
url string | repository_url string | labels_url string | comments_url string | events_url string | html_url string | id int64 | node_id string | number int64 | title string | user dict | labels list | state string | locked bool | assignee dict | assignees list | milestone dict | comments int64 | created_at timestamp[ms] | updated_at timestamp[ms] | closed_at timestamp[ms] | author_association string | type null | sub_issues_summary dict | active_lock_reason null | draft bool | pull_request dict | body string | closed_by dict | reactions dict | timeline_url string | performed_via_github_app null | state_reason string | is_pull_request bool |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5444 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5444/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5444/comments | https://api.github.com/repos/huggingface/datasets/issues/5444/events | https://github.com/huggingface/datasets/issues/5444 | 1,550,185,071 | I_kwDODunzps5cZfJv | 5,444 | info messages logged as warnings | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 7 | 2023-01-20T01:19:18 | 2023-07-12T17:19:31 | 2023-07-12T17:19:31 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Code in `datasets` is using `logger.warning` when it should be using `logger.info`.
Some of these are probably a matter of opinion, but I think anything starting with `logger.warning(f"Loading chached` clearly falls into the info category.
Definitions from the Python docs for reference:
* I... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5444/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5444/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5443 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5443/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5443/comments | https://api.github.com/repos/huggingface/datasets/issues/5443/events | https://github.com/huggingface/datasets/pull/5443 | 1,550,178,914 | PR_kwDODunzps5ILbk8 | 5,443 | Update share tutorial | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 2 | 2023-01-20T01:09:14 | 2023-01-20T15:44:45 | 2023-01-20T15:37:30 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5443",
"html_url": "https://github.com/huggingface/datasets/pull/5443",
"diff_url": "https://github.com/huggingface/datasets/pull/5443.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5443.patch",
"merged_at": "2023-01-20T15:37... | Based on feedback from discussion #5423, this PR updates the sharing tutorial with a mention of writing your own dataset loading script to support more advanced dataset creation options like multiple configs.
I'll open a separate PR to update the *Create a Dataset card* with the new Hub metadata UI update 😄 | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5443/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5443/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5442/comments | https://api.github.com/repos/huggingface/datasets/issues/5442/events | https://github.com/huggingface/datasets/issues/5442 | 1,550,084,450 | I_kwDODunzps5cZGli | 5,442 | OneDrive Integrations with HF Datasets | {
"login": "Mohammed20201991",
"id": 59222637,
"node_id": "MDQ6VXNlcjU5MjIyNjM3",
"avatar_url": "https://avatars.githubusercontent.com/u/59222637?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mohammed20201991",
"html_url": "https://github.com/Mohammed20201991",
"followers_url": "https://... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 2 | 2023-01-19T23:12:08 | 2023-02-24T16:17:51 | 2023-02-24T16:17:51 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
First of all , I would like to thank all community who are developed DataSet storage and make it free available
How to integrate our Onedrive account or any other possible storage clouds (like google drive,...) with the **HF** datasets section.
For example, if I have **50GB** on my **Onedrive*... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5442/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5441 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5441/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5441/comments | https://api.github.com/repos/huggingface/datasets/issues/5441/events | https://github.com/huggingface/datasets/pull/5441 | 1,548,417,594 | PR_kwDODunzps5IFeCW | 5,441 | resolving a weird tar extract issue | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/fo... | [] | open | false | null | [] | null | 4 | 2023-01-19T02:17:21 | 2023-01-20T16:49:22 | null | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5441",
"html_url": "https://github.com/huggingface/datasets/pull/5441",
"diff_url": "https://github.com/huggingface/datasets/pull/5441.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5441.patch",
"merged_at": null
} | ok, every so often, I have been getting a strange failure on dataset install:
```
$ python -c 'import sys; from datasets import load_dataset; ds=load_dataset(sys.argv[1])' HuggingFaceM4/general-pmd-synthetic-testing
No config specified, defaulting to: general-pmd-synthetic-testing/100.unique
Downloading and prep... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5441/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5441/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5440 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5440/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5440/comments | https://api.github.com/repos/huggingface/datasets/issues/5440/events | https://github.com/huggingface/datasets/pull/5440 | 1,538,361,143 | PR_kwDODunzps5HpRbF | 5,440 | Fix documentation about batch samplers | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 3 | 2023-01-18T17:04:27 | 2023-01-18T17:57:29 | 2023-01-18T17:50:04 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5440",
"html_url": "https://github.com/huggingface/datasets/pull/5440",
"diff_url": "https://github.com/huggingface/datasets/pull/5440.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5440.patch",
"merged_at": "2023-01-18T17:50... | null | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5440/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5440/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5439 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5439/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5439/comments | https://api.github.com/repos/huggingface/datasets/issues/5439/events | https://github.com/huggingface/datasets/issues/5439 | 1,537,973,564 | I_kwDODunzps5bq508 | 5,439 | [dataset request] Add Common Voice 12.0 | {
"login": "MohammedRakib",
"id": 31034499,
"node_id": "MDQ6VXNlcjMxMDM0NDk5",
"avatar_url": "https://avatars.githubusercontent.com/u/31034499?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MohammedRakib",
"html_url": "https://github.com/MohammedRakib",
"followers_url": "https://api.githu... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | 2 | 2023-01-18T13:07:05 | 2023-07-21T14:26:10 | 2023-07-21T14:26:09 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Please add the common voice 12_0 datasets. Apart from English, a significant amount of audio-data has been added to the other minor-language datasets.
### Motivation
The dataset link:
https://commonvoice.mozilla.org/en/datasets
| {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5439/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5439/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5438 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5438/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5438/comments | https://api.github.com/repos/huggingface/datasets/issues/5438/events | https://github.com/huggingface/datasets/pull/5438 | 1,537,489,730 | PR_kwDODunzps5HmWA8 | 5,438 | Update actions/checkout in CD Conda release | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-01-18T06:53:15 | 2023-01-18T13:49:51 | 2023-01-18T13:42:49 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5438",
"html_url": "https://github.com/huggingface/datasets/pull/5438",
"diff_url": "https://github.com/huggingface/datasets/pull/5438.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5438.patch",
"merged_at": "2023-01-18T13:42... | This PR updates the "checkout" GitHub Action to its latest version, as previous ones are deprecated: https://github.blog/changelog/2022-09-22-github-actions-all-actions-will-begin-running-on-node16-instead-of-node12/ | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5438/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5437 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5437/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5437/comments | https://api.github.com/repos/huggingface/datasets/issues/5437/events | https://github.com/huggingface/datasets/issues/5437 | 1,536,837,144 | I_kwDODunzps5bmkYY | 5,437 | Can't load png dataset with 4 channel (RGBA) | {
"login": "WiNE-iNEFF",
"id": 41611046,
"node_id": "MDQ6VXNlcjQxNjExMDQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/41611046?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WiNE-iNEFF",
"html_url": "https://github.com/WiNE-iNEFF",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-01-17T18:22:27 | 2023-01-18T20:20:15 | 2023-01-18T20:20:15 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | I try to create dataset which contains about 9000 png images 64x64 in size, and they are all 4-channel (RGBA). When trying to use load_dataset() then a dataset is created from only 2 images. What exactly interferes I can not understand. for extra speed
* Updates `actions/checkout` to `v3` (note that `v2` is [deprecated](https://github.blog/changelog/2022-09-22-github-actions-all-actions-will-begin-running-on-node16-instead... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5436/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5436/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5435 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5435/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5435/comments | https://api.github.com/repos/huggingface/datasets/issues/5435/events | https://github.com/huggingface/datasets/issues/5435 | 1,536,099,300 | I_kwDODunzps5bjwPk | 5,435 | Wrong statement in "Load a Dataset in Streaming mode" leads to data leakage | {
"login": "DanielYang59",
"id": 80093591,
"node_id": "MDQ6VXNlcjgwMDkzNTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/80093591?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DanielYang59",
"html_url": "https://github.com/DanielYang59",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 4 | 2023-01-17T10:04:16 | 2023-01-19T09:56:03 | 2023-01-19T09:56:03 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
In the [Split your dataset with take and skip](https://huggingface.co/docs/datasets/v1.10.2/dataset_streaming.html#split-your-dataset-with-take-and-skip), it states:
> Using take (or skip) prevents future calls to shuffle from shuffling the dataset shards order, otherwise the taken examples cou... | {
"login": "DanielYang59",
"id": 80093591,
"node_id": "MDQ6VXNlcjgwMDkzNTkx",
"avatar_url": "https://avatars.githubusercontent.com/u/80093591?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DanielYang59",
"html_url": "https://github.com/DanielYang59",
"followers_url": "https://api.github.c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5435/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5434 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5434/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5434/comments | https://api.github.com/repos/huggingface/datasets/issues/5434/events | https://github.com/huggingface/datasets/issues/5434 | 1,536,090,042 | I_kwDODunzps5bjt-6 | 5,434 | sample_dataset module not found | {
"login": "nickums",
"id": 15816213,
"node_id": "MDQ6VXNlcjE1ODE2MjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/15816213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nickums",
"html_url": "https://github.com/nickums",
"followers_url": "https://api.github.com/users/nickum... | [] | closed | false | null | [] | null | 3 | 2023-01-17T09:57:54 | 2023-01-19T13:52:12 | 2023-01-19T07:55:11 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | null | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5434/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5434/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5433 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5433/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5433/comments | https://api.github.com/repos/huggingface/datasets/issues/5433/events | https://github.com/huggingface/datasets/issues/5433 | 1,536,017,901 | I_kwDODunzps5bjcXt | 5,433 | Support latest Docker image in CI benchmarks | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 3 | 2023-01-17T09:06:08 | 2023-01-18T06:29:08 | 2023-01-18T06:29:08 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Once we find out the root cause of:
- #5431
we should revert the temporary pin on the Docker image version introduced by:
- #5432 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5433/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5433/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5432 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5432/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5432/comments | https://api.github.com/repos/huggingface/datasets/issues/5432/events | https://github.com/huggingface/datasets/pull/5432 | 1,535,893,019 | PR_kwDODunzps5HhEA8 | 5,432 | Fix CI benchmarks by temporarily pinning Docker image version | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-01-17T07:15:31 | 2023-01-17T08:58:22 | 2023-01-17T08:51:17 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5432",
"html_url": "https://github.com/huggingface/datasets/pull/5432",
"diff_url": "https://github.com/huggingface/datasets/pull/5432.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5432.patch",
"merged_at": "2023-01-17T08:51... | This PR fixes CI benchmarks, by temporarily pinning Docker image version, instead of "latest" tag.
It also updates deprecated `cml-send-comment` command and using `cml comment create` instead.
Fix #5431. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5432/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5432/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5431 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5431/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5431/comments | https://api.github.com/repos/huggingface/datasets/issues/5431/events | https://github.com/huggingface/datasets/issues/5431 | 1,535,862,621 | I_kwDODunzps5bi2dd | 5,431 | CI benchmarks are broken: Unknown arguments: runnerPath, path | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 4296013012,
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance",
"name": "maintenance",
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 0 | 2023-01-17T06:49:57 | 2023-01-18T06:33:24 | 2023-01-17T08:51:18 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Our CI benchmarks are broken, raising `Unknown arguments` error: https://github.com/huggingface/datasets/actions/runs/3932397079/jobs/6724905161
```
Unknown arguments: runnerPath, path
```
Stack trace:
```
100%|██████████| 500/500 [00:01<00:00, 338.98ba/s]
Updating lock file 'dvc.lock'
To track the changes ... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5431/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5431/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5430 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5430/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5430/comments | https://api.github.com/repos/huggingface/datasets/issues/5430/events | https://github.com/huggingface/datasets/issues/5430 | 1,535,856,503 | I_kwDODunzps5bi093 | 5,430 | Support Apache Beam >= 2.44.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2023-01-17T06:42:12 | 2024-02-06T19:24:21 | 2024-02-06T19:24:21 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Once we find out the root cause of:
- #5426
we should revert the temporary pin on apache-beam introduced by:
- #5429 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5430/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5430/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5429 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5429/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5429/comments | https://api.github.com/repos/huggingface/datasets/issues/5429/events | https://github.com/huggingface/datasets/pull/5429 | 1,535,192,687 | PR_kwDODunzps5HeuyT | 5,429 | Fix CI by temporarily pinning apache-beam < 2.44.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 1 | 2023-01-16T16:20:09 | 2023-01-16T16:51:42 | 2023-01-16T16:49:03 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5429",
"html_url": "https://github.com/huggingface/datasets/pull/5429",
"diff_url": "https://github.com/huggingface/datasets/pull/5429.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5429.patch",
"merged_at": "2023-01-16T16:49... | Temporarily pin apache-beam < 2.44.0
Fix #5426. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5429/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5429/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5428 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5428/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5428/comments | https://api.github.com/repos/huggingface/datasets/issues/5428/events | https://github.com/huggingface/datasets/issues/5428 | 1,535,166,139 | I_kwDODunzps5bgMa7 | 5,428 | Load/Save FAISS index using fsspec | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 2 | 2023-01-16T16:08:12 | 2023-03-27T15:18:22 | 2023-03-27T15:18:22 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
From what I understand `faiss` already support this [link](https://github.com/facebookresearch/faiss/wiki/Index-IO,-cloning-and-hyper-parameter-tuning#generic-io-support)
I would like to use a stream as input to `Dataset.load_faiss_index` and `Dataset.save_faiss_index`.
### Motivation
In... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5428/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5428/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5427 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5427/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5427/comments | https://api.github.com/repos/huggingface/datasets/issues/5427/events | https://github.com/huggingface/datasets/issues/5427 | 1,535,162,889 | I_kwDODunzps5bgLoJ | 5,427 | Unable to download dataset id_clickbait | {
"login": "ilos-vigil",
"id": 45941585,
"node_id": "MDQ6VXNlcjQ1OTQxNTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/45941585?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ilos-vigil",
"html_url": "https://github.com/ilos-vigil",
"followers_url": "https://api.github.com/use... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2023-01-16T16:05:36 | 2023-01-18T09:51:28 | 2023-01-18T09:25:19 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I tried to download dataset `id_clickbait`, but receive this error message.
```
FileNotFoundError: Couldn't find file at https://md-datasets-cache-zipfiles-prod.s3.eu-west-1.amazonaws.com/k42j7x2kpn-1.zip
```
When i open the link using browser, i got this XML data.
```xml
<?xml versi... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5427/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5427/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5426 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5426/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5426/comments | https://api.github.com/repos/huggingface/datasets/issues/5426/events | https://github.com/huggingface/datasets/issues/5426 | 1,535,158,555 | I_kwDODunzps5bgKkb | 5,426 | CI tests are broken: SchemaInferenceError | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 0 | 2023-01-16T16:02:07 | 2023-06-02T06:40:32 | 2023-01-16T16:49:04 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | CI test (unit, ubuntu-latest, deps-minimum) is broken, raising a `SchemaInferenceError`: see https://github.com/huggingface/datasets/actions/runs/3930901593/jobs/6721492004
```
FAILED tests/test_beam.py::BeamBuilderTest::test_download_and_prepare_sharded - datasets.arrow_writer.SchemaInferenceError: Please pass `feat... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5426/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5426/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5425 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5425/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5425/comments | https://api.github.com/repos/huggingface/datasets/issues/5425/events | https://github.com/huggingface/datasets/issues/5425 | 1,534,581,850 | I_kwDODunzps5bd9xa | 5,425 | Sort on multiple keys with datasets.Dataset.sort() | {
"login": "rocco-fortuna",
"id": 101344863,
"node_id": "U_kgDOBgpmXw",
"avatar_url": "https://avatars.githubusercontent.com/u/101344863?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rocco-fortuna",
"html_url": "https://github.com/rocco-fortuna",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | null | [] | null | 10 | 2023-01-16T09:22:26 | 2023-02-24T16:15:11 | 2023-02-24T16:15:11 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
From discussion on forum: https://discuss.huggingface.co/t/datasets-dataset-sort-does-not-preserve-ordering/29065/1
`sort()` does not preserve ordering, and it does not support sorting on multiple columns, nor a key function.
The suggested solution:
> ... having something similar to panda... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5425/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5425/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5424 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5424/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5424/comments | https://api.github.com/repos/huggingface/datasets/issues/5424/events | https://github.com/huggingface/datasets/issues/5424 | 1,534,394,756 | I_kwDODunzps5bdQGE | 5,424 | When applying `ReadInstruction` to custom load it's not DatasetDict but list of Dataset? | {
"login": "macabdul9",
"id": 25720695,
"node_id": "MDQ6VXNlcjI1NzIwNjk1",
"avatar_url": "https://avatars.githubusercontent.com/u/25720695?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/macabdul9",
"html_url": "https://github.com/macabdul9",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 1 | 2023-01-16T06:54:28 | 2023-02-24T16:19:00 | 2023-02-24T16:19:00 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I am loading datasets from custom `tsv` files stored locally and applying split instructions for each split. Although the ReadInstruction is being applied correctly and I was expecting it to be `DatasetDict` but instead it is a list of `Dataset`.
### Steps to reproduce the bug
Steps to reproduc... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5424/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5424/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5422 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5422/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5422/comments | https://api.github.com/repos/huggingface/datasets/issues/5422/events | https://github.com/huggingface/datasets/issues/5422 | 1,533,385,239 | I_kwDODunzps5bZZoX | 5,422 | Datasets load error for saved github issues | {
"login": "folterj",
"id": 7360564,
"node_id": "MDQ6VXNlcjczNjA1NjQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7360564?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/folterj",
"html_url": "https://github.com/folterj",
"followers_url": "https://api.github.com/users/folterj/... | [] | open | false | null | [] | null | 7 | 2023-01-14T17:29:38 | 2023-09-14T11:39:57 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Loading a previously downloaded & saved dataset as described in the HuggingFace course:
issues_dataset = load_dataset("json", data_files="issues/datasets-issues.jsonl", split="train")
Gives this error:
datasets.builder.DatasetGenerationError: An error occurred while generating the dataset... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5422/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5422/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5421/comments | https://api.github.com/repos/huggingface/datasets/issues/5421/events | https://github.com/huggingface/datasets/issues/5421 | 1,532,278,307 | I_kwDODunzps5bVLYj | 5,421 | Support case-insensitive Hub dataset name in load_dataset | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 1 | 2023-01-13T13:07:07 | 2023-01-13T20:12:32 | 2023-01-13T20:12:32 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
The dataset name on the Hub is case-insensitive (see https://github.com/huggingface/moon-landing/pull/2399, internal issue), i.e., https://huggingface.co/datasets/GLUE redirects to https://huggingface.co/datasets/glue.
Ideally, we could load the glue dataset using the following:
```
from d... | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5421/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5421/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5420 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5420/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5420/comments | https://api.github.com/repos/huggingface/datasets/issues/5420/events | https://github.com/huggingface/datasets/pull/5420 | 1,532,265,742 | PR_kwDODunzps5HVAhL | 5,420 | ci: 🎡 remove two obsolete issue templates | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | 3 | 2023-01-13T12:58:43 | 2023-01-13T13:36:00 | 2023-01-13T13:29:01 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5420",
"html_url": "https://github.com/huggingface/datasets/pull/5420",
"diff_url": "https://github.com/huggingface/datasets/pull/5420.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5420.patch",
"merged_at": "2023-01-13T13:29... | add-dataset is not needed anymore since the "canonical" datasets are on the Hub. And dataset-viewer is managed within the datasets-server project.
See https://github.com/huggingface/datasets/issues/new/choose
<img width="1245" alt="Capture d’écran 2023-01-13 à 13 59 58" src="https://user-images.githubuserconten... | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5420/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5420/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5419 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5419/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5419/comments | https://api.github.com/repos/huggingface/datasets/issues/5419/events | https://github.com/huggingface/datasets/issues/5419 | 1,531,999,850 | I_kwDODunzps5bUHZq | 5,419 | label_column='labels' in datasets.TextClassification and 'label' or 'label_ids' in transformers.DataColator | {
"login": "CreatixEA",
"id": 172385,
"node_id": "MDQ6VXNlcjE3MjM4NQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/172385?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CreatixEA",
"html_url": "https://github.com/CreatixEA",
"followers_url": "https://api.github.com/users/Crea... | [] | closed | false | null | [] | null | 2 | 2023-01-13T09:40:07 | 2023-07-21T14:27:08 | 2023-07-21T14:27:08 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When preparing a dataset for a task using `datasets.TextClassification`, the output feature is named `labels`. When preparing the trainer using the `transformers.DataCollator` the default column name is `label` if binary or `label_ids` if multi-class problem.
It is required to rename the column... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5419/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5419/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5418 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5418/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5418/comments | https://api.github.com/repos/huggingface/datasets/issues/5418/events | https://github.com/huggingface/datasets/issues/5418 | 1,530,111,184 | I_kwDODunzps5bM6TQ | 5,418 | Add ProgressBar for `to_parquet` | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/use... | [
{
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https:... | null | 4 | 2023-01-12T05:06:20 | 2023-01-24T18:18:24 | 2023-01-24T18:18:24 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Add a progress bar for `Dataset.to_parquet`, similar to how `to_json` works.
### Motivation
It's a bit frustrating to not know how long a dataset will take to write to file and if it's stuck or not without a progress bar
### Your contribution
Sure I can help if needed | {
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5418/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5418/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5416 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5416/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5416/comments | https://api.github.com/repos/huggingface/datasets/issues/5416/events | https://github.com/huggingface/datasets/pull/5416 | 1,526,988,113 | PR_kwDODunzps5HDLmR | 5,416 | Fix RuntimeError: Sharding is ambiguous for this dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 4 | 2023-01-10T08:43:19 | 2023-01-18T17:12:17 | 2023-01-18T14:09:02 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5416",
"html_url": "https://github.com/huggingface/datasets/pull/5416",
"diff_url": "https://github.com/huggingface/datasets/pull/5416.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5416.patch",
"merged_at": "2023-01-18T14:09... | This PR fixes the RuntimeError: Sharding is ambiguous for this dataset.
The error for ambiguous sharding will be raised only if num_proc > 1.
Fix #5415, fix #5414.
Fix https://huggingface.co/datasets/ami/discussions/3. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5416/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5416/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5415 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5415/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5415/comments | https://api.github.com/repos/huggingface/datasets/issues/5415/events | https://github.com/huggingface/datasets/issues/5415 | 1,526,904,861 | I_kwDODunzps5bArgd | 5,415 | RuntimeError: Sharding is ambiguous for this dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 0 | 2023-01-10T07:36:11 | 2023-01-18T14:09:04 | 2023-01-18T14:09:03 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When loading some datasets, a RuntimeError is raised.
For example, for "ami" dataset: https://huggingface.co/datasets/ami/discussions/3
```
.../huggingface/datasets/src/datasets/builder.py in _prepare_split(self, split_generator, check_duplicate_keys, file_format, num_proc, max_shard_size)
... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5415/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5415/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5414 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5414/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5414/comments | https://api.github.com/repos/huggingface/datasets/issues/5414/events | https://github.com/huggingface/datasets/issues/5414 | 1,525,733,818 | I_kwDODunzps5a8Nm6 | 5,414 | Sharding error with Multilingual LibriSpeech | {
"login": "Nithin-Holla",
"id": 19574344,
"node_id": "MDQ6VXNlcjE5NTc0MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/19574344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nithin-Holla",
"html_url": "https://github.com/Nithin-Holla",
"followers_url": "https://api.github.c... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 4 | 2023-01-09T14:45:31 | 2023-01-18T14:09:04 | 2023-01-18T14:09:04 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Loading the German Multilingual LibriSpeech dataset results in a RuntimeError regarding sharding with the following stacktrace:
```
Downloading and preparing dataset multilingual_librispeech/german to /home/nithin/datadrive/cache/huggingface/datasets/facebook___multilingual_librispeech/german/... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5414/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5414/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5413/comments | https://api.github.com/repos/huggingface/datasets/issues/5413/events | https://github.com/huggingface/datasets/issues/5413 | 1,524,591,837 | I_kwDODunzps5a32zd | 5,413 | concatenate_datasets fails when two dataset with shards > 1 and unequal shard numbers | {
"login": "ZeguanXiao",
"id": 38279341,
"node_id": "MDQ6VXNlcjM4Mjc5MzQx",
"avatar_url": "https://avatars.githubusercontent.com/u/38279341?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZeguanXiao",
"html_url": "https://github.com/ZeguanXiao",
"followers_url": "https://api.github.com/use... | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | 1 | 2023-01-08T17:01:52 | 2023-01-26T09:27:21 | 2023-01-26T09:27:21 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When using `concatenate_datasets([dataset1, dataset2], axis = 1)` to concatenate two datasets with shards > 1, it fails:
```
File "/home/xzg/anaconda3/envs/tri-transfer/lib/python3.9/site-packages/datasets/combine.py", line 182, in concatenate_datasets
return _concatenate_map_style_data... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5413/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5413/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5412/comments | https://api.github.com/repos/huggingface/datasets/issues/5412/events | https://github.com/huggingface/datasets/issues/5412 | 1,524,250,269 | I_kwDODunzps5a2jad | 5,412 | load_dataset() cannot find dataset_info.json with multiple training runs in parallel | {
"login": "mtoles",
"id": 7139344,
"node_id": "MDQ6VXNlcjcxMzkzNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mtoles",
"html_url": "https://github.com/mtoles",
"followers_url": "https://api.github.com/users/mtoles/foll... | [] | closed | false | null | [] | null | 4 | 2023-01-08T00:44:32 | 2023-01-19T20:28:43 | 2023-01-19T20:28:43 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I have a custom local dataset in JSON form. I am trying to do multiple training runs in parallel. The first training run runs with no issue. However, when I start another run on another GPU, the following code throws this error.
If there is a workaround to ignore the cache I think that would ... | {
"login": "mtoles",
"id": 7139344,
"node_id": "MDQ6VXNlcjcxMzkzNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mtoles",
"html_url": "https://github.com/mtoles",
"followers_url": "https://api.github.com/users/mtoles/foll... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5412/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5412/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5411 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5411/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5411/comments | https://api.github.com/repos/huggingface/datasets/issues/5411/events | https://github.com/huggingface/datasets/pull/5411 | 1,523,297,786 | PR_kwDODunzps5G23-T | 5,411 | Update docs of S3 filesystem with async aiobotocore | {
"login": "maheshpec",
"id": 5677912,
"node_id": "MDQ6VXNlcjU2Nzc5MTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5677912?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maheshpec",
"html_url": "https://github.com/maheshpec",
"followers_url": "https://api.github.com/users/ma... | [] | closed | false | null | [] | null | 2 | 2023-01-06T23:19:17 | 2023-01-18T11:18:59 | 2023-01-18T11:12:04 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5411",
"html_url": "https://github.com/huggingface/datasets/pull/5411",
"diff_url": "https://github.com/huggingface/datasets/pull/5411.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5411.patch",
"merged_at": "2023-01-18T11:12... | [s3fs has migrated to all async calls](https://github.com/fsspec/s3fs/commit/0de2c6fb3d87c08ea694de96dca0d0834034f8bf).
Updating documentation to use `AioSession` while using s3fs for download manager as well as working with datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5411/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5411/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5410 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5410/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5410/comments | https://api.github.com/repos/huggingface/datasets/issues/5410/events | https://github.com/huggingface/datasets/pull/5410 | 1,521,168,032 | PR_kwDODunzps5GvnJH | 5,410 | Map-style Dataset to IterableDataset | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 22 | 2023-01-05T18:12:17 | 2023-02-01T18:11:45 | 2023-02-01T16:36:01 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5410",
"html_url": "https://github.com/huggingface/datasets/pull/5410",
"diff_url": "https://github.com/huggingface/datasets/pull/5410.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5410.patch",
"merged_at": "2023-02-01T16:36... | Added `ds.to_iterable()` to get an iterable dataset from a map-style arrow dataset.
It also has a `num_shards` argument to split the dataset before converting to an iterable dataset. Sharding is important to enable efficient shuffling and parallel loading of iterable datasets.
TODO:
- [x] tests
- [x] docs
Fi... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5410/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5410/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5409 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5409/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5409/comments | https://api.github.com/repos/huggingface/datasets/issues/5409/events | https://github.com/huggingface/datasets/pull/5409 | 1,520,374,219 | PR_kwDODunzps5Gs3nL | 5,409 | Fix deprecation warning when use_auth_token passed to download_and_prepare | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-01-05T09:10:58 | 2023-01-06T11:06:16 | 2023-01-06T10:59:13 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5409",
"html_url": "https://github.com/huggingface/datasets/pull/5409",
"diff_url": "https://github.com/huggingface/datasets/pull/5409.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5409.patch",
"merged_at": "2023-01-06T10:59... | The `DatasetBuilder.download_and_prepare` argument `use_auth_token` was deprecated in:
- #5302
However, `use_auth_token` is still passed to `download_and_prepare` in our built-in `io` readers (csv, json, parquet,...).
This PR fixes it, so that no deprecation warning is raised.
Fix #5407. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5409/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5409/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5408 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5408/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5408/comments | https://api.github.com/repos/huggingface/datasets/issues/5408/events | https://github.com/huggingface/datasets/issues/5408 | 1,519,890,752 | I_kwDODunzps5al7FA | 5,408 | dataset map function could not be hash properly | {
"login": "Tungway1990",
"id": 68179274,
"node_id": "MDQ6VXNlcjY4MTc5Mjc0",
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tungway1990",
"html_url": "https://github.com/Tungway1990",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 2 | 2023-01-05T01:59:59 | 2023-01-06T13:22:19 | 2023-01-06T13:22:18 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I follow the [blog post](https://huggingface.co/blog/fine-tune-whisper#building-a-demo) to finetune a Cantonese transcribe model.
When using map function to prepare dataset, following warning pop out:
`common_voice = common_voice.map(prepare_dataset,
remove_... | {
"login": "Tungway1990",
"id": 68179274,
"node_id": "MDQ6VXNlcjY4MTc5Mjc0",
"avatar_url": "https://avatars.githubusercontent.com/u/68179274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tungway1990",
"html_url": "https://github.com/Tungway1990",
"followers_url": "https://api.github.com/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5408/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5408/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5407 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5407/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5407/comments | https://api.github.com/repos/huggingface/datasets/issues/5407/events | https://github.com/huggingface/datasets/issues/5407 | 1,519,797,345 | I_kwDODunzps5alkRh | 5,407 | Datasets.from_sql() generates deprecation warning | {
"login": "msummerfield",
"id": 21002157,
"node_id": "MDQ6VXNlcjIxMDAyMTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/21002157?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/msummerfield",
"html_url": "https://github.com/msummerfield",
"followers_url": "https://api.github.c... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2023-01-05T00:43:17 | 2023-01-06T10:59:14 | 2023-01-06T10:59:14 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Calling `Datasets.from_sql()` generates a warning:
`.../site-packages/datasets/builder.py:712: FutureWarning: 'use_auth_token' was deprecated in version 2.7.1 and will be removed in 3.0.0. Pass 'use_auth_token' to the initializer/'load_dataset_builder' instead.`
### Steps to reproduce the ... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5407/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5407/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5406 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5406/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5406/comments | https://api.github.com/repos/huggingface/datasets/issues/5406/events | https://github.com/huggingface/datasets/issues/5406 | 1,519,140,544 | I_kwDODunzps5ajD7A | 5,406 | [2.6.1][2.7.0] Upgrade `datasets` to fix `TypeError: can only concatenate str (not "int") to str` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | open | false | null | [] | null | 11 | 2023-01-04T15:10:04 | 2023-06-21T18:45:38 | null | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | `datasets` 2.6.1 and 2.7.0 started to stop supporting datasets like IMDB, ConLL or MNIST datasets.
When loading a dataset using 2.6.1 or 2.7.0, you may this error when loading certain datasets:
```python
TypeError: can only concatenate str (not "int") to str
```
This is because we started to update the metadat... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5406/reactions",
"total_count": 11,
"+1": 11,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5406/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5405 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5405/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5405/comments | https://api.github.com/repos/huggingface/datasets/issues/5405/events | https://github.com/huggingface/datasets/issues/5405 | 1,517,879,386 | I_kwDODunzps5aeQBa | 5,405 | size_in_bytes the same for all splits | {
"login": "Breakend",
"id": 1609857,
"node_id": "MDQ6VXNlcjE2MDk4NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1609857?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Breakend",
"html_url": "https://github.com/Breakend",
"followers_url": "https://api.github.com/users/Break... | [] | open | false | null | [] | null | 1 | 2023-01-03T20:25:48 | 2023-01-04T09:22:59 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hi, it looks like whenever you pull a dataset and get size_in_bytes, it returns the same size for all splits (and that size is the combined size of all splits). It seems like this shouldn't be the intended behavior since it is misleading. Here's an example:
```
>>> from datasets import load_da... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5405/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5405/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5404 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5404/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5404/comments | https://api.github.com/repos/huggingface/datasets/issues/5404/events | https://github.com/huggingface/datasets/issues/5404 | 1,517,566,331 | I_kwDODunzps5adDl7 | 5,404 | Better integration of BIG-bench | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 1 | 2023-01-03T15:37:57 | 2023-02-09T20:30:26 | null | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Ideally, it would be nice to have a maintained PyPI package for `bigbench`.
### Motivation
We'd like to allow anyone to access, explore and use any task.
### Your contribution
@lhoestq has opened an issue in their repo:
- https://github.com/google/BIG-bench/issues/906 | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5404/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5404/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5403 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5403/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5403/comments | https://api.github.com/repos/huggingface/datasets/issues/5403/events | https://github.com/huggingface/datasets/pull/5403 | 1,517,466,492 | PR_kwDODunzps5Gi3d9 | 5,403 | Replace one letter import in docs | {
"login": "MKhalusova",
"id": 1065417,
"node_id": "MDQ6VXNlcjEwNjU0MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1065417?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MKhalusova",
"html_url": "https://github.com/MKhalusova",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | 4 | 2023-01-03T14:26:32 | 2023-01-03T15:06:18 | 2023-01-03T14:59:01 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5403",
"html_url": "https://github.com/huggingface/datasets/pull/5403",
"diff_url": "https://github.com/huggingface/datasets/pull/5403.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5403.patch",
"merged_at": "2023-01-03T14:59... | This PR updates a code example for consistency across the docs based on [feedback from this comment](https://github.com/huggingface/transformers/pull/20925/files/9fda31634d203a47d3212e4e8d43d3267faf9808#r1058769500):
"In terms of style we usually stay away from one-letter imports like this (even if the community use... | {
"login": "MKhalusova",
"id": 1065417,
"node_id": "MDQ6VXNlcjEwNjU0MTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1065417?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MKhalusova",
"html_url": "https://github.com/MKhalusova",
"followers_url": "https://api.github.com/users... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5403/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5403/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5402 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5402/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5402/comments | https://api.github.com/repos/huggingface/datasets/issues/5402/events | https://github.com/huggingface/datasets/issues/5402 | 1,517,409,429 | I_kwDODunzps5acdSV | 5,402 | Missing state.json when creating a cloud dataset using a dataset_builder | {
"login": "danielfleischer",
"id": 22022514,
"node_id": "MDQ6VXNlcjIyMDIyNTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/22022514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielfleischer",
"html_url": "https://github.com/danielfleischer",
"followers_url": "https://api... | [] | open | false | null | [] | null | 3 | 2023-01-03T13:39:59 | 2023-01-04T17:23:57 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Using `load_dataset_builder` to create a builder, run `download_and_prepare` do upload it to S3. However when trying to load it, there are missing `state.json` files. Complete example:
```python
from aiobotocore.session import AioSession as Session
from datasets import load_from_disk, load_da... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5402/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5402/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5401 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5401/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5401/comments | https://api.github.com/repos/huggingface/datasets/issues/5401/events | https://github.com/huggingface/datasets/pull/5401 | 1,517,160,935 | PR_kwDODunzps5Gh1XQ | 5,401 | Support Dataset conversion from/to Spark | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | open | false | null | [] | null | 4 | 2023-01-03T09:57:40 | 2023-01-05T14:21:33 | null | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5401",
"html_url": "https://github.com/huggingface/datasets/pull/5401",
"diff_url": "https://github.com/huggingface/datasets/pull/5401.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5401.patch",
"merged_at": null
} | This PR implements Spark integration by supporting `Dataset` conversion from/to Spark `DataFrame`. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5401/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5401/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5400 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5400/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5400/comments | https://api.github.com/repos/huggingface/datasets/issues/5400/events | https://github.com/huggingface/datasets/pull/5400 | 1,517,032,972 | PR_kwDODunzps5GhaGI | 5,400 | Support streaming datasets with os.path.exists and Path.exists | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-01-03T07:42:37 | 2023-01-06T10:42:44 | 2023-01-06T10:35:44 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5400",
"html_url": "https://github.com/huggingface/datasets/pull/5400",
"diff_url": "https://github.com/huggingface/datasets/pull/5400.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5400.patch",
"merged_at": "2023-01-06T10:35... | Support streaming datasets with `os.path.exists` and `pathlib.Path.exists`. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5400/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5400/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5399 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5399/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5399/comments | https://api.github.com/repos/huggingface/datasets/issues/5399/events | https://github.com/huggingface/datasets/issues/5399 | 1,515,548,427 | I_kwDODunzps5aVW8L | 5,399 | Got disconnected from remote data host. Retrying in 5sec [2/20] | {
"login": "alhuri",
"id": 46427957,
"node_id": "MDQ6VXNlcjQ2NDI3OTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alhuri",
"html_url": "https://github.com/alhuri",
"followers_url": "https://api.github.com/users/alhuri/fo... | [] | closed | false | null | [] | null | 0 | 2023-01-01T13:00:11 | 2023-01-02T07:21:52 | 2023-01-02T07:21:52 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
While trying to upload my image dataset of a CSV file type to huggingface by running the below code. The dataset consists of a little over 100k of image-caption pairs
### Steps to reproduce the bug
```
df = pd.read_csv('x.csv', encoding='utf-8-sig')
features = Features({
'link': Ima... | {
"login": "alhuri",
"id": 46427957,
"node_id": "MDQ6VXNlcjQ2NDI3OTU3",
"avatar_url": "https://avatars.githubusercontent.com/u/46427957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alhuri",
"html_url": "https://github.com/alhuri",
"followers_url": "https://api.github.com/users/alhuri/fo... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5399/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5399/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5398 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5398/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5398/comments | https://api.github.com/repos/huggingface/datasets/issues/5398/events | https://github.com/huggingface/datasets/issues/5398 | 1,514,425,231 | I_kwDODunzps5aREuP | 5,398 | Unpin pydantic | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 0 | 2022-12-30T10:37:31 | 2022-12-30T10:43:41 | 2022-12-30T10:43:41 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Once `pydantic` fixes their issue in their 1.10.3 version, unpin it.
See issue:
- #5394
See temporary fix:
- #5395 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5398/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5398/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5397 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5397/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5397/comments | https://api.github.com/repos/huggingface/datasets/issues/5397/events | https://github.com/huggingface/datasets/pull/5397 | 1,514,412,246 | PR_kwDODunzps5GYirs | 5,397 | Unpin pydantic test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2022-12-30T10:22:09 | 2022-12-30T10:53:11 | 2022-12-30T10:43:40 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5397",
"html_url": "https://github.com/huggingface/datasets/pull/5397",
"diff_url": "https://github.com/huggingface/datasets/pull/5397.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5397.patch",
"merged_at": "2022-12-30T10:43... | Once pydantic-1.10.3 has been yanked, we can unpin it: https://pypi.org/project/pydantic/1.10.3/
See reply by pydantic team https://github.com/pydantic/pydantic/issues/4885#issuecomment-1367819807
```
v1.10.3 has been yanked.
```
in response to spacy request: https://github.com/pydantic/pydantic/issues/4885#issu... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5397/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5397/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5396 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5396/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5396/comments | https://api.github.com/repos/huggingface/datasets/issues/5396/events | https://github.com/huggingface/datasets/pull/5396 | 1,514,002,934 | PR_kwDODunzps5GXMhp | 5,396 | Fix checksum verification | {
"login": "daskol",
"id": 9336514,
"node_id": "MDQ6VXNlcjkzMzY1MTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daskol",
"html_url": "https://github.com/daskol",
"followers_url": "https://api.github.com/users/daskol/foll... | [] | closed | false | null | [] | null | 7 | 2022-12-29T19:45:17 | 2023-02-13T11:11:22 | 2023-02-13T11:11:22 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5396",
"html_url": "https://github.com/huggingface/datasets/pull/5396",
"diff_url": "https://github.com/huggingface/datasets/pull/5396.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5396.patch",
"merged_at": null
} | Expected checksum was verified against checksum dict (not checksum). | {
"login": "daskol",
"id": 9336514,
"node_id": "MDQ6VXNlcjkzMzY1MTQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9336514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/daskol",
"html_url": "https://github.com/daskol",
"followers_url": "https://api.github.com/users/daskol/foll... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5396/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5396/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5395 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5395/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5395/comments | https://api.github.com/repos/huggingface/datasets/issues/5395/events | https://github.com/huggingface/datasets/pull/5395 | 1,513,997,335 | PR_kwDODunzps5GXLUl | 5,395 | Temporarily pin pydantic test dependency | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 3 | 2022-12-29T19:34:19 | 2022-12-30T06:36:57 | 2022-12-29T21:00:26 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5395",
"html_url": "https://github.com/huggingface/datasets/pull/5395",
"diff_url": "https://github.com/huggingface/datasets/pull/5395.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5395.patch",
"merged_at": "2022-12-29T21:00... | Temporarily pin `pydantic` until a permanent solution is found.
Fix #5394. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5395/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5395/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5394 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5394/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5394/comments | https://api.github.com/repos/huggingface/datasets/issues/5394/events | https://github.com/huggingface/datasets/issues/5394 | 1,513,976,229 | I_kwDODunzps5aPXGl | 5,394 | CI error: TypeError: dataclass_transform() got an unexpected keyword argument 'field_specifiers' | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 2 | 2022-12-29T18:58:44 | 2022-12-30T10:40:51 | 2022-12-29T21:00:27 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
While installing the dependencies, the CI raises a TypeError:
```
Traceback (most recent call last):
File "/opt/hostedtoolcache/Python/3.7.15/x64/lib/python3.7/runpy.py", line 183, in _run_module_as_main
mod_name, mod_spec, code = _get_module_details(mod_name, _Error)
File "/opt/hoste... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5394/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5394/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5393 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5393/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5393/comments | https://api.github.com/repos/huggingface/datasets/issues/5393/events | https://github.com/huggingface/datasets/pull/5393 | 1,512,908,613 | PR_kwDODunzps5GTg0a | 5,393 | Finish deprecating the fs argument | {
"login": "dconathan",
"id": 15098095,
"node_id": "MDQ6VXNlcjE1MDk4MDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15098095?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dconathan",
"html_url": "https://github.com/dconathan",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 6 | 2022-12-28T15:33:17 | 2023-01-18T12:42:33 | 2023-01-18T12:35:32 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5393",
"html_url": "https://github.com/huggingface/datasets/pull/5393",
"diff_url": "https://github.com/huggingface/datasets/pull/5393.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5393.patch",
"merged_at": "2023-01-18T12:35... | See #5385 for some discussion on this
The `fs=` arg was depcrecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in `2.8.0` (to be removed in `3.0.0`). There are a few other places where the `fs=` arg was still used (functions/methods in `datasets.info` and `datasets.load`). This PR adds a similar beha... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5393/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5393/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5392 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5392/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5392/comments | https://api.github.com/repos/huggingface/datasets/issues/5392/events | https://github.com/huggingface/datasets/pull/5392 | 1,512,712,529 | PR_kwDODunzps5GS2DF | 5,392 | Fix Colab notebook link | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2022-12-28T11:44:53 | 2023-01-03T15:36:14 | 2023-01-03T15:27:31 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5392",
"html_url": "https://github.com/huggingface/datasets/pull/5392",
"diff_url": "https://github.com/huggingface/datasets/pull/5392.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5392.patch",
"merged_at": "2023-01-03T15:27... | Fix notebook link to open in Colab. | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5392/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5392/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5391 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5391/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5391/comments | https://api.github.com/repos/huggingface/datasets/issues/5391/events | https://github.com/huggingface/datasets/issues/5391 | 1,510,350,400 | I_kwDODunzps5aBh5A | 5,391 | Whisper Event - RuntimeError: The size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1000/1000 [2:52:21<00:00, 10.34s/it] | {
"login": "catswithbats",
"id": 12885107,
"node_id": "MDQ6VXNlcjEyODg1MTA3",
"avatar_url": "https://avatars.githubusercontent.com/u/12885107?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/catswithbats",
"html_url": "https://github.com/catswithbats",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2022-12-25T15:17:14 | 2023-07-21T14:29:47 | 2023-07-21T14:29:47 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Done in a VM with a GPU (Ubuntu) following the [Whisper Event - PYTHON](https://github.com/huggingface/community-events/tree/main/whisper-fine-tuning-event#python-script) instructions.
Attempted using [RuntimeError: he size of tensor a (504) must match the size of tensor b (448) at non-singleton dimension 1 100% 1... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5391/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5391/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5390 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5390/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5390/comments | https://api.github.com/repos/huggingface/datasets/issues/5390/events | https://github.com/huggingface/datasets/issues/5390 | 1,509,357,553 | I_kwDODunzps5Z9vfx | 5,390 | Error when pushing to the CI hub | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | 5 | 2022-12-23T13:36:37 | 2022-12-23T20:29:02 | 2022-12-23T20:29:02 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Note that it's a special case where the Hub URL is "https://hub-ci.huggingface.co", which does not appear if we do the same on the Hub (https://huggingface.co).
The call to `dataset.push_to_hub(` fails:
```
Pushing dataset shards to the dataset hub: 100%|██████████████████████████████████... | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5390/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5390/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5389 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5389/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5389/comments | https://api.github.com/repos/huggingface/datasets/issues/5389/events | https://github.com/huggingface/datasets/pull/5389 | 1,509,348,626 | PR_kwDODunzps5GHsOo | 5,389 | Fix link in `load_dataset` docstring | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 6 | 2022-12-23T13:26:31 | 2023-01-25T19:00:43 | 2023-01-24T16:33:38 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5389",
"html_url": "https://github.com/huggingface/datasets/pull/5389",
"diff_url": "https://github.com/huggingface/datasets/pull/5389.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5389.patch",
"merged_at": "2023-01-24T16:33... | Fix https://github.com/huggingface/datasets/issues/5387, fix https://github.com/huggingface/datasets/issues/4566 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5389/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5389/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5388 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5388/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5388/comments | https://api.github.com/repos/huggingface/datasets/issues/5388/events | https://github.com/huggingface/datasets/issues/5388 | 1,509,042,348 | I_kwDODunzps5Z8iis | 5,388 | Getting Value Error while loading a dataset.. | {
"login": "valmetisrinivas",
"id": 51160232,
"node_id": "MDQ6VXNlcjUxMTYwMjMy",
"avatar_url": "https://avatars.githubusercontent.com/u/51160232?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/valmetisrinivas",
"html_url": "https://github.com/valmetisrinivas",
"followers_url": "https://api... | [] | closed | false | null | [] | null | 4 | 2022-12-23T08:16:43 | 2022-12-29T08:36:33 | 2022-12-27T17:59:09 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I am trying to load a dataset using Hugging Face Datasets load_dataset method. I am getting the value error as show below. Can someone help with this? I am using Windows laptop and Google Colab notebook.
```
WARNING:datasets.builder:Using custom data configuration default-a1d9e8eaedd958cd
---... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5388/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5388/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5387 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5387/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5387/comments | https://api.github.com/repos/huggingface/datasets/issues/5387/events | https://github.com/huggingface/datasets/issues/5387 | 1,508,740,177 | I_kwDODunzps5Z7YxR | 5,387 | Missing documentation page : improve-performance | {
"login": "astariul",
"id": 43774355,
"node_id": "MDQ6VXNlcjQzNzc0MzU1",
"avatar_url": "https://avatars.githubusercontent.com/u/43774355?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/astariul",
"html_url": "https://github.com/astariul",
"followers_url": "https://api.github.com/users/ast... | [] | closed | false | null | [] | null | 1 | 2022-12-23T01:12:57 | 2023-01-24T16:33:40 | 2023-01-24T16:33:40 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Trying to access https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/cache#improve-performance, the page is missing.
The link is in here : https://huggingface.co/docs/datasets/v2.8.0/en/package_reference/loading_methods#datasets.load_dataset.keep_in_memory
### Steps to reproduce t... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5387/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5387/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5386/comments | https://api.github.com/repos/huggingface/datasets/issues/5386/events | https://github.com/huggingface/datasets/issues/5386 | 1,508,592,918 | I_kwDODunzps5Z600W | 5,386 | `max_shard_size` in `datasets.push_to_hub()` breaks with large files | {
"login": "salieri",
"id": 1086393,
"node_id": "MDQ6VXNlcjEwODYzOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salieri",
"html_url": "https://github.com/salieri",
"followers_url": "https://api.github.com/users/salieri/... | [] | closed | false | null | [] | null | 2 | 2022-12-22T21:50:58 | 2022-12-26T23:45:51 | 2022-12-26T23:45:51 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
`max_shard_size` parameter for `datasets.push_to_hub()` works unreliably with large files, generating shard files that are way past the specified limit.
In my private dataset, which contains unprocessed images of all sizes (up to `~100MB` per file), I've encountered cases where `max_shard_siz... | {
"login": "salieri",
"id": 1086393,
"node_id": "MDQ6VXNlcjEwODYzOTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salieri",
"html_url": "https://github.com/salieri",
"followers_url": "https://api.github.com/users/salieri/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5386/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5386/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5385/comments | https://api.github.com/repos/huggingface/datasets/issues/5385/events | https://github.com/huggingface/datasets/issues/5385 | 1,508,535,532 | I_kwDODunzps5Z6mzs | 5,385 | Is `fs=` deprecated in `load_from_disk()` as well? | {
"login": "dconathan",
"id": 15098095,
"node_id": "MDQ6VXNlcjE1MDk4MDk1",
"avatar_url": "https://avatars.githubusercontent.com/u/15098095?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dconathan",
"html_url": "https://github.com/dconathan",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 3 | 2022-12-22T21:00:45 | 2023-01-23T10:50:05 | 2023-01-23T10:50:04 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
The `fs=` argument was deprecated from `Dataset.save_to_disk` and `Dataset.load_from_disk` in favor of automagically figuring it out via fsspec:
https://github.com/huggingface/datasets/blob/9a7272cd4222383a5b932b0083a4cc173fda44e8/src/datasets/arrow_dataset.py#L1339-L1340
Is there a reason the... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5385/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5385/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5384 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5384/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5384/comments | https://api.github.com/repos/huggingface/datasets/issues/5384/events | https://github.com/huggingface/datasets/pull/5384 | 1,508,152,598 | PR_kwDODunzps5GDmR6 | 5,384 | Handle 0-dim tensors in `cast_to_python_objects` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 2 | 2022-12-22T16:15:30 | 2023-01-13T16:10:15 | 2023-01-13T16:00:52 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5384",
"html_url": "https://github.com/huggingface/datasets/pull/5384",
"diff_url": "https://github.com/huggingface/datasets/pull/5384.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5384.patch",
"merged_at": "2023-01-13T16:00... | Fix #5229 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5384/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5384/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5383 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5383/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5383/comments | https://api.github.com/repos/huggingface/datasets/issues/5383/events | https://github.com/huggingface/datasets/issues/5383 | 1,507,293,968 | I_kwDODunzps5Z13sQ | 5,383 | IterableDataset missing column_names, differs from Dataset interface | {
"login": "iceboundflame",
"id": 933687,
"node_id": "MDQ6VXNlcjkzMzY4Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/933687?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iceboundflame",
"html_url": "https://github.com/iceboundflame",
"followers_url": "https://api.github.co... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "patrickloeber",
"id": 50772274,
"node_id": "MDQ6VXNlcjUwNzcyMjc0",
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickloeber",
"html_url": "https://github.com/patrickloeber",
"followers_url": "https://api.githu... | [
{
"login": "patrickloeber",
"id": 50772274,
"node_id": "MDQ6VXNlcjUwNzcyMjc0",
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickloeber",
"html_url": "https://github.com/patrickloeber",
"followers_url"... | null | 6 | 2022-12-22T05:27:02 | 2023-03-13T19:03:33 | 2023-03-13T19:03:33 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
The documentation on [Stream](https://huggingface.co/docs/datasets/v1.18.2/stream.html) seems to imply that IterableDataset behaves just like a Dataset. However, examples like
```
dataset.map(augment_data, batched=True, remove_columns=dataset.column_names, ...)
```
will not work because `.colu... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5383/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5383/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5382 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5382/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5382/comments | https://api.github.com/repos/huggingface/datasets/issues/5382/events | https://github.com/huggingface/datasets/pull/5382 | 1,504,788,691 | PR_kwDODunzps5F4Q0V | 5,382 | Raise from disconnect error in xopen | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 3 | 2022-12-20T15:52:44 | 2023-01-26T09:51:13 | 2023-01-26T09:42:45 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5382",
"html_url": "https://github.com/huggingface/datasets/pull/5382",
"diff_url": "https://github.com/huggingface/datasets/pull/5382.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5382.patch",
"merged_at": "2023-01-26T09:42... | this way we can know the cause of the disconnect
related to https://github.com/huggingface/datasets/issues/5374 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5382/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5382/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5381/comments | https://api.github.com/repos/huggingface/datasets/issues/5381/events | https://github.com/huggingface/datasets/issues/5381 | 1,504,498,387 | I_kwDODunzps5ZrNLT | 5,381 | Wrong URL for the_pile dataset | {
"login": "LeoGrin",
"id": 45738728,
"node_id": "MDQ6VXNlcjQ1NzM4NzI4",
"avatar_url": "https://avatars.githubusercontent.com/u/45738728?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeoGrin",
"html_url": "https://github.com/LeoGrin",
"followers_url": "https://api.github.com/users/LeoGri... | [] | closed | false | null | [] | null | 1 | 2022-12-20T12:40:14 | 2023-02-15T16:24:57 | 2023-02-15T16:24:57 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5381/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5381/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5380/comments | https://api.github.com/repos/huggingface/datasets/issues/5380/events | https://github.com/huggingface/datasets/issues/5380 | 1,504,404,043 | I_kwDODunzps5Zq2JL | 5,380 | Improve dataset `.skip()` speed in streaming mode | {
"login": "versae",
"id": 173537,
"node_id": "MDQ6VXNlcjE3MzUzNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/173537?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/versae",
"html_url": "https://github.com/versae",
"followers_url": "https://api.github.com/users/versae/follow... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3761482852,
"node_id": "LA_k... | open | false | null | [] | null | 10 | 2022-12-20T11:25:23 | 2023-03-08T10:47:12 | null | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5380/reactions",
"total_count": 7,
"+1": 7,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5380/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5379 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5379/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5379/comments | https://api.github.com/repos/huggingface/datasets/issues/5379/events | https://github.com/huggingface/datasets/pull/5379 | 1,504,010,639 | PR_kwDODunzps5F1r2k | 5,379 | feat: depth estimation dataset guide. | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/... | [] | closed | false | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/... | [
{
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://a... | null | 8 | 2022-12-20T05:32:11 | 2023-01-13T12:30:31 | 2023-01-13T12:23:34 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5379",
"html_url": "https://github.com/huggingface/datasets/pull/5379",
"diff_url": "https://github.com/huggingface/datasets/pull/5379.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5379.patch",
"merged_at": "2023-01-13T12:23... | This PR adds a guide for prepping datasets for depth estimation.
PR to add documentation images is up here: https://huggingface.co/datasets/huggingface/documentation-images/discussions/22 | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5379/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5379/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5378/comments | https://api.github.com/repos/huggingface/datasets/issues/5378/events | https://github.com/huggingface/datasets/issues/5378 | 1,503,887,508 | I_kwDODunzps5Zo4CU | 5,378 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure | {
"login": "shaoyuta",
"id": 52023469,
"node_id": "MDQ6VXNlcjUyMDIzNDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shaoyuta",
"html_url": "https://github.com/shaoyuta",
"followers_url": "https://api.github.com/users/sha... | [] | closed | false | null | [] | null | 1 | 2022-12-20T02:19:13 | 2022-12-20T07:52:54 | 2022-12-20T07:52:54 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset(... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5378/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5378/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5377 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5377/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5377/comments | https://api.github.com/repos/huggingface/datasets/issues/5377/events | https://github.com/huggingface/datasets/pull/5377 | 1,503,477,833 | PR_kwDODunzps5Fz5lw | 5,377 | Add a parallel implementation of to_tf_dataset() | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | 32 | 2022-12-19T19:40:27 | 2023-01-25T16:28:44 | 2023-01-25T16:21:40 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5377",
"html_url": "https://github.com/huggingface/datasets/pull/5377",
"diff_url": "https://github.com/huggingface/datasets/pull/5377.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5377.patch",
"merged_at": "2023-01-25T16:21... | Hey all! Here's a first draft of the PR to add a multiprocessing implementation for `to_tf_dataset()`. It worked in some quick testing for me, but obviously I need to do some much more rigorous testing/benchmarking, and add some proper library tests.
The core idea is that we do everything using `multiprocessing` and... | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.githu... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5377/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5377/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5376 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5376/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5376/comments | https://api.github.com/repos/huggingface/datasets/issues/5376/events | https://github.com/huggingface/datasets/pull/5376 | 1,502,730,559 | PR_kwDODunzps5FxWkM | 5,376 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 1 | 2022-12-19T10:56:56 | 2022-12-19T11:01:55 | 2022-12-19T10:57:16 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5376",
"html_url": "https://github.com/huggingface/datasets/pull/5376",
"diff_url": "https://github.com/huggingface/datasets/pull/5376.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5376.patch",
"merged_at": "2022-12-19T10:57... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5376/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5376/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5375 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5375/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5375/comments | https://api.github.com/repos/huggingface/datasets/issues/5375/events | https://github.com/huggingface/datasets/pull/5375 | 1,502,720,404 | PR_kwDODunzps5FxUbG | 5,375 | Release: 2.8.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 1 | 2022-12-19T10:48:26 | 2022-12-19T10:55:43 | 2022-12-19T10:53:15 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5375",
"html_url": "https://github.com/huggingface/datasets/pull/5375",
"diff_url": "https://github.com/huggingface/datasets/pull/5375.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5375.patch",
"merged_at": "2022-12-19T10:53... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5375/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5375/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5374/comments | https://api.github.com/repos/huggingface/datasets/issues/5374/events | https://github.com/huggingface/datasets/issues/5374 | 1,501,872,945 | I_kwDODunzps5ZhMMx | 5,374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 7 | 2022-12-18T11:38:58 | 2023-07-24T15:23:07 | 2023-07-24T15:23:07 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5374/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5374/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5373/comments | https://api.github.com/repos/huggingface/datasets/issues/5373/events | https://github.com/huggingface/datasets/pull/5373 | 1,501,484,197 | PR_kwDODunzps5FtRU4 | 5,373 | Simplify skipping | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 1 | 2022-12-17T17:23:52 | 2022-12-18T21:43:31 | 2022-12-18T21:40:21 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5373",
"html_url": "https://github.com/huggingface/datasets/pull/5373",
"diff_url": "https://github.com/huggingface/datasets/pull/5373.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5373.patch",
"merged_at": "2022-12-18T21:40... | Was hoping to find a way to speed up the skipping as I'm running into bottlenecks skipping 100M examples on C4 (it takes 12 hours to skip), but didn't find anything better than this small change :(
Maybe there's a way to directly skip whole shards to speed it up? 🧐 | {
"login": "Muennighoff",
"id": 62820084,
"node_id": "MDQ6VXNlcjYyODIwMDg0",
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Muennighoff",
"html_url": "https://github.com/Muennighoff",
"followers_url": "https://api.github.com/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5373/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5373/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5372/comments | https://api.github.com/repos/huggingface/datasets/issues/5372/events | https://github.com/huggingface/datasets/pull/5372 | 1,501,377,802 | PR_kwDODunzps5Fs9w5 | 5,372 | Fix streaming pandas.read_excel | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2022-12-17T12:58:52 | 2023-01-06T11:50:58 | 2023-01-06T11:43:37 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5372",
"html_url": "https://github.com/huggingface/datasets/pull/5372",
"diff_url": "https://github.com/huggingface/datasets/pull/5372.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5372.patch",
"merged_at": "2023-01-06T11:43... | This PR fixes `xpandas_read_excel`:
- Support passing a path string, besides a file-like object
- Support passing `use_auth_token`
- First assumes the host server supports HTTP range requests; only if a ValueError is thrown (Cannot seek streaming HTTP file), then it preserves previous behavior (see [#3355](https://g... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5372/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5372/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5371/comments | https://api.github.com/repos/huggingface/datasets/issues/5371/events | https://github.com/huggingface/datasets/issues/5371 | 1,501,369,036 | I_kwDODunzps5ZfRLM | 5,371 | Add a robustness benchmark dataset for vision | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | {
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://api.github.com/users/... | [
{
"login": "sayakpaul",
"id": 22957388,
"node_id": "MDQ6VXNlcjIyOTU3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sayakpaul",
"html_url": "https://github.com/sayakpaul",
"followers_url": "https://a... | null | 1 | 2022-12-17T12:35:13 | 2022-12-20T06:21:41 | null | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also corre... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5371/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5371/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5369/comments | https://api.github.com/repos/huggingface/datasets/issues/5369/events | https://github.com/huggingface/datasets/pull/5369 | 1,500,622,276 | PR_kwDODunzps5Fqaj- | 5,369 | Distributed support | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 11 | 2022-12-16T17:43:47 | 2023-07-25T12:00:31 | 2023-01-16T13:33:32 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5369",
"html_url": "https://github.com/huggingface/datasets/pull/5369",
"diff_url": "https://github.com/huggingface/datasets/pull/5369.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5369.patch",
"merged_at": "2023-01-16T13:33... | To split your dataset across your training nodes, you can use the new [`datasets.distributed.split_dataset_by_node`]:
```python
import os
from datasets.distributed import split_dataset_by_node
ds = split_dataset_by_node(ds, rank=int(os.environ["RANK"]), world_size=int(os.environ["WORLD_SIZE"]))
```
This wor... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5369/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5369/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5368 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5368/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5368/comments | https://api.github.com/repos/huggingface/datasets/issues/5368/events | https://github.com/huggingface/datasets/pull/5368 | 1,500,322,973 | PR_kwDODunzps5FpZyx | 5,368 | Align remove columns behavior and input dict mutation in `map` with previous behavior | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 1 | 2022-12-16T14:28:47 | 2022-12-16T16:28:08 | 2022-12-16T16:25:12 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5368",
"html_url": "https://github.com/huggingface/datasets/pull/5368",
"diff_url": "https://github.com/huggingface/datasets/pull/5368.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5368.patch",
"merged_at": "2022-12-16T16:25... | Align the `remove_columns` behavior and input dict mutation in `map` with the behavior before https://github.com/huggingface/datasets/pull/5252. | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5368/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5368/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5367 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5367/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5367/comments | https://api.github.com/repos/huggingface/datasets/issues/5367/events | https://github.com/huggingface/datasets/pull/5367 | 1,499,174,749 | PR_kwDODunzps5FlevK | 5,367 | Fix remove columns from lazy dict | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 1 | 2022-12-15T22:04:12 | 2022-12-15T22:27:53 | 2022-12-15T22:24:50 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5367",
"html_url": "https://github.com/huggingface/datasets/pull/5367",
"diff_url": "https://github.com/huggingface/datasets/pull/5367.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5367.patch",
"merged_at": "2022-12-15T22:24... | This was introduced in https://github.com/huggingface/datasets/pull/5252 and causing the transformers CI to break: https://app.circleci.com/pipelines/github/huggingface/transformers/53886/workflows/522faf2e-a053-454c-94f8-a617fde33393/jobs/648597
Basically this code should return a dataset with only one column:
`... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5367/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5367/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5366/comments | https://api.github.com/repos/huggingface/datasets/issues/5366/events | https://github.com/huggingface/datasets/pull/5366 | 1,498,530,851 | PR_kwDODunzps5FjSFl | 5,366 | ExamplesIterable fixes | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 1 | 2022-12-15T14:23:05 | 2022-12-15T14:44:47 | 2022-12-15T14:41:45 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5366",
"html_url": "https://github.com/huggingface/datasets/pull/5366",
"diff_url": "https://github.com/huggingface/datasets/pull/5366.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5366.patch",
"merged_at": "2022-12-15T14:41... | fix typing and ExamplesIterable.shard_data_sources | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5366/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5366/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5365/comments | https://api.github.com/repos/huggingface/datasets/issues/5365/events | https://github.com/huggingface/datasets/pull/5365 | 1,498,422,466 | PR_kwDODunzps5Fi6ZD | 5,365 | fix: image array should support other formats than uint8 | {
"login": "vigsterkr",
"id": 30353,
"node_id": "MDQ6VXNlcjMwMzUz",
"avatar_url": "https://avatars.githubusercontent.com/u/30353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vigsterkr",
"html_url": "https://github.com/vigsterkr",
"followers_url": "https://api.github.com/users/vigsterkr/... | [] | closed | false | null | [] | null | 4 | 2022-12-15T13:17:50 | 2023-01-26T18:46:45 | 2023-01-26T18:39:36 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5365",
"html_url": "https://github.com/huggingface/datasets/pull/5365",
"diff_url": "https://github.com/huggingface/datasets/pull/5365.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5365.patch",
"merged_at": "2023-01-26T18:39... | Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray` [does support mode `F`](https://pillow.readthedocs.io/e... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5365/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5365/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5364 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5364/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5364/comments | https://api.github.com/repos/huggingface/datasets/issues/5364/events | https://github.com/huggingface/datasets/pull/5364 | 1,498,360,628 | PR_kwDODunzps5Fiss1 | 5,364 | Support for writing arrow files directly with BeamWriter | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 6 | 2022-12-15T12:38:05 | 2024-01-11T14:52:33 | 2024-01-11T14:45:15 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5364",
"html_url": "https://github.com/huggingface/datasets/pull/5364",
"diff_url": "https://github.com/huggingface/datasets/pull/5364.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5364.patch",
"merged_at": null
} | Make it possible to write Arrow files directly with `BeamWriter` rather than converting from Parquet to Arrow, which is sub-optimal, especially for big datasets for which Beam is primarily used. | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5364/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5364/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5363/comments | https://api.github.com/repos/huggingface/datasets/issues/5363/events | https://github.com/huggingface/datasets/issues/5363 | 1,498,171,317 | I_kwDODunzps5ZTEe1 | 5,363 | Dataset.from_generator() crashes on simple example | {
"login": "villmow",
"id": 2743060,
"node_id": "MDQ6VXNlcjI3NDMwNjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/villmow",
"html_url": "https://github.com/villmow",
"followers_url": "https://api.github.com/users/villmow/... | [] | closed | false | null | [] | null | 0 | 2022-12-15T10:21:28 | 2022-12-15T11:51:33 | 2022-12-15T11:51:33 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | null | {
"login": "villmow",
"id": 2743060,
"node_id": "MDQ6VXNlcjI3NDMwNjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/villmow",
"html_url": "https://github.com/villmow",
"followers_url": "https://api.github.com/users/villmow/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5363/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5363/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | {
"login": "shaoyuta",
"id": 52023469,
"node_id": "MDQ6VXNlcjUyMDIzNDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shaoyuta",
"html_url": "https://github.com/shaoyuta",
"followers_url": "https://api.github.com/users/sha... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 2 | 2022-12-15T01:23:03 | 2022-12-15T07:45:54 | 2022-12-15T07:45:53 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
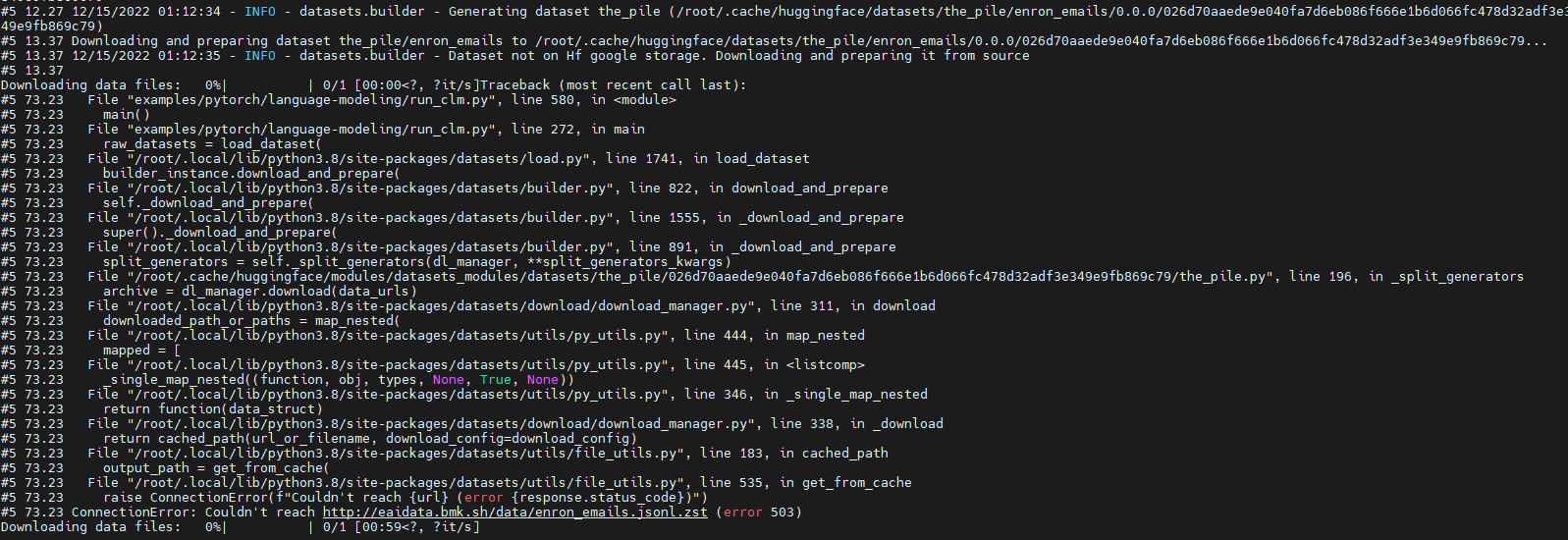
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | https://api.github.com/repos/huggingface/datasets/issues/5361/events | https://github.com/huggingface/datasets/issues/5361 | 1,497,153,889 | I_kwDODunzps5ZPMFh | 5,361 | How concatenate `Audio` elements using batch mapping | {
"login": "bayartsogt-ya",
"id": 43239645,
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bayartsogt-ya",
"html_url": "https://github.com/bayartsogt-ya",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | 3 | 2022-12-14T18:13:55 | 2023-07-21T14:30:51 | 2023-07-21T14:30:51 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5361/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5361/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5360/comments | https://api.github.com/repos/huggingface/datasets/issues/5360/events | https://github.com/huggingface/datasets/issues/5360 | 1,496,947,177 | I_kwDODunzps5ZOZnp | 5,360 | IterableDataset returns duplicated data using PyTorch DDP | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | 11 | 2022-12-14T16:06:19 | 2023-06-15T09:51:13 | 2023-01-16T13:33:33 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5360/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5360/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5359 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5359/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5359/comments | https://api.github.com/repos/huggingface/datasets/issues/5359/events | https://github.com/huggingface/datasets/pull/5359 | 1,495,297,857 | PR_kwDODunzps5FYHWm | 5,359 | Raise error if ClassLabel names is not python list | {
"login": "freddyheppell",
"id": 1475568,
"node_id": "MDQ6VXNlcjE0NzU1Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1475568?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/freddyheppell",
"html_url": "https://github.com/freddyheppell",
"followers_url": "https://api.github.... | [] | closed | false | null | [] | null | 3 | 2022-12-13T23:04:06 | 2022-12-22T16:35:49 | 2022-12-22T16:32:49 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5359",
"html_url": "https://github.com/huggingface/datasets/pull/5359",
"diff_url": "https://github.com/huggingface/datasets/pull/5359.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5359.patch",
"merged_at": "2022-12-22T16:32... | Checks type of names provided to ClassLabel to avoid easy and hard to debug errors (closes #5332 - see for discussion) | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5359/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5359/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5358/comments | https://api.github.com/repos/huggingface/datasets/issues/5358/events | https://github.com/huggingface/datasets/pull/5358 | 1,495,270,822 | PR_kwDODunzps5FYBcq | 5,358 | Fix `fs.open` resource leaks | {
"login": "tkukurin",
"id": 297847,
"node_id": "MDQ6VXNlcjI5Nzg0Nw==",
"avatar_url": "https://avatars.githubusercontent.com/u/297847?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tkukurin",
"html_url": "https://github.com/tkukurin",
"followers_url": "https://api.github.com/users/tkukuri... | [] | closed | false | null | [] | null | 3 | 2022-12-13T22:35:51 | 2023-01-05T16:46:31 | 2023-01-05T15:59:51 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5358",
"html_url": "https://github.com/huggingface/datasets/pull/5358",
"diff_url": "https://github.com/huggingface/datasets/pull/5358.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5358.patch",
"merged_at": "2023-01-05T15:59... | Invoking `{load,save}_from_dict` results in resource leak warnings, this should fix.
Introduces no significant logic changes. | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5358/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5358/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5357 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5357/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5357/comments | https://api.github.com/repos/huggingface/datasets/issues/5357/events | https://github.com/huggingface/datasets/pull/5357 | 1,495,029,602 | PR_kwDODunzps5FXNyR | 5,357 | Support torch dataloader without torch formatting | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 7 | 2022-12-13T19:39:24 | 2023-01-04T12:45:40 | 2022-12-15T19:15:54 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5357",
"html_url": "https://github.com/huggingface/datasets/pull/5357",
"diff_url": "https://github.com/huggingface/datasets/pull/5357.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5357.patch",
"merged_at": "2022-12-15T19:15... | In https://github.com/huggingface/datasets/pull/5084 we make the torch formatting consistent with the map-style datasets formatting: a torch formatted iterable dataset will yield torch tensors.
The previous behavior of the torch formatting for iterable dataset was simply to make the iterable dataset inherit from `to... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5357/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5357/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5356 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5356/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5356/comments | https://api.github.com/repos/huggingface/datasets/issues/5356/events | https://github.com/huggingface/datasets/pull/5356 | 1,494,961,609 | PR_kwDODunzps5FW-c9 | 5,356 | Clean filesystem and logging docstrings | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 1 | 2022-12-13T18:54:09 | 2022-12-14T17:25:58 | 2022-12-14T17:22:16 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5356",
"html_url": "https://github.com/huggingface/datasets/pull/5356",
"diff_url": "https://github.com/huggingface/datasets/pull/5356.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5356.patch",
"merged_at": "2022-12-14T17:22... | This PR cleans the `Filesystems` and `Logging` docstrings. | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5356/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5356/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5355 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5355/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5355/comments | https://api.github.com/repos/huggingface/datasets/issues/5355/events | https://github.com/huggingface/datasets/pull/5355 | 1,493,076,860 | PR_kwDODunzps5FQcYG | 5,355 | Clean up Table class docstrings | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 1 | 2022-12-13T00:29:47 | 2022-12-13T18:17:56 | 2022-12-13T18:14:42 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5355",
"html_url": "https://github.com/huggingface/datasets/pull/5355",
"diff_url": "https://github.com/huggingface/datasets/pull/5355.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5355.patch",
"merged_at": "2022-12-13T18:14... | This PR cleans up the `Table` class docstrings :) | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5355/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5355/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5354/comments | https://api.github.com/repos/huggingface/datasets/issues/5354/events | https://github.com/huggingface/datasets/issues/5354 | 1,492,174,125 | I_kwDODunzps5Y8MUt | 5,354 | Consider using "Sequence" instead of "List" | {
"login": "tranhd95",
"id": 15568078,
"node_id": "MDQ6VXNlcjE1NTY4MDc4",
"avatar_url": "https://avatars.githubusercontent.com/u/15568078?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tranhd95",
"html_url": "https://github.com/tranhd95",
"followers_url": "https://api.github.com/users/tra... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | open | false | {
"login": "avinashsai",
"id": 22453634,
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avinashsai",
"html_url": "https://github.com/avinashsai",
"followers_url": "https://api.github.com/use... | [
{
"login": "avinashsai",
"id": 22453634,
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avinashsai",
"html_url": "https://github.com/avinashsai",
"followers_url": "https:... | null | 10 | 2022-12-12T15:39:45 | 2024-10-05T14:38:44 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5354/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5354/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5353/comments | https://api.github.com/repos/huggingface/datasets/issues/5353/events | https://github.com/huggingface/datasets/issues/5353 | 1,491,880,500 | I_kwDODunzps5Y7Eo0 | 5,353 | Support remote file systems for `Audio` | {
"login": "OllieBroadhurst",
"id": 46894149,
"node_id": "MDQ6VXNlcjQ2ODk0MTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/46894149?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OllieBroadhurst",
"html_url": "https://github.com/OllieBroadhurst",
"followers_url": "https://api... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 1 | 2022-12-12T13:22:13 | 2022-12-12T13:37:14 | 2022-12-12T13:37:14 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but to my knowledge actually copies the datas... | {
"login": "OllieBroadhurst",
"id": 46894149,
"node_id": "MDQ6VXNlcjQ2ODk0MTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/46894149?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OllieBroadhurst",
"html_url": "https://github.com/OllieBroadhurst",
"followers_url": "https://api... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5353/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5353/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5352/comments | https://api.github.com/repos/huggingface/datasets/issues/5352/events | https://github.com/huggingface/datasets/issues/5352 | 1,490,796,414 | I_kwDODunzps5Y279- | 5,352 | __init__() got an unexpected keyword argument 'input_size' | {
"login": "J-shel",
"id": 82662111,
"node_id": "MDQ6VXNlcjgyNjYyMTEx",
"avatar_url": "https://avatars.githubusercontent.com/u/82662111?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/J-shel",
"html_url": "https://github.com/J-shel",
"followers_url": "https://api.github.com/users/J-shel/fo... | [] | open | false | null | [] | null | 2 | 2022-12-12T02:52:03 | 2022-12-19T01:38:48 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I try to define a custom configuration with a input_size attribute following the instructions by "Specifying several dataset configurations" in https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html
But when I load the dataset, I got an error "__init__() got an unexpected keyword argument... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5352/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5352/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5351/comments | https://api.github.com/repos/huggingface/datasets/issues/5351/events | https://github.com/huggingface/datasets/issues/5351 | 1,490,659,504 | I_kwDODunzps5Y2aiw | 5,351 | Do we need to implement `_prepare_split`? | {
"login": "jmwoloso",
"id": 7530947,
"node_id": "MDQ6VXNlcjc1MzA5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmwoloso",
"html_url": "https://github.com/jmwoloso",
"followers_url": "https://api.github.com/users/jmwol... | [] | closed | false | null | [] | null | 11 | 2022-12-12T01:38:54 | 2022-12-20T18:20:57 | 2022-12-12T16:48:56 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to im... | {
"login": "jmwoloso",
"id": 7530947,
"node_id": "MDQ6VXNlcjc1MzA5NDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmwoloso",
"html_url": "https://github.com/jmwoloso",
"followers_url": "https://api.github.com/users/jmwol... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5351/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5351/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5350 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5350/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5350/comments | https://api.github.com/repos/huggingface/datasets/issues/5350/events | https://github.com/huggingface/datasets/pull/5350 | 1,487,559,904 | PR_kwDODunzps5E8y2E | 5,350 | Clean up Loading methods docstrings | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 1 | 2022-12-09T22:25:30 | 2022-12-12T17:27:20 | 2022-12-12T17:24:01 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5350",
"html_url": "https://github.com/huggingface/datasets/pull/5350",
"diff_url": "https://github.com/huggingface/datasets/pull/5350.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5350.patch",
"merged_at": "2022-12-12T17:24... | Clean up for the docstrings in Loading methods! | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5350/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5350/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5349 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5349/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5349/comments | https://api.github.com/repos/huggingface/datasets/issues/5349/events | https://github.com/huggingface/datasets/pull/5349 | 1,487,396,780 | PR_kwDODunzps5E8N6G | 5,349 | Clean up remaining Main Classes docstrings | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 1 | 2022-12-09T20:17:15 | 2022-12-12T17:27:17 | 2022-12-12T17:24:13 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5349",
"html_url": "https://github.com/huggingface/datasets/pull/5349",
"diff_url": "https://github.com/huggingface/datasets/pull/5349.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5349.patch",
"merged_at": "2022-12-12T17:24... | This PR cleans up the remaining docstrings in Main Classes (`IterableDataset`, `IterableDatasetDict`, and `Features`). | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5349/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5349/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5348/comments | https://api.github.com/repos/huggingface/datasets/issues/5348/events | https://github.com/huggingface/datasets/issues/5348 | 1,486,975,626 | I_kwDODunzps5YoXKK | 5,348 | The data downloaded in the download folder of the cache does not respect `umask` | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/fo... | [] | open | false | null | [] | null | 1 | 2022-12-09T15:46:27 | 2022-12-09T17:21:26 | null | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is downloaded by giving read and write permissions only to the user launching the com... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5348/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5348/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5347 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5347/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5347/comments | https://api.github.com/repos/huggingface/datasets/issues/5347/events | https://github.com/huggingface/datasets/pull/5347 | 1,486,920,261 | PR_kwDODunzps5E6jb1 | 5,347 | Force soundfile to return float32 instead of the default float64 | {
"login": "qmeeus",
"id": 25608944,
"node_id": "MDQ6VXNlcjI1NjA4OTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qmeeus",
"html_url": "https://github.com/qmeeus",
"followers_url": "https://api.github.com/users/qmeeus/fo... | [] | open | false | null | [] | null | 8 | 2022-12-09T15:10:24 | 2023-01-17T16:12:49 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5347",
"html_url": "https://github.com/huggingface/datasets/pull/5347",
"diff_url": "https://github.com/huggingface/datasets/pull/5347.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5347.patch",
"merged_at": null
} | (Fixes issue #5345) | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5347/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5347/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5346/comments | https://api.github.com/repos/huggingface/datasets/issues/5346/events | https://github.com/huggingface/datasets/issues/5346 | 1,486,884,983 | I_kwDODunzps5YoBB3 | 5,346 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 3 | 2022-12-09T14:48:02 | 2023-06-02T20:24:44 | 2023-01-25T19:35:40 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Thanks to all of you, Datasets is just about to pass 15k stars!
Since the last survey, a lot has happened: the [diffusers](https://github.com/huggingface/diffusers), [evaluate](https://github.com/huggingface/evaluate) and [skops](https://github.com/skops-dev/skops) libraries were born. `timm` joined the Hugging Face... | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5346/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 3,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5346/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5345/comments | https://api.github.com/repos/huggingface/datasets/issues/5345/events | https://github.com/huggingface/datasets/issues/5345 | 1,486,555,384 | I_kwDODunzps5Ymwj4 | 5,345 | Wrong dtype for array in audio features | {
"login": "qmeeus",
"id": 25608944,
"node_id": "MDQ6VXNlcjI1NjA4OTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/qmeeus",
"html_url": "https://github.com/qmeeus",
"followers_url": "https://api.github.com/users/qmeeus/fo... | [] | open | false | null | [] | null | 3 | 2022-12-09T11:05:11 | 2023-02-10T14:39:28 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When concatenating/interleaving different datasets, I stumble into an error because the features can't be aligned. After some investigation, I understood that the audio arrays had different dtypes, namely `float32` and `float64`. Consequently, the datasets cannot be merged.
### Steps to repro... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5345/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5345/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5344/comments | https://api.github.com/repos/huggingface/datasets/issues/5344/events | https://github.com/huggingface/datasets/pull/5344 | 1,485,628,319 | PR_kwDODunzps5E2BPN | 5,344 | Clean up Dataset and DatasetDict | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 1 | 2022-12-09T00:02:08 | 2022-12-13T00:56:07 | 2022-12-13T00:53:02 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5344",
"html_url": "https://github.com/huggingface/datasets/pull/5344",
"diff_url": "https://github.com/huggingface/datasets/pull/5344.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5344.patch",
"merged_at": "2022-12-13T00:53... | This PR cleans up the docstrings for the other half of the methods in `Dataset` and finishes `DatasetDict`. | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5344/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5344/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5343/comments | https://api.github.com/repos/huggingface/datasets/issues/5343/events | https://github.com/huggingface/datasets/issues/5343 | 1,485,297,823 | I_kwDODunzps5Yh9if | 5,343 | T5 for Q&A produces truncated sentence | {
"login": "junyongyou",
"id": 13484072,
"node_id": "MDQ6VXNlcjEzNDg0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/13484072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/junyongyou",
"html_url": "https://github.com/junyongyou",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-12-08T19:48:46 | 2022-12-08T19:57:17 | 2022-12-08T19:57:17 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to... | {
"login": "junyongyou",
"id": 13484072,
"node_id": "MDQ6VXNlcjEzNDg0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/13484072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/junyongyou",
"html_url": "https://github.com/junyongyou",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5343/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5343/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5342/comments | https://api.github.com/repos/huggingface/datasets/issues/5342/events | https://github.com/huggingface/datasets/issues/5342 | 1,485,244,178 | I_kwDODunzps5YhwcS | 5,342 | Emotion dataset cannot be downloaded | {
"login": "cbarond",
"id": 78887193,
"node_id": "MDQ6VXNlcjc4ODg3MTkz",
"avatar_url": "https://avatars.githubusercontent.com/u/78887193?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cbarond",
"html_url": "https://github.com/cbarond",
"followers_url": "https://api.github.com/users/cbaron... | [
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate",
"name": "duplicate",
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists"
}
] | closed | false | null | [] | null | 7 | 2022-12-08T19:07:09 | 2023-02-23T19:13:19 | 2022-12-09T10:46:11 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022).
### Steps to reproduce the bug
... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5342/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5342/timeline | null | completed | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.