
File size: 10,383 Bytes
aacf7d3 29d9a38 10454ac 92df5c4 e9241cf 92df5c4 e9241cf 92df5c4 e9241cf 92df5c4 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 de9e2da 29d9a38 aacf7d3 29d9a38 860e1a8 29d9a38 92df5c4 29d9a38 6595803 29d9a38 de9e2da aacf7d3 92df5c4 de9e2da 92df5c4 de9e2da 29d9a38 de9e2da 29d9a38 e9241cf 29d9a38 de9e2da 29d9a38 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 | ---
license: apache-2.0
library_name: mlx
pipeline_tag: automatic-speech-recognition
tags:
- mlx
- asr
- automatic-speech-recognition
- speech-recognition
- mimo
base_model:
- XiaomiMiMo/MiMo-V2.5-ASR
language:
- zh
- en
---
Current variant: `bf16`
<div align="center">
<img src="https://raw.githubusercontent.com/XiaomiMiMo/MiMo-V2.5-ASR/main/assets/XiaomiMIMO.png" width="60%" alt="Xiaomi-MiMo" />
</div>
<div align="center">
<h3>
<b>
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span><br/>
MiMo-V2.5-ASR: Robust Speech Recognition Across<br/>
Languages, Dialects, and Complex Acoustic Scenarios<br/>
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span>
</b>
</h3>
</div>
<br/>
<div align="center" style="line-height: 1;">
|
<a href="https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR" target="_blank">🤗 Official Model</a>
|
<a href="https://huggingface.co/spaces/XiaomiMiMo/MiMo-V2.5-ASR" target="_blank">🚀 Official Demo</a>
|
<a href="https://mimo.xiaomi.com/mimo-v2-5-asr" target="_blank">📰 Official Blog</a>
|
<a href="https://github.com/XiaomiMiMo/MiMo-V2.5-ASR" target="_blank">💻 Official Code</a>
|
</div>
<br/>
## MLX Note
This repository is a community MLX conversion of the official `XiaomiMiMo/MiMo-V2.5-ASR` release for Apple silicon. The original model description below is preserved from the official release, and the MLX-specific material in this page is added as an incremental note for local MLX deployment.
## MLX Usage
Current MLX usage is documented in the GitHub forks below:
- [ailuntx/MiMo-V2.5-ASR-MLX](https://github.com/ailuntx/MiMo-V2.5-ASR-MLX)
- [ailuntx/MiMo-Audio-Tokenizer-MLX](https://github.com/ailuntx/MiMo-Audio-Tokenizer-MLX)
Install the current MLX path:
```bash
pip install git+https://github.com/ailuntx/mlx-audio@feat/mimo-v25-asr
```
Download the MLX checkpoints:
```bash
hf download mlx-community/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
hf download mlx-community/MiMo-V2.5-ASR-MLX --local-dir ./models/MiMo-V2.5-ASR-MLX
```
Run transcription from the helper script in `ailuntx/MiMo-V2.5-ASR-MLX`:
```bash
git clone https://github.com/ailuntx/MiMo-V2.5-ASR-MLX.git
cd MiMo-V2.5-ASR-MLX
python run_mimo_asr_mlx.py \
--model ./models/MiMo-V2.5-ASR-MLX \
--audio path/to/audio.wav
```
Python:
```python
from mlx_audio.stt import load
model = load("./models/MiMo-V2.5-ASR-MLX")
result = model.generate("path/to/audio.wav", language="en")
print(result.text)
```
Notes:
- `mlx-community/MiMo-V2.5-ASR-MLX` resolves `mlx-community/MiMo-Audio-Tokenizer` through `mlx_manifest.json`.
- The current install path depends on the MiMo support branch in `ailuntx/mlx-audio`.
- The usage section here will be simplified once MiMo lands in upstream `mlx-audio` and `mlx-audio-swift`.
## Introduction
**MiMo-V2.5-ASR** is a state-of-the-art end-to-end automatic speech recognition (ASR) model developed by the Xiaomi MiMo team. It is built to deliver accurate and robust transcription across Mandarin Chinese and English, multiple Chinese dialects, code-switched speech, song lyrics, knowledge-intensive content, noisy acoustic environments, and multi-speaker conversations. MiMo-V2.5-ASR achieves state-of-the-art results on a wide range of public benchmarks.
## Abstract
Automatic speech recognition systems are expected to faithfully transcribe speech signals that originate from diverse languages, dialects, accents, and domains, and that are captured under a wide variety of acoustic conditions. While conventional end-to-end models perform well on in-domain data, they still fall short of real-world requirements in challenging scenarios such as dialect mixing, code-switching, knowledge-intensive content, noisy environments, and multi-speaker conversations. Therefore, we present **MiMo-V2.5-ASR**, an end-to-end speech recognition model developed by the Xiaomi MiMo team. Through large-scale mid-training, high-quality supervised fine-tuning, and a novel reinforcement-learning algorithm, MiMo-V2.5-ASR achieves systematic improvements along the following dimensions:
- 🗣️ **Chinese Dialects**: Native support for Wu, Cantonese, Hokkien, Sichuanese, and more.
- 🔀 **Code-Switch**: Seamless Chinese-English code-switching transcription with no language tags required.
- 🎵 **Song Recognition**: High-precision lyrics transcription for Chinese and English songs, even with mixed accompaniment and vocals.
- 🔊 **Noisy Environments**: Robust recognition under heavy noise, far-field capture, and other adverse acoustic conditions.
- 👥 **Multi-Speaker**: Accurate transcription of overlapping, multi-party conversations such as meetings.
- 🇬🇧 **Complex English Scenarios**: Leading performance on the Open ASR Leaderboard for challenging English benchmarks such as AMI.
- 📚 **Knowledge-Intensive Recognition**: Precise recognition of classical poetry, technical terminology, personal names, place names, and other knowledge-dense material.
- 📝 **Native Punctuation**: Punctuation generated natively from prosody and semantics, delivering ready-to-use transcripts with no post-processing needed.
## Results
MiMo-V2.5-ASR has been evaluated across a broad set of benchmarks spanning standard Mandarin and English, Chinese dialects, lyric recognition, and internal business scenarios. The chart below summarizes the average performance of MiMo-V2.5-ASR across these scenarios.
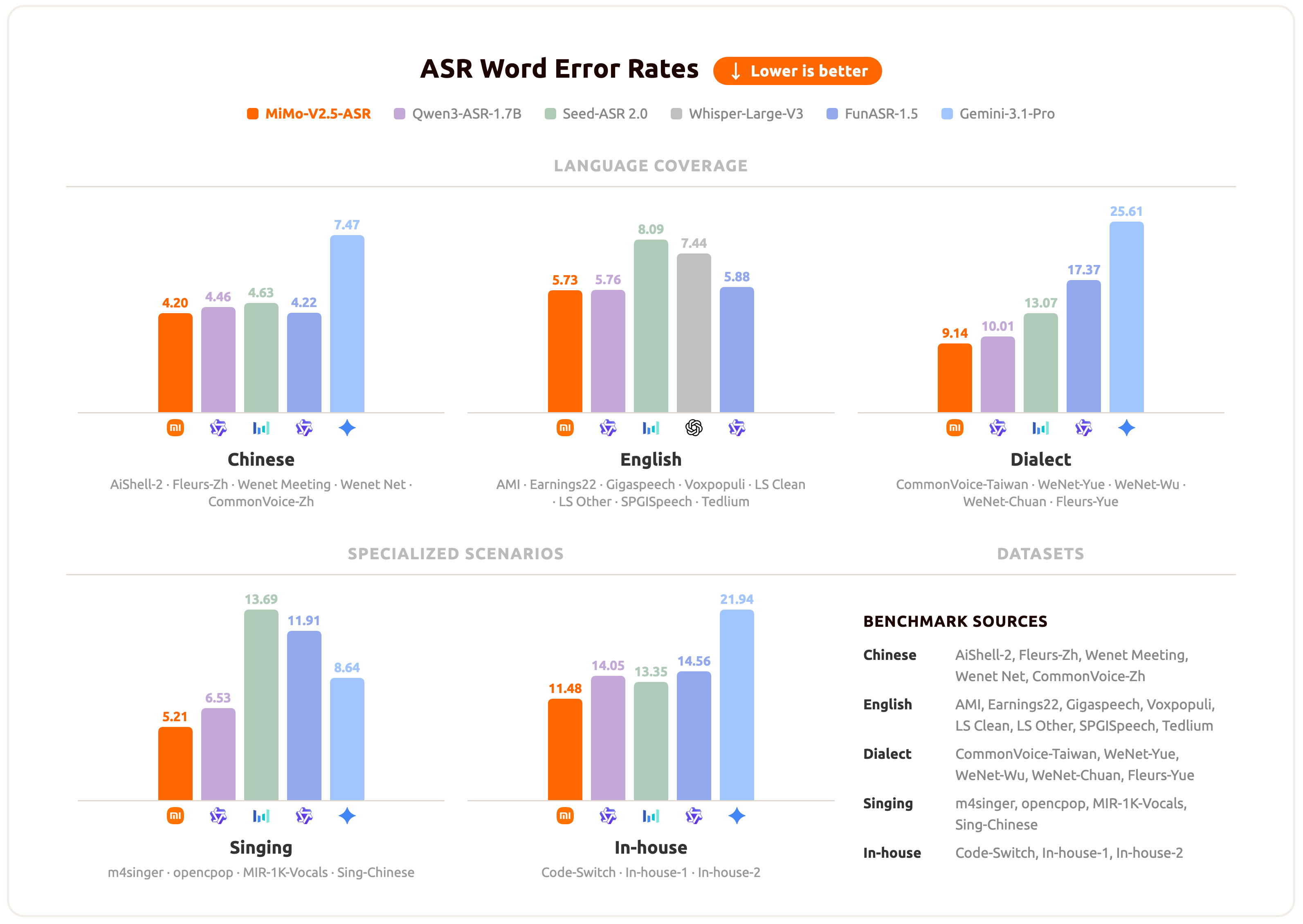
For per-benchmark numbers and specific qualitative cases, please refer to the official [blog](https://mimo.xiaomi.com/mimo-v2-5-asr).
## Model Download
| Models | 🤗 Hugging Face |
|-------|-------|
| MiMo-Audio-Tokenizer | [XiaomiMiMo/MiMo-Audio-Tokenizer](https://huggingface.co/XiaomiMiMo/MiMo-Audio-Tokenizer) |
| MiMo-V2.5-ASR | [XiaomiMiMo/MiMo-V2.5-ASR](https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR) |
```bash
pip install huggingface-hub
hf download XiaomiMiMo/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
hf download XiaomiMiMo/MiMo-V2.5-ASR --local-dir ./models/MiMo-V2.5-ASR
```
## MLX Releases
The following repositories are MLX conversions derived from the official release:
| Variant | Precision | Size | Local smoke time | Smoke result |
| --- | --- | ---: | ---: | --- |
| `MiMo-V2.5-ASR-MLX` | 4bit | 4.2 GB | 0.88 s | `Intention.` |
| `MiMo-V2.5-ASR-MLX-4bit` | 4bit | 4.2 GB | 0.88 s | `Intention.` |
| `MiMo-V2.5-ASR-MLX-8bit` | 8bit | 8.0 GB | 10.80 s | `Intention.` |
| `MiMo-V2.5-ASR-MLX-bf16` | bf16 | 15 GB | - | dense reference export |
| `MiMo-V2.5-ASR-MLX-fp32` | fp32 | 30 GB | - | dense reference export |
MLX conversion notes:
- Base model: `XiaomiMiMo/MiMo-V2.5-ASR`
- Tokenizer resolution: automatic via `mlx-community/MiMo-Audio-Tokenizer`
- Conversion date: `2026-05-12`
- Local validation runtimes: `mlx-audio` and `mlx-audio-swift`
- Recommended default: `MiMo-V2.5-ASR-MLX`
Example downloads:
```bash
hf download mlx-community/MiMo-V2.5-ASR-MLX --local-dir ./models/MiMo-V2.5-ASR-MLX
hf download mlx-community/MiMo-V2.5-ASR-MLX-8bit --local-dir ./models/MiMo-V2.5-ASR-MLX-8bit
```
## Validation
Local smoke validation was run with `mlx-audio` and `mlx-audio-swift`.
- `intention.wav` -> `Intention.`
- `conversational_a.wav` -> expected coffee / Kaldi paragraph
## Getting Started
The following section is preserved from the official project and describes the original Python/CUDA workflow.
Spin up the MiMo-V2.5-ASR demo in minutes with the built-in Gradio app.
### Prerequisites (Linux)
* Python 3.12
* CUDA >= 12.0
### Installation
```bash
git clone https://github.com/XiaomiMiMo/MiMo-V2.5-ASR.git
cd MiMo-V2.5-ASR-MLX
pip install -r requirements.txt
pip install flash-attn==2.7.4.post1
```
> [!Note]
> If the compilation of flash-attn takes too long, you can download the precompiled wheel and install it manually:
>
> * [Download Precompiled Wheel](https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl)
>
> ```sh
> pip install /path/to/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
> ```
### Run the Demo
```bash
python run_mimo_asr.py
```
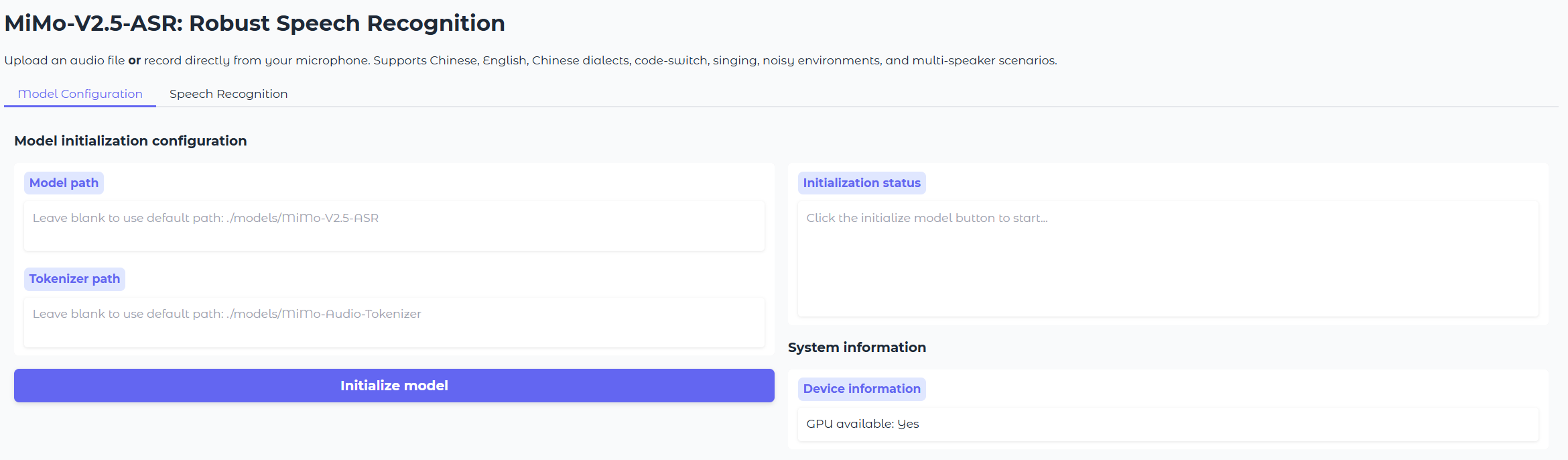
This launches a local Gradio interface for MiMo-V2.5-ASR. You can:
* Upload an audio file **or** record directly from your microphone.
* Optionally specify a **language tag** (Chinese / English / Auto) to bias the model for a specific language, or leave it to **Auto** for automatic language detection (recommended for code-switched speech).
* The demo calls the `asr_sft()` interface under the hood.
To load the model and tokenizer automatically at startup, pass their paths on the command line:
```bash
python run_mimo_asr.py \
--model-path ./models/MiMo-V2.5-ASR \
--tokenizer-path ./models/MiMo-Audio-Tokenizer
```
Otherwise, enter the local paths for `MiMo-Audio-Tokenizer` and `MiMo-V2.5-ASR` in the **Model Configuration** tab, then start transcribing.
## Python API
The following API example is preserved from the official project.
Basic usage with the `asr_sft` interface:
```python
from src.mimo_audio.mimo_audio import MimoAudio
model = MimoAudio(
model_path="./models/MiMo-V2.5-ASR",
tokenizer_path="./models/MiMo-Audio-Tokenizer",
)
# Automatic language detection (recommended for code-switching)
text = model.asr_sft("path/to/audio.wav")
print(text)
# With explicit language tag
text_zh = model.asr_sft("path/to/audio.wav", audio_tag="<chinese>")
text_en = model.asr_sft("path/to/audio.wav", audio_tag="<english>")
```
## Citation
```bibtex
@misc{coreteam2026mimov25asr,
title={MiMo-V2.5-ASR: Robust Speech Recognition Across Languages, Dialects, and Complex Acoustic Scenarios},
author={LLM-Core-Team Xiaomi},
year={2026},
url={https://github.com/XiaomiMiMo/MiMo-V2.5-ASR},
}
```
## Contact
Please contact [mimo@xiaomi.com](mailto:mimo@xiaomi.com) or open an issue in the official project if you have questions about the original model.
|