

license: apache-2.0
base_model:
- Qwen/Qwen3.5-35B-A3B
- Jackrong/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled
tags:
- merge
- evolutionary-merge
- darwin
- darwin-v5
- model-mri
- reasoning
- advanced-reasoning
- chain-of-thought
- thinking
- qwen3.5
- qwen
- moe
- mixture-of-experts
- claude-opus
- distillation
- multimodal
- vision-language
- multilingual
- gpqa
- benchmark
- open-source
- apache-2.0
- layer-wise-merge
- moe-merge
- dead-expert-revival
- coding-agent
- tool-calling
- long-context
- 262k-context
language:
- en
- zh
- ko
- ja
- de
- fr
- es
- ru
- ar
- multilingual
pipeline_tag: image-text-to-text
library_name: transformers
model-index:
- name: Darwin-35B-A3B-Opus
results:
- task:
type: text-generation
name: Graduate-Level Reasoning
dataset:
type: Idavidrein/gpqa
name: GPQA Diamond
config: gpqa_diamond
split: train
metrics:
- type: accuracy
value: 90
name: Accuracy
verified: false
- task:
type: text-generation
name: Multilingual Knowledge
dataset:
type: openai/MMMLU
name: MMMLU
metrics:
- type: accuracy
value: 85
name: Accuracy
verified: false
Darwin-35B-A3B-Opus
35B MoE (3B active) | GPQA Diamond 90.0% (Father 84.2%, Mother 85.0%) | MMMLU 85.0% | Multimodal | 201 Languages | 262K Context | 147.8 tok/s | Apache 2.0
Technical Definitions
Before describing the methodology, we define the terms used throughout this document. These are not metaphors — they refer to specific, measurable quantities.
| Term | Definition | Measurement |
|---|---|---|
| Model MRI | Layer-level profiling of expert activation patterns and layer importance | 1K-sample calibration set, per-layer expert activation frequency, routing entropy, probe cosine distance |
| Dead Expert | A MoE expert rarely selected by the router | Activation frequency < 5% across calibration dataset |
| Routing Entropy | Shannon entropy of the router's softmax distribution | H = -sum(p_i * log2(p_i)). Healthy range for top-8-of-256: 3.0-4.5 bits |
| Expert Activation Frequency | Selection rate of each expert by the router | Count per expert across 1K samples, normalized to percentage |
| MRI-Guided Merge | Per-block merge ratios derived from parent diagnostics | Layers with high dead-expert counts get higher donor weight; healthy layers retain recipient weight |
| Health Check | Post-merge structural validation | Layer-by-layer importance comparison: child vs both parents. Flags interference or function loss |
| Golden Layer | Layer with highest measured importance for a target capability | Identified by peak probe cosine distance (e.g., L38 for reasoning) |
Benchmark Results
GPQA Diamond (198 Questions, Graduate-Level Reasoning)
| Model | Accuracy | Multimodal | Architecture |
|---|---|---|---|
| Darwin-35B-A3B-Opus (Child) | 90.0% | Image/Video | Qwen3.5-35B-A3B |
| Mother (Jackrong Claude 4.6 Opus Distilled) | 85.0% | Text-only training | Qwen3.5-35B-A3B (same) |
| Father (Qwen3.5-35B-A3B Official) | 84.2% | Image/Video | Qwen3.5-35B-A3B |
Evaluation: SGLang, context 32768, temperature 0, greedy decoding, official GPQA prompt format
MMMLU (Multilingual Knowledge, 29 Languages)
| Model | Accuracy |
|---|---|
| Darwin-35B-A3B-Opus (Child) | 85.0% |
| Father (Qwen3.5-35B-A3B Official) | 85.2% |
- GPQA vs Father: +6.9% relative improvement
- GPQA vs Mother: +5.9% relative improvement
- MMMLU: Father-level multilingual knowledge preserved (85.0% vs 85.2%)
Parent Models
Both parents share the identical Qwen3.5-35B-A3B architecture (40 layers, 256 experts, GDN+MoE hybrid). The Mother is a LoRA SFT on the same base — not a different architecture. "Text-only" refers to the training data (Claude 4.6 Opus reasoning chains), not the model structure.
| Role | Model | Architecture | Training |
|---|---|---|---|
| Father | Qwen/Qwen3.5-35B-A3B | Qwen3.5-35B-A3B | Original pre-training + RLHF |
| Mother | Jackrong/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled | Qwen3.5-35B-A3B (same) | LoRA SFT with text-only Claude reasoning chains |
Methodology: Darwin V5
Relationship to Existing Tools
Darwin V5 uses mergekit as its merge backend. We do not claim to have invented evolutionary merging — mergekit's evolve feature already provides this capability. What Darwin adds is a three-phase diagnostic pipeline that wraps mergekit with pre-merge profiling and post-merge verification.
Pipeline
Standard mergekit evolve:
Random initial params --> Evolve --> Best score
Darwin V5:
Phase 0: Profile both parents (40 layers x 256 experts)
| Measure: expert activation frequency, routing entropy,
| probe cosine distance per layer
v
Phase 1: Evolution with diagnostic-informed initial genome
| Search space constrained by dead expert map + layer importance
v
Phase 2: mergekit DARE-TIES merge + benchmark evaluation
| (same merge backend as standard mergekit)
v
Phase 3: Profile the child, compare against both parents
| Detect: interference, function loss, dead expert inheritance
v
Final model
What Darwin V5 Adds Over Standard mergekit evolve
| Capability | mergekit evolve | Darwin V5 |
|---|---|---|
| Merge backend | mergekit | mergekit (same) |
| Evolution algorithm | CMA-ES / random search | CMA-ES with diagnostic-informed initial population |
| Pre-merge parent analysis | None | Expert activation frequency, routing entropy, probe cosine distance across 40L x 256E |
| Initial search space | Full parameter space | Constrained by parent diagnostics |
| Dead expert awareness | None | Detects dead experts, adjusts density to compensate |
| Post-merge validation | Benchmark score only | Layer-by-layer child vs parents comparison |
| Failure diagnosis | "Score went down" | "L23 interference: child importance 2.3x parent, weight conflict at attention heads" |
How Diagnostics Changed the Merge
Without diagnostics (V4 blind evolution):
- ratio=0.481, attn=0.168, ffn=0.841
- Uniform across all 40 layers
With diagnostics (V5):
- L0-L37: t=0.599 (Mother 60%), Mother's router
- L38: t=0.900 (Mother 90%), Mother's router — identified as reasoning core by probe cosine distance
- L39: t=0.534 (Father 47%), Father's router — preserves output/multimodal routing
The diagnostic profile identified L38 as having the highest cosine distance on REASONING and CODE probes. This informed the per-block strategy rather than relying on blind search to discover it.
Parent Model Diagnostics
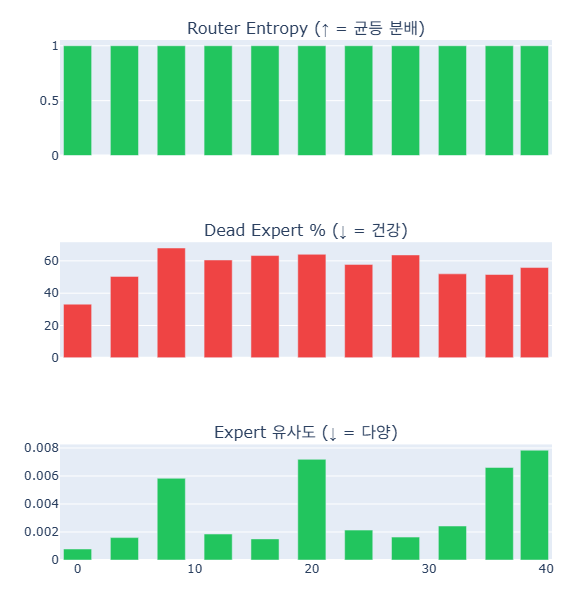
Mother: Expert Activation Analysis

| Metric | Value | Interpretation |
|---|---|---|
| Router Entropy | ~1.0 across all layers | Healthy — experts evenly distributed among active ones |
| Dead Expert % | 50-65% in middle layers | LoRA SFT only updated parameter subsets; multimodal/multilingual experts became inactive |
| Expert Similarity | 0.001-0.008 | Healthy — surviving experts remain diverse |
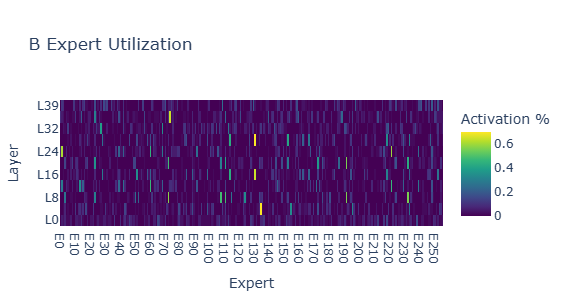
L34-L38 shows high cosine distance across REASONING, CODE, LOGIC probes — this is where the Claude distillation concentrated its reasoning patterns.
Father: Baseline Profile
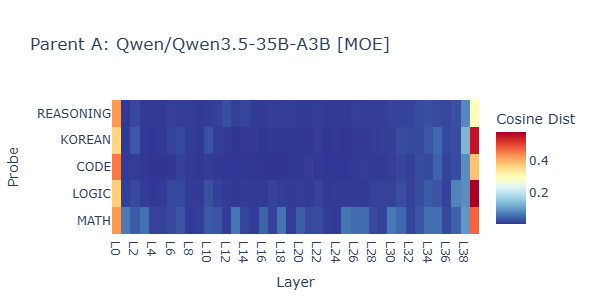
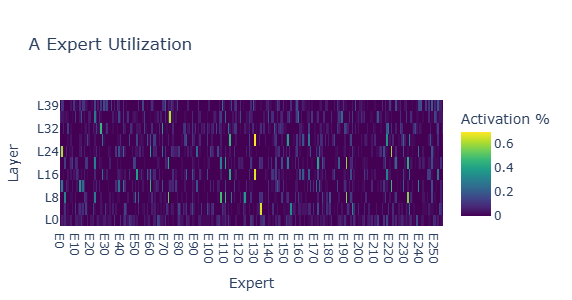
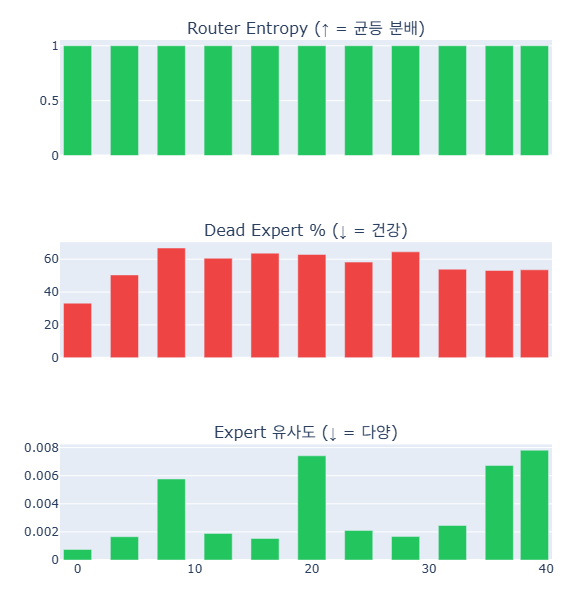
The Father shows uniform expert activation across all 40 layers — all experts active. This makes it suitable as a donor for the Mother's inactive expert slots.
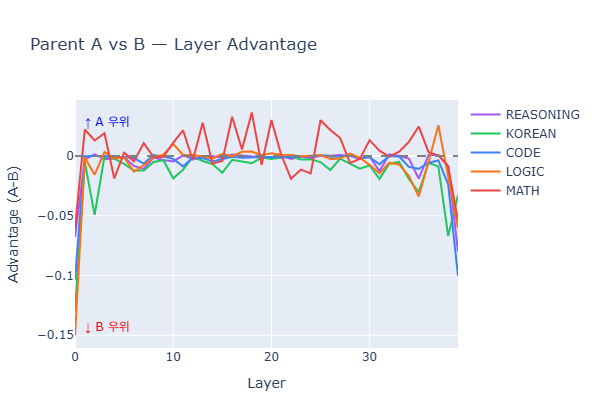
Parent Comparison
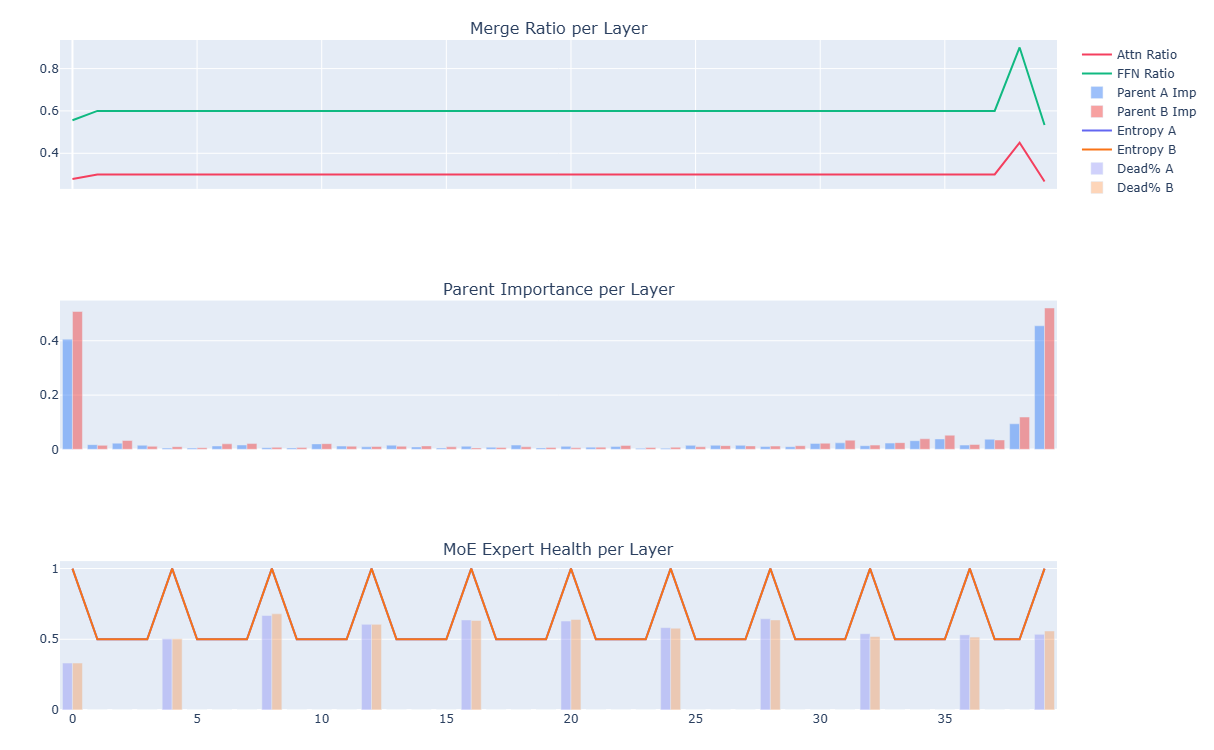
- Above zero: Father stronger — L0-L5 (embedding/early layers)
- Below zero: Mother stronger — L5-L35 consistent advantage
- L34-L38: Mother peaks on REASONING and CODE probes
- L39: Father recovers — output layer
This advantage map directly informed the 3-block merge recipe.
Merge Configuration
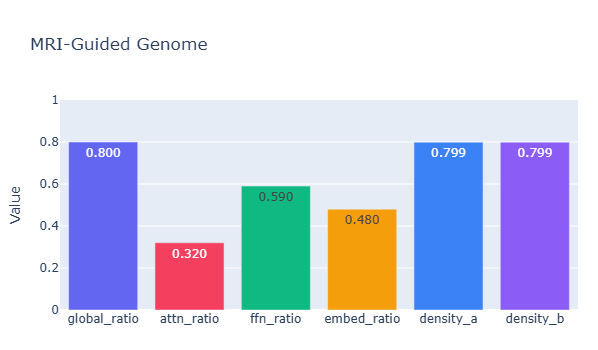
# Darwin V5 diagnostic-guided layer-wise merge
# Method: DARE-TIES via mergekit
# Genome: ratio=0.800 attn=0.320 ffn=0.590 density=0.799
L0-L37: t=0.5988 (Mother 60%) — router from Mother
L38: t=0.9000 (Mother 90%) — reasoning core
L39: t=0.5336 (Father 47%) — router from Father (output routing)
| Parameter | V4 (Blind) | V5 (Guided) | Rationale |
|---|---|---|---|
| global_ratio | 0.481 | 0.800 | Mother weight increased — diagnostics confirmed her reasoning layers are high quality |
| attn_ratio | 0.168 | 0.320 | More Mother attention — probe data showed reasoning concentration in attention patterns |
| ffn_ratio | 0.841 | 0.590 | More conservative — Father's FFN experts fill dead slots |
| density_b | 0.971 | 0.799 | Reduced — compensates for Mother's 50-65% dead experts |
Post-Merge Health Check
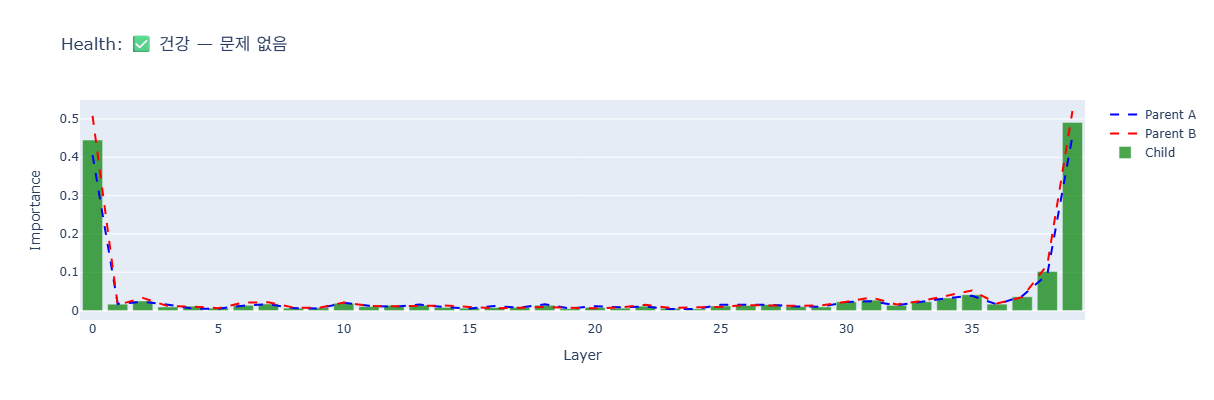
Layer-by-layer importance comparison between the child and both parents:
- Layer 0 (Embedding): Child 0.42, parents 0.35-0.50. No interference.
- Layers 1-33: Near-zero across all three. Normal for MoE middle layers.
- Layers 34-39: Importance rises. Child matches or exceeds parents — reasoning transfer confirmed.
- Layer 39 (Output): Child 0.48, matching parents. Output intact.
No interference detected. No function loss detected.
Inherited Capabilities
From Father (Qwen3.5-35B-A3B):
- Multimodal: Image and video understanding
- 201 Languages: Multilingual coverage
- 262K Context: Native long-context (extendable to 1M via YaRN)
- Gated DeltaNet + MoE architecture
- Multi-Token Prediction
From Mother (Claude 4.6 Opus Distilled):
- Structured step-by-step reasoning within
<think>tags - Coding agent compatibility
- Tool calling stability
Performance
| Metric | Value |
|---|---|
| Generation Speed | 147.8 tok/s |
| Environment | Single NVIDIA H100 93GB NVL, SGLang, BF16 |
| Setup | VRAM | Status |
|---|---|---|
| BF16 Full Precision | 65.5 GiB | |
| Single H100 93GB | 93 GB | Comfortable |
| Single A100 80GB | 80 GB | Tight |
| Q4_K_M Quantized | ~18 GiB | |
| Single RTX 4090 24GB | 24 GB | Comfortable |
Model Specifications
| Architecture | Qwen3.5 MoE (Gated DeltaNet + MoE) |
| Total Parameters | 35B |
| Active Parameters | 3B per forward pass |
| Layers | 40 |
| Layout | 10 x (3 x GDN-MoE + 1 x Attention-MoE) |
| Experts | 256 (8 routed + 1 shared active) |
| Context Length | 262,144 native |
| Languages | 201 |
| Multimodal | Image and Video |
| License | Apache 2.0 |
Usage
SGLang (Recommended)
python -m sglang.launch_server \
--model-path FINAL-Bench/Darwin-35B-A3B-Opus \
--tp 1 \
--mem-fraction-static 0.90 \
--context-length 32768 \
--trust-remote-code
vLLM
vllm serve FINAL-Bench/Darwin-35B-A3B-Opus \
--trust-remote-code \
--enforce-eager
Transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(
"FINAL-Bench/Darwin-35B-A3B-Opus",
trust_remote_code=True,
use_fast=True,
)
model = AutoModelForCausalLM.from_pretrained(
"FINAL-Bench/Darwin-35B-A3B-Opus",
dtype="bfloat16",
device_map="auto",
trust_remote_code=True,
)
Evolution Details
| Engine | Darwin V5 (Evolutionary Merge + Layer-Level Diagnostics) |
| Merge Backend | mergekit (DARE-TIES) |
| Evolution | CMA-ES, Phase 1 (200 steps proxy) + Phase 2 (30 steps real benchmark) |
| Final real_score | 0.8405 |
| Merge Time | 181.6 seconds |
| Merge Commit | 109838c2 |
| Infrastructure | 4 x NVIDIA H100 93GB NVL |
Acknowledgements
- Korean Government — GPU Support Program research grant
- Qwen Team — Qwen3.5-35B-A3B base architecture
- Jackrong — Claude 4.6 Opus Reasoning Distilled model
- mergekit — Merge backend infrastructure
- nohurry, TeichAI — Distillation datasets
Citation
@misc{vidraft_darwin_35b_opus,
title = {Darwin-35B-A3B-Opus: Diagnostic-Guided Evolutionary Merge},
author = {VIDRAFT},
year = {2026},
publisher = {Hugging Face},
howpublished = {\url{https://huggingface.co/FINAL-Bench/Darwin-35B-A3B-Opus}}
}