
File size: 3,908 Bytes
22c2224 7348d83 22c2224 5942e72 22c2224 7348d83 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | ---
language:
- en
license: cc-by-nc-sa-4.0
pipeline_tag: image-to-video
tags:
- motion-generation
- trajectory-prediction
- robotics
- computer-vision
- pytorch
- torch-hub
---
# ZipMo (Learning Long-term Motion Embeddings for Efficient Kinematics Generation)
[](https://compvis.github.io/long-term-motion)
[](https://arxiv.org/abs/2604.11737)
[](https://github.com/CompVis/long-term-motion)
[](https://compvis.github.io/long-term-motion)
ZipMo is a motion-space model for efficient long-horizon kinematics generation. It learns compact long-term motion embeddings from large-scale tracker-derived trajectories and generates plausible future motion directly in this learned motion space. The model supports spatial-poke conditioning for open-domain videos and task/text-embedding conditioning for LIBERO robotics evaluation.
## Paper and Abstract
ZipMo was introduced in the CVPR 2026 paper **Learning Long-term Motion Embeddings for Efficient Kinematics Generation**.
Understanding and predicting motion is a fundamental component of visual intelligence. Although video models can synthesize scene dynamics, exploring many possible futures through full video generation is expensive. ZipMo instead operates directly on long-term motion embeddings learned from tracker trajectories, enabling efficient generation of long, realistic motions while preserving dense reconstruction at arbitrary spatial query points.
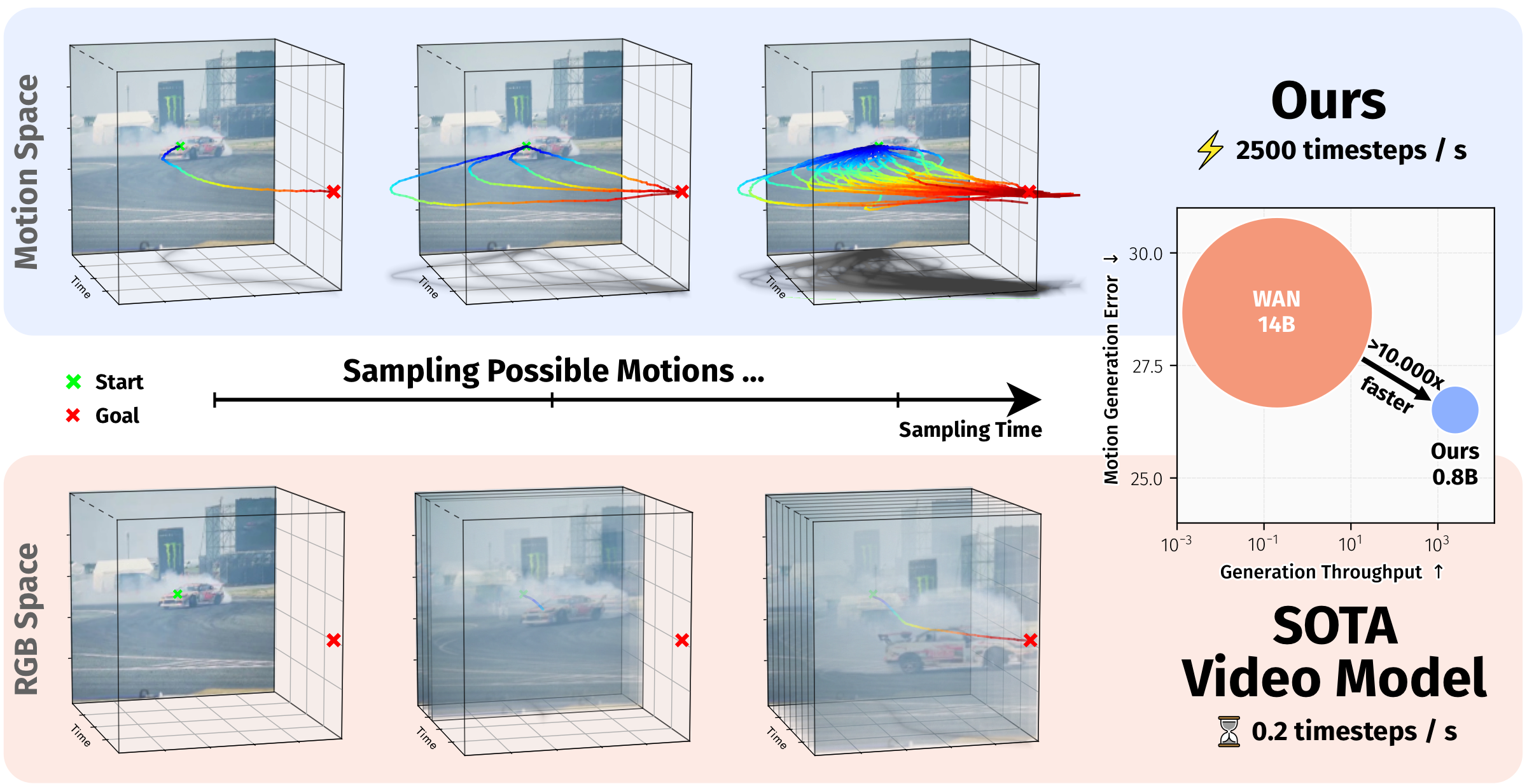
*ZipMo generates long-horizon motion in a compact learned motion space, supporting spatial-poke conditioning for open-domain videos and task-conditioned action prediction on LIBERO.*
## Usage
For programmatic use, the simplest way to use ZipMo is via `torch.hub`:
```python
import torch
repo = "CompVis/long-term-motion"
# Open-domain motion prediction
planner_sparse = torch.hub.load(repo, "zipmo_planner_sparse")
planner_dense = torch.hub.load(repo, "zipmo_planner_dense")
# Motion autoencoder
vae = torch.hub.load(repo, "zipmo_vae")
```
LIBERO planning and policy components can be loaded in the same way:
```python
import torch
repo = "CompVis/long-term-motion"
# LIBERO planners
libero_atm_planner = torch.hub.load(repo, "zipmo_planner_libero", "atm")
libero_tramoe_planner = torch.hub.load(repo, "zipmo_planner_libero", "tramoe")
# LIBERO policy heads
policy_head_atm = torch.hub.load(repo, "zipmo_policy_head", "atm")
policy_head_tramoe_goal = torch.hub.load(repo, "zipmo_policy_head", "tramoe", "goal")
```
Available Torch Hub entries:
- `zipmo_planner_sparse`: sparse-poke planner for open-domain motion prediction.
- `zipmo_planner_dense`: dense-conditioning planner for open-domain motion prediction.
- `zipmo_vae`: long-term motion autoencoder.
- `zipmo_planner_libero`: LIBERO planner with mode `atm` or `tramoe`.
- `zipmo_policy_head`: LIBERO policy head with mode `atm` or `tramoe`. For `tramoe`, pass one of `10`, `goal`, `object`, or `spatial`.
For the interactive demo, standard track prediction evaluation, LIBERO rollout evaluation, and training instructions, see the [GitHub repository](https://github.com/CompVis/long-term-motion).
## Citation
If you find our model or code useful, please cite our paper:
```bibtex
@inproceedings{stracke2026motionembeddings,
title = {Learning Long-term Motion Embeddings for Efficient Kinematics Generation},
author = {Stracke, Nick and Bauer, Kolja and Baumann, Stefan Andreas and Bautista, Miguel Angel and Susskind, Josh and Ommer, Bj{\"o}rn},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year = {2026}
}
``` |