
https://github.com/sid-rp/kube-sre-gym
title: Kube SRE Gym emoji: 🔧 colorFrom: red colorTo: yellow sdk: docker pinned: false app_port: 8000 base_path: /web tags: - openenv
Kube SRE Gym
Can a 0.6B model learn to be an on-call SRE — from scratch?
We gave a tiny language model a pager, a live Kubernetes cluster, and zero knowledge of what a pod even is. No pre-training on DevOps docs. No few-shot examples. Just a PagerDuty alert and a kubectl prompt.
Within 8 episodes, it learned to discover namespaces, read pod statuses, identify OOMKills from CrashLoopBackOffs, and apply the correct fix. By episode 4, it was resolving incidents faster than our hand-written baselines.
This is Kube SRE Gym — a self-improving environment where an RL agent learns to diagnose and fix real production Kubernetes failures through adversarial self-play, curriculum-driven difficulty, and GRPO.
1st Place, OpenEnv Hackathon (PyTorch + Cerebral Valley, $15K prize) | Built with OpenEnv v0.2.1 | Deployed on HF Spaces | Training via HF TRL in Colab
The Story: From Blind to On-Call
Act 1: The Cold Start
Episode 1. The agent receives its first alert: "CRITICAL: payment-gateway pods OOMKilled in payments namespace."
It has never seen Kubernetes before. It doesn't know what namespaces are, what pods look like, or that kubectl even exists. It tries random commands. Everything fails. Reward: -2.0.
Act 2: First Light
Episode 4. Something clicks. The agent discovers kubectl get pods -A — a single command that reveals the entire cluster. It sees OOMKilled in the STATUS column. It connects this to the alert. It runs kubectl set resources deployment/payment-gateway --limits=memory=128Mi -n payments.
The pod restarts. The health check passes. The LLM judge confirms resolution. Reward: +3.95.
Act 3: The Environment Fights Back
As the agent masters simple faults, the Adversarial Designer (Claude) notices. It starts creating compound incidents — an OOMKill in payments and a bad image in frontend simultaneously. Red herrings appear. The agent must learn to triage, not just react.
The Curriculum Controller tracks per-fault-type mastery and escalates: warmup → beginner → intermediate → advanced → expert. The training distribution adapts in real-time. No scenario is ever repeated.
Act 4: The Environment Improves Itself
Here's what made this project different from what we planned: the environment itself had bugs that training exposed.
During training, we discovered our kubectl command parser only accepted deployment/name format (with a slash). The model kept sending perfectly valid kubectl scale deployment frontend-cache --replicas=1 — and the environment rejected it every time. The model was right. Our environment was wrong.
We also found the LLM judge was truncating cluster snapshots at 2000 chars, cutting off pods alphabetically after payment-*. And a race condition between health checks and judge API calls was causing false negatives — pods would appear healthy during the health check but unhealthy by the time the judge snapshot ran.
The agent's failures taught us to fix the environment. This is the self-improvement loop we didn't expect — not just the model getting better, but the training infrastructure co-evolving with it.
Problem Statements Addressed
Primary: Statement 4 — Self-Improvement
Kube SRE Gym is an environment where the agent generates its own challenges, escalates difficulty, and improves through adaptive curricula — exactly the recursive skill amplification described in Statement 4.
- Adversarial self-play: Claude designs incidents that target the agent's tracked weaknesses
- Automatic curriculum: Difficulty escalates as per-fault-type mastery improves (warmup → beginner → intermediate → advanced → expert)
- No manual authoring: The training distribution adapts as the agent learns — infinite novel scenarios
- Co-evolutionary improvement: Training runs exposed environment bugs, making the platform itself better
Secondary: Statement 3.1 — World Modeling / Professional Tasks
The agent interacts with real Kubernetes tools and APIs — not mocked responses or shortcuts. It must maintain internal state across multi-step kubectl workflows and reason about causal effects of its actions on a live cluster.
- Real tool interaction: Every
kubectlcommand executes against a live GKE cluster - Multi-step workflows: Triage → investigate → fix → verify, with no shortcuts
- Persistent world state: Pod restarts, OOM events, and cascading failures are real K8s events
Partner Sub-Theme: Snorkel AI — Simulated Experts-in-the-Loop
The LLM judge uses three expert personas (Junior, Senior, Principal) with progressively stricter evaluation criteria, simulating interaction with subject-matter experts whose requirements change as the agent improves:
- Junior: Lenient scoring, partial credit, provides hints
- Senior: Standard SRE expectations, rewards systematic diagnosis
- Principal: High standards, penalizes inefficiency, rewards elegant fixes
How It Works
┌─────────────────────────────────────────────────────────────────────┐
│ SELF-IMPROVING LOOP │
│ │
│ ┌──────────┐ ┌───────────┐ ┌──────────┐ ┌────────────┐ │
│ │Adversarial│───►│ Real GKE │───►│ Agent │───►│ LLM Judge │ │
│ │ Designer │ │ Cluster │ │(Qwen 1.7B│ │(Claude/ │ │
│ │(Claude) │ │ │ │ + LoRA) │ │ Qwen 14B) │ │
│ └─────▲─────┘ └────────────┘ └────┬─────┘ └─────┬──────┘ │
│ │ │ │ │
│ │ ┌──────────────┐ │ reward │ │
│ │ │ Curriculum │◄───────┴────────────────┘ │
│ └─────────│ Controller │ │
│ weak spots │ (mastery │──► GRPO gradient update │
│ & difficulty │ tracking) │ (TRL + vLLM on H100) │
│ └──────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
The Loop
- Adversarial Designer (Claude) creates targeted incidents based on the agent's weak spots — single faults for warmup, multi-fault cascading failures for harder tiers
- Fault Injection executes real
kubectlcommands against a live GKE cluster (set memory to 4Mi, inject bad images, corrupt env vars, scale to zero) - Agent (Qwen3-1.7B + LoRA) receives a PagerDuty-style alert and must diagnose + fix using only kubectl commands — no hints about cluster topology
- LLM Judge scores each action for SRE workflow correctness (triage → investigate → fix → verify) and verifies resolution by checking actual cluster state
- Curriculum Controller tracks per-fault-type mastery and escalates difficulty — the agent gets harder scenarios as it improves
- GRPO computes advantages across 8 parallel rollouts and updates the policy — the agent gets better at fixing incidents it previously failed
What Makes This Different
- Real cluster, not a simulator — kubectl commands execute against live GKE pods. OOMKills, CrashLoopBackOffs, and ImagePullBackOffs are real Kubernetes events
- Self-generating scenarios — the adversarial designer creates new incident types targeting the agent's weaknesses, so the training distribution adapts as the agent learns
- Multi-layer verification — programmatic health checks (expected pod count, restart tracking, OOM detection) + LLM judge verification prevents false resolution
- No hardcoded knowledge — the agent prompt contains zero information about cluster topology, namespace names, or deployment details. It must discover everything via
kubectl get pods -A - Environment co-evolution — training revealed bugs in our own infrastructure, making the platform better alongside the agent
Architecture
H100 GPU (80GB) GKE Cluster (3 namespaces)
┌──────────────────────────────────┐ ┌─────────────────────────┐
│ │ │ payments/ │
│ OpenEnv Server :8000 │ K8s API │ payment-api (Flask) │
│ ├─ Environment (reset/step) │◄────────►│ payment-gateway │
│ ├─ Fault Injector │ │ payment-worker │
│ ├─ Curriculum Controller │ │ │
│ ├─ Adversarial Designer ──────────►Claude │ frontend/ │
│ └─ LLM Judge ─────────────────────►Claude │ web-app (nginx) │
│ │ │ frontend-cache │
│ GRPO Trainer (TRL 0.29.0) │ │ │
│ ├─ Qwen3-1.7B + LoRA (BF16) │ │ auth/ │
│ ├─ vLLM colocate (inference) │ │ auth-service │
│ └─ 8 rollouts × grad_accum=8 │ └─────────────────────────┘
│ │
└──────────────────────────────────┘
Failure Types
| Type | What Gets Injected | What Agent Must Do |
|---|---|---|
oom_kill |
Memory limit set to 4Mi | Increase to 128Mi via kubectl set resources |
crashloop |
Container command set to exit 1 |
Remove bad command via kubectl patch |
image_pull |
Image set to nginx:nonexistent-tag-99999 |
Fix image tag via kubectl set image |
bad_config |
DATABASE_URL pointed to wrong-host.invalid |
Correct env var via kubectl set env |
scale_zero |
Replicas set to 0 | Scale back up via kubectl scale |
liveness_probe |
Probe path set to /nonexistent |
Fix probe via kubectl patch |
multi-fault |
2-3 faults across different namespaces | Find and fix ALL faults |
Training Signal
The reward function has multiple layers to ensure clean GRPO signal:
- Per-step LLM judge score (-1.0 to +1.0) — evaluates SRE workflow quality (phase-aware: triage, investigate, fix, verify)
- Repeat penalty — -0.15 per repeated command (teaches exploration over repetition)
- Resolution bonus — +1.0 to +5.0 for confirmed fixes (efficiency-scaled: faster fixes get higher bonuses)
- Timeout penalty — failed episodes wiped to net -2.0 total reward
- Judge verification — LLM confirms fix is real by reviewing cluster state + action history
- Phase-order bonus — +0.2 for following correct SRE workflow, -0.3 for skipping phases
This produces clear separation: successful episodes score +3 to +8, failed episodes score -2.0. GRPO needs this variance to compute meaningful advantages.
Results
Training Run 1: Qwen2.5-1.5B — The Cold Start
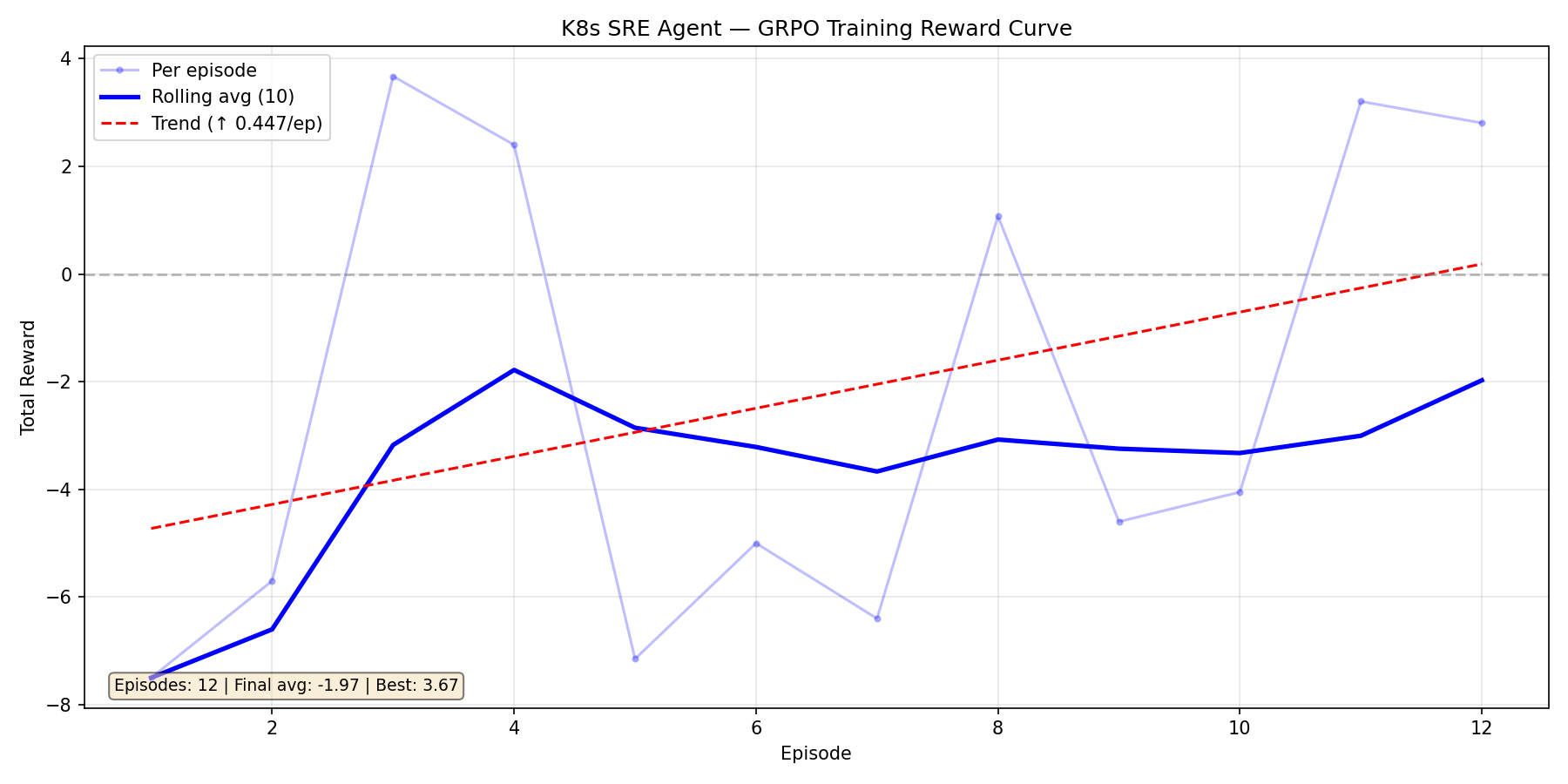
Our first attempt. 12 episodes, massive variance swinging between -7.5 and +3.7. The upward trend (+0.447/ep) was encouraging — the model was learning — but the signal was too noisy. We traced this to environment bugs: our command parser rejected valid kubectl syntax, the error penalty override was masking real progress, and the judge was truncating cluster snapshots.
The model was fighting two battles: learning Kubernetes AND working around our broken environment.
Training Run 2: Qwen3-1.7B — Too Much Reward, Too Soon
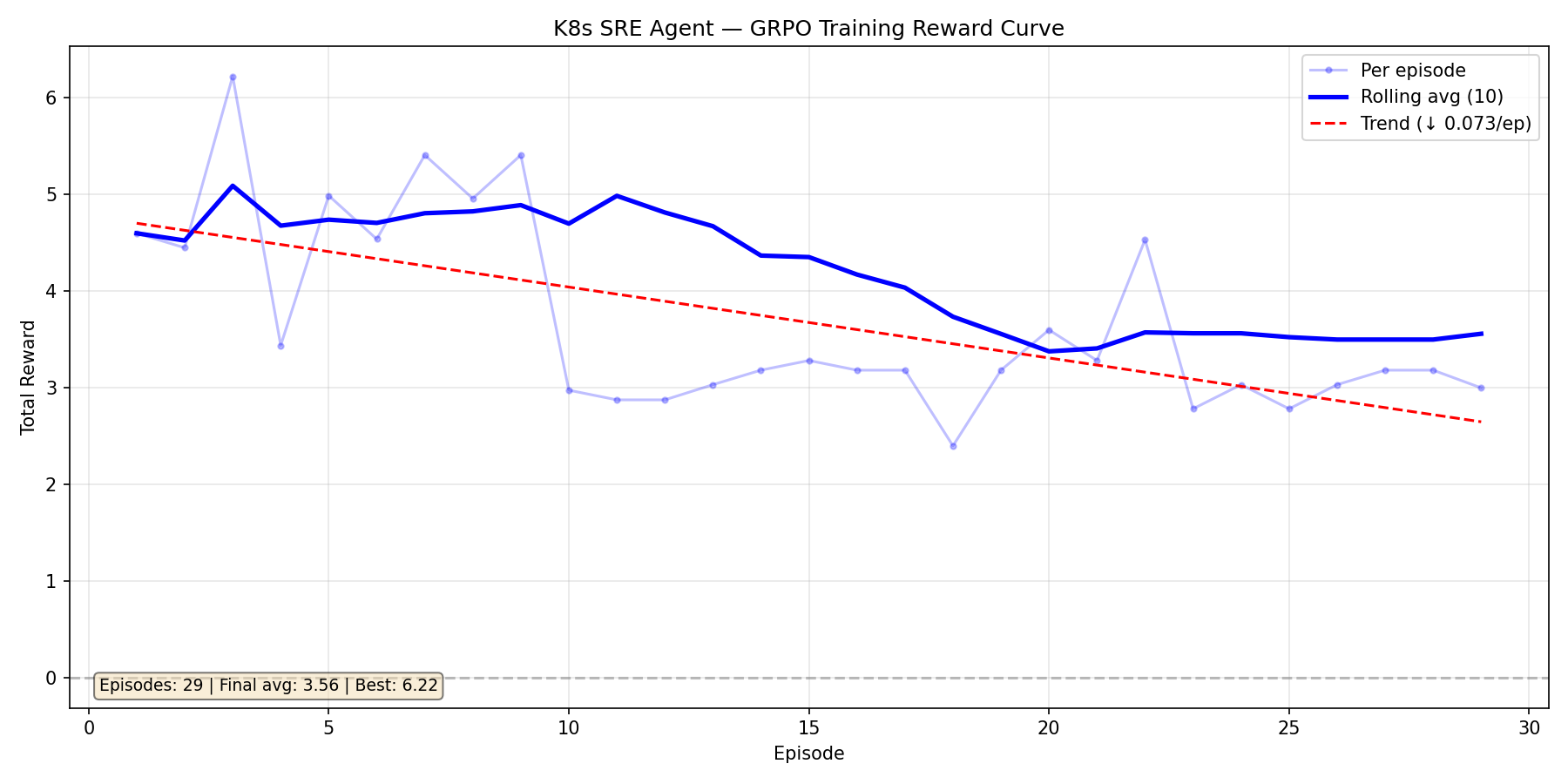
After fixing the environment bugs, we switched to Qwen3-1.7B. It started strong (avg ~5.0) but the reward signal was too generous — the model found a plateau at 3.0-3.5 and stopped improving. The slight downward trend (-0.073/ep) over 29 episodes told us the curriculum wasn't pushing hard enough.
This run taught us that a good environment needs to fight back. We tightened the reward function, added repeat-command penalties, and activated adversarial mode.
Training Run 3: Qwen3-1.7B — Environment Fights Back (Ongoing)
Current run with all fixes applied — adversarial scenarios, tighter rewards, repeat-command circuit breaker:
| Episode | Reward | Diagnosis | Fix |
|---|---|---|---|
| 1 | +1.80 | 0.30 | -0.10 |
| 2 | +5.38 | 0.30 | +0.10 |
| 3 | -2.50 | 0.70 | 0.00 |
| 4 | +6.58 | 0.70 | -0.60 |
| 5 | +5.45 | 0.70 | 0.00 |
| 6 | -2.00 | 0.55 | -0.60 |
| 7 | +6.79 | 0.70 | +0.50 |
| 8 | +6.35 | 0.20 | +0.40 |
Mean: 3.48 | Best: 6.79 — with real adversarial difficulty. The high-variance episodes (ep3, ep6 are negatives; ep4, ep7 are +6.5) show GRPO is getting the signal variance it needs to compute meaningful advantages.
What the agent learned (from reward signal alone)
- Run
kubectl get pods -Ato discover cluster topology - Identify fault types from pod STATUS column (OOMKilled, ImagePullBackOff, CrashLoopBackOff)
- Map fault types to correct fix commands (
set resources,set image,patch,scale) - Check ALL namespaces after each fix — there may be multiple faults
- Never repeat a failed command — try a different approach
What we learned (from the agent's failures)
- Our command parser was too strict — valid kubectl syntax was being rejected
- Judge snapshot truncation hid pods alphabetically after
payment-* - Error penalty override was masking real progress with false negatives
- Too-generous rewards cause plateaus — the environment must fight back
- The environment needs to evolve alongside the agent — static environments miss bugs
Training with HF TRL (Colab)
A complete training notebook is provided at kube_sre_gym_colab.ipynb using HF TRL's GRPO implementation. The notebook covers:
- Connect to the OpenEnv server on HF Spaces
- Configure GRPO training with TRL (
GRPOConfig,GRPOTrainer) - Run training episodes against the live environment
- Save checkpoints to HuggingFace Hub
Training uses TRL's experimental OpenEnv integration (trl.experimental.openenv.generate_rollout_completions) for seamless environment-trainer communication.
Quick Start
from kube_sre_gym import KubeSreGymAction, KubeSreGymEnv
with KubeSreGymEnv(base_url="http://localhost:8000") as client:
obs = client.reset()
print(obs.observation.command_output) # PagerDuty alert
obs = client.step(KubeSreGymAction(command="kubectl get pods -A"))
obs = client.step(KubeSreGymAction(command="kubectl describe pod payment-api-xxx -n payments"))
obs = client.step(KubeSreGymAction(command="fix: kubectl set resources deployment/payment-api --limits=memory=128Mi -n payments"))
# reward > 0 if fix is correct, episode done
Deployment on HF Spaces
The environment is deployed as a Docker-based HF Space using OpenEnv v0.2.1:
# Dockerfile uses openenv-base image
FROM ghcr.io/meta-pytorch/openenv-base:latest
# Serves OpenEnv HTTP/WebSocket API on port 8000
CMD ["uvicorn", "server.app:app", "--host", "0.0.0.0", "--port", "8000"]
Configuration in openenv.yaml:
spec_version: 1
name: kube_sre_gym
type: space
runtime: fastapi
app: server.app:app
port: 8000
Training on H100
Install
git clone https://huggingface.co/spaces/openenv-community/kube-sre-gym && cd kube-sre-gym
pip install -e ".[train]"
Set credentials
export K8S_TOKEN=<gke-bearer-token>
export K8S_ENDPOINT=<gke-api-url>
export K8S_CA_CERT=<base64-ca-cert>
export ANTHROPIC_API_KEY=<key> # for adversarial designer + judge
export HF_TOKEN=<token> # for pushing checkpoints
Launch (2 terminals)
# Terminal 1: Environment server
GYM_MODE=adversarial LLM_BACKEND=anthropic uv run server
# Terminal 2: GRPO training
python train.py --vllm-mode colocate --num-generations 8 --max-steps 8 --save-steps 1 \
--push-to-hub --hub-repo your-name/k8s-sre-agent
The curriculum automatically progresses: warmup (single faults) → intermediate (harder faults) → expert (multi-fault adversarial scenarios designed by Claude).
Evaluation
# Compare base model vs trained checkpoint
python eval.py
Runs both models through random adversarial scenarios and reports resolution rate, average reward, and steps-to-fix.
Configuration
| Variable | Description | Default |
|---|---|---|
K8S_TOKEN |
Bearer token for GKE | required |
K8S_ENDPOINT |
GKE API endpoint | required |
K8S_CA_CERT |
Base64 CA cert | required |
GYM_MODE |
standard or adversarial |
standard |
LLM_BACKEND |
openai, hf, or anthropic |
openai |
ANTHROPIC_API_KEY |
For adversarial designer + judge | required in adversarial mode |
MAX_STEPS |
Max commands per episode | 16 |
EVAL_MIN_DIFFICULTY |
Override min difficulty for eval | 0.0 |
Project Structure
kube-sre-gym/
├── train.py # GRPO training (TRL 0.29.0 + vLLM colocate)
├── eval.py # Base vs trained model comparison
├── kube_sre_gym_colab.ipynb # Google Colab training notebook (HF TRL)
├── plot_rewards.py # Reward curve visualization
├── models.py # Action, Observation, State dataclasses
├── client.py # KubeSreGymEnv sync client
├── Dockerfile # HF Spaces deployment (OpenEnv base image)
├── openenv.yaml # OpenEnv v0.2.1 Space config
├── server/
│ ├── kube_sre_gym_environment.py # Core env: reset → inject → step → judge → reward
│ ├── k8s_backend.py # K8s auth, execute, reset, health checks
│ ├── k8s_commands.py # kubectl command handlers (get/describe/logs/set/patch)
│ ├── k8s_injectors.py # Real fault injection via K8s API
│ ├── adversarial_designer.py # LLM designs multi-step incidents
│ ├── judge.py # LLMJudge + AdversarialJudge (phase-aware SRE scoring)
│ ├── curriculum.py # Progressive difficulty + mastery tracking
│ ├── scenario_generator.py # Fault scenario pool
│ ├── llm_client.py # OpenAI/HF/Anthropic wrapper
│ ├── constants.py # Cluster topology, healthy state definitions
│ └── app.py # FastAPI + WebSocket server
└── sample_app/
├── namespaces.yaml # payments, frontend, auth
└── base/ # Healthy deployment manifests
Key Design Decisions
Real cluster over simulator — Simulators can't reproduce the timing, state transitions, and failure modes of real Kubernetes. OOM kills happen when the kernel actually runs out of memory, not when a flag is set.
Adversarial self-play — The designer targets the agent's weaknesses (tracked by curriculum), creating an automatic curriculum that gets harder as the agent improves. No manual scenario authoring needed.
Multi-layer resolution check — Programmatic (expected pod count + restart tracking + OOM detection) + LLM judge verification. This prevents false resolution from OOM-flapping pods or partial fixes in multi-fault scenarios.
No topology in prompt — The agent receives zero information about namespaces, deployment names, or images. It must learn to discover the cluster layout via
kubectl get pods -A, making the learned policy transferable to any cluster.GRPO over PPO — GRPO compares multiple rollouts of the same prompt, producing stable advantages without a value function. Better suited for sparse, delayed rewards (most reward comes at episode end).
Environment co-evolution — We intentionally treat environment bugs as part of the story. When training exposed issues in our command parser, judge, and health checks, we fixed them — making the environment better alongside the agent. This is recursive self-improvement at the platform level.