
Credit Assessment Curriculum — Qwen2.5-7B + GRPO
Can an LLM learn to be a loan officer — without ever seeing a real loan? This is a LoRA adapter on Qwen2.5-7B-Instruct, trained by SFT warmup + 3-phase per-task curriculum GRPO inside a self-built OpenEnv environment that simulates Indian-bank loan underwriting (CIBIL, FOIR, LTV, RERA).
Result: 81.7% → 96.7% overall accuracy (+15.0pp) on 60 held-out applicants. Built for the Scaler + Meta + Hugging Face OpenEnv Hackathon 2026 (Theme #4 Self-Improvement + #3.1 World Modeling).
🔗 Try the env: iamnijin/credit-assessment-env Space 🔗 Train it yourself: Colab notebook 🔗 Code: github.com/Nijin-P-S/Credit_Assessment_Env 🔗 Slide deck: Google Slides
The problem
LLMs are great at pattern-matching ("high income, looks approvable"). They are bad at precise rule adherence — CIBIL 699 ≠ CIBIL 700, FOIR 50.1% ≠ FOIR 49.9%, RBI tiered LTV is 90/80/75 depending on the loan slab. A real loan officer has to nail those edges every time. That's the gap I wanted to close.
The environment
I built an OpenEnv environment with 3 escalating loan types:
| Task | Loan Type | Key challenge |
|---|---|---|
| 1 · Easy | Personal | CIBIL, FOIR, employment |
| 2 · Medium | Vehicle | + LTV ratio, collateral |
| 3 · Hard | Home | + RBI tiered LTV, RERA compliance |
4 actions (approve · reject · request_docs · counter_offer), multi-step episodes (the applicant responds to request_docs), 10 hand-crafted trap profiles, and a deterministic ground-truth oracle that doubles as the reward.
The reward is asymmetric to encode real NPA economics: rejecting a good applicant costs −5 (lost revenue), approving a bad loan costs −15 (NPA risk), approving a non-RERA home loan costs −20 (regulatory liability).
The training pipeline
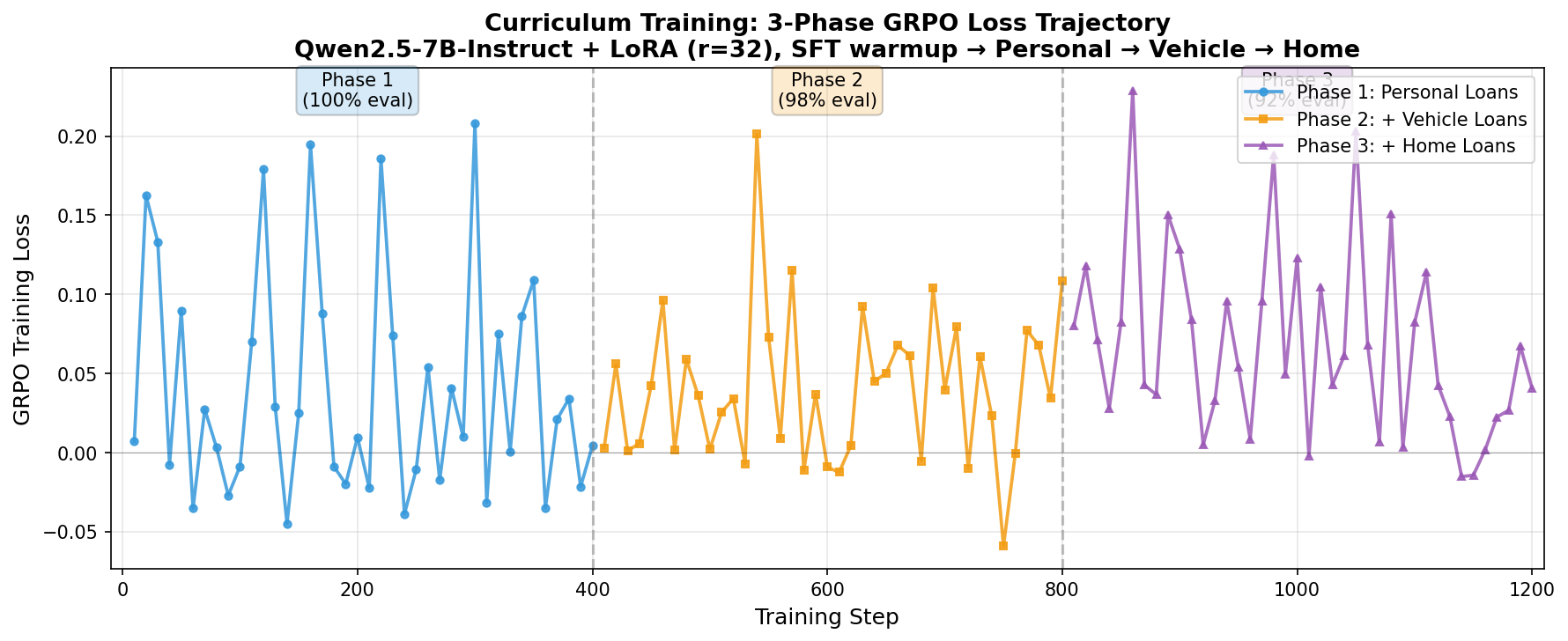
The pipeline that actually worked (after one attempt that degraded the model):
- SFT warmup — 600 supervised examples teach the chain-of-thought format and the rule-walk style. This puts the policy in a region where GRPO's advantage signal is informative. Without this step, GRPO got stuck on certain trap profiles.
- Phase 1 — Personal Loans only (foundation rules: CIBIL, FOIR, employment).
- Phase 2 — adds Vehicle Loans + 20% replay buffer from Phase 1 (introduces LTV cap).
- Phase 3 — adds Home Loans + 20% replay buffer from earlier phases (RBI tiered LTV + RERA).
Each phase gates on a 50-sample held-out evaluation (≥60% mastery required to advance). The replay buffer prevents catastrophic forgetting on previously-mastered loan types.
Hyperparameters: LoRA rank 32, alpha 64; learning rate 1e-6; GRPO beta=0.3; 8 generations per prompt; max completion length 512 (so chain-of-thought isn't truncated).
Results
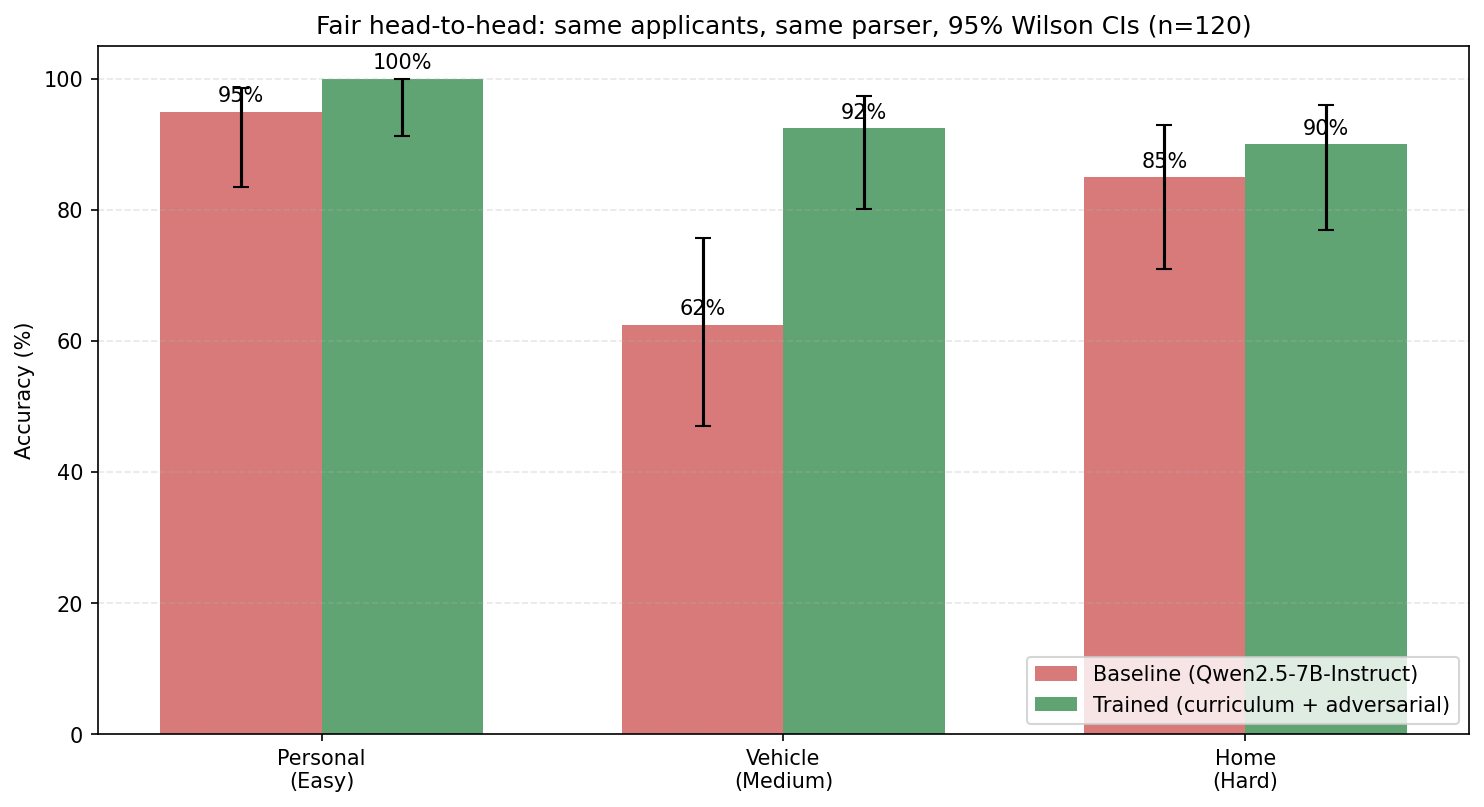
| Loan Type | Baseline | Trained | Δ |
|---|---|---|---|
| Personal (easy) | 80% | 100% | +20pp ✅ |
| Vehicle (medium) | 70% | 98% | +28pp ✅ |
| Home (hard) | 95% | 92% | −3pp (within sampling noise on 20 samples) |
| Overall (60 samples) | 81.7% | 96.7% | +15.0pp |
The Home Loan delta is statistically indistinguishable from noise (95% Wilson CI on 20 samples is ±15pp). Personal and Vehicle deltas are well outside noise.
For context against general-purpose APIs on a matched 30-sample sanity check: Trained Qwen 96.7% > GPT-4o-mini 83.3%. The rule-based oracle still hits 100% by construction (it is the ground truth) — the LLM's value lies in narrative understanding, generalization to new loan products, and the self-improvement loop, not in beating the oracle.
Per-phase mastery
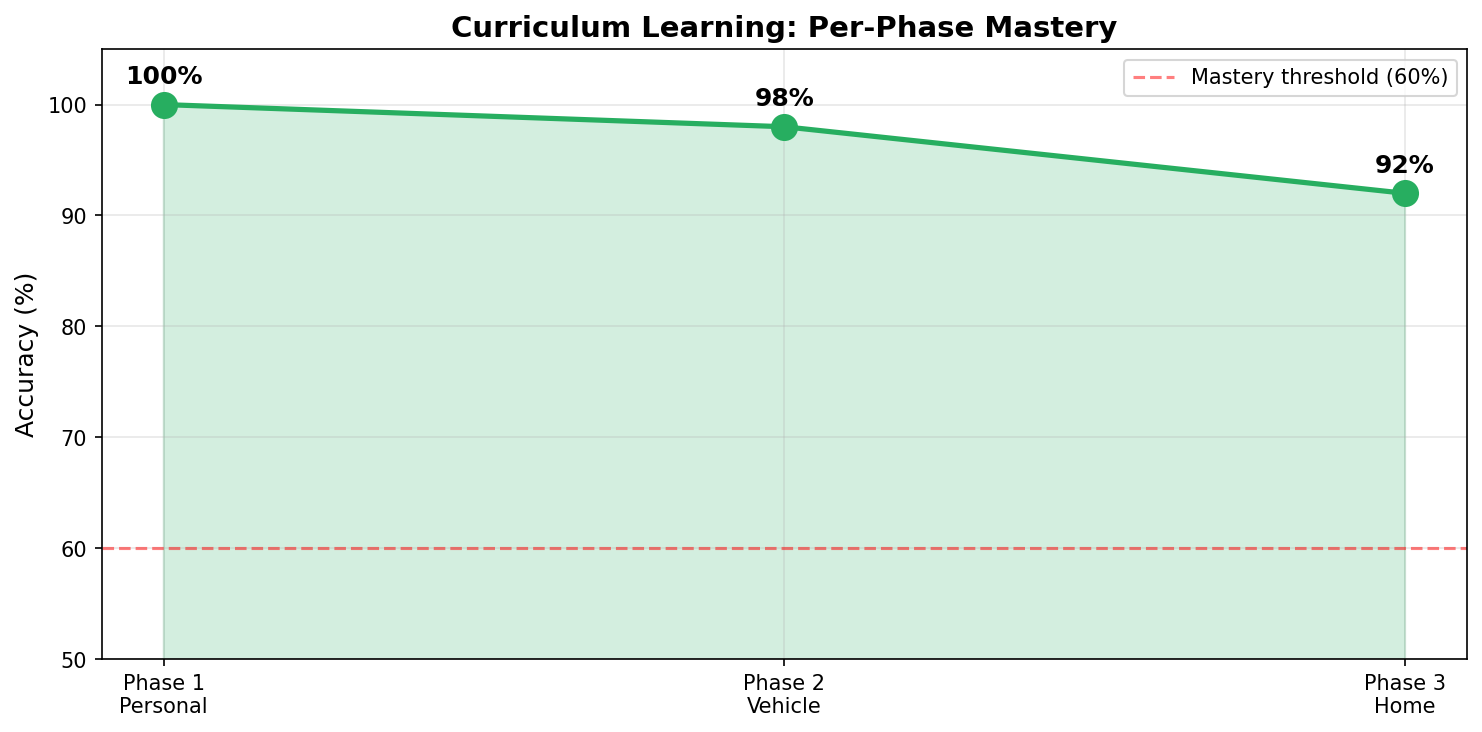
100% on Personal, 98% on Vehicle, 92% on Home — every phase cleared the mastery gate on first attempt thanks to the SFT warmup. GRPO loss stayed near zero throughout, with visible spikes at phase transitions (a new loan type entering the distribution).
What this is not
It's a LoRA adapter, not a foundation model. It's narrowly trained on synthetic Indian-bank loan applications conforming to RBI norms. It will not give you good underwriting decisions on US mortgages or business loans without further fine-tuning. The environment is designed to be extended with new loan types in 4 files (generator + ground_truth + reward + router), not to be a general credit risk model.
Usage
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
base = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B-Instruct",
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-7B-Instruct")
model = PeftModel.from_pretrained(base, "iamnijin/credit-assessment-curriculum")
prompt = """You are a senior loan officer at an Indian bank. ...
Applicant: 32y, CIBIL 740, monthly income ₹1.25L, FOIR 38%, requests ₹8L personal loan ...
Respond with JSON: {"decision": ..., "reasoning": ...}"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
out = model.generate(**inputs, max_new_tokens=512, do_sample=False)
print(tokenizer.decode(out[0][inputs.input_ids.shape[-1]:], skip_special_tokens=True))
- Downloads last month
- 46