
Detector-Empowered Video Large Language Model for Efficient Spatio-Temporal Grounding
Paper • 2512.06673 • Published
# Load model directly
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("gaostar/DeViL-7B", trust_remote_code=True, dtype="auto")Official checkpoint for "Detector-Empowered Video Large Language Model for Efficient Spatio-Temporal Grounding"
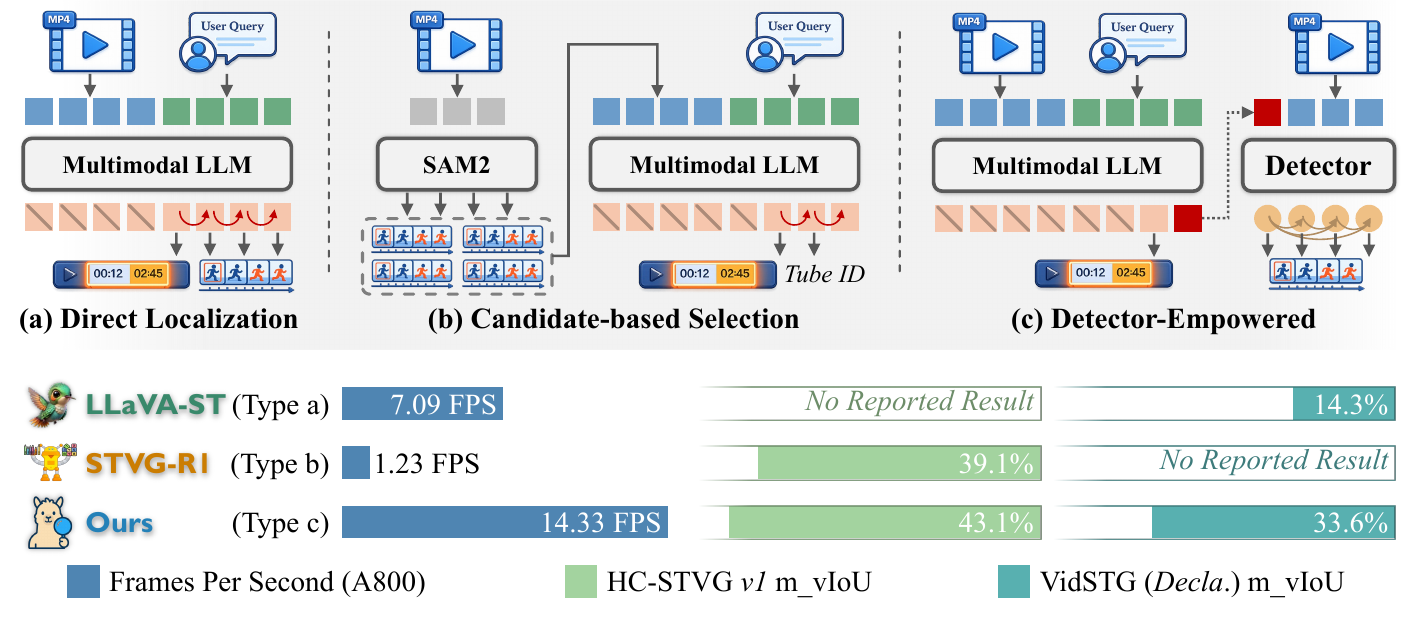
DeViL is a detector-empowered video large language model designed for efficient spatio-temporal video grounding (STVG) and grounded video reasoning. Instead of relying on long autoregressive coordinate decoding or expensive candidate construction, DeViL offloads dense spatial grounding to a fully parallel detector. It distills the user query into a detector-compatible reference-semantic token and uses temporal consistency regularization to maintain object coherence across frames.
This repository hosts the official DeViL-7B checkpoint released by the authors.
Base model
Qwen/Qwen2.5-7B
# Use a pipeline as a high-level helper from transformers import pipeline pipe = pipeline("text-generation", model="gaostar/DeViL-7B", trust_remote_code=True) messages = [ {"role": "user", "content": "Who are you?"}, ] pipe(messages)