
MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Paper • 2604.04771 • Published • 114
![]()
![]()
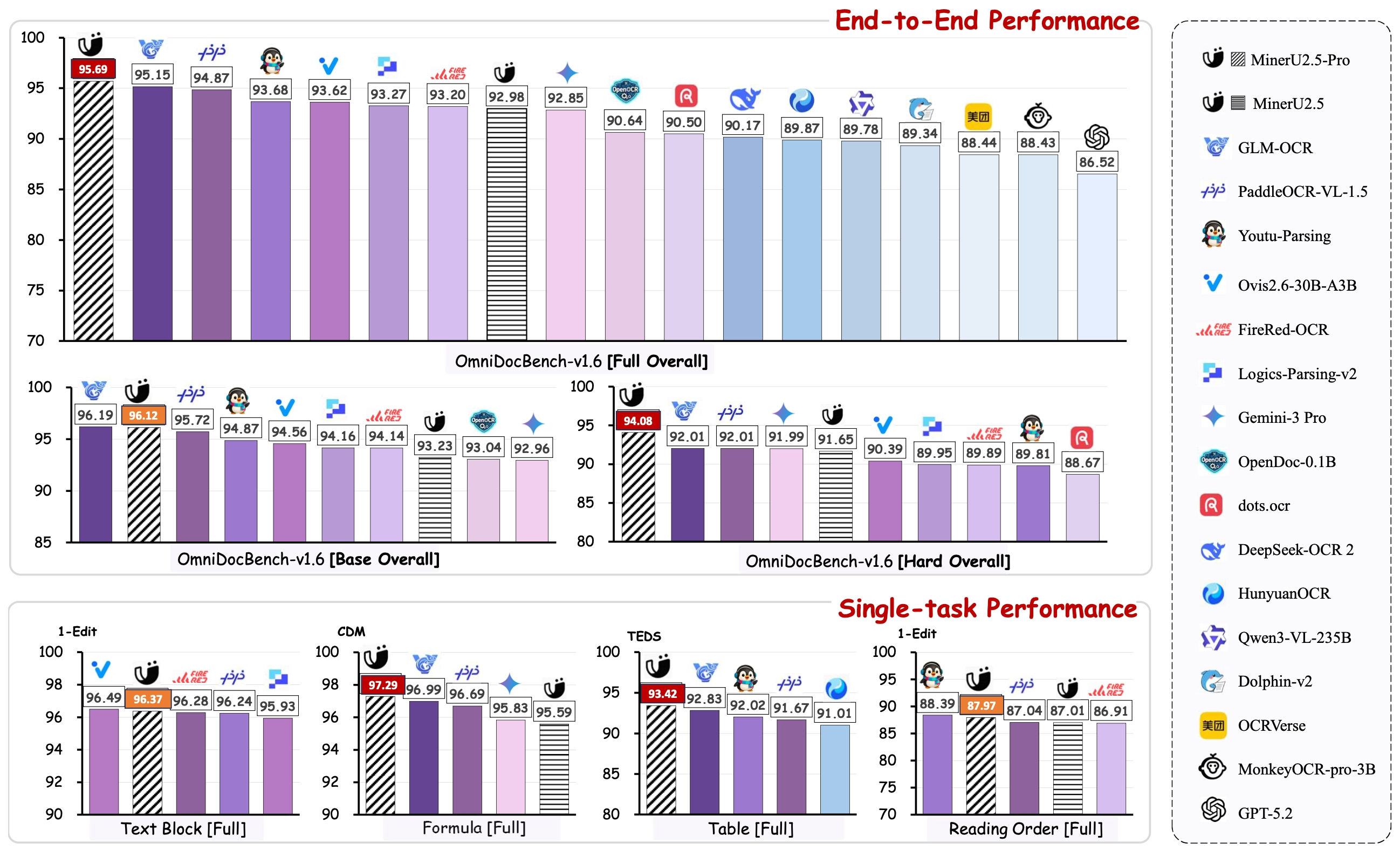
MinerU2.5-Pro is our latest document parsing model (PDF-to-Markdown) that establishes a new industry standard. By focusing entirely on data engineering without altering the original 1.2B-parameter architecture, it delivers exceptional results across the board:
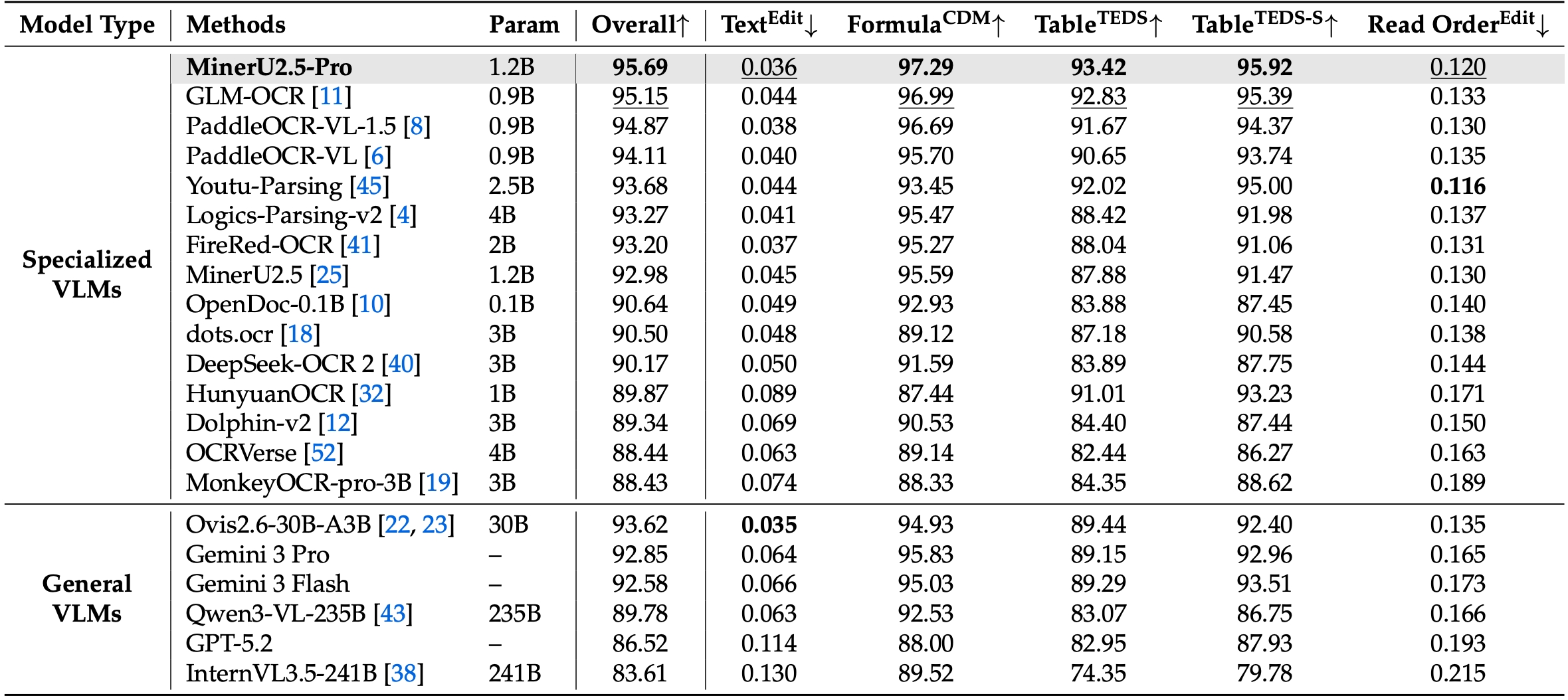
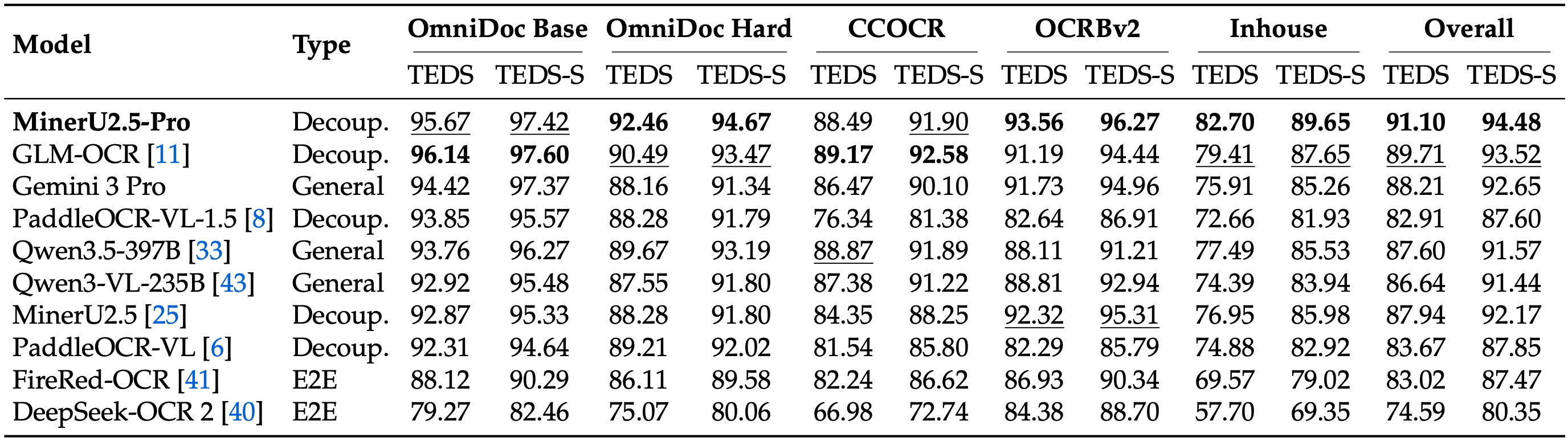
1. Defeating Leading Models on OmniDocBench v1.6 On the newly proposed, highly rigorous OmniDocBench v1.6, MinerU2.5-Pro achieves the absolute SOTA overall score of 95.69. It comprehensively outperforms both top-tier specialized OCR models (GLM-OCR, PaddleOCR-VL-1.5) and massive frontier VLMs (Gemini 3 Pro, Qwen3-VL-235B).
2. Massive Leap from MinerU 2.5 via Data Engineering Compared to the previous MinerU 2.5 baseline, the overall score skyrocketed from 92.98 to 95.69. This breakthrough was achieved not by scaling model parameters, but through meticulous data engineering—drastically expanding data scale, enriching distribution and difficulty diversity, and systematically elevating annotation quality.
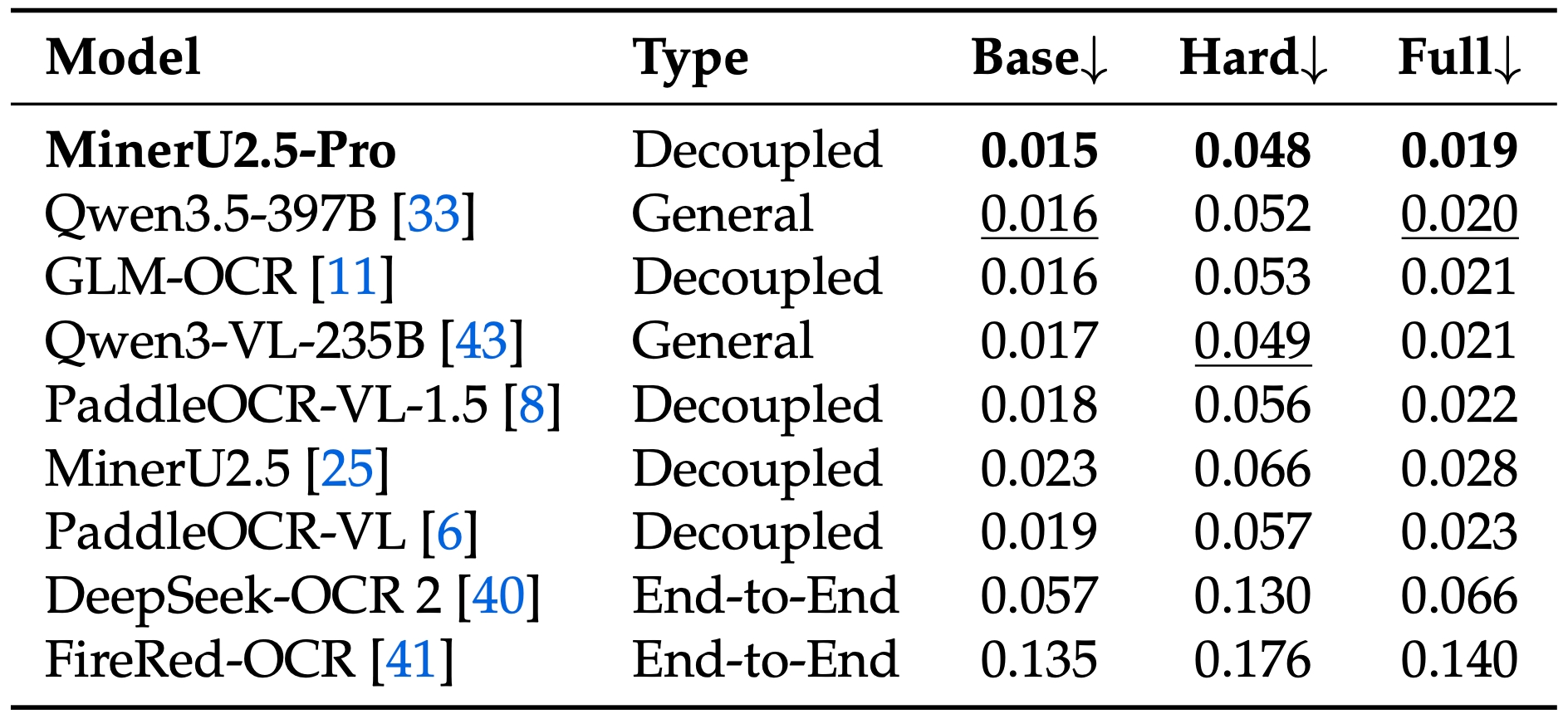
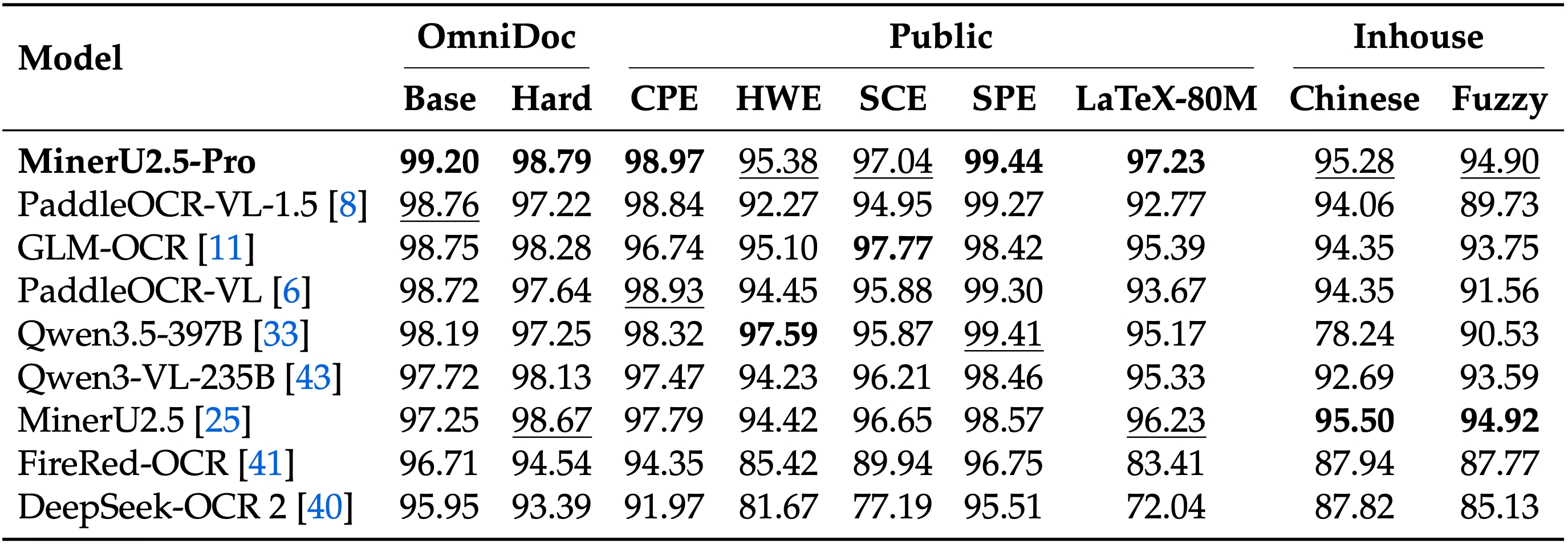
3. Exceptional Modality-Specific Breakthroughs
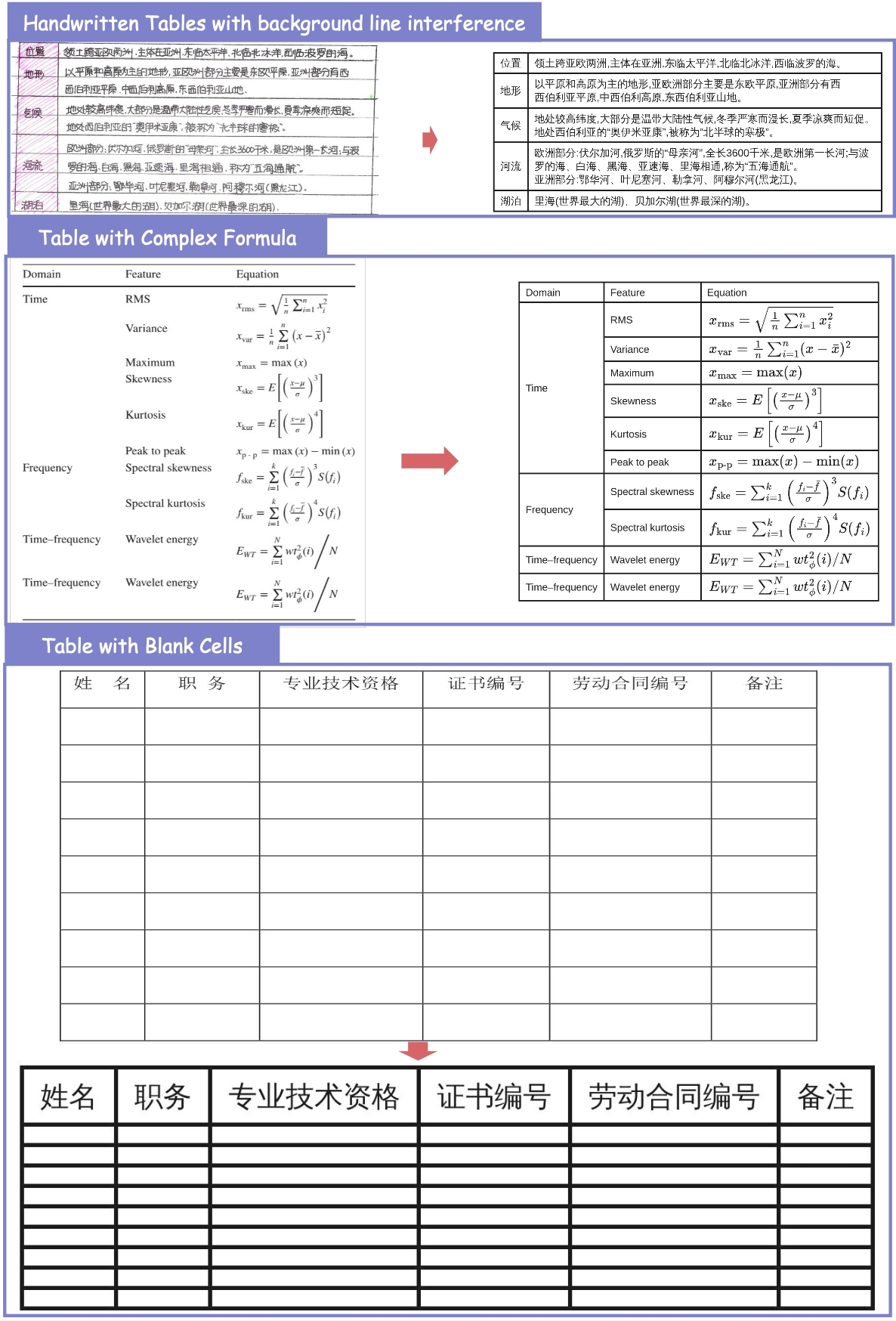
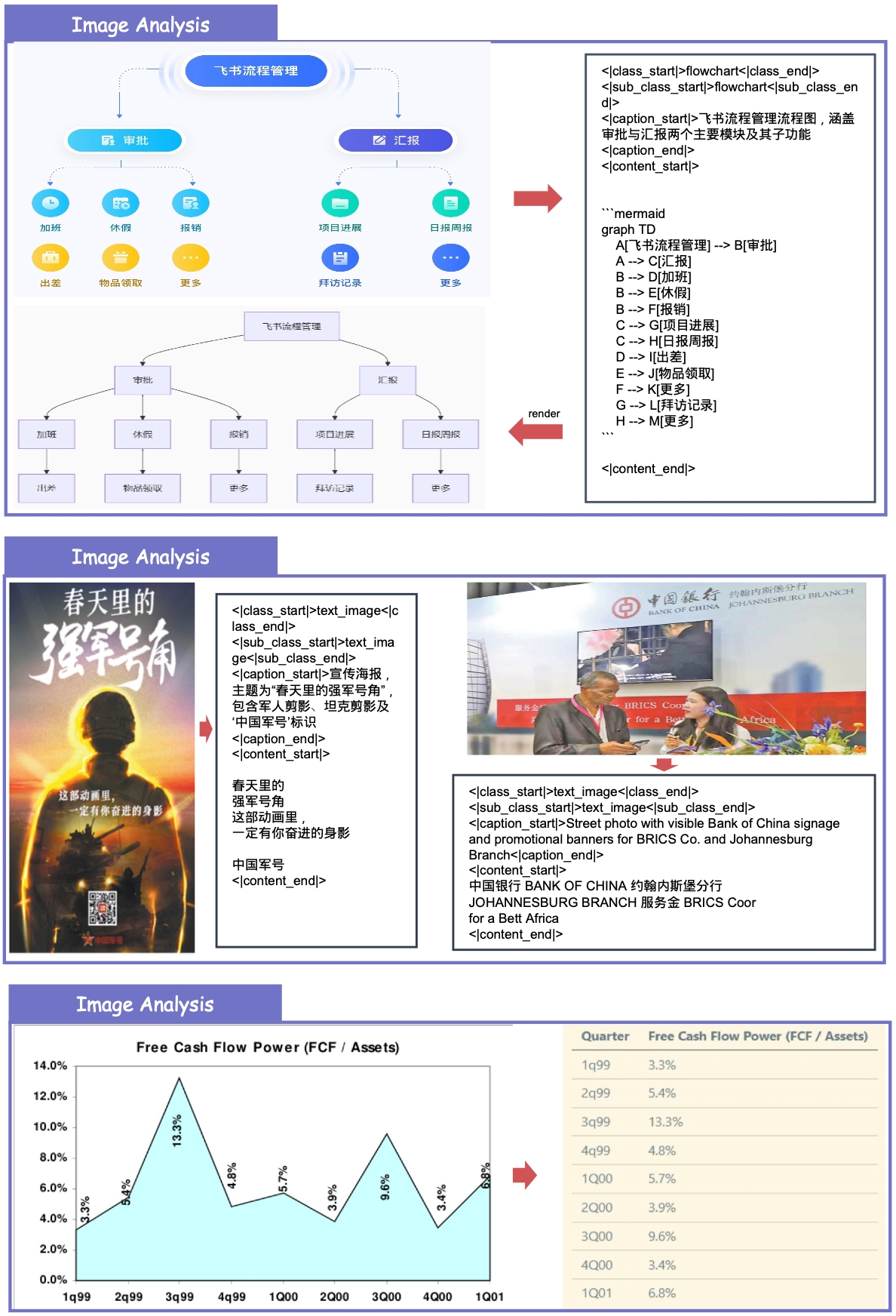
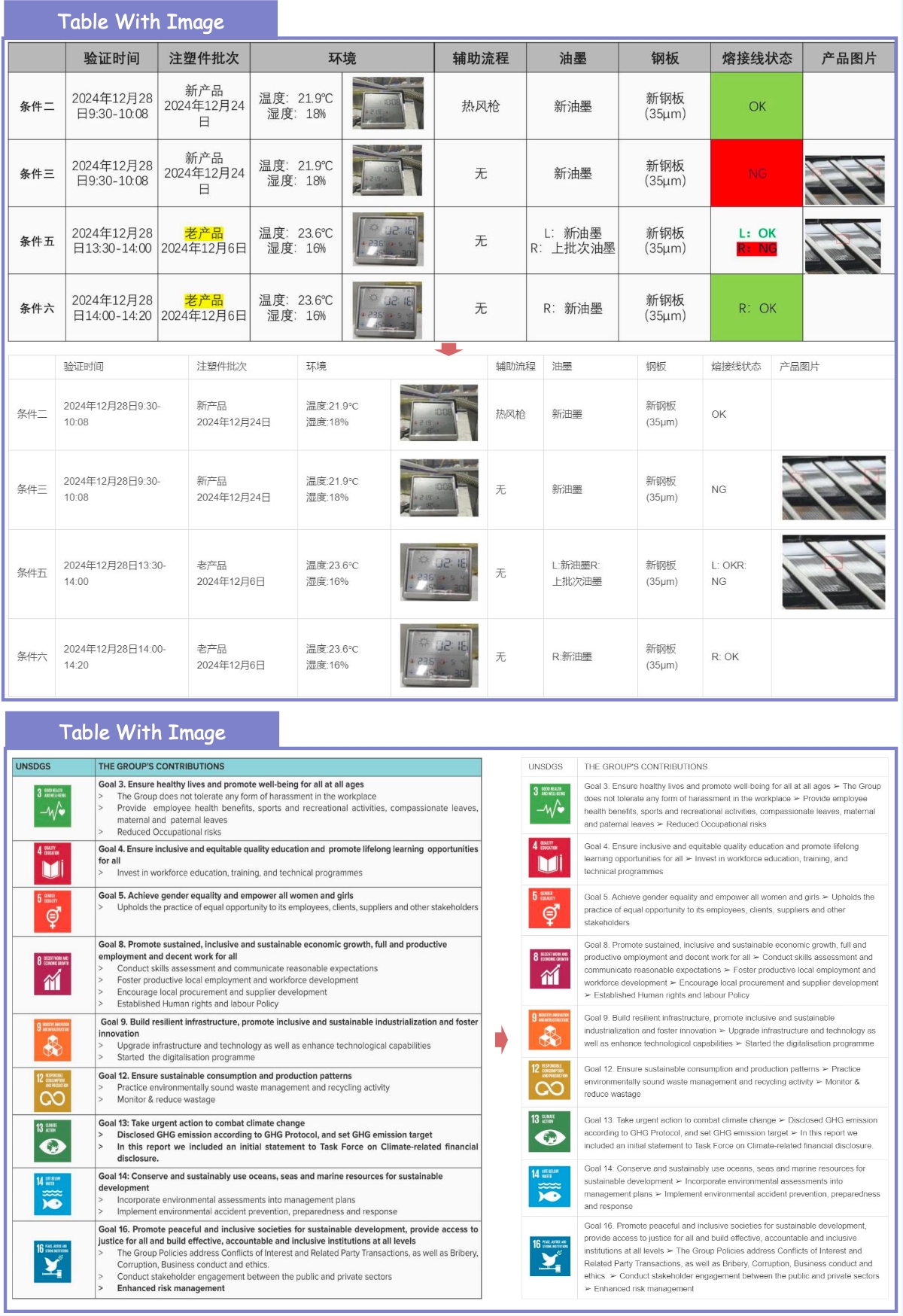
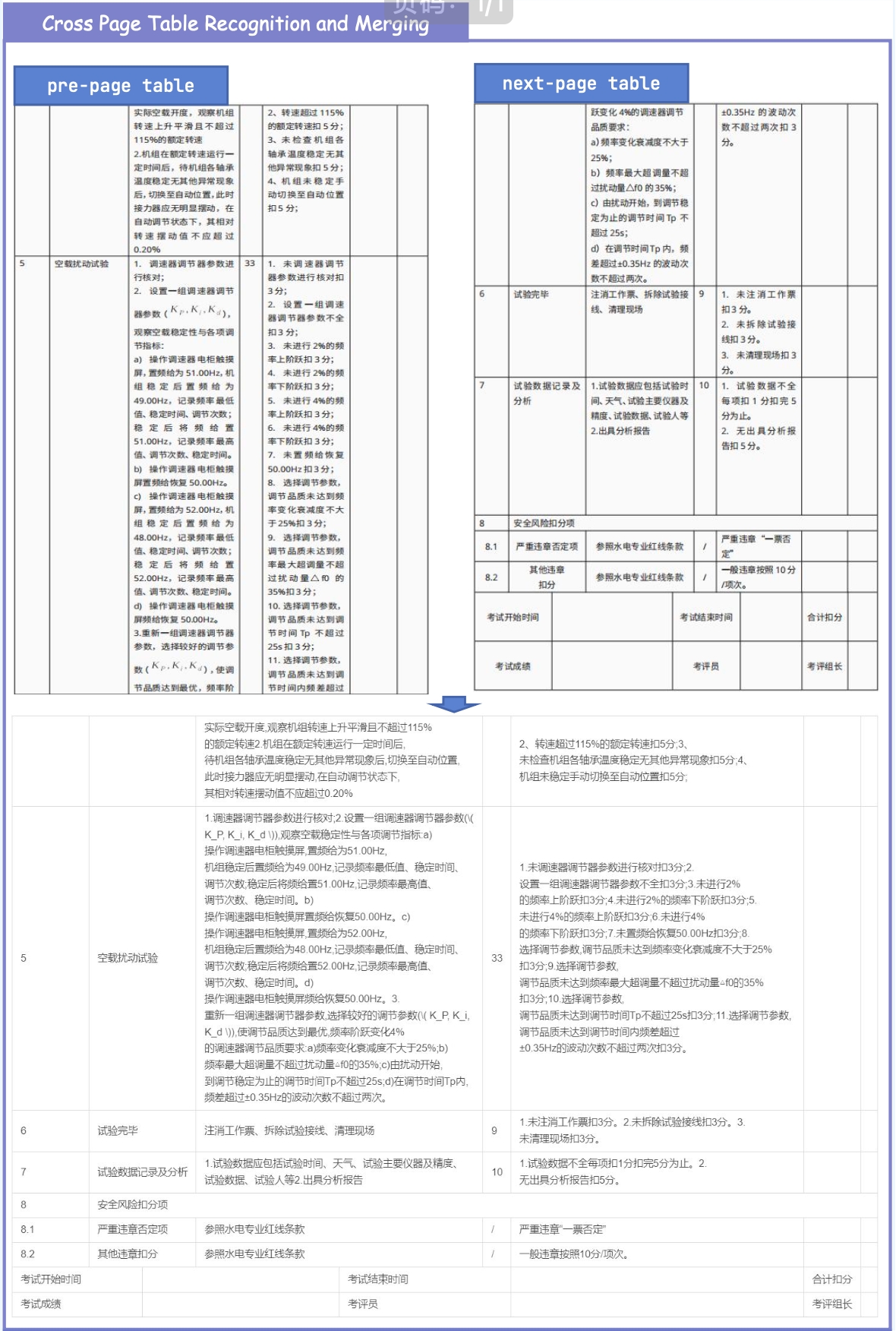
4. ✨ New Practical Capabilities Beyond metric improvements, MinerU2.5-Pro now natively supports: Image & Chart Parsing, Truncated Paragraph Merging, Cross-Page Table Merging and In-Table Image Recognition.
Current SOTA models (regardless of architecture) consistently fail on the same set of complex layouts. We realized the true bottleneck is training data deficiency and annotation noise. To fix this, we built a novel Data Engine:
Bottom Line: MinerU2.5-Pro proves that systematic data engineering is the ultimate lever for document parsing, providing the most accurate structural extraction available today for LLM data pipelines and advanced RAG systems.
For convenience, we provide mineru-vl-utils, a Python package that simplifies the process of sending requests and handling responses from MinerU2.5-Pro Vision-Language Model. Here we give some examples to use MinerU2.5-Pro. For more information and usages, please refer to mineru-vl-utils.
📌 We strongly recommend using vllm for inference, as the vllm-async-engine can achieve a concurrent inference speed of 2.12 fps on one A100.
# For `transformers` backend
pip install "mineru-vl-utils[transformers]"
# For `vllm-engine` and `vllm-async-engine` backend
pip install "mineru-vl-utils[vllm]"
transformers Example
from transformers import AutoProcessor, Qwen2VLForConditionalGeneration
from PIL import Image
from mineru_vl_utils import MinerUClient
# for transformers>=4.56.0
model = Qwen2VLForConditionalGeneration.from_pretrained(
"opendatalab/MinerU2.5-Pro-2604-1.2B", dtype="auto", device_map="auto"
)
processor = AutoProcessor.from_pretrained(
"opendatalab/MinerU2.5-Pro-2604-1.2B", use_fast=True
)
client = MinerUClient(
backend="transformers", model=model, processor=processor,
image_analysis=False # default False, set True to enable image/chart analysis
)
print(client.two_step_extract(Image.open("/path/to/page.png")))
vllm-engine Example (Recommended!)
from vllm import LLM
from PIL import Image
from mineru_vl_utils import MinerUClient
from mineru_vl_utils import MinerULogitsProcessor # if vllm>=0.10.1
llm = LLM(
model="opendatalab/MinerU2.5-Pro-2604-1.2B",
logits_processors=[MinerULogitsProcessor] # if vllm>=0.10.1
)
client = MinerUClient(
backend="vllm-engine", vllm_llm=llm,
image_analysis=False # default False, set True to enable image/chart analysis
)
print(client.two_step_extract(Image.open("/path/to/page.png")))
from mineru_vl_utils.post_process import json2md
# ... omit client initialize
content_list = client.two_step_extract(Image.open("path/to/page.png"))
md_res = json2md(content_list)
🚧 Cross-Page Table Merging: Currently under integration. Stay tuned!



We would like to thank Qwen Team, vLLM, OmniDocBench, PaddleOCR, UniMERNet, DocLayout-YOLO for providing valuable code and models. We also appreciate everyone's contribution to this open-source project!
If you find our work useful in your research, please consider giving a star ⭐ and citation 📝 :
@misc{wang2026mineru25propushinglimitsdatacentric,
title={MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale},
author={Bin, Wang and Tianyao, He and Linke, Ouyang and Fan, Wu and Zhiyuan, Zhao and Tao, Chu and Yuan, Qu and Zhenjiang, Jin and Weijun, Zeng and Ziyang, Miao and Bangrui, Xu and Junbo, Niu and others},
year={2026},
eprint={2604.04771},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.04771},
}