
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Paper • 2406.12793 • Published • 34
I can no longer upload new models unless I can cover the cost of additional storage.
I host 70+ free models as an independent contributor and this work is unpaid.
Without your support, no more new models can be uploaded.
🎉 Patreon (Monthly) | ☕ Ko-fi (One-time)
Every contribution goes directly toward Hugging Face storage fees to keep models free for everyone.
Creating these models takes significant time, work and compute. If you find them useful consider supporting me:

| Platform | Link | What you get |
|---|---|---|
| 🎉 Patreon | Monthly support | Priority model requests |
| ☕ Ko-fi | One-time tip | My eternal gratitude |
Your help will motivate me and would go into further improving my workflow and coverings fees for storage, compute and may even help uncensoring bigger model with rental Cloud GPUs.
| Parameter | Value |
|---|---|
| start_layer_index | 18 |
| end_layer_index | 43 |
| preserve_good_behavior_weight | 0.7515 |
| steer_bad_behavior_weight | 0.0001 |
| overcorrect_relative_weight | 1.0641 |
| neighbor_count | 8 |
| Metric | This model | Original model (zai-org/GLM-Z1-32B-0414) |
|---|---|---|
| KL divergence | 0.0007 | 0 (by definition) |
| Refusals | ✅ 26/100 | ❌ 94/100 |
Original:
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| piqa | 1 | none | 0 | acc | ↑ | 0.8156 | ± | 0.0090 |
| none | 0 | acc_norm | ↑ | 0.8210 | ± | 0.0089 |
Heretic:
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| piqa | 1 | none | 0 | acc | ↑ | 0.8139 | ± | 0.0091 |
| none | 0 | acc_norm | ↑ | 0.8172 | ± | 0.0090 |
Lower refusals indicate fewer content restrictions, while lower KL divergence indicates more closeness to the original model's baseline. Higher refusals cause more rejections, objections, pushbacks, lecturing, censorship, softening and deflections. PIQA (Physical Intuition Question Answering) a ~1,800 questions tests common-sense understanding of how the physical world works with benchmark scores to measure physical reasoning ability. The Heretic model's acc and acc_norm scores closer to the original model's indicate better capability preservation, a big decrease in acc and acc_norm in the Heretic model compared to Original model's results means a big decrease in the Hereticated model capabilities. acc measures raw accuracy (which answer gets higher probability), while acc_norm measures length-normalized accuracy (corrects for answer length bias). For this purpose, acc_norm matters more because longer answers naturally have lower probabilities (more tokens = more chances to lose probability). Without normalization, models favor shorter answers unfairly. acc_norm divides by answer length to correct this.
Original:
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| mmlu | 2 | none | acc | ↑ | 0.7001 | ± | 0.0036 | |
| - humanities | 2 | none | acc | ↑ | 0.6193 | ± | 0.0066 | |
| - formal_logic | 1 | none | 0 | acc | ↑ | 0.6111 | ± | 0.0436 |
| - high_school_european_history | 1 | none | 0 | acc | ↑ | 0.8182 | ± | 0.0301 |
| - high_school_us_history | 1 | none | 0 | acc | ↑ | 0.8873 | ± | 0.0222 |
| - high_school_world_history | 1 | none | 0 | acc | ↑ | 0.8608 | ± | 0.0225 |
| - international_law | 1 | none | 0 | acc | ↑ | 0.8017 | ± | 0.0364 |
| - jurisprudence | 1 | none | 0 | acc | ↑ | 0.8056 | ± | 0.0383 |
| - logical_fallacies | 1 | none | 0 | acc | ↑ | 0.8037 | ± | 0.0312 |
| - moral_disputes | 1 | none | 0 | acc | ↑ | 0.6965 | ± | 0.0248 |
| - moral_scenarios | 1 | none | 0 | acc | ↑ | 0.3844 | ± | 0.0163 |
| - philosophy | 1 | none | 0 | acc | ↑ | 0.7106 | ± | 0.0258 |
| - prehistory | 1 | none | 0 | acc | ↑ | 0.7870 | ± | 0.0228 |
| - professional_law | 1 | none | 0 | acc | ↑ | 0.5163 | ± | 0.0128 |
| - world_religions | 1 | none | 0 | acc | ↑ | 0.8713 | ± | 0.0257 |
| - other | 2 | none | acc | ↑ | 0.7580 | ± | 0.0073 | |
| - business_ethics | 1 | none | 0 | acc | ↑ | 0.7700 | ± | 0.0423 |
| - clinical_knowledge | 1 | none | 0 | acc | ↑ | 0.8000 | ± | 0.0246 |
| - college_medicine | 1 | none | 0 | acc | ↑ | 0.6879 | ± | 0.0353 |
| - global_facts | 1 | none | 0 | acc | ↑ | 0.3700 | ± | 0.0485 |
| - human_aging | 1 | none | 0 | acc | ↑ | 0.7399 | ± | 0.0294 |
| - management | 1 | none | 0 | acc | ↑ | 0.8252 | ± | 0.0376 |
| - marketing | 1 | none | 0 | acc | ↑ | 0.8889 | ± | 0.0206 |
| - medical_genetics | 1 | none | 0 | acc | ↑ | 0.8300 | ± | 0.0378 |
| - miscellaneous | 1 | none | 0 | acc | ↑ | 0.8659 | ± | 0.0122 |
| - nutrition | 1 | none | 0 | acc | ↑ | 0.7810 | ± | 0.0237 |
| - professional_accounting | 1 | none | 0 | acc | ↑ | 0.5567 | ± | 0.0296 |
| - professional_medicine | 1 | none | 0 | acc | ↑ | 0.7794 | ± | 0.0252 |
| - virology | 1 | none | 0 | acc | ↑ | 0.5000 | ± | 0.0389 |
| - social sciences | 2 | none | acc | ↑ | 0.8021 | ± | 0.0070 | |
| - econometrics | 1 | none | 0 | acc | ↑ | 0.5526 | ± | 0.0468 |
| - high_school_geography | 1 | none | 0 | acc | ↑ | 0.8384 | ± | 0.0262 |
| - high_school_government_and_politics | 1 | none | 0 | acc | ↑ | 0.8912 | ± | 0.0225 |
| - high_school_macroeconomics | 1 | none | 0 | acc | ↑ | 0.7949 | ± | 0.0205 |
| - high_school_microeconomics | 1 | none | 0 | acc | ↑ | 0.8992 | ± | 0.0196 |
| - high_school_psychology | 1 | none | 0 | acc | ↑ | 0.8844 | ± | 0.0137 |
| - human_sexuality | 1 | none | 0 | acc | ↑ | 0.7786 | ± | 0.0364 |
| - professional_psychology | 1 | none | 0 | acc | ↑ | 0.7320 | ± | 0.0179 |
| - public_relations | 1 | none | 0 | acc | ↑ | 0.7091 | ± | 0.0435 |
| - security_studies | 1 | none | 0 | acc | ↑ | 0.7184 | ± | 0.0288 |
| - sociology | 1 | none | 0 | acc | ↑ | 0.8607 | ± | 0.0245 |
| - us_foreign_policy | 1 | none | 0 | acc | ↑ | 0.8400 | ± | 0.0368 |
| - stem | 2 | none | acc | ↑ | 0.6641 | ± | 0.0081 | |
| - abstract_algebra | 1 | none | 0 | acc | ↑ | 0.5000 | ± | 0.0503 |
| - anatomy | 1 | none | 0 | acc | ↑ | 0.6741 | ± | 0.0405 |
| - astronomy | 1 | none | 0 | acc | ↑ | 0.8158 | ± | 0.0315 |
| - college_biology | 1 | none | 0 | acc | ↑ | 0.8750 | ± | 0.0277 |
| - college_chemistry | 1 | none | 0 | acc | ↑ | 0.5300 | ± | 0.0502 |
| - college_computer_science | 1 | none | 0 | acc | ↑ | 0.6400 | ± | 0.0482 |
| - college_mathematics | 1 | none | 0 | acc | ↑ | 0.5200 | ± | 0.0502 |
| - college_physics | 1 | none | 0 | acc | ↑ | 0.5196 | ± | 0.0497 |
| - computer_security | 1 | none | 0 | acc | ↑ | 0.7500 | ± | 0.0435 |
| - conceptual_physics | 1 | none | 0 | acc | ↑ | 0.7489 | ± | 0.0283 |
| - electrical_engineering | 1 | none | 0 | acc | ↑ | 0.7310 | ± | 0.0370 |
| - elementary_mathematics | 1 | none | 0 | acc | ↑ | 0.5767 | ± | 0.0254 |
| - high_school_biology | 1 | none | 0 | acc | ↑ | 0.8516 | ± | 0.0202 |
| - high_school_chemistry | 1 | none | 0 | acc | ↑ | 0.6601 | ± | 0.0333 |
| - high_school_computer_science | 1 | none | 0 | acc | ↑ | 0.7400 | ± | 0.0441 |
| - high_school_mathematics | 1 | none | 0 | acc | ↑ | 0.4556 | ± | 0.0304 |
| - high_school_physics | 1 | none | 0 | acc | ↑ | 0.6225 | ± | 0.0396 |
| - high_school_statistics | 1 | none | 0 | acc | ↑ | 0.6991 | ± | 0.0313 |
| - machine_learning | 1 | none | 0 | acc | ↑ | 0.5893 | ± | 0.0467 |
| Groups | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| mmlu | 2 | none | acc | ↑ | 0.7001 | ± | 0.0036 | |
| - humanities | 2 | none | acc | ↑ | 0.6193 | ± | 0.0066 | |
| - other | 2 | none | acc | ↑ | 0.7580 | ± | 0.0073 | |
| - social sciences | 2 | none | acc | ↑ | 0.8021 | ± | 0.0070 | |
| - stem | 2 | none | acc | ↑ | 0.6641 | ± | 0.0081 |
Heretic:
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| mmlu | 2 | none | acc | ↑ | 0.6960 | ± | 0.0037 | |
| - humanities | 2 | none | acc | ↑ | 0.6181 | ± | 0.0067 | |
| - formal_logic | 1 | none | 0 | acc | ↑ | 0.6032 | ± | 0.0438 |
| - high_school_european_history | 1 | none | 0 | acc | ↑ | 0.8121 | ± | 0.0305 |
| - high_school_us_history | 1 | none | 0 | acc | ↑ | 0.8775 | ± | 0.0230 |
| - high_school_world_history | 1 | none | 0 | acc | ↑ | 0.8565 | ± | 0.0228 |
| - international_law | 1 | none | 0 | acc | ↑ | 0.7934 | ± | 0.0370 |
| - jurisprudence | 1 | none | 0 | acc | ↑ | 0.7778 | ± | 0.0402 |
| - logical_fallacies | 1 | none | 0 | acc | ↑ | 0.8037 | ± | 0.0312 |
| - moral_disputes | 1 | none | 0 | acc | ↑ | 0.6965 | ± | 0.0248 |
| - moral_scenarios | 1 | none | 0 | acc | ↑ | 0.4246 | ± | 0.0165 |
| - philosophy | 1 | none | 0 | acc | ↑ | 0.7106 | ± | 0.0258 |
| - prehistory | 1 | none | 0 | acc | ↑ | 0.7870 | ± | 0.0228 |
| - professional_law | 1 | none | 0 | acc | ↑ | 0.4954 | ± | 0.0128 |
| - world_religions | 1 | none | 0 | acc | ↑ | 0.8655 | ± | 0.0262 |
| - other | 2 | none | acc | ↑ | 0.7593 | ± | 0.0073 | |
| - business_ethics | 1 | none | 0 | acc | ↑ | 0.7600 | ± | 0.0429 |
| - clinical_knowledge | 1 | none | 0 | acc | ↑ | 0.7887 | ± | 0.0251 |
| - college_medicine | 1 | none | 0 | acc | ↑ | 0.6936 | ± | 0.0351 |
| - global_facts | 1 | none | 0 | acc | ↑ | 0.4100 | ± | 0.0494 |
| - human_aging | 1 | none | 0 | acc | ↑ | 0.7444 | ± | 0.0293 |
| - management | 1 | none | 0 | acc | ↑ | 0.8252 | ± | 0.0376 |
| - marketing | 1 | none | 0 | acc | ↑ | 0.8889 | ± | 0.0206 |
| - medical_genetics | 1 | none | 0 | acc | ↑ | 0.8700 | ± | 0.0338 |
| - miscellaneous | 1 | none | 0 | acc | ↑ | 0.8633 | ± | 0.0123 |
| - nutrition | 1 | none | 0 | acc | ↑ | 0.7778 | ± | 0.0238 |
| - professional_accounting | 1 | none | 0 | acc | ↑ | 0.5426 | ± | 0.0297 |
| - professional_medicine | 1 | none | 0 | acc | ↑ | 0.7794 | ± | 0.0252 |
| - virology | 1 | none | 0 | acc | ↑ | 0.5301 | ± | 0.0389 |
| - social sciences | 2 | none | acc | ↑ | 0.7910 | ± | 0.0072 | |
| - econometrics | 1 | none | 0 | acc | ↑ | 0.5439 | ± | 0.0469 |
| - high_school_geography | 1 | none | 0 | acc | ↑ | 0.8333 | ± | 0.0266 |
| - high_school_government_and_politics | 1 | none | 0 | acc | ↑ | 0.9067 | ± | 0.0210 |
| - high_school_macroeconomics | 1 | none | 0 | acc | ↑ | 0.7846 | ± | 0.0208 |
| - high_school_microeconomics | 1 | none | 0 | acc | ↑ | 0.8824 | ± | 0.0209 |
| - high_school_psychology | 1 | none | 0 | acc | ↑ | 0.8716 | ± | 0.0143 |
| - human_sexuality | 1 | none | 0 | acc | ↑ | 0.7710 | ± | 0.0369 |
| - professional_psychology | 1 | none | 0 | acc | ↑ | 0.7075 | ± | 0.0184 |
| - public_relations | 1 | none | 0 | acc | ↑ | 0.7000 | ± | 0.0439 |
| - security_studies | 1 | none | 0 | acc | ↑ | 0.7102 | ± | 0.0290 |
| - sociology | 1 | none | 0 | acc | ↑ | 0.8607 | ± | 0.0245 |
| - us_foreign_policy | 1 | none | 0 | acc | ↑ | 0.8300 | ± | 0.0378 |
| - stem | 2 | none | acc | ↑ | 0.6572 | ± | 0.0082 | |
| - abstract_algebra | 1 | none | 0 | acc | ↑ | 0.4600 | ± | 0.0501 |
| - anatomy | 1 | none | 0 | acc | ↑ | 0.6741 | ± | 0.0405 |
| - astronomy | 1 | none | 0 | acc | ↑ | 0.8026 | ± | 0.0324 |
| - college_biology | 1 | none | 0 | acc | ↑ | 0.8472 | ± | 0.0301 |
| - college_chemistry | 1 | none | 0 | acc | ↑ | 0.5400 | ± | 0.0501 |
| - college_computer_science | 1 | none | 0 | acc | ↑ | 0.6300 | ± | 0.0485 |
| - college_mathematics | 1 | none | 0 | acc | ↑ | 0.5400 | ± | 0.0501 |
| - college_physics | 1 | none | 0 | acc | ↑ | 0.5392 | ± | 0.0496 |
| - computer_security | 1 | none | 0 | acc | ↑ | 0.7300 | ± | 0.0446 |
| - conceptual_physics | 1 | none | 0 | acc | ↑ | 0.7574 | ± | 0.0280 |
| - electrical_engineering | 1 | none | 0 | acc | ↑ | 0.7103 | ± | 0.0378 |
| - elementary_mathematics | 1 | none | 0 | acc | ↑ | 0.5926 | ± | 0.0253 |
| - high_school_biology | 1 | none | 0 | acc | ↑ | 0.8355 | ± | 0.0211 |
| - high_school_chemistry | 1 | none | 0 | acc | ↑ | 0.6453 | ± | 0.0337 |
| - high_school_computer_science | 1 | none | 0 | acc | ↑ | 0.7700 | ± | 0.0423 |
| - high_school_mathematics | 1 | none | 0 | acc | ↑ | 0.4222 | ± | 0.0301 |
| - high_school_physics | 1 | none | 0 | acc | ↑ | 0.6093 | ± | 0.0398 |
| - high_school_statistics | 1 | none | 0 | acc | ↑ | 0.6898 | ± | 0.0315 |
| - machine_learning | 1 | none | 0 | acc | ↑ | 0.5804 | ± | 0.0468 |
| Groups | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| mmlu | 2 | none | acc | ↑ | 0.6960 | ± | 0.0037 | |
| - humanities | 2 | none | acc | ↑ | 0.6181 | ± | 0.0067 | |
| - other | 2 | none | acc | ↑ | 0.7593 | ± | 0.0073 | |
| - social sciences | 2 | none | acc | ↑ | 0.7910 | ± | 0.0072 | |
| - stem | 2 | none | acc | ↑ | 0.6572 | ± | 0.0082 |
MMLU - Massive Multitask Language Understanding, ~14,000 multiple-choice questions across 57 subjects (math, history, law, medicine, etc.).
The GLM family welcomes a new generation of open-source models, the GLM-4-32B-0414 series, featuring 32 billion parameters. Its performance is comparable to OpenAI's GPT series and DeepSeek's V3/R1 series, and it supports very user-friendly local deployment features. GLM-4-32B-Base-0414 was pre-trained on 15T of high-quality data, including a large amount of reasoning-type synthetic data, laying the foundation for subsequent reinforcement learning extensions. In the post-training stage, in addition to human preference alignment for dialogue scenarios, we also enhanced the model's performance in instruction following, engineering code, and function calling using techniques such as rejection sampling and reinforcement learning, strengthening the atomic capabilities required for agent tasks. GLM-4-32B-0414 achieves good results in areas such as engineering code, Artifact generation, function calling, search-based Q&A, and report generation. Some benchmarks even rival larger models like GPT-4o and DeepSeek-V3-0324 (671B).
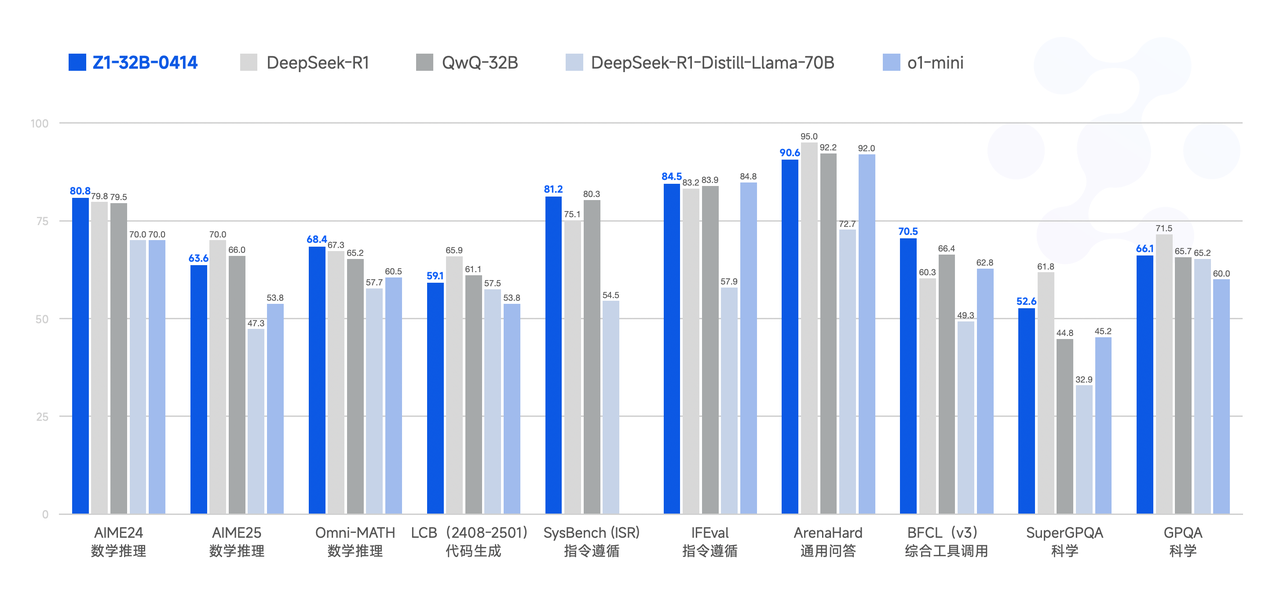
GLM-Z1-32B-0414 is a reasoning model with deep thinking capabilities. This was developed based on GLM-4-32B-0414 through cold start and extended reinforcement learning, as well as further training of the model on tasks involving mathematics, code, and logic. Compared to the base model, GLM-Z1-32B-0414 significantly improves mathematical abilities and the capability to solve complex tasks. During the training process, we also introduced general reinforcement learning based on pairwise ranking feedback, further enhancing the model's general capabilities.
GLM-Z1-Rumination-32B-0414 is a deep reasoning model with rumination capabilities (benchmarked against OpenAI's Deep Research). Unlike typical deep thinking models, the rumination model employs longer periods of deep thought to solve more open-ended and complex problems (e.g., writing a comparative analysis of AI development in two cities and their future development plans). The rumination model integrates search tools during its deep thinking process to handle complex tasks and is trained by utilizing multiple rule-based rewards to guide and extend end-to-end reinforcement learning. Z1-Rumination shows significant improvements in research-style writing and complex retrieval tasks.
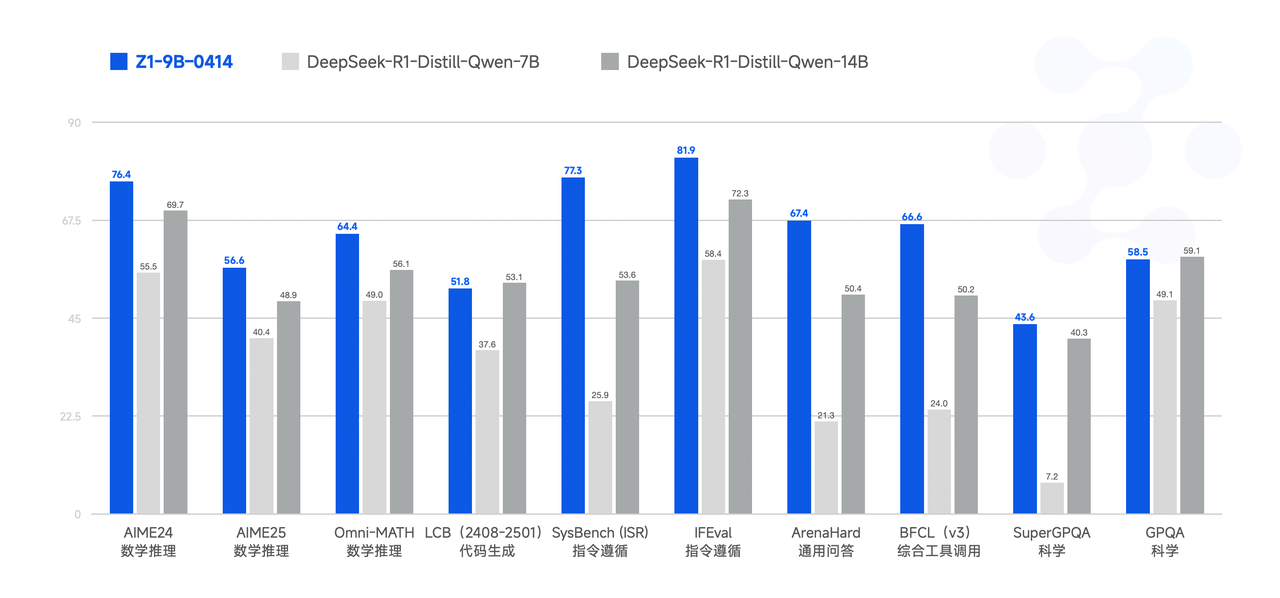
Finally, GLM-Z1-9B-0414 is a surprise. We employed the aforementioned series of techniques to train a 9B small-sized model that maintains the open-source tradition. Despite its smaller scale, GLM-Z1-9B-0414 still exhibits excellent capabilities in mathematical reasoning and general tasks. Its overall performance is already at a leading level among open-source models of the same size. Especially in resource-constrained scenarios, this model achieves an excellent balance between efficiency and effectiveness, providing a powerful option for users seeking lightweight deployment.
| Parameter | Recommended Value | Description |
|---|---|---|
| temperature | 0.6 | Balances creativity and stability |
| top_p | 0.95 | Cumulative probability threshold for sampling |
| top_k | 40 | Filters out rare tokens while maintaining diversity |
| max_new_tokens | 30000 | Leaves enough tokens for thinking |
chat_template.jinja, the prompt is automatically injected to enforce this behaviorchat_template.jinjaWhen input length exceeds 8,192 tokens, consider enabling YaRN (Rope Scaling)
In supported frameworks, add the following snippet to config.json:
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
Static YaRN applies uniformly to all text. It may slightly degrade performance on short texts, so enable as needed.
Make Sure Using transforemrs>=4.51.3.
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
If you find our work useful, please consider citing the following paper.
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}