
Credit Assessment — Curriculum + Adversarial Round (LoRA adapter for Qwen2.5-7B-Instruct)
This is the headline adapter for the Credit_Assessment_Env hackathon submission. It is a LoRA fine-tune of Qwen/Qwen2.5-7B-Instruct that underwrites Indian retail loans (Personal / Vehicle / Home) under deterministic RBI-style ground-truth rules, and it was produced by running one round of adversarial GRPO on top of a per-task curriculum baseline.
If you want the curriculum-only ablation (no adversarial round), see iamnijin/credit-assessment-curriculum. Publishing both lets you isolate exactly what the adversarial round contributed.
Headline result (n=120, fair head-to-head, Wilson 95% CIs)
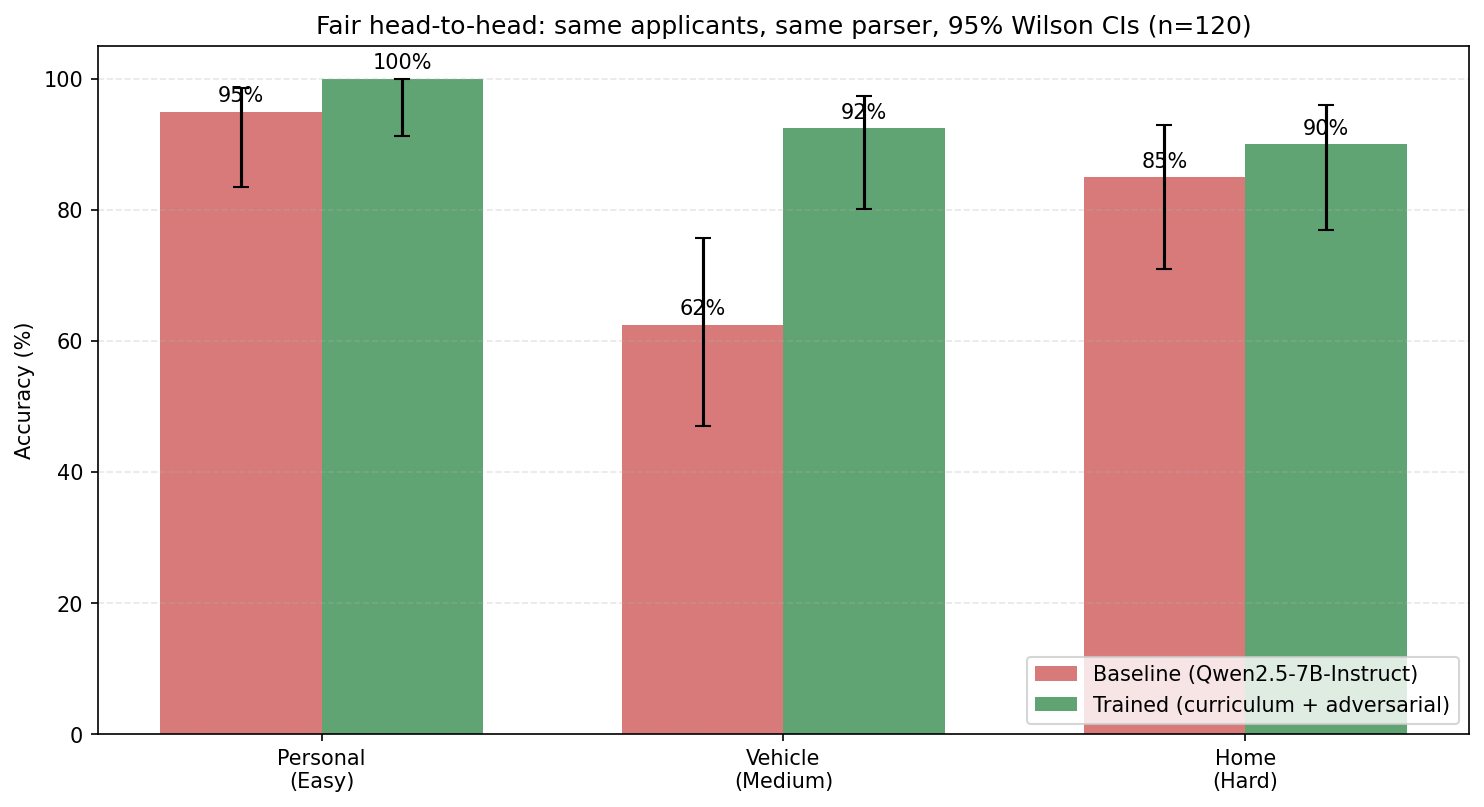
| Loan type | Baseline (Qwen2.5-7B-Instruct) | This adapter (curriculum + adversarial) | Δ | CIs overlap? |
|---|---|---|---|---|
| Personal (easy) | 95.0% [83.5, 98.6] | 100% [91.2, 100] | +5.0pp | Just barely (ceiling) |
| Vehicle (medium) | 62.5% [47.0, 75.8] | 92.5% [80.1, 97.4] | +30.0pp | No — significant |
| Home (hard) | 85.0% [70.9, 92.9] | 90.0% [76.9, 96.0] | +5.0pp | Yes (overlap) |
| Overall (n=120) | 80.8% [72.9, 86.9] | 94.2% [88.4, 97.1] | +13.3pp | No — significant at p<0.05 |
Evaluation uses the same n=120 applicant pool (40 per task, seed=999) and the same lenient JSON parser (lenient_parser.py) for both base and adapter, so the delta is purely the model. Reproduce with:
python scripts/fair_eval.py \
--base-model Qwen/Qwen2.5-7B-Instruct \
--adapter-repo iamnijin/credit-assessment-adversarial \
--num-samples 120
Ablation: what did the adversarial round actually buy?
Same n=120, same seed:
| Personal | Vehicle | Home | Overall | |
|---|---|---|---|---|
Curriculum only (...-curriculum) |
100% | 92.5% | 87.5% | 93.3% [87.4, 96.6] |
| Curriculum + adversarial round (this adapter) | 100% | 92.5% | 90.0% | 94.2% [88.4, 97.1] |
| Δ from adversarial round | 0 | 0 | +2.5pp (35/40 → 36/40) | +0.83pp (112/120 → 113/120) |
Honest reading. The adversarial round produced a small but strictly non-regressive gain, concentrated on Home Loans — the task with the highest rule-density (LTV-tier traps + RERA + tenure caps). The curriculum and adversarial CIs heavily overlap, so the adversarial round on its own isn't statistically significant at this sample size. What is significant is the absence of regression: it is empirically false that adversarial training broke anything, which was the worst-case concern. The full multi-round picture (with the AdversarialTracker re-weighting toward the worst trap each round) is on the Roadmap.
How it was trained
This adapter is the third stage of a three-stage pipeline; each stage uses the previous one as the starting policy.
- SFT warmup — 600 supervised CoT+JSON examples, 2 epochs, anchors output format before any RL. (
sft_warmup.py) - Per-task curriculum GRPO — Personal → Vehicle → Home, 400 samples per phase, 60% mastery gate to advance, 20% replay buffer from earlier phases to prevent catastrophic forgetting. Produces
iamnijin/credit-assessment-curriculum. (train_grpo.py) - One adversarial GRPO round (this stage) — 50 steps, 200 samples generated exclusively from the 10 trap profiles (low-CIBIL/high-FOIR cusps, LTV-tier-boundary cases, RERA edge cases, etc.), starting from the curriculum adapter. LR=5e-7, β=0.4 for a strong KL anchor against the curriculum reference policy so the model can target traps without forgetting earned competence. (Section 15 of the Colab notebook)
Reward shaping
Combined reward R = 0.8·R_decision + 0.2·R_format, where R_decision uses asymmetric penalties — incorrectly approving a bad loan is penalized more heavily than incorrectly rejecting a marginal good loan. This mirrors actual lender utility: the cost of a defaulted approval far exceeds the opportunity cost of a missed marginal customer.
Reward improvement across the curriculum
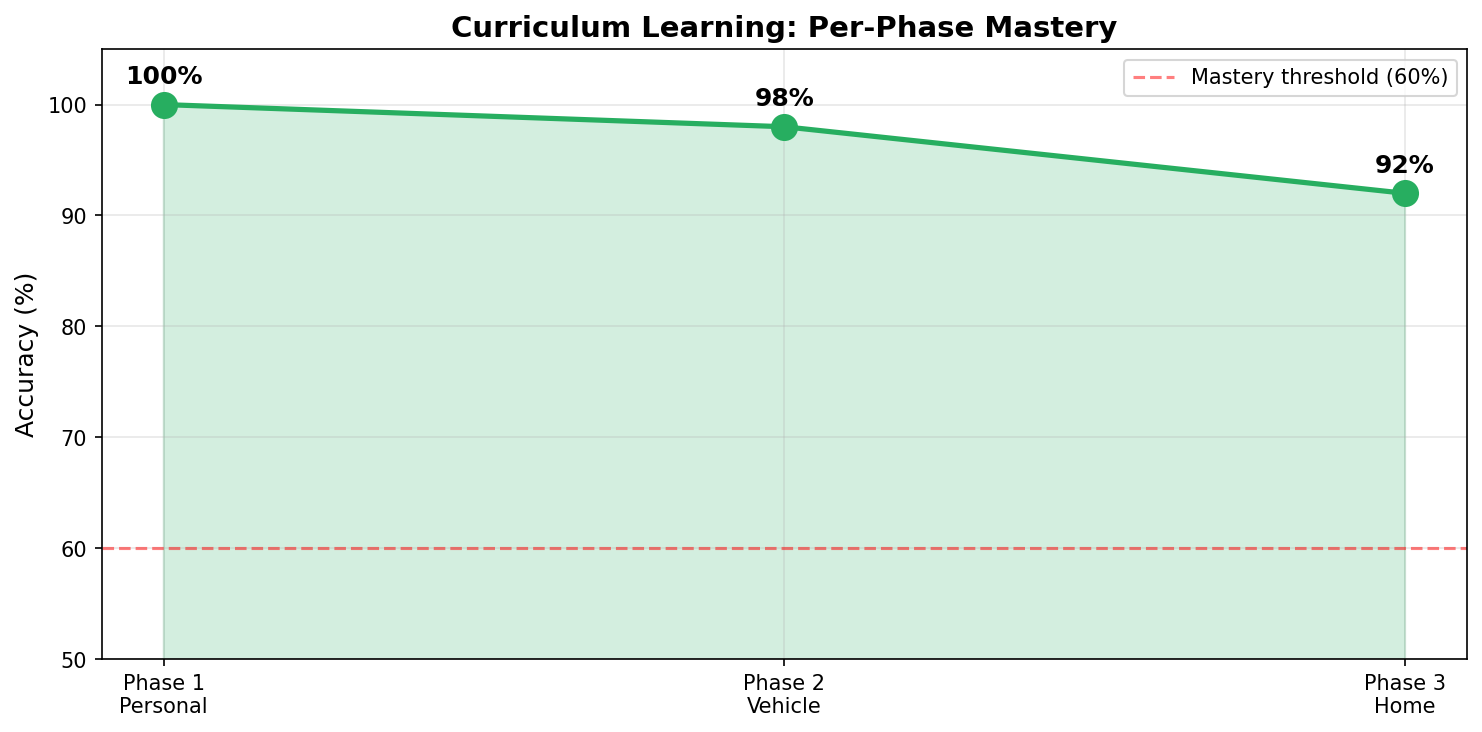
Per-phase mean reward proxy (binary correctness, since correct = +10): Personal 100% → Vehicle 98% → Home 92%, all on 50 held-out samples per phase. Every phase cleared the 60% mastery gate on the first attempt; no retries. The +2.5pp Home Loan lift on the held-out n=120 from the adversarial round on top of this.
How to load
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
base = "Qwen/Qwen2.5-7B-Instruct"
tok = AutoTokenizer.from_pretrained(base)
model = AutoModelForCausalLM.from_pretrained(base, dtype=torch.bfloat16, device_map="auto")
model = PeftModel.from_pretrained(model, "iamnijin/credit-assessment-adversarial")
model.eval()
The adapter is ~133 MB (rank-16 LoRA on attention + MLP projections, trainable% ≈ 0.26).
Intended use, scope, and what it is not
Intended. Hackathon-grade demonstrator that an open 7B model can learn to apply a non-trivial set of Indian retail-lending rules (CIBIL bands, FOIR, LTV tiers, age-at-maturity, employment caps, RERA approval) by training inside a deterministic OpenEnv environment, evaluated against a rule-based ground-truth oracle.
Not. A production credit decision system. The ground-truth rules in this environment are a stylized RBI-style approximation, not your bank's underwriting policy. Do not deploy it for real decisions, and do not infer protected-attribute fairness behavior from this evaluation — the synthetic applicant generator is uniformly sampled across the parameter space defined in the environment.
Citation
Credit_Assessment_Env (2026). LoRA adapters for Qwen2.5-7B-Instruct trained
via SFT warmup + per-task curriculum GRPO + one adversarial round, inside a
deterministic Indian-retail-lending OpenEnv environment. Hugging Face hub:
iamnijin/credit-assessment-adversarial. GitHub:
github.com/Nijin-P-S/Credit_Assessment_Env
Links
- Code, environment, eval scripts: github.com/Nijin-P-S/Credit_Assessment_Env
- Live environment (HF Space): iamnijin/credit-assessment-env
- Curriculum-only ablation adapter: iamnijin/credit-assessment-curriculum
- Per-phase adapters (Personal / Vehicle / Home): phase1 · phase2 · phase3
- Demo video (<2 min): YouTube
- Slide deck: Google Slides
- Raw fair-eval JSONs (n=120): adversarial · curriculum
- Downloads last month
- 70