

Replace README with official card plus MLX additions
Browse files
README.md
CHANGED
|
@@ -15,53 +15,85 @@ language:
|
|
| 15 |
- en
|
| 16 |
---
|
| 17 |
|
| 18 |
-
# MiMo-V2.5-ASR-MLX-bf16
|
| 19 |
-
|
| 20 |
Current variant: `bf16`
|
| 21 |
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
## Introduction
|
| 33 |
|
| 34 |
-
**MiMo-V2.5-ASR** is
|
|
|
|
|
|
|
| 35 |
|
| 36 |
-
|
| 37 |
|
| 38 |
-
- Native support for
|
| 39 |
-
- Seamless Chinese-English code-switching transcription
|
| 40 |
-
-
|
| 41 |
-
- Robust recognition under heavy noise
|
| 42 |
-
- Accurate transcription
|
| 43 |
-
-
|
| 44 |
-
-
|
| 45 |
-
- Native
|
| 46 |
|
| 47 |
## Results
|
| 48 |
|
| 49 |
-
|
| 50 |
|
| 51 |
-
|
| 52 |
-
- Official blog: `mimo.xiaomi.com/mimo-v2-5-asr`
|
| 53 |
|
| 54 |
-
|
| 55 |
|
| 56 |
-
|
| 57 |
|
| 58 |
-
|
| 59 |
-
-
|
| 60 |
-
-
|
| 61 |
-
-
|
| 62 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
-
|
| 65 |
|
| 66 |
| Variant | Precision | Size | Local smoke time | Smoke result |
|
| 67 |
| --- | --- | ---: | ---: | --- |
|
|
@@ -71,15 +103,104 @@ This repository packages the official release as an MLX-ready model family for A
|
|
| 71 |
| `MiMo-V2.5-ASR-MLX-bf16` | bf16 | 15 GB | - | dense reference export |
|
| 72 |
| `MiMo-V2.5-ASR-MLX-fp32` | fp32 | 30 GB | - | dense reference export |
|
| 73 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 74 |
## Validation
|
| 75 |
|
| 76 |
Local smoke validation was run with `mlx-audio-swift` on `Tests/media/intention.wav`.
|
| 77 |
|
| 78 |
- Output: `Intention.`
|
| 79 |
|
| 80 |
-
##
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 81 |
|
| 82 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 83 |
|
| 84 |
```bibtex
|
| 85 |
@misc{coreteam2026mimov25asr,
|
|
@@ -92,7 +213,4 @@ If you use the original model, please cite the official project:
|
|
| 92 |
|
| 93 |
## Contact
|
| 94 |
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
- `mimo@xiaomi.com`
|
| 98 |
-
- `XiaomiMiMo/MiMo-V2.5-ASR`
|
|
|
|
| 15 |
- en
|
| 16 |
---
|
| 17 |
|
|
|
|
|
|
|
| 18 |
Current variant: `bf16`
|
| 19 |
|
| 20 |
+
<div align="center">
|
| 21 |
+
<img src="https://raw.githubusercontent.com/XiaomiMiMo/MiMo-V2.5-ASR/main/assets/XiaomiMIMO.png" width="60%" alt="Xiaomi-MiMo" />
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
<div align="center">
|
| 25 |
+
<h3>
|
| 26 |
+
<b>
|
| 27 |
+
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span><br/>
|
| 28 |
+
MiMo-V2.5-ASR: Robust Speech Recognition Across<br/>
|
| 29 |
+
Languages, Dialects, and Complex Acoustic Scenarios<br/>
|
| 30 |
+
<span>━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━</span>
|
| 31 |
+
</b>
|
| 32 |
+
</h3>
|
| 33 |
+
</div>
|
| 34 |
+
|
| 35 |
+
<br/>
|
| 36 |
+
|
| 37 |
+
<div align="center" style="line-height: 1;">
|
| 38 |
+
|
|
| 39 |
+
<a href="https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR" target="_blank">🤗 Official Model</a>
|
| 40 |
+
|
|
| 41 |
+
<a href="https://huggingface.co/spaces/XiaomiMiMo/MiMo-V2.5-ASR" target="_blank">🚀 Official Demo</a>
|
| 42 |
+
|
|
| 43 |
+
<a href="https://mimo.xiaomi.com/mimo-v2-5-asr" target="_blank">📰 Official Blog</a>
|
| 44 |
+
|
|
| 45 |
+
<a href="https://github.com/XiaomiMiMo/MiMo-V2.5-ASR" target="_blank">💻 Official Code</a>
|
| 46 |
+
|
|
| 47 |
+
</div>
|
| 48 |
+
|
| 49 |
+
<br/>
|
| 50 |
+
|
| 51 |
+
## MLX Note
|
| 52 |
+
|
| 53 |
+
This repository is a community MLX conversion of the official `XiaomiMiMo/MiMo-V2.5-ASR` release for Apple silicon. The original model description below is preserved from the official release, and the MLX-specific material in this page is added as an incremental note for local MLX deployment.
|
| 54 |
|
| 55 |
## Introduction
|
| 56 |
|
| 57 |
+
**MiMo-V2.5-ASR** is a state-of-the-art end-to-end automatic speech recognition (ASR) model developed by the Xiaomi MiMo team. It is built to deliver accurate and robust transcription across Mandarin Chinese and English, multiple Chinese dialects, code-switched speech, song lyrics, knowledge-intensive content, noisy acoustic environments, and multi-speaker conversations. MiMo-V2.5-ASR achieves state-of-the-art results on a wide range of public benchmarks.
|
| 58 |
+
|
| 59 |
+
## Abstract
|
| 60 |
|
| 61 |
+
Automatic speech recognition systems are expected to faithfully transcribe speech signals that originate from diverse languages, dialects, accents, and domains, and that are captured under a wide variety of acoustic conditions. While conventional end-to-end models perform well on in-domain data, they still fall short of real-world requirements in challenging scenarios such as dialect mixing, code-switching, knowledge-intensive content, noisy environments, and multi-speaker conversations. Therefore, we present **MiMo-V2.5-ASR**, an end-to-end speech recognition model developed by the Xiaomi MiMo team. Through large-scale mid-training, high-quality supervised fine-tuning, and a novel reinforcement-learning algorithm, MiMo-V2.5-ASR achieves systematic improvements along the following dimensions:
|
| 62 |
|
| 63 |
+
- 🗣️ **Chinese Dialects**: Native support for Wu, Cantonese, Hokkien, Sichuanese, and more.
|
| 64 |
+
- 🔀 **Code-Switch**: Seamless Chinese-English code-switching transcription with no language tags required.
|
| 65 |
+
- 🎵 **Song Recognition**: High-precision lyrics transcription for Chinese and English songs, even with mixed accompaniment and vocals.
|
| 66 |
+
- 🔊 **Noisy Environments**: Robust recognition under heavy noise, far-field capture, and other adverse acoustic conditions.
|
| 67 |
+
- 👥 **Multi-Speaker**: Accurate transcription of overlapping, multi-party conversations such as meetings.
|
| 68 |
+
- 🇬🇧 **Complex English Scenarios**: Leading performance on the Open ASR Leaderboard for challenging English benchmarks such as AMI.
|
| 69 |
+
- 📚 **Knowledge-Intensive Recognition**: Precise recognition of classical poetry, technical terminology, personal names, place names, and other knowledge-dense material.
|
| 70 |
+
- 📝 **Native Punctuation**: Punctuation generated natively from prosody and semantics, delivering ready-to-use transcripts with no post-processing needed.
|
| 71 |
|
| 72 |
## Results
|
| 73 |
|
| 74 |
+
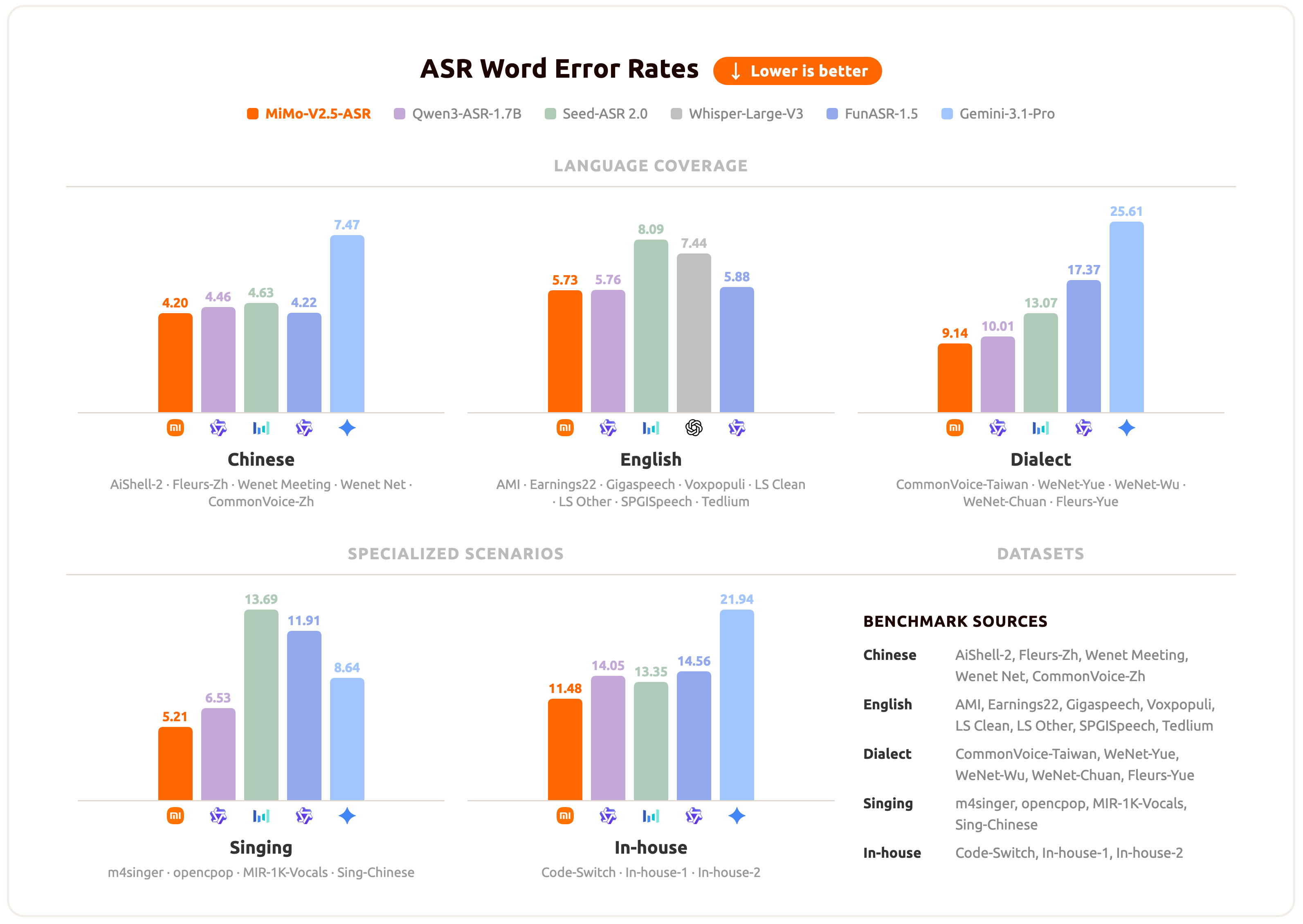
MiMo-V2.5-ASR has been evaluated across a broad set of benchmarks spanning standard Mandarin and English, Chinese dialects, lyric recognition, and internal business scenarios. The chart below summarizes the average performance of MiMo-V2.5-ASR across these scenarios.
|
| 75 |
|
| 76 |
+
|
|
|
|
| 77 |
|
| 78 |
+
For per-benchmark numbers and specific qualitative cases, please refer to the official [blog](https://mimo.xiaomi.com/mimo-v2-5-asr).
|
| 79 |
|
| 80 |
+
## Model Download
|
| 81 |
|
| 82 |
+
| Models | 🤗 Hugging Face |
|
| 83 |
+
|-------|-------|
|
| 84 |
+
| MiMo-Audio-Tokenizer | [XiaomiMiMo/MiMo-Audio-Tokenizer](https://huggingface.co/XiaomiMiMo/MiMo-Audio-Tokenizer) |
|
| 85 |
+
| MiMo-V2.5-ASR | [XiaomiMiMo/MiMo-V2.5-ASR](https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR) |
|
| 86 |
+
|
| 87 |
+
```bash
|
| 88 |
+
pip install huggingface-hub
|
| 89 |
+
|
| 90 |
+
hf download XiaomiMiMo/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
|
| 91 |
+
hf download XiaomiMiMo/MiMo-V2.5-ASR --local-dir ./models/MiMo-V2.5-ASR
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## MLX Releases
|
| 95 |
|
| 96 |
+
The following repositories are MLX conversions derived from the official release:
|
| 97 |
|
| 98 |
| Variant | Precision | Size | Local smoke time | Smoke result |
|
| 99 |
| --- | --- | ---: | ---: | --- |
|
|
|
|
| 103 |
| `MiMo-V2.5-ASR-MLX-bf16` | bf16 | 15 GB | - | dense reference export |
|
| 104 |
| `MiMo-V2.5-ASR-MLX-fp32` | fp32 | 30 GB | - | dense reference export |
|
| 105 |
|
| 106 |
+
MLX conversion notes:
|
| 107 |
+
|
| 108 |
+
- Base model: `XiaomiMiMo/MiMo-V2.5-ASR`
|
| 109 |
+
- Required tokenizer: `XiaomiMiMo/MiMo-Audio-Tokenizer`
|
| 110 |
+
- Conversion date: `2026-05-12`
|
| 111 |
+
- Local validation runtime: `mlx-audio-swift`
|
| 112 |
+
- Recommended default: `MiMo-V2.5-ASR-MLX`
|
| 113 |
+
|
| 114 |
+
Example downloads:
|
| 115 |
+
|
| 116 |
+
```bash
|
| 117 |
+
hf download ailuntz/MiMo-V2.5-ASR-MLX --local-dir ./models/MiMo-V2.5-ASR-MLX
|
| 118 |
+
hf download ailuntz/MiMo-V2.5-ASR-MLX-8bit --local-dir ./models/MiMo-V2.5-ASR-MLX-8bit
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
## Validation
|
| 122 |
|
| 123 |
Local smoke validation was run with `mlx-audio-swift` on `Tests/media/intention.wav`.
|
| 124 |
|
| 125 |
- Output: `Intention.`
|
| 126 |
|
| 127 |
+
## Getting Started
|
| 128 |
+
|
| 129 |
+
The following section is preserved from the official project and describes the original Python/CUDA workflow.
|
| 130 |
+
|
| 131 |
+
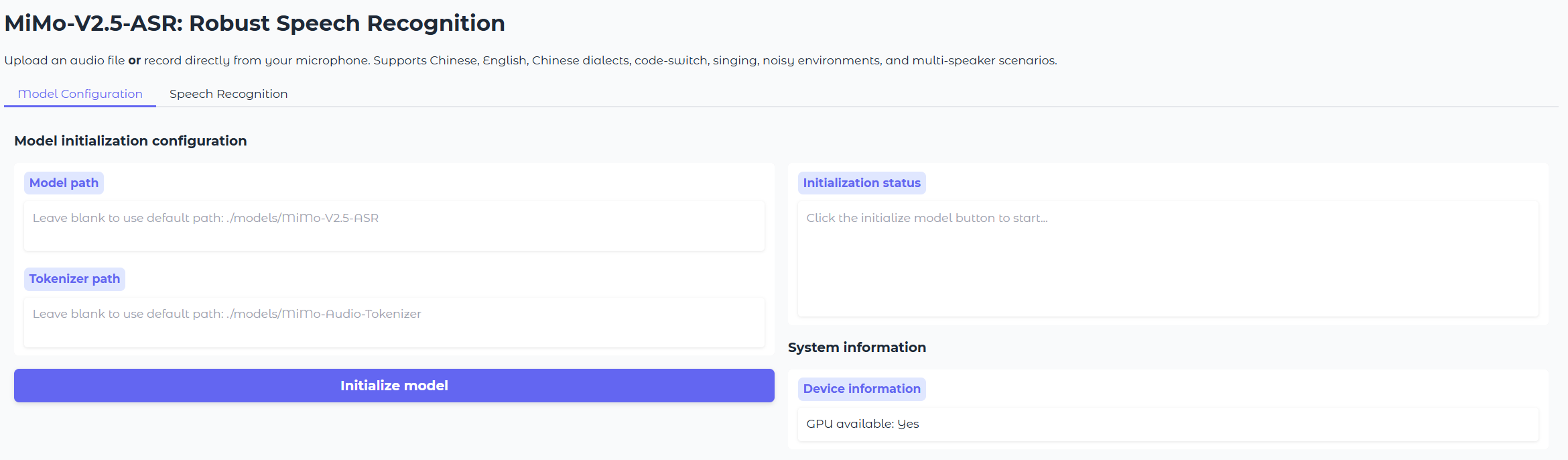
Spin up the MiMo-V2.5-ASR demo in minutes with the built-in Gradio app.
|
| 132 |
+
|
| 133 |
+
### Prerequisites (Linux)
|
| 134 |
|
| 135 |
+
* Python 3.12
|
| 136 |
+
* CUDA >= 12.0
|
| 137 |
+
|
| 138 |
+
### Installation
|
| 139 |
+
|
| 140 |
+
```bash
|
| 141 |
+
git clone https://github.com/XiaomiMiMo/MiMo-V2.5-ASR.git
|
| 142 |
+
cd MiMo-V2.5-ASR
|
| 143 |
+
pip install -r requirements.txt
|
| 144 |
+
pip install flash-attn==2.7.4.post1
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
> [!Note]
|
| 148 |
+
> If the compilation of flash-attn takes too long, you can download the precompiled wheel and install it manually:
|
| 149 |
+
>
|
| 150 |
+
> * [Download Precompiled Wheel](https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl)
|
| 151 |
+
>
|
| 152 |
+
> ```sh
|
| 153 |
+
> pip install /path/to/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
|
| 154 |
+
> ```
|
| 155 |
+
|
| 156 |
+
### Run the Demo
|
| 157 |
+
|
| 158 |
+
```bash
|
| 159 |
+
python run_mimo_asr.py
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
This launches a local Gradio interface for MiMo-V2.5-ASR. You can:
|
| 165 |
+
|
| 166 |
+
* Upload an audio file **or** record directly from your microphone.
|
| 167 |
+
* Optionally specify a **language tag** (Chinese / English / Auto) to bias the model for a specific language, or leave it to **Auto** for automatic language detection (recommended for code-switched speech).
|
| 168 |
+
* The demo calls the `asr_sft()` interface under the hood.
|
| 169 |
+
|
| 170 |
+
To load the model and tokenizer automatically at startup, pass their paths on the command line:
|
| 171 |
+
|
| 172 |
+
```bash
|
| 173 |
+
python run_mimo_asr.py \
|
| 174 |
+
--model-path ./models/MiMo-V2.5-ASR \
|
| 175 |
+
--tokenizer-path ./models/MiMo-Audio-Tokenizer
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
Otherwise, enter the local paths for `MiMo-Audio-Tokenizer` and `MiMo-V2.5-ASR` in the **Model Configuration** tab, then start transcribing.
|
| 179 |
+
|
| 180 |
+
## Python API
|
| 181 |
+
|
| 182 |
+
The following API example is preserved from the official project.
|
| 183 |
+
|
| 184 |
+
Basic usage with the `asr_sft` interface:
|
| 185 |
+
|
| 186 |
+
```python
|
| 187 |
+
from src.mimo_audio.mimo_audio import MimoAudio
|
| 188 |
+
|
| 189 |
+
model = MimoAudio(
|
| 190 |
+
model_path="./models/MiMo-V2.5-ASR",
|
| 191 |
+
tokenizer_path="./models/MiMo-Audio-Tokenizer",
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
# Automatic language detection (recommended for code-switching)
|
| 195 |
+
text = model.asr_sft("path/to/audio.wav")
|
| 196 |
+
print(text)
|
| 197 |
+
|
| 198 |
+
# With explicit language tag
|
| 199 |
+
text_zh = model.asr_sft("path/to/audio.wav", audio_tag="<chinese>")
|
| 200 |
+
text_en = model.asr_sft("path/to/audio.wav", audio_tag="<english>")
|
| 201 |
+
```
|
| 202 |
+
|
| 203 |
+
## Citation
|
| 204 |
|
| 205 |
```bibtex
|
| 206 |
@misc{coreteam2026mimov25asr,
|
|
|
|
| 213 |
|
| 214 |
## Contact
|
| 215 |
|
| 216 |
+
Please contact [mimo@xiaomi.com](mailto:mimo@xiaomi.com) or open an issue in the official project if you have questions about the original model.
|
|
|
|
|
|
|
|
|