
{kind=link}
OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis
Paper • 2603.20278 • Published • 96
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("OpenResearcher/OpenResearcher-30B-A3B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OpenResearcher/OpenResearcher-30B-A3B", trust_remote_code=True)
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(tokenizer.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
🤗 HuggingFace |  Slack |
Slack |  WeChat
WeChat
OpenResearcher-30B-A3B is an agentic large language model designed for long-horizon deep research fine-tuned from NVIDIA-Nemotron-3-Nano-30B-A3B-Base-BF16 on 96K OpenResearcher dataset with 100+ turns. The dataset is derived by distilling GPT-OSS-120B with native browser tools. More info can be found on the dataset card at OpenResearcher dataset.
The model achieves an impressive 54.8% accuracy on BrowseComp-Plus, surpassing performance of GPT-4.1, Claude-Opus-4, Gemini-2.5-Pro, DeepSeek-R1 and Tongyi-DeepResearch.

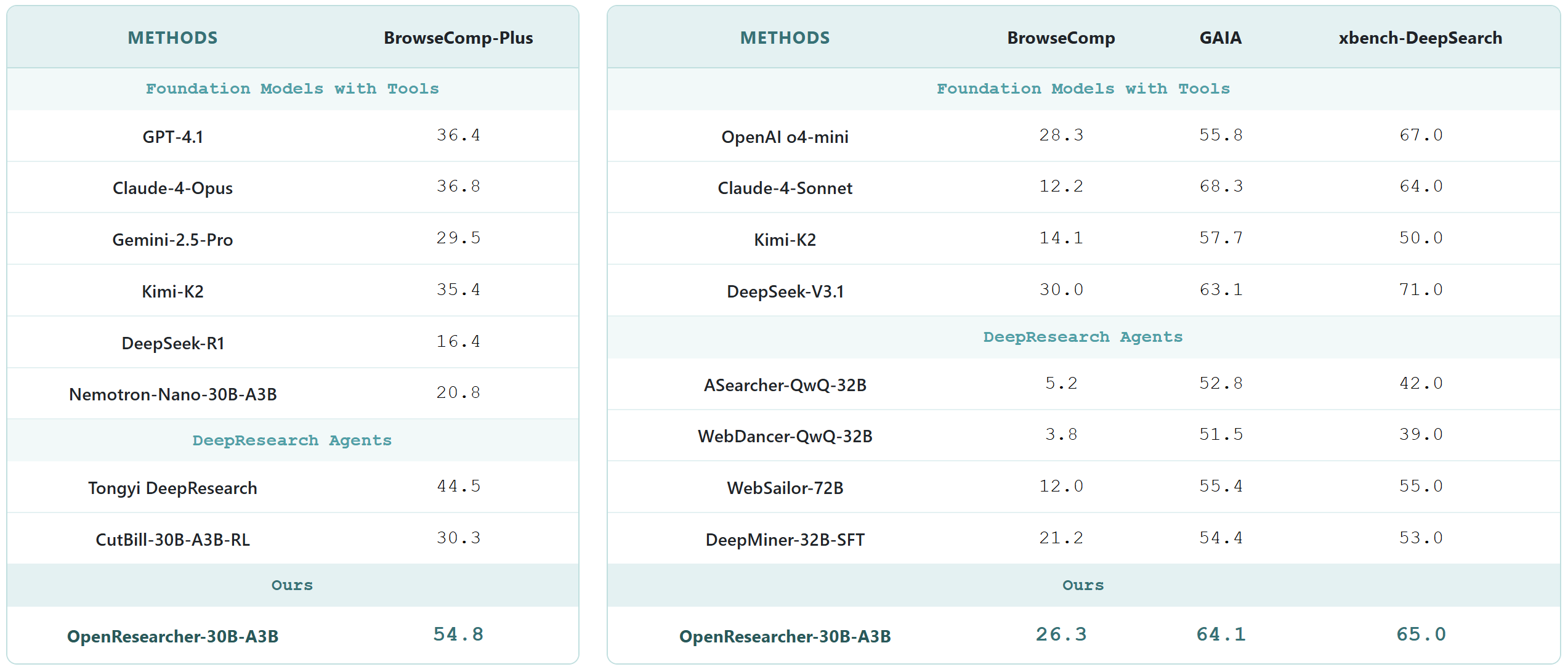
We evaluate OpenResearcher-30B-A3B across a range of deep research benchmarks, including BrowseComp-Plus, BrowseComp, GAIA, xbench-DeepSearch. Please find more details in GitHub.
We provide a quick-start in GitHub that demonstrates how to use OpenResearcher-30B-A3B for deep research.
@article{li2026openresearcher,
title={{OpenResearcher: A Fully Open Pipeline for Long-Horizon Deep Research Trajectory Synthesis}},
author={Li, Zhuofeng and Jiang, Dongfu and Ma, Xueguang and Zhang, Haoxiang and Nie, Ping and Zhang, Yuyu and Zou, Kai and Xie, Jianwen and Zhang, Yu and Chen, Wenhu},
journal={arXiv preprint arXiv:2603.20278},
year={2026}
}
# Use a pipeline as a high-level helper from transformers import pipeline pipe = pipeline("text-generation", model="OpenResearcher/OpenResearcher-30B-A3B", trust_remote_code=True) messages = [ {"role": "user", "content": "Who are you?"}, ] pipe(messages)