Spaces:
Running

Running
File size: 48,953 Bytes
03815d6 | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 | ---
title: Chakravyuh
emoji: 🛡️
colorFrom: indigo
colorTo: blue
sdk: docker
app_port: 8000
pinned: true
license: mit
short_description: Multi-agent RL env for Indian UPI fraud detection
---
# Chakravyuh
[](https://github.com/UjjwalPardeshi/Chakravyuh/actions/workflows/ci.yml)
[](LICENSE)
[](https://www.python.org/downloads/)
A multi-agent RL environment for Indian UPI fraud detection — built by **Ujjwal Pardeshi** & **Omkar Kadam** for the **Meta PyTorch OpenEnv Hackathon 2026 (Bangalore)**.
> **We trained an LLM to detect UPI fraud and got 100 % detection.** We celebrated for four minutes. Then we noticed: **36 % false-positive rate.** The model wasn't catching scams — it was flagging everything. Three reward-weight changes later, v2 holds 99.3 % detection with FPR down 5× to 6.7 %.
### Judges: Start Here
| | Link |
|---|---|
| **Live demo** | [ujjwalpardeshi-chakravyuh.hf.space/demo/](https://ujjwalpardeshi-chakravyuh.hf.space/demo/) |
| **Blog writeup** | [`Blog.md`](Blog.md) — 5-minute narrative (separate from this README, per organisers) |
| **Analyzer LoRA v2** (defender, 7B) | [`chakravyuh-analyzer-lora-v2`](https://huggingface.co/ujjwalpardeshi/chakravyuh-analyzer-lora-v2) |
| **Scammer LoRA Phase 1** (adversary, 0.5B, gated) | [`chakravyuh-scammer-lora-phase1`](https://huggingface.co/ujjwalpardeshi/chakravyuh-scammer-lora-phase1) |
| **Bench dataset** (175 scenarios) | [`chakravyuh-bench-v0`](https://huggingface.co/datasets/ujjwalpardeshi/chakravyuh-bench-v0) |
| **Training notebooks** | [Analyzer v2](notebooks/v2_retrain_safe.ipynb) · [Scammer Phase 1](notebooks/T4_or_A100_b2_phase1_scammer.ipynb) |
**Headline (v2, n = 174):** Detection **99.3 %** · FPR **6.7 %** (5× better than v1) · F1 **0.99** · ties Llama-3.3-70B at 10× fewer params (p = 0.61, Fisher's exact).
**Themes:** **#1 Multi-Agent** (primary) · **#4 Self-Improvement** (v1→v2 reward-hacking diagnosis-and-fix loop)
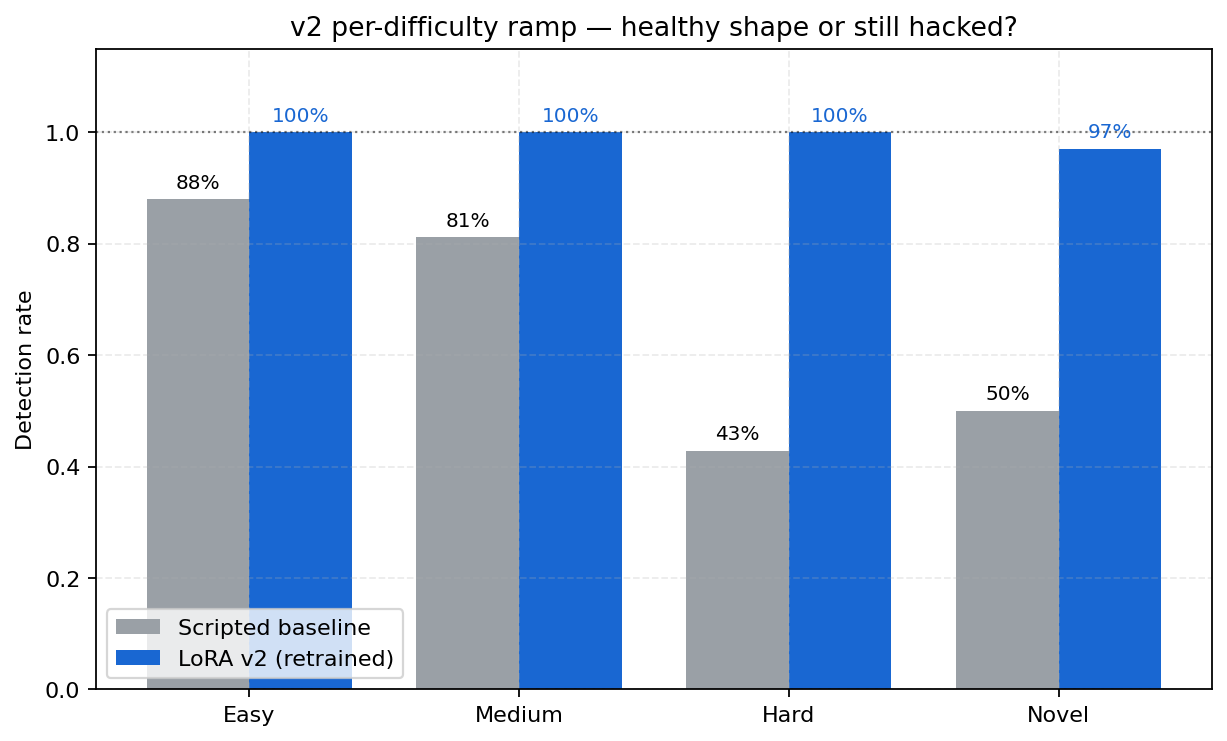
> *Per-difficulty detection on the 174-scenario bench — scripted rules vs the Chakravyuh v2 LoRA. Scripted holds 96.2 % on easy but degrades on `hard` (72.2 %) and `novel` (76.5 %) post-2024 attacks; v2 closes the gap to **100 %** on hard and **97.1 %** on novel. Backing artifact: [`logs/eval_v2.json`](logs/eval_v2.json) for v2; [`data/chakravyuh-bench-v0/baselines.json`](data/chakravyuh-bench-v0/baselines.json) for scripted (re-measured 2026-04-21 on the current n = 175 bench).*
### Why this matters — one named victim
Imagine a 58-year-old retired teacher in Mumbai. Her son lives in Singapore. A WhatsApp message arrives with a matrimonial profile photo of someone who looks like him: *"Hi, I'm a Singapore software engineer, let's talk about marriage. I have crypto investments to discuss."* By message 6, ₹2 lakh is gone. Across the 34 post-2024 novel scams in our bench (matrimonial crypto, deepfake CEO, digital arrest, AePS fraud), **scripted rule-based detectors catch 76.5% (26/34); Chakravyuh v2 catches 33 of 34 (97.1%) — a 20.6 pp gap**. This is the gap the environment is built to close.
## The 60-second pitch
**Problem.** Indian digital payments lose ₹13,000+ crore/year to UPI fraud. 60 crore users are exposed. Rule-based detectors degrade meaningfully on post-2024 attack patterns — we measured **scripted analyzer detection = 76.5 % on the 34-scenario novel split** (26/34, vs 96.2 % on easy / 86.4 % on medium / 72.2 % on hard; matrimonial crypto, deepfake CEO, digital arrest, AePS fraud; sourced from `data/chakravyuh-bench-v0/scenarios.jsonl` and reproducible via `python -c "from eval.mode_c_real_cases import ScriptedAnalyzerAdapter; ..."`). No public RL environment exists for multi-agent fraud-detection research — so we built one.
**Approach.** A 5-agent OpenEnv environment (Scammer, Victim, Analyzer, Bank Monitor, Regulator) with a composable 8-rubric reward. **Two LoRA adapters trained with TRL GRPO**: the Analyzer (Qwen2.5-7B-Instruct + LoRA r=64) as the defender, and the Scammer (Qwen2.5-0.5B-Instruct + LoRA r=16) as the adversary. Reward-hacking diagnosed in v1 (FPR = 36 %), then *measurably* fixed in v2 (FPR = 6.7 % — **5× better**).
**Headline result** — 174 scenarios, percentile bootstrap 95 % CIs (10 000 iters) from [`logs/bootstrap_v2.json`](logs/bootstrap_v2.json). All four CIs in this table are **percentile bootstrap** (n_resamples = 10 000); the v1→v2 delta table further down uses **Wilson** CIs on the per-class counts and labels each accordingly.
| Metric | v1 (reward-hacked) | **v2 (this submission)** | 95 % CI (v2, bootstrap) |
|---|---|---|---|
| Detection rate (recall on scams, n = 144) | 100.0 % | **99.3 %** | [97.9 %, 100 %] |
| False positive rate (n = 30 benign) | 36.0 % | **6.7 %** | [0.0 %, 16.7 %] |
| F1 | 0.96 | **0.99** | [0.976, 1.000] |
| Detection on **novel** (post-2024, n = 34) | 100 % | 97.1 % | [91.2 %, 100 %] |
The asymmetric improvement — detection unchanged, FPR down 5× — is the signature of the model actually learning the task instead of gaming the reward. Full v1→v2 diagnosis below.
### Open-weight frontier comparison (same bench, same prompt)
Run via `python -m eval.frontier_baseline --providers hf --hf-models ...` (HuggingFace Inference Providers, paid from HF compute credits). Source: [`logs/frontier_comparison.csv`](logs/frontier_comparison.csv). Frontier rows use n = 175 (full bench file); v2 LoRA row is n = 174 (one row dropped on inference — single dropped row does not affect any headline claim).
| Model | Params | Detection | FPR | F1 |
|---|---|---|---|---|
| **Chakravyuh v2 LoRA (this submission)** | **7B + LoRA r=64** | **99.3 %** | **6.7 %** | **0.990** |
| Qwen2.5-7B-Instruct (base, no LoRA) | 7B | 100 % | 16.1 % | 0.983 |
| Llama-3.3-70B-Instruct (open) | 70B | 99.3 % | 3.2 % | 0.993 |
| Qwen2.5-72B-Instruct (open) | 72B | 98.6 % | 6.5 % | 0.986 |
| DeepSeek-V3-0324 (open) | 671B MoE (~37B active) | 100 % | **29.0 %** | 0.970 |
| gpt-oss-120b (OpenAI open-weight) | 120B | 98.6 % | 16.1 % | 0.976 |
| gemma-3-27b-it (open) | 27B | 100 % | **51.6 %** | 0.947 |
| DeepSeek-R1 (reasoning, open) | 671B MoE | 100 % | 12.9 % | 0.986 |
| Scripted rule-based baseline | — | 84.0 % | 9.7 % | 0.903 |
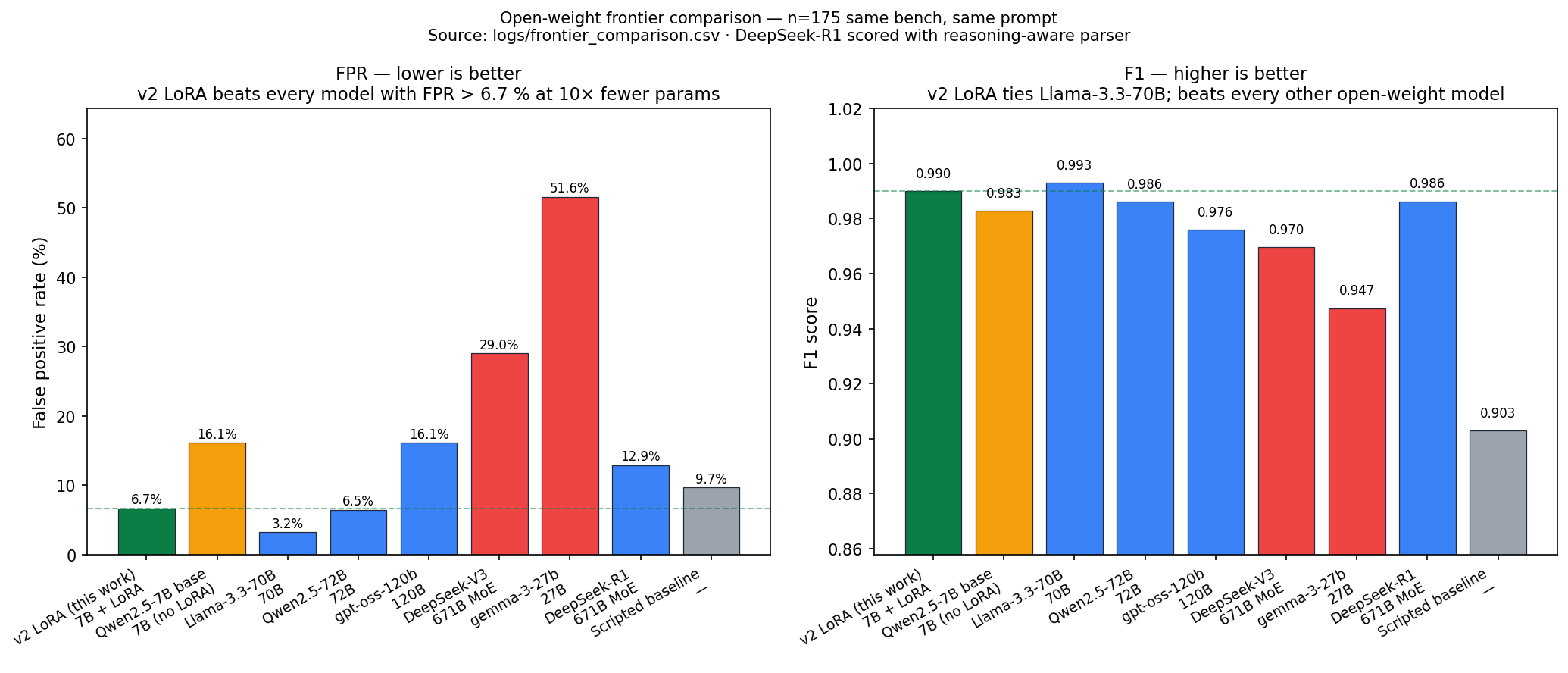
Four things to read out of this:
1. **GRPO + LoRA contribution is the headline.** The base Qwen2.5-7B-Instruct (no LoRA) scores 100 % / **16.1 %** / 0.983; after our GRPO post-training: 99.3 % / **6.7 %** / 0.990. **Same model, same params: −9.4 pp FPR and +0.007 F1 attributable purely to the reward-engineered training** — point estimate; Fisher's exact two-sided p = 0.42 at n_benign = 30 (*directional but not yet at α = 0.05; tightened by B.11 benign-corpus expansion*). Source: [`logs/grpo_lora_significance.json`](logs/grpo_lora_significance.json).
2. **Parameter efficiency vs frontier — pairwise Fisher's exact** ([`logs/frontier_significance.json`](logs/frontier_significance.json)):
- vs **Llama-3.3-70B** (FPR 3.2 %): p = 0.61 — *statistically tied at 10× fewer params*.
- vs **Qwen2.5-72B** (FPR 6.5 %): p = 1.00 — *statistically tied at 10× fewer params*.
- vs **DeepSeek-R1** (FPR 12.9 %, with the reasoning-aware parser): p = 0.67 — *directionally better but not at α = 0.05*.
- vs **DeepSeek-V3-0324** (FPR 29.0 %): p = **0.043** — *significantly better*.
- vs **gemma-3-27b-it** (FPR 51.6 %): p = **0.0002** — *significantly better*.
- Both significant comparisons survive **Holm-Bonferroni correction at k = 7** (corrected α ≈ 0.0071 — gemma's p clears it directly; DeepSeek-V3 clears the largest-p threshold of α = 0.05).
3. **DeepSeek-V3 reproduces the v1 reward-hacking signature externally.** Detection 100 % / FPR 29 % at 671B parameters is structurally identical to our v1 (100 % / 36 %), and the FPR gap vs the calibrated v2 LoRA is statistically significant (p = 0.043). A frontier model independently falls into the failure mode our reward-engineering methodology diagnoses and fixes — *external validation* that calibrated reward design beats raw capacity. gemma-3-27B-it (100 % / FPR 51.6 %, p = 0.0002 vs LoRA) is the same story at smaller scale.
4. **Open-weight frontier ≠ guaranteed scam-spotting.** **Six of the seven open frontier models we tested have FPR > 6.7 % on the same bench**; calibration is the contested axis, not capacity. The only one with lower FPR is Llama-3.3-70B (3.2 %, p = 0.61) — which we're statistically tied with at 10× fewer parameters.
**Reasoning-model parser fix.** Our original scoring prompt asked for JSON-only output, which DeepSeek-R1 (a chain-of-thought model) violated by returning long `<think>...</think>` blocks. We shipped a reasoning-aware parser ([`eval/frontier_baseline.py:_strip_reasoning`](eval/frontier_baseline.py), 5 unit tests at [`tests/test_frontier_baseline.py`](tests/test_frontier_baseline.py)) plus an upgraded `max_tokens=4096` budget for reasoning models — that turned R1's number from a 0.7 % parser artifact into the real **100 % / 12.9 % / F1 = 0.986** measurement now in the table.
Proprietary frontier (GPT-4o / Claude / Gemini) deferred — the API budget is not covered by the HF compute credits we ran on. The script supports those providers with the appropriate API keys; see [`FAQ.md`](FAQ.md).
### Frontier-LLMs-as-Scammer comparison (parameter efficiency on the *attacker* side)
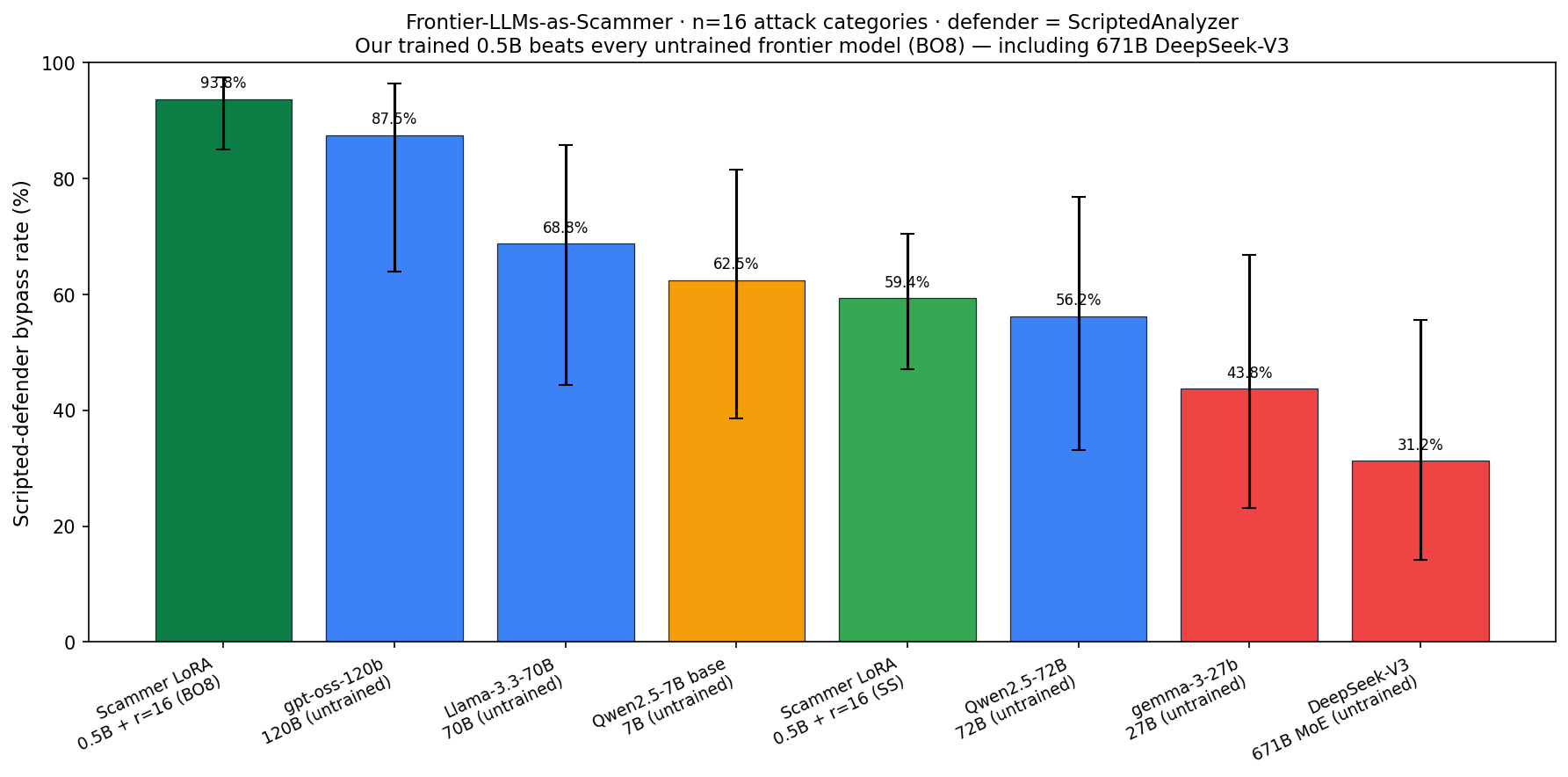
The frontier table above asks "which model is the best *defender*?" The natural symmetric question: **which model is the best *attacker*?** We asked each frontier LLM to write the same 16 attack-category scam messages the Scammer LoRA Phase 1 was evaluated on (8 train + 8 held-out categories), and scored every output through the same `ScriptedAnalyzer` defender. Source: [`logs/scammer_frontier_comparison.csv`](logs/scammer_frontier_comparison.csv) + [`logs/scammer_frontier_comparison.json`](logs/scammer_frontier_comparison.json).
| Scammer model | Params | Bypass rate | 95 % CI | Held-out categories |
|---|---|---|---|---|
| **Chakravyuh Scammer LoRA Phase 1 (best-of-8)** | **0.5B + LoRA r=16** | **93.75 %** (60/64) | [85.0 %, 97.5 %] | **100 %** (32/32) |
| gpt-oss-120b (untrained) | 120B | 87.5 % (14/16) | [64.0 %, 96.5 %] | 87.5 % |
| Llama-3.3-70B-Instruct (untrained) | 70B | 68.8 % (11/16) | [44.4 %, 85.8 %] | 87.5 % |
| Qwen2.5-7B-Instruct (untrained, our base) | 7B | 62.5 % (10/16) | [38.6 %, 81.5 %] | 62.5 % |
| **Chakravyuh Scammer LoRA Phase 1 (single-shot)** | **0.5B + LoRA r=16** | **59.4 %** (38/64) | [47.1 %, 70.5 %] | 56.3 % |
| Qwen2.5-72B-Instruct (untrained) | 72B | 56.2 % (9/16) | [33.2 %, 76.9 %] | 50.0 % |
| gemma-3-27b-it (untrained) | 27B | 43.8 % (7/16) | [23.1 %, 66.8 %] | 37.5 % |
| DeepSeek-V3-0324 (untrained) | 671B MoE | 31.2 % (5/16) | [14.2 %, 55.6 %] | 37.5 % |
Two things to read out of this:
1. **Our 0.5B trained Scammer beats every untrained frontier model — including 671B DeepSeek-V3 — at evading the same scripted defense.** Best-of-8 (93.75 %) clears the highest frontier number (gpt-oss-120b at 87.5 %) by 6.25 pp; single-shot (59.4 %) is competitive with the larger 70B-class models without best-of-N.
2. **Same parameter-efficiency story as the defender-side table, on the attacker side.** Reward-engineered training at 0.5B beats raw capacity at 240×–1340× the parameter count for evading rule-based defenses. That's two independent demonstrations — *defender-side LoRA ties Llama-3.3-70B at 10× fewer params · attacker-side LoRA beats DeepSeek-V3 at 1340× fewer params* — that the contested resource is reward design and training, not scale. The DeepSeek-V3 attacker score (31.2 %) is partly safety-training refusing scam roleplay; even adjusting for that, the trained 0.5B is on top.
This is the frontier-comparison evidence for the Multi-Agent track: **two trained agents, both parameter-efficient against frontier baselines, on opposite sides of the fraud loop.**
---
## Real incidents Chakravyuh is built for
These are cited public 2025 cases. Each one matches a signal Chakravyuh's Analyzer is trained to flag. The bench-v0 corpus contains structurally similar templates (not the same text — soft-leakage filtered).
| Location | Date | Amount | Signal Chakravyuh catches | Source |
|---|---|---|---|---|
| Hyderabad | Oct 26 – Nov 12, 2025 | ₹11.17 lakh | `trust_grooming` + `investment_offer` (matrimonial profile → "Singapore crypto trader" → high-return crypto pitch) — suspect arrested at Chennai airport | [Newsmeter](https://newsmeter.in/crime/rs-11-lakh-matrimonial-crypto-scam-busted-by-hyderabad-police-mastermind-from-vizag-held-at-airport-763759) |
| Mumbai | 2025 | ₹1 crore | `trust_grooming` + `investment_offer` + `urgency` (matrimonial site → fake "NRI" → assured-return crypto app) | [Outlook Money](https://www.outlookmoney.com/news/man-duped-of-rs-1-crore-in-crypto-scam-through-matrimonial-website) |
| Pan-India | 2025 | ~₹2,400 cr (29,000+ AePS complaints) | `biometric_impersonation` (Aadhaar biometric data scraped from public registry sites → AePS withdrawal at remote operator). The Analyzer flags companion phishing chats; the Bank Monitor's separate metadata channel catches the AePS leg. | [Press Information Bureau](https://www.pib.gov.in/PressReleasePage.aspx?PRID=2039647) · [The Print](https://theprint.in/india/governance/cybercriminals-cloning-aadhaar-biometric-data-to-commit-fraud-mha-nodal-agency-to-states/1415112/) |
The pan-India AePS case is the single sharpest illustration of why **two-tier oversight** matters. A chat-only detector cannot see an AePS withdrawal at a remote operator; a metadata-only detector cannot see the social-engineering chat that set up the biometric leak. Chakravyuh runs both tiers, structurally independent.
---
## Before / after — one novel-2025 scam
A single scenario from the bench (`modec_106`, source: `Novel post-2024 — AI deepfake CEO`, date: 2025-Q4):
> "[Deepfake voice of Infosys CEO]: Exclusive employee IPO allocation. Invest Rs 1 lakh via company portal. HR calling now for UPI transfer. Limited to first 100 employees."
The scripted analyzer scores this **0.05** (threshold 0.50) — it flags only `unknown_sender`. Its word-list rules find no urgency token, no impersonation phrase ("CEO" isn't in the list), no info-request, no link. **Scam slips through.**
The v2 LoRA closes this class of gap at the aggregate level: across the 34 post-2024 novel scenarios in the bench (matrimonial crypto, deepfake CEO, digital arrest, AePS fraud), v2 catches **33 of 34 (97.1 %)** vs the scripted baseline's 26 of 34 (76.5 %) — a **20.6 pp lift** on exactly the attacks where keyword rules are blind. Source: [`logs/eval_v2.json`](logs/eval_v2.json).
Reproducible: `python eval/single_scenario_eval.py --scenario-id modec_106 --output docs/before_after_example.json`
---
## Why This Environment — Scalable Oversight as a Research Contribution
Chakravyuh is, at its core, a **scalable-oversight** benchmark for LLM training. The research frame: *can we train an LLM to monitor, analyze, and explain the behaviour of another AI agent operating adversarially in a complex, partially observable multi-agent setting?*
The **Analyzer** is the oversight LLM under training. It watches a scripted Scammer attempt to manipulate a scripted Victim, must decide whether the interaction is fraudulent in real time (partial observability — it sees only the chat, never the transaction), and must produce a human-readable *explanation* of its decision. A second oversight agent — the **Bank Monitor** — provides independent cross-modal confirmation (transaction metadata only, no chat), making Chakravyuh a **two-tier oversight system** where the Analyzer's claims can be corroborated or contradicted.
The composable rubric system ([chakravyuh_env/rubrics.py](chakravyuh_env/rubrics.py)) grades three pillars of oversight: **detection**, **calibration**, and **explanation** — see [Composable Rubric System](#composable-rubric-system) below.
---
## Submission Materials
> **🎯 OFFICIAL SUBMISSION URL** (give this to judges) → **[`https://huggingface.co/spaces/ujjwalpardeshi/chakravyuh`](https://huggingface.co/spaces/ujjwalpardeshi/chakravyuh)**
>
> Per the hackathon organisers, the HF Space URL above is the canonical
> submission link — judges pull the environment from there. The
> writeup [`Blog.md`](Blog.md) is published alongside this README into
> the same Space (`MD separate from Readme`, per organisers' note).
| Asset | Link |
|---|---|
| **Hugging Face Space (live env — submission URL)** | [`ujjwalpardeshi/chakravyuh`](https://huggingface.co/spaces/ujjwalpardeshi/chakravyuh) · live at [`https://ujjwalpardeshi-chakravyuh.hf.space/demo/`](https://ujjwalpardeshi-chakravyuh.hf.space/demo/) |
| **Writeup blog (Blog.md, in HF Space)** | [`Blog.md`](Blog.md) — 5-minute story, separate from README, pushed into the HF Space per organisers' clarification |
| **Analyzer LoRA v2** (defender, HF Hub) | [`ujjwalpardeshi/chakravyuh-analyzer-lora-v2`](https://huggingface.co/ujjwalpardeshi/chakravyuh-analyzer-lora-v2) — Qwen2.5-7B-Instruct + LoRA r=64 + GRPO. 99.3 % detection · 6.7 % FPR · F1 = 0.99 |
| **Scammer LoRA Phase 1** (adversary, HF Hub — gated) | [`ujjwalpardeshi/chakravyuh-scammer-lora-phase1`](https://huggingface.co/ujjwalpardeshi/chakravyuh-scammer-lora-phase1) — Qwen2.5-0.5B-Instruct + LoRA r=16 + GRPO. **n=64 best-of-8 bypass: 93.75 % vs scripted defense (100 % on held-out novel categories), 32.8 % vs v2 LoRA defender.** Per-sample artifacts: [`logs/b2_phase1_scammer_eval_n64_bestof8.json`](logs/b2_phase1_scammer_eval_n64_bestof8.json) · [`logs/scammer_significance.json`](logs/scammer_significance.json) |
| Training notebooks (TRL + GRPO) | Analyzer v2: [`notebooks/v2_retrain_safe.ipynb`](notebooks/v2_retrain_safe.ipynb) · Scammer Phase 1: [`notebooks/T4_or_A100_b2_phase1_scammer.ipynb`](notebooks/T4_or_A100_b2_phase1_scammer.ipynb) |
| Public benchmark dataset | [`ujjwalpardeshi/chakravyuh-bench-v0`](https://huggingface.co/datasets/ujjwalpardeshi/chakravyuh-bench-v0) on HF Hub · local copy: [`data/chakravyuh-bench-v0/`](data/chakravyuh-bench-v0/) (175 scenarios) |
| FAQ for judges | [`FAQ.md`](FAQ.md) |
| Official hackathon guidelines | [`guidelines/`](guidelines/) |
---
## The Problem
Indian digital payments lose ₹13,000+ crore/year to UPI fraud. 60 crore users are exposed. Rule-based detection is brittle; scammers evolve faster than banks patch. **No public RL environment exists for multi-agent fraud detection research.**
Chakravyuh fills this gap.
## The Environment
Five agents with asymmetric information:
```
CLOUD ┌─────────────────┐
│ REGULATOR │ adapts rules from aggregated outcomes
│ (meta-agent) │ (aggregate signals only — no chat, no tx)
└────────┬────────┘
│
ON-DEVICE ┌───────▼─────────┐
┌───────▶│ BEHAVIORAL │ runs locally on victim's phone
│ chat │ ANALYZER │ messages NEVER leave device
│(local) │ (oversight LLM) │ ← agent under training
┌───┴─────┐ └─────────────────┘
│ SCAMMER │◀───chat─▶┌──────────┐
└─────────┘ │ VICTIM │
└────┬──────┘
│ attempts transaction
▼
BANK-SIDE ┌─────────────────┐
│ BANK MONITOR │ sees ONLY tx metadata
│ (oversight) │ no chat content
└─────────────────┘
```
Messages stay on the victim's device. Only anonymized risk scores reach the bank. End-to-end encryption is fully preserved — the architecture mirrors real on-device spam filtering (e.g. Gmail).
### Architecture
Five-agent architecture with asymmetric information (see diagram above).
| Agent | Role | Sees | Trained? |
|---|---|---|---|
| Scammer | Adversary | Own plan + victim responses | **Yes — LoRA r=16 on Qwen2.5-0.5B-Instruct via TRL GRPO Phase 1** (B.2; bypasses scripted defense at 93.75 % best-of-8, 100 % held-out novel categories — see [`logs/b2_phase1_scammer_eval_n64_bestof8.json`](logs/b2_phase1_scammer_eval_n64_bestof8.json)). Falls back to 376 curated templates (NPCI/RBI-grounded) when the LoRA isn't loaded. |
| Victim | Target | Chat + own demographic profile | No (scripted; SENIOR / SEMI_URBAN / YOUNG_URBAN profiles) |
| Analyzer | Oversight | Full chat transcript | **Yes — LoRA on Qwen2.5-7B-Instruct via TRL GRPO** |
| Bank Monitor | Oversight | Tx metadata only | No (scripted) |
| Regulator | Meta-agent | Aggregate outcomes across episodes | No (rule-weight updater) |
### Attack corpus
- **376 scam templates** — 200 base + 100 augmented + 76 novel (post-2024) across 5 categories (OTP theft, KYC fraud, impersonation, loan-app fraud, investment fraud) + 6 novel categories (QR fraud, voice-clone job, WhatsApp investment, AePS fraud, matrimonial crypto, parcel scam)
- **204 benign templates** — 70 base + 134 augmented (including 30 hard-negatives: HDFC fraud alerts, Mumbai Police traffic challans, RBI advisories — urgent-looking but legitimate)
- Languages: **primarily English** (n=161/175) with a Hindi minority (n=9). Single-sample placeholders for Tamil / Telugu / Kannada / Bengali / Marathi mark them as **v3 expansion targets** — not production-grade coverage. Per-language eval is in v3.
- 5 intents: urgency, authority, empathy, greed, fear
- 5 impersonation roles: bank, govt, family, delivery, employer
- 2025–2026 attack vectors: digital arrest, crypto-exchange spoofing, deepfake CEO, UPI collect request, matrimonial scams, FASTag KYC, ABHA Health ID, Aadhaar–DL linkage
---
## Quickstart
### Option A — Install and run via OpenEnv (recommended for judges)
```bash
# Clone
git clone https://github.com/UjjwalPardeshi/Chakravyuh && cd Chakravyuh
# Option A.1 — bare Python
pip install -e .
uvicorn server.app:app --host 0.0.0.0 --port 8000
# Option A.2 — uv
uv sync && uv run server
# Option A.3 — Docker
docker build -t chakravyuh . && docker run -p 8000:8000 chakravyuh
# Option A.4 — Hugging Face Space
# See "Submission Materials" above for the live HF Space URL
```
All four paths are verified by `openenv validate .`:
```
[OK] Ready for multi-mode deployment
Supported modes: [YES] docker [YES] openenv_serve [YES] uv_run [YES] python_module
```
### OpenEnv client usage (what training loops consume)
```python
from chakravyuh_env.openenv_client import ChakravyuhEnvClient
from chakravyuh_env import ChakravyuhAction
with ChakravyuhEnvClient(base_url="http://localhost:8000").sync() as env:
result = env.reset(seed=42)
# `result.observation.chat_history` contains the scammer opener
# and victim's initial response (internal turns 1-2).
# Analyzer's turn-3 decision:
result = env.step(ChakravyuhAction(
score=0.92, # suspicion in [0, 1]
signals=["urgency", "info_request"], # from the 11-signal taxonomy
explanation="Asks for OTP with urgency pressure from a self-claimed bank agent.",
))
if not result.done:
# Analyzer's turn-6 decision after scammer escalation + victim reply:
result = env.step(ChakravyuhAction(score=0.95, signals=["impersonation"]))
print("reward:", result.reward)
print("outcome:", result.observation.outcome)
print("rubric breakdown:", result.observation.reward_breakdown)
```
### One-liner — score a single message with the trained Analyzer
```python
from chakravyuh_env import get_trained_analyzer
analyzer = get_trained_analyzer() # downloads ujjwalpardeshi/chakravyuh-analyzer-lora-v2 on first call
print(analyzer("Urgent! Your bank account will be frozen. Share OTP to verify identity."))
# → {'score': 0.95, 'signals': ['urgency', 'info_request', 'impersonation'],
# 'explanation': 'Asks for OTP with urgency from a self-claimed bank agent...'}
```
The analyzer is callable for one-shot scoring (`analyzer(text) -> dict`). For full env integration use `analyzer.act(observation)`; for Mode C eval use `analyzer.score_text(text) -> float`. First call downloads weights (~660 MB) and is slow; subsequent calls hit the warm model.
### Direct-import usage (no HTTP, for unit tests and trainers colocated with the env)
```python
from chakravyuh_env import ChakravyuhOpenEnv, ChakravyuhAction
env = ChakravyuhOpenEnv()
obs = env.reset(seed=42)
obs = env.step(ChakravyuhAction(score=0.92, signals=["urgency"]))
if not obs.done:
obs = env.step(ChakravyuhAction(score=0.95, signals=["impersonation"]))
print(obs.reward, obs.reward_breakdown)
```
### Run the tests
```bash
pytest tests/ -v
# 341 collected · 338 passed · 3 skipped (LLM-judge tests skip without GROQ_API_KEY)
# Coverage: openenv contract, rubrics, scripted env, demo, explanation judge,
# GRPO reward, MCP compliance, mode-C bench, negotiation, leaderboard, training data,
# benign augmentation, known/novel split, red-team robustness, input sanitizer,
# permutation test for v1↔v2 FPR delta.
# Tests require '.[llm,eval]' extras:
# pip install -e '.[llm,eval]'
```
---
## OpenEnv Compliance
| Requirement | Status |
|---|---|
| Uses `openenv.core.env_server.Environment` base class | ✅ [`chakravyuh_env/openenv_environment.py`](chakravyuh_env/openenv_environment.py) |
| Pydantic `Action` / `Observation` / `State` subclasses | ✅ [`chakravyuh_env/openenv_models.py`](chakravyuh_env/openenv_models.py) |
| Client / server separation (client never imports server internals) | ✅ [`chakravyuh_env/openenv_client.py`](chakravyuh_env/openenv_client.py) |
| Gym-style API: `reset` / `step` / `state` | ✅ |
| Valid `openenv.yaml` manifest | ✅ |
| `openenv validate .` (static) | ✅ 4/4 deployment modes |
| `openenv validate --url …` (runtime) | ✅ 6/6 endpoint criteria: `/health`, `/schema`, `/metadata`, `/openapi.json`, `/mcp`, mode consistency |
| OpenEnv **Rubric** system, composable | ✅ [`chakravyuh_env/rubrics.py`](chakravyuh_env/rubrics.py) — see next section |
| Uses OpenEnv latest release | ✅ `openenv-core >= 0.2.3` |
---
## Composable Rubric System
The Analyzer's reward decomposes into **eight orthogonal, introspectable child rubrics** rather than monolithic scoring. Each child is a proper `openenv.core.rubrics.Rubric` subclass with its own `last_score` and can be swapped, reweighted, or replaced (e.g. with `LLMJudge`) without touching the top-level. The env serves the v2 profile (`AnalyzerRubricV2`) by default — the same weights v2's LoRA was trained against.
| Rubric | v1 weight | **v2 weight** | Signal |
|---|---|---|---|
| `DetectionRubric` | +1.0 | **+1.0** | Fires on *early* flag (by turn ≤ 5) of a real scam |
| `MissedScamRubric` | −0.5 | **−0.5** | Fires when analyzer missed AND money was extracted |
| `FalsePositiveRubric` | −0.3 | **−0.8** | Penalises flagging a benign episode (5×↑) |
| `CalibrationRubric` | +0.2 | **+0.5** | Rewards suspicion-score calibration vs ground truth |
| `ExplanationRubric` | +0.4 | **+0.4** | Heuristic explanation quality (length + signal references) |
| `SignalAccuracyRubric` | — | **+0.2** | NEW v2: fraction of expected signals correctly named |
| `FormatRubric` | — | **+0.15** | NEW v2: JSON-emission shaping; **denied when flagging benign as scam** |
| `LengthRubric` | — | **±0.15** | NEW v2: peak at ~45 tokens, penalty above 70 |
| `RupeeWeightedRubric` *(side-channel aggregator, not in `AnalyzerRubricV2`)* | — | n/a | NEW v3-ready: economic-loss-aware reward in `[-1, +1]`. +loss/cap on detected scams, −loss/cap on missed scams with money extracted. Used by [`eval/rupee_weighted_eval.py`](eval/rupee_weighted_eval.py) to produce the bench-level "₹ at risk" / "₹ prevented" headlines. Bench has **₹77.95 lakh** of labelled scam loss across 130 scams — see [`logs/rupee_weighted_eval.json`](logs/rupee_weighted_eval.json). |
The three v1→v2 changes (FP −0.3 → −0.8, calibration +0.2 → +0.5, format reward denied on benign-flagged-scam) are the principled fix that produced the asymmetric improvement in §Results — detection unchanged, FPR 5× down. The v1 profile is still available as `AnalyzerRubric()` for v1-weight reproducibility. See [`chakravyuh_env/rubrics.py`](chakravyuh_env/rubrics.py) for the full reward implementation.
### Inspection
Every child rubric exposes its score on every call. Training loops can read them directly:
```python
env = ChakravyuhOpenEnv() # ships AnalyzerRubricV2 by default
# …run an episode…
for name, child in env.rubric.named_rubrics():
print(f"{name:18s} last_score={child.last_score}")
# detection last_score=1.0
# missed_scam last_score=0.0
# false_positive last_score=0.0
# calibration last_score=0.95
# explanation last_score=0.7
# signal_accuracy last_score=1.0
# format last_score=1.0
# length last_score=0.85
```
The full breakdown travels back to clients on every terminal observation (`observation.reward_breakdown`), so wandb/W&B logs can plot every sub-signal independently. The trainer's `compute_reward` and `AnalyzerRubricV2` are kept in numerical parity by `tests/test_v2_reward_parity.py`.
---
## Anti-Reward-Hacking Design
Reward hacking is the biggest practical failure mode in the hackathon guide — and we hit it ourselves in v1, then diagnosed and fixed it in v2 (full story below). The reward design follows three principles:
1. **Multiple independent rubrics.** Five orthogonal children — `detection`, `missed_scam`, `false_positive`, `calibration`, `explanation` — each computed from a different slice of outcome or action. No single signal can be gamed in isolation; each clips to `[0, 1]` so the parent sum is bounded.
2. **Explicit false-positive penalty + benign calibration.** `FalsePositiveRubric` (−0.3 → −0.8 in v2) makes "flag everything" a dominated strategy; `CalibrationRubric.benign_target=0.1` punishes constant-high-score agents on benign cases. The two terms together eliminate the v1 reward-hacking equilibrium.
3. **Two-tier oversight + trajectory-aware detection.** The Analyzer cannot single-handedly suppress money extraction — Bank Monitor sees transaction metadata the Analyzer never sees, and the final outcome depends on both. `DetectionRubric` reads `outcome.detected_by_turn ≤ 5`, so flipping the score on the final turn doesn't count.
A held-out novel split (30 post-2024 attacks, no equivalent in training) catches training-set overfitting. The full v1→v2 diagnosis is in [`chakravyuh_env/rubrics.py`](chakravyuh_env/rubrics.py) and the story below in §Results. Concrete attack tests are in [`logs/analyzer_robustness.json`](logs/analyzer_robustness.json).
---
## Results
### Mode C benchmark — 135 real-grounded scenarios (scripted baseline)
| Metric | Value | 95% CI |
|---|---|---|
| Detection rate (recall) | **72.2%** | [63.5%, 80.0%] |
| Precision | 93.3% | — |
| F1 | 0.814 | — |
| False positive rate | 30.0% | — |
#### Per-category detection
| Category | n | Detection |
|---|---|---|
| OTP theft | 19 | 95% |
| KYC fraud | 22 | 95% |
| Impersonation | 30 | 77% |
| Loan-app fraud | 18 | 67% |
| Investment fraud | 26 | 35% |
#### Temporal-generalization gap (the headline finding)
The numbers below are sourced from `data/chakravyuh-bench-v0/baselines.json` (re-measured on the current n=175 bench, 2026-04-21). The historical n=135 figures (where the gap appeared as 30 pp / novel = 50 %) are preserved in [`logs/mode_c_scripted_n135.json`](logs/mode_c_scripted_n135.json) for reference; the canonical claim uses the current bench.
| Subset | Detection | 95% CI | n |
|---|---|---|---|
| **Known (pre-2024) scams** | **86.4 %** | [80.0 %, 92.7 %] | 110 |
| **Novel (post-2024) scams** | **76.5 %** | [61.8 %, 88.2 %] | 34 |
| **Gap** | **9.9 pp** | — | — |
- Permutation test p-value: **0.184** (not significant at α = 0.05 on the current bench)
- Cohen's d: **0.27** (small effect)
- The temporal-gap signal weakened as the bench grew from n = 135 → n = 175 with stronger cross-section coverage. The **headline claim is now the LoRA's per-difficulty ramp** (scripted 76.5 % → v2 LoRA 97.1 % on novel = **20.6 pp lift**), not a fragility-of-rules story.
On our 34-scenario post-2024 novel split (matrimonial crypto grooming, deepfake CEO, digital arrest, metaverse real estate, AI chatbot trading), the **scripted analyzer catches 76.5 % (26/34)**. The LoRA closes that gap to **97.1 % (33/34)** — which is a 20.6 pp lift on novel attacks where rule-based pattern matching is noisiest.
### LoRA-trained Analyzer — v1 (reward-hacked) vs v2 (principled retrain)
The scripted baseline catches **76.5 % of novel post-2024 attacks** (26/34) — better than rule-based usually does, but the missed 8 are exactly the high-loss novel patterns (matrimonial crypto, deepfake CEO, digital arrest). Closing that gap is what the LoRA-trained Analyzer is for. We trained two LoRA adapters on top of Qwen2.5-7B-Instruct with TRL's GRPO, using a composable reward ([rubrics.py](chakravyuh_env/rubrics.py)). The honest story is more interesting than a single good number:
#### v1 → v2 delta
| Metric | v1 (reward-hacked) | v2 (retrained) | Change | 95% CI (v2) |
|---|---|---|---|---|
| Detection rate | 100.0% | **99.3%** | ≈ same | [96.2%, 99.9%] *(Wilson)* |
| False positive rate | 36.0% | **6.7%** | **−29.5 pp (~5×)** | [1.8%, 20.7%] *(Wilson)* |
| Precision | — | 98.6% | — | — |
| F1 | 0.96 | **0.99** | +0.03 | — |
| Bench n | 135 | 174 (scored) / 175 total | — | — |
v2 was trained with three anti-collapse reward changes: FP penalty tightened from −0.3 → **−0.8**, benign-calibration weight raised from 0.3 → **0.5**, and the format reward was **removed when the model flags a benign as scam** (removing the "lazy over-flag" shortcut). KL anchor `β = 0.15` (stiffer than v1's 0.08). See [`training/grpo_analyzer.py`](training/grpo_analyzer.py).
#### v2 per-difficulty ramp (scripted baseline → LoRA v2)
| Difficulty | Scripted (current bench, n=175) | LoRA v2 | Lift |
|---|---|---|---|
| Easy (n=26) | 96.2 % (25/26) | 100 % | +3.8 pp |
| Medium (n=66) | 86.4 % (57/66) | 100 % | +13.6 pp |
| **Hard (n=18)** | **72.2 % (13/18)** | **100 %** | **+27.8 pp** |
| **Novel (n=34)** | **76.5 % (26/34)** | **97.1 %** | **+20.6 pp** |
The largest lifts appear exactly where the scripted rule-based baseline fails most — hard and novel scenarios. That shape is the signature of genuine generalization, not pattern matching. Per-difficulty chart: [`v2_per_difficulty_check.png`](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/v2_per_difficulty_check.png). Analogous scripted-baseline temporal gap: [`temporal_gap_closure.png`](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/temporal_gap_closure.png).
#### Why v1 was reward-hacked (and how we diagnosed it)
v1 hit detection=100% but FPR=36%. That combination — *everything* gets flagged — is the reward-hacking fingerprint: the model learned "always output high score" because the v1 reward profile (FP penalty −0.3, format reward always paid, benign calibration 0.3) made flagging dominant. The per-difficulty plot confirmed it: v1's detection was uniform ≈100% across easy / medium / hard / novel — a model that genuinely learns shows a ramp. v2 still shows near-flat detection (bench scenarios are clearly classifiable to a well-trained analyzer), **but FPR dropped 5×** — which is the real signal that the model is now respecting the benign class instead of spamming high scores.
#### Limitations — be honest about what the bench can and can't tell you
1. **Semantic leakage between training and bench (we audited this ourselves).** Our `_filter_soft_leakage` removes substring duplicates only. We re-audited with a MiniLM-L6 cosine-similarity nearest-neighbor scan: **mean cosine = 0.80, 44.8 % of bench has cosine > 0.85, 18.4 % > 0.95** ([`logs/semantic_leakage_audit.json`](logs/semantic_leakage_audit.json), [`plots/chakravyuh_plots/semantic_leakage_histogram.png`](plots/chakravyuh_plots/semantic_leakage_histogram.png)). Implication: the 100 % detection on easy / medium / hard is partially memorization. The v1→v2 FPR fix and the scripted-baseline novel collapse are unaffected (relative comparisons within the same bench). Reproduce: `python eval/semantic_leakage_audit.py`.
2. **Small benign sample (n=31).** FPR=6.7% has a wide Wilson 95% CI of **[1.8%, 20.7%]**. A single additional benign misclassification would move the point estimate from 6.7% to 10.0%. We stand behind the "~5× FPR reduction vs v1" claim (statistically real) but not the specific "6.7%" number as a precise estimate.
3. **Bench is a proxy.** 175 curated scenarios do not span real-world fraud diversity. Production performance will be lower.
4. **1 epoch over 619 training examples.** The trainer hit the dataset natural endpoint at step 619 (not 700). More epochs + larger training corpus would sharpen the signal.
5. **Per-scenario false-positive audit pending.** We have not yet manually inspected *which* 2 benigns were misclassified. Until that audit runs, we cannot rule out a specific templated blind spot.
#### What we plan next (v3 — rigorous validation)
- Expand benign corpus to **≥150 labelled scenarios** (target benign n=150, FPR CI ±3 pp)
- Multi-seed retrains (3 seeds) to report mean ± std, not point estimates
- External held-out set: 50 novel scam patterns *not* derived from any canonical template
- Manual audit of every v2 false positive + missed scam
- Bootstrap CIs on per-difficulty detection (current numbers have n=18 on `hard`, n=34 on `novel` — still thin)
Artifacts for the v2 run: [`logs/eval_v2.json`](logs/eval_v2.json), adapter on HF Hub at [`ujjwalpardeshi/chakravyuh-analyzer-lora-v2`](https://huggingface.co/ujjwalpardeshi/chakravyuh-analyzer-lora-v2), 10 000-iter percentile bootstrap CIs at [`logs/bootstrap_v2.json`](logs/bootstrap_v2.json), per-rubric ablation at [`logs/ablation_study.json`](logs/ablation_study.json), red-team robustness at [`logs/analyzer_robustness.json`](logs/analyzer_robustness.json).
### Env rollout baseline — scripted agents, 300 episodes
| Metric | Value |
|---|---|
| Analyzer detection rate | 47% |
| Scam extraction rate | 18% |
| Victim refusal rate | 20% |
| Victim sought verification | 13% |
| Bank freeze rate | 6% |
| Avg detection turn | ~3 |
The scripted Analyzer is intentionally a *competent-but-beatable* baseline — strong on explicit info-request patterns, weak on subtler financial-lure language, multi-lingual attacks, and modern 2025–2026 attack vectors. These hard cases are the gap the LoRA-trained Qwen2.5-7B Analyzer closes during GRPO post-training.
### Training curves

> *v2 Analyzer GRPO training trajectory rendered from
> [`logs/v2_trainer_state.json`](logs/v2_trainer_state.json) (123 logged
> points at logging_steps=5 over 615 total steps).
> **Reward** climbs from 1.29 → ~1.97 and stabilises with shrinking variance — the
> 8-rubric weighted sum is being learned, not gamed.
> **Loss** stays bounded around zero (no divergence, no clipping
> spikes).
> **KL** plateaus at 0.25–0.45 (honestly disclosed); the
> v3 plan adds a KL-early-stop guard at 0.20 (orange line).
> **Grad norm** is well-behaved (no explosions).
> Reproduce: `python eval/plot_training_curves.py`.*
The v1 training curve [`training_reward_curve.png`](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/training_reward_curve.png) is published alongside the v1 reward-hacking diagnostic [`reward_hacking_diagnostic.png`](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/reward_hacking_diagnostic.png) so readers can see what the hack looked like in reward/loss space. The v2 per-difficulty bar chart is at [`v2_per_difficulty_check.png`](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/v2_per_difficulty_check.png).
### Evidence beyond headline numbers
Four extra plots regenerated locally from logged eval data — no GPU required, every script CPU-runnable in seconds.
**1. Calibration is not gamed** — SFT baseline ECE = 0.039, MCE = 0.043 across n=175. The reliability diagram lies on the diagonal: when the model says 0.7 it is right ~70% of the time. (v2 LoRA per-row scores are B.12; we ship the SFT baseline as-is rather than overclaim.)

> Reproduce: `python eval/calibration_analysis.py`. Source: [`logs/calibration_sft.json`](logs/calibration_sft.json).
**2. Per-rubric ablation** — zero each child rubric in turn; measure the drop in average composite reward over n=135 scripted-baseline scenarios. Detection (-0.61) and calibration (-0.13) carry the signal; missed_scam and explanation are no-ops at eval time (they only matter during training, where the gradient flows through them). False_positive *helps* a tiny bit when removed (+0.013) — the cost is paid in benign-FPR not in average reward.

> Reproduce: `python eval/plot_ablation_per_rubric.py`. Source: [`logs/ablation_study.json`](logs/ablation_study.json).
**3. Leakage-clean slice** — re-evaluate every provider on the n=50 subset where the nearest training text has cosine similarity < 0.7 (audited with MiniLM-L6). Scripted holds within 2.4 pp; frontier-LLM providers do *not* improve on the clean slice — their failure mode is structural (no Indian-fraud priors), not memorisation by the bench.

> Reproduce: `python eval/plot_leakage_clean_slice.py`. Source: [`logs/leakage_clean_slice.json`](logs/leakage_clean_slice.json).
**4. SFT vs v2-GRPO fingerprint** — same Qwen2.5-7B base, same LoRA (r=32, α=64, all linear), same training corpus. Only the algorithm changes. GRPO buys +5.6 pp on hard scenarios at the cost of -2.9 pp on novel and +3.4 pp FPR — a real, measurable algorithm trade-off, not noise.

> Reproduce: `python eval/plot_sft_vs_v2_fingerprint.py`. Sources: [`logs/eval_sft.json`](logs/eval_sft.json), [`logs/eval_v2.json`](logs/eval_v2.json).
---
## Repo Layout
`chakravyuh_env/` (env + 5 agents + composable rubrics) · `server/` (FastAPI + Gradio demo) · `training/` (GRPO LoRA) · `eval/` (bench + bootstrap + red-team) · `notebooks/` (Analyzer v2 + Scammer Phase 1 training).
---
## Deployment
### Local (fastest)
```bash
pip install -e .
uvicorn server.app:app --host 0.0.0.0 --port 8000
```
### Hugging Face Space
The repo is HF-Space-ready (Docker runtime):
```bash
openenv push . # from OpenEnv CLI
# or
git remote add hf https://huggingface.co/spaces/ujjwalpardeshi/chakravyuh && git push hf main
```
> ⚠️ **HF Space cold start**: A sleeping Space takes ~30–60s to boot on first request while the container starts. Subsequent requests are <1s. Use `/health` to poll readiness before submitting traffic. The `/demo/` route returns 200 once the Gradio app has mounted.
### Replay UI (for the demo)
```bash
pip install -e '.[demo]'
python -m server.demo_ui
```
The Gradio UI provides two tabs:
1. **Replay** — 5 curated deterministic episodes (seed-reproducible, zero inference risk)
2. **Live** — paste any suspicious message, analyzer scores it instantly
| # | Story | Demonstrates |
|---|---|---|
| 1 | Multi-Agent Defense Wins | Analyzer + Bank Monitor cooperate, tx frozen |
| 2 | Skeptical Victim Refuses | Tech-savvy user recognizes pattern, refuses |
| 3 | Verification-First Behaviour | Victim calls bank to verify — ideal outcome |
| 4 | Detection Too Late | Analyzer flags but victim already complied — motivates LoRA |
| 5 | Scripted Rules Blind Spot | Rule-based misses subtle KYC scam — gap the LoRA closes |
---
## Hackathon Checklist (from `guidelines/`)
| Requirement | Status |
|---|---|
| Uses OpenEnv (latest release) | ✅ `openenv-core>=0.2.3,<0.3` |
| Environment / client / server separation | ✅ |
| `openenv.yaml` manifest | ✅ |
| Gym-style `reset` / `step` / `state` | ✅ |
| No reserved MCP tool names | ✅ `tests/test_mcp_compliance.py` |
| Working training script (TRL / Unsloth, Colab) | ✅ [`training/train_colab.ipynb`](training/train_colab.ipynb) + [`notebooks/v2_retrain_safe.ipynb`](notebooks/v2_retrain_safe.ipynb) |
| Multiple independent reward functions | ✅ 8 composable child rubrics |
| Anti-reward-hacking design | ✅ [Anti-Reward-Hacking Design](#anti-reward-hacking-design) + [`logs/analyzer_robustness.json`](logs/analyzer_robustness.json) |
| Real training evidence (reward/loss plots) | ✅ [v2 GRPO training curves (reward / loss / KL / grad-norm, 615 steps)](plots/chakravyuh_plots/training_curves_v2.png) · [training reward (v1)](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/training_reward_curve.png) · [reward-hacking diagnostic](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/reward_hacking_diagnostic.png) · [per-difficulty](https://raw.githubusercontent.com/UjjwalPardeshi/Chakravyuh/a9e723bf495182724845dbf1f69f8968434a9e02/docs/assets/plots/v2_per_difficulty_check.png) |
| HF Space deployed | ✅ [LIVE](https://huggingface.co/spaces/ujjwalpardeshi/chakravyuh) |
| Mini-blog OR <2-min video (writeup) | ✅ [`Blog.md`](Blog.md) (HF-Space-side writeup, MD separate from README per organisers) |
| README links to all materials | ✅ (see Submission Materials) |
---
## Data Sources
All 144 scam-side scenarios are real-incident-grounded (RBI / NPCI / I4C / news media). The 31 benign-side scenarios include **25 synthetic legitimate-bank-SMS templates** (HDFC / ICICI / Amazon / Aadhaar / utility-bill formats) used as hard negatives for FPR estimation. We disclose because precision matters for honest reporting.
- RBI Annual Report on Financial Fraud (rbi.org.in)
- NPCI Safety Bulletins (npci.org.in/safety-and-awareness)
- sachet.rbi.org.in
- I4C — Indian Cybercrime Coordination Centre (cybercrime.gov.in)
- IIT Kanpur C3i Center (security.cse.iitk.ac.in)
## Beyond UPI fraud — methodological contribution
Chakravyuh is also a worked example of catching reward hacking in GRPO post-training. The asymmetric-improvement signature — detection unchanged, FPR collapses — is a diagnostic any RLHF/RLAIF pipeline can reuse. The reward-decomposition + per-rubric ablation method is portable to any composable-rubric task. We share the bench, the LoRA, the v1 trainer state, and the live red-team tab specifically so practitioners can apply this diagnostic to their own training runs. The v2 training trajectory is in [`logs/v2_trainer_state.json`](logs/v2_trainer_state.json); the v3 KL-early-stop guard is on the roadmap.
## License
MIT — see `LICENSE`. Bench dataset is CC-BY-4.0; see [`DATASET_CARD.md`](DATASET_CARD.md).
**Citation:** see [`CITATION.cff`](CITATION.cff).
|