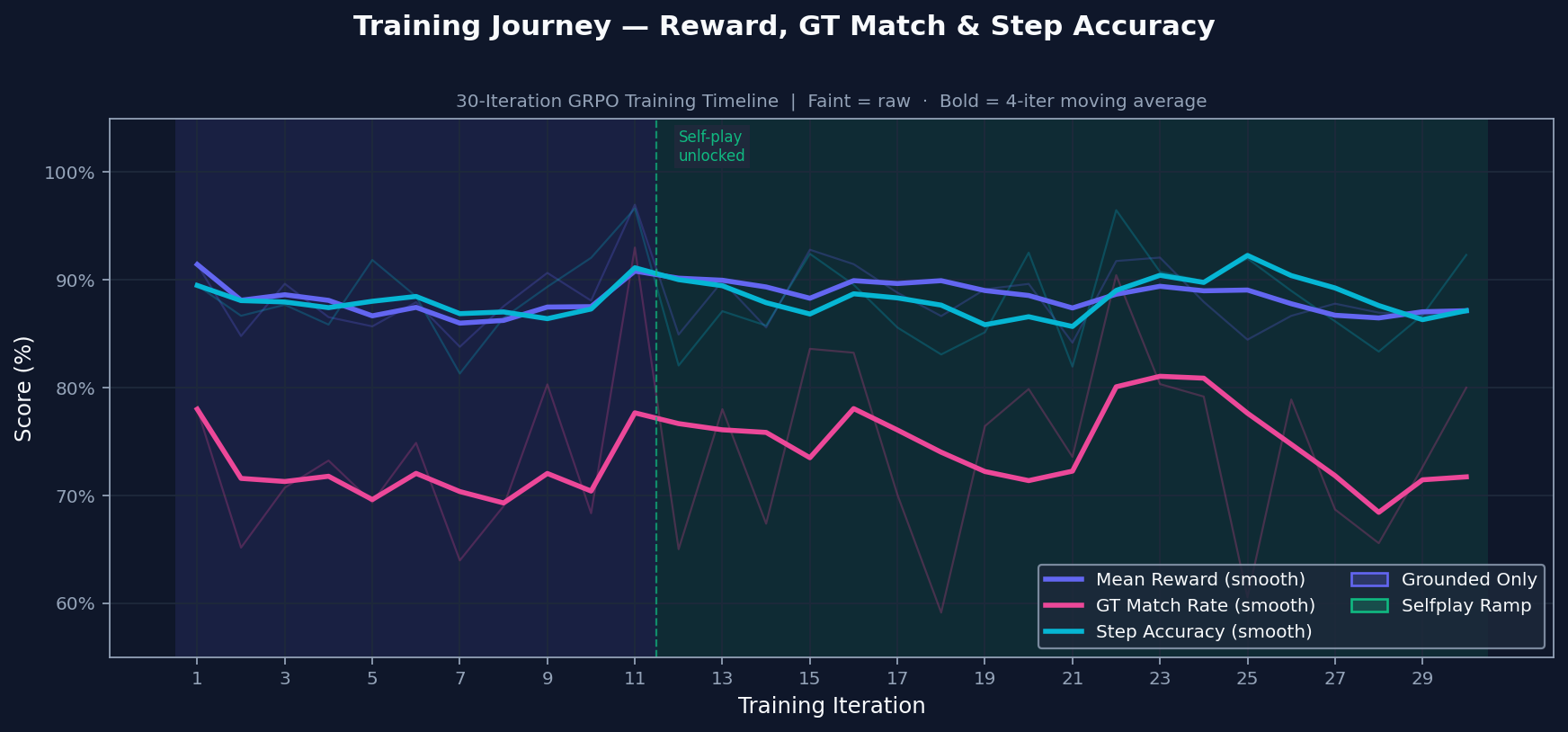
Training starts with grounded practice on problems with known answers. Self-play is introduced only after the grounded signal is stable, so the model does not train on its own generated problems too early. The transition is conditional, not just a timer.
|
| 118 |
|
| 119 |
### Self-Play Curriculum
|
| 120 |
|
| 121 |
+
|
| 122 |
|
| 123 |
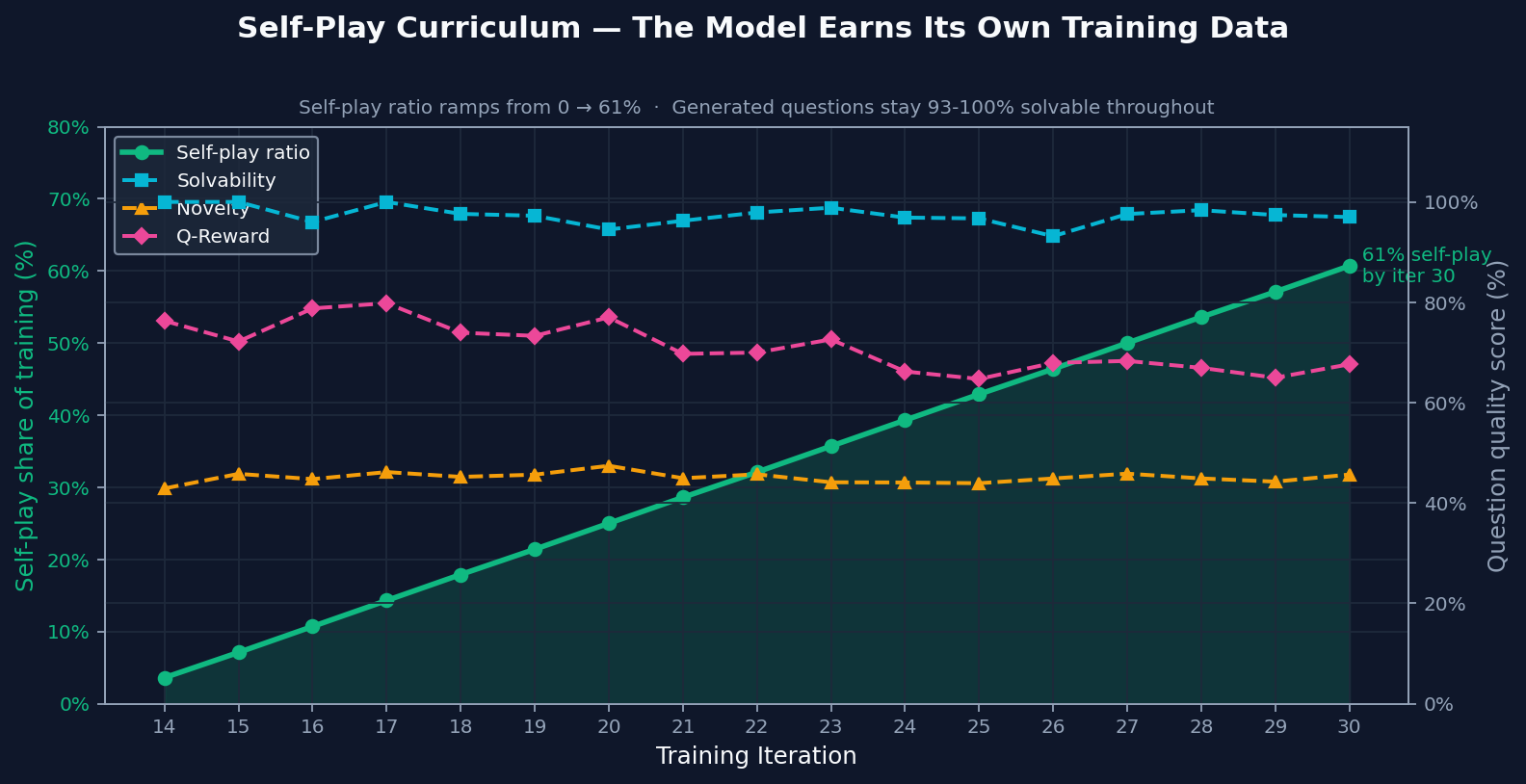
By the end of training, most practice came from self-play. The important part is that generated problems stayed solvable and novel even after self-play became a larger share of training. That makes the ramp meaningful: self-play added useful practice instead of recycled noise.
|
| 124 |
|
| 125 |
### Reward Confidence
|
| 126 |
|
| 127 |
+
|
| 128 |
|
| 129 |
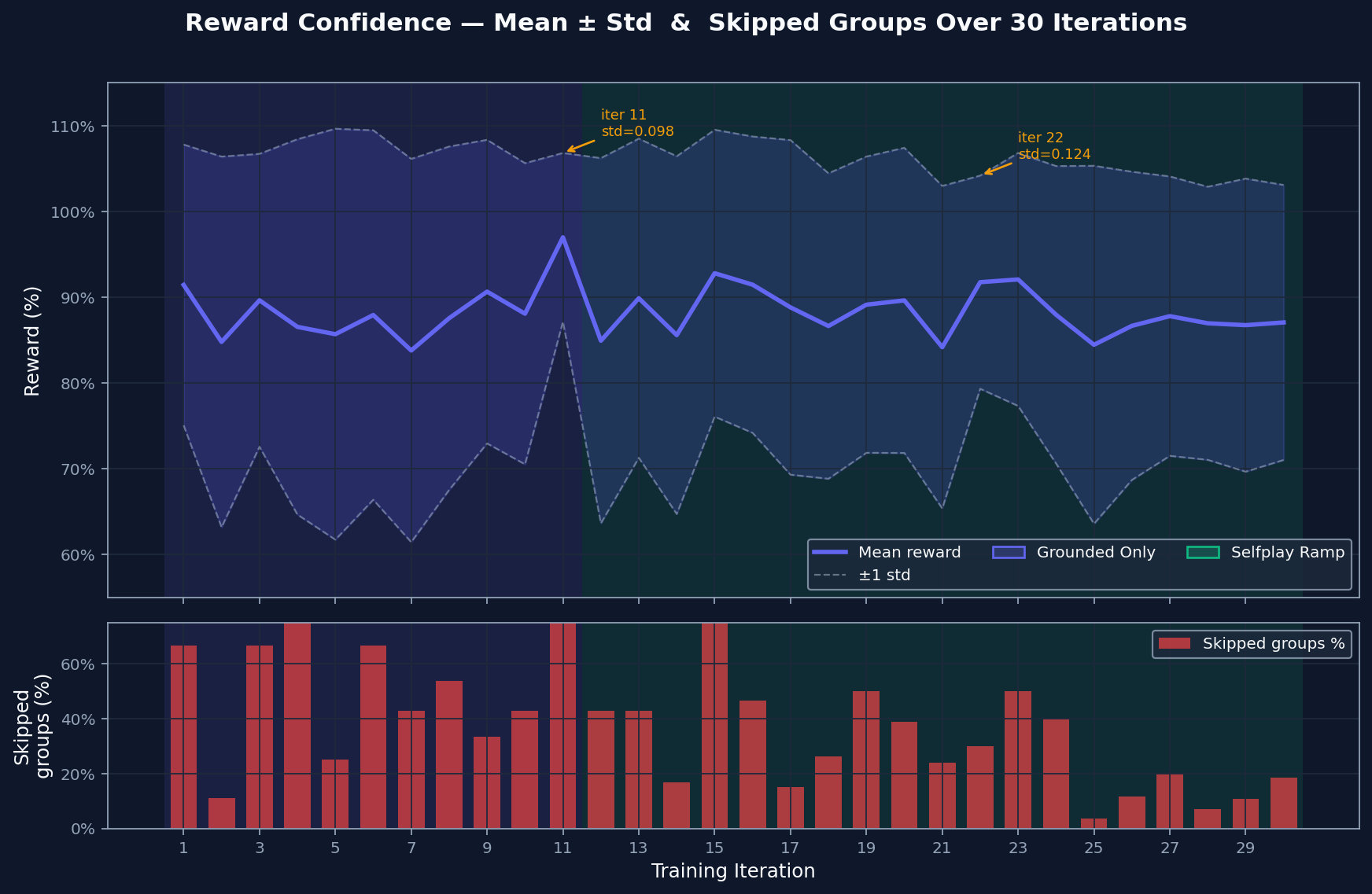
The reward spread shows how much contrast exists between the model's best and worst attempts. Wide spread gives GRPO something to learn from. Skipped groups are cases where attempts are too similar to compare usefully. That rate falls as harder material enters the curriculum, which suggests the comparison signal stays useful.
|
| 130 |
|
| 131 |
### Step-Level Reasoning Quality
|
| 132 |
|
| 133 |
+
|
| 134 |
|
| 135 |
Step accuracy checks whether each line of reasoning is valid. Chain integrity checks whether those valid steps form an unbroken path to the answer. Both improve together, which means the model is building solutions that hold together more often instead of only producing better-looking outputs.
|
| 136 |
|