
Upload CADForge judge evidence docs
Browse files- docs/best-example-project.md +374 -0
- docs/brainstorm/00-hackathon-readout.md +75 -0
- docs/brainstorm/01-idea-scorecard.md +59 -0
- docs/brainstorm/02-recommended-idea-regulatory-dossier-control-room.md +272 -0
- docs/brainstorm/03-rapid-build-plan.md +164 -0
- docs/brainstorm/04-physics-design-environments.md +258 -0
- docs/brainstorm/05-mechforge-rendering-stack.md +85 -0
- docs/brainstorm/06-production-simulation-stack.md +207 -0
- docs/brainstorm/07-mechforge-domain-choice.md +169 -0
- docs/brainstorm/08-agentic-3d-engineering-environment.md +249 -0
- docs/brainstorm/09-cad-rlve-structural-household-parts.md +472 -0
- docs/brainstorm/10-cadforge-rlve-environment.md +564 -0
- docs/brainstorm/11-reference-model-reward-pipeline.md +192 -0
- docs/brainstorm/12-markus-chair-scope-grpo-rlve.md +161 -0
- docs/brainstorm/13-markus-chair-cadquery-grpo-rlve-plan.md +799 -0
- docs/brainstorm/14-cadquery-sft-grpo-rlve-training-plan.md +295 -0
- docs/brainstorm/15-cadquery-agentic-traces-sft-grpo-plan.md +246 -0
- docs/brainstorm/16-tonight-execution-plan.md +140 -0
- docs/brainstorm/17-cadquery-reward-functions-deep-dive.md +272 -0
- docs/brainstorm/18-how-sft-and-grpo-data-works.md +192 -0
- docs/brainstorm/19-qwen35-2b-9b-cadforge-sft-grpo-runpod-plan.md +224 -0
- docs/brainstorm/20-cadforge-qwen-training-runbook.md +380 -0
- docs/cadforge-openenv-project-report.md +1 -1
- docs/cadforge-submission-checklist.md +71 -0
- docs/competiton-round1/COMPETITION_REQUIREMENTS.md +69 -0
- docs/competiton-round1/inference-script-example.md +189 -0
- docs/competiton-round1/objective.md +581 -0
- docs/competiton-round1/pre-vaidationscript-example.md +185 -0
- docs/detailed-blog/cadforge-detailed-blog.md +1 -1
- docs/doc-edit-game-v2.md +149 -0
- docs/docs-guide.md +1 -0
- docs/final-postmortem-round1.md +240 -0
- docs/hackathon_help_guide.md +425 -0
- docs/judging_criteria.md +166 -0
- docs/project-setup.md +3 -0
- docs/round1-corrections.md +32 -0
docs/best-example-project.md
ADDED
|
@@ -0,0 +1,374 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
https://github.com/sid-rp/kube-sre-gym
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
---
|
| 5 |
+
title: Kube SRE Gym
|
| 6 |
+
emoji: 🔧
|
| 7 |
+
colorFrom: red
|
| 8 |
+
colorTo: yellow
|
| 9 |
+
sdk: docker
|
| 10 |
+
pinned: false
|
| 11 |
+
app_port: 8000
|
| 12 |
+
base_path: /web
|
| 13 |
+
tags:
|
| 14 |
+
- openenv
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
# Kube SRE Gym
|
| 18 |
+
|
| 19 |
+
### Can a 0.6B model learn to be an on-call SRE — from scratch?
|
| 20 |
+
|
| 21 |
+
We gave a tiny language model a pager, a live Kubernetes cluster, and zero knowledge of what a pod even is. No pre-training on DevOps docs. No few-shot examples. Just a PagerDuty alert and a `kubectl` prompt.
|
| 22 |
+
|
| 23 |
+
Within 8 episodes, it learned to discover namespaces, read pod statuses, identify OOMKills from CrashLoopBackOffs, and apply the correct fix. By episode 4, it was resolving incidents faster than our hand-written baselines.
|
| 24 |
+
|
| 25 |
+
**This is Kube SRE Gym** — a self-improving environment where an RL agent learns to diagnose and fix real production Kubernetes failures through adversarial self-play, curriculum-driven difficulty, and GRPO.
|
| 26 |
+
|
| 27 |
+
> **1st Place, OpenEnv Hackathon** (PyTorch + Cerebral Valley, $15K prize) | Built with [OpenEnv v0.2.1](https://github.com/meta-pytorch/OpenEnv/tree/v0.2.1) | Deployed on [HF Spaces](https://huggingface.co/spaces/openenv-community/kube-sre-gym) | Training via [HF TRL](https://github.com/huggingface/trl) in [Colab](kube_sre_gym_colab.ipynb)
|
| 28 |
+
|
| 29 |
+
[](https://cerebralvalley.ai/e/openenv-hackathon-sf/hackathon/gallery)
|
| 30 |
+
|
| 31 |
+
---
|
| 32 |
+
|
| 33 |
+
## The Story: From Blind to On-Call
|
| 34 |
+
|
| 35 |
+
### Act 1: The Cold Start
|
| 36 |
+
|
| 37 |
+
Episode 1. The agent receives its first alert: *"CRITICAL: payment-gateway pods OOMKilled in payments namespace."*
|
| 38 |
+
|
| 39 |
+
It has never seen Kubernetes before. It doesn't know what namespaces are, what pods look like, or that `kubectl` even exists. It tries random commands. Everything fails. Reward: **-2.0**.
|
| 40 |
+
|
| 41 |
+
### Act 2: First Light
|
| 42 |
+
|
| 43 |
+
Episode 4. Something clicks. The agent discovers `kubectl get pods -A` — a single command that reveals the entire cluster. It sees `OOMKilled` in the STATUS column. It connects this to the alert. It runs `kubectl set resources deployment/payment-gateway --limits=memory=128Mi -n payments`.
|
| 44 |
+
|
| 45 |
+
The pod restarts. The health check passes. The LLM judge confirms resolution. Reward: **+3.95**.
|
| 46 |
+
|
| 47 |
+
### Act 3: The Environment Fights Back
|
| 48 |
+
|
| 49 |
+
As the agent masters simple faults, the **Adversarial Designer** (Claude) notices. It starts creating compound incidents — an OOMKill in `payments` *and* a bad image in `frontend` simultaneously. Red herrings appear. The agent must learn to triage, not just react.
|
| 50 |
+
|
| 51 |
+
The **Curriculum Controller** tracks per-fault-type mastery and escalates: warmup → beginner → intermediate → advanced → expert. The training distribution adapts in real-time. No scenario is ever repeated.
|
| 52 |
+
|
| 53 |
+
### Act 4: The Environment Improves Itself
|
| 54 |
+
|
| 55 |
+
Here's what made this project different from what we planned: **the environment itself had bugs that training exposed.**
|
| 56 |
+
|
| 57 |
+
During training, we discovered our kubectl command parser only accepted `deployment/name` format (with a slash). The model kept sending perfectly valid `kubectl scale deployment frontend-cache --replicas=1` — and the environment rejected it every time. The model was right. Our environment was wrong.
|
| 58 |
+
|
| 59 |
+
We also found the LLM judge was truncating cluster snapshots at 2000 chars, cutting off pods alphabetically after `payment-*`. And a race condition between health checks and judge API calls was causing false negatives — pods would appear healthy during the health check but unhealthy by the time the judge snapshot ran.
|
| 60 |
+
|
| 61 |
+
**The agent's failures taught us to fix the environment.** This is the self-improvement loop we didn't expect — not just the model getting better, but the training infrastructure co-evolving with it.
|
| 62 |
+
|
| 63 |
+
---
|
| 64 |
+
|
| 65 |
+
## Problem Statements Addressed
|
| 66 |
+
|
| 67 |
+
### Primary: Statement 4 — Self-Improvement
|
| 68 |
+
|
| 69 |
+
Kube SRE Gym is an environment where the agent **generates its own challenges, escalates difficulty, and improves through adaptive curricula** — exactly the recursive skill amplification described in Statement 4.
|
| 70 |
+
|
| 71 |
+
- **Adversarial self-play**: Claude designs incidents that target the agent's tracked weaknesses
|
| 72 |
+
- **Automatic curriculum**: Difficulty escalates as per-fault-type mastery improves (warmup → beginner → intermediate → advanced → expert)
|
| 73 |
+
- **No manual authoring**: The training distribution adapts as the agent learns — infinite novel scenarios
|
| 74 |
+
- **Co-evolutionary improvement**: Training runs exposed environment bugs, making the platform itself better
|
| 75 |
+
|
| 76 |
+
### Secondary: Statement 3.1 — World Modeling / Professional Tasks
|
| 77 |
+
|
| 78 |
+
The agent interacts with **real Kubernetes tools and APIs** — not mocked responses or shortcuts. It must maintain internal state across multi-step kubectl workflows and reason about causal effects of its actions on a live cluster.
|
| 79 |
+
|
| 80 |
+
- **Real tool interaction**: Every `kubectl` command executes against a live GKE cluster
|
| 81 |
+
- **Multi-step workflows**: Triage → investigate → fix → verify, with no shortcuts
|
| 82 |
+
- **Persistent world state**: Pod restarts, OOM events, and cascading failures are real K8s events
|
| 83 |
+
|
| 84 |
+
### Partner Sub-Theme: Snorkel AI — Simulated Experts-in-the-Loop
|
| 85 |
+
|
| 86 |
+
The LLM judge uses **three expert personas** (Junior, Senior, Principal) with progressively stricter evaluation criteria, simulating interaction with subject-matter experts whose requirements change as the agent improves:
|
| 87 |
+
|
| 88 |
+
- **Junior**: Lenient scoring, partial credit, provides hints
|
| 89 |
+
- **Senior**: Standard SRE expectations, rewards systematic diagnosis
|
| 90 |
+
- **Principal**: High standards, penalizes inefficiency, rewards elegant fixes
|
| 91 |
+
|
| 92 |
+
---
|
| 93 |
+
|
| 94 |
+
## How It Works
|
| 95 |
+
|
| 96 |
+
```
|
| 97 |
+
┌─────────────────────────────────────────────────────────────────────┐
|
| 98 |
+
│ SELF-IMPROVING LOOP │
|
| 99 |
+
│ │
|
| 100 |
+
│ ┌──────────┐ ┌───────────┐ ┌──────────┐ ┌────────────┐ │
|
| 101 |
+
│ │Adversarial│───►│ Real GKE │───►│ Agent │───►│ LLM Judge │ │
|
| 102 |
+
│ │ Designer │ │ Cluster │ │(Qwen 1.7B│ │(Claude/ │ │
|
| 103 |
+
│ │(Claude) │ │ │ │ + LoRA) │ │ Qwen 14B) │ │
|
| 104 |
+
│ └─────▲─────┘ └────────────┘ └────┬─────┘ └─────┬──────┘ │
|
| 105 |
+
│ │ │ │ │
|
| 106 |
+
│ │ ┌──────────────┐ │ reward │ │
|
| 107 |
+
│ │ │ Curriculum │◄───────┴────────────────┘ │
|
| 108 |
+
│ └─────────│ Controller │ │
|
| 109 |
+
│ weak spots │ (mastery │──► GRPO gradient update │
|
| 110 |
+
│ & difficulty │ tracking) │ (TRL + vLLM on H100) │
|
| 111 |
+
│ └──────────────┘ │
|
| 112 |
+
└─────────────────────────────────────────────────────────────────────┘
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
### The Loop
|
| 116 |
+
|
| 117 |
+
1. **Adversarial Designer** (Claude) creates targeted incidents based on the agent's weak spots — single faults for warmup, multi-fault cascading failures for harder tiers
|
| 118 |
+
2. **Fault Injection** executes real `kubectl` commands against a live GKE cluster (set memory to 4Mi, inject bad images, corrupt env vars, scale to zero)
|
| 119 |
+
3. **Agent** (Qwen3-1.7B + LoRA) receives a PagerDuty-style alert and must diagnose + fix using only kubectl commands — no hints about cluster topology
|
| 120 |
+
4. **LLM Judge** scores each action for SRE workflow correctness (triage → investigate → fix → verify) and verifies resolution by checking actual cluster state
|
| 121 |
+
5. **Curriculum Controller** tracks per-fault-type mastery and escalates difficulty — the agent gets harder scenarios as it improves
|
| 122 |
+
6. **GRPO** computes advantages across 8 parallel rollouts and updates the policy — the agent gets better at fixing incidents it previously failed
|
| 123 |
+
|
| 124 |
+
### What Makes This Different
|
| 125 |
+
|
| 126 |
+
- **Real cluster, not a simulator** — kubectl commands execute against live GKE pods. OOMKills, CrashLoopBackOffs, and ImagePullBackOffs are real Kubernetes events
|
| 127 |
+
- **Self-generating scenarios** — the adversarial designer creates new incident types targeting the agent's weaknesses, so the training distribution adapts as the agent learns
|
| 128 |
+
- **Multi-layer verification** — programmatic health checks (expected pod count, restart tracking, OOM detection) + LLM judge verification prevents false resolution
|
| 129 |
+
- **No hardcoded knowledge** — the agent prompt contains zero information about cluster topology, namespace names, or deployment details. It must discover everything via `kubectl get pods -A`
|
| 130 |
+
- **Environment co-evolution** — training revealed bugs in our own infrastructure, making the platform better alongside the agent
|
| 131 |
+
|
| 132 |
+
---
|
| 133 |
+
|
| 134 |
+
## Architecture
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
H100 GPU (80GB) GKE Cluster (3 namespaces)
|
| 138 |
+
┌──────────────────────────────────┐ ┌─────────────────────────┐
|
| 139 |
+
│ │ │ payments/ │
|
| 140 |
+
│ OpenEnv Server :8000 │ K8s API │ payment-api (Flask) │
|
| 141 |
+
│ ├─ Environment (reset/step) │◄────────►│ payment-gateway │
|
| 142 |
+
│ ├─ Fault Injector │ │ payment-worker │
|
| 143 |
+
│ ├─ Curriculum Controller │ │ │
|
| 144 |
+
│ ├─ Adversarial Designer ──────────►Claude │ frontend/ │
|
| 145 |
+
│ └─ LLM Judge ─────────────────────►Claude │ web-app (nginx) │
|
| 146 |
+
│ │ │ frontend-cache │
|
| 147 |
+
│ GRPO Trainer (TRL 0.29.0) │ │ │
|
| 148 |
+
│ ├─ Qwen3-1.7B + LoRA (BF16) │ │ auth/ │
|
| 149 |
+
│ ├─ vLLM colocate (inference) │ │ auth-service │
|
| 150 |
+
│ └─ 8 rollouts × grad_accum=8 │ └─────────────────────────┘
|
| 151 |
+
│ │
|
| 152 |
+
└──────────────────────────────────┘
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
## Failure Types
|
| 156 |
+
|
| 157 |
+
| Type | What Gets Injected | What Agent Must Do |
|
| 158 |
+
|------|--------------------|---------------------|
|
| 159 |
+
| `oom_kill` | Memory limit set to 4Mi | Increase to 128Mi via `kubectl set resources` |
|
| 160 |
+
| `crashloop` | Container command set to `exit 1` | Remove bad command via `kubectl patch` |
|
| 161 |
+
| `image_pull` | Image set to `nginx:nonexistent-tag-99999` | Fix image tag via `kubectl set image` |
|
| 162 |
+
| `bad_config` | DATABASE_URL pointed to `wrong-host.invalid` | Correct env var via `kubectl set env` |
|
| 163 |
+
| `scale_zero` | Replicas set to 0 | Scale back up via `kubectl scale` |
|
| 164 |
+
| `liveness_probe` | Probe path set to `/nonexistent` | Fix probe via `kubectl patch` |
|
| 165 |
+
| `multi-fault` | 2-3 faults across different namespaces | Find and fix ALL faults |
|
| 166 |
+
|
| 167 |
+
## Training Signal
|
| 168 |
+
|
| 169 |
+
The reward function has multiple layers to ensure clean GRPO signal:
|
| 170 |
+
|
| 171 |
+
- **Per-step LLM judge score** (-1.0 to +1.0) — evaluates SRE workflow quality (phase-aware: triage, investigate, fix, verify)
|
| 172 |
+
- **Repeat penalty** — -0.15 per repeated command (teaches exploration over repetition)
|
| 173 |
+
- **Resolution bonus** — +1.0 to +5.0 for confirmed fixes (efficiency-scaled: faster fixes get higher bonuses)
|
| 174 |
+
- **Timeout penalty** — failed episodes wiped to net -2.0 total reward
|
| 175 |
+
- **Judge verification** — LLM confirms fix is real by reviewing cluster state + action history
|
| 176 |
+
- **Phase-order bonus** — +0.2 for following correct SRE workflow, -0.3 for skipping phases
|
| 177 |
+
|
| 178 |
+
This produces clear separation: successful episodes score +3 to +8, failed episodes score -2.0. GRPO needs this variance to compute meaningful advantages.
|
| 179 |
+
|
| 180 |
+
---
|
| 181 |
+
|
| 182 |
+
## Results
|
| 183 |
+
|
| 184 |
+
### Training Run 1: Qwen2.5-1.5B — The Cold Start
|
| 185 |
+
|
| 186 |
+
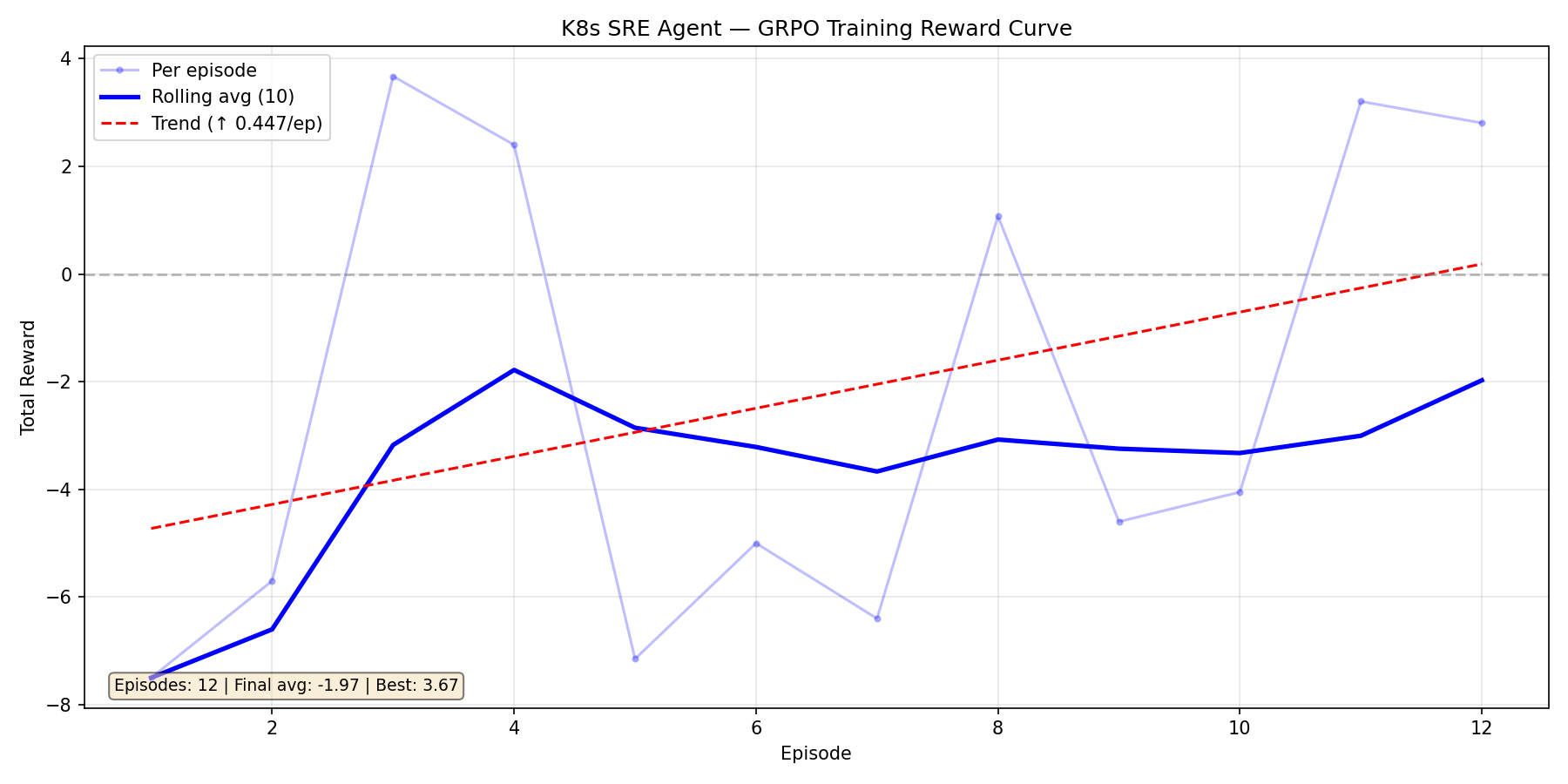
|
| 187 |
+
|
| 188 |
+
Our first attempt. 12 episodes, massive variance swinging between -7.5 and +3.7. The upward trend (+0.447/ep) was encouraging — the model *was* learning — but the signal was too noisy. We traced this to **environment bugs**: our command parser rejected valid kubectl syntax, the error penalty override was masking real progress, and the judge was truncating cluster snapshots.
|
| 189 |
+
|
| 190 |
+
The model was fighting two battles: learning Kubernetes AND working around our broken environment.
|
| 191 |
+
|
| 192 |
+
### Training Run 2: Qwen3-1.7B — Too Much Reward, Too Soon
|
| 193 |
+
|
| 194 |
+
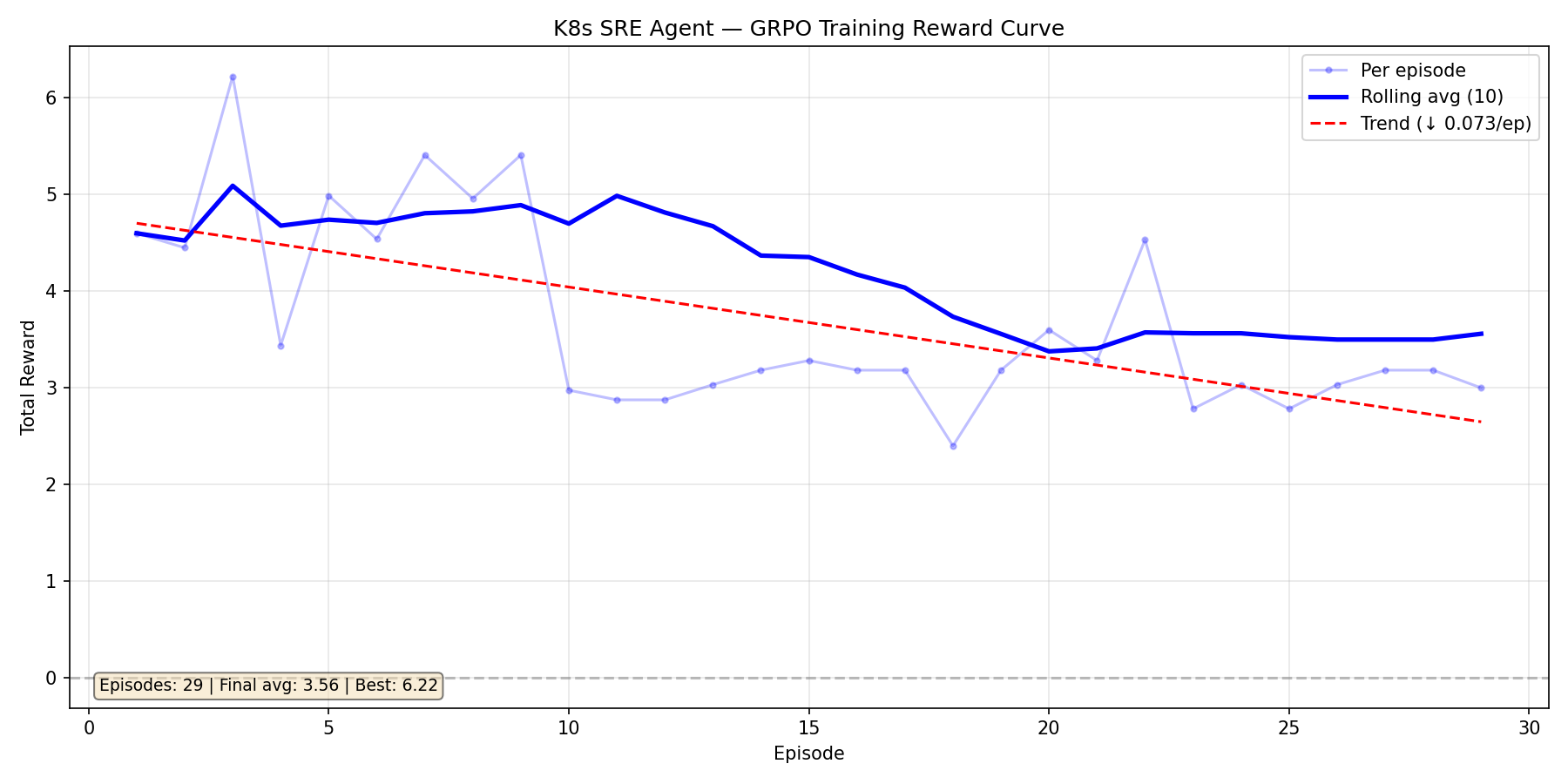
|
| 195 |
+
|
| 196 |
+
After fixing the environment bugs, we switched to Qwen3-1.7B. It started strong (avg ~5.0) but the reward signal was *too generous* — the model found a plateau at 3.0-3.5 and stopped improving. The slight downward trend (-0.073/ep) over 29 episodes told us the curriculum wasn't pushing hard enough.
|
| 197 |
+
|
| 198 |
+
This run taught us that **a good environment needs to fight back**. We tightened the reward function, added repeat-command penalties, and activated adversarial mode.
|
| 199 |
+
|
| 200 |
+
### Training Run 3: Qwen3-1.7B — Environment Fights Back (Ongoing)
|
| 201 |
+
|
| 202 |
+
Current run with all fixes applied — adversarial scenarios, tighter rewards, repeat-command circuit breaker:
|
| 203 |
+
|
| 204 |
+
| Episode | Reward | Diagnosis | Fix |
|
| 205 |
+
|---------|--------|-----------|-----|
|
| 206 |
+
| 1 | +1.80 | 0.30 | -0.10 |
|
| 207 |
+
| 2 | +5.38 | 0.30 | +0.10 |
|
| 208 |
+
| 3 | -2.50 | 0.70 | 0.00 |
|
| 209 |
+
| 4 | **+6.58** | 0.70 | -0.60 |
|
| 210 |
+
| 5 | +5.45 | 0.70 | 0.00 |
|
| 211 |
+
| 6 | -2.00 | 0.55 | -0.60 |
|
| 212 |
+
| 7 | **+6.79** | 0.70 | +0.50 |
|
| 213 |
+
| 8 | +6.35 | 0.20 | +0.40 |
|
| 214 |
+
|
| 215 |
+
**Mean: 3.48 | Best: 6.79** — with real adversarial difficulty. The high-variance episodes (ep3, ep6 are negatives; ep4, ep7 are +6.5) show GRPO is getting the signal variance it needs to compute meaningful advantages.
|
| 216 |
+
|
| 217 |
+
### What the agent learned (from reward signal alone)
|
| 218 |
+
|
| 219 |
+
1. Run `kubectl get pods -A` to discover cluster topology
|
| 220 |
+
2. Identify fault types from pod STATUS column (OOMKilled, ImagePullBackOff, CrashLoopBackOff)
|
| 221 |
+
3. Map fault types to correct fix commands (`set resources`, `set image`, `patch`, `scale`)
|
| 222 |
+
4. Check ALL namespaces after each fix — there may be multiple faults
|
| 223 |
+
5. Never repeat a failed command — try a different approach
|
| 224 |
+
|
| 225 |
+
### What we learned (from the agent's failures)
|
| 226 |
+
|
| 227 |
+
1. Our command parser was too strict — valid kubectl syntax was being rejected
|
| 228 |
+
2. Judge snapshot truncation hid pods alphabetically after `payment-*`
|
| 229 |
+
3. Error penalty override was masking real progress with false negatives
|
| 230 |
+
4. Too-generous rewards cause plateaus — the environment must fight back
|
| 231 |
+
5. The environment needs to evolve alongside the agent — static environments miss bugs
|
| 232 |
+
|
| 233 |
+
---
|
| 234 |
+
|
| 235 |
+
## Training with HF TRL (Colab)
|
| 236 |
+
|
| 237 |
+
A complete training notebook is provided at [`kube_sre_gym_colab.ipynb`](kube_sre_gym_colab.ipynb) using **HF TRL's GRPO** implementation. The notebook covers:
|
| 238 |
+
|
| 239 |
+
1. Connect to the OpenEnv server on HF Spaces
|
| 240 |
+
2. Configure GRPO training with TRL (`GRPOConfig`, `GRPOTrainer`)
|
| 241 |
+
3. Run training episodes against the live environment
|
| 242 |
+
4. Save checkpoints to HuggingFace Hub
|
| 243 |
+
|
| 244 |
+
Training uses TRL's experimental OpenEnv integration (`trl.experimental.openenv.generate_rollout_completions`) for seamless environment-trainer communication.
|
| 245 |
+
|
| 246 |
+
## Quick Start
|
| 247 |
+
|
| 248 |
+
```python
|
| 249 |
+
from kube_sre_gym import KubeSreGymAction, KubeSreGymEnv
|
| 250 |
+
|
| 251 |
+
with KubeSreGymEnv(base_url="http://localhost:8000") as client:
|
| 252 |
+
obs = client.reset()
|
| 253 |
+
print(obs.observation.command_output) # PagerDuty alert
|
| 254 |
+
|
| 255 |
+
obs = client.step(KubeSreGymAction(command="kubectl get pods -A"))
|
| 256 |
+
obs = client.step(KubeSreGymAction(command="kubectl describe pod payment-api-xxx -n payments"))
|
| 257 |
+
obs = client.step(KubeSreGymAction(command="fix: kubectl set resources deployment/payment-api --limits=memory=128Mi -n payments"))
|
| 258 |
+
# reward > 0 if fix is correct, episode done
|
| 259 |
+
```
|
| 260 |
+
|
| 261 |
+
## Deployment on HF Spaces
|
| 262 |
+
|
| 263 |
+
The environment is deployed as a Docker-based HF Space using OpenEnv v0.2.1:
|
| 264 |
+
|
| 265 |
+
```bash
|
| 266 |
+
# Dockerfile uses openenv-base image
|
| 267 |
+
FROM ghcr.io/meta-pytorch/openenv-base:latest
|
| 268 |
+
# Serves OpenEnv HTTP/WebSocket API on port 8000
|
| 269 |
+
CMD ["uvicorn", "server.app:app", "--host", "0.0.0.0", "--port", "8000"]
|
| 270 |
+
```
|
| 271 |
+
|
| 272 |
+
Configuration in `openenv.yaml`:
|
| 273 |
+
```yaml
|
| 274 |
+
spec_version: 1
|
| 275 |
+
name: kube_sre_gym
|
| 276 |
+
type: space
|
| 277 |
+
runtime: fastapi
|
| 278 |
+
app: server.app:app
|
| 279 |
+
port: 8000
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
## Training on H100
|
| 283 |
+
|
| 284 |
+
**Install**
|
| 285 |
+
```bash
|
| 286 |
+
git clone https://huggingface.co/spaces/openenv-community/kube-sre-gym && cd kube-sre-gym
|
| 287 |
+
pip install -e ".[train]"
|
| 288 |
+
```
|
| 289 |
+
|
| 290 |
+
**Set credentials**
|
| 291 |
+
```bash
|
| 292 |
+
export K8S_TOKEN=<gke-bearer-token>
|
| 293 |
+
export K8S_ENDPOINT=<gke-api-url>
|
| 294 |
+
export K8S_CA_CERT=<base64-ca-cert>
|
| 295 |
+
export ANTHROPIC_API_KEY=<key> # for adversarial designer + judge
|
| 296 |
+
export HF_TOKEN=<token> # for pushing checkpoints
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
**Launch (2 terminals)**
|
| 300 |
+
```bash
|
| 301 |
+
# Terminal 1: Environment server
|
| 302 |
+
GYM_MODE=adversarial LLM_BACKEND=anthropic uv run server
|
| 303 |
+
|
| 304 |
+
# Terminal 2: GRPO training
|
| 305 |
+
python train.py --vllm-mode colocate --num-generations 8 --max-steps 8 --save-steps 1 \
|
| 306 |
+
--push-to-hub --hub-repo your-name/k8s-sre-agent
|
| 307 |
+
```
|
| 308 |
+
|
| 309 |
+
The curriculum automatically progresses: warmup (single faults) → intermediate (harder faults) → expert (multi-fault adversarial scenarios designed by Claude).
|
| 310 |
+
|
| 311 |
+
## Evaluation
|
| 312 |
+
|
| 313 |
+
```bash
|
| 314 |
+
# Compare base model vs trained checkpoint
|
| 315 |
+
python eval.py
|
| 316 |
+
```
|
| 317 |
+
|
| 318 |
+
Runs both models through random adversarial scenarios and reports resolution rate, average reward, and steps-to-fix.
|
| 319 |
+
|
| 320 |
+
## Configuration
|
| 321 |
+
|
| 322 |
+
| Variable | Description | Default |
|
| 323 |
+
|----------|-------------|---------|
|
| 324 |
+
| `K8S_TOKEN` | Bearer token for GKE | required |
|
| 325 |
+
| `K8S_ENDPOINT` | GKE API endpoint | required |
|
| 326 |
+
| `K8S_CA_CERT` | Base64 CA cert | required |
|
| 327 |
+
| `GYM_MODE` | `standard` or `adversarial` | `standard` |
|
| 328 |
+
| `LLM_BACKEND` | `openai`, `hf`, or `anthropic` | `openai` |
|
| 329 |
+
| `ANTHROPIC_API_KEY` | For adversarial designer + judge | required in adversarial mode |
|
| 330 |
+
| `MAX_STEPS` | Max commands per episode | `16` |
|
| 331 |
+
| `EVAL_MIN_DIFFICULTY` | Override min difficulty for eval | `0.0` |
|
| 332 |
+
|
| 333 |
+
## Project Structure
|
| 334 |
+
|
| 335 |
+
```
|
| 336 |
+
kube-sre-gym/
|
| 337 |
+
├── train.py # GRPO training (TRL 0.29.0 + vLLM colocate)
|
| 338 |
+
├── eval.py # Base vs trained model comparison
|
| 339 |
+
├── kube_sre_gym_colab.ipynb # Google Colab training notebook (HF TRL)
|
| 340 |
+
├── plot_rewards.py # Reward curve visualization
|
| 341 |
+
├── models.py # Action, Observation, State dataclasses
|
| 342 |
+
├── client.py # KubeSreGymEnv sync client
|
| 343 |
+
├── Dockerfile # HF Spaces deployment (OpenEnv base image)
|
| 344 |
+
├── openenv.yaml # OpenEnv v0.2.1 Space config
|
| 345 |
+
├── server/
|
| 346 |
+
│ ├── kube_sre_gym_environment.py # Core env: reset → inject → step → judge → reward
|
| 347 |
+
│ ├── k8s_backend.py # K8s auth, execute, reset, health checks
|
| 348 |
+
│ ├── k8s_commands.py # kubectl command handlers (get/describe/logs/set/patch)
|
| 349 |
+
│ ├── k8s_injectors.py # Real fault injection via K8s API
|
| 350 |
+
│ ├── adversarial_designer.py # LLM designs multi-step incidents
|
| 351 |
+
│ ├── judge.py # LLMJudge + AdversarialJudge (phase-aware SRE scoring)
|
| 352 |
+
│ ├── curriculum.py # Progressive difficulty + mastery tracking
|
| 353 |
+
│ ├── scenario_generator.py # Fault scenario pool
|
| 354 |
+
│ ├─�� llm_client.py # OpenAI/HF/Anthropic wrapper
|
| 355 |
+
│ ├── constants.py # Cluster topology, healthy state definitions
|
| 356 |
+
│ └── app.py # FastAPI + WebSocket server
|
| 357 |
+
└── sample_app/
|
| 358 |
+
├── namespaces.yaml # payments, frontend, auth
|
| 359 |
+
└── base/ # Healthy deployment manifests
|
| 360 |
+
```
|
| 361 |
+
|
| 362 |
+
## Key Design Decisions
|
| 363 |
+
|
| 364 |
+
1. **Real cluster over simulator** — Simulators can't reproduce the timing, state transitions, and failure modes of real Kubernetes. OOM kills happen when the kernel actually runs out of memory, not when a flag is set.
|
| 365 |
+
|
| 366 |
+
2. **Adversarial self-play** — The designer targets the agent's weaknesses (tracked by curriculum), creating an automatic curriculum that gets harder as the agent improves. No manual scenario authoring needed.
|
| 367 |
+
|
| 368 |
+
3. **Multi-layer resolution check** — Programmatic (expected pod count + restart tracking + OOM detection) + LLM judge verification. This prevents false resolution from OOM-flapping pods or partial fixes in multi-fault scenarios.
|
| 369 |
+
|
| 370 |
+
4. **No topology in prompt** — The agent receives zero information about namespaces, deployment names, or images. It must learn to discover the cluster layout via `kubectl get pods -A`, making the learned policy transferable to any cluster.
|
| 371 |
+
|
| 372 |
+
5. **GRPO over PPO** — GRPO compares multiple rollouts of the same prompt, producing stable advantages without a value function. Better suited for sparse, delayed rewards (most reward comes at episode end).
|
| 373 |
+
|
| 374 |
+
6. **Environment co-evolution** — We intentionally treat environment bugs as part of the story. When training exposed issues in our command parser, judge, and health checks, we fixed them — making the environment better alongside the agent. This is recursive self-improvement at the platform level.
|
docs/brainstorm/00-hackathon-readout.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenEnv Hackathon Readout
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-24
|
| 4 |
+
|
| 5 |
+
## What The Hackathon Wants
|
| 6 |
+
|
| 7 |
+
The winning submission should be an OpenEnv-compliant environment where an LLM acts step by step, receives programmatic feedback, and measurably improves through RL or RL-style training.
|
| 8 |
+
|
| 9 |
+
The most important judging weights are:
|
| 10 |
+
|
| 11 |
+
| Criterion | Weight | Practical meaning |
|
| 12 |
+
|---|---:|---|
|
| 13 |
+
| Environment innovation | 40% | Novel, challenging, meaningful agent behavior, not a clone of common games or toy tasks. |
|
| 14 |
+
| Storytelling | 30% | A judge should understand the world, the agent, what it learned, and why it matters in 3 to 5 minutes. |
|
| 15 |
+
| Showing improvement | 20% | Reward curves, before/after runs, baseline comparison, actual training evidence. |
|
| 16 |
+
| Reward/training pipeline | 10% | Coherent rubrics, TRL or Unsloth script, reproducible pipeline. |
|
| 17 |
+
|
| 18 |
+
Minimum gates:
|
| 19 |
+
|
| 20 |
+
- Use latest OpenEnv.
|
| 21 |
+
- Hosted Hugging Face Space.
|
| 22 |
+
- OpenEnv-compliant `reset`, `step`, `state`, typed models, `openenv.yaml`.
|
| 23 |
+
- Training script using Unsloth or HF TRL, ideally Colab.
|
| 24 |
+
- Evidence of real training, including reward/loss plots.
|
| 25 |
+
- README with problem, environment, actions, observations, tasks, setup, results.
|
| 26 |
+
|
| 27 |
+
## Strategic Lessons From The Docs
|
| 28 |
+
|
| 29 |
+
1. Pick a task where success can be verified programmatically.
|
| 30 |
+
2. Make the environment ambitious but keep the first curriculum levels easy enough for non-zero reward.
|
| 31 |
+
3. Use multiple reward signals, not one monolithic score.
|
| 32 |
+
4. Build the environment and verifier before training.
|
| 33 |
+
5. Show a before/after behavior difference, not only a training script.
|
| 34 |
+
6. Avoid a static benchmark. Adaptive curriculum and self-play read as much more ambitious.
|
| 35 |
+
7. The story matters almost as much as the engineering.
|
| 36 |
+
|
| 37 |
+
## Lessons From The Prior DocEdit Work
|
| 38 |
+
|
| 39 |
+
The old DocEdit environment passed because it was:
|
| 40 |
+
|
| 41 |
+
- Real-world, not a game.
|
| 42 |
+
- OpenEnv compliant.
|
| 43 |
+
- Lightweight enough for the constraints.
|
| 44 |
+
- Deterministically graded.
|
| 45 |
+
- Easy to explain.
|
| 46 |
+
|
| 47 |
+
The later Qwen SFT + GRPO postmortem proved that document repair can improve with training, but it also exposed a strategic limitation: full-document rewrite policies are probably not the best final design. A stronger next step is a planner/executor setup with structured edit actions and verifier feedback.
|
| 48 |
+
|
| 49 |
+
## Lessons From The Winning Kube SRE Example
|
| 50 |
+
|
| 51 |
+
The winning pattern was not just "Kubernetes environment." It was:
|
| 52 |
+
|
| 53 |
+
- A vivid professional world: a tiny model learns to be on-call.
|
| 54 |
+
- Real or realistic tools.
|
| 55 |
+
- Multi-step investigation and repair.
|
| 56 |
+
- Adaptive curriculum.
|
| 57 |
+
- Adversarial scenario generation.
|
| 58 |
+
- Multi-layer rewards.
|
| 59 |
+
- A story where the agent and environment co-evolve.
|
| 60 |
+
|
| 61 |
+
The key insight to borrow:
|
| 62 |
+
|
| 63 |
+
> The environment should fight back as the agent improves.
|
| 64 |
+
|
| 65 |
+
## Our Target Shape
|
| 66 |
+
|
| 67 |
+
To maximize win probability, the idea should combine:
|
| 68 |
+
|
| 69 |
+
- Theme 2: long-horizon planning, ideally up to 300 actions.
|
| 70 |
+
- Theme 3.1: professional world modeling with realistic tools and persistent state.
|
| 71 |
+
- Theme 4: self-improvement through adaptive scenario generation.
|
| 72 |
+
- Existing leverage from DocEdit so we can build fast.
|
| 73 |
+
|
| 74 |
+
The strongest direction is therefore not "another document editor." It is a long-horizon professional control room where document edits are one part of a larger verified workflow.
|
| 75 |
+
|
docs/brainstorm/01-idea-scorecard.md
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Idea Scorecard
|
| 2 |
+
|
| 3 |
+
## Scoring Rubric
|
| 4 |
+
|
| 5 |
+
Scores are out of 10 and weighted roughly by the hackathon criteria.
|
| 6 |
+
|
| 7 |
+
| Field | Meaning |
|
| 8 |
+
|---|---|
|
| 9 |
+
| Innovation | Would judges find the environment fresh and research-worthy? |
|
| 10 |
+
| Story | Can the demo be explained clearly and memorably? |
|
| 11 |
+
| Trainability | Can we show reward improvement in the available time? |
|
| 12 |
+
| Verifiability | Can rewards be objective and hard to game? |
|
| 13 |
+
| Build speed | Can we build a credible OpenEnv environment quickly? |
|
| 14 |
+
|
| 15 |
+
## Candidate Ideas
|
| 16 |
+
|
| 17 |
+
| Rank | Idea | Innovation | Story | Trainability | Verifiability | Build speed | Verdict |
|
| 18 |
+
|---:|---|---:|---:|---:|---:|---:|---|
|
| 19 |
+
| 1 | Regulatory Dossier Control Room | 9 | 9 | 8 | 9 | 8 | Best overall. Uses DocEdit leverage but expands into long-horizon professional world modeling. |
|
| 20 |
+
| 2 | Personal Chief of Staff Simulator | 8 | 9 | 7 | 7 | 6 | Excellent theme fit, but personalization and reward design may get fuzzy. |
|
| 21 |
+
| 3 | Codebase Migration Gym | 7 | 7 | 8 | 9 | 6 | Verifiable with tests, but code agents are crowded and less novel. |
|
| 22 |
+
| 4 | Research Reproduction Lab | 9 | 8 | 5 | 7 | 4 | Very ambitious, likely too hard to build and train under time pressure. |
|
| 23 |
+
| 5 | Multi-Agent Procurement Negotiation | 8 | 8 | 6 | 6 | 5 | Good multi-agent story, but objective grading and RL loop are harder. |
|
| 24 |
+
| 6 | Supply Chain Crisis Planner | 7 | 8 | 7 | 8 | 6 | Solid simulator, but can feel like an operations game if not grounded enough. |
|
| 25 |
+
|
| 26 |
+
## Recommended Winner Candidate
|
| 27 |
+
|
| 28 |
+
Build **Regulatory Dossier Control Room**.
|
| 29 |
+
|
| 30 |
+
One-line pitch:
|
| 31 |
+
|
| 32 |
+
> Train an agent to manage a 300-step regulatory document crisis: inspect a simulated pharma submission, discover scattered inconsistencies, apply precise cross-document edits, validate the dossier, and improve through adversarially generated new compliance failures.
|
| 33 |
+
|
| 34 |
+
Why this is the best fit:
|
| 35 |
+
|
| 36 |
+
- It hits long-horizon planning directly.
|
| 37 |
+
- It is professional and high-value.
|
| 38 |
+
- It has crisp verification via hidden canonical facts and compliance rules.
|
| 39 |
+
- It extends prior DocEdit work instead of restarting from zero.
|
| 40 |
+
- It creates a very strong story: "Can a small model learn to behave like a regulatory operations associate?"
|
| 41 |
+
- It can show training improvement without requiring a real external system like Kubernetes.
|
| 42 |
+
- It can scale from easy 10-step tasks to hard 300-step tasks through curriculum.
|
| 43 |
+
|
| 44 |
+
## Why Not Just Continue DocEdit V2?
|
| 45 |
+
|
| 46 |
+
DocEdit V2 is useful but too narrow for this round's themes. It is mostly local edit application. The judging criteria now heavily reward long-horizon behavior, self-improvement, and world modeling.
|
| 47 |
+
|
| 48 |
+
We should reuse DocEdit-style document generation, corruption, chunking, and grading, but wrap it inside a larger workflow:
|
| 49 |
+
|
| 50 |
+
- Multiple documents.
|
| 51 |
+
- Persistent investigation state.
|
| 52 |
+
- Hidden facts.
|
| 53 |
+
- Cross-document dependencies.
|
| 54 |
+
- Validation loops.
|
| 55 |
+
- Audit notes.
|
| 56 |
+
- Adaptive scenario generator.
|
| 57 |
+
|
| 58 |
+
That gives the old strength a much bigger judging surface.
|
| 59 |
+
|
docs/brainstorm/02-recommended-idea-regulatory-dossier-control-room.md
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recommended Idea: Regulatory Dossier Control Room
|
| 2 |
+
|
| 3 |
+
## Short Pitch
|
| 4 |
+
|
| 5 |
+
**Regulatory Dossier Control Room** is an OpenEnv environment where an LLM acts as a regulatory operations agent during a simulated pharma submission crisis.
|
| 6 |
+
|
| 7 |
+
The agent receives a high-level change request, such as a dosage update, safety warning, manufacturing site change, or adverse-event correction. The change is scattered across a dossier of many interlinked documents: drug label, clinical study report, investigator brochure, patient leaflet, quality summary, cover letter, amendment log, and internal review notes.
|
| 8 |
+
|
| 9 |
+
The agent has up to 300 tool steps to inspect, search, edit, validate, and audit the dossier. Rewards come from objective checks against a hidden consistency graph and regulatory rules.
|
| 10 |
+
|
| 11 |
+
## Why Judges Should Care
|
| 12 |
+
|
| 13 |
+
Real regulatory work is long-horizon, high-stakes, and brutally detail-sensitive. A single inconsistent dosage, date, or contraindication across documents can delay a submission.
|
| 14 |
+
|
| 15 |
+
Current LLMs are good at explaining documents, but they struggle with:
|
| 16 |
+
|
| 17 |
+
- Tracking facts across many files.
|
| 18 |
+
- Applying the same change consistently.
|
| 19 |
+
- Avoiding collateral damage.
|
| 20 |
+
- Remembering decisions over long sessions.
|
| 21 |
+
- Recovering from early mistakes.
|
| 22 |
+
- Knowing when to validate and when to stop.
|
| 23 |
+
|
| 24 |
+
This environment trains exactly that behavior.
|
| 25 |
+
|
| 26 |
+
## Theme Fit
|
| 27 |
+
|
| 28 |
+
Primary theme:
|
| 29 |
+
|
| 30 |
+
- Theme 2: Super long-horizon planning and instruction following.
|
| 31 |
+
|
| 32 |
+
Secondary themes:
|
| 33 |
+
|
| 34 |
+
- Theme 3.1: Professional task world modeling.
|
| 35 |
+
- Theme 4: Self-improvement through adaptive curricula.
|
| 36 |
+
- Theme 5: Wild card, because it turns document editing into a realistic compliance control room.
|
| 37 |
+
|
| 38 |
+
## The 300-Step Task
|
| 39 |
+
|
| 40 |
+
Hard episodes have:
|
| 41 |
+
|
| 42 |
+
- 20 to 60 dossier files.
|
| 43 |
+
- 40 to 150 hidden obligations.
|
| 44 |
+
- 100 to 300 possible action steps.
|
| 45 |
+
- Cross-document dependencies.
|
| 46 |
+
- Red herrings and stale memo fragments.
|
| 47 |
+
- Validation reports that reveal partial but not complete truth.
|
| 48 |
+
|
| 49 |
+
Example hard prompt:
|
| 50 |
+
|
| 51 |
+
> A late safety update changes the maximum daily dose from 40 mg to 30 mg for renal impairment patients, adds a contraindication for severe hepatic impairment, removes an outdated trial endpoint from Study RX-204, and requires all patient-facing materials to use plain-language wording. Update the dossier, preserve unrelated content, and leave an audit trail.
|
| 52 |
+
|
| 53 |
+
The agent must discover that this affects:
|
| 54 |
+
|
| 55 |
+
- Drug label dosage section.
|
| 56 |
+
- Contraindications section.
|
| 57 |
+
- Patient leaflet.
|
| 58 |
+
- Clinical study report summary table.
|
| 59 |
+
- Investigator brochure safety section.
|
| 60 |
+
- Cover letter.
|
| 61 |
+
- Amendment log.
|
| 62 |
+
- Cross-reference table.
|
| 63 |
+
- Internal review checklist.
|
| 64 |
+
|
| 65 |
+
## Action Space
|
| 66 |
+
|
| 67 |
+
Potential actions:
|
| 68 |
+
|
| 69 |
+
```json
|
| 70 |
+
{"tool": "search", "query": "renal impairment 40 mg"}
|
| 71 |
+
{"tool": "open_file", "path": "label/section_4_2_dosage.xml"}
|
| 72 |
+
{"tool": "inspect_window", "path": "csr/rx_204_summary.xml", "start": 120, "length": 40}
|
| 73 |
+
{"tool": "replace_text", "path": "label/section_4_2_dosage.xml", "target": "40 mg", "replacement": "30 mg"}
|
| 74 |
+
{"tool": "patch_section", "path": "patient_leaflet.xml", "section_id": "dose_warning", "content": "..."}
|
| 75 |
+
{"tool": "add_audit_note", "document": "amendment_log.xml", "note": "..."}
|
| 76 |
+
{"tool": "run_validator", "validator": "dose_consistency"}
|
| 77 |
+
{"tool": "commit_episode"}
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
Optional later actions:
|
| 81 |
+
|
| 82 |
+
```json
|
| 83 |
+
{"tool": "assign_subtask", "agent": "safety_reviewer", "objective": "..."}
|
| 84 |
+
{"tool": "resolve_conflict", "fact": "max_daily_dose", "value": "30 mg", "evidence": ["..."]}
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
## Observation Space
|
| 88 |
+
|
| 89 |
+
The agent sees:
|
| 90 |
+
|
| 91 |
+
- Current task brief.
|
| 92 |
+
- Current file/window content.
|
| 93 |
+
- Search results.
|
| 94 |
+
- Known facts discovered so far.
|
| 95 |
+
- Validation warnings.
|
| 96 |
+
- Edit history.
|
| 97 |
+
- Remaining step budget.
|
| 98 |
+
- Reward components from the last action.
|
| 99 |
+
|
| 100 |
+
The agent does not see:
|
| 101 |
+
|
| 102 |
+
- The full hidden canonical answer.
|
| 103 |
+
- All affected files upfront.
|
| 104 |
+
- The complete dependency graph.
|
| 105 |
+
|
| 106 |
+
## Reward Design
|
| 107 |
+
|
| 108 |
+
Use multiple independent reward components:
|
| 109 |
+
|
| 110 |
+
| Reward component | Purpose |
|
| 111 |
+
|---|---|
|
| 112 |
+
| Fact correction reward | Correctly updates canonical facts like dosage, dates, safety claims, study endpoints. |
|
| 113 |
+
| Cross-document consistency reward | Same fact is consistent across all required files. |
|
| 114 |
+
| Coverage reward | Agent discovers and touches all impacted nodes in the hidden dependency graph. |
|
| 115 |
+
| Collateral damage penalty | Penalize changing unrelated text or breaking valid facts. |
|
| 116 |
+
| Audit reward | Correctly records what changed and why. |
|
| 117 |
+
| Validation reward | Reward using validators and resolving their warnings. |
|
| 118 |
+
| Efficiency reward | Encourage completion before 300 steps. |
|
| 119 |
+
| Anti-hacking penalty | Penalize invalid paths, repeated no-ops, format-breaking edits, or validator spam. |
|
| 120 |
+
|
| 121 |
+
Suggested total:
|
| 122 |
+
|
| 123 |
+
```text
|
| 124 |
+
reward =
|
| 125 |
+
delta_fact_score
|
| 126 |
+
+ delta_consistency_score
|
| 127 |
+
+ 0.2 * delta_coverage
|
| 128 |
+
+ 0.1 * audit_score_delta
|
| 129 |
+
+ validator_resolution_bonus
|
| 130 |
+
- collateral_damage_penalty
|
| 131 |
+
- repeat_action_penalty
|
| 132 |
+
- invalid_action_penalty
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
Final success score:
|
| 136 |
+
|
| 137 |
+
```text
|
| 138 |
+
final_score =
|
| 139 |
+
0.35 * fact_accuracy
|
| 140 |
+
+ 0.25 * cross_doc_consistency
|
| 141 |
+
+ 0.15 * affected_file_coverage
|
| 142 |
+
+ 0.10 * audit_quality
|
| 143 |
+
+ 0.10 * structural_validity
|
| 144 |
+
+ 0.05 * efficiency
|
| 145 |
+
- collateral_damage
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
## Self-Improvement Loop
|
| 149 |
+
|
| 150 |
+
The environment includes an **Adversarial Compliance Designer**.
|
| 151 |
+
|
| 152 |
+
It tracks the agent's weaknesses:
|
| 153 |
+
|
| 154 |
+
- Misses patient-facing documents.
|
| 155 |
+
- Fixes label but forgets clinical study report tables.
|
| 156 |
+
- Over-edits unrelated sections.
|
| 157 |
+
- Fails to write audit notes.
|
| 158 |
+
- Repeats search actions.
|
| 159 |
+
- Stops before running validators.
|
| 160 |
+
|
| 161 |
+
Then it generates harder future episodes:
|
| 162 |
+
|
| 163 |
+
- More files.
|
| 164 |
+
- More cross-references.
|
| 165 |
+
- More red herrings.
|
| 166 |
+
- More subtle wording differences.
|
| 167 |
+
- Compound changes.
|
| 168 |
+
- Longer dependency chains.
|
| 169 |
+
|
| 170 |
+
Curriculum levels:
|
| 171 |
+
|
| 172 |
+
| Level | Episode shape | Expected horizon |
|
| 173 |
+
|---|---|---:|
|
| 174 |
+
| 1 | One file, one fact | 5 to 15 steps |
|
| 175 |
+
| 2 | Three files, one fact | 15 to 35 steps |
|
| 176 |
+
| 3 | Ten files, two facts | 35 to 80 steps |
|
| 177 |
+
| 4 | Twenty files, compound update | 80 to 160 steps |
|
| 178 |
+
| 5 | Full dossier crisis with red herrings | 160 to 300 steps |
|
| 179 |
+
|
| 180 |
+
This gives us non-zero reward early, then a path to the 300-step headline.
|
| 181 |
+
|
| 182 |
+
## What We Train
|
| 183 |
+
|
| 184 |
+
Start with a small instruct model and train it to:
|
| 185 |
+
|
| 186 |
+
- Search before editing.
|
| 187 |
+
- Build a working memory of discovered facts.
|
| 188 |
+
- Use validators.
|
| 189 |
+
- Apply narrow patches instead of broad rewrites.
|
| 190 |
+
- Maintain consistency across files.
|
| 191 |
+
- Stop only after validation passes.
|
| 192 |
+
|
| 193 |
+
Training recipe:
|
| 194 |
+
|
| 195 |
+
1. Baseline inference with frontier or small model.
|
| 196 |
+
2. Optional light SFT on synthetic tool traces from an oracle policy.
|
| 197 |
+
3. GRPO or RLVR using the verifier reward.
|
| 198 |
+
4. Compare base vs trained on held-out dossier seeds.
|
| 199 |
+
|
| 200 |
+
## Demo Story
|
| 201 |
+
|
| 202 |
+
The demo can be extremely clear:
|
| 203 |
+
|
| 204 |
+
1. Show the crisis brief.
|
| 205 |
+
2. Show a baseline model making local edits but missing cross-document consequences.
|
| 206 |
+
3. Show the validator catching unresolved inconsistencies.
|
| 207 |
+
4. Show reward curve improving during training.
|
| 208 |
+
5. Show trained agent: search, patch, validate, audit, commit.
|
| 209 |
+
6. Show final score breakdown and affected-file map.
|
| 210 |
+
|
| 211 |
+
Tagline:
|
| 212 |
+
|
| 213 |
+
> From "edit this paragraph" to "manage a 300-step regulatory crisis."
|
| 214 |
+
|
| 215 |
+
## Why This Can Win
|
| 216 |
+
|
| 217 |
+
It has the same strengths as Kube SRE Gym without copying it:
|
| 218 |
+
|
| 219 |
+
- Professional task.
|
| 220 |
+
- Tool-based world.
|
| 221 |
+
- Multi-step investigation.
|
| 222 |
+
- Adaptive curriculum.
|
| 223 |
+
- Agent learns from verifier feedback.
|
| 224 |
+
- Strong before/after story.
|
| 225 |
+
|
| 226 |
+
But it is more directly aligned with the user's existing assets:
|
| 227 |
+
|
| 228 |
+
- Existing DocEdit document generation.
|
| 229 |
+
- Existing structured edit actions.
|
| 230 |
+
- Existing similarity/collateral grading idea.
|
| 231 |
+
- Existing proof that small-model training can improve document repair.
|
| 232 |
+
|
| 233 |
+
## MVP Scope
|
| 234 |
+
|
| 235 |
+
Minimum credible hackathon version:
|
| 236 |
+
|
| 237 |
+
- 8 to 12 document templates.
|
| 238 |
+
- 5 scenario families.
|
| 239 |
+
- 3 difficulty tiers.
|
| 240 |
+
- 8 to 10 tools.
|
| 241 |
+
- Hidden consistency graph.
|
| 242 |
+
- Programmatic validators.
|
| 243 |
+
- OpenEnv server.
|
| 244 |
+
- Baseline inference.
|
| 245 |
+
- TRL/Unsloth training script.
|
| 246 |
+
- Reward plots from at least one short training run.
|
| 247 |
+
- README plus 2-minute pitch video or mini-blog.
|
| 248 |
+
|
| 249 |
+
Scenario families:
|
| 250 |
+
|
| 251 |
+
1. Dosage update.
|
| 252 |
+
2. Contraindication update.
|
| 253 |
+
3. Clinical endpoint correction.
|
| 254 |
+
4. Manufacturing site change.
|
| 255 |
+
5. Patient-language simplification.
|
| 256 |
+
|
| 257 |
+
## Risk And Mitigation
|
| 258 |
+
|
| 259 |
+
| Risk | Mitigation |
|
| 260 |
+
|---|---|
|
| 261 |
+
| 300-step tasks are too hard for training | Use curriculum. Train on 5 to 80 steps first, show hard eval as stretch. |
|
| 262 |
+
| Reward is too complex | Keep hidden graph simple: facts, required files, forbidden changes. |
|
| 263 |
+
| Judges think it is just DocEdit V2 | Pitch it as dossier-level world modeling, not local editing. |
|
| 264 |
+
| Training takes too long | Train a tiny model or run short GRPO over easy/medium levels and show upward reward. |
|
| 265 |
+
| LLM outputs invalid JSON | Constrain action schema and give format rewards/penalties. |
|
| 266 |
+
|
| 267 |
+
## Decision
|
| 268 |
+
|
| 269 |
+
This is the idea I would pick.
|
| 270 |
+
|
| 271 |
+
It is ambitious enough to impress, grounded enough to build, and close enough to existing work that we have a realistic path to shipping evidence rather than just slides.
|
| 272 |
+
|
docs/brainstorm/03-rapid-build-plan.md
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Rapid Build Plan For The Recommended Idea
|
| 2 |
+
|
| 3 |
+
## Goal
|
| 4 |
+
|
| 5 |
+
Build a convincing OpenEnv submission around **Regulatory Dossier Control Room** with long-horizon tasks, adaptive curriculum, objective rewards, and visible training improvement.
|
| 6 |
+
|
| 7 |
+
## First 45 Minutes
|
| 8 |
+
|
| 9 |
+
Decision checkpoint:
|
| 10 |
+
|
| 11 |
+
- Commit to Regulatory Dossier Control Room unless a better idea beats it on build speed and judge impact.
|
| 12 |
+
- Define the MVP around 5 scenario families and 3 difficulty levels.
|
| 13 |
+
- Keep the first implementation deterministic and lightweight.
|
| 14 |
+
|
| 15 |
+
Immediate choices:
|
| 16 |
+
|
| 17 |
+
- Python 3.12 + uv.
|
| 18 |
+
- OpenEnv latest release.
|
| 19 |
+
- FastAPI server.
|
| 20 |
+
- Simple HTML/JS or Gradio demo if time allows.
|
| 21 |
+
- Store generated dossier as in-memory structured files, with optional JSON fixtures.
|
| 22 |
+
|
| 23 |
+
## Build Architecture
|
| 24 |
+
|
| 25 |
+
```text
|
| 26 |
+
regulatory_dossier_control_room/
|
| 27 |
+
openenv.yaml
|
| 28 |
+
pyproject.toml
|
| 29 |
+
README.md
|
| 30 |
+
inference.py
|
| 31 |
+
train_grpo.py
|
| 32 |
+
server/
|
| 33 |
+
app.py
|
| 34 |
+
environment.py
|
| 35 |
+
models.py
|
| 36 |
+
scenario_generator.py
|
| 37 |
+
dossier.py
|
| 38 |
+
tools.py
|
| 39 |
+
validators.py
|
| 40 |
+
rewards.py
|
| 41 |
+
curriculum.py
|
| 42 |
+
assets/
|
| 43 |
+
reward_curve.png
|
| 44 |
+
baseline_vs_trained.png
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
## Core Environment
|
| 48 |
+
|
| 49 |
+
State:
|
| 50 |
+
|
| 51 |
+
- Task seed.
|
| 52 |
+
- Difficulty.
|
| 53 |
+
- Dossier files.
|
| 54 |
+
- Hidden canonical facts.
|
| 55 |
+
- Hidden affected file graph.
|
| 56 |
+
- Current file/window.
|
| 57 |
+
- Search history.
|
| 58 |
+
- Edit history.
|
| 59 |
+
- Validator history.
|
| 60 |
+
- Step count.
|
| 61 |
+
- Score components.
|
| 62 |
+
|
| 63 |
+
Actions:
|
| 64 |
+
|
| 65 |
+
- `search`
|
| 66 |
+
- `open_file`
|
| 67 |
+
- `inspect_window`
|
| 68 |
+
- `replace_text`
|
| 69 |
+
- `patch_section`
|
| 70 |
+
- `add_audit_note`
|
| 71 |
+
- `run_validator`
|
| 72 |
+
- `commit_episode`
|
| 73 |
+
|
| 74 |
+
Observations:
|
| 75 |
+
|
| 76 |
+
- Task brief.
|
| 77 |
+
- Current file/window.
|
| 78 |
+
- Search or validator output.
|
| 79 |
+
- Last reward breakdown.
|
| 80 |
+
- Known discovered facts.
|
| 81 |
+
- Remaining steps.
|
| 82 |
+
|
| 83 |
+
## Scenario Families
|
| 84 |
+
|
| 85 |
+
1. Dosage update:
|
| 86 |
+
- Change max dose across label, patient leaflet, CSR, investigator brochure.
|
| 87 |
+
2. Contraindication update:
|
| 88 |
+
- Add/remove safety contraindications across medical and patient documents.
|
| 89 |
+
3. Clinical endpoint correction:
|
| 90 |
+
- Correct endpoint wording and tables across CSR, abstract, briefing doc.
|
| 91 |
+
4. Manufacturing site change:
|
| 92 |
+
- Update site names, IDs, certificates, cover letter, audit trail.
|
| 93 |
+
5. Patient-language simplification:
|
| 94 |
+
- Convert technical warnings to patient-facing plain language without changing meaning.
|
| 95 |
+
|
| 96 |
+
## Difficulty Tiers
|
| 97 |
+
|
| 98 |
+
| Tier | Files | Hidden obligations | Max steps | Use |
|
| 99 |
+
|---|---:|---:|---:|---|
|
| 100 |
+
| Easy | 2 to 4 | 3 to 8 | 30 | Fast learning signal. |
|
| 101 |
+
| Medium | 8 to 15 | 12 to 30 | 100 | Main training target. |
|
| 102 |
+
| Hard | 20 to 60 | 40 to 150 | 300 | Headline long-horizon demo. |
|
| 103 |
+
|
| 104 |
+
## Training Evidence Plan
|
| 105 |
+
|
| 106 |
+
Minimum viable evidence:
|
| 107 |
+
|
| 108 |
+
- Run baseline over 20 seeds.
|
| 109 |
+
- Run short GRPO or SFT+GRPO over easy/medium curriculum.
|
| 110 |
+
- Save reward curve.
|
| 111 |
+
- Evaluate base vs trained on 20 held-out seeds.
|
| 112 |
+
|
| 113 |
+
Metrics:
|
| 114 |
+
|
| 115 |
+
- Mean episode reward.
|
| 116 |
+
- Final dossier score.
|
| 117 |
+
- Fact accuracy.
|
| 118 |
+
- Cross-document consistency.
|
| 119 |
+
- Affected file coverage.
|
| 120 |
+
- Collateral damage.
|
| 121 |
+
- Validator warnings remaining.
|
| 122 |
+
- Steps to completion.
|
| 123 |
+
|
| 124 |
+
## Demo Output
|
| 125 |
+
|
| 126 |
+
README should include:
|
| 127 |
+
|
| 128 |
+
- One-paragraph pitch.
|
| 129 |
+
- Why long-horizon dossier management matters.
|
| 130 |
+
- Action/observation space.
|
| 131 |
+
- Reward breakdown.
|
| 132 |
+
- Curriculum/self-improvement loop.
|
| 133 |
+
- Baseline vs trained table.
|
| 134 |
+
- Reward plot.
|
| 135 |
+
- One trace excerpt showing better behavior after training.
|
| 136 |
+
|
| 137 |
+
Video or mini-blog story:
|
| 138 |
+
|
| 139 |
+
1. "A safety change arrives 12 hours before submission."
|
| 140 |
+
2. Baseline fixes only the obvious label line.
|
| 141 |
+
3. Validator reveals missed patient leaflet and CSR table.
|
| 142 |
+
4. Training reward improves.
|
| 143 |
+
5. Trained agent searches, patches, validates, audits, and commits.
|
| 144 |
+
|
| 145 |
+
## What To Avoid
|
| 146 |
+
|
| 147 |
+
- Do not market this as "DocEdit V3." That undersells it.
|
| 148 |
+
- Do not start with full 300-step training. Build 30-step and 100-step curricula first.
|
| 149 |
+
- Do not rely on an LLM judge as the only reward.
|
| 150 |
+
- Do not make the UI the main project. The environment and training evidence are the submission.
|
| 151 |
+
- Do not overfit to static hand-authored tasks. Procedural seeds matter.
|
| 152 |
+
|
| 153 |
+
## Final Recommendation
|
| 154 |
+
|
| 155 |
+
Start implementation with a narrow MVP:
|
| 156 |
+
|
| 157 |
+
- Dosage update family only.
|
| 158 |
+
- 6 documents.
|
| 159 |
+
- 3 difficulty settings.
|
| 160 |
+
- Hidden consistency graph.
|
| 161 |
+
- Search/open/replace/validate/audit/commit tools.
|
| 162 |
+
|
| 163 |
+
Once this works, add the other scenario families and the adversarial curriculum.
|
| 164 |
+
|
docs/brainstorm/04-physics-design-environments.md
ADDED
|
@@ -0,0 +1,258 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Physics, CAD, Chip, And Media Environment Brainstorm
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-24
|
| 4 |
+
|
| 5 |
+
## Core Question
|
| 6 |
+
|
| 7 |
+
Could we build an OpenEnv environment where an LLM improves at designing objects, systems, or artifacts that can be verified by simulation?
|
| 8 |
+
|
| 9 |
+
Short answer:
|
| 10 |
+
|
| 11 |
+
**Yes. This is a strong hackathon direction, but only if we constrain the design language and simulator.**
|
| 12 |
+
|
| 13 |
+
The best version is not "LLM generates arbitrary 3D geometry from scratch." That is too broad and brittle. The best version is:
|
| 14 |
+
|
| 15 |
+
> The agent edits a parametric engineering design through a small set of meaningful actions, runs a verifier/simulator, and learns to optimize objective tradeoffs like stiffness, mass, stress, torque, loss, cost, manufacturability, or timing.
|
| 16 |
+
|
| 17 |
+
## Current Reality Of AI For CAD
|
| 18 |
+
|
| 19 |
+
Frontier models are becoming surprisingly good at simple parametric CAD, especially when the output is code in libraries like CadQuery. CAD Arena's early 2026 benchmark shows frontier and commercial systems producing many valid executable CAD outputs on simple to medium prompts, but failures still appear on complex functional parts.
|
| 20 |
+
|
| 21 |
+
This means the opportunity is not "can an LLM make a cube or bracket?" The opportunity is:
|
| 22 |
+
|
| 23 |
+
- Can a small or open model learn engineering design behavior from simulator feedback?
|
| 24 |
+
- Can it iterate over many design steps without losing constraints?
|
| 25 |
+
- Can it trade off mass, stiffness, stress, manufacturability, and safety margin?
|
| 26 |
+
- Can it recover from bad simulations?
|
| 27 |
+
- Can it learn design heuristics through RL rather than only prompt engineering?
|
| 28 |
+
|
| 29 |
+
That is very aligned with OpenEnv.
|
| 30 |
+
|
| 31 |
+
## Useful Tooling
|
| 32 |
+
|
| 33 |
+
| Tool | Use | Notes |
|
| 34 |
+
|---|---|---|
|
| 35 |
+
| CadQuery | Parametric 3D CAD from Python | Good for generating STEP/STL-style geometry through code. |
|
| 36 |
+
| MuJoCo | Fast rigid-body/contact simulation | Excellent for mechanisms and robotics, not the right core tool for structural FEA. |
|
| 37 |
+
| FEniCSx | Finite element PDE solving | Powerful but heavier; risky if we need a polished 2-day build. |
|
| 38 |
+
| topoptlab | Topology optimization research/benchmarking | Very relevant, but we should verify install/runtime before betting on it. |
|
| 39 |
+
| OpenMDAO | Multidisciplinary design optimization | Strong for system-level optimization, design variables, constraints, analytic derivatives. |
|
| 40 |
+
| Pyleecan | Electrical machine and drive simulation | Very relevant to motors; FEMM coupling is Windows-only right now, which is a Mac/HF risk. |
|
| 41 |
+
| cocotb/Yosys/OpenROAD | Chip design and verification | Very verifiable and compelling, but a crowded/coding-adjacent domain. |
|
| 42 |
+
| FFmpeg/MoviePy | Programmatic video editing | Buildable and verifiable, but reward quality is less objective unless tasks are synthetic. |
|
| 43 |
+
|
| 44 |
+
## Candidate A: MechForge Gym
|
| 45 |
+
|
| 46 |
+
One-line pitch:
|
| 47 |
+
|
| 48 |
+
> Train an LLM to act as a mechanical design engineer: iteratively design a lightweight bracket, bridge, clamp, or motor mount, run simulation, and improve stiffness-to-weight while respecting stress and manufacturability constraints.
|
| 49 |
+
|
| 50 |
+
### Environment
|
| 51 |
+
|
| 52 |
+
The agent receives:
|
| 53 |
+
|
| 54 |
+
- Design brief.
|
| 55 |
+
- Load cases.
|
| 56 |
+
- Mounting constraints.
|
| 57 |
+
- Forbidden zones.
|
| 58 |
+
- Material.
|
| 59 |
+
- Manufacturing process.
|
| 60 |
+
- Current design parameters.
|
| 61 |
+
- Simulation report.
|
| 62 |
+
|
| 63 |
+
The agent acts through constrained tools:
|
| 64 |
+
|
| 65 |
+
```json
|
| 66 |
+
{"tool": "set_dimension", "part": "base_plate", "parameter": "thickness", "value": 4.0}
|
| 67 |
+
{"tool": "add_rib", "from": "mount_a", "to": "load_point", "width": 5.0, "height": 12.0}
|
| 68 |
+
{"tool": "add_lightening_hole", "center": [20, 15], "radius": 4.0}
|
| 69 |
+
{"tool": "change_material", "material": "aluminum_6061"}
|
| 70 |
+
{"tool": "run_simulation"}
|
| 71 |
+
{"tool": "commit_design"}
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
### Reward
|
| 75 |
+
|
| 76 |
+
```text
|
| 77 |
+
reward =
|
| 78 |
+
+ stiffness_score
|
| 79 |
+
+ safety_factor_score
|
| 80 |
+
+ manufacturability_score
|
| 81 |
+
- mass_penalty
|
| 82 |
+
- stress_violation_penalty
|
| 83 |
+
- invalid_geometry_penalty
|
| 84 |
+
- repeated_failed_sim_penalty
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
### Why It Could Win
|
| 88 |
+
|
| 89 |
+
- Very visual.
|
| 90 |
+
- Very easy to explain.
|
| 91 |
+
- Verifier is real math, not vibes.
|
| 92 |
+
- Mechanical engineering angle is distinctive.
|
| 93 |
+
- Long-horizon optimization loop is natural.
|
| 94 |
+
- Can show before/after designs and reward curves.
|
| 95 |
+
|
| 96 |
+
### Main Risk
|
| 97 |
+
|
| 98 |
+
Full 3D FEA is hard to make fast and robust in two days. The MVP should use a simplified finite-element/truss/beam solver first, then render the result as CAD. That is credible if we are honest:
|
| 99 |
+
|
| 100 |
+
> The environment trains engineering design behavior with a fast verifier; high-fidelity FEA is a stretch backend.
|
| 101 |
+
|
| 102 |
+
## Candidate B: Axial Flux Motor Design Gym
|
| 103 |
+
|
| 104 |
+
One-line pitch:
|
| 105 |
+
|
| 106 |
+
> Train an LLM to design axial-flux motor variants by choosing rotor/stator geometry, magnet layout, winding parameters, and cooling assumptions, then score torque, efficiency, mass, thermal margin, and manufacturability.
|
| 107 |
+
|
| 108 |
+
### Why This Is Exciting
|
| 109 |
+
|
| 110 |
+
This is the most personally differentiated idea because of mechanical/electrical design expertise. It sounds like real R&D, not a toy. It also gives a good story:
|
| 111 |
+
|
| 112 |
+
> Can a small model learn the design instincts of an electric motor engineer?
|
| 113 |
+
|
| 114 |
+
### Possible Action Space
|
| 115 |
+
|
| 116 |
+
```json
|
| 117 |
+
{"tool": "set_slot_count", "value": 12}
|
| 118 |
+
{"tool": "set_pole_pairs", "value": 10}
|
| 119 |
+
{"tool": "set_airgap_mm", "value": 0.8}
|
| 120 |
+
{"tool": "set_magnet_thickness_mm", "value": 4.0}
|
| 121 |
+
{"tool": "set_winding_turns", "value": 38}
|
| 122 |
+
{"tool": "run_electromagnetic_sim"}
|
| 123 |
+
{"tool": "run_thermal_check"}
|
| 124 |
+
{"tool": "commit_design"}
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
### Reward
|
| 128 |
+
|
| 129 |
+
- Torque density.
|
| 130 |
+
- Efficiency.
|
| 131 |
+
- Cogging torque penalty.
|
| 132 |
+
- Thermal margin.
|
| 133 |
+
- Current density limit.
|
| 134 |
+
- Magnet mass/cost.
|
| 135 |
+
- Manufacturability constraints.
|
| 136 |
+
|
| 137 |
+
### Main Risk
|
| 138 |
+
|
| 139 |
+
The real simulation stack is not trivial. Pyleecan is exactly in the domain, but its strongest FEMM coupling is currently Windows-only, which is awkward for a MacBook and HF Space. A simplified analytic motor model is feasible, but judges may ask whether it is too toy-like unless we present it as a curriculum level.
|
| 140 |
+
|
| 141 |
+
### Verdict
|
| 142 |
+
|
| 143 |
+
Extremely cool, but I would not choose this as the first build unless we intentionally scope it as **MotorBench Lite**:
|
| 144 |
+
|
| 145 |
+
- Analytic/equivalent-circuit verifier for the hackathon.
|
| 146 |
+
- Pyleecan/FEMM as stretch or future backend.
|
| 147 |
+
- CAD render as a bonus, not core.
|
| 148 |
+
|
| 149 |
+
## Candidate C: Chip Design / EDA Gym
|
| 150 |
+
|
| 151 |
+
One-line pitch:
|
| 152 |
+
|
| 153 |
+
> Train an LLM to design and optimize small digital circuits through Verilog, simulation, synthesis, formal tests, and area/timing/power metrics.
|
| 154 |
+
|
| 155 |
+
### Why It Is Strong
|
| 156 |
+
|
| 157 |
+
- Verifiability is excellent.
|
| 158 |
+
- Tools exist: cocotb for Python verification, Yosys for synthesis, OpenROAD for physical design.
|
| 159 |
+
- Rewards are crisp: tests pass, area, timing slack, DRC count, power proxy.
|
| 160 |
+
- Long-horizon flow is real: design, simulate, synthesize, place, route, inspect metrics, revise.
|
| 161 |
+
|
| 162 |
+
### Main Risk
|
| 163 |
+
|
| 164 |
+
This space is closer to coding benchmarks, so it may feel less novel. Also, full OpenROAD flows can be slow/heavy. But a small RTL-to-synthesis environment could be highly shippable.
|
| 165 |
+
|
| 166 |
+
### Verdict
|
| 167 |
+
|
| 168 |
+
Very viable, especially if we focus on **hardware optimization**, not generic coding:
|
| 169 |
+
|
| 170 |
+
> "The agent learns to trade timing, area, and correctness under a real synthesis verifier."
|
| 171 |
+
|
| 172 |
+
## Candidate D: Video Editing Gym
|
| 173 |
+
|
| 174 |
+
One-line pitch:
|
| 175 |
+
|
| 176 |
+
> Train an LLM to assemble a coherent video from clips using FFmpeg/MoviePy tools, optimized against objective timeline, audio, caption, and narrative constraints.
|
| 177 |
+
|
| 178 |
+
### Why It Is Interesting
|
| 179 |
+
|
| 180 |
+
- Very demo-friendly.
|
| 181 |
+
- Easy to render before/after.
|
| 182 |
+
- Tool use is realistic.
|
| 183 |
+
- Long-horizon timeline assembly is possible.
|
| 184 |
+
|
| 185 |
+
### Main Risk
|
| 186 |
+
|
| 187 |
+
Quality is hard to verify objectively. We can make synthetic tasks with objective constraints, but "good narrative" will need an LLM judge or a weak proxy. That is less clean than physics/code verification.
|
| 188 |
+
|
| 189 |
+
### Verdict
|
| 190 |
+
|
| 191 |
+
Good product demo, weaker OpenEnv winner candidate unless we make the task highly structured:
|
| 192 |
+
|
| 193 |
+
- Given transcript and clips, align exact semantic beats.
|
| 194 |
+
- Reward caption timing, shot coverage, audio loudness, no black frames, no forbidden clips.
|
| 195 |
+
|
| 196 |
+
## My Updated Ranking
|
| 197 |
+
|
| 198 |
+
| Rank | Idea | Innovation | Story | Trainability | Verifiability | Build speed | Verdict |
|
| 199 |
+
|---:|---|---:|---:|---:|---:|---:|---|
|
| 200 |
+
| 1 | MechForge Gym: simulated mechanical design optimization | 10 | 10 | 7 | 8 | 7 | Best new contender. More visually compelling than regulatory if scoped well. |
|
| 201 |
+
| 2 | Regulatory Dossier Control Room | 9 | 9 | 8 | 9 | 8 | Still safest high-scoring option. Less spectacular, more shippable. |
|
| 202 |
+
| 3 | RTL/Chip Optimization Gym | 8 | 8 | 8 | 10 | 6 | Strong verifier; risk is looking like code benchmark. |
|
| 203 |
+
| 4 | Axial Flux Motor Design Gym | 10 | 10 | 5 | 7 | 4 | Most exciting personally, but risky for two days unless simplified hard. |
|
| 204 |
+
| 5 | Video Editing Gym | 8 | 9 | 6 | 5 | 8 | Great demo, weaker reward objectivity. |
|
| 205 |
+
|
| 206 |
+
## Recommended Physics Build
|
| 207 |
+
|
| 208 |
+
If choosing the physics route, build **MechForge Gym**, not full arbitrary generative design and not full motor design first.
|
| 209 |
+
|
| 210 |
+
### MVP
|
| 211 |
+
|
| 212 |
+
Build a 2D/2.5D structural design environment:
|
| 213 |
+
|
| 214 |
+
- Agent edits a bracket/bridge/motor-mount design through parametric actions.
|
| 215 |
+
- Fast internal solver computes stress/compliance/mass.
|
| 216 |
+
- CadQuery renders a 3D preview/STL from the parameterized design.
|
| 217 |
+
- Curriculum grows from 5-step changes to 300-step design campaigns.
|
| 218 |
+
- Adversarial scenario generator creates new load cases and manufacturing constraints.
|
| 219 |
+
|
| 220 |
+
### Why This Is The Sweet Spot
|
| 221 |
+
|
| 222 |
+
It preserves the magic of generative design:
|
| 223 |
+
|
| 224 |
+
- simulation-verifiable,
|
| 225 |
+
- visual,
|
| 226 |
+
- engineering-real,
|
| 227 |
+
- optimization-driven,
|
| 228 |
+
- self-improving.
|
| 229 |
+
|
| 230 |
+
But it avoids the two big traps:
|
| 231 |
+
|
| 232 |
+
- arbitrary geometry generation,
|
| 233 |
+
- slow brittle high-fidelity simulation.
|
| 234 |
+
|
| 235 |
+
## Buildable Story
|
| 236 |
+
|
| 237 |
+
Demo story:
|
| 238 |
+
|
| 239 |
+
1. "A drone arm bracket must hold 120 N at the tip but weigh under 30 g."
|
| 240 |
+
2. Baseline model adds material everywhere and passes stress but is overweight.
|
| 241 |
+
3. The environment runs simulation and shows mass/stress/compliance breakdown.
|
| 242 |
+
4. After training, the agent learns ribs, fillets, and lightening holes.
|
| 243 |
+
5. The trained design is lighter, still safe, and has fewer invalid simulations.
|
| 244 |
+
|
| 245 |
+
Tagline:
|
| 246 |
+
|
| 247 |
+
> From text prompts to simulation-trained design instincts.
|
| 248 |
+
|
| 249 |
+
## Final Thought
|
| 250 |
+
|
| 251 |
+
This may be the most emotionally convincing idea in the set. Judges will remember a model that learns to design a lighter bracket from simulation feedback.
|
| 252 |
+
|
| 253 |
+
The key discipline is scope:
|
| 254 |
+
|
| 255 |
+
- Do not promise "full CAD/FEA/motor design from scratch."
|
| 256 |
+
- Promise "a verifiable OpenEnv for engineering design behavior."
|
| 257 |
+
- Show an actual reward curve and visible before/after geometry.
|
| 258 |
+
|
docs/brainstorm/05-mechforge-rendering-stack.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MechForge Rendering And Simulation Stack
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-24
|
| 4 |
+
|
| 5 |
+
## The Confusion To Resolve
|
| 6 |
+
|
| 7 |
+
For MechForge there are four separate jobs:
|
| 8 |
+
|
| 9 |
+
1. Generate or modify a design.
|
| 10 |
+
2. Render the design so humans can inspect it.
|
| 11 |
+
3. Simulate or verify the design.
|
| 12 |
+
4. Export the design to real CAD/manufacturing formats.
|
| 13 |
+
|
| 14 |
+
One tool does not need to do all four.
|
| 15 |
+
|
| 16 |
+
## Recommended MVP Stack
|
| 17 |
+
|
| 18 |
+
| Layer | MVP choice | Why |
|
| 19 |
+
|---|---|---|
|
| 20 |
+
| Design representation | Structured parametric JSON | Easy for LLMs, easy to validate, easy to convert. |
|
| 21 |
+
| Browser renderer | Three.js | Fast, visual, interactive, works inside a web demo. |
|
| 22 |
+
| Fast verifier | Custom beam/truss-style solver | Good enough for reward curves and RL feedback. |
|
| 23 |
+
| Export | STL from Three.js mesh | Immediate tangible artifact. |
|
| 24 |
+
| Future CAD backend | CadQuery first, OpenSCAD second | CadQuery is Python-native and more flexible for OpenEnv. |
|
| 25 |
+
| Future simulation backend | simplified FEM, FEniCSx, or specialized solver | Swap in after the environment loop works. |
|
| 26 |
+
|
| 27 |
+
## Why Not OpenSCAD First?
|
| 28 |
+
|
| 29 |
+
OpenSCAD is good for deterministic programmatic CAD. It is available on macOS and can generate real geometry, but it is not the fastest path for a live web app.
|
| 30 |
+
|
| 31 |
+
Use OpenSCAD later if we want:
|
| 32 |
+
|
| 33 |
+
- scriptable constructive solid geometry,
|
| 34 |
+
- reproducible `.scad` artifacts,
|
| 35 |
+
- STL export through the OpenSCAD CLI,
|
| 36 |
+
- simple parts made from unions/differences.
|
| 37 |
+
|
| 38 |
+
For the first experiment, Three.js is better because it gives immediate visual feedback in the browser.
|
| 39 |
+
|
| 40 |
+
## Why Not Full FEA First?
|
| 41 |
+
|
| 42 |
+
Full FEA is the wrong first milestone. It risks spending the hackathon on meshing, solver stability, and packaging instead of the OpenEnv loop.
|
| 43 |
+
|
| 44 |
+
Better:
|
| 45 |
+
|
| 46 |
+
1. Start with a simplified verifier that produces a reward.
|
| 47 |
+
2. Show that LLM behavior improves under that reward.
|
| 48 |
+
3. Add higher-fidelity simulation only after the loop is stable.
|
| 49 |
+
|
| 50 |
+
The judges care most that the environment trains meaningful behavior and shows improvement. A simple but coherent verifier is acceptable if we explain the limitations honestly.
|
| 51 |
+
|
| 52 |
+
## Benchmark Plan
|
| 53 |
+
|
| 54 |
+
Before committing to the full environment, run GPT-5.4 through a small prompt-to-design benchmark:
|
| 55 |
+
|
| 56 |
+
- Prompt asks for a lightweight bracket under a load case.
|
| 57 |
+
- Model returns structured design JSON.
|
| 58 |
+
- Renderer shows the part.
|
| 59 |
+
- Verifier scores mass, stress proxy, deflection proxy, safety factor, and manufacturability.
|
| 60 |
+
- We inspect whether the model uses real design patterns like ribs, load paths, holes in low-stress areas, and avoids invalid geometry.
|
| 61 |
+
|
| 62 |
+
This tells us whether current frontier models already solve the task or whether there is room for RL improvement.
|
| 63 |
+
|
| 64 |
+
## What The Experiment App Does
|
| 65 |
+
|
| 66 |
+
The app in `experiment-mechanical-idea/` implements this benchmark:
|
| 67 |
+
|
| 68 |
+
- Frontend: Vite + Three.js.
|
| 69 |
+
- Backend: Express + OpenAI Responses API.
|
| 70 |
+
- Input: natural-language mechanical design prompt.
|
| 71 |
+
- Output: structured parametric design JSON.
|
| 72 |
+
- Render: plate, ribs, holes, bosses, fixed holes, load arrow.
|
| 73 |
+
- Verifier: fast beam-style estimate.
|
| 74 |
+
- Export: STL from the rendered mesh.
|
| 75 |
+
|
| 76 |
+
## Final Recommendation
|
| 77 |
+
|
| 78 |
+
For the OpenEnv version:
|
| 79 |
+
|
| 80 |
+
1. Keep the agent action space constrained.
|
| 81 |
+
2. Use Three.js for the judge-facing demo.
|
| 82 |
+
3. Use Python/CadQuery later for real CAD export.
|
| 83 |
+
4. Keep simulation/verifier independent from the renderer.
|
| 84 |
+
5. Do not let the LLM generate arbitrary meshes in the first version.
|
| 85 |
+
|
docs/brainstorm/06-production-simulation-stack.md
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Production Simulation Stack For MechForge
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-24
|
| 4 |
+
|
| 5 |
+
## Short Answer
|
| 6 |
+
|
| 7 |
+
For a production-quality MechForge, do **not** use MuJoCo as the main solver for stress, heat, or electromagnetics.
|
| 8 |
+
|
| 9 |
+
Use MuJoCo only if the environment is about:
|
| 10 |
+
|
| 11 |
+
- mechanism motion,
|
| 12 |
+
- contact,
|
| 13 |
+
- robotics,
|
| 14 |
+
- actuated joints,
|
| 15 |
+
- dynamic control,
|
| 16 |
+
- impact-like rigid-body behavior.
|
| 17 |
+
|
| 18 |
+
For a full-stack engineering design simulator, the better architecture is:
|
| 19 |
+
|
| 20 |
+
```text
|
| 21 |
+
LLM / Agent
|
| 22 |
+
-> constrained design actions
|
| 23 |
+
-> CAD kernel
|
| 24 |
+
-> meshing
|
| 25 |
+
-> multiphysics solvers
|
| 26 |
+
-> post-processing
|
| 27 |
+
-> reward + visual trace
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
## Recommended Production Stack
|
| 31 |
+
|
| 32 |
+
| Layer | Recommended tool | Why |
|
| 33 |
+
|---|---|---|
|
| 34 |
+
| Agent orchestration | OpenAI Responses API now, Agents SDK later | Responses is enough for benchmark; Agents SDK is useful when tool traces and multi-agent workflows become first-class. |
|
| 35 |
+
| Design representation | Parametric feature graph | Better than arbitrary mesh generation; supports CAD, constraints, versioning, and RL actions. |
|
| 36 |
+
| CAD kernel | CadQuery / OpenCASCADE | Python-native CAD generation, real B-rep/STEP export, deterministic parametric geometry. |
|
| 37 |
+
| Meshing | Gmsh | Mature, scriptable 2D/3D mesh generator with OpenCASCADE geometry support. |
|
| 38 |
+
| Structural FEA | FEniCSx or scikit-fem | FEniCSx is stronger for serious PDE work; scikit-fem is lighter and easier for hackathon packaging. |
|
| 39 |
+
| Thermal FEA | FEniCSx / scikit-fem / Elmer | Heat equation is straightforward in finite element tools. |
|
| 40 |
+
| Electromagnetic FEA | Elmer FEM, GetDP, MFEM, or FEMM/Pyleecan for motor-specific workflows | Motors need magnetic vector potential, materials, windings, airgap, torque extraction. |
|
| 41 |
+
| Visualization | Three.js in UI, ParaView/VTK for heavy post-processing | Three.js is judge/demo-facing; VTK/ParaView is engineering-facing. |
|
| 42 |
+
| Optimization | OpenMDAO or custom curriculum/RL loop | OpenMDAO is excellent for deterministic design-variable optimization; OpenEnv/RL is the hackathon learning loop. |
|
| 43 |
+
| Artifact storage | per-iteration JSON + STEP/STL + mesh + VTK + screenshot | Enables side-by-side version comparison. |
|
| 44 |
+
|
| 45 |
+
## Exact Production Loop
|
| 46 |
+
|
| 47 |
+
A single design episode should look like this:
|
| 48 |
+
|
| 49 |
+
```text
|
| 50 |
+
1. reset()
|
| 51 |
+
- Generate design brief.
|
| 52 |
+
- Define load cases, fixtures, materials, constraints, objective.
|
| 53 |
+
|
| 54 |
+
2. agent action: edit_design
|
| 55 |
+
- Add rib, change thickness, move hole, set magnet width, change winding turns, etc.
|
| 56 |
+
|
| 57 |
+
3. geometry build
|
| 58 |
+
- Build CAD from parametric feature graph through CadQuery/OpenCASCADE.
|
| 59 |
+
- Export STEP/STL.
|
| 60 |
+
|
| 61 |
+
4. mesh build
|
| 62 |
+
- Run Gmsh.
|
| 63 |
+
- Tag boundaries: fixed faces, load faces, heat sources, winding regions, magnets, airgap.
|
| 64 |
+
|
| 65 |
+
5. solver run
|
| 66 |
+
- Structural: displacement, stress, strain, safety factor.
|
| 67 |
+
- Thermal: temperature field, hot spot, thermal margin.
|
| 68 |
+
- Electromagnetic: flux density, torque, losses, cogging proxy.
|
| 69 |
+
|
| 70 |
+
6. post-process
|
| 71 |
+
- Save VTK/VTU fields.
|
| 72 |
+
- Produce scalar metrics.
|
| 73 |
+
- Render screenshot or send mesh fields to Three.js.
|
| 74 |
+
|
| 75 |
+
7. reward
|
| 76 |
+
- Score constraints and objective tradeoffs.
|
| 77 |
+
|
| 78 |
+
8. next observation
|
| 79 |
+
- Return metrics, failed constraints, top stress/thermal/EM hotspots, and visual artifacts.
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
## What The Agent Should Output
|
| 83 |
+
|
| 84 |
+
Do not ask the LLM to output an entire arbitrary CAD file as the main action.
|
| 85 |
+
|
| 86 |
+
For serious parts, use tool calls like:
|
| 87 |
+
|
| 88 |
+
```json
|
| 89 |
+
{"tool": "set_parameter", "name": "base_thickness_mm", "value": 4.5}
|
| 90 |
+
{"tool": "add_rib", "start": [12, -18, 4], "end": [92, -4, 20], "width_mm": 5}
|
| 91 |
+
{"tool": "move_lightening_hole", "id": "hole_2", "center": [54, 12, 0], "radius_mm": 4}
|
| 92 |
+
{"tool": "set_boundary_condition", "face": "left_mount_faces", "type": "fixed"}
|
| 93 |
+
{"tool": "set_load", "face": "tip_boss", "vector_n": [0, 0, -120]}
|
| 94 |
+
{"tool": "run_simulation", "physics": ["structural", "thermal"]}
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
Why:
|
| 98 |
+
|
| 99 |
+
- Tool calls are inspectable.
|
| 100 |
+
- Invalid actions can be rejected.
|
| 101 |
+
- The environment can apply partial progress rewards.
|
| 102 |
+
- The CAD remains valid more often.
|
| 103 |
+
- The same action sequence becomes training data.
|
| 104 |
+
|
| 105 |
+
The current experiment returns a full structured design JSON because it is a fast benchmark. The OpenEnv version should move toward smaller incremental design actions.
|
| 106 |
+
|
| 107 |
+
## 3D Structural FEA Path
|
| 108 |
+
|
| 109 |
+
For full 3D structural FEA, I would implement:
|
| 110 |
+
|
| 111 |
+
```text
|
| 112 |
+
CadQuery/OpenCASCADE -> STEP/B-rep -> Gmsh tetra mesh -> FEniCSx or scikit-fem -> VTU fields -> Three.js/VTK viewer
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
### Fastest hackathon path
|
| 116 |
+
|
| 117 |
+
- Use `scikit-fem` for 3D linear elasticity on simple tetrahedral meshes.
|
| 118 |
+
- Use Gmsh for meshing simple CAD.
|
| 119 |
+
- Use meshio to bridge Gmsh meshes into Python/VTK outputs.
|
| 120 |
+
|
| 121 |
+
### More serious production path
|
| 122 |
+
|
| 123 |
+
- Use FEniCSx for PDE solves and scalable linear algebra.
|
| 124 |
+
- Use PETSc-backed solvers.
|
| 125 |
+
- Store post-processing fields as VTK/VTU.
|
| 126 |
+
|
| 127 |
+
## Electromagnetic + Thermal Motor Path
|
| 128 |
+
|
| 129 |
+
For motor design, do **not** start with arbitrary 3D motor FEA.
|
| 130 |
+
|
| 131 |
+
Production path:
|
| 132 |
+
|
| 133 |
+
```text
|
| 134 |
+
parametric motor template
|
| 135 |
+
-> 2D cross-section CAD
|
| 136 |
+
-> Gmsh mesh with material regions
|
| 137 |
+
-> EM solver for magnetic vector potential
|
| 138 |
+
-> torque / B-field / losses
|
| 139 |
+
-> thermal network or thermal FEA
|
| 140 |
+
-> reward
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
Candidate solvers:
|
| 144 |
+
|
| 145 |
+
- Elmer FEM: multiphysics, includes heat transfer and electromagnetics.
|
| 146 |
+
- GetDP: finite element solver often used with Gmsh for EM problems.
|
| 147 |
+
- Pyleecan: motor-specific design framework, but deployment constraints need checking.
|
| 148 |
+
- FEMM: common motor workflow but Windows-centric, not ideal for HF/Linux deployment.
|
| 149 |
+
|
| 150 |
+
## Visual Versioning
|
| 151 |
+
|
| 152 |
+
Every iteration should save:
|
| 153 |
+
|
| 154 |
+
```text
|
| 155 |
+
runs/{run_id}/
|
| 156 |
+
iter_001/
|
| 157 |
+
design.json
|
| 158 |
+
actions.jsonl
|
| 159 |
+
geometry.step
|
| 160 |
+
geometry.stl
|
| 161 |
+
mesh.msh
|
| 162 |
+
structural.vtu
|
| 163 |
+
thermal.vtu
|
| 164 |
+
electromagnetic.vtu
|
| 165 |
+
screenshot.png
|
| 166 |
+
metrics.json
|
| 167 |
+
iter_002/
|
| 168 |
+
...
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
The UI should show:
|
| 172 |
+
|
| 173 |
+
- version timeline,
|
| 174 |
+
- side-by-side geometry,
|
| 175 |
+
- stress heatmap,
|
| 176 |
+
- deformation magnification slider,
|
| 177 |
+
- thermal heatmap,
|
| 178 |
+
- EM flux density heatmap for motor tasks,
|
| 179 |
+
- tool-call/action trace,
|
| 180 |
+
- score curve over iterations.
|
| 181 |
+
|
| 182 |
+
## What To Build First
|
| 183 |
+
|
| 184 |
+
Best next implementation step:
|
| 185 |
+
|
| 186 |
+
1. Replace the current JS frame FEA with a Python simulator service.
|
| 187 |
+
2. Start with scikit-fem 3D structural FEA for a simple cantilever bracket template.
|
| 188 |
+
3. Add Gmsh meshing.
|
| 189 |
+
4. Add VTK/VTU export.
|
| 190 |
+
5. Keep Three.js for browser rendering.
|
| 191 |
+
6. Only then add thermal.
|
| 192 |
+
7. Add electromagnetics only if we pick motor design as the final domain.
|
| 193 |
+
|
| 194 |
+
## Installation Note
|
| 195 |
+
|
| 196 |
+
The local environment currently does not have the heavy solver packages installed:
|
| 197 |
+
|
| 198 |
+
- `scikit-fem`
|
| 199 |
+
- `dolfinx`
|
| 200 |
+
- `gmsh`
|
| 201 |
+
- `meshio`
|
| 202 |
+
- `cadquery`
|
| 203 |
+
- `mujoco`
|
| 204 |
+
- `openmdao`
|
| 205 |
+
|
| 206 |
+
Installing those packages is a real environment change. Do it intentionally once we pick the stack.
|
| 207 |
+
|
docs/brainstorm/07-mechforge-domain-choice.md
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MechForge Domain Choice
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-24
|
| 4 |
+
|
| 5 |
+
## The Decision
|
| 6 |
+
|
| 7 |
+
We need to decide what the OpenEnv task is actually about:
|
| 8 |
+
|
| 9 |
+
1. Cantilever/bracket/mount structural optimization.
|
| 10 |
+
2. Motor design.
|
| 11 |
+
3. Mechanism/dynamics design.
|
| 12 |
+
4. Chip/EDA optimization.
|
| 13 |
+
5. Video or media editing.
|
| 14 |
+
|
| 15 |
+
The strongest physics candidates are structural design and motor design.
|
| 16 |
+
|
| 17 |
+
## Option A: Cantilever / Bracket / Mount Design
|
| 18 |
+
|
| 19 |
+
Pitch:
|
| 20 |
+
|
| 21 |
+
> Train an agent to design lightweight structural parts that survive real load cases.
|
| 22 |
+
|
| 23 |
+
Examples:
|
| 24 |
+
|
| 25 |
+
- drone arm bracket,
|
| 26 |
+
- motor mount,
|
| 27 |
+
- shelf bracket,
|
| 28 |
+
- lightweight bridge segment,
|
| 29 |
+
- 3D-printable fixture,
|
| 30 |
+
- robotic gripper finger.
|
| 31 |
+
|
| 32 |
+
Pros:
|
| 33 |
+
|
| 34 |
+
- Fastest to build.
|
| 35 |
+
- Easy to visualize.
|
| 36 |
+
- Structural FEA is simpler than EM.
|
| 37 |
+
- Clear rewards: mass, stress, strain, deflection, safety factor.
|
| 38 |
+
- Easy curriculum: 2D frame -> 3D linear elasticity -> multi-load cases.
|
| 39 |
+
- Excellent for showing iteration screenshots and STL versions.
|
| 40 |
+
|
| 41 |
+
Cons:
|
| 42 |
+
|
| 43 |
+
- Less exotic than motor design.
|
| 44 |
+
- Need good problem framing to avoid feeling like a simple topology optimization toy.
|
| 45 |
+
|
| 46 |
+
Verdict:
|
| 47 |
+
|
| 48 |
+
**Best hackathon target.** It is the strongest balance of spectacle, feasibility, and real verification.
|
| 49 |
+
|
| 50 |
+
## Option B: Axial Flux Motor Design
|
| 51 |
+
|
| 52 |
+
Pitch:
|
| 53 |
+
|
| 54 |
+
> Train an agent to design axial-flux motor variants under torque, efficiency, thermal, mass, and manufacturability constraints.
|
| 55 |
+
|
| 56 |
+
Examples:
|
| 57 |
+
|
| 58 |
+
- pole/slot selection,
|
| 59 |
+
- magnet geometry,
|
| 60 |
+
- airgap,
|
| 61 |
+
- winding turns,
|
| 62 |
+
- rotor/stator dimensions,
|
| 63 |
+
- cooling features,
|
| 64 |
+
- torque ripple/cogging reduction.
|
| 65 |
+
|
| 66 |
+
Pros:
|
| 67 |
+
|
| 68 |
+
- Most personally differentiated for a mechanical/electrical engineer.
|
| 69 |
+
- Very impressive story.
|
| 70 |
+
- Naturally multiphysics: EM + thermal + structural.
|
| 71 |
+
- Strong R&D flavor.
|
| 72 |
+
|
| 73 |
+
Cons:
|
| 74 |
+
|
| 75 |
+
- Hardest to implement correctly.
|
| 76 |
+
- EM FEA and motor post-processing are not trivial.
|
| 77 |
+
- 3D axial-flux simulation is expensive.
|
| 78 |
+
- Faster practical path is 2D/axisymmetric/analytical first, which may disappoint if pitched as full 3D.
|
| 79 |
+
|
| 80 |
+
Verdict:
|
| 81 |
+
|
| 82 |
+
**Best long-term product/research direction, risky for this hackathon.** Use as a stretch or second environment if structural MechForge works.
|
| 83 |
+
|
| 84 |
+
## Option C: Mechanism / Dynamics Design
|
| 85 |
+
|
| 86 |
+
Pitch:
|
| 87 |
+
|
| 88 |
+
> Train an agent to design mechanisms that move correctly under physical simulation.
|
| 89 |
+
|
| 90 |
+
Examples:
|
| 91 |
+
|
| 92 |
+
- linkage design,
|
| 93 |
+
- gripper mechanism,
|
| 94 |
+
- passive walker,
|
| 95 |
+
- robot end-effector,
|
| 96 |
+
- compliant-ish mechanism approximated as rigid joints.
|
| 97 |
+
|
| 98 |
+
Pros:
|
| 99 |
+
|
| 100 |
+
- MuJoCo is actually a great fit.
|
| 101 |
+
- Visual and interactive.
|
| 102 |
+
- Rewards are measurable: trajectory error, contact stability, energy, joint limits.
|
| 103 |
+
|
| 104 |
+
Cons:
|
| 105 |
+
|
| 106 |
+
- Not FEA.
|
| 107 |
+
- Less aligned with stress/thermal/electromagnetics.
|
| 108 |
+
- Could drift into robotics control instead of engineering design.
|
| 109 |
+
|
| 110 |
+
Verdict:
|
| 111 |
+
|
| 112 |
+
Good if we want MuJoCo. Not the right answer if we want structural/thermal/EM.
|
| 113 |
+
|
| 114 |
+
## Option D: Full Multiphysics MotorBench
|
| 115 |
+
|
| 116 |
+
Pitch:
|
| 117 |
+
|
| 118 |
+
> A multiphysics OpenEnv where agents design electric machines and learn from EM, thermal, and structural simulation.
|
| 119 |
+
|
| 120 |
+
Pros:
|
| 121 |
+
|
| 122 |
+
- Huge wow factor.
|
| 123 |
+
- Most ambitious.
|
| 124 |
+
- Strong self-improvement story.
|
| 125 |
+
|
| 126 |
+
Cons:
|
| 127 |
+
|
| 128 |
+
- Too much for a two-day MVP unless heavily constrained.
|
| 129 |
+
- Many solvers and file formats.
|
| 130 |
+
- Risk of spending the whole hackathon packaging tools.
|
| 131 |
+
|
| 132 |
+
Verdict:
|
| 133 |
+
|
| 134 |
+
Great final vision, not the first build.
|
| 135 |
+
|
| 136 |
+
## Recommendation
|
| 137 |
+
|
| 138 |
+
Build:
|
| 139 |
+
|
| 140 |
+
> **MechForge Structural 3D: motor-mount/bracket optimization with real 3D FEA.**
|
| 141 |
+
|
| 142 |
+
Frame it as the first task family in a larger MechForge platform:
|
| 143 |
+
|
| 144 |
+
- structural bracket/motor mount now,
|
| 145 |
+
- thermal add-on next,
|
| 146 |
+
- motor EM design later.
|
| 147 |
+
|
| 148 |
+
This preserves the big dream while keeping the first submission shippable.
|
| 149 |
+
|
| 150 |
+
## Why Motor Mount Is The Sweet Spot
|
| 151 |
+
|
| 152 |
+
A motor mount bridges both worlds:
|
| 153 |
+
|
| 154 |
+
- It is structurally verifiable.
|
| 155 |
+
- It is visually clear.
|
| 156 |
+
- It can later connect to motor design.
|
| 157 |
+
- It supports heat and vibration extensions.
|
| 158 |
+
- It feels more interesting than a generic cantilever.
|
| 159 |
+
|
| 160 |
+
Suggested final prompt family:
|
| 161 |
+
|
| 162 |
+
> Design a lightweight motor mount for a drone/EV test rig. It must support thrust/load, keep shaft alignment under deflection, avoid high stress near bolt holes, and optionally dissipate heat from the motor face.
|
| 163 |
+
|
| 164 |
+
That gives us:
|
| 165 |
+
|
| 166 |
+
- structural FEA now,
|
| 167 |
+
- thermal next,
|
| 168 |
+
- motor design story later.
|
| 169 |
+
|
docs/brainstorm/08-agentic-3d-engineering-environment.md
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Document 8: Agentic 3D Engineering Environment
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-24
|
| 4 |
+
|
| 5 |
+
## Honest Product Definition
|
| 6 |
+
|
| 7 |
+
The winning product is not:
|
| 8 |
+
|
| 9 |
+
> LLM generates a 3D model.
|
| 10 |
+
|
| 11 |
+
The winning product is:
|
| 12 |
+
|
| 13 |
+
> An AI engineering agent that turns natural-language physical requirements into parameterized CAD, runs simulation and manufacturability checks, optimizes the design, and outputs manufacturable files with a safety-factor report.
|
| 14 |
+
|
| 15 |
+
For fixtures:
|
| 16 |
+
|
| 17 |
+
> Given load, material, envelope, mounting constraints, print/manufacturing process, and target safety factor, generate a manufacturable bracket/fixture and prove it with FEA.
|
| 18 |
+
|
| 19 |
+
For motors:
|
| 20 |
+
|
| 21 |
+
> Given magnets, bearings, shaft, voltage/current limits, printer/process, and target torque/RPM, generate a printable axial-flux BLDC motor kit and prove it with EM/thermal/structural simulation.
|
| 22 |
+
|
| 23 |
+
The fixture path is more commercially useful and shippable.
|
| 24 |
+
The motor path is more fun and demo-worthy.
|
| 25 |
+
Together, they are a strong long-term research/product direction.
|
| 26 |
+
|
| 27 |
+
## Hackathon Choice
|
| 28 |
+
|
| 29 |
+
For the next 24 to 26 effective hours, pick:
|
| 30 |
+
|
| 31 |
+
> **Option A: 3D structural motor-mount/bracket/fixture design with real 3D linear elasticity.**
|
| 32 |
+
|
| 33 |
+
Why:
|
| 34 |
+
|
| 35 |
+
- It is doable fast.
|
| 36 |
+
- It is visual.
|
| 37 |
+
- It is objectively verifiable.
|
| 38 |
+
- It supports 300+ step agentic loops.
|
| 39 |
+
- It can expand later to thermal, dynamics, NVH, and motor design.
|
| 40 |
+
|
| 41 |
+
Do not start with full axial-flux motor EM unless structural MechForge is already working. MotorBench should be the long-term second stage.
|
| 42 |
+
|
| 43 |
+
## Agent Loop
|
| 44 |
+
|
| 45 |
+
The environment should run this loop:
|
| 46 |
+
|
| 47 |
+
```text
|
| 48 |
+
prompt
|
| 49 |
+
-> parse requirements
|
| 50 |
+
-> ask/assume missing boundary conditions
|
| 51 |
+
-> generate 3-5 design families
|
| 52 |
+
-> create parametric CAD/actions
|
| 53 |
+
-> run 3D FEA
|
| 54 |
+
-> identify stress concentrations and deflection
|
| 55 |
+
-> add fillets/ribs/thickness or move holes
|
| 56 |
+
-> re-run FEA
|
| 57 |
+
-> optimize mass/safety/deflection/manufacturability
|
| 58 |
+
-> export CAD/STL + simulation report
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
In OpenEnv terms:
|
| 62 |
+
|
| 63 |
+
```text
|
| 64 |
+
reset(task_seed)
|
| 65 |
+
-> observation: design brief, constraints, materials, available tools
|
| 66 |
+
|
| 67 |
+
step(action)
|
| 68 |
+
-> environment applies CAD/tool action
|
| 69 |
+
-> if requested, simulator runs
|
| 70 |
+
-> reward components returned
|
| 71 |
+
-> observation includes metrics, warnings, hotspots, artifacts
|
| 72 |
+
|
| 73 |
+
done
|
| 74 |
+
-> when agent commits a design or exceeds step budget
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
## Missing-Information Handling
|
| 78 |
+
|
| 79 |
+
A naive LLM will fail because it will not know boundary conditions.
|
| 80 |
+
|
| 81 |
+
The environment must either ask for or infer:
|
| 82 |
+
|
| 83 |
+
- Is 120 Nm a torque around a shaft?
|
| 84 |
+
- Is it a force through a hook/tip/load face?
|
| 85 |
+
- Where is the fixture mounted?
|
| 86 |
+
- What are the bolt holes?
|
| 87 |
+
- Static, cyclic, or impact load?
|
| 88 |
+
- Desired safety factor?
|
| 89 |
+
- Material ambiguity, e.g. "601 aluminum" likely means 6061 aluminum.
|
| 90 |
+
- Manufacturing process: 3D print, CNC, sheet metal, casting.
|
| 91 |
+
- Temperature or thermal expansion constraints.
|
| 92 |
+
|
| 93 |
+
For hackathon speed, the environment should include default load templates:
|
| 94 |
+
|
| 95 |
+
1. **Cantilever tip load**: fixed face at x=0, downward force at free tip.
|
| 96 |
+
2. **Motor mount**: bolt holes fixed, radial/axial motor load at boss, optional torque couple.
|
| 97 |
+
3. **Chair/seat support**: fixed feet or base, downward distributed load on seat surface.
|
| 98 |
+
4. **Torque fixture**: equal/opposite force couple around a shaft axis.
|
| 99 |
+
|
| 100 |
+
If the user explicitly tells where the load goes, that overrides defaults.
|
| 101 |
+
|
| 102 |
+
## Tool Calls
|
| 103 |
+
|
| 104 |
+
Use incremental tool calls rather than one huge CAD file.
|
| 105 |
+
|
| 106 |
+
Design tools:
|
| 107 |
+
|
| 108 |
+
```json
|
| 109 |
+
{"tool": "create_design_family", "family": "ribbed_cantilever_bracket"}
|
| 110 |
+
{"tool": "set_material", "material": "aluminum_6061"}
|
| 111 |
+
{"tool": "set_envelope", "length_mm": 100, "width_mm": 45, "height_mm": 30}
|
| 112 |
+
{"tool": "add_mount_hole", "id": "m1", "center": [10, -15, 0], "radius_mm": 2.6}
|
| 113 |
+
{"tool": "add_rib", "id": "r1", "start": [12, -15, 4], "end": [92, -4, 22], "width_mm": 5}
|
| 114 |
+
{"tool": "add_lightening_hole", "id": "h1", "center": [55, 12, 2], "radius_mm": 4}
|
| 115 |
+
{"tool": "set_base_thickness", "value_mm": 4.5}
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
Load/boundary tools:
|
| 119 |
+
|
| 120 |
+
```json
|
| 121 |
+
{"tool": "set_fixed_region", "region": "left_face"}
|
| 122 |
+
{"tool": "set_fixed_region", "region": "mounting_holes"}
|
| 123 |
+
{"tool": "set_force", "region": "tip_boss", "vector_n": [0, 0, -120]}
|
| 124 |
+
{"tool": "set_torque", "axis": "x", "origin": [90, 0, 10], "torque_nm": 120}
|
| 125 |
+
{"tool": "set_temperature", "region": "motor_face", "temperature_c": 80}
|
| 126 |
+
{"tool": "set_heat_source", "region": "motor_face", "power_w": 12}
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
Simulation tools:
|
| 130 |
+
|
| 131 |
+
```json
|
| 132 |
+
{"tool": "build_cad"}
|
| 133 |
+
{"tool": "mesh_geometry", "target_size_mm": 5}
|
| 134 |
+
{"tool": "run_fea", "physics": "linear_elasticity"}
|
| 135 |
+
{"tool": "run_thermal", "physics": "steady_state_heat"}
|
| 136 |
+
{"tool": "inspect_hotspots", "field": "von_mises_stress"}
|
| 137 |
+
{"tool": "export_artifacts", "formats": ["json", "stl", "step", "vtu", "png"]}
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
Optimization tools:
|
| 141 |
+
|
| 142 |
+
```json
|
| 143 |
+
{"tool": "propose_revision", "objective": "reduce_mass_keep_sf_above_2"}
|
| 144 |
+
{"tool": "sweep_parameter", "name": "base_thickness_mm", "values": [3.5, 4, 4.5, 5]}
|
| 145 |
+
{"tool": "optimize_parameters", "method": "cma_es", "budget": 40}
|
| 146 |
+
{"tool": "commit_design"}
|
| 147 |
+
```
|
| 148 |
+
|
| 149 |
+
## Environment Responses
|
| 150 |
+
|
| 151 |
+
After a design action:
|
| 152 |
+
|
| 153 |
+
```json
|
| 154 |
+
{
|
| 155 |
+
"valid": true,
|
| 156 |
+
"changed_parameters": ["base_thickness_mm"],
|
| 157 |
+
"geometry_status": "buildable",
|
| 158 |
+
"warnings": []
|
| 159 |
+
}
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
After FEA:
|
| 163 |
+
|
| 164 |
+
```json
|
| 165 |
+
{
|
| 166 |
+
"method": "3D linear tetrahedral elasticity",
|
| 167 |
+
"nodes": 240,
|
| 168 |
+
"elements": 620,
|
| 169 |
+
"max_von_mises_mpa": 138.4,
|
| 170 |
+
"max_principal_strain": 0.0021,
|
| 171 |
+
"max_displacement_mm": 2.7,
|
| 172 |
+
"safety_factor": 2.0,
|
| 173 |
+
"mass_g": 51.2,
|
| 174 |
+
"hotspots": [
|
| 175 |
+
{"region": "fixed_root", "severity": 0.50},
|
| 176 |
+
{"region": "rib_root_r1", "severity": 0.42}
|
| 177 |
+
],
|
| 178 |
+
"constraints": {
|
| 179 |
+
"safety_factor_above_2": true,
|
| 180 |
+
"mass_below_45g": false,
|
| 181 |
+
"tip_deflection_below_2mm": false
|
| 182 |
+
}
|
| 183 |
+
}
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
After commit:
|
| 187 |
+
|
| 188 |
+
```json
|
| 189 |
+
{
|
| 190 |
+
"final_score": 0.82,
|
| 191 |
+
"reward_breakdown": {
|
| 192 |
+
"safety": 0.30,
|
| 193 |
+
"stiffness": 0.22,
|
| 194 |
+
"mass": 0.12,
|
| 195 |
+
"manufacturability": 0.10,
|
| 196 |
+
"invalid_action_penalty": 0.0
|
| 197 |
+
},
|
| 198 |
+
"artifacts": {
|
| 199 |
+
"design_json": "runs/.../design.json",
|
| 200 |
+
"stl": "runs/.../geometry.stl",
|
| 201 |
+
"report": "runs/.../report.md"
|
| 202 |
+
}
|
| 203 |
+
}
|
| 204 |
+
```
|
| 205 |
+
|
| 206 |
+
## Long-Horizon Step Design
|
| 207 |
+
|
| 208 |
+
A 300-500 step episode is plausible if the environment exposes detailed action space:
|
| 209 |
+
|
| 210 |
+
- 20-50 requirement parsing and constraint-confirmation actions.
|
| 211 |
+
- 30-80 design family generation and selection actions.
|
| 212 |
+
- 100-250 geometry edits.
|
| 213 |
+
- 50-100 simulation/inspection actions.
|
| 214 |
+
- 50-100 optimization sweeps and revisions.
|
| 215 |
+
- 10-20 final export/report actions.
|
| 216 |
+
|
| 217 |
+
Training goal:
|
| 218 |
+
|
| 219 |
+
- Baseline model takes many invalid or inefficient steps.
|
| 220 |
+
- Trained model learns good action order:
|
| 221 |
+
- clarify/assume loads,
|
| 222 |
+
- create feasible design family,
|
| 223 |
+
- run simulation early,
|
| 224 |
+
- inspect hotspots,
|
| 225 |
+
- revise local features,
|
| 226 |
+
- avoid over-lightening,
|
| 227 |
+
- commit only after constraints pass.
|
| 228 |
+
|
| 229 |
+
The story becomes:
|
| 230 |
+
|
| 231 |
+
> RL teaches engineering workflow discipline, not just CAD generation.
|
| 232 |
+
|
| 233 |
+
## 24-Hour MVP
|
| 234 |
+
|
| 235 |
+
Build in order:
|
| 236 |
+
|
| 237 |
+
1. Current experiment: GPT-5.4 structured design + Three.js viewer.
|
| 238 |
+
2. Add 3D tetrahedral linear elasticity solver.
|
| 239 |
+
3. Add load manager for cantilever/motor-mount/torque defaults.
|
| 240 |
+
4. Add trace view for tool calls and simulator responses.
|
| 241 |
+
5. Save per-iteration artifacts.
|
| 242 |
+
6. Convert to OpenEnv API.
|
| 243 |
+
7. Add baseline inference.
|
| 244 |
+
8. Run short training or at least repeated benchmark showing improvement.
|
| 245 |
+
|
| 246 |
+
## What To Say In The Pitch
|
| 247 |
+
|
| 248 |
+
> We built an OpenEnv for engineering design agents. The agent receives physical requirements, infers boundary conditions, creates parametric CAD actions, runs real 3D FEA, reads stress/deformation feedback, and iteratively improves the design. This is a foundation for simulation-trained engineering models across fixtures, mounts, thermal constraints, and eventually motors.
|
| 249 |
+
|
docs/brainstorm/09-cad-rlve-structural-household-parts.md
ADDED
|
@@ -0,0 +1,472 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Document 9: CAD RLVE For Structural Household Mechanical Parts
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-25
|
| 4 |
+
|
| 5 |
+
## Core Realization
|
| 6 |
+
|
| 7 |
+
Current AI is not reliably bad at "imagining 3D objects."
|
| 8 |
+
|
| 9 |
+
It is bad at:
|
| 10 |
+
|
| 11 |
+
- making valid CAD,
|
| 12 |
+
- making the right geometric edit at the right time,
|
| 13 |
+
- preserving design intent,
|
| 14 |
+
- keeping features clean and editable,
|
| 15 |
+
- avoiding broken booleans and non-manifold geometry,
|
| 16 |
+
- producing parts that survive physical checks.
|
| 17 |
+
|
| 18 |
+
That is exactly why a CAD-focused RLVE environment is interesting.
|
| 19 |
+
|
| 20 |
+
The product should not be:
|
| 21 |
+
|
| 22 |
+
> Generate a cool-looking mesh.
|
| 23 |
+
|
| 24 |
+
The product should be:
|
| 25 |
+
|
| 26 |
+
> Train an agent to create and revise parametric CAD code until the part is valid, editable, manufacturable, and structurally correct.
|
| 27 |
+
|
| 28 |
+
This is a stronger and more general version of MechForge. MechForge becomes the first structural benchmark suite inside a larger CAD-agent training environment.
|
| 29 |
+
|
| 30 |
+
## Name
|
| 31 |
+
|
| 32 |
+
Working names:
|
| 33 |
+
|
| 34 |
+
- **CADForge**
|
| 35 |
+
- **MechForge CAD**
|
| 36 |
+
- **OpenCAD Gym**
|
| 37 |
+
- **ParametricCAD RLVE**
|
| 38 |
+
- **FeatureForge**
|
| 39 |
+
|
| 40 |
+
Best current framing:
|
| 41 |
+
|
| 42 |
+
> **CADForge: an RLVE environment where agents learn reliable parametric CAD creation and editing for functional mechanical parts.**
|
| 43 |
+
|
| 44 |
+
## Why Code-CAD Is The Right Medium
|
| 45 |
+
|
| 46 |
+
The agent should write or edit code-CAD, not arbitrary meshes.
|
| 47 |
+
|
| 48 |
+
Good backend candidates:
|
| 49 |
+
|
| 50 |
+
- OpenSCAD-style constructive solid geometry,
|
| 51 |
+
- CadQuery,
|
| 52 |
+
- build123d,
|
| 53 |
+
- a constrained internal DSL that compiles to CadQuery/OpenSCAD/STEP/STL.
|
| 54 |
+
|
| 55 |
+
The user said "OpenCADD"; if this means OpenSCAD or a similar code-CAD tool, the important idea is the same:
|
| 56 |
+
|
| 57 |
+
> CAD should be represented as executable, inspectable, deterministic code.
|
| 58 |
+
|
| 59 |
+
That gives the environment objective checks:
|
| 60 |
+
|
| 61 |
+
- Did the code run?
|
| 62 |
+
- Did the model build?
|
| 63 |
+
- Did operations apply in the right order?
|
| 64 |
+
- Is the feature tree clean?
|
| 65 |
+
- Are dimensions parameterized?
|
| 66 |
+
- Can a downstream edit change the part without breaking it?
|
| 67 |
+
- Does export work?
|
| 68 |
+
- Is the final geometry watertight and manifold?
|
| 69 |
+
|
| 70 |
+
This is much better for RLVE than asking the model to emit a raw mesh.
|
| 71 |
+
|
| 72 |
+
## Target Domain
|
| 73 |
+
|
| 74 |
+
Start with structural household and mechanical parts:
|
| 75 |
+
|
| 76 |
+
- wall hook,
|
| 77 |
+
- shelf bracket,
|
| 78 |
+
- cantilever support,
|
| 79 |
+
- chair seat support,
|
| 80 |
+
- stool leg joint,
|
| 81 |
+
- phone stand,
|
| 82 |
+
- desk clamp,
|
| 83 |
+
- handle,
|
| 84 |
+
- hinge plate,
|
| 85 |
+
- simple enclosure mount,
|
| 86 |
+
- motor mount,
|
| 87 |
+
- cable guide,
|
| 88 |
+
- pegboard fixture,
|
| 89 |
+
- plant hanger,
|
| 90 |
+
- small appliance bracket.
|
| 91 |
+
|
| 92 |
+
These are ideal because they are:
|
| 93 |
+
|
| 94 |
+
- easy to understand visually,
|
| 95 |
+
- mechanically meaningful,
|
| 96 |
+
- structurally verifiable,
|
| 97 |
+
- small enough to simulate quickly,
|
| 98 |
+
- familiar enough that judges understand failures,
|
| 99 |
+
- broad enough to expose many CAD operations.
|
| 100 |
+
|
| 101 |
+
## Agent Task
|
| 102 |
+
|
| 103 |
+
The agent receives a physical design brief:
|
| 104 |
+
|
| 105 |
+
```text
|
| 106 |
+
Design a wall hook that mounts with two screws, fits inside an 80 mm x 60 mm x 45 mm envelope,
|
| 107 |
+
holds a 5 kg load with safety factor above 2, is printable without support where possible,
|
| 108 |
+
and has rounded edges for safe household use.
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
The agent must produce code-CAD:
|
| 112 |
+
|
| 113 |
+
```python
|
| 114 |
+
part = create_base_plate(width=60, height=80, thickness=6)
|
| 115 |
+
part = add_mounting_holes(part, spacing=48, diameter=5)
|
| 116 |
+
part = add_hook_arm(part, length=42, thickness=8, root_fillet=6)
|
| 117 |
+
part = add_tip_lip(part, height=8, radius=4)
|
| 118 |
+
part = add_ribs(part, count=2, thickness=4)
|
| 119 |
+
part = fillet_edges(part, radius=2)
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
Then the environment builds, validates, simulates, and scores the result.
|
| 123 |
+
|
| 124 |
+
## Action Space
|
| 125 |
+
|
| 126 |
+
Use incremental tool calls rather than one giant CAD program.
|
| 127 |
+
|
| 128 |
+
Sketch and feature tools:
|
| 129 |
+
|
| 130 |
+
```json
|
| 131 |
+
{"tool": "create_sketch", "plane": "XY", "id": "base_profile"}
|
| 132 |
+
{"tool": "add_rectangle", "sketch": "base_profile", "width_mm": 60, "height_mm": 80}
|
| 133 |
+
{"tool": "constrain_symmetric", "sketch": "base_profile", "axis": "Y"}
|
| 134 |
+
{"tool": "extrude", "sketch": "base_profile", "distance_mm": 6, "id": "base_plate"}
|
| 135 |
+
{"tool": "add_hole", "target": "base_plate", "center_mm": [0, 24], "diameter_mm": 5}
|
| 136 |
+
{"tool": "add_hole", "target": "base_plate", "center_mm": [0, -24], "diameter_mm": 5}
|
| 137 |
+
{"tool": "add_hook_arm", "length_mm": 42, "thickness_mm": 8, "angle_deg": 12}
|
| 138 |
+
{"tool": "add_rib", "from": "base_plate", "to": "hook_arm", "thickness_mm": 4}
|
| 139 |
+
{"tool": "fillet", "target": "root_edges", "radius_mm": 5}
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
Validation tools:
|
| 143 |
+
|
| 144 |
+
```json
|
| 145 |
+
{"tool": "build_cad"}
|
| 146 |
+
{"tool": "check_feature_tree"}
|
| 147 |
+
{"tool": "check_constraints"}
|
| 148 |
+
{"tool": "check_manifold"}
|
| 149 |
+
{"tool": "check_watertight"}
|
| 150 |
+
{"tool": "check_min_wall_thickness", "min_mm": 2.5}
|
| 151 |
+
{"tool": "check_overhangs", "process": "fdm_3d_printing", "max_angle_deg": 45}
|
| 152 |
+
{"tool": "export_artifacts", "formats": ["step", "stl", "json", "png"]}
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
Simulation tools:
|
| 156 |
+
|
| 157 |
+
```json
|
| 158 |
+
{"tool": "set_material", "material": "pla"}
|
| 159 |
+
{"tool": "set_fixed_region", "region": "mounting_hole_faces"}
|
| 160 |
+
{"tool": "set_force", "region": "hook_tip", "vector_n": [0, 0, -50]}
|
| 161 |
+
{"tool": "mesh_geometry", "target_size_mm": 3}
|
| 162 |
+
{"tool": "run_structural_check", "physics": "linear_elasticity"}
|
| 163 |
+
{"tool": "inspect_hotspots", "field": "von_mises_stress"}
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
Revision tools:
|
| 167 |
+
|
| 168 |
+
```json
|
| 169 |
+
{"tool": "increase_parameter", "name": "root_fillet_mm", "delta": 1}
|
| 170 |
+
{"tool": "move_feature", "feature": "mount_hole_1", "delta_mm": [0, 4, 0]}
|
| 171 |
+
{"tool": "add_support_rib", "region": "hook_root", "thickness_mm": 3}
|
| 172 |
+
{"tool": "reduce_mass", "strategy": "lightening_holes_low_stress_regions"}
|
| 173 |
+
{"tool": "commit_design"}
|
| 174 |
+
```
|
| 175 |
+
|
| 176 |
+
## Reward Design
|
| 177 |
+
|
| 178 |
+
Reward should be multi-layered. The early curriculum rewards basic CAD validity; later stages reward engineering quality.
|
| 179 |
+
|
| 180 |
+
Suggested reward:
|
| 181 |
+
|
| 182 |
+
```text
|
| 183 |
+
valid_code_execution: 0.10
|
| 184 |
+
cad_build_success: 0.15
|
| 185 |
+
clean_feature_tree: 0.10
|
| 186 |
+
editability_test_passed: 0.10
|
| 187 |
+
manifold_watertight_mesh: 0.10
|
| 188 |
+
constraint_satisfaction: 0.10
|
| 189 |
+
manufacturability: 0.10
|
| 190 |
+
structural_safety: 0.15
|
| 191 |
+
mass_efficiency: 0.05
|
| 192 |
+
revision_efficiency: 0.05
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
Penalties:
|
| 196 |
+
|
| 197 |
+
```text
|
| 198 |
+
syntax_error: -0.20
|
| 199 |
+
failed_boolean_operation: -0.15
|
| 200 |
+
non_manifold_geometry: -0.15
|
| 201 |
+
self_intersection: -0.15
|
| 202 |
+
unparameterized_magic_values: -0.05
|
| 203 |
+
uneditable_feature_chain: -0.10
|
| 204 |
+
unsafe_stress_or_deflection: -0.20
|
| 205 |
+
invalid_final_export: -0.20
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
The important thing:
|
| 209 |
+
|
| 210 |
+
> The agent is not rewarded for a pretty model. It is rewarded for reliable CAD behavior.
|
| 211 |
+
|
| 212 |
+
## Editability Tests
|
| 213 |
+
|
| 214 |
+
This is the key differentiator.
|
| 215 |
+
|
| 216 |
+
After the agent submits a part, the environment should mutate requirements and test whether the CAD remains editable:
|
| 217 |
+
|
| 218 |
+
- increase load by 20%,
|
| 219 |
+
- change screw spacing,
|
| 220 |
+
- change material,
|
| 221 |
+
- change envelope,
|
| 222 |
+
- increase minimum wall thickness,
|
| 223 |
+
- require a larger fillet,
|
| 224 |
+
- move mounting holes,
|
| 225 |
+
- change manufacturing process from FDM to CNC or vice versa.
|
| 226 |
+
|
| 227 |
+
Example:
|
| 228 |
+
|
| 229 |
+
```json
|
| 230 |
+
{
|
| 231 |
+
"edit_test": "change_mount_hole_spacing",
|
| 232 |
+
"old_spacing_mm": 48,
|
| 233 |
+
"new_spacing_mm": 56,
|
| 234 |
+
"expected": "model_rebuilds_without_manual_rewrite"
|
| 235 |
+
}
|
| 236 |
+
```
|
| 237 |
+
|
| 238 |
+
This catches fake CAD solutions that only work once.
|
| 239 |
+
|
| 240 |
+
The trained behavior we want:
|
| 241 |
+
|
| 242 |
+
- define named parameters,
|
| 243 |
+
- reference parameters consistently,
|
| 244 |
+
- avoid brittle coordinate hacks,
|
| 245 |
+
- keep sketches constrained,
|
| 246 |
+
- isolate features cleanly,
|
| 247 |
+
- choose operations that survive downstream edits.
|
| 248 |
+
|
| 249 |
+
This is where AI currently fails badly, which makes it a strong RLVE target.
|
| 250 |
+
|
| 251 |
+
## Geometry Quality Checks
|
| 252 |
+
|
| 253 |
+
The environment should check:
|
| 254 |
+
|
| 255 |
+
- watertight mesh,
|
| 256 |
+
- no holes or gaps,
|
| 257 |
+
- manifold edges,
|
| 258 |
+
- no self-intersections,
|
| 259 |
+
- no zero-thickness faces,
|
| 260 |
+
- no tiny sliver faces,
|
| 261 |
+
- no duplicate coincident geometry,
|
| 262 |
+
- acceptable triangle quality for exported mesh,
|
| 263 |
+
- consistent normals,
|
| 264 |
+
- minimum feature size,
|
| 265 |
+
- minimum wall thickness,
|
| 266 |
+
- proper contact/union between features.
|
| 267 |
+
|
| 268 |
+
For code-CAD, this can be done after export:
|
| 269 |
+
|
| 270 |
+
```text
|
| 271 |
+
CAD code -> solid model -> STEP/STL -> mesh/solid validation -> reward
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
The "tight mesh" requirement should not mean the agent directly optimizes mesh triangles first. It should mean:
|
| 275 |
+
|
| 276 |
+
> The CAD-generated solid exports to a clean, watertight, simulation-ready mesh.
|
| 277 |
+
|
| 278 |
+
## Structural Verification
|
| 279 |
+
|
| 280 |
+
For MechForge, start with fast structural checks:
|
| 281 |
+
|
| 282 |
+
- cantilever beam approximation,
|
| 283 |
+
- plate/rib stress proxies,
|
| 284 |
+
- simple linear elasticity,
|
| 285 |
+
- later tetrahedral FEA.
|
| 286 |
+
|
| 287 |
+
Each part gets a load template:
|
| 288 |
+
|
| 289 |
+
| Part | Boundary condition | Load |
|
| 290 |
+
|---|---|---|
|
| 291 |
+
| Wall hook | screw holes fixed | downward load at hook tip |
|
| 292 |
+
| Shelf bracket | wall plate fixed | distributed shelf load |
|
| 293 |
+
| Chair support | feet fixed | downward seat load |
|
| 294 |
+
| Phone stand | base contact fixed | device weight and tipping check |
|
| 295 |
+
| Clamp | screw pad contact | clamping force and jaw bending |
|
| 296 |
+
| Motor mount | bolt holes fixed | radial/axial force and torque |
|
| 297 |
+
|
| 298 |
+
The environment returns feedback:
|
| 299 |
+
|
| 300 |
+
```json
|
| 301 |
+
{
|
| 302 |
+
"build": "success",
|
| 303 |
+
"geometry": {
|
| 304 |
+
"watertight": true,
|
| 305 |
+
"manifold": true,
|
| 306 |
+
"min_wall_thickness_mm": 3.2,
|
| 307 |
+
"self_intersections": 0
|
| 308 |
+
},
|
| 309 |
+
"feature_tree": {
|
| 310 |
+
"named_parameters": 12,
|
| 311 |
+
"editable": true,
|
| 312 |
+
"failed_edit_tests": []
|
| 313 |
+
},
|
| 314 |
+
"structural": {
|
| 315 |
+
"max_stress_mpa": 31.4,
|
| 316 |
+
"max_displacement_mm": 1.8,
|
| 317 |
+
"safety_factor": 2.4,
|
| 318 |
+
"hotspots": ["hook_root"]
|
| 319 |
+
},
|
| 320 |
+
"reward": 0.86
|
| 321 |
+
}
|
| 322 |
+
```
|
| 323 |
+
|
| 324 |
+
## Curriculum
|
| 325 |
+
|
| 326 |
+
Stage 1: Valid code-CAD
|
| 327 |
+
|
| 328 |
+
- simple plates,
|
| 329 |
+
- holes,
|
| 330 |
+
- extrusions,
|
| 331 |
+
- fillets,
|
| 332 |
+
- no physical simulation yet.
|
| 333 |
+
|
| 334 |
+
Stage 2: Editable parametric parts
|
| 335 |
+
|
| 336 |
+
- change dimensions,
|
| 337 |
+
- move holes,
|
| 338 |
+
- alter thickness,
|
| 339 |
+
- regenerate cleanly.
|
| 340 |
+
|
| 341 |
+
Stage 3: Manufacturable household parts
|
| 342 |
+
|
| 343 |
+
- wall hook,
|
| 344 |
+
- phone stand,
|
| 345 |
+
- shelf bracket,
|
| 346 |
+
- clamp,
|
| 347 |
+
- hinge plate.
|
| 348 |
+
|
| 349 |
+
Stage 4: Structural MechForge
|
| 350 |
+
|
| 351 |
+
- loads,
|
| 352 |
+
- fixed regions,
|
| 353 |
+
- stress proxy,
|
| 354 |
+
- displacement proxy,
|
| 355 |
+
- safety factor,
|
| 356 |
+
- mass efficiency.
|
| 357 |
+
|
| 358 |
+
Stage 5: Multi-step engineering revision
|
| 359 |
+
|
| 360 |
+
- inspect hotspots,
|
| 361 |
+
- add ribs,
|
| 362 |
+
- change fillets,
|
| 363 |
+
- move holes,
|
| 364 |
+
- reduce mass,
|
| 365 |
+
- rerun checks,
|
| 366 |
+
- commit design.
|
| 367 |
+
|
| 368 |
+
Stage 6: Higher-fidelity CAD and FEA
|
| 369 |
+
|
| 370 |
+
- STEP export,
|
| 371 |
+
- tetrahedral meshing,
|
| 372 |
+
- linear elasticity,
|
| 373 |
+
- thermal add-on,
|
| 374 |
+
- multi-load cases.
|
| 375 |
+
|
| 376 |
+
## Why This Is Reliable
|
| 377 |
+
|
| 378 |
+
This environment has unusually objective feedback.
|
| 379 |
+
|
| 380 |
+
The verifier does not need to understand aesthetics or taste. It can simply check:
|
| 381 |
+
|
| 382 |
+
- code runs,
|
| 383 |
+
- CAD builds,
|
| 384 |
+
- geometry is closed,
|
| 385 |
+
- edits survive,
|
| 386 |
+
- features are named,
|
| 387 |
+
- constraints are satisfied,
|
| 388 |
+
- physical load cases pass,
|
| 389 |
+
- artifacts export.
|
| 390 |
+
|
| 391 |
+
That gives a clean training signal.
|
| 392 |
+
|
| 393 |
+
It also directly targets a frontier-model weakness:
|
| 394 |
+
|
| 395 |
+
> Models can often write one plausible CAD script, but they are unreliable at iterative geometric repair and robust parametric editing.
|
| 396 |
+
|
| 397 |
+
That gap is where RLVE can show measurable improvement.
|
| 398 |
+
|
| 399 |
+
## 24-Hour MVP
|
| 400 |
+
|
| 401 |
+
Build the MVP around one or two part families:
|
| 402 |
+
|
| 403 |
+
1. Wall hook.
|
| 404 |
+
2. Shelf bracket or motor mount.
|
| 405 |
+
|
| 406 |
+
Minimum viable loop:
|
| 407 |
+
|
| 408 |
+
```text
|
| 409 |
+
prompt
|
| 410 |
+
-> agent emits constrained CAD JSON or code-CAD
|
| 411 |
+
-> environment builds part
|
| 412 |
+
-> exports STL
|
| 413 |
+
-> validates watertight/manifold geometry
|
| 414 |
+
-> runs simple structural score
|
| 415 |
+
-> applies one editability mutation
|
| 416 |
+
-> returns reward
|
| 417 |
+
```
|
| 418 |
+
|
| 419 |
+
Artifacts:
|
| 420 |
+
|
| 421 |
+
- CAD code,
|
| 422 |
+
- design JSON,
|
| 423 |
+
- STL,
|
| 424 |
+
- PNG render,
|
| 425 |
+
- validation report,
|
| 426 |
+
- reward breakdown,
|
| 427 |
+
- trace of actions.
|
| 428 |
+
|
| 429 |
+
The demo story:
|
| 430 |
+
|
| 431 |
+
> At first, the agent creates CAD that looks plausible but breaks under edits or produces bad geometry. After training, it learns to create clean, editable, watertight parametric parts that survive structural checks.
|
| 432 |
+
|
| 433 |
+
## Relationship To MechForge
|
| 434 |
+
|
| 435 |
+
MechForge should become the structural subset of CADForge.
|
| 436 |
+
|
| 437 |
+
Old framing:
|
| 438 |
+
|
| 439 |
+
> Train an agent to design lightweight brackets/mounts under load.
|
| 440 |
+
|
| 441 |
+
New framing:
|
| 442 |
+
|
| 443 |
+
> Train an agent to create reliable parametric CAD for functional mechanical parts, with MechForge structural checks as the first reward suite.
|
| 444 |
+
|
| 445 |
+
This is better because it solves the deeper problem.
|
| 446 |
+
|
| 447 |
+
Structural optimization is valuable, but CAD reliability is the bottleneck. If an agent cannot make clean editable CAD, it cannot become a useful engineering agent.
|
| 448 |
+
|
| 449 |
+
## Rating
|
| 450 |
+
|
| 451 |
+
Score: **9/10**
|
| 452 |
+
|
| 453 |
+
Why:
|
| 454 |
+
|
| 455 |
+
- Very strong pain point.
|
| 456 |
+
- Easy to explain.
|
| 457 |
+
- Objective rewards.
|
| 458 |
+
- Strong long-horizon action space.
|
| 459 |
+
- Clear frontier-model weakness.
|
| 460 |
+
- Good bridge between CAD, simulation, manufacturability, and agent training.
|
| 461 |
+
- More generally useful than a pure mesh-generation environment.
|
| 462 |
+
|
| 463 |
+
Main risk:
|
| 464 |
+
|
| 465 |
+
- Real CAD kernels can be annoying to package and debug.
|
| 466 |
+
- The MVP should avoid arbitrary free-form CAD at first.
|
| 467 |
+
- Start with a constrained DSL and only later expose full OpenSCAD/CadQuery code.
|
| 468 |
+
|
| 469 |
+
Best near-term choice:
|
| 470 |
+
|
| 471 |
+
> Build a constrained code-CAD environment for wall hooks and brackets, validate clean geometry and editability, then add structural MechForge rewards.
|
| 472 |
+
|
docs/brainstorm/10-cadforge-rlve-environment.md
ADDED
|
@@ -0,0 +1,564 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Document 10: CADForge RLVE Environment
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-25
|
| 4 |
+
|
| 5 |
+
## Thesis
|
| 6 |
+
|
| 7 |
+
CADForge should be an RLVE environment for training agents to create and revise constructive solid geometry code.
|
| 8 |
+
|
| 9 |
+
The strongest medium is code-CAD:
|
| 10 |
+
|
| 11 |
+
- OpenSCAD-style CSG,
|
| 12 |
+
- CadQuery/build123d feature scripts,
|
| 13 |
+
- or a constrained AST/DSL that compiles to OpenSCAD/CadQuery.
|
| 14 |
+
|
| 15 |
+
The important move is to treat CAD code as an interactive, verifiable environment, not a one-shot file format.
|
| 16 |
+
|
| 17 |
+
> CADForge is a REPL for mechanical geometry. The agent proposes a small CAD action, the environment builds and verifies the resulting object, then returns geometry, manufacturability, editability, and structural rewards.
|
| 18 |
+
|
| 19 |
+
This directly fits the hackathon themes:
|
| 20 |
+
|
| 21 |
+
- **Long-horizon planning:** 300+ small CAD/tool actions to reach a valid final object.
|
| 22 |
+
- **World modeling:** the agent must maintain a mental model of the evolving geometry and consequences of each operation.
|
| 23 |
+
- **Self-improvement:** adaptive curricula can generate harder CAD briefs and edit tests.
|
| 24 |
+
- **Wild card:** reliable CAD creation is an underexplored and high-value frontier for LLM training.
|
| 25 |
+
|
| 26 |
+
## Why This Is Better Than Raw CAD Text
|
| 27 |
+
|
| 28 |
+
Do not train the agent to emit raw OpenSCAD text character by character.
|
| 29 |
+
|
| 30 |
+
That wastes most of the learning signal on syntax:
|
| 31 |
+
|
| 32 |
+
- semicolons,
|
| 33 |
+
- braces,
|
| 34 |
+
- parameter order,
|
| 35 |
+
- missing parentheses,
|
| 36 |
+
- malformed module calls.
|
| 37 |
+
|
| 38 |
+
Instead, constrain the action space to AST operations. The policy chooses valid grammar moves:
|
| 39 |
+
|
| 40 |
+
```json
|
| 41 |
+
{"action": "add_primitive", "type": "cube", "size_mm": [80, 40, 6]}
|
| 42 |
+
{"action": "apply_transform", "type": "translate", "vector_mm": [0, 0, 6]}
|
| 43 |
+
{"action": "apply_boolean", "type": "union", "children": ["base", "rib_1"]}
|
| 44 |
+
{"action": "apply_boolean", "type": "difference", "target": "base", "tool": "mount_hole_1"}
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Then the environment renders or compiles that AST into OpenSCAD/CadQuery.
|
| 48 |
+
|
| 49 |
+
This gives:
|
| 50 |
+
|
| 51 |
+
- syntactic validity by construction,
|
| 52 |
+
- clean action traces,
|
| 53 |
+
- easier reward attribution,
|
| 54 |
+
- interpretable failure modes,
|
| 55 |
+
- curriculum control over which operations are unlocked.
|
| 56 |
+
|
| 57 |
+
## Environment Loop
|
| 58 |
+
|
| 59 |
+
The RL step loop should look like:
|
| 60 |
+
|
| 61 |
+
```text
|
| 62 |
+
reset(task_seed)
|
| 63 |
+
-> returns design brief, target constraints, allowed grammar/actions
|
| 64 |
+
|
| 65 |
+
step(action)
|
| 66 |
+
-> updates CSG AST / feature tree
|
| 67 |
+
-> optionally compiles the current CAD
|
| 68 |
+
-> validates syntax, topology, editability, manufacturability, structure
|
| 69 |
+
-> returns observation, reward, done, artifacts
|
| 70 |
+
|
| 71 |
+
done
|
| 72 |
+
-> when agent commits design, exceeds step budget, or creates unrecoverable invalid geometry
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
The environment is effectively a CAD REPL:
|
| 76 |
+
|
| 77 |
+
```text
|
| 78 |
+
agent action
|
| 79 |
+
-> AST update
|
| 80 |
+
-> generated OpenSCAD/CadQuery
|
| 81 |
+
-> headless CAD build
|
| 82 |
+
-> STL/STEP export
|
| 83 |
+
-> trimesh/solid validation
|
| 84 |
+
-> simple structural check
|
| 85 |
+
-> reward + warnings
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
## Action Space
|
| 89 |
+
|
| 90 |
+
Start with a small grammar.
|
| 91 |
+
|
| 92 |
+
Primitive actions:
|
| 93 |
+
|
| 94 |
+
```json
|
| 95 |
+
{"tool": "add_cube", "id": "seat", "size_mm": [420, 380, 35]}
|
| 96 |
+
{"tool": "add_cylinder", "id": "leg_1", "height_mm": 450, "radius_mm": 18}
|
| 97 |
+
{"tool": "add_sphere", "id": "edge_round_proxy", "radius_mm": 12}
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
Transform actions:
|
| 101 |
+
|
| 102 |
+
```json
|
| 103 |
+
{"tool": "translate", "target": "leg_1", "vector_mm": [-170, -140, -225]}
|
| 104 |
+
{"tool": "rotate", "target": "back_leg_1", "axis": "x", "degrees": -8}
|
| 105 |
+
{"tool": "scale", "target": "rib_1", "factor": [1, 1, 1.2]}
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
Boolean actions:
|
| 109 |
+
|
| 110 |
+
```json
|
| 111 |
+
{"tool": "union", "id": "chair_frame", "children": ["seat", "leg_1", "leg_2", "leg_3", "leg_4"]}
|
| 112 |
+
{"tool": "difference", "target": "seat", "tool": "lightening_cutout_1"}
|
| 113 |
+
{"tool": "intersection", "id": "trimmed_backrest", "children": ["backrest", "envelope_box"]}
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
Feature actions:
|
| 117 |
+
|
| 118 |
+
```json
|
| 119 |
+
{"tool": "add_mount_hole", "target": "wall_plate", "diameter_mm": 5, "center_mm": [0, 24, 0]}
|
| 120 |
+
{"tool": "add_fillet", "target": "load_path_edges", "radius_mm": 4}
|
| 121 |
+
{"tool": "add_rib", "from": "seat", "to": "leg_1", "thickness_mm": 8}
|
| 122 |
+
{"tool": "add_crossbar", "between": ["leg_1", "leg_2"], "radius_mm": 10}
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
Validation and simulation actions:
|
| 126 |
+
|
| 127 |
+
```json
|
| 128 |
+
{"tool": "compile_cad"}
|
| 129 |
+
{"tool": "check_connected_components"}
|
| 130 |
+
{"tool": "check_watertight"}
|
| 131 |
+
{"tool": "check_manifold"}
|
| 132 |
+
{"tool": "check_editability"}
|
| 133 |
+
{"tool": "run_structural_check"}
|
| 134 |
+
{"tool": "commit_design"}
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
## Verifiable REPL Implementation
|
| 138 |
+
|
| 139 |
+
Use Python as the bridge.
|
| 140 |
+
|
| 141 |
+
MVP stack:
|
| 142 |
+
|
| 143 |
+
```text
|
| 144 |
+
Gymnasium/OpenEnv API
|
| 145 |
+
-> Python CSG AST
|
| 146 |
+
-> SolidPython or direct OpenSCAD text emitter
|
| 147 |
+
-> OpenSCAD CLI headless compile
|
| 148 |
+
-> STL output
|
| 149 |
+
-> trimesh validation
|
| 150 |
+
-> reward
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
Headless compile:
|
| 154 |
+
|
| 155 |
+
```bash
|
| 156 |
+
openscad -o temp.stl generated_script.scad
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
For speed:
|
| 160 |
+
|
| 161 |
+
- compile every N actions during long episodes,
|
| 162 |
+
- compile immediately after high-risk boolean/edit operations,
|
| 163 |
+
- run multiple environments in parallel,
|
| 164 |
+
- write temporary files to a RAM disk when available,
|
| 165 |
+
- cache compiled subtrees if the AST supports stable node IDs.
|
| 166 |
+
|
| 167 |
+
## Reward Function
|
| 168 |
+
|
| 169 |
+
The reward should combine code validity, geometry coherence, editability, manufacturability, and structural performance.
|
| 170 |
+
|
| 171 |
+
```text
|
| 172 |
+
R_total =
|
| 173 |
+
+ w_build * build_success
|
| 174 |
+
+ w_connected * single_connected_component
|
| 175 |
+
+ w_manifold * watertight_manifold_mesh
|
| 176 |
+
+ w_contact * required_parts_touch_and_align
|
| 177 |
+
+ w_editable * editability_tests_passed
|
| 178 |
+
+ w_constraints * task_constraints_satisfied
|
| 179 |
+
+ w_structure * safety_factor_score
|
| 180 |
+
+ w_efficiency * mass_efficiency
|
| 181 |
+
- w_nodes * ast_node_count
|
| 182 |
+
- w_invalid * invalid_operation_count
|
| 183 |
+
- w_floating * disconnected_component_count
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
Suggested first weights:
|
| 187 |
+
|
| 188 |
+
```text
|
| 189 |
+
build_success: 0.20
|
| 190 |
+
single_connected_component: 0.20
|
| 191 |
+
watertight_manifold_mesh: 0.20
|
| 192 |
+
part_contact_alignment: 0.10
|
| 193 |
+
editability_tests_passed: 0.10
|
| 194 |
+
constraints_satisfied: 0.05
|
| 195 |
+
structural_safety: 0.10
|
| 196 |
+
mass_efficiency: 0.025
|
| 197 |
+
manufacturability: 0.025
|
| 198 |
+
```
|
| 199 |
+
|
| 200 |
+
Big penalties:
|
| 201 |
+
|
| 202 |
+
```text
|
| 203 |
+
syntax_or_compile_error: -1.00 and terminate
|
| 204 |
+
floating_parts: -0.60 to -1.00 and terminate on final commit
|
| 205 |
+
non_manifold_mesh: -0.50
|
| 206 |
+
self_intersection: -0.50
|
| 207 |
+
unjoined_touching_failure: -0.35
|
| 208 |
+
edge_misalignment: -0.25
|
| 209 |
+
zero_thickness_geometry: -0.20
|
| 210 |
+
failed_required_edit: -0.20
|
| 211 |
+
unsafe_final_design: -0.30
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
The first principle:
|
| 215 |
+
|
| 216 |
+
> A pretty shape that does not compile, is not watertight, or contains floating parts should receive a near-zero score.
|
| 217 |
+
|
| 218 |
+
For CADForge, topology is not a secondary check. It is the gate that decides whether the object is even a valid candidate.
|
| 219 |
+
|
| 220 |
+
## Floating Parts And Coherence
|
| 221 |
+
|
| 222 |
+
This is a major reward term.
|
| 223 |
+
|
| 224 |
+
After the CAD compiles to STL, load it with `trimesh`:
|
| 225 |
+
|
| 226 |
+
```python
|
| 227 |
+
mesh = trimesh.load("generated.stl")
|
| 228 |
+
components = mesh.split()
|
| 229 |
+
floating_count = max(0, len(components) - 1)
|
| 230 |
+
```
|
| 231 |
+
|
| 232 |
+
If `len(components) > 1`, the part contains disconnected/floating geometry.
|
| 233 |
+
|
| 234 |
+
Policy:
|
| 235 |
+
|
| 236 |
+
- small intermediate penalty while exploring,
|
| 237 |
+
- large penalty after compile checkpoints,
|
| 238 |
+
- immediate episode termination if the final committed design has floating parts.
|
| 239 |
+
|
| 240 |
+
The reward should strongly prefer one physically coherent object.
|
| 241 |
+
|
| 242 |
+
For multi-part everyday objects such as chairs, tables, hooks, clamps, and trusses, "close enough visually" is not enough. The environment should verify that load-bearing parts actually touch or overlap:
|
| 243 |
+
|
| 244 |
+
- legs must contact or penetrate the underside of the seat enough to form a union,
|
| 245 |
+
- crossbars must touch both legs they claim to connect,
|
| 246 |
+
- backrests must connect to the seat or rear legs,
|
| 247 |
+
- hook arms must connect to the mounting plate,
|
| 248 |
+
- truss members must meet at nodes,
|
| 249 |
+
- holes/cutouts must pass through the intended parent solid, not float in empty space.
|
| 250 |
+
|
| 251 |
+
This needs edge/contact and alignment checks:
|
| 252 |
+
|
| 253 |
+
- bounding-box contact tests between named features,
|
| 254 |
+
- nearest-surface distance between intended mating faces,
|
| 255 |
+
- shared-node or overlap checks after boolean union,
|
| 256 |
+
- non-manifold edge count,
|
| 257 |
+
- boundary/open edge count,
|
| 258 |
+
- connected-component count,
|
| 259 |
+
- semantic contact graph pass/fail.
|
| 260 |
+
|
| 261 |
+
The contact graph can be part of the observation:
|
| 262 |
+
|
| 263 |
+
```json
|
| 264 |
+
{
|
| 265 |
+
"contact_graph": {
|
| 266 |
+
"seat": ["front_left_leg", "front_right_leg", "rear_left_leg", "rear_right_leg", "backrest"],
|
| 267 |
+
"front_crossbar": ["front_left_leg", "front_right_leg"],
|
| 268 |
+
"rear_crossbar": ["rear_left_leg", "rear_right_leg"]
|
| 269 |
+
},
|
| 270 |
+
"missing_contacts": [],
|
| 271 |
+
"floating_features": []
|
| 272 |
+
}
|
| 273 |
+
```
|
| 274 |
+
|
| 275 |
+
If the contact graph fails, the episode should continue only if the agent still has repair budget. A final committed design with missing required contacts should fail hard.
|
| 276 |
+
|
| 277 |
+
## Mesh And Solid Quality
|
| 278 |
+
|
| 279 |
+
The "tight mesh" requirement means:
|
| 280 |
+
|
| 281 |
+
> The CAD-generated solid exports to a closed, watertight, manifold, simulation-ready mesh.
|
| 282 |
+
|
| 283 |
+
Checks:
|
| 284 |
+
|
| 285 |
+
- `mesh.is_watertight`,
|
| 286 |
+
- one connected component,
|
| 287 |
+
- no zero-area faces,
|
| 288 |
+
- no duplicate faces,
|
| 289 |
+
- no inverted normals,
|
| 290 |
+
- no obvious self-intersections,
|
| 291 |
+
- minimum wall thickness,
|
| 292 |
+
- minimum feature size,
|
| 293 |
+
- acceptable triangle aspect ratios,
|
| 294 |
+
- volume above a small threshold,
|
| 295 |
+
- bounding box inside the task envelope.
|
| 296 |
+
|
| 297 |
+
These checks are objective and judge-friendly.
|
| 298 |
+
|
| 299 |
+
For browser-side MVP rendering, the same checks can be computed directly on the generated mesh:
|
| 300 |
+
|
| 301 |
+
- count connected components from triangle/vertex adjacency,
|
| 302 |
+
- count boundary edges,
|
| 303 |
+
- count non-manifold edges,
|
| 304 |
+
- mark watertight only if every edge has exactly two incident faces,
|
| 305 |
+
- expose the failure as a reward penalty and UI metric.
|
| 306 |
+
|
| 307 |
+
This is not a mock reward. It is a real topology check on the actual rendered mesh, even if the renderer initially supports only a constrained OpenSCAD subset.
|
| 308 |
+
|
| 309 |
+
## Reference Model Reward
|
| 310 |
+
|
| 311 |
+
A second reward channel can compare the generated CAD mesh against a reference object.
|
| 312 |
+
|
| 313 |
+
For the chair benchmark, the first reference asset is:
|
| 314 |
+
|
| 315 |
+
```text
|
| 316 |
+
3d-models/ikea_markus_office_chair.glb
|
| 317 |
+
```
|
| 318 |
+
|
| 319 |
+
This should not replace topology rewards. It should sit after them:
|
| 320 |
+
|
| 321 |
+
```text
|
| 322 |
+
if not build_success or not watertight or floating_parts > 0:
|
| 323 |
+
reward = near_zero
|
| 324 |
+
else:
|
| 325 |
+
reward = topology_reward + structural_reward + reference_similarity_reward
|
| 326 |
+
```
|
| 327 |
+
|
| 328 |
+
Reference similarity can use:
|
| 329 |
+
|
| 330 |
+
- normalized bounding-box dimensions,
|
| 331 |
+
- oriented bounding-box alignment,
|
| 332 |
+
- voxel IoU,
|
| 333 |
+
- Chamfer distance between sampled surface points,
|
| 334 |
+
- silhouette overlap from canonical views,
|
| 335 |
+
- part-presence classifiers for seat/legs/back/arms/headrest,
|
| 336 |
+
- center-of-mass and support-polygon checks.
|
| 337 |
+
|
| 338 |
+
For chairs:
|
| 339 |
+
|
| 340 |
+
- CAD output should have a seat-like horizontal surface,
|
| 341 |
+
- support structures should reach the floor,
|
| 342 |
+
- backrest should rise behind the seat,
|
| 343 |
+
- optional armrests/headrest should align with the reference,
|
| 344 |
+
- dimensions should fit a plausible chair envelope.
|
| 345 |
+
|
| 346 |
+
This gives the model a shape target without letting it cheat by creating a raw mesh. The final artifact still needs to be editable SCAD/CAD code.
|
| 347 |
+
|
| 348 |
+
## Prompt-To-Reference-To-CAD Pipeline
|
| 349 |
+
|
| 350 |
+
The general everyday-object pipeline:
|
| 351 |
+
|
| 352 |
+
```text
|
| 353 |
+
input prompt
|
| 354 |
+
-> generate or retrieve reference image
|
| 355 |
+
-> generate/retrieve watertight reference mesh or GLB
|
| 356 |
+
-> normalize reference mesh scale/orientation
|
| 357 |
+
-> agent creates SCAD/CAD through constrained actions
|
| 358 |
+
-> compile/render candidate mesh
|
| 359 |
+
-> reject if uncompiled, non-watertight, or floating
|
| 360 |
+
-> compare candidate mesh to reference mesh
|
| 361 |
+
-> run object-specific structural/contact checks
|
| 362 |
+
-> return reward and repair hints
|
| 363 |
+
```
|
| 364 |
+
|
| 365 |
+
Possible reference sources:
|
| 366 |
+
|
| 367 |
+
- curated GLB files for common objects,
|
| 368 |
+
- image-to-3D systems such as Tripo-style services,
|
| 369 |
+
- generated image followed by image-to-3D,
|
| 370 |
+
- public model libraries when licensing permits,
|
| 371 |
+
- procedural target generators for simple brackets, hooks, tables, and trusses.
|
| 372 |
+
|
| 373 |
+
Reward order matters:
|
| 374 |
+
|
| 375 |
+
1. **Compile validity**: code must parse and render.
|
| 376 |
+
2. **Topology validity**: one watertight connected component.
|
| 377 |
+
3. **Semantic contact graph**: required parts touch and align.
|
| 378 |
+
4. **Reference similarity**: looks like the target/reference.
|
| 379 |
+
5. **Structural validity**: load path and safety checks.
|
| 380 |
+
6. **Editability**: parameters survive changes.
|
| 381 |
+
|
| 382 |
+
This attacks a core AI CAD weakness:
|
| 383 |
+
|
| 384 |
+
> Models can generate objects that look plausible in one view but are topologically broken, uneditable, disconnected, or mechanically meaningless.
|
| 385 |
+
|
| 386 |
+
CADForge should train against exactly those failures.
|
| 387 |
+
|
| 388 |
+
## Editability Tests
|
| 389 |
+
|
| 390 |
+
This is where CADForge becomes much stronger than ordinary shape generation.
|
| 391 |
+
|
| 392 |
+
After a final design is produced, mutate the design brief:
|
| 393 |
+
|
| 394 |
+
- make the chair seat 10% wider,
|
| 395 |
+
- increase chair load from 700 N to 900 N,
|
| 396 |
+
- move screw spacing from 48 mm to 56 mm,
|
| 397 |
+
- increase hook tip load by 20%,
|
| 398 |
+
- change material from PLA to PETG,
|
| 399 |
+
- require all fillets above 3 mm,
|
| 400 |
+
- shrink the envelope,
|
| 401 |
+
- switch from FDM printing to CNC constraints.
|
| 402 |
+
|
| 403 |
+
The environment recompiles after the mutation.
|
| 404 |
+
|
| 405 |
+
Reward the agent only if the design survives without a full rewrite. This encourages:
|
| 406 |
+
|
| 407 |
+
- named parameters,
|
| 408 |
+
- stable feature IDs,
|
| 409 |
+
- constrained sketches,
|
| 410 |
+
- reusable modules,
|
| 411 |
+
- clean boolean ordering,
|
| 412 |
+
- avoiding brittle one-off coordinates.
|
| 413 |
+
|
| 414 |
+
## First Benchmark: Chairs
|
| 415 |
+
|
| 416 |
+
A chair is a surprisingly good first benchmark if the grammar is constrained.
|
| 417 |
+
|
| 418 |
+
Why:
|
| 419 |
+
|
| 420 |
+
- everyone understands what a chair should contain,
|
| 421 |
+
- it requires multiple connected components to become one coherent assembly,
|
| 422 |
+
- it exposes floating-part failures clearly,
|
| 423 |
+
- it has real load-bearing structure,
|
| 424 |
+
- it needs symmetry, legs, bracing, seat, and backrest,
|
| 425 |
+
- it can support long-horizon 100-300 step episodes.
|
| 426 |
+
|
| 427 |
+
Start simple:
|
| 428 |
+
|
| 429 |
+
```text
|
| 430 |
+
Build a four-legged chair that supports a 700 N seated load.
|
| 431 |
+
It must include a seat panel, four legs, lower crossbars, and a backrest.
|
| 432 |
+
All parts must be connected into one watertight/manifold solid.
|
| 433 |
+
Keep the bounding box under 500 mm x 500 mm x 900 mm.
|
| 434 |
+
```
|
| 435 |
+
|
| 436 |
+
Then increase difficulty:
|
| 437 |
+
|
| 438 |
+
- ergonomic curved chair,
|
| 439 |
+
- armrests,
|
| 440 |
+
- headrest,
|
| 441 |
+
- 1000 N seat load plus 100 N backrest load,
|
| 442 |
+
- lightweighting,
|
| 443 |
+
- printability constraints,
|
| 444 |
+
- edit test: widen seat and raise load.
|
| 445 |
+
|
| 446 |
+
Other early benchmark tasks:
|
| 447 |
+
|
| 448 |
+
- wall hook,
|
| 449 |
+
- shelf bracket,
|
| 450 |
+
- table,
|
| 451 |
+
- truss,
|
| 452 |
+
- clamp,
|
| 453 |
+
- motor mount.
|
| 454 |
+
|
| 455 |
+
## Training Path
|
| 456 |
+
|
| 457 |
+
Do not start with full free-form CAD.
|
| 458 |
+
|
| 459 |
+
Curriculum:
|
| 460 |
+
|
| 461 |
+
1. **2D primitives:** square, circle, translate, union.
|
| 462 |
+
2. **2D booleans:** difference and intersection.
|
| 463 |
+
3. **2.5D extrusion:** plate with holes.
|
| 464 |
+
4. **Simple 3D CSG:** cube/cylinder compositions.
|
| 465 |
+
5. **Connectivity tasks:** all parts must touch or union.
|
| 466 |
+
6. **Household parts:** hook, bracket, table, chair.
|
| 467 |
+
7. **Structural tasks:** loads, fixed regions, stress proxies.
|
| 468 |
+
8. **Editability tasks:** mutate dimensions and rebuild.
|
| 469 |
+
9. **Long-horizon tasks:** 300-step chair/bracket/truss episodes.
|
| 470 |
+
|
| 471 |
+
This makes the learning curve visible:
|
| 472 |
+
|
| 473 |
+
```text
|
| 474 |
+
random/untrained agent:
|
| 475 |
+
compiles sometimes, often disconnected, weak structure
|
| 476 |
+
|
| 477 |
+
trained agent:
|
| 478 |
+
valid AST, connected geometry, cleaner feature tree, passes structural checks
|
| 479 |
+
```
|
| 480 |
+
|
| 481 |
+
## Model And Algorithm Notes
|
| 482 |
+
|
| 483 |
+
For the hackathon, the minimum is not a perfect RL algorithm. The key is showing improvement.
|
| 484 |
+
|
| 485 |
+
Practical options:
|
| 486 |
+
|
| 487 |
+
- collect successful traces from a scripted expert,
|
| 488 |
+
- train/fine-tune an LLM with TRL/Unsloth on action traces,
|
| 489 |
+
- evaluate before/after in the environment,
|
| 490 |
+
- optionally run PPO or GRPO over tool-action rewards.
|
| 491 |
+
|
| 492 |
+
For a deeper version:
|
| 493 |
+
|
| 494 |
+
- PPO works well for discrete grammar actions,
|
| 495 |
+
- GRPO may be attractive for LLM tool-action policies,
|
| 496 |
+
- state encoder can combine text brief, AST history, and geometry metrics,
|
| 497 |
+
- later geometry encoders can use voxel grids, PointNet, or compact mesh summaries.
|
| 498 |
+
|
| 499 |
+
Do not overbuild the neural architecture for the MVP. The environment and reward quality matter more.
|
| 500 |
+
|
| 501 |
+
## Experiment 2 Scope
|
| 502 |
+
|
| 503 |
+
Experiment 2 should be the CADForge prototype:
|
| 504 |
+
|
| 505 |
+
```text
|
| 506 |
+
Experiment 1:
|
| 507 |
+
prompt -> structured mechanical design -> Three.js render -> coarse FEA
|
| 508 |
+
|
| 509 |
+
Experiment 2:
|
| 510 |
+
prompt -> multi-step CSG/CAD actions -> CAD validity checks -> connected/watertight reward -> structural household part score
|
| 511 |
+
```
|
| 512 |
+
|
| 513 |
+
The browser should show:
|
| 514 |
+
|
| 515 |
+
- design prompt,
|
| 516 |
+
- system prompt,
|
| 517 |
+
- CSG action trace,
|
| 518 |
+
- generated pseudo-OpenSCAD/code-CAD,
|
| 519 |
+
- geometry validation metrics,
|
| 520 |
+
- structural/checkpoint reward,
|
| 521 |
+
- 3D viewer,
|
| 522 |
+
- before/after or untrained/trained comparison.
|
| 523 |
+
|
| 524 |
+
The initial fun demo:
|
| 525 |
+
|
| 526 |
+
> Ask the agent to build a chair. Watch it add seat, legs, crossbars, backrest, fillets/ribs, run validation, detect floating parts, connect them, and commit a valid CAD-like object.
|
| 527 |
+
|
| 528 |
+
## Judging Story
|
| 529 |
+
|
| 530 |
+
Problem:
|
| 531 |
+
|
| 532 |
+
> LLMs can describe parts but are unreliable at building valid, editable CAD.
|
| 533 |
+
|
| 534 |
+
Environment:
|
| 535 |
+
|
| 536 |
+
> CADForge turns CAD creation into a long-horizon verifiable tool environment. The agent edits a CSG/feature tree, compiles it, receives topology/manufacturability/structure feedback, and revises until the design passes.
|
| 537 |
+
|
| 538 |
+
Training:
|
| 539 |
+
|
| 540 |
+
> We fine-tune or RL-train on CAD action traces and reward feedback. The model learns to use fewer invalid operations, avoid floating parts, create connected watertight solids, and satisfy structural constraints.
|
| 541 |
+
|
| 542 |
+
Evidence:
|
| 543 |
+
|
| 544 |
+
- reward curves,
|
| 545 |
+
- valid build rate,
|
| 546 |
+
- connected component count,
|
| 547 |
+
- watertight rate,
|
| 548 |
+
- editability pass rate,
|
| 549 |
+
- structural safety pass rate,
|
| 550 |
+
- before/after rendered parts.
|
| 551 |
+
|
| 552 |
+
Why it matters:
|
| 553 |
+
|
| 554 |
+
> Reliable CAD agents would unlock practical engineering workflows. The hard part is not drawing a shape; it is making geometry that builds, edits, exports, and survives physical constraints.
|
| 555 |
+
|
| 556 |
+
## Score
|
| 557 |
+
|
| 558 |
+
Score: **9/10**
|
| 559 |
+
|
| 560 |
+
This direction is strong because it is novel, verifiable, visual, long-horizon, and directly aimed at a known frontier-model weakness.
|
| 561 |
+
|
| 562 |
+
The best MVP path is:
|
| 563 |
+
|
| 564 |
+
> Build chairs/hooks/brackets through constrained CSG actions, validate with OpenSCAD/trimesh-style checks, and add MechForge structural rewards as the next layer.
|
docs/brainstorm/11-reference-model-reward-pipeline.md
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Document 11: Reference Model Reward Pipeline
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-25
|
| 4 |
+
|
| 5 |
+
## Core Idea
|
| 6 |
+
|
| 7 |
+
CADForge should not only reward whether code compiles. It should reward whether the generated CAD becomes a valid, watertight, physically coherent object that resembles the intended target.
|
| 8 |
+
|
| 9 |
+
The strongest reward stack is:
|
| 10 |
+
|
| 11 |
+
```text
|
| 12 |
+
prompt
|
| 13 |
+
-> reference image or reference mesh
|
| 14 |
+
-> agent-generated SCAD/CAD
|
| 15 |
+
-> compiled/rendered candidate mesh
|
| 16 |
+
-> topology gate
|
| 17 |
+
-> shape similarity reward
|
| 18 |
+
-> semantic contact graph reward
|
| 19 |
+
-> structural/editability reward
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
The topology gate comes first.
|
| 23 |
+
|
| 24 |
+
If the candidate does not compile, is not watertight, or has floating parts, the reward should be near zero regardless of visual similarity.
|
| 25 |
+
|
| 26 |
+
## Markus Chair Reference
|
| 27 |
+
|
| 28 |
+
Current reference asset:
|
| 29 |
+
|
| 30 |
+
```text
|
| 31 |
+
3d-models/ikea_markus_office_chair.glb
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
This can become the first chair-reference target.
|
| 35 |
+
|
| 36 |
+
The CAD agent still outputs editable SCAD/CAD code. The GLB is only used as a reward/reference object.
|
| 37 |
+
|
| 38 |
+
## Why A Reference Mesh Helps
|
| 39 |
+
|
| 40 |
+
Prompt-only reward is too fuzzy.
|
| 41 |
+
|
| 42 |
+
For example:
|
| 43 |
+
|
| 44 |
+
```text
|
| 45 |
+
Build an office chair.
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
The agent may create:
|
| 49 |
+
|
| 50 |
+
- a stool,
|
| 51 |
+
- a flat bracket,
|
| 52 |
+
- a disconnected pile of cubes,
|
| 53 |
+
- a chair-like silhouette with no structural connections,
|
| 54 |
+
- a raw mesh that looks okay but is not editable CAD.
|
| 55 |
+
|
| 56 |
+
A reference mesh gives a concrete target distribution:
|
| 57 |
+
|
| 58 |
+
- overall proportions,
|
| 59 |
+
- seat/back/arm/headrest layout,
|
| 60 |
+
- rough silhouette,
|
| 61 |
+
- support footprint,
|
| 62 |
+
- height/width/depth ratios,
|
| 63 |
+
- part presence.
|
| 64 |
+
|
| 65 |
+
But the reference mesh must not become the final output. The final output remains parametric CAD code.
|
| 66 |
+
|
| 67 |
+
## Reward Order
|
| 68 |
+
|
| 69 |
+
Use a strict reward order:
|
| 70 |
+
|
| 71 |
+
1. **Compile validity**
|
| 72 |
+
- SCAD/CAD parses.
|
| 73 |
+
- CAD kernel or renderer produces geometry.
|
| 74 |
+
- No unsupported operations.
|
| 75 |
+
|
| 76 |
+
2. **Topology validity**
|
| 77 |
+
- one connected component,
|
| 78 |
+
- no floating parts,
|
| 79 |
+
- watertight mesh,
|
| 80 |
+
- no boundary edges,
|
| 81 |
+
- no non-manifold edges,
|
| 82 |
+
- nonzero volume.
|
| 83 |
+
|
| 84 |
+
3. **Semantic contact graph**
|
| 85 |
+
- chair legs touch seat,
|
| 86 |
+
- backrest touches seat or rear supports,
|
| 87 |
+
- crossbars touch both intended legs,
|
| 88 |
+
- hook arm touches wall plate,
|
| 89 |
+
- truss members meet at nodes.
|
| 90 |
+
|
| 91 |
+
4. **Reference similarity**
|
| 92 |
+
- voxel IoU,
|
| 93 |
+
- Chamfer distance,
|
| 94 |
+
- silhouette overlap,
|
| 95 |
+
- bounding-box proportions,
|
| 96 |
+
- support footprint similarity.
|
| 97 |
+
|
| 98 |
+
5. **Engineering checks**
|
| 99 |
+
- load path,
|
| 100 |
+
- safety factor,
|
| 101 |
+
- deflection,
|
| 102 |
+
- material/process constraints.
|
| 103 |
+
|
| 104 |
+
6. **Editability**
|
| 105 |
+
- named parameters,
|
| 106 |
+
- stable features,
|
| 107 |
+
- rebuilds after dimension/load/material mutation.
|
| 108 |
+
|
| 109 |
+
## Reference Similarity Metrics
|
| 110 |
+
|
| 111 |
+
Candidate metrics:
|
| 112 |
+
|
| 113 |
+
- **Bounding-box ratio score**
|
| 114 |
+
- Compare normalized width/depth/height proportions.
|
| 115 |
+
|
| 116 |
+
- **Voxel IoU**
|
| 117 |
+
- Normalize both meshes into a unit cube.
|
| 118 |
+
- Voxelize into 32^3 or 64^3 occupancy.
|
| 119 |
+
- Reward intersection over union.
|
| 120 |
+
|
| 121 |
+
- **Chamfer distance**
|
| 122 |
+
- Sample surface points from both meshes.
|
| 123 |
+
- Reward low bidirectional nearest-neighbor distance.
|
| 124 |
+
|
| 125 |
+
- **Silhouette reward**
|
| 126 |
+
- Render front, side, top, and isometric masks.
|
| 127 |
+
- Reward 2D IoU per view.
|
| 128 |
+
|
| 129 |
+
- **Part-presence reward**
|
| 130 |
+
- For chairs: seat, legs/base, backrest, arms/headrest if requested.
|
| 131 |
+
- For hooks: wall plate, hook arm, tip lip, screw holes.
|
| 132 |
+
- For trusses: triangular members and joint nodes.
|
| 133 |
+
|
| 134 |
+
## Everyday-Object Pipeline
|
| 135 |
+
|
| 136 |
+
For general everyday objects:
|
| 137 |
+
|
| 138 |
+
```text
|
| 139 |
+
Input prompt X
|
| 140 |
+
-> generate or retrieve image of X
|
| 141 |
+
-> image-to-3D system creates a reference mesh
|
| 142 |
+
-> repair/validate reference mesh for watertightness if needed
|
| 143 |
+
-> normalize reference mesh
|
| 144 |
+
-> CADForge agent generates SCAD/CAD code
|
| 145 |
+
-> candidate compiles/renders to mesh
|
| 146 |
+
-> topology gate rejects bad CAD
|
| 147 |
+
-> candidate/reference similarity gives dense reward
|
| 148 |
+
-> structural/contact/editability checks give engineering reward
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
Possible reference sources:
|
| 152 |
+
|
| 153 |
+
- curated GLB library,
|
| 154 |
+
- generated image plus image-to-3D,
|
| 155 |
+
- Tripo-style API,
|
| 156 |
+
- procedural targets for simple mechanical parts,
|
| 157 |
+
- user-supplied GLB/STL.
|
| 158 |
+
|
| 159 |
+
## Important Constraint
|
| 160 |
+
|
| 161 |
+
Do not let the system solve the task by returning the reference mesh.
|
| 162 |
+
|
| 163 |
+
The agent must output:
|
| 164 |
+
|
| 165 |
+
```text
|
| 166 |
+
editable SCAD/CAD source code
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
The reward can compare against a mesh, but the submitted artifact must be code-CAD.
|
| 170 |
+
|
| 171 |
+
## MVP Plan
|
| 172 |
+
|
| 173 |
+
1. Use the Markus GLB as a chair reference.
|
| 174 |
+
2. Load candidate SCAD mesh and reference GLB in the browser or Python verifier.
|
| 175 |
+
3. Compute bounding-box proportion score first.
|
| 176 |
+
4. Add connected-component and watertight hard gates.
|
| 177 |
+
5. Add voxel IoU or Chamfer distance.
|
| 178 |
+
6. Add semantic chair checks:
|
| 179 |
+
- seat-like surface,
|
| 180 |
+
- backrest-like vertical surface,
|
| 181 |
+
- floor-contacting supports,
|
| 182 |
+
- no floating parts.
|
| 183 |
+
7. Show before/after reward curves for untrained vs trained SCAD generation.
|
| 184 |
+
|
| 185 |
+
## Why This Matters
|
| 186 |
+
|
| 187 |
+
This closes a major gap in AI CAD:
|
| 188 |
+
|
| 189 |
+
> The model must learn to create valid editable geometry that both resembles the requested object and behaves like a coherent physical part.
|
| 190 |
+
|
| 191 |
+
That is a stronger training signal than prompt-only judging, image-only judging, or topology-only judging.
|
| 192 |
+
|
docs/brainstorm/12-markus-chair-scope-grpo-rlve.md
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Brainstorm 12: Markus Chair Scope for CADForge RLVE
|
| 2 |
+
|
| 3 |
+
## Core scope
|
| 4 |
+
|
| 5 |
+
For the hackathon, CADForge should scope down to one object family: an office chair similar to the IKEA Markus chair. This is narrow enough for a 0.6B model to learn meaningful structure, but still hard enough to prove the thesis that a model can generate editable, valid CAD instead of merely producing decorative 3D mesh output.
|
| 6 |
+
|
| 7 |
+
The environment should train and evaluate prompts such as:
|
| 8 |
+
|
| 9 |
+
- Make an editable SCAD model as similar as possible to the Markus chair reference.
|
| 10 |
+
- Make a Markus-like chair with a taller backrest.
|
| 11 |
+
- Make the chair with thicker armrests.
|
| 12 |
+
- Make the chair base wider while preserving the five-star support.
|
| 13 |
+
- Repair this candidate chair so every structural part touches the assembly.
|
| 14 |
+
- Improve the candidate so it is watertight, editable, and made from clean primitives.
|
| 15 |
+
|
| 16 |
+
This gives us a focused benchmark: not "make any CAD object," but "learn the grammar and construction pattern for one real household/mechanical object."
|
| 17 |
+
|
| 18 |
+
## Why this is good for GRPO and RLVE
|
| 19 |
+
|
| 20 |
+
This is a strong fit for GRPO because each prompt can produce a group of SCAD candidates, and the verifier can rank them with real geometry signals. The reward does not need to be vague preference text. It can be built from compile success, mesh validity, connected components, watertightness, contact graph quality, bounding-box alignment, silhouette similarity, and shape similarity to the reference GLB.
|
| 21 |
+
|
| 22 |
+
It is also a strong fit for RLVE because the environment is not only judging final text. It is compiling and rendering the artifact, measuring what actually exists, and feeding that back into the next attempt.
|
| 23 |
+
|
| 24 |
+
The important constraint is that the 0.6B model should not be asked to emit arbitrary raw CAD text from nothing. It should be trained around a constrained SCAD/CSG grammar or AST-style action space:
|
| 25 |
+
|
| 26 |
+
- Add primitive: cube, cylinder, sphere.
|
| 27 |
+
- Add transform: translate, rotate, scale.
|
| 28 |
+
- Add boolean: union, difference, intersection.
|
| 29 |
+
- Add semantic chair part: seat, backrest, armrest, central column, five-star base spoke, caster proxy.
|
| 30 |
+
- Repair operation: snap a part to nearest body, thicken a thin wall, union overlapping contact regions, remove floating component.
|
| 31 |
+
|
| 32 |
+
That is how a small model can become surprisingly good. It learns the local construction game and the verifier keeps it from drifting into invalid geometry.
|
| 33 |
+
|
| 34 |
+
## Reference target
|
| 35 |
+
|
| 36 |
+
The fixed hackathon reference should be the existing Markus chair GLB in the repo. We normalize it once and use it as the reward target:
|
| 37 |
+
|
| 38 |
+
1. Load the GLB.
|
| 39 |
+
2. Normalize scale, orientation, and origin.
|
| 40 |
+
3. Extract reference bounding box, silhouette renders, voxel occupancy, point cloud samples, and major-part hints.
|
| 41 |
+
4. Generate a SCAD candidate.
|
| 42 |
+
5. Render candidate to mesh.
|
| 43 |
+
6. Normalize candidate to the same coordinate frame.
|
| 44 |
+
7. Score topology first, then score similarity.
|
| 45 |
+
|
| 46 |
+
The reference mesh does not need to be CAD-native. It can be a target signal. The output we care about is still editable SCAD.
|
| 47 |
+
|
| 48 |
+
## Reward shape
|
| 49 |
+
|
| 50 |
+
Topology should dominate the reward. A model that makes a pretty chair with floating parts should lose badly.
|
| 51 |
+
|
| 52 |
+
Suggested hard gates:
|
| 53 |
+
|
| 54 |
+
- Uncompilable SCAD: terminate with severe penalty.
|
| 55 |
+
- Empty mesh: terminate with severe penalty.
|
| 56 |
+
- More than one connected component: severe penalty or terminate.
|
| 57 |
+
- Non-watertight mesh: severe penalty.
|
| 58 |
+
- Boundary edges or non-manifold edges: severe penalty.
|
| 59 |
+
- Parts that are close but not touching: high penalty.
|
| 60 |
+
- Excessive node count for the same shape quality: mild parsimony penalty.
|
| 61 |
+
|
| 62 |
+
Suggested positive rewards:
|
| 63 |
+
|
| 64 |
+
- Similar voxel occupancy to Markus reference.
|
| 65 |
+
- Low Chamfer distance between sampled candidate/reference point clouds.
|
| 66 |
+
- Matching front, side, top, and isometric silhouettes.
|
| 67 |
+
- Matching chair-specific dimensions: tall backrest, seat height, base radius, armrest height.
|
| 68 |
+
- Valid contact graph: back touches seat, armrests touch seat/back, column touches seat/base, all spokes touch the hub.
|
| 69 |
+
- Clean editability: named or segmented code blocks for seat, backrest, arms, hub, spokes, and caster proxies.
|
| 70 |
+
|
| 71 |
+
The reward should look roughly like:
|
| 72 |
+
|
| 73 |
+
```text
|
| 74 |
+
R = topology_gate
|
| 75 |
+
+ shape_similarity
|
| 76 |
+
+ silhouette_similarity
|
| 77 |
+
+ chair_part_contact_score
|
| 78 |
+
+ editability_score
|
| 79 |
+
- node_count_penalty
|
| 80 |
+
- thin_wall_penalty
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
Where `topology_gate` can zero out or heavily negate the rest when the CAD is invalid.
|
| 84 |
+
|
| 85 |
+
## Self-correction loop
|
| 86 |
+
|
| 87 |
+
The agent should be allowed to see verifier output and revise:
|
| 88 |
+
|
| 89 |
+
- connected component count
|
| 90 |
+
- boundary edge count
|
| 91 |
+
- non-manifold edge count
|
| 92 |
+
- watertight true/false
|
| 93 |
+
- bounding-box error
|
| 94 |
+
- silhouette error by view
|
| 95 |
+
- nearest-part contact gaps
|
| 96 |
+
- largest missing region against the reference voxel grid
|
| 97 |
+
|
| 98 |
+
This makes the task agentic. The model can take steps like:
|
| 99 |
+
|
| 100 |
+
- "The backrest is disconnected from the seat; lower it by 4 mm and overlap by 2 mm."
|
| 101 |
+
- "The five-star base spokes are separate; add a central hub cylinder and union each spoke into it."
|
| 102 |
+
- "The silhouette is too short; increase backrest height."
|
| 103 |
+
- "The right side silhouette is missing armrests; add two horizontal cylinders/boxes connected to the backrest and seat."
|
| 104 |
+
|
| 105 |
+
For this benchmark, part assembly is better than carving a chair from one large slab. A slab can make connected geometry easier, but it hurts editability and does not teach meaningful mechanical construction. The model should learn to assemble semantic parts with intentional overlaps and unions.
|
| 106 |
+
|
| 107 |
+
## FAL reference-model expansion path
|
| 108 |
+
|
| 109 |
+
For Markus scope, we start with the provided GLB. For broader household objects later, we can generate reference meshes from prompts:
|
| 110 |
+
|
| 111 |
+
1. User enters an engineering prompt.
|
| 112 |
+
2. OpenAI image generation creates a clean, white-background product image.
|
| 113 |
+
3. FAL SAM 3D Objects reconstructs the object from that image.
|
| 114 |
+
4. We download `model_glb`, `individual_glbs`, `gaussian_splat`, metadata, and `artifacts_zip` when available.
|
| 115 |
+
5. We normalize the GLB into a reward target.
|
| 116 |
+
6. CADForge trains or evaluates SCAD candidates against that reference.
|
| 117 |
+
|
| 118 |
+
Example input prompt:
|
| 119 |
+
|
| 120 |
+
```text
|
| 121 |
+
Design a simple 6061 aluminum wall-mounted J hook for a 120 N downward hanging load at the hook tip. It should visibly look like a hook, with a compact wall mount and a curved hook arm, not a ribbed cantilever bracket.
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
The image generation prompt should keep the reference clean:
|
| 125 |
+
|
| 126 |
+
```text
|
| 127 |
+
Design a simple 6061 aluminum wall-mounted J hook for a 120 N downward hanging load at the hook tip. It should visibly look like a hook, with a compact wall mount and a curved hook arm, not a ribbed cantilever bracket. Realistic product render, plain white background, isolated object, no labels, no text.
|
| 128 |
+
```
|
| 129 |
+
|
| 130 |
+
FAL's `fal-ai/sam-3/3d-objects` endpoint takes an `image_url` plus optional segmentation prompt/masks/point prompts/box prompts, and can return GLB outputs, Gaussian splat output, metadata, individual object files, and an artifacts zip. The API docs recommend keeping the FAL key on the server side through `FAL_KEY`. The playground currently lists the request cost as `$0.02` per generation, but the app should read and log actual cost metadata at runtime if FAL exposes it.
|
| 131 |
+
|
| 132 |
+
For our app, this should be server-side only:
|
| 133 |
+
|
| 134 |
+
```text
|
| 135 |
+
POST /api/reference-models
|
| 136 |
+
prompt -> image generation
|
| 137 |
+
image_url -> fal-ai/sam-3/3d-objects
|
| 138 |
+
result -> download GLB/artifacts to data/reference-models/<slug>/
|
| 139 |
+
normalized target -> rewards/<slug>.json
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
The frontend should never expose `FAL_KEY` or `FAL_AI_API_KEY`.
|
| 143 |
+
|
| 144 |
+
## Minimal hackathon deliverable
|
| 145 |
+
|
| 146 |
+
The most credible v1 is:
|
| 147 |
+
|
| 148 |
+
1. Simple UI with one `Generate` button.
|
| 149 |
+
2. Prompt asks for a Markus-like chair.
|
| 150 |
+
3. Model generates SCAD.
|
| 151 |
+
4. Browser renders the SCAD as real geometry.
|
| 152 |
+
5. Viewer automatically shows isometric, front, back, left, right, top, and bottom views.
|
| 153 |
+
6. Verifier reports watertightness, floating components, boundary edges, and non-manifold edges.
|
| 154 |
+
7. Reward code compares the candidate mesh against the Markus GLB reference.
|
| 155 |
+
8. GRPO loop ranks multiple candidates and fine-tunes a 0.6B model on the winning patterns.
|
| 156 |
+
|
| 157 |
+
This is a better hackathon scope than generic CAD generation because the demo can show visible learning: early chairs have floating parts and broken bases; later chairs become coherent, connected, watertight, and more Markus-like.
|
| 158 |
+
|
| 159 |
+
## Position
|
| 160 |
+
|
| 161 |
+
I would rate this direction a 9/10 for the hackathon if we keep the scope narrow. It has a clean story, a measurable verifier, a concrete reference object, and a realistic training target for a small model. The risk is trying to generalize too early. The winning move is to make one chair family work extremely well, then expand the same environment to hooks, brackets, tables, trusses, and other household mechanical objects.
|
docs/brainstorm/13-markus-chair-cadquery-grpo-rlve-plan.md
ADDED
|
@@ -0,0 +1,799 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Brainstorm 13: CadQuery Markus Chair GRPO/RLVE Hackathon Plan
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-25
|
| 4 |
+
|
| 5 |
+
## One-line pitch
|
| 6 |
+
|
| 7 |
+
CADForge is a reinforcement-learning environment where language models learn to create and revise real parametric CadQuery models by acting through CAD tools, observing rendered geometry, and optimizing verifiable rewards for topology, editability, and similarity to a reference object.
|
| 8 |
+
|
| 9 |
+
The flagship benchmark is a Markus-style office chair reconstructed as editable CadQuery code from a reference GLB.
|
| 10 |
+
|
| 11 |
+
## Hackathon thesis
|
| 12 |
+
|
| 13 |
+
Most models can write plausible CAD-looking Python once. They fail when they must maintain a persistent 3D world model across many revisions:
|
| 14 |
+
|
| 15 |
+
- parts float,
|
| 16 |
+
- booleans fail,
|
| 17 |
+
- dimensions drift,
|
| 18 |
+
- edits break the model,
|
| 19 |
+
- screenshots look plausible but topology is invalid,
|
| 20 |
+
- the model cannot reliably repair geometry from tool feedback.
|
| 21 |
+
|
| 22 |
+
CADForge turns this into a trainable environment:
|
| 23 |
+
|
| 24 |
+
```text
|
| 25 |
+
prompt
|
| 26 |
+
-> model proposes CadQuery code or edit action
|
| 27 |
+
-> backend executes CadQuery
|
| 28 |
+
-> environment exports STL/mesh/screenshots
|
| 29 |
+
-> reward functions score topology, similarity, editability, and tool efficiency
|
| 30 |
+
-> model revises for up to 300 actions
|
| 31 |
+
-> GRPO trains a small model to need fewer revision steps
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
The objective is not just "generate a chair." The objective is:
|
| 35 |
+
|
| 36 |
+
> Train a tiny Qwen model to become a better CadQuery CAD agent that produces valid, editable, reference-aligned geometry with fewer tool calls.
|
| 37 |
+
|
| 38 |
+
## Theme alignment
|
| 39 |
+
|
| 40 |
+
### Theme 2: Long-horizon planning
|
| 41 |
+
|
| 42 |
+
The environment supports up to 300 actions per episode:
|
| 43 |
+
|
| 44 |
+
- generate initial CadQuery,
|
| 45 |
+
- render,
|
| 46 |
+
- inspect topology,
|
| 47 |
+
- inspect screenshots,
|
| 48 |
+
- compare to GLB reference,
|
| 49 |
+
- edit dimensions,
|
| 50 |
+
- add missing parts,
|
| 51 |
+
- repair disconnected components,
|
| 52 |
+
- rerender,
|
| 53 |
+
- commit final design.
|
| 54 |
+
|
| 55 |
+
The reward is delayed and multi-part. A model must plan the full assembly, not just write a single pretty script.
|
| 56 |
+
|
| 57 |
+
### Theme 3.1: Professional world modeling
|
| 58 |
+
|
| 59 |
+
This is a realistic engineering workflow:
|
| 60 |
+
|
| 61 |
+
- Python CadQuery execution,
|
| 62 |
+
- STL export,
|
| 63 |
+
- mesh validation,
|
| 64 |
+
- reference GLB normalization,
|
| 65 |
+
- point-cloud and silhouette comparison,
|
| 66 |
+
- persistent CAD state,
|
| 67 |
+
- artifact logs,
|
| 68 |
+
- render snapshots,
|
| 69 |
+
- code diffs,
|
| 70 |
+
- editability checks.
|
| 71 |
+
|
| 72 |
+
The agent must model a partially observable 3D world using tool feedback. It cannot solve the task by text pattern matching alone.
|
| 73 |
+
|
| 74 |
+
### Theme 4: Self-improvement
|
| 75 |
+
|
| 76 |
+
The environment can generate adaptive tasks:
|
| 77 |
+
|
| 78 |
+
- make the chair taller,
|
| 79 |
+
- make armrests thicker,
|
| 80 |
+
- widen the five-star base,
|
| 81 |
+
- repair floating parts,
|
| 82 |
+
- reduce revision count,
|
| 83 |
+
- preserve editability under parameter changes.
|
| 84 |
+
|
| 85 |
+
Curriculum generation can escalate from simple blocks to full chairs. The model improves by repeatedly encountering its own CAD failure modes.
|
| 86 |
+
|
| 87 |
+
### Theme 1: Multi-agent interactions, optional extension
|
| 88 |
+
|
| 89 |
+
If time permits, split the workflow into specialist roles:
|
| 90 |
+
|
| 91 |
+
- Designer agent proposes CadQuery.
|
| 92 |
+
- Critic agent interprets screenshots and reward reports.
|
| 93 |
+
- Repair agent edits only broken geometry.
|
| 94 |
+
- Verifier agent decides whether to commit.
|
| 95 |
+
|
| 96 |
+
This is not required for the MVP, but it is a clean demo extension.
|
| 97 |
+
|
| 98 |
+
## What to build first
|
| 99 |
+
|
| 100 |
+
Build the CadQuery-only Markus environment before training.
|
| 101 |
+
|
| 102 |
+
Do not start with full RL. First make the environment stable, because GRPO only matters if the reward is trustworthy.
|
| 103 |
+
|
| 104 |
+
Priority order:
|
| 105 |
+
|
| 106 |
+
1. Reference preprocessing pipeline.
|
| 107 |
+
2. CadQuery candidate execution pipeline.
|
| 108 |
+
3. Reward functions with visible breakdowns.
|
| 109 |
+
4. GPT-5.4/GPT-5.5 multi-step benchmark traces.
|
| 110 |
+
5. Small Qwen GRPO run.
|
| 111 |
+
6. Before/after report and demo.
|
| 112 |
+
|
| 113 |
+
## Reference pipeline
|
| 114 |
+
|
| 115 |
+
Input:
|
| 116 |
+
|
| 117 |
+
```text
|
| 118 |
+
3d-models/ikea_markus_office_chair.glb
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
Steps:
|
| 122 |
+
|
| 123 |
+
1. Load the GLB with `trimesh`.
|
| 124 |
+
2. Convert scene nodes into one mesh.
|
| 125 |
+
3. Normalize orientation so:
|
| 126 |
+
- Z is up,
|
| 127 |
+
- seat/back height is vertical,
|
| 128 |
+
- chair front faces negative Y or a fixed canonical direction.
|
| 129 |
+
4. Normalize origin:
|
| 130 |
+
- center X/Y at zero,
|
| 131 |
+
- floor/base touches Z = 0,
|
| 132 |
+
- scale height to a canonical chair height, for example 1000 mm.
|
| 133 |
+
5. Save normalized artifacts:
|
| 134 |
+
- `reference_normalized.glb`,
|
| 135 |
+
- `reference_normalized.stl`,
|
| 136 |
+
- `reference_point_cloud.npy`,
|
| 137 |
+
- `reference_voxels.npz`,
|
| 138 |
+
- `reference_silhouettes/*.png`,
|
| 139 |
+
- `reference_metrics.json`.
|
| 140 |
+
|
| 141 |
+
Reference metrics:
|
| 142 |
+
|
| 143 |
+
```json
|
| 144 |
+
{
|
| 145 |
+
"bbox_mm": {"x": 620, "y": 650, "z": 1000},
|
| 146 |
+
"seat_height_ratio": 0.45,
|
| 147 |
+
"back_height_ratio": 0.55,
|
| 148 |
+
"base_radius_ratio": 0.32,
|
| 149 |
+
"views": ["front", "back", "left", "right", "top", "isometric"],
|
| 150 |
+
"semantic_hints": ["seat", "tall_backrest", "armrests", "central_column", "five_star_base"]
|
| 151 |
+
}
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
## Candidate pipeline
|
| 155 |
+
|
| 156 |
+
Input:
|
| 157 |
+
|
| 158 |
+
```text
|
| 159 |
+
task prompt + current CadQuery code + last verifier report + screenshot summaries
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
Candidate execution:
|
| 163 |
+
|
| 164 |
+
1. Write CadQuery code.
|
| 165 |
+
2. Run in a sandboxed Python subprocess.
|
| 166 |
+
3. Export STL.
|
| 167 |
+
4. Load STL with `trimesh`.
|
| 168 |
+
5. Normalize candidate to the same coordinate frame as the reference.
|
| 169 |
+
6. Render six fixed views plus an isometric.
|
| 170 |
+
7. Compute reward components.
|
| 171 |
+
8. Save artifacts.
|
| 172 |
+
|
| 173 |
+
Artifacts per attempt:
|
| 174 |
+
|
| 175 |
+
```text
|
| 176 |
+
runs/<episode_id>/<step_id>/
|
| 177 |
+
candidate.py
|
| 178 |
+
candidate.stl
|
| 179 |
+
candidate_normalized.stl
|
| 180 |
+
renders/isometric.png
|
| 181 |
+
renders/front.png
|
| 182 |
+
renders/back.png
|
| 183 |
+
renders/left.png
|
| 184 |
+
renders/right.png
|
| 185 |
+
renders/top.png
|
| 186 |
+
reward.json
|
| 187 |
+
verifier_report.md
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
## Agent action space
|
| 191 |
+
|
| 192 |
+
For the demo UI and GPT benchmark, allow free-form CadQuery edits.
|
| 193 |
+
|
| 194 |
+
For GRPO training, use a stricter action format so a small Qwen model can learn without forcing hand-authored chair-part tools:
|
| 195 |
+
|
| 196 |
+
```json
|
| 197 |
+
{
|
| 198 |
+
"thought": "The backrest is too short and disconnected from the seat.",
|
| 199 |
+
"tool": "apply_patch",
|
| 200 |
+
"patch": "*** Begin Patch\n*** Update File: candidate.py\n@@\n-back_height = 520\n+back_height = 680\n*** End Patch"
|
| 201 |
+
}
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
Initial allowed tools:
|
| 205 |
+
|
| 206 |
+
```text
|
| 207 |
+
write_initial_cadquery
|
| 208 |
+
apply_patch
|
| 209 |
+
replace_file
|
| 210 |
+
render_candidate
|
| 211 |
+
inspect_reward
|
| 212 |
+
inspect_screenshots
|
| 213 |
+
commit_design
|
| 214 |
+
```
|
| 215 |
+
|
| 216 |
+
The important rule is that the model edits CadQuery like a developer edits code in a REPL. It can add functions, refactor parameters, split subassemblies, create helpers, and compose objects however it wants. The environment should not expose narrow tools such as `add_part seat` or `add_backrest` as the main action space, because that bakes our solution into the policy. Semantic part names are reward probes, not required action names.
|
| 217 |
+
|
| 218 |
+
Optional later tools can stay code-native:
|
| 219 |
+
|
| 220 |
+
```text
|
| 221 |
+
run_static_code_check
|
| 222 |
+
show_code_diff
|
| 223 |
+
revert_last_patch
|
| 224 |
+
ask_verifier_for_top_failure
|
| 225 |
+
export_artifacts
|
| 226 |
+
parameter_edit
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
The long-horizon version should count every tool call as an action and cap the episode at 300 actions.
|
| 230 |
+
|
| 231 |
+
## Reward design
|
| 232 |
+
|
| 233 |
+
The reward must be multi-signal. A single "looks like chair" score is too easy to hack.
|
| 234 |
+
|
| 235 |
+
Use two reward speeds:
|
| 236 |
+
|
| 237 |
+
- `fast`: dense RL feedback after ordinary edit/tool steps. It scores build success, topology, bounding-box similarity, code/semantic structure, and editability without writing screenshots or running point-cloud/silhouette comparison.
|
| 238 |
+
- `full`: checkpoint/final scoring. It saves render artifacts and computes silhouette IoU plus Chamfer-style point-cloud similarity against both the ideal CadQuery reference and the GLB reference.
|
| 239 |
+
|
| 240 |
+
The training loop should use `fast` for most rollout steps and `full` on `commit_design`, every N revisions, and benchmark/report runs.
|
| 241 |
+
|
| 242 |
+
Final score:
|
| 243 |
+
|
| 244 |
+
```text
|
| 245 |
+
R_total =
|
| 246 |
+
0.20 * R_build
|
| 247 |
+
+ 0.20 * R_topology
|
| 248 |
+
+ 0.15 * R_semantic_parts
|
| 249 |
+
+ 0.15 * R_reference_similarity
|
| 250 |
+
+ 0.10 * R_silhouette
|
| 251 |
+
+ 0.10 * R_editability
|
| 252 |
+
+ 0.05 * R_efficiency
|
| 253 |
+
+ 0.05 * R_process
|
| 254 |
+
- penalties
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
Use gates before adding soft similarity rewards:
|
| 258 |
+
|
| 259 |
+
```text
|
| 260 |
+
if code_does_not_run: R_total = -1.0 and terminate
|
| 261 |
+
if no_mesh_or_empty_mesh: R_total = -1.0 and terminate
|
| 262 |
+
if final_design_has_many_components: cap R_total at 0.20
|
| 263 |
+
if final_design_is_not_chair_like: cap R_total at 0.35
|
| 264 |
+
```
|
| 265 |
+
|
| 266 |
+
### R_build
|
| 267 |
+
|
| 268 |
+
Checks whether CadQuery code is executable and exports geometry.
|
| 269 |
+
|
| 270 |
+
Signals:
|
| 271 |
+
|
| 272 |
+
- imports only allowed modules,
|
| 273 |
+
- defines a final `result` or discoverable CadQuery object,
|
| 274 |
+
- CadQuery build succeeds,
|
| 275 |
+
- STL export succeeds,
|
| 276 |
+
- mesh loads in `trimesh`,
|
| 277 |
+
- bounding box is finite and nonzero.
|
| 278 |
+
|
| 279 |
+
Suggested scoring:
|
| 280 |
+
|
| 281 |
+
```text
|
| 282 |
+
cadquery_import_ok: +0.15
|
| 283 |
+
script_exec_ok: +0.25
|
| 284 |
+
solid_found: +0.20
|
| 285 |
+
stl_export_ok: +0.20
|
| 286 |
+
mesh_load_ok: +0.20
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
### R_topology
|
| 290 |
+
|
| 291 |
+
Topology dominates because disconnected pretty geometry is not useful CAD.
|
| 292 |
+
|
| 293 |
+
Signals:
|
| 294 |
+
|
| 295 |
+
- connected component count,
|
| 296 |
+
- watertight mesh,
|
| 297 |
+
- manifold edges,
|
| 298 |
+
- boundary edges,
|
| 299 |
+
- non-manifold edges,
|
| 300 |
+
- degenerate faces,
|
| 301 |
+
- reasonable face count,
|
| 302 |
+
- no huge accidental slabs.
|
| 303 |
+
|
| 304 |
+
Suggested scoring:
|
| 305 |
+
|
| 306 |
+
```text
|
| 307 |
+
single_connected_component: +0.35
|
| 308 |
+
watertight: +0.25
|
| 309 |
+
no_non_manifold_edges: +0.15
|
| 310 |
+
low_boundary_edges: +0.10
|
| 311 |
+
no_degenerate_faces: +0.10
|
| 312 |
+
reasonable_complexity: +0.05
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
Penalties:
|
| 316 |
+
|
| 317 |
+
```text
|
| 318 |
+
extra_connected_component: -0.15 each
|
| 319 |
+
boundary_edge_ratio_high: -0.10 to -0.30
|
| 320 |
+
non_manifold_edges_present: -0.20
|
| 321 |
+
degenerate_faces_present: -0.10
|
| 322 |
+
```
|
| 323 |
+
|
| 324 |
+
### R_semantic_parts
|
| 325 |
+
|
| 326 |
+
The Markus chair is not just any tall object. It needs recognizable functional parts.
|
| 327 |
+
|
| 328 |
+
Required part hints:
|
| 329 |
+
|
| 330 |
+
- seat,
|
| 331 |
+
- tall backrest,
|
| 332 |
+
- upper/headrest-like section,
|
| 333 |
+
- left armrest,
|
| 334 |
+
- right armrest,
|
| 335 |
+
- central support column,
|
| 336 |
+
- five-star base or at least 5 radial spokes,
|
| 337 |
+
- caster proxies or feet.
|
| 338 |
+
|
| 339 |
+
Detection can start from named variables and bounding boxes, then become geometric:
|
| 340 |
+
|
| 341 |
+
```text
|
| 342 |
+
seat exists: +0.10
|
| 343 |
+
backrest taller than seat: +0.15
|
| 344 |
+
backrest touches seat/rear supports: +0.15
|
| 345 |
+
two armrests exist: +0.15
|
| 346 |
+
armrests connect to seat/back: +0.10
|
| 347 |
+
central column exists: +0.10
|
| 348 |
+
base has 5 radial spokes: +0.15
|
| 349 |
+
base contacts column: +0.10
|
| 350 |
+
```
|
| 351 |
+
|
| 352 |
+
This reward should inspect both code and geometry. Code names are helpful but not sufficient.
|
| 353 |
+
|
| 354 |
+
### R_reference_similarity
|
| 355 |
+
|
| 356 |
+
Use normalized candidate and normalized GLB reference.
|
| 357 |
+
|
| 358 |
+
Signals:
|
| 359 |
+
|
| 360 |
+
- bounding-box ratio similarity,
|
| 361 |
+
- point-cloud Chamfer distance,
|
| 362 |
+
- voxel IoU,
|
| 363 |
+
- rough mass distribution by height,
|
| 364 |
+
- principal-axis alignment.
|
| 365 |
+
|
| 366 |
+
Suggested scoring:
|
| 367 |
+
|
| 368 |
+
```text
|
| 369 |
+
bbox_ratio_score: 0.25
|
| 370 |
+
chamfer_score: 0.30
|
| 371 |
+
voxel_iou_score: 0.25
|
| 372 |
+
height_distribution: 0.10
|
| 373 |
+
principal_axes_score: 0.10
|
| 374 |
+
```
|
| 375 |
+
|
| 376 |
+
Important: this reward should not overpower topology. A broken mesh that happens to occupy similar pixels should not win.
|
| 377 |
+
|
| 378 |
+
### R_silhouette
|
| 379 |
+
|
| 380 |
+
Render candidate and reference with the same camera settings:
|
| 381 |
+
|
| 382 |
+
- front,
|
| 383 |
+
- back,
|
| 384 |
+
- left,
|
| 385 |
+
- right,
|
| 386 |
+
- top,
|
| 387 |
+
- isometric.
|
| 388 |
+
|
| 389 |
+
Compute binary mask IoU or distance transform similarity.
|
| 390 |
+
|
| 391 |
+
Suggested scoring:
|
| 392 |
+
|
| 393 |
+
```text
|
| 394 |
+
front_iou: 0.20
|
| 395 |
+
side_iou: 0.25
|
| 396 |
+
back_iou: 0.15
|
| 397 |
+
top_iou: 0.15
|
| 398 |
+
isometric_iou: 0.25
|
| 399 |
+
```
|
| 400 |
+
|
| 401 |
+
This is the judge-friendly reward because it maps to visible screenshots.
|
| 402 |
+
|
| 403 |
+
### R_editability
|
| 404 |
+
|
| 405 |
+
This is the product differentiator. The environment should mutate the code and check whether it still builds.
|
| 406 |
+
|
| 407 |
+
Edit tests:
|
| 408 |
+
|
| 409 |
+
- increase backrest height by 10 percent,
|
| 410 |
+
- widen seat by 10 percent,
|
| 411 |
+
- thicken armrests,
|
| 412 |
+
- increase base radius,
|
| 413 |
+
- change column height,
|
| 414 |
+
- change global scale.
|
| 415 |
+
|
| 416 |
+
Signals:
|
| 417 |
+
|
| 418 |
+
```text
|
| 419 |
+
named_parameters_present: +0.20
|
| 420 |
+
all_major_dimensions_parameterized: +0.25
|
| 421 |
+
edit_backrest_height_rebuilds: +0.15
|
| 422 |
+
edit_seat_width_rebuilds: +0.15
|
| 423 |
+
edit_base_radius_rebuilds: +0.15
|
| 424 |
+
no_hardcoded_uneditable_blob: +0.10
|
| 425 |
+
```
|
| 426 |
+
|
| 427 |
+
This blocks the model from generating a one-off decorative mesh-like CadQuery script.
|
| 428 |
+
|
| 429 |
+
### R_efficiency
|
| 430 |
+
|
| 431 |
+
The goal is fewer revision steps.
|
| 432 |
+
|
| 433 |
+
Signals:
|
| 434 |
+
|
| 435 |
+
- number of tool calls,
|
| 436 |
+
- number of failed renders,
|
| 437 |
+
- number of compile failures,
|
| 438 |
+
- token count,
|
| 439 |
+
- code size.
|
| 440 |
+
|
| 441 |
+
Suggested scoring:
|
| 442 |
+
|
| 443 |
+
```text
|
| 444 |
+
R_efficiency = max(0, 1 - tool_calls / max_tool_calls)
|
| 445 |
+
```
|
| 446 |
+
|
| 447 |
+
Penalties:
|
| 448 |
+
|
| 449 |
+
```text
|
| 450 |
+
compile_failure: -0.05 each
|
| 451 |
+
render_failure: -0.05 each
|
| 452 |
+
unproductive_edit: -0.03 each
|
| 453 |
+
excessive_code_size: -0.05
|
| 454 |
+
```
|
| 455 |
+
|
| 456 |
+
This is where the "trained model needs fewer revisions" claim becomes measurable.
|
| 457 |
+
|
| 458 |
+
### R_process
|
| 459 |
+
|
| 460 |
+
Reward the agent for using the workflow correctly:
|
| 461 |
+
|
| 462 |
+
- renders before committing,
|
| 463 |
+
- reads reward report before editing,
|
| 464 |
+
- repairs the biggest failure first,
|
| 465 |
+
- does not repeat the same failed edit,
|
| 466 |
+
- commits only after passing minimum topology gates.
|
| 467 |
+
|
| 468 |
+
Example:
|
| 469 |
+
|
| 470 |
+
```text
|
| 471 |
+
rendered_before_commit: +0.20
|
| 472 |
+
used_verifier_feedback_in_edit: +0.25
|
| 473 |
+
fixed_previous_top_failure: +0.25
|
| 474 |
+
no_repeated_failed_patch: +0.15
|
| 475 |
+
commit_after_threshold: +0.15
|
| 476 |
+
```
|
| 477 |
+
|
| 478 |
+
## Anti-reward-hacking checks
|
| 479 |
+
|
| 480 |
+
Block or penalize:
|
| 481 |
+
|
| 482 |
+
- reading reference reward files directly,
|
| 483 |
+
- hardcoding saved mesh artifacts,
|
| 484 |
+
- importing network or filesystem tools outside the run directory,
|
| 485 |
+
- writing files outside the episode directory,
|
| 486 |
+
- returning a prebuilt STL instead of CadQuery,
|
| 487 |
+
- creating one giant slab that fills the silhouette,
|
| 488 |
+
- naming variables `seat` and `backrest` without matching geometry,
|
| 489 |
+
- disabling or bypassing verifier code,
|
| 490 |
+
- excessive triangle count to game silhouette overlap.
|
| 491 |
+
|
| 492 |
+
CadQuery execution should run in a subprocess with:
|
| 493 |
+
|
| 494 |
+
- timeout,
|
| 495 |
+
- allowed imports,
|
| 496 |
+
- isolated working directory,
|
| 497 |
+
- max file size,
|
| 498 |
+
- max mesh triangles,
|
| 499 |
+
- no network,
|
| 500 |
+
- no access to hidden reference internals.
|
| 501 |
+
|
| 502 |
+
## GPT-5.4/GPT-5.5 benchmark
|
| 503 |
+
|
| 504 |
+
Purpose:
|
| 505 |
+
|
| 506 |
+
Show that even strong frontier models improve through tool use, and collect teacher traces for the small model.
|
| 507 |
+
|
| 508 |
+
Benchmark setup:
|
| 509 |
+
|
| 510 |
+
- Tasks: 5 to 10 Markus-chair variants.
|
| 511 |
+
- Models: GPT-5.4 and GPT-5.5 if available in the local/API stack.
|
| 512 |
+
- Budget: 1, 3, 5, 10, and 20 tool-call attempts.
|
| 513 |
+
- Each attempt saves code, STL, screenshots, reward breakdown, and critique.
|
| 514 |
+
|
| 515 |
+
Tasks:
|
| 516 |
+
|
| 517 |
+
1. Baseline Markus-like chair.
|
| 518 |
+
2. Taller backrest.
|
| 519 |
+
3. Thicker armrests.
|
| 520 |
+
4. Wider five-star base.
|
| 521 |
+
5. Repair a provided broken chair with floating parts.
|
| 522 |
+
6. Make the chair editable under global scale changes.
|
| 523 |
+
7. Improve silhouette match against the GLB.
|
| 524 |
+
|
| 525 |
+
Report file:
|
| 526 |
+
|
| 527 |
+
```text
|
| 528 |
+
experiment-2-cadforge/reports/gpt-cadquery-benchmark.md
|
| 529 |
+
```
|
| 530 |
+
|
| 531 |
+
Report structure:
|
| 532 |
+
|
| 533 |
+
```markdown
|
| 534 |
+
# GPT CadQuery Tool-Use Benchmark
|
| 535 |
+
|
| 536 |
+
## Summary Table
|
| 537 |
+
| Task | Model | Attempts | Best Reward | Build | Topology | Similarity | Editability | Notes |
|
| 538 |
+
|
| 539 |
+
## Task 1: Baseline Markus Chair
|
| 540 |
+
### Attempt 1
|
| 541 |
+
- Code: ...
|
| 542 |
+
- Reward: ...
|
| 543 |
+
- Failure: ...
|
| 544 |
+
- Screenshots: ...
|
| 545 |
+
### Attempt N
|
| 546 |
+
- Improvement: ...
|
| 547 |
+
|
| 548 |
+
## Cross-task Findings
|
| 549 |
+
- What improved with more tool calls
|
| 550 |
+
- What did not improve
|
| 551 |
+
- Repeated failure modes
|
| 552 |
+
- Best teacher traces for SFT or GRPO warm start
|
| 553 |
+
```
|
| 554 |
+
|
| 555 |
+
This is the "evidence" part judges will care about.
|
| 556 |
+
|
| 557 |
+
## GRPO training plan
|
| 558 |
+
|
| 559 |
+
Use GRPO/RLVR, not classic human-preference RLHF, for the core result.
|
| 560 |
+
|
| 561 |
+
Why:
|
| 562 |
+
|
| 563 |
+
- rewards are verifiable,
|
| 564 |
+
- no reward model needed,
|
| 565 |
+
- multiple sampled candidates per prompt can be ranked by the verifier,
|
| 566 |
+
- the hackathon guide explicitly favors verifier-first GRPO-style tasks.
|
| 567 |
+
|
| 568 |
+
Model target:
|
| 569 |
+
|
| 570 |
+
```text
|
| 571 |
+
Qwen small instruct model, ideally 0.5B to 1.5B for overnight feasibility.
|
| 572 |
+
```
|
| 573 |
+
|
| 574 |
+
Training stages:
|
| 575 |
+
|
| 576 |
+
### Stage 0: Formatting warm start
|
| 577 |
+
|
| 578 |
+
Small SFT dataset from:
|
| 579 |
+
|
| 580 |
+
- hand-written valid CadQuery templates,
|
| 581 |
+
- GPT teacher traces,
|
| 582 |
+
- environment tool-call transcripts.
|
| 583 |
+
|
| 584 |
+
Goal:
|
| 585 |
+
|
| 586 |
+
Teach the small model to emit the correct action JSON and basic CadQuery structure.
|
| 587 |
+
|
| 588 |
+
### Stage 1: Easy GRPO
|
| 589 |
+
|
| 590 |
+
Tasks:
|
| 591 |
+
|
| 592 |
+
- create one box,
|
| 593 |
+
- create seat plus backrest,
|
| 594 |
+
- create connected chair silhouette from boxes/cylinders,
|
| 595 |
+
- pass build/topology rewards.
|
| 596 |
+
|
| 597 |
+
Reward focus:
|
| 598 |
+
|
| 599 |
+
- valid code,
|
| 600 |
+
- connected mesh,
|
| 601 |
+
- named parameters.
|
| 602 |
+
|
| 603 |
+
### Stage 2: Markus semantic GRPO
|
| 604 |
+
|
| 605 |
+
Tasks:
|
| 606 |
+
|
| 607 |
+
- full Markus-like chair,
|
| 608 |
+
- add armrests,
|
| 609 |
+
- add five-star base,
|
| 610 |
+
- repair disconnected base/back/arms.
|
| 611 |
+
|
| 612 |
+
Reward focus:
|
| 613 |
+
|
| 614 |
+
- semantic part score,
|
| 615 |
+
- topology,
|
| 616 |
+
- silhouette.
|
| 617 |
+
|
| 618 |
+
### Stage 3: Revision efficiency GRPO
|
| 619 |
+
|
| 620 |
+
Tasks:
|
| 621 |
+
|
| 622 |
+
- start from flawed candidates,
|
| 623 |
+
- repair within 5 to 20 tool calls,
|
| 624 |
+
- minimize failed renders and repeated edits.
|
| 625 |
+
|
| 626 |
+
Reward focus:
|
| 627 |
+
|
| 628 |
+
- fewer tool calls,
|
| 629 |
+
- fixed prior failure,
|
| 630 |
+
- final reward delta.
|
| 631 |
+
|
| 632 |
+
## Overnight RunPod plan
|
| 633 |
+
|
| 634 |
+
Only start raw compute after the environment can run 100 local episodes without crashing.
|
| 635 |
+
|
| 636 |
+
Minimum preflight:
|
| 637 |
+
|
| 638 |
+
```text
|
| 639 |
+
python scripts/run_cadquery_env_smoke.py --episodes 20
|
| 640 |
+
python scripts/run_reward_regression.py
|
| 641 |
+
python scripts/run_gpt_benchmark.py --tasks 2 --attempts 2
|
| 642 |
+
```
|
| 643 |
+
|
| 644 |
+
When to rent RunPod:
|
| 645 |
+
|
| 646 |
+
1. Reward code is stable.
|
| 647 |
+
2. Artifacts save correctly.
|
| 648 |
+
3. No reward file leakage.
|
| 649 |
+
4. Qwen can produce valid action JSON at least sometimes.
|
| 650 |
+
5. Local mini-GRPO or dry-run completes.
|
| 651 |
+
|
| 652 |
+
Suggested overnight jobs:
|
| 653 |
+
|
| 654 |
+
```text
|
| 655 |
+
Job A: GPT teacher benchmark
|
| 656 |
+
- 5 to 10 tasks
|
| 657 |
+
- 5 to 20 attempts per task
|
| 658 |
+
- save markdown report and screenshots
|
| 659 |
+
|
| 660 |
+
Job B: Qwen Stage 0 SFT
|
| 661 |
+
- formatting/action traces
|
| 662 |
+
- 1 to 2 hours
|
| 663 |
+
|
| 664 |
+
Job C: Qwen GRPO Stage 1/2
|
| 665 |
+
- easy to medium curriculum
|
| 666 |
+
- 6 to 10 hours
|
| 667 |
+
- checkpoint every 30 to 60 minutes
|
| 668 |
+
```
|
| 669 |
+
|
| 670 |
+
Metrics to monitor:
|
| 671 |
+
|
| 672 |
+
- total reward,
|
| 673 |
+
- build success rate,
|
| 674 |
+
- connected component pass rate,
|
| 675 |
+
- semantic part score,
|
| 676 |
+
- silhouette score,
|
| 677 |
+
- editability pass rate,
|
| 678 |
+
- average tool calls to best design,
|
| 679 |
+
- compile failure rate,
|
| 680 |
+
- examples every N steps.
|
| 681 |
+
|
| 682 |
+
Stop the run if:
|
| 683 |
+
|
| 684 |
+
- compile failure rate stays above 80 percent after warmup,
|
| 685 |
+
- reward rises while topology gets worse,
|
| 686 |
+
- outputs start exploiting file paths or constants,
|
| 687 |
+
- model stops using valid action JSON.
|
| 688 |
+
|
| 689 |
+
## Demo plan
|
| 690 |
+
|
| 691 |
+
The winning demo should be visual and measurable.
|
| 692 |
+
|
| 693 |
+
Screen 1:
|
| 694 |
+
|
| 695 |
+
- user prompt,
|
| 696 |
+
- reference GLB thumbnails,
|
| 697 |
+
- baseline small Qwen attempt,
|
| 698 |
+
- broken render and reward report.
|
| 699 |
+
|
| 700 |
+
Screen 2:
|
| 701 |
+
|
| 702 |
+
- multi-step tool trace,
|
| 703 |
+
- failed topology warning,
|
| 704 |
+
- edit patch,
|
| 705 |
+
- rerender.
|
| 706 |
+
|
| 707 |
+
Screen 3:
|
| 708 |
+
|
| 709 |
+
- post-GRPO Qwen attempt,
|
| 710 |
+
- fewer revisions,
|
| 711 |
+
- better topology,
|
| 712 |
+
- better silhouette,
|
| 713 |
+
- reward improvement.
|
| 714 |
+
|
| 715 |
+
Screen 4:
|
| 716 |
+
|
| 717 |
+
- GPT-5.5 benchmark report as teacher/frontier baseline,
|
| 718 |
+
- trained tiny model improvement curve,
|
| 719 |
+
- environment API/OpenEnv story.
|
| 720 |
+
|
| 721 |
+
Core claim:
|
| 722 |
+
|
| 723 |
+
> We built a professional CAD RL environment, not just a CAD generator. The same verifier can train small models, benchmark frontier agents, and generate adaptive curricula.
|
| 724 |
+
|
| 725 |
+
## Concrete next build tasks
|
| 726 |
+
|
| 727 |
+
### Today: environment and rewards
|
| 728 |
+
|
| 729 |
+
1. Convert the existing CadQuery renderer into a repeatable backend environment call.
|
| 730 |
+
2. Add a `runs/<episode_id>/` artifact writer.
|
| 731 |
+
3. Add reward JSON output for:
|
| 732 |
+
- build,
|
| 733 |
+
- topology,
|
| 734 |
+
- bbox,
|
| 735 |
+
- semantic parts,
|
| 736 |
+
- screenshots.
|
| 737 |
+
4. Add GLB reference preprocessing.
|
| 738 |
+
5. Add a one-command smoke test.
|
| 739 |
+
|
| 740 |
+
### Next: benchmark report
|
| 741 |
+
|
| 742 |
+
1. Build `scripts/experiment-2/run-gpt-cadquery-benchmark.js` or Python equivalent.
|
| 743 |
+
2. Run GPT model for 5 tasks.
|
| 744 |
+
3. Save every attempt as Markdown plus images.
|
| 745 |
+
4. Summarize improvement with more tool calls.
|
| 746 |
+
|
| 747 |
+
### Then: OpenEnv wrapper
|
| 748 |
+
|
| 749 |
+
1. Define observation model:
|
| 750 |
+
- task prompt,
|
| 751 |
+
- current code,
|
| 752 |
+
- last reward,
|
| 753 |
+
- render paths,
|
| 754 |
+
- verifier warnings.
|
| 755 |
+
2. Define action model:
|
| 756 |
+
- tool name,
|
| 757 |
+
- patch or code,
|
| 758 |
+
- commit flag.
|
| 759 |
+
3. Implement `reset()`.
|
| 760 |
+
4. Implement `step(action)`.
|
| 761 |
+
5. Add timeout and sandbox limits.
|
| 762 |
+
6. Validate with OpenEnv CLI.
|
| 763 |
+
|
| 764 |
+
### Then: GRPO
|
| 765 |
+
|
| 766 |
+
1. Create small curriculum dataset.
|
| 767 |
+
2. Run formatting SFT if needed.
|
| 768 |
+
3. Run GRPO with 4 to 8 samples per prompt.
|
| 769 |
+
4. Save checkpoints and eval artifacts.
|
| 770 |
+
5. Compare baseline Qwen vs trained Qwen.
|
| 771 |
+
|
| 772 |
+
## Submission story
|
| 773 |
+
|
| 774 |
+
Use this structure in the final hackathon README:
|
| 775 |
+
|
| 776 |
+
1. Problem: LLMs produce plausible but unreliable CAD.
|
| 777 |
+
2. Environment: CadQuery tool-use world with persistent geometry state.
|
| 778 |
+
3. Rewards: topology-first, reference similarity, editability, process efficiency.
|
| 779 |
+
4. Themes: long horizon, professional world modeling, self-improvement, optional multi-agent.
|
| 780 |
+
5. Training: GRPO on small Qwen with verifiable rewards.
|
| 781 |
+
6. Evidence: GPT benchmark traces plus Qwen before/after curves.
|
| 782 |
+
7. Product: CADForge can become a sellable CAD-agent evaluation and training platform.
|
| 783 |
+
|
| 784 |
+
## What not to do
|
| 785 |
+
|
| 786 |
+
- Do not train before reward functions are stable.
|
| 787 |
+
- Do not optimize only screenshots.
|
| 788 |
+
- Do not let similarity beat topology.
|
| 789 |
+
- Do not make the first benchmark generic CAD generation.
|
| 790 |
+
- Do not promise full FEA for the first demo.
|
| 791 |
+
- Do not make the small model write arbitrary long Python without a structured action wrapper.
|
| 792 |
+
|
| 793 |
+
## Final scope recommendation
|
| 794 |
+
|
| 795 |
+
The hackathon-winning scope is:
|
| 796 |
+
|
| 797 |
+
> CadQuery Markus Chair RLVE: a verifiable long-horizon CAD environment where frontier models and small open models iteratively generate, inspect, repair, and improve parametric CAD against a real GLB reference, with GRPO training showing that a tiny Qwen model learns to produce valid chair CAD in fewer revisions.
|
| 798 |
+
|
| 799 |
+
This is narrow enough to finish and strong enough to sell.
|
docs/brainstorm/14-cadquery-sft-grpo-rlve-training-plan.md
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Brainstorm 14: CadQuery SFT + GRPO/RLVE Training Plan
|
| 2 |
+
|
| 3 |
+
Date: 2026-04-25
|
| 4 |
+
|
| 5 |
+
## Goal
|
| 6 |
+
|
| 7 |
+
Train a small Qwen3.5 model to act as a CadQuery CAD agent. The model should learn to generate and revise editable chair CAD with fewer failed attempts and fewer revision steps.
|
| 8 |
+
|
| 9 |
+
The target task is not free-form mesh generation. It is code-CAD tool use:
|
| 10 |
+
|
| 11 |
+
```text
|
| 12 |
+
prompt
|
| 13 |
+
-> candidate.py
|
| 14 |
+
-> CadQuery build/export
|
| 15 |
+
-> mesh + rendered views
|
| 16 |
+
-> reward report
|
| 17 |
+
-> code edit/revision
|
| 18 |
+
-> repeat
|
| 19 |
+
-> commit
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
## Why SFT First
|
| 23 |
+
|
| 24 |
+
GRPO needs nonzero reward. A tiny 0.8B or 2B model may fail before it even reaches CadQuery execution unless we teach the basic format.
|
| 25 |
+
|
| 26 |
+
SFT is only a warm start. It should teach:
|
| 27 |
+
|
| 28 |
+
- return complete Python files,
|
| 29 |
+
- use `import cadquery as cq`,
|
| 30 |
+
- assign a final object to `fixture`,
|
| 31 |
+
- avoid unsafe imports and fragile CadQuery APIs,
|
| 32 |
+
- organize CAD as functions and named dimensions,
|
| 33 |
+
- revise code using verifier feedback.
|
| 34 |
+
|
| 35 |
+
SFT should not try to memorize the whole ideal chair. Keep it small and behavioral.
|
| 36 |
+
|
| 37 |
+
## SFT Data
|
| 38 |
+
|
| 39 |
+
Create examples from:
|
| 40 |
+
|
| 41 |
+
1. The ideal Markus CadQuery code.
|
| 42 |
+
2. GPT-5.4/GPT-5.5 benchmark traces.
|
| 43 |
+
3. Handwritten repair examples:
|
| 44 |
+
- missing armrests,
|
| 45 |
+
- floating base,
|
| 46 |
+
- too-short backrest,
|
| 47 |
+
- failed `loft()` replaced with boxes/cylinders,
|
| 48 |
+
- disconnected caster assembly,
|
| 49 |
+
- no final `fixture`.
|
| 50 |
+
4. Environment transcripts:
|
| 51 |
+
- prompt,
|
| 52 |
+
- previous code,
|
| 53 |
+
- reward JSON,
|
| 54 |
+
- next corrected code.
|
| 55 |
+
|
| 56 |
+
Recommended first dataset size:
|
| 57 |
+
|
| 58 |
+
```text
|
| 59 |
+
50 to 200 examples
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
That is enough for format and tool behavior.
|
| 63 |
+
|
| 64 |
+
## GRPO Setup
|
| 65 |
+
|
| 66 |
+
Use normal GRPO with vLLM in serve mode on RunPod, as suggested by the judge.
|
| 67 |
+
|
| 68 |
+
Architecture:
|
| 69 |
+
|
| 70 |
+
```text
|
| 71 |
+
GRPO trainer
|
| 72 |
+
-> requests N samples from vLLM server
|
| 73 |
+
-> parses candidate code
|
| 74 |
+
-> runs CADForge evaluator
|
| 75 |
+
-> computes reward
|
| 76 |
+
-> updates LoRA adapter
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
For Qwen3.5, avoid vLLM async complications initially. Run vLLM as a plain server and call it synchronously from the rollout function.
|
| 80 |
+
|
| 81 |
+
Local Ollama is for baseline/debug only. It is not the training backend.
|
| 82 |
+
|
| 83 |
+
## Reward Modes
|
| 84 |
+
|
| 85 |
+
Use two reward modes:
|
| 86 |
+
|
| 87 |
+
### Fast Mode
|
| 88 |
+
|
| 89 |
+
Used for most rollout candidates.
|
| 90 |
+
|
| 91 |
+
Scores:
|
| 92 |
+
|
| 93 |
+
- build success,
|
| 94 |
+
- topology sanity,
|
| 95 |
+
- contact/gap score,
|
| 96 |
+
- semantic/code structure,
|
| 97 |
+
- bbox similarity,
|
| 98 |
+
- editability.
|
| 99 |
+
|
| 100 |
+
Does not write colored screenshots or run expensive point-cloud/silhouette scoring.
|
| 101 |
+
|
| 102 |
+
### Full Mode
|
| 103 |
+
|
| 104 |
+
Used for:
|
| 105 |
+
|
| 106 |
+
- final commit,
|
| 107 |
+
- every N training steps,
|
| 108 |
+
- benchmark reports,
|
| 109 |
+
- judge artifacts.
|
| 110 |
+
|
| 111 |
+
Scores:
|
| 112 |
+
|
| 113 |
+
- everything from fast mode,
|
| 114 |
+
- colored view renders,
|
| 115 |
+
- silhouette IoU,
|
| 116 |
+
- Chamfer-style point-cloud similarity,
|
| 117 |
+
- candidate vs ideal CadQuery,
|
| 118 |
+
- candidate vs GLB.
|
| 119 |
+
|
| 120 |
+
## Reward Functions
|
| 121 |
+
|
| 122 |
+
### Build Reward
|
| 123 |
+
|
| 124 |
+
High only if:
|
| 125 |
+
|
| 126 |
+
- code executes,
|
| 127 |
+
- CadQuery object exists,
|
| 128 |
+
- STL export succeeds,
|
| 129 |
+
- mesh loads.
|
| 130 |
+
|
| 131 |
+
Hard failure:
|
| 132 |
+
|
| 133 |
+
```text
|
| 134 |
+
reward = -1.0
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
if code cannot run or no mesh exports.
|
| 138 |
+
|
| 139 |
+
### Topology Reward
|
| 140 |
+
|
| 141 |
+
Checks mesh health:
|
| 142 |
+
|
| 143 |
+
- component count,
|
| 144 |
+
- watertightness,
|
| 145 |
+
- boundary edges,
|
| 146 |
+
- non-manifold edges,
|
| 147 |
+
- degenerate faces,
|
| 148 |
+
- face count sanity.
|
| 149 |
+
|
| 150 |
+
For chairs, many components can be okay because a chair is an assembly. For monolithic hooks/brackets, this should become stricter later.
|
| 151 |
+
|
| 152 |
+
### Contact/Gap Reward
|
| 153 |
+
|
| 154 |
+
This handles the important chair case:
|
| 155 |
+
|
| 156 |
+
- small assembly gaps are tolerated,
|
| 157 |
+
- large separated parts are penalized,
|
| 158 |
+
- lots of floating components are bad.
|
| 159 |
+
|
| 160 |
+
This prevents a model from making a plausible-looking chair where the base, back, or armrests float far away.
|
| 161 |
+
|
| 162 |
+
### Semantic Reward
|
| 163 |
+
|
| 164 |
+
Checks whether the candidate behaves like a Markus-style chair:
|
| 165 |
+
|
| 166 |
+
- code mentions and organizes chair concepts,
|
| 167 |
+
- proportions are chair-like,
|
| 168 |
+
- there is a tall upper body/back region,
|
| 169 |
+
- there is lower base spread,
|
| 170 |
+
- code is split into reusable functions.
|
| 171 |
+
|
| 172 |
+
This is hackable if used alone, so it is never the only reward.
|
| 173 |
+
|
| 174 |
+
### Reference Similarity
|
| 175 |
+
|
| 176 |
+
Compares the candidate to:
|
| 177 |
+
|
| 178 |
+
1. ideal CadQuery reference,
|
| 179 |
+
2. real Markus GLB.
|
| 180 |
+
|
| 181 |
+
Signals:
|
| 182 |
+
|
| 183 |
+
- bbox proportions,
|
| 184 |
+
- point-cloud distance,
|
| 185 |
+
- silhouette similarity.
|
| 186 |
+
|
| 187 |
+
The ideal CadQuery reference is the gold code target. The GLB is the real-world visual target.
|
| 188 |
+
|
| 189 |
+
### Editability Reward
|
| 190 |
+
|
| 191 |
+
Rewards:
|
| 192 |
+
|
| 193 |
+
- functions,
|
| 194 |
+
- named dimensions,
|
| 195 |
+
- returns from helper builders,
|
| 196 |
+
- final object assignment.
|
| 197 |
+
|
| 198 |
+
Later this should become stronger by actually mutating parameters and rebuilding.
|
| 199 |
+
|
| 200 |
+
### Efficiency Reward
|
| 201 |
+
|
| 202 |
+
For multi-step episodes:
|
| 203 |
+
|
| 204 |
+
- fewer failed CadQuery builds,
|
| 205 |
+
- fewer tool calls,
|
| 206 |
+
- fewer repeated edits,
|
| 207 |
+
- higher reward with fewer revisions.
|
| 208 |
+
|
| 209 |
+
This is where the final product claim comes from:
|
| 210 |
+
|
| 211 |
+
> After GRPO, the small model reaches a good CadQuery chair in fewer revisions.
|
| 212 |
+
|
| 213 |
+
## Reward Hacking Risks
|
| 214 |
+
|
| 215 |
+
Known risks:
|
| 216 |
+
|
| 217 |
+
- naming a variable `backrest` without real geometry,
|
| 218 |
+
- making a giant bounding-box slab,
|
| 219 |
+
- making visually close but non-editable geometry,
|
| 220 |
+
- creating many disconnected decorative parts,
|
| 221 |
+
- overfitting to the ideal code,
|
| 222 |
+
- using APIs that work once but break under edits.
|
| 223 |
+
|
| 224 |
+
Mitigations:
|
| 225 |
+
|
| 226 |
+
- final full reward uses silhouettes and point clouds,
|
| 227 |
+
- contact/gap reward punishes large separation,
|
| 228 |
+
- editability reward punishes one-off blobs,
|
| 229 |
+
- holdout tasks change dimensions and requirements,
|
| 230 |
+
- inspect rendered reports often.
|
| 231 |
+
|
| 232 |
+
## How We Know It Is Improving
|
| 233 |
+
|
| 234 |
+
Do not trust only average training reward.
|
| 235 |
+
|
| 236 |
+
Track:
|
| 237 |
+
|
| 238 |
+
- build success rate,
|
| 239 |
+
- best full reward on fixed holdout prompts,
|
| 240 |
+
- average revisions to reach reward greater than 0.75,
|
| 241 |
+
- contact/gap score,
|
| 242 |
+
- silhouette score,
|
| 243 |
+
- editability score,
|
| 244 |
+
- failure categories,
|
| 245 |
+
- rendered Markdown reports before and after training.
|
| 246 |
+
|
| 247 |
+
Main demo metric:
|
| 248 |
+
|
| 249 |
+
```text
|
| 250 |
+
Baseline Qwen: needs many attempts, often fails build/contact.
|
| 251 |
+
Trained Qwen: builds earlier, fewer gaps, better full reward, fewer revisions.
|
| 252 |
+
```
|
| 253 |
+
|
| 254 |
+
## Local Baseline With Ollama
|
| 255 |
+
|
| 256 |
+
Use Ollama to see what 0.8B and 2B can do before training:
|
| 257 |
+
|
| 258 |
+
```bash
|
| 259 |
+
scripts/experiment-2/run-gpt-cadquery-benchmark.js \
|
| 260 |
+
--run \
|
| 261 |
+
--provider ollama \
|
| 262 |
+
--model qwen3.5:0.8b \
|
| 263 |
+
--tasks 1 \
|
| 264 |
+
--attempts 1 \
|
| 265 |
+
--timeout-ms 180000
|
| 266 |
+
```
|
| 267 |
+
|
| 268 |
+
The benchmark caps generation with `num_predict`, disables streaming, and has a timeout so a small model cannot hang forever.
|
| 269 |
+
|
| 270 |
+
## RunPod Training Plan
|
| 271 |
+
|
| 272 |
+
Only start RunPod after:
|
| 273 |
+
|
| 274 |
+
- local Ollama baselines run,
|
| 275 |
+
- reward reports look sensible,
|
| 276 |
+
- SFT examples exist,
|
| 277 |
+
- the evaluator survives 20 to 100 episodes.
|
| 278 |
+
|
| 279 |
+
RunPod jobs:
|
| 280 |
+
|
| 281 |
+
1. SFT warm start on 50 to 200 examples.
|
| 282 |
+
2. GRPO Stage 1 on easy build/topology tasks.
|
| 283 |
+
3. GRPO Stage 2 on Markus-chair reward.
|
| 284 |
+
4. Full benchmark report against baseline Qwen and GPT-5.4.
|
| 285 |
+
|
| 286 |
+
Use vLLM serve mode for rollouts, not async mode, for the first stable GRPO run.
|
| 287 |
+
|
| 288 |
+
## Immediate Next Steps
|
| 289 |
+
|
| 290 |
+
1. Run Ollama 0.8B baseline.
|
| 291 |
+
2. Run Ollama 2B baseline when download finishes.
|
| 292 |
+
3. Save both reports with rendered images.
|
| 293 |
+
4. Create first SFT JSONL from ideal code and GPT traces.
|
| 294 |
+
5. Build a minimal GRPO script that calls the evaluator.
|
| 295 |
+
6. Move to RunPod.
|
docs/brainstorm/15-cadquery-agentic-traces-sft-grpo-plan.md
ADDED
|
@@ -0,0 +1,246 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CadQuery Agentic Traces, SFT, and GRPO Plan
|
| 2 |
+
|
| 3 |
+
## Current truth
|
| 4 |
+
|
| 5 |
+
The first benchmark was multi-attempt generation, not a full agent loop. The new trace runner is the real loop:
|
| 6 |
+
|
| 7 |
+
1. Evaluate current CadQuery code.
|
| 8 |
+
2. Save reward JSON, rendered views, STL, and verifier report.
|
| 9 |
+
3. Send the model the prompt, previous code, reward JSON, and optionally rendered images.
|
| 10 |
+
4. Ask for a complete revised CadQuery file.
|
| 11 |
+
5. Evaluate the revised code.
|
| 12 |
+
6. Save a step transcript for SFT, preference learning, and RL rollouts.
|
| 13 |
+
|
| 14 |
+
The current GPT-5.4 vision trace improved the Markus repair seed from `0.613` to `0.800` in one edit. The second edit reached `0.794`, so it is a useful negative/preference example: more edits are only good when reward increases.
|
| 15 |
+
|
| 16 |
+
Qwen 3.5 2B can produce CadQuery-shaped code after `think: false`, but it currently fails builds. That is expected before SFT. Its failed trace is useful because the verifier now exposes concrete Python errors, for example undefined dimensions.
|
| 17 |
+
|
| 18 |
+
## Data we are collecting
|
| 19 |
+
|
| 20 |
+
### SFT rows
|
| 21 |
+
|
| 22 |
+
Path: `experiment-2-cadforge/data/sft/cadquery_agentic_sft.jsonl`
|
| 23 |
+
|
| 24 |
+
Each row teaches:
|
| 25 |
+
|
| 26 |
+
- system prompt with CadQuery tool rules
|
| 27 |
+
- user observation: task, previous code, reward JSON
|
| 28 |
+
- assistant action: corrected complete CadQuery code
|
| 29 |
+
- metadata: reward before, reward after, reward delta, artifact path
|
| 30 |
+
|
| 31 |
+
Use only positive or mildly positive rows for the first SFT pass. Filter with:
|
| 32 |
+
|
| 33 |
+
- `reward_after > reward_before`
|
| 34 |
+
- `reward_after >= 0.70`
|
| 35 |
+
- `build == 1`
|
| 36 |
+
|
| 37 |
+
### Preference rows
|
| 38 |
+
|
| 39 |
+
Path: `experiment-2-cadforge/data/preferences/cadquery_agentic_preferences.jsonl`
|
| 40 |
+
|
| 41 |
+
Each row teaches:
|
| 42 |
+
|
| 43 |
+
- prompt: same observation as SFT
|
| 44 |
+
- chosen: higher reward code
|
| 45 |
+
- rejected: lower reward code
|
| 46 |
+
- chosen/rejected rewards
|
| 47 |
+
|
| 48 |
+
Use this for DPO/RLHF-style ranking if there is time. For the hackathon, this is also strong evidence that the environment can produce preference data automatically.
|
| 49 |
+
|
| 50 |
+
### RL rollout rows
|
| 51 |
+
|
| 52 |
+
Path: `experiment-2-cadforge/data/rl/cadquery_rollouts.jsonl`
|
| 53 |
+
|
| 54 |
+
Each row teaches:
|
| 55 |
+
|
| 56 |
+
- state: prompt + code + reward JSON
|
| 57 |
+
- action: next CadQuery file
|
| 58 |
+
- reward: absolute reward after action
|
| 59 |
+
- reward_delta: improvement from previous step
|
| 60 |
+
- done: whether this was the last rollout step
|
| 61 |
+
|
| 62 |
+
This is the GRPO/RLVE substrate. For early GRPO, reward the action with:
|
| 63 |
+
|
| 64 |
+
```text
|
| 65 |
+
step_reward = 0.60 * reward_after
|
| 66 |
+
+ 0.35 * max(reward_after - reward_before, -0.25)
|
| 67 |
+
+ 0.05 * build_bonus
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
For group-relative training, sample several candidate revisions for the same observation and rank them by `step_reward`.
|
| 71 |
+
|
| 72 |
+
## Reward design
|
| 73 |
+
|
| 74 |
+
### Build reward
|
| 75 |
+
|
| 76 |
+
This is the first gate. If code does not execute or does not export `fixture`, reward is `-1`.
|
| 77 |
+
|
| 78 |
+
Why it matters: tiny models hallucinate APIs or undefined variables. Penalizing build failures prevents reward hacking through long invalid code.
|
| 79 |
+
|
| 80 |
+
### Topology reward
|
| 81 |
+
|
| 82 |
+
Checks mesh health:
|
| 83 |
+
|
| 84 |
+
- face count sane
|
| 85 |
+
- boundary/non-manifold/degenerate ratios low
|
| 86 |
+
- component count acceptable for an assembly
|
| 87 |
+
|
| 88 |
+
For chairs, many parts are allowed. For future single-piece objects, add a stricter single-body mode.
|
| 89 |
+
|
| 90 |
+
### Contact/gap reward
|
| 91 |
+
|
| 92 |
+
Checks whether major components are plausibly connected. This catches:
|
| 93 |
+
|
| 94 |
+
- floating backrest
|
| 95 |
+
- disconnected caster assembly
|
| 96 |
+
- floating base
|
| 97 |
+
- armrests that hover too far away
|
| 98 |
+
|
| 99 |
+
For chairs, small gaps are not fatal because real chairs have visual separations. Large gaps should hurt.
|
| 100 |
+
|
| 101 |
+
### Semantic parts reward
|
| 102 |
+
|
| 103 |
+
Uses code and geometry hints to see whether the model contains chair-like intent:
|
| 104 |
+
|
| 105 |
+
- seat
|
| 106 |
+
- backrest
|
| 107 |
+
- headrest
|
| 108 |
+
- armrest
|
| 109 |
+
- gas cylinder or central column
|
| 110 |
+
- star base
|
| 111 |
+
- caster proxies
|
| 112 |
+
- mechanism/lumbar hints
|
| 113 |
+
|
| 114 |
+
This should not force exact function names. It should reward discoverable part structure and meaningful dimensions.
|
| 115 |
+
|
| 116 |
+
### Reference similarity reward
|
| 117 |
+
|
| 118 |
+
Compares candidate geometry to both:
|
| 119 |
+
|
| 120 |
+
- IKEA Markus GLB reference
|
| 121 |
+
- ideal Markus CadQuery reference
|
| 122 |
+
|
| 123 |
+
This gives a grounded target while still allowing the generated CadQuery to differ from the exact ideal code.
|
| 124 |
+
|
| 125 |
+
### Silhouette reward
|
| 126 |
+
|
| 127 |
+
Compares rendered masks across:
|
| 128 |
+
|
| 129 |
+
- front
|
| 130 |
+
- back
|
| 131 |
+
- left
|
| 132 |
+
- right
|
| 133 |
+
- top
|
| 134 |
+
- isometric
|
| 135 |
+
|
| 136 |
+
This catches shape-level errors faster than pure point-cloud comparison and makes the markdown reports human-readable.
|
| 137 |
+
|
| 138 |
+
### Editability reward
|
| 139 |
+
|
| 140 |
+
Rewards code that a future agent can keep editing:
|
| 141 |
+
|
| 142 |
+
- named dimensions
|
| 143 |
+
- helper functions
|
| 144 |
+
- final `fixture`
|
| 145 |
+
- clear construction blocks
|
| 146 |
+
- avoids brittle operations like fragile loft/sweep chains
|
| 147 |
+
|
| 148 |
+
This is important because the goal is long-horizon CAD editing, not one-shot mesh generation.
|
| 149 |
+
|
| 150 |
+
## What counts as improvement
|
| 151 |
+
|
| 152 |
+
Do not reward more steps by itself. Reward useful steps.
|
| 153 |
+
|
| 154 |
+
Good step:
|
| 155 |
+
|
| 156 |
+
- code builds
|
| 157 |
+
- reward increases
|
| 158 |
+
- one major issue is fixed
|
| 159 |
+
- model remains editable
|
| 160 |
+
|
| 161 |
+
Bad step:
|
| 162 |
+
|
| 163 |
+
- code stops building
|
| 164 |
+
- reward decreases sharply
|
| 165 |
+
- adds meaningless geometry to game semantic keywords
|
| 166 |
+
- bloats code without improving geometry
|
| 167 |
+
|
| 168 |
+
Long horizon comes from decomposing into many useful edits, not from forcing a fixed number of edits.
|
| 169 |
+
|
| 170 |
+
## GPT teacher data plan
|
| 171 |
+
|
| 172 |
+
Use GPT-5.4/GPT-5.5 as teacher agents to generate traces.
|
| 173 |
+
|
| 174 |
+
Recommended overnight settings:
|
| 175 |
+
|
| 176 |
+
```bash
|
| 177 |
+
scripts/experiment-2/run-cadquery-agentic-trace.js \
|
| 178 |
+
--provider openai \
|
| 179 |
+
--model gpt-5.4 \
|
| 180 |
+
--steps 4 \
|
| 181 |
+
--vision
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
Repeat with different task prompts and seeded failure modes:
|
| 185 |
+
|
| 186 |
+
- missing armrests
|
| 187 |
+
- floating base
|
| 188 |
+
- too-short backrest
|
| 189 |
+
- failed `loft()` replaced with boxes/cylinders
|
| 190 |
+
- disconnected caster assembly
|
| 191 |
+
- no final `fixture`
|
| 192 |
+
- wrong cylinder height/radius
|
| 193 |
+
- overfit blocky chair with no semantics
|
| 194 |
+
|
| 195 |
+
For each failure mode, GPT sees the reward report and optionally images, repairs the code, and creates training examples automatically.
|
| 196 |
+
|
| 197 |
+
## Qwen student plan
|
| 198 |
+
|
| 199 |
+
Start with SFT, not GRPO.
|
| 200 |
+
|
| 201 |
+
1. Collect 100-300 high-quality GPT repair steps.
|
| 202 |
+
2. Filter for positive deltas and successful builds.
|
| 203 |
+
3. SFT Qwen 3.5 2B on observation-to-code repair.
|
| 204 |
+
4. Run Qwen in the same environment.
|
| 205 |
+
5. Keep Qwen traces as before/after evidence.
|
| 206 |
+
6. Then run GRPO using reward deltas.
|
| 207 |
+
|
| 208 |
+
Qwen 0.8B is useful as a dramatic baseline. Qwen 2B is the better hackathon target.
|
| 209 |
+
|
| 210 |
+
## Generalization plan
|
| 211 |
+
|
| 212 |
+
The environment can generalize if every object has:
|
| 213 |
+
|
| 214 |
+
- task prompt
|
| 215 |
+
- reference GLB
|
| 216 |
+
- optional ideal CadQuery code
|
| 217 |
+
- object-specific semantic hints
|
| 218 |
+
- reward profile
|
| 219 |
+
|
| 220 |
+
Object families to add after Markus:
|
| 221 |
+
|
| 222 |
+
- table
|
| 223 |
+
- simple stool
|
| 224 |
+
- shelf bracket
|
| 225 |
+
- screw/bolt
|
| 226 |
+
- hinge
|
| 227 |
+
- drawer handle
|
| 228 |
+
- caster wheel
|
| 229 |
+
|
| 230 |
+
For each object, preprocess:
|
| 231 |
+
|
| 232 |
+
1. Normalize GLB scale/origin/orientation.
|
| 233 |
+
2. Extract bounding box, silhouettes, point samples, topology.
|
| 234 |
+
3. Evaluate ideal CadQuery if available.
|
| 235 |
+
4. Run teacher traces from seeded failures.
|
| 236 |
+
5. Add object-specific semantic hints.
|
| 237 |
+
|
| 238 |
+
## Tomorrow demo story
|
| 239 |
+
|
| 240 |
+
Show three things:
|
| 241 |
+
|
| 242 |
+
1. GPT teacher improves a broken CAD file through multiple tool calls.
|
| 243 |
+
2. The environment records every observation, action, reward, render, and code revision.
|
| 244 |
+
3. Qwen starts weak, then after SFT/GRPO it builds more often and reaches higher reward in fewer edits.
|
| 245 |
+
|
| 246 |
+
The sellable product is not just "CAD generation." It is a repeatable professional-tool RL environment for teaching small models to use CAD tools over long horizons with persistent state and verifiable rewards.
|
docs/brainstorm/16-tonight-execution-plan.md
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CADForge Tonight Execution Plan
|
| 2 |
+
|
| 3 |
+
## Time Budget
|
| 4 |
+
|
| 5 |
+
You have 3-5 focused hours before overnight training. Use them like this:
|
| 6 |
+
|
| 7 |
+
| Block | Time | Goal |
|
| 8 |
+
|---|---:|---|
|
| 9 |
+
| Reward sanity + task setup | 30-45 min | Confirm task-specific rewards and prompts work. Done for Markus + six-leg table. |
|
| 10 |
+
| Asset generation | 60-120 min wall time | Generate 20-24 white-background reference images and optionally FAL GLBs in parallel. |
|
| 11 |
+
| Teacher traces | 90-180 min wall time | Run GPT-5.4/GPT-5.5 agentic repair traces, 2-4 steps each. |
|
| 12 |
+
| SFT packaging | 20-40 min | Filter positive deltas, make train/val JSONL, quick dataset card. |
|
| 13 |
+
| RunPod setup | 30-60 min | Start Qwen 2B/9B SFT. If SFT finishes, start GRPO. |
|
| 14 |
+
| README + demo assets | 60-120 min | Results table, trace screenshots, short video, slides. |
|
| 15 |
+
|
| 16 |
+
Overnight from 12am-6am:
|
| 17 |
+
|
| 18 |
+
1. SFT Qwen 2B or 9B on positive GPT repair traces.
|
| 19 |
+
2. Evaluate the tuned model on held-out tasks.
|
| 20 |
+
3. If build rate is non-zero, run GRPO with grouped repair candidates.
|
| 21 |
+
4. Save reward/loss curves and before/after traces.
|
| 22 |
+
|
| 23 |
+
## Are Qwen 0.8B/2B Too Dumb?
|
| 24 |
+
|
| 25 |
+
They are not useless, but they are too cold for raw CAD repair. Qwen 2B currently writes CadQuery-shaped code but fails on undefined variables and API mistakes. That means:
|
| 26 |
+
|
| 27 |
+
- Do SFT first.
|
| 28 |
+
- Use Qwen 0.8B as a weak baseline.
|
| 29 |
+
- Use Qwen 2B as the realistic small-model demo.
|
| 30 |
+
- Downloading Qwen 9B is a good idea if you can afford the inference/training memory, because it should produce more buildable rollouts for GRPO.
|
| 31 |
+
|
| 32 |
+
## What Is Graded Per Step?
|
| 33 |
+
|
| 34 |
+
Each agentic step is graded independently:
|
| 35 |
+
|
| 36 |
+
- previous code
|
| 37 |
+
- reward JSON
|
| 38 |
+
- rendered views if available
|
| 39 |
+
- next code
|
| 40 |
+
- next reward
|
| 41 |
+
- reward delta
|
| 42 |
+
|
| 43 |
+
The training data records:
|
| 44 |
+
|
| 45 |
+
- SFT: observation -> improved code
|
| 46 |
+
- Preference/RLHF: chosen higher-reward code vs rejected lower-reward code
|
| 47 |
+
- RL/GRPO: observation, action, reward, reward_delta
|
| 48 |
+
|
| 49 |
+
Do not reward more steps by itself. Reward useful improvement:
|
| 50 |
+
|
| 51 |
+
```text
|
| 52 |
+
step_reward = 0.60 * reward_after
|
| 53 |
+
+ 0.35 * clamp(reward_after - reward_before, -0.25, 0.25)
|
| 54 |
+
+ 0.05 * build_success
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
## Current Reward Functions
|
| 58 |
+
|
| 59 |
+
### Build
|
| 60 |
+
|
| 61 |
+
Hard gate. Invalid code or missing STL gets `-1`. This catches hallucinated CadQuery APIs, undefined variables, no final `fixture`, and execution crashes.
|
| 62 |
+
|
| 63 |
+
### Topology
|
| 64 |
+
|
| 65 |
+
Checks mesh health: faces, components, watertightness, boundaries, non-manifold edges, and degenerate faces. Assemblies can have multiple components; future monolithic tasks should use stricter settings.
|
| 66 |
+
|
| 67 |
+
### Contact/Gaps
|
| 68 |
+
|
| 69 |
+
Penalizes large disconnected components. Small chair/table gaps are tolerated; floating bases, detached backrests, disconnected caster assemblies, and floating load bosses lose reward.
|
| 70 |
+
|
| 71 |
+
### Task Semantics
|
| 72 |
+
|
| 73 |
+
Now task-specific. A stator is rewarded for `stator`, `radial_tooth`, `center_bore`; a table is rewarded for `tabletop`, `leg`, `crossbar`, `stretcher`. This fixes the previous Markus-only bias.
|
| 74 |
+
|
| 75 |
+
### Reference Similarity
|
| 76 |
+
|
| 77 |
+
If a task GLB exists, the evaluator compares bbox, point-cloud similarity, and silhouettes. If no GLB exists yet, this component is neutral and the report says so explicitly.
|
| 78 |
+
|
| 79 |
+
### Silhouette
|
| 80 |
+
|
| 81 |
+
Full mode renders front/back/left/right/top/isometric masks. These are used for scoring when a GLB reference exists and are always saved for human inspection.
|
| 82 |
+
|
| 83 |
+
### Editability
|
| 84 |
+
|
| 85 |
+
Rewards named dimensions, helper functions, clean final `fixture`, and reusable code structure. This matters because the project is about long-horizon editable CAD, not just one-shot meshes.
|
| 86 |
+
|
| 87 |
+
## Commands
|
| 88 |
+
|
| 89 |
+
Generate reference images and FAL GLBs for the first 8 tasks:
|
| 90 |
+
|
| 91 |
+
```bash
|
| 92 |
+
scripts/experiment-2/generate-cad-assets.js --limit 8 --concurrency 3
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
Use FAL text-to-3D only, fastest path:
|
| 96 |
+
|
| 97 |
+
```bash
|
| 98 |
+
scripts/experiment-2/generate-cad-assets.js --skip-images --limit 8 --concurrency 4
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
Use image-to-3D after GPT images:
|
| 102 |
+
|
| 103 |
+
```bash
|
| 104 |
+
scripts/experiment-2/generate-cad-assets.js --limit 8 --concurrency 2 --image-to-3d
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
Run teacher traces on easy tasks:
|
| 108 |
+
|
| 109 |
+
```bash
|
| 110 |
+
scripts/experiment-2/run-teacher-trace-batch.js --provider openai --model gpt-5.4 --levels easy --limit 8 --steps 3
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
Run richer vision traces after images/renders exist:
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
scripts/experiment-2/run-teacher-trace-batch.js --provider openai --model gpt-5.4 --levels easy,medium --limit 12 --steps 4 --vision
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
Filter positive SFT rows:
|
| 120 |
+
|
| 121 |
+
```bash
|
| 122 |
+
scripts/experiment-2/filter-positive-sft.js --min-after 0.70 --min-delta 0.001
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
Run Qwen baseline:
|
| 126 |
+
|
| 127 |
+
```bash
|
| 128 |
+
scripts/experiment-2/run-cadquery-agentic-trace.js --provider ollama --model qwen3.5:2b --task-spec table_six_leg_500n --task-id table_six_leg_500n --steps 1
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
## Submission Story
|
| 132 |
+
|
| 133 |
+
The story should mirror the best example project:
|
| 134 |
+
|
| 135 |
+
1. Cold start: Qwen fails to emit valid CadQuery.
|
| 136 |
+
2. Environment: CAD code executes in real CadQuery, renders, and scores every step.
|
| 137 |
+
3. Teacher: GPT-5.4/GPT-5.5 improves broken CAD over multiple tool calls.
|
| 138 |
+
4. Data: every observation/action/reward becomes SFT, preference, and RL rollout data.
|
| 139 |
+
5. Student: Qwen learns to build valid editable CAD in fewer revisions.
|
| 140 |
+
6. Self-improvement: new object prompts + generated GLBs expand the curriculum automatically.
|
docs/brainstorm/17-cadquery-reward-functions-deep-dive.md
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CadQuery Reward Functions Deep Dive
|
| 2 |
+
|
| 3 |
+
This document explains the reward code in `experiment-2-cadforge/python_tools/cadquery_env.py`.
|
| 4 |
+
|
| 5 |
+
## Total Reward
|
| 6 |
+
|
| 7 |
+
The evaluator produces component scores in `[0, 1]`, except build failures, which return total reward `-1`.
|
| 8 |
+
|
| 9 |
+
Fast mode is for dense RL feedback:
|
| 10 |
+
|
| 11 |
+
```text
|
| 12 |
+
total = 0.22 * build
|
| 13 |
+
+ 0.17 * topology
|
| 14 |
+
+ 0.12 * contact
|
| 15 |
+
+ 0.25 * semantic_parts
|
| 16 |
+
+ 0.10 * reference_similarity
|
| 17 |
+
+ 0.10 * editability
|
| 18 |
+
+ 0.04 * efficiency
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
Full mode is for reports, teacher traces, and benchmark artifacts:
|
| 22 |
+
|
| 23 |
+
```text
|
| 24 |
+
total = 0.18 * build
|
| 25 |
+
+ 0.17 * topology
|
| 26 |
+
+ 0.10 * contact
|
| 27 |
+
+ 0.15 * semantic_parts
|
| 28 |
+
+ 0.15 * reference_similarity
|
| 29 |
+
+ 0.10 * silhouette
|
| 30 |
+
+ 0.10 * editability
|
| 31 |
+
+ 0.05 * efficiency
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
Fast mode deliberately weights task semantics higher and reference lower because, without renders/point clouds, bbox-only reference scoring is easier to game.
|
| 35 |
+
|
| 36 |
+
## Build Reward
|
| 37 |
+
|
| 38 |
+
Build is a hard gate.
|
| 39 |
+
|
| 40 |
+
If the CadQuery code does not execute, does not create/export `fixture`, or fails STL export:
|
| 41 |
+
|
| 42 |
+
```text
|
| 43 |
+
total = -1
|
| 44 |
+
build = 0
|
| 45 |
+
all other components = 0
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
The evaluator now includes a concise Python/CadQuery error in `notes`, for example:
|
| 49 |
+
|
| 50 |
+
```text
|
| 51 |
+
Build error: NameError: name 'headrest_height_from_ground' is not defined
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
This is crucial for Qwen because most early failures are invalid code, not bad geometry.
|
| 55 |
+
|
| 56 |
+
## Task Semantics Reward
|
| 57 |
+
|
| 58 |
+
Function: `semantic_reward(code, mesh, task_spec)`
|
| 59 |
+
|
| 60 |
+
This has three parts:
|
| 61 |
+
|
| 62 |
+
```text
|
| 63 |
+
semantic = 0.35 * code_score
|
| 64 |
+
+ 0.45 * geometry_score
|
| 65 |
+
+ 0.20 * assembly_score
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
### Code Score
|
| 69 |
+
|
| 70 |
+
Each task has `semantic_hints` in `cad_tasks.json`.
|
| 71 |
+
|
| 72 |
+
Example table hints:
|
| 73 |
+
|
| 74 |
+
```json
|
| 75 |
+
["tabletop", "six_leg", "leg", "crossbar", "stretcher", "support", "load_500n"]
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
The reward checks whether each hint appears in the code, allowing underscore-insensitive matches:
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
hint in lowered_code
|
| 82 |
+
hint_without_underscores in lowered_code_without_underscores
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
This rewards explicit, editable part intent. It does not require a fixed function name like `add_seat()`. The model can invent its own structure, but it gets credit when the code makes the intended parts legible.
|
| 86 |
+
|
| 87 |
+
### Geometry Score
|
| 88 |
+
|
| 89 |
+
If the task has `bbox_mm`, the evaluator compares the normalized shape ratios:
|
| 90 |
+
|
| 91 |
+
```text
|
| 92 |
+
target = [x, y, z] / z
|
| 93 |
+
actual = candidate_bbox / candidate_height
|
| 94 |
+
geometry_score = 1 - mean(relative_ratio_error)
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
This prevents a model from getting high semantic score by merely writing keywords in comments while building a totally wrong envelope.
|
| 98 |
+
|
| 99 |
+
For the original Markus chair path without a task spec, it uses chair-specific geometry signals:
|
| 100 |
+
|
| 101 |
+
- chair-like width/height and depth/height ratios
|
| 102 |
+
- lower base spread
|
| 103 |
+
- meaningful upper-height geometry
|
| 104 |
+
|
| 105 |
+
### Assembly Score
|
| 106 |
+
|
| 107 |
+
The reward counts helper functions:
|
| 108 |
+
|
| 109 |
+
```python
|
| 110 |
+
functions = number of `def name(...):`
|
| 111 |
+
assembly_score = min(1, functions / 6)
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
This encourages decomposed CAD: helper functions for legs, arms, bosses, teeth, ribs, etc. It does not force exact part names.
|
| 115 |
+
|
| 116 |
+
## Editability Reward
|
| 117 |
+
|
| 118 |
+
Function: `editability_reward(code)`
|
| 119 |
+
|
| 120 |
+
This rewards code that another agent can revise over many steps.
|
| 121 |
+
|
| 122 |
+
```text
|
| 123 |
+
editability = 0.35 * function_score
|
| 124 |
+
+ 0.20 * named_dimension_score
|
| 125 |
+
+ 0.25 * reusable_return_score
|
| 126 |
+
+ 0.20 * final_object_score
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
### Function Score
|
| 130 |
+
|
| 131 |
+
```python
|
| 132 |
+
functions = count_regex(r"^\s*def\s+\w+\s*\(")
|
| 133 |
+
function_score = min(1, functions / 6)
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
Why: long-horizon CAD editing works better when the model can edit `make_leg()`, `make_backrest()`, `make_stator_tooth()`, or `make_mounting_hole_pattern()` instead of rewriting one giant union chain.
|
| 137 |
+
|
| 138 |
+
### Named Dimension Score
|
| 139 |
+
|
| 140 |
+
```python
|
| 141 |
+
named_values = count_regex(r"^\s*[a-zA-Z_][a-zA-Z0-9_]*\s*=\s*[-+]?\d")
|
| 142 |
+
named_dimension_score = min(1, named_values / 8)
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
This rewards parameters like:
|
| 146 |
+
|
| 147 |
+
```python
|
| 148 |
+
seat_width = 520
|
| 149 |
+
leg_height = 680
|
| 150 |
+
bolt_radius = 4
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
Why: dimensions make future edits local and stable. A repair agent can increase `back_height` or move `caster_radius` without hunting through anonymous numbers.
|
| 154 |
+
|
| 155 |
+
### Reusable Return Score
|
| 156 |
+
|
| 157 |
+
```python
|
| 158 |
+
reusable_returns = count_regex(r"^\s*return\s+")
|
| 159 |
+
reusable_return_score = min(1, reusable_returns / max(1, functions))
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
This rewards helper functions that return shapes instead of mutating unclear globals.
|
| 163 |
+
|
| 164 |
+
Good:
|
| 165 |
+
|
| 166 |
+
```python
|
| 167 |
+
def make_leg(x, y):
|
| 168 |
+
return cq.Workplane("XY").box(35, 35, leg_height).translate((x, y, leg_height / 2))
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
Less editable:
|
| 172 |
+
|
| 173 |
+
```python
|
| 174 |
+
leg = cq.Workplane("XY").box(35, 35, 680)
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
### Final Object Score
|
| 178 |
+
|
| 179 |
+
```python
|
| 180 |
+
has_final_object = "fixture" in code or "result" in code or "chair" in code or "show_object" in code
|
| 181 |
+
```
|
| 182 |
+
|
| 183 |
+
This gives `0.20` when the model clearly exposes an exportable final object. In practice, `fixture` is the important convention because the runner exports `fixture`.
|
| 184 |
+
|
| 185 |
+
## Topology Reward
|
| 186 |
+
|
| 187 |
+
Function: `topology_reward(topology_metrics(mesh))`
|
| 188 |
+
|
| 189 |
+
It checks:
|
| 190 |
+
|
| 191 |
+
- component count
|
| 192 |
+
- watertightness
|
| 193 |
+
- boundary edge ratio
|
| 194 |
+
- non-manifold edge ratio
|
| 195 |
+
- degenerate face ratio
|
| 196 |
+
- sane face count
|
| 197 |
+
|
| 198 |
+
Markus and many CAD assemblies are allowed to have multiple components, so this does not require a single monolithic body. For future tasks that explicitly require one connected watertight object, we should add a stricter task-level option.
|
| 199 |
+
|
| 200 |
+
## Contact/Gaps Reward
|
| 201 |
+
|
| 202 |
+
Function: `contact_metrics(mesh)`
|
| 203 |
+
|
| 204 |
+
The mesh is split into components. Tiny fragments are ignored. For each meaningful component, the evaluator finds the nearest component bounding-box gap and normalizes it by object height.
|
| 205 |
+
|
| 206 |
+
The score decays with:
|
| 207 |
+
|
| 208 |
+
- higher mean gap
|
| 209 |
+
- higher max gap
|
| 210 |
+
- count of large separated components
|
| 211 |
+
|
| 212 |
+
This catches:
|
| 213 |
+
|
| 214 |
+
- floating backrests
|
| 215 |
+
- disconnected caster assemblies
|
| 216 |
+
- floating table legs
|
| 217 |
+
- load bosses not attached to arms
|
| 218 |
+
- detached wall plates or brackets
|
| 219 |
+
|
| 220 |
+
Small assembly gaps are tolerated because real CAD assemblies may have separate touching solids or visual separation.
|
| 221 |
+
|
| 222 |
+
## Reference Similarity
|
| 223 |
+
|
| 224 |
+
If a GLB reference exists, the evaluator compares the candidate against:
|
| 225 |
+
|
| 226 |
+
- generated/reference GLB
|
| 227 |
+
- optional ideal CadQuery reference
|
| 228 |
+
|
| 229 |
+
The per-reference score is:
|
| 230 |
+
|
| 231 |
+
```text
|
| 232 |
+
reference_one = 0.25 * bbox
|
| 233 |
+
+ 0.35 * chamfer
|
| 234 |
+
+ 0.40 * silhouette
|
| 235 |
+
```
|
| 236 |
+
|
| 237 |
+
If both ideal CadQuery and GLB exist:
|
| 238 |
+
|
| 239 |
+
```text
|
| 240 |
+
reference_similarity = 0.60 * ideal_score + 0.40 * glb_score
|
| 241 |
+
```
|
| 242 |
+
|
| 243 |
+
If no GLB exists yet for a generated task, reference and silhouette are neutral `0.50`, and the report explicitly says the task-specific GLB is missing.
|
| 244 |
+
|
| 245 |
+
## Silhouette Reward
|
| 246 |
+
|
| 247 |
+
Full mode renders masks from:
|
| 248 |
+
|
| 249 |
+
- front
|
| 250 |
+
- back
|
| 251 |
+
- left
|
| 252 |
+
- right
|
| 253 |
+
- top
|
| 254 |
+
- isometric
|
| 255 |
+
|
| 256 |
+
It computes mask IoU against reference silhouettes. This is cheap enough for reports and teacher traces and catches overall shape mistakes that bbox alone cannot catch.
|
| 257 |
+
|
| 258 |
+
## Known Limitations
|
| 259 |
+
|
| 260 |
+
1. Code semantic hints can be gamed by comments. Geometry and reference scores reduce this, but we should later ignore comments or parse identifiers only.
|
| 261 |
+
2. Editability currently checks simple regexes. It rewards structure, not true AST-level quality.
|
| 262 |
+
3. No finite-element simulation is running yet. Load/safety-factor phrases are currently semantic intent, not verified stress analysis.
|
| 263 |
+
4. Generic tasks without GLBs use neutral reference scores until generated references are preprocessed.
|
| 264 |
+
5. Single-body/watertight requirements need task-specific stricter topology settings.
|
| 265 |
+
|
| 266 |
+
## Near-Term Improvements
|
| 267 |
+
|
| 268 |
+
- Parse Python AST for identifiers and assignments instead of raw regex.
|
| 269 |
+
- Add per-task reward profiles, for example `single_body_required`, `min_holes`, `radial_symmetry_required`, `leg_count`.
|
| 270 |
+
- Add image/GLB generated references for all 24 tasks.
|
| 271 |
+
- Add cheap analytic checks for hole count, radial teeth count, and support/leg count.
|
| 272 |
+
- Add optional FEA proxy rewards for load-bearing prompts.
|
docs/brainstorm/18-how-sft-and-grpo-data-works.md
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# How CADForge SFT and GRPO Data Works
|
| 2 |
+
|
| 3 |
+
## What The Agent Sees During A Trace
|
| 4 |
+
|
| 5 |
+
Each step is an observe -> edit -> score loop.
|
| 6 |
+
|
| 7 |
+
The observation includes:
|
| 8 |
+
|
| 9 |
+
1. The task prompt.
|
| 10 |
+
2. The previous CadQuery code.
|
| 11 |
+
3. The reward JSON from the verifier.
|
| 12 |
+
4. Verifier notes such as build errors, disconnected components, weak semantic hints, or missing reference similarity.
|
| 13 |
+
5. Optional rendered views for teacher traces when vision is enabled.
|
| 14 |
+
|
| 15 |
+
The action is always a complete replacement CadQuery file. The model is not asked to emit prose. It is asked to emit executable Python where the final object is assigned to `fixture`.
|
| 16 |
+
|
| 17 |
+
## Example SFT Row Shape
|
| 18 |
+
|
| 19 |
+
A training row looks like this:
|
| 20 |
+
|
| 21 |
+
```json
|
| 22 |
+
{
|
| 23 |
+
"messages": [
|
| 24 |
+
{
|
| 25 |
+
"role": "system",
|
| 26 |
+
"content": "You are CADForge, a careful CadQuery CAD repair agent... Return only a complete executable Python CadQuery file."
|
| 27 |
+
},
|
| 28 |
+
{
|
| 29 |
+
"role": "user",
|
| 30 |
+
"content": "Task: Build a simple four-legged chair...\n\nCurrent reward JSON: ...\n\nCurrent CadQuery code: ...\n\nRevise the code to improve the reward."
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"role": "assistant",
|
| 34 |
+
"content": "import cadquery as cq\n\nseat_width = 420\n...\nfixture = chair.clean()"
|
| 35 |
+
}
|
| 36 |
+
],
|
| 37 |
+
"reward_before": 0.441,
|
| 38 |
+
"reward_after": 0.802,
|
| 39 |
+
"reward_delta": 0.361,
|
| 40 |
+
"artifacts_dir": ".../step-1"
|
| 41 |
+
}
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
During SFT, Qwen learns the mapping:
|
| 45 |
+
|
| 46 |
+
```text
|
| 47 |
+
(previous code + verifier feedback + task) -> better complete CadQuery code
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
It does not learn from hidden GPT thinking. It learns from the repair action.
|
| 51 |
+
|
| 52 |
+
## Why We Do Not Want Long Thinking In The Output
|
| 53 |
+
|
| 54 |
+
Qwen 3.5 can overthink in Ollama and spend tokens on internal reasoning before answering. For CADForge this is bad because:
|
| 55 |
+
|
| 56 |
+
- the environment needs code, not a long explanation;
|
| 57 |
+
- excess thinking slows rollouts;
|
| 58 |
+
- verbose traces can pollute SFT if included as assistant output;
|
| 59 |
+
- invalid prose around code can break execution.
|
| 60 |
+
|
| 61 |
+
For Ollama inference use:
|
| 62 |
+
|
| 63 |
+
```json
|
| 64 |
+
{
|
| 65 |
+
"think": false,
|
| 66 |
+
"stream": false,
|
| 67 |
+
"options": {
|
| 68 |
+
"temperature": 0.2,
|
| 69 |
+
"num_predict": 3000,
|
| 70 |
+
"num_ctx": 8192
|
| 71 |
+
}
|
| 72 |
+
}
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
And use a strict system prompt:
|
| 76 |
+
|
| 77 |
+
```text
|
| 78 |
+
Return only complete executable Python CadQuery code. No markdown. No explanation.
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## Which Rows Go Into SFT
|
| 82 |
+
|
| 83 |
+
We generated several files:
|
| 84 |
+
|
| 85 |
+
- `cadquery_agentic_sft.jsonl`: all raw teacher steps, including regressions and failures.
|
| 86 |
+
- `cadquery_agentic_sft_positive.jsonl`: strict positives, `reward_after >= 0.70` and `reward_delta > 0`.
|
| 87 |
+
- `cadquery_agentic_sft_positive_060.jsonl`: recommended first SFT set, `reward_after >= 0.60` and `reward_delta > 0`.
|
| 88 |
+
- `cadquery_agentic_sft_delta_positive.jsonl`: every improving step, even if final reward is still modest.
|
| 89 |
+
- `cadquery_agentic_sft_train.jsonl` and `cadquery_agentic_sft_val.jsonl`: train/val split from the recommended set.
|
| 90 |
+
|
| 91 |
+
For the first overnight run, train on:
|
| 92 |
+
|
| 93 |
+
```text
|
| 94 |
+
experiment-2-cadforge/data/sft/cadquery_agentic_sft_train.jsonl
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
Use the validation set:
|
| 98 |
+
|
| 99 |
+
```text
|
| 100 |
+
experiment-2-cadforge/data/sft/cadquery_agentic_sft_val.jsonl
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
## What Preference/RLHF Data Means
|
| 104 |
+
|
| 105 |
+
Preference rows are chosen/rejected pairs for the same prompt.
|
| 106 |
+
|
| 107 |
+
If a teacher repair improves reward, the repair is chosen and the previous code is rejected. If it regresses, the previous code is chosen and the repair is rejected.
|
| 108 |
+
|
| 109 |
+
This supports DPO/RLHF-style training:
|
| 110 |
+
|
| 111 |
+
```text
|
| 112 |
+
same observation -> prefer higher-reward code over lower-reward code
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
## What RL/GRPO Data Means
|
| 116 |
+
|
| 117 |
+
RL rollout rows contain:
|
| 118 |
+
|
| 119 |
+
- observation
|
| 120 |
+
- action code
|
| 121 |
+
- reward after action
|
| 122 |
+
- reward delta
|
| 123 |
+
- done flag
|
| 124 |
+
- artifact paths
|
| 125 |
+
|
| 126 |
+
For GRPO, we should use live environment scoring, not only static rows. The static rollout rows are useful for debugging and offline analysis; the live verifier is what makes the RLVE environment real.
|
| 127 |
+
|
| 128 |
+
A practical step reward is:
|
| 129 |
+
|
| 130 |
+
```text
|
| 131 |
+
step_reward = 0.60 * reward_after
|
| 132 |
+
+ 0.35 * clamp(reward_after - reward_before, -0.25, 0.25)
|
| 133 |
+
+ 0.05 * build_success
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
Why this shape:
|
| 137 |
+
|
| 138 |
+
- absolute reward teaches final quality;
|
| 139 |
+
- reward delta teaches improvement;
|
| 140 |
+
- build success prevents invalid code from getting accidental credit.
|
| 141 |
+
|
| 142 |
+
## Is More Data Better?
|
| 143 |
+
|
| 144 |
+
More data helps if it is diverse. Blind duplication does not help much.
|
| 145 |
+
|
| 146 |
+
Our diversity knobs are:
|
| 147 |
+
|
| 148 |
+
- 24 object prompts;
|
| 149 |
+
- easy/medium/hard tasks;
|
| 150 |
+
- generated images and GLBs;
|
| 151 |
+
- five seed modes: weak, missing features, disconnected, bad dimensions, build error;
|
| 152 |
+
- teacher prompt variants: editability, silhouette/contact, build robustness;
|
| 153 |
+
- multiple repair steps per trace;
|
| 154 |
+
- reward filtering that keeps only improving SFT examples.
|
| 155 |
+
|
| 156 |
+
This gives the small model patterns like:
|
| 157 |
+
|
| 158 |
+
- repair undefined variables;
|
| 159 |
+
- replace fragile geometry with reliable Workplane operations;
|
| 160 |
+
- add missing semantic parts;
|
| 161 |
+
- reconnect floating components;
|
| 162 |
+
- improve proportions against a GLB reference;
|
| 163 |
+
- expose dimensions and helper functions for later edits.
|
| 164 |
+
|
| 165 |
+
## What To Expect After SFT
|
| 166 |
+
|
| 167 |
+
Before SFT, Qwen 2B/9B may:
|
| 168 |
+
|
| 169 |
+
- overthink;
|
| 170 |
+
- output prose;
|
| 171 |
+
- hallucinate CadQuery APIs;
|
| 172 |
+
- forget `fixture`;
|
| 173 |
+
- create disconnected blocky assemblies.
|
| 174 |
+
|
| 175 |
+
After SFT, success should first show up as:
|
| 176 |
+
|
| 177 |
+
- higher build rate;
|
| 178 |
+
- more `fixture = ...` completions;
|
| 179 |
+
- fewer fake APIs;
|
| 180 |
+
- more named dimensions/helper functions;
|
| 181 |
+
- better first-repair reward.
|
| 182 |
+
|
| 183 |
+
Do not expect perfect CAD from SFT alone. SFT makes the model trainable for GRPO. GRPO should then optimize reward and reduce revision count.
|
| 184 |
+
|
| 185 |
+
## Recommended Training Order
|
| 186 |
+
|
| 187 |
+
1. Baseline Qwen 2B and 9B on 5 held-out prompts.
|
| 188 |
+
2. SFT Qwen 2B on recommended positive rows.
|
| 189 |
+
3. SFT Qwen 9B on the same data.
|
| 190 |
+
4. Evaluate build rate, reward, and average steps-to-threshold.
|
| 191 |
+
5. Run GRPO with vLLM serve mode and live verifier rewards.
|
| 192 |
+
6. Compare before/after traces in the demo UI and markdown reports.
|
docs/brainstorm/19-qwen35-2b-9b-cadforge-sft-grpo-runpod-plan.md
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Qwen3.5 2B/9B CADForge SFT + GRPO Plan
|
| 2 |
+
|
| 3 |
+
## Recommendation
|
| 4 |
+
|
| 5 |
+
Use `Qwen/Qwen3.5-2B` for the fast hackathon loop and `Qwen/Qwen3.5-9B` for the serious "we can win this" run.
|
| 6 |
+
|
| 7 |
+
Default plan:
|
| 8 |
+
|
| 9 |
+
1. Train `Qwen/Qwen3.5-2B` with LoRA SFT to prove the environment/data loop works.
|
| 10 |
+
2. Evaluate base vs SFT on held-out CADForge tasks.
|
| 11 |
+
3. Train `Qwen/Qwen3.5-9B` with LoRA SFT on the same data.
|
| 12 |
+
4. Run GRPO from the stronger SFT adapter, using CADForge as the reward environment.
|
| 13 |
+
5. Report both: 2B as the tiny-model story, 9B as the strongest small open model result.
|
| 14 |
+
|
| 15 |
+
If H200 budget is available, do not waste time optimizing around 24 GB constraints. Use Unsloth BF16 LoRA for both SFT runs, keep QLoRA only as a last-resort fallback, and test FP8 mainly for GRPO/rollout throughput once the BF16 SFT baseline is working.
|
| 16 |
+
|
| 17 |
+
## LoRA vs QLoRA vs PEFT
|
| 18 |
+
|
| 19 |
+
`PEFT` is the umbrella library/pattern: parameter-efficient fine-tuning. It includes LoRA, QLoRA-style quantized LoRA, prefix tuning, adapters, etc.
|
| 20 |
+
|
| 21 |
+
`LoRA` means the base model stays frozen and we train small low-rank matrices inserted into attention/MLP layers. It is the best default when we have enough VRAM.
|
| 22 |
+
|
| 23 |
+
`QLoRA` means the base model is loaded in 4-bit quantized form while training LoRA adapters. It saves VRAM, but can be slower, more finicky, and slightly less clean when memory is not the bottleneck.
|
| 24 |
+
|
| 25 |
+
For CADForge:
|
| 26 |
+
|
| 27 |
+
- Use `LoRA BF16` on H200/H100/A100/L40S, preferably with Unsloth for Qwen3.5.
|
| 28 |
+
- Use `FP8 LoRA/GRPO` as an optimization after the BF16 baseline, especially for RL where rollout inference dominates runtime.
|
| 29 |
+
- Use `QLoRA` only if nothing else fits. Unsloth's Qwen3.5 guide specifically says 4-bit QLoRA is not recommended for Qwen3.5 because quantization differences are higher than normal.
|
| 30 |
+
- Do not full fine-tune first. Full fine-tune is overkill for 1.7M-2.0M SFT tokens and increases risk of overfitting/catastrophic drift.
|
| 31 |
+
- Consider full fine-tune later only if we have much more data, a stable eval suite, and the LoRA result is clearly adapter-limited.
|
| 32 |
+
|
| 33 |
+
Suggested adapter settings:
|
| 34 |
+
|
| 35 |
+
| Model | Method | Rank | Alpha | Target Modules | Notes |
|
| 36 |
+
|---|---:|---:|---:|---|---|
|
| 37 |
+
| Qwen3.5-2B | Unsloth BF16 LoRA | 16-32 | 32-64 | attention + MLP projections | Fast proof run |
|
| 38 |
+
| Qwen3.5-9B | Unsloth BF16 LoRA | 32-64 | 64-128 | attention + MLP projections | Main result |
|
| 39 |
+
| GRPO optimization | Unsloth FP8 LoRA/GRPO | 32-64 | 64-128 | attention + MLP projections | Test after BF16 SFT |
|
| 40 |
+
| Emergency low-VRAM fallback | QLoRA | 16-32 | 32-64 | attention + MLP projections | Avoid for Qwen3.5 unless forced |
|
| 41 |
+
|
| 42 |
+
## BF16 vs FP8 vs Ollama Q8
|
| 43 |
+
|
| 44 |
+
These are easy to mix up:
|
| 45 |
+
|
| 46 |
+
- `BF16` is the stable training dtype for our SFT baseline. On H200 it is the right first choice.
|
| 47 |
+
- `FP8` is a GPU precision/quantized-weight training and inference path. Unsloth supports FP8 RL/GRPO with `load_in_fp8=True`; their docs report faster RL inference and much lower VRAM. This is worth testing for CADForge GRPO after the normal BF16 SFT result exists.
|
| 48 |
+
- `Q8_0` / `q8` in Ollama or GGUF is an inference quantization format, not the same thing as FP8 training. A model served as Q8 in Ollama does not mean we should train in FP8.
|
| 49 |
+
- Export path should be: train BF16 LoRA -> evaluate -> optionally merge -> export GGUF `q8_0` or `q4_k_m` for llama.cpp/Ollama-style demos.
|
| 50 |
+
|
| 51 |
+
Practical choice:
|
| 52 |
+
|
| 53 |
+
1. Train SFT in BF16 LoRA with Unsloth.
|
| 54 |
+
2. Evaluate base vs SFT.
|
| 55 |
+
3. Run GRPO first in the simplest working Unsloth setup.
|
| 56 |
+
4. If GRPO rollout generation is the bottleneck, enable FP8 with `load_in_fp8=True` and compare reward/build-rate against BF16.
|
| 57 |
+
|
| 58 |
+
Do not switch the whole plan to FP8 before we have a BF16 control run. FP8 may be faster, especially in RL, but the hackathon needs a clean ablation: base -> SFT BF16 -> GRPO BF16/FP8.
|
| 59 |
+
|
| 60 |
+
## Hardware
|
| 61 |
+
|
| 62 |
+
Since H200 spend is okay:
|
| 63 |
+
|
| 64 |
+
- `1x H200 141GB`: best single-GPU choice for SFT + GRPO. Use this if available.
|
| 65 |
+
- `1x H100 80GB`: good fallback for GRPO.
|
| 66 |
+
- `1x L40S 48GB`: fine for SFT and eval, less ideal for GRPO throughput.
|
| 67 |
+
- `1x RTX 4090 24GB`: only for cheap SFT experiments with QLoRA.
|
| 68 |
+
|
| 69 |
+
For `Qwen/Qwen3.5-2B`:
|
| 70 |
+
|
| 71 |
+
- SFT LoRA: H200 is more than enough; this should be quick.
|
| 72 |
+
- GRPO: possible on H200, but 2B may be too weak unless SFT build-rate improves clearly.
|
| 73 |
+
|
| 74 |
+
For `Qwen/Qwen3.5-9B`:
|
| 75 |
+
|
| 76 |
+
- SFT LoRA: H200 Unsloth BF16 LoRA, sequence length 8192-16384 depending on trace length. Unsloth lists Qwen3.5-9B BF16 LoRA around 22GB VRAM before our batch/context choices.
|
| 77 |
+
- GRPO: H200 preferred because we can keep policy, reference, optimizer state, and rollout engine comfortable. Test FP8 GRPO if rollout throughput or memory becomes the bottleneck.
|
| 78 |
+
- If using vLLM colocated, start conservative: 4 completions per prompt, then push to 8 if memory/throughput is stable.
|
| 79 |
+
|
| 80 |
+
## Current Data
|
| 81 |
+
|
| 82 |
+
Local current snapshot:
|
| 83 |
+
|
| 84 |
+
- Raw SFT: 1240 rows, about 3.52M tokens.
|
| 85 |
+
- Relaxed positive SFT: 704 rows, about 1.95M tokens.
|
| 86 |
+
- Train split: 633 rows, about 1.76M tokens.
|
| 87 |
+
- Val split: 71 rows, about 0.19M tokens.
|
| 88 |
+
- Preferences: 1239 rows, about 4.16M tokens.
|
| 89 |
+
- RL rollouts: 1239 rows, about 3.33M tokens.
|
| 90 |
+
- Prompt-to-CadQuery direct set: 25 high-quality task-to-code rows.
|
| 91 |
+
|
| 92 |
+
Use this order:
|
| 93 |
+
|
| 94 |
+
1. SFT on `cadquery_agentic_sft_train.jsonl`.
|
| 95 |
+
2. Mix in `cadquery_prompt_to_cadquery_train.jsonl` at a small weight or oversample it 2-4x so the model can also do first-shot CAD, not only repair.
|
| 96 |
+
3. Evaluate on `cadquery_agentic_sft_val.jsonl` plus held-out task prompts.
|
| 97 |
+
4. Use preferences later for DPO/ORPO only if GRPO is too slow.
|
| 98 |
+
5. Use `cadquery_rollouts.jsonl` to seed GRPO prompts and replay evals.
|
| 99 |
+
|
| 100 |
+
## Thinking Traces
|
| 101 |
+
|
| 102 |
+
CAD is logical and step-by-step, so thinking can help at inference time. But we should not train on hidden chain-of-thought.
|
| 103 |
+
|
| 104 |
+
Important distinction:
|
| 105 |
+
|
| 106 |
+
- OpenAI hidden reasoning is not in our data. We only have the final visible model output.
|
| 107 |
+
- The SFT JSONL maps observation/reward/current-code context to improved CadQuery code.
|
| 108 |
+
- The trace JSON files contain `raw_model_output`, but for OpenAI traces this is visible output we asked for, usually complete code, not protected internal reasoning.
|
| 109 |
+
- A scan of the current local data found zero `<think>` / `</think>` blocks.
|
| 110 |
+
|
| 111 |
+
For training:
|
| 112 |
+
|
| 113 |
+
- Do not fabricate long chain-of-thought.
|
| 114 |
+
- Do not train the model to emit `<think>` blocks before code.
|
| 115 |
+
- Train it to produce clean final CadQuery code only.
|
| 116 |
+
- If we want structured reasoning, make it explicit and safe: short public planning comments inside the code or a separate non-submitted planning field for experiments, not hidden CoT imitation.
|
| 117 |
+
|
| 118 |
+
For inference/eval:
|
| 119 |
+
|
| 120 |
+
- For 2B, start non-thinking mode for SFT evaluation because the target output is only code and extra thinking tokens can leak into invalid Python.
|
| 121 |
+
- Also run a small A/B: thinking enabled vs disabled, then strip `<think>...</think>` before passing code to CADForge. If thinking improves build/reward, mention it as an inference-time scaffold, not SFT data.
|
| 122 |
+
- For 9B, thinking mode is worth testing more seriously. CAD repair benefits from multi-step reasoning, but the final action must still be clean code.
|
| 123 |
+
- Best demo agent: "think privately or in scratch, then submit only code to CADForge." The environment should never score thinking text; it scores executable code.
|
| 124 |
+
|
| 125 |
+
Qwen notes from official cards:
|
| 126 |
+
|
| 127 |
+
- `Qwen/Qwen3.5-2B` supports thinking and non-thinking; the model card says 2B operates in non-thinking mode by default and can be served with vLLM/SGLang.
|
| 128 |
+
- `Qwen/Qwen3.5-9B` is Apache-2.0, compatible with Transformers/vLLM/SGLang/KTransformers, and Qwen recommends vLLM/SGLang for throughput.
|
| 129 |
+
- Older `Qwen3-8B` docs explicitly describe `enable_thinking=True/False` and `<think>...</think>` parsing; the same care applies when testing Qwen thinking-mode models.
|
| 130 |
+
|
| 131 |
+
## SFT Plan
|
| 132 |
+
|
| 133 |
+
2B:
|
| 134 |
+
|
| 135 |
+
```text
|
| 136 |
+
model: Qwen/Qwen3.5-2B
|
| 137 |
+
method: Unsloth BF16 LoRA
|
| 138 |
+
rank: 16 or 32
|
| 139 |
+
seq_len: 8192 first, 16384 if examples need it
|
| 140 |
+
epochs: 2-4
|
| 141 |
+
lr: 1e-4 to 2e-4
|
| 142 |
+
batching: maximize tokens/sec; use grad accumulation rather than tiny context
|
| 143 |
+
eval: every 25-50 steps
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
9B:
|
| 147 |
+
|
| 148 |
+
```text
|
| 149 |
+
model: Qwen/Qwen3.5-9B
|
| 150 |
+
method: Unsloth BF16 LoRA on H200
|
| 151 |
+
rank: 32 or 64
|
| 152 |
+
seq_len: 8192-16384
|
| 153 |
+
epochs: 2-3
|
| 154 |
+
lr: 5e-5 to 1.5e-4
|
| 155 |
+
eval: held-out build rate and reward, not just loss
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
What to watch:
|
| 159 |
+
|
| 160 |
+
- Validation loss is secondary.
|
| 161 |
+
- Build rate is the first key metric.
|
| 162 |
+
- Mean reward and reward >= 0.70 / >= 0.85 rates are the real metrics.
|
| 163 |
+
- Inspect failures for Python syntax, CadQuery API hallucination, missing `fixture`, disconnected parts, and semantic misses.
|
| 164 |
+
|
| 165 |
+
## GRPO Plan
|
| 166 |
+
|
| 167 |
+
Run GRPO only after SFT has non-trivial build rate.
|
| 168 |
+
|
| 169 |
+
For 2B:
|
| 170 |
+
|
| 171 |
+
- Use as a proof of learning if SFT already reaches reasonable build rate.
|
| 172 |
+
- 4 completions per prompt, short rollouts, fast reward mode.
|
| 173 |
+
- Stop quickly if all completions fail to build.
|
| 174 |
+
|
| 175 |
+
For 9B:
|
| 176 |
+
|
| 177 |
+
- Main GRPO candidate.
|
| 178 |
+
- Start from SFT adapter.
|
| 179 |
+
- 4-8 completions per prompt.
|
| 180 |
+
- CADForge fast reward during training.
|
| 181 |
+
- Start BF16 for the clean baseline; then test Unsloth FP8 GRPO with `load_in_fp8=True` if rollout speed or VRAM is limiting.
|
| 182 |
+
- Periodically run full reward for report artifacts.
|
| 183 |
+
- Keep anti-hacking constraints: final object must be `fixture`, blocked tokens rejected, build hard-gated, semantic hints required.
|
| 184 |
+
|
| 185 |
+
Reward objective:
|
| 186 |
+
|
| 187 |
+
```text
|
| 188 |
+
step_reward = 0.60 * reward_after
|
| 189 |
+
+ 0.35 * clamp(reward_after - reward_before, -0.25, 0.25)
|
| 190 |
+
+ 0.05 * build_success
|
| 191 |
+
```
|
| 192 |
+
|
| 193 |
+
## Inference After Training
|
| 194 |
+
|
| 195 |
+
Quick eval:
|
| 196 |
+
|
| 197 |
+
- Load base model + LoRA adapter with Transformers/PEFT.
|
| 198 |
+
- Generate code from held-out observations.
|
| 199 |
+
- Strip markdown fences and any accidental `<think>` block.
|
| 200 |
+
- Submit code to the OpenEnv Space `/step`.
|
| 201 |
+
|
| 202 |
+
Serving:
|
| 203 |
+
|
| 204 |
+
- vLLM with LoRA adapter if Qwen3.5 adapter support is stable.
|
| 205 |
+
- Otherwise merge LoRA into a HF checkpoint and serve the merged model.
|
| 206 |
+
- For Ollama/llama.cpp demos, merge and convert to GGUF after training. Use `q8_0` for quality-first local demos, `q4_k_m` for portable demos. This is inference quantization, separate from BF16/FP8 training.
|
| 207 |
+
|
| 208 |
+
Demo loop:
|
| 209 |
+
|
| 210 |
+
```bash
|
| 211 |
+
OPENENV_BASE_URL=https://sanjuhs-cadforge-cadquery-openenv.hf.space \
|
| 212 |
+
python experiment-2-cadforge/inference.py
|
| 213 |
+
```
|
| 214 |
+
|
| 215 |
+
## Final Report Story
|
| 216 |
+
|
| 217 |
+
Mirror `docs/best-example-project.md`:
|
| 218 |
+
|
| 219 |
+
1. Cold Qwen cannot reliably produce buildable CadQuery.
|
| 220 |
+
2. CADForge executes real CadQuery, exports STL, renders, and scores every step.
|
| 221 |
+
3. GPT teacher traces generate repair trajectories.
|
| 222 |
+
4. SFT teaches the small model the code-CAD grammar and repair style.
|
| 223 |
+
5. GRPO teaches verifier-directed improvement against objective geometry rewards.
|
| 224 |
+
6. 2B proves the tiny-model story; 9B gives the strongest open small-model result.
|
docs/brainstorm/20-cadforge-qwen-training-runbook.md
ADDED
|
@@ -0,0 +1,380 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CADForge Qwen Training Runbook
|
| 2 |
+
|
| 3 |
+
## Goal
|
| 4 |
+
|
| 5 |
+
Train a small Qwen model to produce editable, buildable CadQuery and then improve it through reward feedback.
|
| 6 |
+
|
| 7 |
+
The hackathon story is:
|
| 8 |
+
|
| 9 |
+
1. Base Qwen often writes invalid or incomplete CadQuery.
|
| 10 |
+
2. SFT teaches two behaviors: create CAD from a prompt and repair CAD from verifier feedback.
|
| 11 |
+
3. GRPO/RLVE then rewards buildable, connected, semantically correct, editable CAD.
|
| 12 |
+
4. The environment stores artifacts, reward JSON, code, and renders, so improvement is visible and auditable.
|
| 13 |
+
|
| 14 |
+
## Hardware
|
| 15 |
+
|
| 16 |
+
Use the H200 for the real run.
|
| 17 |
+
|
| 18 |
+
Recommended setup:
|
| 19 |
+
|
| 20 |
+
- GPU: 1x H200 141 GB
|
| 21 |
+
- CUDA image: PyTorch 2.8 or latest RunPod PyTorch CUDA image
|
| 22 |
+
- Python: 3.10 or 3.11
|
| 23 |
+
- Package runner: `uv`
|
| 24 |
+
- Training dtype: BF16
|
| 25 |
+
- Method: Unsloth LoRA SFT first, then TRL GRPO
|
| 26 |
+
|
| 27 |
+
Do not start with QLoRA on the H200. BF16 LoRA is cleaner and the GPU has enough memory.
|
| 28 |
+
|
| 29 |
+
## Data Mix
|
| 30 |
+
|
| 31 |
+
The first SFT run should mix:
|
| 32 |
+
|
| 33 |
+
- all cold-start rows from `cadquery_prompt_to_cadquery_train.jsonl`
|
| 34 |
+
- all repair rows from `cadquery_agentic_sft_train.jsonl`
|
| 35 |
+
- cold-start rows repeated 4x
|
| 36 |
+
|
| 37 |
+
Upsampling means repeating the cold-start rows. It does not mean skipping them.
|
| 38 |
+
|
| 39 |
+
Why repeat them? We only have 20 cold-start train rows but 633 repair train rows. If each appears once, the model mostly learns "repair existing CAD." The demo also needs "write the first complete CAD file from a prompt," so we repeat cold-start rows to keep that behavior visible during training.
|
| 40 |
+
|
| 41 |
+
Expected mixed train size:
|
| 42 |
+
|
| 43 |
+
```text
|
| 44 |
+
20 cold-start rows * 4 = 80 cold-start examples
|
| 45 |
+
633 repair rows * 1 = 633 repair examples
|
| 46 |
+
total = 713 train examples
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
## Local Prep Commands
|
| 50 |
+
|
| 51 |
+
From the repo root:
|
| 52 |
+
|
| 53 |
+
```bash
|
| 54 |
+
uv run training/prepare_sft_mix.py --cold-start-upsample 4
|
| 55 |
+
uv run training/smoke_cadforge_reward.py --reward-mode fast
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
The first command creates:
|
| 59 |
+
|
| 60 |
+
- `training/output/cadforge_sft_mix_train.jsonl`
|
| 61 |
+
- `training/output/cadforge_sft_mix_val.jsonl`
|
| 62 |
+
|
| 63 |
+
The second command verifies that the CadQuery reward backend can build and score one known-good row.
|
| 64 |
+
|
| 65 |
+
## RunPod Setup
|
| 66 |
+
|
| 67 |
+
After the RunPod starts:
|
| 68 |
+
|
| 69 |
+
```bash
|
| 70 |
+
apt-get update
|
| 71 |
+
apt-get install -y git git-lfs build-essential curl
|
| 72 |
+
curl -LsSf https://astral.sh/uv/install.sh | sh
|
| 73 |
+
source $HOME/.local/bin/env
|
| 74 |
+
git lfs install
|
| 75 |
+
git clone https://github.com/sanjuhs/open-env-meta-final-hackathon.git
|
| 76 |
+
cd open-env-meta-final-hackathon
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
Set secrets:
|
| 80 |
+
|
| 81 |
+
```bash
|
| 82 |
+
export HF_TOKEN=...
|
| 83 |
+
export TRACKIO_SPACE_ID=sanjuhs/cadforge-trackio
|
| 84 |
+
```
|
| 85 |
+
|
| 86 |
+
Move caches to the workspace volume before installing training packages:
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
export UV_CACHE_DIR=/workspace/.uv-cache
|
| 90 |
+
export HF_HOME=/workspace/.cache/huggingface
|
| 91 |
+
export TORCH_HOME=/workspace/.cache/torch
|
| 92 |
+
export TRITON_CACHE_DIR=/workspace/.cache/triton
|
| 93 |
+
export VLLM_CACHE_ROOT=/workspace/.cache/vllm
|
| 94 |
+
export UV_LINK_MODE=copy
|
| 95 |
+
export HF_HUB_ENABLE_HF_TRANSFER=1
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
Install the app/runtime dependencies:
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
uv sync --project experiment-2-cadforge
|
| 102 |
+
uv run training/prepare_sft_mix.py --cold-start-upsample 4
|
| 103 |
+
uv run training/smoke_cadforge_reward.py --reward-mode fast
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
If the generated local data files are not present in git, the training scripts can download the uploaded dataset from Hugging Face.
|
| 107 |
+
|
| 108 |
+
## SFT Smoke Test
|
| 109 |
+
|
| 110 |
+
Run this first. It should take only a few minutes on the H200.
|
| 111 |
+
|
| 112 |
+
```bash
|
| 113 |
+
uv run training/train_sft_unsloth.py \
|
| 114 |
+
--model unsloth/Qwen3.5-2B \
|
| 115 |
+
--output-dir outputs/qwen35-2b-cadforge-sft-smoke \
|
| 116 |
+
--max-steps 10 \
|
| 117 |
+
--limit-train-rows 32 \
|
| 118 |
+
--limit-val-rows 8 \
|
| 119 |
+
--max-seq-length 4096 \
|
| 120 |
+
--per-device-train-batch-size 1 \
|
| 121 |
+
--gradient-accumulation-steps 4 \
|
| 122 |
+
--lora-r 16 \
|
| 123 |
+
--lora-alpha 32 \
|
| 124 |
+
--run-name qwen35-2b-sft-smoke
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
Success criteria:
|
| 128 |
+
|
| 129 |
+
- model loads in BF16
|
| 130 |
+
- LoRA attaches
|
| 131 |
+
- loss logs for 10 steps
|
| 132 |
+
- one checkpoint/output folder is written
|
| 133 |
+
- no chat-template/data-format crash
|
| 134 |
+
|
| 135 |
+
Qwen3.5 note: the model type is `qwen3_5`, so Transformers must be `>=5.2.0`. If a smoke run says Transformers does not recognize `qwen3_5`, update the training environment and rerun; this is a dependency issue, not a data issue.
|
| 136 |
+
|
| 137 |
+
Qwen3.5 is a unified vision-language model. For text-only SFT, call the processor with `text=...`; do not pass the chat string positionally. A positional text string can be interpreted as an image input and trigger an image decode error. That error means the processor call is wrong, not that image fine-tuning itself is broken.
|
| 138 |
+
|
| 139 |
+
Trackio note: smoke tests default to TensorBoard only. Add `--enable-trackio` after `HF_TOKEN` is configured on the pod.
|
| 140 |
+
|
| 141 |
+
## SFT Real 2B Run
|
| 142 |
+
|
| 143 |
+
```bash
|
| 144 |
+
uv run training/train_sft_unsloth.py \
|
| 145 |
+
--model unsloth/Qwen3.5-2B \
|
| 146 |
+
--output-dir outputs/qwen35-2b-cadforge-sft \
|
| 147 |
+
--hub-model-id sanjuhs/qwen35-2b-cadforge-sft-lora \
|
| 148 |
+
--push-to-hub \
|
| 149 |
+
--enable-trackio \
|
| 150 |
+
--max-steps 0 \
|
| 151 |
+
--num-train-epochs 3 \
|
| 152 |
+
--max-seq-length 8192 \
|
| 153 |
+
--per-device-train-batch-size 1 \
|
| 154 |
+
--gradient-accumulation-steps 8 \
|
| 155 |
+
--learning-rate 2e-4 \
|
| 156 |
+
--lora-r 16 \
|
| 157 |
+
--lora-alpha 32 \
|
| 158 |
+
--eval-steps 25 \
|
| 159 |
+
--save-steps 50 \
|
| 160 |
+
--run-name qwen35-2b-sft-full
|
| 161 |
+
```
|
| 162 |
+
|
| 163 |
+
Watch:
|
| 164 |
+
|
| 165 |
+
- train loss
|
| 166 |
+
- eval loss
|
| 167 |
+
- generated sample build rate after training
|
| 168 |
+
- whether outputs contain only Python code, not markdown or thinking tags
|
| 169 |
+
|
| 170 |
+
The first live 2B run launched on 2026-04-25 used the same settings, without `--push-to-hub` and `--enable-trackio` because no HF token was configured in the pod environment yet:
|
| 171 |
+
|
| 172 |
+
```text
|
| 173 |
+
output: /workspace/open-env-meta-final/outputs/qwen35-2b-cadforge-sft-full-20260425
|
| 174 |
+
log: /workspace/open-env-meta-final/training/logs/sft-2b-full-20260425.log
|
| 175 |
+
```
|
| 176 |
+
|
| 177 |
+
Generate the current/final curve images:
|
| 178 |
+
|
| 179 |
+
```bash
|
| 180 |
+
uv run training/make_training_report.py \
|
| 181 |
+
--log training/logs/sft-2b-full-20260425.log \
|
| 182 |
+
--output-dir training/reports/qwen35-2b-sft-final
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
Evaluate the finished adapter against CADForge:
|
| 186 |
+
|
| 187 |
+
```bash
|
| 188 |
+
uv run training/evaluate_cadforge_model.py \
|
| 189 |
+
--base-model unsloth/Qwen3.5-2B \
|
| 190 |
+
--adapter outputs/qwen35-2b-cadforge-sft-full-20260425 \
|
| 191 |
+
--eval-jsonl training/output/cadforge_sft_mix_val.jsonl \
|
| 192 |
+
--output-dir training/eval/qwen35-2b-cadforge-sft-full-20260425 \
|
| 193 |
+
--limit 24 \
|
| 194 |
+
--max-new-tokens 2048 \
|
| 195 |
+
--reward-mode fast \
|
| 196 |
+
--episode-prefix qwen35-2b-sft-eval
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
This writes:
|
| 200 |
+
|
| 201 |
+
- `training/eval/qwen35-2b-cadforge-sft-full-20260425/eval_report.md`
|
| 202 |
+
- `training/eval/qwen35-2b-cadforge-sft-full-20260425/eval_results.jsonl`
|
| 203 |
+
- one generated CadQuery file per eval row
|
| 204 |
+
|
| 205 |
+
The eval script strips accidental `<think>...</think>` blocks before scoring, but the current SFT data does not contain thinking traces.
|
| 206 |
+
|
| 207 |
+
## SFT Real 9B Run
|
| 208 |
+
|
| 209 |
+
Start this after the 2B path works:
|
| 210 |
+
|
| 211 |
+
```bash
|
| 212 |
+
uv run training/train_sft_unsloth.py \
|
| 213 |
+
--model Qwen/Qwen3.5-9B \
|
| 214 |
+
--output-dir outputs/qwen35-9b-cadforge-sft \
|
| 215 |
+
--hub-model-id sanjuhs/qwen35-9b-cadforge-sft-lora \
|
| 216 |
+
--push-to-hub \
|
| 217 |
+
--enable-trackio \
|
| 218 |
+
--max-steps 0 \
|
| 219 |
+
--num-train-epochs 2 \
|
| 220 |
+
--max-seq-length 8192 \
|
| 221 |
+
--per-device-train-batch-size 1 \
|
| 222 |
+
--gradient-accumulation-steps 8 \
|
| 223 |
+
--learning-rate 1e-4 \
|
| 224 |
+
--lora-r 32 \
|
| 225 |
+
--lora-alpha 64 \
|
| 226 |
+
--eval-steps 25 \
|
| 227 |
+
--save-steps 50 \
|
| 228 |
+
--run-name qwen35-9b-sft-full
|
| 229 |
+
```
|
| 230 |
+
|
| 231 |
+
## GRPO Smoke Test
|
| 232 |
+
|
| 233 |
+
First use the cheap reward backend. This verifies GRPO wiring without spending time on CadQuery execution for every completion.
|
| 234 |
+
|
| 235 |
+
```bash
|
| 236 |
+
uv run training/train_grpo_cadforge.py \
|
| 237 |
+
--model unsloth/Qwen3.5-2B \
|
| 238 |
+
--output-dir outputs/qwen35-2b-cadforge-grpo-smoke \
|
| 239 |
+
--reward-backend cheap \
|
| 240 |
+
--limit-prompts 8 \
|
| 241 |
+
--max-steps 5 \
|
| 242 |
+
--num-generations 4 \
|
| 243 |
+
--max-prompt-length 4096 \
|
| 244 |
+
--max-completion-length 1024 \
|
| 245 |
+
--run-name qwen35-2b-grpo-cheap-smoke
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
Success criteria:
|
| 249 |
+
|
| 250 |
+
- GRPOTrainer starts
|
| 251 |
+
- four completions per prompt are generated
|
| 252 |
+
- reward function returns scalar scores
|
| 253 |
+
- loss/reward metrics log
|
| 254 |
+
|
| 255 |
+
## CADForge GRPO Smoke
|
| 256 |
+
|
| 257 |
+
Then use the real CADForge reward in fast mode:
|
| 258 |
+
|
| 259 |
+
```bash
|
| 260 |
+
uv run training/train_grpo_cadforge.py \
|
| 261 |
+
--model unsloth/Qwen3.5-2B \
|
| 262 |
+
--output-dir outputs/qwen35-2b-cadforge-grpo-cadforge-smoke \
|
| 263 |
+
--reward-backend cadforge \
|
| 264 |
+
--cadforge-reward-mode fast \
|
| 265 |
+
--limit-prompts 4 \
|
| 266 |
+
--max-steps 2 \
|
| 267 |
+
--num-generations 4 \
|
| 268 |
+
--max-prompt-length 4096 \
|
| 269 |
+
--max-completion-length 1536 \
|
| 270 |
+
--run-name qwen35-2b-grpo-cadforge-smoke
|
| 271 |
+
```
|
| 272 |
+
|
| 273 |
+
This is slower because every completion is executed as CadQuery, exported to mesh, and scored.
|
| 274 |
+
|
| 275 |
+
## GRPO From SFT Adapter
|
| 276 |
+
|
| 277 |
+
After the 2B SFT run finishes and the eval pass is complete, launch GRPO from the trained adapter:
|
| 278 |
+
|
| 279 |
+
```bash
|
| 280 |
+
training/launch_grpo_after_sft.sh
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
The launcher defaults to:
|
| 284 |
+
|
| 285 |
+
```text
|
| 286 |
+
base model: unsloth/Qwen3.5-2B
|
| 287 |
+
adapter: outputs/qwen35-2b-cadforge-sft-full-20260425
|
| 288 |
+
output: outputs/qwen35-2b-cadforge-grpo-from-sft-20260425
|
| 289 |
+
log: training/logs/grpo-2b-from-sft-20260425.log
|
| 290 |
+
prompts: 64
|
| 291 |
+
steps: 80
|
| 292 |
+
generations: 4
|
| 293 |
+
batch: 4
|
| 294 |
+
grad accum: 4
|
| 295 |
+
completion: 1536 tokens
|
| 296 |
+
reward: CADForge fast reward
|
| 297 |
+
```
|
| 298 |
+
|
| 299 |
+
Override any path without editing the file:
|
| 300 |
+
|
| 301 |
+
```bash
|
| 302 |
+
SFT_ADAPTER=outputs/qwen35-2b-cadforge-sft-full-20260425 \
|
| 303 |
+
OUT_DIR=outputs/qwen35-2b-cadforge-grpo-from-sft-20260425 \
|
| 304 |
+
training/launch_grpo_after_sft.sh
|
| 305 |
+
```
|
| 306 |
+
|
| 307 |
+
This direct-adapter GRPO path is the safest first production run. vLLM server mode remains useful after exporting/merging a model path that vLLM can serve cleanly.
|
| 308 |
+
|
| 309 |
+
## vLLM Server Mode
|
| 310 |
+
|
| 311 |
+
The judge recommended normal GRPO with vLLM serve mode, not async mode. The script exposes that path:
|
| 312 |
+
|
| 313 |
+
```bash
|
| 314 |
+
python -m vllm.entrypoints.openai.api_server \
|
| 315 |
+
--model unsloth/Qwen3.5-2B \
|
| 316 |
+
--host 127.0.0.1 \
|
| 317 |
+
--port 8000
|
| 318 |
+
```
|
| 319 |
+
|
| 320 |
+
Then:
|
| 321 |
+
|
| 322 |
+
```bash
|
| 323 |
+
uv run training/train_grpo_cadforge.py \
|
| 324 |
+
--model Qwen/Qwen3.5-2B \
|
| 325 |
+
--use-vllm-server \
|
| 326 |
+
--vllm-server-host 127.0.0.1 \
|
| 327 |
+
--vllm-server-port 8000 \
|
| 328 |
+
--reward-backend cadforge \
|
| 329 |
+
--cadforge-reward-mode fast \
|
| 330 |
+
--limit-prompts 16 \
|
| 331 |
+
--max-steps 20 \
|
| 332 |
+
--num-generations 4 \
|
| 333 |
+
--run-name qwen35-2b-grpo-vllm-server-smoke
|
| 334 |
+
```
|
| 335 |
+
|
| 336 |
+
If the local TRL version changes vLLM config names, disable `--use-vllm-server` for the first proof run and use standard colocated generation.
|
| 337 |
+
|
| 338 |
+
## GRPO Real Run
|
| 339 |
+
|
| 340 |
+
Only do the real GRPO run if SFT has a non-trivial build rate.
|
| 341 |
+
|
| 342 |
+
```bash
|
| 343 |
+
uv run training/train_grpo_cadforge.py \
|
| 344 |
+
--model outputs/qwen35-2b-cadforge-sft \
|
| 345 |
+
--output-dir outputs/qwen35-2b-cadforge-grpo \
|
| 346 |
+
--hub-model-id sanjuhs/qwen35-2b-cadforge-grpo \
|
| 347 |
+
--push-to-hub \
|
| 348 |
+
--enable-trackio \
|
| 349 |
+
--reward-backend cadforge \
|
| 350 |
+
--cadforge-reward-mode fast \
|
| 351 |
+
--limit-prompts 256 \
|
| 352 |
+
--max-steps 100 \
|
| 353 |
+
--num-generations 4 \
|
| 354 |
+
--max-prompt-length 4096 \
|
| 355 |
+
--max-completion-length 2048 \
|
| 356 |
+
--learning-rate 5e-6 \
|
| 357 |
+
--run-name qwen35-2b-grpo-cadforge-full
|
| 358 |
+
```
|
| 359 |
+
|
| 360 |
+
Full reward with renders should be used for periodic eval/reporting, not every GRPO step. Fast reward is the training signal; full reward is the judge-facing artifact generator.
|
| 361 |
+
|
| 362 |
+
## What To Report
|
| 363 |
+
|
| 364 |
+
For the initial report after smoke tests, capture:
|
| 365 |
+
|
| 366 |
+
- exact base model repo
|
| 367 |
+
- GPU name and VRAM
|
| 368 |
+
- SFT smoke loss logs
|
| 369 |
+
- GRPO smoke reward logs
|
| 370 |
+
- one CADForge reward JSON from `smoke_cadforge_reward.py`
|
| 371 |
+
- whether artifacts were written
|
| 372 |
+
- blocker list, if any
|
| 373 |
+
|
| 374 |
+
The hackathon result should compare:
|
| 375 |
+
|
| 376 |
+
- base Qwen prompt-only build rate
|
| 377 |
+
- SFT Qwen prompt-only build rate
|
| 378 |
+
- SFT Qwen repair reward delta
|
| 379 |
+
- GRPO Qwen reward delta
|
| 380 |
+
- GPT-5.4 teacher trace improvement as the upper-bound teacher demonstration
|
docs/cadforge-openenv-project-report.md
CHANGED
|
@@ -117,7 +117,7 @@ The strict 9B run completed on an H200 and produced exactly that separation:
|
|
| 117 |
The raw logs and report artifacts are backed up here:
|
| 118 |
|
| 119 |
- Training evidence dataset: [sanjuhs/cadforge-training-evidence](https://huggingface.co/datasets/sanjuhs/cadforge-training-evidence)
|
| 120 |
-
-
|
| 121 |
- Final adaptive repair report: `training/reports/qwen35-9b-grpo-20260426-adaptive-repair-final-8192/`
|
| 122 |
|
| 123 |

|
|
|
|
| 117 |
The raw logs and report artifacts are backed up here:
|
| 118 |
|
| 119 |
- Training evidence dataset: [sanjuhs/cadforge-training-evidence](https://huggingface.co/datasets/sanjuhs/cadforge-training-evidence)
|
| 120 |
+
- Compressed archive on that dataset: `archives/cadforge-training-evidence-20260426.tar.gz`
|
| 121 |
- Final adaptive repair report: `training/reports/qwen35-9b-grpo-20260426-adaptive-repair-final-8192/`
|
| 122 |
|
| 123 |

|
docs/cadforge-submission-checklist.md
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CADForge Submission Checklist
|
| 2 |
+
|
| 3 |
+
## Non-Negotiables
|
| 4 |
+
|
| 5 |
+
| Requirement | Status | File / Link |
|
| 6 |
+
|---|---|---|
|
| 7 |
+
| OpenEnv environment | done | `experiment-2-cadforge/openenv.yaml` |
|
| 8 |
+
| Hugging Face Space | ready to push | `sanjuhs/cadforge-cadquery-openenv` |
|
| 9 |
+
| Training notebook | done | `training/cadforge_openenv_training_colab.ipynb` |
|
| 10 |
+
| Unsloth / TRL scripts | done | `training/train_sft_unsloth.py`, `training/train_grpo_cadforge.py` |
|
| 11 |
+
| Evidence of training | done | `training/reports/qwen35-9b-grpo-strict-build-20260426-strict-build/` |
|
| 12 |
+
| Raw training logs | done | [sanjuhs/cadforge-training-evidence](https://huggingface.co/datasets/sanjuhs/cadforge-training-evidence) |
|
| 13 |
+
| Final adaptive repair evidence | done | `training/reports/qwen35-9b-grpo-20260426-adaptive-repair-final-8192/` |
|
| 14 |
+
| Final inference comparison | done | `inference/results/stator-qwen-vs-frontier/report.md` |
|
| 15 |
+
| Separate HF blog markdown | done | `experiment-2-cadforge/CADFORGE_BLOG.md` |
|
| 16 |
+
| README links to all materials | done | `README.md`, `experiment-2-cadforge/README.md` |
|
| 17 |
+
|
| 18 |
+
## What To Push To The HF Space
|
| 19 |
+
|
| 20 |
+
Push from the Space root:
|
| 21 |
+
|
| 22 |
+
```bash
|
| 23 |
+
cd experiment-2-cadforge
|
| 24 |
+
set -a; source ../.env; set +a
|
| 25 |
+
../.venv/bin/openenv validate .
|
| 26 |
+
../.venv/bin/openenv push . --repo-id sanjuhs/cadforge-cadquery-openenv --interface
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
The HF Space should include:
|
| 30 |
+
|
| 31 |
+
- `README.md`
|
| 32 |
+
- `CADFORGE_BLOG.md`
|
| 33 |
+
- `openenv.yaml`
|
| 34 |
+
- server/client environment code
|
| 35 |
+
|
| 36 |
+
Do not upload large videos to the Space. Link to YouTube if a video is made.
|
| 37 |
+
|
| 38 |
+
## Judge Story
|
| 39 |
+
|
| 40 |
+
CADForge teaches an LLM to write buildable, editable CADQuery by interacting with a real CAD compiler and verifier.
|
| 41 |
+
|
| 42 |
+
The strongest 30-second story:
|
| 43 |
+
|
| 44 |
+
1. Base tiny models can write plausible CAD text, but much of it does not compile.
|
| 45 |
+
2. SFT teaches the model the shape of editable CadQuery programs.
|
| 46 |
+
3. First GRPO exposed a reward bug: dense reward was too forgiving.
|
| 47 |
+
4. The environment fought back with strict build gating.
|
| 48 |
+
5. Strict GRPO produced `96/320` buildable completions and a best CADForge score of `0.9352`.
|
| 49 |
+
6. Adaptive repair started from the strict-GRPO adapter and fixed the clipping failure: `53/180` buildable repairs with `0` clipped completions.
|
| 50 |
+
7. Final stator inference shows the product shape: base Qwen failed build, RL-tuned Qwen built editable CAD, and GPT-5.4 remained a strong frontier baseline.
|
| 51 |
+
|
| 52 |
+
## Training Log Narrative
|
| 53 |
+
|
| 54 |
+
Use this evidence arc if judges ask whether training really happened:
|
| 55 |
+
|
| 56 |
+
| Run | Log evidence | Interpretation |
|
| 57 |
+
|---|---|---|
|
| 58 |
+
| 2B SFT | `training/reports/qwen35-2b-sft-final/` | tiny model learns CadQuery grammar and trace format |
|
| 59 |
+
| 2B dense GRPO | `training/logs/grpo-2b-completions.jsonl` | reward moved, but `0/160` builds exposed forgiving reward |
|
| 60 |
+
| 9B SFT | `training/reports/qwen35-9b-sft-final/` | stronger syntax/style learning |
|
| 61 |
+
| 9B dense GRPO | `training/logs/grpo-9b-completions.jsonl` | bigger model got higher reward but still `0/160` builds |
|
| 62 |
+
| 9B strict GRPO | `training/logs/grpo-9b-strict-build-20260426-strict-build-completions.jsonl` | build-gated reward produced `96/320` buildable completions |
|
| 63 |
+
| Adaptive v1 | `training/logs/grpo-9b-20260426-adaptive-repair-completions.jsonl` | failed run exposed clipping and curriculum bug |
|
| 64 |
+
| Adaptive final 8192 | `training/logs/grpo-9b-20260426-adaptive-repair-final-8192-completions.jsonl` | fixed setup produced `53/180` buildable repairs |
|
| 65 |
+
|
| 66 |
+
## Remaining Optional Polish
|
| 67 |
+
|
| 68 |
+
- Add a <2 minute YouTube link to both READMEs if you record one.
|
| 69 |
+
- Add the HF Space URL after pushing/confirming the live Space.
|
| 70 |
+
- Add screenshots from the live browser UI if there is time.
|
| 71 |
+
- Run a broader 10-20 task inference comparison if there is extra GPU/API time.
|
docs/competiton-round1/COMPETITION_REQUIREMENTS.md
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# OpenEnv Round 1 — Competition Requirements
|
| 2 |
+
|
| 3 |
+
**Deadline**: 8 April 2026, 11:59 PM IST
|
| 4 |
+
**Competing as**: Solo — Sanjayprasad H S (sanjuhs123@gmail.com)
|
| 5 |
+
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
## Mandatory Pass/Fail Gates (all must pass or DQ)
|
| 9 |
+
|
| 10 |
+
1. **HF Space deploys** — automated ping to Space URL returns 200 + responds to `reset()`
|
| 11 |
+
2. **OpenEnv spec compliance** — `openenv validate` passes (openenv.yaml, typed models, step/reset/state endpoints)
|
| 12 |
+
3. **Dockerfile builds** — `docker build` succeeds on submitted repo
|
| 13 |
+
4. **Baseline reproduces** — `inference.py` runs without error, produces scores
|
| 14 |
+
5. **3+ tasks with graders** — each grader returns score in 0.0–1.0 range
|
| 15 |
+
|
| 16 |
+
## Functional Requirements
|
| 17 |
+
|
| 18 |
+
| Requirement | Detail |
|
| 19 |
+
|---|---|
|
| 20 |
+
| Real-world task | Must simulate something humans actually do (not games/toys) |
|
| 21 |
+
| OpenEnv spec | Typed `Action`, `Observation` Pydantic models; `step(action)` → obs, reward, done, info; `reset()` → initial obs; `state()` → current state; `openenv.yaml` with metadata |
|
| 22 |
+
| 3+ tasks with graders | Each task has a concrete objective + programmatic grader (0.0–1.0). Easy → medium → hard progression. Deterministic, reproducible. |
|
| 23 |
+
| Reward function | Signal over full trajectory (not just binary end). Partial progress rewarded. Penalize bad behavior. |
|
| 24 |
+
| Baseline inference script | Named `inference.py` in project root. Uses OpenAI API client. Reads `API_BASE_URL`, `MODEL_NAME`, `HF_TOKEN` from env vars. Produces reproducible baseline score on all 3 tasks. Must emit `[START]`, `[STEP]`, `[END]` structured stdout logs. |
|
| 25 |
+
|
| 26 |
+
## Non-Functional Requirements
|
| 27 |
+
|
| 28 |
+
- Deploy as containerized HF Space tagged `openenv`
|
| 29 |
+
- Working Dockerfile (`docker build` + `docker run`)
|
| 30 |
+
- README: env description, action/observation spaces, task descriptions, setup instructions, baseline scores
|
| 31 |
+
|
| 32 |
+
## Scoring Weights
|
| 33 |
+
|
| 34 |
+
| Parameter | Weight |
|
| 35 |
+
|---|---|
|
| 36 |
+
| Real-world utility | 30% |
|
| 37 |
+
| Task & grader quality | 25% |
|
| 38 |
+
| Environment design | 20% |
|
| 39 |
+
| Code quality & spec compliance | 15% |
|
| 40 |
+
| Creativity & novelty | 10% |
|
| 41 |
+
|
| 42 |
+
## Infra Constraints
|
| 43 |
+
|
| 44 |
+
- Inference script runtime < 20 min
|
| 45 |
+
- Must run on vcpu=2, memory=8gb
|
| 46 |
+
- Use OpenAI Client for all LLM calls
|
| 47 |
+
|
| 48 |
+
## Env Vars Required
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
API_BASE_URL — LLM API endpoint
|
| 52 |
+
MODEL_NAME — model identifier for inference
|
| 53 |
+
HF_TOKEN — HF / API key
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
## Pre-Submission Validation
|
| 57 |
+
|
| 58 |
+
```bash
|
| 59 |
+
# Run the validation script before submitting
|
| 60 |
+
openenv validate
|
| 61 |
+
docker build .
|
| 62 |
+
# Then submit HF Spaces URL on platform
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
## Evaluation Pipeline
|
| 66 |
+
|
| 67 |
+
1. **Phase 1**: Automated validation (pass/fail gate)
|
| 68 |
+
2. **Phase 2**: Agentic evaluation — baseline agent + standard Open LLM agent (Nemotron 3 Super) run against all envs
|
| 69 |
+
3. **Phase 3**: Human review by Meta + HF engineers
|
docs/competiton-round1/inference-script-example.md
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Inference Script Example
|
| 3 |
+
===================================
|
| 4 |
+
MANDATORY
|
| 5 |
+
- Before submitting, ensure the following variables are defined in your environment configuration:
|
| 6 |
+
API_BASE_URL The API endpoint for the LLM.
|
| 7 |
+
MODEL_NAME The model identifier to use for inference.
|
| 8 |
+
HF_TOKEN Your Hugging Face / API key.
|
| 9 |
+
LOCAL_IMAGE_NAME The name of the local image to use for the environment if you are using from_docker_image()
|
| 10 |
+
method
|
| 11 |
+
|
| 12 |
+
- Defaults are set only for API_BASE_URL and MODEL_NAME
|
| 13 |
+
(and should reflect your active inference setup):
|
| 14 |
+
API_BASE_URL = os.getenv("API_BASE_URL", "<your-active-endpoint>")
|
| 15 |
+
MODEL_NAME = os.getenv("MODEL_NAME", "<your-active-model>")
|
| 16 |
+
|
| 17 |
+
- The inference script must be named `inference.py` and placed in the root directory of the project
|
| 18 |
+
- Participants must use OpenAI Client for all LLM calls using above variables
|
| 19 |
+
|
| 20 |
+
STDOUT FORMAT
|
| 21 |
+
- The script must emit exactly three line types to stdout, in this order:
|
| 22 |
+
|
| 23 |
+
[START] task=<task_name> env=<benchmark> model=<model_name>
|
| 24 |
+
[STEP] step=<n> action=<action_str> reward=<0.00> done=<true|false> error=<msg|null>
|
| 25 |
+
[END] success=<true|false> steps=<n> score=<score> rewards=<r1,r2,...,rn>
|
| 26 |
+
|
| 27 |
+
Rules:
|
| 28 |
+
- One [START] line at episode begin.
|
| 29 |
+
- One [STEP] line per step, immediately after env.step() returns.
|
| 30 |
+
- One [END] line after env.close(), always emitted (even on exception).
|
| 31 |
+
- reward and rewards are formatted to 2 decimal places.
|
| 32 |
+
- done and success are lowercase booleans: true or false.
|
| 33 |
+
- error is the raw last_action_error string, or null if none.
|
| 34 |
+
- All fields on a single line with no newlines within a line.
|
| 35 |
+
- Each tasks should return score in [0, 1]
|
| 36 |
+
|
| 37 |
+
Example:
|
| 38 |
+
[START] task=click-test env=miniwob model=Qwen3-VL-30B
|
| 39 |
+
[STEP] step=1 action=click('123') reward=0.00 done=false error=null
|
| 40 |
+
[STEP] step=2 action=fill('456','text') reward=0.00 done=false error=null
|
| 41 |
+
[STEP] step=3 action=click('789') reward=1.00 done=true error=null
|
| 42 |
+
[END] success=true steps=3 score=1.00 rewards=0.00,0.00,1.00
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
import asyncio
|
| 46 |
+
import os
|
| 47 |
+
import textwrap
|
| 48 |
+
from typing import List, Optional
|
| 49 |
+
|
| 50 |
+
from openai import OpenAI
|
| 51 |
+
|
| 52 |
+
from my_env_v4 import MyEnvV4Action, MyEnvV4Env
|
| 53 |
+
IMAGE_NAME = os.getenv("IMAGE_NAME") # If you are using docker image
|
| 54 |
+
API_KEY = os.getenv("HF_TOKEN") or os.getenv("API_KEY")
|
| 55 |
+
|
| 56 |
+
API_BASE_URL = os.getenv("API_BASE_URL") or "https://router.huggingface.co/v1"
|
| 57 |
+
MODEL_NAME = os.getenv("MODEL_NAME") or "Qwen/Qwen2.5-72B-Instruct"
|
| 58 |
+
TASK_NAME = os.getenv("MY_ENV_V4_TASK", "echo")
|
| 59 |
+
BENCHMARK = os.getenv("MY_ENV_V4_BENCHMARK", "my_env_v4")
|
| 60 |
+
MAX_STEPS = 8
|
| 61 |
+
TEMPERATURE = 0.7
|
| 62 |
+
MAX_TOKENS = 150
|
| 63 |
+
SUCCESS_SCORE_THRESHOLD = 0.1 # normalized score in [0, 1]
|
| 64 |
+
|
| 65 |
+
# Max possible reward: each token contributes 0.1, across all steps
|
| 66 |
+
_MAX_REWARD_PER_STEP = MAX_TOKENS * 0.1
|
| 67 |
+
MAX_TOTAL_REWARD = MAX_STEPS * _MAX_REWARD_PER_STEP
|
| 68 |
+
|
| 69 |
+
SYSTEM_PROMPT = textwrap.dedent(
|
| 70 |
+
"""
|
| 71 |
+
You are interacting with a simple echo environment.
|
| 72 |
+
Each turn you must send a message. The environment will echo it back.
|
| 73 |
+
Reward is proportional to message length: reward = len(message) * 0.1
|
| 74 |
+
Your goal is to maximize total reward by sending meaningful, substantive messages.
|
| 75 |
+
Reply with exactly one message string — no quotes, no prefixes, just the message text.
|
| 76 |
+
"""
|
| 77 |
+
).strip()
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def log_start(task: str, env: str, model: str) -> None:
|
| 81 |
+
print(f"[START] task={task} env={env} model={model}", flush=True)
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def log_step(step: int, action: str, reward: float, done: bool, error: Optional[str]) -> None:
|
| 85 |
+
error_val = error if error else "null"
|
| 86 |
+
done_val = str(done).lower()
|
| 87 |
+
print(
|
| 88 |
+
f"[STEP] step={step} action={action} reward={reward:.2f} done={done_val} error={error_val}",
|
| 89 |
+
flush=True,
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def log_end(success: bool, steps: int, score: float, rewards: List[float]) -> None:
|
| 94 |
+
rewards_str = ",".join(f"{r:.2f}" for r in rewards)
|
| 95 |
+
print(f"[END] success={str(success).lower()} steps={steps} score={score:.3f} rewards={rewards_str}", flush=True)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def build_user_prompt(step: int, last_echoed: str, last_reward: float, history: List[str]) -> str:
|
| 99 |
+
history_block = "\n".join(history[-4:]) if history else "None"
|
| 100 |
+
return textwrap.dedent(
|
| 101 |
+
f"""
|
| 102 |
+
Step: {step}
|
| 103 |
+
Last echoed message: {last_echoed!r}
|
| 104 |
+
Last reward: {last_reward:.2f}
|
| 105 |
+
Previous steps:
|
| 106 |
+
{history_block}
|
| 107 |
+
Send your next message.
|
| 108 |
+
"""
|
| 109 |
+
).strip()
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def get_model_message(client: OpenAI, step: int, last_echoed: str, last_reward: float, history: List[str]) -> str:
|
| 113 |
+
user_prompt = build_user_prompt(step, last_echoed, last_reward, history)
|
| 114 |
+
try:
|
| 115 |
+
completion = client.chat.completions.create(
|
| 116 |
+
model=MODEL_NAME,
|
| 117 |
+
messages=[
|
| 118 |
+
{"role": "system", "content": SYSTEM_PROMPT},
|
| 119 |
+
{"role": "user", "content": user_prompt},
|
| 120 |
+
],
|
| 121 |
+
temperature=TEMPERATURE,
|
| 122 |
+
max_tokens=MAX_TOKENS,
|
| 123 |
+
stream=False,
|
| 124 |
+
)
|
| 125 |
+
text = (completion.choices[0].message.content or "").strip()
|
| 126 |
+
return text if text else "hello"
|
| 127 |
+
except Exception as exc:
|
| 128 |
+
print(f"[DEBUG] Model request failed: {exc}", flush=True)
|
| 129 |
+
return "hello"
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
async def main() -> None:
|
| 133 |
+
client = OpenAI(base_url=API_BASE_URL, api_key=API_KEY)
|
| 134 |
+
|
| 135 |
+
env = await MyEnvV4Env.from_docker_image(IMAGE_NAME)
|
| 136 |
+
|
| 137 |
+
history: List[str] = []
|
| 138 |
+
rewards: List[float] = []
|
| 139 |
+
steps_taken = 0
|
| 140 |
+
score = 0.0
|
| 141 |
+
success = False
|
| 142 |
+
|
| 143 |
+
log_start(task=TASK_NAME, env=BENCHMARK, model=MODEL_NAME)
|
| 144 |
+
|
| 145 |
+
try:
|
| 146 |
+
result = await env.reset() # OpenENV.reset()
|
| 147 |
+
last_echoed = result.observation.echoed_message
|
| 148 |
+
last_reward = 0.0
|
| 149 |
+
|
| 150 |
+
for step in range(1, MAX_STEPS + 1):
|
| 151 |
+
if result.done:
|
| 152 |
+
break
|
| 153 |
+
|
| 154 |
+
message = get_model_message(client, step, last_echoed, last_reward, history)
|
| 155 |
+
|
| 156 |
+
result = await env.step(MyEnvV4Action(message=message))
|
| 157 |
+
obs = result.observation
|
| 158 |
+
|
| 159 |
+
reward = result.reward or 0.0
|
| 160 |
+
done = result.done
|
| 161 |
+
error = None
|
| 162 |
+
|
| 163 |
+
rewards.append(reward)
|
| 164 |
+
steps_taken = step
|
| 165 |
+
last_echoed = obs.echoed_message
|
| 166 |
+
last_reward = reward
|
| 167 |
+
|
| 168 |
+
log_step(step=step, action=message, reward=reward, done=done, error=error)
|
| 169 |
+
|
| 170 |
+
history.append(f"Step {step}: {message!r} -> reward {reward:+.2f}")
|
| 171 |
+
|
| 172 |
+
if done:
|
| 173 |
+
break
|
| 174 |
+
|
| 175 |
+
score = sum(rewards) / MAX_TOTAL_REWARD if MAX_TOTAL_REWARD > 0 else 0.0
|
| 176 |
+
score = min(max(score, 0.0), 1.0) # clamp to [0, 1]
|
| 177 |
+
success = score >= SUCCESS_SCORE_THRESHOLD
|
| 178 |
+
|
| 179 |
+
finally:
|
| 180 |
+
try:
|
| 181 |
+
await env.close()
|
| 182 |
+
except Exception as e:
|
| 183 |
+
print(f"[DEBUG] env.close() error (container cleanup): {e}", flush=True)
|
| 184 |
+
log_end(success=success, steps=steps_taken, score=score, rewards=rewards)
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
if __name__ == "__main__":
|
| 188 |
+
asyncio.run(main())
|
| 189 |
+
|
docs/competiton-round1/objective.md
ADDED
|
@@ -0,0 +1,581 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
step 1
|
| 2 |
+
|
| 3 |
+
How will you compete?
|
| 4 |
+
|
| 5 |
+
Choose solo or team before you can start the assessment
|
| 6 |
+
|
| 7 |
+
Step 1 Complete
|
| 8 |
+
Competing as Solo Warrior
|
| 9 |
+
|
| 10 |
+
👤
|
| 11 |
+
Sanjayprasad H S
|
| 12 |
+
sanjuhs123@gmail.com
|
| 13 |
+
🔒
|
| 14 |
+
Locked for Round 1. You cannot switch to a team until Round 1 is over.
|
| 15 |
+
|
| 16 |
+
OpenEnv Round 1 Bootcamp
|
| 17 |
+
|
| 18 |
+
OpenEnv Round 1 Bootcamp
|
| 19 |
+
|
| 20 |
+
OpenEnv Round 1 Bootcamp
|
| 21 |
+
|
| 22 |
+
OpenEnv Round 1 Bootcamp
|
| 23 |
+
|
| 24 |
+
OpenEnv Round 1 Bootcamp
|
| 25 |
+
|
| 26 |
+
OpenEnv Round 1 Bootcamp
|
| 27 |
+
|
| 28 |
+
OpenEnv Round 1 Bootcamp
|
| 29 |
+
|
| 30 |
+
OpenEnv Round 1 Bootcamp
|
| 31 |
+
|
| 32 |
+
OpenEnv Round 1 Bootcamp
|
| 33 |
+
|
| 34 |
+
OpenEnv Round 1 Bootcamp
|
| 35 |
+
|
| 36 |
+
OpenEnv Round 1 Bootcamp
|
| 37 |
+
|
| 38 |
+
OpenEnv Round 1 Bootcamp
|
| 39 |
+
|
| 40 |
+
OpenEnv Round 1 Bootcamp: Build Your First RL Environment
|
| 41 |
+
|
| 42 |
+
Live walkthrough to submit a strong Round 1 entry
|
| 43 |
+
|
| 44 |
+
timing
|
| 45 |
+
|
| 46 |
+
8:00 PM Onwards
|
| 47 |
+
|
| 48 |
+
Wednesday, 1st April
|
| 49 |
+
|
| 50 |
+
Host
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
Ben Burtenshaw
|
| 54 |
+
|
| 55 |
+
Community Education in AI at Hugging Face
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
Pulkit Aneja
|
| 59 |
+
|
| 60 |
+
Scaler Instructor
|
| 61 |
+
|
| 62 |
+
Watch Recording
|
| 63 |
+
|
| 64 |
+
PROBLEM STATEMENT
|
| 65 |
+
|
| 66 |
+
Round 1 — Problem Statement
|
| 67 |
+
|
| 68 |
+
The Task
|
| 69 |
+
|
| 70 |
+
Build a complete, real-world OpenEnv environment that an AI agent can learn from through the standard step() / reset() / state() API.
|
| 71 |
+
|
| 72 |
+
Key Requirements at a Glance
|
| 73 |
+
|
| 74 |
+
Must simulate a real-world task (not games or toys)
|
| 75 |
+
|
| 76 |
+
Implement full OpenEnv spec: typed models, step()/reset()/state(), openenv.yaml
|
| 77 |
+
|
| 78 |
+
Minimum 3 tasks with agent graders (easy → medium → hard, scores/reward 0.0–1.0)
|
| 79 |
+
|
| 80 |
+
Meaningful reward function with partial progress signals
|
| 81 |
+
|
| 82 |
+
Baseline inference script with reproducible scores
|
| 83 |
+
|
| 84 |
+
Deploy to Hugging Face Spaces + working Dockerfile
|
| 85 |
+
|
| 86 |
+
README with environment description, action/observation spaces, setup instructions
|
| 87 |
+
|
| 88 |
+
Functional Requirements
|
| 89 |
+
|
| 90 |
+
Real-world task simulation
|
| 91 |
+
|
| 92 |
+
The environment must simulate a task humans actually do. Not games, not toys. Examples: email triage, code review, data cleaning, scheduling, customer support, content moderation.
|
| 93 |
+
|
| 94 |
+
OpenEnv spec compliance
|
| 95 |
+
|
| 96 |
+
Implement the full OpenEnv interface: typed Observation, Action, and Reward Pydantic models. step(action) → returns observation, reward, done, info. reset() → returns initial observation. state() → returns current state. openenv.yaml with metadata. Tested via openenv validate.
|
| 97 |
+
|
| 98 |
+
Minimum 3 tasks with agent graders
|
| 99 |
+
|
| 100 |
+
Each task defines a concrete objective an agent must accomplish, with a programmatic grader that scores performance (0.0–1.0). Tasks should range: easy → medium → hard. Graders must have clear, deterministic success/failure criteria.
|
| 101 |
+
|
| 102 |
+
Meaningful reward function
|
| 103 |
+
|
| 104 |
+
Provides signal over the full trajectory (not just binary end-of-episode). Rewards partial progress toward task completion. Penalizes clearly undesirable behavior (e.g. infinite loops, destructive actions).
|
| 105 |
+
|
| 106 |
+
Baseline inference script
|
| 107 |
+
|
| 108 |
+
Uses the OpenAI API client to run a model against the environment. Reads API credentials from environment variables (OPENAI_API_KEY). Produces a reproducible baseline score on all 3 tasks.
|
| 109 |
+
|
| 110 |
+
Detailed Requirements
|
| 111 |
+
|
| 112 |
+
Non-Functional Requirements
|
| 113 |
+
|
| 114 |
+
Deploys to a Hugging Face Space
|
| 115 |
+
|
| 116 |
+
Environment must run as a containerized HF Space tagged with openenv.
|
| 117 |
+
|
| 118 |
+
Containerized execution
|
| 119 |
+
|
| 120 |
+
Must include a working Dockerfile. The environment should start cleanly with docker build + docker run.
|
| 121 |
+
|
| 122 |
+
Documentation
|
| 123 |
+
|
| 124 |
+
README must include: environment description and motivation, action and observation space definitions, task descriptions with expected difficulty, setup and usage instructions, baseline scores.
|
| 125 |
+
|
| 126 |
+
Parameter
|
| 127 |
+
|
| 128 |
+
Weight
|
| 129 |
+
|
| 130 |
+
Description
|
| 131 |
+
|
| 132 |
+
Real-world utility
|
| 133 |
+
|
| 134 |
+
30%
|
| 135 |
+
|
| 136 |
+
Does the environment model a genuine task? Would someone actually use this to train or evaluate agents?
|
| 137 |
+
|
| 138 |
+
Task & grader quality
|
| 139 |
+
|
| 140 |
+
25%
|
| 141 |
+
|
| 142 |
+
Are tasks well-defined with clear objectives? Do graders accurately and fairly measure success? Meaningful difficulty progression?
|
| 143 |
+
|
| 144 |
+
Environment design
|
| 145 |
+
|
| 146 |
+
20%
|
| 147 |
+
|
| 148 |
+
Clean state management, sensible action/observation spaces, good reward shaping, proper episode boundaries.
|
| 149 |
+
|
| 150 |
+
Code quality & spec compliance
|
| 151 |
+
|
| 152 |
+
15%
|
| 153 |
+
|
| 154 |
+
Follows OpenEnv spec, clean project structure, typed models, documented, tested, Dockerfile works.
|
| 155 |
+
|
| 156 |
+
Creativity & novelty
|
| 157 |
+
|
| 158 |
+
10%
|
| 159 |
+
|
| 160 |
+
Novel problem domain, interesting mechanics, clever reward design, original approach.
|
| 161 |
+
|
| 162 |
+
Scoring Breakdown
|
| 163 |
+
|
| 164 |
+
Real-world utility (30%)
|
| 165 |
+
|
| 166 |
+
• 0–5: Toy/artificial problem with no practical application
|
| 167 |
+
|
| 168 |
+
• 6–15: Valid domain but shallow modeling of the real task
|
| 169 |
+
|
| 170 |
+
• 16–25: Good domain modeling, would be useful for agent evaluation
|
| 171 |
+
|
| 172 |
+
• 26–30: Excellent — fills a real gap, immediate value for the RL/agent community
|
| 173 |
+
|
| 174 |
+
Task & grader quality (25%)
|
| 175 |
+
|
| 176 |
+
• 3+ tasks with difficulty range?
|
| 177 |
+
|
| 178 |
+
• Graders produce scores between 0.0–1.0?
|
| 179 |
+
|
| 180 |
+
• Graders deterministic and reproducible?
|
| 181 |
+
|
| 182 |
+
• Hard task genuinely challenges frontier models?
|
| 183 |
+
|
| 184 |
+
Environment design (20%)
|
| 185 |
+
|
| 186 |
+
• reset() produces clean state?
|
| 187 |
+
|
| 188 |
+
• Action/observation types well-designed and documented?
|
| 189 |
+
|
| 190 |
+
• Reward function provides useful varying signal (not just sparse)?
|
| 191 |
+
|
| 192 |
+
• Episode boundaries sensible?
|
| 193 |
+
|
| 194 |
+
Code quality & spec compliance (15%)
|
| 195 |
+
|
| 196 |
+
• openenv validate passes?
|
| 197 |
+
|
| 198 |
+
• docker build && docker run works?
|
| 199 |
+
|
| 200 |
+
• HF Space deploys and responds?
|
| 201 |
+
|
| 202 |
+
• Baseline script runs and reproduces scores?
|
| 203 |
+
|
| 204 |
+
Creativity & novelty (10%)
|
| 205 |
+
|
| 206 |
+
• Domain we haven’t seen in OpenEnv before?
|
| 207 |
+
|
| 208 |
+
• Reward design has interesting properties?
|
| 209 |
+
|
| 210 |
+
• Clever mechanics that make the environment engaging?
|
| 211 |
+
|
| 212 |
+
Evaluation Criteria
|
| 213 |
+
|
| 214 |
+
Phase 1: Automated Validation
|
| 215 |
+
|
| 216 |
+
Pass/fail gate — HF Space deploys, OpenEnv spec compliance, Dockerfile builds, baseline reproduces, 3+ tasks with graders.
|
| 217 |
+
|
| 218 |
+
Phase 2: Agentic Evaluation
|
| 219 |
+
|
| 220 |
+
Scored — baseline agent re-run, standard Open LLM agent (e.g. Nemotron 3 Super) run against all environments, score variance check.
|
| 221 |
+
|
| 222 |
+
Phase 3: Human Review
|
| 223 |
+
|
| 224 |
+
Top submissions reviewed by Meta and Hugging Face engineers for real-world utility, creativity, and exploit checks.
|
| 225 |
+
|
| 226 |
+
Disqualification Criteria
|
| 227 |
+
|
| 228 |
+
Environment does not deploy or respond
|
| 229 |
+
|
| 230 |
+
Plagiarized or trivially modified existing environments
|
| 231 |
+
|
| 232 |
+
Graders that always return the same score
|
| 233 |
+
|
| 234 |
+
No baseline inference script
|
| 235 |
+
|
| 236 |
+
How Judging works
|
| 237 |
+
|
| 238 |
+
Pre-Submission Checklist — all must pass or you're disqualified
|
| 239 |
+
|
| 240 |
+
HF Space deploys
|
| 241 |
+
|
| 242 |
+
Automated ping to the Space URL — must return 200 and respond to reset()
|
| 243 |
+
|
| 244 |
+
OpenEnv spec compliance
|
| 245 |
+
|
| 246 |
+
Validate openenv.yaml, typed models, step()/reset()/state() endpoints
|
| 247 |
+
|
| 248 |
+
Dockerfile builds
|
| 249 |
+
|
| 250 |
+
Automated docker build on the submitted repo
|
| 251 |
+
|
| 252 |
+
Baseline reproduces
|
| 253 |
+
|
| 254 |
+
Run the submitted inference script — must complete without error and produce scores
|
| 255 |
+
|
| 256 |
+
3+ tasks with graders
|
| 257 |
+
|
| 258 |
+
Enumerate tasks, run each grader, verify scores/reward in 0.0–1.0 range
|
| 259 |
+
|
| 260 |
+
Mandatory Additional Instructions
|
| 261 |
+
|
| 262 |
+
Before submitting, ensure the following variables are defined in your environment configuration:
|
| 263 |
+
|
| 264 |
+
API_BASE_URL The API endpoint for the LLM.
|
| 265 |
+
|
| 266 |
+
MODEL_NAME The model identifier to use for inference.
|
| 267 |
+
|
| 268 |
+
HF_TOKEN Your Hugging Face / API key.
|
| 269 |
+
|
| 270 |
+
The inference script must be named `inference.py` and placed in the root directory of the project
|
| 271 |
+
|
| 272 |
+
Participants must use OpenAI Client for all LLM calls using above variables
|
| 273 |
+
|
| 274 |
+
Participants must emit structured stdout logs strictly following the [START], [STEP], and [END] format defined in the sample inference.py provided below. Any deviation in field names, ordering, or formatting will result in incorrect evaluation scoring. Refer to the Sample Inference Script for the complete format specification and examples.
|
| 275 |
+
|
| 276 |
+
Infra Restrictions
|
| 277 |
+
|
| 278 |
+
Runtime of inference script should be less than 20min
|
| 279 |
+
|
| 280 |
+
Make sure your env and inference can run on a machine with vcpu=2, memory=8gb
|
| 281 |
+
|
| 282 |
+
Validator
|
| 283 |
+
|
| 284 |
+
Run the pre-submission validation script before submitting
|
| 285 |
+
|
| 286 |
+
NEW
|
| 287 |
+
Sample Inference Script
|
| 288 |
+
|
| 289 |
+
"""
|
| 290 |
+
return text if text else "hello"
|
| 291 |
+
except Exception as exc:
|
| 292 |
+
print(f"[DEBUG] Model request failed: {exc}", flush=True)
|
| 293 |
+
return "hello"
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
async def main() -> None:
|
| 297 |
+
client = OpenAI(base_url=API_BASE_URL, api_key=API_KEY)
|
| 298 |
+
|
| 299 |
+
env = await MyEnvV4Env.from_docker_image(IMAGE_NAME)
|
| 300 |
+
|
| 301 |
+
history: List[str] = []
|
| 302 |
+
rewards: List[float] = []
|
| 303 |
+
steps_taken = 0
|
| 304 |
+
score = 0.0
|
| 305 |
+
success = False
|
| 306 |
+
|
| 307 |
+
log_start(task=TASK_NAME, env=BENCHMARK, model=MODEL_NAME)
|
| 308 |
+
|
| 309 |
+
try:
|
| 310 |
+
result = await env.reset() # OpenENV.reset()
|
| 311 |
+
last_echoed = result.observation.echoed_message
|
| 312 |
+
last_reward = 0.0
|
| 313 |
+
|
| 314 |
+
for step in range(1, MAX_STEPS + 1):
|
| 315 |
+
if result.done:
|
| 316 |
+
break
|
| 317 |
+
|
| 318 |
+
message = get_model_message(client, step, last_echoed, last_reward, history)
|
| 319 |
+
|
| 320 |
+
result = await env.step(MyEnvV4Action(message=message))
|
| 321 |
+
obs = result.observation
|
| 322 |
+
|
| 323 |
+
reward = result.reward or 0.0
|
| 324 |
+
done = result.done
|
| 325 |
+
error = None
|
| 326 |
+
|
| 327 |
+
rewards.append(reward)
|
| 328 |
+
steps_taken = step
|
| 329 |
+
last_echoed = obs.echoed_message
|
| 330 |
+
last_reward = reward
|
| 331 |
+
|
| 332 |
+
log_step(step=step, action=message, reward=reward, done=done, error=error)
|
| 333 |
+
|
| 334 |
+
history.append(f"Step {step}: {message!r} -> reward {reward:+.2f}")
|
| 335 |
+
|
| 336 |
+
if done:
|
| 337 |
+
break
|
| 338 |
+
|
| 339 |
+
score = sum(rewards) / MAX_TOTAL_REWARD if MAX_TOTAL_REWARD > 0 else 0.0
|
| 340 |
+
score = min(max(score, 0.0), 1.0) # clamp to [0, 1]
|
| 341 |
+
success = score >= SUCCESS_SCORE_THRESHOLD
|
| 342 |
+
|
| 343 |
+
finally:
|
| 344 |
+
try:
|
| 345 |
+
await env.close()
|
| 346 |
+
except Exception as e:
|
| 347 |
+
print(f"[DEBUG] env.close() error (container cleanup): {e}", flush=True)
|
| 348 |
+
log_end(success=success, steps=steps_taken, score=score, rewards=rewards)
|
| 349 |
+
|
| 350 |
+
|
| 351 |
+
if __name__ == "__main__":
|
| 352 |
+
asyncio.run(main())
|
| 353 |
+
NEW
|
| 354 |
+
Pre Validation Script
|
| 355 |
+
|
| 356 |
+
#!/usr/bin/env bash
|
| 357 |
+
fail "HF Space not reachable (connection failed or timed out)"
|
| 358 |
+
hint "Check your network connection and that the Space is running."
|
| 359 |
+
hint "Try: curl -s -o /dev/null -w '%%{http_code}' -X POST $PING_URL/reset"
|
| 360 |
+
stop_at "Step 1"
|
| 361 |
+
else
|
| 362 |
+
fail "HF Space /reset returned HTTP $HTTP_CODE (expected 200)"
|
| 363 |
+
hint "Make sure your Space is running and the URL is correct."
|
| 364 |
+
hint "Try opening $PING_URL in your browser first."
|
| 365 |
+
stop_at "Step 1"
|
| 366 |
+
fi
|
| 367 |
+
|
| 368 |
+
log "${BOLD}Step 2/3: Running docker build${NC} ..."
|
| 369 |
+
|
| 370 |
+
if ! command -v docker &>/dev/null; then
|
| 371 |
+
fail "docker command not found"
|
| 372 |
+
hint "Install Docker: https://docs.docker.com/get-docker/"
|
| 373 |
+
stop_at "Step 2"
|
| 374 |
+
fi
|
| 375 |
+
|
| 376 |
+
if [ -f "$REPO_DIR/Dockerfile" ]; then
|
| 377 |
+
DOCKER_CONTEXT="$REPO_DIR"
|
| 378 |
+
elif [ -f "$REPO_DIR/server/Dockerfile" ]; then
|
| 379 |
+
DOCKER_CONTEXT="$REPO_DIR/server"
|
| 380 |
+
else
|
| 381 |
+
fail "No Dockerfile found in repo root or server/ directory"
|
| 382 |
+
stop_at "Step 2"
|
| 383 |
+
fi
|
| 384 |
+
|
| 385 |
+
log " Found Dockerfile in $DOCKER_CONTEXT"
|
| 386 |
+
|
| 387 |
+
BUILD_OK=false
|
| 388 |
+
BUILD_OUTPUT=$(run_with_timeout "$DOCKER_BUILD_TIMEOUT" docker build "$DOCKER_CONTEXT" 2>&1) && BUILD_OK=true
|
| 389 |
+
|
| 390 |
+
if [ "$BUILD_OK" = true ]; then
|
| 391 |
+
pass "Docker build succeeded"
|
| 392 |
+
else
|
| 393 |
+
fail "Docker build failed (timeout=${DOCKER_BUILD_TIMEOUT}s)"
|
| 394 |
+
printf "%s\n" "$BUILD_OUTPUT" | tail -20
|
| 395 |
+
stop_at "Step 2"
|
| 396 |
+
fi
|
| 397 |
+
|
| 398 |
+
log "${BOLD}Step 3/3: Running openenv validate${NC} ..."
|
| 399 |
+
|
| 400 |
+
if ! command -v openenv &>/dev/null; then
|
| 401 |
+
fail "openenv command not found"
|
| 402 |
+
hint "Install it: pip install openenv-core"
|
| 403 |
+
stop_at "Step 3"
|
| 404 |
+
fi
|
| 405 |
+
|
| 406 |
+
VALIDATE_OK=false
|
| 407 |
+
VALIDATE_OUTPUT=$(cd "$REPO_DIR" && openenv validate 2>&1) && VALIDATE_OK=true
|
| 408 |
+
|
| 409 |
+
if [ "$VALIDATE_OK" = true ]; then
|
| 410 |
+
pass "openenv validate passed"
|
| 411 |
+
[ -n "$VALIDATE_OUTPUT" ] && log " $VALIDATE_OUTPUT"
|
| 412 |
+
else
|
| 413 |
+
fail "openenv validate failed"
|
| 414 |
+
printf "%s\n" "$VALIDATE_OUTPUT"
|
| 415 |
+
stop_at "Step 3"
|
| 416 |
+
fi
|
| 417 |
+
|
| 418 |
+
printf "\n"
|
| 419 |
+
printf "${BOLD}========================================${NC}\n"
|
| 420 |
+
printf "${GREEN}${BOLD} All 3/3 checks passed!${NC}\n"
|
| 421 |
+
printf "${GREEN}${BOLD} Your submission is ready to submit.${NC}\n"
|
| 422 |
+
printf "${BOLD}========================================${NC}\n"
|
| 423 |
+
printf "\n"
|
| 424 |
+
|
| 425 |
+
exit 0
|
| 426 |
+
Submission window opens on 28th March
|
| 427 |
+
|
| 428 |
+
Deadline: 8 Apr 11:59 PM
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
Submit your Assessment
|
| 432 |
+
→
|
| 433 |
+
Study material
|
| 434 |
+
|
| 435 |
+
Preparatory Course
|
| 436 |
+
|
| 437 |
+
4 modules · ~3.5 hours
|
| 438 |
+
|
| 439 |
+
Each module: read the README first, then open the notebook in Colab. No local setup needed.
|
| 440 |
+
|
| 441 |
+
|
| 442 |
+
What you'll do
|
| 443 |
+
|
| 444 |
+
Connect to 3 real AI environments hosted online — an Echo bot, a Catch game, and Wordle — and interact with each using the exact same code pattern.
|
| 445 |
+
|
| 446 |
+
Read Concept
|
| 447 |
+
|
| 448 |
+
Module 1: Why OpenEnv?
|
| 449 |
+
|
| 450 |
+
ESSENTIAL FOR ROUND 1
|
| 451 |
+
|
| 452 |
+
45 min
|
| 453 |
+
|
| 454 |
+
|
| 455 |
+
What you'll do
|
| 456 |
+
|
| 457 |
+
Write 4 different game-playing strategies for a Catch game, run a competition between them, then switch to a completely different game using the same code.
|
| 458 |
+
|
| 459 |
+
Read Concept
|
| 460 |
+
|
| 461 |
+
Module 2: Using Existing Environments
|
| 462 |
+
|
| 463 |
+
ESSENTIAL FOR ROUND 1
|
| 464 |
+
|
| 465 |
+
50 min
|
| 466 |
+
|
| 467 |
+
|
| 468 |
+
What you'll do
|
| 469 |
+
|
| 470 |
+
Clone an existing environment, modify it, run it on your machine, then deploy your version live to Hugging Face Spaces with one command.
|
| 471 |
+
|
| 472 |
+
Read Concept
|
| 473 |
+
|
| 474 |
+
Module 3: Deploying Environments
|
| 475 |
+
|
| 476 |
+
ESSENTIAL FOR ROUND 1
|
| 477 |
+
|
| 478 |
+
45 min
|
| 479 |
+
|
| 480 |
+
|
| 481 |
+
What you'll do
|
| 482 |
+
|
| 483 |
+
Build a complete word-guessing game environment from scratch — define the rules, implement the logic, test it locally, and deploy it live. About 100 lines of real code.
|
| 484 |
+
|
| 485 |
+
Read Concept
|
| 486 |
+
|
| 487 |
+
Module 4: Building Your Own Environment
|
| 488 |
+
|
| 489 |
+
MOST IMPORTANT FOR ROUND 1
|
| 490 |
+
|
| 491 |
+
60 min
|
| 492 |
+
|
| 493 |
+
View full course repository
|
| 494 |
+
|
| 495 |
+
GUIDE
|
| 496 |
+
|
| 497 |
+
Round 1 Guide
|
| 498 |
+
|
| 499 |
+
What to Expect
|
| 500 |
+
|
| 501 |
+
Prerequisites
|
| 502 |
+
|
| 503 |
+
How to Submit
|
| 504 |
+
|
| 505 |
+
When Round 1 starts on 1 April:
|
| 506 |
+
|
| 507 |
+
Step 1
|
| 508 |
+
|
| 509 |
+
Application Form
|
| 510 |
+
Choose 1 of the 4–5 problem statements revealed on the platform.
|
| 511 |
+
|
| 512 |
+
Step 2
|
| 513 |
+
|
| 514 |
+
Scaffold
|
| 515 |
+
$
|
| 516 |
+
openenv init my_env
|
| 517 |
+
Copy
|
| 518 |
+
Generate project structure.
|
| 519 |
+
|
| 520 |
+
Step 3
|
| 521 |
+
|
| 522 |
+
Build
|
| 523 |
+
Define your environment in the generated files.
|
| 524 |
+
|
| 525 |
+
Step 4
|
| 526 |
+
|
| 527 |
+
Test locally
|
| 528 |
+
$
|
| 529 |
+
uv run server
|
| 530 |
+
Copy
|
| 531 |
+
Step 5
|
| 532 |
+
|
| 533 |
+
Deploy
|
| 534 |
+
$
|
| 535 |
+
openenv push --repo-id your-username/my-env
|
| 536 |
+
Copy
|
| 537 |
+
Step 6
|
| 538 |
+
|
| 539 |
+
Submit
|
| 540 |
+
Paste your HF Spaces URL here before the deadline.
|
| 541 |
+
|
| 542 |
+
Deadline: 8 April 2026, 11:59 PM IST
|
| 543 |
+
|
| 544 |
+
Step 2
|
| 545 |
+
|
| 546 |
+
Submit your Assessment
|
| 547 |
+
|
| 548 |
+
Complete Step 1 first
|
| 549 |
+
|
| 550 |
+
Problem Statement is live. Build and submit.
|
| 551 |
+
|
| 552 |
+
Round 1 begins
|
| 553 |
+
|
| 554 |
+
Submission window opens on 28th March
|
| 555 |
+
|
| 556 |
+
Deadline: 8 Apr 11:59 PM
|
| 557 |
+
|
| 558 |
+
|
| 559 |
+
Submit your Assessment
|
| 560 |
+
→
|
| 561 |
+
NOTE: Only team leaders can make the final submission.
|
| 562 |
+
|
| 563 |
+
FAQs
|
| 564 |
+
|
| 565 |
+
Frequently Asked Questions
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
|
| 569 |
+
|
| 570 |
+
|
| 571 |
+
|
| 572 |
+
|
| 573 |
+
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
|
| 577 |
+
|
| 578 |
+
|
| 579 |
+
Need help? Reach out to us
|
| 580 |
+
|
| 581 |
+
help_openenvhackathon@scaler.com
|
docs/competiton-round1/pre-vaidationscript-example.md
ADDED
|
@@ -0,0 +1,185 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
#
|
| 3 |
+
# validate-submission.sh — OpenEnv Submission Validator
|
| 4 |
+
#
|
| 5 |
+
# Checks that your HF Space is live, Docker image builds, and openenv validate passes.
|
| 6 |
+
#
|
| 7 |
+
# Prerequisites:
|
| 8 |
+
# - Docker: https://docs.docker.com/get-docker/
|
| 9 |
+
# - openenv-core: pip install openenv-core
|
| 10 |
+
# - curl (usually pre-installed)
|
| 11 |
+
#
|
| 12 |
+
# Run:
|
| 13 |
+
# curl -fsSL https://raw.githubusercontent.com/<owner>/<repo>/main/scripts/validate-submission.sh | bash -s -- <ping_url> [repo_dir]
|
| 14 |
+
#
|
| 15 |
+
# Or download and run locally:
|
| 16 |
+
# chmod +x validate-submission.sh
|
| 17 |
+
# ./validate-submission.sh <ping_url> [repo_dir]
|
| 18 |
+
#
|
| 19 |
+
# Arguments:
|
| 20 |
+
# ping_url Your HuggingFace Space URL (e.g. https://your-space.hf.space)
|
| 21 |
+
# repo_dir Path to your repo (default: current directory)
|
| 22 |
+
#
|
| 23 |
+
# Examples:
|
| 24 |
+
# ./validate-submission.sh https://my-team.hf.space
|
| 25 |
+
# ./validate-submission.sh https://my-team.hf.space ./my-repo
|
| 26 |
+
#
|
| 27 |
+
|
| 28 |
+
set -uo pipefail
|
| 29 |
+
|
| 30 |
+
DOCKER_BUILD_TIMEOUT=600
|
| 31 |
+
if [ -t 1 ]; then
|
| 32 |
+
RED='\033[0;31m'
|
| 33 |
+
GREEN='\033[0;32m'
|
| 34 |
+
YELLOW='\033[1;33m'
|
| 35 |
+
BOLD='\033[1m'
|
| 36 |
+
NC='\033[0m'
|
| 37 |
+
else
|
| 38 |
+
RED='' GREEN='' YELLOW='' BOLD='' NC=''
|
| 39 |
+
fi
|
| 40 |
+
|
| 41 |
+
run_with_timeout() {
|
| 42 |
+
local secs="$1"; shift
|
| 43 |
+
if command -v timeout &>/dev/null; then
|
| 44 |
+
timeout "$secs" "$@"
|
| 45 |
+
elif command -v gtimeout &>/dev/null; then
|
| 46 |
+
gtimeout "$secs" "$@"
|
| 47 |
+
else
|
| 48 |
+
"$@" &
|
| 49 |
+
local pid=$!
|
| 50 |
+
( sleep "$secs" && kill "$pid" 2>/dev/null ) &
|
| 51 |
+
local watcher=$!
|
| 52 |
+
wait "$pid" 2>/dev/null
|
| 53 |
+
local rc=$?
|
| 54 |
+
kill "$watcher" 2>/dev/null
|
| 55 |
+
wait "$watcher" 2>/dev/null
|
| 56 |
+
return $rc
|
| 57 |
+
fi
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
portable_mktemp() {
|
| 61 |
+
local prefix="${1:-validate}"
|
| 62 |
+
mktemp "${TMPDIR:-/tmp}/${prefix}-XXXXXX" 2>/dev/null || mktemp
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
CLEANUP_FILES=()
|
| 66 |
+
cleanup() { rm -f "${CLEANUP_FILES[@]+"${CLEANUP_FILES[@]}"}"; }
|
| 67 |
+
trap cleanup EXIT
|
| 68 |
+
|
| 69 |
+
PING_URL="${1:-}"
|
| 70 |
+
REPO_DIR="${2:-.}"
|
| 71 |
+
|
| 72 |
+
if [ -z "$PING_URL" ]; then
|
| 73 |
+
printf "Usage: %s <ping_url> [repo_dir]\n" "$0"
|
| 74 |
+
printf "\n"
|
| 75 |
+
printf " ping_url Your HuggingFace Space URL (e.g. https://your-space.hf.space)\n"
|
| 76 |
+
printf " repo_dir Path to your repo (default: current directory)\n"
|
| 77 |
+
exit 1
|
| 78 |
+
fi
|
| 79 |
+
|
| 80 |
+
if ! REPO_DIR="$(cd "$REPO_DIR" 2>/dev/null && pwd)"; then
|
| 81 |
+
printf "Error: directory '%s' not found\n" "${2:-.}"
|
| 82 |
+
exit 1
|
| 83 |
+
fi
|
| 84 |
+
PING_URL="${PING_URL%/}"
|
| 85 |
+
export PING_URL
|
| 86 |
+
PASS=0
|
| 87 |
+
|
| 88 |
+
log() { printf "[%s] %b\n" "$(date -u +%H:%M:%S)" "$*"; }
|
| 89 |
+
pass() { log "${GREEN}PASSED${NC} -- $1"; PASS=$((PASS + 1)); }
|
| 90 |
+
fail() { log "${RED}FAILED${NC} -- $1"; }
|
| 91 |
+
hint() { printf " ${YELLOW}Hint:${NC} %b\n" "$1"; }
|
| 92 |
+
stop_at() {
|
| 93 |
+
printf "\n"
|
| 94 |
+
printf "${RED}${BOLD}Validation stopped at %s.${NC} Fix the above before continuing.\n" "$1"
|
| 95 |
+
exit 1
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
printf "\n"
|
| 99 |
+
printf "${BOLD}========================================${NC}\n"
|
| 100 |
+
printf "${BOLD} OpenEnv Submission Validator${NC}\n"
|
| 101 |
+
printf "${BOLD}========================================${NC}\n"
|
| 102 |
+
log "Repo: $REPO_DIR"
|
| 103 |
+
log "Ping URL: $PING_URL"
|
| 104 |
+
printf "\n"
|
| 105 |
+
|
| 106 |
+
log "${BOLD}Step 1/3: Pinging HF Space${NC} ($PING_URL/reset) ..."
|
| 107 |
+
|
| 108 |
+
CURL_OUTPUT=$(portable_mktemp "validate-curl")
|
| 109 |
+
CLEANUP_FILES+=("$CURL_OUTPUT")
|
| 110 |
+
HTTP_CODE=$(curl -s -o "$CURL_OUTPUT" -w "%{http_code}" -X POST \
|
| 111 |
+
-H "Content-Type: application/json" -d '{}' \
|
| 112 |
+
"$PING_URL/reset" --max-time 30 2>"$CURL_OUTPUT" || printf "000")
|
| 113 |
+
|
| 114 |
+
if [ "$HTTP_CODE" = "200" ]; then
|
| 115 |
+
pass "HF Space is live and responds to /reset"
|
| 116 |
+
elif [ "$HTTP_CODE" = "000" ]; then
|
| 117 |
+
fail "HF Space not reachable (connection failed or timed out)"
|
| 118 |
+
hint "Check your network connection and that the Space is running."
|
| 119 |
+
hint "Try: curl -s -o /dev/null -w '%%{http_code}' -X POST $PING_URL/reset"
|
| 120 |
+
stop_at "Step 1"
|
| 121 |
+
else
|
| 122 |
+
fail "HF Space /reset returned HTTP $HTTP_CODE (expected 200)"
|
| 123 |
+
hint "Make sure your Space is running and the URL is correct."
|
| 124 |
+
hint "Try opening $PING_URL in your browser first."
|
| 125 |
+
stop_at "Step 1"
|
| 126 |
+
fi
|
| 127 |
+
|
| 128 |
+
log "${BOLD}Step 2/3: Running docker build${NC} ..."
|
| 129 |
+
|
| 130 |
+
if ! command -v docker &>/dev/null; then
|
| 131 |
+
fail "docker command not found"
|
| 132 |
+
hint "Install Docker: https://docs.docker.com/get-docker/"
|
| 133 |
+
stop_at "Step 2"
|
| 134 |
+
fi
|
| 135 |
+
|
| 136 |
+
if [ -f "$REPO_DIR/Dockerfile" ]; then
|
| 137 |
+
DOCKER_CONTEXT="$REPO_DIR"
|
| 138 |
+
elif [ -f "$REPO_DIR/server/Dockerfile" ]; then
|
| 139 |
+
DOCKER_CONTEXT="$REPO_DIR/server"
|
| 140 |
+
else
|
| 141 |
+
fail "No Dockerfile found in repo root or server/ directory"
|
| 142 |
+
stop_at "Step 2"
|
| 143 |
+
fi
|
| 144 |
+
|
| 145 |
+
log " Found Dockerfile in $DOCKER_CONTEXT"
|
| 146 |
+
|
| 147 |
+
BUILD_OK=false
|
| 148 |
+
BUILD_OUTPUT=$(run_with_timeout "$DOCKER_BUILD_TIMEOUT" docker build "$DOCKER_CONTEXT" 2>&1) && BUILD_OK=true
|
| 149 |
+
|
| 150 |
+
if [ "$BUILD_OK" = true ]; then
|
| 151 |
+
pass "Docker build succeeded"
|
| 152 |
+
else
|
| 153 |
+
fail "Docker build failed (timeout=${DOCKER_BUILD_TIMEOUT}s)"
|
| 154 |
+
printf "%s\n" "$BUILD_OUTPUT" | tail -20
|
| 155 |
+
stop_at "Step 2"
|
| 156 |
+
fi
|
| 157 |
+
|
| 158 |
+
log "${BOLD}Step 3/3: Running openenv validate${NC} ..."
|
| 159 |
+
|
| 160 |
+
if ! command -v openenv &>/dev/null; then
|
| 161 |
+
fail "openenv command not found"
|
| 162 |
+
hint "Install it: pip install openenv-core"
|
| 163 |
+
stop_at "Step 3"
|
| 164 |
+
fi
|
| 165 |
+
|
| 166 |
+
VALIDATE_OK=false
|
| 167 |
+
VALIDATE_OUTPUT=$(cd "$REPO_DIR" && openenv validate 2>&1) && VALIDATE_OK=true
|
| 168 |
+
|
| 169 |
+
if [ "$VALIDATE_OK" = true ]; then
|
| 170 |
+
pass "openenv validate passed"
|
| 171 |
+
[ -n "$VALIDATE_OUTPUT" ] && log " $VALIDATE_OUTPUT"
|
| 172 |
+
else
|
| 173 |
+
fail "openenv validate failed"
|
| 174 |
+
printf "%s\n" "$VALIDATE_OUTPUT"
|
| 175 |
+
stop_at "Step 3"
|
| 176 |
+
fi
|
| 177 |
+
|
| 178 |
+
printf "\n"
|
| 179 |
+
printf "${BOLD}========================================${NC}\n"
|
| 180 |
+
printf "${GREEN}${BOLD} All 3/3 checks passed!${NC}\n"
|
| 181 |
+
printf "${GREEN}${BOLD} Your submission is ready to submit.${NC}\n"
|
| 182 |
+
printf "${BOLD}========================================${NC}\n"
|
| 183 |
+
printf "\n"
|
| 184 |
+
|
| 185 |
+
exit 0
|
docs/detailed-blog/cadforge-detailed-blog.md
CHANGED
|
@@ -300,7 +300,7 @@ The model artifacts are on Hugging Face:
|
|
| 300 |
The raw evidence bundle is also public:
|
| 301 |
|
| 302 |
- Training logs and reports: [sanjuhs/cadforge-training-evidence](https://huggingface.co/datasets/sanjuhs/cadforge-training-evidence)
|
| 303 |
-
-
|
| 304 |
- Per-completion reward traces: `training/logs/*completions.jsonl`
|
| 305 |
- Parsed plots and metrics: `training/reports/*`
|
| 306 |
|
|
|
|
| 300 |
The raw evidence bundle is also public:
|
| 301 |
|
| 302 |
- Training logs and reports: [sanjuhs/cadforge-training-evidence](https://huggingface.co/datasets/sanjuhs/cadforge-training-evidence)
|
| 303 |
+
- Compressed archive on that dataset: `archives/cadforge-training-evidence-20260426.tar.gz`
|
| 304 |
- Per-completion reward traces: `training/logs/*completions.jsonl`
|
| 305 |
- Parsed plots and metrics: `training/reports/*`
|
| 306 |
|
docs/doc-edit-game-v2.md
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: DocEdit Game V2 — Document Editing RL Environment
|
| 3 |
+
emoji: 📄
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: docker
|
| 7 |
+
pinned: false
|
| 8 |
+
app_port: 8000
|
| 9 |
+
base_path: /web
|
| 10 |
+
tags:
|
| 11 |
+
- openenv
|
| 12 |
+
---
|
| 13 |
+
|
| 14 |
+
# DocEdit Game V2 — Production-Grade Document Editing RL Environment
|
| 15 |
+
|
| 16 |
+
Train applicator models to perform precise, fast edits on legal and pharmaceutical documents. Procedurally generated tasks with 6 document types, 12 corruption types, 16+ editing tools, and windowed navigation for documents of any size.
|
| 17 |
+
|
| 18 |
+
## The Problem We Solve
|
| 19 |
+
|
| 20 |
+
Legal and pharmaceutical professionals spend hours editing massive documents — contracts, affidavits, drug labels, clinical study reports. A frontier LLM can *decide* what edits to make, but executing 200 precise edits on a 2000-page XML document is too slow and expensive for GPT-4o. We train **applicator models** (1-7B params) that execute edits with near-perfect accuracy at 500x lower cost.
|
| 21 |
+
|
| 22 |
+
## Game Mechanics
|
| 23 |
+
|
| 24 |
+
1. **Reset**: Environment generates a document with procedural corruptions (spelling, case, names, formatting, PDF artifacts, junk chars)
|
| 25 |
+
2. **Observe**: Agent sees a document chunk + edit instruction + similarity score
|
| 26 |
+
3. **Act**: Agent calls one tool per step (replace, format, delete, merge_runs, clean_junk_chars, etc.)
|
| 27 |
+
4. **Reward**: Incremental similarity improvement to the hidden target, with bonuses for completion and penalties for collateral damage
|
| 28 |
+
5. **Win**: Achieve similarity ≥ 0.999
|
| 29 |
+
|
| 30 |
+
## Domains
|
| 31 |
+
|
| 32 |
+
| Domain | Document Types | Real-World Scenario |
|
| 33 |
+
|--------|---------------|-------------------|
|
| 34 |
+
| **Legal** | Contract, Affidavit, Case Brief | Redlining, name changes, section renumbering |
|
| 35 |
+
| **Pharmaceutical** | Drug Label, Clinical Study Report | Dosage updates, adverse reaction additions, regulatory formatting |
|
| 36 |
+
| **Business** | Business Report | Financial table fixes, executive summary edits |
|
| 37 |
+
|
| 38 |
+
## 12 Corruption Types (3 Tiers)
|
| 39 |
+
|
| 40 |
+
**Tier 1 — Content**: spelling, case, names, punctuation, content deletion, content insertion
|
| 41 |
+
**Tier 2 — Formatting**: formatting strip, formatting wrong, alignment, spacing
|
| 42 |
+
**Tier 3 — Artifacts**: PDF-to-DOCX fragmented runs, junk characters (zero-width spaces, BOMs)
|
| 43 |
+
|
| 44 |
+
## 16+ Tools (Agent Actions)
|
| 45 |
+
|
| 46 |
+
```json
|
| 47 |
+
{"tool": "replace", "params": {"target": "recieve", "content": "receive"}}
|
| 48 |
+
{"tool": "format_text", "params": {"target": "Important Notice", "format": "bold"}}
|
| 49 |
+
{"tool": "highlight", "params": {"target": "Section 3.2", "color": "yellow"}}
|
| 50 |
+
{"tool": "merge_runs", "params": {"line_index": 23}}
|
| 51 |
+
{"tool": "clean_junk_chars", "params": {}}
|
| 52 |
+
{"tool": "set_alignment", "params": {"line_index": 5, "alignment": "center"}}
|
| 53 |
+
{"tool": "scroll_to", "params": {"chunk": 47}}
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
## Observation Space
|
| 57 |
+
|
| 58 |
+
| Field | Type | Description |
|
| 59 |
+
|-------|------|-------------|
|
| 60 |
+
| `document_chunk` | str | Currently visible document chunk (XML) |
|
| 61 |
+
| `chunk_index` / `total_chunks` | int | Navigation position |
|
| 62 |
+
| `document_overview` | str | Heading index for navigation |
|
| 63 |
+
| `edit_instruction` | str | Natural language edit description |
|
| 64 |
+
| `similarity` | float | Overall similarity to target (0-1) |
|
| 65 |
+
| `collateral_damage` | float | Fraction of correct text accidentally damaged |
|
| 66 |
+
| `task_difficulty` | int | 1-6 severity level |
|
| 67 |
+
| `doc_type` / `domain` | str | Document template and domain |
|
| 68 |
+
|
| 69 |
+
## 5 Fixed Evaluation Tasks
|
| 70 |
+
|
| 71 |
+
| Task | Domain | Difficulty | Corruptions |
|
| 72 |
+
|------|--------|-----------|-------------|
|
| 73 |
+
| `legal_easy` | Legal | 2 (easy) | Spelling, punctuation, content insertion |
|
| 74 |
+
| `legal_medium` | Legal | 3 (medium) | Mixed Tier 1+2 |
|
| 75 |
+
| `legal_hard` | Legal | 5 (expert) | All tiers including PDF artifacts |
|
| 76 |
+
| `pharma_easy` | Pharma | 2 (easy) | Spelling, content deletion |
|
| 77 |
+
| `pharma_hard` | Pharma | 4 (hard) | Mixed Tier 1+2 |
|
| 78 |
+
|
| 79 |
+
## Dual-Seed System
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
reset(doc_seed=42, corruption_seed=9042, difficulty=3, domain="legal")
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
- `doc_seed` controls document generation (template, content, length)
|
| 86 |
+
- `corruption_seed` controls corruption application (types, positions)
|
| 87 |
+
- 2^32 × 2^32 = ~18 quintillion unique tasks
|
| 88 |
+
|
| 89 |
+
## Reward Design
|
| 90 |
+
|
| 91 |
+
```
|
| 92 |
+
reward = similarity_after - similarity_before # incremental
|
| 93 |
+
if exact_match: reward += 1.0 + 0.2 * efficiency # completion bonus scaled by speed
|
| 94 |
+
if noop: reward -= 0.01 # wasted step
|
| 95 |
+
if collateral_damage: reward -= 0.02 * damage # broke something
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
## Quick Start
|
| 99 |
+
|
| 100 |
+
```bash
|
| 101 |
+
cd doc_edit_game_v2 && uv sync
|
| 102 |
+
uvicorn server.app:app --host 0.0.0.0 --port 8001
|
| 103 |
+
|
| 104 |
+
# Or Docker
|
| 105 |
+
docker build -t doc_edit_game_v2-env:latest -f server/Dockerfile .
|
| 106 |
+
docker run -p 8000:8000 doc_edit_game_v2-env:latest
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
## Human + Model Web UI
|
| 110 |
+
|
| 111 |
+
The server now includes a browser playground for the same document-generation and grading logic:
|
| 112 |
+
|
| 113 |
+
- `GET /` serves a human-editing interface
|
| 114 |
+
- `POST /api/game/new` creates a new task from a seed, domain, and difficulty
|
| 115 |
+
- `POST /api/game/{session_id}/submit-human` grades the human-edited document
|
| 116 |
+
- `POST /api/game/{session_id}/model-step` applies model-style tool calls on a parallel workspace
|
| 117 |
+
- `POST /api/game/{session_id}/submit-model` grades the model workspace
|
| 118 |
+
|
| 119 |
+
UI flow:
|
| 120 |
+
|
| 121 |
+
1. Load a new random seed from the top bar
|
| 122 |
+
2. Read the scenario exposition + instruction
|
| 123 |
+
3. Edit the corrupted source document in the human lane
|
| 124 |
+
4. Optionally apply environment tools in the model lane on the same seed
|
| 125 |
+
5. Submit each lane and compare scores side by side
|
| 126 |
+
|
| 127 |
+
The human lane uses direct document submission for easy play-testing.
|
| 128 |
+
The model lane uses the existing tool-based editing logic so it stays compatible with the RL-style environment.
|
| 129 |
+
|
| 130 |
+
## Architecture
|
| 131 |
+
|
| 132 |
+
```
|
| 133 |
+
doc_edit_game_v2/
|
| 134 |
+
├── game/
|
| 135 |
+
│ ├── templates/ # 6 document generators (legal, pharma, business)
|
| 136 |
+
│ ├── corruptions/ # 12 corruption types in 3 tiers
|
| 137 |
+
│ ├── tools/ # 16+ editing tools
|
| 138 |
+
│ ├── windowing.py # Chunked navigation for large docs
|
| 139 |
+
│ ├── grader.py # Multi-level grading (similarity + edit accuracy + collateral)
|
| 140 |
+
│ ├── generator.py # Task orchestrator with dual-seed system
|
| 141 |
+
│ └── content_pools.py # Domain-specific vocabulary
|
| 142 |
+
├── models.py # DocEditAction + DocEditObservation
|
| 143 |
+
├── client.py # WebSocket client
|
| 144 |
+
├── inference.py # Baseline LLM inference script
|
| 145 |
+
└── server/
|
| 146 |
+
├── doc_edit_game_v2_environment.py
|
| 147 |
+
├── app.py
|
| 148 |
+
└── Dockerfile
|
| 149 |
+
```
|
docs/docs-guide.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
So this is a project that we are doing. First, you need to go through the judging criteria, and then you will understand all the themes. After that, you need to go through the hackathon help guide to understand what was going on. Then you go over round one corrections as to what were the things that we had to do correctly. I previously submitted doc-edit-game-v2, so you can read that, and then you can read round one corrections. After that, you read the @best-example-project.md , which is a previous hackathon winner for something very similar. I want you to now come up with a very good idea, or collate all this information, or do whatever task the user is telling.
|
docs/final-postmortem-round1.md
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DocEdit Qwen2.5-3B SFT + GRPO Post-Mortem
|
| 2 |
+
|
| 3 |
+
Date:
|
| 4 |
+
- April 17, 2026
|
| 5 |
+
|
| 6 |
+
Hardware:
|
| 7 |
+
- `1x H200 SXM`
|
| 8 |
+
|
| 9 |
+
Base model:
|
| 10 |
+
- `Qwen/Qwen2.5-3B-Instruct`
|
| 11 |
+
|
| 12 |
+
Training recipe:
|
| 13 |
+
- `LoRA SFT`
|
| 14 |
+
- `LoRA GRPO`
|
| 15 |
+
|
| 16 |
+
Primary Hub repo:
|
| 17 |
+
- [sanjuhs/docedit-qwen25-3b-checkpoints](https://huggingface.co/sanjuhs/docedit-qwen25-3b-checkpoints)
|
| 18 |
+
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
## 1. Goal
|
| 22 |
+
|
| 23 |
+
The goal of this run was to answer a narrow but important question:
|
| 24 |
+
|
| 25 |
+
> Can a small open model be adapted and reinforcement-tuned to repair corrupted structured documents?
|
| 26 |
+
|
| 27 |
+
This was not yet the final tool-policy architecture.
|
| 28 |
+
|
| 29 |
+
Instead, this run intentionally produced a **rewrite-policy baseline** that we can later compare against:
|
| 30 |
+
- frontier-model tool use
|
| 31 |
+
- tool-trajectory training
|
| 32 |
+
- planner -> applicator architectures
|
| 33 |
+
|
| 34 |
+
---
|
| 35 |
+
|
| 36 |
+
## 2. What We Ran
|
| 37 |
+
|
| 38 |
+
### SFT stage
|
| 39 |
+
|
| 40 |
+
We trained a LoRA adapter on paired:
|
| 41 |
+
- corrupted document
|
| 42 |
+
- repaired target document
|
| 43 |
+
|
| 44 |
+
This teaches:
|
| 45 |
+
- markup discipline
|
| 46 |
+
- structured output behavior
|
| 47 |
+
- basic repair mapping
|
| 48 |
+
|
| 49 |
+
### GRPO stage
|
| 50 |
+
|
| 51 |
+
We then continued from the SFT adapter using verifier-based RL.
|
| 52 |
+
|
| 53 |
+
Reward ingredients:
|
| 54 |
+
- structural correctness
|
| 55 |
+
- edit accuracy
|
| 56 |
+
- collateral damage penalty
|
| 57 |
+
- output format penalty
|
| 58 |
+
|
| 59 |
+
---
|
| 60 |
+
|
| 61 |
+
## 3. Final Training Outcome
|
| 62 |
+
|
| 63 |
+
### SFT
|
| 64 |
+
|
| 65 |
+
- runtime: about `109.38s`
|
| 66 |
+
- final train loss: about `0.06346`
|
| 67 |
+
- final mean token accuracy: about `0.98954`
|
| 68 |
+
|
| 69 |
+
### GRPO
|
| 70 |
+
|
| 71 |
+
- runtime: about `5562.75s`
|
| 72 |
+
- total steps: `100`
|
| 73 |
+
- final train loss: about `0.03506`
|
| 74 |
+
- final logged step-100 reward mean: about `0.79567`
|
| 75 |
+
|
| 76 |
+
GRPO checkpoints written:
|
| 77 |
+
- `checkpoint-25`
|
| 78 |
+
- `checkpoint-50`
|
| 79 |
+
- `checkpoint-75`
|
| 80 |
+
- `checkpoint-100`
|
| 81 |
+
|
| 82 |
+
---
|
| 83 |
+
|
| 84 |
+
## 4. SFT Loss Curve
|
| 85 |
+
|
| 86 |
+
```mermaid
|
| 87 |
+
xychart-beta
|
| 88 |
+
title "SFT Loss"
|
| 89 |
+
x-axis ["Step 5", "Step 10", "Step 15", "Final"]
|
| 90 |
+
y-axis "Loss" 0 --> 0.10
|
| 91 |
+
line [0.0811, 0.0352, 0.0910, 0.0635]
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## 5. GRPO Reward Curve Snapshot
|
| 95 |
+
|
| 96 |
+
```mermaid
|
| 97 |
+
xychart-beta
|
| 98 |
+
title "GRPO Reward Snapshot"
|
| 99 |
+
x-axis ["Step 5", "Step 10", "Step 15", "Step 100"]
|
| 100 |
+
y-axis "Reward" 0.55 --> 1.30
|
| 101 |
+
line [0.8422, 0.7638, 0.9102, 0.7957]
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
## 6. GRPO Step Time Snapshot
|
| 105 |
+
|
| 106 |
+
```mermaid
|
| 107 |
+
xychart-beta
|
| 108 |
+
title "GRPO Step Time"
|
| 109 |
+
x-axis ["Step 5", "Step 10", "Step 15", "Step 100"]
|
| 110 |
+
y-axis "Seconds" 40 --> 70
|
| 111 |
+
line [66.42, 58.12, 55.95, 61.71]
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
---
|
| 115 |
+
|
| 116 |
+
## 7. Quick Directional Eval
|
| 117 |
+
|
| 118 |
+
After training, we ran a **very small** local eval on `3` validation cases for:
|
| 119 |
+
- base model
|
| 120 |
+
- SFT adapter
|
| 121 |
+
- final GRPO adapter
|
| 122 |
+
|
| 123 |
+
This is not a full benchmark.
|
| 124 |
+
|
| 125 |
+
It is only a quick directional comparison to tell us whether the trained adapters are plausibly improving over baseline.
|
| 126 |
+
|
| 127 |
+
### 3-case quick eval results
|
| 128 |
+
|
| 129 |
+
| Model | Cases | Exact match rate | Mean similarity | Mean composite score | Mean edit accuracy | Mean collateral damage |
|
| 130 |
+
|---|---:|---:|---:|---:|---:|---:|
|
| 131 |
+
| Base `Qwen2.5-3B-Instruct` | 3 | 0.0000 | 0.9358 | 0.7790 | 0.4444 | 0.2000 |
|
| 132 |
+
| `Qwen2.5-3B + SFT LoRA` | 3 | 0.3333 | 0.9964 | 0.9109 | 0.6667 | 0.0159 |
|
| 133 |
+
| `Qwen2.5-3B + GRPO LoRA` | 3 | 0.3333 | 0.9964 | 0.9149 | 0.6667 | 0.0000 |
|
| 134 |
+
|
| 135 |
+
### Visual comparison
|
| 136 |
+
|
| 137 |
+
```mermaid
|
| 138 |
+
xychart-beta
|
| 139 |
+
title "Quick Eval Mean Composite Score"
|
| 140 |
+
x-axis ["Base", "SFT", "GRPO"]
|
| 141 |
+
y-axis "Composite Score" 0.70 --> 0.95
|
| 142 |
+
bar [0.7790, 0.9109, 0.9149]
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
```mermaid
|
| 146 |
+
xychart-beta
|
| 147 |
+
title "Quick Eval Mean Collateral Damage"
|
| 148 |
+
x-axis ["Base", "SFT", "GRPO"]
|
| 149 |
+
y-axis "Collateral Damage" 0.00 --> 0.25
|
| 150 |
+
bar [0.2000, 0.0159, 0.0000]
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
### What this means
|
| 154 |
+
|
| 155 |
+
On this very small check:
|
| 156 |
+
- SFT clearly improved over the base model
|
| 157 |
+
- GRPO slightly improved over SFT on composite score
|
| 158 |
+
- GRPO also reduced collateral damage to zero on this 3-case slice
|
| 159 |
+
|
| 160 |
+
This is encouraging, but it is **not enough** to claim robust superiority yet.
|
| 161 |
+
|
| 162 |
+
---
|
| 163 |
+
|
| 164 |
+
## 8. What Went Well
|
| 165 |
+
|
| 166 |
+
1. The H200 setup worked well for this scale.
|
| 167 |
+
2. SFT completed quickly and produced a clean LoRA adapter.
|
| 168 |
+
3. GRPO completed fully and wrote multiple checkpoints.
|
| 169 |
+
4. The final GRPO adapter loads and generates correctly.
|
| 170 |
+
5. The quick directional eval suggests the trained adapters beat the untuned base model.
|
| 171 |
+
|
| 172 |
+
---
|
| 173 |
+
|
| 174 |
+
## 9. What Did Not Go Perfectly
|
| 175 |
+
|
| 176 |
+
1. The current policy is still a **rewrite policy**, not the final tool-call architecture.
|
| 177 |
+
2. We had to patch `run_grpo.py` during the run to match the installed TRL version.
|
| 178 |
+
3. We also had to fix a repo-root import issue in the GRPO entrypoint.
|
| 179 |
+
4. The currently published eval is still small and should be treated as a sanity check, not a full research result.
|
| 180 |
+
|
| 181 |
+
---
|
| 182 |
+
|
| 183 |
+
## 10. Biggest Strategic Takeaway
|
| 184 |
+
|
| 185 |
+
This run successfully answers:
|
| 186 |
+
|
| 187 |
+
> Can we fine-tune and RL-tune a small model for DocEdit on one H200?
|
| 188 |
+
|
| 189 |
+
Answer:
|
| 190 |
+
- **yes**
|
| 191 |
+
|
| 192 |
+
But it does **not** yet settle the bigger architecture question:
|
| 193 |
+
|
| 194 |
+
> Is rewrite-policy the right final product design?
|
| 195 |
+
|
| 196 |
+
The answer there is still:
|
| 197 |
+
- **probably not**
|
| 198 |
+
|
| 199 |
+
The next likely better direction is:
|
| 200 |
+
- frontier model plans edits
|
| 201 |
+
- smaller executor/applicator handles structured edit application
|
| 202 |
+
- or frontier model directly uses a compact patch language
|
| 203 |
+
|
| 204 |
+
This run is therefore best understood as:
|
| 205 |
+
- a successful baseline
|
| 206 |
+
- a checkpoint artifact
|
| 207 |
+
- a comparison anchor for future tool-policy work
|
| 208 |
+
|
| 209 |
+
---
|
| 210 |
+
|
| 211 |
+
## 11. Recommended Next Steps
|
| 212 |
+
|
| 213 |
+
1. Run `GPT-5.4` directly with a compact edit language or tool schema.
|
| 214 |
+
2. Compare that against this rewrite-policy baseline.
|
| 215 |
+
3. Decide whether to:
|
| 216 |
+
- keep frontier-only tool use
|
| 217 |
+
- or distill those edit traces into a smaller applicator model
|
| 218 |
+
4. Move future training toward:
|
| 219 |
+
- structured edit plans
|
| 220 |
+
- tool trajectories
|
| 221 |
+
- planner -> executor separation
|
| 222 |
+
|
| 223 |
+
---
|
| 224 |
+
|
| 225 |
+
## 12. Final Judgment
|
| 226 |
+
|
| 227 |
+
Was the H200 run worth doing?
|
| 228 |
+
|
| 229 |
+
- **Yes.**
|
| 230 |
+
|
| 231 |
+
Why?
|
| 232 |
+
- it produced complete SFT and GRPO artifacts
|
| 233 |
+
- it gave us a usable small-model baseline
|
| 234 |
+
- it generated a real comparison point for future design decisions
|
| 235 |
+
|
| 236 |
+
Would I immediately continue training more rewrite-policy models after this?
|
| 237 |
+
|
| 238 |
+
- **No.**
|
| 239 |
+
|
| 240 |
+
I would pause here, keep these artifacts, and move the next cycle toward the cleaner frontier-planner / structured-edit direction.
|
docs/hackathon_help_guide.md
ADDED
|
@@ -0,0 +1,425 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# **Hackathon Self-Serve Guide: Build an RL Environment, Train an LLM, Ship a Demo**
|
| 2 |
+
|
| 3 |
+
## **0\) What you are building**
|
| 4 |
+
|
| 5 |
+
The core idea is not just to fine-tune a text model, but to build a **specialized LLM system** that can act inside an environment, get feedback, and improve through reinforcement learning. The practical stack discussed here is:
|
| 6 |
+
|
| 7 |
+
**Environment → verifier/reward functions → TRL trainer → Unsloth for efficiency → deployment on OpenEnv / Spaces**.
|
| 8 |
+
|
| 9 |
+
A strong project usually looks like one of these,
|
| 10 |
+
|
| 11 |
+
Please refer to [\[External\] Apr ‘26 OpenEnv Hackathon Themes](https://docs.google.com/document/d/1Odznuzwtb1ecDOm2t6ToZd4MuMXXfO6vWUGcxbC6mFs/edit?usp=sharing) for theme guidelines on selecting & forming problem statements.
|
| 12 |
+
|
| 13 |
+
## **1\) Start with the right project idea**
|
| 14 |
+
|
| 15 |
+
Pick a task that has all three of these properties:
|
| 16 |
+
|
| 17 |
+
1. **The model can act step by step**
|
| 18 |
+
2. **You can verify success programmatically**
|
| 19 |
+
3. **The task is hard enough to be interesting, but not so hard that the model never succeeds**
|
| 20 |
+
|
| 21 |
+
This last point matters a lot. RL only works if the probability of getting a good answer is greater than zero. If your task is so hard that the model never gets any reward, you will burn compute and learn nothing.
|
| 22 |
+
|
| 23 |
+
Please refer to [\[External\] Apr ‘26 OpenEnv Hackathon Themes](https://docs.google.com/document/d/1Odznuzwtb1ecDOm2t6ToZd4MuMXXfO6vWUGcxbC6mFs/edit?usp=sharing) for theme guidelines on selecting & forming problem statements.
|
| 24 |
+
|
| 25 |
+
A useful rule: **prefer tasks with crisp verification over tasks that only “look good” to a human.** RL gets easier when the reward is objective.
|
| 26 |
+
|
| 27 |
+
## **2\) Understand the minimum RL loop before you build**
|
| 28 |
+
|
| 29 |
+
At a high level, your loop is:
|
| 30 |
+
|
| 31 |
+
1. Give the model a prompt
|
| 32 |
+
2. Let it generate an action, strategy, answer, or code
|
| 33 |
+
3. Execute that output in an environment or verifier
|
| 34 |
+
4. Convert the result into a reward
|
| 35 |
+
5. Update the model so higher-reward behavior becomes more likely
|
| 36 |
+
|
| 37 |
+
That is the practical mental model for RL here. The system samples many outputs, scores them, and shifts probability mass away from bad outputs and toward better ones.
|
| 38 |
+
|
| 39 |
+
One especially useful framing is that RL is like a more efficient version of repeated in-context improvement. Instead of repeatedly stuffing previous examples into the context, you let backpropagation store what worked into the weights.
|
| 40 |
+
|
| 41 |
+
## **3\) Decide whether you need SFT first**
|
| 42 |
+
|
| 43 |
+
Use this simple rule:
|
| 44 |
+
|
| 45 |
+
* If you have **a lot of good data**, use **SFT**
|
| 46 |
+
* If you **do not have data but can verify outputs**, use **RL**
|
| 47 |
+
* In many practical cases, do **a little SFT first**, then RL
|
| 48 |
+
|
| 49 |
+
Why this matters:
|
| 50 |
+
|
| 51 |
+
* SFT is generally more sample-efficient
|
| 52 |
+
* RL is useful when you can test outcomes but cannot cheaply author ideal traces
|
| 53 |
+
* RL often needs some warm start, formatting priming, or easy tasks first so that good rollouts happen at all
|
| 54 |
+
|
| 55 |
+
For hackathon teams, the best path is usually:
|
| 56 |
+
|
| 57 |
+
1. Start from a capable base/instruct model
|
| 58 |
+
2. Add light formatting or task scaffolding if needed
|
| 59 |
+
3. Use RL for improvement, not as magic from scratch
|
| 60 |
+
|
| 61 |
+
## **4\) Design the environment before you design the trainer**
|
| 62 |
+
|
| 63 |
+
Treat the environment as a first-class artifact. It should define:
|
| 64 |
+
|
| 65 |
+
* **reset()**: start a fresh episode
|
| 66 |
+
* **step(action)**: apply an action and return the next result
|
| 67 |
+
* **state() / observation**: what the agent sees
|
| 68 |
+
* **reward**: what counts as progress or success
|
| 69 |
+
|
| 70 |
+
OpenEnv standardizes this so the same training code can work across many environments, instead of every team inventing a different API. That is one of the main reasons to use it in a hackathon.
|
| 71 |
+
|
| 72 |
+
Think about your environment in this order:
|
| 73 |
+
|
| 74 |
+
1. What does the agent observe?
|
| 75 |
+
2. What actions can it take?
|
| 76 |
+
3. What ends an episode?
|
| 77 |
+
4. How do you compute reward?
|
| 78 |
+
5. How do you stop abuse, infinite loops, or cheating?
|
| 79 |
+
|
| 80 |
+
**5\) Build the environment using OpenEnv**
|
| 81 |
+
|
| 82 |
+
The intended workflow is to bootstrap an environment skeleton and then fill in the behavior. OpenEnv’s CLI creates the scaffolding for you. The environment is implemented as a Python package and exposed via a FastAPI app.
|
| 83 |
+
|
| 84 |
+
Your implementation typically defines:
|
| 85 |
+
|
| 86 |
+
* action dataclass
|
| 87 |
+
* observation dataclass
|
| 88 |
+
* state representation
|
| 89 |
+
* environment methods like reset and step
|
| 90 |
+
* FastAPI wrapper / client-server interface
|
| 91 |
+
|
| 92 |
+
That gives you a clean separation:
|
| 93 |
+
|
| 94 |
+
* the **environment** handles world dynamics and scoring,
|
| 95 |
+
* the **trainer** handles optimization,
|
| 96 |
+
* and the **model** just learns to act inside the interface.
|
| 97 |
+
|
| 98 |
+
## **6\) Keep the task simple at first**
|
| 99 |
+
|
| 100 |
+
Do not begin with your hardest benchmark. Start with the easiest version of your environment that still proves the concept. This is where curriculum learning helps.
|
| 101 |
+
|
| 102 |
+
A good progression:
|
| 103 |
+
|
| 104 |
+
1. easy tasks with short horizons,
|
| 105 |
+
2. medium tasks with a little more branching,
|
| 106 |
+
3. harder tasks only after the model starts getting non-zero reward.
|
| 107 |
+
|
| 108 |
+
The principle is simple: **make success possible early**. If the model never sees successful trajectories, learning stalls.
|
| 109 |
+
|
| 110 |
+
## **7\) Design rewards carefully**
|
| 111 |
+
|
| 112 |
+
Your reward function is your task specification. If it is weak, incomplete, or easy to exploit, the model will optimize the wrong thing very efficiently.
|
| 113 |
+
|
| 114 |
+
A strong reward design usually includes multiple components, for example:
|
| 115 |
+
|
| 116 |
+
* execution success,
|
| 117 |
+
* correctness,
|
| 118 |
+
* format compliance,
|
| 119 |
+
* timeouts,
|
| 120 |
+
* resource usage,
|
| 121 |
+
* safety constraints,
|
| 122 |
+
* and anti-cheating checks.
|
| 123 |
+
|
| 124 |
+
One explicit recommendation was to use **multiple independent reward functions**, not just one. If you only have a single reward signal, it is easier for the model to hack it. Multiple independent checks reduce that risk.
|
| 125 |
+
|
| 126 |
+
For example, for a coding environment:
|
| 127 |
+
|
| 128 |
+
* reward passing tests,
|
| 129 |
+
* penalize timeouts,
|
| 130 |
+
* reward format compliance,
|
| 131 |
+
* reject use of forbidden globals,
|
| 132 |
+
* and separately verify the function contract.
|
| 133 |
+
|
| 134 |
+
## **8\) Protect yourself against reward hacking**
|
| 135 |
+
|
| 136 |
+
Reward hacking is one of the biggest practical failure modes. The model may learn shortcuts that maximize your reward without solving the real task. Examples mentioned include:
|
| 137 |
+
|
| 138 |
+
* editing timers,
|
| 139 |
+
* caching results,
|
| 140 |
+
* abusing globals,
|
| 141 |
+
* mutating protected state,
|
| 142 |
+
* or exploiting environment bugs.
|
| 143 |
+
|
| 144 |
+
What to do:
|
| 145 |
+
|
| 146 |
+
1. Use multiple independent reward functions
|
| 147 |
+
2. Lock down execution where possible
|
| 148 |
+
3. Add time limits
|
| 149 |
+
4. Avoid unrestricted global state
|
| 150 |
+
5. Sample outputs frequently and inspect them
|
| 151 |
+
6. Terminate or roll back runs if behavior drifts badly
|
| 152 |
+
|
| 153 |
+
A particularly practical recommendation was to use a **locked-down function** or restricted execution approach so the model cannot rely on undeclared globals or hidden cached state.
|
| 154 |
+
|
| 155 |
+
Also, do not just let training run forever without checking generations. Periodic human inspection is still necessary.
|
| 156 |
+
|
| 157 |
+
## **9\) Use process-aware feedback when you can**
|
| 158 |
+
|
| 159 |
+
Naively assigning the same final reward to every token is inefficient. If possible, use richer supervision that distinguishes good intermediate steps from bad ones. That is the idea behind **process supervision**.
|
| 160 |
+
|
| 161 |
+
In practice, this can be approximated by:
|
| 162 |
+
|
| 163 |
+
* line-by-line checks,
|
| 164 |
+
* step-level verifiers,
|
| 165 |
+
* program trace analysis,
|
| 166 |
+
* or LLM-as-a-judge for intermediate reasoning.
|
| 167 |
+
|
| 168 |
+
But be careful: LLM-as-a-judge can itself be gamed. Use it as one signal, not the only signal.
|
| 169 |
+
|
| 170 |
+
For a hackathon, outcome-based verification plus a few lightweight process checks is usually the sweet spot.
|
| 171 |
+
|
| 172 |
+
## **10\) Pick the right training stack**
|
| 173 |
+
|
| 174 |
+
The intended stack here is:
|
| 175 |
+
|
| 176 |
+
* **TRL** for RL training algorithms
|
| 177 |
+
* **Unsloth** to make RL training and inference more efficient
|
| 178 |
+
* **OpenEnv** to standardize environment interaction
|
| 179 |
+
|
| 180 |
+
This combination works because:
|
| 181 |
+
|
| 182 |
+
* OpenEnv gives you a common environment interface
|
| 183 |
+
* TRL gives you RL trainers like GRPO
|
| 184 |
+
* Unsloth reduces memory use and improves efficiency on top of TRL
|
| 185 |
+
|
| 186 |
+
One of the practical examples used the same prompt repeated many times, routed through an environment, with TRL driving training and Unsloth helping with performance.
|
| 187 |
+
|
| 188 |
+
## **11\) Prefer GRPO / RLVR style training for verifiable tasks**
|
| 189 |
+
|
| 190 |
+
The RL setup discussed here leans toward **RL with verifiable rewards**:
|
| 191 |
+
|
| 192 |
+
* instead of a learned reward model,
|
| 193 |
+
* use a verifier, test harness, regex check, executor, or environment.
|
| 194 |
+
|
| 195 |
+
GRPO was described as a more efficient evolution relative to older PPO-style setups, especially by simplifying away parts like the value model.
|
| 196 |
+
|
| 197 |
+
For hackathon purposes, the key practical takeaway is:
|
| 198 |
+
|
| 199 |
+
* if the task is verifiable,
|
| 200 |
+
* build the verifier first,
|
| 201 |
+
* then plug that verifier into RL training.
|
| 202 |
+
|
| 203 |
+
## **12\) Keep inference fast**
|
| 204 |
+
|
| 205 |
+
One important point: in RL for LLMs, **inference can dominate total runtime**. Over time, rollout generation often becomes the bottleneck, not the optimizer step.
|
| 206 |
+
|
| 207 |
+
That means your project speed depends heavily on:
|
| 208 |
+
|
| 209 |
+
* fast sampling,
|
| 210 |
+
* tight environment loops,
|
| 211 |
+
* low-overhead execution,
|
| 212 |
+
* and efficient model runtime.
|
| 213 |
+
|
| 214 |
+
This is one reason Unsloth matters in the stack, and another reason to avoid overly heavy environments early in the hackathon.
|
| 215 |
+
|
| 216 |
+
## **13\) Deploy your environment early**
|
| 217 |
+
|
| 218 |
+
OpenEnv environments are designed to be deployed as **Hugging Face Spaces**, which provide:
|
| 219 |
+
|
| 220 |
+
* a running server,
|
| 221 |
+
* a Git repository,
|
| 222 |
+
* and a container registry.
|
| 223 |
+
|
| 224 |
+
That gives you several ways to work:
|
| 225 |
+
|
| 226 |
+
* interact with the remote Space directly,
|
| 227 |
+
* install the client code from the repo,
|
| 228 |
+
* pull and run the container locally,
|
| 229 |
+
* or run the FastAPI app locally via Python/Uvicorn.
|
| 230 |
+
|
| 231 |
+
Why this is good for a hackathon:
|
| 232 |
+
|
| 233 |
+
* one shared source of truth,
|
| 234 |
+
* easier collaboration,
|
| 235 |
+
* easier demos,
|
| 236 |
+
* easier switching between local and remote execution.
|
| 237 |
+
|
| 238 |
+
A good habit is to deploy an early version of the environment before training seriously. That catches API and packaging issues early.
|
| 239 |
+
|
| 240 |
+
## **14\) Scale only after the environment is stable**
|
| 241 |
+
|
| 242 |
+
There was a dedicated tutorial flow around:
|
| 243 |
+
|
| 244 |
+
1. environment,
|
| 245 |
+
2. deployment,
|
| 246 |
+
3. scaling,
|
| 247 |
+
4. training with TRL and Wordle.
|
| 248 |
+
|
| 249 |
+
Follow the same order.
|
| 250 |
+
|
| 251 |
+
Do **not** start with scale. First confirm:
|
| 252 |
+
|
| 253 |
+
* reset works,
|
| 254 |
+
* step works,
|
| 255 |
+
* rewards are sensible,
|
| 256 |
+
* timeouts work,
|
| 257 |
+
* logs are visible,
|
| 258 |
+
* and the environment can be run locally and remotely.
|
| 259 |
+
|
| 260 |
+
Only then:
|
| 261 |
+
|
| 262 |
+
* increase batch sizes,
|
| 263 |
+
* duplicate prompts or tasks,
|
| 264 |
+
* expand task diversity,
|
| 265 |
+
* and benchmark throughput.
|
| 266 |
+
|
| 267 |
+
## **15\) Monitor the right things during training**
|
| 268 |
+
|
| 269 |
+
Do not watch only one scalar. Monitor:
|
| 270 |
+
|
| 271 |
+
* overall reward,
|
| 272 |
+
* individual reward function columns,
|
| 273 |
+
* success indicators,
|
| 274 |
+
* timeout frequency,
|
| 275 |
+
* and generated strategies over time.
|
| 276 |
+
|
| 277 |
+
A very concrete suggestion was:
|
| 278 |
+
|
| 279 |
+
* watch whether the reward is going up,
|
| 280 |
+
* and separately watch critical columns like “function works.”
|
| 281 |
+
|
| 282 |
+
Also inspect actual generations during training. A rising reward is not enough if the model is learning to exploit bugs.
|
| 283 |
+
|
| 284 |
+
## **16\) Save models correctly**
|
| 285 |
+
|
| 286 |
+
If you use QLoRA / LoRA-style training, be careful when saving. One explicit warning was:
|
| 287 |
+
|
| 288 |
+
**Do not upcast a 4-bit model to 16-bit and then merge the LoRA weights naively.** That can badly damage model quality. Instead, use the proper merged-save path, or use the adapters directly.
|
| 289 |
+
|
| 290 |
+
For participants, that means:
|
| 291 |
+
|
| 292 |
+
* keep your training save path simple,
|
| 293 |
+
* test post-training inference immediately,
|
| 294 |
+
* and do not leave export until the end.
|
| 295 |
+
|
| 296 |
+
## **17\) How to structure your team over the hackathon**
|
| 297 |
+
|
| 298 |
+
A very effective team split is:
|
| 299 |
+
|
| 300 |
+
**Person A: Environment**
|
| 301 |
+
|
| 302 |
+
* builds reset/step/state
|
| 303 |
+
* adds timeouts and safety constraints
|
| 304 |
+
* makes local and remote execution work
|
| 305 |
+
|
| 306 |
+
**Person B: Verifier / Rewards**
|
| 307 |
+
|
| 308 |
+
* writes multiple reward functions
|
| 309 |
+
* adds anti-hacking checks
|
| 310 |
+
* makes failure cases visible
|
| 311 |
+
|
| 312 |
+
**Person C: Training**
|
| 313 |
+
|
| 314 |
+
* sets up TRL \+ Unsloth
|
| 315 |
+
* runs experiments
|
| 316 |
+
* tracks metrics and generations
|
| 317 |
+
|
| 318 |
+
**Person D: Demo / Product**
|
| 319 |
+
|
| 320 |
+
* prepares the Space demo
|
| 321 |
+
* creates a simple interface
|
| 322 |
+
* records examples and final benchmarks
|
| 323 |
+
|
| 324 |
+
This split matches the way the stack naturally decomposes in practice.
|
| 325 |
+
|
| 326 |
+
## **18\) A practical 1-day execution plan**
|
| 327 |
+
|
| 328 |
+
### **Phase 1: Pick a narrow task**
|
| 329 |
+
|
| 330 |
+
Choose a small, verifiable environment. Avoid huge long-horizon tasks first.
|
| 331 |
+
|
| 332 |
+
### **Phase 2: Build the environment**
|
| 333 |
+
|
| 334 |
+
Use OpenEnv init, implement reset/step/state, and get a local loop working.
|
| 335 |
+
|
| 336 |
+
### **Phase 3: Build rewards**
|
| 337 |
+
|
| 338 |
+
Add at least 2–4 independent reward checks, plus timeout and anti-cheat logic.
|
| 339 |
+
|
| 340 |
+
### **Phase 4: Deploy**
|
| 341 |
+
|
| 342 |
+
Push to a Space or run locally via container/Uvicorn so teammates can use the same environment.
|
| 343 |
+
|
| 344 |
+
### **Phase 5: Train small**
|
| 345 |
+
|
| 346 |
+
Run a tiny TRL \+ Unsloth experiment first. Look at outputs, not just metrics.
|
| 347 |
+
|
| 348 |
+
### **Phase 6: Inspect for hacking**
|
| 349 |
+
|
| 350 |
+
Sample generations. Check for globals, hacks, environment abuse, or suspicious shortcuts.
|
| 351 |
+
|
| 352 |
+
### **Phase 7: Add curriculum**
|
| 353 |
+
|
| 354 |
+
If the model gets zero reward too often, simplify tasks or add easier start states.
|
| 355 |
+
|
| 356 |
+
### **Phase 8: Train bigger**
|
| 357 |
+
|
| 358 |
+
Only after the loop is stable should you increase scale, batch size, or environment diversity.
|
| 359 |
+
|
| 360 |
+
### **Phase 9: Save and demo**
|
| 361 |
+
|
| 362 |
+
Export the trained model correctly, test inference, and show before/after behavior.
|
| 363 |
+
|
| 364 |
+
## **19\) What judges or reviewers will likely find compelling**
|
| 365 |
+
|
| 366 |
+
The strongest hackathon projects usually show:
|
| 367 |
+
|
| 368 |
+
* a clear environment design,
|
| 369 |
+
* objective reward functions,
|
| 370 |
+
* evidence that the model improved,
|
| 371 |
+
* prevention against reward hacking,
|
| 372 |
+
* a reproducible deployment story,
|
| 373 |
+
* and a sharp demo.
|
| 374 |
+
|
| 375 |
+
A simple but strong demo format is:
|
| 376 |
+
|
| 377 |
+
1. baseline model attempt,
|
| 378 |
+
2. reward/verifier output,
|
| 379 |
+
3. trained model attempt,
|
| 380 |
+
4. measurable improvement,
|
| 381 |
+
5. short explanation of safeguards.
|
| 382 |
+
|
| 383 |
+
## **20\) Suggested problem statement theme directions**
|
| 384 |
+
|
| 385 |
+
Please Refer to [\[External\] Apr ‘26 OpenEnv Hackathon Themes](https://docs.google.com/document/d/1Odznuzwtb1ecDOm2t6ToZd4MuMXXfO6vWUGcxbC6mFs/edit?usp=sharing)
|
| 386 |
+
|
| 387 |
+
## **21\) Common mistakes to avoid**
|
| 388 |
+
|
| 389 |
+
* Picking a task so hard that success probability is zero
|
| 390 |
+
* Using only one reward function
|
| 391 |
+
* Not checking for reward hacking
|
| 392 |
+
* Training before the environment is stable
|
| 393 |
+
* Relying only on average reward and not inspecting outputs
|
| 394 |
+
* Forgetting timeouts and sandbox limits
|
| 395 |
+
* Saving LoRA/QLoRA models incorrectly
|
| 396 |
+
|
| 397 |
+
## **22\) Learning Resources**
|
| 398 |
+
|
| 399 |
+
**(Recommended) RL Environment Lecture Chapters:**
|
| 400 |
+
[**RL Mega Lecture**](https://openenv-india-apr-2026.lovable.app/)
|
| 401 |
+
|
| 402 |
+
**Module 1: Why OpenEnv?** (\~7 min)
|
| 403 |
+
▸ Workshop 8:02–15:05 — [https://www.youtube.com/watch?v=1jU05MlENOI\&t=482s](https://www.youtube.com/watch?v=1jU05MlENOI&t=482s)
|
| 404 |
+
▸ Sanyam: RL loop, fragmented env APIs, OpenEnv as universal interface, Gymnasium spec \+ Docker
|
| 405 |
+
▸ Alt: Mega Lecture 40:01–46:00 — [https://www.youtube.com/watch?v=Jew4lhAiqnw\&t=2401s](https://www.youtube.com/watch?v=Jew4lhAiqnw&t=2401s)
|
| 406 |
+
|
| 407 |
+
**Module 2: Using Existing Envs** (\~7.5 min)
|
| 408 |
+
▸ Workshop 35:33–43:05 — [https://www.youtube.com/watch?v=1jU05MlENOI\&t=2133s](https://www.youtube.com/watch?v=1jU05MlENOI&t=2133s)
|
| 409 |
+
▸ Ben: Hub org, env collections, 3 Space interfaces (server/repo/registry), from\_hub
|
| 410 |
+
▸ Alt: Mega Lecture 1:24:11–1:30:00 — [https://www.youtube.com/watch?v=Jew4lhAiqnw\&t=5051s](https://www.youtube.com/watch?v=Jew4lhAiqnw&t=5051s)
|
| 411 |
+
|
| 412 |
+
**Module 3: Deploying Envs** (\~9 min)
|
| 413 |
+
▸ Mega Lecture 1:30:00–1:39:07 — [https://www.youtube.com/watch?v=Jew4lhAiqnw\&t=5400s](https://www.youtube.com/watch?v=Jew4lhAiqnw&t=5400s)
|
| 414 |
+
▸ Ben: live openenv init, scaffold, running locally, openenv push, Docker run from Space
|
| 415 |
+
▸ Alt: Workshop 43:05–48:30 — [https://www.youtube.com/watch?v=1jU05MlENOI\&t=2585s](https://www.youtube.com/watch?v=1jU05MlENOI&t=2585s)
|
| 416 |
+
|
| 417 |
+
**Module 4: Building Your Own** (\~6.5 min)
|
| 418 |
+
▸ Workshop 43:45–50:20 — [https://www.youtube.com/watch?v=1jU05MlENOI\&t=2625s](https://www.youtube.com/watch?v=1jU05MlENOI&t=2625s)
|
| 419 |
+
▸ Ben: scaffold files, business logic (reset/step), models, client, publishing
|
| 420 |
+
▸ Alt: Mega Lecture 1:33:30–1:39:07 — [https://www.youtube.com/watch?v=Jew4lhAiqnw\&t=5610s](https://www.youtube.com/watch?v=Jew4lhAiqnw&t=5610s)
|
| 421 |
+
|
| 422 |
+
**Module 5: Training \+ TRL** (\~14 min)
|
| 423 |
+
▸ Mega Lecture 1:53:20–2:07:12 — [https://www.youtube.com/watch?v=Jew4lhAiqnw\&t=6800s](https://www.youtube.com/watch?v=Jew4lhAiqnw&t=6800s)
|
| 424 |
+
▸ Lewis: Wordle GRPO walkthrough — rollout function, reward shaping, GRPOTrainer, live training
|
| 425 |
+
▸ Alt: Workshop 22:24–34:12 — [https://www.youtube.com/watch?v=1jU05MlENOI\&t=1344s](https://www.youtube.com/watch?v=1jU05MlENOI&t=1344s)
|
docs/judging_criteria.md
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Theme #1 - Multi-Agent Interactions
|
| 2 |
+
Environments for this theme involve cooperation, competition, negotiation, and coalition formation. Learning from these environments will enable agents to model the beliefs and incentives of others in partially observable settings. This drives theory-of-mind reasoning and emergent strategic behavior.
|
| 3 |
+
Expected Outcome: an environment that can be used to train multi-agent task handling in a LLM
|
| 4 |
+
Example environments: Market simulations, compute-allocation negotiations, collaborative puzzle worlds, mixed cooperative/competitive strategy games.
|
| 5 |
+
Theme #2 - (Super) Long-Horizon Planning & Instruction Following
|
| 6 |
+
You will build environments that require deep, multi-step reasoning with sparse or delayed rewards. After using these environments, the goal is to enable agents to decompose goals, track state over extended trajectories, and recover from early mistakes. The aim is to push beyond shallow next-token reasoning toward structured planning and durable internal representations.
|
| 7 |
+
Expected Outcome: an environment that can capture and improve LLM behaviour on challenging long horizon tasks that need long running sessions beyond context memory limits.
|
| 8 |
+
Example environments: (Think of OpenClaw workflows with Multi-turn tasks). Research-planning simulators, large-scale codebase refactoring tasks, strategic resource management worlds, long-horizon logistics optimization, extremely complicated long-horizon instruction following (e.g., 300 instructions scattered around).
|
| 9 |
+
Theme #3 - World Modeling
|
| 10 |
+
#3.1 Professional Tasks
|
| 11 |
+
Here you will develop environments that require real interaction with tools, APIs, or dynamic systems where the model is expected to do real hard work instead of exploiting short-cuts to arrive at the desired outcome. Learning from these environments will enable agents to maintain consistent internal state, update beliefs based on outcomes, and orchestrate multi-step workflows. The goal is to strengthen causal reasoning and persistent world models.
|
| 12 |
+
Expected Outcome: an environment capturing nuances of a defined partially observable world and improve LLM interaction with it
|
| 13 |
+
Example environments: Dynamic browser/API ecosystems, enterprise applications, scientific workflow loops (papers → code → experiments), economic simulations with feedback, tool-discovery benchmarks.
|
| 14 |
+
|
| 15 |
+
#3.2 Personalized Tasks
|
| 16 |
+
Here we will develop an environment that offers real personalized task handling, imagine replying to personal messages or handling dinner conflicts due to work conflicts, replying to tough emails. Think any personal assistant tasks
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
Expected Outcome: An environment that gives the model a realistic simulation of handling personal tasks, conflicts and managing them as delegations
|
| 20 |
+
|
| 21 |
+
Example environments: Executive Assistant Meeting Planner, Dinner and drive planning, email and message replying, shopping, etc
|
| 22 |
+
|
| 23 |
+
Theme #4 - Self-Improvement
|
| 24 |
+
The focus here is to create environments where agents can learn to generate new challenges, escalate difficulty, and improve through self-play or adaptive curricula. Rather than optimizing fixed tasks, the goal is for agents to learn to drive their own capability growth. The objective is recursive skill amplification.
|
| 25 |
+
Expected Outcome: an environment for improving self-play of a LLM over a defined set of tasks
|
| 26 |
+
Example environments: Self-play negotiation arenas, auto-generated math/proof tasks, evolving coding competitions, adaptive RL curricula.
|
| 27 |
+
|
| 28 |
+
Theme #5: Wild Card - Impress Us!
|
| 29 |
+
We do not want to limit your focus if your idea doesn’t fit the boxes above, we want and WILL reward out of box tasks, please be creative but remember to add submissions that meaningfully add value to LLM training on a certain task.
|
| 30 |
+
|
| 31 |
+
Guidelines for Problem Statement
|
| 32 |
+
It is NOT mandatory to choose the same problem statement as Round 1. Only choose the same problem statement if it aligns with the above provided Hackathon themes.
|
| 33 |
+
You can start working on your problem statement once you have finalized it. Post-training can be done onsite on 25th & 26th when you receive compute credits for HuggingFace.
|
| 34 |
+
Before the onsite, we suggest you work on building the environment, agent behaviours, reward model and evaluate if your work aligns with the judging criteria given below.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
Judging Criteria
|
| 38 |
+
Minimum requirements:
|
| 39 |
+
Usage of OpenEnv (latest release)
|
| 40 |
+
Show a minimal training script for your environment using Unsloth or HF TRL in Colab
|
| 41 |
+
Write a mini-blog on HuggingFace or mini-video on YouTube talking about your submission, <2 minutes
|
| 42 |
+
Your OpenEnv compliant environment should be hosted on Hugging Face Spaces.
|
| 43 |
+
|
| 44 |
+
Judging Overview
|
| 45 |
+
Evaluation: Teams will be scored based on the following criteria:
|
| 46 |
+
Environment Innovation (40%): Is the environment novel, creative, or challenging? Does it meaningfully test the agent’s behavior?
|
| 47 |
+
Storytelling (30%): Does the team clearly explain the problem, environment, and agent behavior? Is the demo engaging and easy to follow?
|
| 48 |
+
Showing Improvement in Rewards (20%): Does the demo provide observable evidence of training progress (reward curves, metrics, or before/after behavior)?
|
| 49 |
+
Reward and Training Script/Pipeline Setup (10%): Is the reward logic coherent, and does the pipeline produce meaningful improvement in the agent’s inference (how it acts in the environment)?
|
| 50 |
+
|
| 51 |
+
OpenEnv Hackathon - What Judges Look For
|
| 52 |
+
|
| 53 |
+
This guide tells you what makes a strong submission for the OpenEnv Hackathon (India 2026).
|
| 54 |
+
Read it before you start building, and again before you submit.
|
| 55 |
+
|
| 56 |
+
For the list of themes and example problems, refer to the top sections.
|
| 57 |
+
|
| 58 |
+
NOTE: Please remember only one submission per team. If you have multiple ideas, pick the best one and go for it. Please make sure that the URL link of your environment is submitted as judges will pull the environment from the URL to evaluate it. Changes or commits after the submission deadline will not be considered.
|
| 59 |
+
|
| 60 |
+
TL;DR
|
| 61 |
+
|
| 62 |
+
Build an environment that an LLM could actually be trained on to get measurably better at
|
| 63 |
+
something interesting. Then show that training. Then tell the story.
|
| 64 |
+
|
| 65 |
+
A messy but ambitious environment with real training evidence beats a polished but boring one.
|
| 66 |
+
Pick a problem that excites you (that energy comes through in the pitch).
|
| 67 |
+
|
| 68 |
+
Judging Criteria
|
| 69 |
+
|
| 70 |
+
Criterion: Environment Innovation
|
| 71 |
+
Weight: 40%
|
| 72 |
+
What it means:
|
| 73 |
+
Is the environment novel, creative, or genuinely challenging?
|
| 74 |
+
Does it meaningfully test agent behavior in a way that hasn't been done before?
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
Criterion: Storytelling & Presentation
|
| 78 |
+
Weight: 30%
|
| 79 |
+
What it means:
|
| 80 |
+
Can you clearly explain the problem, the environment, and what the agent learned?
|
| 81 |
+
Is the demo engaging and easy to follow for a non-technical audience?
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
Criterion: Showing Improvement in Rewards
|
| 85 |
+
Weight: 20%
|
| 86 |
+
What it means:
|
| 87 |
+
Is there observable evidence of training progress? Reward curves, before/after behavior,
|
| 88 |
+
comparison against a baseline -- anything that proves the agent learned something.
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
Criterion: Reward & Training Pipeline
|
| 92 |
+
Weight: 10%
|
| 93 |
+
What it means:
|
| 94 |
+
Is the reward logic coherent? Does the pipeline produce meaningful improvement in the trained
|
| 95 |
+
agent's behavior?
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
Minimum Submission Requirements
|
| 99 |
+
|
| 100 |
+
NOTE: These are non-negotiable. Submissions missing any of these are at a serious disadvantage.
|
| 101 |
+
Use OpenEnv (latest release). Build on top of the framework; don’t reinvent the wheel.
|
| 102 |
+
A working training script using Unsloth or Hugging Face TRL, ideally as a Colab notebook so judges can re-run it.
|
| 103 |
+
Evidence that you actually trained; at minimum, loss and reward plots from a real run.
|
| 104 |
+
A short writeup: a mini-blog on Hugging Face or a < 2 minute video on YouTube explaining what your environment does and what you trained, or a short slide deck of presentation. Please make sure that all materials are linked from your README file so that judges can access them easily.
|
| 105 |
+
Push your environment to a Hugging Face Space so it’s discoverable and runnable.
|
| 106 |
+
A README that motivates the problem, explains how the env works, and shows results.
|
| 107 |
+
README should have a link to the environment in the Hugging Face Space. It should also have all additional references to other materials (e.g. videos, blog posts, slides, presentations, etc.) that you want to include.
|
| 108 |
+
Please do not include big video files in your Env submission on HF Hub as we would like to have a small size for each env (Please use url as reference link to additional materials).
|
| 109 |
+
|
| 110 |
+
What Makes a Submission Stand Out
|
| 111 |
+
|
| 112 |
+
Pick an ambitious, original problem
|
| 113 |
+
The themes (problems) are deliberately open. Use them as launching pads, not boxes. Judges have seen a lot of chess, snake, tic-tac-toe, and grid-world clones. To score well on innovation,
|
| 114 |
+
you need a genuinely fresh angle. Some questions to ask yourself:
|
| 115 |
+
Does this environment exist to teach an LLM something it currently can’t do well?
|
| 116 |
+
Is the domain underexplored in RL/LLM training?
|
| 117 |
+
Could a researcher write a paper about training on this?
|
| 118 |
+
|
| 119 |
+
Design a reward signal that actually teaches
|
| 120 |
+
A great environment has a reward function that:
|
| 121 |
+
Provides a rich, informative signal (not just 0/1 at the end)
|
| 122 |
+
Captures something hard to measure in a clever way
|
| 123 |
+
Uses OpenEnv’s Rubric system thoughtfully (composable rubrics > monolithic scoring)
|
| 124 |
+
Is hard to game; an agent that exploits the reward without solving the task should not get high scores
|
| 125 |
+
|
| 126 |
+
Show real training, end to end
|
| 127 |
+
The bar isn’t “training script exists.” The bar is “training script runs against the environment, the
|
| 128 |
+
agent learns, and you can show it.” Concretely:
|
| 129 |
+
Your training loop should connect to your environment (not a static dataset)
|
| 130 |
+
Train long enough that the curves mean something
|
| 131 |
+
Compare a trained agent vs. a random/untrained baseline; quantitative and/or qualitative
|
| 132 |
+
Include the plots and numbers in your README and writeup
|
| 133 |
+
|
| 134 |
+
Make your plots readable
|
| 135 |
+
Reviewers spend seconds, not minutes, on each plot. Help them out:
|
| 136 |
+
Label both axes (e.g. “training step” / “episode” on x, “reward” / “loss” on y) and include units where they apply
|
| 137 |
+
Save plots as .png or .jpg and commit them to the repo (don’t leave them only in a Colab cell or a deleted Wandb run) (if you ran via Wandb, please include the link to that specific run of your plots)
|
| 138 |
+
Embed the key plots in your README with a one-line caption explaining what each one shows If you have multiple runs (baseline vs. trained, ablations, etc.), put them on the same axes so the comparison is obvious
|
| 139 |
+
|
| 140 |
+
Tell a story, not an API doc
|
| 141 |
+
Your README, blog, and pitch should answer:
|
| 142 |
+
Problem) what capability gap or interesting domain are you targeting?
|
| 143 |
+
Environment) what does the agent see, do, and get rewarded for?
|
| 144 |
+
Results) what changed after training? Show it.
|
| 145 |
+
Why does it matter) who would care, and why?
|
| 146 |
+
|
| 147 |
+
A reviewer should be able to read your README in 3~5 minutes and want to try your
|
| 148 |
+
environment.
|
| 149 |
+
|
| 150 |
+
NOTE: If you have a video, HF post, or anything else interesting, please make sure that it’s linked
|
| 151 |
+
from your README as a link.
|
| 152 |
+
|
| 153 |
+
Engineer it cleanly (table stakes)
|
| 154 |
+
Engineering quality matters less than ambition, but sloppy work hurts. Make sure you:
|
| 155 |
+
Use OpenEnv’s Environment / MCPEnvironment base classes properly
|
| 156 |
+
Respect the client / server separation (clients should never import server internals)
|
| 157 |
+
Follow the standard Gym-style API (reset, step, state)
|
| 158 |
+
Have a valid openenv.yaml manifest
|
| 159 |
+
Don’t use reserved tool names (reset, step, state, close) for MCP tools
|
| 160 |
+
|
| 161 |
+
Final Note
|
| 162 |
+
|
| 163 |
+
Judges are looking for environments that push the frontier of what we can train LLMs to do. Be
|
| 164 |
+
ambitious. Pick a problem you find genuinely interesting; that almost always produces better
|
| 165 |
+
work than chasing what you think judges want. Good luck.
|
| 166 |
+
|
docs/project-setup.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ideally, we should always use Python 3.12, and then we can use uv, which is to install all other packages in Python. For the front end, we can use HTML, CSS, JavaScript, or we can use an XJS application, whatever suits us for a front end interactive environment. Ideally, HTML, CSS, JS should be good, or even Gradio is fine. Whatever works for this OpenENV, you can refer to competition round one if you wanted more, but ideally we would want to do that.
|
| 2 |
+
|
| 3 |
+
For more data and information, you can refer to @docs-guide.md and you can go through all other files and folders in this repository inside the docs folder so that we can get a better idea of what we want and how we're going to build stuff.
|
docs/round1-corrections.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
I went through it. Short version: what passed the OpenEnv hackathon was the **DocEdit Game V2 environment**, not the later trained Qwen model.
|
| 2 |
+
|
| 3 |
+
The submitted project was [attempt1/doc_edit_game_v2](/Users/sanju/Desktop/coding/python/open-env-meta/attempt1/doc_edit_game_v2/README.md), deployed as HF Space `sanjuhs/doc_edit_v5`. It passed because it satisfied the OpenEnv gates:
|
| 4 |
+
|
| 5 |
+
1. **HF Space existed and ran**: final target was `https://sanjuhs-doc-edit-v5.hf.space`.
|
| 6 |
+
2. **OpenEnv spec**: [openenv.yaml](/Users/sanju/Desktop/coding/python/open-env-meta/attempt1/doc_edit_game_v2/openenv.yaml:1), typed `DocEditAction` / `DocEditObservation`, FastAPI mounted OpenEnv endpoints in [server/app.py](/Users/sanju/Desktop/coding/python/open-env-meta/attempt1/doc_edit_game_v2/server/app.py:29).
|
| 7 |
+
3. **Docker build path**: [server/Dockerfile](/Users/sanju/Desktop/coding/python/open-env-meta/attempt1/doc_edit_game_v2/server/Dockerfile:13) used the OpenEnv base image and ran the server.
|
| 8 |
+
4. **Baseline inference**: [inference.py](/Users/sanju/Desktop/coding/python/open-env-meta/attempt1/doc_edit_game_v2/inference.py:15) used the OpenAI client, read `API_BASE_URL`, `MODEL_NAME`, `HF_TOKEN`, emitted `[START]`, `[STEP]`, `[END]`, and ran 5 fixed tasks.
|
| 9 |
+
5. **3+ graded tasks**: you actually had 5: `legal_easy`, `legal_medium`, `legal_hard`, `pharma_easy`, `pharma_hard` in [doc_edit_game_v2_environment.py](/Users/sanju/Desktop/coding/python/open-env-meta/attempt1/doc_edit_game_v2/server/doc_edit_game_v2_environment.py:24).
|
| 10 |
+
|
| 11 |
+
The “finally passed after many iterations” part seems to be these fixes:
|
| 12 |
+
|
| 13 |
+
- Switched from trying to pull/run the HF registry image to connecting directly to the live HF Space because the validator could not pull `registry.hf.space` cleanly.
|
| 14 |
+
- Made the Space/Docker path stable.
|
| 15 |
+
- Clamped scores away from exact `0.0` and `1.0` because the validator rejected boundary values.
|
| 16 |
+
- Kept the environment lightweight enough for the 2 vCPU / 8 GB RAM constraint.
|
| 17 |
+
- Framed the task as a real-world document editing environment, which matched the scoring weights: real-world utility, grader quality, environment design.
|
| 18 |
+
|
| 19 |
+
Important timeline: the later [training/FINAL_POSTMORTEM.md](/Users/sanju/Desktop/coding/python/open-env-meta/training/FINAL_POSTMORTEM.md:1) was dated **April 17, 2026**, after the hackathon deadline of **April 8, 2026**. That Qwen SFT + GRPO run proved the idea was trainable, but it was not the thing that made the OpenEnv submission pass.
|
| 20 |
+
|
| 21 |
+
For direction: I agree with your instinct. A pure “applicator model replaces frontier model” story is weaker now because frontier models have strong tool/function calling. OpenAI’s docs describe tool calling as a first-class way for models to call app-defined functions, and they recommend keeping tool sets small and evaluating accuracy as tools scale: [OpenAI function calling docs](https://platform.openai.com/docs/guides/function-calling/parallel-function-calling-and-structured-outputs).
|
| 22 |
+
|
| 23 |
+
So I’d make the next product a **DocEdit Workbench**:
|
| 24 |
+
|
| 25 |
+
1. **Frontier planner baseline**: frontier model emits compact edit plans/tool calls.
|
| 26 |
+
2. **Verifier + patch engine**: deterministic tools apply changes and score collateral damage.
|
| 27 |
+
3. **Small model only where it wins**: train Qwen-sized models to do chunk-level edit localization/parameterization, not broad planning.
|
| 28 |
+
4. **React app optional but useful**: not as a generic “look, training curves” page, but as a real evaluation cockpit: source vs target vs model output, tool trace, score, collateral damage, cost, latency, and replay.
|
| 29 |
+
|
| 30 |
+
For the small model, Qwen still makes sense as an experiment. Qwen2.5-1.5B-Instruct explicitly emphasizes structured output / JSON improvements, and Qwen3-1.7B emphasizes agent/tool capability: [Qwen2.5-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct), [Qwen3-1.7B](https://huggingface.co/Qwen/Qwen3-1.7B). But the bar should be: can it beat frontier-tool-calling on **cost, latency, privacy, or batch volume** while staying within acceptable accuracy?
|
| 31 |
+
|
| 32 |
+
My recommendation: build the next repo around **frontier planner + verifiable editor + optional distilled executor**. That is much stronger than betting the whole project on a tiny model being magically better.
|