
Paris 2.0: A Decentralized Diffusion Model for Video Generation
Paper • 2605.26064 • Published
Access is granted on a per-request basis after manual review by Bagel Labs.
Each request is reviewed individually. Typical turnaround is 2-3 business days.
By requesting access, you agree to abide by the license and Bagel Labs acceptable use policy. These model weights are released for research and evaluation. Commercial use is not granted by default and requires written agreement with Bagel Labs.
Log in or Sign Up to review the conditions and access this model content.
![]()
Paris 2.0 is a Decentralized Diffusion Model (DDM) for video generation, extending the Paris 1.0 DDM recipe from image generation to temporally coherent video. A DDM trains independent expert diffusion models without gradient synchronization, parameter sharing, or activation exchange, then uses a lightweight router to select experts during denoising.

Prompt: A woman with long, blond, wavy hair is speaking directly to the camera.

Prompt: A person's hands perform a paper-folding craft on a green cutting mat.

Prompt: A pair of hands interacts with translucent blue slime.
In a low-resolution text-to-video study, Paris 2.0 is compared against a monolithic model trained on the same data under a matched total compute budget. The decentralized model reduces FVD from 561.04 to 279.01 and improves CLIP text-video similarity and aesthetic score under the same generation protocol.
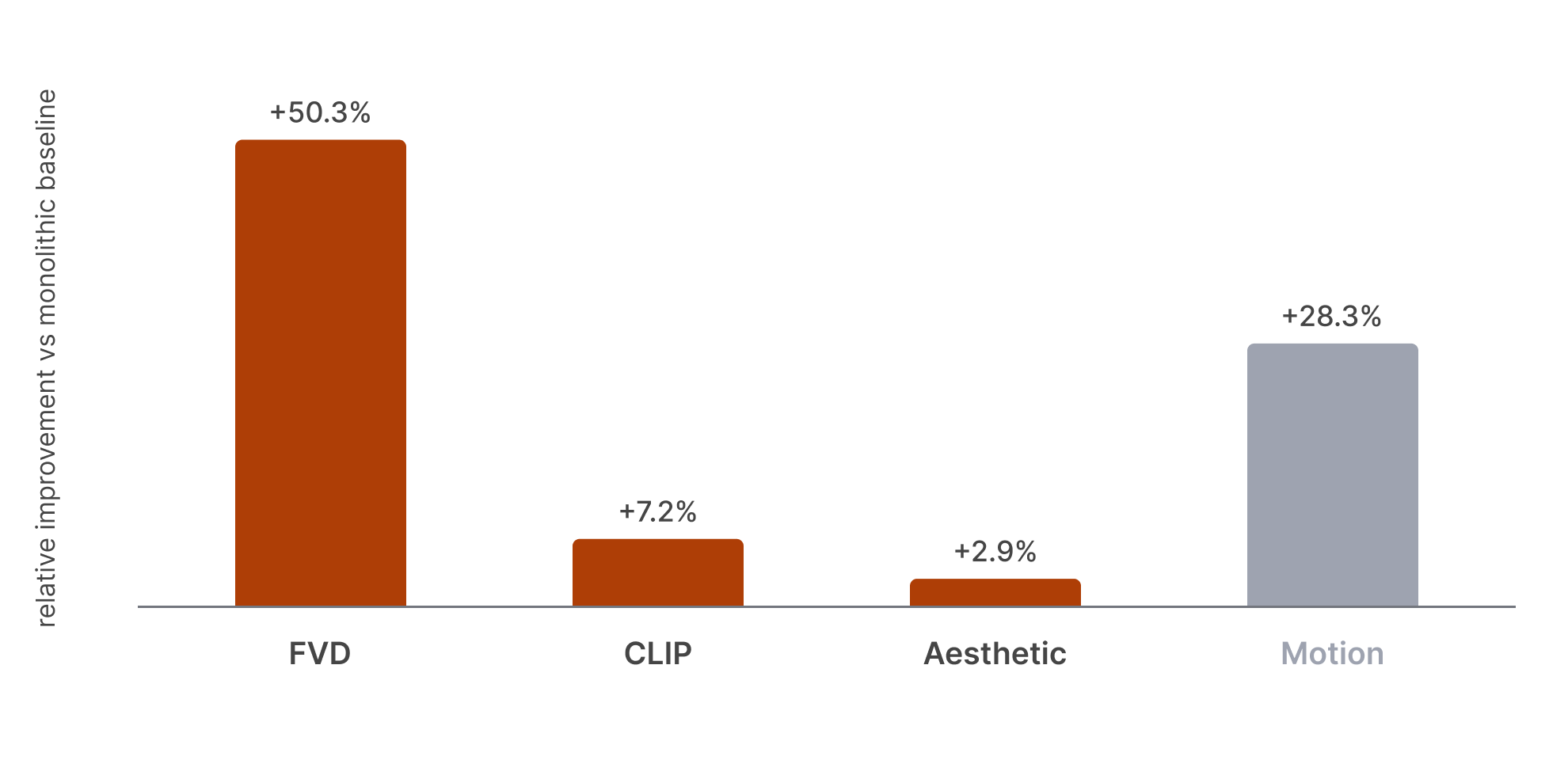
Relative improvement over the monolithic baseline. Each bar shows the gain over monolithic, so a taller bar means a larger improvement (for FVD this corresponds to a lower distance, for CLIP and aesthetic to a higher score). Motion is descriptive and has no preferred direction.
| Metric | Paris 2.0 DDM | Monolithic baseline |
|---|---|---|
| FVD ↓ | 279.01 | 561.04 |
| CLIP text-video ↑ | 0.2178 ± 0.0012 | 0.2032 ± 0.0011 |
| Aesthetic ↑ | 3.9036 ± 0.0082 | 3.7950 ± 0.0077 |
| Motion (px/frame) | 0.712 ± 0.057 | 0.555 ± 0.043 |
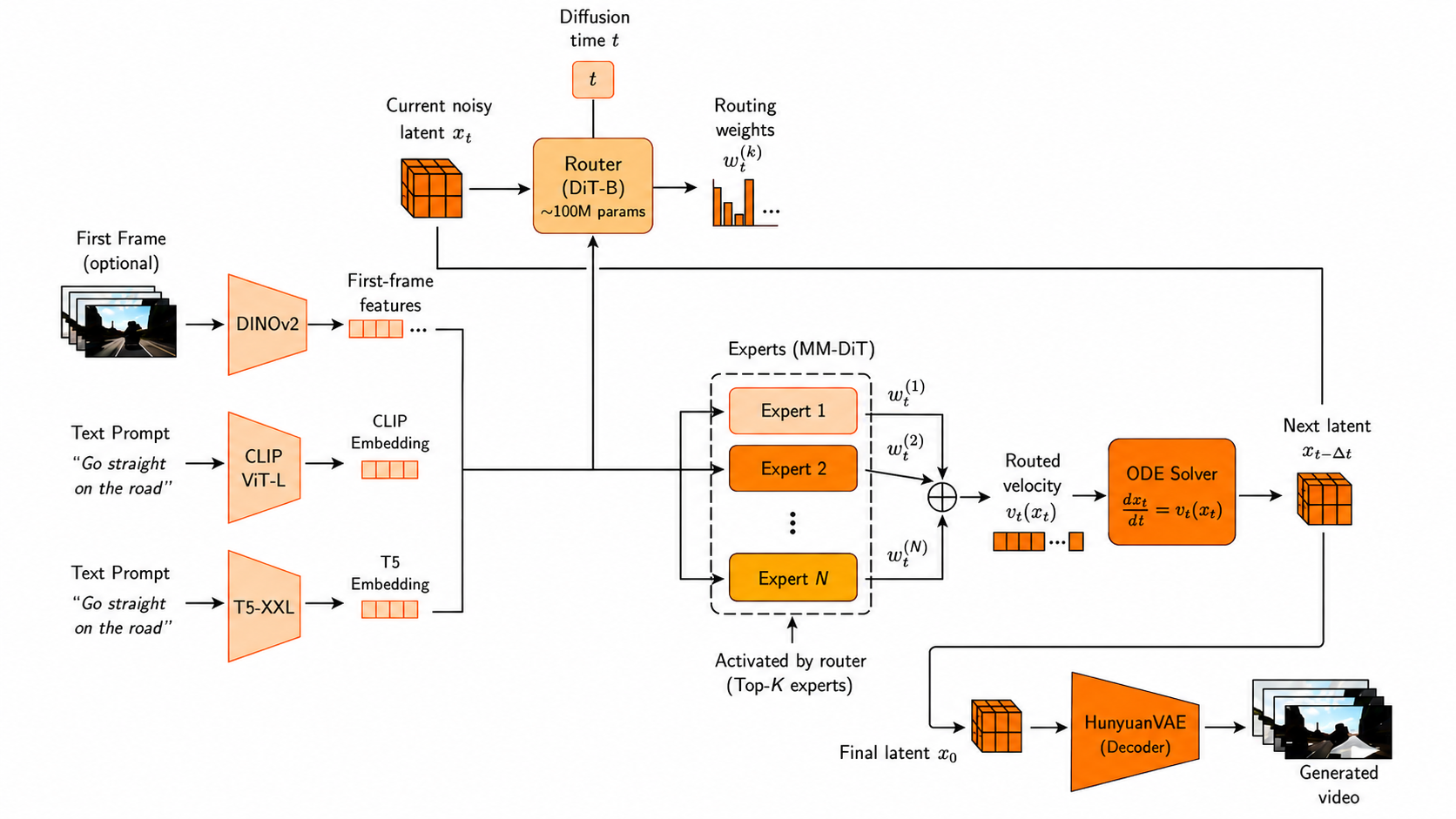
A lightweight router selects top-K Flux MM-DiT experts at each denoising step, and the routed velocity is decoded into video through HunyuanVAE.
This repository contains the Paris 2.0 expert pool and learned router. Each expert includes Stage 2 and Stage 3 checkpoints for 256×256 and 768×768 video resolutions.
expert1/ Expert 1
expert2/ Expert 2
expert3/ Expert 3
Router/ Routing model
model_index.json
Each checkpoint is provided in both unwrapped single-file
(master.safetensors) and sharded (model/) formats for compatibility with
different inference frameworks.
Inference requires four third-party components that are not bundled in this repository. Each is released by its original authors under its own license, and you should fetch them directly from the upstream sources. After downloading, place them in the working directory alongside the contents of this repo using the layout below.
# 1. Hunyuan Video VAE (Tencent)
hf download tencent/HunyuanVideo hunyuan-video-t2v-720p/vae/pytorch_model.pt --local-dir ./hunyuan_vae
mv ./hunyuan_vae/hunyuan-video-t2v-720p/vae/pytorch_model.pt ./vae.pt
# 2. T5 text encoder, fp16, encoder-only (community-maintained Flux variant)
hf download comfyanonymous/flux_text_encoders t5xxl_fp16.safetensors --local-dir ./t5
mv ./t5/t5xxl_fp16.safetensors ./t5/model.safetensors
# 3. T5 tokenizer + config (Google)
hf download google/t5-v1_1-xxl config.json spiece.model special_tokens_map.json tokenizer_config.json --local-dir ./t5
# 4. CLIP ViT-L/14 (OpenAI)
hf download openai/clip-vit-large-patch14 --local-dir ./clip
Final layout after running the four commands above plus this repo:
.
├── expert1/ expert2/ expert3/ Router/ (this repo)
├── model_index.json (this repo)
├── vae.pt (Tencent HunyuanVideo)
├── t5/ (Google T5 + Flux encoder-only safetensors)
└── clip/ (OpenAI CLIP)
| Component | Upstream | License |
|---|---|---|
| Hunyuan Video VAE | tencent/HunyuanVideo |
Tencent Hunyuan Community License |
| T5 text encoder weights (encoder-only fp16) | comfyanonymous/flux_text_encoders |
Apache 2.0 (derived from Google T5-v1.1) |
| T5 tokenizer and config | google/t5-v1_1-xxl |
Apache 2.0 |
| CLIP ViT-L/14 | openai/clip-vit-large-patch14 |
MIT |
Use of each component is governed by its own upstream license. The license field on this repository applies only to the expert and router weights we trained.
The null-conditioning tensors null_clip.pt and null_t5.pt referenced by
model_index.json for classifier-free guidance are produced by encoding an
empty string through CLIP and T5 respectively; once you have the encoders
above, you can regenerate them yourself with a few lines of code.
| Component | Specification |
|---|---|
| Architecture | Flux MM-DiT |
| Parameters per Expert | 11B |
| Number of Experts | 3 |
| Routing Model | Lightweight transformer router |
| Text Conditioning | T5 + CLIP ViT-L/14 |
| Video VAE | Hunyuan Video VAE (4× temporal, 8× spatial) |
| Latent Resolution (stage 2) | 32×32 per frame |
| Latent Resolution (stage 3) | 96×96 per frame |
| Video Resolution (stage 2) | 256×256 |
| Video Resolution (stage 3) | 768×768 |
| Generation Modes | text-to-video, image-to-video |
@misc{rouzbayani2026paris20decentralizeddiffusion,
title={Paris 2.0: A Decentralized Diffusion Model for Video Generation},
author={Ali Rouzbayani and Bidhan Roy and Marcos Villagra and Zhiying Jiang},
year={2026},
eprint={2605.26064},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.26064},
}
See the license field above. Released for research and evaluation. By
requesting access you agree to the terms of the license and the acceptable
use policy.