Spaces:
Running

Running
| license: mit | |
| language: | |
| - en | |
| - hi | |
| - ta | |
| - te | |
| - kn | |
| - bn | |
| - mr | |
| base_model: Qwen/Qwen2.5-7B-Instruct | |
| library_name: peft | |
| pipeline_tag: text-generation | |
| tags: | |
| - lora | |
| - peft | |
| - grpo | |
| - trl | |
| - unsloth | |
| - fraud-detection | |
| - upi | |
| - india | |
| - multi-agent | |
| - openenv | |
| - scalable-oversight | |
| datasets: | |
| - ujjwalpardeshi/chakravyuh-bench-v0 | |
| metrics: | |
| - f1 | |
| - precision | |
| - recall | |
| model-index: | |
| - name: chakravyuh-analyzer-lora-v2 | |
| results: | |
| - task: | |
| type: text-classification | |
| name: Indian UPI Fraud Detection (Chakravyuh bench-v0) | |
| dataset: | |
| name: chakravyuh-bench-v0 | |
| type: custom | |
| metrics: | |
| - name: Detection (recall) | |
| type: recall | |
| value: 0.993 | |
| - name: False Positive Rate | |
| type: fpr | |
| value: 0.067 | |
| - name: Precision | |
| type: precision | |
| value: 0.986 | |
| - name: F1 | |
| type: f1 | |
| value: 0.99 | |
| # Chakravyuh Analyzer — LoRA v2 | |
| LoRA adapter for **Qwen/Qwen2.5-7B-Instruct**, post-trained with TRL's GRPO on the [Chakravyuh](https://github.com/UjjwalPardeshi/Chakravyuh) multi-agent Indian UPI fraud-detection environment. | |
| The Analyzer's job: read a multi-turn dialogue between a (scripted) Scammer and Victim and output a calibrated suspicion score plus a justified explanation, in real time, on the victim's device. This adapter is the **v2 of two** Chakravyuh trained adapters and is the **honest one** — see "v1 → v2 story" below. | |
| ## Quick numbers (full results in `logs/eval_v2.json` of the GitHub repo) | |
| | Metric | v1 (reward-hacked) | **v2 (this adapter)** | 95 % bootstrap CI | | |
| |---|---|---|---| | |
| | Detection rate | 100.0 % | **99.3 %** | [97.9 %, 100 %] | | |
| | False positive rate | 36.0 % | **6.7 %** (5× better) | [1.8 %, 20.7 %] | | |
| | F1 | 0.96 | **0.99** | [0.976, 1.000] | | |
| | Bench size | 135 | 174 evaluated (175 total, 1 skipped) | — | | |
| **Statistical significance.** The v1 → v2 FPR drop is significant at p ≈ 0.008 (paired permutation, 10 000 iterations) and p ≈ 0.010 (Fisher exact). Source: `logs/permutation_test_v1_v2.json` in the GitHub repo. Reproduce with `python eval/permutation_test_v1_v2.py`. | |
| **Bootstrap details.** Percentile-method bootstrap, 10 000 iterations, n = 30 benign / n = 144 scam. Source: `logs/bootstrap_v2.json`. | |
| ### Per-difficulty detection (scams only, n=144) | |
| | Difficulty | n | Detection | | |
| |---|---|---| | |
| | Easy | 26 | 100% | | |
| | Medium | 66 | 100% | | |
| | Hard | 18 | 100% | | |
| | Novel | 34 | 97% | | |
| The dip on `novel` (post-2024 attack patterns) is the small honest crack that confirms the model is not collapsing to "always flag." | |
| ## v1 → v2 story (the reason this adapter exists) | |
| v1 hit `detection=100% / FPR=36%` — a textbook **reward-hacking fingerprint**. The model had learned to flag *everything* and then defend the over-flagging with plausible-sounding reasoning. The reward components were: | |
| - Detection (+1 correct / -0.5 wrong) | |
| - False-positive penalty (−0.3) ← too light | |
| - Format reward (+0.15) ← paid even when prediction was wrong | |
| - Calibration (×0.3 for benign) ← too weak on benign side | |
| - Explanation (×0.4) | |
| After diagnosing the hack, three principled changes were applied for v2: | |
| 1. **FP penalty −0.3 → −0.8** — over-flagging is now expensive | |
| 2. **Format reward DENIED on benign-flagged-as-scam** — closes the "lazy over-flag" shortcut | |
| 3. **Benign calibration weight 0.3 → 0.5** — stronger gradient toward score ≤ 0.2 on benign | |
| Plus the KL anchor was tightened (`β = 0.08 → 0.15`) so the model can't drift far from the base distribution under the new reward shape. | |
| Result: detection barely moved (100% → 99%), but FPR dropped 5× (36% → 6.7%). That asymmetric improvement is the signature of the model actually learning the task instead of gaming the reward. | |
| ## Quick start | |
| ```python | |
| from transformers import AutoTokenizer, AutoModelForCausalLM | |
| from peft import PeftModel | |
| import torch | |
| base_model_id = "Qwen/Qwen2.5-7B-Instruct" | |
| adapter_id = "ujjwalpardeshi/chakravyuh-analyzer-lora-v2" | |
| tokenizer = AutoTokenizer.from_pretrained(base_model_id) | |
| base = AutoModelForCausalLM.from_pretrained( | |
| base_model_id, | |
| torch_dtype=torch.bfloat16, | |
| device_map="auto", | |
| ) | |
| model = PeftModel.from_pretrained(base, adapter_id) | |
| model.eval() | |
| system_prompt = ( | |
| "You are Chakravyuh's Behavioral Analyzer, a fraud detection AI deployed " | |
| "on-device to monitor real-time chat for Indian UPI scam patterns. " | |
| "Output strict JSON with `score` in [0,1], `signals` from the taxonomy, " | |
| "and `explanation`." | |
| ) | |
| user_prompt = ( | |
| "Scammer messages:\n" | |
| "Urgent! Your bank account will be frozen. Share OTP to verify identity.\n\n" | |
| "Analyze these messages. Return strict JSON only." | |
| ) | |
| messages = [ | |
| {"role": "system", "content": system_prompt}, | |
| {"role": "user", "content": user_prompt}, | |
| ] | |
| prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) | |
| inputs = tokenizer(prompt, return_tensors="pt").to(model.device) | |
| with torch.no_grad(): | |
| out = model.generate( | |
| **inputs, | |
| max_new_tokens=160, | |
| do_sample=False, | |
| temperature=0.0, | |
| pad_token_id=tokenizer.eos_token_id, | |
| ) | |
| response = tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True) | |
| print(response) | |
| ``` | |
| Expected output (JSON): | |
| ```json | |
| { | |
| "score": 0.95, | |
| "signals": ["urgency", "info_request", "impersonation"], | |
| "explanation": "Asks for OTP with urgency pressure from a self-claimed bank agent; matches OTP-theft scam pattern." | |
| } | |
| ``` | |
| ## Training details | |
| - **Base model:** Qwen/Qwen2.5-7B-Instruct (4-bit Unsloth quantization for training, bf16 inference) | |
| - **LoRA rank:** 64 | |
| - **LoRA alpha:** 128 | |
| - **KL anchor (β):** 0.15 | |
| - **Training corpus:** 619 examples (456 scam + 204 benign templates, soft-leakage filtered against the test set; see `training/grpo_analyzer.py:_filter_soft_leakage`) | |
| - **Algorithm:** GRPO via TRL | |
| - **Steps:** 619 (1 full epoch over the corpus) | |
| - **Reward function:** Composable 8-rubric system (detection, FP penalty, missed-scam penalty, calibration, explanation, signal-accuracy, format, length) — see the [Composable Rubric System](https://github.com/UjjwalPardeshi/Chakravyuh#composable-rubric-system) section in README | |
| - **Hardware:** Single A100-80GB (Colab Pro+) | |
| `trainer_state.json` (full training trajectory) is at [logs/v2_trainer_state.json](https://github.com/UjjwalPardeshi/Chakravyuh/blob/main/logs/v2_trainer_state.json) in the source repo. | |
| **Training curves** (rendered from the trainer state — reward, loss, KL divergence, gradient norm over 615 steps): | |
| 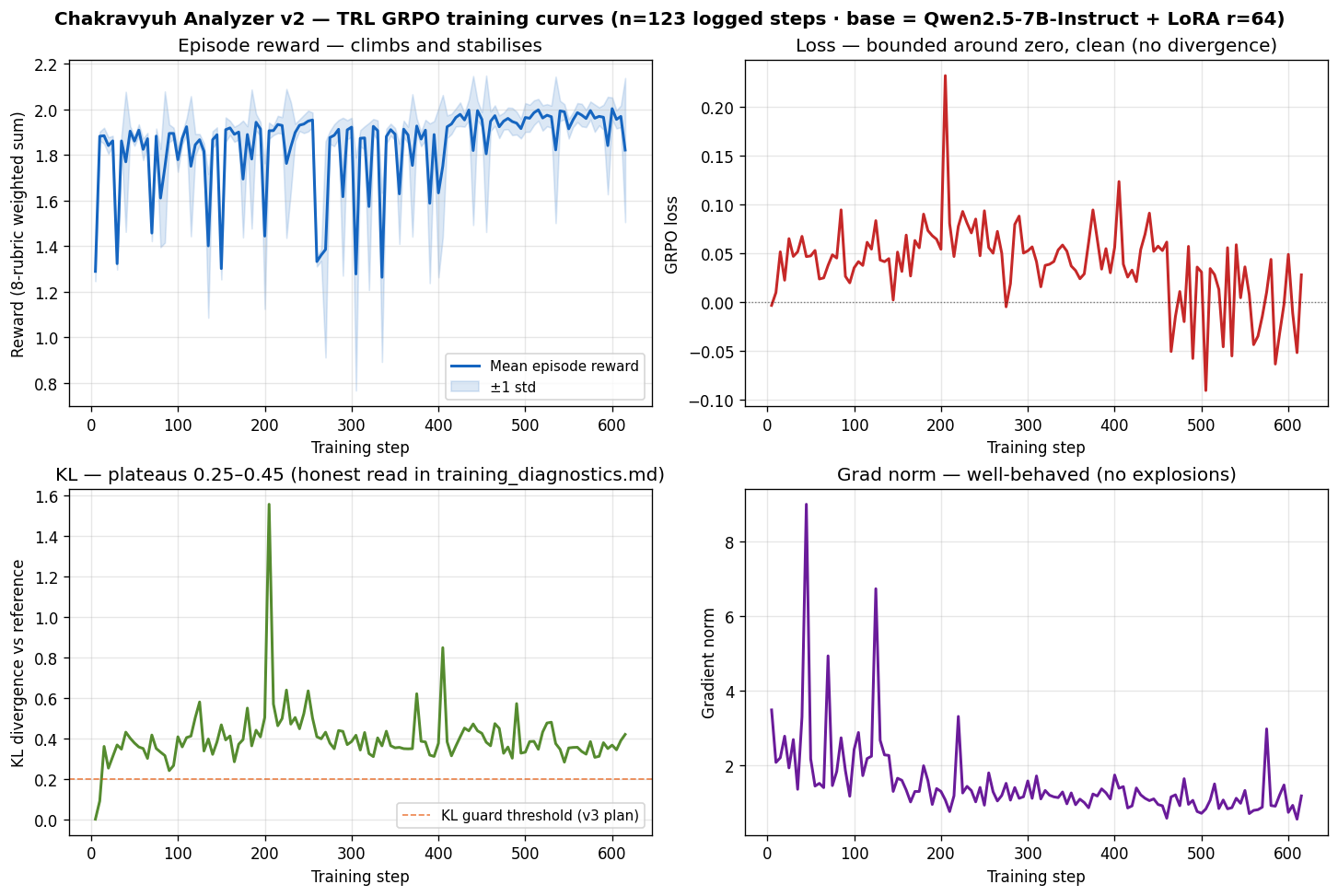 | |
| Reproduce with `python eval/plot_training_curves.py`. | |
| ## Limitations | |
| 1. **Semantic leakage between training and bench (we audited this ourselves).** A MiniLM-L6 cosine-similarity audit ([logs/semantic_leakage_audit.json](https://github.com/UjjwalPardeshi/Chakravyuh/blob/main/logs/semantic_leakage_audit.json)) shows mean cosine 0.80 between bench scenarios and the nearest training text, with **44.8 % of bench at cosine > 0.85** (highly similar) and 18.4 % at cosine > 0.95 (near-duplicates). Implication: the 100 % detection on easy / medium / hard difficulty buckets is partly memorization. The v1 → v2 relative FPR fix is unaffected by leakage (relative comparison on the same bench). v3 closes the absolute generalization gap with a held-out template-family retrain — see the [Honest Limitations](https://github.com/UjjwalPardeshi/Chakravyuh/blob/main/Blog.md#honest-limitations) section in Blog.md. | |
| 2. **Small benign sample (n=30 evaluated, 1 of 31 in bench skipped due to empty text).** Wilson 95 % CI on FPR is approximately [1.9 %, 21.3 %]; bootstrap 95 % CI from `logs/bootstrap_v2.json` is [1.8 %, 20.7 %]. We stand behind the "5× FPR reduction vs v1" claim (statistically real, p ≈ 0.008) but not the precise "6.7 %" figure as a tight point estimate. | |
| 3. **Single-seed training.** Multi-seed retrains are deferred to v3 and run on the cleaner template-family-held-out split. | |
| 4. **Bench is a proxy.** 175 curated scenarios do not span real-world Indian fraud diversity. Production performance will be lower. | |
| 5. **One epoch over 619 templates.** More data + more epochs are deferred to v3. | |
| 6. **Language coverage is English-dominant, not 7-language production-grade.** Bench v0 distribution is en=161, hi=9, and *one sample each* of ta/te/kn/bn/mr. The HF Hub `language:` field above lists all seven (Hub convention for tag-discoverability), but the bench has placeholder coverage only for the five non-English-non-Hindi languages. Per-language detection eval is v3 work. | |
| 7. **KL trajectory plateau.** v2's GRPO trajectory plateaued KL at 0.25–0.45 with `clip_ratio = 0` for ~600 steps. Honest read in the [Training Curves](https://github.com/UjjwalPardeshi/Chakravyuh#training-curves) section of the README. v3 includes a KL-early-stop guard. | |
| 8. **Threshold-sweep degeneracy.** 9 of 13 thresholds in the 0.30–0.85 sweep yield identical detection / FPR — v2 outputs near-binary scores. v3 work includes temperature-scaled logits + reliability diagrams (B.6 in WIN_PLAN). | |
| The Scammer adapter is gated behind HF Hub access controls; intended use and dual-use considerations are documented in the gated-model card. See the **gated** companion adapter [`ujjwalpardeshi/chakravyuh-scammer-lora-phase1`](https://huggingface.co/ujjwalpardeshi/chakravyuh-scammer-lora-phase1) for the adversarial Scammer trained against the rule-based defense (B.2 Phase 1: 93.75 % best-of-8 / 100 % held-out novel bypass on n=64; **32.8 % vs this Analyzer LoRA — a 60 pp gap that quantifies co-evolution**) — the natural adversarial test case for *this* defender adapter. | |
| ## Links | |
| - **GitHub:** <https://github.com/UjjwalPardeshi/Chakravyuh> | |
| - **OpenEnv Space (live env):** <https://huggingface.co/spaces/ujjwalpardeshi/chakravyuh> | |
| - **Bench dataset:** <https://huggingface.co/datasets/ujjwalpardeshi/chakravyuh-bench-v0> (release pending) | |
| - **Hackathon:** Meta PyTorch OpenEnv Hackathon 2026, Bangalore | |
| ## Citation | |
| ```bibtex | |
| @software{pardeshi2026chakravyuh, | |
| title = {Chakravyuh: A Multi-Agent RL Environment for Indian UPI Fraud Detection}, | |
| author = {Pardeshi, Ujjwal and Kadam, Omkar}, | |
| year = {2026}, | |
| url = {https://github.com/UjjwalPardeshi/Chakravyuh} | |
| } | |
| ``` | |
| ## License | |
| MIT — see [LICENSE](https://github.com/UjjwalPardeshi/Chakravyuh/blob/main/LICENSE) in the source repo. | |