
MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs
Paper • 2505.19800 • Published • 2
category string | split string | Name string | Subsets string | HF Link null | Link string | License string | Year int64 | Language string | Dialect string | Domain string | Form string | Collection Style null | Description string | Volume float64 | Unit string | Ethical Risks null | Provider string | Derived From null | Paper Title null | Paper Link null | Script string | Tokenized bool | Host string | Access string | Cost string | Test Split null | Tasks string | Venue Title null | Venue Type null | Venue Name null | Authors string | Affiliations string | Abstract string | Name_exist int64 | Subsets_exist int64 | HF Link_exist null | Link_exist int64 | License_exist int64 | Year_exist int64 | Language_exist int64 | Dialect_exist int64 | Domain_exist int64 | Form_exist int64 | Collection Style_exist null | Description_exist int64 | Volume_exist int64 | Unit_exist int64 | Ethical Risks_exist null | Provider_exist int64 | Derived From_exist null | Paper Title_exist null | Paper Link_exist null | Script_exist int64 | Tokenized_exist int64 | Host_exist int64 | Access_exist int64 | Cost_exist int64 | Test Split_exist null | Tasks_exist int64 | Venue Title_exist null | Venue Type_exist null | Venue Name_exist null | Authors_exist int64 | Affiliations_exist int64 | Abstract_exist int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ar | valid | 101 Billion Arabic Words Dataset | [] | null | https://hf.co/datasets/ClusterlabAi/101_billion_arabic_words_dataset | Apache-2.0 | 2,024 | ar | mixed | ['web pages'] | text | null | The 101 Billion Arabic Words Dataset is curated by the Clusterlab team and consists of 101 billion words extracted and cleaned from web content, specifically targeting Arabic text. This dataset is intended for use in natural language processing applications, particularly in training and fine-tuning Large Language Model... | 101,000,000,000 | tokens | null | ['Clusterlab'] | null | null | null | Arab | false | HuggingFace | Free | null | ['text generation', 'language modeling'] | null | null | null | ['Manel Aloui', 'Hasna Chouikhi', 'Ghaith Chaabane', 'Haithem Kchaou', 'Chehir Dhaouadi'] | ['Clusterlab'] | In recent years, Large Language Models (LLMs) have revolutionized the field of natural language processing, showcasing an impressive rise predominantly in English-centric domains. These advancements have set a global benchmark, inspiring significant efforts toward developing Arabic LLMs capable of understanding and gen... | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 0 | null | null | null | 1 | 1 | 1 | |
ar | valid | WinoMT | [] | null | https://github.com/gabrielStanovsky/mt_gender | MIT License | 2,019 | multilingual | Modern Standard Arabic | ['public datasets'] | text | null | Evaluating Gender Bias in Machine Translation | 3,888 | sentences | null | [] | null | null | null | Arab | false | GitHub | Free | null | ['machine translation'] | null | null | null | ['Gabriel Stanovsky', 'Noah A. Smith', 'Luke Zettlemoyer'] | ['Allen Institute for Artificial Intelligence', 'University of Washington', 'University of Washington', 'Facebook'] | We present the first challenge set and evaluation protocol for the analysis of gender bias in machine translation (MT). Our approach uses two recent coreference resolution datasets composed of English sentences which cast participants into non-stereotypical gender roles (e.g., “The doctor asked the nurse to help her in... | 1 | 1 | null | 0 | 0 | 1 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | valid | ArabicMMLU | [] | null | https://github.com/mbzuai-nlp/ArabicMMLU | CC BY-NC-SA 4.0 | 2,024 | ar | Modern Standard Arabic | ['web pages'] | text | null | ArabicMMLU is the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic ... | 14,575 | sentences | null | ['MBZUAI'] | null | null | null | Arab | false | GitHub | Free | null | ['question answering', 'multiple choice question answering'] | null | null | null | ['Fajri Koto', 'Haonan Li', 'Sara Shatnawi', 'Jad Doughman', 'Abdelrahman Boda Sadallah', 'Aisha Alraeesi', 'Khalid Almubarak', 'Zaid Alyafeai', 'Neha Sengupta', 'Shady Shehata', 'Nizar Habash', 'Preslav Nakov', 'Timothy Baldwin'] | [] | The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availabili... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | valid | CIDAR | [] | null | https://hf.co/datasets/arbml/CIDAR | CC BY-NC 4.0 | 2,024 | ar | Modern Standard Arabic | ['commentary', 'LLM'] | text | null | CIDAR contains 10,000 instructions and their output. The dataset was created by selecting around 9,109 samples from Alpagasus dataset then translating it to Arabic using ChatGPT. In addition, we append that with around 891 Arabic grammar instructions from the webiste Ask the teacher. | 10,000 | sentences | null | ['ARBML'] | null | null | null | Arab | false | HuggingFace | Free | null | ['instruction tuning', 'question answering'] | null | null | null | ['Zaid Alyafeai', 'Khalid Almubarak', 'Ahmed Ashraf', 'Deema Alnuhait', 'Saied Alshahrani', 'Gubran A. Q. Abdulrahman', 'Gamil Ahmed', 'Qais Gawah', 'Zead Saleh', 'Mustafa Ghaleb', 'Yousef Ali', 'Maged S. Al-Shaibani'] | [] | Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions.
However, current instruction datasets predominantly cater to English or are derived from
English-dominated LLMs, resulting in inherent
biases toward Western culture. This bias significantly impact... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | valid | Belebele | [{'Name': 'acm_Arab', 'Dialect': 'Iraq', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'arb_Arab', 'Dialect': 'Modern Standard Arabic', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'apc_Arab', 'Dialect': 'Levant', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'ars_Arab', 'Dialect': 'Saudi Arabia', 'Volume': 900.... | null | https://github.com/facebookresearch/belebele | CC BY-SA 4.0 | 2,024 | multilingual | mixed | ['wikipedia', 'public datasets'] | text | null | A multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. | 5,400 | sentences | null | ['Facebook'] | null | null | null | Arab | false | GitHub | Free | null | ['question answering', 'multiple choice question answering'] | null | null | null | ['Lucas Bandarkar', 'Davis Liang', 'Benjamin Muller', 'Mikel Artetxe', 'Satya Narayan Shukla', 'Donald Husa', 'Naman Goyal', 'Abhinandan Krishnan', 'Luke Zettlemoyer', 'Madian Khabsa'] | [] | We present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each ques... | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | valid | MGB-2 | [] | null | https://arabicspeech.org/resources/mgb2 | unknown | 2,019 | ar | Modern Standard Arabic | ['TV Channels', 'captions'] | audio | null | from Aljazeera TV programs have been manually captioned with no timing information | 1,200 | hours | null | ['QCRI'] | null | null | null | Arab | false | other | Upon-Request | null | ['speech recognition'] | null | null | null | ['Ahmed Ali', 'Peter Bell', 'James Glass', 'Yacine Messaoui', 'Hamdy Mubarak', 'Steve Renals', 'Yifan Zhang'] | [] | This paper describes the Arabic MGB-3 Challenge — Arabic Speech Recognition in the Wild. Unlike last year's Arabic MGB-2 Challenge, for which the recognition task was based on more than 1,200 hours broadcast TV news recordings from Aljazeera Arabic TV programs, MGB-3 emphasises dialectal Arabic using a multi-genre coll... | 1 | 1 | null | 0 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 0 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | ANETAC | [] | null | https://github.com/MohamedHadjAmeur/ANETAC | unknown | 2,019 | multilingual | Modern Standard Arabic | ['public datasets'] | text | null | English-Arabic named entity transliteration and classification dataset | 79,924 | tokens | null | ['USTHB University', 'University of Salford'] | null | null | null | Arab | false | GitHub | Free | null | ['named entity recognition', 'transliteration', 'machine translation'] | null | null | null | ['Mohamed Seghir Hadj Ameur', 'Farid Meziane', 'Ahmed Guessoum'] | ['USTHB University', 'University of Salford', 'USTHB University'] | In this paper, we make freely accessible ANETAC our English-Arabic named entity transliteration and classification dataset that we built from freely available parallel translation corpora. The dataset contains 79,924 instances, each instance is a triplet (e, a, c), where e is the English named entity, a is its Arabic t... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | TUNIZI | [] | null | https://github.com/chaymafourati/TUNIZI-Sentiment-Analysis-Tunisian-Arabizi-Dataset | unknown | 2,020 | ar | Tunisia | ['social media', 'commentary'] | text | null | first Tunisian Arabizi Dataset including 3K sentences, balanced, covering different topics, preprocessed and annotated as positive and negative | 9,210 | sentences | null | ['iCompass'] | null | null | null | Latin | false | GitHub | Free | null | ['sentiment analysis'] | null | null | null | ['Chayma Fourati', 'Abir Messaoudi', 'Hatem Haddad'] | ['iCompass', 'iCompass', 'iCompass'] | On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called "Tunisian Arabizi". Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer ... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | Shamela | [] | null | https://github.com/OpenArabic/ | unknown | 2,016 | ar | Classical Arabic | ['books'] | text | null | a large-scale, historical corpus of Arabic of about 1 billion
words from diverse periods of time | 6,100 | documents | null | [] | null | null | null | Arab | true | GitHub | Free | null | ['text generation', 'language modeling', 'part of speech tagging', 'morphological analysis'] | null | null | null | ['Yonatan Belinkov', 'Alexander Magidow', 'Maxim Romanov', 'Avi Shmidman', 'Moshe Koppel'] | [] | Arabic is a widely-spoken language with a rich and long history spanning more than fourteen centuries. Yet existing Arabic corpora largely focus on the modern period or lack sufficient diachronic information. We develop a large-scale, historical corpus of Arabic of about 1 billion words from diverse periods of time. We... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 0 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | POLYGLOT-NER | [] | null | https://huggingface.co/datasets/rmyeid/polyglot_ner | unknown | 2,014 | multilingual | Modern Standard Arabic | ['wikipedia'] | text | null | Polyglot-NER A training dataset automatically generated from Wikipedia and Freebase the task of named entity recognition. The dataset contains the basic Wikipedia based training data for 40 languages we have (with coreference resolution) for the task of named entity recognition. | 10,000,144 | tokens | null | ['Stony Brook University'] | null | null | null | Arab | false | HuggingFace | Free | null | ['named entity recognition'] | null | null | null | ['Rami Al-Rfou', 'Vivek Kulkarni', 'Bryan Perozzi', 'Steven Skiena'] | ['Stony Brook University'] | The increasing diversity of languages used on the web introduces a new level of complexity to Information Retrieval (IR) systems. We can no longer assume that textual content is written in one language or even the same language family. In this paper, we demonstrate how to build massive multilingual annotators with mini... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 0 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | DODa | [] | null | https://github.com/darija-open-dataset/dataset | MIT License | 2,021 | multilingual | Morocco | ['other'] | text | null | DODa presents words under different spellings, offers verb-to-noun and masculine-to-feminine correspondences contains the conjugation of hundreds of verbs in different tenses, | 10,000 | tokens | null | [] | null | null | null | Arab-Latin | true | GitHub | Free | null | ['transliteration', 'machine translation', 'part of speech tagging'] | null | null | null | ['Aissam Outchakoucht', 'Hamza Es-Samaali'] | [] | Darija Open Dataset (DODa) is an open-source project for the Moroccan dialect. With more than 10,000 entries DODa is arguably the largest open-source collaborative project for Darija-English translation built for Natural Language Processing purposes. In fact, besides semantic categorization, DODa also adopts a syntacti... | 1 | 1 | null | 1 | 1 | 0 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | LASER | [] | null | https://github.com/facebookresearch/LASER | BSD | 2,019 | multilingual | Modern Standard Arabic | ['public datasets'] | text | null | Aligned sentences in 112 languages extracted from Tatoeba | 8,200,000 | sentences | null | ['Facebook'] | null | null | null | Arab | false | GitHub | Free | null | ['machine translation', 'embedding evaluation'] | null | null | null | ['Mikel Artetxe', 'Holger Schwenk'] | ['University of the Basque Country', 'Facebook AI Research'] | We introduce an architecture to learn joint multilingual sentence representations for 93 languages, belonging to more than 30 different families and written in 28 different scripts. Our system uses a single BiLSTM encoder with a shared BPE vocabulary for all languages, which is coupled with an auxiliary decoder and tra... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | MGB-3 | [] | null | https://github.com/qcri/dialectID | MIT License | 2,017 | ar | Egypt | ['social media', 'captions'] | audio | null | A multi-genre collection of Egyptian YouTube videos. Seven genres were used for the data collection: comedy, cooking, family/kids, fashion, drama, sports, and science (TEDx). A total of 16 hours of videos, split evenly across the different genres | 16 | hours | null | ['QCRI'] | null | null | null | Arab | false | GitHub | Free | null | ['speech recognition'] | null | null | null | ['Ahmed Ali', 'Stephan Vogel', 'Steve Renals'] | [] | This paper describes the Arabic MGB-3 Challenge - Arabic Speech Recognition in the Wild. Unlike last year's Arabic MGB-2 Challenge, for which the recognition task was based on more than 1,200 hours broadcast TV news recordings from Aljazeera Arabic TV programs, MGB-3 emphasises dialectal Arabic using a multi-genre coll... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | Arap-Tweet | [] | null | https://arap.qatar.cmu.edu/templates/research.html | unknown | 2,018 | ar | mixed | ['social media'] | text | null | Arap-Tweet is a large-scale, multi-dialectal Arabic Twitter corpus containing 2.4 million tweets from 11 regions across 16 countries in the Arab world. The dataset includes annotations for dialect, age group, and gender of the users. | 2,400,000 | sentences | null | ['Hamad Bin Khalifa University', 'Carnegie Mellon University Qatar'] | null | null | null | Arab | false | other | Upon-Request | null | ['dialect identification', 'gender identification'] | null | null | null | ['Wajdi Zaghouani', 'Anis Charfi'] | ['Hamad Bin Khalifa University', 'Carnegie Mellon University Qatar'] | In this paper, we present Arap-Tweet, which is a large-scale and multi-dialectal corpus of Tweets from 11 regions and 16 countries in the Arab world representing the major Arabic dialectal varieties. To build this corpus, we collected data from Twitter and we provided a team of experienced annotators with annotation gu... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 0 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | FLORES-101 | [] | null | https://github.com/facebookresearch/flores/tree/main/previous_releases/flores101 | CC BY-SA 4.0 | 2,021 | multilingual | Modern Standard Arabic | ['wikipedia', 'books', 'news articles'] | text | null | The FLORES-101 evaluation benchmark consists of 3001 sentences extracted from English Wikipedia and covers various topics and domains. These sentences have been translated into 101 languages by professional translators through a carefully controlled process. | 3,001 | sentences | null | ['Facebook'] | null | null | null | Arab | false | GitHub | Free | null | ['machine translation'] | null | null | null | ['Naman Goyal', 'Cynthia Gao', 'Vishrav Chaudhary', 'Guillaume Wenzek', 'Da Ju', 'Sanjan Krishnan', "Marc'Aurelio Ranzato", 'Francisco Guzmán', 'Angela Fan'] | ['Facebook AI Research'] | One of the biggest challenges hindering progress in low-resource and multilingual machine translation is the lack of good evaluation benchmarks. Current evaluation benchmarks either lack good coverage of low-resource languages, consider only restricted domains, or are low quality because they are constructed using semi... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | Transliteration | [] | null | https://github.com/google/transliteration | Apache-2.0 | 2,016 | multilingual | Modern Standard Arabic | ['wikipedia'] | text | null | Arabic-English transliteration dataset mined from Wikipedia. | 15,898 | tokens | null | ['Google'] | null | null | null | Arab-Latin | false | GitHub | Free | null | ['transliteration', 'machine translation'] | null | null | null | ['Mihaela Rosca', 'Thomas Breuel'] | ['Google'] | Transliteration is a key component of machine translation systems and software internationalization. This paper demonstrates that neural sequence-to-sequence models obtain state of the art or close to state of the art results on existing datasets. In an effort to make machine transliteration accessible, we open source ... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | ADI-5 | [{'Name': 'Egyptian', 'Dialect': 'Egypt', 'Volume': 14.4, 'Unit': 'hours'}, {'Name': 'Gulf', 'Dialect': 'Gulf', 'Volume': 14.1, 'Unit': 'hours'}, {'Name': 'Levantine', 'Dialect': 'Levant', 'Volume': 14.3, 'Unit': 'hours'}, {'Name': 'MSA', 'Dialect': 'Modern Standard Arabic', 'Volume': 14.3, 'Unit': 'hours'}, {'Name': '... | null | https://github.com/Qatar-Computing-Research-Institute/dialectID | MIT License | 2,016 | ar | mixed | ['TV Channels'] | audio | null | This will be divided across the five major Arabic dialects; Egyptian (EGY), Levantine (LAV), Gulf (GLF), North African (NOR), and Modern Standard Arabic (MSA) | 74.5 | hours | null | ['QCRI'] | null | null | null | Arab | false | GitHub | Free | null | ['dialect identification'] | null | null | null | ['A. Ali', 'Najim Dehak', 'P. Cardinal', 'Sameer Khurana', 'S. Yella', 'James R. Glass', 'P. Bell', 'S. Renals'] | [] | We investigate different approaches for dialect identification in Arabic broadcast speech, using phonetic, lexical features obtained from a speech recognition system, and acoustic features using the i-vector framework. We studied both generative and discriminate classifiers, and we combined these features using a multi... | 1 | 1 | null | 1 | 0 | 0 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | Maknuune | [] | null | https://www.palestine-lexicon.org | CC BY-SA 4.0 | 2,022 | multilingual | Palestine | ['captions', 'public datasets', 'other'] | text | null | A large open lexicon for the Palestinian Arabic dialect. Maknuune has over 36K entries from 17K lemmas,and 3.7K roots. All entries include diacritized Arabic orthography, phonological transcription and English glosses. | 36,302 | tokens | null | ['New York University Abu Dhabi', 'University of Oxford', 'UNRWA'] | null | null | null | Arab-Latin | true | Gdrive | Free | null | ['morphological analysis', 'lexicon analysis'] | null | null | null | ['Shahd Dibas', 'Christian Khairallah', 'Nizar Habash', 'Omar Fayez Sadi', 'Tariq Sairafy', 'Karmel Sarabta', 'Abrar Ardah'] | ['NYUAD', 'University of Oxford', 'UNRWA'] | We present Maknuune, a large open lexicon for the Palestinian Arabic dialect. Maknuune has over 36K entries from 17K lemmas, and 3.7K roots. All entries include diacritized Arabic orthography, phonological transcription and English glosses. Some entries are enriched with additional information such as broken plurals an... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | EmojisAnchors | [] | null | https://codalab.lisn.upsaclay.fr/competitions/2324 | custom | 2,022 | ar | mixed | ['social media', 'public datasets'] | text | null | Fine-Grained Hate Speech Detection on Arabic Twitter | 12,698 | sentences | null | ['QCRI', 'University of Pittsburgh'] | null | null | null | Arab | false | CodaLab | Free | null | ['offensive language detection'] | null | null | null | ['Hamdy Mubarak', 'Hend Al-Khalifa', 'AbdulMohsen Al-Thubaity'] | ['Qatar Computing Research Institute', 'King Saud University', 'King Abdulaziz City for Science and Technology (KACST)'] | We introduce a generic, language-independent method to collect a large percentage of offensive and hate tweets regardless of their topics or genres. We harness the extralinguistic information embedded in the emojis to collect a large number of offensive tweets. We apply the proposed method on Arabic tweets and compare ... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | Calliar | [] | null | https://github.com/ARBML/Calliar | MIT License | 2,021 | ar | Modern Standard Arabic | ['web pages'] | images | null | Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic calligraphy. This repository contains the dataset for the following paper | 2,500 | images | null | ['ARBML'] | null | null | null | Arab | false | GitHub | Free | null | ['optical character recognition'] | null | null | null | ['Zaid Alyafeai', 'Maged S. Al-shaibani', 'Mustafa Ghaleb & Yousif Ahmed Al-Wajih'] | ['KFUPM', 'KFUPM', 'KFUPM', 'KFUPM'] | Calligraphy is an essential part of the Arabic heritage and culture. It has been used in the past for the decoration of houses and mosques. Usually, such calligraphy is designed manually by experts with aesthetic insights. In the past few years, there has been a considerable effort to digitize such type of art by eithe... | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | LABR | [] | null | https://github.com/mohamedadaly/LABR | GPL-2.0 | 2,015 | ar | mixed | ['social media', 'reviews'] | text | null | A large Arabic book review dataset for sentiment analysis | 63,257 | sentences | null | ['Cairo University'] | null | null | null | Arab | false | GitHub | Free | null | ['review classification', 'sentiment analysis'] | null | null | null | ['Mahmoud Nabil', 'Mohamed Aly', 'Amir F. Atiya'] | ['Cairo University', 'Cairo University', 'Cairo University'] | We introduce LABR, the largest sentiment analysis dataset to-date for the Arabic language. It consists of over 63,000 book reviews, each rated on a scale of 1 to 5 stars. We investigate the properties of the dataset, and present its statistics. We explore using the dataset for two tasks: (1) sentiment polarity classifi... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | ACVA | [] | null | https://github.com/FreedomIntelligence/AceGPT | Apache-2.0 | 2,023 | ar | Modern Standard Arabic | ['LLM'] | text | null | ACVA is a Yes-No question dataset, comprising over 8000 questions, generated by GPT-3.5 Turbo from 50 designed Arabic topics to assess model alignment with Arabic values and cultures | 8,000 | sentences | null | ['FreedomIntelligence'] | null | null | null | Arab | false | GitHub | Free | null | ['question answering'] | null | null | null | ['Huang Huang', 'Fei Yu', 'Jianqing Zhu', 'Xuening Sun', 'Hao Cheng', 'Dingjie Song', 'Zhihong Chen', 'Abdulmohsen Alharthi', 'Bang An', 'Juncai He', 'Ziche Liu', 'Zhiyi Zhang', 'Junying Chen', 'Jianquan Li', 'Benyou Wang', 'Lian Zhang', 'Ruoyu Sun', 'Xiang Wan', 'Haizhou Li', 'Jinchao Xu'] | [] | This paper is devoted to the development of a localized Large Language Model (LLM) specifically for Arabic, a language imbued with unique cultural characteristics inadequately addressed by current mainstream models. Significant concerns emerge when addressing cultural sensitivity and local values. To address this, the ... | 1 | 1 | null | 1 | 0 | 0 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | ATHAR | [] | null | https://hf.co/datasets/mohamed-khalil/ATHAR | CC BY-SA 4.0 | 2,024 | multilingual | Classical Arabic | ['books'] | text | null | The ATHAR dataset comprises 66,000 translation pairs from Classical Arabic to English. It spans a wide array of subjects, aiming to enhance the development of NLP models specialized in Classical Arabic. | 66,000 | sentences | null | ['ADAPT/DCU'] | null | null | null | Arab | false | HuggingFace | Free | null | ['machine translation'] | null | null | null | ['Mohammed Khalil', 'Mohammed Sabry'] | ['Independent Researcher', 'ADAPT/DCU'] | Classical Arabic represents a significant era, encompassing the golden age of Arab culture, philosophy, and scientific literature. With a broad consensus on the importance of translating these literatures to enrich knowledge dissemination across communities, the advent of large language models (LLMs) and translation sy... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | OpenITI-proc | [] | null | https://zenodo.org/record/2535593#.YWh7FS8RozU | CC BY 4.0 | 2,018 | ar | Classical Arabic | ['public datasets', 'books'] | text | null | A linguistically annotated version of the OpenITI corpus, with annotations for lemmas, POS tags, parse trees, and morphological segmentation | 7,144 | documents | null | [] | null | null | null | Arab | false | zenodo | Free | null | ['text generation', 'language modeling'] | null | null | null | ['Yonatan Belinkov', 'Alexander Magidow', 'Alberto Barrón-Cedeño', 'Avi Shmidman', 'Maxim Romanov'] | [] | Arabic is a widely-spoken language with a long and rich history, but existing corpora and language technology focus mostly on modern Arabic and its varieties. Therefore, studying the history of the language has so far been mostly limited to manual analyses on a small scale. In this work, we present a large-scale histor... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 0 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | AraDangspeech | [] | null | https://github.com/UBC-NLP/Arabic-Dangerous-Dataset | unknown | 2,020 | ar | mixed | ['social media'] | text | null | Dangerous speech detection | 5,011 | sentences | null | ['The University of British Columbia'] | null | null | null | Arab | false | GitHub | Free | null | ['offensive language detection'] | null | null | null | ['Ali Alshehri', 'El Moatez Billah Nagoudi', 'Muhammad Abdul-Mageed'] | ['The University of British Columbia'] | Social media communication has become a significant part of daily activity in modern societies. For this reason, ensuring safety in social media platforms is a necessity. Use of dangerous language such as physical threats in online environments is a somewhat rare, yet remains highly important. Although several works ha... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | Arabic-Hebrew TED Talks Parallel Corpus | [] | null | https://github.com/ajinkyakulkarni14/TED-Multilingual-Parallel-Corpus | unknown | 2,016 | multilingual | Modern Standard Arabic | ['captions', 'public datasets'] | text | null | This dataset consists of 2023 TED talks with aligned Arabic and Hebrew subtitles. Sentences were rebuilt and aligned using English as a pivot to improve accuracy, offering a valuable resource for Arabic-Hebrew machine translation tasks. | 225,000 | sentences | null | ['FBK'] | null | null | null | Arab | false | GitHub | Free | null | ['machine translation'] | null | null | null | ['Mauro Cettolo'] | ['Fondazione Bruno Kessler (FBK)'] | We describe an Arabic-Hebrew parallel corpus of TED talks built upon WIT3, the Web inventory that repurposes the original content of the TED website in a way which is more convenient for MT researchers. The benchmark consists of about 2,000 talks, whose subtitles in Arabic and Hebrew have been accurately aligned and re... | 1 | 1 | null | 0 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
ar | test | ARASPIDER | [] | null | https://github.com/ahmedheakl/AraSpider | MIT License | 2,024 | ar | Modern Standard Arabic | ['public datasets', 'LLM'] | text | null | AraSpider is a translated version of the Spider dataset, which is commonly used for semantic parsing and text-to-SQL generation. The dataset includes 200 databases across 138 domains with 10,181 questions and 5,693 unique complex SQL queries. | 10,181 | sentences | null | ['Egypt-Japan University of Science and Technology'] | null | null | null | Arab | false | GitHub | Free | null | ['semantic parsing', 'text to SQL'] | null | null | null | ['Ahmed Heakl', 'Youssef Mohamed', 'Ahmed B. Zaky'] | ['Egypt-Japan University of Science and Technology', 'Egypt-Japan University of Science and Technology', 'Egypt-Japan University of Science and Technology'] | This study presents AraSpider, the first Arabic version of the Spider dataset, aimed at improving natural language processing (NLP) in the Arabic-speaking community. Four multilingual translation models were tested for their effectiveness in translating English to Arabic. Additionally, two models were assessed for thei... | 1 | 1 | null | 1 | 0 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | HellaSwag | null | null | https://rowanzellers.com/hellaswag | MIT License | 2,019 | en | null | ['captions', 'public datasets', 'wikipedia'] | text | null | HellaSwag is a dataset for physically situated commonsense reasoning. | 70,000 | sentences | null | ['Allen Institute of Artificial Intelligence'] | null | null | null | null | false | other | Free | null | ['natural language inference'] | null | null | null | ['Rowan Zellers', 'Ari Holtzman', 'Yonatan Bisk', 'Ali Farhadi', 'Yejin Choi'] | ['University of Washington', 'Allen Institute of Artificial Intelligence'] | Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys." With the introduction of BERT, near human-level performance was reached.... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | GPQA | null | null | https://github.com/idavidrein/gpqa/ | CC BY 4.0 | 2,023 | en | null | ['other'] | text | null | A challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. The questions are designed to be difficult for both state-of-the-art AI systems and skilled non-experts, even with access to the web. | 448 | sentences | null | ['New York University', 'Cohere', 'Anthropic'] | null | null | null | null | false | GitHub | Free | null | ['multiple choice question answering'] | null | null | null | ['David Rein', 'Betty Li Hou', 'Asa Cooper Stickland', 'Jackson Petty', 'Richard Yuanzhe Pang', 'Julien Dirani', 'Julian Michael', 'Samuel R. Bowman'] | ['New York University', 'Cohere', 'Anthropic, PBC'] | We present GPQA, a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry. We ensure that the questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy (74% when discounting clear m... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | GoEmotions | null | null | https://github.com/google-research/google-research/tree/master/goemotions | Apache-2.0 | 2,020 | en | null | ['social media'] | text | null | A large-scale, manually annotated dataset of 58,009 English Reddit comments. The comments are labeled for 27 fine-grained emotion categories or Neutral, designed for emotion classification and understanding tasks. The dataset was curated to balance sentiment and reduce profanity and harmful content. | 58,009 | sentences | null | ['Google Research'] | null | null | null | null | false | GitHub | Free | null | ['emotion classification'] | null | null | null | ['Dorottya Demszky', 'Dana Movshovitz-Attias', 'Jeongwoo Ko', 'Alan Cowen', 'Gaurav Nemade', 'Sujith Ravi'] | ['Stanford Linguistics', 'Google Research', 'Amazon Alexa'] | Understanding emotion expressed in language has a wide range of applications, from building empathetic chatbots to detecting harmful online behavior. Advancement in this area can be improved using large-scale datasets with a fine-grained typology, adaptable to multiple downstream tasks. We introduce GoEmotions, the lar... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | SQuAD 2.0 | null | null | https://rajpurkar.github.io/SQuAD-explorer/ | CC BY-SA 4.0 | 2,018 | en | null | ['wikipedia'] | text | null | A version of the Stanford Question Answering Dataset (SQuAD) that combines existing SQuAD 1.1 data with over 50,000 new, unanswerable questions written adversarially by crowdworkers. | 151,054 | sentences | null | ['Stanford University'] | null | null | null | null | false | GitHub | Free | null | ['question answering'] | null | null | null | ['Pranav Rajpurkar', 'Robin Jia', 'Percy Liang'] | ['Stanford University'] | Extractive reading comprehension systems can often locate the correct answer to a question in a context document, but they also tend to make unreliable guesses on questions for which the correct answer is not stated in the context. Existing datasets either focus exclusively on answerable questions, or use automatically... | 1 | null | null | 0 | 1 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | LAMBADA | null | null | https://huggingface.co/datasets/cimec/lambada | unknown | 2,016 | en | null | ['books', 'public datasets'] | text | null | A dataset of narrative passages designed for a word prediction task. The key characteristic is that human subjects can easily guess the final word of a passage when given the full context, but find it nearly impossible when only shown the last sentence. | 10,022 | documents | null | ['University of Trento', 'University of Amsterdam'] | null | null | null | null | false | HuggingFace | Free | null | ['word prediction'] | null | null | null | ['Denis Paperno', 'Germán Kruszewski', 'Angeliki Lazaridou', 'Quan Ngoc Pham', 'Raffaella Bernardi', 'Sandro Pezzelle', 'Marco Baroni', 'Gemma Boleda', 'Raquel Fernández'] | ['University of Trento', 'University of Amsterdam'] | We introduce LAMBADA, a dataset to evaluate the capabilities of computational models for text understanding by means of a word prediction task. LAMBADA is a collection of narrative passages sharing the characteristic that human subjects are able to guess their last word if they are exposed to the whole passage, but not... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 0 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | ClimbMix | null | null | https://huggingface.co/datasets/nvidia/ClimbMix | CC BY-NC 4.0 | 2,025 | en | null | ['web pages', 'LLM', 'other'] | text | null | ClimbMix is a compact 400-billion-token dataset designed for efficient language model pre-training. It was created by applying the CLIMB framework to find an optimal mixture from the ClimbLab corpus (derived from Nemotron-CC and smollm-corpus), delivering superior performance under an equal token budget. | 400,000,000,000 | tokens | null | ['NVIDIA'] | null | null | null | null | true | HuggingFace | Free | null | ['language modeling'] | null | null | null | ['Shizhe Diao', 'Yu Yang', 'Yonggan Fu', 'Xin Dong', 'Dan Su', 'Markus Kliegl', 'Zijia Chen', 'Peter Belcak', 'Yoshi Suhara', 'Hongxu Yin', 'Mostofa Patwary', 'Yingyan (Celine) Lin', 'Jan Kautz', 'Pavlo Molchanov'] | ['NVIDIA'] | Pre-training datasets are typically collected from web content and lack inherent domain divisions. For instance, widely used datasets like Common Crawl do not include explicit domain labels, while manually curating labeled datasets such as The Pile is labor-intensive. Consequently, identifying an optimal pre-training d... | 1 | null | null | 1 | 1 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | RACE | null | null | http://www.cs.cmu.edu/~glai1/data/race/ | custom | 2,017 | en | null | ['web pages'] | text | null | A large-scale reading comprehension dataset collected from English exams for middle and high school Chinese students. It consists of nearly 28,000 passages and 100,000 multiple-choice questions designed by human experts to evaluate understanding and reasoning abilities, covering a variety of topics. | 97,687 | sentences | null | ['Carnegie Mellon University'] | null | null | null | null | false | other | Free | null | ['multiple choice question answering'] | null | null | null | ['Guokun Lai', 'Qizhe Xie', 'Hanxiao Liu', 'Yiming Yang', 'Eduard Hovy'] | ['Carnegie Mellon University'] | We present RACE, a new dataset for benchmark evaluation of methods in the reading comprehension task. Collected from the English exams for middle and high school Chinese students in the age range between 12 to 18, RACE consists of near 28,000 passages and near 100,000 questions generated by human experts (English instr... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | MMLU-Pro | null | null | https://huggingface.co/datasets/TIGER-Lab/MMLU-Pro | MIT License | 2,024 | en | null | ['public datasets', 'web pages', 'LLM'] | text | null | An enhanced version of the MMLU benchmark, MMLU-Pro features more challenging, reasoning-focused questions with an expanded choice set of ten options. It was created by filtering trivial and noisy questions from MMLU and integrating new questions, followed by expert review, to be more discriminative and robust. | 12,032 | sentences | null | ['University of Waterloo', 'University of Toronto', 'Carnegie Mellon University'] | null | null | null | null | false | HuggingFace | Free | null | ['multiple choice question answering'] | null | null | null | ['Yubo Wang', 'Xueguang Ma', 'Ge Zhang', 'Yuansheng Ni', 'Abhranil Chandra', 'Shiguang Guo', 'Weiming Ren', 'Aaran Arulraj', 'Xuan He', 'Ziyan Jiang', 'Tianle Li', 'Max Ku', 'Kai Wang', 'Alex Zhuang', 'Rongqi Fan', 'Xiang Yue', 'Wenhu Chen'] | ['University of Waterloo', 'University of Toronto', 'Carnegie Mellon University'] | In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks ... | 1 | null | null | 1 | 1 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | BoolQ | null | null | https://github.com/google-research-datasets/boolean-questions | CC BY-SA 3.0 | 2,019 | en | null | ['wikipedia', 'web pages'] | text | null | A reading comprehension dataset of 16,000 naturally occurring yes/no questions. Questions are gathered from unprompted Google search queries and paired with a Wikipedia paragraph containing the answer. The dataset is designed to be challenging, requiring complex, non-factoid inference. | 16,000 | sentences | null | ['Google AI'] | null | null | null | null | false | GitHub | Free | null | ['question answering'] | null | null | null | ['Christopher Clark', 'Kenton Lee', 'Ming-Wei Chang', 'Tom Kwiatkowski', 'Michael Collins', 'Kristina Toutanova'] | ['Paul G. Allen School of CSE, University of Washington', 'Google AI Language'] | In this paper we study yes/no questions that are naturally occurring --- meaning that they are generated in unprompted and unconstrained settings. We build a reading comprehension dataset, BoolQ, of such questions, and show that they are unexpectedly challenging. They often query for complex, non-factoid information, a... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | GSM8K | null | null | https://github.com/openai/grade-school-math | MIT License | 2,021 | en | null | ['other'] | text | null | GSM8K is a dataset of 8.5K high quality grade school math problems created by human problem writers. The dataset is designed to have high linguistic diversity while relying on relatively simple grade school math concepts. | 8,500 | sentences | null | ['OpenAI'] | null | null | null | null | false | GitHub | Free | null | ['question answering'] | null | null | null | ['Karl Cobbe', 'Vineet Kosaraju', 'Mohammad Bavarian', 'Mark Chen', 'Heewoo Jun', 'Łukasz Kaiser', 'Matthias Plappert', 'Jerry Tworek', 'Jacob Hilton', 'Reiichiro Nakano', 'Christopher Hesse', 'John Schulman'] | ['OpenAI'] | State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word pro... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | HotpotQA | null | null | https://hotpotqa.github.io | CC BY-SA 4.0 | 2,018 | en | null | ['wikipedia'] | text | null | A large-scale dataset with 113k Wikipedia-based question-answer pairs. It requires reasoning over multiple supporting documents, features diverse questions, provides sentence-level supporting facts for explainability, and includes factoid comparison questions to test systems' ability to extract and compare facts. | 112,779 | sentences | null | ['Carnegie Mellon University', 'Stanford University', 'Mila, Université de Montréal', 'Google AI'] | null | null | null | null | true | GitHub | Free | null | ['question answering'] | null | null | null | ['Zhilin Yang', 'Peng Qi', 'Saizheng Zhang', 'Yoshua Bengio', 'William W. Cohen', 'Ruslan Salakhutdinov', 'Christopher D. Manning'] | ['Carnegie Mellon University', 'Stanford University', 'Mila, Université de Montréal', 'Google AI'] | Existing question answering (QA) datasets fail to train QA systems to perform complex reasoning and provide explanations for answers. We introduce HotpotQA, a new dataset with 113k Wikipedia-based question-answer pairs with four key features: (1) the questions require finding and reasoning over multiple supporting docu... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | SQuAD | null | null | https://rajpurkar.github.io/SQuAD-explorer/ | CC BY-SA 4.0 | 2,016 | en | null | ['wikipedia'] | text | null | A reading comprehension dataset consisting of over 100,000 questions posed by crowdworkers on a set of Wikipedia articles. The answer to each question is a segment of text, or span, from the corresponding reading passage. | 107,785 | sentences | null | ['Stanford University'] | null | null | null | null | false | GitHub | Free | null | ['question answering'] | null | null | null | ['Pranav Rajpurkar', 'Jian Zhang', 'Konstantin Lopyrev', 'Percy Liang'] | ['Stanford University'] | We present the Stanford Question Answering Dataset (SQuAD), a new reading comprehension dataset consisting of 100,000+ questions posed by crowdworkers on a set of Wikipedia articles, where the answer to each question is a segment of text from the corresponding reading passage. We analyze the dataset to understand the t... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | RefinedWeb | null | null | https://huggingface.co/datasets/tiiuae/falcon-refinedweb | ODC-By | 2,023 | en | null | ['web pages'] | text | null | A large-scale, five trillion token English pretraining dataset derived from CommonCrawl. It was created using extensive filtering and deduplication to demonstrate that high-quality web data alone can produce models that outperform those trained on curated corpora. A 600 billion token extract is publicly available. | 600,000,000,000 | tokens | null | ['Technology Innovation Institute'] | null | null | null | null | false | HuggingFace | Free | null | ['language modeling'] | null | null | null | ['Guilherme Penedo', 'Quentin Malartic', 'Daniel Hesslow', 'Ruxandra Cojocaru', 'Alessandro Cappelli', 'Hamza Alobeidli', 'Baptiste Pannier', 'Ebtesam Almazrouei', 'Julien Launay'] | ['LightOn', 'Technology Innovation Institute', 'LPENS, École normale supérieure'] | Large language models are commonly trained on a mixture of filtered web data and curated high-quality corpora, such as social media conversations, books, or technical papers. This curation process is believed to be necessary to produce performant models with broad zero-shot generalization abilities. However, as larger ... | 1 | null | null | 1 | 1 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | MMLU | null | null | https://github.com/hendrycks/test | MIT License | 2,021 | en | null | ['web pages', 'books'] | text | null | The MMLU dataset is a collection of 57 tasks covering a wide range of subjects, including elementary mathematics, US history, computer science, law, and more. The dataset is designed to measure a text model's multitask accuracy and requires models to possess extensive world knowledge and problem-solving ability. | 15,908 | sentences | null | ['UC Berkeley', 'Columbia University', 'UChicago', 'UIUC'] | null | null | null | null | false | GitHub | Free | null | ['multiple choice question answering'] | null | null | null | ['Dan Hendrycks', 'Collin Burns', 'Steven Basart', 'Andy Zou', 'Mantas Mazeika', 'Dawn Song', 'Jacob Steinhardt'] | ['UC Berkeley', 'Columbia University', 'UChicago', 'UIUC'] | We propose a new test to measure a text model's multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability. We find that while most recent mode... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | PIQA | null | null | http://yonatanbisk.com/piqa | AFL-3.0 | 2,019 | en | null | ['web pages'] | text | null | A benchmark dataset for physical commonsense reasoning, presented as multiple-choice question answering. It contains goal-solution pairs inspired by how-to instructions from instructables.com, designed to test a model's understanding of physical properties, affordances, and object manipulation. The dataset was cleaned ... | 21,000 | sentences | null | ['Allen Institute for Artificial Intelligence', 'Microsoft Research AI', 'Carnegie Mellon University', 'University of Washington'] | null | null | null | null | false | GitHub | Free | null | ['question answering', 'multiple choice question answering', 'commonsense reasoning'] | null | null | null | ['Yonatan Bisk', 'Rowan Zellers', 'Ronan Le Bras', 'Jianfeng Gao', 'Yejin Choi'] | ['Allen Institute for Artificial Intelligence', 'Microsoft Research AI', 'Carnegie Mellon University', 'Paul G. Allen School for Computer Science and Engineering, University of Washington'] | To apply eyeshadow without a brush, should I use a cotton swab or a toothpick? Questions requiring this kind of physical commonsense pose a challenge to today's natural language understanding systems. While recent pretrained models (such as BERT) have made progress on question answering over more abstract domains - suc... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 0 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | BRIGHT | null | null | https://github.com/xlang-ai/BRIGHT | CC BY 4.0 | 2,025 | en | null | ['web pages', 'public datasets', 'LLM'] | text | null | BRIGHT is a new benchmark for reasoning-intensive retrieval. It consists of 12 datasets from diverse and advanced domains where relevance between queries and documents requires intensive reasoning beyond simple keyword or semantic matching. | 1,384 | sentences | null | ['The University of Hong Kong', 'Princeton University', 'Stanford University', 'University of Washington', 'Google Cloud AI Research'] | null | null | null | null | false | GitHub | Free | null | ['information retrieval', 'question answering'] | null | null | null | ['Hongjin Su', 'Howard Yen', 'Mengzhou Xia', 'Weijia Shi', 'Niklas Muennighoff', 'Han-yu Wang', 'Haisu Liu', 'Quan Shi', 'Zachary S. Siegel', 'Michael Tang', 'Ruoxi Sun', 'Jinsung Yoon', 'Sercan Ö. Arık', 'Danqi Chen', 'Tao Yu'] | ['The University of Hong Kong', 'Princeton University', 'Stanford University', 'University of Washington', 'Google Cloud AI Research'] | Existing retrieval benchmarks primarily consist of information-seeking queries (e.g., aggregated questions from search engines) where keyword or semantic-based retrieval is usually sufficient. However, many complex real-world queries require in-depth reasoning to identify relevant documents that go beyond surface form ... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | HLE | null | null | https://lastexam.ai | MIT License | 2,025 | en | null | ['other'] | text | null | Humanity's Last Exam (HLE) is a dataset of 3,000 challenging questions designed to assess the capabilities of large language models (LLMs). The questions are diverse, covering a wide range of topics and requiring different reasoning abilities. The dataset is still under development and accepting new questions. | 2,500 | sentences | null | ['Center for AI Safety', 'Scale AI'] | null | null | null | null | false | other | Free | null | ['question answering', 'multiple choice question answering'] | null | null | null | ['Long Phan', 'Alice Gatti', 'Ziwen Han', 'Nathaniel Li', 'Josephina Hu', 'Hugh Zhang', 'Sean Shi', 'Michael Choi', 'Anish Agrawal', 'Arnav Chopra', 'Adam Khoja', 'Ryan Kim', 'Richard Ren', 'Jason Hausenloy', 'Oliver Zhang', 'Mantas Mazeika', 'Summer Yue', 'Alexandr Wang', 'Dan Hendrycks'] | ['Center for AI Safety', 'Scale AI'] | Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we ... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | TinyStories | null | null | https://huggingface.co/datasets/roneneldan/TinyStories | CDLA-SHARING-1.0 | 2,023 | en | null | ['LLM'] | text | null | TinyStories is a synthetic dataset of short stories generated by GPT-3.5 and GPT-4. The stories are designed to be simple, using only words that a typical 3 to 4-year-old understands. It is intended to train and evaluate small language models on their ability to generate coherent text and demonstrate reasoning. | 2,141,709 | documents | null | ['Microsoft Research'] | null | null | null | null | false | HuggingFace | Free | null | ['language modeling', 'text generation', 'instruction tuning'] | null | null | null | ['Ronen Eldan', 'Yuanzhi Li'] | ['Microsoft Research'] | Language models (LMs) are powerful tools for natural language processing, but they often struggle to produce coherent and fluent text when they are small. Models with around 125M parameters such as GPT-Neo (small) or GPT-2 (small) can rarely generate coherent and consistent English text beyond a few words even after ex... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 0 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | WinoGrande | null | null | http://winogrande.allenai.org | CC BY 4.0 | 2,019 | en | null | ['web pages'] | text | null | WinoGrande is a large-scale dataset of 44,000 problems inspired by the original Winograd Schema Challenge (WSC). The dataset was constructed through a carefully designed crowdsourcing procedure followed by a systematic bias reduction. | 43,972 | sentences | null | ['Allen Institute for Artificial Intelligence', 'University of Washington'] | null | null | null | null | false | other | Free | null | ['commonsense reasoning'] | null | null | null | ['Keisuke Sakaguchi', 'Ronan Le Bras', 'Chandra Bhagavatula', 'Yejin Choi'] | ['Allen Institute for Artificial Intelligence', 'University of Washington'] | The Winograd Schema Challenge (WSC) (Levesque, Davis, and Morgenstern 2011), a benchmark for commonsense reasoning, is a set of 273 expert-crafted pronoun resolution problems originally designed to be unsolvable for statistical models that rely on selectional preferences or word associations. However, recent advances i... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | SciQ | null | null | https://huggingface.co/datasets/allenai/sciq | CC BY-NC 3.0 | 2,017 | en | null | ['books', 'web pages'] | text | null | SciQ is a dataset containing 13,679 multiple-choice science exam questions. It was created using a novel crowdsourcing method that leverages a large corpus of domain-specific text (science textbooks) and a model trained on existing questions to suggest document selections and answer distractors, aiding human workers in... | 13,679 | sentences | null | ['Allen Institute for Artificial Intelligence'] | null | null | null | null | false | HuggingFace | Free | null | ['multiple choice question answering', 'question answering'] | null | null | null | ['Johannes Welbl', 'Nelson F. Liu', 'Matt Gardner'] | ['Allen Institute for Artificial Intelligence', 'University of Washington', 'University College London'] | We present a novel method for obtaining high-quality, domain-targeted multiple choice questions from crowd workers. Generating these questions can be difficult without trading away originality, relevance or diversity in the answer options. Our method addresses these problems by leveraging a large corpus of domain-speci... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 0 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
en | test | TriviaQA | null | null | http://nlp.cs.washington.edu/triviaqa | Apache-2.0 | 2,017 | en | null | ['wikipedia', 'web pages'] | text | null | TriviaQA is a challenging reading comprehension dataset containing over 650K question-answer-evidence triples. TriviaQA includes 95K question-answer pairs authored by trivia enthusiasts and independently gathered evidence documents, six per question on average, that provide high quality distant supervision for answerin... | 650,000 | documents | null | ['University of Washington'] | null | null | null | null | false | other | Free | null | ['question answering', 'information retrieval'] | null | null | null | ['Mandar Joshi', 'Eunsol Choi', 'Daniel S. Weld', 'Luke Zettlemoyer'] | ['Allen Institute for Artificial Intelligence', 'University of Washington'] | We present TriviaQA, a challenging reading comprehension dataset containing over 650K question-answer-evidence triples. TriviaQA includes 95K question-answer pairs authored by trivia enthusiasts and independently gathered evidence documents, six per question on average, that provide high quality distant supervision for... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | null | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JEC | null | null | https://github.com/tmu-nlp/autoJQE | unknown | 2,022 | jp | null | ['public datasets'] | text | null | A quality estimation (QE) dataset created for building an automatic evaluation model for Japanese Grammatical Error Correction (GEC). | 4,391 | sentences | null | ['Tokyo Metropolitan University', 'RIKEN'] | null | null | null | mixed | false | GitHub | Free | null | ['grammatical error correction'] | null | null | null | ['Daisuke Suzuki', 'Yujin Takahashi', 'Ikumi Yamashita', 'Taichi Aida', 'Tosho Hirasawa', 'Michitaka Nakatsuji', 'Masato Mita', 'Mamoru Komachi'] | ['Tokyo Metropolitan University', 'RIKEN'] | In grammatical error correction (GEC), automatic evaluation is an important factor for research and development of GEC systems. Previous studies on automatic evaluation have demonstrated that quality estimation models built from datasets with manual evaluation can achieve high performance in automatic evaluation of Eng... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JParaCrawl | null | null | http://www.kecl.ntt.co.jp/icl/lirg/jparacrawl | custom | 2,020 | multilingual | null | ['web pages'] | text | null | JParaCrawl is a large web-based English-Japanese parallel corpus that was created by crawling the web and finding English-Japanese bitexts. It contains around 8.7 million parallel sentences. | 8,763,995 | sentences | null | ['NTT'] | null | null | null | mixed | false | other | Free | null | ['machine translation'] | null | null | null | ['Makoto Morishita', 'Jun Suzuki', 'Masaaki Nagata'] | ['NTT Corporation'] | Recent machine translation algorithms mainly rely on parallel corpora. However, since the availability of parallel corpora remains limited, only some resource-rich language pairs can benefit from them. We constructed a parallel corpus for English-Japanese, for which the amount of publicly available parallel corpora is ... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | KaoKore | null | null | https://github.com/rois-codh/kaokore | CC BY-SA 4.0 | 2,020 | jp | null | ['web pages'] | images | null | KaoKore is a dataset of 5,552 face images extracted from pre-modern Japanese artwork from the 16th to 17th centuries. It is derived from the 'Collection of Facial Expressions' dataset and provides labels for gender and social status, along with official train/dev/test splits for classification and generative tasks. | 5,552 | images | null | ['Google Brain', 'ROIS-DS Center for Open Data in the Humanities', 'NII', 'University of Cambridge', 'MILA', "Universit'e de Montr'eal"] | null | null | null | mixed | false | GitHub | Free | null | ['gender identification', 'other'] | null | null | null | ['Yingtao Tian', 'Chikahiko Suzuki', 'Tarin Clanuwat', 'Mikel Bober-Irizar', 'Alex Lamb', 'Asanobu Kitamoto'] | ['Google Brain', 'ROIS-DS Center for Open Data in the Humanities', 'NII', 'University of Cambridge', 'MILA', "Universit'e de Montr'eal"] | From classifying handwritten digits to generating strings of text, the datasets which have received long-time focus from the machine learning community vary greatly in their subject matter. This has motivated a renewed interest in building datasets which are socially and culturally relevant, so that algorithmic researc... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | llm-japanese-dataset v0 | null | null | https://huggingface.co/datasets/izumi-lab/llm-japanese-dataset | CC BY-SA 4.0 | 2,023 | multilingual | null | ['public datasets', 'wikipedia', 'news articles', 'LLM'] | text | null | A Japanese chat dataset of approximately 8.4 million records, created for tuning large language models. It is composed of various sub-datasets covering tasks like translation, knowledge-based Q&A, summarization, and more, derived from sources like Wikipedia, WordNet, and other publicly available corpora. | 8,393,726 | sentences | null | ['The University of Tokyo'] | null | null | null | mixed | false | HuggingFace | Free | null | ['machine translation', 'text generation', 'instruction tuning'] | null | null | null | ['Masanori HIRANO', 'Masahiro SUZUKI', 'Hiroki SAKAJI'] | ['The University of Tokyo'] | This study constructed a Japanese chat dataset for tuning large language models (LLMs), which consist of about 8.4 million records. Recently, LLMs have been developed and gaining popularity. However, high-performing LLMs are usually mainly for English. There are two ways to support languages other than English by those... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JaLeCoN | null | null | https://github.com/naist-nlp/jalecon | CC BY-NC-SA 3.0 | 2,023 | jp | null | ['news articles', 'public datasets', 'web pages'] | text | null | JaLeCoN is a Dataset of Japanese Lexical Complexity for Non-Native Readers. It can be used to train or evaluate Japanese lexical complexity prediction models. | 600 | sentences | null | ['NAIST'] | null | null | null | mixed | false | GitHub | Free | null | ['other'] | null | null | null | ['Yusuke Ide', 'Masato Mita', 'Adam Nohejl', 'Hiroki Ouchi', 'Taro Watanabe'] | ['NAIST', 'CyberAgent Inc.', 'RIKEN'] | Lexical complexity prediction (LCP) is the task of predicting the complexity of words in a text on a continuous scale. It plays a vital role in simplifying or annotating complex words to assist readers. To study lexical complexity in Japanese, we construct the first Japanese LCP dataset. Our dataset provides separate c... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JaQuAD | null | null | https://github.com/SkelterLabsInc/JaQuAD | CC BY-SA 3.0 | 2,022 | jp | null | ['wikipedia'] | text | null | JaQuAD is a Japanese Question Answering dataset consisting of 39,696 extractive question-answer pairs on Japanese Wikipedia articles. The dataset was annotated by humans and is available on GitHub. | 39,696 | sentences | null | ['Skelter Labs'] | null | null | null | mixed | false | GitHub | Free | null | ['question answering'] | null | null | null | ['ByungHoon So', 'Kyuhong Byun', 'Kyungwon Kang', 'Seongjin Cho'] | ['Skelter Labs'] | Question Answering (QA) is a task in which a machine understands a given document and a question to find an answer. Despite impressive progress in the NLP area, QA is still a challenging problem, especially for non-English languages due to the lack of annotated datasets. In this paper, we present the Japanese Question ... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JAFFE | null | null | https://zenodo.org/record/3451524 | custom | 2,021 | jp | null | ['other'] | images | null | The Japanese Female Facial Expression (JAFFE) dataset is a set of 213 images depicting facial expressions posed by 10 Japanese women. The set includes six basic facial expressions plus a neutral face. The dataset also includes semantic ratings for each image from 60 Japanese female observers. | 213 | images | null | ['Kyushu University', 'Advanced Telecommunications Research Institute International'] | null | null | null | mixed | false | zenodo | Free | null | ['other'] | null | null | null | ['Michael J. Lyons'] | ['Ritsumeikan University'] | Twenty-five years ago, my colleagues Miyuki Kamachi and Jiro Gyoba and I designed and photographed JAFFE, a set of facial expression images intended for use in a study of face perception. In 2019, without seeking permission or informing us, Kate Crawford and Trevor Paglen exhibited JAFFE in two widely publicized art sh... | 1 | null | null | 1 | 1 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JaFIn | null | null | https://huggingface.co/datasets/Sakaji-Lab/JaFIn | CC BY-NC-SA 4.0 | 2,024 | jp | null | ['wikipedia', 'web pages'] | text | null | JaFIn is a Japanese financial instruction dataset that was manually curated from various sources, including government websites, Wikipedia, and financial institutions. | 1,490 | sentences | null | ['Hokkaido University', 'University of Tokyo'] | null | null | null | mixed | false | HuggingFace | Free | null | ['instruction tuning', 'question answering'] | null | null | null | ['Kota Tanabe', 'Masahiro Suzuki', 'Hiroki Sakaji', 'Itsuki Noda'] | ['Hokkaido University', 'University of Tokyo'] | We construct an instruction dataset for the large language model (LLM) in the Japanese finance domain. Domain adaptation of language models, including LLMs, is receiving more attention as language models become more popular. This study demonstrates the effectiveness of domain adaptation through instruction tuning. To a... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | Japanese Fake News Dataset | null | null | https://hkefka385.github.io/dataset/fakenews-japanese/ | CC BY-NC-ND 4.0 | 2,022 | jp | null | ['news articles', 'social media'] | text | null | The first Japanese fake news dataset, annotated with a novel, fine-grained scheme. It goes beyond factuality to include disseminator's intent, harm, target, and purpose, based on 307 news stories from Twitter verified by Fact Check Initiative Japan. | 307 | documents | null | ['SANKEN Osaka University', 'NAIST'] | null | null | null | mixed | false | GitHub | Free | null | ['fake news detection'] | null | null | null | ['Taichi Murayama', 'Shohei Hisada', 'Makoto Uehara', 'Shoko Wakamiya', 'Eiji Aramaki'] | ['SANKEN Osaka University', 'NARA Institute of Science and Technology'] | Fake news provokes many societal problems; therefore, there has been extensive research on fake news detection tasks to counter it. Many fake news datasets were constructed as resources to facilitate this task. Contemporary research focuses almost exclusively on the factuality aspect of the news. However, this aspect a... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JMultiWOZ | null | null | https://github.com/nu-dialogue/jmultiwoz | CC BY-SA 4.0 | 2,024 | jp | null | ['web pages'] | text | null | JMultiWOZ is the first Japanese language large-scale multi-domain task-oriented dialogue dataset. It contains 4,246 conversations spanning six travel-related domains: tourist attractions, accommodation, restaurants, shopping facilities, taxis, and weather. It provides dialogue state annotations for benchmarking dialogu... | 52,405 | sentences | null | ['Nagoya University'] | null | null | null | mixed | false | GitHub | Free | null | ['other'] | null | null | null | ['Atsumoto Ohashi', 'Ryu Hirai', 'Shinya Iizuka', 'Ryuichiro Higashinaka'] | ['Nagoya University'] | Dialogue datasets are crucial for deep learning-based task-oriented dialogue system research. While numerous English language multi-domain task-oriented dialogue datasets have been developed and contributed to significant advancements in task-oriented dialogue systems, such a dataset does not exist in Japanese, and res... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | Japanese Web Corpus | null | null | https://github.com/llm-jp/llm-jp-corpus | unknown | 2,024 | jp | null | ['web pages', 'public datasets'] | text | null | A large-scale Japanese web corpus created from 21 Common Crawl snapshots (crawled between 2020 and 2023). The corpus consists of approximately 312.1 billion characters from 173 million pages. | 173,350,375 | documents | null | ['Tokyo Institute of Technology'] | null | null | null | mixed | false | GitHub | Free | null | ['language modeling'] | null | null | null | ['Naoaki Okazaki', 'Kakeru Hattori', 'Hirai Shota', 'Hiroki Iida', 'Masanari Ohi', 'Kazuki Fujii', 'Taishi Nakamura', 'Mengsay Loem', 'Rio Yokota', 'Sakae Mizuki'] | ['Tokyo Institute of Technology'] | Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snap... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | J-CRe3 | null | null | https://github.com/riken-grp/J-CRe3 | CC BY-SA 4.0 | 2,024 | jp | null | ['other'] | text | null | A Japanese multimodal dataset containing egocentric video and dialogue audio of real-world conversations between a master and an assistant robot at home. | 11,000 | images | null | ['RIKEN'] | null | null | null | mixed | false | GitHub | Free | null | ['other'] | null | null | null | ['Nobuhiro Ueda', 'Hideko Habe', 'Yoko Matsui', 'Akishige Yuguchi', 'Seiya Kawano', 'Yasutomo Kawanishi', 'Sadao Kurohashi', 'Koichiro Yoshino'] | ['Kyoto University', 'Guardian Robot Project, R-IH, RIKEN', 'Tokyo University of Science', 'Nara Institute of Science and Technology', 'National Institute of Informatics'] | Understanding expressions that refer to the physical world is crucial for such human-assisting systems in the real world, as robots that must perform actions that are expected by users. In real-world reference resolution, a system must ground the verbal information that appears in user interactions to the visual inform... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JSUT | null | null | https://sites.google.com/site/shinnosuketakamichi/publication/jsut | CC BY-SA 4.0 | 2,017 | jp | null | ['wikipedia', 'public datasets'] | audio | null | The corpus consists of 10 hours of reading-style speech
data and its transcription and covers all of the main pronun-
ciations of daily-use Japanese characters. | 10 | hours | null | [] | null | null | null | mixed | false | other | Free | null | ['speech recognition'] | null | null | null | ['Ryosuke Sonobe', 'Shinnosuke Takamichi', 'Hiroshi Saruwatari'] | ['University of Tokyo'] | Thanks to improvements in machine learning techniques including deep learning, a free large-scale speech corpus that can be shared between academic institutions and commercial companies has an important role. However, such a corpus for Japanese speech synthesis does not exist. In this paper, we designed a novel Japanes... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | Japanese Word Similarity Dataset | null | null | https://github.com/tmu-nlp/JapaneseWordSimilarityDataset | CC BY-SA 3.0 | 2,018 | jp | null | ['public datasets'] | text | null | A Japanese word similarity dataset (JWSD) containing 4,851 word pairs with human-annotated similarity scores. The dataset includes various parts of speech (nouns, verbs, adjectives, adverbs) and covers both common and rare words, designed for evaluating Japanese distributed word representations. | 4,851 | sentences | null | ['Tokyo Metropolitan University'] | null | null | null | mixed | false | GitHub | Free | null | ['word similarity'] | null | null | null | ['Yuya Sakaizawa', 'Mamoru Komachi'] | ['Tokyo Metropolitan University'] | An evaluation of distributed word representation is generally conducted using a word similarity task and/or a word analogy task. There are many datasets readily available for these tasks in English. However, evaluating distributed representation in languages that do not have such resources (e.g., Japanese) is difficult... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | STAIR Captions | null | null | http://captions.stair.center/ | CC BY 4.0 | 2,017 | jp | null | ['captions', 'public datasets'] | text | null | A large-scale image caption dataset in Japanese, based on the COCO dataset. It contains 820,310 Japanese captions for 164,062 images, collected via crowdsourcing. | 820,310 | sentences | null | ['The University of Tokyo', 'National Institute of Informatics'] | null | null | null | mixed | false | other | Free | null | ['image captioning'] | null | null | null | ['Yuya Yoshikawa', 'Yutaro Shigeto', 'Akikazu Takeuchi'] | ['The University of Tokyo', 'National Institute of Informatics'] | In recent years, automatic generation of image descriptions (captions), that is, image captioning, has attracted a great deal of attention. In this paper, we particularly consider generating Japanese captions for images. Since most available caption datasets have been constructed for English language, there are few dat... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | Arukikata Travelogue | null | null | https://www.nii.ac.jp/news/release/2022/1124.html | custom | 2,023 | jp | null | ['web pages'] | text | null | A Japanese text dataset with over 31 million characters, comprising 4,672 domestic and 9,607 overseas travelogues from the Arukikata website. It was created to provide a shared resource for research, ensuring transparency and reproducibility in analyzing human-place interactions from text. | 14,279 | documents | null | ['Arukikata Co., Ltd.'] | null | null | null | mixed | false | other | Free | null | ['other'] | null | null | null | ['Hiroki Ouchi', 'Hiroyuki Shindo', 'Shoko Wakamiya', 'Yuki Matsuda', 'Naoya Inoue', 'Shohei Higashiyama', 'Satoshi Nakamura', 'Taro Watanabe'] | ['NAIST', 'JAIST', 'NICT', 'RIKEN'] | We have constructed Arukikata Travelogue Dataset and released it free of charge for academic research. This dataset is a Japanese text dataset with a total of over 31 million words, comprising 4,672 Japanese domestic travelogues and 9,607 overseas travelogues. Before providing our dataset, there was a scarcity of widel... | 1 | null | null | 0 | 1 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JTubeSpeech | null | null | https://github.com/sarulab-speech/jtubespeech | Apache-2.0 | 2,021 | jp | null | ['social media'] | audio | null | A large-scale Japanese speech corpus collected from YouTube videos and their subtitles. It is designed for both automatic speech recognition (ASR) and automatic speaker verification (ASV) tasks, containing over 1,300 hours for ASR and 900 hours for ASV. | 1,300 | hours | null | ['The University of Tokyo', 'Technical University of Munich', 'Tokyo Metropolitan University', 'Carnegie Mellon University'] | null | null | null | mixed | false | GitHub | Free | null | ['speech recognition', 'speaker identification'] | null | null | null | ['Shinnosuke Takamichi', 'Ludwig Kürzinger', 'Takaaki Saeki', 'Sayaka Shiota', 'Shinji Watanabe'] | ['The University of Tokyo', 'Technical University of Munich', 'Tokyo Metropolitan University', 'Carnegie Mellon University'] | In this paper, we construct a new Japanese speech corpus called "JTubeSpeech." Although recent end-to-end learning requires large-size speech corpora, open-sourced such corpora for languages other than English have not yet been established. In this paper, we describe the construction of a corpus from YouTube videos and... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JCoLA | null | null | https://github.com/osekilab/JCoLA | custom | 2,023 | jp | null | ['books'] | text | null | JCoLA (Japanese Corpus of Linguistic Acceptability) consists of 10,020 sentences annotated with binary acceptability judgments. The sentences are manually extracted from linguistics textbooks, handbooks, and journal articles, and are split into in-domain and out-of-domain data. | 10,020 | sentences | null | ['The University of Tokyo'] | null | null | null | mixed | false | GitHub | Free | null | ['linguistic acceptability'] | null | null | null | ['Taiga Someya', 'Yushi Sugimoto', 'Yohei Oseki'] | ['The University of Tokyo'] | Neural language models have exhibited outstanding performance in a range of downstream tasks. However, there is limited understanding regarding the extent to which these models internalize syntactic knowledge, so that various datasets have recently been constructed to facilitate syntactic evaluation of language models ... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JESC | null | null | https://nlp.stanford.edu/projects/jesc | CC BY-SA 4.0 | 2,018 | multilingual | null | ['captions', 'TV Channels'] | text | null | JESC is a large Japanese-English parallel corpus covering the underrepresented domain of conversational dialogue. It consists of more than 3.2 million examples, making it the largest freely available dataset of its kind. | 3,240,661 | sentences | null | ['Stanford University', 'Rakuten Institute of Technology', 'Google Brain'] | null | null | null | mixed | false | other | Free | null | ['machine translation'] | null | null | null | ['Reid Pryzant', 'Youngjoo Chung', 'Dan Jurafsky', 'Denny Britz'] | ['Stanford University', 'Rakuten Institute of Technology', 'Google Brain'] | In this paper we describe the Japanese-English Subtitle Corpus (JESC). JESC is a large Japanese-English parallel corpus covering the underrepresented domain of conversational dialogue. It consists of more than 3.2 million examples, making it the largest freely available dataset of its kind. The corpus was assembled by ... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | JDocQA | null | null | https://github.com/mizuumi/JDocQA | CC BY-SA 3.0 | 2,024 | jp | null | ['web pages'] | images | null | JDocQA is a large-scale Japanese document-based QA dataset, comprising 5,504 documents in PDF format and 11,600 annotated question-and-answer instances. It requires both visual and textual information to answer questions, and includes multiple question categories and unanswerable questions to mitigate model hallucinati... | 11,600 | sentences | null | ['Nara Institute of Science and Technology', 'RIKEN', 'ATR'] | null | null | null | mixed | false | GitHub | Free | null | ['question answering'] | null | null | null | ['Eri Onami', 'Shuhei Kurita', 'Taiki Miyanishi', 'Taro Watanabe'] | ['Nara Institute of Science and Technology', 'RIKEN', 'ATR'] | Document question answering is a task of question answering on given documents such as reports, slides, pamphlets, and websites, and it is a truly demanding task as paper and electronic forms of documents are so common in our society. This is known as a quite challenging task because it requires not only text understan... | 1 | null | null | 0 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 0 | 0 | 0 | null | 1 | null | null | null | 1 | 1 | 1 | |
jp | test | Jamp | null | null | https://github.com/tomo-ut/temporalNLI_dataset | CC BY-SA 4.0 | 2,023 | jp | null | ['public datasets'] | text | null | Jamp is a Japanese Natural Language Inference (NLI) benchmark focused on temporal inference. It was created using a template-based approach, generating diverse examples by combining templates derived from formal semantics test suites with a Japanese case frame dictionary, allowing for controlled distribution of inferen... | 10,094 | sentences | null | ['The University of Tokyo'] | null | null | null | mixed | false | GitHub | Free | null | ['natural language inference'] | null | null | null | ['Tomoki Sugimoto', 'Yasumasa Onoe', 'Hitomi Yanaka'] | ['The University of Tokyo', 'The University of Texas at Austin'] | Natural Language Inference (NLI) tasks involving temporal inference remain challenging for pre-trained language models (LMs). Although various datasets have been created for this task, they primarily focus on English and do not address the need for resources in other languages. It is unclear whether current LMs realize... | 1 | null | null | 1 | 0 | 1 | 1 | null | 1 | 1 | null | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 | 1 | 1 | null | 1 | null | null | null | 1 | 1 | 1 |
MOLE is a dataset for evaluating and validating metadata extracted from scientific papers. The paper can be found here.
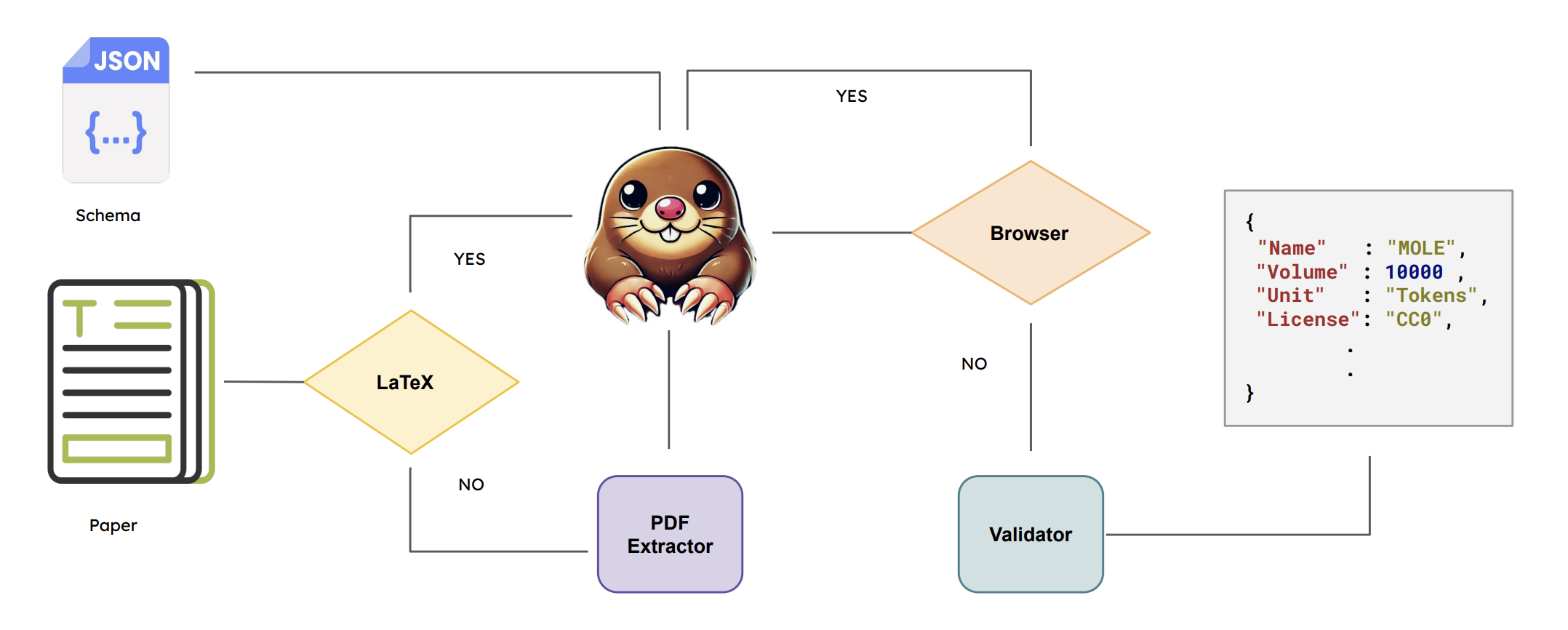
The main datasets attributes are shown below. Also for earch feature there is binary value attribute_exist. The value is 1 if the attribute is retrievable form the paper, otherwise it is 0.
Name (str): What is the name of the dataset?Subsets (List[Dict[Name, Volume, Unit, Dialect]]): What are the dialect subsets of this dataset?Link (url): What is the link to access the dataset?HF Link (url): What is the Huggingface link of the dataset?License (str): What is the license of the dataset?Year (date[year]): What year was the dataset published?Language (str): What languages are in the dataset?Dialect (str): What is the dialect of the dataset?Domain (List[str]): What is the source of the dataset?Form (str): What is the form of the data?Collection Style (List[str]): How was this dataset collected?Description (str): Write a brief description about the dataset.Volume (float): What is the size of the dataset?Unit (str): What kind of examples does the dataset include?Ethical Risks (str): What is the level of the ethical risks of the dataset?Provider (List[str]): What entity is the provider of the dataset?Derived From (List[str]): What datasets were used to create the dataset?Paper Title (str): What is the title of the paper?Paper Link (url): What is the link to the paper?Script (str): What is the script of this dataset?Tokenized (bool): Is the dataset tokenized?Host (str): What is name of the repository that hosts the dataset?Access (str): What is the accessibility of the dataset?Cost (str): If the dataset is not free, what is the cost?Test Split (bool): Does the dataset contain a train/valid and test split?Tasks (List[str]): What NLP tasks is this dataset intended for?Venue Title (str): What is the venue title of the published paper?Venue Type (str): What is the venue type?Venue Name (str): What is the full name of the venue that published the paper?Authors (List[str]): Who are the authors of the paper?Affiliations (List[str]): What are the affiliations of the authors?Abstract (str): What is the abstract of the paper?How to load the dataset
from datasets import load_dataset
dataset = load_dataset('IVUL-KAUST/mole')
A sample for an annotated paper
{
"metadata": {
"Name": "TUNIZI",
"Subsets": [],
"Link": "https://github.com/chaymafourati/TUNIZI-Sentiment-Analysis-Tunisian-Arabizi-Dataset",
"HF Link": "",
"License": "unknown",
"Year": 2020,
"Language": "ar",
"Dialect": "Tunisia",
"Domain": [
"social media"
],
"Form": "text",
"Collection Style": [
"crawling",
"manual curation",
"human annotation"
],
"Description": "TUNIZI is a sentiment analysis dataset of over 9,000 Tunisian Arabizi sentences collected from YouTube comments, preprocessed, and manually annotated by native Tunisian speakers.",
"Volume": 9210.0,
"Unit": "sentences",
"Ethical Risks": "Medium",
"Provider": [
"iCompass"
],
"Derived From": [],
"Paper Title": "TUNIZI: A TUNISIAN ARABIZI SENTIMENT ANALYSIS DATASET",
"Paper Link": "https://arxiv.org/abs/2004.14303",
"Script": "Latin",
"Tokenized": false,
"Host": "GitHub",
"Access": "Free",
"Cost": "",
"Test Split": false,
"Tasks": [
"sentiment analysis"
],
"Venue Title": "International Conference on Learning Representations",
"Venue Type": "conference",
"Venue Name": "International Conference on Learning Representations 2020",
"Authors": [
"Chayma Fourati",
"Abir Messaoudi",
"Hatem Haddad"
],
"Affiliations": [
"iCompass"
],
"Abstract": "On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called 'Tunisian Arabizi'. Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI as a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers."
},
}
The dataset contains 52 annotated papers, it might be limited to truely evaluate LLMs. We are working on increasing the size of the dataset.
@misc{mole,
title={MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs},
author={Zaid Alyafeai and Maged S. Al-Shaibani and Bernard Ghanem},
year={2025},
eprint={2505.19800},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.19800},
}