
D-FINE-seg: Object Detection and Instance Segmentation Framework with multi-backend deployment
Paper • 2602.23043 • Published
Real-Time Object Detection and Instance Segmentation. A DETR-style detector (D-FINE) extended with a lightweight mask head, segmentation-aware training, and mask-aware Hungarian matching. Outperforms Ultralytics YOLO26 in fine-tuning F1-score on TACO and VisDrone under a unified TensorRT FP16 end-to-end benchmarking protocol, while maintaining competitive latency.
D-FINE-seg adds an instance segmentation head to D-FINE without changing its detection core. The mask head fuses HybridEncoder PAN features at strides 8/16/32 to 1/4 resolution; per-query mask embeddings (3-layer MLP) are dot-producted with shared mask features to produce per-instance masks. Training adds box-cropped BCE + Dice mask losses, mask-aware contrastive denoising, and mask costs in the Hungarian matcher.
This is not a fork of D-FINE. The detection core is based on the original D-FINE paper; everything else (segmentation head, training pipeline, export, inference, augmentations) was reimplemented from scratch. The mask head design follows the Mask DINO paradigm.
All weights are PyTorch .pt files. Filename pattern: dfine[_seg]_<size>_<dataset>.pt.
| File | Size (M params) | Notes |
|---|---|---|
dfine_n_coco.pt |
3.8 | Nano |
dfine_s_coco.pt |
10.3 | Small |
dfine_m_coco.pt |
19.6 | Medium |
dfine_l_coco.pt |
31.2 | Large |
dfine_x_coco.pt |
62.6 | Extra-Large |
dfine_{s,m,l,x}_obj2coco.pt — same architectures, pretrained on Objects365, then fine-tuned
on COCO. Generally a stronger init for downstream fine-tuning.
| File | Size (M params) | Notes |
|---|---|---|
dfine_seg_n_coco.pt |
5.1 | Nano |
dfine_seg_s_coco.pt |
11.9 | Small |
dfine_seg_m_coco.pt |
21.2 | Medium |
dfine_seg_l_coco.pt |
32.8 | Large |
dfine_seg_x_coco.pt |
64.3 | Extra-Large |
Note on
transformersintegration. This model is not (yet) wrapped as atransformers.AutoModel. The recommended path is to use the official training/inference repo — weights auto-download from this Hub repo on first use. For anAutoModel-style API on a closely related architecture, seeRTDetrV2ForObjectDetection.
git clone https://github.com/ArgoHA/D-FINE-seg.git
cd D-FINE-seg
pip install -r requirements.txt
Weights are auto-downloaded from this repo into pretrained/ on first use. No manual setup
needed; just point at the size and dataset you want:
from src.infer.torch_model import Torch_model
import cv2
model = Torch_model(
model_name="s", # n / s / m / l / x
model_path="pretrained/dfine_seg_s_coco.pt",
n_outputs=80, # COCO classes
input_width=640,
input_height=640,
conf_thresh=0.5,
enable_mask_head=True, # False for detection checkpoints
device="cuda", # cuda / mps / cpu
)
img = cv2.imread("path/to/image.jpg") # BGR
results = model(img) # [{"boxes", "scores", "labels", "masks"?}]
huggingface_hub
from huggingface_hub import hf_hub_download
ckpt = hf_hub_download(
repo_id="ArgoSA/D-FINE-seg",
filename="dfine_seg_s_coco.pt",
)
# Then load with the official repo's Torch_model (see Option 1).
python -m demo.demo
| Use case | Datasets used |
|---|---|
| COCO detection / segmentation pretraining | COCO 2017 |
| Objects365 → COCO checkpoints | Objects365 → COCO 2017 |
| Reported drone benchmarks | VisDrone (~6.5k train / ~550 val / ~1.6k test-dev) |
| Reported waste benchmarks | TACO (1500 images, 59 effective classes, 86/14 batch-ID split) |
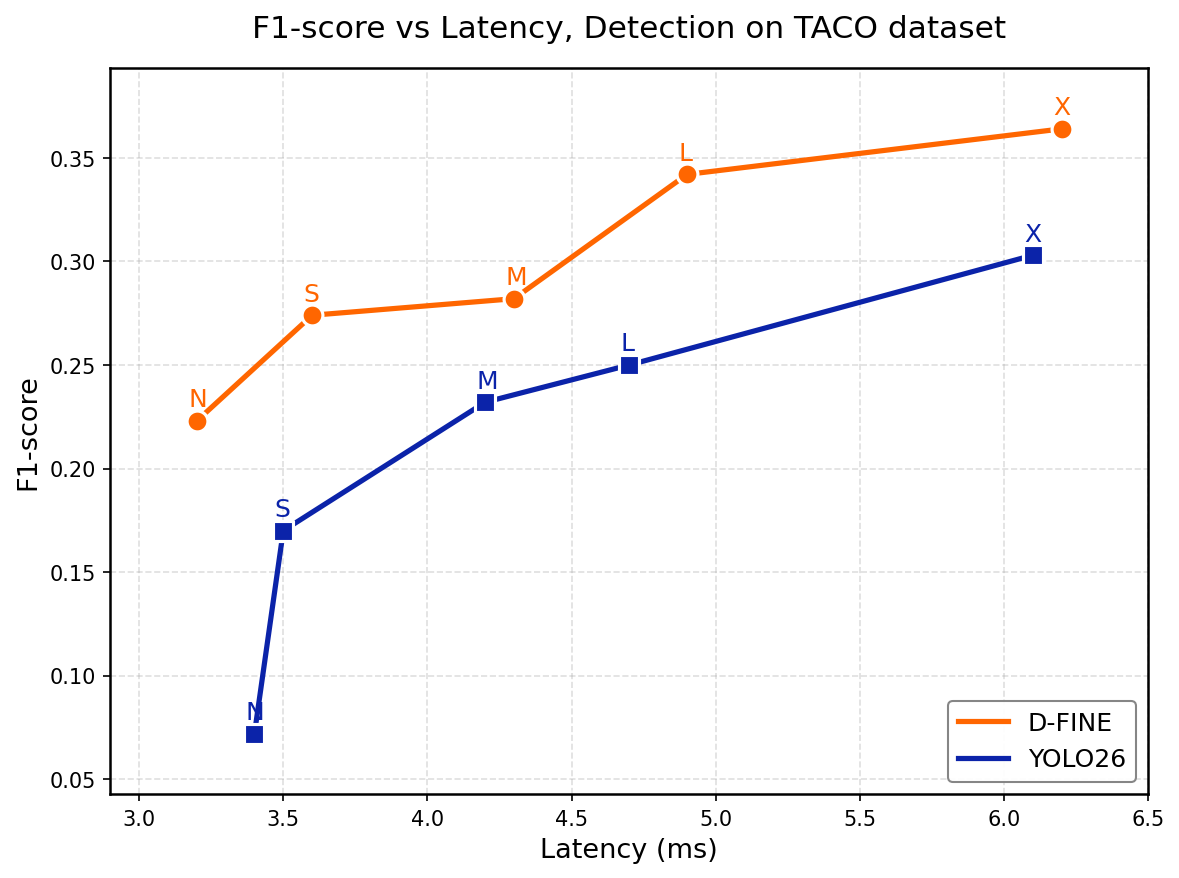
End-to-end latency (preprocessing + forward + postprocessing), RTX 5070 Ti, TensorRT FP16, 640×640, batch size 1. F1-score at IoU 0.5.
| Model | F1 | IoU | Latency (ms) |
|---|---|---|---|
| D-FINE N | 0.531 | 0.288 | 1.6 |
| YOLO26 N | 0.455 | 0.226 | 2.8 |
| D-FINE S | 0.584 | 0.332 | 2.1 |
| YOLO26 S | 0.510 | 0.264 | 3.1 |
| D-FINE M | 0.605 | 0.351 | 2.7 |
| YOLO26 M | 0.562 | 0.301 | 3.6 |
| D-FINE L | 0.606 | 0.351 | 3.3 |
| YOLO26 L | 0.568 | 0.308 | 4.1 |
| D-FINE X | 0.611 | 0.354 | 4.5 |
| YOLO26 X | 0.584 | 0.319 | 5.3 |
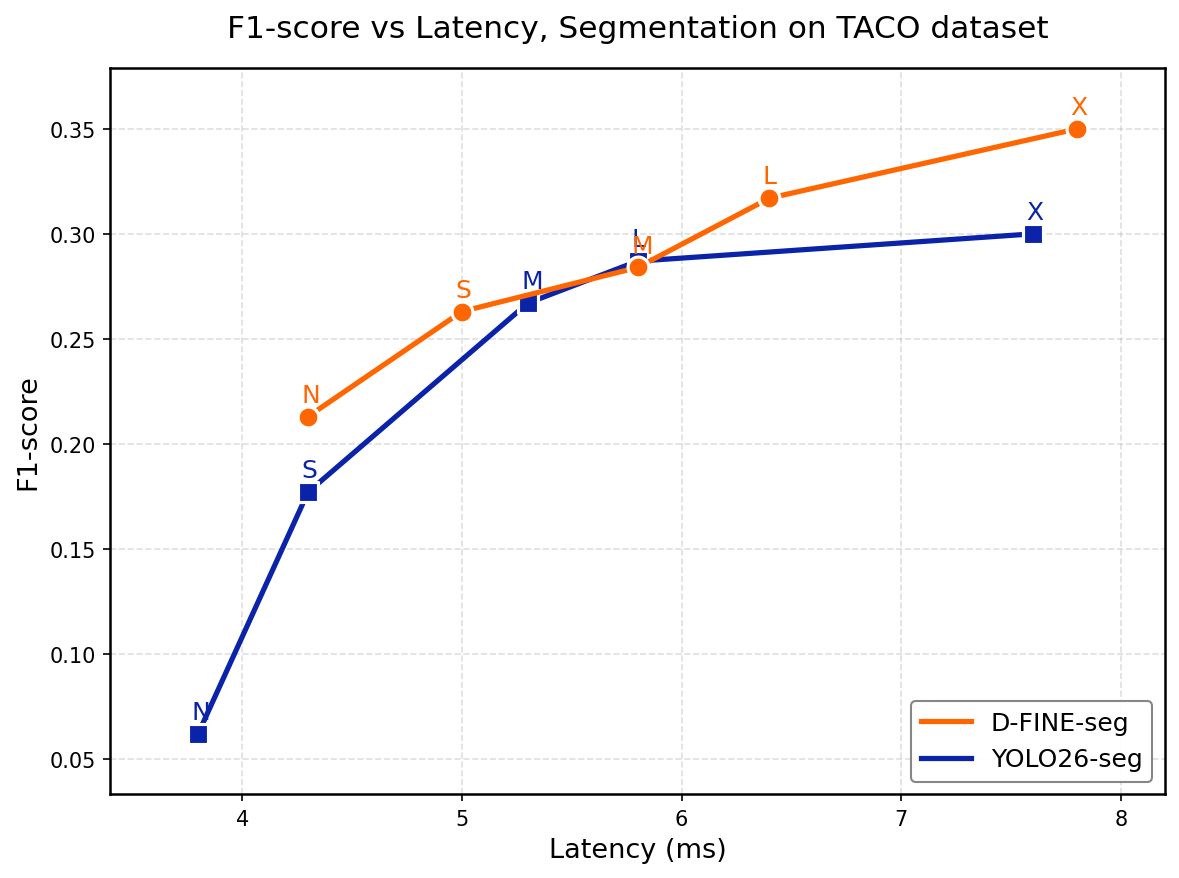
| Model | F1 | IoU | Latency (ms) |
|---|---|---|---|
| D-FINE-seg N | 0.231 | 0.106 | 3.2 |
| YOLO26-seg N | 0.062 | 0.027 | 3.8 |
| D-FINE-seg S | 0.281 | 0.134 | 3.7 |
| YOLO26-seg S | 0.177 | 0.080 | 4.3 |
| D-FINE-seg M | 0.296 | 0.140 | 4.5 |
| YOLO26-seg M | 0.267 | 0.128 | 5.3 |
| D-FINE-seg L | 0.342 | 0.167 | 5.0 |
| YOLO26-seg L | 0.287 | 0.137 | 5.8 |
| D-FINE-seg X | 0.380 | 0.190 | 6.3 |
| YOLO26-seg X | 0.300 | 0.146 | 7.6 |
See the GitHub README for full TACO detection results, COCO-style mask/box AP, and cross-format (Torch/TRT/OpenVINO/CoreML) comparisons on desktop, edge (Intel N150), and Apple Silicon.
Intended use. General-purpose object detection and instance segmentation, particularly when (a) low end-to-end latency matters and (b) the deployment target is GPU (TensorRT), CPU/iGPU (OpenVINO), or Apple Silicon (CoreML).
Out of scope.
Known limitations.
mosaic_augs.mosaic_prob toward 0 if masks look wrong.@article{saakyan2026dfineseg,
title = {D-FINE-seg: Object Detection and Instance Segmentation Framework with Multi-Backend Deployment},
author = {Saakyan, Argo and Solntsev, Dmitry},
journal = {arXiv preprint arXiv:2602.23043},
year = {2026},
eprint = {2602.23043}
}
@misc{peng2024dfine,
title = {D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement},
author = {Yansong Peng and Hebei Li and Peixi Wu and Yueyi Zhang and Xiaoyan Sun and Feng Wu},
year = {2024},
eprint = {2410.13842},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
Detection core based on D-FINE (Peng et al., 2024). Mask head design follows Mask DINO. Benchmarks use VisDrone and TACO.
# No code snippets available yet for this library. # To use this model, check the repository files and the library's documentation. # Want to help? PRs adding snippets are welcome at: # https://github.com/huggingface/huggingface.js