
script stringlengths 113 767k |
|---|
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# # 1. Load Data & Check Information
df_net = pd.read_csv("../input/netflix-shows/netflix_tit... |
import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
from keras import models
from keras.utils import to_categorical, np_utils
from tensorflow import convert_to_tensor
from tensorflow.image import grayscale_to_rgb
from tensorflow.data import Dataset
from tensorflow.keras.layers import Flatte... |
# #### EEMT 5400 IT for E-Commerce Applications
# ##### HW4 Max score: (1+1+1)+(1+1+2+2)+(1+2)+2
# You will use two different datasets in this homework and you can find their csv files in the below hyperlinks.
# 1. Car Seat:
# https://raw.githubusercontent.com/selva86/datasets/master/Carseats.csv
# 2. Bank Personal Loa... |
# 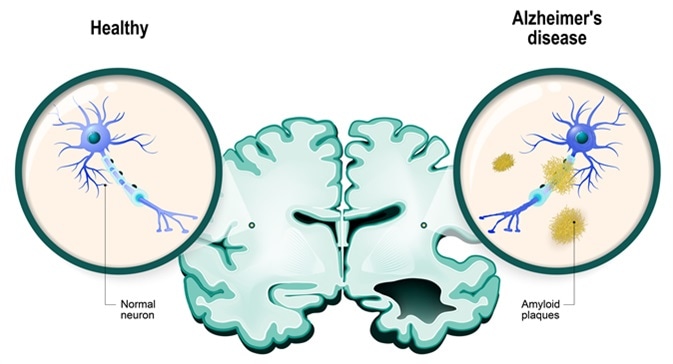
# **Alzheimer's disease** is the most common type of dementia. It is a progressive disease beginning with mild memory loss and possibly leading to loss of the ability to carry on a conversation and respond to the environment. Al... |
# # Tracking COVID-19 from New York City wastewater
# **TABLE OF CONTENTS**
# * [1. Introduction](#chapter_1)
# * [2. Data exploration](#chapter_2)
# * [3. Analysis](#chapter_3)
# * [4. Baseline model](#chapter_4)
# ## 1. Introduction
# The **New York City OpenData Project** (*link:* __[project home page](https://opend... |
# ## Project 4
# We're going to start with the dataset from Project 1.
# This time the goal is to compare data wrangling runtime by either using **Pandas** or **Polar**.
data_dir = "/kaggle/input/project-4-dataset/data-p1"
sampled = False
path_suffix = "" if not sampled else "_sampled"
from time import time
import pand... |
# This notebook reveals my solution for __RFM Analysis Task__ offered by Renat Alimbekov.
# This task is part of the __Task Series__ for Data Analysts/Scientists
# __Task Series__ - is a rubric where Alimbekov challenges his followers to solve tasks and share their solutions.
# So here I am :)
# Original solution can b... |
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
# from ... |
# Note: This notebook was referece for my self-training from https://www.kaggle.com/mathchi/ab-test-for-real-data/ by [Mehmet A.](https://www.kaggle.com/mathchi)
# Since the original dataset is private, I faked one for running it through. Some row of the data was copied data from originally showed. Others was kind of r... |
# The main goal of this notebook is provide step by step data analysis, data preprocessing and implement various machine learning tasks. The goal is not just to build a model which gives better results but also to learn various analysis and modeling techniques in the process of building the best model.
# import the req... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all ... |
a = 2
print(a)
type(a)
b = 3.4
print(b)
type(b)
c = "abc"
print(c)
type(c)
# **Variable with number**
# **interger , floating , complex numbar**
d = 3 + 4j
print(d)
type(d)
# **Working with numerical variable**
Gross_profit = 30
Revenue = 100
Gross_profit_margin = (Gross_profit / Revenue) * 100
print(Gross_profit_mar... |
# # Setup
import os
import gc
import time
import warnings
gc.enable()
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
pd.set_option("display.max_columns", None)
pd.set_option("display.precision", 4)
import matplotlib.pyplot as plt
import seaborn as sns
SEED = 23
os.environ["PYTHONHASHSEED"] ... |
# # Electricity DayAhead Prices 2022
# This dataset provides hourly day ahead electricity prices for France and interconnections, sourced from the ENTSO-E Transparency Platform, which is a reputable market data provider for European electricity markets. It is valuable resource for businesses, investors, researchers, an... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Log... |
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
train_csv = pd.read_csv("/kaggle/input/playground-series-s3e12/train.csv")
test_csv = pd.read_csv("/kaggle/input/playground-series-s3e12/test.csv")
train_csv.head()
train_csv.shape
train_csv.describe()
import seaborn as sns
f... |
import pandas as pd
import re
import numpy as np
sla = pd.read_excel(
r"../input/shopee-code-league-20/_DA_Logistics/SLA_matrix.xlsx", engine="openpyxl"
)
orders = pd.read_csv(
r"../input/shopee-code-league-20/_DA_Logistics/delivery_orders_march.csv"
)
sla
# 看起來很奇怪,不過從表中,大概可以猜出是一個對照表,而且index是出發地(from),column是目... |
# # Introduction
# Recommender systems are a big part of our lives, recommending products and movies that we want to buy or watch. Recommender systems have been around for decades but have recently come into the spotlight.
# In this notebook, We will discuss three types of recommender system: **(1)Association rule lear... |
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname... |
End of preview. Expand in Data Studio
README.md exists but content is empty.
- Downloads last month
- 11