
datasetId large_stringlengths 6 123 | author large_stringlengths 2 42 | last_modified large_stringdate 2021-02-22 10:20:34 2026-04-22 02:08:28 | downloads int64 0 2.75M | likes int64 0 9.68k | tags large listlengths 1 6.16k | task_categories large listlengths 0 0 | createdAt large_stringdate 2022-03-02 23:29:22 2026-04-22 02:07:43 | trending_score float64 0 200 | card large_stringlengths 31 29.7M |
|---|---|---|---|---|---|---|---|---|---|
ClarusC64/fusion-pfc-failure-horizon-and-maintenance-routing-v0.1 | ClarusC64 | 2026-02-11T11:54:54Z | 12 | 0 | [
"task_categories:tabular-regression",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"region:us",
"clarusc64",
"fusion",
"predictive-maintenance",
"plasma-facing-components",
"tungsten",
"beryllium"
] | [] | 2026-02-11T11:53:24Z | 0 | ---
language:
- en
license: mit
pretty_name: Fusion PFC Failure Horizon and Maintenance Routing v0.1
dataset_name: fusion-pfc-failure-horizon-and-maintenance-routing-v0.1
tags:
- clarusc64
- fusion
- predictive-maintenance
- plasma-facing-components
- tungsten
- beryllium
task_categories:
- tabular-regr... |
NLP-FBK/synthetic-crf-train | NLP-FBK | 2025-12-12T14:54:08Z | 10 | 0 | [
"size_categories:n<1K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-12-02T11:49:04Z | 0 |
---
dataset_info:
features:
- name: document_id
dtype: string
- name: clinical_note
dtype: string
- name: crf_type
dtype: int64
- name: annotations
list:
- name: item
dtype: string
- name: ground_truth
dtype: string
splits:
- name: it
num_bytes: 412610
num_exam... |
picard47at/punctuation_restoration_1200 | picard47at | 2025-06-04T05:40:00Z | 2 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-04T05:39:53Z | 0 | # punctuation_restoration
## Dataset Summary
This dataset is designed for **instruction fine-tuning** of large language models (LLMs), especially for the **Qwen3** family, to perform **punctuation restoration** on Mandarin Chinese text.
It is derived from the [`AWeirdDev/zh-tw-articles-6k`](https://h... |
antoniomari/libero_90 | antoniomari | 2026-03-06T16:04:52Z | 1,608 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:timeseries",
"library:datasets",
"library:dask",
"library:polars",
"library:mlcroissant",
"region:us",
"LeRobot",
"libero",
"panda",
"rlds"
] | [] | 2026-03-06T15:50:15Z | 0 | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- libero
- panda
- rlds
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper... |
rzhang139/so100_test | rzhang139 | 2025-03-01T02:11:48Z | 16 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so100",
"tutorial"
] | [] | 2025-03-01T02:11:38Z | 0 | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so100
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [... |
qownscks/bae_add1 | qownscks | 2026-02-06T06:47:52Z | 7 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"region:us",
"LeRobot"
] | [] | 2026-02-06T06:47:49Z | 0 | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Ne... |
buschbd7/chapter_36B_general_statutes | buschbd7 | 2026-02-07T18:29:56Z | 9 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-02-07T18:29:55Z | 0 | ---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
- name: embedding
list: float64
- name: metadata
struct:
- name: article_title
dtype: string
- name: section_title
dtype: string
- name: subchapter_title
dtype: string
- name: type... |
II-Vietnam/inspect_simpleqa_qwen3_4b | II-Vietnam | 2025-06-30T17:19:48Z | 140 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-30T17:19:45Z | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: extracted_answer
dtype: string
- name: pred
dtype: string
- name: answer
dtype: string
- name: is_correct
dtype: bool
splits:
- name: train
num_bytes: 2351371
num_examples: 4326
download_size: 1421107
datase... |
dgambettavuw/D_gen8_run0_llama2-7b_sciabs_doc1000_real96_synt32_vuw | dgambettavuw | 2024-12-24T12:58:39Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-12-24T12:58:35Z | 0 | ---
dataset_info:
features:
- name: id
dtype: int64
- name: doc
dtype: string
splits:
- name: train
num_bytes: 765014
num_examples: 1000
download_size: 407117
dataset_size: 765014
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
sengi/put_the_doll_into_the_box_4_adv | sengi | 2026-01-21T02:53:50Z | 15 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us",
"LeRobot"
] | [] | 2026-01-21T02:53:46Z | 0 | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Ne... |
andrewsiah/PersonaPromptPersonalLLM_880 | andrewsiah | 2024-11-15T11:54:34Z | 6 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-11-15T11:54:31Z | 0 | ---
dataset_info:
features:
- name: personaid_880_response_1_llama3_sfairx
dtype: float64
- name: personaid_880_response_2_llama3_sfairx
dtype: float64
- name: personaid_880_response_3_llama3_sfairx
dtype: float64
- name: personaid_880_response_4_llama3_sfairx
dtype: float64
- name: personai... |
argilla-internal-testing/test_import_dataset_from_hub_with_classlabel_a577ed17-8b65-47b2-9e5b-e044f9a2afc5 | argilla-internal-testing | 2024-10-07T08:47:42Z | 2 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-10-07T08:47:41Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': positive
'1': negative
splits:
- name: train
num_bytes: 111
num_examples: 3
download_size: 1454
dataset_size: 111
configs:
- config_name: default
data_fi... |
DatPySci/Qwen2.5-Math-7B-deepscaler | DatPySci | 2025-09-16T14:21:55Z | 11 | 1 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-09-16T14:20:54Z | 0 | ---
dataset_info:
features:
- name: index
dtype: int64
- name: prompt
list:
- name: content
dtype: string
- name: role
dtype: string
- name: response
dtype: string
- name: extra_info
struct:
- name: index
dtype: int64
- name: split
dtype: string
- name... |
chuotchuilacduong/deepstock-stock-historical-prices-dataset-processed | chuotchuilacduong | 2025-08-31T12:47:42Z | 5 | 1 | [
"size_categories:10M<n<100M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-08-31T12:46:55Z | 0 | ---
dataset_info:
features:
- name: stock
dtype: string
- name: date
dtype: string
- name: open
dtype: float64
- name: close
dtype: float64
splits:
- name: train
num_bytes: 529623473
num_examples: 14158224
download_size: 278994369
dataset_size: 529623473
configs:
- config_name:... |
jinghan23/test1 | jinghan23 | 2025-02-26T21:19:44Z | 57 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-26T20:56:00Z | 0 | # LVBench Dataset
This is a video question-answering dataset with subsets: cartoon, documentary, live, selfmedia, sport, and tv.
|
ayselzeren42/munir2 | ayselzeren42 | 2025-01-17T17:17:58Z | 4 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-01-17T17:16:41Z | 0 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 2397
num_examples: 1
- name: test
num_bytes: 2308
num_examples: 1
download_size: 34360
dataset_size: 4705
configs:
- con... |
Dongkkka/Box_Packing_0325_merged_lerobot | Dongkkka | 2026-03-25T05:47:40Z | 0 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-03-25T05:46:40Z | 0 | # dataset-robotis-box-packing-0325-merged-lerobot
|
chengfu0118/Unroll-Qwen2.5-7B-Instruct_1754614407_eval_6419_livecodebench_skip_attn_idx_21 | chengfu0118 | 2025-08-08T01:45:40Z | 6 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-08-08T00:56:33Z | 0 | # chengfu0118/Unroll-Qwen2.5-7B-Instruct_1754614407_eval_6419_livecodebench_skip_attn_idx_21
Precomputed model outputs for evaluation.
## Evaluation Results
### LiveCodeBench
- **Average Accuracy**: 26.94% ± 0.55%
- **Number of Runs**: 6
| Run | Accuracy | Questions Solved | Total Questions |
|-----|----------|---... |
hmzkhnswt/guanaco-llama2-200 | hmzkhnswt | 2024-01-31T09:50:57Z | 4 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-01-31T09:50:55Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 338808
num_examples: 200
download_size: 201258
dataset_size: 338808
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Dataset Card for "guanaco-llama2-200"
[More Inf... |
Sswa12/thesis-reconstructed-trajectories | Sswa12 | 2026-04-16T00:47:45Z | 27 | 0 | [
"task_categories:robotics",
"license:mit",
"region:us"
] | [] | 2026-04-15T20:42:39Z | 0 | ---
license: mit
task_categories:
- robotics
---
# Reconstructed GNM Trajectories
GNM-format trajectories reconstructed from RECON, SCAND, GoStanford2, and other navigation datasets.
Used as training data for the CAST safety pipeline and Neural CBF.
## Structure
```
{dataset_name}/{trajectory_name}/
├── 0.jpg, 1.jp... |
motionlabs/realworld-search-queries-24k | motionlabs | 2025-10-02T05:29:14Z | 8 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-10-02T05:29:11Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 11918889
num_examples: 24069
download_size: 5773004
dataset_size: 11918889
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
eduhk-compling/11500512_KaurSukhvir | eduhk-compling | 2026-02-05T15:44:06Z | 53 | 0 | [
"language:en",
"language:pa",
"license:cc-by-4.0",
"size_categories:n<1K",
"format:audiofolder",
"modality:audio",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us",
"audio",
"speech"
] | [] | 2026-02-05T09:47:57Z | 0 | ---
license: cc-by-4.0
language:
- en
- pa
tags:
- audio
- speech
---
### Dataset Description
I have created a dataset containing 50 short Punjabi sentences, totaling about 3.5 minutes of speech. I recorded all the sentences myself in a quiet room using a consistent microphone setup to ensure clear and natural audio... |
MilaWang/aime-validation-2223 | MilaWang | 2026-01-12T06:44:12Z | 4 | 0 | [
"size_categories:n<1K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-01-12T06:39:56Z | 0 | ---
dataset_info:
features:
- name: id
dtype: string
- name: problem
dtype: string
- name: solution
dtype: string
- name: answer
list: string
- name: url
dtype: string
- name: golden_answers
list: string
splits:
- name: test
num_bytes: 382366
num_examples: 60
download... |
snorfyang/captioned-seedbench2 | snorfyang | 2024-08-09T05:39:19Z | 21 | 1 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2311.17092",
"region:us"
] | [] | 2024-08-09T05:29:48Z | 0 | ---
dataset_info:
features:
- name: answer
dtype: string
- name: choice_a
dtype: string
- name: choice_b
dtype: string
- name: choice_c
dtype: string
- name: choice_d
dtype: string
- name: data_id
sequence: string
- name: data_type
dtype: string
- name: data_source
dtyp... |
electricsheepafrica/africa-world-bank-infrastructure-indicators-for-benin | electricsheepafrica | 2026-04-14T21:33:17Z | 0 | 0 | [
"task_categories:tabular-classification",
"annotations_creators:no-annotation",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"region:us",
"africa",
"humanitarian",
"hdx",
"electric-sheep-... | [] | 2026-04-14T21:32:19Z | 0 | ---
annotations_creators:
- no-annotation
language_creators:
- found
language:
- en
license: cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 1K<n<10K
source_datasets:
- original
task_categories:
- tabular-classification
task_ids: []
tags:
- africa
- humanitarian
- hdx
- electric-sheep-africa
- facilities-in... |
Pullo-Africa-Protagonist/pulal | Pullo-Africa-Protagonist | 2025-01-02T12:47:37Z | 2 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-01-02T12:35:26Z | 0 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: transcription
dtype: string
- name: speaker_name
dtype: string
- name: duration
dtype: float32
splits:
- name: train
num_bytes: 2372083716.408
num_examples: 7967
download_size: 2307... |
kothasuhas/residual-teacher-iter-2-lr0.003-bs4096-epochs1.0-ctx16-6400000 | kothasuhas | 2025-05-29T09:37:29Z | 4 | 0 | [
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-29T09:36:58Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: input_ids
sequence: int32
splits:
- name: train
num_bytes: 844472283
num_examples: 6400000
download_size: 602204884
dataset_size: 844472283
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
-... |
shambhuDATA/Pixmo_dataset_223994 | shambhuDATA | 2025-01-18T10:09:21Z | 2 | 0 | [
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-01-01T09:21:15Z | 0 | ---
dataset_info:
features:
- name: url
dtype: string
- name: expected_hash
dtype: string
- name: row_index
dtype: int64
- name: points
list:
- name: x
dtype: float64
- name: 'y'
dtype: float64
- name: label
dtype: string
- name: counts
dtype: 'null'
splits:
... |
ThiHien3/robot-vision-sample-dataset | ThiHien3 | 2026-02-02T16:51:11Z | 8 | 0 | [
"task_categories:image-classification",
"license:apache-2.0",
"size_categories:n<1K",
"format:text",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2026-02-02T16:48:21Z | 0 | ---
license: apache-2.0
task_categories:
- image-classification
---
# Robot Vision Sample Dataset
This dataset is created for experimental robotics vision and perception training purposes.
|
yuan1618/others | yuan1618 | 2026-03-24T02:33:29Z | 2,633 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-01-23T02:56:15Z | 0 | ---
dataset_info:
- config_name: cirr
features:
- name: qry
dtype: string
- name: qry_image_path
dtype: string
- name: pos_text
dtype: string
- name: pos_image_path
sequence: string
- name: env_prob
sequence: float64
splits:
- name: original
num_bytes: 7874112
num_examples: 2... |
abdouaziz/wolof_synthetic_data_augmented | abdouaziz | 2026-04-03T12:00:55Z | 0 | 0 | [
"region:us"
] | [] | 2026-04-03T11:44:30Z | 0 | ---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: transcription
dtype: string
splits:
- name: train
num_bytes: 16546964515.31
num_examples: 113514
- name: validation
num_bytes: 2058011397.289
num_examples: 14189
- name: test
num_... |
Peter341/Multi-View-UAV-Dataset | Peter341 | 2025-05-20T15:46:08Z | 23 | 3 | [
"license:mit",
"arxiv:2504.18317",
"region:us"
] | [] | 2025-05-18T04:01:21Z | 0 | ---
license: mit
---
# Multi-View UAV Dataset
A comprehensive multi-view UAV dataset for visual navigation research in GPS-denied urban environments, collected using the CARLA simulator.
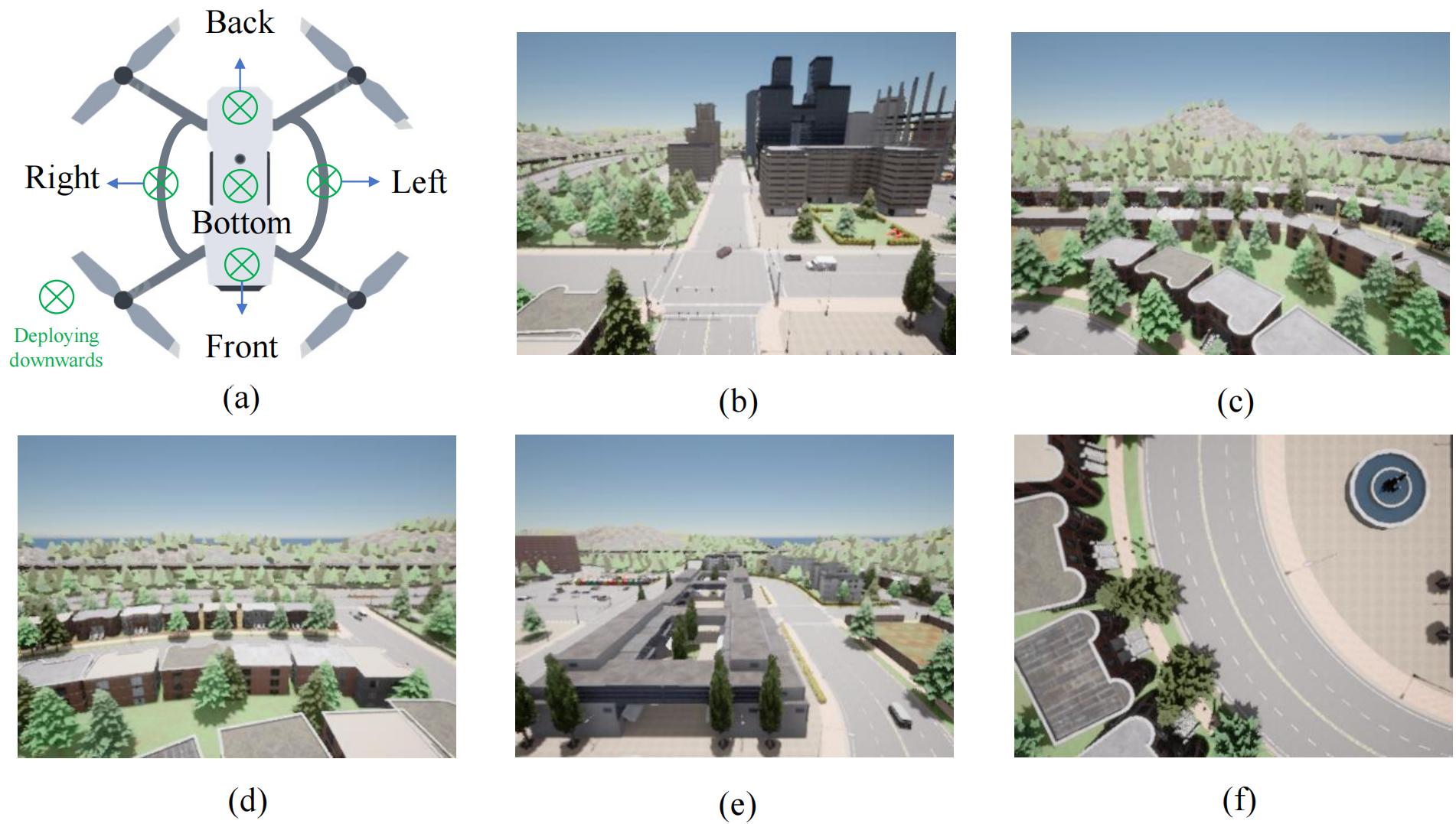
[![Li... |
ai2-adapt-dev/tulu-3-sft-92k-criteria-gpt4o-classified-rewritten-math-shortqa-ifeval | ai2-adapt-dev | 2025-05-01T17:34:37Z | 13 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-01T17:34:30Z | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: dataset
dtype: string
- name: ground_truth
sequence: string
- name: openai_response
dtype: string
- name: task
dtype:... |
french-open-data/marche-de-service-livraison-en-liaison-froide-de-repas-a-domicile-de-personnes-dependantes-avec | french-open-data | 2025-11-21T19:03:55Z | 6 | 0 | [
"language:fra",
"region:us",
"decp",
"marche-de-services",
"marches-publics",
"dataset_for_agent"
] | [] | 2025-11-21T19:03:54Z | 0 | ---
language:
- fra
tags:
- decp
- marche-de-services
- marches-publics
- dataset_for_agent
---
# Marché de Service : Livraison en liaison froide de repas à domicile de personnes dépendantes avec veille sociale
> [!NOTE]
> Ce jeu de données Hugging Face est vide. Cette carte sert seulement à référencer le jeu de donn... |
ma-zn/new_rt-rel-amazon__item-ltv | ma-zn | 2025-09-20T22:49:00Z | 5 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-09-20T22:47:08Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: textWPrompt
dtype: string
- name: label
dtype: float32
splits:
- name: train
num_bytes: 3391428464
num_examples: 10240
- name: test
num_bytes: 3391428464
num_examples: 10240
download_size: 3787645694
dataset_siz... |
VisualSphinx/VisualSphinx-V1-Raw-Panels | VisualSphinx | 2025-10-30T19:36:15Z | 69 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-10-30T13:03:21Z | 0 | ---
dataset_info:
features:
- name: id
dtype: string
- name: prompt
dtype: string
- name: question_images
sequence: image
- name: answer_images
sequence: image
- name: options
sequence: string
- name: correct_answer
dtype: string
- name: explanation
sequence: string
- name:... |
mlfoundations-dev/c1_math_nod_1s_3k_eval_636d | mlfoundations-dev | 2025-04-28T05:39:48Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-04-28T05:08:07Z | 0 | # mlfoundations-dev/c1_math_nod_1s_3k_eval_636d
Precomputed model outputs for evaluation.
## Evaluation Results
### Summary
| Metric | AIME24 | AMC23 | MATH500 | MMLUPro | JEEBench | GPQADiamond | LiveCodeBench | CodeElo | CodeForces |
|--------|------|-----|-------|-------|--------|-----------|-------------|------... |
mlfoundations-dev/open-thoughts-science | mlfoundations-dev | 2025-03-24T21:21:12Z | 62 | 0 | [
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"curator"
] | [] | 2025-03-24T21:21:08Z | 0 | ---
language: en
license: mit
tags:
- curator
---
<a href="https://github.com/bespokelabsai/curator/">
<img src="https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k/resolve/main/made_with_curator.png" alt="Made with Curator" width=200px>
</a>
## Dataset card for open-thoughts-science
This dataset was ma... |
yuanqiuye/qrcode_image_100k_r16 | yuanqiuye | 2024-09-15T10:04:50Z | 8 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-09-15T09:52:05Z | 0 | ---
dataset_info:
features:
- name: image
dtype: image
- name: control_image
dtype: image
- name: caption
dtype: string
splits:
- name: train
num_bytes: 9391492656.0
num_examples: 100000
download_size: 9237330168
dataset_size: 9391492656.0
configs:
- config_name: default
data_files... |
neoneye/simon-arc-solve-grid-v3 | neoneye | 2024-08-21T20:18:45Z | 9 | 0 | [
"task_categories:image-to-text",
"task_categories:text-to-image",
"language:en",
"license:mit",
"size_categories:100K<n<1M",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-08-21T20:15:34Z | 0 | ---
license: mit
task_categories:
- image-to-text
- text-to-image
language:
- en
pretty_name: simons ARC (abstraction & reasoning corpus) solve grid version 3
size_categories:
- 10K<n<100K
configs:
- config_name: default
data_files:
- split: train
path: data.jsonl
---
# Version 1
ARC-AGI Tasks whe... |
msmandelbrot/green-lego_p2 | msmandelbrot | 2025-09-23T13:17:35Z | 4 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot"
] | [] | 2025-09-22T15:30:09Z | 0 | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Ne... |
vatolinalex/czech_product_review_sentiment | vatolinalex | 2025-07-05T17:39:16Z | 7 | 1 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-07-05T17:39:09Z | 0 | ---
dataset_info:
features:
- name: review_id
dtype: string
- name: label
dtype: string
- name: rating_int
dtype: int64
- name: comment_language
dtype: string
- name: text
dtype: string
splits:
- name: train
num_bytes: 4199384.0175
num_examples: 19593
- name: validation
... |
adriansanz/sqv-test1-tmp | adriansanz | 2024-08-21T08:25:21Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-08-21T08:25:20Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 652300
num_examples: 4885
download_size: 121600
dataset_size: 652300
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ServiceNow/repliqa_inference_tests_2 | ServiceNow | 2024-05-17T09:21:32Z | 5 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-05-17T09:21:29Z | 0 | ---
dataset_info:
features:
- name: topic
dtype: string
- name: context
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: predicted_answer
dtype: string
- name: retrieved_topic
dtype: string
splits:
- name: mistral_large
num_bytes: 17506
... |
finnbusse/v2testing | finnbusse | 2026-01-27T15:04:41Z | 47 | 0 | [
"task_categories:text-generation",
"language:de",
"license:mit",
"size_categories:n<1K",
"modality:image",
"modality:text",
"region:us",
"handwriting",
"stroke-data",
"rnn-training",
"stylus",
"s-pen",
"parquet",
"jsonl"
] | [] | 2026-01-22T11:02:19Z | 0 | ---
license: mit
task_categories:
- text-generation
language:
- de
tags:
- handwriting
- stroke-data
- rnn-training
- stylus
- s-pen
- parquet
- jsonl
size_categories:
- n<1K
configs:
- config_name: default
data_files:
- split: train
path: data/*.parquet
---
# v2testing
This da... |
ahm3texe/intern-voice-tr-corpus | ahm3texe | 2025-08-14T12:30:54Z | 10 | 1 | [
"license:cc-by-nc-nd-4.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-08-14T11:13:08Z | 0 | ---
license: cc-by-nc-nd-4.0
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: transcription
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 5134025475.064
num_examples: 7182
download_size: 39840878... |
kdercksen/pragtag_sentence_classification | kdercksen | 2024-02-28T12:14:28Z | 6 | 0 | [
"language:en",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-02-23T15:11:35Z | 0 | ---
language:
- en
dataset_info:
features:
- name: sentence
dtype: string
- name: label
dtype: string
splits:
- name: train
num_bytes: 454998
num_examples: 3560
- name: validation
num_bytes: 63674
num_examples: 463
- name: test
num_bytes: 114554
num_examples: 888
download... |
michaeldinzinger/webfaq-v2 | michaeldinzinger | 2026-02-17T15:16:29Z | 240 | 1 | [
"task_categories:text-retrieval",
"task_ids:document-retrieval",
"multilinguality:multilingual",
"language:afr",
"language:amh",
"language:ara",
"language:arz",
"language:asm",
"language:aze",
"language:bak",
"language:bel",
"language:ben",
"language:bos",
"language:bre",
"language:bul",... | [] | 2026-02-12T09:56:25Z | 0 | ---
language:
- afr
- amh
- ara
- arz
- asm
- aze
- bak
- bel
- ben
- bos
- bre
- bul
- cat
- ceb
- ces
- ckb
- cym
- dan
- deu
- div
- ell
- eng
- epo
- est
- eus
- fas
- fin
- fra
- fry
- gla
- gle
- glg
- gom
- guj
- hat
- hbs
- heb
- hin
- hrv
- hun
- hye
- ilo
- ind
- isl
- ita
- jav
- jpn
- kan
- kat
- kaz
- khm
... |
EEGDash/ds005642 | EEGDash | 2026-04-20T16:29:38Z | 0 | 0 | [
"task_categories:other",
"license:cc0-1.0",
"size_categories:n<1K",
"region:us",
"eeg",
"neuroscience",
"eegdash",
"brain-computer-interface",
"pytorch",
"visual",
"perception"
] | [] | 2026-04-20T16:29:37Z | 0 | ---
pretty_name: "illusory-face-eeg"
license: cc0-1.0
tags:
- eeg
- neuroscience
- eegdash
- brain-computer-interface
- pytorch
- visual
- perception
size_categories:
- n<1K
task_categories:
- other
---
# illusory-face-eeg
**Dataset ID:** `ds005642`
_Robinson2024_illusory_
> **At a glance:** EEG ·... |
gankun/G-flow-chart-of-an-instruction | gankun | 2025-05-17T19:50:22Z | 3 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"datadreamer",
"datadreamer-0.28.0",
"synthetic",
"gpt-4.1"
] | [] | 2025-05-17T19:50:06Z | 0 | ---
dataset_info:
features:
- name: metadata
dtype: string
- name: topic
dtype: string
- name: data
dtype: string
- name: code
dtype: string
- name: image
dtype: image
- name: qa
dtype: string
splits:
- name: train
num_bytes: 52155216.0
num_examples: 374
download_size... |
LangAGI-Lab/magpie-reasoning-v1-20k-thought-summary-math-verifiable | LangAGI-Lab | 2025-02-09T20:51:02Z | 3 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-09T20:50:54Z | 0 | ---
dataset_info:
features:
- name: uuid
dtype: string
- name: instruction
dtype: string
- name: response
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: gen_input_configs
struct:
- name: extract_input
... |
bilalinan/turkishReviews-ds-mini | bilalinan | 2024-05-23T07:33:36Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-05-07T19:17:50Z | 0 | ---
dataset_info:
features:
- name: review
dtype: string
- name: review_length
dtype: int64
splits:
- name: train
num_bytes: 1252876.2642514652
num_examples: 3378
- name: validation
num_bytes: 139455.7357485349
num_examples: 376
download_size: 896651
dataset_size: 1392332.0
confi... |
JoelMba/MantraGSC_medline | JoelMba | 2026-04-02T22:19:29Z | 0 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-04-02T22:19:25Z | 0 | ---
dataset_info:
features:
- name: id
dtype: string
- name: tokens
list: string
- name: ner_tags
sequence:
class_label:
names:
'0': B-Disorders
'1': I-Disorders
'2': O
- name: ner_tag_labels
sequence: string
splits:
- name: train
num_bytes: ... |
nhagar/CC-MAIN-2016-30_urls | nhagar | 2025-05-15T04:31:51Z | 4 | 0 | [
"size_categories:10M<n<100M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"doi:10.57967/hf/4115",
"region:us"
] | [] | 2025-01-09T01:47:37Z | 0 | ---
dataset_info:
features:
- name: crawl
dtype: string
- name: url_host_name
dtype: string
- name: url_count
dtype: int64
splits:
- name: train
num_bytes: 1788261213
num_examples: 33895181
download_size: 593710863
dataset_size: 1788261213
configs:
- config_name: default
data_files... |
TheFactoryX/edition_0161_cornell-movie-review-data-rotten_tomatoes-readymade | TheFactoryX | 2025-11-07T16:36:38Z | 4 | 0 | [
"license:other",
"size_categories:n<1K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us",
"readymades",
"art",
"shuffled",
"duchamp"
] | [] | 2025-11-07T16:36:37Z | 0 | ---
tags:
- readymades
- art
- shuffled
- duchamp
license: other
---
# edition_0161_cornell-movie-review-data-rotten_tomatoes-readymade
**A Readymade by TheFactoryX**
## Original Dataset
[cornell-movie-review-data/rotten_tomatoes](https://huggingface.co/datasets/cornell-movie-review-data/rotten_tomatoes)
## Process... |
CK0607/Xlam-function-calling-60k-RL2-format | CK0607 | 2025-10-24T15:54:09Z | 5 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-10-24T15:52:08Z | 0 | ---
dataset_info:
features:
- name: messages
list:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 87746120
num_examples: 60000
download_size: 30972274
dataset_size: 87746120
configs:
- config_name: default
data_files:
- split: tr... |
PristipleProgress/Wicker_Character_Sheet | PristipleProgress | 2025-09-08T06:55:20Z | 4 | 0 | [
"task_categories:text-generation",
"language:en",
"license:llama3.2",
"region:us",
"agent"
] | [] | 2025-09-08T06:54:34Z | 0 | ---
license: llama3.2
task_categories:
- text-generation
language:
- en
tags:
- agent
--- |
XuZhao2025/panda_0511_10 | XuZhao2025 | 2025-05-11T21:01:29Z | 40 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-11T21:01:28Z | 0 | ---
dataset_info:
features:
- name: images
sequence: image
- name: problem
dtype: string
- name: answer
sequence: int16
splits:
- name: train
num_bytes: 483540.0
num_examples: 8
- name: validation
num_bytes: 60442.5
num_examples: 1
- name: test
num_bytes: 60376.0
num_... |
LiuFeng2317/OpenSWI | LiuFeng2317 | 2025-08-13T08:39:38Z | 1,022 | 2 | [
"language:en",
"size_categories:10B<n<100B",
"region:us",
"inversion",
"seismic",
"imaging",
"subsurface"
] | [] | 2025-07-22T13:03:21Z | 0 | ---
language:
- en
tags:
- inversion
- seismic
- imaging
- subsurface
size_categories:
- 10B<n<100B
viewer: false
---
<h1 align="center">
<span style="font-family: 'Papyrus', sans-serif; color: red; font-weight: bold;">OpenSWI</span>:
<span style="font-family: 'Papyrus', sans-serif; color:rgb(14, 126, 146);">A Mas... |
leeroy-jankins/Outlays | leeroy-jankins | 2025-05-08T13:26:36Z | 4 | 0 | [
"license:mit",
"region:us"
] | [] | 2025-05-08T01:22:12Z | 0 | ---
license: mit
---
# 💸 U.S. Federal Outlays Dataset – Budget Execution in Action
**Maintainer**: [Terry Eppler](https://gravatar.com/terryepplerphd)
**Source**: Office of Management and Budget (OMB), U.S. Department of the Treasury
**Standards**: OMB Circular A-11, DATA Act (Pub. L. 113–101), Treasury GTAS
--... |
sghosts/orcun_processed_Kimi | sghosts | 2025-09-08T02:52:23Z | 4 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-09-08T02:52:18Z | 0 | ---
dataset_info:
features:
- name: images
dtype: image
- name: predictions
dtype: string
- name: page_number
dtype: int64
- name: title
dtype: string
- name: author
dtype: string
- name: thesis_id
dtype: string
- name: university
dtype: string
- name: department
dtype:... |
llm-slice/babylm-switchboard-preprocessed | llm-slice | 2025-06-28T22:37:41Z | 4 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-06-28T22:37:28Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 7071253
num_examples: 161740
- name: validation
num_bytes: 778013
num_examples: 18000
- name: test
num_bytes: 883158
num_examples: 20000
download_size: 5008467
dataset_size: 8732424
config... |
HungVu2003/opt-350m_beta_0.5_alpha_0.0_num-company_2_dataset_0_for_gen_18_v2 | HungVu2003 | 2025-05-05T20:04:14Z | 3 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-05T20:04:13Z | 0 | ---
dataset_info:
features:
- name: question
dtype: string
splits:
- name: train
num_bytes: 980914
num_examples: 12500
download_size: 629999
dataset_size: 980914
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Fredithefish/ToolCalls-1k-tokenized-Qwen3.5 | Fredithefish | 2026-03-24T12:23:59Z | 6 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-03-24T12:23:54Z | 0 | ---
dataset_info:
features:
- name: source_dataset
dtype: string
- name: source_split
dtype: string
- name: input_ids
list: int32
- name: attention_mask
list: int8
splits:
- name: train
num_bytes: 19500771
num_examples: 1894
download_size: 31055928
dataset_size: 19500771
config... |
french-open-data/cartographie-des-enjeux-sraddet-preservation-de-la-biodiversite | french-open-data | 2025-11-21T21:07:30Z | 9 | 0 | [
"language:fra",
"region:us",
"biodiversite",
"centralite",
"cours-d-eau",
"preservation",
"sraddet",
"trame-verte-et-bleue",
"tvb",
"dataset_for_agent"
] | [] | 2025-11-21T21:07:29Z | 0 | ---
language:
- fra
tags:
- biodiversite
- centralite
- cours-d-eau
- preservation
- sraddet
- trame-verte-et-bleue
- tvb
- dataset_for_agent
---
# Cartographie des enjeux SRADDET_Préservation de la biodiversité
> [!NOTE]
> Ce jeu de données Hugging Face est vide. Cette carte sert seulement à référencer le jeu de don... |
mxcui/gpt2-imdb-preference-ALPHA0.73-len512-random | mxcui | 2026-03-05T23:50:29Z | 17 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"format:optimized-parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-03-05T23:48:22Z | 0 | ---
dataset_info:
features:
- name: group_id
dtype: int64
- name: group_name
dtype: string
- name: score_0
dtype: float64
- name: score_1
dtype: float64
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: chosen_index
dtype: int64
- name: rejected_index
... |
Yunan90/w6 | Yunan90 | 2025-12-29T05:25:55Z | 5 | 0 | [
"license:bigcode-openrail-m",
"region:us"
] | [] | 2025-12-29T05:25:55Z | 0 | ---
license: bigcode-openrail-m
---
|
SayantanJoker/audio_hindi_karya_tts_description_37 | SayantanJoker | 2025-03-30T17:16:52Z | 5 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-03-30T17:11:19Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: file_name
dtype: string
- name: utterance_pitch_mean
dtype: float64
- name: utterance_pitch_std
dtype: float64
- name: snr
dtype: float64
- name: c50
dtype: float64
- name: speaking_rate
dtype: string
- name: ph... |
Backup-CaML/3krows_20percentours_80percentalpaca | Backup-CaML | 2026-02-15T16:18:43Z | 15 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-02-15T16:18:40Z | 0 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 1602142.2
num_examples: 2700
- name: test
num_bytes: 178015.8
num_examples: 300
download_size: 1069117
dataset_size: 1780158.0
configs:
- config_name: defau... |
mlfoundations-dev/no_pipeline_code_300k | mlfoundations-dev | 2025-05-02T21:25:58Z | 5 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-05-02T21:22:10Z | 0 | ---
dataset_info:
features:
- name: instruction_seed
dtype: string
- name: reasoning
dtype: string
- name: deepseek_solution
dtype: string
- name: source
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: shard_i... |
kylemontgomery/deepresearch-tasks | kylemontgomery | 2026-03-11T05:33:50Z | 32 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"format:optimized-parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-03-03T01:48:41Z | 0 | ---
dataset_info:
- config_name: default
features:
- name: id
dtype: string
- name: question
dtype: string
- name: ground_truth
dtype: string
- name: data_source
dtype: string
- name: parametric_acc
dtype: float64
- name: requires_web_search
dtype: bool
- name: requires_code_inte... |
TheFactoryX/edition_0863_ryanmarten-OpenThoughts-1k-sample-readymade | TheFactoryX | 2025-11-30T15:40:31Z | 5 | 0 | [
"license:other",
"size_categories:n<1K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us",
"readymades",
"art",
"shuffled",
"duchamp"
] | [] | 2025-11-30T15:40:28Z | 0 | ---
tags:
- readymades
- art
- shuffled
- duchamp
license: other
---
# edition_0863_ryanmarten-OpenThoughts-1k-sample-readymade
**A Readymade by TheFactoryX**
## Original Dataset
[ryanmarten/OpenThoughts-1k-sample](https://huggingface.co/datasets/ryanmarten/OpenThoughts-1k-sample)
## Process
This dataset is a "read... |
LeeBJ/never-economy-news2stock | LeeBJ | 2026-01-26T03:18:58Z | 8 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-01-26T03:18:55Z | 0 | ---
dataset_info:
features:
- name: system
dtype: string
- name: user
dtype: string
- name: assistant
dtype: string
splits:
- name: train
num_bytes: 4427606
num_examples: 1000
download_size: 1928151
dataset_size: 4427606
configs:
- config_name: default
data_files:
- split: train
... |
alybet/naira24-866 | alybet | 2026-03-27T18:35:59Z | 0 | 0 | [
"region:us"
] | [] | 2026-03-27T18:35:59Z | 0 | # Naira24 Deep Dive - Sports Betting Nigeria
In an era where online entertainment options are virtually limitless, the sports betting industry has undergone a remarkable transformation. Naira24 stands at the forefront of this evolution, delivering a platform that combines sophisticated analytics with an intuitive user... |
ShambhaviJoshi/Neural_3D_Reconstruction_and_Immersive_VR_Visualization_of_Row_Crops | ShambhaviJoshi | 2026-04-01T16:16:15Z | 5 | 0 | [
"region:us",
"Nerf",
"Gsplat",
"BBCH",
"Agronomy",
"ComputerVision",
"VR",
"UnrealEngine",
"Glomap"
] | [] | 2026-03-31T03:42:51Z | 0 | ---
tags:
- Nerf
- Gsplat
- BBCH
- Agronomy
- ComputerVision
- VR
- UnrealEngine
- Glomap
---
# 🌱 BBCH-NeRF Plant Dataset
This dataset accompanies the paper:
**Neural 3D reconstruction and immersive VR visualization of row crops across phenological growth stages**
---
## Overview
This dataset contains data for... |
bitmind/ffhq-jpg | bitmind | 2024-07-28T07:04:57Z | 48 | 0 | [
"region:us"
] | [] | 2024-07-28T06:21:18Z | 0 | ---
dataset_info:
features:
- name: image
dtype: image
splits:
- name: train
num_bytes: 69140167810.0
num_examples: 70000
download_size: 70032577350
dataset_size: 69140167810.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
danielgi97/EjercicioFinetunningSquad | danielgi97 | 2024-06-16T21:01:23Z | 2 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-06-16T20:59:43Z | 0 | ---
dataset_info:
features:
- name: title
dtype: string
- name: paragraphs
list:
- name: context
dtype: string
- name: qas
list:
- name: answers
list:
- name: answer_start
dtype: int64
- name: text
dtype: string
- name: id
... |
mengct00/test_public | mengct00 | 2026-01-30T15:43:49Z | 9 | 0 | [
"size_categories:n<1K",
"format:parquet",
"format:optimized-parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2026-01-30T14:47:13Z | 0 | ---
dataset_info:
features:
- name: audio
dtype: audio
- name: arn
dtype: string
- name: spa
dtype: string
splits:
- name: train
num_bytes: 495356
num_examples: 1
- name: validation
num_bytes: 361976
num_examples: 1
- name: test
num_bytes: 184705
num_examples: 1
dow... |
french-open-data/pnrcmo-plantes-vasculaires-menacees-regionales-periode-moderne-par-maille-1-km2 | french-open-data | 2025-11-21T20:39:08Z | 5 | 0 | [
"language:fra",
"region:us",
"flore",
"maille-1-km2",
"menace-regionale",
"parc-naturel-regional-des-caps-et-marais-dopale-pnrcmo",
"periode-moderne-depuis-2000",
"plantes-vasculaires",
"dataset_for_agent"
] | [] | 2025-11-21T20:39:07Z | 0 | ---
language:
- fra
tags:
- flore
- maille-1-km2
- menace-regionale
- parc-naturel-regional-des-caps-et-marais-dopale-pnrcmo
- periode-moderne-depuis-2000
- plantes-vasculaires
- dataset_for_agent
---
# PNRCMO - Plantes vasculaires menacées régionales (Période moderne - Par maille 1 km²)
> [!NOTE]
> Ce jeu de données... |
BuVezz/trec-fine-split | BuVezz | 2025-11-08T16:39:51Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-11-08T16:39:42Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: coarse_label
dtype: string
- name: fine_label
dtype: string
splits:
- name: train
num_bytes: 368071
num_examples: 4906
- name: validation
num_bytes: 41162
num_examples: 546
- name: test
num_bytes: 30095
nu... |
MRMRbenchmark/negation | MRMRbenchmark | 2025-12-10T00:04:52Z | 16 | 0 | [
"license:mit",
"size_categories:1K<n<10K",
"format:parquet",
"format:optimized-parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-10-07T06:11:19Z | 0 | ---
dataset_info:
- config_name: corpus
features:
- name: id
dtype: string
- name: modality
dtype: string
- name: text
dtype: string
- name: image
dtype: image
- name: vision
dtype: image
splits:
- name: test
num_bytes: 7627022
num_examples: 800
download_size: 4200044
dat... |
GeorgeCrawford15/finetuning_demo | GeorgeCrawford15 | 2025-02-17T03:17:46Z | 4 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-17T03:17:44Z | 0 | ---
dataset_info:
features:
- name: prompt
dtype: string
splits:
- name: train
num_bytes: 57318
num_examples: 32
download_size: 24350
dataset_size: 57318
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
xaviviro/cv_eu_snac_short | xaviviro | 2025-11-05T13:50:21Z | 7 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-11-05T13:37:15Z | 0 | ---
dataset_info:
features:
- name: text
dtype: string
- name: snac_layer_1
sequence: int64
- name: snac_layer_2
sequence: int64
- name: snac_layer_3
sequence: int64
- name: encoded_len
dtype: int64
- name: duration
dtype: float64
- name: speaker
dtype: string
splits:
- n... |
AgentPublic/DILA-Vectors | AgentPublic | 2025-02-04T15:15:20Z | 60 | 2 | [
"language:fr",
"region:us"
] | [] | 2025-02-04T09:16:10Z | 0 | ---
language:
- fr
---
# French Legal Document Vector Database
## Overview of DILA Repository Datasets
This set is a collection of four vector databases which contains documents produced by various French governmental institutions made available by the DILA (Direction de l'Information légale et administrative) reposit... |
mlfoundations-dev/b2_math_fasttext_pos_brando_olympiad_neg_lap1official_math_eval_636d | mlfoundations-dev | 2025-04-24T02:36:05Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-04-24T01:57:39Z | 0 | # mlfoundations-dev/b2_math_fasttext_pos_brando_olympiad_neg_lap1official_math_eval_636d
Precomputed model outputs for evaluation.
## Evaluation Results
### Summary
| Metric | AIME24 | AMC23 | MATH500 | MMLUPro | JEEBench | GPQADiamond | LiveCodeBench | CodeElo | CodeForces |
|--------|------|-----|-------|-------|... |
airabbitX/my-distiset-04615e24 | airabbitX | 2025-01-25T11:43:46Z | 4 | 0 | [
"task_categories:text-generation",
"task_categories:question-answering",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"library:distilabel",
"region:us",
"synthetic",
"distilabel",
"rlaif",
"datac... | [] | 2025-01-25T11:39:34Z | 0 | ---
size_categories: n<1K
task_categories:
- text-generation
- text2text-generation
- question-answering
dataset_info:
features:
- name: prompt
dtype: string
- name: completion
dtype: string
- name: system_prompt
dtype: string
splits:
- name: train
num_bytes: 14352
num_examples: 12
dow... |
hirundo-io/2000-telecomm-forget-national-id-and-is-subscribed | hirundo-io | 2025-11-24T10:54:53Z | 4 | 0 | [
"size_categories:1K<n<10K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-11-24T10:54:51Z | 0 | ---
dataset_info:
features:
- name: name
dtype: string
- name: national_id_number
dtype: string
- name: is_subscribed
dtype: string
splits:
- name: train
num_bytes: 70612
num_examples: 2000
download_size: 44478
dataset_size: 70612
configs:
- config_name: default
data_files:
- spl... |
strich/spyder-ide-lbl-all-2x | strich | 2024-04-23T08:57:33Z | 36 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-04-05T09:26:59Z | 0 | ---
dataset_info:
features:
- name: meta_data
struct:
- name: contains_class
dtype: bool
- name: contains_function
dtype: bool
- name: end_line
dtype: int64
- name: file_imports
sequence: string
- name: file_name
dtype: string
- name: module
dtype: str... |
BSC-LT/ACAData | BSC-LT | 2026-03-06T14:10:16Z | 49 | 2 | [
"task_categories:translation",
"language:es",
"language:en",
"language:ca",
"language:pt",
"language:fr",
"language:eu",
"language:gl",
"language:de",
"language:nl",
"language:el",
"language:it",
"license:cc-by-4.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"li... | [] | 2025-10-14T09:32:52Z | 0 | ---
license: cc-by-4.0
task_categories:
- translation
language:
- es
- en
- ca
- pt
- fr
- eu
- gl
- de
- nl
- el
- it
size_categories:
- 1M<n<10M
configs:
- config_name: default
data_files:
- split: train
path: acadtrain.parquet
- split: test
path: acadbench/acadbench.parquet
---
# Dataset Card ... |
tommyp111/pythia-70m-layer-4-pile-resid-post-activations-through-time | tommyp111 | 2024-11-16T18:18:20Z | 28 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-11-16T16:14:02Z | 0 | ---
dataset_info:
features:
- name: '1000'
dtype:
array2_d:
shape:
- 128
- 512
dtype: float32
- name: '5000'
dtype:
array2_d:
shape:
- 128
- 512
dtype: float32
- name: '10000'
dtype:
array2_d:
shape:
- ... |
datasets-CNRS/contractions | datasets-CNRS | 2025-03-29T21:48:23Z | 3 | 0 | [
"language:fra",
"region:us"
] | [] | 2024-10-25T18:41:08Z | 0 | ---
language:
- fra
---
> [!NOTE]
> Dataset origin: https://www.ortolang.fr/market/corpora/sldr000795
> [!CAUTION]
> Vous devez vous rendre sur le site d'Ortholang et vous connecter afin de télécharger les données.
## Description
Corpus de parole spontanée et de lecture pour la comparaison des contract... |
yuzhenm/GSA-PT-Qwen2-7B-Instruct-chunk32-data | yuzhenm | 2026-04-06T04:05:47Z | 0 | 0 | [
"source_datasets:HuggingFaceFW/fineweb",
"license:odc-by",
"region:us",
"gsa",
"gist-sparse-attention",
"long-context",
"pretraining"
] | [] | 2026-04-06T04:05:22Z | 0 | ---
license: odc-by
tags:
- gsa
- gist-sparse-attention
- long-context
- pretraining
source_datasets:
- HuggingFaceFW/fineweb
---
# GSA-PT-Qwen2-7B-Instruct-chunk32-data
This is the **continue pretraining dataset** used for training GSA (Gist Sparse Attention) models based on Qwen2-7B-Instruct with chunk si... |
Lots-of-LoRAs/task425_hindienglish_corpora_en_hi_translation | Lots-of-LoRAs | 2025-01-02T14:22:43Z | 10 | 0 | [
"task_categories:text-generation",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:... | [] | 2025-01-02T14:22:41Z | 0 | ---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- apache-2.0
task_categories:
- text-generation
pretty_name: task425_hindienglish_corpora_en_hi_translation
dataset_info:
config_name: plain_text
features:
- name: input
dtype: string
- name: output
dtype:... |
mlfoundations-dev/multiple_samples_shortest_numina_aime_w_openthoughts | mlfoundations-dev | 2025-02-17T23:51:29Z | 4 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-17T23:50:34Z | 0 | ---
dataset_info:
features:
- name: system
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: problem
dtype: string
- name: reasoning
dtype: string
- name: deepseek_solution
dtype: string
- name: id
dtype: st... |
MikeGreen2710/12_jun_hn_pred_p1 | MikeGreen2710 | 2024-06-17T02:53:02Z | 5 | 0 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-06-15T02:32:51Z | 0 | ---
dataset_info:
features:
- name: id
dtype: string
- name: text
dtype: string
- name: STR
sequence: string
- name: LEG
sequence: string
- name: LOC
sequence: string
- name: CIT
sequence: string
- name: WAR
sequence: string
- name: NUM
sequence: string
- name: DIS
... |
french-open-data/bornes-de-recharge-clem-mobilite | french-open-data | 2025-11-21T19:40:54Z | 6 | 0 | [
"language:fra",
"region:us",
"borne-de-recharge",
"bornes-de-recharge",
"irve",
"recharge-vehicule-electrique-fra",
"recharge-voiture-electrique-fran",
"dataset_for_agent"
] | [] | 2025-11-21T19:40:54Z | 0 | ---
language:
- fra
tags:
- borne-de-recharge
- bornes-de-recharge
- irve
- recharge-vehicule-electrique-fra
- recharge-voiture-electrique-fran
- dataset_for_agent
---
# Bornes de recharge Clem' Mobilité
> [!NOTE]
> Ce jeu de données Hugging Face est vide. Cette carte sert seulement à référencer le jeu de données **B... |
Yagmurrr/yagmur16 | Yagmurrr | 2025-02-19T12:58:21Z | 4 | 0 | [
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-19T12:57:34Z | 0 | ---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: float64
- name: response
dtype: string
splits:
- name: train
num_bytes: 1414.4
num_examples: 4
- name: test
num_bytes: 340
num_examples: 1
download_size: 8147
dataset_size: 1754.4
configs:
- ... |
tahamajs/bitcoin-sllm-instruct_v2 | tahamajs | 2025-08-11T11:23:03Z | 15 | 0 | [
"task_categories:time-series-forecasting",
"task_categories:text-classification",
"task_categories:tabular-regression",
"language:en",
"license:other",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
... | [] | 2025-08-11T11:22:47Z | 0 | ---
pretty_name: Bitcoin SLLM Instruction Dataset
tags:
- bitcoin
- finance
- instruction-tuning
- sft
license: other
language:
- en
task_categories:
- time-series-forecasting
- text-classification
- tabular-regression
size_categories:
- 1K<n<10K
---
# Bitcoin SLLM Instruction Dataset
Daily BTC context transformed in... |
DCAgent/exp_tas_repetition_penalty_1.05_traces | DCAgent | 2026-01-01T11:45:29Z | 14 | 0 | [
"size_categories:10K<n<100K",
"format:parquet",
"format:optimized-parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:polars",
"library:mlcroissant",
"region:us"
] | [] | 2025-12-30T18:22:21Z | 0 | ---
dataset_info:
features:
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
- name: agent
dtype: string
- name: model
dtype: string
- name: model_provider
dtype: string
- name: date
dtype: string
- name: task
dtype: string
... |
RobotisSW/ffw_sg2_rev1_task_327_0205_jungmin_1 | RobotisSW | 2026-02-05T06:22:52Z | 271 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"modality:video",
"library:datasets",
"library:mlcroissant",
"region:us",
"LeRobot",
"ffw_sg2_rev1",
"robotis"
] | [] | 2026-02-05T06:21:31Z | 0 | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- ffw_sg2_rev1
- robotis
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Pape... |
Subsets and Splits
Recent Trending Datasets
Lists newly created datasets from the past week, sorted by trending score, creation date, likes, and downloads, highlighting popular and recently active datasets.
Evaluated Benchmark Datasets
Retrieves records tagged with 'eval', 'evaluation', or 'benchmark', ordered by the last modified date, providing basic filtering for relevant entries.