
url string | repository_url string | labels_url string | comments_url string | events_url string | html_url string | id int64 | node_id string | number int64 | title string | user dict | labels list | state string | locked bool | assignee dict | assignees list | milestone dict | comments int64 | created_at timestamp[ms] | updated_at timestamp[ms] | closed_at timestamp[ms] | author_association string | type null | sub_issues_summary dict | active_lock_reason null | draft bool | pull_request dict | body string | closed_by dict | reactions dict | timeline_url string | performed_via_github_app null | state_reason string | is_pull_request bool |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5649/comments | https://api.github.com/repos/huggingface/datasets/issues/5649/events | https://github.com/huggingface/datasets/issues/5649 | 1,630,173,460 | I_kwDODunzps5hKnkU | 5,649 | The index column created with .to_sql() is dependent on the batch_size when writing | {
"login": "lsb",
"id": 45281,
"node_id": "MDQ6VXNlcjQ1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lsb",
"html_url": "https://github.com/lsb",
"followers_url": "https://api.github.com/users/lsb/followers",
"following... | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 2 | 2023-03-18T05:25:17 | 2023-06-17T07:01:57 | 2023-06-17T07:01:57 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
It seems like the "index" column is designed to be unique? The values are only unique per batch. The SQL index is not a unique index.
This can be a problem, for instance, when building a faiss index on a dataset and then trying to match up ids with a sql export.
### Steps to reproduce the ... | {
"login": "lsb",
"id": 45281,
"node_id": "MDQ6VXNlcjQ1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lsb",
"html_url": "https://github.com/lsb",
"followers_url": "https://api.github.com/users/lsb/followers",
"following... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5649/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5649/timeline | null | not_planned | false |
https://api.github.com/repos/huggingface/datasets/issues/5648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5648/comments | https://api.github.com/repos/huggingface/datasets/issues/5648/events | https://github.com/huggingface/datasets/issues/5648 | 1,629,253,719 | I_kwDODunzps5hHHBX | 5,648 | flatten_indices doesn't work with pandas format | {
"login": "alialamiidrissi",
"id": 14365168,
"node_id": "MDQ6VXNlcjE0MzY1MTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alialamiidrissi",
"html_url": "https://github.com/alialamiidrissi",
"followers_url": "https://api... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | 1 | 2023-03-17T12:44:25 | 2023-03-21T13:12:03 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hi,
I noticed that `flatten_indices` throws an error when the batch format is `pandas`. This is probably due to the fact that flatten_indices uses map internally which doesn't accept dataframes as the transformation function output
### Steps to reproduce the bug
tabular_data = pd.DataFrame(np.r... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5648/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5648/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5647/comments | https://api.github.com/repos/huggingface/datasets/issues/5647/events | https://github.com/huggingface/datasets/issues/5647 | 1,628,225,544 | I_kwDODunzps5hDMAI | 5,647 | Make all print statements optional | {
"login": "gagan3012",
"id": 49101362,
"node_id": "MDQ6VXNlcjQ5MTAxMzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gagan3012",
"html_url": "https://github.com/gagan3012",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 2 | 2023-03-16T20:30:07 | 2023-07-21T14:20:25 | 2023-07-21T14:20:24 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Make all print statements optional to speed up the development
### Motivation
Im loading multiple tiny datasets and all the print statements make the loading slower
### Your contribution
I can help contribute | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5647/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5647/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5646 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5646/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5646/comments | https://api.github.com/repos/huggingface/datasets/issues/5646/events | https://github.com/huggingface/datasets/pull/5646 | 1,627,838,762 | PR_kwDODunzps5MOqjj | 5,646 | Allow self as key in `Features` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-03-16T16:17:03 | 2023-03-16T17:21:58 | 2023-03-16T17:14:50 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5646",
"html_url": "https://github.com/huggingface/datasets/pull/5646",
"diff_url": "https://github.com/huggingface/datasets/pull/5646.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5646.patch",
"merged_at": "2023-03-16T17:14... | Fix #5641 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5646/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5646/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5645/comments | https://api.github.com/repos/huggingface/datasets/issues/5645/events | https://github.com/huggingface/datasets/issues/5645 | 1,627,108,278 | I_kwDODunzps5g-7O2 | 5,645 | Datasets map and select(range()) is giving dill error | {
"login": "Tanya-11",
"id": 90728105,
"node_id": "MDQ6VXNlcjkwNzI4MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tanya-11",
"html_url": "https://github.com/Tanya-11",
"followers_url": "https://api.github.com/users/Tan... | [] | closed | false | null | [] | null | 2 | 2023-03-16T10:01:28 | 2023-03-17T04:24:51 | 2023-03-17T04:24:51 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I'm using Huggingface Datasets library to load the dataset in google colab
When I do,
> data = train_dataset.select(range(10))
or
> train_datasets = train_dataset.map(
> process_data_to_model_inputs,
> batched=True,
> batch_size=batch_size,
> remove_columns... | {
"login": "Tanya-11",
"id": 90728105,
"node_id": "MDQ6VXNlcjkwNzI4MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Tanya-11",
"html_url": "https://github.com/Tanya-11",
"followers_url": "https://api.github.com/users/Tan... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5645/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5645/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5644 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5644/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5644/comments | https://api.github.com/repos/huggingface/datasets/issues/5644/events | https://github.com/huggingface/datasets/pull/5644 | 1,626,204,046 | PR_kwDODunzps5MJHUi | 5,644 | Allow direct cast from binary to Audio/Image | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-03-15T20:02:54 | 2023-03-16T14:20:44 | 2023-03-16T14:12:55 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5644",
"html_url": "https://github.com/huggingface/datasets/pull/5644",
"diff_url": "https://github.com/huggingface/datasets/pull/5644.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5644.patch",
"merged_at": "2023-03-16T14:12... | To address https://github.com/huggingface/datasets/discussions/5593.
| {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5644/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5644/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5643 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5643/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5643/comments | https://api.github.com/repos/huggingface/datasets/issues/5643/events | https://github.com/huggingface/datasets/pull/5643 | 1,626,160,220 | PR_kwDODunzps5MI9zO | 5,643 | Support PyArrow arrays as column values in `from_dict` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-03-15T19:32:40 | 2023-03-16T17:23:06 | 2023-03-16T17:15:40 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5643",
"html_url": "https://github.com/huggingface/datasets/pull/5643",
"diff_url": "https://github.com/huggingface/datasets/pull/5643.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5643.patch",
"merged_at": "2023-03-16T17:15... | For consistency with `pa.Table.from_pydict`, which supports both Python lists and PyArrow arrays as column values.
"Fixes" https://discuss.huggingface.co/t/pyarrow-lib-floatarray-did-not-recognize-python-value-type-when-inferring-an-arrow-data-type/33417 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5643/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5643/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5642 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5642/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5642/comments | https://api.github.com/repos/huggingface/datasets/issues/5642/events | https://github.com/huggingface/datasets/pull/5642 | 1,626,043,177 | PR_kwDODunzps5MIjw9 | 5,642 | Bump hfh to 0.11.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 6 | 2023-03-15T18:26:07 | 2023-03-20T12:34:09 | 2023-03-20T12:26:58 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5642",
"html_url": "https://github.com/huggingface/datasets/pull/5642",
"diff_url": "https://github.com/huggingface/datasets/pull/5642.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5642.patch",
"merged_at": "2023-03-20T12:26... | to fix errors like
```
requests.exceptions.HTTPError: 400 Client Error: Bad Request for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/...
```
(e.g. from this [failing CI](https://github.com/huggingface/datasets/actions/runs/4428956210/jobs/7769160997))
0.11.0 is the current mini... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5642/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5642/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5641/comments | https://api.github.com/repos/huggingface/datasets/issues/5641/events | https://github.com/huggingface/datasets/issues/5641 | 1,625,942,730 | I_kwDODunzps5g6erK | 5,641 | Features cannot be named "self" | {
"login": "alialamiidrissi",
"id": 14365168,
"node_id": "MDQ6VXNlcjE0MzY1MTY4",
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alialamiidrissi",
"html_url": "https://github.com/alialamiidrissi",
"followers_url": "https://api... | [] | closed | false | null | [] | null | 0 | 2023-03-15T17:16:40 | 2023-03-16T17:14:51 | 2023-03-16T17:14:51 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hi,
I noticed that we cannot create a HuggingFace dataset from Pandas DataFrame with a column named `self`.
The error seems to be coming from arguments validation in the `Features.from_dict` function.
### Steps to reproduce the bug
```python
import datasets
dummy_pandas = pd.DataFrame([0... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5641/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5641/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5640 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5640/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5640/comments | https://api.github.com/repos/huggingface/datasets/issues/5640/events | https://github.com/huggingface/datasets/pull/5640 | 1,625,896,057 | PR_kwDODunzps5MID3I | 5,640 | Less zip false positives | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 6 | 2023-03-15T16:48:59 | 2023-03-16T13:47:37 | 2023-03-16T13:40:12 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5640",
"html_url": "https://github.com/huggingface/datasets/pull/5640",
"diff_url": "https://github.com/huggingface/datasets/pull/5640.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5640.patch",
"merged_at": "2023-03-16T13:40... | `zipfile.is_zipfile` return false positives for some Parquet files. It causes errors when loading certain parquet datasets, where some files are considered ZIP files by `zipfile.is_zipfile`
This is a known issue: https://github.com/python/cpython/issues/72680
At first I wanted to rely only on magic numbers, but t... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5640/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5640/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5639/comments | https://api.github.com/repos/huggingface/datasets/issues/5639/events | https://github.com/huggingface/datasets/issues/5639 | 1,625,737,098 | I_kwDODunzps5g5seK | 5,639 | Parquet file wrongly recognized as zip prevents loading a dataset | {
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 0 | 2023-03-15T15:20:45 | 2023-03-16T13:40:14 | 2023-03-16T13:40:14 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When trying to `load_dataset_builder` for `HuggingFaceGECLM/StackExchange_Mar2023`, extraction fails, because parquet file [devops-00000-of-00001-22fe902fd8702892.parquet](https://huggingface.co/datasets/HuggingFaceGECLM/StackExchange_Mar2023/resolve/1f8c9a2ab6f7d0f9ae904b8b922e4384592ae1a5/data... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5639/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5639/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5638/comments | https://api.github.com/repos/huggingface/datasets/issues/5638/events | https://github.com/huggingface/datasets/issues/5638 | 1,625,564,471 | I_kwDODunzps5g5CU3 | 5,638 | xPath to implement all operations for Path | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 5 | 2023-03-15T13:47:11 | 2023-03-17T13:21:12 | 2023-03-17T13:21:12 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Current xPath implementation is a great extension of Path in order to work with remote objects. However some methods such as `mkdir` are not implemented correctly. It should instead rely on `fsspec` methods, instead of defaulting do `Path` methods which only work locally.
### Motivation
I'm using... | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5638/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5638/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5637/comments | https://api.github.com/repos/huggingface/datasets/issues/5637/events | https://github.com/huggingface/datasets/issues/5637 | 1,625,295,691 | I_kwDODunzps5g4AtL | 5,637 | IterableDataset with_format does not support 'device' keyword for jax | {
"login": "Lime-Cakes",
"id": 91322985,
"node_id": "MDQ6VXNlcjkxMzIyOTg1",
"avatar_url": "https://avatars.githubusercontent.com/u/91322985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Lime-Cakes",
"html_url": "https://github.com/Lime-Cakes",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | 3 | 2023-03-15T11:04:12 | 2025-01-07T06:59:33 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
As seen here: https://huggingface.co/docs/datasets/use_with_jax dataset.with_format() supports the keyword 'device', to put data on a specific device when loaded as jax. However, when called on an IterableDataset, I got the error `TypeError: with_format() got an unexpected keyword argument 'devi... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5637/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5637/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5636 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5636/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5636/comments | https://api.github.com/repos/huggingface/datasets/issues/5636/events | https://github.com/huggingface/datasets/pull/5636 | 1,623,721,577 | PR_kwDODunzps5MAunR | 5,636 | Fix CI: ignore C901 ("some_func" is to complex) in `ruff` | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2023-03-14T15:29:11 | 2023-03-14T16:37:06 | 2023-03-14T16:29:52 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5636",
"html_url": "https://github.com/huggingface/datasets/pull/5636",
"diff_url": "https://github.com/huggingface/datasets/pull/5636.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5636.patch",
"merged_at": "2023-03-14T16:29... | idk if I should have added this ignore to `ruff` too, but I added :) | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5636/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5636/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5635/comments | https://api.github.com/repos/huggingface/datasets/issues/5635/events | https://github.com/huggingface/datasets/pull/5635 | 1,623,682,558 | PR_kwDODunzps5MAmLU | 5,635 | Pass custom metadata filename to Image/Audio folders | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | open | false | null | [] | null | 4 | 2023-03-14T15:08:16 | 2023-03-22T17:50:31 | null | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5635",
"html_url": "https://github.com/huggingface/datasets/pull/5635",
"diff_url": "https://github.com/huggingface/datasets/pull/5635.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5635.patch",
"merged_at": null
} | This is a quick fix.
Now it requires to pass data via `data_files` parameters and include a required metadata file there and pass its filename as `metadata_filename` parameter.
For example, with the structure like:
```
data
images_dir/
im1.jpg
im2.jpg
...
metadata_dir/
meta_file... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5635/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5635/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5634/comments | https://api.github.com/repos/huggingface/datasets/issues/5634/events | https://github.com/huggingface/datasets/issues/5634 | 1,622,424,174 | I_kwDODunzps5gtDpu | 5,634 | Not all progress bars are showing up when they should for downloading dataset | {
"login": "garlandz-db",
"id": 110427462,
"node_id": "U_kgDOBpT9Rg",
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/garlandz-db",
"html_url": "https://github.com/garlandz-db",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 2 | 2023-03-13T23:04:18 | 2023-10-11T16:30:16 | 2023-10-11T16:30:16 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
During downloading the rotten tomatoes dataset, not all progress bars are displayed properly. This might be related to [this ticket](https://github.com/huggingface/datasets/issues/5117) as it raised the same concern but its not clear if the fix solves this issue too.
ipywidgets
<img width=... | {
"login": "garlandz-db",
"id": 110427462,
"node_id": "U_kgDOBpT9Rg",
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/garlandz-db",
"html_url": "https://github.com/garlandz-db",
"followers_url": "https://api.github.com/users/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5634/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5634/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"login": "eerio",
"id": 11250555,
"node_id": "MDQ6VXNlcjExMjUwNTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eerio",
"html_url": "https://github.com/eerio",
"followers_url": "https://api.github.com/users/eerio/follow... | [] | closed | false | null | [] | null | 1 | 2023-03-13T13:14:44 | 2023-03-13T17:54:19 | 2023-03-13T17:54:19 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Pl... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5632/comments | https://api.github.com/repos/huggingface/datasets/issues/5632/events | https://github.com/huggingface/datasets/issues/5632 | 1,621,177,391 | I_kwDODunzps5goTQv | 5,632 | Dataset cannot convert too large dictionnary | {
"login": "MaraLac",
"id": 108518627,
"node_id": "U_kgDOBnfc4w",
"avatar_url": "https://avatars.githubusercontent.com/u/108518627?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MaraLac",
"html_url": "https://github.com/MaraLac",
"followers_url": "https://api.github.com/users/MaraLac/foll... | [] | open | false | null | [] | null | 1 | 2023-03-13T10:14:40 | 2023-03-16T15:28:57 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hello everyone!
I tried to build a new dataset with the command "dict_valid = datasets.Dataset.from_dict({'input_values': values_array})".
However, I have a very large dataset (~400Go) and it seems that dataset cannot handle this.
Indeed, I can create the dataset until a certain size of m... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5632/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5632/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5631/comments | https://api.github.com/repos/huggingface/datasets/issues/5631/events | https://github.com/huggingface/datasets/issues/5631 | 1,620,442,854 | I_kwDODunzps5glf7m | 5,631 | Custom split names | {
"login": "ErfanMoosaviMonazzah",
"id": 79091831,
"node_id": "MDQ6VXNlcjc5MDkxODMx",
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ErfanMoosaviMonazzah",
"html_url": "https://github.com/ErfanMoosaviMonazzah",
"followers_url... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 1 | 2023-03-12T17:21:43 | 2023-03-24T14:13:00 | 2023-03-24T14:13:00 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Hi,
I participated in multiple NLP tasks where there are more than just train, test, validation splits, there could be multiple validation sets or test sets. But it seems currently only those mentioned three splits supported. It would be nice to have the support for more splits on the hub. (curren... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5631/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5631/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5630 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5630/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5630/comments | https://api.github.com/repos/huggingface/datasets/issues/5630/events | https://github.com/huggingface/datasets/pull/5630 | 1,620,327,510 | PR_kwDODunzps5L1ahF | 5,630 | adds early exit if url is `PathLike` | {
"login": "vvvm23",
"id": 44398246,
"node_id": "MDQ6VXNlcjQ0Mzk4MjQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/44398246?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vvvm23",
"html_url": "https://github.com/vvvm23",
"followers_url": "https://api.github.com/users/vvvm23/fo... | [] | open | false | null | [] | null | 1 | 2023-03-12T11:23:28 | 2023-03-15T11:58:38 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5630",
"html_url": "https://github.com/huggingface/datasets/pull/5630",
"diff_url": "https://github.com/huggingface/datasets/pull/5630.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5630.patch",
"merged_at": null
} | Closes #4864
Should fix errors thrown when attempting to load `json` dataset using `pathlib.Path` in `data_files` argument. | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5630/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5630/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5629/comments | https://api.github.com/repos/huggingface/datasets/issues/5629/events | https://github.com/huggingface/datasets/issues/5629 | 1,619,921,247 | I_kwDODunzps5gjglf | 5,629 | load_dataset gives "403" error when using Financial phrasebank | {
"login": "Jimchoo91",
"id": 67709789,
"node_id": "MDQ6VXNlcjY3NzA5Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/67709789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Jimchoo91",
"html_url": "https://github.com/Jimchoo91",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 1 | 2023-03-11T07:46:39 | 2023-03-13T18:27:26 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | When I try to load this dataset, I receive the following error:
ConnectionError: Couldn't reach https://www.researchgate.net/profile/Pekka_Malo/publication/251231364_FinancialPhraseBank-v10/data/0c96051eee4fb1d56e000000/FinancialPhraseBank-v10.zip (error 403)
Has this been seen before? Thanks. The website loads ... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5629/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5629/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5628 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5628/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5628/comments | https://api.github.com/repos/huggingface/datasets/issues/5628/events | https://github.com/huggingface/datasets/pull/5628 | 1,619,641,810 | PR_kwDODunzps5LzVKi | 5,628 | add kwargs to index search | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/fo... | [] | closed | false | null | [] | null | 1 | 2023-03-10T21:24:58 | 2023-03-15T14:48:47 | 2023-03-15T14:46:04 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5628",
"html_url": "https://github.com/huggingface/datasets/pull/5628",
"diff_url": "https://github.com/huggingface/datasets/pull/5628.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5628.patch",
"merged_at": "2023-03-15T14:46... | This PR proposes to add kwargs to index search methods.
This is particularly useful for setting the timeout of a query on elasticsearch.
A typical use case would be:
```python
dset.add_elasticsearch_index("filename", es_client=es_client)
scores, examples = dset.get_nearest_examples("filename", "my_name-train_2... | {
"login": "SaulLu",
"id": 55560583,
"node_id": "MDQ6VXNlcjU1NTYwNTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SaulLu",
"html_url": "https://github.com/SaulLu",
"followers_url": "https://api.github.com/users/SaulLu/fo... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5628/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5628/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5627/comments | https://api.github.com/repos/huggingface/datasets/issues/5627/events | https://github.com/huggingface/datasets/issues/5627 | 1,619,336,609 | I_kwDODunzps5ghR2h | 5,627 | Unable to load AutoTrain-generated dataset from the hub | {
"login": "ijmiller2",
"id": 8560151,
"node_id": "MDQ6VXNlcjg1NjAxNTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/8560151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ijmiller2",
"html_url": "https://github.com/ijmiller2",
"followers_url": "https://api.github.com/users/ij... | [] | open | false | null | [] | null | 2 | 2023-03-10T17:25:58 | 2023-03-11T15:44:42 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
DatasetGenerationError: An error occurred while generating the dataset -> ValueError: Couldn't cast ... because column names don't match
```
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5627/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5627/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5626 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5626/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5626/comments | https://api.github.com/repos/huggingface/datasets/issues/5626/events | https://github.com/huggingface/datasets/pull/5626 | 1,619,252,984 | PR_kwDODunzps5LyBT4 | 5,626 | Support streaming datasets with numpy.load | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-03-10T16:33:39 | 2023-03-21T06:36:05 | 2023-03-21T06:28:54 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5626",
"html_url": "https://github.com/huggingface/datasets/pull/5626",
"diff_url": "https://github.com/huggingface/datasets/pull/5626.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5626.patch",
"merged_at": "2023-03-21T06:28... | Support streaming datasets with `numpy.load`.
See: https://huggingface.co/datasets/qgallouedec/gia_dataset/discussions/1 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5626/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5626/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5625/comments | https://api.github.com/repos/huggingface/datasets/issues/5625/events | https://github.com/huggingface/datasets/issues/5625 | 1,618,971,855 | I_kwDODunzps5gf4zP | 5,625 | Allow "jsonl" data type signifier | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 2 | 2023-03-10T13:21:48 | 2023-03-11T10:35:39 | null | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
`load_dataset` currently does not accept `jsonl` as type but only `json`.
### Motivation
I was working with one of the `run_translation` scripts and used my own datasets (`.jsonl`) as train_dataset. But the default code did not work because
```
FileNotFoundError: Couldn't find a dataset scri... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5625/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5625/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5624/comments | https://api.github.com/repos/huggingface/datasets/issues/5624/events | https://github.com/huggingface/datasets/issues/5624 | 1,617,400,192 | I_kwDODunzps5gZ5GA | 5,624 | glue datasets returning -1 for test split | {
"login": "lithafnium",
"id": 8939967,
"node_id": "MDQ6VXNlcjg5Mzk5Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8939967?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lithafnium",
"html_url": "https://github.com/lithafnium",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | 1 | 2023-03-09T14:47:18 | 2023-03-09T16:49:29 | 2023-03-09T16:49:29 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Downloading any dataset from GLUE has -1 as class labels for test split. Train and validation have regular 0/1 class labels. This is also present in the dataset card online.
### Steps to reproduce the bug
```
dataset = load_dataset("glue", "sst2")
for d in dataset:
# prints out -1
... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5624/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5624/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5623 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5623/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5623/comments | https://api.github.com/repos/huggingface/datasets/issues/5623/events | https://github.com/huggingface/datasets/pull/5623 | 1,616,712,665 | PR_kwDODunzps5Lpb4q | 5,623 | Remove set_access_token usage + fail tests if FutureWarning | {
"login": "Wauplin",
"id": 11801849,
"node_id": "MDQ6VXNlcjExODAxODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wauplin",
"html_url": "https://github.com/Wauplin",
"followers_url": "https://api.github.com/users/Waupli... | [] | closed | false | null | [] | null | 6 | 2023-03-09T08:46:01 | 2023-03-09T15:39:00 | 2023-03-09T15:31:59 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5623",
"html_url": "https://github.com/huggingface/datasets/pull/5623",
"diff_url": "https://github.com/huggingface/datasets/pull/5623.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5623.patch",
"merged_at": "2023-03-09T15:31... | `set_access_token` is deprecated and will be removed in `huggingface_hub>=0.14`.
This PR removes it from the tests (it was not used in `datasets` source code itself). FYI, it was not needed since `set_access_token` was just setting git credentials and `datasets` doesn't seem to use git anywhere.
In the future, us... | {
"login": "Wauplin",
"id": 11801849,
"node_id": "MDQ6VXNlcjExODAxODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wauplin",
"html_url": "https://github.com/Wauplin",
"followers_url": "https://api.github.com/users/Waupli... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5623/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5623/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5622/comments | https://api.github.com/repos/huggingface/datasets/issues/5622/events | https://github.com/huggingface/datasets/pull/5622 | 1,615,190,942 | PR_kwDODunzps5LkSj8 | 5,622 | Update README template to better template | {
"login": "emiltj",
"id": 54767532,
"node_id": "MDQ6VXNlcjU0NzY3NTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/54767532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emiltj",
"html_url": "https://github.com/emiltj",
"followers_url": "https://api.github.com/users/emiltj/fo... | [] | closed | false | null | [] | null | 3 | 2023-03-08T12:30:23 | 2023-03-11T05:07:38 | 2023-03-11T05:07:38 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5622",
"html_url": "https://github.com/huggingface/datasets/pull/5622",
"diff_url": "https://github.com/huggingface/datasets/pull/5622.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5622.patch",
"merged_at": null
} | null | {
"login": "emiltj",
"id": 54767532,
"node_id": "MDQ6VXNlcjU0NzY3NTMy",
"avatar_url": "https://avatars.githubusercontent.com/u/54767532?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/emiltj",
"html_url": "https://github.com/emiltj",
"followers_url": "https://api.github.com/users/emiltj/fo... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5622/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5622/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5621 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5621/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5621/comments | https://api.github.com/repos/huggingface/datasets/issues/5621/events | https://github.com/huggingface/datasets/pull/5621 | 1,615,029,615 | PR_kwDODunzps5LjwD8 | 5,621 | Adding Oracle Cloud to docs | {
"login": "ahosler",
"id": 29129502,
"node_id": "MDQ6VXNlcjI5MTI5NTAy",
"avatar_url": "https://avatars.githubusercontent.com/u/29129502?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahosler",
"html_url": "https://github.com/ahosler",
"followers_url": "https://api.github.com/users/ahosle... | [] | closed | false | null | [] | null | 2 | 2023-03-08T10:22:50 | 2023-03-11T00:57:18 | 2023-03-11T00:49:56 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5621",
"html_url": "https://github.com/huggingface/datasets/pull/5621",
"diff_url": "https://github.com/huggingface/datasets/pull/5621.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5621.patch",
"merged_at": "2023-03-11T00:49... | Adding Oracle Cloud's fsspec implementation to the list of supported cloud storage providers. | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5621/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5621/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5620 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5620/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5620/comments | https://api.github.com/repos/huggingface/datasets/issues/5620/events | https://github.com/huggingface/datasets/pull/5620 | 1,613,460,520 | PR_kwDODunzps5LefAf | 5,620 | Bump pyarrow to 8.0.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 12 | 2023-03-07T13:31:53 | 2023-03-08T14:01:27 | 2023-03-08T13:54:22 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5620",
"html_url": "https://github.com/huggingface/datasets/pull/5620",
"diff_url": "https://github.com/huggingface/datasets/pull/5620.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5620.patch",
"merged_at": "2023-03-08T13:54... | Fix those for Pandas 2.0 (tested [here](https://github.com/huggingface/datasets/actions/runs/4346221280/jobs/7592010397) with pandas==2.0.0.rc0):
```python
=========================== short test summary info ============================
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_to_parquet_in_memory... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5620/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5620/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5619 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5619/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5619/comments | https://api.github.com/repos/huggingface/datasets/issues/5619/events | https://github.com/huggingface/datasets/pull/5619 | 1,613,439,709 | PR_kwDODunzps5LeaYP | 5,619 | unpin fsspec | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 3 | 2023-03-07T13:22:41 | 2023-03-07T13:47:01 | 2023-03-07T13:39:02 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5619",
"html_url": "https://github.com/huggingface/datasets/pull/5619",
"diff_url": "https://github.com/huggingface/datasets/pull/5619.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5619.patch",
"merged_at": "2023-03-07T13:39... | close https://github.com/huggingface/datasets/issues/5618 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5619/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5619/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 0 | 2023-03-07T08:41:51 | 2023-03-07T13:39:03 | 2023-03-07T13:39:03 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5617 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5617/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5617/comments | https://api.github.com/repos/huggingface/datasets/issues/5617/events | https://github.com/huggingface/datasets/pull/5617 | 1,612,947,422 | PR_kwDODunzps5LcvI- | 5,617 | Fix CI by temporarily pinning fsspec < 2023.3.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-03-07T08:18:20 | 2023-03-07T08:44:55 | 2023-03-07T08:37:28 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5617",
"html_url": "https://github.com/huggingface/datasets/pull/5617",
"diff_url": "https://github.com/huggingface/datasets/pull/5617.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5617.patch",
"merged_at": "2023-03-07T08:37... | As a hotfix for our CI, temporarily pin `fsspec`:
Fix #5616.
Until root cause is fixed, see:
- #5614 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5617/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5617/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5616/comments | https://api.github.com/repos/huggingface/datasets/issues/5616/events | https://github.com/huggingface/datasets/issues/5616 | 1,612,932,508 | I_kwDODunzps5gI2Wc | 5,616 | CI is broken after fsspec-2023.3.0 release | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 0 | 2023-03-07T08:06:39 | 2023-03-07T08:37:29 | 2023-03-07T08:37:29 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5616/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5616/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"login": "zsaladin",
"id": 6466389,
"node_id": "MDQ6VXNlcjY0NjYzODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zsaladin",
"html_url": "https://github.com/zsaladin",
"followers_url": "https://api.github.com/users/zsala... | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] | closed | false | null | [] | null | 1 | 2023-03-07T01:52:00 | 2023-03-09T15:24:05 | 2023-03-09T15:23:54 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5614 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5614/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5614/comments | https://api.github.com/repos/huggingface/datasets/issues/5614/events | https://github.com/huggingface/datasets/pull/5614 | 1,611,896,357 | PR_kwDODunzps5LZOTd | 5,614 | Fix archive fs test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 4 | 2023-03-06T17:28:09 | 2023-03-07T13:27:50 | 2023-03-07T13:20:57 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5614",
"html_url": "https://github.com/huggingface/datasets/pull/5614",
"diff_url": "https://github.com/huggingface/datasets/pull/5614.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5614.patch",
"merged_at": "2023-03-07T13:20... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5614/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5614/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5613/comments | https://api.github.com/repos/huggingface/datasets/issues/5613/events | https://github.com/huggingface/datasets/issues/5613 | 1,611,875,473 | I_kwDODunzps5gE0SR | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | {
"login": "adampauls",
"id": 1243668,
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adampauls",
"html_url": "https://github.com/adampauls",
"followers_url": "https://api.github.com/users/ad... | [] | open | false | null | [] | null | 6 | 2023-03-06T17:14:41 | 2024-04-05T20:13:52 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/... | {
"login": "adampauls",
"id": 1243668,
"node_id": "MDQ6VXNlcjEyNDM2Njg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/adampauls",
"html_url": "https://github.com/adampauls",
"followers_url": "https://api.github.com/users/ad... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions",
"total_count": 10,
"+1": 10,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5613/timeline | null | reopened | false |
https://api.github.com/repos/huggingface/datasets/issues/5612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5612/comments | https://api.github.com/repos/huggingface/datasets/issues/5612/events | https://github.com/huggingface/datasets/issues/5612 | 1,611,262,510 | I_kwDODunzps5gCeou | 5,612 | Arrow map type in parquet files unsupported | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/... | [] | open | false | null | [] | null | 4 | 2023-03-06T12:03:24 | 2024-03-15T18:56:12 | null | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5612/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 5
} | https://api.github.com/repos/huggingface/datasets/issues/5612/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5611/comments | https://api.github.com/repos/huggingface/datasets/issues/5611/events | https://github.com/huggingface/datasets/pull/5611 | 1,611,197,906 | PR_kwDODunzps5LW2Lx | 5,611 | add Dataset.to_list | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 3 | 2023-03-06T11:21:57 | 2023-03-27T13:34:19 | 2023-03-27T13:26:38 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5611",
"html_url": "https://github.com/huggingface/datasets/pull/5611",
"diff_url": "https://github.com/huggingface/datasets/pull/5611.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5611.patch",
"merged_at": "2023-03-27T13:26... | close https://github.com/huggingface/datasets/issues/5606
This PR is for adding the `Dataset.to_list` method.
Thank you in advance.
| {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5611/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5611/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"login": "gromzhu",
"id": 15223544,
"node_id": "MDQ6VXNlcjE1MjIzNTQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gromzhu",
"html_url": "https://github.com/gromzhu",
"followers_url": "https://api.github.com/users/gromzh... | [] | open | false | null | [] | null | 3 | 2023-03-06T05:26:49 | 2024-03-07T01:11:32 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.g... | [] | open | false | null | [] | null | 4 | 2023-03-05T05:27:15 | 2023-07-13T18:48:05 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/follower... | [] | closed | false | null | [] | null | 2 | 2023-03-05T00:14:45 | 2023-03-12T00:02:57 | 2023-03-12T00:02:57 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"login": "jcho19",
"id": 107211437,
"node_id": "U_kgDOBmPqrQ",
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jcho19",
"html_url": "https://github.com/jcho19",
"followers_url": "https://api.github.com/users/jcho19/follower... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5607 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5607/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5607/comments | https://api.github.com/repos/huggingface/datasets/issues/5607/events | https://github.com/huggingface/datasets/pull/5607 | 1,609,166,035 | PR_kwDODunzps5LQPbG | 5,607 | Fix outdated `verification_mode` values | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2023-03-03T19:50:29 | 2023-03-09T17:34:13 | 2023-03-09T17:27:07 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5607",
"html_url": "https://github.com/huggingface/datasets/pull/5607",
"diff_url": "https://github.com/huggingface/datasets/pull/5607.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5607.patch",
"merged_at": "2023-03-09T17:27... | ~I think it makes sense not to save `dataset_info.json` file to a dataset cache directory when loading dataset with `verification_mode="no_checks"` because otherwise when next time the dataset is loaded **without** `verification_mode="no_checks"`, it will be loaded successfully, despite some values in info might not co... | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5607/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5607/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://api.github.com/users/... | [
{
"login": "kyoto7250",
"id": 50972773,
"node_id": "MDQ6VXNlcjUwOTcyNzcz",
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kyoto7250",
"html_url": "https://github.com/kyoto7250",
"followers_url": "https://a... | null | 3 | 2023-03-03T16:17:10 | 2023-03-27T13:26:40 | 2023-03-27T13:26:40 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5605 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5605/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5605/comments | https://api.github.com/repos/huggingface/datasets/issues/5605/events | https://github.com/huggingface/datasets/pull/5605 | 1,608,865,460 | PR_kwDODunzps5LPPf5 | 5,605 | Update README logo | {
"login": "gary149",
"id": 3841370,
"node_id": "MDQ6VXNlcjM4NDEzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gary149",
"html_url": "https://github.com/gary149",
"followers_url": "https://api.github.com/users/gary149/... | [] | closed | false | null | [] | null | 3 | 2023-03-03T15:46:31 | 2023-03-03T21:57:18 | 2023-03-03T21:50:17 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5605",
"html_url": "https://github.com/huggingface/datasets/pull/5605",
"diff_url": "https://github.com/huggingface/datasets/pull/5605.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5605.patch",
"merged_at": "2023-03-03T21:50... | null | {
"login": "gary149",
"id": 3841370,
"node_id": "MDQ6VXNlcjM4NDEzNzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/3841370?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gary149",
"html_url": "https://github.com/gary149",
"followers_url": "https://api.github.com/users/gary149/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5605/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5605/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"login": "sentialx",
"id": 11065386,
"node_id": "MDQ6VXNlcjExMDY1Mzg2",
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sentialx",
"html_url": "https://github.com/sentialx",
"followers_url": "https://api.github.com/users/sen... | [] | closed | false | null | [] | null | 7 | 2023-03-03T09:52:08 | 2023-10-14T02:15:52 | 2023-03-24T12:44:25 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
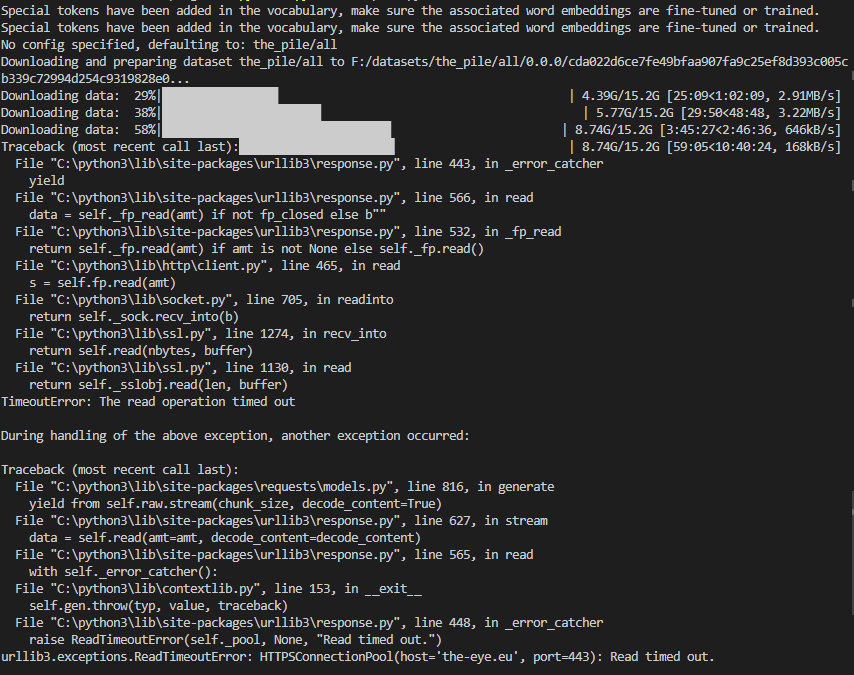
Here are the downloaded files:
,
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"login": "OleksandrKorovii",
"id": 107404835,
"node_id": "U_kgDOBmbeIw",
"avatar_url": "https://avatars.githubusercontent.com/u/107404835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/OleksandrKorovii",
"html_url": "https://github.com/OleksandrKorovii",
"followers_url": "https://api.gi... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"login": "salahiguiliz",
"id": 76955987,
"node_id": "MDQ6VXNlcjc2OTU1OTg3",
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/salahiguiliz",
"html_url": "https://github.com/salahiguiliz",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 1 | 2023-03-02T11:00:27 | 2023-03-13T17:59:35 | 2023-03-13T17:59:35 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5598/comments | https://api.github.com/repos/huggingface/datasets/issues/5598/events | https://github.com/huggingface/datasets/pull/5598 | 1,605,018,478 | PR_kwDODunzps5LCMiX | 5,598 | Fix push_to_hub with no dataset_infos | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 2 | 2023-03-01T13:54:06 | 2023-03-02T13:47:13 | 2023-03-02T13:40:17 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5598",
"html_url": "https://github.com/huggingface/datasets/pull/5598",
"diff_url": "https://github.com/huggingface/datasets/pull/5598.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5598.patch",
"merged_at": "2023-03-02T13:40... | As reported in https://github.com/vijaydwivedi75/lrgb/issues/10, `push_to_hub` fails if the remote repository already exists and has a README.md without `dataset_info` in the YAML tags
cc @clefourrier | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5598/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5598/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | {
"login": "speedcell4",
"id": 3585459,
"node_id": "MDQ6VXNlcjM1ODU0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/speedcell4",
"html_url": "https://github.com/speedcell4",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] | closed | false | null | [] | null | 3 | 2023-03-01T12:58:18 | 2023-03-02T13:30:41 | 2023-03-02T03:47:00 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Datas... | {
"login": "speedcell4",
"id": 3585459,
"node_id": "MDQ6VXNlcjM1ODU0NTk=",
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/speedcell4",
"html_url": "https://github.com/speedcell4",
"followers_url": "https://api.github.com/users... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | {
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 5 | 2023-03-01T12:53:08 | 2023-12-05T03:22:00 | 2023-03-02T11:12:11 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wr... | {
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5595/comments | https://api.github.com/repos/huggingface/datasets/issues/5595/events | https://github.com/huggingface/datasets/pull/5595 | 1,604,070,629 | PR_kwDODunzps5K--V9 | 5,595 | Unpins sqlAlchemy | {
"login": "lazarust",
"id": 46943923,
"node_id": "MDQ6VXNlcjQ2OTQzOTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/46943923?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lazarust",
"html_url": "https://github.com/lazarust",
"followers_url": "https://api.github.com/users/laz... | [] | closed | false | null | [] | null | 3 | 2023-03-01T01:33:45 | 2023-04-04T08:20:19 | 2023-04-04T08:19:14 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5595",
"html_url": "https://github.com/huggingface/datasets/pull/5595",
"diff_url": "https://github.com/huggingface/datasets/pull/5595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5595.patch",
"merged_at": null
} | Closes #5477 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5595/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5594/comments | https://api.github.com/repos/huggingface/datasets/issues/5594/events | https://github.com/huggingface/datasets/issues/5594 | 1,603,980,995 | I_kwDODunzps5fms7D | 5,594 | Error while downloading the xtreme udpos dataset | {
"login": "simran-khanuja",
"id": 24687672,
"node_id": "MDQ6VXNlcjI0Njg3Njcy",
"avatar_url": "https://avatars.githubusercontent.com/u/24687672?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simran-khanuja",
"html_url": "https://github.com/simran-khanuja",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | null | 21 | 2023-02-28T23:40:53 | 2023-11-04T20:45:56 | 2023-07-24T14:22:18 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5594/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5592/comments | https://api.github.com/repos/huggingface/datasets/issues/5592/events | https://github.com/huggingface/datasets/pull/5592 | 1,603,619,124 | PR_kwDODunzps5K9dWr | 5,592 | Fix docstring example | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | [] | closed | false | null | [] | null | 2 | 2023-02-28T18:42:37 | 2023-02-28T19:26:33 | 2023-02-28T19:19:15 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5592",
"html_url": "https://github.com/huggingface/datasets/pull/5592",
"diff_url": "https://github.com/huggingface/datasets/pull/5592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5592.patch",
"merged_at": "2023-02-28T19:19... | Fixes #5581 to use the correct output for the `set_format` method. | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5592/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5591/comments | https://api.github.com/repos/huggingface/datasets/issues/5591/events | https://github.com/huggingface/datasets/pull/5591 | 1,603,571,407 | PR_kwDODunzps5K9S79 | 5,591 | set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 3 | 2023-02-28T18:09:05 | 2023-02-28T18:16:31 | 2023-02-28T18:09:15 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5591",
"html_url": "https://github.com/huggingface/datasets/pull/5591",
"diff_url": "https://github.com/huggingface/datasets/pull/5591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5591.patch",
"merged_at": "2023-02-28T18:09... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5591/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5590/comments | https://api.github.com/repos/huggingface/datasets/issues/5590/events | https://github.com/huggingface/datasets/pull/5590 | 1,603,549,504 | PR_kwDODunzps5K9N_H | 5,590 | Release: 2.10.1 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 5 | 2023-02-28T17:58:11 | 2023-02-28T18:16:27 | 2023-02-28T18:06:08 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5590",
"html_url": "https://github.com/huggingface/datasets/pull/5590",
"diff_url": "https://github.com/huggingface/datasets/pull/5590.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5590.patch",
"merged_at": "2023-02-28T18:06... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5590/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5590/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5589/comments | https://api.github.com/repos/huggingface/datasets/issues/5589/events | https://github.com/huggingface/datasets/pull/5589 | 1,603,535,704 | PR_kwDODunzps5K9K1i | 5,589 | Revert "pass the dataset features to the IterableDataset.from_generator" | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 5 | 2023-02-28T17:52:04 | 2023-09-24T10:07:33 | 2023-03-21T14:18:18 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5589",
"html_url": "https://github.com/huggingface/datasets/pull/5589",
"diff_url": "https://github.com/huggingface/datasets/pull/5589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5589.patch",
"merged_at": null
} | This reverts commit b91070b9c09673e2e148eec458036ab6a62ac042 (temporarily)
It hurts iterable dataset performance a lot (e.g. x4 slower because it encodes+decodes images unnecessarily). I think we need to fix this before re-adding it
cc @mariosasko @Hubert-Bonisseur | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5589/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5588/comments | https://api.github.com/repos/huggingface/datasets/issues/5588/events | https://github.com/huggingface/datasets/pull/5588 | 1,603,304,766 | PR_kwDODunzps5K8YYz | 5,588 | Flatten dataset on the fly in `save_to_disk` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-02-28T15:37:46 | 2023-02-28T17:28:35 | 2023-02-28T17:21:17 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5588",
"html_url": "https://github.com/huggingface/datasets/pull/5588",
"diff_url": "https://github.com/huggingface/datasets/pull/5588.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5588.patch",
"merged_at": "2023-02-28T17:21... | Flatten a dataset on the fly in `save_to_disk` instead of doing it with `flatten_indices` to avoid creating an additional cache file.
(this is one of the sub-tasks in https://github.com/huggingface/datasets/issues/5507) | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5588/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5588/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5587/comments | https://api.github.com/repos/huggingface/datasets/issues/5587/events | https://github.com/huggingface/datasets/pull/5587 | 1,603,139,420 | PR_kwDODunzps5K70pp | 5,587 | Fix `sort` with indices mapping | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-02-28T14:05:08 | 2023-02-28T17:28:57 | 2023-02-28T17:21:58 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5587",
"html_url": "https://github.com/huggingface/datasets/pull/5587",
"diff_url": "https://github.com/huggingface/datasets/pull/5587.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5587.patch",
"merged_at": "2023-02-28T17:21... | Fixes the `key` range in the `query_table` call in `sort` to account for an indices mapping
Fix #5586 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5587/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5587/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5586/comments | https://api.github.com/repos/huggingface/datasets/issues/5586/events | https://github.com/huggingface/datasets/issues/5586 | 1,602,961,544 | I_kwDODunzps5fi0CI | 5,586 | .sort() is broken when used after .filter(), only in 2.10.0 | {
"login": "MattYoon",
"id": 57797966,
"node_id": "MDQ6VXNlcjU3Nzk3OTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/57797966?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MattYoon",
"html_url": "https://github.com/MattYoon",
"followers_url": "https://api.github.com/users/Mat... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 1 | 2023-02-28T12:18:09 | 2023-02-28T18:17:26 | 2023-02-28T17:21:59 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hi, thank you for your support!
It seems like the addition of multiple key sort (#5502) in 2.10.0 broke the `.sort()` method.
After filtering a dataset with `.filter()`, the `.sort()` seems to refer to the query_table index of the previous unfiltered dataset, resulting in an IndexError.
... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5586/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5586/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5585/comments | https://api.github.com/repos/huggingface/datasets/issues/5585/events | https://github.com/huggingface/datasets/issues/5585 | 1,602,190,030 | I_kwDODunzps5ff3rO | 5,585 | Cache is not transportable | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 2 | 2023-02-28T00:53:06 | 2023-02-28T21:26:52 | 2023-02-28T21:26:52 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | {
"login": "davidgilbertson",
"id": 4443482,
"node_id": "MDQ6VXNlcjQ0NDM0ODI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidgilbertson",
"html_url": "https://github.com/davidgilbertson",
"followers_url": "https://api.g... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5585/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5584/comments | https://api.github.com/repos/huggingface/datasets/issues/5584/events | https://github.com/huggingface/datasets/issues/5584 | 1,601,821,808 | I_kwDODunzps5fedxw | 5,584 | Unable to load coyo700M dataset | {
"login": "manuaero",
"id": 3059998,
"node_id": "MDQ6VXNlcjMwNTk5OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manuaero",
"html_url": "https://github.com/manuaero",
"followers_url": "https://api.github.com/users/manua... | [] | closed | false | null | [] | null | 1 | 2023-02-27T19:35:03 | 2023-02-28T07:27:59 | 2023-02-28T07:27:58 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Seeing this error when downloading https://huggingface.co/datasets/kakaobrain/coyo-700m:
```ArrowInvalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.```
Full stack trace
```Downloading and preparing dataset parquet/kakaobrain--coy... | {
"login": "manuaero",
"id": 3059998,
"node_id": "MDQ6VXNlcjMwNTk5OTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3059998?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manuaero",
"html_url": "https://github.com/manuaero",
"followers_url": "https://api.github.com/users/manua... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5584/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5583/comments | https://api.github.com/repos/huggingface/datasets/issues/5583/events | https://github.com/huggingface/datasets/pull/5583 | 1,601,583,625 | PR_kwDODunzps5K2mIz | 5,583 | Do no write index by default when exporting a dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-02-27T17:04:46 | 2023-02-28T13:52:15 | 2023-02-28T13:44:04 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5583",
"html_url": "https://github.com/huggingface/datasets/pull/5583",
"diff_url": "https://github.com/huggingface/datasets/pull/5583.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5583.patch",
"merged_at": "2023-02-28T13:44... | Ensures all the writers that use Pandas for conversion (JSON, CSV, SQL) do not export `index` by default (https://github.com/huggingface/datasets/pull/5490 only did this for CSV) | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5583/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5583/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5582/comments | https://api.github.com/repos/huggingface/datasets/issues/5582/events | https://github.com/huggingface/datasets/pull/5582 | 1,600,932,092 | PR_kwDODunzps5K0ZcN | 5,582 | Add column_names to IterableDataset | {
"login": "patrickloeber",
"id": 50772274,
"node_id": "MDQ6VXNlcjUwNzcyMjc0",
"avatar_url": "https://avatars.githubusercontent.com/u/50772274?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickloeber",
"html_url": "https://github.com/patrickloeber",
"followers_url": "https://api.githu... | [] | closed | false | null | [] | null | 2 | 2023-02-27T10:50:07 | 2023-03-13T19:10:22 | 2023-03-13T19:03:32 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5582",
"html_url": "https://github.com/huggingface/datasets/pull/5582",
"diff_url": "https://github.com/huggingface/datasets/pull/5582.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5582.patch",
"merged_at": "2023-03-13T19:03... | This PR closes #5383
* Add column_names property to IterableDataset
* Add multiple tests for this new property | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5582/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5582/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5581/comments | https://api.github.com/repos/huggingface/datasets/issues/5581/events | https://github.com/huggingface/datasets/issues/5581 | 1,600,675,489 | I_kwDODunzps5faF6h | 5,581 | [DOC] Mistaken docs on set_format | {
"login": "NightMachinery",
"id": 36224762,
"node_id": "MDQ6VXNlcjM2MjI0NzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/36224762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NightMachinery",
"html_url": "https://github.com/NightMachinery",
"followers_url": "https://api.gi... | [
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | closed | false | null | [] | null | 1 | 2023-02-27T08:03:09 | 2023-02-28T19:19:17 | 2023-02-28T19:19:17 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
https://huggingface.co/docs/datasets/v2.10.0/en/package_reference/main_classes#datasets.Dataset.set_format
<img width="700" alt="image" src="https://user-images.githubusercontent.com/36224762/221506973-ae2e3991-60a7-4d4e-99f8-965c6eb61e59.png">
While actually running it will result in:
<img w... | {
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/ste... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5581/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5581/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5580/comments | https://api.github.com/repos/huggingface/datasets/issues/5580/events | https://github.com/huggingface/datasets/pull/5580 | 1,600,431,792 | PR_kwDODunzps5Kys1c | 5,580 | Support cloud storage in load_dataset via fsspec | {
"login": "dwyatte",
"id": 2512762,
"node_id": "MDQ6VXNlcjI1MTI3NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/2512762?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dwyatte",
"html_url": "https://github.com/dwyatte",
"followers_url": "https://api.github.com/users/dwyatte/... | [] | closed | false | null | [] | null | 8 | 2023-02-27T04:06:05 | 2024-11-27T01:25:39 | 2023-03-11T00:55:40 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5580",
"html_url": "https://github.com/huggingface/datasets/pull/5580",
"diff_url": "https://github.com/huggingface/datasets/pull/5580.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5580.patch",
"merged_at": "2023-03-11T00:55... | Closes https://github.com/huggingface/datasets/issues/5281
This PR uses fsspec to support datasets on cloud storage (tested manually with GCS). ETags are currently unsupported for cloud storage. In general, a much larger refactor could be done to just use fsspec for all schemes (ftp, http/s, s3, gcs) to unify the in... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5580/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5580/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5579 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5579/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5579/comments | https://api.github.com/repos/huggingface/datasets/issues/5579/events | https://github.com/huggingface/datasets/pull/5579 | 1,599,732,211 | PR_kwDODunzps5Kwgo4 | 5,579 | Add instructions to create `DataLoader` from augmented dataset in object detection guide | {
"login": "Laurent2916",
"id": 21087104,
"node_id": "MDQ6VXNlcjIxMDg3MTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Laurent2916",
"html_url": "https://github.com/Laurent2916",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 3 | 2023-02-25T14:53:17 | 2023-03-23T19:24:59 | 2023-03-23T19:24:50 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5579",
"html_url": "https://github.com/huggingface/datasets/pull/5579",
"diff_url": "https://github.com/huggingface/datasets/pull/5579.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5579.patch",
"merged_at": null
} | The following adds instructions on how to create a `DataLoader` from the guide on how to use object detection with augmentations (#4710). I am open to hearing any suggestions for improvement ! | {
"login": "Laurent2916",
"id": 21087104,
"node_id": "MDQ6VXNlcjIxMDg3MTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/21087104?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Laurent2916",
"html_url": "https://github.com/Laurent2916",
"followers_url": "https://api.github.com/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5579/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5579/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5578 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5578/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5578/comments | https://api.github.com/repos/huggingface/datasets/issues/5578/events | https://github.com/huggingface/datasets/pull/5578 | 1,598,863,119 | PR_kwDODunzps5Kto96 | 5,578 | Add `huggingface_hub` version to env cli command | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 4 | 2023-02-24T15:37:43 | 2023-02-27T17:28:25 | 2023-02-27T17:21:09 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5578",
"html_url": "https://github.com/huggingface/datasets/pull/5578",
"diff_url": "https://github.com/huggingface/datasets/pull/5578.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5578.patch",
"merged_at": "2023-02-27T17:21... | Add the `huggingface_hub` version to the `env` command's output. | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5578/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5577/comments | https://api.github.com/repos/huggingface/datasets/issues/5577/events | https://github.com/huggingface/datasets/issues/5577 | 1,598,587,665 | I_kwDODunzps5fSIMR | 5,577 | Cannot load `the_pile_openwebtext2` | {
"login": "wjfwzzc",
"id": 5126316,
"node_id": "MDQ6VXNlcjUxMjYzMTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wjfwzzc",
"html_url": "https://github.com/wjfwzzc",
"followers_url": "https://api.github.com/users/wjfwzzc/... | [] | closed | false | null | [] | null | 1 | 2023-02-24T13:01:48 | 2023-02-24T14:01:09 | 2023-02-24T14:01:09 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
I met the same bug mentioned in #3053 which is never fixed. Because several `reddit_scores` are larger than `int8` even `int16`. https://huggingface.co/datasets/the_pile_openwebtext2/blob/main/the_pile_openwebtext2.py#L62
### Steps to reproduce the bug
```python3
from datasets import load... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5577/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5577/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5576/comments | https://api.github.com/repos/huggingface/datasets/issues/5576/events | https://github.com/huggingface/datasets/issues/5576 | 1,598,582,744 | I_kwDODunzps5fSG_Y | 5,576 | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers. | {
"login": "wjfwzzc",
"id": 5126316,
"node_id": "MDQ6VXNlcjUxMjYzMTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wjfwzzc",
"html_url": "https://github.com/wjfwzzc",
"followers_url": "https://api.github.com/users/wjfwzzc/... | [] | closed | false | null | [] | null | 1 | 2023-02-24T12:57:49 | 2023-02-24T12:58:31 | 2023-02-24T12:58:18 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | I was getting a similar error `pyarrow.lib.ArrowInvalid: Integer value 528 not in range: -128 to 127` - AFAICT, this is because the type specified for `reddit_scores` is `datasets.Sequence(datasets.Value("int8"))`, but the actual values can be well outside the max range for 8-bit integers.
I worked aro... | {
"login": "wjfwzzc",
"id": 5126316,
"node_id": "MDQ6VXNlcjUxMjYzMTY=",
"avatar_url": "https://avatars.githubusercontent.com/u/5126316?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wjfwzzc",
"html_url": "https://github.com/wjfwzzc",
"followers_url": "https://api.github.com/users/wjfwzzc/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5576/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5576/timeline | null | not_planned | false |
https://api.github.com/repos/huggingface/datasets/issues/5575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5575/comments | https://api.github.com/repos/huggingface/datasets/issues/5575/events | https://github.com/huggingface/datasets/issues/5575 | 1,598,396,552 | I_kwDODunzps5fRZiI | 5,575 | Metadata for each column | {
"login": "parsa-ra",
"id": 11356471,
"node_id": "MDQ6VXNlcjExMzU2NDcx",
"avatar_url": "https://avatars.githubusercontent.com/u/11356471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/parsa-ra",
"html_url": "https://github.com/parsa-ra",
"followers_url": "https://api.github.com/users/par... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | {
"url": "https://api.github.com/repos/huggingface/datasets/milestones/10",
"html_url": "https://github.com/huggingface/datasets/milestone/10",
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/10/labels",
"id": 9038583,
"node_id": "MI_kwDODunzps4Aier3",
"number": 10,
"title": "3... | 5 | 2023-02-24T10:53:44 | 2024-01-05T21:48:35 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Being able to put some metadata for each column as a string or any other type.
### Motivation
I will bring the motivation by an example, lets say we are experimenting with embedding produced by some image encoder network, and we want to iterate through a couple of preprocessing and see which on... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5575/reactions",
"total_count": 10,
"+1": 10,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5575/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5574/comments | https://api.github.com/repos/huggingface/datasets/issues/5574/events | https://github.com/huggingface/datasets/issues/5574 | 1,598,104,691 | I_kwDODunzps5fQSRz | 5,574 | c4 dataset streaming fails with `FileNotFoundError` | {
"login": "krasserm",
"id": 202907,
"node_id": "MDQ6VXNlcjIwMjkwNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/krasserm",
"html_url": "https://github.com/krasserm",
"followers_url": "https://api.github.com/users/krasser... | [] | closed | false | null | [] | null | 12 | 2023-02-24T07:57:32 | 2023-12-18T07:32:32 | 2023-02-27T04:03:38 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Loading the `c4` dataset in streaming mode with `load_dataset("c4", "en", split="validation", streaming=True)` and then using it fails with a `FileNotFoundException`.
### Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("c4", "en", split="train", ... | {
"login": "krasserm",
"id": 202907,
"node_id": "MDQ6VXNlcjIwMjkwNw==",
"avatar_url": "https://avatars.githubusercontent.com/u/202907?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/krasserm",
"html_url": "https://github.com/krasserm",
"followers_url": "https://api.github.com/users/krasser... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5574/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5574/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5573/comments | https://api.github.com/repos/huggingface/datasets/issues/5573/events | https://github.com/huggingface/datasets/pull/5573 | 1,597,400,836 | PR_kwDODunzps5Kop7n | 5,573 | Use soundfile for mp3 decoding instead of torchaudio | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 7 | 2023-02-23T19:19:44 | 2023-02-28T20:25:14 | 2023-02-28T20:16:02 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5573",
"html_url": "https://github.com/huggingface/datasets/pull/5573",
"diff_url": "https://github.com/huggingface/datasets/pull/5573.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5573.patch",
"merged_at": "2023-02-28T20:16... | I've removed `torchaudio` completely and switched to use `soundfile` for everything. With the new version of `soundfile` package this should work smoothly because the `libsndfile` C library is bundled, in Linux wheels too.
Let me know if you think it's too harsh and we should continue to support `torchaudio` decodi... | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5573/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 3,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5573/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5572/comments | https://api.github.com/repos/huggingface/datasets/issues/5572/events | https://github.com/huggingface/datasets/issues/5572 | 1,597,257,624 | I_kwDODunzps5fNDeY | 5,572 | Datasets 2.10.0 does not reuse the dataset cache | {
"login": "lsb",
"id": 45281,
"node_id": "MDQ6VXNlcjQ1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lsb",
"html_url": "https://github.com/lsb",
"followers_url": "https://api.github.com/users/lsb/followers",
"following... | [] | closed | false | null | [] | null | 0 | 2023-02-23T17:28:11 | 2023-02-23T18:03:55 | 2023-02-23T18:03:55 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
download_mode="reuse_dataset_if_exists" will always consider that a dataset doesn't exist.
Specifically, upon losing an internet connection trying to load a dataset for a second time in ten seconds, a connection error results, showing a breakpoint of:
```
File ~/jupyterlab/.direnv/python-... | {
"login": "lsb",
"id": 45281,
"node_id": "MDQ6VXNlcjQ1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lsb",
"html_url": "https://github.com/lsb",
"followers_url": "https://api.github.com/users/lsb/followers",
"following... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5572/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5572/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5571/comments | https://api.github.com/repos/huggingface/datasets/issues/5571/events | https://github.com/huggingface/datasets/issues/5571 | 1,597,198,953 | I_kwDODunzps5fM1Jp | 5,571 | load_dataset fails for JSON in windows | {
"login": "abinashsahu",
"id": 11876897,
"node_id": "MDQ6VXNlcjExODc2ODk3",
"avatar_url": "https://avatars.githubusercontent.com/u/11876897?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abinashsahu",
"html_url": "https://github.com/abinashsahu",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 2 | 2023-02-23T16:50:11 | 2023-02-24T13:21:47 | 2023-02-24T13:21:47 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Steps:
1. Created a dataset in a Linux VM and created a small sample using dataset.to_json() method.
2. Downloaded the JSON file to my local Windows machine for working and saved in say - r"C:\Users\name\file.json"
3. I am reading the file in my local PyCharm - the location of python file is di... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5571/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5571/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5570/comments | https://api.github.com/repos/huggingface/datasets/issues/5570/events | https://github.com/huggingface/datasets/issues/5570 | 1,597,190,926 | I_kwDODunzps5fMzMO | 5,570 | load_dataset gives FileNotFoundError on imagenet-1k if license is not accepted on the hub | {
"login": "buoi",
"id": 38630200,
"node_id": "MDQ6VXNlcjM4NjMwMjAw",
"avatar_url": "https://avatars.githubusercontent.com/u/38630200?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/buoi",
"html_url": "https://github.com/buoi",
"followers_url": "https://api.github.com/users/buoi/followers"... | [] | closed | false | null | [] | null | 2 | 2023-02-23T16:44:32 | 2023-07-24T15:18:50 | 2023-07-24T15:18:50 | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
When calling ```load_dataset('imagenet-1k')``` FileNotFoundError is raised, if not logged in and if logged in with huggingface-cli but not having accepted the licence on the hub. There is no error once accepting.
### Steps to reproduce the bug
```
from datasets import load_dataset
imagenet =... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5570/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5570/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5569/comments | https://api.github.com/repos/huggingface/datasets/issues/5569/events | https://github.com/huggingface/datasets/pull/5569 | 1,597,132,383 | PR_kwDODunzps5KnwHD | 5,569 | pass the dataset features to the IterableDataset.from_generator function | {
"login": "bruno-hays",
"id": 48770768,
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bruno-hays",
"html_url": "https://github.com/bruno-hays",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2023-02-23T16:06:04 | 2023-02-24T14:06:37 | 2023-02-23T18:15:16 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5569",
"html_url": "https://github.com/huggingface/datasets/pull/5569",
"diff_url": "https://github.com/huggingface/datasets/pull/5569.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5569.patch",
"merged_at": "2023-02-23T18:15... | [5558](https://github.com/huggingface/datasets/issues/5568) | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5569/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5569/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5568/comments | https://api.github.com/repos/huggingface/datasets/issues/5568/events | https://github.com/huggingface/datasets/issues/5568 | 1,596,900,532 | I_kwDODunzps5fLsS0 | 5,568 | dataset.to_iterable_dataset() loses useful info like dataset features | {
"login": "bruno-hays",
"id": 48770768,
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bruno-hays",
"html_url": "https://github.com/bruno-hays",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6... | closed | false | {
"login": "bruno-hays",
"id": 48770768,
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bruno-hays",
"html_url": "https://github.com/bruno-hays",
"followers_url": "https://api.github.com/use... | [
{
"login": "bruno-hays",
"id": 48770768,
"node_id": "MDQ6VXNlcjQ4NzcwNzY4",
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bruno-hays",
"html_url": "https://github.com/bruno-hays",
"followers_url": "https:... | null | 3 | 2023-02-23T13:45:33 | 2023-02-24T13:22:36 | 2023-02-24T13:22:36 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
Hello,
I like the new `to_iterable_dataset` feature but I noticed something that seems to be missing.
When using `to_iterable_dataset` to transform your map style dataset into iterable dataset, you lose valuable metadata like the features.
These metadata are useful if you want to interleav... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5568/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5568/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5566/comments | https://api.github.com/repos/huggingface/datasets/issues/5566/events | https://github.com/huggingface/datasets/issues/5566 | 1,595,916,674 | I_kwDODunzps5fH8GC | 5,566 | Directly reading parquet files in a s3 bucket from the load_dataset method | {
"login": "shamanez",
"id": 16892570,
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shamanez",
"html_url": "https://github.com/shamanez",
"followers_url": "https://api.github.com/users/sha... | [
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate",
"name": "duplicate",
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists"
},
{
"id": 1935892871,
"... | open | false | null | [] | null | 1 | 2023-02-22T22:13:40 | 2023-02-23T11:03:29 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Right now, we have to read the get the parquet file to the local storage. So having ability to read given the bucket directly address would be benificial
### Motivation
In a production set up, this feature can help us a lot. So we do not need move training datafiles in between storage.
### Yo... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5566/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5566/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5565/comments | https://api.github.com/repos/huggingface/datasets/issues/5565/events | https://github.com/huggingface/datasets/pull/5565 | 1,595,281,752 | PR_kwDODunzps5KhfTH | 5,565 | Add writer_batch_size for ArrowBasedBuilder | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 6 | 2023-02-22T15:09:30 | 2023-03-10T13:53:03 | 2023-03-10T13:45:43 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5565",
"html_url": "https://github.com/huggingface/datasets/pull/5565",
"diff_url": "https://github.com/huggingface/datasets/pull/5565.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5565.patch",
"merged_at": "2023-03-10T13:45... | This way we can control the size of the record_batches/row_groups of arrow/parquet files.
This can be useful for `datasets-server` to keep control of the row groups size which can affect random access performance for audio/image/video datasets
Right now having 1,000 examples per row group cause some image dataset... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5565/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5565/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5564/comments | https://api.github.com/repos/huggingface/datasets/issues/5564/events | https://github.com/huggingface/datasets/pull/5564 | 1,595,064,698 | PR_kwDODunzps5KgwzU | 5,564 | Set dev version | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 3 | 2023-02-22T13:00:09 | 2023-02-22T13:09:26 | 2023-02-22T13:00:25 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5564",
"html_url": "https://github.com/huggingface/datasets/pull/5564",
"diff_url": "https://github.com/huggingface/datasets/pull/5564.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5564.patch",
"merged_at": "2023-02-22T13:00... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5564/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5564/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5563/comments | https://api.github.com/repos/huggingface/datasets/issues/5563/events | https://github.com/huggingface/datasets/pull/5563 | 1,595,049,025 | PR_kwDODunzps5KgtbL | 5,563 | Release: 2.10.0 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 4 | 2023-02-22T12:48:52 | 2023-02-22T13:05:55 | 2023-02-22T12:56:48 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5563",
"html_url": "https://github.com/huggingface/datasets/pull/5563",
"diff_url": "https://github.com/huggingface/datasets/pull/5563.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5563.patch",
"merged_at": "2023-02-22T12:56... | null | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5563/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5563/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5562/comments | https://api.github.com/repos/huggingface/datasets/issues/5562/events | https://github.com/huggingface/datasets/pull/5562 | 1,594,625,539 | PR_kwDODunzps5KfTUT | 5,562 | Update csv.py | {
"login": "xdoubleu",
"id": 54279069,
"node_id": "MDQ6VXNlcjU0Mjc5MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/54279069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xdoubleu",
"html_url": "https://github.com/xdoubleu",
"followers_url": "https://api.github.com/users/xdo... | [] | closed | false | null | [] | null | 4 | 2023-02-22T07:56:10 | 2023-02-23T11:07:49 | 2023-02-23T11:00:58 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5562",
"html_url": "https://github.com/huggingface/datasets/pull/5562",
"diff_url": "https://github.com/huggingface/datasets/pull/5562.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5562.patch",
"merged_at": "2023-02-23T11:00... | Removed mangle_dup_cols=True from BuilderConfig.
It triggered following deprecation warning:
/usr/local/lib/python3.8/dist-packages/datasets/download/streaming_download_manager.py:776: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the ... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5562/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5562/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5561/comments | https://api.github.com/repos/huggingface/datasets/issues/5561/events | https://github.com/huggingface/datasets/pull/5561 | 1,593,862,388 | PR_kwDODunzps5Kcxw_ | 5,561 | Add pre-commit config yaml file to enable automatic code formatting | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 6 | 2023-02-21T17:35:07 | 2023-02-28T15:37:22 | 2023-02-23T18:23:29 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5561",
"html_url": "https://github.com/huggingface/datasets/pull/5561",
"diff_url": "https://github.com/huggingface/datasets/pull/5561.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5561.patch",
"merged_at": "2023-02-23T18:23... | @huggingface/datasets do you think it would be useful? Motivation - sometimes PRs are like 30% "fix: style" commits :)
If so - I need to double check the config but for me locally it works as expected. | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5561/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5561/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5560/comments | https://api.github.com/repos/huggingface/datasets/issues/5560/events | https://github.com/huggingface/datasets/pull/5560 | 1,593,809,978 | PR_kwDODunzps5Kcml6 | 5,560 | Ensure last tqdm update in `map` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 10 | 2023-02-21T16:56:17 | 2023-02-21T18:26:23 | 2023-02-21T18:19:09 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5560",
"html_url": "https://github.com/huggingface/datasets/pull/5560",
"diff_url": "https://github.com/huggingface/datasets/pull/5560.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5560.patch",
"merged_at": "2023-02-21T18:19... | This PR modifies `map` to:
* ensure the TQDM bar gets the last progress update
* when a map function fails, avoid throwing a chained exception in the single-proc mode | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5560/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5560/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5559/comments | https://api.github.com/repos/huggingface/datasets/issues/5559/events | https://github.com/huggingface/datasets/pull/5559 | 1,593,676,489 | PR_kwDODunzps5KcKSb | 5,559 | Fix map suffix_template | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 4 | 2023-02-21T15:26:26 | 2023-02-21T17:21:37 | 2023-02-21T17:14:29 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5559",
"html_url": "https://github.com/huggingface/datasets/pull/5559",
"diff_url": "https://github.com/huggingface/datasets/pull/5559.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5559.patch",
"merged_at": "2023-02-21T17:14... | #5455 introduced a small bug that lead `map` to ignore the `suffix_template` argument and not put suffixes to cached files in multiprocessing.
I fixed this and also improved a few things:
- regarding logging: "Loading cached processed dataset" is now logged only once even in multiprocessing (it used to be logged ... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5559/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5559/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5558/comments | https://api.github.com/repos/huggingface/datasets/issues/5558/events | https://github.com/huggingface/datasets/pull/5558 | 1,593,655,815 | PR_kwDODunzps5KcF5E | 5,558 | Remove instructions for `ffmpeg` system package installation on Colab | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2023-02-21T15:13:36 | 2023-03-01T13:46:04 | 2023-02-23T13:50:27 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5558",
"html_url": "https://github.com/huggingface/datasets/pull/5558",
"diff_url": "https://github.com/huggingface/datasets/pull/5558.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5558.patch",
"merged_at": "2023-02-23T13:50... | Colab now has Ubuntu 20.04 which already has `ffmpeg` of required (>4) version. | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5558/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5558/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5557/comments | https://api.github.com/repos/huggingface/datasets/issues/5557/events | https://github.com/huggingface/datasets/pull/5557 | 1,593,545,324 | PR_kwDODunzps5Kbube | 5,557 | Add filter desc | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 3 | 2023-02-21T14:04:42 | 2023-02-21T14:19:54 | 2023-02-21T14:12:39 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5557",
"html_url": "https://github.com/huggingface/datasets/pull/5557",
"diff_url": "https://github.com/huggingface/datasets/pull/5557.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5557.patch",
"merged_at": "2023-02-21T14:12... | Otherwise it would show a `Map` progress bar, since it uses `map` under the hood | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5557/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5557/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5556/comments | https://api.github.com/repos/huggingface/datasets/issues/5556/events | https://github.com/huggingface/datasets/pull/5556 | 1,593,246,936 | PR_kwDODunzps5KauVL | 5,556 | Use default audio resampling type | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 5 | 2023-02-21T10:45:50 | 2023-02-21T12:49:50 | 2023-02-21T12:42:52 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5556",
"html_url": "https://github.com/huggingface/datasets/pull/5556",
"diff_url": "https://github.com/huggingface/datasets/pull/5556.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5556.patch",
"merged_at": "2023-02-21T12:42... | ...instead of relying on the optional librosa dependency `resampy`.
It was only used for `_decode_non_mp3_file_like` anyway and not for the other ones - removing it fixes consistency between decoding methods (except torchaudio decoding)
Therefore I think it is a better solution than adding `resampy` as a dependen... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5556/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5556/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5555/comments | https://api.github.com/repos/huggingface/datasets/issues/5555/events | https://github.com/huggingface/datasets/issues/5555 | 1,592,469,938 | I_kwDODunzps5e6ymy | 5,555 | `.shuffle` throwing error `ValueError: Protocol not known: parent` | {
"login": "prabhakar267",
"id": 10768588,
"node_id": "MDQ6VXNlcjEwNzY4NTg4",
"avatar_url": "https://avatars.githubusercontent.com/u/10768588?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prabhakar267",
"html_url": "https://github.com/prabhakar267",
"followers_url": "https://api.github.c... | [] | open | false | null | [] | null | 4 | 2023-02-20T21:33:45 | 2023-02-27T09:23:34 | null | NONE | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Describe the bug
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [16], line 1
----> 1 train_dataset = train_dataset.shuffle()
File /opt/conda/envs/pytorch/lib/python3.9/site-packages/dataset... | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5555/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5555/timeline | null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5554/comments | https://api.github.com/repos/huggingface/datasets/issues/5554/events | https://github.com/huggingface/datasets/pull/5554 | 1,592,285,062 | PR_kwDODunzps5KXhZh | 5,554 | Add resampy dep | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 5 | 2023-02-20T18:15:43 | 2023-09-24T10:07:29 | 2023-02-21T12:43:38 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5554",
"html_url": "https://github.com/huggingface/datasets/pull/5554",
"diff_url": "https://github.com/huggingface/datasets/pull/5554.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5554.patch",
"merged_at": null
} | In librosa 0.10 they removed the `resmpy` dependency and set it to optional.
However it is necessary for resampling. I added it to the "audio" extra dependencies. | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5554/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5554/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5553/comments | https://api.github.com/repos/huggingface/datasets/issues/5553/events | https://github.com/huggingface/datasets/pull/5553 | 1,592,236,998 | PR_kwDODunzps5KXXUq | 5,553 | improved message error row formatting | {
"login": "Plutone11011",
"id": 26489385,
"node_id": "MDQ6VXNlcjI2NDg5Mzg1",
"avatar_url": "https://avatars.githubusercontent.com/u/26489385?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Plutone11011",
"html_url": "https://github.com/Plutone11011",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 2 | 2023-02-20T17:29:14 | 2023-02-21T13:08:25 | 2023-02-21T12:58:12 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5553",
"html_url": "https://github.com/huggingface/datasets/pull/5553",
"diff_url": "https://github.com/huggingface/datasets/pull/5553.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5553.patch",
"merged_at": "2023-02-21T12:58... | Solves #5539 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5553/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5553/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5552/comments | https://api.github.com/repos/huggingface/datasets/issues/5552/events | https://github.com/huggingface/datasets/pull/5552 | 1,592,186,703 | PR_kwDODunzps5KXMjA | 5,552 | Make tiktoken tokenizers hashable | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 4 | 2023-02-20T16:50:09 | 2023-02-21T13:20:42 | 2023-02-21T13:13:05 | COLLABORATOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5552",
"html_url": "https://github.com/huggingface/datasets/pull/5552",
"diff_url": "https://github.com/huggingface/datasets/pull/5552.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5552.patch",
"merged_at": "2023-02-21T13:13... | Fix for https://discord.com/channels/879548962464493619/1075729627546406912/1075729627546406912
| {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5552/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5552/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5551/comments | https://api.github.com/repos/huggingface/datasets/issues/5551/events | https://github.com/huggingface/datasets/pull/5551 | 1,592,140,836 | PR_kwDODunzps5KXCof | 5,551 | Suggest scikit-learn instead of sklearn | {
"login": "osbm",
"id": 74963545,
"node_id": "MDQ6VXNlcjc0OTYzNTQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/74963545?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osbm",
"html_url": "https://github.com/osbm",
"followers_url": "https://api.github.com/users/osbm/followers"... | [] | closed | false | null | [] | null | 4 | 2023-02-20T16:16:57 | 2023-02-21T13:27:57 | 2023-02-21T13:21:07 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5551",
"html_url": "https://github.com/huggingface/datasets/pull/5551",
"diff_url": "https://github.com/huggingface/datasets/pull/5551.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5551.patch",
"merged_at": "2023-02-21T13:21... | This is kinda unimportant fix but, the suggested `pip install sklearn` does not work.
The current error message if sklearn is not installed:
```
ImportError: To be able to use [dataset name], you need to install the following dependency: sklearn.
Please install it using 'pip install sklearn' for instance.
```
... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5551/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5551/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5550/comments | https://api.github.com/repos/huggingface/datasets/issues/5550/events | https://github.com/huggingface/datasets/pull/5550 | 1,591,409,475 | PR_kwDODunzps5KUl5i | 5,550 | Resolve four broken refs in the docs | {
"login": "tomaarsen",
"id": 37621491,
"node_id": "MDQ6VXNlcjM3NjIxNDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/37621491?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tomaarsen",
"html_url": "https://github.com/tomaarsen",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 3 | 2023-02-20T08:52:11 | 2023-02-20T15:16:13 | 2023-02-20T15:09:13 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5550",
"html_url": "https://github.com/huggingface/datasets/pull/5550",
"diff_url": "https://github.com/huggingface/datasets/pull/5550.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5550.patch",
"merged_at": "2023-02-20T15:09... | Hello!
## Pull Request overview
* Resolve 4 broken references in the docs
## The problems
Two broken references [here](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Dataset.class_encode_column):
![image](https://user-images.githubusercontent.com/37621491/220056232-366b64dc-33c9-... | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5550/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5550/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5549/comments | https://api.github.com/repos/huggingface/datasets/issues/5549/events | https://github.com/huggingface/datasets/pull/5549 | 1,590,836,848 | PR_kwDODunzps5KSsi3 | 5,549 | Apply ruff flake8-comprehension checks | {
"login": "Skylion007",
"id": 2053727,
"node_id": "MDQ6VXNlcjIwNTM3Mjc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2053727?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Skylion007",
"html_url": "https://github.com/Skylion007",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | 2 | 2023-02-19T20:09:28 | 2023-02-23T14:06:39 | 2023-02-23T13:59:39 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5549",
"html_url": "https://github.com/huggingface/datasets/pull/5549",
"diff_url": "https://github.com/huggingface/datasets/pull/5549.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5549.patch",
"merged_at": "2023-02-23T13:59... | Fix #5548
Apply ruff's flake8-comprehension checks for better performance, and more readable code. | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5549/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5549/timeline | null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5548/comments | https://api.github.com/repos/huggingface/datasets/issues/5548/events | https://github.com/huggingface/datasets/issues/5548 | 1,590,835,479 | I_kwDODunzps5e0jkX | 5,548 | Apply flake8-comprehensions to codebase | {
"login": "Skylion007",
"id": 2053727,
"node_id": "MDQ6VXNlcjIwNTM3Mjc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2053727?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Skylion007",
"html_url": "https://github.com/Skylion007",
"followers_url": "https://api.github.com/users... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | 0 | 2023-02-19T20:05:38 | 2023-02-23T13:59:41 | 2023-02-23T13:59:41 | CONTRIBUTOR | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | null | null | ### Feature request
Apply ruff flake8 comprehension checks to codebase.
### Motivation
This should strictly improve the performance / readability of the codebase by removing unnecessary iteration, function calls, etc. This should generate better Python bytecode which should strictly improve performance.
I alread... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5548/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5548/timeline | null | completed | false |
https://api.github.com/repos/huggingface/datasets/issues/5547 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5547/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5547/comments | https://api.github.com/repos/huggingface/datasets/issues/5547/events | https://github.com/huggingface/datasets/pull/5547 | 1,590,468,200 | PR_kwDODunzps5KRmcf | 5,547 | Add JAX device selection when formatting | {
"login": "alvarobartt",
"id": 36760800,
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alvarobartt",
"html_url": "https://github.com/alvarobartt",
"followers_url": "https://api.github.com/... | [] | closed | false | null | [] | null | 9 | 2023-02-18T20:57:40 | 2023-02-21T16:10:55 | 2023-02-21T16:04:03 | MEMBER | null | {
"total": 0,
"completed": 0,
"percent_completed": 0
} | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5547",
"html_url": "https://github.com/huggingface/datasets/pull/5547",
"diff_url": "https://github.com/huggingface/datasets/pull/5547.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5547.patch",
"merged_at": "2023-02-21T16:04... | ## What's in this PR?
After exploring for a while the JAX integration in 🤗`datasets`, I found out that, even though JAX prioritizes the TPU and GPU as the default device when available, the `JaxFormatter` doesn't let you specify the device where you want to place the `jax.Array`s in case you don't want to rely on J... | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/5547/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/5547/timeline | null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.