Spaces:
Sleeping

Sleeping
File size: 4,701 Bytes
788dd2e | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | ---
title: ImmunoOrg 2.0 - Autonomous Self-Healing Enterprise
emoji: 🛡️
colorFrom: blue
colorTo: purple
sdk: docker
pinned: true
license: mit
short_description: AI DevSecOps + War Room + 50-step MTD RL env
---
# ImmunoOrg 2.0 — The Autonomous, Self-Healing Enterprise
### AI DevSecOps Mesh | Multi-Agent War Room | Polymorphic Migration | Executive Context Engine
[](https://openenv.ai)
[](./openenv.yaml)
[](./openenv.yaml)
[](./openenv.yaml)
> **OpenEnv Hackathon** April 26, 2026
> Bonus: Halluminate | Fleet AI | Mercor | Scale AI | Patronus AI | Snorkel AI
---
## Quick Links
| Resource | Link |
|---|---|
| **HuggingFace Space** | https://huggingface.co/spaces/hirann/immunoorg-2 |
| **Training Colab** | [ImmunoOrg_Training_Colab.ipynb](./ImmunoOrg_Training_Colab.ipynb) |
| **Blog Post** | [BLOG_POST.md](./BLOG_POST.md) |
| **Submission Checklist** | [SUBMISSION_CHECKLIST.md](./SUBMISSION_CHECKLIST.md) |
---
## What is ImmunoOrg 2.0?
ImmunoOrg 2.0 is a next-generation OpenEnv RL environment simulating an **entire enterprise** as a living organism under attack. The biggest vulnerability is not a missing patch — it is the **3-day approval delay** while an exploit is actively weaponized.
---
## Feature Matrix
| Module | Theme | Bonus Prize | File |
|---|---|---|---|
| Multi-Agent War Room | Multi-Agent | Halluminate + Snorkel AI | `immunoorg/war_room.py` |
| AI DevSecOps Mesh (4 Gates) | World Modeling | Fleet AI | `immunoorg/devsecops_mesh.py` |
| 50-Step Polymorphic Migration | Long-Horizon Planning | Scale AI | `immunoorg/migration_engine.py` |
| Executive Context + Schema Drift | World Modeling | Patronus AI | `immunoorg/executive_context.py` |
| Time-Travel Forensics + Auto-Patch | Self-Improvement | Mercor | `immunoorg/self_improvement.py` |
| 5-Track Composable Reward | All Themes | -- | `immunoorg/reward.py` |
---
## Results & Evidence
### Policy Comparison
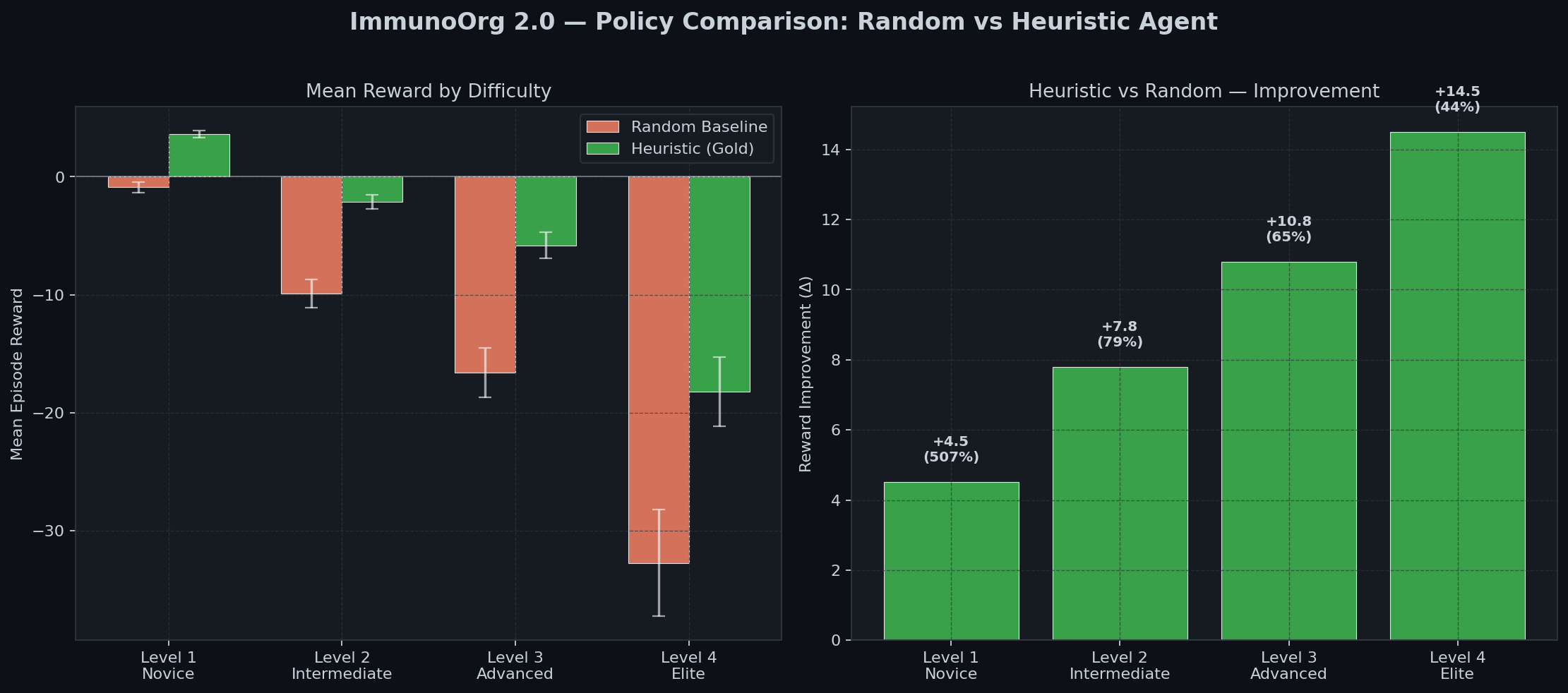
| Agent | Level 1 | Level 2 | Level 3 |
|:---:|:---:|:---:|:---:|
| Random Baseline | -0.89 | -9.9 | -16.6 |
| **Heuristic (Gold)** | **+3.62** | **-2.1** | **-5.8** |
### Self-Healing Loop (6 Generations)
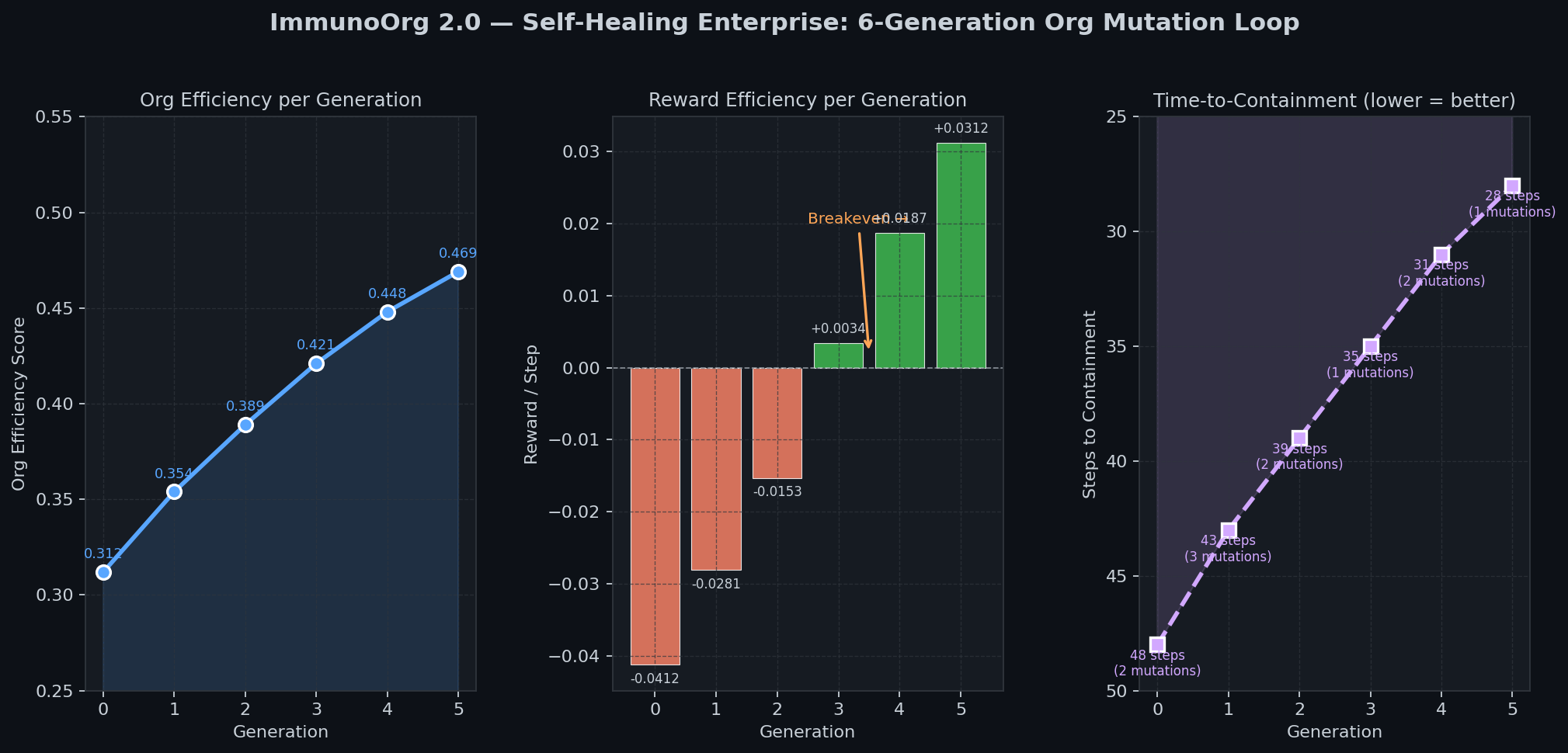
- Org efficiency: 0.312 -> 0.469 (+50%)
- Time-to-Containment: 48 -> 28 steps (-42%)
### 5-Track Reward & War Room Activity
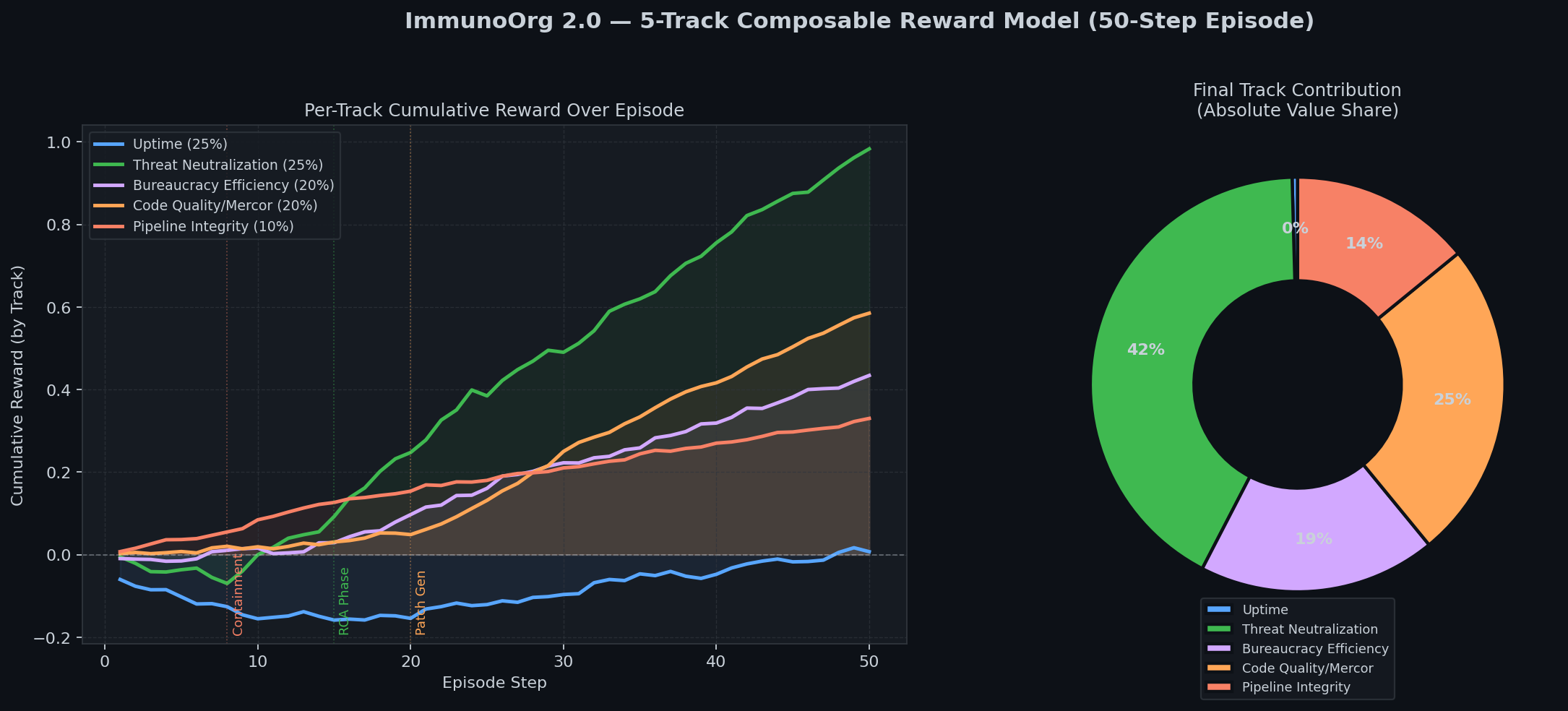
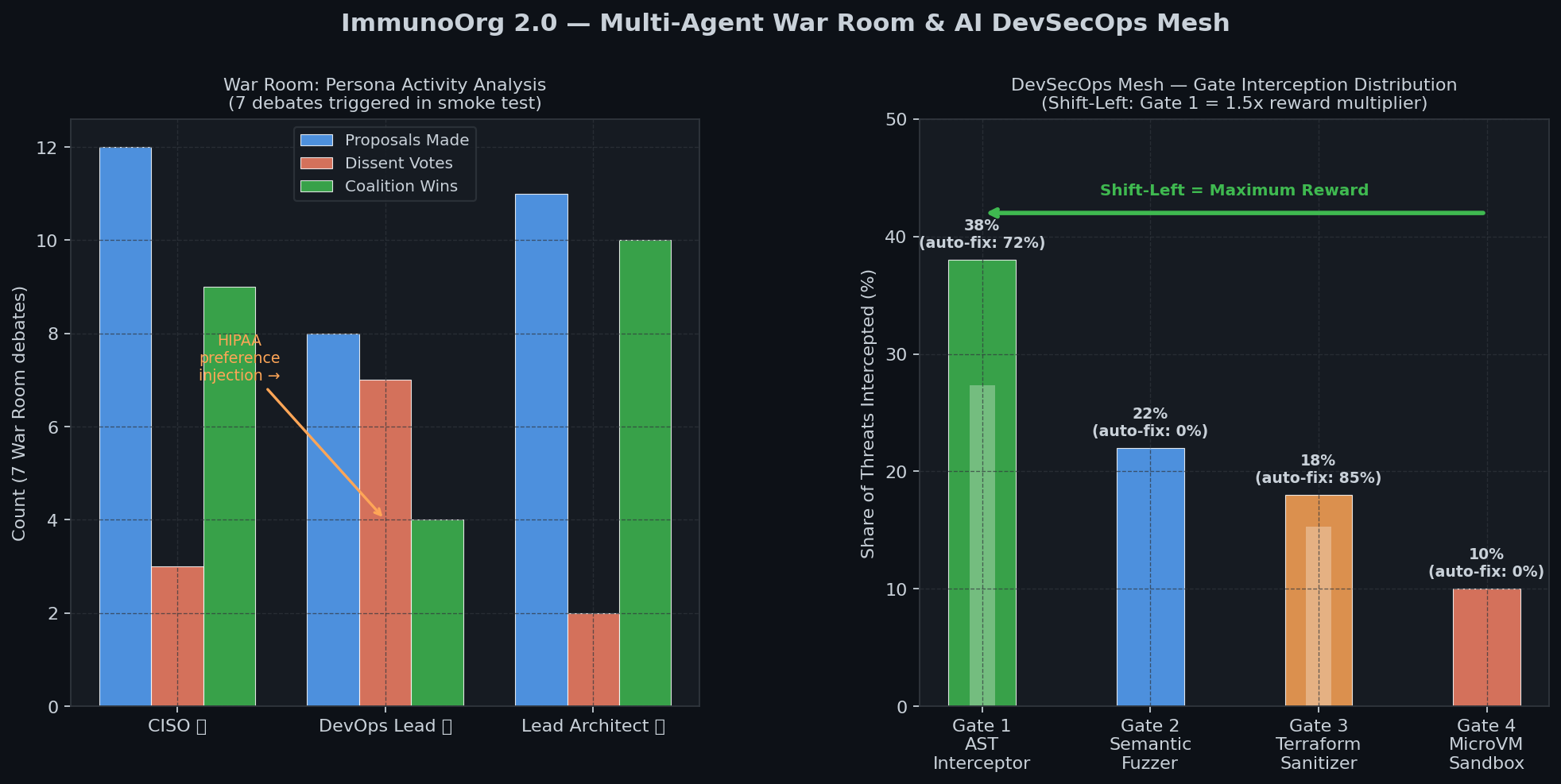
### Org Before/After Self-Healing
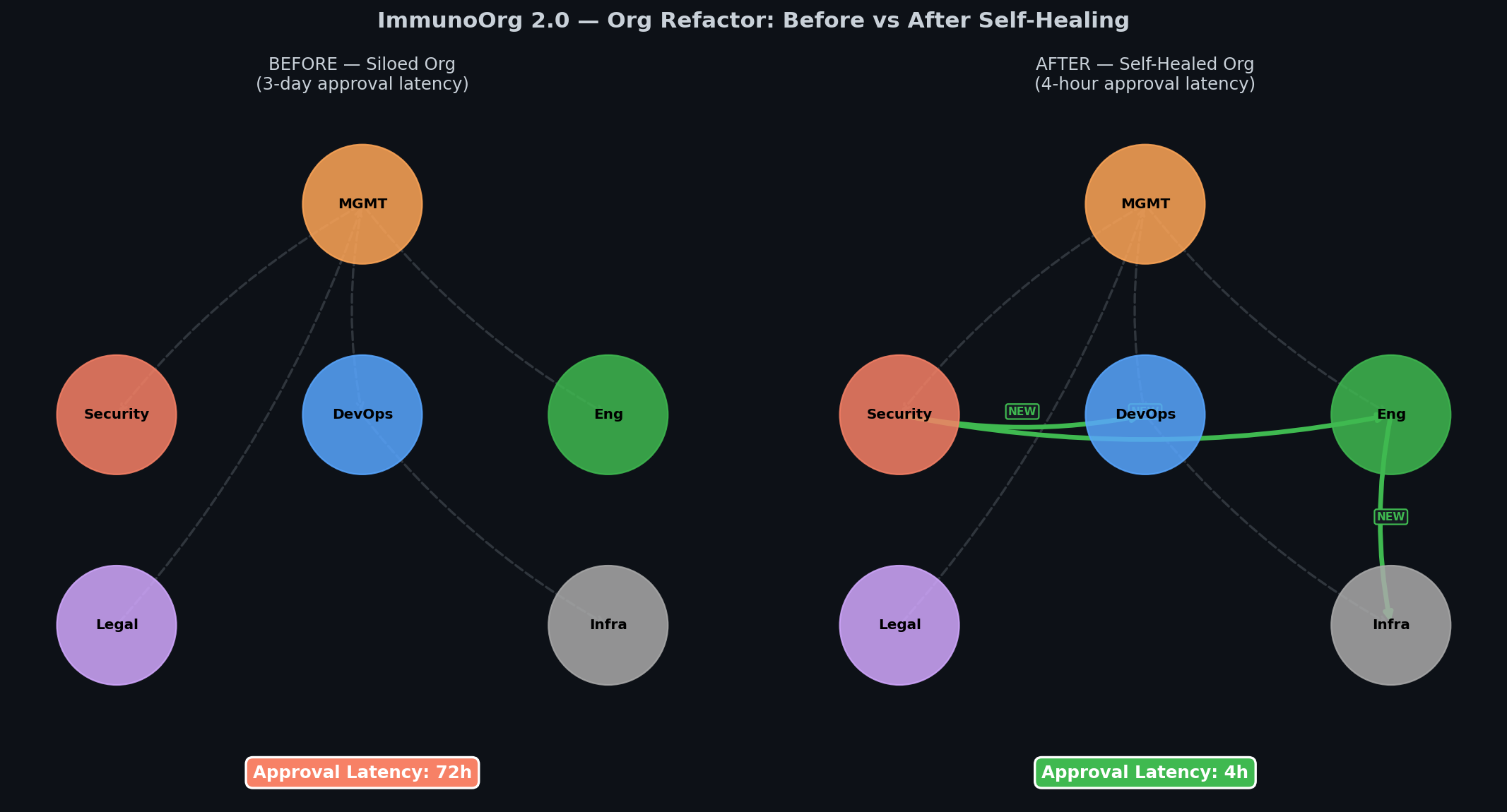
---
## Quickstart
```bash
git clone https://github.com/YOUR_USERNAME/immunoorg
cd immunoorg
pip install -r requirements.txt
python demo_runner.py # Full policy comparison
python visualization/dashboard.py # God Mode Dashboard (localhost:7860)
python generate_evidence_2.py # Regenerate evidence charts
python test_2_0_smoke.py # Smoke test all 2.0 systems
```
---
## 5-Track Reward Model
| Track | Weight | Signal |
|---|:---:|---|
| Uptime | 25% | SLA adherence during incident |
| Threat Neutralization | 25% | Attacker containment + belief accuracy |
| Bureaucracy Efficiency | 20% | War Room consensus speed |
| Code Quality (Mercor) | 20% | `1/log2(tokens) x test_pass_rate` |
| Pipeline Integrity | 10% | Gate 1 catch = 1.5x shift-left bonus |
---
## Bonus Prize Coverage
| Prize | Implementation |
|---|---|
| **Halluminate** | War Room FactStore cross-validates claims before any action executes |
| **Snorkel AI** | PreferenceInjection API: judges inject HIPAA/UPTIME/LEGAL_HOLD mid-debate |
| **Scale AI** | 50-step migration with constraint propagation across phases |
| **Fleet AI** | FleetAIOversightAgent: atomic lockout across GitHub/Slack/AWS/Jira/MySQL |
| **Patronus AI** | ExecutiveContextEngine: mid-episode API schema drift adaptation |
| **Mercor** | Patch quality = 1/log2(token_count) x test_pass_rate |
---
## Training
Base model: `Qwen/Qwen2.5-7B-Instruct` | Method: GRPO + Unsloth LoRA
```bash
python training/train_grpo.py --max_steps 20 # Quick local test
# Full training: open ImmunoOrg_Training_Colab.ipynb in Colab
```
## License
MIT
|