
url stringlengths 61 61 | repository_url stringclasses 1
value | labels_url stringlengths 75 75 | comments_url stringlengths 70 70 | events_url stringlengths 68 68 | html_url stringlengths 49 51 | id int64 971M 1.13B | node_id stringlengths 18 32 | number int64 2.8k 3.71k | title stringlengths 2 276 | user dict | labels list | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees list | milestone dict | comments int64 0 18 | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3
values | active_lock_reason null | body stringlengths 9 36.2k ⌀ | reactions dict | timeline_url stringlengths 70 70 | performed_via_github_app null | draft bool 2
classes | pull_request dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3604/comments | https://api.github.com/repos/huggingface/datasets/issues/3604/events | https://github.com/huggingface/datasets/issues/3604 | 1,108,477,316 | I_kwDODunzps5CEgWE | 3,604 | Dataset Viewer not showing Previews for Private Datasets | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidl... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | 1 | 2022-01-19T19:29:26 | 2022-01-20T08:11:28 | null | MEMBER | null | ## Dataset viewer issue for 'abidlabs/test-audio-13'
It seems that the dataset viewer does not show previews for `private` datasets, even for the user who's private dataset it is. See [1] for example. If I change the visibility to public, then it does show, but it would be useful to have the viewer even for private ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3604/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3604/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3603/comments | https://api.github.com/repos/huggingface/datasets/issues/3603/events | https://github.com/huggingface/datasets/pull/3603 | 1,108,392,141 | PR_kwDODunzps4xR1ih | 3,603 | Add British Library books dataset | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/us... | [] | closed | false | null | [] | null | 4 | 2022-01-19T17:53:05 | 2022-01-31T17:22:51 | 2022-01-31T17:01:49 | CONTRIBUTOR | null | This pull request adds a dataset of text from digitised (primarily 19th Century) books from the British Library. This collection has previously been used for training language models, e.g. https://github.com/dbmdz/clef-hipe/blob/main/hlms.md. It would be nice to make this dataset more accessible for others to use throu... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3603/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3603/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3603",
"html_url": "https://github.com/huggingface/datasets/pull/3603",
"diff_url": "https://github.com/huggingface/datasets/pull/3603.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3603.patch",
"merged_at": "2022-01-31T17:01... |
https://api.github.com/repos/huggingface/datasets/issues/3602 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3602/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3602/comments | https://api.github.com/repos/huggingface/datasets/issues/3602/events | https://github.com/huggingface/datasets/pull/3602 | 1,108,247,870 | PR_kwDODunzps4xRXVm | 3,602 | Update url for conll2003 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 2 | 2022-01-19T15:35:04 | 2022-01-20T16:23:03 | 2022-01-19T15:43:53 | MEMBER | null | Following https://github.com/huggingface/datasets/issues/3582 I'm changing the download URL of the conll2003 data files, since the previous host doesn't have the authorization to redistribute the data | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3602/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3602/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3602",
"html_url": "https://github.com/huggingface/datasets/pull/3602",
"diff_url": "https://github.com/huggingface/datasets/pull/3602.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3602.patch",
"merged_at": "2022-01-19T15:43... |
https://api.github.com/repos/huggingface/datasets/issues/3601 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3601/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3601/comments | https://api.github.com/repos/huggingface/datasets/issues/3601/events | https://github.com/huggingface/datasets/pull/3601 | 1,108,207,131 | PR_kwDODunzps4xROtF | 3,601 | Add conll2003 licensing | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 0 | 2022-01-19T15:00:41 | 2022-01-19T17:17:28 | 2022-01-19T17:17:28 | MEMBER | null | Following https://github.com/huggingface/datasets/issues/3582, this PR updates the licensing section of the CoNLL2003 dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3601/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3601/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3601",
"html_url": "https://github.com/huggingface/datasets/pull/3601",
"diff_url": "https://github.com/huggingface/datasets/pull/3601.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3601.patch",
"merged_at": "2022-01-19T17:17... |
https://api.github.com/repos/huggingface/datasets/issues/3600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3600/comments | https://api.github.com/repos/huggingface/datasets/issues/3600/events | https://github.com/huggingface/datasets/pull/3600 | 1,108,131,878 | PR_kwDODunzps4xQ-vt | 3,600 | Use old url for conll2003 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 0 | 2022-01-19T13:56:49 | 2022-01-19T14:16:28 | 2022-01-19T14:16:28 | MEMBER | null | As reported in https://github.com/huggingface/datasets/issues/3582 the CoNLL2003 data files are not available in the master branch of the repo that used to host them.
For now we can use the URL from an older commit to access the data files | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3600/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3600/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3600",
"html_url": "https://github.com/huggingface/datasets/pull/3600",
"diff_url": "https://github.com/huggingface/datasets/pull/3600.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3600.patch",
"merged_at": "2022-01-19T14:16... |
https://api.github.com/repos/huggingface/datasets/issues/3599 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3599/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3599/comments | https://api.github.com/repos/huggingface/datasets/issues/3599/events | https://github.com/huggingface/datasets/issues/3599 | 1,108,111,607 | I_kwDODunzps5CDHD3 | 3,599 | The `add_column()` method does not work if used on dataset sliced with `select()` | {
"login": "ThGouzias",
"id": 59422506,
"node_id": "MDQ6VXNlcjU5NDIyNTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/59422506?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ThGouzias",
"html_url": "https://github.com/ThGouzias",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | 1 | 2022-01-19T13:36:50 | 2022-01-28T15:35:57 | 2022-01-28T15:35:57 | NONE | null | Hello, I posted this as a question on the forums ([here](https://discuss.huggingface.co/t/add-column-does-not-work-if-used-on-dataset-sliced-with-select/13893)):
I have a dataset with 2000 entries
> dataset = Dataset.from_dict({'colA': list(range(2000))})
and from which I want to extract the first one thousan... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3599/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3599/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3598 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3598/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3598/comments | https://api.github.com/repos/huggingface/datasets/issues/3598/events | https://github.com/huggingface/datasets/issues/3598 | 1,108,107,199 | I_kwDODunzps5CDF-_ | 3,598 | Readme info not being parsed to show on Dataset card page | {
"login": "davidcanovas",
"id": 79796807,
"node_id": "MDQ6VXNlcjc5Nzk2ODA3",
"avatar_url": "https://avatars.githubusercontent.com/u/79796807?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davidcanovas",
"html_url": "https://github.com/davidcanovas",
"followers_url": "https://api.github.c... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 4 | 2022-01-19T13:32:29 | 2022-01-21T10:20:01 | 2022-01-21T10:20:01 | NONE | null | ## Describe the bug
The info contained in the README.md file is not being shown in the dataset main page. Basic info and table of contents are properly formatted in the README.
## Steps to reproduce the bug
# Sample code to reproduce the bug
The README file is this one: https://huggingface.co/datasets/softcatal... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3598/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3598/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3597/comments | https://api.github.com/repos/huggingface/datasets/issues/3597/events | https://github.com/huggingface/datasets/issues/3597 | 1,108,092,864 | I_kwDODunzps5CDCfA | 3,597 | ERROR: File "setup.py" or "setup.cfg" not found. Directory cannot be installed in editable mode: /content | {
"login": "amitkml",
"id": 49492030,
"node_id": "MDQ6VXNlcjQ5NDkyMDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/49492030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amitkml",
"html_url": "https://github.com/amitkml",
"followers_url": "https://api.github.com/users/amitkm... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 1 | 2022-01-19T13:19:28 | 2022-01-20T13:26:50 | null | NONE | null | ## Bug
The install of streaming dataset is giving following error.
## Steps to reproduce the bug
```python
! git clone https://github.com/huggingface/datasets.git
! cd datasets
! pip install -e ".[streaming]"
```
## Actual results
Cloning into 'datasets'...
remote: Enumerating objects: 50816, done.
remot... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3597/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3597/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3596/comments | https://api.github.com/repos/huggingface/datasets/issues/3596/events | https://github.com/huggingface/datasets/issues/3596 | 1,107,345,338 | I_kwDODunzps5CAL-6 | 3,596 | Loss of cast `Image` feature on certain dataset method | {
"login": "davanstrien",
"id": 8995957,
"node_id": "MDQ6VXNlcjg5OTU5NTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8995957?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/davanstrien",
"html_url": "https://github.com/davanstrien",
"followers_url": "https://api.github.com/us... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 7 | 2022-01-18T20:44:01 | 2022-01-21T18:07:28 | 2022-01-21T18:07:28 | CONTRIBUTOR | null | ## Describe the bug
When an a column is cast to an `Image` feature, the cast type appears to be lost during certain operations. I first noticed this when using the `push_to_hub` method on a dataset that contained urls pointing to images which had been cast to an `image`. This also happens when using select on a data... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3596/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3596/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3595/comments | https://api.github.com/repos/huggingface/datasets/issues/3595/events | https://github.com/huggingface/datasets/pull/3595 | 1,107,260,527 | PR_kwDODunzps4xOIxH | 3,595 | Add ImageNet toy datasets from fastai | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | 0 | 2022-01-18T19:03:35 | 2022-01-19T11:33:36 | null | CONTRIBUTOR | null | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3595/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3595/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3594/comments | https://api.github.com/repos/huggingface/datasets/issues/3594/events | https://github.com/huggingface/datasets/pull/3594 | 1,107,174,619 | PR_kwDODunzps4xN3Kk | 3,594 | fix multiple language downloading in mC4 | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.c... | [] | closed | false | null | [] | null | 1 | 2022-01-18T17:25:19 | 2022-01-19T11:22:57 | 2022-01-18T19:10:22 | CONTRIBUTOR | null | If we try to access multiple languages of the [mC4 dataset](https://github.com/huggingface/datasets/tree/master/datasets/mc4), it will throw an error. For example, if we do
```python
mc4_subset_two_langs = load_dataset("mc4", languages=["st", "su"])
```
we got
```
FileNotFoundError: Couldn't find file at https:/... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3594/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3594/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3594",
"html_url": "https://github.com/huggingface/datasets/pull/3594",
"diff_url": "https://github.com/huggingface/datasets/pull/3594.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3594.patch",
"merged_at": "2022-01-18T19:10... |
https://api.github.com/repos/huggingface/datasets/issues/3593 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3593/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3593/comments | https://api.github.com/repos/huggingface/datasets/issues/3593/events | https://github.com/huggingface/datasets/pull/3593 | 1,107,070,852 | PR_kwDODunzps4xNhTu | 3,593 | Update README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/follower... | [] | closed | false | null | [] | null | 0 | 2022-01-18T15:52:16 | 2022-01-20T17:14:53 | 2022-01-20T17:14:53 | CONTRIBUTOR | null | Towards license of Tweet Eval parts | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3593/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3593/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3593",
"html_url": "https://github.com/huggingface/datasets/pull/3593",
"diff_url": "https://github.com/huggingface/datasets/pull/3593.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3593.patch",
"merged_at": "2022-01-20T17:14... |
https://api.github.com/repos/huggingface/datasets/issues/3592 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3592/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3592/comments | https://api.github.com/repos/huggingface/datasets/issues/3592/events | https://github.com/huggingface/datasets/pull/3592 | 1,107,026,723 | PR_kwDODunzps4xNYIW | 3,592 | Add QuickDraw dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | open | false | null | [] | null | 0 | 2022-01-18T15:13:39 | 2022-01-18T15:13:39 | null | CONTRIBUTOR | null | Add the QuickDraw dataset.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3592/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3592/timeline | null | true | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3592",
"html_url": "https://github.com/huggingface/datasets/pull/3592",
"diff_url": "https://github.com/huggingface/datasets/pull/3592.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3592.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3591 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3591/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3591/comments | https://api.github.com/repos/huggingface/datasets/issues/3591/events | https://github.com/huggingface/datasets/pull/3591 | 1,106,928,613 | PR_kwDODunzps4xNDoB | 3,591 | Add support for time, date, duration, and decimal dtypes | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 2 | 2022-01-18T13:46:05 | 2022-01-31T18:29:34 | 2022-01-20T17:37:33 | CONTRIBUTOR | null | Add support for the pyarrow time (maps to `datetime.time` in python), date (maps to `datetime.time` in python), duration (maps to `datetime.timedelta` in python), and decimal (maps to `decimal.decimal` in python) dtypes. This should be helpful when writing scripts for time-series datasets. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3591/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3591/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3591",
"html_url": "https://github.com/huggingface/datasets/pull/3591",
"diff_url": "https://github.com/huggingface/datasets/pull/3591.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3591.patch",
"merged_at": "2022-01-20T17:37... |
https://api.github.com/repos/huggingface/datasets/issues/3590 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3590/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3590/comments | https://api.github.com/repos/huggingface/datasets/issues/3590/events | https://github.com/huggingface/datasets/pull/3590 | 1,106,784,860 | PR_kwDODunzps4xMlGg | 3,590 | Update ANLI README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/follower... | [] | closed | false | null | [] | null | 0 | 2022-01-18T11:22:53 | 2022-01-20T16:58:41 | 2022-01-20T16:58:41 | CONTRIBUTOR | null | Update license and little things concerning ANLI | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3590/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3590/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3590",
"html_url": "https://github.com/huggingface/datasets/pull/3590",
"diff_url": "https://github.com/huggingface/datasets/pull/3590.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3590.patch",
"merged_at": "2022-01-20T16:58... |
https://api.github.com/repos/huggingface/datasets/issues/3589 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3589/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3589/comments | https://api.github.com/repos/huggingface/datasets/issues/3589/events | https://github.com/huggingface/datasets/pull/3589 | 1,106,766,114 | PR_kwDODunzps4xMhGp | 3,589 | Pin torchmetrics to fix the COMET test | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 0 | 2022-01-18T11:03:49 | 2022-01-18T11:04:56 | 2022-01-18T11:04:55 | MEMBER | null | Torchmetrics 0.7.0 got released and has issues with `transformers` (see https://github.com/PyTorchLightning/metrics/issues/770)
I'm pinning it to 0.6.0 in the CI, since 0.7.0 makes the COMET metric test fail. COMET requires torchmetrics==0.6.0 anyway. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3589/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3589/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3589",
"html_url": "https://github.com/huggingface/datasets/pull/3589",
"diff_url": "https://github.com/huggingface/datasets/pull/3589.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3589.patch",
"merged_at": "2022-01-18T11:04... |
https://api.github.com/repos/huggingface/datasets/issues/3588 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3588/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3588/comments | https://api.github.com/repos/huggingface/datasets/issues/3588/events | https://github.com/huggingface/datasets/pull/3588 | 1,106,749,000 | PR_kwDODunzps4xMdiC | 3,588 | Update HellaSwag README.md | {
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/follower... | [] | closed | false | null | [] | null | 0 | 2022-01-18T10:46:15 | 2022-01-20T16:57:43 | 2022-01-20T16:57:43 | CONTRIBUTOR | null | Adding information from the git repo and paper that were missing | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3588/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3588/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3588",
"html_url": "https://github.com/huggingface/datasets/pull/3588",
"diff_url": "https://github.com/huggingface/datasets/pull/3588.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3588.patch",
"merged_at": "2022-01-20T16:57... |
https://api.github.com/repos/huggingface/datasets/issues/3587 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3587/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3587/comments | https://api.github.com/repos/huggingface/datasets/issues/3587/events | https://github.com/huggingface/datasets/issues/3587 | 1,106,719,182 | I_kwDODunzps5B9zHO | 3,587 | No module named 'fsspec.archive' | {
"login": "shuuchen",
"id": 13246825,
"node_id": "MDQ6VXNlcjEzMjQ2ODI1",
"avatar_url": "https://avatars.githubusercontent.com/u/13246825?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shuuchen",
"html_url": "https://github.com/shuuchen",
"followers_url": "https://api.github.com/users/shu... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 0 | 2022-01-18T10:17:01 | 2022-01-18T10:33:10 | 2022-01-18T10:33:10 | NONE | null | ## Describe the bug
Cannot import datasets after installation.
## Steps to reproduce the bug
```shell
$ python
Python 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import datasets
Traceback (most recent... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3587/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3587/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3586/comments | https://api.github.com/repos/huggingface/datasets/issues/3586/events | https://github.com/huggingface/datasets/issues/3586 | 1,106,455,672 | I_kwDODunzps5B8yx4 | 3,586 | Revisit `enable/disable_` toggle function prefix | {
"login": "jaketae",
"id": 25360440,
"node_id": "MDQ6VXNlcjI1MzYwNDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/25360440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jaketae",
"html_url": "https://github.com/jaketae",
"followers_url": "https://api.github.com/users/jaketa... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2022-01-18T04:09:55 | 2022-01-18T04:09:55 | null | CONTRIBUTOR | null | As discussed in https://github.com/huggingface/transformers/pull/15167, we should revisit the `enable/disable_` toggle function prefix, potentially in favor of `set_enabled_`. Concretely, this translates to
- De-deprecating `disable_progress_bar()`
- Adding `enable_progress_bar()`
- On the caching side, adding `en... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3586/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3586/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3585/comments | https://api.github.com/repos/huggingface/datasets/issues/3585/events | https://github.com/huggingface/datasets/issues/3585 | 1,105,821,470 | I_kwDODunzps5B6X8e | 3,585 | Datasets streaming + map doesn't work for `Audio` | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODk... | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2022-01-17T12:55:42 | 2022-01-20T13:28:00 | 2022-01-20T13:28:00 | MEMBER | null | ## Describe the bug
When using audio datasets in streaming mode, applying a `map(...)` before iterating leads to an error as the key `array` does not exist anymore.
## Steps to reproduce the bug
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "en", streaming=True, split="train")... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3585/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3585/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3584 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3584/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3584/comments | https://api.github.com/repos/huggingface/datasets/issues/3584/events | https://github.com/huggingface/datasets/issues/3584 | 1,105,231,768 | I_kwDODunzps5B4H-Y | 3,584 | https://huggingface.co/datasets/huggingface/transformers-metadata | {
"login": "ecankirkic",
"id": 37082592,
"node_id": "MDQ6VXNlcjM3MDgyNTky",
"avatar_url": "https://avatars.githubusercontent.com/u/37082592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ecankirkic",
"html_url": "https://github.com/ecankirkic",
"followers_url": "https://api.github.com/use... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | open | false | null | [] | null | 0 | 2022-01-17T00:18:14 | 2022-01-17T09:21:54 | null | NONE | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3584/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3584/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3583 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3583/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3583/comments | https://api.github.com/repos/huggingface/datasets/issues/3583/events | https://github.com/huggingface/datasets/issues/3583 | 1,105,195,144 | I_kwDODunzps5B3_CI | 3,583 | Add The Medical Segmentation Decathlon Dataset | {
"login": "omarespejel",
"id": 4755430,
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omarespejel",
"html_url": "https://github.com/omarespejel",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
... | open | false | null | [] | null | 1 | 2022-01-16T21:42:25 | 2022-02-09T19:39:16 | null | NONE | null | ## Adding a Dataset
- **Name:** *The Medical Segmentation Decathlon Dataset*
- **Description:** The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data, and small objects.
- **Paper:*... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3583/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3583/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3582 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3582/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3582/comments | https://api.github.com/repos/huggingface/datasets/issues/3582/events | https://github.com/huggingface/datasets/issues/3582 | 1,104,877,303 | I_kwDODunzps5B2xb3 | 3,582 | conll 2003 dataset source url is no longer valid | {
"login": "rcanand",
"id": 303900,
"node_id": "MDQ6VXNlcjMwMzkwMA==",
"avatar_url": "https://avatars.githubusercontent.com/u/303900?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rcanand",
"html_url": "https://github.com/rcanand",
"followers_url": "https://api.github.com/users/rcanand/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | 4 | 2022-01-15T23:04:17 | 2022-01-21T16:57:32 | 2022-01-21T16:57:32 | NONE | null | ## Describe the bug
Loading `conll2003` dataset fails because it was removed (just yesterday 1/14/2022) from the location it is looking for.
## Steps to reproduce the bug
```python
from datasets import load_dataset
load_dataset("conll2003")
```
## Expected results
The dataset should load.
## Actual r... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3582/reactions",
"total_count": 5,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 5,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3582/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3581 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3581/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3581/comments | https://api.github.com/repos/huggingface/datasets/issues/3581/events | https://github.com/huggingface/datasets/issues/3581 | 1,104,857,822 | I_kwDODunzps5B2sre | 3,581 | Unable to create a dataset from a parquet file in S3 | {
"login": "regCode",
"id": 18012903,
"node_id": "MDQ6VXNlcjE4MDEyOTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/18012903?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/regCode",
"html_url": "https://github.com/regCode",
"followers_url": "https://api.github.com/users/regCod... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 1 | 2022-01-15T21:34:16 | 2022-01-21T16:58:56 | null | NONE | null | ## Describe the bug
Trying to create a dataset from a parquet file in S3.
## Steps to reproduce the bug
```python
import s3fs
from datasets import Dataset
s3 = s3fs.S3FileSystem(anon=False)
with s3.open(PATH_LTR_TOY_CLEAN_DATASET, 'rb') as s3file:
dataset = Dataset.from_parquet(s3file)
```
## Expe... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3581/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3581/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | {
"login": "tuhinjubcse",
"id": 3104771,
"node_id": "MDQ6VXNlcjMxMDQ3NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3104771?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuhinjubcse",
"html_url": "https://github.com/tuhinjubcse",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | 4 | 2022-01-15T10:04:33 | 2022-01-31T08:38:09 | 2022-01-31T08:38:09 | NONE | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
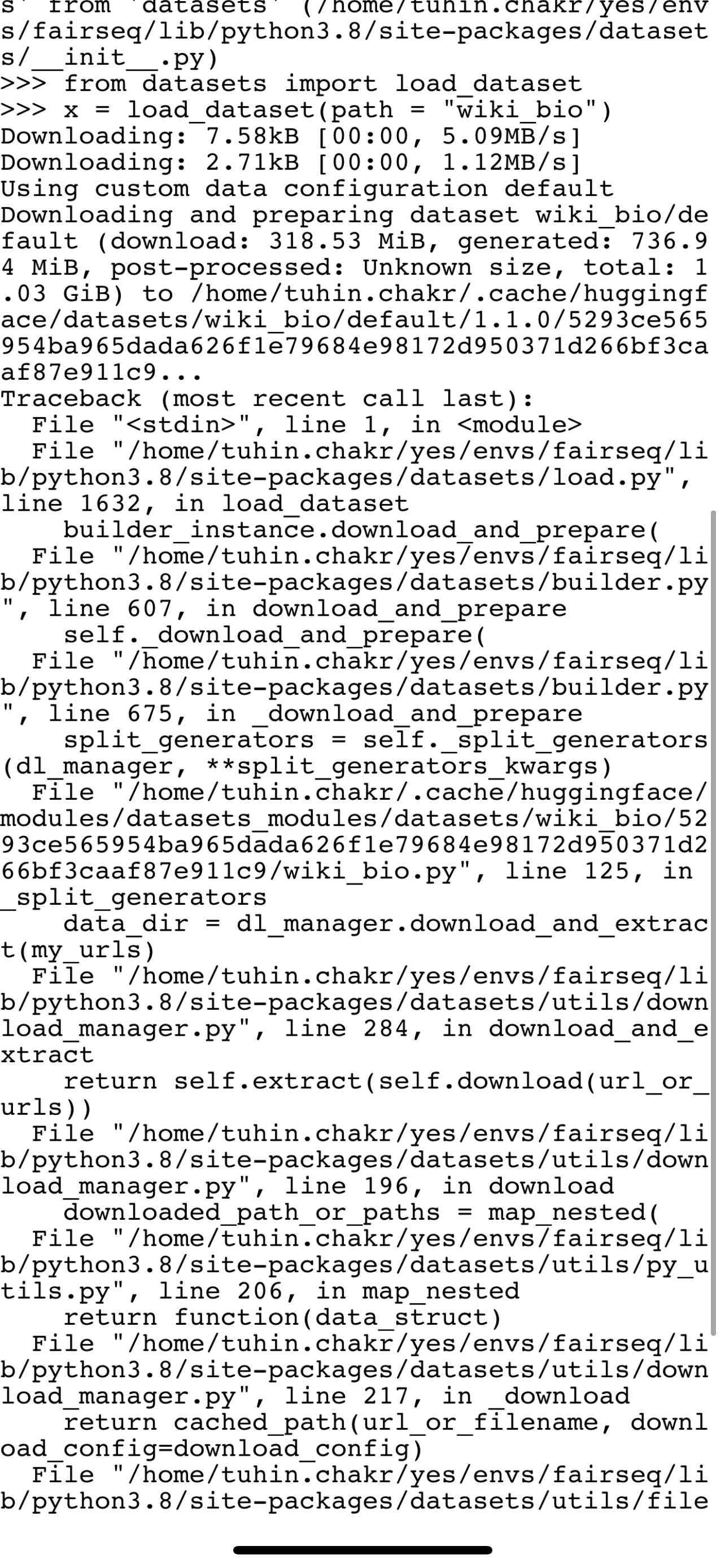

dataset.save_to_disk("normal_save")
# save ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3578/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3578/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3577 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3577/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3577/comments | https://api.github.com/repos/huggingface/datasets/issues/3577/events | https://github.com/huggingface/datasets/issues/3577 | 1,102,598,241 | I_kwDODunzps5BuFBh | 3,577 | Add The Mexican Emotional Speech Database (MESD) | {
"login": "omarespejel",
"id": 4755430,
"node_id": "MDQ6VXNlcjQ3NTU0MzA=",
"avatar_url": "https://avatars.githubusercontent.com/u/4755430?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omarespejel",
"html_url": "https://github.com/omarespejel",
"followers_url": "https://api.github.com/us... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
... | open | false | null | [] | null | 0 | 2022-01-13T23:49:36 | 2022-01-27T14:14:38 | null | NONE | null | ## Adding a Dataset
- **Name:** *The Mexican Emotional Speech Database (MESD)*
- **Description:** *Contains 864 voice recordings with six different prosodies: anger, disgust, fear, happiness, neutral, and sadness. Furthermore, three voice categories are included: female adult, male adult, and child. *
- **Paper:** *... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3577/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3577/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3576 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3576/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3576/comments | https://api.github.com/repos/huggingface/datasets/issues/3576/events | https://github.com/huggingface/datasets/pull/3576 | 1,102,059,651 | PR_kwDODunzps4w8sUm | 3,576 | Add PASS dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-13T17:16:07 | 2022-01-20T16:50:48 | 2022-01-20T16:50:47 | CONTRIBUTOR | null | This PR adds the PASS dataset.
Closes #3043 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3576/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3576/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3576",
"html_url": "https://github.com/huggingface/datasets/pull/3576",
"diff_url": "https://github.com/huggingface/datasets/pull/3576.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3576.patch",
"merged_at": "2022-01-20T16:50... |
https://api.github.com/repos/huggingface/datasets/issues/3575 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3575/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3575/comments | https://api.github.com/repos/huggingface/datasets/issues/3575/events | https://github.com/huggingface/datasets/pull/3575 | 1,101,947,955 | PR_kwDODunzps4w8Usm | 3,575 | Add Arrow type casting to struct for Image and Audio + Support nested casting | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 7 | 2022-01-13T15:36:59 | 2022-01-21T13:22:28 | 2022-01-21T13:22:27 | MEMBER | null | ## Intro
1. Currently, it's not possible to have nested features containing Audio or Image.
2. Moreover one can keep an Arrow array as a StringArray to store paths to images, but such arrays can't be directly concatenated to another image array if it's stored an another Arrow type (typically, a StructType).
3... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3575/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3575/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3575",
"html_url": "https://github.com/huggingface/datasets/pull/3575",
"diff_url": "https://github.com/huggingface/datasets/pull/3575.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3575.patch",
"merged_at": "2022-01-21T13:22... |
https://api.github.com/repos/huggingface/datasets/issues/3574 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3574/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3574/comments | https://api.github.com/repos/huggingface/datasets/issues/3574/events | https://github.com/huggingface/datasets/pull/3574 | 1,101,781,401 | PR_kwDODunzps4w7vu6 | 3,574 | Fix qa4mre tags | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 0 | 2022-01-13T13:56:59 | 2022-01-13T14:03:02 | 2022-01-13T14:03:01 | MEMBER | null | The YAML tags were invalid. I also fixed the dataset mirroring logging that failed because of this issue [here](https://github.com/huggingface/datasets/actions/runs/1690109581) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3574/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3574/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3574",
"html_url": "https://github.com/huggingface/datasets/pull/3574",
"diff_url": "https://github.com/huggingface/datasets/pull/3574.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3574.patch",
"merged_at": "2022-01-13T14:03... |
https://api.github.com/repos/huggingface/datasets/issues/3573 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3573/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3573/comments | https://api.github.com/repos/huggingface/datasets/issues/3573/events | https://github.com/huggingface/datasets/pull/3573 | 1,101,157,676 | PR_kwDODunzps4w5oE_ | 3,573 | Add Mauve metric | {
"login": "jthickstun",
"id": 2321244,
"node_id": "MDQ6VXNlcjIzMjEyNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/2321244?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jthickstun",
"html_url": "https://github.com/jthickstun",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | 1 | 2022-01-13T03:52:48 | 2022-01-20T15:00:08 | 2022-01-20T15:00:08 | CONTRIBUTOR | null | Add support for the [Mauve](https://github.com/krishnap25/mauve) metric introduced in this [paper](https://arxiv.org/pdf/2102.01454.pdf) (Neurips, 2021). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3573/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3573/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3573",
"html_url": "https://github.com/huggingface/datasets/pull/3573",
"diff_url": "https://github.com/huggingface/datasets/pull/3573.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3573.patch",
"merged_at": "2022-01-20T15:00... |
https://api.github.com/repos/huggingface/datasets/issues/3572 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3572/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3572/comments | https://api.github.com/repos/huggingface/datasets/issues/3572/events | https://github.com/huggingface/datasets/issues/3572 | 1,100,634,244 | I_kwDODunzps5BmliE | 3,572 | ConnectionError: Couldn't reach https://storage.googleapis.com/ai4bharat-public-indic-nlp-corpora/evaluations/wikiann-ner.tar.gz (error 403) | {
"login": "sahoodib",
"id": 79107194,
"node_id": "MDQ6VXNlcjc5MTA3MTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/79107194?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sahoodib",
"html_url": "https://github.com/sahoodib",
"followers_url": "https://api.github.com/users/sah... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | open | false | null | [] | null | 0 | 2022-01-12T17:59:36 | 2022-01-17T13:15:28 | null | NONE | null | ## Adding a Dataset
- **Name:**IndicGLUE**
- **Description:** *natural language understanding benchmark for Indian languages*
- **Paper:** *(https://indicnlp.ai4bharat.org/home/)*
- **Data:** *https://huggingface.co/datasets/indic_glue#data-fields*
- **Motivation:** *I am trying to train my model on Indian languag... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3572/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3572/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3571 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3571/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3571/comments | https://api.github.com/repos/huggingface/datasets/issues/3571/events | https://github.com/huggingface/datasets/pull/3571 | 1,100,519,604 | PR_kwDODunzps4w3fVQ | 3,571 | Add missing tasks to MuchoCine dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-12T16:07:32 | 2022-01-20T16:51:08 | 2022-01-20T16:51:07 | CONTRIBUTOR | null | Addresses the 2nd bullet point in #2520.
I'm also removing the licensing information, because I couldn't verify that it is correct. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3571/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3571/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3571",
"html_url": "https://github.com/huggingface/datasets/pull/3571",
"diff_url": "https://github.com/huggingface/datasets/pull/3571.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3571.patch",
"merged_at": "2022-01-20T16:51... |
https://api.github.com/repos/huggingface/datasets/issues/3570 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3570/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3570/comments | https://api.github.com/repos/huggingface/datasets/issues/3570/events | https://github.com/huggingface/datasets/pull/3570 | 1,100,480,791 | PR_kwDODunzps4w3Xez | 3,570 | Add the KMWP dataset (extension of #3564) | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 1 | 2022-01-12T15:33:08 | 2022-01-26T02:16:48 | null | NONE | null | New pull request of #3564 (Add the KMWP dataset) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3570/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3570/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3570",
"html_url": "https://github.com/huggingface/datasets/pull/3570",
"diff_url": "https://github.com/huggingface/datasets/pull/3570.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3570.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3569 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3569/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3569/comments | https://api.github.com/repos/huggingface/datasets/issues/3569/events | https://github.com/huggingface/datasets/pull/3569 | 1,100,478,994 | PR_kwDODunzps4w3XGo | 3,569 | Add the DKTC dataset (Extension of #3564) | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 7 | 2022-01-12T15:31:29 | 2022-01-26T02:16:21 | null | NONE | null | New pull request of #3564. (for DKTC)
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3569/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3569/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3569",
"html_url": "https://github.com/huggingface/datasets/pull/3569",
"diff_url": "https://github.com/huggingface/datasets/pull/3569.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3569.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3568 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3568/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3568/comments | https://api.github.com/repos/huggingface/datasets/issues/3568/events | https://github.com/huggingface/datasets/issues/3568 | 1,100,380,631 | I_kwDODunzps5BlnnX | 3,568 | Downloading Hugging Face Medical Dialog Dataset NonMatchingSplitsSizesError | {
"login": "fabianslife",
"id": 49265757,
"node_id": "MDQ6VXNlcjQ5MjY1NzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/49265757?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fabianslife",
"html_url": "https://github.com/fabianslife",
"followers_url": "https://api.github.com/... | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | open | false | null | [] | null | 0 | 2022-01-12T14:03:44 | 2022-01-17T13:15:41 | null | NONE | null | I wanted to download the Nedical Dialog Dataset from huggingface, using this github link:
https://github.com/huggingface/datasets/tree/master/datasets/medical_dialog
After downloading the raw datasets from google drive, i unpacked everything and put it in the same folder as the medical_dialog.py which is:
```
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3568/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3568/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3567 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3567/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3567/comments | https://api.github.com/repos/huggingface/datasets/issues/3567/events | https://github.com/huggingface/datasets/pull/3567 | 1,100,296,696 | PR_kwDODunzps4w2xDl | 3,567 | Fix push to hub to allow individual split push | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [] | open | false | null | [] | null | 0 | 2022-01-12T12:42:58 | 2022-01-12T13:29:01 | null | MEMBER | null | # Description of the issue
If one decides to push a split on a datasets repo, he uploads the dataset and overrides the config. However previous config splits end up being lost despite still having the dataset necessary.
The new flow is the following:
- query the old config from the repo
- update into a new co... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3567/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3567/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3567",
"html_url": "https://github.com/huggingface/datasets/pull/3567",
"diff_url": "https://github.com/huggingface/datasets/pull/3567.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3567.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3566 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3566/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3566/comments | https://api.github.com/repos/huggingface/datasets/issues/3566/events | https://github.com/huggingface/datasets/pull/3566 | 1,100,155,902 | PR_kwDODunzps4w2Tcc | 3,566 | Add initial electricity time series dataset | {
"login": "kashif",
"id": 8100,
"node_id": "MDQ6VXNlcjgxMDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8100?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kashif",
"html_url": "https://github.com/kashif",
"followers_url": "https://api.github.com/users/kashif/followers",
... | [] | open | false | null | [] | null | 0 | 2022-01-12T10:21:32 | 2022-02-11T12:02:39 | null | NONE | null | Here is an initial prototype time series dataset | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3566/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3566/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3566",
"html_url": "https://github.com/huggingface/datasets/pull/3566",
"diff_url": "https://github.com/huggingface/datasets/pull/3566.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3566.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3565 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3565/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3565/comments | https://api.github.com/repos/huggingface/datasets/issues/3565/events | https://github.com/huggingface/datasets/pull/3565 | 1,099,296,693 | PR_kwDODunzps4wzjhH | 3,565 | Add parameter `preserve_index` to `from_pandas` | {
"login": "Sorrow321",
"id": 20703486,
"node_id": "MDQ6VXNlcjIwNzAzNDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/20703486?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sorrow321",
"html_url": "https://github.com/Sorrow321",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 2 | 2022-01-11T15:26:37 | 2022-01-12T16:11:27 | 2022-01-12T16:11:27 | CONTRIBUTOR | null | Added optional parameter, so that user can get rid of useless index preserving. [Issue](https://github.com/huggingface/datasets/issues/3563) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3565/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3565/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3565",
"html_url": "https://github.com/huggingface/datasets/pull/3565",
"diff_url": "https://github.com/huggingface/datasets/pull/3565.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3565.patch",
"merged_at": "2022-01-12T16:11... |
https://api.github.com/repos/huggingface/datasets/issues/3564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3564/comments | https://api.github.com/repos/huggingface/datasets/issues/3564/events | https://github.com/huggingface/datasets/pull/3564 | 1,099,214,403 | PR_kwDODunzps4wzSOL | 3,564 | Add the KMWP & DKTC dataset. | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 3 | 2022-01-11T14:14:08 | 2022-01-12T15:33:49 | 2022-01-12T15:33:28 | NONE | null | Add the DKTC dataset.
- https://github.com/tunib-ai/DKTC | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3564/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3564/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3564",
"html_url": "https://github.com/huggingface/datasets/pull/3564",
"diff_url": "https://github.com/huggingface/datasets/pull/3564.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3564.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3563 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3563/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3563/comments | https://api.github.com/repos/huggingface/datasets/issues/3563/events | https://github.com/huggingface/datasets/issues/3563 | 1,099,070,368 | I_kwDODunzps5Bgnug | 3,563 | Dataset.from_pandas preserves useless index | {
"login": "Sorrow321",
"id": 20703486,
"node_id": "MDQ6VXNlcjIwNzAzNDg2",
"avatar_url": "https://avatars.githubusercontent.com/u/20703486?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Sorrow321",
"html_url": "https://github.com/Sorrow321",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | 1 | 2022-01-11T12:07:07 | 2022-01-12T16:11:27 | 2022-01-12T16:11:27 | CONTRIBUTOR | null | ## Describe the bug
Let's say that you want to create a Dataset object from pandas dataframe. Most likely you will write something like this:
```
import pandas as pd
from datasets import Dataset
df = pd.read_csv('some_dataset.csv')
# Some DataFrame preprocessing code...
dataset = Dataset.from_pandas(df)
`... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3563/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3563/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3562 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3562/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3562/comments | https://api.github.com/repos/huggingface/datasets/issues/3562/events | https://github.com/huggingface/datasets/pull/3562 | 1,098,341,351 | PR_kwDODunzps4wwa44 | 3,562 | Allow multiple task templates of the same type | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-10T20:32:07 | 2022-01-11T14:16:47 | 2022-01-11T14:16:47 | CONTRIBUTOR | null | Add support for multiple task templates of the same type. Fixes (partially) #2520.
CC: @lewtun | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3562/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3562/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3562",
"html_url": "https://github.com/huggingface/datasets/pull/3562",
"diff_url": "https://github.com/huggingface/datasets/pull/3562.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3562.patch",
"merged_at": "2022-01-11T14:16... |
https://api.github.com/repos/huggingface/datasets/issues/3561 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3561/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3561/comments | https://api.github.com/repos/huggingface/datasets/issues/3561/events | https://github.com/huggingface/datasets/issues/3561 | 1,098,328,870 | I_kwDODunzps5Bdysm | 3,561 | Cannot load ‘bookcorpusopen’ | {
"login": "HUIYINXUE",
"id": 54684403,
"node_id": "MDQ6VXNlcjU0Njg0NDAz",
"avatar_url": "https://avatars.githubusercontent.com/u/54684403?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HUIYINXUE",
"html_url": "https://github.com/HUIYINXUE",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | null | [] | null | 2 | 2022-01-10T20:17:18 | 2022-01-20T17:23:50 | null | NONE | null | ## Describe the bug
Cannot load 'bookcorpusopen'
## Steps to reproduce the bug
```python
dataset = load_dataset('bookcorpusopen')
```
or
```python
dataset = load_dataset('bookcorpusopen',script_version='master')
```
## Actual results
ConnectionError: Couldn't reach https://the-eye.eu/public/AI/pile_pre... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3561/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3561/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3560/comments | https://api.github.com/repos/huggingface/datasets/issues/3560/events | https://github.com/huggingface/datasets/pull/3560 | 1,098,280,652 | PR_kwDODunzps4wwOMf | 3,560 | Run pyupgrade for Python 3.6+ | {
"login": "bryant1410",
"id": 3905501,
"node_id": "MDQ6VXNlcjM5MDU1MDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3905501?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bryant1410",
"html_url": "https://github.com/bryant1410",
"followers_url": "https://api.github.com/users... | [] | closed | false | null | [] | null | 3 | 2022-01-10T19:20:53 | 2022-01-31T13:38:49 | 2022-01-31T09:37:34 | CONTRIBUTOR | null | Run the command:
```bash
pyupgrade $(find . -name "*.py" -type f) --py36-plus
```
Which mainly avoids unnecessary lists creations and also removes unnecessary code for Python 3.6+.
It was originally part of #3489.
Tip for reviewing faster: use the CLI (`git diff`) and scroll. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3560/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3560/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3560",
"html_url": "https://github.com/huggingface/datasets/pull/3560",
"diff_url": "https://github.com/huggingface/datasets/pull/3560.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3560.patch",
"merged_at": "2022-01-31T09:37... |
https://api.github.com/repos/huggingface/datasets/issues/3559 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3559/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3559/comments | https://api.github.com/repos/huggingface/datasets/issues/3559/events | https://github.com/huggingface/datasets/pull/3559 | 1,098,178,222 | PR_kwDODunzps4wv420 | 3,559 | Fix `DuplicatedKeysError` and improve card in `tweet_qa` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-10T17:27:40 | 2022-01-12T15:13:58 | 2022-01-12T15:13:57 | CONTRIBUTOR | null | Fix #3555 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3559/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3559/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3559",
"html_url": "https://github.com/huggingface/datasets/pull/3559",
"diff_url": "https://github.com/huggingface/datasets/pull/3559.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3559.patch",
"merged_at": "2022-01-12T15:13... |
https://api.github.com/repos/huggingface/datasets/issues/3558 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3558/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3558/comments | https://api.github.com/repos/huggingface/datasets/issues/3558/events | https://github.com/huggingface/datasets/issues/3558 | 1,098,025,866 | I_kwDODunzps5BcouK | 3,558 | Integrate Milvus (pymilvus) library | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2022-01-10T15:20:29 | 2022-01-10T15:20:29 | null | CONTRIBUTOR | null | Milvus is a popular open-source vector database. We should add a new vector index to support this project. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3558/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3558/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3557 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3557/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3557/comments | https://api.github.com/repos/huggingface/datasets/issues/3557/events | https://github.com/huggingface/datasets/pull/3557 | 1,097,946,034 | PR_kwDODunzps4wvIHl | 3,557 | Fix bug in `ImageClassifcation` task template | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 3 | 2022-01-10T14:09:59 | 2022-01-11T15:47:52 | 2022-01-11T15:47:52 | CONTRIBUTOR | null | Fixes a bug in the `ImageClassification` task template which requires specifying class labels twice in dataset scripts. Additionally, this PR refactors the API around the classification task templates for cleaner `labels` handling.
CC: @lewtun @nateraw | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3557/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3557/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3557",
"html_url": "https://github.com/huggingface/datasets/pull/3557",
"diff_url": "https://github.com/huggingface/datasets/pull/3557.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3557.patch",
"merged_at": "2022-01-11T15:47... |
https://api.github.com/repos/huggingface/datasets/issues/3556 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3556/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3556/comments | https://api.github.com/repos/huggingface/datasets/issues/3556/events | https://github.com/huggingface/datasets/pull/3556 | 1,097,907,724 | PR_kwDODunzps4wvALx | 3,556 | Preserve encoding/decoding with features in `Iterable.map` call | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-10T13:32:20 | 2022-01-18T19:54:08 | 2022-01-18T19:54:07 | CONTRIBUTOR | null | As described in https://github.com/huggingface/datasets/issues/3505#issuecomment-1004755657, this PR uses a generator expression to encode/decode examples with `features` (which are set to None in `map`) before applying a map transform.
Fix #3505 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3556/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3556/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3556",
"html_url": "https://github.com/huggingface/datasets/pull/3556",
"diff_url": "https://github.com/huggingface/datasets/pull/3556.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3556.patch",
"merged_at": "2022-01-18T19:54... |
https://api.github.com/repos/huggingface/datasets/issues/3555 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3555/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3555/comments | https://api.github.com/repos/huggingface/datasets/issues/3555/events | https://github.com/huggingface/datasets/issues/3555 | 1,097,736,982 | I_kwDODunzps5BbiMW | 3,555 | DuplicatedKeysError when loading tweet_qa dataset | {
"login": "LeonieWeissweiler",
"id": 30300891,
"node_id": "MDQ6VXNlcjMwMzAwODkx",
"avatar_url": "https://avatars.githubusercontent.com/u/30300891?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LeonieWeissweiler",
"html_url": "https://github.com/LeonieWeissweiler",
"followers_url": "https... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | 1 | 2022-01-10T10:53:11 | 2022-01-12T15:17:33 | 2022-01-12T15:13:56 | NONE | null | When loading the tweet_qa dataset with `load_dataset('tweet_qa')`, the following error occurs:
`DuplicatedKeysError: FAILURE TO GENERATE DATASET !
Found duplicate Key: 2a167f9e016ba338e1813fed275a6a1e
Keys should be unique and deterministic in nature
`
Might be related to issues #2433 and #2333
- `datasets` ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3555/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3555/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3554 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3554/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3554/comments | https://api.github.com/repos/huggingface/datasets/issues/3554/events | https://github.com/huggingface/datasets/issues/3554 | 1,097,711,367 | I_kwDODunzps5Bbb8H | 3,554 | ImportError: cannot import name 'is_valid_waiter_error' | {
"login": "danielbellhv",
"id": 84714841,
"node_id": "MDQ6VXNlcjg0NzE0ODQx",
"avatar_url": "https://avatars.githubusercontent.com/u/84714841?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielbellhv",
"html_url": "https://github.com/danielbellhv",
"followers_url": "https://api.github.c... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 3 | 2022-01-10T10:32:04 | 2022-01-21T09:30:24 | null | NONE | null | Based on [SO post](https://stackoverflow.com/q/70606147/17840900).
I'm following along to this [Notebook][1], cell "**Loading the dataset**".
Kernel: `conda_pytorch_p36`.
I run:
```
! pip install datasets transformers optimum[intel]
```
Output:
```
Requirement already satisfied: datasets in /home/ec2-u... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3554/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3554/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3553 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3553/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3553/comments | https://api.github.com/repos/huggingface/datasets/issues/3553/events | https://github.com/huggingface/datasets/issues/3553 | 1,097,252,275 | I_kwDODunzps5BZr2z | 3,553 | set_format("np") no longer works for Image data | {
"login": "cgarciae",
"id": 5862228,
"node_id": "MDQ6VXNlcjU4NjIyMjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/5862228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cgarciae",
"html_url": "https://github.com/cgarciae",
"followers_url": "https://api.github.com/users/cgarc... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | 4 | 2022-01-09T17:18:13 | 2022-01-13T13:39:26 | null | NONE | null | ## Describe the bug
`dataset.set_format("np")` no longer works for image data, previously you could load the MNIST like this:
```python
dataset = load_dataset("mnist")
dataset.set_format("np")
X_train = dataset["train"]["image"][..., None] # <== No longer a numpy array
```
but now it doesn't work, `set_format(... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3553/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3553/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3552 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3552/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3552/comments | https://api.github.com/repos/huggingface/datasets/issues/3552/events | https://github.com/huggingface/datasets/pull/3552 | 1,096,985,204 | PR_kwDODunzps4wsM29 | 3,552 | Add the KMWP & DKTC dataset. | {
"login": "sooftware",
"id": 42150335,
"node_id": "MDQ6VXNlcjQyMTUwMzM1",
"avatar_url": "https://avatars.githubusercontent.com/u/42150335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sooftware",
"html_url": "https://github.com/sooftware",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 0 | 2022-01-08T17:12:14 | 2022-01-11T14:13:30 | 2022-01-11T14:13:30 | NONE | null | Add the KMWP & DKTC dataset.
Additional notes:
- Both datasets will be released on January 10 through the GitHub link below.
- https://github.com/tunib-ai/DKTC
- https://github.com/tunib-ai/KMWP
- So it doesn't work as a link at the moment, but the code will work soon (after it is released on January 10). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3552/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3552/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3552",
"html_url": "https://github.com/huggingface/datasets/pull/3552",
"diff_url": "https://github.com/huggingface/datasets/pull/3552.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3552.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3551 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3551/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3551/comments | https://api.github.com/repos/huggingface/datasets/issues/3551/events | https://github.com/huggingface/datasets/pull/3551 | 1,096,561,111 | PR_kwDODunzps4wq_AO | 3,551 | Add more compression types for `to_json` | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.gi... | [] | open | false | null | [] | null | 8 | 2022-01-07T18:25:02 | 2022-02-04T14:06:39 | null | CONTRIBUTOR | null | This PR adds `bz2`, `xz`, and `zip` (WIP) for `to_json`. I also plan to add `infer` like how `pandas` does it | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3551/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3551/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3551",
"html_url": "https://github.com/huggingface/datasets/pull/3551",
"diff_url": "https://github.com/huggingface/datasets/pull/3551.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3551.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3550 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3550/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3550/comments | https://api.github.com/repos/huggingface/datasets/issues/3550/events | https://github.com/huggingface/datasets/issues/3550 | 1,096,522,377 | I_kwDODunzps5BW5qJ | 3,550 | Bug in `openbookqa` dataset | {
"login": "lucadiliello",
"id": 23355969,
"node_id": "MDQ6VXNlcjIzMzU1OTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucadiliello",
"html_url": "https://github.com/lucadiliello",
"followers_url": "https://api.github.c... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | 0 | 2022-01-07T17:32:57 | 2022-01-17T13:16:33 | null | CONTRIBUTOR | null | ## Describe the bug
Dataset entries contains a typo.
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> obqa = load_dataset('openbookqa', 'main')
>>> obqa['train'][0]
```
## Expected results
```python
{'id': '7-980', 'question_stem': 'The sun is responsible for', 'choices'... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3550/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3550/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3549 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3549/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3549/comments | https://api.github.com/repos/huggingface/datasets/issues/3549/events | https://github.com/huggingface/datasets/pull/3549 | 1,096,426,996 | PR_kwDODunzps4wqkGt | 3,549 | Fix sem_eval_2018_task_1 download location | {
"login": "maxpel",
"id": 31095360,
"node_id": "MDQ6VXNlcjMxMDk1MzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/31095360?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxpel",
"html_url": "https://github.com/maxpel",
"followers_url": "https://api.github.com/users/maxpel/fo... | [] | closed | false | null | [] | null | 2 | 2022-01-07T15:37:52 | 2022-01-27T15:52:03 | 2022-01-27T15:52:03 | CONTRIBUTOR | null | This changes the download location of sem_eval_2018_task_1 files to include the test set labels as discussed in https://github.com/huggingface/datasets/issues/2745#issuecomment-954588500_ with @lhoestq. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3549/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3549/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3549",
"html_url": "https://github.com/huggingface/datasets/pull/3549",
"diff_url": "https://github.com/huggingface/datasets/pull/3549.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3549.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3548 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3548/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3548/comments | https://api.github.com/repos/huggingface/datasets/issues/3548/events | https://github.com/huggingface/datasets/issues/3548 | 1,096,409,512 | I_kwDODunzps5BWeGo | 3,548 | Specify the feature types of a dataset on the Hub without needing a dataset script | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.github.com/users/abidl... | [
{
"login": "abidlabs",
"id": 1778297,
"node_id": "MDQ6VXNlcjE3NzgyOTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/1778297?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abidlabs",
"html_url": "https://github.com/abidlabs",
"followers_url": "https://api.gi... | null | 1 | 2022-01-07T15:17:06 | 2022-01-20T14:48:38 | 2022-01-20T14:48:38 | MEMBER | null | **Is your feature request related to a problem? Please describe.**
Currently if I upload a CSV with paths to audio files, the column type is string instead of Audio.
**Describe the solution you'd like**
I'd like to be able to specify the types of the column, so that when loading the dataset I directly get the feat... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3548/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3548/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3547 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3547/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3547/comments | https://api.github.com/repos/huggingface/datasets/issues/3547/events | https://github.com/huggingface/datasets/issues/3547 | 1,096,405,515 | I_kwDODunzps5BWdIL | 3,547 | Datasets created with `push_to_hub` can't be accessed in offline mode | {
"login": "TevenLeScao",
"id": 26709476,
"node_id": "MDQ6VXNlcjI2NzA5NDc2",
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TevenLeScao",
"html_url": "https://github.com/TevenLeScao",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | 1 | 2022-01-07T15:12:25 | 2022-01-10T10:44:44 | null | MEMBER | null | ## Describe the bug
In offline mode, one can still access previously-cached datasets. This fails with datasets created with `push_to_hub`.
## Steps to reproduce the bug
in Python:
```
import datasets
mpwiki = datasets.load_dataset("teven/matched_passages_wikidata")
```
in bash:
```
export HF_DATASETS_OFFLIN... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3547/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3547/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3546 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3546/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3546/comments | https://api.github.com/repos/huggingface/datasets/issues/3546/events | https://github.com/huggingface/datasets/pull/3546 | 1,096,367,684 | PR_kwDODunzps4wqYIV | 3,546 | Remove print statements in datasets | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 1 | 2022-01-07T14:30:24 | 2022-01-07T18:09:16 | 2022-01-07T18:09:15 | CONTRIBUTOR | null | This is a second time I'm removing print statements in our datasets, so I've added a test to avoid these issues in the future. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3546/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3546/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3546",
"html_url": "https://github.com/huggingface/datasets/pull/3546",
"diff_url": "https://github.com/huggingface/datasets/pull/3546.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3546.patch",
"merged_at": "2022-01-07T18:09... |
https://api.github.com/repos/huggingface/datasets/issues/3545 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3545/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3545/comments | https://api.github.com/repos/huggingface/datasets/issues/3545/events | https://github.com/huggingface/datasets/pull/3545 | 1,096,189,889 | PR_kwDODunzps4wpziv | 3,545 | fix: 🐛 pass token when retrieving the split names | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/foll... | [] | closed | false | null | [] | null | 3 | 2022-01-07T10:29:22 | 2022-01-10T10:51:47 | 2022-01-10T10:51:46 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3545/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3545/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3545",
"html_url": "https://github.com/huggingface/datasets/pull/3545",
"diff_url": "https://github.com/huggingface/datasets/pull/3545.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3545.patch",
"merged_at": "2022-01-10T10:51... |
https://api.github.com/repos/huggingface/datasets/issues/3544 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3544/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3544/comments | https://api.github.com/repos/huggingface/datasets/issues/3544/events | https://github.com/huggingface/datasets/issues/3544 | 1,095,784,681 | I_kwDODunzps5BUFjp | 3,544 | Ability to split a dataset in multiple files. | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2022-01-06T23:02:25 | 2022-01-06T23:02:25 | null | CONTRIBUTOR | null | Hello,
**Is your feature request related to a problem? Please describe.**
My use case is that I have one writer that adds columns and multiple workers reading the same `Dataset`. Each worker should have access to columns added by the writer when they reload the dataset.
I understand that we shouldn't overwrite... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3544/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3544/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3543 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3543/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3543/comments | https://api.github.com/repos/huggingface/datasets/issues/3543/events | https://github.com/huggingface/datasets/issues/3543 | 1,095,226,438 | I_kwDODunzps5BR9RG | 3,543 | Allow loading community metrics from the hub, just like datasets | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 2067400324,
"node_id": "MDU6... | open | false | null | [] | null | 3 | 2022-01-06T11:26:26 | 2022-01-09T20:28:13 | null | CONTRIBUTOR | null | **Is your feature request related to a problem? Please describe.**
Currently, I can load a metric implemented by me by providing the local path to the file in `load_metric`.
However, there is no option to do it with the metric uploaded to the hub.
This means that if I want to allow other users to use it, they must d... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3543/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3543/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3542 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3542/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3542/comments | https://api.github.com/repos/huggingface/datasets/issues/3542/events | https://github.com/huggingface/datasets/pull/3542 | 1,095,088,485 | PR_kwDODunzps4wmPIP | 3,542 | Update the CC-100 dataset card | {
"login": "aajanki",
"id": 353043,
"node_id": "MDQ6VXNlcjM1MzA0Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/353043?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aajanki",
"html_url": "https://github.com/aajanki",
"followers_url": "https://api.github.com/users/aajanki/fo... | [] | closed | false | null | [] | null | 0 | 2022-01-06T08:35:18 | 2022-01-06T18:37:44 | 2022-01-06T18:37:44 | CONTRIBUTOR | null | * summary from the dataset homepage
* more details about the data structure
* this dataset does not contain annotations | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3542/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3542/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3542",
"html_url": "https://github.com/huggingface/datasets/pull/3542",
"diff_url": "https://github.com/huggingface/datasets/pull/3542.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3542.patch",
"merged_at": "2022-01-06T18:37... |
https://api.github.com/repos/huggingface/datasets/issues/3541 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3541/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3541/comments | https://api.github.com/repos/huggingface/datasets/issues/3541/events | https://github.com/huggingface/datasets/issues/3541 | 1,095,033,828 | I_kwDODunzps5BROPk | 3,541 | Support 7-zip compressed data files | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 1 | 2022-01-06T07:11:03 | 2022-01-19T14:01:18 | null | MEMBER | null | **Is your feature request related to a problem? Please describe.**
We should support 7-zip compressed data files:
- in `extract`
- in `iter_archive`
both in streaming and non-streaming modes.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3541/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3541/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3540 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3540/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3540/comments | https://api.github.com/repos/huggingface/datasets/issues/3540/events | https://github.com/huggingface/datasets/issues/3540 | 1,094,900,336 | I_kwDODunzps5BQtpw | 3,540 | How to convert torch.utils.data.Dataset to datasets.arrow_dataset.Dataset? | {
"login": "CindyTing",
"id": 35062414,
"node_id": "MDQ6VXNlcjM1MDYyNDE0",
"avatar_url": "https://avatars.githubusercontent.com/u/35062414?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CindyTing",
"html_url": "https://github.com/CindyTing",
"followers_url": "https://api.github.com/users/... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | 0 | 2022-01-06T02:13:42 | 2022-01-06T02:17:39 | null | NONE | null | Hi,
I use torch.utils.data.Dataset to define my own data, but I need to use the 'map' function of datasets.arrow_dataset.Dataset later, so I hope to convert torch.utils.data.Dataset to datasets.arrow_dataset.Dataset.
Here is an example.
```
from torch.utils.data import Dataset
from datasets.arrow_dataset import ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3540/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3540/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3539 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3539/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3539/comments | https://api.github.com/repos/huggingface/datasets/issues/3539/events | https://github.com/huggingface/datasets/pull/3539 | 1,094,813,242 | PR_kwDODunzps4wlXU4 | 3,539 | Research wording for nc licenses | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 1 | 2022-01-05T23:01:38 | 2022-01-06T18:58:20 | 2022-01-06T18:58:19 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3539/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3539/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3539",
"html_url": "https://github.com/huggingface/datasets/pull/3539",
"diff_url": "https://github.com/huggingface/datasets/pull/3539.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3539.patch",
"merged_at": "2022-01-06T18:58... |
https://api.github.com/repos/huggingface/datasets/issues/3538 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3538/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3538/comments | https://api.github.com/repos/huggingface/datasets/issues/3538/events | https://github.com/huggingface/datasets/pull/3538 | 1,094,756,755 | PR_kwDODunzps4wlLmD | 3,538 | Readme usage update | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-05T21:26:28 | 2022-01-05T23:34:25 | 2022-01-05T23:24:15 | CONTRIBUTOR | null | Noticing that the recent commit throws a lot of errors in the automatic checks. It looks to me that those errors are simply errors that were already there (metadata issues), unrelated to what I've just changed, but worth another look to make sure. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3538/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3538/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3538",
"html_url": "https://github.com/huggingface/datasets/pull/3538",
"diff_url": "https://github.com/huggingface/datasets/pull/3538.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3538.patch",
"merged_at": "2022-01-05T23:24... |
https://api.github.com/repos/huggingface/datasets/issues/3537 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3537/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3537/comments | https://api.github.com/repos/huggingface/datasets/issues/3537/events | https://github.com/huggingface/datasets/pull/3537 | 1,094,738,734 | PR_kwDODunzps4wlH1d | 3,537 | added PII statements and license links to data cards | {
"login": "mcmillanmajora",
"id": 26722925,
"node_id": "MDQ6VXNlcjI2NzIyOTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/26722925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mcmillanmajora",
"html_url": "https://github.com/mcmillanmajora",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | null | 0 | 2022-01-05T20:59:21 | 2022-01-05T22:02:37 | 2022-01-05T22:02:37 | CONTRIBUTOR | null | Updates for the following datacards:
multilingual_librispeech
openslr
speech commands
superb
timit_asr
vctk | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3537/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3537/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3537",
"html_url": "https://github.com/huggingface/datasets/pull/3537",
"diff_url": "https://github.com/huggingface/datasets/pull/3537.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3537.patch",
"merged_at": "2022-01-05T22:02... |
https://api.github.com/repos/huggingface/datasets/issues/3536 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3536/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3536/comments | https://api.github.com/repos/huggingface/datasets/issues/3536/events | https://github.com/huggingface/datasets/pull/3536 | 1,094,645,771 | PR_kwDODunzps4wk0Yb | 3,536 | update `pretty_name` for all datasets | {
"login": "bhavitvyamalik",
"id": 19718818,
"node_id": "MDQ6VXNlcjE5NzE4ODE4",
"avatar_url": "https://avatars.githubusercontent.com/u/19718818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhavitvyamalik",
"html_url": "https://github.com/bhavitvyamalik",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | null | 1 | 2022-01-05T18:45:05 | 2022-01-12T22:59:46 | 2022-01-12T22:59:45 | CONTRIBUTOR | null | This PR updates `pretty_name` for all datasets. Previous PR #3498 had done this for only first 200 datasets | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3536/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3536/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3536",
"html_url": "https://github.com/huggingface/datasets/pull/3536",
"diff_url": "https://github.com/huggingface/datasets/pull/3536.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3536.patch",
"merged_at": "2022-01-12T22:59... |
https://api.github.com/repos/huggingface/datasets/issues/3535 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3535/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3535/comments | https://api.github.com/repos/huggingface/datasets/issues/3535/events | https://github.com/huggingface/datasets/pull/3535 | 1,094,633,214 | PR_kwDODunzps4wkxv0 | 3,535 | Add SVHN dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-05T18:29:09 | 2022-01-12T14:14:35 | 2022-01-12T14:14:35 | CONTRIBUTOR | null | Add the SVHN dataset.
Additional notes:
* compared to the TFDS implementation, exposes additional the "full numbers" config
* adds the streaming support for `os.path.splitext` and `scipy.io.loadmat`
* adds `h5py` to the requirements list for the dummy data test | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3535/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3535/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3535",
"html_url": "https://github.com/huggingface/datasets/pull/3535",
"diff_url": "https://github.com/huggingface/datasets/pull/3535.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3535.patch",
"merged_at": "2022-01-12T14:14... |
https://api.github.com/repos/huggingface/datasets/issues/3534 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3534/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3534/comments | https://api.github.com/repos/huggingface/datasets/issues/3534/events | https://github.com/huggingface/datasets/pull/3534 | 1,094,352,449 | PR_kwDODunzps4wj3LE | 3,534 | Update wiki_dpr README.md | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoest... | [] | closed | false | null | [] | null | 0 | 2022-01-05T13:29:44 | 2022-01-05T14:16:52 | 2022-01-05T14:16:51 | MEMBER | null | Some infos of wiki_dpr were missing as noted in https://github.com/huggingface/datasets/issues/3510, I added them and updated the tags and the examples | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3534/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3534/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3534",
"html_url": "https://github.com/huggingface/datasets/pull/3534",
"diff_url": "https://github.com/huggingface/datasets/pull/3534.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3534.patch",
"merged_at": "2022-01-05T14:16... |
https://api.github.com/repos/huggingface/datasets/issues/3533 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3533/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3533/comments | https://api.github.com/repos/huggingface/datasets/issues/3533/events | https://github.com/huggingface/datasets/issues/3533 | 1,094,156,147 | I_kwDODunzps5BN39z | 3,533 | Task search function on hub not working correctly | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2022-01-05T09:36:30 | 2022-01-05T10:03:08 | null | MEMBER | null | When I want to look at all datasets of the category: `speech-processing` *i.e.* https://huggingface.co/datasets?task_categories=task_categories:speech-processing&sort=downloads , then the following dataset doesn't show up for some reason:
- https://huggingface.co/datasets/speech_commands
even thought it's task t... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3533/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3533/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3532 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3532/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3532/comments | https://api.github.com/repos/huggingface/datasets/issues/3532/events | https://github.com/huggingface/datasets/pull/3532 | 1,094,035,066 | PR_kwDODunzps4wi1ft | 3,532 | Give clearer instructions to add the YAML tags | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [] | closed | false | null | [] | null | 1 | 2022-01-05T06:47:52 | 2022-01-17T15:54:37 | 2022-01-17T15:54:36 | MEMBER | null | Fix #3531.
CC: @julien-c @VictorSanh | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3532/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3532/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3532",
"html_url": "https://github.com/huggingface/datasets/pull/3532",
"diff_url": "https://github.com/huggingface/datasets/pull/3532.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3532.patch",
"merged_at": "2022-01-17T15:54... |
https://api.github.com/repos/huggingface/datasets/issues/3531 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3531/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3531/comments | https://api.github.com/repos/huggingface/datasets/issues/3531/events | https://github.com/huggingface/datasets/issues/3531 | 1,094,033,280 | I_kwDODunzps5BNZ-A | 3,531 | Give clearer instructions to add the YAML tags | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 0 | 2022-01-05T06:44:20 | 2022-01-17T15:54:36 | 2022-01-17T15:54:36 | MEMBER | null | ## Describe the bug
As reported by @julien-c, many community datasets contain the line `YAML tags:` at the top of the YAML section in the header of the README file. See e.g.: https://huggingface.co/datasets/bigscience/P3/commit/a03bea08cf4d58f268b469593069af6aeb15de32
Maybe we should give clearer instruction/hints... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3531/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3531/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3530 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3530/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3530/comments | https://api.github.com/repos/huggingface/datasets/issues/3530/events | https://github.com/huggingface/datasets/pull/3530 | 1,093,894,732 | PR_kwDODunzps4wiZCw | 3,530 | Update README.md | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-05T01:32:07 | 2022-01-05T12:50:51 | 2022-01-05T12:50:50 | CONTRIBUTOR | null | Removing reference to "Common Voice" in Personal and Sensitive Information section.
Adding link to license.
Correct license type in metadata. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3530/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3530/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3530",
"html_url": "https://github.com/huggingface/datasets/pull/3530",
"diff_url": "https://github.com/huggingface/datasets/pull/3530.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3530.patch",
"merged_at": "2022-01-05T12:50... |
https://api.github.com/repos/huggingface/datasets/issues/3529 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3529/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3529/comments | https://api.github.com/repos/huggingface/datasets/issues/3529/events | https://github.com/huggingface/datasets/pull/3529 | 1,093,846,356 | PR_kwDODunzps4wiPA9 | 3,529 | Update README.md | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-04T23:52:47 | 2022-01-05T12:50:15 | 2022-01-05T12:50:14 | CONTRIBUTOR | null | Updating licensing information & personal and sensitive information. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3529/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3529/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3529",
"html_url": "https://github.com/huggingface/datasets/pull/3529",
"diff_url": "https://github.com/huggingface/datasets/pull/3529.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3529.patch",
"merged_at": "2022-01-05T12:50... |
https://api.github.com/repos/huggingface/datasets/issues/3528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3528/comments | https://api.github.com/repos/huggingface/datasets/issues/3528/events | https://github.com/huggingface/datasets/pull/3528 | 1,093,844,616 | PR_kwDODunzps4wiOqH | 3,528 | Update README.md | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-04T23:48:11 | 2022-01-05T12:49:41 | 2022-01-05T12:49:40 | CONTRIBUTOR | null | Updating license with appropriate capitalization & a link.
Updating Personal and Sensitive Information to address PII concern. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3528/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3528/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3528",
"html_url": "https://github.com/huggingface/datasets/pull/3528",
"diff_url": "https://github.com/huggingface/datasets/pull/3528.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3528.patch",
"merged_at": "2022-01-05T12:49... |
https://api.github.com/repos/huggingface/datasets/issues/3527 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3527/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3527/comments | https://api.github.com/repos/huggingface/datasets/issues/3527/events | https://github.com/huggingface/datasets/pull/3527 | 1,093,840,707 | PR_kwDODunzps4wiN1w | 3,527 | Update README.md | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-04T23:39:41 | 2022-01-05T00:23:50 | 2022-01-05T00:23:50 | CONTRIBUTOR | null | Adding licensing information. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3527/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3527/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3527",
"html_url": "https://github.com/huggingface/datasets/pull/3527",
"diff_url": "https://github.com/huggingface/datasets/pull/3527.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3527.patch",
"merged_at": "2022-01-05T00:23... |
https://api.github.com/repos/huggingface/datasets/issues/3526 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3526/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3526/comments | https://api.github.com/repos/huggingface/datasets/issues/3526/events | https://github.com/huggingface/datasets/pull/3526 | 1,093,833,446 | PR_kwDODunzps4wiMaQ | 3,526 | Update README.md | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | open | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-04T23:25:23 | 2022-01-04T23:30:08 | null | CONTRIBUTOR | null | Not entirely sure, following the links here, but it seems the relevant license is at https://github.com/soskek/bookcorpus/blob/master/LICENSE | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3526/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3526/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3526",
"html_url": "https://github.com/huggingface/datasets/pull/3526",
"diff_url": "https://github.com/huggingface/datasets/pull/3526.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3526.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3525 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3525/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3525/comments | https://api.github.com/repos/huggingface/datasets/issues/3525/events | https://github.com/huggingface/datasets/pull/3525 | 1,093,831,268 | PR_kwDODunzps4wiL8p | 3,525 | Adding license information for Openbookcorpus | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | open | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 2 | 2022-01-04T23:20:36 | 2022-01-05T12:48:38 | null | CONTRIBUTOR | null | Not entirely sure, following the links here, but it seems the relevant license is at https://github.com/soskek/bookcorpus/blob/master/LICENSE | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3525/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3525/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3525",
"html_url": "https://github.com/huggingface/datasets/pull/3525",
"diff_url": "https://github.com/huggingface/datasets/pull/3525.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3525.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3524 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3524/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3524/comments | https://api.github.com/repos/huggingface/datasets/issues/3524/events | https://github.com/huggingface/datasets/pull/3524 | 1,093,826,723 | PR_kwDODunzps4wiK_v | 3,524 | Adding link to license. | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 0 | 2022-01-04T23:11:48 | 2022-01-05T12:31:38 | 2022-01-05T12:31:37 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3524/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3524/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3524",
"html_url": "https://github.com/huggingface/datasets/pull/3524",
"diff_url": "https://github.com/huggingface/datasets/pull/3524.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3524.patch",
"merged_at": "2022-01-05T12:31... |
https://api.github.com/repos/huggingface/datasets/issues/3523 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3523/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3523/comments | https://api.github.com/repos/huggingface/datasets/issues/3523/events | https://github.com/huggingface/datasets/pull/3523 | 1,093,819,227 | PR_kwDODunzps4wiJc2 | 3,523 | Added links to licensing and PII message in vctk dataset | {
"login": "mcmillanmajora",
"id": 26722925,
"node_id": "MDQ6VXNlcjI2NzIyOTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/26722925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mcmillanmajora",
"html_url": "https://github.com/mcmillanmajora",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | null | 0 | 2022-01-04T22:56:58 | 2022-01-06T19:33:50 | 2022-01-06T19:33:50 | CONTRIBUTOR | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3523/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3523/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3523",
"html_url": "https://github.com/huggingface/datasets/pull/3523",
"diff_url": "https://github.com/huggingface/datasets/pull/3523.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3523.patch",
"merged_at": "2022-01-06T19:33... |
https://api.github.com/repos/huggingface/datasets/issues/3522 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3522/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3522/comments | https://api.github.com/repos/huggingface/datasets/issues/3522/events | https://github.com/huggingface/datasets/issues/3522 | 1,093,807,586 | I_kwDODunzps5BMi3i | 3,522 | wmt19 is broken (zh-en) | {
"login": "AjayP13",
"id": 5404177,
"node_id": "MDQ6VXNlcjU0MDQxNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5404177?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AjayP13",
"html_url": "https://github.com/AjayP13",
"followers_url": "https://api.github.com/users/AjayP13/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | null | [] | null | 0 | 2022-01-04T22:33:45 | 2022-01-17T13:16:55 | null | NONE | null | ## Describe the bug
A clear and concise description of what the bug is.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("wmt19", 'zh-en')
```
## Expected results
The dataset should download.
## Actual results
`ConnectionError: Couldn't reach ftp://cwmt-wm... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3522/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3522/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3521 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3521/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3521/comments | https://api.github.com/repos/huggingface/datasets/issues/3521/events | https://github.com/huggingface/datasets/pull/3521 | 1,093,797,947 | PR_kwDODunzps4wiFCs | 3,521 | Vivos license update | {
"login": "mcmillanmajora",
"id": 26722925,
"node_id": "MDQ6VXNlcjI2NzIyOTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/26722925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mcmillanmajora",
"html_url": "https://github.com/mcmillanmajora",
"followers_url": "https://api.gi... | [] | closed | false | null | [] | null | 0 | 2022-01-04T22:17:47 | 2022-01-04T22:18:16 | 2022-01-04T22:18:16 | CONTRIBUTOR | null | Updated the license information with the link to the license text | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3521/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3521/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3521",
"html_url": "https://github.com/huggingface/datasets/pull/3521",
"diff_url": "https://github.com/huggingface/datasets/pull/3521.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3521.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/datasets/issues/3520 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3520/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3520/comments | https://api.github.com/repos/huggingface/datasets/issues/3520/events | https://github.com/huggingface/datasets/pull/3520 | 1,093,747,753 | PR_kwDODunzps4wh6oD | 3,520 | Audio datacard update - first pass | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [] | closed | false | {
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"followers_url": "https://api... | [
{
"login": "meg-huggingface",
"id": 90473723,
"node_id": "MDQ6VXNlcjkwNDczNzIz",
"avatar_url": "https://avatars.githubusercontent.com/u/90473723?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/meg-huggingface",
"html_url": "https://github.com/meg-huggingface",
"follower... | null | 2 | 2022-01-04T20:58:25 | 2022-01-05T12:30:21 | 2022-01-05T12:30:20 | CONTRIBUTOR | null | Filling out data card "Personal and Sensitive Information" for speech datasets to note PII concerns | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3520/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3520/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3520",
"html_url": "https://github.com/huggingface/datasets/pull/3520",
"diff_url": "https://github.com/huggingface/datasets/pull/3520.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3520.patch",
"merged_at": "2022-01-05T12:30... |
https://api.github.com/repos/huggingface/datasets/issues/3519 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3519/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3519/comments | https://api.github.com/repos/huggingface/datasets/issues/3519/events | https://github.com/huggingface/datasets/pull/3519 | 1,093,655,205 | PR_kwDODunzps4whnXH | 3,519 | CC100: Using HTTPS for the data source URL fixes load_dataset() | {
"login": "aajanki",
"id": 353043,
"node_id": "MDQ6VXNlcjM1MzA0Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/353043?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aajanki",
"html_url": "https://github.com/aajanki",
"followers_url": "https://api.github.com/users/aajanki/fo... | [] | closed | false | null | [] | null | 0 | 2022-01-04T18:45:54 | 2022-01-05T17:28:34 | 2022-01-05T17:28:34 | CONTRIBUTOR | null | Without this change the following script (with any lang parameter) consistently fails. After changing to the HTTPS URL, the script works as expected.
```python
from datasets import load_dataset
dataset = load_dataset("cc100", lang="en")
```
This is the error produced by the previous script:
```sh
Using cus... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3519/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3519/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3519",
"html_url": "https://github.com/huggingface/datasets/pull/3519",
"diff_url": "https://github.com/huggingface/datasets/pull/3519.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3519.patch",
"merged_at": "2022-01-05T17:28... |
https://api.github.com/repos/huggingface/datasets/issues/3518 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3518/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3518/comments | https://api.github.com/repos/huggingface/datasets/issues/3518/events | https://github.com/huggingface/datasets/issues/3518 | 1,093,063,455 | I_kwDODunzps5BJtMf | 3,518 | Add PubMed Central Open Access dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 3 | 2022-01-04T06:54:35 | 2022-01-17T15:25:57 | 2022-01-17T15:25:57 | MEMBER | null | ## Adding a Dataset
- **Name:** PubMed Central Open Access
- **Description:** The PMC Open Access Subset includes more than 3.4 million journal articles and preprints that are made available under license terms that allow reuse.
- **Paper:** *link to the dataset paper if available*
- **Data:** https://www.ncbi.nlm.... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3518/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3518/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3517 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3517/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3517/comments | https://api.github.com/repos/huggingface/datasets/issues/3517/events | https://github.com/huggingface/datasets/pull/3517 | 1,092,726,651 | PR_kwDODunzps4wemwU | 3,517 | Add CPPE-5 dataset | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 1 | 2022-01-03T18:31:20 | 2022-01-19T02:23:37 | 2022-01-05T18:53:02 | CONTRIBUTOR | null | Adds the recently released CPPE-5 dataset. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3517/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3517/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3517",
"html_url": "https://github.com/huggingface/datasets/pull/3517",
"diff_url": "https://github.com/huggingface/datasets/pull/3517.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3517.patch",
"merged_at": "2022-01-05T18:53... |
https://api.github.com/repos/huggingface/datasets/issues/3516 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3516/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3516/comments | https://api.github.com/repos/huggingface/datasets/issues/3516/events | https://github.com/huggingface/datasets/pull/3516 | 1,092,657,738 | PR_kwDODunzps4weYhE | 3,516 | dataset `asset` - change to raw.githubusercontent.com URLs | {
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-03T16:43:57 | 2022-01-03T17:39:02 | 2022-01-03T17:39:01 | MEMBER | null | Changed the URLs to the ones it was automatically re-directing.
Before, the download was failing | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3516/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3516/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3516",
"html_url": "https://github.com/huggingface/datasets/pull/3516",
"diff_url": "https://github.com/huggingface/datasets/pull/3516.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3516.patch",
"merged_at": "2022-01-03T17:39... |
https://api.github.com/repos/huggingface/datasets/issues/3515 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3515/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3515/comments | https://api.github.com/repos/huggingface/datasets/issues/3515/events | https://github.com/huggingface/datasets/issues/3515 | 1,092,624,695 | I_kwDODunzps5BICE3 | 3,515 | `ExpectedMoreDownloadedFiles` for `evidence_infer_treatment` | {
"login": "VictorSanh",
"id": 16107619,
"node_id": "MDQ6VXNlcjE2MTA3NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/16107619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/VictorSanh",
"html_url": "https://github.com/VictorSanh",
"followers_url": "https://api.github.com/use... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | null | [] | null | 0 | 2022-01-03T15:58:38 | 2022-01-17T13:25:37 | null | MEMBER | null | ## Describe the bug
I am trying to load a dataset called `evidence_infer_treatment`. The first subset (`1.1`) works fine but the second returns an error (`2.0`). It downloads a file but crashes during the checksums.
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> load_dataset("e... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3515/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3515/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3514 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3514/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3514/comments | https://api.github.com/repos/huggingface/datasets/issues/3514/events | https://github.com/huggingface/datasets/pull/3514 | 1,092,606,383 | PR_kwDODunzps4weN9W | 3,514 | Fix to_tf_dataset references in docs | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 1 | 2022-01-03T15:31:39 | 2022-01-05T18:52:48 | 2022-01-05T18:52:48 | CONTRIBUTOR | null | Fix the `to_tf_dataset` references in the docs. The currently failing example of usage will be fixed by #3338. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3514/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3514/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3514",
"html_url": "https://github.com/huggingface/datasets/pull/3514",
"diff_url": "https://github.com/huggingface/datasets/pull/3514.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3514.patch",
"merged_at": "2022-01-05T18:52... |
https://api.github.com/repos/huggingface/datasets/issues/3513 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3513/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3513/comments | https://api.github.com/repos/huggingface/datasets/issues/3513/events | https://github.com/huggingface/datasets/pull/3513 | 1,092,569,802 | PR_kwDODunzps4weGWl | 3,513 | Add desc parameter to filter | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [] | closed | false | null | [] | null | 0 | 2022-01-03T14:44:18 | 2022-01-05T18:31:25 | 2022-01-05T18:31:25 | CONTRIBUTOR | null | Fix #3317 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3513/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3513/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3513",
"html_url": "https://github.com/huggingface/datasets/pull/3513",
"diff_url": "https://github.com/huggingface/datasets/pull/3513.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3513.patch",
"merged_at": "2022-01-05T18:31... |
https://api.github.com/repos/huggingface/datasets/issues/3512 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3512/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3512/comments | https://api.github.com/repos/huggingface/datasets/issues/3512/events | https://github.com/huggingface/datasets/issues/3512 | 1,092,359,973 | I_kwDODunzps5BHBcl | 3,512 | No Data format found | {
"login": "shazzad47",
"id": 57741378,
"node_id": "MDQ6VXNlcjU3NzQxMzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/57741378?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shazzad47",
"html_url": "https://github.com/shazzad47",
"followers_url": "https://api.github.com/users/... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | 1 | 2022-01-03T09:41:11 | 2022-01-17T13:26:05 | 2022-01-17T13:26:05 | NONE | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3512/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3512/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3511 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3511/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3511/comments | https://api.github.com/repos/huggingface/datasets/issues/3511/events | https://github.com/huggingface/datasets/issues/3511 | 1,092,170,411 | I_kwDODunzps5BGTKr | 3,511 | Dataset | {
"login": "MIKURI0114",
"id": 92849978,
"node_id": "U_kgDOBYjHOg",
"avatar_url": "https://avatars.githubusercontent.com/u/92849978?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MIKURI0114",
"html_url": "https://github.com/MIKURI0114",
"followers_url": "https://api.github.com/users/MIKUR... | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | 2 | 2022-01-03T02:03:23 | 2022-01-03T08:41:26 | 2022-01-03T08:23:07 | NONE | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** *link to the dataset viewer page*
*short description of the issue*
Am I the one who added this dataset ? Yes-No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3511/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3511/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3510 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3510/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3510/comments | https://api.github.com/repos/huggingface/datasets/issues/3510/events | https://github.com/huggingface/datasets/issues/3510 | 1,091,997,004 | I_kwDODunzps5BFo1M | 3,510 | `wiki_dpr` details for Open Domain Question Answering tasks | {
"login": "pk1130",
"id": 40918514,
"node_id": "MDQ6VXNlcjQwOTE4NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/40918514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pk1130",
"html_url": "https://github.com/pk1130",
"followers_url": "https://api.github.com/users/pk1130/fo... | [] | open | false | null | [] | null | 1 | 2022-01-02T11:04:01 | 2022-01-05T13:16:05 | null | NONE | null | Hey guys!
Thanks for creating the `wiki_dpr` dataset!
I am currently trying to use the dataset for context retrieval using DPR on NQ questions and need details about what each of the files and data instances mean, which version of the Wikipedia dump it uses, etc. Please respond at your earliest convenience regard... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3510/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3510/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3507 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3507/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3507/comments | https://api.github.com/repos/huggingface/datasets/issues/3507/events | https://github.com/huggingface/datasets/issues/3507 | 1,091,214,808 | I_kwDODunzps5BCp3Y | 3,507 | Discuss whether support canonical datasets w/o dataset_infos.json and/or dummy data | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 2067400324,
"node_id": "MDU6... | open | false | null | [] | null | 11 | 2021-12-30T17:04:25 | 2022-02-10T17:18:10 | null | MEMBER | null | I open this PR to have a public discussion about this topic and make a decision.
As previously discussed, once we have the metadata in the dataset card (README file, containing both Markdown info and YAML tags), what is the point of having also the JSON metadata (dataset_infos.json file)?
On the other hand, the d... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3507/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3507/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3506 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3506/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3506/comments | https://api.github.com/repos/huggingface/datasets/issues/3506/events | https://github.com/huggingface/datasets/pull/3506 | 1,091,166,595 | PR_kwDODunzps4wZpot | 3,506 | Allows DatasetDict.filter to have batching option | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [] | closed | false | null | [] | null | 0 | 2021-12-30T15:22:22 | 2022-01-04T10:24:28 | 2022-01-04T10:24:27 | MEMBER | null | - Related to: #3244
- Fixes: #3503
We extends `.filter( ... batched: bool)` support to DatasetDict. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3506/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3506/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3506",
"html_url": "https://github.com/huggingface/datasets/pull/3506",
"diff_url": "https://github.com/huggingface/datasets/pull/3506.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/3506.patch",
"merged_at": "2022-01-04T10:24... |
https://api.github.com/repos/huggingface/datasets/issues/3505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3505/comments | https://api.github.com/repos/huggingface/datasets/issues/3505/events | https://github.com/huggingface/datasets/issues/3505 | 1,091,150,820 | I_kwDODunzps5BCaPk | 3,505 | cast_column function not working with map function in streaming mode for Audio features | {
"login": "ashu5644",
"id": 8268102,
"node_id": "MDQ6VXNlcjgyNjgxMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8268102?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashu5644",
"html_url": "https://github.com/ashu5644",
"followers_url": "https://api.github.com/users/ashu5... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/use... | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | 1 | 2021-12-30T14:52:01 | 2022-01-18T19:54:07 | 2022-01-18T19:54:07 | NONE | null | ## Describe the bug
I am trying to use Audio class for loading audio features using custom dataset. I am able to cast 'audio' feature into 'Audio' format with cast_column function. On using map function, I am not getting 'Audio' casted feature but getting path of audio file only.
I am getting features of 'audio' of s... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3505/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3505/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3504 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3504/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3504/comments | https://api.github.com/repos/huggingface/datasets/issues/3504/events | https://github.com/huggingface/datasets/issues/3504 | 1,090,682,230 | I_kwDODunzps5BAn12 | 3,504 | Unable to download PUBMED_title_abstracts_2019_baseline.jsonl.zst | {
"login": "ToddMorrill",
"id": 12600692,
"node_id": "MDQ6VXNlcjEyNjAwNjky",
"avatar_url": "https://avatars.githubusercontent.com/u/12600692?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ToddMorrill",
"html_url": "https://github.com/ToddMorrill",
"followers_url": "https://api.github.com/... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.g... | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | 1 | 2021-12-29T18:23:20 | 2022-01-17T13:28:53 | null | NONE | null | ## Describe the bug
I am unable to download the PubMed dataset from the link provided in the [Hugging Face Course (Chapter 5 Section 4)](https://huggingface.co/course/chapter5/4?fw=pt).
https://the-eye.eu/public/AI/pile_preliminary_components/PUBMED_title_abstracts_2019_baseline.jsonl.zst
## Steps to reproduce ... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3504/timeline | null | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3503 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3503/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3503/comments | https://api.github.com/repos/huggingface/datasets/issues/3503/events | https://github.com/huggingface/datasets/issues/3503 | 1,090,472,735 | I_kwDODunzps5A_0sf | 3,503 | Batched in filter throws error | {
"login": "gpucce",
"id": 32967787,
"node_id": "MDQ6VXNlcjMyOTY3Nzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/32967787?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gpucce",
"html_url": "https://github.com/gpucce",
"followers_url": "https://api.github.com/users/gpucce/fo... | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://api.github.com/users/... | [
{
"login": "thomasw21",
"id": 24695242,
"node_id": "MDQ6VXNlcjI0Njk1MjQy",
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomasw21",
"html_url": "https://github.com/thomasw21",
"followers_url": "https://a... | null | 0 | 2021-12-29T12:01:04 | 2022-01-04T10:24:27 | 2022-01-04T10:24:27 | NONE | null | I hope this is really a bug, I could not find it among the open issues
## Describe the bug
using `batched=False` in DataSet.filter throws error
```python
TypeError: filter() got an unexpected keyword argument 'batched'
```
but in the docs it is lister as an argument.
## Steps to reproduce the bug
```python
... | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3503/timeline | null | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.