
Relational Visual Similarity
Paper • 2512.07833 • Published • 25

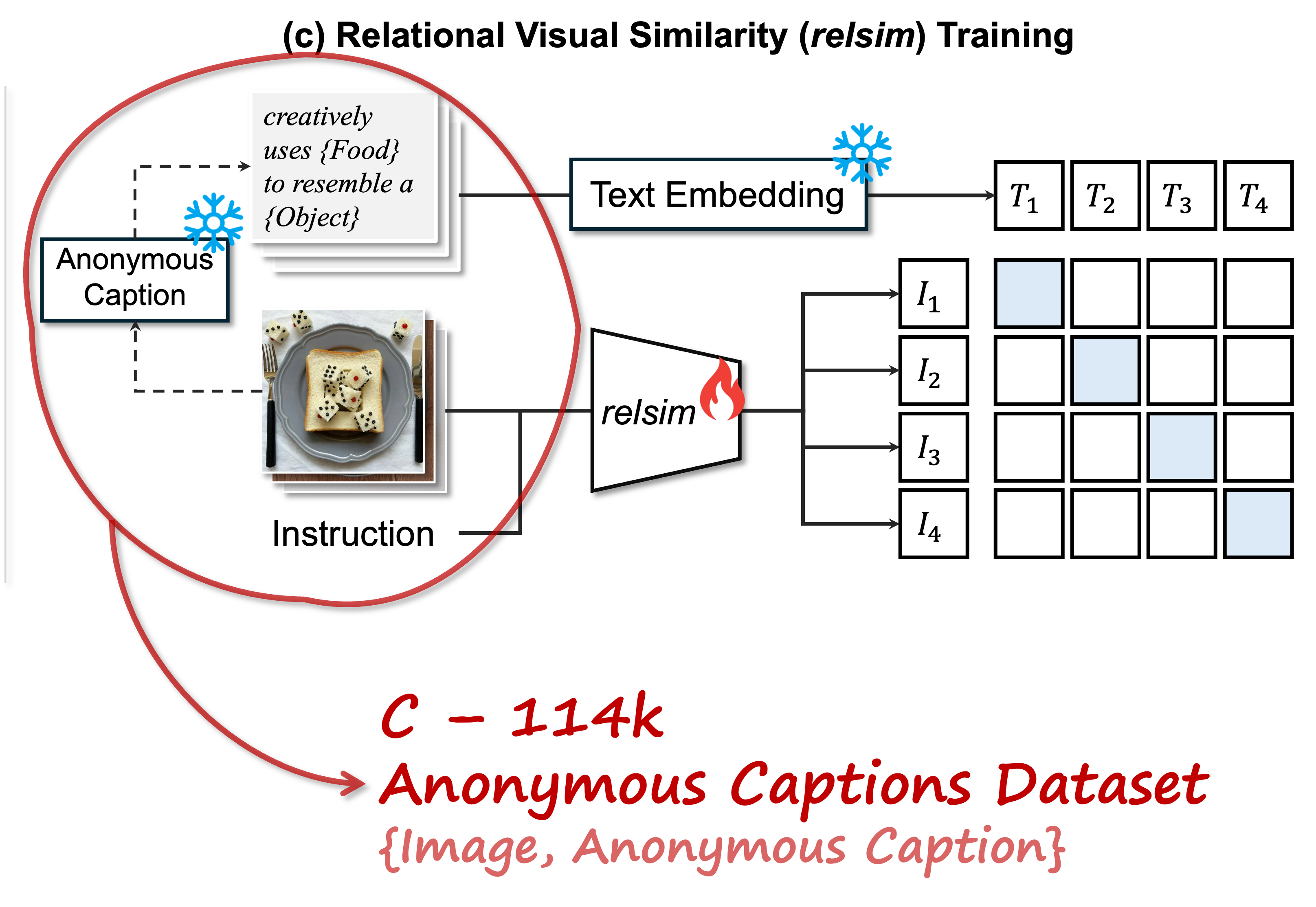 |
|---|
TL;DR: We introduce a new visual similarity notion: relational visual similarity, which complements traditional attribute-based perceptual similarity (e.g., LPIPS, CLIP, DINO).
Anonymous captions are image captions that do not refer to specific visible objects but instead capture the relational logic conveyed by the image.
You can use this anonymous captioning model as below:
import torch
from transformers import AutoProcessor, Qwen2_5_VLForConditionalGeneration
from peft import PeftModel
from qwen_vl_utils import process_vision_info
from PIL import Image
import requests
# Load model from HuggingFace
base_model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto"
)
model = PeftModel.from_pretrained(base_model, "thaoshibe/relsim-anonymous-caption-qwen25vl-lora")
processor = AutoProcessor.from_pretrained("thaoshibe/relsim-anonymous-caption-qwen25vl-lora", trust_remote_code=True)
# this is the test image
image_url = "https://raw.githubusercontent.com/thaoshibe/relsim/refs/heads/main/anonymous_caption/mam2.jpg"
image = Image.open(requests.get(image_url, stream=True).raw).convert("RGB").resize((448, 448))
####################################################
#
# Uncomment this and put your local image_path here
#
####################################################
# image = Image.open("imag_path").convert("RGB").resize((448, 448))
FIXED_PROMPT = '''
You are given a single image.
Carefully analyze it to understand its underlying logic, layout, structure, or creative concept. Then generate a single, reusable anonymous caption that could describe any image following the same concept.
The caption must:
- Fully capture the general logic or analogy of the image.
- Include placeholders (e.g., {Object}, {Word}, {Character}, {Meaning}, {Color}, etc.) wherever variations can occur.
- Be concise and standalone.
Important: Only output the anonymous caption. Do not provide any explanations or additional text.
'''
messages = [{
"role": "user",
"content": [
{"type": "image", "image": image},
{"type": "text", "text": FIXED_PROMPT}
]
}]
# Process and generate
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info([messages])
inputs = processor(text=[text], images=image_inputs, videos=video_inputs, return_tensors="pt").to(model.device)
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=128, temperature=0.7, top_p=0.9)
caption = processor.decode(output[0][len(inputs.input_ids[0]):], skip_special_tokens=True)
print(f"Anonymous caption: {caption}")
The result of above code should be as follows:
| Input image | Generated anonymous captions (Different run) |
|---|---|
 |
Example: python anonymous_caption/anonymous_caption.py --image_path anonymous_caption/mam.jpgRun 1: "Curious {Animal} peering out from behind a {Object}." Run 2: "Curious {Animal} peeking out from behind the {Object} in an unexpected and playful way." Run 3: "Curious {Cat} looking through a {Doorway} into the {Room}." Run 4: "A curious {Animal} peeking from behind a {Barrier}." Run 5: "A {Cat} peeking out from behind a {Door} with curious eyes." ... |
For more details, or training code, data, etc. Please visit: https://github.com/thaoshibe/relsim.
Thank you!!
@misc{nguyen2025relationalvisualsimilarity,
title={Relational Visual Similarity},
author={Thao Nguyen and Sicheng Mo and Krishna Kumar Singh and Yilin Wang and Jing Shi and Nicholas Kolkin and Eli Shechtman and Yong Jae Lee and Yuheng Li},
year={2025},
eprint={2512.07833},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.07833},
}
Base model
Qwen/Qwen2.5-VL-7B-Instruct