Spaces:
Sleeping

Sleeping
Commit ·
9234e75
1
Parent(s): 3ba37b2
Sync blog.md from main: add results section, links; add axiomforgeai.svg
Browse files- blog.md +48 -23
- images/axiomforgeai.svg +571 -0
blog.md
CHANGED
|
@@ -10,41 +10,43 @@ AxiomForgeAI is built around that idea.
|
|
| 10 |
|
| 11 |
Instead of treating math reasoning as a one-shot generation problem, AxiomForgeAI turns it into a practice environment. The model does not simply answer a question and move on. It attempts the same problem multiple ways, receives feedback on both the reasoning path and the final answer, and learns from the attempts where the two agree.
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
| 14 |
|
| 15 |
-
|
| 16 |
|
| 17 |
-
AxiomForgeAI
|
| 18 |
|
| 19 |
-
|
| 20 |
|
| 21 |
-
|
| 22 |
|
| 23 |
-
|
| 24 |
|
| 25 |
-
|
| 26 |
|
| 27 |
-
|
| 28 |
|
| 29 |
-
|
| 30 |
|
| 31 |
-
|
| 32 |
|
| 33 |
-
|
| 34 |
|
| 35 |
## What Gets Checked
|
| 36 |
|
| 37 |
-

|
| 38 |
|
| 39 |
-
AxiomForgeAI does not rely on a single reward signal.
|
| 40 |
|
| 41 |
-
For
|
| 42 |
|
| 43 |
-
The result is one score per attempt. That score
|
| 44 |
|
| 45 |
## Why GRPO Fits
|
| 46 |
|
| 47 |
-

|
| 48 |
|
| 49 |
GRPO turns a problem into a small comparison game. The model samples several attempts for the same prompt. Some are wrong, some are partially right, and one may be clearly better because the answer follows from the steps.
|
| 50 |
|
|
@@ -68,16 +70,39 @@ The model learns to solve problems with reasoning that supports the answer. It a
|
|
| 68 |
|
| 69 |
That makes the loop different from ordinary fine-tuning. The model is not only seeing more answers. It is practicing, being checked, and learning from the solution paths that survived verification.
|
| 70 |
|
| 71 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 72 |
|
| 73 |
-
|
| 74 |
|
| 75 |
-
|
| 76 |
-
- an example where the model guessed correctly but the reasoning was weak
|
| 77 |
-
- an example after training where the reasoning chain and final answer agree
|
| 78 |
-
- a self-generated problem that passed the quality checks
|
| 79 |
|
| 80 |
-
|
| 81 |
|
| 82 |
## Why This Matters
|
| 83 |
|
|
|
|
| 10 |
|
| 11 |
Instead of treating math reasoning as a one-shot generation problem, AxiomForgeAI turns it into a practice environment. The model does not simply answer a question and move on. It attempts the same problem multiple ways, receives feedback on both the reasoning path and the final answer, and learns from the attempts where the two agree.
|
| 12 |
|
| 13 |
+
[GitHub Code](https://github.com/Prem01-cyber/AxiomForgeAI)
|
| 14 |
+
|
| 15 |
+
[Hugging Face Space](https://huggingface.co/spaces/jampuramprem/AxiomForgeAI)
|
| 16 |
|
| 17 |
+
## The Architecture
|
| 18 |
|
| 19 |
+

|
| 20 |
|
| 21 |
+
AxiomForgeAI is a phase-controlled practice loop. It starts with grounded-only training, ramps self-play once grounded answer and step quality are stable, then keeps a grounded fallback if quality drops. Each selected problem is solved multiple ways, scored, and compared with GRPO.
|
| 22 |
|
| 23 |
+
Grounded problems come from GSM8K or MATH and include a known answer. Self-play problems start from a curriculum target, then the model writes the question. After either path produces one selected problem, the model samples `K` solution attempts.
|
| 24 |
|
| 25 |
+
Those attempts are scored for answer correctness, reasoning quality, chain consistency, formatting, and question quality when self-play is used. GRPO compares attempts only within the same problem group, so the learning signal is contrast: which reasoning path held together best.
|
| 26 |
|
| 27 |
+
## Grounded And Self-Play Practice
|
| 28 |
|
| 29 |
+

|
| 30 |
|
| 31 |
+
The grounded path is the anchor. It gives the reward system a known final answer, which keeps training tied to objective correctness while the model is still learning the format and reasoning style.
|
| 32 |
|
| 33 |
+
The self-play path adds new practice only after that anchor is stable. Here, the generated question is also judged before its solution reward is trusted. A useful self-play question should match the target topic, fit the target difficulty, be clear, be novel, and be solvable.
|
| 34 |
|
| 35 |
+
That is why self-play is not just “more data.” It is filtered practice. Bad questions do not become useful training signal just because the model wrote them.
|
| 36 |
|
| 37 |
## What Gets Checked
|
| 38 |
|
| 39 |
+

|
| 40 |
|
| 41 |
+
AxiomForgeAI does not rely on a single reward signal. Grounded attempts are anchored by the gold final answer, but the environment also checks whether the reasoning steps are valid, whether the correct prefix stays unbroken, and whether the final answer is parseable.
|
| 42 |
|
| 43 |
+
For self-play, the question is part of the reward too. The generated problem is checked for topic fit, difficulty fit, clarity, novelty, and solvability. The solution reward is still dominated by reasoning quality and chain integrity, and the question bonus is gated if the solution is broken.
|
| 44 |
|
| 45 |
+
The result is one score per attempt. That score becomes useful only because the model produced other attempts for the same problem, giving GRPO something to compare.
|
| 46 |
|
| 47 |
## Why GRPO Fits
|
| 48 |
|
| 49 |
+

|
| 50 |
|
| 51 |
GRPO turns a problem into a small comparison game. The model samples several attempts for the same prompt. Some are wrong, some are partially right, and one may be clearly better because the answer follows from the steps.
|
| 52 |
|
|
|
|
| 70 |
|
| 71 |
That makes the loop different from ordinary fine-tuning. The model is not only seeing more answers. It is practicing, being checked, and learning from the solution paths that survived verification.
|
| 72 |
|
| 73 |
+
## Results
|
| 74 |
+
|
| 75 |
+
These plots come from a single GPU training run and focus on the core question: did the model get better at making its reasoning and final answer agree?
|
| 76 |
+
|
| 77 |
+
### Evaluation Quality Over Training
|
| 78 |
+
|
| 79 |
+
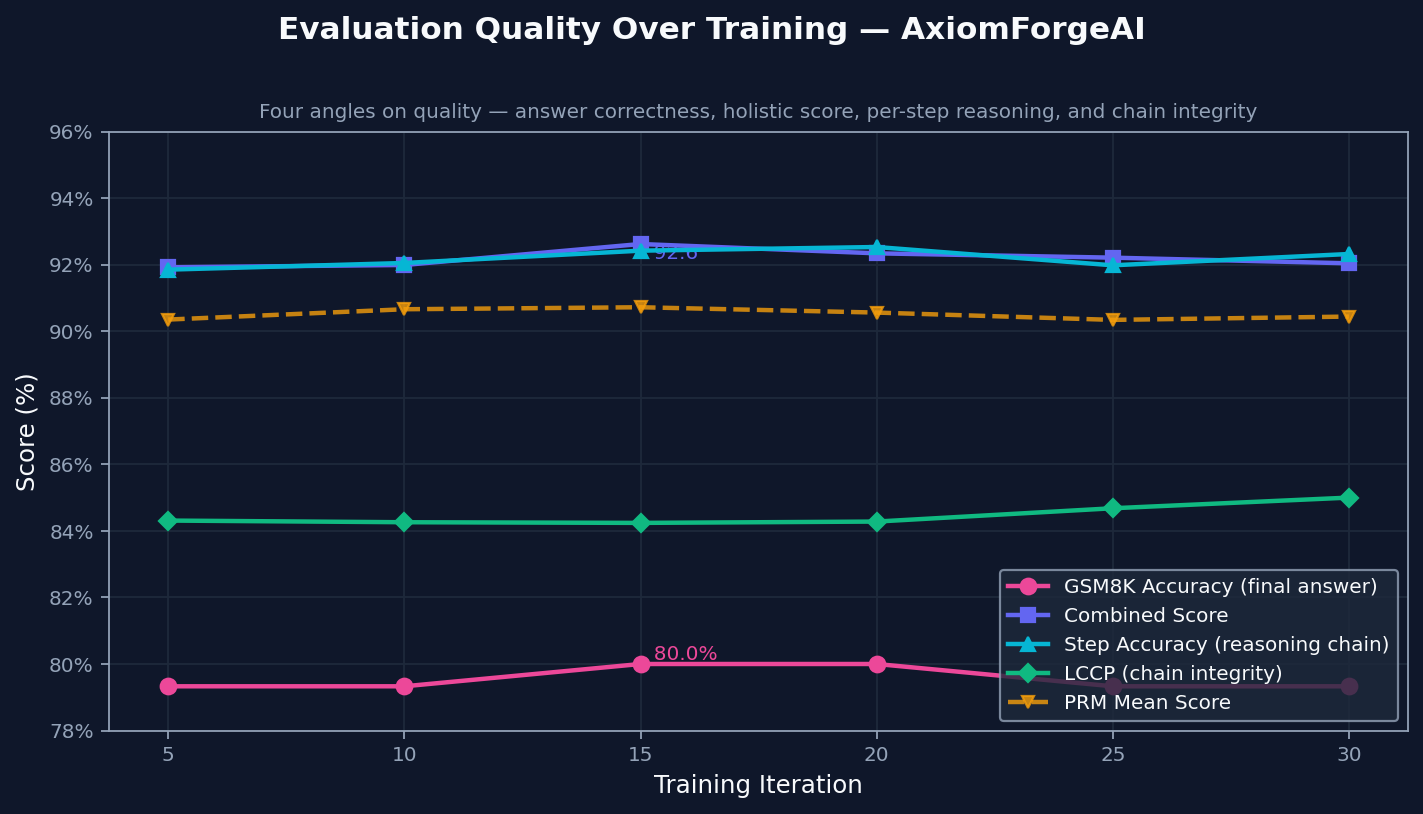
|
| 80 |
+
|
| 81 |
+
The environment tracks final correctness, solution quality, step validity, and how long the reasoning chain stays correct. All four move upward together, which suggests the model is not just finding better final answers. It is also producing reasoning that holds up longer.
|
| 82 |
+
|
| 83 |
+
### Training Journey
|
| 84 |
+
|
| 85 |
+
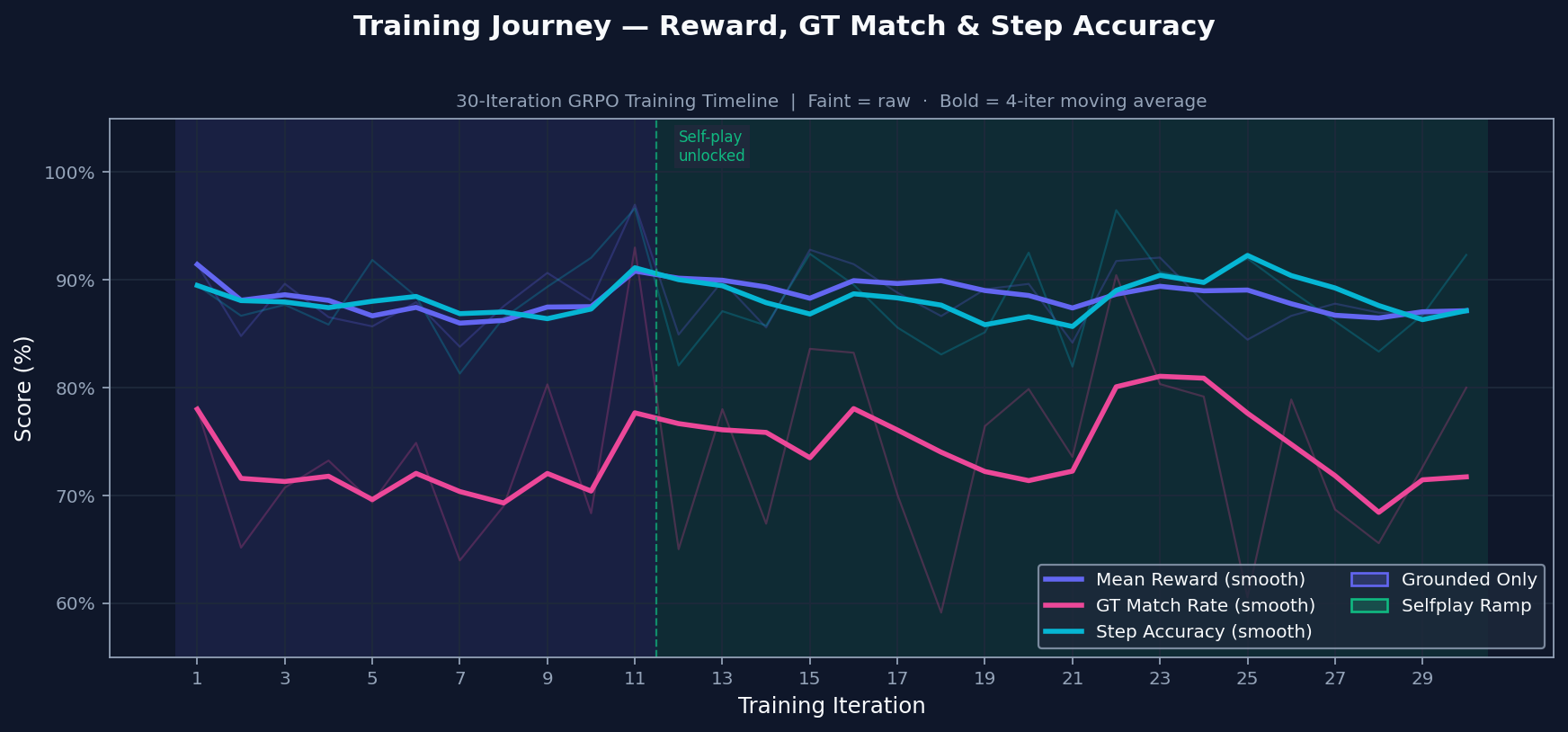
|
| 86 |
+
|
| 87 |
+
Training starts with grounded practice on problems with known answers. Self-play is introduced only after the grounded signal is stable, so the model does not train on its own generated problems too early. The transition is conditional, not just a timer.
|
| 88 |
+
|
| 89 |
+
### Self-Play Curriculum
|
| 90 |
+
|
| 91 |
+
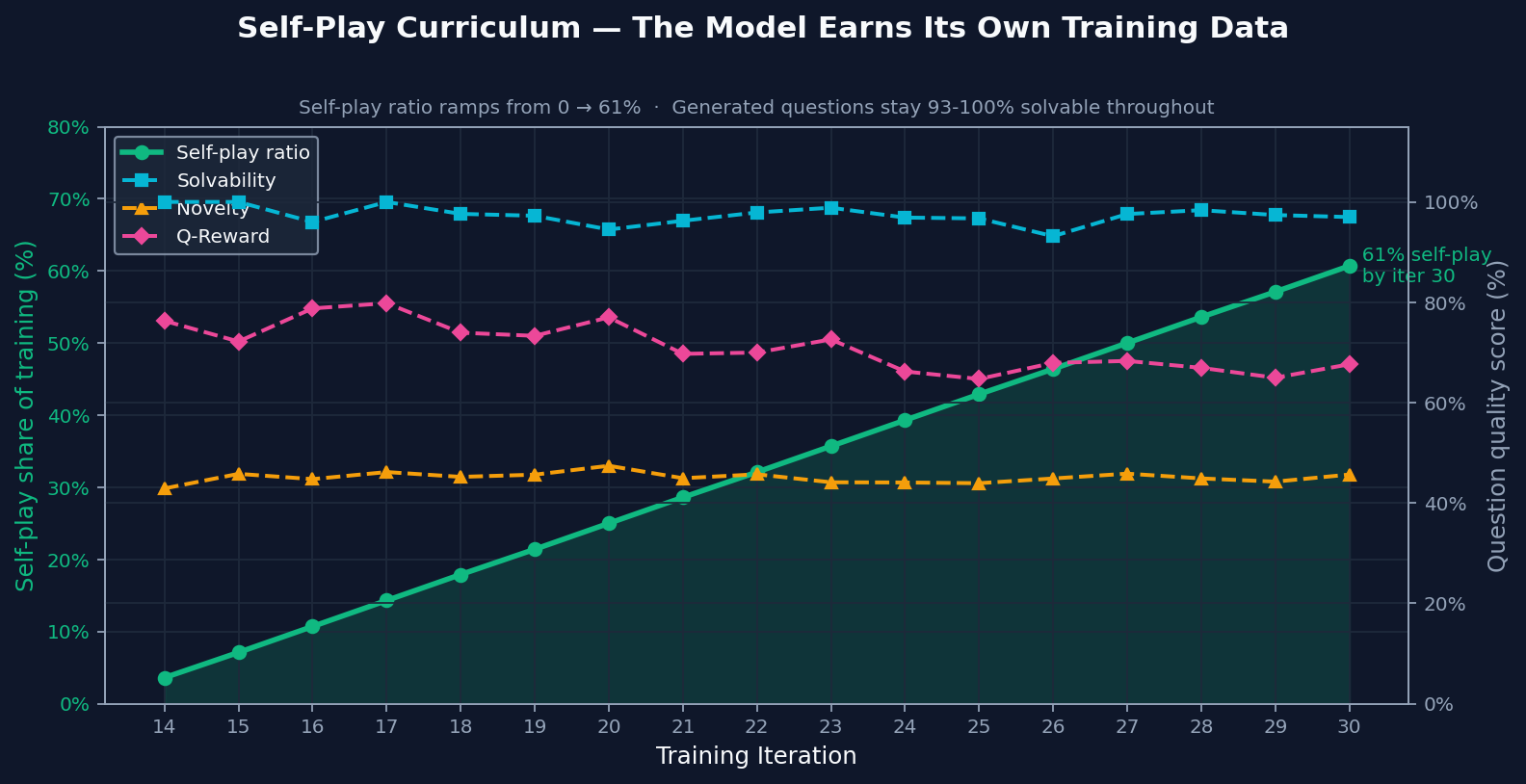
|
| 92 |
+
|
| 93 |
+
By the end of training, most practice came from self-play. The important part is that generated problems stayed solvable and novel even after self-play became a larger share of training. That makes the ramp meaningful: self-play added useful practice instead of recycled noise.
|
| 94 |
+
|
| 95 |
+
### Reward Confidence
|
| 96 |
+
|
| 97 |
+
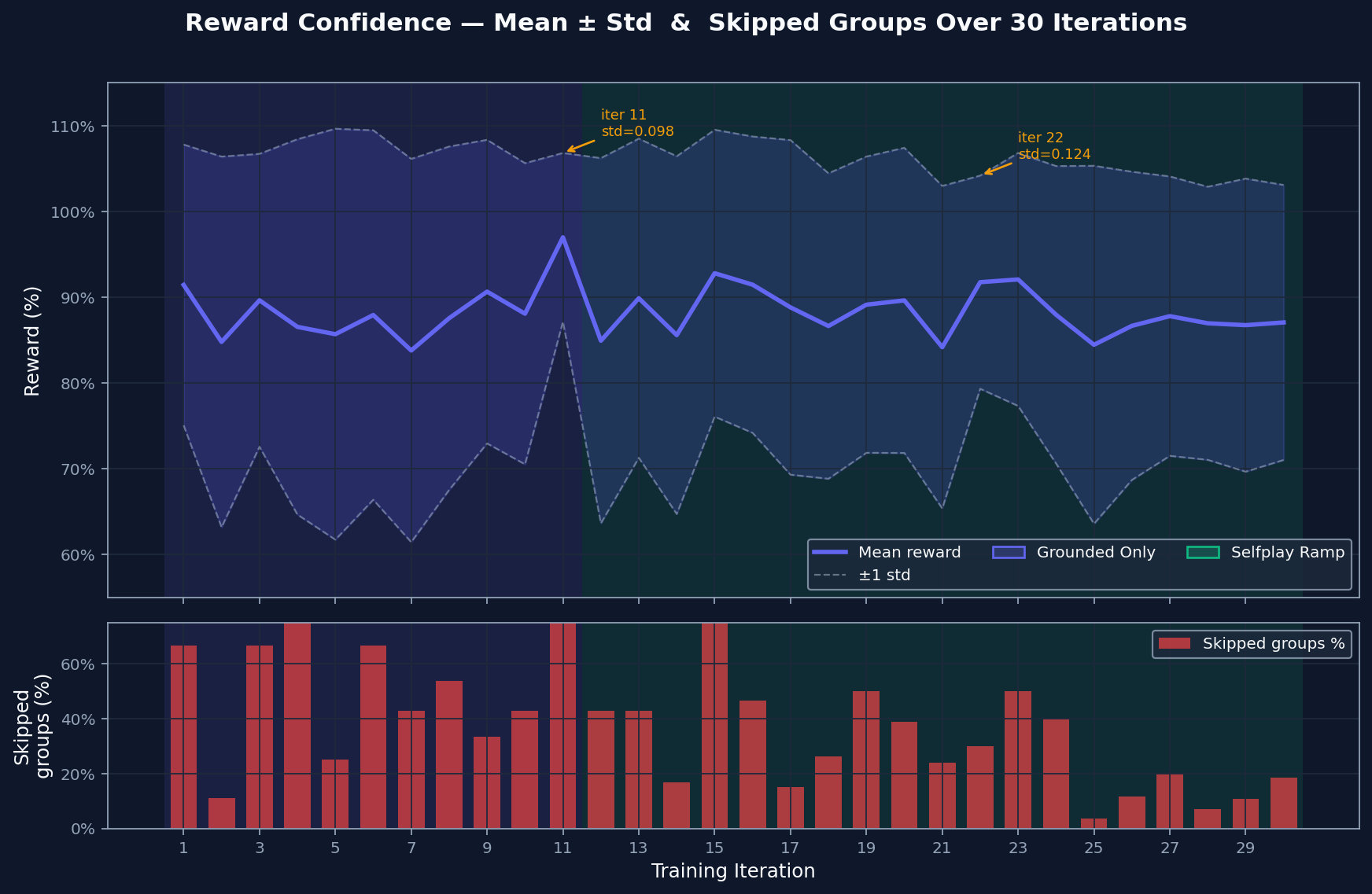
|
| 98 |
+
|
| 99 |
+
The reward spread shows how much contrast exists between the model's best and worst attempts. Wide spread gives GRPO something to learn from. Skipped groups are cases where attempts are too similar to compare usefully. That rate falls as harder material enters the curriculum, which suggests the comparison signal stays useful.
|
| 100 |
|
| 101 |
+
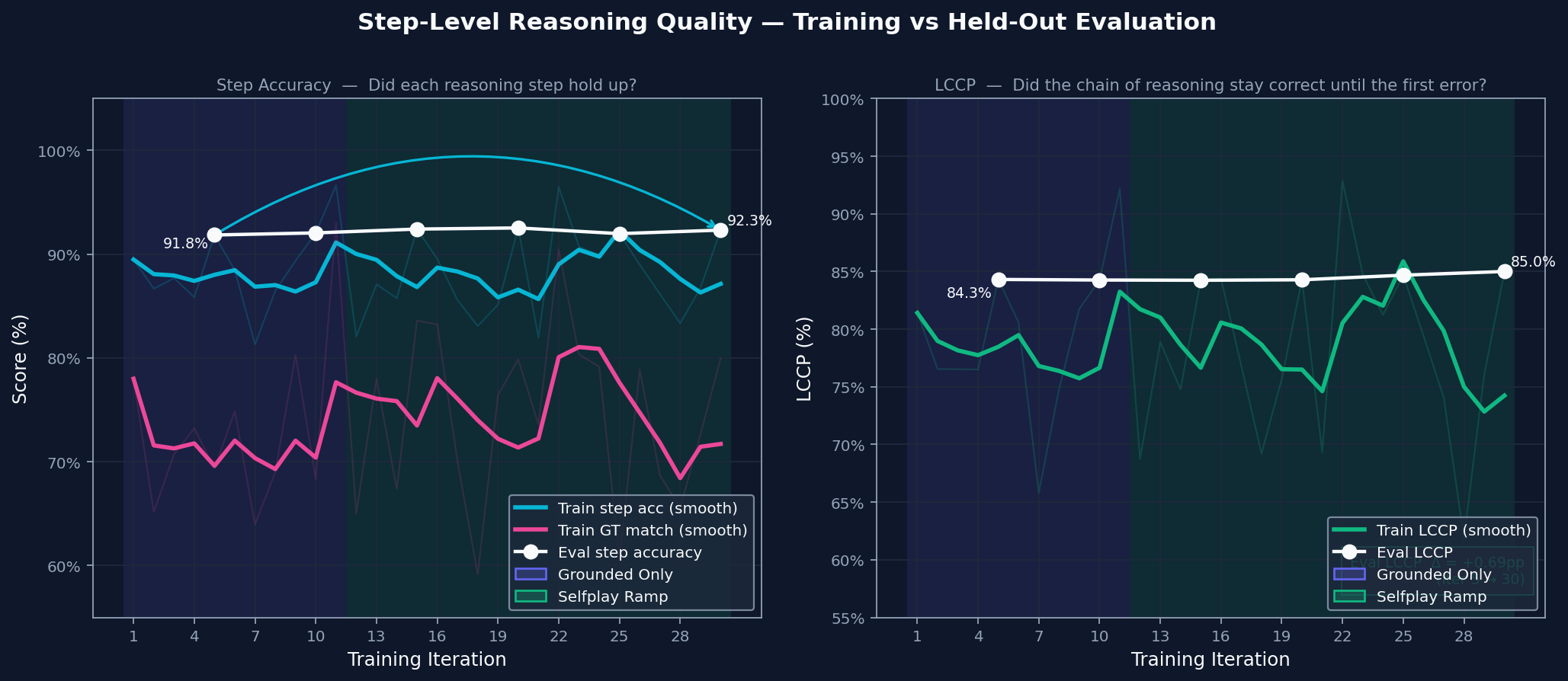
### Step-Level Reasoning Quality
|
| 102 |
|
| 103 |
+
|
|
|
|
|
|
|
|
|
|
| 104 |
|
| 105 |
+
Step accuracy checks whether each line of reasoning is valid. Chain integrity checks whether those valid steps form an unbroken path to the answer. Both improve together, which means the model is building solutions that hold together more often instead of only producing better-looking outputs.
|
| 106 |
|
| 107 |
## Why This Matters
|
| 108 |
|
images/axiomforgeai.svg
ADDED

|