
license: cc-by-4.0
language:
- en
- zh
tags:
- survey
- llm-agents
- agent-harness
- agent-frameworks
- harness-engineering
- evaluation
- agent-memory
- multi-agent-systems
pretty_name: 'Agent Harness for Large Language Model Agents: A Survey'
size_categories:
- n<1K


⭐ 本 survey 持续更新中。如果对你有帮助,欢迎 Star 关注最新进展,也帮助更多人发现它。
Agent Harness——而非模型本身——是智能体大规模部署可靠性的首要决定因素。
本综述将Agent Harness形式化为一级架构对象 **H = (E, T, C, S, L, V)**,系统调研了涵盖23个系统的110余篇论文、博客和报告,并总结了9项开放性技术挑战。
📄 阅读最新版论文 (PDF) (最新版本,目前在审)
🌐 阅读 Preprints 版本 (v2)
✉️ 勘误与建议:gloriamenng@gmail.com; wangyanan@mail.dlut.edu.cn; chenliyi@xiaohongshu.com
如果本综述对您有所帮助,请引用:
@article{meng2026agentharness,
title = {Agent Harness for Large Language Model Agents: A Survey},
author = {Meng, Qianyu* and Wang, Yanan* and Chen, Liyi and Wang, Qimeng and
Lu, Chengqiang and Wu, Wei and Gao, Yan and Wu, Yi and Hu, Yao},
year = {2026},
doi = {10.20944/preprints202604.0428.v2},
url = {https://www.preprints.org/manuscript/202604.0428/v2},
publisher = {Preprints},
note = {* Equal contribution. Under review, latest version available at: https://github.com/Gloriaameng/LLM-Agent-Harness-Survey}
}
🆕 新闻与更新
- [2026-04-03] 首次发布
- [2026-04-07] 仓库更新
- [2026-04-07] 预印本索引
目录
概述
大语言模型(LLM)智能体正日益部署于自主规划、工具使用和多步骤交互环境中。主流叙事将智能体性能归因于底层模型能力。本综述挑战了这一假设。
我们提出了Agent Harness的形式化定义,将其定义为包含六个组件的元组:
| 组件 | 符号 | 作用 |
|---|---|---|
| 执行循环 | E | 观察-思考-行动循环,终止条件,错误恢复 |
| 工具注册表 | T | 类型化工具目录,路由,监控,模式校验 |
| 上下文管理器 | C | 上下文窗口内容选择,压缩,检索 |
| 状态存储 | S | 跨回合/会话持久化,崩溃恢复 |
| 生命周期钩子 | L | 认证,日志,策略执行,监测埋点 |
| 评估接口 | V | 行动轨迹,中间状态,成功信号 |
Agent Harness重要性的关键实证证据:
- 🔥 Pi Research:Grok Code Fast 1 模型在 SWE-bench 上从 **6.7% → 68.3%**,仅通过修改Agent Harness的编辑工具格式——模型不变
- 💀 OpenAI Codex:5个月内生成100万行代码,0行手写——失败归因于"环境规范不足"而非模型能力
- ⚡ Stripe Minions:每周1300个PR,0行人工代码——Agent Harness优先
- 📉 METR:通过基准测试的PR人工合并率低24.2个百分点,差距以9.6pp/年速度扩大——评估Agent Harness有效性危机
- 💬 "Agent Harness是底盘;模型是引擎。" ——2026年业界共识

本综述的学术贡献
概念贡献:我们将Agent Harness形式化为具有六个可治理组件(E, T, C, S, L, V)的架构对象,将其从隐式基础设施提升为显式研究目标。
实证范围:我们系统性地综述了110余篇论文,涵盖学术研究(评估基准、安全框架、记忆架构)和生产部署(Stripe、OpenAI、Cursor、METR),确立了Agent Harness设计是已部署智能体可靠性的约束瓶颈这一观点。
方法论进展:我们引入了Agent Harness完备性矩阵——一个结构化评估框架,映射每个系统实现了六个组件中的哪些——使得先前综述无法实现的异构智能体系统直接对比成为可能。
已识别的开放挑战:我们记录了九项技术挑战,这些挑战当前研究仅提供了部分解决方案而无生产级基础设施:形式化安全模型、跨工程框架可移植性、协议互操作性(MCP/A2A)、百万级token/任务的上下文经济性、多智能体系统中的拜占庭容错、组合式验证。
学术界与业界的桥梁:与先前仅关注模型能力或孤立组件(记忆、规划、工具使用)的综述不同,我们综合了同行评审研究与生产部署报告,展示了理论与实践的交汇点——以及仍存在的关键差距。
目标读者:设计智能体基础设施的研究者、构建生产系统的实践者、以及试图理解为何基准测试性能常无法预测部署结果的评估者。
历史时间线

| 年份 | 里程碑 | 意义 |
|---|---|---|
| 1997–2005 | JUnit, TestNG, xUnit 家族 | 软件测试Harness范式;标准化观察-断言生命周期 |
| 2016 | OpenAI Gym (Brockman et al.) | 强化学习环境Harness框架;step/reset API 成为规范接口 |
| 2022年11月 | ChatGPT 公开发布;LangChain 出现 | 面向LLM的智能体框架萌芽;工具使用成为一级公民 |
| 2023 | ReAct, Toolformer, MemGPT, Reflexion, Voyager, AutoGPT | 核心智能体模式:推理-行动、记忆、反思、技能积累 |
| 2023 | CAMEL, ChatDev, Generative Agents | 多智能体协同;社会仿真Harness |
| 2023 | AgentBench, SWE-bench | 智能体评估基础设施涌现 |
| 2024 | MetaGPT, WebArena, ToolLLM, SWE-agent, OSWorld | 全栈执行器;真实世界环境基准测试 |
| 2024 | CodeAct, LATS, Tree of Thoughts | 结构化动作空间;搜索增强规划 |
| 2024年11月 | Anthropic 发布 MCP 协议 | 首个主要工具↔Harness标准化(2–15ms延迟) |
| 2025 | HAL, AIOS, LangGraph | 基准测试统一(21,730次评估);操作系统级调度(2.1×加速) |
| 2025 | Google 发布 A2A 协议 | 智能体↔智能体标准化(50–200ms) |
| 2025 | MemoryOS, SkillsBench†, AgentBound† | 记忆操作系统抽象;技能即上下文(+16.2pp);安全认证 |
| 2026年1–3月 | AgencyBench†, SandboxEscapeBench†, PRISM†, AEGIS†, SkillFortify†, Schema First† | 计算经济学;15–35%逃逸率;运行时安全;模式规范 |
† 表示预印本,尚未经同行评审
Agent Harness完备性矩阵
图例: ✓ 完全支持 · ≈ 部分支持 · ✗ 缺失
| 类别 | 系统 | E | T | C | S | L | V |
|---|---|---|---|---|---|---|---|
| 全栈式 Agent Harness |
Claude Code | ✓ | ✓ | ✓ | ✓ | ✓ | ≈ |
| OpenClaw / PRISM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| AIOS | ✓ | ✓ | ✓ | ✓ | ✓ | ≈ | |
| OpenHands | ✓ | ✓ | ✓ | ✓ | ✓ | ≈ | |
| 多智能体 执行器 |
MetaGPT | ✓ | ✓ | ≈ | ≈ | ≈ | ≈ |
| AutoGen | ✓ | ✓ | ≈ | ≈ | ≈ | ≈ | |
| ChatDev | ✓ | ≈ | ≈ | ≈ | ≈ | ≈ | |
| CAMEL | ✓ | ≈ | ≈ | ≈ | ✗ | ≈ | |
| DeerFlow | ✓ | ✓ | ≈ | ≈ | ≈ | ≈ | |
| DeepAgents | ✓ | ✓ | ≈ | ≈ | ≈ | ≈ | |
| 通用 框架 |
LangChain | ✓ | ✓ | ✓ | ≈ | ≈ | ✗ |
| LangGraph | ✓ | ≈ | ≈ | ≈ | ✗ | ✗ | |
| LlamaIndex | ≈ | ✓ | ✓ | ≈ | ✗ | ✗ | |
| 专用 约束工程 |
SWE-agent | ✓ | ✓ | ✓ | ≈ | ≈ | ✓ |
| 能力 模块 |
MemGPT | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ |
| Voyager | ✓ | ✓ | ≈ | ✓ | ✗ | ≈ | |
| Reflexion | ≈ | ✗ | ≈ | ✓ | ✗ | ≈ | |
| Generative Agents | ✓ | ✗ | ≈ | ✓ | ✗ | ≈ | |
| Concordia | ✓ | ✗ | ≈ | ✓ | ✗ | ≈ | |
| 评估 基础设施 |
HAL | ✓ | ✓ | ≈ | ≈ | ≈ | ✓ |
| AgentBench | ✓ | ≈ | ≈ | ≈ | ✗ | ✓ | |
| OSWorld | ✓ | ≈ | ≈ | ≈ | ✗ | ✓ | |
| BrowserGym | ✓ | ✓ | ≈ | ≈ | ✗ | ✓ |
论文列表
历史渊源
软件测试Harness (1990s–2000s)
- JUnit: "JUnit: A Cook's Tour". Beck & Gamma. Java Report, 4(5), May 1999. [文章]
强化学习环境Harness框架 (2016–2022)
- OpenAI Gym: "OpenAI Gym". Brockman et al. arXiv 2016. [论文] [代码]
- Gymnasium: "Gymnasium: A Standard Interface for Reinforcement Learning Environments". Towers et al. NeurIPS 2025. [论文] [代码]
早期LLM Agent Harness (2023–2024)
- ReAct: "ReAct: Synergizing Reasoning and Acting in Language Models". Yao et al. ICLR 2023. [论文] [代码]
- Toolformer: "Toolformer: Language Models Can Teach Themselves to Use Tools". Schick et al. NeurIPS 2023. [论文]
- AutoGPT: "Auto-GPT: An Autonomous GPT-4 Experiment". Gravitas et al. GitHub 2023. [代码]
- LangChain: "LangChain: Building Applications with LLMs through Composability". Chase et al. GitHub 2022. [代码]
Agent Harness分类
分类依据:我们根据Agent Harness完备性对智能体系统进行分类——即每个系统实现了六个组件(E, T, C, S, L, V)中的哪些——从而区分全栈Harness(全部六个组件)与专用框架(部分实现)。
重要性:先前的分类法按应用领域(编程、网页导航、具身AI)或模型架构(单智能体、多智能体)对智能体进行分类。这些分类无法解释为何使用相似模型的系统会产生不同的可靠性结果。我们以Agent Harness框架为中心的分类法揭示,生产级系统收敛于完整的ETCSLV实现,而研究原型往往仅实现2-3个组件。
核心发现:没有任何智能体框架能够在不实现全部六个治理组件的情况下达到生产可靠性。缺少L组件(生命周期钩子)的系统无法执行安全策略。缺少V组件(评估接口)的系统无法调试故障。缺少S组件(状态持久化)的系统无法从崩溃中恢复。
全栈式Agent Harness
- PRISM/OpenClaw: "OpenClaw PRISM: A Zero-Fork, Defense-in-Depth Runtime Security Layer for Tool-Augmented LLM Agents". Li. arXiv 2026. [论文]
- AIOS: "AIOS: LLM Agent Operating System". Mei et al. COLM 2025. [论文] [代码]
- OpenHands: "OpenHands: An Open Platform for AI Software Developers as Generalist Agents". Wang et al. ICLR 2025. [论文] [代码]
- SWE-agent: "SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering". Yang et al. NeurIPS 2024. [论文] [代码]
- HAL: "Holistic Agent Leaderboard: The Missing Infrastructure for AI Agent Evaluation". Kapoor et al. ICLR 2026. [论文]
多智能体Agent Harness
- MetaGPT: "MetaGPT: Meta Programming for a Multi-Agent Collaborative Framework". Hong et al. ICLR 2024. [论文] [代码]
- AutoGen: "AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation". Wu et al. arXiv 2023. [论文] [代码]
- ChatDev: "ChatDev: Communicative Agents for Software Development". Qian et al. ACL 2024. [论文] [代码]
- CAMEL: "CAMEL: Communicative Agents for 'Mind' Exploration of Large Language Model Society". Li et al. NeurIPS 2023. [论文] [代码]
框架与模块
- LangGraph: "LangGraph: Build Resilient Language Agents as Graphs". LangChain team. GitHub 2024. [代码]
- MemGPT: "MemGPT: Towards LLMs as Operating Systems". Packer et al. NeurIPS 2023. [论文] [代码]
- Voyager: "Voyager: An Open-Ended Embodied Agent with Large Language Models". Wang et al. arXiv 2023. [论文] [代码]
- Reflexion: "Reflexion: Language Agents with Verbal Reinforcement Learning". Shinn et al. NeurIPS 2023. [论文] [代码]
- Generative Agents: "Generative Agents: Interactive Simulacra of Human Behavior". Park et al. UIST 2023. [论文] [代码]
- LangChain: "LangChain: Building Applications with LLMs through Composability". Chase et al. GitHub 2022. [代码]
- LlamaIndex: "LlamaIndex: A Data Framework for LLM Applications". Liu et al. GitHub 2022. [代码]
- DeerFlow: "DeerFlow: Distributed Workflow Engine for LLM Agents". GitHub 2024. [代码]
- DeepAgents: "DeepAgents: Multi-Agent Framework for Deep Learning". GitHub 2024. [代码]
评估基础设施
- AgentBench: "AgentBench: Evaluating LLMs as Agents". Liu et al. ICLR 2024. [论文] [代码]
- SWE-bench: "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?". Jimenez et al. ICLR 2024. [论文] [代码]
- OSWorld: "OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments". Xie et al. NeurIPS 2024. [论文] [代码]
- WebArena: "WebArena: A Realistic Web Environment for Building Autonomous Agents". Zhou et al. ICLR 2024. [论文] [代码]
- GAIA: "GAIA: A Benchmark for General AI Assistants". Mialon et al. ICLR 2024. [论文]
- Mind2Web: "Mind2Web: Towards a Generalist Agent for the Web". Deng et al. NeurIPS 2023. [论文]
- AgentBoard: "AgentBoard: An Analytical Evaluation Board of Multi-Turn LLM Agents". Ma et al. NeurIPS 2024. [论文]
- InterCode: "InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback". Yang et al. NeurIPS 2023. [论文]
技术挑战
范围界定:我们识别了九项开放研究问题,当前Agent Harness基础设施针对这些问题仅提供了部分解决方案,而缺乏生产级、可推广的框架。每项挑战都代表了学术原型所展示的成果与已部署系统所需条件之间的差距。
评估标准:对于每项挑战,我们评估:(1) 学术覆盖度——同行评审解决方案(如有);(2) 生产成熟度——是否有任何已部署系统在规模上解决了该问题;(3) 阻塞严重性——未解决的问题是阻止部署还是仅限制性能。
横切主题:大多数挑战源于组合问题——单个组件(安全沙箱、记忆存储、评估指标)可以独立工作,但将它们组合成连贯的执行器会浮现涌现性故障。形式化验证、可移植性测试和协议互操作性都需要当前研究尚未解决的组合式推理。
安全与沙箱
挑战:智能体沙箱必须防止恶意工具使用,同时允许合法的系统访问——这比传统应用沙箱更困难,因为智能体有意地与敏感资源(文件系统、网络API、shell命令)交互。
技术现状:SandboxEscapeBench 显示前沿模型能够逃逸容器;PRISM 展示了零分叉纵深防御是可能的,但需要操作系统级监测。尚不存在适用于所有智能体用例且无需人工逐任务配置的通用沙箱。
开放问题:组合式安全属性(证明智能体+Harness+环境满足安全规范)仍未解决。当前防御是反应式的(检测逃逸)而非预防式的(证明逃逸不可能)。
关键数据:SandboxEscapeBench——前沿LLM达到15–35%容器逃逸率;PRISM——10个钩子的零分叉运行时将逃逸降至接近零,开销<5ms。
- SandboxEscapeBench†: "Quantifying Frontier LLM Capabilities for Container Sandbox Escape". Marchand et al. arXiv 2026. [Paper]
- InjecAgent: "InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents". Zhan et al. arXiv 2024. [Paper]
- ToolHijacker†: "Prompt Injection Attack to Tool Selection in LLM Agents". Shi et al. NDSS 2026. [Paper]
- Securing MCP†: "Securing the Model Context Protocol (MCP): Risks, Controls, and Governance". Errico et al. arXiv 2025. [Paper]
- SHIELDA†: "SHIELDA: Structured Handling of Exceptions in LLM-Driven Agentic Workflows". Zhou et al. arXiv 2025. [Paper]
- PALADIN†: "PALADIN: Self-Correcting Language Model Agents to Cure Tool-Failure Cases". Vuddanti et al. ICLR 2026. [Paper]
- AgentBound†: "Securing AI Agent Execution". Bühler et al. arXiv 2025. [Paper]
- AgentSys†: "AgentSys: Secure and Dynamic LLM Agents Through Explicit Hierarchical Memory Management". Wen et al. arXiv 2026. [Paper]
- Indirect Prompt Injection: "Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection". Greshake et al. AISec 2023. [Paper]
- AgentHarm†: "AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents". Andriushchenko et al. arXiv 2024. [Paper]
- TrustAgent: "TrustAgent: Towards Safe and Trustworthy LLM-Based Agents". Hua et al. EMNLP 2024. [Paper]
- ToolEmu†: "Identifying the Risks of LM Agents with an LM-Emulated Sandbox". Ruan et al. arXiv 2023. [Paper]
- Ignore Previous Prompt: "Ignore Previous Prompt: Attack Techniques For Language Models". Perez & Ribeiro. NeurIPS ML Safety Workshop 2022. [Paper]
评估与基准测试
关键数据:HAL 统一了20,000+次评估,将数周的评估压缩至数小时;OSWorld 报告了28%假阴性率的自动化评估;METR 发现通过基准测试的PR人工合并率低24.2个百分点,差距以9.6pp/年速度扩大。
- AgencyBench†: "AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts". Li et al. arXiv 2026. [Paper]
- AEGIS†: "AEGIS: No Tool Call Left Unchecked -- A Pre-Execution Firewall and Audit Layer for AI Agents". Yuan et al. arXiv 2026. [Paper]
- Hell or High Water†: "Hell or High Water: Evaluating Agentic Recovery from External Failures". Wang et al. COLM 2025. [Paper]
- SearchLLM†: "Aligning Large Language Models with Searcher Preferences". Wu et al. arXiv 2026. [Paper]
- Meta-Harness†: "Meta-Harness: End-to-End Optimization of Model Harnesses". Lee et al. arXiv 2026. [Paper]
- TheAgentCompany†: "TheAgentCompany: Benchmarking LLM Agents on Consequential Real-World Tasks". Xu et al. arXiv 2024. [Paper]
- BrowserGym†: "The BrowserGym Ecosystem for Web Agent Research". Le Sellier De Chezelles et al. arXiv 2024. [Paper]
- WorkArena†: "WorkArena: How Capable are Web Agents at Solving Common Knowledge Work Tasks?". Drouin et al. arXiv 2024. [Paper]
- R-Judge: "R-Judge: Benchmarking Safety Risk Awareness for LLM Agents". Yuan et al. EMNLP 2024. [Paper]
- R2E: "R2E: Turning any GitHub Repository into a Programming Agent Environment". Jain et al. ICML 2024. [Paper]
- Evaluation Survey: "Evaluation and Benchmarking of LLM Agents: A Survey". Mohammadi et al. KDD 2025. [Paper]
- PentestJudge†: "PentestJudge: Judging Agent Behavior Against Operational Requirements". Caldwell et al. arXiv 2025. [Paper]
协议标准化
关键数据:MCP(工具↔约束工程):2–15ms延迟;A2A(智能体↔智能体):50–200ms;ACP(意图级,IBM)——三种协议服务于互补角色。
- MCP: "Model Context Protocol". Anthropic. Technical Report 2024. [Spec]
- A2A: "Agent-to-Agent Protocol". Google. Technical Report 2025. [Spec]
- Protocol Comparison†: "A Survey of Agent Interoperability Protocols: Model Context Protocol (MCP), Agent Communication Protocol (ACP), Agent-to-Agent Protocol (A2A), and Agent Network Protocol (ANP)". Ehtesham et al. arXiv 2025. [Paper]
- Gorilla: "Gorilla: Large Language Model Connected with Massive APIs". Patil et al. NeurIPS 2023. [Paper] [Code]
运行时上下文管理
关键数据:SkillsBench——精选技能注入产生**+16.2pp*改进;"迷失在中间"效应已被记录;长上下文模型将问题从保留转移至显著性*。
- SkillsBench†: "SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks". Li et al. arXiv 2026. [Paper]
- ReadAgent: "A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts". Lee et al. ICML 2024. [Paper]
- MemoryOS: "Memory OS of AI Agent". Kang et al. arXiv 2025. [Paper]
- CoALA: "Cognitive Architectures for Language Agents". Sumers et al. TMLR 2024. [Paper]
- SkillFortify†: "Formal Analysis and Supply Chain Security for Agentic AI Skills". Bhardwaj. arXiv 2026. [Paper]
- Lost in the Middle: "Lost in the Middle: How Language Models Use Long Contexts". Liu et al. TACL 2024. [Paper]
- Context Engineering Survey†: "Context Engineering: A Survey of 1,400 Papers on Effective Context Management for LLM Agents". Mei et al. arXiv 2025. [Paper]
工具使用与注册
关键数据:Vercel 发现移除80%工具比任何模型升级都更有帮助;Schema First (Sigdel & Baral, 2026) —— 一项受控的初步研究表明,基于 schema 的工具契约可以减少接口层面的误用(如格式校验失败),但无法减少语义层面的误用(即格式正确但任务不当的调用),且各实验条件下端到端任务成功率均为零,表明仅靠接口设计不足以保证工具调用的可靠性;CodeAct 在17/17项Mint基准上表现优异,**回合数减少20%**。
- CodeAct: "Executable Code Actions Elicit Better LLM Agents". Wang et al. ICML 2024. [Paper] [Code]
- Schema First†: "Schema First Tool APIs for LLM Agents: A Controlled Study of Tool Misuse, Recovery, and Budgeted Performance". Sigdel & Baral. arXiv 2026. [Paper]
- ToolLLM: "ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs". Qin et al. ICLR 2024. [Paper] [Code]
- ToolSandbox†: "ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities". Lu et al. arXiv 2024. [Paper]
- AutoTool†: "AutoTool: Efficient Tool Selection for Large Language Model Agents". Jia & Li. AAAI 2026. [Paper]
- Tool Learning Survey: "Tool Learning with Large Language Models: A Survey". Qu et al. Frontiers of Computer Science 2024. [Paper]
- GoEX†: "GoEX: Perspectives and Designs Towards a Runtime for Autonomous LLM Applications". Patil et al. arXiv 2024. [Paper]
- AgentTuning: "AgentTuning: Enabling Generalized Agent Abilities for LLMs". Zeng et al. ACL 2024. [Paper]
记忆架构
关键数据:Mem0 实现了相比完整上下文90% token减少;Zep 时序知识:**+18.5% QA准确率;Agent Workflow Memory:在Mind2Web上+14.9%**。六种架构模式:平面缓冲区→层次化→情节式→语义式→过程式→图式。
- Agent Workflow Memory (AWM)†: "Agent Workflow Memory". Wang et al. arXiv 2024. [Paper]
- Mem0†: "Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory". Khant et al. arXiv 2025. [Paper]
- A-MEM†: "A-MEM: Agentic Memory for LLM Agents". Xu et al. NeurIPS 2025. [Paper]
- MemAct†: "Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks". Zhang et al. arXiv 2025. [Paper]
- Memory Survey†: "Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers". Du. arXiv 2026. [Paper]
- MemoryBank: "MemoryBank: Enhancing Large Language Models with Long-Term Memory". Zhong et al. AAAI 2024. [Paper]
- LoCoMo†: "Evaluating Very Long-Term Conversational Memory of LLM Agents". Maharana et al. arXiv 2024. [Paper]
- Memory Mechanisms Survey†: "A Survey on the Memory Mechanism of Large Language Model Based Agents". Zhang et al. arXiv 2024. [Paper]
- Evo-Memory†: "Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory". Wei et al. arXiv 2025. [Paper]
规划与推理
关键数据:SWE-agent ACI 研究表明,接口设计超越模型能力成为性能的首要决定因素。LATS 将MCTS与语言模型反馈集成用于状态空间搜索。Plan-on-Graph通过引导、记忆和反思机制在知识图谱上实现自适应自我修正规划。
- Tree of Thoughts: "Tree of Thoughts: Deliberate Problem Solving with Large Language Models". Yao et al. NeurIPS 2023. [Paper] [Code]
- LATS: "Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models". Zhou et al. arXiv 2023. [Paper] [Code]
- Plan-on-Graph: "Plan-on-Graph: Self-Correcting Adaptive Planning of Large Language Model on Knowledge Graphs". Chen et al. NeurIPS 2024. [Paper]
- AFlow†: "AFlow: Automating Agentic Workflow Generation". Zhang et al. arXiv 2024. [Paper]
- Agent Q†: "Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents". Putta et al. arXiv 2024. [Paper]
- OPENDEV†: "Building Effective AI Coding Agents for the Terminal: Scaffolding, Harness, Context Engineering, and Lessons Learned". Bui. arXiv 2026. [Paper]
- AOrchestra†: "AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration". Ruan et al. arXiv 2026. [Paper]
- RAP: "Reasoning with Language Model is Planning with World Model". Hao et al. EMNLP 2023. [Paper]
- Inner Monologue: "Inner Monologue: Embodied Reasoning Through Planning with Language Models". Huang et al. CoRL 2022. [Paper]
- Agent-Oriented Planning: "Agent-Oriented Planning in Multi-Agent Systems". Li et al. ICLR 2025. [Paper]
- ExACT†: "ExACT: Teaching AI Agents to Explore with Reflective-MCTS and Exploratory Learning". Yu et al. arXiv 2024. [Paper]
多智能体协同
关键数据:AgencyBench——智能体在原生SDKAgent Harness上达到48.4%成功率,而在独立Agent Harness上显著更低,展示了Harness和Agent之间的紧密耦合。对抗性多智能体设置中的拜占庭容错仍是开放问题。
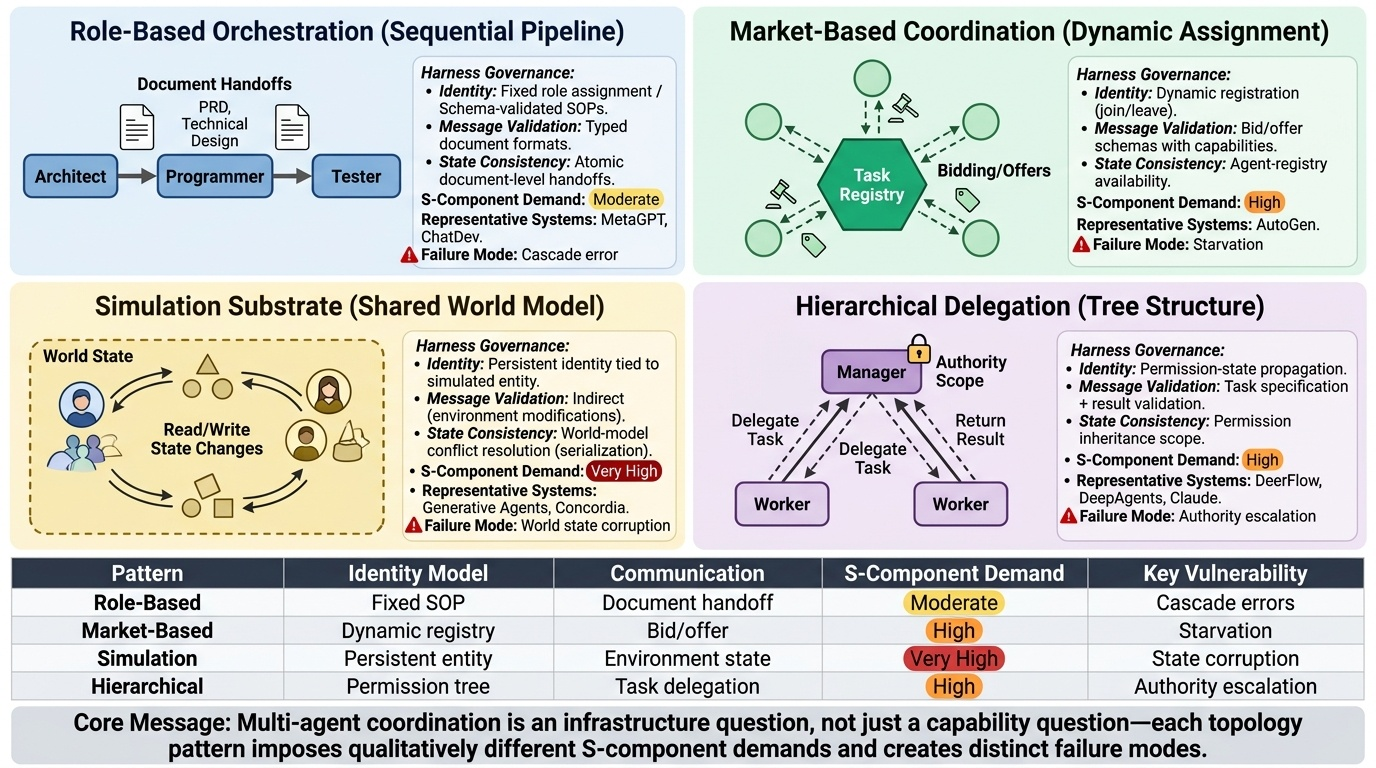
- SAGA†: "SAGA: A Security Architecture for Governing AI Agentic Systems". Syros et al. NDSS 2026. [Paper]
- MAS-FIRE†: "MAS-FIRE: Fault Injection and Reliability Evaluation for LLM-Based Multi-Agent Systems". Jia et al. arXiv 2026. [Paper]
- Byzantine fault tolerance†: "Rethinking the Reliability of Multi-agent System: A Perspective from Byzantine Fault Tolerance". Zheng et al. arXiv 2025. [Paper]
- Multi-agent baseline study†: "Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline". Xu et al. arXiv 2026. [Paper]
- AgentVerse†: "AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors". Chen et al. arXiv 2023. [Paper]
- Mixture-of-Agents†: "Mixture-of-Agents Enhances Large Language Model Capabilities". Wang et al. arXiv 2024. [Paper]
- Multi-Agent Survey: "Large Language Model Based Multi-Agents: A Survey of Progress and Challenges". Guo et al. IJCAI 2024. [Paper]
- Concordia†: "Generative Agent-Based Modeling with Actions Grounded in Physical, Social, or Digital Space Using Concordia". Vezhnevets et al. arXiv 2023. [Paper]
计算经济学
关键数据:OpenRouter 报告每周13T tokens(2026年2月),每4周翻倍;AgencyBench 测量平均1M tokens/任务;预计2027年智能体计算量增长1000倍;AIOS 通过恰当的智能体调度实现2.1×吞吐加速。
- Repo2Run†: "Repo2Run: Automated Building Executable Environment for Code Repository at Scale". Hu et al. arXiv 2025. [Paper]
- Policy-First†: "Guardrails as Infrastructure: Policy-First Control for Tool-Orchestrated Workflows". Sigdel & Baral. arXiv 2026. [Paper]
新兴主题
- Self-Evolving Agents Survey†: "A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence". Gao et al. TMLR 2026. [Paper]
- Self-RAG: "Self-RAG: Learning to Retrieve, Generate, and Critique Through Self-Reflection". Asai et al. ICLR 2024. [Paper]
- Constitutional AI: "Constitutional AI: Harmlessness from AI Feedback". Bai et al. arXiv 2022. [Paper]
- AppAgent†: "AppAgent: Multimodal Agents as Smartphone Users". Zhang et al. arXiv 2023. [Paper]
相关综述
- LLM Agents Survey: "A Survey on Large Language Model Based Autonomous Agents". Wang et al. arXiv 2023. [Paper]
- Rise of LLM Agents: "The Rise and Potential of Large Language Model Based Agents: A Survey". Xi et al. arXiv 2023. [Paper]
- LLM Survey: "A Survey of Large Language Models". Zhao et al. arXiv 2023. [Paper]
- AI Agent Systems†: "AI Agent Systems: Architectures, Applications, and Evaluation". Xu. arXiv 2025. [Paper]
业界实践报告与洞察
来自 Stripe、OpenAI、Cursor、METR 及其他前沿实践者的生产部署经验。
- Stripe Minions: "Minions: Stripe's one-shot, end-to-end coding agents". Gray. Stripe Dev Blog, Feb 2026. [Blog]
- Harness Engineering (OpenAI): "Harness engineering: leveraging Codex in an agent-first world". Lopopolo. OpenAI Blog, Feb 2026. [Blog]
- Self-Driving Codebases: "Towards self-driving codebases". Lin. Cursor Blog, Feb 2026. [Blog]
- METR SWE-bench Analysis: "Many SWE-bench-Passing PRs Would Not Be Merged into Main". Whitfill et al. METR Notes, Mar 2026. [Report]
未来方向
综述中识别的八个开放研究方向(无精选论文列表——这些是前瞻性方向):
- 形式化Agent Harness规范语言 — 用于指定和验证 H=(E,T,C,S,L,V) 组件的领域特定语言(DSL)
- 跨Agent Harness基准测试套件 — 跨不兼容执行器生态系统的可移植性测试
- 安全分类与威胁模型 — 将OWASP Top 10扩展至智能体执行器攻击面
- 协议互操作性(MCP/A2A) — 桥接工具级和智能体级协议
- 长时域评估方法论 — 在多会话、多天任务下不会退化的指标
- Agent Harness感知微调 — 训练模型使其感知执行环境
- 记忆接口标准化 — 跨平面式、情节式和图式存储的可移植记忆API
- Agent Harness透明性规范 — 运行时决策的可审计性和可解释性
引用
参见本 README 顶部的 BibTeX 引用格式。
更新日志
| 版本 | 日期 | 变更 |
|---|---|---|
| v1 | 2026-04-03 | 首次预印本 |
| v2 | 2026-04-07 | 仓库更新 |
| v3 | 2026-04-09 | 预印本索引 |
† 表示预印本,尚未经同行评审。
本综述正在积极开发中;完整手稿将于近期发布。
由 Qianyu Meng, Yanan Wang与 Liyi Chen 维护。欢迎提交缺失论文或更新链接的 PR。