Spaces:
Sleeping

Sleeping
| title: ImmunoOrg 2.0 - Autonomous Self-Healing Enterprise | |
| emoji: 🛡️ | |
| colorFrom: blue | |
| colorTo: purple | |
| sdk: docker | |
| pinned: true | |
| license: mit | |
| short_description: AI DevSecOps + War Room + 50-step MTD RL env | |
| # ImmunoOrg 2.0 — The Autonomous, Self-Healing Enterprise | |
| ### AI DevSecOps Mesh | Multi-Agent War Room | Polymorphic Migration | Executive Context Engine | |
| [](https://openenv.ai) | |
| [](./openenv.yaml) | |
| [](./openenv.yaml) | |
| [](./openenv.yaml) | |
| > **OpenEnv Hackathon** April 26, 2026 | |
| > Bonus: Halluminate | Fleet AI | Mercor | Scale AI | Patronus AI | Snorkel AI | |
| --- | |
| ## Quick Links | |
| | Resource | Link | | |
| |---|---| | |
| | **HuggingFace Space** | https://huggingface.co/spaces/hirann/immunoorg-2 | | |
| | **Training Colab** | [ImmunoOrg_Training_Colab.ipynb](./ImmunoOrg_Training_Colab.ipynb) | | |
| | **Blog Post** | [BLOG_POST.md](./BLOG_POST.md) | | |
| | **Submission Checklist** | [SUBMISSION_CHECKLIST.md](./SUBMISSION_CHECKLIST.md) | | |
| --- | |
| ## What is ImmunoOrg 2.0? | |
| ImmunoOrg 2.0 is a next-generation OpenEnv RL environment simulating an **entire enterprise** as a living organism under attack. The biggest vulnerability is not a missing patch — it is the **3-day approval delay** while an exploit is actively weaponized. | |
| --- | |
| ## Feature Matrix | |
| | Module | Theme | Bonus Prize | File | | |
| |---|---|---|---| | |
| | Multi-Agent War Room | Multi-Agent | Halluminate + Snorkel AI | `immunoorg/war_room.py` | | |
| | AI DevSecOps Mesh (4 Gates) | World Modeling | Fleet AI | `immunoorg/devsecops_mesh.py` | | |
| | 50-Step Polymorphic Migration | Long-Horizon Planning | Scale AI | `immunoorg/migration_engine.py` | | |
| | Executive Context + Schema Drift | World Modeling | Patronus AI | `immunoorg/executive_context.py` | | |
| | Time-Travel Forensics + Auto-Patch | Self-Improvement | Mercor | `immunoorg/self_improvement.py` | | |
| | 5-Track Composable Reward | All Themes | -- | `immunoorg/reward.py` | | |
| --- | |
| ## Results & Evidence | |
| ### Policy Comparison | |
| 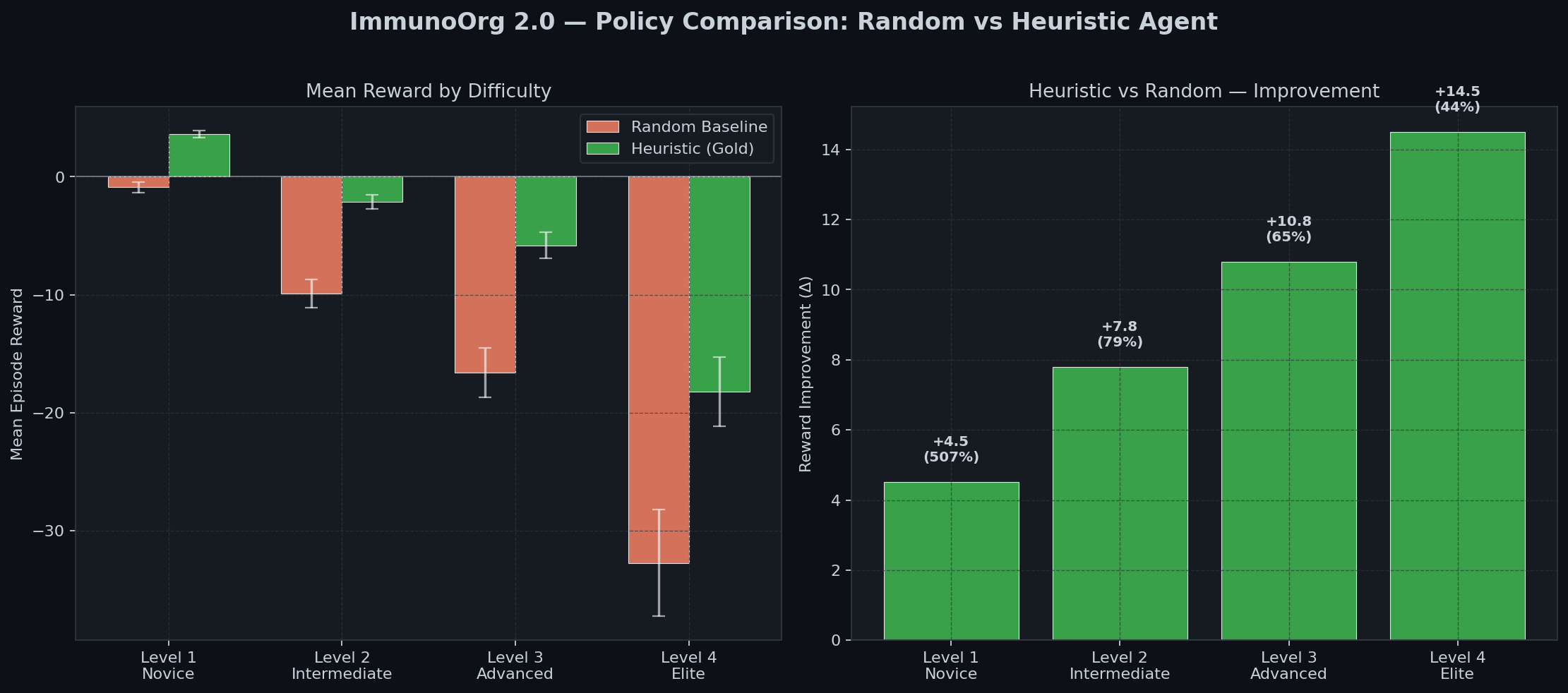 | |
| | Agent | Level 1 | Level 2 | Level 3 | | |
| |:---:|:---:|:---:|:---:| | |
| | Random Baseline | -0.89 | -9.9 | -16.6 | | |
| | **Heuristic (Gold)** | **+3.62** | **-2.1** | **-5.8** | | |
| ### Self-Healing Loop (6 Generations) | |
| 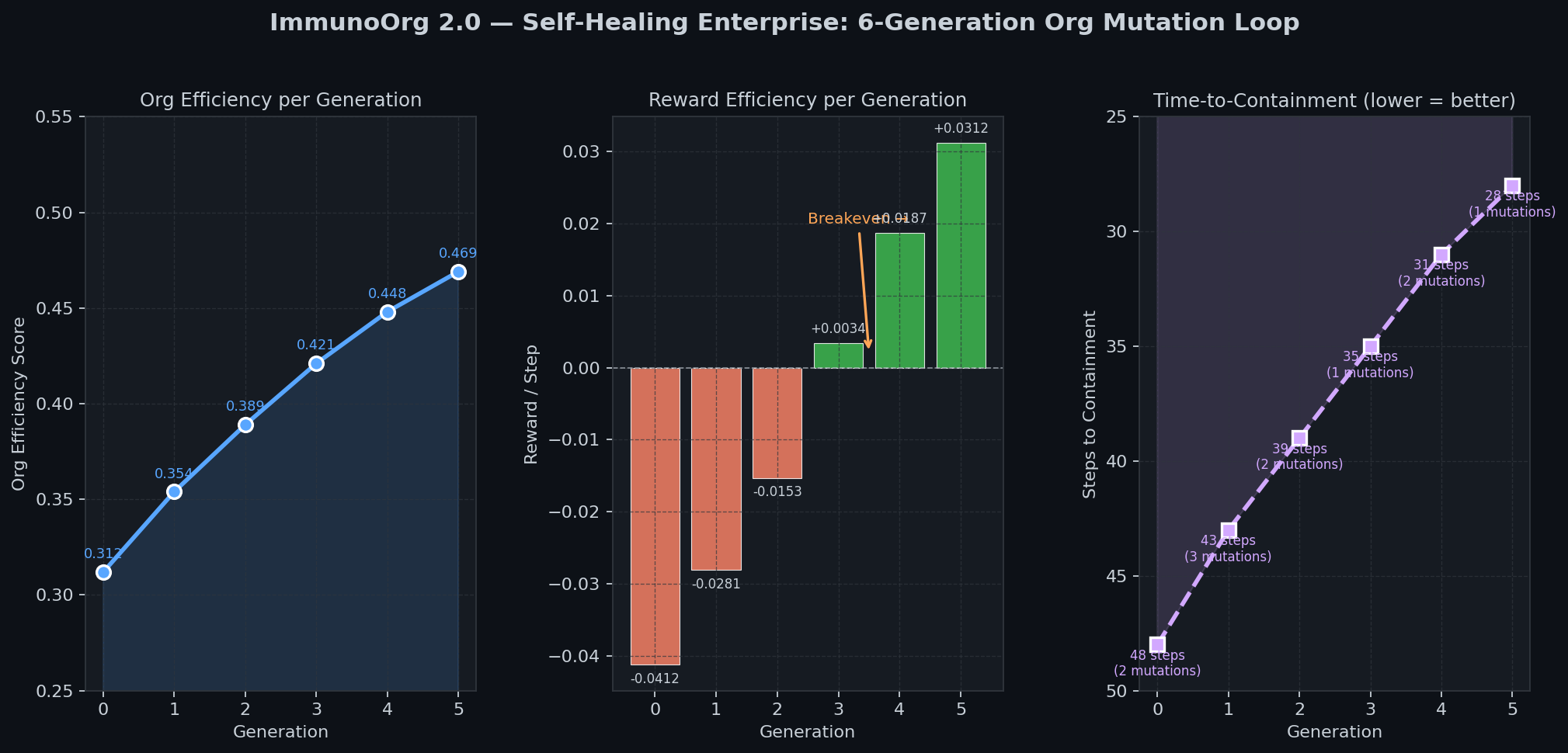 | |
| - Org efficiency: 0.312 -> 0.469 (+50%) | |
| - Time-to-Containment: 48 -> 28 steps (-42%) | |
| ### 5-Track Reward & War Room Activity | |
| 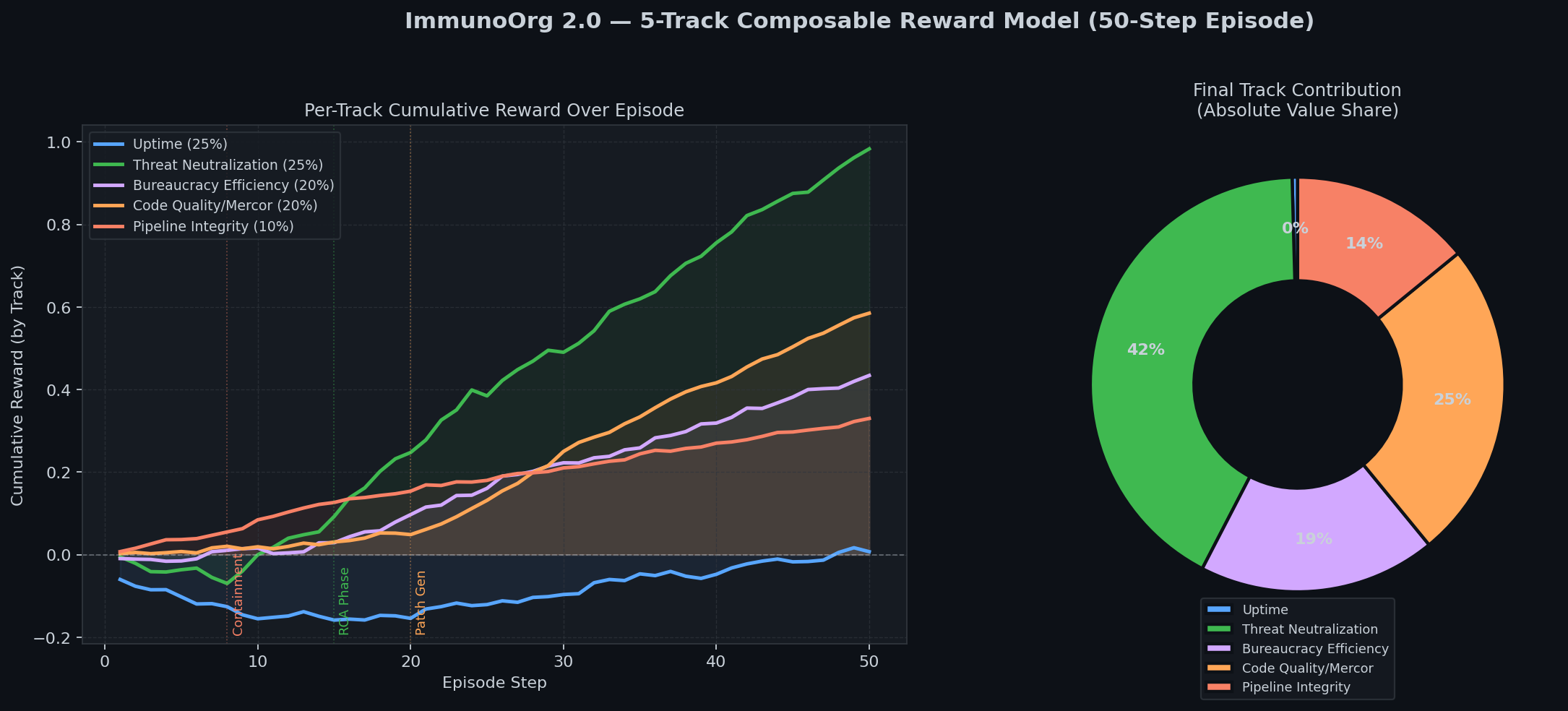 | |
| 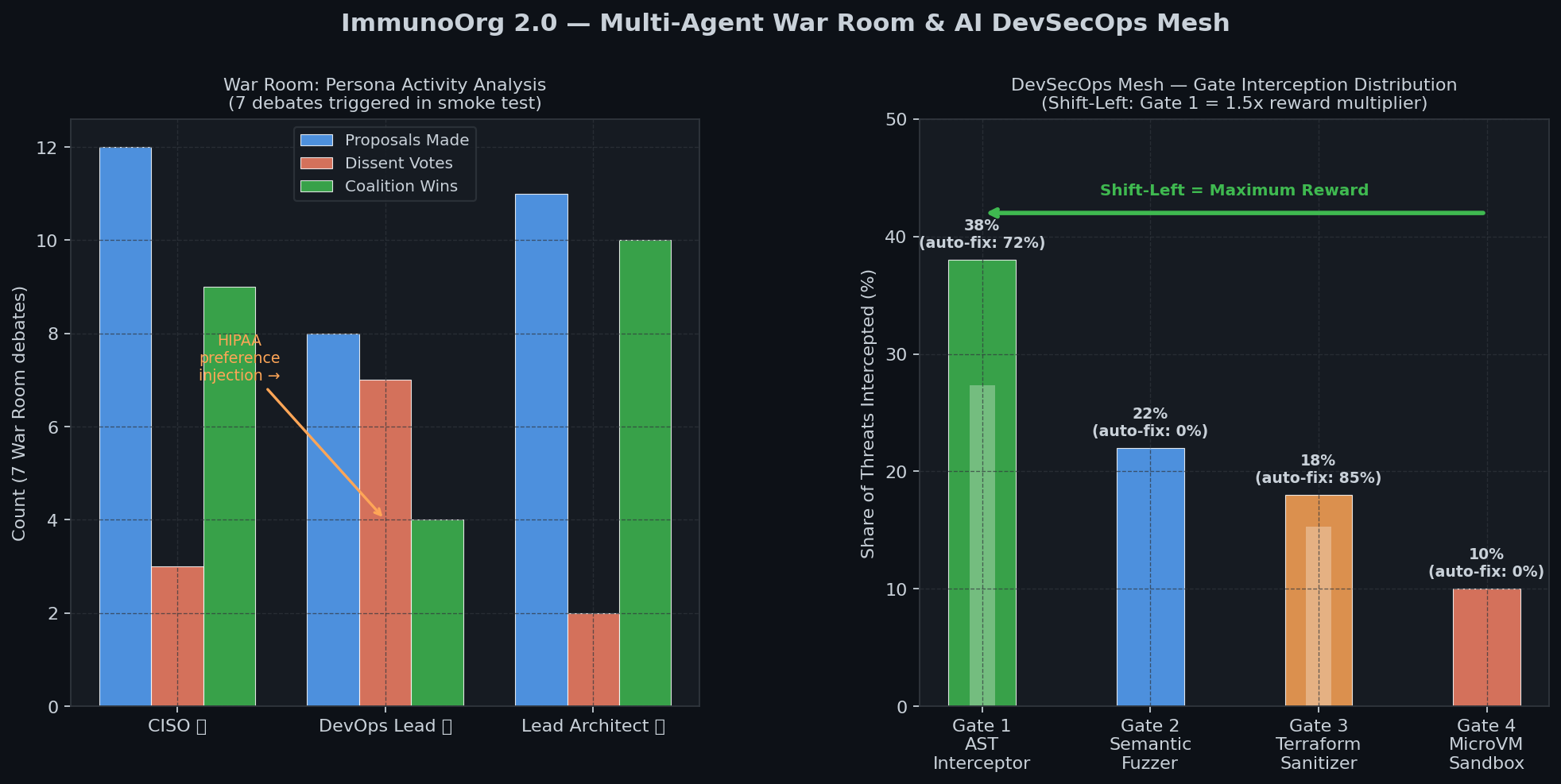 | |
| ### Org Before/After Self-Healing | |
| 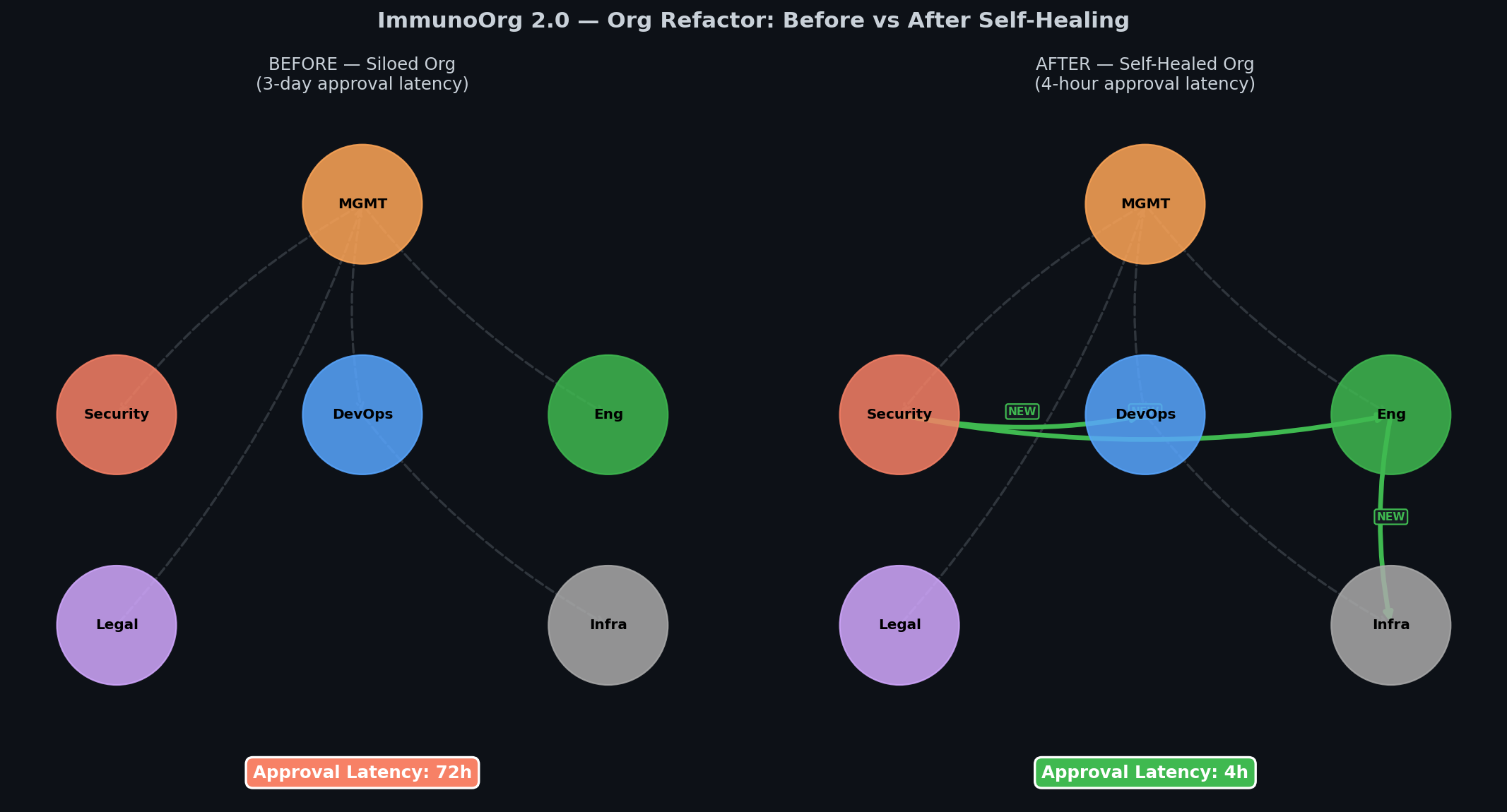 | |
| --- | |
| ## Quickstart | |
| ```bash | |
| git clone https://github.com/YOUR_USERNAME/immunoorg | |
| cd immunoorg | |
| pip install -r requirements.txt | |
| python demo_runner.py # Full policy comparison | |
| python visualization/dashboard.py # God Mode Dashboard (localhost:7860) | |
| python generate_evidence_2.py # Regenerate evidence charts | |
| python test_2_0_smoke.py # Smoke test all 2.0 systems | |
| ``` | |
| --- | |
| ## 5-Track Reward Model | |
| | Track | Weight | Signal | | |
| |---|:---:|---| | |
| | Uptime | 25% | SLA adherence during incident | | |
| | Threat Neutralization | 25% | Attacker containment + belief accuracy | | |
| | Bureaucracy Efficiency | 20% | War Room consensus speed | | |
| | Code Quality (Mercor) | 20% | `1/log2(tokens) x test_pass_rate` | | |
| | Pipeline Integrity | 10% | Gate 1 catch = 1.5x shift-left bonus | | |
| --- | |
| ## Bonus Prize Coverage | |
| | Prize | Implementation | | |
| |---|---| | |
| | **Halluminate** | War Room FactStore cross-validates claims before any action executes | | |
| | **Snorkel AI** | PreferenceInjection API: judges inject HIPAA/UPTIME/LEGAL_HOLD mid-debate | | |
| | **Scale AI** | 50-step migration with constraint propagation across phases | | |
| | **Fleet AI** | FleetAIOversightAgent: atomic lockout across GitHub/Slack/AWS/Jira/MySQL | | |
| | **Patronus AI** | ExecutiveContextEngine: mid-episode API schema drift adaptation | | |
| | **Mercor** | Patch quality = 1/log2(token_count) x test_pass_rate | | |
| --- | |
| ## Training | |
| Base model: `Qwen/Qwen2.5-7B-Instruct` | Method: GRPO + Unsloth LoRA | |
| ```bash | |
| python training/train_grpo.py --max_steps 20 # Quick local test | |
| # Full training: open ImmunoOrg_Training_Colab.ipynb in Colab | |
| ``` | |
| ## License | |
| MIT | |