
Update pipeline tag to robotics and improve model card
#1
by nielsr HF Staff - opened
README.md
CHANGED
|
@@ -2,11 +2,10 @@
|
|
| 2 |
language:
|
| 3 |
- en
|
| 4 |
license: cc-by-nc-sa-4.0
|
| 5 |
-
pipeline_tag:
|
| 6 |
tags:
|
| 7 |
- motion-generation
|
| 8 |
- trajectory-prediction
|
| 9 |
-
- robotics
|
| 10 |
- computer-vision
|
| 11 |
- pytorch
|
| 12 |
- torch-hub
|
|
@@ -15,17 +14,15 @@ tags:
|
|
| 15 |
# ZipMo (Learning Long-term Motion Embeddings for Efficient Kinematics Generation)
|
| 16 |
|
| 17 |
[](https://compvis.github.io/long-term-motion)
|
| 18 |
-
[](https://
|
| 19 |
[](https://github.com/CompVis/long-term-motion)
|
| 20 |
[](https://compvis.github.io/long-term-motion)
|
| 21 |
|
| 22 |
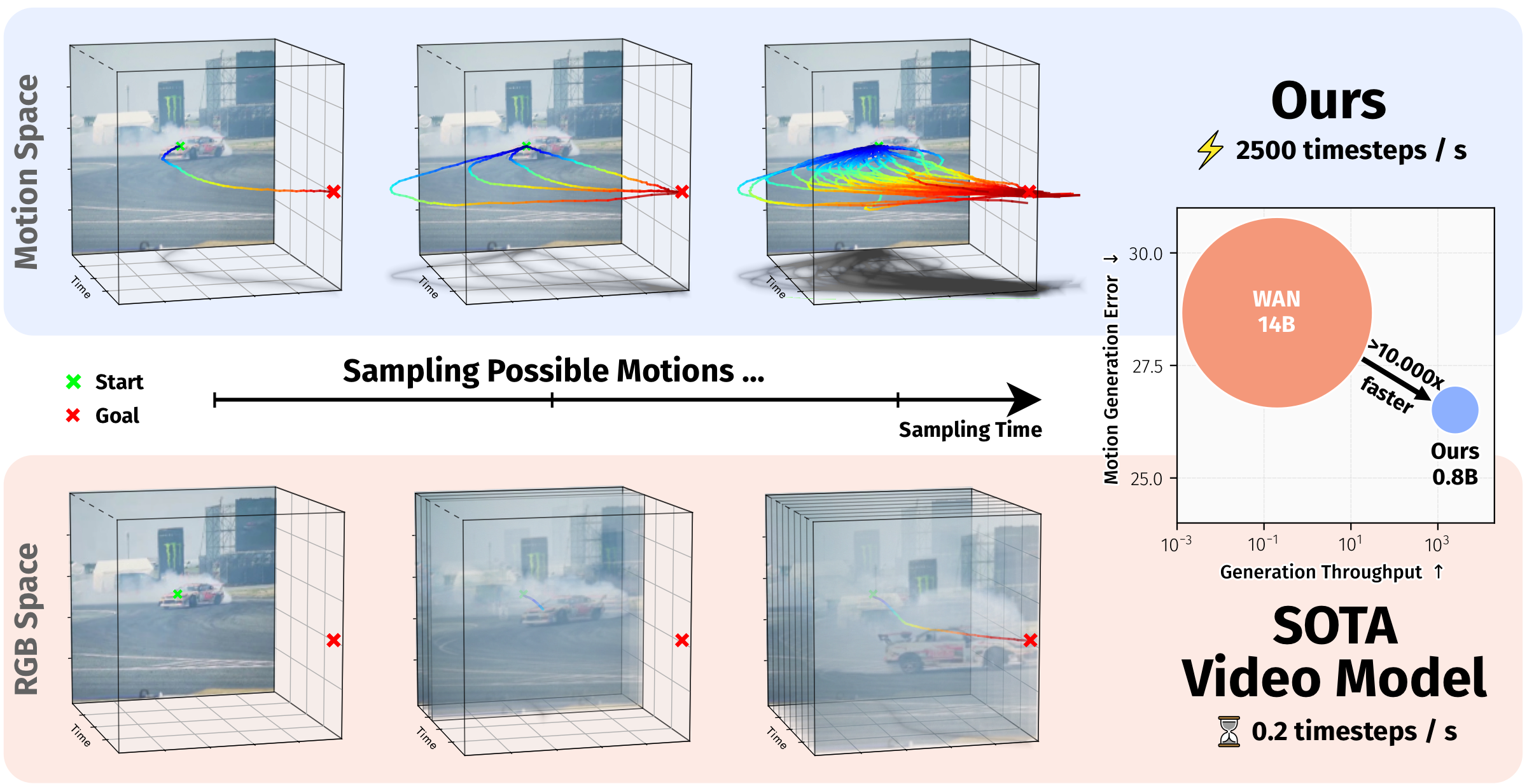
ZipMo is a motion-space model for efficient long-horizon kinematics generation. It learns compact long-term motion embeddings from large-scale tracker-derived trajectories and generates plausible future motion directly in this learned motion space. The model supports spatial-poke conditioning for open-domain videos and task/text-embedding conditioning for LIBERO robotics evaluation.
|
| 23 |
|
| 24 |
-
##
|
| 25 |
|
| 26 |
-
ZipMo
|
| 27 |
-
|
| 28 |
-
Understanding and predicting motion is a fundamental component of visual intelligence. Although video models can synthesize scene dynamics, exploring many possible futures through full video generation is expensive. ZipMo instead operates directly on long-term motion embeddings learned from tracker trajectories, enabling efficient generation of long, realistic motions while preserving dense reconstruction at arbitrary spatial query points.
|
| 29 |
|
| 30 |
|
| 31 |
*ZipMo generates long-horizon motion in a compact learned motion space, supporting spatial-poke conditioning for open-domain videos and task-conditioned action prediction on LIBERO.*
|
|
@@ -71,7 +68,7 @@ Available Torch Hub entries:
|
|
| 71 |
- `zipmo_planner_libero`: LIBERO planner with mode `atm` or `tramoe`.
|
| 72 |
- `zipmo_policy_head`: LIBERO policy head with mode `atm` or `tramoe`. For `tramoe`, pass one of `10`, `goal`, `object`, or `spatial`.
|
| 73 |
|
| 74 |
-
For the interactive demo,
|
| 75 |
|
| 76 |
## Citation
|
| 77 |
|
|
@@ -80,7 +77,7 @@ If you find our model or code useful, please cite our paper:
|
|
| 80 |
```bibtex
|
| 81 |
@inproceedings{stracke2026motionembeddings,
|
| 82 |
title = {Learning Long-term Motion Embeddings for Efficient Kinematics Generation},
|
| 83 |
-
author = {Stracke, Nick and Bauer, Kolja and Baumann, Stefan Andreas and Bautista, Miguel Angel and Susskind, Josh and Ommer, Bj{\"
|
| 84 |
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 85 |
year = {2026}
|
| 86 |
}
|
|
|
|
| 2 |
language:
|
| 3 |
- en
|
| 4 |
license: cc-by-nc-sa-4.0
|
| 5 |
+
pipeline_tag: robotics
|
| 6 |
tags:
|
| 7 |
- motion-generation
|
| 8 |
- trajectory-prediction
|
|
|
|
| 9 |
- computer-vision
|
| 10 |
- pytorch
|
| 11 |
- torch-hub
|
|
|
|
| 14 |
# ZipMo (Learning Long-term Motion Embeddings for Efficient Kinematics Generation)
|
| 15 |
|
| 16 |
[](https://compvis.github.io/long-term-motion)
|
| 17 |
+
[](https://huggingface.co/papers/2604.11737)
|
| 18 |
[](https://github.com/CompVis/long-term-motion)
|
| 19 |
[](https://compvis.github.io/long-term-motion)
|
| 20 |
|
| 21 |
ZipMo is a motion-space model for efficient long-horizon kinematics generation. It learns compact long-term motion embeddings from large-scale tracker-derived trajectories and generates plausible future motion directly in this learned motion space. The model supports spatial-poke conditioning for open-domain videos and task/text-embedding conditioning for LIBERO robotics evaluation.
|
| 22 |
|
| 23 |
+
## Abstract
|
| 24 |
|
| 25 |
+
Understanding and predicting motion is a fundamental component of visual intelligence. Although modern video models exhibit strong comprehension of scene dynamics, exploring multiple possible futures through full video synthesis remains prohibitively inefficient. ZipMo models scene dynamics by directly operating on a long-term motion embedding learned from large-scale trajectories. This enables efficient generation of long, realistic motions that fulfill goals specified via text prompts or spatial pokes.
|
|
|
|
|
|
|
| 26 |
|
| 27 |

|
| 28 |
*ZipMo generates long-horizon motion in a compact learned motion space, supporting spatial-poke conditioning for open-domain videos and task-conditioned action prediction on LIBERO.*
|
|
|
|
| 68 |
- `zipmo_planner_libero`: LIBERO planner with mode `atm` or `tramoe`.
|
| 69 |
- `zipmo_policy_head`: LIBERO policy head with mode `atm` or `tramoe`. For `tramoe`, pass one of `10`, `goal`, `object`, or `spatial`.
|
| 70 |
|
| 71 |
+
For the interactive demo, evaluation scripts, and training instructions, see the [GitHub repository](https://github.com/CompVis/long-term-motion).
|
| 72 |
|
| 73 |
## Citation
|
| 74 |
|
|
|
|
| 77 |
```bibtex
|
| 78 |
@inproceedings{stracke2026motionembeddings,
|
| 79 |
title = {Learning Long-term Motion Embeddings for Efficient Kinematics Generation},
|
| 80 |
+
author = {Stracke, Nick and Bauer, Kolja and Baumann, Stefan Andreas and Bautista, Miguel Angel and Susskind, Josh and Ommer, Bj{\"}rn},
|
| 81 |
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 82 |
year = {2026}
|
| 83 |
}
|