
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +88 -0
- README.md +7 -14
- dpm/aggregator.py +24 -11
- dpm/decoder.py +24 -2
- dpm/model.py +110 -11
- gradio_demo.py +144 -70
- test.ipynb +101 -0
- vggt-low-vram/.gitattributes +2 -0
- vggt-low-vram/.gitignore +155 -0
- vggt-low-vram/CODE_OF_CONDUCT.md +80 -0
- vggt-low-vram/CONTRIBUTING.md +31 -0
- vggt-low-vram/LICENSE.txt +115 -0
- vggt-low-vram/README.md +398 -0
- vggt-low-vram/benchmark/benchmark.py +64 -0
- vggt-low-vram/benchmark/benchmark_baseline.py +65 -0
- vggt-low-vram/benchmark/plot_recon.py +247 -0
- vggt-low-vram/benchmark/run_benchmark.bash +28 -0
- vggt-low-vram/demo_colmap.py +337 -0
- vggt-low-vram/demo_gradio.py +684 -0
- vggt-low-vram/demo_viser.py +400 -0
- vggt-low-vram/docs/package.md +45 -0
- vggt-low-vram/examples/kitchen/images/00.png +3 -0
- vggt-low-vram/examples/kitchen/images/01.png +3 -0
- vggt-low-vram/examples/kitchen/images/02.png +3 -0
- vggt-low-vram/examples/kitchen/images/03.png +3 -0
- vggt-low-vram/examples/kitchen/images/04.png +3 -0
- vggt-low-vram/examples/kitchen/images/05.png +3 -0
- vggt-low-vram/examples/kitchen/images/06.png +3 -0
- vggt-low-vram/examples/kitchen/images/07.png +3 -0
- vggt-low-vram/examples/kitchen/images/08.png +3 -0
- vggt-low-vram/examples/kitchen/images/09.png +3 -0
- vggt-low-vram/examples/kitchen/images/10.png +3 -0
- vggt-low-vram/examples/kitchen/images/11.png +3 -0
- vggt-low-vram/examples/kitchen/images/12.png +3 -0
- vggt-low-vram/examples/kitchen/images/13.png +3 -0
- vggt-low-vram/examples/kitchen/images/14.png +3 -0
- vggt-low-vram/examples/kitchen/images/15.png +3 -0
- vggt-low-vram/examples/kitchen/images/16.png +3 -0
- vggt-low-vram/examples/kitchen/images/17.png +3 -0
- vggt-low-vram/examples/kitchen/images/18.png +3 -0
- vggt-low-vram/examples/kitchen/images/19.png +3 -0
- vggt-low-vram/examples/kitchen/images/20.png +3 -0
- vggt-low-vram/examples/kitchen/images/21.png +3 -0
- vggt-low-vram/examples/kitchen/images/22.png +3 -0
- vggt-low-vram/examples/kitchen/images/23.png +3 -0
- vggt-low-vram/examples/kitchen/images/24.png +3 -0
- vggt-low-vram/examples/llff_fern/images/000.png +3 -0
- vggt-low-vram/examples/llff_fern/images/001.png +3 -0
- vggt-low-vram/examples/llff_fern/images/002.png +3 -0
- vggt-low-vram/examples/llff_fern/images/003.png +3 -0
.gitattributes
CHANGED
|
@@ -127,3 +127,91 @@ input_images_20260127_235812_906867/images/000001.png filter=lfs diff=lfs merge=
|
|
| 127 |
input_images_20260127_235812_906867/images/000002.png filter=lfs diff=lfs merge=lfs -text
|
| 128 |
input_images_20260127_235812_906867/images/000003.png filter=lfs diff=lfs merge=lfs -text
|
| 129 |
4dgs-dpm/bin/ruff filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 127 |
input_images_20260127_235812_906867/images/000002.png filter=lfs diff=lfs merge=lfs -text
|
| 128 |
input_images_20260127_235812_906867/images/000003.png filter=lfs diff=lfs merge=lfs -text
|
| 129 |
4dgs-dpm/bin/ruff filter=lfs diff=lfs merge=lfs -text
|
| 130 |
+
vggt-low-vram/examples/kitchen/images/00.png filter=lfs diff=lfs merge=lfs -text
|
| 131 |
+
vggt-low-vram/examples/kitchen/images/01.png filter=lfs diff=lfs merge=lfs -text
|
| 132 |
+
vggt-low-vram/examples/kitchen/images/02.png filter=lfs diff=lfs merge=lfs -text
|
| 133 |
+
vggt-low-vram/examples/kitchen/images/03.png filter=lfs diff=lfs merge=lfs -text
|
| 134 |
+
vggt-low-vram/examples/kitchen/images/04.png filter=lfs diff=lfs merge=lfs -text
|
| 135 |
+
vggt-low-vram/examples/kitchen/images/05.png filter=lfs diff=lfs merge=lfs -text
|
| 136 |
+
vggt-low-vram/examples/kitchen/images/06.png filter=lfs diff=lfs merge=lfs -text
|
| 137 |
+
vggt-low-vram/examples/kitchen/images/07.png filter=lfs diff=lfs merge=lfs -text
|
| 138 |
+
vggt-low-vram/examples/kitchen/images/08.png filter=lfs diff=lfs merge=lfs -text
|
| 139 |
+
vggt-low-vram/examples/kitchen/images/09.png filter=lfs diff=lfs merge=lfs -text
|
| 140 |
+
vggt-low-vram/examples/kitchen/images/10.png filter=lfs diff=lfs merge=lfs -text
|
| 141 |
+
vggt-low-vram/examples/kitchen/images/11.png filter=lfs diff=lfs merge=lfs -text
|
| 142 |
+
vggt-low-vram/examples/kitchen/images/12.png filter=lfs diff=lfs merge=lfs -text
|
| 143 |
+
vggt-low-vram/examples/kitchen/images/13.png filter=lfs diff=lfs merge=lfs -text
|
| 144 |
+
vggt-low-vram/examples/kitchen/images/14.png filter=lfs diff=lfs merge=lfs -text
|
| 145 |
+
vggt-low-vram/examples/kitchen/images/15.png filter=lfs diff=lfs merge=lfs -text
|
| 146 |
+
vggt-low-vram/examples/kitchen/images/16.png filter=lfs diff=lfs merge=lfs -text
|
| 147 |
+
vggt-low-vram/examples/kitchen/images/17.png filter=lfs diff=lfs merge=lfs -text
|
| 148 |
+
vggt-low-vram/examples/kitchen/images/18.png filter=lfs diff=lfs merge=lfs -text
|
| 149 |
+
vggt-low-vram/examples/kitchen/images/19.png filter=lfs diff=lfs merge=lfs -text
|
| 150 |
+
vggt-low-vram/examples/kitchen/images/20.png filter=lfs diff=lfs merge=lfs -text
|
| 151 |
+
vggt-low-vram/examples/kitchen/images/21.png filter=lfs diff=lfs merge=lfs -text
|
| 152 |
+
vggt-low-vram/examples/kitchen/images/22.png filter=lfs diff=lfs merge=lfs -text
|
| 153 |
+
vggt-low-vram/examples/kitchen/images/23.png filter=lfs diff=lfs merge=lfs -text
|
| 154 |
+
vggt-low-vram/examples/kitchen/images/24.png filter=lfs diff=lfs merge=lfs -text
|
| 155 |
+
vggt-low-vram/examples/llff_fern/images/000.png filter=lfs diff=lfs merge=lfs -text
|
| 156 |
+
vggt-low-vram/examples/llff_fern/images/001.png filter=lfs diff=lfs merge=lfs -text
|
| 157 |
+
vggt-low-vram/examples/llff_fern/images/002.png filter=lfs diff=lfs merge=lfs -text
|
| 158 |
+
vggt-low-vram/examples/llff_fern/images/003.png filter=lfs diff=lfs merge=lfs -text
|
| 159 |
+
vggt-low-vram/examples/llff_fern/images/004.png filter=lfs diff=lfs merge=lfs -text
|
| 160 |
+
vggt-low-vram/examples/llff_fern/images/005.png filter=lfs diff=lfs merge=lfs -text
|
| 161 |
+
vggt-low-vram/examples/llff_fern/images/006.png filter=lfs diff=lfs merge=lfs -text
|
| 162 |
+
vggt-low-vram/examples/llff_fern/images/007.png filter=lfs diff=lfs merge=lfs -text
|
| 163 |
+
vggt-low-vram/examples/llff_fern/images/008.png filter=lfs diff=lfs merge=lfs -text
|
| 164 |
+
vggt-low-vram/examples/llff_fern/images/009.png filter=lfs diff=lfs merge=lfs -text
|
| 165 |
+
vggt-low-vram/examples/llff_fern/images/010.png filter=lfs diff=lfs merge=lfs -text
|
| 166 |
+
vggt-low-vram/examples/llff_fern/images/011.png filter=lfs diff=lfs merge=lfs -text
|
| 167 |
+
vggt-low-vram/examples/llff_fern/images/012.png filter=lfs diff=lfs merge=lfs -text
|
| 168 |
+
vggt-low-vram/examples/llff_fern/images/013.png filter=lfs diff=lfs merge=lfs -text
|
| 169 |
+
vggt-low-vram/examples/llff_fern/images/014.png filter=lfs diff=lfs merge=lfs -text
|
| 170 |
+
vggt-low-vram/examples/llff_fern/images/015.png filter=lfs diff=lfs merge=lfs -text
|
| 171 |
+
vggt-low-vram/examples/llff_fern/images/016.png filter=lfs diff=lfs merge=lfs -text
|
| 172 |
+
vggt-low-vram/examples/llff_fern/images/017.png filter=lfs diff=lfs merge=lfs -text
|
| 173 |
+
vggt-low-vram/examples/llff_fern/images/018.png filter=lfs diff=lfs merge=lfs -text
|
| 174 |
+
vggt-low-vram/examples/llff_fern/images/019.png filter=lfs diff=lfs merge=lfs -text
|
| 175 |
+
vggt-low-vram/examples/llff_flower/images/000.png filter=lfs diff=lfs merge=lfs -text
|
| 176 |
+
vggt-low-vram/examples/llff_flower/images/001.png filter=lfs diff=lfs merge=lfs -text
|
| 177 |
+
vggt-low-vram/examples/llff_flower/images/002.png filter=lfs diff=lfs merge=lfs -text
|
| 178 |
+
vggt-low-vram/examples/llff_flower/images/003.png filter=lfs diff=lfs merge=lfs -text
|
| 179 |
+
vggt-low-vram/examples/llff_flower/images/004.png filter=lfs diff=lfs merge=lfs -text
|
| 180 |
+
vggt-low-vram/examples/llff_flower/images/005.png filter=lfs diff=lfs merge=lfs -text
|
| 181 |
+
vggt-low-vram/examples/llff_flower/images/006.png filter=lfs diff=lfs merge=lfs -text
|
| 182 |
+
vggt-low-vram/examples/llff_flower/images/007.png filter=lfs diff=lfs merge=lfs -text
|
| 183 |
+
vggt-low-vram/examples/llff_flower/images/008.png filter=lfs diff=lfs merge=lfs -text
|
| 184 |
+
vggt-low-vram/examples/llff_flower/images/009.png filter=lfs diff=lfs merge=lfs -text
|
| 185 |
+
vggt-low-vram/examples/llff_flower/images/010.png filter=lfs diff=lfs merge=lfs -text
|
| 186 |
+
vggt-low-vram/examples/llff_flower/images/011.png filter=lfs diff=lfs merge=lfs -text
|
| 187 |
+
vggt-low-vram/examples/llff_flower/images/012.png filter=lfs diff=lfs merge=lfs -text
|
| 188 |
+
vggt-low-vram/examples/llff_flower/images/013.png filter=lfs diff=lfs merge=lfs -text
|
| 189 |
+
vggt-low-vram/examples/llff_flower/images/014.png filter=lfs diff=lfs merge=lfs -text
|
| 190 |
+
vggt-low-vram/examples/llff_flower/images/015.png filter=lfs diff=lfs merge=lfs -text
|
| 191 |
+
vggt-low-vram/examples/llff_flower/images/016.png filter=lfs diff=lfs merge=lfs -text
|
| 192 |
+
vggt-low-vram/examples/llff_flower/images/017.png filter=lfs diff=lfs merge=lfs -text
|
| 193 |
+
vggt-low-vram/examples/llff_flower/images/018.png filter=lfs diff=lfs merge=lfs -text
|
| 194 |
+
vggt-low-vram/examples/llff_flower/images/019.png filter=lfs diff=lfs merge=lfs -text
|
| 195 |
+
vggt-low-vram/examples/llff_flower/images/020.png filter=lfs diff=lfs merge=lfs -text
|
| 196 |
+
vggt-low-vram/examples/llff_flower/images/021.png filter=lfs diff=lfs merge=lfs -text
|
| 197 |
+
vggt-low-vram/examples/llff_flower/images/022.png filter=lfs diff=lfs merge=lfs -text
|
| 198 |
+
vggt-low-vram/examples/llff_flower/images/023.png filter=lfs diff=lfs merge=lfs -text
|
| 199 |
+
vggt-low-vram/examples/llff_flower/images/024.png filter=lfs diff=lfs merge=lfs -text
|
| 200 |
+
vggt-low-vram/examples/room/images/no_overlap_1.png filter=lfs diff=lfs merge=lfs -text
|
| 201 |
+
vggt-low-vram/examples/room/images/no_overlap_2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 202 |
+
vggt-low-vram/examples/room/images/no_overlap_3.jpg filter=lfs diff=lfs merge=lfs -text
|
| 203 |
+
vggt-low-vram/examples/room/images/no_overlap_4.jpg filter=lfs diff=lfs merge=lfs -text
|
| 204 |
+
vggt-low-vram/examples/room/images/no_overlap_5.jpg filter=lfs diff=lfs merge=lfs -text
|
| 205 |
+
vggt-low-vram/examples/room/images/no_overlap_6.jpg filter=lfs diff=lfs merge=lfs -text
|
| 206 |
+
vggt-low-vram/examples/room/images/no_overlap_7.jpg filter=lfs diff=lfs merge=lfs -text
|
| 207 |
+
vggt-low-vram/examples/room/images/no_overlap_8.jpg filter=lfs diff=lfs merge=lfs -text
|
| 208 |
+
vggt-low-vram/examples/single_cartoon/images/model_was_never_trained_on_single_image_or_cartoon.jpg filter=lfs diff=lfs merge=lfs -text
|
| 209 |
+
vggt-low-vram/examples/single_oil_painting/images/model_was_never_trained_on_single_image_or_oil_painting.png filter=lfs diff=lfs merge=lfs -text
|
| 210 |
+
vggt-low-vram/examples/videos/Colosseum.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 211 |
+
vggt-low-vram/examples/videos/fern.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 212 |
+
vggt-low-vram/examples/videos/great_wall.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 213 |
+
vggt-low-vram/examples/videos/kitchen.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 214 |
+
vggt-low-vram/examples/videos/pyramid.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 215 |
+
vggt-low-vram/examples/videos/room.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 216 |
+
vggt-low-vram/examples/videos/single_cartoon.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 217 |
+
vggt-low-vram/examples/videos/single_oil_painting.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -4,21 +4,19 @@ app_file: gradio_demo.py
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.17.1
|
| 6 |
---
|
| 7 |
-
<div align="center">
|
| 8 |
-
<h1>V-DPM: 4D Video Reconstruction with Dynamic Point Maps</h1>
|
| 9 |
|
| 10 |
-
|
| 11 |
-
<a href="https://huggingface.co/spaces/edgarsucar/vdpm"><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
|
| 12 |
|
| 13 |
-
|
| 14 |
|
|
|
|
| 15 |
|
| 16 |
-
[Edgar Sucar](https://edgarsucar.github.io/)\*, [Eldar Insafutdinov](https://eldar.insafutdinov.com/)\*, [Zihang Lai](https://scholar.google.com/citations?user=31eXgMYAAAAJ), [Andrea Vedaldi](https://www.robots.ox.ac.uk/~vedaldi/)
|
| 17 |
-
</div>
|
| 18 |
|
| 19 |
-
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
-
First, clone the repository and setup a virtual environment with [uv](https://github.com/astral-sh/uv):
|
| 22 |
|
| 23 |
```bash
|
| 24 |
git clone git@github.com:eldar/vdpm.git
|
|
@@ -33,11 +31,6 @@ uv pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pyt
|
|
| 33 |
uv pip install -r requirements.txt
|
| 34 |
```
|
| 35 |
|
| 36 |
-
## Viser demo
|
| 37 |
-
```bash
|
| 38 |
-
python visualise.py ++vis.input_video=examples/videos/camel.mp4
|
| 39 |
-
```
|
| 40 |
-
|
| 41 |
## Gradio demo
|
| 42 |
```bash
|
| 43 |
python gradio_demo.py
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.17.1
|
| 6 |
---
|
|
|
|
|
|
|
| 7 |
|
| 8 |
+
## V-DPM Low-VRAM Multi-View Inference
|
|
|
|
| 9 |
|
| 10 |
+
Multi-view modification of V-DPM with low-vram modification to improve inference speed on consumer graphics cards and allow longer sequences to finish. Tested on 3070Ti, H200, PRO 6000,
|
| 11 |
|
| 12 |
+
First, clone the repository and setup a virtual environment with [uv](https://github.com/astral-sh/uv):
|
| 13 |
|
|
|
|
|
|
|
| 14 |
|
| 15 |
+
Original model's aggregator stores intermediate outputs of all 24 attention blocks, but only 4 of them is used by prediction heads. Made it return only that 4.
|
| 16 |
+
del unused intermediate tensors to free memory for subsequent code
|
| 17 |
+
@torch.compile some functions (e.g. MLP with GELU, LayerNorm)
|
| 18 |
+
torch.cuda.empty_cache() when helpful
|
| 19 |
|
|
|
|
| 20 |
|
| 21 |
```bash
|
| 22 |
git clone git@github.com:eldar/vdpm.git
|
|
|
|
| 31 |
uv pip install -r requirements.txt
|
| 32 |
```
|
| 33 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
## Gradio demo
|
| 35 |
```bash
|
| 36 |
python gradio_demo.py
|
dpm/aggregator.py
CHANGED
|
@@ -245,9 +245,12 @@ class Aggregator(nn.Module):
|
|
| 245 |
|
| 246 |
frame_idx = 0
|
| 247 |
global_idx = 0
|
| 248 |
-
|
|
|
|
|
|
|
| 249 |
|
| 250 |
-
|
|
|
|
| 251 |
for attn_type in self.aa_order:
|
| 252 |
if attn_type == "frame":
|
| 253 |
tokens, frame_idx, frame_intermediates = self._process_frame_attention(
|
|
@@ -260,15 +263,25 @@ class Aggregator(nn.Module):
|
|
| 260 |
else:
|
| 261 |
raise ValueError(f"Unknown attention type: {attn_type}")
|
| 262 |
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
|
| 270 |
-
|
| 271 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 272 |
|
| 273 |
def _process_frame_attention(self, tokens, B, S, P, C, frame_idx, pos=None):
|
| 274 |
"""
|
|
|
|
| 245 |
|
| 246 |
frame_idx = 0
|
| 247 |
global_idx = 0
|
| 248 |
+
# Only store intermediates for layers actually used by prediction heads
|
| 249 |
+
used_layer_idx = {4, 11, 17, 23}#{4, 11, 17, 23}
|
| 250 |
+
output_dict = {}
|
| 251 |
|
| 252 |
+
max_used_layer = max(used_layer_idx)
|
| 253 |
+
for block_iter in range(self.aa_block_num):
|
| 254 |
for attn_type in self.aa_order:
|
| 255 |
if attn_type == "frame":
|
| 256 |
tokens, frame_idx, frame_intermediates = self._process_frame_attention(
|
|
|
|
| 263 |
else:
|
| 264 |
raise ValueError(f"Unknown attention type: {attn_type}")
|
| 265 |
|
| 266 |
+
if block_iter in used_layer_idx:
|
| 267 |
+
for i in range(len(frame_intermediates)):
|
| 268 |
+
# concat frame and global intermediates, [B x S x P x 2C]
|
| 269 |
+
concat_inter = torch.cat([frame_intermediates[i], global_intermediates[i]], dim=-1)
|
| 270 |
+
# Store merged intermediates in FP16 to reduce GPU memory usage.
|
| 271 |
+
output_dict[block_iter] = concat_inter.half()
|
| 272 |
+
|
| 273 |
+
# Stop after the highest used layer to skip unnecessary blocks
|
| 274 |
+
if block_iter >= max_used_layer:
|
| 275 |
+
break
|
| 276 |
+
|
| 277 |
+
# Clean up
|
| 278 |
+
if 'frame_intermediates' in locals():
|
| 279 |
+
del frame_intermediates
|
| 280 |
+
if 'global_intermediates' in locals():
|
| 281 |
+
del global_intermediates
|
| 282 |
+
# Alias for CameraHead which indexes with [-1]
|
| 283 |
+
output_dict[-1] = output_dict[max_used_layer]
|
| 284 |
+
return output_dict, self.patch_start_idx
|
| 285 |
|
| 286 |
def _process_frame_attention(self, tokens, B, S, P, C, frame_idx, pos=None):
|
| 287 |
"""
|
dpm/decoder.py
CHANGED
|
@@ -167,7 +167,7 @@ class Decoder(nn.Module):
|
|
| 167 |
self,
|
| 168 |
cfg,
|
| 169 |
dim_in: int,
|
| 170 |
-
intermediate_layer_idx: List[int] =
|
| 171 |
patch_size=14,
|
| 172 |
embed_dim=1024,
|
| 173 |
depth=2,
|
|
@@ -279,13 +279,35 @@ class Decoder(nn.Module):
|
|
| 279 |
|
| 280 |
self.use_reentrant = False # hardcoded to False
|
| 281 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 282 |
def get_condition_tokens(
|
| 283 |
self,
|
| 284 |
aggregated_tokens_list: List[torch.Tensor],
|
| 285 |
cond_view_idxs: torch.Tensor
|
| 286 |
):
|
| 287 |
# Use tokens from the last block for conditioning
|
| 288 |
-
tokens_last = aggregated_tokens_list[-1] # [B S N_tok D]
|
| 289 |
# Extract the camera tokens
|
| 290 |
cond_token_idx = 1
|
| 291 |
camera_tokens = tokens_last[:, :, [cond_token_idx]] # [B S D]
|
|
|
|
| 167 |
self,
|
| 168 |
cfg,
|
| 169 |
dim_in: int,
|
| 170 |
+
intermediate_layer_idx: List[int] = [4, 11, 17, 23],
|
| 171 |
patch_size=14,
|
| 172 |
embed_dim=1024,
|
| 173 |
depth=2,
|
|
|
|
| 279 |
|
| 280 |
self.use_reentrant = False # hardcoded to False
|
| 281 |
|
| 282 |
+
# Track whether we have compiled the attention blocks for faster inference.
|
| 283 |
+
# We postpone compilation until after weights are loaded to keep state_dict names stable.
|
| 284 |
+
self._compiled = False
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
def compile_blocks(self):
|
| 288 |
+
"""Compile decoder attention blocks for faster inference (Linux/macOS only)."""
|
| 289 |
+
import sys
|
| 290 |
+
if self._compiled or self.old_decoder:
|
| 291 |
+
return
|
| 292 |
+
if sys.platform.startswith("win"):
|
| 293 |
+
print("[vdpm] torch.compile is not supported on Windows; running in eager mode.")
|
| 294 |
+
self._compiled = True
|
| 295 |
+
return
|
| 296 |
+
for module_list in self.frame_blocks:
|
| 297 |
+
for i in range(len(module_list)):
|
| 298 |
+
module_list[i] = torch.compile(module_list[i])
|
| 299 |
+
for module_list in self.global_blocks:
|
| 300 |
+
for i in range(len(module_list)):
|
| 301 |
+
module_list[i] = torch.compile(module_list[i])
|
| 302 |
+
self._compiled = True
|
| 303 |
+
|
| 304 |
def get_condition_tokens(
|
| 305 |
self,
|
| 306 |
aggregated_tokens_list: List[torch.Tensor],
|
| 307 |
cond_view_idxs: torch.Tensor
|
| 308 |
):
|
| 309 |
# Use tokens from the last block for conditioning
|
| 310 |
+
tokens_last = aggregated_tokens_list[self.intermediate_layer_idx[-1]] # [B S N_tok D]
|
| 311 |
# Extract the camera tokens
|
| 312 |
cond_token_idx = 1
|
| 313 |
camera_tokens = tokens_last[:, :, [cond_token_idx]] # [B S D]
|
dpm/model.py
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
import torch
|
| 2 |
import torch.nn as nn
|
| 3 |
|
|
@@ -37,6 +38,7 @@ class VDPM(nn.Module):
|
|
| 37 |
self.point_head = DPTHead(dim_in=2 * embed_dim, output_dim=4, activation="inv_log", conf_activation="expp1")
|
| 38 |
|
| 39 |
self.camera_head = CameraHead(dim_in=2 * embed_dim)
|
|
|
|
| 40 |
self.set_freeze()
|
| 41 |
|
| 42 |
def set_freeze(self):
|
|
@@ -64,9 +66,10 @@ class VDPM(nn.Module):
|
|
| 64 |
aggregated_tokens_list, images, patch_start_idx
|
| 65 |
)
|
| 66 |
|
| 67 |
-
padded_decoded_tokens =
|
| 68 |
-
|
| 69 |
-
|
|
|
|
| 70 |
pts3d_dyn, pts3d_dyn_conf = self.point_head(
|
| 71 |
padded_decoded_tokens, images, patch_start_idx
|
| 72 |
)
|
|
@@ -91,19 +94,37 @@ class VDPM(nn.Module):
|
|
| 91 |
images=None,
|
| 92 |
num_timesteps=None
|
| 93 |
):
|
| 94 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 95 |
|
| 96 |
if images is None:
|
| 97 |
images = torch.stack([view["img"] for view in views], dim=1)
|
| 98 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 99 |
with autocast_amp:
|
| 100 |
aggregated_tokens_list, patch_start_idx = self.aggregator(images)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 101 |
S = images.shape[1]
|
| 102 |
|
| 103 |
# Determine number of timesteps to query
|
| 104 |
if num_timesteps is None:
|
| 105 |
-
# Default to S if not specified (legacy behavior)
|
| 106 |
-
# But if views has indices, try to infer max time
|
| 107 |
if views is not None and "view_idxs" in views[0]:
|
| 108 |
try:
|
| 109 |
all_idxs = torch.cat([v["view_idxs"][:, 1] for v in views])
|
|
@@ -116,32 +137,110 @@ class VDPM(nn.Module):
|
|
| 116 |
predictions = dict()
|
| 117 |
pointmaps = []
|
| 118 |
ones = torch.ones(1, S, dtype=torch.int64)
|
|
|
|
| 119 |
for time_ in range(num_timesteps):
|
| 120 |
cond_view_idxs = ones * time_
|
| 121 |
|
|
|
|
|
|
|
|
|
|
| 122 |
with autocast_amp:
|
| 123 |
decoded_tokens = self.decoder(images, aggregated_tokens_list, patch_start_idx, cond_view_idxs)
|
| 124 |
-
padded_decoded_tokens = [None] * len(aggregated_tokens_list)
|
| 125 |
-
for idx, layer_idx in enumerate(self.point_head.intermediate_layer_idx):
|
| 126 |
-
padded_decoded_tokens[layer_idx] = decoded_tokens[idx]
|
| 127 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 128 |
pts3d, pts3d_conf = self.point_head(
|
| 129 |
padded_decoded_tokens, images, patch_start_idx
|
| 130 |
)
|
| 131 |
|
|
|
|
|
|
|
|
|
|
| 132 |
pointmaps.append(dict(
|
| 133 |
pts3d=pts3d,
|
| 134 |
conf=pts3d_conf
|
| 135 |
))
|
| 136 |
|
|
|
|
|
|
|
|
|
|
| 137 |
pose_enc_list = self.camera_head(aggregated_tokens_list)
|
| 138 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 139 |
predictions["pose_enc_list"] = pose_enc_list
|
| 140 |
predictions["pointmaps"] = pointmaps
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 141 |
return predictions
|
| 142 |
|
| 143 |
def load_state_dict(self, ckpt, is_VGGT_static=False, **kw):
|
| 144 |
# don't load these VGGT heads as not needed
|
| 145 |
exclude = ["depth_head", "track_head"]
|
| 146 |
ckpt = {k:v for k, v in ckpt.items() if k.split('.')[0] not in exclude}
|
| 147 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
import torch
|
| 3 |
import torch.nn as nn
|
| 4 |
|
|
|
|
| 38 |
self.point_head = DPTHead(dim_in=2 * embed_dim, output_dim=4, activation="inv_log", conf_activation="expp1")
|
| 39 |
|
| 40 |
self.camera_head = CameraHead(dim_in=2 * embed_dim)
|
| 41 |
+
self.profile = False
|
| 42 |
self.set_freeze()
|
| 43 |
|
| 44 |
def set_freeze(self):
|
|
|
|
| 66 |
aggregated_tokens_list, images, patch_start_idx
|
| 67 |
)
|
| 68 |
|
| 69 |
+
padded_decoded_tokens = {
|
| 70 |
+
layer_idx: decoded_tokens[idx]
|
| 71 |
+
for idx, layer_idx in enumerate(self.point_head.intermediate_layer_idx)
|
| 72 |
+
}
|
| 73 |
pts3d_dyn, pts3d_dyn_conf = self.point_head(
|
| 74 |
padded_decoded_tokens, images, patch_start_idx
|
| 75 |
)
|
|
|
|
| 94 |
images=None,
|
| 95 |
num_timesteps=None
|
| 96 |
):
|
| 97 |
+
profile = self.profile and torch.cuda.is_available()
|
| 98 |
+
if profile:
|
| 99 |
+
ev = lambda: torch.cuda.Event(enable_timing=True)
|
| 100 |
+
e_start, e_agg, e_cam_end = ev(), ev(), ev()
|
| 101 |
+
e_dec_starts, e_dec_ends = [], []
|
| 102 |
+
e_head_starts, e_head_ends = [], []
|
| 103 |
+
e_cam_start = ev()
|
| 104 |
+
mem_before = torch.cuda.memory_allocated() / 1024**3
|
| 105 |
+
e_start.record()
|
| 106 |
+
|
| 107 |
+
autocast_amp = torch.amp.autocast("cuda", enabled=True, dtype=torch.float16)
|
| 108 |
|
| 109 |
if images is None:
|
| 110 |
images = torch.stack([view["img"] for view in views], dim=1)
|
| 111 |
|
| 112 |
+
# If not profiling per-stage, measure a single total inference time (minimal overhead)
|
| 113 |
+
if not profile:
|
| 114 |
+
torch.cuda.synchronize()
|
| 115 |
+
_t_start = time.time()
|
| 116 |
+
|
| 117 |
with autocast_amp:
|
| 118 |
aggregated_tokens_list, patch_start_idx = self.aggregator(images)
|
| 119 |
+
|
| 120 |
+
if profile:
|
| 121 |
+
e_agg.record()
|
| 122 |
+
mem_after_agg = torch.cuda.memory_allocated() / 1024**3
|
| 123 |
+
|
| 124 |
S = images.shape[1]
|
| 125 |
|
| 126 |
# Determine number of timesteps to query
|
| 127 |
if num_timesteps is None:
|
|
|
|
|
|
|
| 128 |
if views is not None and "view_idxs" in views[0]:
|
| 129 |
try:
|
| 130 |
all_idxs = torch.cat([v["view_idxs"][:, 1] for v in views])
|
|
|
|
| 137 |
predictions = dict()
|
| 138 |
pointmaps = []
|
| 139 |
ones = torch.ones(1, S, dtype=torch.int64)
|
| 140 |
+
|
| 141 |
for time_ in range(num_timesteps):
|
| 142 |
cond_view_idxs = ones * time_
|
| 143 |
|
| 144 |
+
if profile:
|
| 145 |
+
e_ds = ev(); e_ds.record(); e_dec_starts.append(e_ds)
|
| 146 |
+
|
| 147 |
with autocast_amp:
|
| 148 |
decoded_tokens = self.decoder(images, aggregated_tokens_list, patch_start_idx, cond_view_idxs)
|
|
|
|
|
|
|
|
|
|
| 149 |
|
| 150 |
+
if profile:
|
| 151 |
+
e_de = ev(); e_de.record(); e_dec_ends.append(e_de)
|
| 152 |
+
|
| 153 |
+
padded_decoded_tokens = {
|
| 154 |
+
layer_idx: decoded_tokens[idx]
|
| 155 |
+
for idx, layer_idx in enumerate(self.point_head.intermediate_layer_idx)
|
| 156 |
+
}
|
| 157 |
+
|
| 158 |
+
if profile:
|
| 159 |
+
e_hs = ev(); e_hs.record(); e_head_starts.append(e_hs)
|
| 160 |
pts3d, pts3d_conf = self.point_head(
|
| 161 |
padded_decoded_tokens, images, patch_start_idx
|
| 162 |
)
|
| 163 |
|
| 164 |
+
if profile:
|
| 165 |
+
e_he = ev(); e_he.record(); e_head_ends.append(e_he)
|
| 166 |
+
|
| 167 |
pointmaps.append(dict(
|
| 168 |
pts3d=pts3d,
|
| 169 |
conf=pts3d_conf
|
| 170 |
))
|
| 171 |
|
| 172 |
+
if profile:
|
| 173 |
+
e_cam_start.record()
|
| 174 |
+
|
| 175 |
pose_enc_list = self.camera_head(aggregated_tokens_list)
|
| 176 |
+
|
| 177 |
+
if profile:
|
| 178 |
+
e_cam_end.record()
|
| 179 |
+
torch.cuda.synchronize() # single sync at the very end
|
| 180 |
+
mem_peak = torch.cuda.max_memory_allocated() / 1024**3
|
| 181 |
+
|
| 182 |
+
t_agg = e_start.elapsed_time(e_agg) / 1000
|
| 183 |
+
t_dec = sum(s.elapsed_time(e) / 1000 for s, e in zip(e_dec_starts, e_dec_ends))
|
| 184 |
+
t_head = sum(s.elapsed_time(e) / 1000 for s, e in zip(e_head_starts, e_head_ends))
|
| 185 |
+
t_cam = e_cam_start.elapsed_time(e_cam_end) / 1000
|
| 186 |
+
t_total = e_start.elapsed_time(e_cam_end) / 1000
|
| 187 |
+
|
| 188 |
+
print(f" [PROFILE] Aggregator: {t_agg:.3f}s | VRAM: {mem_before:.2f} -> {mem_after_agg:.2f} GB (+{mem_after_agg - mem_before:.2f})")
|
| 189 |
+
print(f" [PROFILE] Stored layers: {sorted(k for k in aggregated_tokens_list if k >= 0)}")
|
| 190 |
+
print(f" [PROFILE] Decoder: {t_dec:.3f}s ({num_timesteps} timesteps, {t_dec/max(num_timesteps,1)*1000:.0f}ms each)")
|
| 191 |
+
print(f" [PROFILE] Point Head: {t_head:.3f}s ({num_timesteps} timesteps, {t_head/max(num_timesteps,1)*1000:.0f}ms each)")
|
| 192 |
+
print(f" [PROFILE] Camera Head:{t_cam:.3f}s")
|
| 193 |
+
print(f" [PROFILE] Total: {t_total:.3f}s | Peak VRAM: {mem_peak:.2f} GB")
|
| 194 |
+
print(f" [PROFILE] Breakdown: Agg {t_agg/t_total*100:.0f}% | Dec {t_dec/t_total*100:.0f}% | PtHead {t_head/t_total*100:.0f}% | CamHead {t_cam/t_total*100:.0f}%")
|
| 195 |
+
|
| 196 |
+
predictions["pose_enc"] = pose_enc_list[-1]
|
| 197 |
predictions["pose_enc_list"] = pose_enc_list
|
| 198 |
predictions["pointmaps"] = pointmaps
|
| 199 |
+
|
| 200 |
+
if not profile:
|
| 201 |
+
# single final sync and lightweight wall-clock timing
|
| 202 |
+
torch.cuda.synchronize()
|
| 203 |
+
t_total = time.time() - _t_start
|
| 204 |
+
print(f" [PROFILE] Total inference time: {t_total:.3f}s")
|
| 205 |
+
|
| 206 |
return predictions
|
| 207 |
|
| 208 |
def load_state_dict(self, ckpt, is_VGGT_static=False, **kw):
|
| 209 |
# don't load these VGGT heads as not needed
|
| 210 |
exclude = ["depth_head", "track_head"]
|
| 211 |
ckpt = {k:v for k, v in ckpt.items() if k.split('.')[0] not in exclude}
|
| 212 |
+
|
| 213 |
+
res = super().load_state_dict(ckpt, **kw)
|
| 214 |
+
|
| 215 |
+
# Compile decoder blocks after weights are loaded so state_dict keys match the checkpoint.
|
| 216 |
+
if hasattr(self, "decoder") and hasattr(self.decoder, "compile_blocks"):
|
| 217 |
+
self.decoder.compile_blocks()
|
| 218 |
+
|
| 219 |
+
return res
|
| 220 |
+
|
| 221 |
+
def to_fp16(self, keep_norm_fp32: bool = False):
|
| 222 |
+
"""Convert model parameters and buffers to FP16 for inference.
|
| 223 |
+
|
| 224 |
+
Args:
|
| 225 |
+
keep_norm_fp32 (bool): If True, keep normalization layers (LayerNorm/BatchNorm)
|
| 226 |
+
in FP32 for numerical stability. If False, convert everything to FP16.
|
| 227 |
+
"""
|
| 228 |
+
# Convert whole model to half first
|
| 229 |
+
self.half()
|
| 230 |
+
|
| 231 |
+
if keep_norm_fp32:
|
| 232 |
+
for m in self.modules():
|
| 233 |
+
if isinstance(m, (torch.nn.LayerNorm, torch.nn.BatchNorm1d, torch.nn.BatchNorm2d, torch.nn.SyncBatchNorm)):
|
| 234 |
+
m.float()
|
| 235 |
+
|
| 236 |
+
# Ensure any stored dtype-sensitive tensors are converted appropriately
|
| 237 |
+
try:
|
| 238 |
+
# camera/register/time tokens are Parameters and are handled by self.half(),
|
| 239 |
+
# but ensure any other buffers are also cast
|
| 240 |
+
for name, buf in list(self._buffers.items()):
|
| 241 |
+
if isinstance(buf, torch.Tensor):
|
| 242 |
+
self.register_buffer(name, buf.half(), persistent=(getattr(buf, 'persistent', False)))
|
| 243 |
+
except Exception:
|
| 244 |
+
pass
|
| 245 |
+
|
| 246 |
+
return self
|
gradio_demo.py
CHANGED
|
@@ -27,7 +27,11 @@ from dpm.model import VDPM
|
|
| 27 |
from vggt.utils.load_fn import load_and_preprocess_images
|
| 28 |
from util.depth import write_depth_to_png
|
| 29 |
|
| 30 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 31 |
# ============================================================================
|
| 32 |
# MEMORY OPTIMIZATION SETTINGS FOR 8GB GPUs (RTX 3070 Ti, 3060 Ti, etc.)
|
| 33 |
# ============================================================================
|
|
@@ -65,17 +69,17 @@ if device == "cuda":
|
|
| 65 |
|
| 66 |
print(f"\u2713 GPU Detected: {torch.cuda.get_device_name(0)} ({vram_gb:.1f} GB VRAM)")
|
| 67 |
|
| 68 |
-
if vram_gb >=
|
| 69 |
MAX_FRAMES = 80
|
| 70 |
print(f" -> High VRAM detected! Increased MAX_FRAMES to {MAX_FRAMES}")
|
| 71 |
-
elif vram_gb >=
|
| 72 |
-
MAX_FRAMES =
|
| 73 |
print(f" -> Medium VRAM detected! Increased MAX_FRAMES to {MAX_FRAMES}")
|
| 74 |
elif vram_gb >= 7.5: # RTX 3070 Ti, 2080, etc (8GB)
|
| 75 |
-
MAX_FRAMES =
|
| 76 |
print(f" -> 8GB VRAM detected. Set MAX_FRAMES to {MAX_FRAMES}")
|
| 77 |
else:
|
| 78 |
-
MAX_FRAMES =
|
| 79 |
print(f" -> Low VRAM (<8GB). Keeping MAX_FRAMES at {MAX_FRAMES} to prevent OOM")
|
| 80 |
print(f"\u2713 TF32 enabled for faster matrix operations")
|
| 81 |
|
|
@@ -84,7 +88,12 @@ if device == "cuda":
|
|
| 84 |
def load_cfg_from_cli() -> "omegaconf.DictConfig":
|
| 85 |
if GlobalHydra.instance().is_initialized():
|
| 86 |
GlobalHydra.instance().clear()
|
| 87 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 88 |
with initialize(config_path="configs"):
|
| 89 |
return compose(config_name="visualise", overrides=overrides)
|
| 90 |
|
|
@@ -121,15 +130,23 @@ def load_model(cfg) -> VDPM:
|
|
| 121 |
|
| 122 |
# Option 1: Use FP16/BF16 for all model weights (simple, ~2x memory/speed boost)
|
| 123 |
if USE_HALF_PRECISION and not USE_QUANTIZATION:
|
| 124 |
-
# Use BF16 on
|
| 125 |
-
|
| 126 |
-
|
|
|
|
| 127 |
model = model.to(torch.bfloat16)
|
| 128 |
-
print("✓ Model converted to BF16
|
| 129 |
else:
|
| 130 |
print("Converting model to FP16 precision...")
|
| 131 |
-
|
| 132 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 133 |
|
| 134 |
# Option 2: Apply INT8 dynamic quantization (more aggressive, ~3-4x reduction)
|
| 135 |
if USE_QUANTIZATION:
|
|
@@ -150,14 +167,8 @@ def load_model(cfg) -> VDPM:
|
|
| 150 |
model = model.to(device)
|
| 151 |
|
| 152 |
# Enable torch.compile for faster inference (PyTorch 2.0+)
|
| 153 |
-
#
|
| 154 |
-
|
| 155 |
-
try:
|
| 156 |
-
print("Compiling model with torch.compile for faster inference...")
|
| 157 |
-
model = torch.compile(model, mode="reduce-overhead")
|
| 158 |
-
print("✓ Model compilation successful")
|
| 159 |
-
except Exception as e:
|
| 160 |
-
print(f"Warning: torch.compile not available or failed: {e}")
|
| 161 |
|
| 162 |
return model
|
| 163 |
|
|
@@ -241,7 +252,7 @@ def compute_normals_from_pointmap(point_map: np.ndarray) -> tuple[np.ndarray, np
|
|
| 241 |
tangent_x_np = tangent_x_np.reshape(T, V, H, W, 3)
|
| 242 |
tangent_y_np = tangent_y_np.reshape(T, V, H, W, 3)
|
| 243 |
|
| 244 |
-
return normals_np.astype(np.
|
| 245 |
|
| 246 |
|
| 247 |
def compute_smooth_normals(normals: np.ndarray, kernel_size: int = 5) -> np.ndarray:
|
|
@@ -291,7 +302,7 @@ def compute_smooth_normals(normals: np.ndarray, kernel_size: int = 5) -> np.ndar
|
|
| 291 |
if normals.ndim == 5:
|
| 292 |
result = result.reshape(T, V, H, W, 3)
|
| 293 |
|
| 294 |
-
return result.astype(np.
|
| 295 |
|
| 296 |
|
| 297 |
def compute_optical_flow(world_points: np.ndarray, extrinsics: np.ndarray = None, intrinsics: np.ndarray = None, num_views: int = 1) -> np.ndarray:
|
|
@@ -405,6 +416,18 @@ def write_optical_flow_to_png(outpath: str, flow: np.ndarray, max_flow: float =
|
|
| 405 |
PIL.Image.fromarray(rgb).save(outpath)
|
| 406 |
|
| 407 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 408 |
def create_output_zip(target_dir: str) -> str:
|
| 409 |
"""Create a zip file containing all outputs for download.
|
| 410 |
|
|
@@ -422,12 +445,14 @@ def create_output_zip(target_dir: str) -> str:
|
|
| 422 |
"tracks.npz",
|
| 423 |
"poses.npz",
|
| 424 |
"depths.npz",
|
| 425 |
-
"
|
| 426 |
-
"
|
| 427 |
-
"
|
| 428 |
-
"
|
| 429 |
-
"
|
| 430 |
-
"
|
|
|
|
|
|
|
| 431 |
"meta.json",
|
| 432 |
]
|
| 433 |
|
|
@@ -1142,7 +1167,7 @@ def run_model(target_dir: str, model: VDPM, frame_id_arg=0, use_temporal_trackin
|
|
| 1142 |
extrinsics, intrinsics = None, None
|
| 1143 |
|
| 1144 |
# ============================================================================
|
| 1145 |
-
# COMPUTE AND SAVE NORMALS
|
| 1146 |
# ============================================================================
|
| 1147 |
print("Computing surface normals from point maps...")
|
| 1148 |
normals, tangent_x, tangent_y = compute_normals_from_pointmap(world_points_full)
|
|
@@ -1151,17 +1176,15 @@ def run_model(target_dir: str, model: VDPM, frame_id_arg=0, use_temporal_trackin
|
|
| 1151 |
print("Computing smooth normals...")
|
| 1152 |
smooth_normals = compute_smooth_normals(normals, kernel_size=7)
|
| 1153 |
|
| 1154 |
-
# Save
|
| 1155 |
-
|
| 1156 |
-
print(f"Saving normals to {
|
| 1157 |
np.savez_compressed(
|
| 1158 |
-
|
| 1159 |
-
|
| 1160 |
-
smooth_normals=smooth_normals,
|
| 1161 |
-
tangent_x=tangent_x,
|
| 1162 |
-
tangent_y=tangent_y,
|
| 1163 |
-
num_views=num_views,
|
| 1164 |
-
num_timesteps=num_timesteps
|
| 1165 |
)
|
| 1166 |
|
| 1167 |
# Save individual normal images as PNGs
|
|
@@ -1185,39 +1208,77 @@ def run_model(target_dir: str, model: VDPM, frame_id_arg=0, use_temporal_trackin
|
|
| 1185 |
print(f"✓ Saved {T_norm * V_norm * 2} normal images (raw + smooth)")
|
| 1186 |
|
| 1187 |
# ============================================================================
|
| 1188 |
-
# COMPUTE AND SAVE
|
| 1189 |
# ============================================================================
|
| 1190 |
-
|
| 1191 |
-
|
| 1192 |
-
|
| 1193 |
-
#
|
| 1194 |
-
|
| 1195 |
-
|
| 1196 |
-
|
| 1197 |
-
|
| 1198 |
-
optical_flow=optical_flow,
|
| 1199 |
-
num_views=num_views,
|
| 1200 |
-
num_timesteps=num_timesteps
|
| 1201 |
-
)
|
| 1202 |
|
| 1203 |
-
|
| 1204 |
-
|
| 1205 |
-
os.makedirs(flow_dir, exist_ok=True)
|
| 1206 |
-
print(f"Saving flow images to {flow_dir}/")
|
| 1207 |
|
| 1208 |
-
|
| 1209 |
-
|
| 1210 |
-
|
| 1211 |
-
|
| 1212 |
|
| 1213 |
-
|
| 1214 |
-
|
| 1215 |
-
|
| 1216 |
-
|
| 1217 |
-
|
| 1218 |
-
write_optical_flow_to_png(png_path, flow_map, max_flow=max_flow_magnitude)
|
| 1219 |
|
| 1220 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1221 |
|
| 1222 |
# (Moved saving logic to the end of function to capture all viz variables)
|
| 1223 |
|
|
@@ -1336,13 +1397,26 @@ def run_model(target_dir: str, model: VDPM, frame_id_arg=0, use_temporal_trackin
|
|
| 1336 |
|
| 1337 |
|
| 1338 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1339 |
# Save Results for Download (Final Format)
|
| 1340 |
output_path = os.path.join(target_dir, "output_4d.npz")
|
| 1341 |
save_dict = {
|
| 1342 |
"world_points": world_points_s,
|
| 1343 |
"world_points_conf": world_points_conf_s,
|
| 1344 |
-
"world_points_tracks":
|
| 1345 |
-
"world_points_conf_tracks": world_points_conf_tracks, # (S, T, H, W)
|
| 1346 |
"images": img_np_viz,
|
| 1347 |
"images_raw": img_np[:, :, ::2, ::2], # Original images subsampled
|
| 1348 |
"num_views": num_views,
|
|
|
|
| 27 |
from vggt.utils.load_fn import load_and_preprocess_images
|
| 28 |
from util.depth import write_depth_to_png
|
| 29 |
|
| 30 |
+
import torch
|
| 31 |
+
import torch._dynamo
|
| 32 |
+
torch._dynamo.config.suppress_errors = True
|
| 33 |
+
# This disables the specific fused GELU that's crashing
|
| 34 |
+
torch.set_float32_matmul_precision('high')
|
| 35 |
# ============================================================================
|
| 36 |
# MEMORY OPTIMIZATION SETTINGS FOR 8GB GPUs (RTX 3070 Ti, 3060 Ti, etc.)
|
| 37 |
# ============================================================================
|
|
|
|
| 69 |
|
| 70 |
print(f"\u2713 GPU Detected: {torch.cuda.get_device_name(0)} ({vram_gb:.1f} GB VRAM)")
|
| 71 |
|
| 72 |
+
if vram_gb >= 30: # A10G (24GB), A100 (40/80GB), RTX 3090/4090 (24GB)
|
| 73 |
MAX_FRAMES = 80
|
| 74 |
print(f" -> High VRAM detected! Increased MAX_FRAMES to {MAX_FRAMES}")
|
| 75 |
+
elif vram_gb >= 15: # T4 (16GB), 4080 (16GB)
|
| 76 |
+
MAX_FRAMES = 32
|
| 77 |
print(f" -> Medium VRAM detected! Increased MAX_FRAMES to {MAX_FRAMES}")
|
| 78 |
elif vram_gb >= 7.5: # RTX 3070 Ti, 2080, etc (8GB)
|
| 79 |
+
MAX_FRAMES = 24
|
| 80 |
print(f" -> 8GB VRAM detected. Set MAX_FRAMES to {MAX_FRAMES}")
|
| 81 |
else:
|
| 82 |
+
MAX_FRAMES = 8
|
| 83 |
print(f" -> Low VRAM (<8GB). Keeping MAX_FRAMES at {MAX_FRAMES} to prevent OOM")
|
| 84 |
print(f"\u2713 TF32 enabled for faster matrix operations")
|
| 85 |
|
|
|
|
| 88 |
def load_cfg_from_cli() -> "omegaconf.DictConfig":
|
| 89 |
if GlobalHydra.instance().is_initialized():
|
| 90 |
GlobalHydra.instance().clear()
|
| 91 |
+
# In notebooks or some interactive shells, sys.argv contains kernel launch flags
|
| 92 |
+
# like `--f=...` which Hydra cannot parse as overrides. Filter those out.
|
| 93 |
+
if GlobalHydra.instance().is_initialized():
|
| 94 |
+
GlobalHydra.instance().clear()
|
| 95 |
+
raw_overrides = sys.argv[1:]
|
| 96 |
+
overrides = [o for o in raw_overrides if not (o.startswith("--f=") or "kernel" in o)]
|
| 97 |
with initialize(config_path="configs"):
|
| 98 |
return compose(config_name="visualise", overrides=overrides)
|
| 99 |
|
|
|
|
| 130 |
|
| 131 |
# Option 1: Use FP16/BF16 for all model weights (simple, ~2x memory/speed boost)
|
| 132 |
if USE_HALF_PRECISION and not USE_QUANTIZATION:
|
| 133 |
+
# Use BF16 only on Hopper+ (compute >= 9) where BF16 throughput matches FP16
|
| 134 |
+
# On Ampere (compute 8.x, e.g. 3070Ti), FP16 tensor cores are ~2x faster than BF16
|
| 135 |
+
if torch.cuda.is_available() and torch.cuda.get_device_capability()[0] >= 9:
|
| 136 |
+
print("Converting model to BF16 precision (Hopper+ GPU detected)...")
|
| 137 |
model = model.to(torch.bfloat16)
|
| 138 |
+
print("✓ Model converted to BF16")
|
| 139 |
else:
|
| 140 |
print("Converting model to FP16 precision...")
|
| 141 |
+
# Convert model to full FP16 (with helper that can preserve norm layers if desired)
|
| 142 |
+
try:
|
| 143 |
+
model = model.to_fp16(keep_norm_fp32=False)
|
| 144 |
+
print("✓ Model converted to FP16 via to_fp16()")
|
| 145 |
+
except Exception:
|
| 146 |
+
# Fallback to half() if helper not available
|
| 147 |
+
model = model.half()
|
| 148 |
+
print("✓ Model converted to FP16 via half() (fallback)")
|
| 149 |
+
|
| 150 |
|
| 151 |
# Option 2: Apply INT8 dynamic quantization (more aggressive, ~3-4x reduction)
|
| 152 |
if USE_QUANTIZATION:
|
|
|
|
| 167 |
model = model.to(device)
|
| 168 |
|
| 169 |
# Enable torch.compile for faster inference (PyTorch 2.0+)
|
| 170 |
+
# torch.compile is handled per-block in decoder.compile_blocks()
|
| 171 |
+
# called during load_state_dict above
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
|
| 173 |
return model
|
| 174 |
|
|
|
|
| 252 |
tangent_x_np = tangent_x_np.reshape(T, V, H, W, 3)
|
| 253 |
tangent_y_np = tangent_y_np.reshape(T, V, H, W, 3)
|
| 254 |
|
| 255 |
+
return normals_np.astype(np.float32), tangent_x_np.astype(np.float32), tangent_y_np.astype(np.float32)
|
| 256 |
|
| 257 |
|
| 258 |
def compute_smooth_normals(normals: np.ndarray, kernel_size: int = 5) -> np.ndarray:
|
|
|
|
| 302 |
if normals.ndim == 5:
|
| 303 |
result = result.reshape(T, V, H, W, 3)
|
| 304 |
|
| 305 |
+
return result.astype(np.float32)
|
| 306 |
|
| 307 |
|
| 308 |
def compute_optical_flow(world_points: np.ndarray, extrinsics: np.ndarray = None, intrinsics: np.ndarray = None, num_views: int = 1) -> np.ndarray:
|
|
|
|
| 416 |
PIL.Image.fromarray(rgb).save(outpath)
|
| 417 |
|
| 418 |
|
| 419 |
+
def _flow_to_image_3d(flow_hw3: np.ndarray) -> np.ndarray:
|
| 420 |
+
"""Convert a 3D flow map (H, W, 3) to an RGB image.
|
| 421 |
+
|
| 422 |
+
Maps each XYZ component to R, G, B scaled by the global max magnitude.
|
| 423 |
+
"""
|
| 424 |
+
mag = np.linalg.norm(flow_hw3, axis=-1, keepdims=True)
|
| 425 |
+
max_mag = float(mag.max()) + 1e-8
|
| 426 |
+
norm = flow_hw3 / max_mag
|
| 427 |
+
rgb = np.clip((norm + 1.0) * 0.5, 0.0, 1.0)
|
| 428 |
+
return (rgb * 255).astype(np.uint8)
|
| 429 |
+
|
| 430 |
+
|
| 431 |
def create_output_zip(target_dir: str) -> str:
|
| 432 |
"""Create a zip file containing all outputs for download.
|
| 433 |
|
|
|
|
| 445 |
"tracks.npz",
|
| 446 |
"poses.npz",
|
| 447 |
"depths.npz",
|
| 448 |
+
"depth_normals.npz",
|
| 449 |
+
"scene_flow.npz",
|
| 450 |
+
"angular_flow.npz",
|
| 451 |
+
"depths", # directory
|
| 452 |
+
"normals", # directory
|
| 453 |
+
"scene_flow", # directory
|
| 454 |
+
"angular_flow", # directory
|
| 455 |
+
"images", # directory
|
| 456 |
"meta.json",
|
| 457 |
]
|
| 458 |
|
|
|
|
| 1167 |
extrinsics, intrinsics = None, None
|
| 1168 |
|
| 1169 |
# ============================================================================
|
| 1170 |
+
# COMPUTE AND SAVE NORMALS (depth_normals.npz — matches trainer format)
|
| 1171 |
# ============================================================================
|
| 1172 |
print("Computing surface normals from point maps...")
|
| 1173 |
normals, tangent_x, tangent_y = compute_normals_from_pointmap(world_points_full)
|
|
|
|
| 1176 |
print("Computing smooth normals...")
|
| 1177 |
smooth_normals = compute_smooth_normals(normals, kernel_size=7)
|
| 1178 |
|
| 1179 |
+
# Save as depth_normals.npz (the name the trainer/viewer expect)
|
| 1180 |
+
depth_normals_path = os.path.join(target_dir, "depth_normals.npz")
|
| 1181 |
+
print(f"Saving normals to {depth_normals_path}")
|
| 1182 |
np.savez_compressed(
|
| 1183 |
+
depth_normals_path,
|
| 1184 |
+
depth_normals=normals.astype(np.float16), # key must be 'depth_normals'
|
| 1185 |
+
smooth_normals=smooth_normals.astype(np.float16),
|
| 1186 |
+
tangent_x=tangent_x.astype(np.float16),
|
| 1187 |
+
tangent_y=tangent_y.astype(np.float16),
|
|
|
|
|
|
|
| 1188 |
)
|
| 1189 |
|
| 1190 |
# Save individual normal images as PNGs
|
|
|
|
| 1208 |
print(f"✓ Saved {T_norm * V_norm * 2} normal images (raw + smooth)")
|
| 1209 |
|
| 1210 |
# ============================================================================
|
| 1211 |
+
# COMPUTE AND SAVE SCENE FLOW + ANGULAR FLOW (matches trainer format)
|
| 1212 |
# ============================================================================
|
| 1213 |
+
# The trainer expects:
|
| 1214 |
+
# scene_flow.npz — keys "tXXXX_vYY" → (H, W, 3) float32
|
| 1215 |
+
# angular_flow.npz — keys "tXXXX_vYY" → (H, W, 9) float32
|
| 1216 |
+
# Computed from world_points_raw which has the full pairwise DPM output:
|
| 1217 |
+
# world_points_raw[t, s, h, w] = P_s(t, π₀)
|
| 1218 |
+
# tracks[frame_idx, ref_idx] style indexing
|
| 1219 |
+
# ============================================================================
|
| 1220 |
+
print("Computing scene flow and angular flow from pairwise DPM output...")
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1221 |
|
| 1222 |
+
sf_npz_dict = {}
|
| 1223 |
+
af_npz_dict = {}
|
|
|
|
|
|
|
| 1224 |
|
| 1225 |
+
sf_dir = os.path.join(target_dir, "scene_flow")
|
| 1226 |
+
af_dir = os.path.join(target_dir, "angular_flow")
|
| 1227 |
+
os.makedirs(sf_dir, exist_ok=True)
|
| 1228 |
+
os.makedirs(af_dir, exist_ok=True)
|
| 1229 |
|
| 1230 |
+
# world_points_raw: (T_query, S_source, H, W, 3)
|
| 1231 |
+
# For multi-view: S = num_views * num_timesteps, interleaved as
|
| 1232 |
+
# [v0_t0, v1_t0, ..., v0_t1, v1_t1, ...]
|
| 1233 |
+
# frame_idx = t * num_views + v (same as the trainer's convention)
|
| 1234 |
+
H_raw, W_raw = world_points_raw.shape[2:4]
|
|
|
|
| 1235 |
|
| 1236 |
+
sf_count = 0
|
| 1237 |
+
for t in range(num_timesteps - 1):
|
| 1238 |
+
for v in range(num_views):
|
| 1239 |
+
frame_idx = t * num_views + v
|
| 1240 |
+
next_frame_idx = (t + 1) * num_views + v
|
| 1241 |
+
|
| 1242 |
+
# P(t): points at current time (frame queries itself)
|
| 1243 |
+
P_t = world_points_raw[frame_idx, frame_idx].astype(np.float32) # (H, W, 3)
|
| 1244 |
+
# P(t+1): where frame t's points are at time t+1
|
| 1245 |
+
P_t1 = world_points_raw[frame_idx, next_frame_idx].astype(np.float32) # (H, W, 3)
|
| 1246 |
+
|
| 1247 |
+
scene_flow = np.nan_to_num(P_t1 - P_t, nan=0.0, posinf=0.0, neginf=0.0)
|
| 1248 |
+
|
| 1249 |
+
key = f"t{t:04d}_v{v:02d}"
|
| 1250 |
+
sf_npz_dict[key] = scene_flow.astype(np.float32)
|
| 1251 |
+
|
| 1252 |
+
# Angular flow: normal difference + tangent frame difference
|
| 1253 |
+
n_t, tx_t, ty_t = compute_normals_from_pointmap(P_t[np.newaxis])
|
| 1254 |
+
n_t1, tx_t1, ty_t1 = compute_normals_from_pointmap(P_t1[np.newaxis])
|
| 1255 |
+
|
| 1256 |
+
delta_n = np.nan_to_num(n_t1[0] - n_t[0], nan=0.0)
|
| 1257 |
+
delta_tx = np.nan_to_num(tx_t1[0] - tx_t[0], nan=0.0)
|
| 1258 |
+
delta_ty = np.nan_to_num(ty_t1[0] - ty_t[0], nan=0.0)
|
| 1259 |
+
angular_flow = np.concatenate([delta_n, delta_tx, delta_ty], axis=-1) # (H, W, 9)
|
| 1260 |
+
af_npz_dict[key] = angular_flow.astype(np.float32)
|
| 1261 |
+
|
| 1262 |
+
# Save debug images
|
| 1263 |
+
try:
|
| 1264 |
+
sf_img = _flow_to_image_3d(scene_flow)
|
| 1265 |
+
PIL.Image.fromarray(sf_img).save(os.path.join(sf_dir, f"{key}.png"))
|
| 1266 |
+
af_img = _flow_to_image_3d(delta_n)
|
| 1267 |
+
PIL.Image.fromarray(af_img).save(os.path.join(af_dir, f"{key}.png"))
|
| 1268 |
+
except Exception:
|
| 1269 |
+
pass
|
| 1270 |
+
|
| 1271 |
+
sf_count += 1
|
| 1272 |
+
if sf_count <= 4:
|
| 1273 |
+
mag = np.linalg.norm(scene_flow, axis=-1)
|
| 1274 |
+
print(f" [{key}] scene flow: mean={mag.mean():.6f}, max={mag.max():.6f}")
|
| 1275 |
+
|
| 1276 |
+
sf_npz_path = os.path.join(target_dir, "scene_flow.npz")
|
| 1277 |
+
af_npz_path = os.path.join(target_dir, "angular_flow.npz")
|
| 1278 |
+
np.savez_compressed(sf_npz_path, **sf_npz_dict)
|
| 1279 |
+
np.savez_compressed(af_npz_path, **af_npz_dict)
|
| 1280 |
+
print(f"✓ Saved {sf_count} scene flow entries to {sf_npz_path}")
|
| 1281 |
+
print(f"✓ Saved {sf_count} angular flow entries (9ch) to {af_npz_path}")
|
| 1282 |
|
| 1283 |
# (Moved saving logic to the end of function to capture all viz variables)
|
| 1284 |
|
|
|
|
| 1397 |
|
| 1398 |
|
| 1399 |
|
| 1400 |
+
# ================================================================
|
| 1401 |
+
# BUILD world_points_tracks in (TV, TV, H, W, 3) pairwise format
|
| 1402 |
+
# ================================================================
|
| 1403 |
+
# The trainer's _ensure_flow_targets expects:
|
| 1404 |
+
# tracks[frame_idx, ref_idx] where frame_idx = t * V + v
|
| 1405 |
+
# world_points_raw is (T_query, S_source, H, W, 3) — this IS the
|
| 1406 |
+
# pairwise DPM output with T_query = S_source = T * V.
|
| 1407 |
+
# We just need to save it at full resolution (no subsampling).
|
| 1408 |
+
TV = num_timesteps * num_views
|
| 1409 |
+
assert world_points_raw.shape[0] == TV and world_points_raw.shape[1] == TV, \
|
| 1410 |
+
f"Expected ({TV}, {TV}, H, W, 3) but got {world_points_raw.shape}"
|
| 1411 |
+
world_points_tracks_full = world_points_raw # (TV, TV, H, W, 3)
|
| 1412 |
+
|
| 1413 |
# Save Results for Download (Final Format)
|
| 1414 |
output_path = os.path.join(target_dir, "output_4d.npz")
|
| 1415 |
save_dict = {
|
| 1416 |
"world_points": world_points_s,
|
| 1417 |
"world_points_conf": world_points_conf_s,
|
| 1418 |
+
"world_points_tracks": world_points_tracks_full, # (TV, TV, H, W, 3) pairwise
|
| 1419 |
+
"world_points_conf_tracks": world_points_conf_tracks, # (S, T, H, W) for full_sample
|
| 1420 |
"images": img_np_viz,
|
| 1421 |
"images_raw": img_np[:, :, ::2, ::2], # Original images subsampled
|
| 1422 |
"num_views": num_views,
|
test.ipynb
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "code",
|
| 5 |
+
"execution_count": null,
|
| 6 |
+
"id": "bd12eb72",
|
| 7 |
+
"metadata": {},
|
| 8 |
+
"outputs": [
|
| 9 |
+
{
|
| 10 |
+
"name": "stdout",
|
| 11 |
+
"output_type": "stream",
|
| 12 |
+
"text": [
|
| 13 |
+
"allocated MB: 0.0\n",
|
| 14 |
+
"reserved MB: 0.0\n"
|
| 15 |
+
]
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"ename": "AttributeError",
|
| 19 |
+
"evalue": "module 'dpm.model' has no attribute 'parameters'",
|
| 20 |
+
"output_type": "error",
|
| 21 |
+
"traceback": [
|
| 22 |
+
"\u001b[31m---------------------------------------------------------------------------\u001b[39m",
|
| 23 |
+
"\u001b[31mAttributeError\u001b[39m Traceback (most recent call last)",
|
| 24 |
+
"\u001b[36mCell\u001b[39m\u001b[36m \u001b[39m\u001b[32mIn[8]\u001b[39m\u001b[32m, line 12\u001b[39m\n\u001b[32m 9\u001b[39m \u001b[38;5;28mprint\u001b[39m(\u001b[33m\"\u001b[39m\u001b[33mallocated MB:\u001b[39m\u001b[33m\"\u001b[39m, torch.cuda.memory_allocated()/\u001b[32m1024\u001b[39m**\u001b[32m2\u001b[39m)\n\u001b[32m 10\u001b[39m \u001b[38;5;28mprint\u001b[39m(\u001b[33m\"\u001b[39m\u001b[33mreserved MB:\u001b[39m\u001b[33m\"\u001b[39m, torch.cuda.memory_reserved()/\u001b[32m1024\u001b[39m**\u001b[32m2\u001b[39m)\n\u001b[32m---> \u001b[39m\u001b[32m12\u001b[39m params_bytes = \u001b[38;5;28msum\u001b[39m(p.numel()*p.element_size() \u001b[38;5;28;01mfor\u001b[39;00m p \u001b[38;5;129;01min\u001b[39;00m \u001b[43mmodel\u001b[49m\u001b[43m.\u001b[49m\u001b[43mparameters\u001b[49m())\n\u001b[32m 13\u001b[39m \u001b[38;5;28mprint\u001b[39m(\u001b[33m\"\u001b[39m\u001b[33mparams MB:\u001b[39m\u001b[33m\"\u001b[39m, params_bytes/\u001b[32m1024\u001b[39m**\u001b[32m2\u001b[39m)\n\u001b[32m 15\u001b[39m dtype_bytes = {}\n",
|
| 25 |
+
"\u001b[31mAttributeError\u001b[39m: module 'dpm.model' has no attribute 'parameters'"
|
| 26 |
+
]
|
| 27 |
+
}
|
| 28 |
+
],
|
| 29 |
+
"source": [
|
| 30 |
+
"import torch\n",
|
| 31 |
+
"# Load model using the project's loader (may download if missing)\n",
|
| 32 |
+
"from gradio_demo import load_cfg_from_cli, load_model\n",
|
| 33 |
+
"cfg = load_cfg_from_cli()\n",
|
| 34 |
+
"vdpm_model = load_model(cfg)\n",
|
| 35 |
+
"vdpm_model.eval()\n",
|
| 36 |
+
"\n",
|
| 37 |
+
"# Lightweight diagnostics: VRAM and dtype breakdown\n",
|
| 38 |
+
"import gc\n",
|
| 39 |
+
"from collections import Counter\n",
|
| 40 |
+
"gc.collect()\n",
|
| 41 |
+
"torch.cuda.synchronize()\n",
|
| 42 |
+
"torch.cuda.empty_cache()\n",
|
| 43 |
+
"torch.cuda.synchronize()\n",
|
| 44 |
+
"print('allocated MB:', torch.cuda.memory_allocated()/1024**2)\n",
|
| 45 |
+
"print('reserved MB:', torch.cuda.memory_reserved()/1024**2)\n",
|
| 46 |
+
"# Ensure we have an nn.Module instance (some imports may shadow the name 'model')\n",
|
| 47 |
+
"import types\n",
|
| 48 |
+
"if isinstance(vdpm_model, types.ModuleType):\n",
|
| 49 |
+
" print('Warning: loader returned a module, not an instance. Trying to instantiate via load_model again.')\n",
|
| 50 |
+
" vdpm_model = load_model(cfg)\n",
|
| 51 |
+
"assert hasattr(vdpm_model, 'parameters'), f'Loaded object has no parameters: {type(vdpm_model)}'\n",
|
| 52 |
+
"params_bytes = sum(p.numel()*p.element_size() for p in vdpm_model.parameters())\n",
|
| 53 |
+
"print('params MB:', params_bytes/1024**2)\n",
|
| 54 |
+
"dtype_bytes = {}\n",
|
| 55 |
+
"for p in vdpm_model.parameters():\n",
|
| 56 |
+
" k = str(p.dtype)\n",
|
| 57 |
+
" dtype_bytes[k] = dtype_bytes.get(k,0) + p.numel()*p.element_size()\n",
|
| 58 |
+
"print('param bytes by dtype (MB):', {k:v/1024**2 for k,v in dtype_bytes.items()})\n",
|
| 59 |
+
"print('buffer dtype counts:', Counter(getattr(b,'dtype',None) for b in vdpm_model.buffers()))\n",
|
| 60 |
+
"\n",
|
| 61 |
+
"# Small aggregator inspect (one small dummy batch)\n",
|
| 62 |
+
"B, S, H, W = 1, min(4, 1 if not torch.cuda.is_available() else 4), 518, 518\n",
|
| 63 |
+
"dummy = torch.rand(B, S, 3, H, W, device='cuda' if torch.cuda.is_available() else 'cpu')\n",
|
| 64 |
+
"agg, patch_start = vdpm_model.aggregator(dummy)\n",
|
| 65 |
+
"for k, t in sorted(agg.items()):\n",
|
| 66 |
+
" print(k, t.device, t.dtype, tuple(t.shape), f\"{t.numel()*t.element_size()/1024**2:.2f} MB\")\n",
|
| 67 |
+
"\n",
|
| 68 |
+
"# Warmup + one timed inference\n",
|
| 69 |
+
"import time\n",
|
| 70 |
+
"for _ in range(2):\n",
|
| 71 |
+
" _ = vdpm_model.inference([{'img': torch.rand(1,3,518,518, device='cuda' if torch.cuda.is_available() else 'cpu')}])\n",
|
| 72 |
+
"torch.cuda.synchronize()\n",
|
| 73 |
+
"t0 = time.time()\n",
|
| 74 |
+
"_ = vdpm_model.inference([{'img': torch.rand(1,3,518,518, device='cuda' if torch.cuda.is_available() else 'cpu')}])\n",
|
| 75 |
+
"torch.cuda.synchronize()\n",
|
| 76 |
+
"print('inference time (s):', time.time() - t0)"
|
| 77 |
+
]
|
| 78 |
+
}
|
| 79 |
+
],
|
| 80 |
+
"metadata": {
|
| 81 |
+
"kernelspec": {
|
| 82 |
+
"display_name": "4dgs-dpm",
|
| 83 |
+
"language": "python",
|
| 84 |
+
"name": "python3"
|
| 85 |
+
},
|
| 86 |
+
"language_info": {
|
| 87 |
+
"codemirror_mode": {
|
| 88 |
+
"name": "ipython",
|
| 89 |
+
"version": 3
|
| 90 |
+
},
|
| 91 |
+
"file_extension": ".py",
|
| 92 |
+
"mimetype": "text/x-python",
|
| 93 |
+
"name": "python",
|
| 94 |
+
"nbconvert_exporter": "python",
|
| 95 |
+
"pygments_lexer": "ipython3",
|
| 96 |
+
"version": "3.12.12"
|
| 97 |
+
}
|
| 98 |
+
},
|
| 99 |
+
"nbformat": 4,
|
| 100 |
+
"nbformat_minor": 5
|
| 101 |
+
}
|
vggt-low-vram/.gitattributes
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SCM syntax highlighting & preventing 3-way merges
|
| 2 |
+
pixi.lock merge=binary linguist-language=YAML linguist-generated=true
|
vggt-low-vram/.gitignore
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.hydra/
|
| 2 |
+
output/
|
| 3 |
+
ckpt/
|
| 4 |
+
.gradio/
|
| 5 |
+
input_images_*
|
| 6 |
+
examples/*/sparse/
|
| 7 |
+
examples/*/outputs
|
| 8 |
+
examples/*/transforms.json
|
| 9 |
+
examples/*/sparse_pc.ply
|
| 10 |
+
# Byte-compiled / optimized / DLL files
|
| 11 |
+
__pycache__/
|
| 12 |
+
**/__pycache__/
|
| 13 |
+
*.py[cod]
|
| 14 |
+
*$py.class
|
| 15 |
+
|
| 16 |
+
# C extensions
|
| 17 |
+
*.so
|
| 18 |
+
|
| 19 |
+
# Distribution / packaging
|
| 20 |
+
.Python
|
| 21 |
+
build/
|
| 22 |
+
develop-eggs/
|
| 23 |
+
dist/
|
| 24 |
+
downloads/
|
| 25 |
+
eggs/
|
| 26 |
+
.eggs/
|
| 27 |
+
lib/
|
| 28 |
+
lib64/
|
| 29 |
+
parts/
|
| 30 |
+
sdist/
|
| 31 |
+
var/
|
| 32 |
+
wheels/
|
| 33 |
+
pip-wheel-metadata/
|
| 34 |
+
share/python-wheels/
|
| 35 |
+
*.egg-info/
|
| 36 |
+
.installed.cfg
|
| 37 |
+
*.egg
|
| 38 |
+
MANIFEST
|
| 39 |
+
|
| 40 |
+
# PyInstaller
|
| 41 |
+
# Usually these files are written by a python script from a template
|
| 42 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 43 |
+
*.manifest
|
| 44 |
+
*.spec
|
| 45 |
+
|
| 46 |
+
# Installer logs
|
| 47 |
+
pip-log.txt
|
| 48 |
+
pip-delete-this-directory.txt
|
| 49 |
+
|
| 50 |
+
# Unit test / coverage reports
|
| 51 |
+
htmlcov/
|
| 52 |
+
.tox/
|
| 53 |
+
.nox/
|
| 54 |
+
.coverage
|
| 55 |
+
.coverage.*
|
| 56 |
+
.cache
|
| 57 |
+
nosetests.xml
|
| 58 |
+
coverage.xml
|
| 59 |
+
*.cover
|
| 60 |
+
*.py,cover
|
| 61 |
+
.hypothesis/
|
| 62 |
+
.pytest_cache/
|
| 63 |
+
cover/
|
| 64 |
+
|
| 65 |
+
# Translations
|
| 66 |
+
*.mo
|
| 67 |
+
*.pot
|
| 68 |
+
|
| 69 |
+
# Django stuff:
|
| 70 |
+
*.log
|
| 71 |
+
local_settings.py
|
| 72 |
+
db.sqlite3
|
| 73 |
+
db.sqlite3-journal
|
| 74 |
+
|
| 75 |
+
# Flask stuff:
|
| 76 |
+
instance/
|
| 77 |
+
.webassets-cache
|
| 78 |
+
|
| 79 |
+
# Scrapy stuff:
|
| 80 |
+
.scrapy
|
| 81 |
+
|
| 82 |
+
# Sphinx documentation
|
| 83 |
+
docs/_build/
|
| 84 |
+
|
| 85 |
+
# PyBuilder
|
| 86 |
+
target/
|
| 87 |
+
|
| 88 |
+
# Jupyter Notebook
|
| 89 |
+
.ipynb_checkpoints
|
| 90 |
+
|
| 91 |
+
# IPython
|
| 92 |
+
profile_default/
|
| 93 |
+
ipython_config.py
|
| 94 |
+
|
| 95 |
+
# pyenv
|
| 96 |
+
.python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
| 106 |
+
__pypackages__/
|
| 107 |
+
|
| 108 |
+
# Celery stuff
|
| 109 |
+
celerybeat-schedule
|
| 110 |
+
celerybeat.pid
|
| 111 |
+
|
| 112 |
+
# SageMath parsed files
|
| 113 |
+
*.sage.py
|
| 114 |
+
|
| 115 |
+
# Environments
|
| 116 |
+
.env
|
| 117 |
+
.venv
|
| 118 |
+
env/
|
| 119 |
+
venv/
|
| 120 |
+
ENV/
|
| 121 |
+
env.bak/
|
| 122 |
+
venv.bak/
|
| 123 |
+
|
| 124 |
+
# Spyder project settings
|
| 125 |
+
.spyderproject
|
| 126 |
+
.spyproject
|
| 127 |
+
|
| 128 |
+
# Rope project settings
|
| 129 |
+
.ropeproject
|
| 130 |
+
|
| 131 |
+
# mkdocs documentation
|
| 132 |
+
/site
|
| 133 |
+
|
| 134 |
+
# mypy
|
| 135 |
+
.mypy_cache/
|
| 136 |
+
.dmypy.json
|
| 137 |
+
dmypy.json
|
| 138 |
+
|
| 139 |
+
# Pyre type checker
|
| 140 |
+
.pyre/
|
| 141 |
+
|
| 142 |
+
# pytype static type analyzer
|
| 143 |
+
.pytype/
|
| 144 |
+
|
| 145 |
+
# Profiling data
|
| 146 |
+
.prof
|
| 147 |
+
|
| 148 |
+
# Folder specific to your needs
|
| 149 |
+
**/tmp/
|
| 150 |
+
**/outputs/skyseg.onnx
|
| 151 |
+
skyseg.onnx
|
| 152 |
+
|
| 153 |
+
# pixi environments
|
| 154 |
+
.pixi
|
| 155 |
+
*.egg-info
|
vggt-low-vram/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to make participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
* Using welcoming and inclusive language
|
| 18 |
+
* Being respectful of differing viewpoints and experiences
|
| 19 |
+
* Gracefully accepting constructive criticism
|
| 20 |
+
* Focusing on what is best for the community
|
| 21 |
+
* Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
* Public or private harassment
|
| 29 |
+
* Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies within all project spaces, and it also applies when
|
| 49 |
+
an individual is representing the project or its community in public spaces.
|
| 50 |
+
Examples of representing a project or community include using an official
|
| 51 |
+
project e-mail address, posting via an official social media account, or acting
|
| 52 |
+
as an appointed representative at an online or offline event. Representation of
|
| 53 |
+
a project may be further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
This Code of Conduct also applies outside the project spaces when there is a
|
| 56 |
+
reasonable belief that an individual's behavior may have a negative impact on
|
| 57 |
+
the project or its community.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported by contacting the project team at <opensource-conduct@meta.com>. All
|
| 63 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 64 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 65 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 66 |
+
Further details of specific enforcement policies may be posted separately.
|
| 67 |
+
|
| 68 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 69 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 70 |
+
members of the project's leadership.
|
| 71 |
+
|
| 72 |
+
## Attribution
|
| 73 |
+
|
| 74 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 75 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 76 |
+
|
| 77 |
+
[homepage]: https://www.contributor-covenant.org
|
| 78 |
+
|
| 79 |
+
For answers to common questions about this code of conduct, see
|
| 80 |
+
https://www.contributor-covenant.org/faq
|
vggt-low-vram/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to vggt
|
| 2 |
+
We want to make contributing to this project as easy and transparent as
|
| 3 |
+
possible.
|
| 4 |
+
|
| 5 |
+
## Pull Requests
|
| 6 |
+
We actively welcome your pull requests.
|
| 7 |
+
|
| 8 |
+
1. Fork the repo and create your branch from `main`.
|
| 9 |
+
2. If you've added code that should be tested, add tests.
|
| 10 |
+
3. If you've changed APIs, update the documentation.
|
| 11 |
+
4. Ensure the test suite passes.
|
| 12 |
+
5. Make sure your code lints.
|
| 13 |
+
6. If you haven't already, complete the Contributor License Agreement ("CLA").
|
| 14 |
+
|
| 15 |
+
## Contributor License Agreement ("CLA")
|
| 16 |
+
In order to accept your pull request, we need you to submit a CLA. You only need
|
| 17 |
+
to do this once to work on any of Facebook's open source projects.
|
| 18 |
+
|
| 19 |
+
Complete your CLA here: <https://code.facebook.com/cla>
|
| 20 |
+
|
| 21 |
+
## Issues
|
| 22 |
+
We use GitHub issues to track public bugs. Please ensure your description is
|
| 23 |
+
clear and has sufficient instructions to be able to reproduce the issue.
|
| 24 |
+
|
| 25 |
+
Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
|
| 26 |
+
disclosure of security bugs. In those cases, please go through the process
|
| 27 |
+
outlined on that page and do not file a public issue.
|
| 28 |
+
|
| 29 |
+
## License
|
| 30 |
+
By contributing to vggt, you agree that your contributions will be licensed
|
| 31 |
+
under the LICENSE file in the root directory of this source tree.
|
vggt-low-vram/LICENSE.txt
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
VGGT License
|
| 2 |
+
|
| 3 |
+
v1 Last Updated: July 29, 2025
|
| 4 |
+
|
| 5 |
+
“Acceptable Use Policy” means the Acceptable Use Policy, applicable to Research Materials, that is incorporated into this Agreement.
|
| 6 |
+
|
| 7 |
+
“Agreement” means the terms and conditions for use, reproduction, distribution and modification of the Research Materials set forth herein.
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
“Documentation” means the specifications, manuals and documentation accompanying
|
| 11 |
+
Research Materials distributed by Meta.
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
“Licensee” or “you” means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.
|
| 15 |
+
|
| 16 |
+
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
|
| 17 |
+
“Research Materials” means, collectively, Documentation and the models, software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code, demonstration materials and other elements of the foregoing distributed by Meta and made available under this Agreement.
|
| 18 |
+
|
| 19 |
+
By clicking “I Accept” below or by using or distributing any portion or element of the Research Materials, you agree to be bound by this Agreement.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
1. License Rights and Redistribution.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Research Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Research Materials.
|
| 26 |
+
|
| 27 |
+
b. Redistribution and Use.
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
i. Distribution of Research Materials, and any derivative works thereof, are subject to the terms of this Agreement. If you distribute or make the Research Materials, or any derivative works thereof, available to a third party, you may only do so under the terms of this Agreement. You shall also provide a copy of this Agreement to such third party.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
ii. If you submit for publication the results of research you perform on, using, or otherwise in connection with Research Materials, you must acknowledge the use of Research Materials in your publication.
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
iii. Your use of the Research Materials must comply with applicable laws and regulations (including Trade Control Laws) and adhere to the Acceptable Use Policy, which is hereby incorporated by reference into this Agreement.
|
| 37 |
+
2. User Support. Your use of the Research Materials is done at your own discretion; Meta does not process any information nor provide any service in relation to such use. Meta is under no obligation to provide any support services for the Research Materials. Any support provided is “as is”, “with all faults”, and without warranty of any kind.
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE RESEARCH MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE RESEARCH MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE RESEARCH MATERIALS AND ANY OUTPUT AND RESULTS.
|
| 41 |
+
|
| 42 |
+
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY DIRECT OR INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
|
| 43 |
+
|
| 44 |
+
5. Intellectual Property.
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
a. Subject to Meta’s ownership of Research Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Research Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.
|
| 48 |
+
|
| 49 |
+
b. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Research Materials, outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Research Materials.
|
| 50 |
+
|
| 51 |
+
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Research Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Research Materials. Sections 5, 6 and 9 shall survive the termination of this Agreement.
|
| 52 |
+
|
| 53 |
+
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement.
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
8. Modifications and Amendments. Meta may modify this Agreement from time to time; provided that they are similar in spirit to the current version of the Agreement, but may differ in detail to address new problems or concerns. All such changes will be effective immediately. Your continued use of the Research Materials after any modification to this Agreement constitutes your agreement to such modification. Except as provided in this Agreement, no modification or addition to any provision of this Agreement will be binding unless it is in writing and signed by an authorized representative of both you and Meta.
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
Acceptable Use Policy
|
| 60 |
+
|
| 61 |
+
Meta seeks to further understanding of new and existing research domains with the mission of advancing the state-of-the-art in artificial intelligence through open research for the benefit of all.
|
| 62 |
+
|
| 63 |
+
As part of this mission, Meta makes certain research materials available for use in accordance with this Agreement (including the Acceptable Use Policy). Meta is committed to promoting the safe and responsible use of such research materials.
|
| 64 |
+
|
| 65 |
+
Prohibited Uses
|
| 66 |
+
|
| 67 |
+
You agree you will not use, or allow others to use, Research Materials to:
|
| 68 |
+
|
| 69 |
+
Violate the law or others’ rights, including to:
|
| 70 |
+
Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
|
| 71 |
+
Violence or terrorism
|
| 72 |
+
Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
|
| 73 |
+
Human trafficking, exploitation, and sexual violence
|
| 74 |
+
The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
|
| 75 |
+
Sexual solicitation
|
| 76 |
+
Any other criminal activity
|
| 77 |
+
|
| 78 |
+
Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
|
| 79 |
+
|
| 80 |
+
Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
|
| 81 |
+
|
| 82 |
+
Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
|
| 83 |
+
|
| 84 |
+
Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
|
| 85 |
+
|
| 86 |
+
Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any technology using Research Materials
|
| 87 |
+
|
| 88 |
+
Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
|
| 89 |
+
|
| 90 |
+
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of research artifacts related to the following:
|
| 91 |
+
|
| 92 |
+
Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
|
| 93 |
+
|
| 94 |
+
Guns and illegal weapons (including weapon development)
|
| 95 |
+
|
| 96 |
+
Illegal drugs and regulated/controlled substances
|
| 97 |
+
Operation of critical infrastructure, transportation technologies, or heavy machinery
|
| 98 |
+
|
| 99 |
+
Self-harm or harm to others, including suicide, cutting, and eating disorders
|
| 100 |
+
Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
|
| 101 |
+
|
| 102 |
+
3. Intentionally deceive or mislead others, including use of Research Materials related to the following:
|
| 103 |
+
|
| 104 |
+
Generating, promoting, or furthering fraud or the creation or promotion of disinformation
|
| 105 |
+
Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
|
| 106 |
+
|
| 107 |
+
Generating, promoting, or further distributing spam
|
| 108 |
+
|
| 109 |
+
Impersonating another individual without consent, authorization, or legal right
|
| 110 |
+
|
| 111 |
+
Representing that outputs of research materials or outputs from technology using Research Materials are human-generated
|
| 112 |
+
|
| 113 |
+
Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
|
| 114 |
+
|
| 115 |
+
4. Fail to appropriately disclose to end users any known dangers of your Research Materials.
|
vggt-low-vram/README.md
ADDED
|
@@ -0,0 +1,398 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Low-VRAM VGGT Inference
|
| 2 |
+
|
| 3 |
+
End-to-end 3D reconstruction model [VGGT](https://github.com/facebookresearch/vggt) optimized for VRAM usage. This fork is for **inference only**.
|
| 4 |
+
|
| 5 |
+
This optimized version uses **6 times less VRAM** than original without significant slow down. We have successfully run reconstruction for **150 images** with 8GB VRAM, or **1100 images** with 32GB VRAM.
|
| 6 |
+
|
| 7 |
+
## Main optimizations
|
| 8 |
+
- Original model's aggregator stores intermediate outputs of all 24 attention blocks, but only 4 of them is used by prediction heads. Made it return only that 4.
|
| 9 |
+
- `torch.cuda.amp.autocast` doesn't seem to be smart. A lot of large tensors are still stored in FP32. Do mixed precision manually instead.
|
| 10 |
+
- For a lot of modules, `self.training` is True even with `torch.no_grad()`. Removed all branches that involve `self.training` that potentially lead to overhead.
|
| 11 |
+
- `del` unused intermediate tensors to free memory for subsequent code
|
| 12 |
+
- `@torch.compile` some functions (e.g. MLP with GELU, LayerNorm)
|
| 13 |
+
- `torch.cuda.empty_cache()` when helpful
|
| 14 |
+
|
| 15 |
+
## Benchmark
|
| 16 |
+
|
| 17 |
+
Each benchmark runs a full forward through embedding, aggregator, and camera/depth/point heads. See `benchmark/` for code used for benchmark.
|
| 18 |
+
|
| 19 |
+
### Ours results ([commit](https://github.com/harry7557558/vggt-low-vram/commit/100f7b5813c35561a425b1dd32f9d8bef10063fb)):
|
| 20 |
+
|
| 21 |
+
| | example room (8) | example kitchen (25) | Mip-NeRF 360 stump (125) | Mip-NeRF 360 room (311) | Zip-NeRF nyc (990) | IMC-PT bdbg-gate (1363) | Zip-NeRF london (1874) |
|
| 22 |
+
| :------- | :------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: |
|
| 23 |
+
| VRAM | 3.27 GB | 3.50 GB | 5.83 GB | 10.97 GB | 25.37 GB | 58.03 GB | 45.92 GB |
|
| 24 |
+
| RTX 5070<br>laptop (8GB) | 1.97 s | 4.80 s | 48.47 s | - | - | - | - |
|
| 25 |
+
| RTX 4090<br>(24GB) | 2.65 s | 4.31 s | 16.49 s | 66.42 s | - | - | - |
|
| 26 |
+
| RTX 5090<br>(32GB) | 0.97 s | 1.61 s | 9.97 s | 44.06 s | 275.91 s | - | - |
|
| 27 |
+
| RTX A6000<br>(48GB) | 1.40 s | 3.47 s | 21.71 s | 103.45 s | 687.31 s | - | - |
|
| 28 |
+
| A100 SXM4<br>(80GB) | 2.88 s | 4.10 s | 15.36 s | 62.86 s | 376.65 s | 2163.30 s | 1326.58 s |
|
| 29 |
+
| H100 NVL<br>(94GB) | 1.10 s | 1.67 s | 8.52 s | 42.41 s | 288.55 s | 1733.15 s | 1052.18 s |
|
| 30 |
+
|
| 31 |
+
### Baseline results ([commit](https://github.com/facebookresearch/vggt/commit/8492456ce358ee9a4fe3274e36d73106b640fb5c)):
|
| 32 |
+
|
| 33 |
+
| | example room (8) | example kitchen (25) | Mip-NeRF 360 stump (125) | Mip-NeRF 360 room (311) | Zip-NeRF nyc (990) | IMC-PT bdbg-gate (1363) | Zip-NeRF london (1874) |
|
| 34 |
+
| :------- | :------: | :-------: | :-------: | :-------: | :-------: | :-------: | :-------: |
|
| 35 |
+
| VRAM | 9.72 GB | 12.34 GB | 31.52 GB | 68.95 GB | - | - | - |
|
| 36 |
+
| RTX 5070<br>laptop (8GB) | - | - | - | - | - | - | - |
|
| 37 |
+
| RTX 4090<br>(24GB) | 0.86 s | 1.80 s | - | - | - | - | - |
|
| 38 |
+
| RTX 5090<br>(32GB) | 0.57 s | 1.22 s | - | - | - | - | - |
|
| 39 |
+
| RTX A6000<br>(48GB) | 0.92 s | 2.22 s | 19.77 s | - | - | - | - |
|
| 40 |
+
| A100 SXM4<br>(80GB) | 1.09 s | 1.74 s | 11.39 s | 54.54 s | - | - | - |
|
| 41 |
+
| H100 NVL<br>(94GB) | 0.53 s | 1.00 s | 7.99 s | 41.15 s | - | - | - |
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
### Baseline vs. Ours<br/>
|
| 45 |
+
<!-- (time is ratio of total time of runs that are successful with both methods) -->
|
| 46 |
+
|
| 47 |
+
Ours use multiple times less VRAM. Ours is consistently slower, but time difference is less significant for larger datasets.
|
| 48 |
+
|
| 49 |
+
| # images | 8 | 25 | 125 | 311 |
|
| 50 |
+
| :------- | :------: | :-------: | :-------: | :-------: |
|
| 51 |
+
| VRAM | 3.0 x | 3.5 x | 5.4 x | 6.3 x |
|
| 52 |
+
| Time | 0.44 x | 0.53 x | 0.86 x | 0.91 x |
|
| 53 |
+
|
| 54 |
+
### Additional details
|
| 55 |
+
|
| 56 |
+
Hardware and platform:
|
| 57 |
+
- RTX 5070 is my local device (CUDA 12.8, PyTorch 2.7.1, Python 3.12, Ubuntu 24.04).
|
| 58 |
+
- Rest of GPUs are provided by https://cloud.vast.ai/ with "PyTorch (Vast)" image without further modification (CUDA 12.4/12.8, PyTorch 2.5.1/2.7.1, Python 3.10/3.12).
|
| 59 |
+
|
| 60 |
+
## To Use
|
| 61 |
+
|
| 62 |
+
This fork can be installed in the same way as the original VGGT (i.e. follow the original instruction but change the git clone link). It runs the same checkpoints.
|
| 63 |
+
|
| 64 |
+
`demo_gradio.py` and `demo_viser.py` should work as before. `demo_colmap.py` may also work, although not throughly tested.
|
| 65 |
+
|
| 66 |
+
See `benchmark/benchmark.py` for a full example. For basic usage:
|
| 67 |
+
|
| 68 |
+
```py
|
| 69 |
+
import torch
|
| 70 |
+
from vggt.models.vggt import VGGT
|
| 71 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 72 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 73 |
+
|
| 74 |
+
dtype = torch.bfloat16 # or torch.float16 or torch.float32
|
| 75 |
+
model = VGGT.from_pretrained("facebook/VGGT-1B").cuda().to(dtype)
|
| 76 |
+
images = load_and_preprocess_images(["...list of image paths"]).cuda().to(dtype)
|
| 77 |
+
with torch.no_grad():
|
| 78 |
+
predictions = model(images, verbose=True) # will compute in (mostly) dtype and output in FP32
|
| 79 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions['pose_enc'], images.shape[-2:])
|
| 80 |
+
```
|
| 81 |
+
|
| 82 |
+
Some notes:
|
| 83 |
+
|
| 84 |
+
- Model weights and input images must have the same dtype. Model inference will run computation and store intermediate results largely in `images.dtype`.
|
| 85 |
+
|
| 86 |
+
- Do not use `autocast`. This fork does mixed precision manually in the FP16/BF16 case, doing so can lead to some intermediate tensors being stored in FP32 and increase VRAM usage.
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
## Breaking Changes
|
| 90 |
+
- Precision loss caused by FP32 -> FP16/BF16
|
| 91 |
+
- You can always make it use FP32 and still enjoy significant VRAM reduction
|
| 92 |
+
- Notes in "To Use" section above
|
| 93 |
+
- Occasional compatibility issues introduced by `@torch.compile`
|
| 94 |
+
- Does not support training
|
| 95 |
+
|
| 96 |
+
### Not (yet) tested, feel free to issue/PR if you are experiencing problems:
|
| 97 |
+
- Point tracking
|
| 98 |
+
- Different OS/Python/PyTorch/CUDA versions from above Benchmark section
|
| 99 |
+
- Multi GPU, or running on CPU
|
| 100 |
+
|
| 101 |
+
<div><br/></div>
|
| 102 |
+
|
| 103 |
+
----
|
| 104 |
+
# ==== Original README below ====
|
| 105 |
+
|
| 106 |
+
<div><br/></div>
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
<div align="center">
|
| 110 |
+
<h1>VGGT: Visual Geometry Grounded Transformer</h1>
|
| 111 |
+
|
| 112 |
+
<a href="https://jytime.github.io/data/VGGT_CVPR25.pdf" target="_blank" rel="noopener noreferrer">
|
| 113 |
+
<img src="https://img.shields.io/badge/Paper-VGGT" alt="Paper PDF">
|
| 114 |
+
</a>
|
| 115 |
+
<a href="https://arxiv.org/abs/2503.11651"><img src="https://img.shields.io/badge/arXiv-2503.11651-b31b1b" alt="arXiv"></a>
|
| 116 |
+
<a href="https://vgg-t.github.io/"><img src="https://img.shields.io/badge/Project_Page-green" alt="Project Page"></a>
|
| 117 |
+
<a href='https://huggingface.co/spaces/facebook/vggt'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Demo-blue'></a>
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
**[Visual Geometry Group, University of Oxford](https://www.robots.ox.ac.uk/~vgg/)**; **[Meta AI](https://ai.facebook.com/research/)**
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
[Jianyuan Wang](https://jytime.github.io/), [Minghao Chen](https://silent-chen.github.io/), [Nikita Karaev](https://nikitakaraevv.github.io/), [Andrea Vedaldi](https://www.robots.ox.ac.uk/~vedaldi/), [Christian Rupprecht](https://chrirupp.github.io/), [David Novotny](https://d-novotny.github.io/)
|
| 124 |
+
</div>
|
| 125 |
+
|
| 126 |
+
```bibtex
|
| 127 |
+
@inproceedings{wang2025vggt,
|
| 128 |
+
title={VGGT: Visual Geometry Grounded Transformer},
|
| 129 |
+
author={Wang, Jianyuan and Chen, Minghao and Karaev, Nikita and Vedaldi, Andrea and Rupprecht, Christian and Novotny, David},
|
| 130 |
+
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
|
| 131 |
+
year={2025}
|
| 132 |
+
}
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
## Updates
|
| 136 |
+
|
| 137 |
+
- [July 29, 2025] We've updated the license for VGGT to permit **commercial use** (excluding military applications). All code in this repository is now under a commercial-use-friendly license. However, only the newly released checkpoint [**VGGT-1B-Commercial**](https://huggingface.co/facebook/VGGT-1B-Commercial) is licensed for commercial usage — the original checkpoint remains non-commercial. Full license details are available [here](https://github.com/facebookresearch/vggt/blob/main/LICENSE.txt). Access to the checkpoint requires completing an application form, which is processed by a system similar to LLaMA's approval workflow, automatically. The new checkpoint delivers similar performance to the original model. Please submit an issue if you notice a significant performance discrepancy.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
- [July 6, 2025] Training code is now available in the `training` folder, including an example to finetune VGGT on a custom dataset.
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
- [June 13, 2025] Honored to receive the Best Paper Award at CVPR 2025! Apologies if I’m slow to respond to queries or GitHub issues these days. If you’re interested, our oral presentation is available [here](https://docs.google.com/presentation/d/1JVuPnuZx6RgAy-U5Ezobg73XpBi7FrOh/edit?usp=sharing&ouid=107115712143490405606&rtpof=true&sd=true). Another long presentation can be found [here](https://docs.google.com/presentation/d/1aSv0e5PmH1mnwn2MowlJIajFUYZkjqgw/edit?usp=sharing&ouid=107115712143490405606&rtpof=true&sd=true) (Note: it’s shared in .pptx format with animations — quite large, but feel free to use it as a template if helpful.)
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
- [June 2, 2025] Added a script to run VGGT and save predictions in COLMAP format, with bundle adjustment support optional. The saved COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) or other NeRF/Gaussian splatting libraries.
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
- [May 3, 2025] Evaluation code for reproducing our camera pose estimation results on Co3D is now available in the [evaluation](https://github.com/facebookresearch/vggt/tree/evaluation) branch.
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
## Overview
|
| 154 |
+
|
| 155 |
+
Visual Geometry Grounded Transformer (VGGT, CVPR 2025) is a feed-forward neural network that directly infers all key 3D attributes of a scene, including extrinsic and intrinsic camera parameters, point maps, depth maps, and 3D point tracks, **from one, a few, or hundreds of its views, within seconds**.
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
## Quick Start
|
| 159 |
+
|
| 160 |
+
First, clone this repository to your local machine, and install the dependencies (torch, torchvision, numpy, Pillow, and huggingface_hub).
|
| 161 |
+
|
| 162 |
+
```bash
|
| 163 |
+
git clone git@github.com:facebookresearch/vggt.git
|
| 164 |
+
cd vggt
|
| 165 |
+
pip install -r requirements.txt
|
| 166 |
+
```
|
| 167 |
+
|
| 168 |
+
Alternatively, you can install VGGT as a package (<a href="docs/package.md">click here</a> for details).
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
Now, try the model with just a few lines of code:
|
| 172 |
+
|
| 173 |
+
```python
|
| 174 |
+
import torch
|
| 175 |
+
from vggt.models.vggt import VGGT
|
| 176 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 177 |
+
|
| 178 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 179 |
+
# bfloat16 is supported on Ampere GPUs (Compute Capability 8.0+)
|
| 180 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 181 |
+
|
| 182 |
+
# Initialize the model and load the pretrained weights.
|
| 183 |
+
# This will automatically download the model weights the first time it's run, which may take a while.
|
| 184 |
+
model = VGGT.from_pretrained("facebook/VGGT-1B").to(device)
|
| 185 |
+
|
| 186 |
+
# Load and preprocess example images (replace with your own image paths)
|
| 187 |
+
image_names = ["path/to/imageA.png", "path/to/imageB.png", "path/to/imageC.png"]
|
| 188 |
+
images = load_and_preprocess_images(image_names).to(device)
|
| 189 |
+
|
| 190 |
+
with torch.no_grad():
|
| 191 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 192 |
+
# Predict attributes including cameras, depth maps, and point maps.
|
| 193 |
+
predictions = model(images)
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
The model weights will be automatically downloaded from Hugging Face. If you encounter issues such as slow loading, you can manually download them [here](https://huggingface.co/facebook/VGGT-1B/blob/main/model.pt) and load, or:
|
| 197 |
+
|
| 198 |
+
```python
|
| 199 |
+
model = VGGT()
|
| 200 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 201 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
## Detailed Usage
|
| 205 |
+
|
| 206 |
+
<details>
|
| 207 |
+
<summary>Click to expand</summary>
|
| 208 |
+
|
| 209 |
+
You can also optionally choose which attributes (branches) to predict, as shown below. This achieves the same result as the example above. This example uses a batch size of 1 (processing a single scene), but it naturally works for multiple scenes.
|
| 210 |
+
|
| 211 |
+
```python
|
| 212 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 213 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 214 |
+
|
| 215 |
+
with torch.no_grad():
|
| 216 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 217 |
+
images = images[None] # add batch dimension
|
| 218 |
+
aggregated_tokens_list, ps_idx = model.aggregator(images)
|
| 219 |
+
|
| 220 |
+
# Predict Cameras
|
| 221 |
+
pose_enc = model.camera_head(aggregated_tokens_list)[-1]
|
| 222 |
+
# Extrinsic and intrinsic matrices, following OpenCV convention (camera from world)
|
| 223 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, images.shape[-2:])
|
| 224 |
+
|
| 225 |
+
# Predict Depth Maps
|
| 226 |
+
depth_map, depth_conf = model.depth_head(aggregated_tokens_list, images, ps_idx)
|
| 227 |
+
|
| 228 |
+
# Predict Point Maps
|
| 229 |
+
point_map, point_conf = model.point_head(aggregated_tokens_list, images, ps_idx)
|
| 230 |
+
|
| 231 |
+
# Construct 3D Points from Depth Maps and Cameras
|
| 232 |
+
# which usually leads to more accurate 3D points than point map branch
|
| 233 |
+
point_map_by_unprojection = unproject_depth_map_to_point_map(depth_map.squeeze(0),
|
| 234 |
+
extrinsic.squeeze(0),
|
| 235 |
+
intrinsic.squeeze(0))
|
| 236 |
+
|
| 237 |
+
# Predict Tracks
|
| 238 |
+
# choose your own points to track, with shape (N, 2) for one scene
|
| 239 |
+
query_points = torch.FloatTensor([[100.0, 200.0],
|
| 240 |
+
[60.72, 259.94]]).to(device)
|
| 241 |
+
track_list, vis_score, conf_score = model.track_head(aggregated_tokens_list, images, ps_idx, query_points=query_points[None])
|
| 242 |
+
```
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
Furthermore, if certain pixels in the input frames are unwanted (e.g., reflective surfaces, sky, or water), you can simply mask them by setting the corresponding pixel values to 0 or 1. Precise segmentation masks aren't necessary - simple bounding box masks work effectively (check this [issue](https://github.com/facebookresearch/vggt/issues/47) for an example).
|
| 246 |
+
|
| 247 |
+
</details>
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
## Interactive Demo
|
| 251 |
+
|
| 252 |
+
We provide multiple ways to visualize your 3D reconstructions. Before using these visualization tools, install the required dependencies:
|
| 253 |
+
|
| 254 |
+
```bash
|
| 255 |
+
pip install -r requirements_demo.txt
|
| 256 |
+
```
|
| 257 |
+
|
| 258 |
+
### Interactive 3D Visualization
|
| 259 |
+
|
| 260 |
+
**Please note:** VGGT typically reconstructs a scene in less than 1 second. However, visualizing 3D points may take tens of seconds due to third-party rendering, independent of VGGT's processing time. The visualization is slow especially when the number of images is large.
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
#### Gradio Web Interface
|
| 264 |
+
|
| 265 |
+
Our Gradio-based interface allows you to upload images/videos, run reconstruction, and interactively explore the 3D scene in your browser. You can launch this in your local machine or try it on [Hugging Face](https://huggingface.co/spaces/facebook/vggt).
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
```bash
|
| 269 |
+
python demo_gradio.py
|
| 270 |
+
```
|
| 271 |
+
|
| 272 |
+
<details>
|
| 273 |
+
<summary>Click to preview the Gradio interactive interface</summary>
|
| 274 |
+
|
| 275 |
+
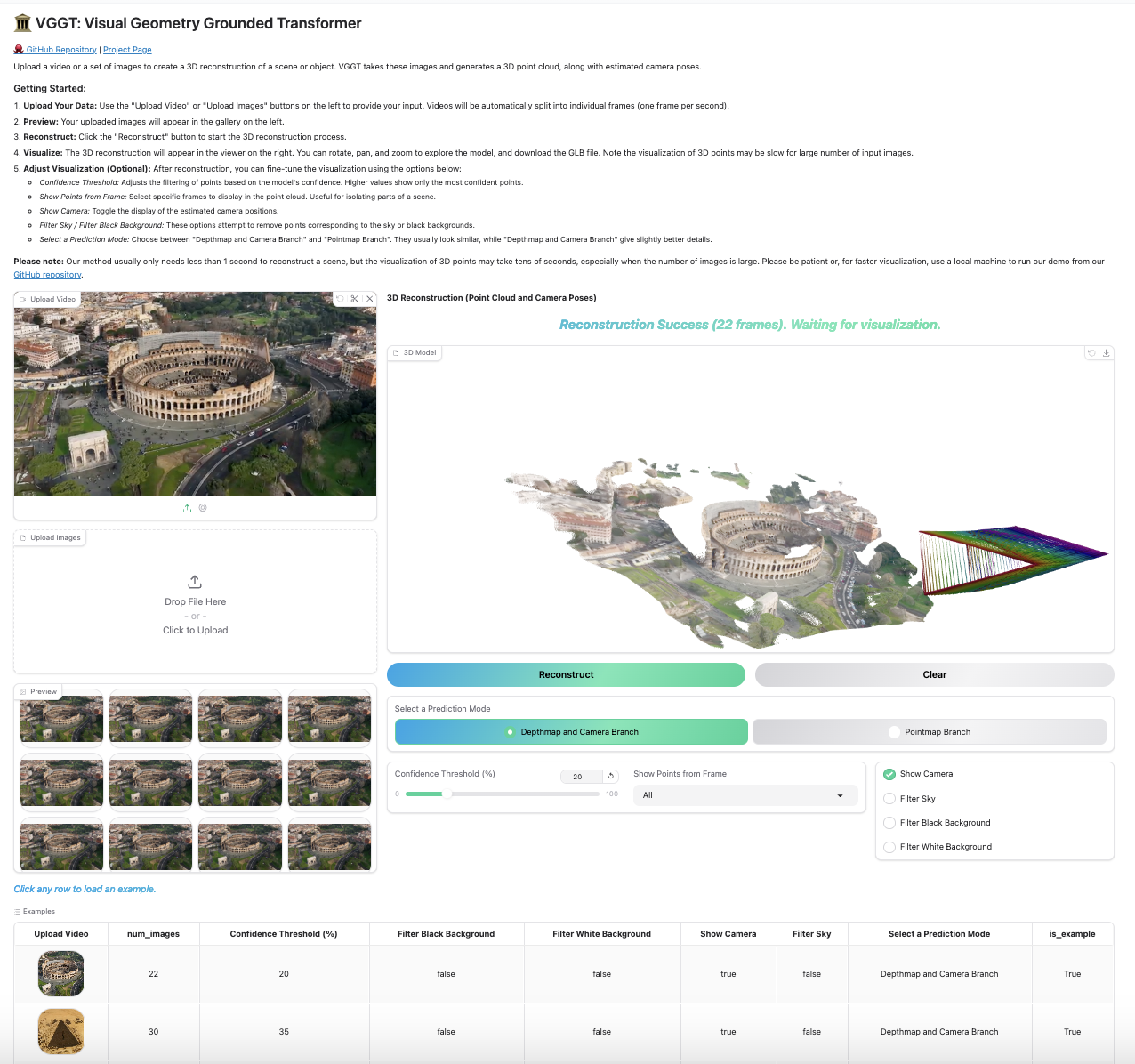
|
| 276 |
+
</details>
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
#### Viser 3D Viewer
|
| 280 |
+
|
| 281 |
+
Run the following command to run reconstruction and visualize the point clouds in viser. Note this script requires a path to a folder containing images. It assumes only image files under the folder. You can set `--use_point_map` to use the point cloud from the point map branch, instead of the depth-based point cloud.
|
| 282 |
+
|
| 283 |
+
```bash
|
| 284 |
+
python demo_viser.py --image_folder path/to/your/images/folder
|
| 285 |
+
```
|
| 286 |
+
|
| 287 |
+
## Exporting to COLMAP Format
|
| 288 |
+
|
| 289 |
+
We also support exporting VGGT's predictions directly to COLMAP format, by:
|
| 290 |
+
|
| 291 |
+
```bash
|
| 292 |
+
# Feedforward prediction only
|
| 293 |
+
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/
|
| 294 |
+
|
| 295 |
+
# With bundle adjustment
|
| 296 |
+
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --use_ba
|
| 297 |
+
|
| 298 |
+
# Run with bundle adjustment using reduced parameters for faster processing
|
| 299 |
+
# Reduces max_query_pts from 4096 (default) to 2048 and query_frame_num from 8 (default) to 5
|
| 300 |
+
# Trade-off: Faster execution but potentially less robust reconstruction in complex scenes (you may consider setting query_frame_num equal to your total number of images)
|
| 301 |
+
# See demo_colmap.py for additional bundle adjustment configuration options
|
| 302 |
+
python demo_colmap.py --scene_dir=/YOUR/SCENE_DIR/ --use_ba --max_query_pts=2048 --query_frame_num=5
|
| 303 |
+
```
|
| 304 |
+
|
| 305 |
+
Please ensure that the images are stored in `/YOUR/SCENE_DIR/images/`. This folder should contain only the images. Check the examples folder for the desired data structure.
|
| 306 |
+
|
| 307 |
+
The reconstruction result (camera parameters and 3D points) will be automatically saved under `/YOUR/SCENE_DIR/sparse/` in the COLMAP format, such as:
|
| 308 |
+
|
| 309 |
+
```
|
| 310 |
+
SCENE_DIR/
|
| 311 |
+
├── images/
|
| 312 |
+
└── sparse/
|
| 313 |
+
├── cameras.bin
|
| 314 |
+
├── images.bin
|
| 315 |
+
└── points3D.bin
|
| 316 |
+
```
|
| 317 |
+
|
| 318 |
+
## Integration with Gaussian Splatting
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
The exported COLMAP files can be directly used with [gsplat](https://github.com/nerfstudio-project/gsplat) for Gaussian Splatting training. Install `gsplat` following their official instructions (we recommend `gsplat==1.3.0`):
|
| 322 |
+
|
| 323 |
+
An example command to train the model is:
|
| 324 |
+
```
|
| 325 |
+
cd gsplat
|
| 326 |
+
python examples/simple_trainer.py default --data_factor 1 --data_dir /YOUR/SCENE_DIR/ --result_dir /YOUR/RESULT_DIR/
|
| 327 |
+
```
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
## Zero-shot Single-view Reconstruction
|
| 332 |
+
|
| 333 |
+
Our model shows surprisingly good performance on single-view reconstruction, although it was never trained for this task. The model does not need to duplicate the single-view image to a pair, instead, it can directly infer the 3D structure from the tokens of the single view image. Feel free to try it with our demos above, which naturally works for single-view reconstruction.
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
We did not quantitatively test monocular depth estimation performance ourselves, but [@kabouzeid](https://github.com/kabouzeid) generously provided a comparison of VGGT to recent methods [here](https://github.com/facebookresearch/vggt/issues/36). VGGT shows competitive or better results compared to state-of-the-art monocular approaches such as DepthAnything v2 or MoGe, despite never being explicitly trained for single-view tasks.
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
## Runtime and GPU Memory
|
| 341 |
+
|
| 342 |
+
We benchmark the runtime and GPU memory usage of VGGT's aggregator on a single NVIDIA H100 GPU across various input sizes.
|
| 343 |
+
|
| 344 |
+
| **Input Frames** | 1 | 2 | 4 | 8 | 10 | 20 | 50 | 100 | 200 |
|
| 345 |
+
|:----------------:|:-:|:-:|:-:|:-:|:--:|:--:|:--:|:---:|:---:|
|
| 346 |
+
| **Time (s)** | 0.04 | 0.05 | 0.07 | 0.11 | 0.14 | 0.31 | 1.04 | 3.12 | 8.75 |
|
| 347 |
+
| **Memory (GB)** | 1.88 | 2.07 | 2.45 | 3.23 | 3.63 | 5.58 | 11.41 | 21.15 | 40.63 |
|
| 348 |
+
|
| 349 |
+
Note that these results were obtained using Flash Attention 3, which is faster than the default Flash Attention 2 implementation while maintaining almost the same memory usage. Feel free to compile Flash Attention 3 from source to get better performance.
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
## Research Progression
|
| 353 |
+
|
| 354 |
+
Our work builds upon a series of previous research projects. If you're interested in understanding how our research evolved, check out our previous works:
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
<table border="0" cellspacing="0" cellpadding="0">
|
| 358 |
+
<tr>
|
| 359 |
+
<td align="left">
|
| 360 |
+
<a href="https://github.com/jytime/Deep-SfM-Revisited">Deep SfM Revisited</a>
|
| 361 |
+
</td>
|
| 362 |
+
<td style="white-space: pre;">──┐</td>
|
| 363 |
+
<td></td>
|
| 364 |
+
</tr>
|
| 365 |
+
<tr>
|
| 366 |
+
<td align="left">
|
| 367 |
+
<a href="https://github.com/facebookresearch/PoseDiffusion">PoseDiffusion</a>
|
| 368 |
+
</td>
|
| 369 |
+
<td style="white-space: pre;">─────►</td>
|
| 370 |
+
<td>
|
| 371 |
+
<a href="https://github.com/facebookresearch/vggsfm">VGGSfM</a> ──►
|
| 372 |
+
<a href="https://github.com/facebookresearch/vggt">VGGT</a>
|
| 373 |
+
</td>
|
| 374 |
+
</tr>
|
| 375 |
+
<tr>
|
| 376 |
+
<td align="left">
|
| 377 |
+
<a href="https://github.com/facebookresearch/co-tracker">CoTracker</a>
|
| 378 |
+
</td>
|
| 379 |
+
<td style="white-space: pre;">──┘</td>
|
| 380 |
+
<td></td>
|
| 381 |
+
</tr>
|
| 382 |
+
</table>
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
## Acknowledgements
|
| 386 |
+
|
| 387 |
+
Thanks to these great repositories: [PoseDiffusion](https://github.com/facebookresearch/PoseDiffusion), [VGGSfM](https://github.com/facebookresearch/vggsfm), [CoTracker](https://github.com/facebookresearch/co-tracker), [DINOv2](https://github.com/facebookresearch/dinov2), [Dust3r](https://github.com/naver/dust3r), [Moge](https://github.com/microsoft/moge), [PyTorch3D](https://github.com/facebookresearch/pytorch3d), [Sky Segmentation](https://github.com/xiongzhu666/Sky-Segmentation-and-Post-processing), [Depth Anything V2](https://github.com/DepthAnything/Depth-Anything-V2), [Metric3D](https://github.com/YvanYin/Metric3D) and many other inspiring works in the community.
|
| 388 |
+
|
| 389 |
+
## Checklist
|
| 390 |
+
|
| 391 |
+
- [x] Release the training code
|
| 392 |
+
- [ ] Release VGGT-500M and VGGT-200M
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
## License
|
| 396 |
+
See the [LICENSE](./LICENSE.txt) file for details about the license under which this code is made available.
|
| 397 |
+
|
| 398 |
+
Please note that only this [model checkpoint](https://huggingface.co/facebook/VGGT-1B-Commercial) allows commercial usage. This new checkpoint achieves the same performance level (might be slightly better) as the original one, e.g., AUC@30: 90.37 vs. 89.98 on the Co3D dataset.
|
vggt-low-vram/benchmark/benchmark.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from vggt.models.vggt import VGGT
|
| 3 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 4 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 5 |
+
from time import perf_counter
|
| 6 |
+
import os
|
| 7 |
+
from typing import List
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def main(image_list: List[str], plot: bool):
|
| 11 |
+
device = "cuda"
|
| 12 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 13 |
+
# dtype = torch.float32
|
| 14 |
+
|
| 15 |
+
print("Loading model")
|
| 16 |
+
model = VGGT.from_pretrained("facebook/VGGT-1B").to(device).to(dtype)
|
| 17 |
+
|
| 18 |
+
print(f"Loading {len(image_list)} images")
|
| 19 |
+
images = load_and_preprocess_images(image_list).to(device).to(dtype)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
torch.cuda.synchronize()
|
| 23 |
+
mem = torch.cuda.memory_allocated() / (1024**3)
|
| 24 |
+
print(f"Current VRAM usage (model weights + images): {mem:.2f} GiB")
|
| 25 |
+
|
| 26 |
+
torch.cuda.reset_peak_memory_stats()
|
| 27 |
+
time0 = perf_counter()
|
| 28 |
+
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
predictions = model(images, verbose=True)
|
| 31 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions['pose_enc'], images.shape[-2:])
|
| 32 |
+
|
| 33 |
+
torch.cuda.synchronize()
|
| 34 |
+
mem = torch.cuda.max_memory_allocated() / (1024**3)
|
| 35 |
+
print(f"Peak inference VRAM (including model/images): {mem:.2f} GiB")
|
| 36 |
+
dt = perf_counter() - time0
|
| 37 |
+
print(f"Inference time: {dt:.2f} s")
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
if not plot:
|
| 41 |
+
return
|
| 42 |
+
|
| 43 |
+
from plot_recon import plot_recon
|
| 44 |
+
|
| 45 |
+
plot_recon(
|
| 46 |
+
extrinsic.float().cpu().numpy()[0],
|
| 47 |
+
intrinsic.float().cpu().numpy()[0],
|
| 48 |
+
predictions["world_points"].float().cpu().numpy()[0],
|
| 49 |
+
images.float().cpu().numpy(),
|
| 50 |
+
frustum_size=0.05,
|
| 51 |
+
point_subsample=5000
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
if __name__ == "__main__":
|
| 56 |
+
import argparse
|
| 57 |
+
parser = argparse.ArgumentParser()
|
| 58 |
+
parser.add_argument("--image_dir", type=str, required=True)
|
| 59 |
+
parser.add_argument("--plot", action="store_true")
|
| 60 |
+
args = parser.parse_args()
|
| 61 |
+
|
| 62 |
+
images = [os.path.join(args.image_dir, f) for f in sorted(os.listdir(args.image_dir))]
|
| 63 |
+
main(images, args.plot)
|
| 64 |
+
|
vggt-low-vram/benchmark/benchmark_baseline.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from vggt.models.vggt import VGGT
|
| 3 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 4 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 5 |
+
from time import perf_counter
|
| 6 |
+
import os
|
| 7 |
+
from typing import List
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def main(image_list: List[str], plot: bool):
|
| 11 |
+
device = "cuda"
|
| 12 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 13 |
+
# dtype = torch.float32
|
| 14 |
+
|
| 15 |
+
print("Loading model")
|
| 16 |
+
model = VGGT.from_pretrained("facebook/VGGT-1B").to(device)
|
| 17 |
+
|
| 18 |
+
print(f"Loading {len(image_list)} images")
|
| 19 |
+
images = load_and_preprocess_images(image_list).to(device)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
torch.cuda.synchronize()
|
| 23 |
+
mem = torch.cuda.memory_allocated() / (1024**3)
|
| 24 |
+
print(f"Current VRAM usage (model weights + images): {mem:.2f} GiB")
|
| 25 |
+
|
| 26 |
+
torch.cuda.reset_peak_memory_stats()
|
| 27 |
+
time0 = perf_counter()
|
| 28 |
+
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
with torch.cuda.amp.autocast(dtype=dtype):
|
| 31 |
+
predictions = model(images)
|
| 32 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions['pose_enc'], images.shape[-2:])
|
| 33 |
+
|
| 34 |
+
torch.cuda.synchronize()
|
| 35 |
+
mem = torch.cuda.max_memory_allocated() / (1024**3)
|
| 36 |
+
print(f"Peak inference VRAM (including model/images): {mem:.2f} GiB")
|
| 37 |
+
dt = perf_counter() - time0
|
| 38 |
+
print(f"Inference time: {dt:.2f} s")
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
if not plot:
|
| 42 |
+
return
|
| 43 |
+
|
| 44 |
+
from plot_recon import plot_recon
|
| 45 |
+
|
| 46 |
+
plot_recon(
|
| 47 |
+
extrinsic.float().cpu().numpy()[0],
|
| 48 |
+
intrinsic.float().cpu().numpy()[0],
|
| 49 |
+
predictions["world_points"].float().cpu().numpy()[0],
|
| 50 |
+
images.float().cpu().numpy(),
|
| 51 |
+
frustum_size=0.05,
|
| 52 |
+
point_subsample=5000
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
if __name__ == "__main__":
|
| 57 |
+
import argparse
|
| 58 |
+
parser = argparse.ArgumentParser()
|
| 59 |
+
parser.add_argument("--image_dir", type=str, required=True)
|
| 60 |
+
parser.add_argument("--plot", action="store_true")
|
| 61 |
+
args = parser.parse_args()
|
| 62 |
+
|
| 63 |
+
images = [os.path.join(args.image_dir, f) for f in sorted(os.listdir(args.image_dir))]
|
| 64 |
+
main(images, args.plot)
|
| 65 |
+
|
vggt-low-vram/benchmark/plot_recon.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# thanks Claude
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
from mpl_toolkits.mplot3d import Axes3D
|
| 6 |
+
from mpl_toolkits.mplot3d.art3d import Poly3DCollection
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def plot_recon(camera_poses, camera_matrices, world_points, rgb_images,
|
| 10 |
+
frustum_size=1.0, point_subsample=1000, camera_colors=None,
|
| 11 |
+
figsize=(12, 10), show_plot=True):
|
| 12 |
+
"""
|
| 13 |
+
Plot 3D reconstruction results with camera frustums and point cloud.
|
| 14 |
+
|
| 15 |
+
Parameters:
|
| 16 |
+
-----------
|
| 17 |
+
camera_poses : np.ndarray, shape (N, 3, 4)
|
| 18 |
+
Camera poses in world coordinates [R|t] format
|
| 19 |
+
camera_matrices : np.ndarray, shape (N, 3, 3)
|
| 20 |
+
Camera intrinsic matrices K in OpenCV convention
|
| 21 |
+
world_points : np.ndarray, shape (N, H, W, 3)
|
| 22 |
+
Dense world-space points for each camera view
|
| 23 |
+
rgb_images : np.ndarray, shape (N, 3, H, W) or (N, H, W, 3)
|
| 24 |
+
Input RGB images corresponding to each camera
|
| 25 |
+
frustum_size : float, default=1.0
|
| 26 |
+
Size scaling factor for camera frustums
|
| 27 |
+
point_subsample : int, default=1000
|
| 28 |
+
Number of points to subsample from point cloud for visualization
|
| 29 |
+
camera_colors : list or None
|
| 30 |
+
Colors for each camera frustum. If None, uses default colormap
|
| 31 |
+
figsize : tuple, default=(12, 10)
|
| 32 |
+
Figure size for the plot
|
| 33 |
+
show_plot : bool, default=True
|
| 34 |
+
Whether to display the plot
|
| 35 |
+
|
| 36 |
+
Returns:
|
| 37 |
+
--------
|
| 38 |
+
fig : matplotlib.figure.Figure
|
| 39 |
+
The created figure object
|
| 40 |
+
ax : matplotlib.axes._subplots.Axes3DSubplot
|
| 41 |
+
The 3D axes object
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
# Handle different RGB image formats
|
| 45 |
+
if rgb_images.shape[1] == 3: # (N, 3, H, W) format
|
| 46 |
+
rgb_images = rgb_images.transpose(0, 2, 3, 1) # Convert to (N, H, W, 3)
|
| 47 |
+
|
| 48 |
+
N, H, W = world_points.shape[:3]
|
| 49 |
+
|
| 50 |
+
# Create figure and 3D axis
|
| 51 |
+
fig = plt.figure(figsize=figsize)
|
| 52 |
+
ax = fig.add_subplot(111, projection='3d')
|
| 53 |
+
|
| 54 |
+
# Extract and plot point cloud
|
| 55 |
+
valid_points = []
|
| 56 |
+
colors = []
|
| 57 |
+
|
| 58 |
+
for i in range(N):
|
| 59 |
+
# Get valid points (assuming invalid points have all zeros or very large values)
|
| 60 |
+
points_3d = world_points[i].reshape(-1, 3)
|
| 61 |
+
rgb_vals = rgb_images[i].reshape(-1, 3)
|
| 62 |
+
|
| 63 |
+
# Filter out invalid points (you may need to adjust this condition)
|
| 64 |
+
valid_mask = np.all(np.abs(points_3d) < 1000, axis=1) & np.any(points_3d != 0, axis=1)
|
| 65 |
+
|
| 66 |
+
if np.sum(valid_mask) > 0:
|
| 67 |
+
valid_points.append(points_3d[valid_mask])
|
| 68 |
+
colors.append(rgb_vals[valid_mask])
|
| 69 |
+
|
| 70 |
+
if valid_points:
|
| 71 |
+
all_points = np.vstack(valid_points)
|
| 72 |
+
all_colors = np.vstack(colors)
|
| 73 |
+
|
| 74 |
+
# Subsample points for visualization
|
| 75 |
+
if len(all_points) > point_subsample:
|
| 76 |
+
indices = np.random.choice(len(all_points), point_subsample, replace=False)
|
| 77 |
+
all_points = all_points[indices]
|
| 78 |
+
all_colors = all_colors[indices]
|
| 79 |
+
|
| 80 |
+
# Normalize colors to [0, 1] if needed
|
| 81 |
+
if all_colors.max() > 1.0:
|
| 82 |
+
all_colors = all_colors / 255.0
|
| 83 |
+
|
| 84 |
+
# Plot point cloud
|
| 85 |
+
ax.scatter(all_points[:, 0], all_points[:, 1], all_points[:, 2],
|
| 86 |
+
c=all_colors, s=1, alpha=0.6)
|
| 87 |
+
|
| 88 |
+
# Set up camera colors
|
| 89 |
+
if camera_colors is None:
|
| 90 |
+
cmap = plt.cm.tab10
|
| 91 |
+
camera_colors = [cmap(i % 10) for i in range(N)]
|
| 92 |
+
|
| 93 |
+
# Plot camera frustums
|
| 94 |
+
for i in range(N):
|
| 95 |
+
pose = camera_poses[i] # (3, 4) matrix [R|t]
|
| 96 |
+
K = camera_matrices[i] # (3, 3) intrinsic matrix
|
| 97 |
+
|
| 98 |
+
# Extract rotation and translation
|
| 99 |
+
R = pose[:, :3] # (3, 3) rotation matrix
|
| 100 |
+
t = pose[:, 3] # (3,) translation vector
|
| 101 |
+
|
| 102 |
+
# Camera center in world coordinates
|
| 103 |
+
camera_center = -R.T @ t
|
| 104 |
+
|
| 105 |
+
# Define image corners in pixel coordinates
|
| 106 |
+
corners_2d = np.array([
|
| 107 |
+
[0, 0, 1],
|
| 108 |
+
[W-1, 0, 1],
|
| 109 |
+
[W-1, H-1, 1],
|
| 110 |
+
[0, H-1, 1]
|
| 111 |
+
]).T # (3, 4)
|
| 112 |
+
|
| 113 |
+
# Backproject to normalized camera coordinates
|
| 114 |
+
K_inv = np.linalg.inv(K)
|
| 115 |
+
corners_normalized = K_inv @ corners_2d # (3, 4)
|
| 116 |
+
|
| 117 |
+
# Scale by frustum size and transform to world coordinates
|
| 118 |
+
corners_cam = corners_normalized * frustum_size
|
| 119 |
+
corners_world = R.T @ corners_cam + camera_center[:, np.newaxis]
|
| 120 |
+
|
| 121 |
+
# Create frustum vertices
|
| 122 |
+
frustum_vertices = np.concatenate([
|
| 123 |
+
camera_center.reshape(1, 3),
|
| 124 |
+
corners_world.T
|
| 125 |
+
], 0) # (5, 3) - camera center + 4 corners
|
| 126 |
+
|
| 127 |
+
# Define frustum faces (triangular faces forming the pyramid)
|
| 128 |
+
faces = [
|
| 129 |
+
[0, 1, 2], # Camera center to corner 0-1
|
| 130 |
+
[0, 2, 3], # Camera center to corner 1-2
|
| 131 |
+
[0, 3, 4], # Camera center to corner 2-3
|
| 132 |
+
[0, 4, 1], # Camera center to corner 3-0
|
| 133 |
+
[1, 2, 3, 4] # Far plane (rectangle)
|
| 134 |
+
]
|
| 135 |
+
|
| 136 |
+
# Create and add frustum faces
|
| 137 |
+
frustum_collection = []
|
| 138 |
+
for face in faces[:-1]: # Triangular faces
|
| 139 |
+
triangle = frustum_vertices[face]
|
| 140 |
+
frustum_collection.append(triangle)
|
| 141 |
+
|
| 142 |
+
# Add rectangular far plane
|
| 143 |
+
rectangle = frustum_vertices[faces[-1]]
|
| 144 |
+
frustum_collection.append(rectangle)
|
| 145 |
+
|
| 146 |
+
# Add frustum to plot
|
| 147 |
+
poly3d = Poly3DCollection(frustum_collection,
|
| 148 |
+
facecolors=camera_colors[i],
|
| 149 |
+
alpha=0.3,
|
| 150 |
+
edgecolors='black',
|
| 151 |
+
linewidths=0.5)
|
| 152 |
+
ax.add_collection3d(poly3d)
|
| 153 |
+
|
| 154 |
+
# Plot camera center
|
| 155 |
+
# ax.scatter(camera_center[0], camera_center[1], camera_center[2],
|
| 156 |
+
# c=[camera_colors[i]], s=50, marker='o')
|
| 157 |
+
|
| 158 |
+
# Add camera label
|
| 159 |
+
ax.text(camera_center[0], camera_center[1], camera_center[2],
|
| 160 |
+
f' {i}', fontsize=8)
|
| 161 |
+
|
| 162 |
+
# Set axis properties
|
| 163 |
+
ax.set_xlabel('X')
|
| 164 |
+
ax.set_ylabel('Y')
|
| 165 |
+
ax.set_zlabel('Z')
|
| 166 |
+
ax.set_title(f'3D Reconstruction')
|
| 167 |
+
|
| 168 |
+
# Set equal aspect ratio
|
| 169 |
+
if valid_points:
|
| 170 |
+
max_range = np.max(all_points.max(axis=0) - all_points.min(axis=0)) / 2.0
|
| 171 |
+
mid_x = (all_points[:, 0].max() + all_points[:, 0].min()) * 0.5
|
| 172 |
+
mid_y = (all_points[:, 1].max() + all_points[:, 1].min()) * 0.5
|
| 173 |
+
mid_z = (all_points[:, 2].max() + all_points[:, 2].min()) * 0.5
|
| 174 |
+
|
| 175 |
+
ax.set_xlim(mid_x - max_range, mid_x + max_range)
|
| 176 |
+
ax.set_ylim(mid_y - max_range, mid_y + max_range)
|
| 177 |
+
ax.set_zlim(mid_z - max_range, mid_z + max_range)
|
| 178 |
+
|
| 179 |
+
# Show plot if requested
|
| 180 |
+
if show_plot:
|
| 181 |
+
plt.show()
|
| 182 |
+
|
| 183 |
+
return fig, ax
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
# Example usage function
|
| 187 |
+
def example_usage():
|
| 188 |
+
"""
|
| 189 |
+
Example of how to use the plot_3d_reconstruction function.
|
| 190 |
+
"""
|
| 191 |
+
# Create synthetic data for demonstration
|
| 192 |
+
N = 5 # Number of cameras
|
| 193 |
+
H, W = 480, 640 # Image dimensions
|
| 194 |
+
|
| 195 |
+
# Synthetic camera poses (circular arrangement)
|
| 196 |
+
camera_poses = []
|
| 197 |
+
for i in range(N):
|
| 198 |
+
angle = 2 * np.pi * i / N
|
| 199 |
+
|
| 200 |
+
# Rotation matrix (looking towards center)
|
| 201 |
+
R = np.array([
|
| 202 |
+
[np.cos(angle), 0, np.sin(angle)],
|
| 203 |
+
[0, 1, 0],
|
| 204 |
+
[-np.sin(angle), 0, np.cos(angle)]
|
| 205 |
+
])
|
| 206 |
+
|
| 207 |
+
# Translation (positioned in circle)
|
| 208 |
+
t = np.array([3 * np.cos(angle), 0, 3 * np.sin(angle)])
|
| 209 |
+
|
| 210 |
+
pose = np.column_stack([R, t])
|
| 211 |
+
camera_poses.append(pose)
|
| 212 |
+
|
| 213 |
+
camera_poses = np.array(camera_poses)
|
| 214 |
+
|
| 215 |
+
# Synthetic camera matrices
|
| 216 |
+
focal_length = 500
|
| 217 |
+
cx, cy = W // 2, H // 2
|
| 218 |
+
K = np.array([
|
| 219 |
+
[focal_length, 0, cx],
|
| 220 |
+
[0, focal_length, cy],
|
| 221 |
+
[0, 0, 1]
|
| 222 |
+
])
|
| 223 |
+
camera_matrices = np.tile(K[np.newaxis], (N, 1, 1))
|
| 224 |
+
|
| 225 |
+
# Synthetic world points (random point cloud)
|
| 226 |
+
world_points = np.random.randn(N, H, W, 3) * 2
|
| 227 |
+
|
| 228 |
+
# Synthetic RGB images
|
| 229 |
+
rgb_images = np.random.rand(N, H, W, 3)
|
| 230 |
+
|
| 231 |
+
# Plot the reconstruction
|
| 232 |
+
fig, ax = plot_3d_reconstruction(
|
| 233 |
+
camera_poses=camera_poses,
|
| 234 |
+
camera_matrices=camera_matrices,
|
| 235 |
+
world_points=world_points,
|
| 236 |
+
rgb_images=rgb_images,
|
| 237 |
+
frustum_size=0.5,
|
| 238 |
+
point_subsample=5000
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
return fig, ax
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
if __name__ == "__main__":
|
| 245 |
+
# Run example
|
| 246 |
+
example_usage()
|
| 247 |
+
|
vggt-low-vram/benchmark/run_benchmark.bash
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
datasets=(
|
| 4 |
+
# warmup runs
|
| 5 |
+
"./examples/single_cartoon/images" # warmup run
|
| 6 |
+
"./examples/room/images" # warmup run
|
| 7 |
+
"./examples/kitchen/images" # warmup run
|
| 8 |
+
|
| 9 |
+
# examples that comes with original repository
|
| 10 |
+
"./examples/single_cartoon/images" # 1 image
|
| 11 |
+
"./examples/room/images" # 8 images
|
| 12 |
+
"./examples/kitchen/images" # 25 images
|
| 13 |
+
|
| 14 |
+
# larger public benchmark datasets
|
| 15 |
+
"../vggt_low_vram_benchmark/360_v2_stump_images_4" # 125 images
|
| 16 |
+
"../vggt_low_vram_benchmark/tnt_family" # 152 images
|
| 17 |
+
"../vggt_low_vram_benchmark/360_v2_room_images_4" # 311 images
|
| 18 |
+
"../vggt_low_vram_benchmark/zipnerf_nyc_undistorted_images_2" # 990 images
|
| 19 |
+
"../vggt_low_vram_benchmark/imc_pt_brandenburg_gate" # 1363 images
|
| 20 |
+
"../vggt_low_vram_benchmark/zipnerf_london_undistorted_images_2" # 1874 images
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
for dataset in "${datasets[@]}"; do
|
| 24 |
+
echo "Running $dataset"
|
| 25 |
+
python benchmark/benchmark.py --image_dir $dataset #--plot
|
| 26 |
+
# python benchmark/benchmark_baseline.py --image_dir $dataset #--plot
|
| 27 |
+
echo ""
|
| 28 |
+
done
|
vggt-low-vram/demo_colmap.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import random
|
| 8 |
+
import numpy as np
|
| 9 |
+
import glob
|
| 10 |
+
import os
|
| 11 |
+
import copy
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn.functional as F
|
| 14 |
+
|
| 15 |
+
# Configure CUDA settings
|
| 16 |
+
torch.backends.cudnn.enabled = True
|
| 17 |
+
torch.backends.cudnn.benchmark = True
|
| 18 |
+
torch.backends.cudnn.deterministic = False
|
| 19 |
+
|
| 20 |
+
import argparse
|
| 21 |
+
from pathlib import Path
|
| 22 |
+
import trimesh
|
| 23 |
+
import pycolmap
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
from vggt.models.vggt import VGGT
|
| 27 |
+
from vggt.utils.load_fn import load_and_preprocess_images_square
|
| 28 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 29 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 30 |
+
from vggt.utils.helper import create_pixel_coordinate_grid, randomly_limit_trues
|
| 31 |
+
from vggt.dependency.track_predict import predict_tracks
|
| 32 |
+
from vggt.dependency.np_to_pycolmap import batch_np_matrix_to_pycolmap, batch_np_matrix_to_pycolmap_wo_track
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# TODO: add support for masks
|
| 36 |
+
# TODO: add iterative BA
|
| 37 |
+
# TODO: add support for radial distortion, which needs extra_params
|
| 38 |
+
# TODO: test with more cases
|
| 39 |
+
# TODO: test different camera types
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def parse_args():
|
| 43 |
+
parser = argparse.ArgumentParser(description="VGGT Demo")
|
| 44 |
+
parser.add_argument("--scene_dir", type=str, required=True, help="Directory containing the scene images")
|
| 45 |
+
parser.add_argument("--seed", type=int, default=42, help="Random seed for reproducibility")
|
| 46 |
+
parser.add_argument("--use_ba", action="store_true", default=False, help="Use BA for reconstruction")
|
| 47 |
+
######### BA parameters #########
|
| 48 |
+
parser.add_argument(
|
| 49 |
+
"--max_reproj_error", type=float, default=8.0, help="Maximum reprojection error for reconstruction"
|
| 50 |
+
)
|
| 51 |
+
parser.add_argument("--shared_camera", action="store_true", default=False, help="Use shared camera for all images")
|
| 52 |
+
parser.add_argument("--camera_type", type=str, default="SIMPLE_PINHOLE", help="Camera type for reconstruction")
|
| 53 |
+
parser.add_argument("--vis_thresh", type=float, default=0.2, help="Visibility threshold for tracks")
|
| 54 |
+
parser.add_argument("--query_frame_num", type=int, default=8, help="Number of frames to query")
|
| 55 |
+
parser.add_argument("--max_query_pts", type=int, default=4096, help="Maximum number of query points")
|
| 56 |
+
parser.add_argument(
|
| 57 |
+
"--fine_tracking", action="store_true", default=True, help="Use fine tracking (slower but more accurate)"
|
| 58 |
+
)
|
| 59 |
+
parser.add_argument(
|
| 60 |
+
"--conf_thres_value", type=float, default=5.0, help="Confidence threshold value for depth filtering (wo BA)"
|
| 61 |
+
)
|
| 62 |
+
return parser.parse_args()
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def run_VGGT(model, images, device, dtype, resolution=518):
|
| 66 |
+
# images: [B, 3, H, W]
|
| 67 |
+
|
| 68 |
+
assert len(images.shape) == 4
|
| 69 |
+
assert images.shape[1] == 3
|
| 70 |
+
|
| 71 |
+
# hard-coded to use 518 for VGGT
|
| 72 |
+
images = F.interpolate(images, size=(resolution, resolution), mode="bilinear", align_corners=False)
|
| 73 |
+
images = images.to(device, dtype)
|
| 74 |
+
|
| 75 |
+
with torch.no_grad():
|
| 76 |
+
images = images[None] # add batch dimension
|
| 77 |
+
aggregated_tokens_list, ps_idx = model.aggregator(images, verbose=True)
|
| 78 |
+
|
| 79 |
+
# Predict Cameras
|
| 80 |
+
pose_enc = model.camera_head(aggregated_tokens_list)[-1]
|
| 81 |
+
# Extrinsic and intrinsic matrices, following OpenCV convention (camera from world)
|
| 82 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(pose_enc, images.shape[-2:])
|
| 83 |
+
# Predict Depth Maps
|
| 84 |
+
depth_map, depth_conf = model.depth_head(aggregated_tokens_list, images, ps_idx)
|
| 85 |
+
|
| 86 |
+
extrinsic = extrinsic.squeeze(0).cpu().numpy()
|
| 87 |
+
intrinsic = intrinsic.squeeze(0).cpu().numpy()
|
| 88 |
+
depth_map = depth_map.squeeze(0).cpu().numpy()
|
| 89 |
+
depth_conf = depth_conf.squeeze(0).cpu().numpy()
|
| 90 |
+
return extrinsic, intrinsic, depth_map, depth_conf
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def demo_fn(args):
|
| 94 |
+
# Print configuration
|
| 95 |
+
print("Arguments:", vars(args))
|
| 96 |
+
|
| 97 |
+
# Set seed for reproducibility
|
| 98 |
+
np.random.seed(args.seed)
|
| 99 |
+
torch.manual_seed(args.seed)
|
| 100 |
+
random.seed(args.seed)
|
| 101 |
+
if torch.cuda.is_available():
|
| 102 |
+
torch.cuda.manual_seed(args.seed)
|
| 103 |
+
torch.cuda.manual_seed_all(args.seed) # for multi-GPU
|
| 104 |
+
print(f"Setting seed as: {args.seed}")
|
| 105 |
+
|
| 106 |
+
# Set device and dtype
|
| 107 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 108 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 109 |
+
print(f"Using device: {device}")
|
| 110 |
+
print(f"Using dtype: {dtype}")
|
| 111 |
+
|
| 112 |
+
# Run VGGT for camera and depth estimation
|
| 113 |
+
model = VGGT()
|
| 114 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 115 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 116 |
+
model.eval()
|
| 117 |
+
model = model.to(dtype=dtype, device=device)
|
| 118 |
+
print(f"Model loaded")
|
| 119 |
+
|
| 120 |
+
# Get image paths and preprocess them
|
| 121 |
+
image_dir = os.path.join(args.scene_dir, "images")
|
| 122 |
+
image_path_list = glob.glob(os.path.join(image_dir, "*"))
|
| 123 |
+
if len(image_path_list) == 0:
|
| 124 |
+
raise ValueError(f"No images found in {image_dir}")
|
| 125 |
+
base_image_path_list = [os.path.basename(path) for path in image_path_list]
|
| 126 |
+
|
| 127 |
+
# Load images and original coordinates
|
| 128 |
+
# Load Image in 1024, while running VGGT with 518
|
| 129 |
+
vggt_fixed_resolution = 518
|
| 130 |
+
img_load_resolution = 1024
|
| 131 |
+
|
| 132 |
+
images, original_coords = load_and_preprocess_images_square(image_path_list, img_load_resolution)
|
| 133 |
+
print(f"Loaded {len(images)} images from {image_dir}")
|
| 134 |
+
|
| 135 |
+
# Run VGGT to estimate camera and depth
|
| 136 |
+
# Run with 518x518 images
|
| 137 |
+
extrinsic, intrinsic, depth_map, depth_conf = run_VGGT(model, images, device, dtype, vggt_fixed_resolution)
|
| 138 |
+
points_3d = unproject_depth_map_to_point_map(depth_map, extrinsic, intrinsic)
|
| 139 |
+
# images = images.float()
|
| 140 |
+
|
| 141 |
+
del model # free memory
|
| 142 |
+
torch.cuda.empty_cache()
|
| 143 |
+
|
| 144 |
+
images = images.to(device, dtype)
|
| 145 |
+
original_coords = original_coords.to(device)
|
| 146 |
+
|
| 147 |
+
if args.use_ba:
|
| 148 |
+
image_size = np.array(images.shape[-2:])
|
| 149 |
+
scale = img_load_resolution / vggt_fixed_resolution
|
| 150 |
+
shared_camera = args.shared_camera
|
| 151 |
+
|
| 152 |
+
# TODO: use VGGT tracker
|
| 153 |
+
with torch.inference_mode():
|
| 154 |
+
# Predicting Tracks
|
| 155 |
+
# Using VGGSfM tracker instead of VGGT tracker for efficiency
|
| 156 |
+
# VGGT tracker requires multiple backbone runs to query different frames (this is a problem caused by the training process)
|
| 157 |
+
# Will be fixed in VGGT v2
|
| 158 |
+
|
| 159 |
+
# You can also change the pred_tracks to tracks from any other methods
|
| 160 |
+
# e.g., from COLMAP, from CoTracker, or by chaining 2D matches from Lightglue/LoFTR.
|
| 161 |
+
pred_tracks, pred_vis_scores, pred_confs, points_3d, points_rgb = predict_tracks(
|
| 162 |
+
images,
|
| 163 |
+
conf=depth_conf,
|
| 164 |
+
points_3d=points_3d,
|
| 165 |
+
masks=None,
|
| 166 |
+
max_query_pts=args.max_query_pts,
|
| 167 |
+
query_frame_num=args.query_frame_num,
|
| 168 |
+
keypoint_extractor="aliked+sp",
|
| 169 |
+
fine_tracking=args.fine_tracking,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
torch.cuda.empty_cache()
|
| 173 |
+
|
| 174 |
+
# rescale the intrinsic matrix from 518 to 1024
|
| 175 |
+
intrinsic[:, :2, :] *= scale
|
| 176 |
+
track_mask = pred_vis_scores > args.vis_thresh
|
| 177 |
+
|
| 178 |
+
# TODO: radial distortion, iterative BA, masks
|
| 179 |
+
reconstruction, valid_track_mask = batch_np_matrix_to_pycolmap(
|
| 180 |
+
points_3d,
|
| 181 |
+
extrinsic,
|
| 182 |
+
intrinsic,
|
| 183 |
+
pred_tracks,
|
| 184 |
+
image_size,
|
| 185 |
+
masks=track_mask,
|
| 186 |
+
max_reproj_error=args.max_reproj_error,
|
| 187 |
+
shared_camera=shared_camera,
|
| 188 |
+
camera_type=args.camera_type,
|
| 189 |
+
points_rgb=points_rgb,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
if reconstruction is None:
|
| 193 |
+
raise ValueError("No reconstruction can be built with BA")
|
| 194 |
+
|
| 195 |
+
# Bundle Adjustment
|
| 196 |
+
ba_options = pycolmap.BundleAdjustmentOptions()
|
| 197 |
+
pycolmap.bundle_adjustment(reconstruction, ba_options)
|
| 198 |
+
|
| 199 |
+
reconstruction_resolution = img_load_resolution
|
| 200 |
+
else:
|
| 201 |
+
conf_thres_value = args.conf_thres_value
|
| 202 |
+
max_points_for_colmap = 100000 # randomly sample 3D points
|
| 203 |
+
shared_camera = False # in the feedforward manner, we do not support shared camera
|
| 204 |
+
camera_type = "PINHOLE" # in the feedforward manner, we only support PINHOLE camera
|
| 205 |
+
|
| 206 |
+
image_size = np.array([vggt_fixed_resolution, vggt_fixed_resolution])
|
| 207 |
+
num_frames, height, width, _ = points_3d.shape
|
| 208 |
+
images = images.float()
|
| 209 |
+
|
| 210 |
+
points_rgb = F.interpolate(
|
| 211 |
+
images, size=(vggt_fixed_resolution, vggt_fixed_resolution), mode="bilinear", align_corners=False
|
| 212 |
+
)
|
| 213 |
+
points_rgb = (points_rgb.cpu().numpy() * 255).astype(np.uint8)
|
| 214 |
+
points_rgb = points_rgb.transpose(0, 2, 3, 1)
|
| 215 |
+
|
| 216 |
+
# (S, H, W, 3), with x, y coordinates and frame indices
|
| 217 |
+
points_xyf = create_pixel_coordinate_grid(num_frames, height, width)
|
| 218 |
+
|
| 219 |
+
conf_mask = depth_conf >= conf_thres_value
|
| 220 |
+
# at most writing 100000 3d points to colmap reconstruction object
|
| 221 |
+
conf_mask = randomly_limit_trues(conf_mask, max_points_for_colmap)
|
| 222 |
+
|
| 223 |
+
points_3d = points_3d[conf_mask]
|
| 224 |
+
points_xyf = points_xyf[conf_mask]
|
| 225 |
+
points_rgb = points_rgb[conf_mask]
|
| 226 |
+
|
| 227 |
+
print("Converting to COLMAP format")
|
| 228 |
+
reconstruction = batch_np_matrix_to_pycolmap_wo_track(
|
| 229 |
+
points_3d,
|
| 230 |
+
points_xyf,
|
| 231 |
+
points_rgb,
|
| 232 |
+
extrinsic,
|
| 233 |
+
intrinsic,
|
| 234 |
+
image_size,
|
| 235 |
+
shared_camera=shared_camera,
|
| 236 |
+
camera_type=camera_type,
|
| 237 |
+
)
|
| 238 |
+
|
| 239 |
+
reconstruction_resolution = vggt_fixed_resolution
|
| 240 |
+
|
| 241 |
+
reconstruction = rename_colmap_recons_and_rescale_camera(
|
| 242 |
+
reconstruction,
|
| 243 |
+
base_image_path_list,
|
| 244 |
+
original_coords.cpu().numpy(),
|
| 245 |
+
img_size=reconstruction_resolution,
|
| 246 |
+
shift_point2d_to_original_res=True,
|
| 247 |
+
shared_camera=shared_camera,
|
| 248 |
+
)
|
| 249 |
+
|
| 250 |
+
print(f"Saving reconstruction to {args.scene_dir}/sparse")
|
| 251 |
+
sparse_reconstruction_dir = os.path.join(args.scene_dir, "sparse")
|
| 252 |
+
os.makedirs(sparse_reconstruction_dir, exist_ok=True)
|
| 253 |
+
reconstruction.write(sparse_reconstruction_dir)
|
| 254 |
+
|
| 255 |
+
# Save point cloud for fast visualization
|
| 256 |
+
trimesh.PointCloud(points_3d, colors=points_rgb).export(os.path.join(args.scene_dir, "sparse/points.ply"))
|
| 257 |
+
|
| 258 |
+
return True
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def rename_colmap_recons_and_rescale_camera(
|
| 262 |
+
reconstruction, image_paths, original_coords, img_size, shift_point2d_to_original_res=False, shared_camera=False
|
| 263 |
+
):
|
| 264 |
+
rescale_camera = True
|
| 265 |
+
|
| 266 |
+
for pyimageid in reconstruction.images:
|
| 267 |
+
# Reshaped the padded&resized image to the original size
|
| 268 |
+
# Rename the images to the original names
|
| 269 |
+
pyimage = reconstruction.images[pyimageid]
|
| 270 |
+
pycamera = reconstruction.cameras[pyimage.camera_id]
|
| 271 |
+
pyimage.name = image_paths[pyimageid - 1]
|
| 272 |
+
|
| 273 |
+
if rescale_camera:
|
| 274 |
+
# Rescale the camera parameters
|
| 275 |
+
pred_params = copy.deepcopy(pycamera.params)
|
| 276 |
+
|
| 277 |
+
real_image_size = original_coords[pyimageid - 1, -2:]
|
| 278 |
+
resize_ratio = max(real_image_size) / img_size
|
| 279 |
+
pred_params = pred_params * resize_ratio
|
| 280 |
+
real_pp = real_image_size / 2
|
| 281 |
+
pred_params[-2:] = real_pp # center of the image
|
| 282 |
+
|
| 283 |
+
pycamera.params = pred_params
|
| 284 |
+
pycamera.width = real_image_size[0]
|
| 285 |
+
pycamera.height = real_image_size[1]
|
| 286 |
+
|
| 287 |
+
if shift_point2d_to_original_res:
|
| 288 |
+
# Also shift the point2D to original resolution
|
| 289 |
+
top_left = original_coords[pyimageid - 1, :2]
|
| 290 |
+
|
| 291 |
+
for point2D in pyimage.points2D:
|
| 292 |
+
point2D.xy = (point2D.xy - top_left) * resize_ratio
|
| 293 |
+
|
| 294 |
+
if shared_camera:
|
| 295 |
+
# If shared_camera, all images share the same camera
|
| 296 |
+
# no need to rescale any more
|
| 297 |
+
rescale_camera = False
|
| 298 |
+
|
| 299 |
+
return reconstruction
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
if __name__ == "__main__":
|
| 303 |
+
args = parse_args()
|
| 304 |
+
with torch.no_grad():
|
| 305 |
+
demo_fn(args)
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
# Work in Progress (WIP)
|
| 309 |
+
|
| 310 |
+
"""
|
| 311 |
+
VGGT Runner Script
|
| 312 |
+
=================
|
| 313 |
+
|
| 314 |
+
A script to run the VGGT model for 3D reconstruction from image sequences.
|
| 315 |
+
|
| 316 |
+
Directory Structure
|
| 317 |
+
------------------
|
| 318 |
+
Input:
|
| 319 |
+
input_folder/
|
| 320 |
+
└── images/ # Source images for reconstruction
|
| 321 |
+
|
| 322 |
+
Output:
|
| 323 |
+
output_folder/
|
| 324 |
+
├── images/
|
| 325 |
+
├── sparse/ # Reconstruction results
|
| 326 |
+
│ ├── cameras.bin # Camera parameters (COLMAP format)
|
| 327 |
+
│ ├── images.bin # Pose for each image (COLMAP format)
|
| 328 |
+
│ ├── points3D.bin # 3D points (COLMAP format)
|
| 329 |
+
│ └── points.ply # Point cloud visualization file
|
| 330 |
+
└── visuals/ # Visualization outputs TODO
|
| 331 |
+
|
| 332 |
+
Key Features
|
| 333 |
+
-----------
|
| 334 |
+
• Dual-mode Support: Run reconstructions using either VGGT or VGGT+BA
|
| 335 |
+
• Resolution Preservation: Maintains original image resolution in camera parameters and tracks
|
| 336 |
+
• COLMAP Compatibility: Exports results in standard COLMAP sparse reconstruction format
|
| 337 |
+
"""
|
vggt-low-vram/demo_gradio.py
ADDED
|
@@ -0,0 +1,684 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import cv2
|
| 9 |
+
import torch
|
| 10 |
+
import numpy as np
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import sys
|
| 13 |
+
import shutil
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
import glob
|
| 16 |
+
import gc
|
| 17 |
+
import time
|
| 18 |
+
|
| 19 |
+
sys.path.append("vggt/")
|
| 20 |
+
|
| 21 |
+
from visual_util import predictions_to_glb
|
| 22 |
+
from vggt.models.vggt import VGGT
|
| 23 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 24 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 25 |
+
from vggt.utils.geometry import unproject_depth_map_to_point_map
|
| 26 |
+
|
| 27 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 28 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 29 |
+
|
| 30 |
+
print("Initializing and loading VGGT model...")
|
| 31 |
+
# model = VGGT.from_pretrained("facebook/VGGT-1B") # another way to load the model
|
| 32 |
+
|
| 33 |
+
model = VGGT()
|
| 34 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 35 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 36 |
+
model.eval()
|
| 37 |
+
model = model.to(dtype=dtype, device=device)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
# -------------------------------------------------------------------------
|
| 41 |
+
# 1) Core model inference
|
| 42 |
+
# -------------------------------------------------------------------------
|
| 43 |
+
def run_model(target_dir, model) -> dict:
|
| 44 |
+
"""
|
| 45 |
+
Run the VGGT model on images in the 'target_dir/images' folder and return predictions.
|
| 46 |
+
"""
|
| 47 |
+
print(f"Processing images from {target_dir}")
|
| 48 |
+
|
| 49 |
+
# Device check
|
| 50 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 51 |
+
if not torch.cuda.is_available():
|
| 52 |
+
raise ValueError("CUDA is not available. Check your environment.")
|
| 53 |
+
|
| 54 |
+
# Load and preprocess images
|
| 55 |
+
image_names = glob.glob(os.path.join(target_dir, "images", "*"))
|
| 56 |
+
image_names = sorted(image_names)
|
| 57 |
+
print(f"Found {len(image_names)} images")
|
| 58 |
+
if len(image_names) == 0:
|
| 59 |
+
raise ValueError("No images found. Check your upload.")
|
| 60 |
+
|
| 61 |
+
images = load_and_preprocess_images(image_names).to(dtype=dtype, device=device)
|
| 62 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 63 |
+
|
| 64 |
+
# Run inference
|
| 65 |
+
print("Running inference...")
|
| 66 |
+
|
| 67 |
+
with torch.no_grad():
|
| 68 |
+
predictions = model(images, verbose=True)
|
| 69 |
+
|
| 70 |
+
# Convert pose encoding to extrinsic and intrinsic matrices
|
| 71 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 72 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 73 |
+
predictions["extrinsic"] = extrinsic
|
| 74 |
+
predictions["intrinsic"] = intrinsic
|
| 75 |
+
|
| 76 |
+
# Convert tensors to numpy
|
| 77 |
+
for key in predictions.keys():
|
| 78 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 79 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension
|
| 80 |
+
predictions['pose_enc_list'] = None # remove pose_enc_list
|
| 81 |
+
|
| 82 |
+
# Generate world points from depth map
|
| 83 |
+
print("Computing world points from depth map...")
|
| 84 |
+
depth_map = predictions["depth"] # (S, H, W, 1)
|
| 85 |
+
world_points = unproject_depth_map_to_point_map(depth_map, predictions["extrinsic"], predictions["intrinsic"])
|
| 86 |
+
predictions["world_points_from_depth"] = world_points
|
| 87 |
+
|
| 88 |
+
# Clean up
|
| 89 |
+
torch.cuda.empty_cache()
|
| 90 |
+
return predictions
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
# -------------------------------------------------------------------------
|
| 94 |
+
# 2) Handle uploaded video/images --> produce target_dir + images
|
| 95 |
+
# -------------------------------------------------------------------------
|
| 96 |
+
def handle_uploads(input_video, input_images):
|
| 97 |
+
"""
|
| 98 |
+
Create a new 'target_dir' + 'images' subfolder, and place user-uploaded
|
| 99 |
+
images or extracted frames from video into it. Return (target_dir, image_paths).
|
| 100 |
+
"""
|
| 101 |
+
start_time = time.time()
|
| 102 |
+
gc.collect()
|
| 103 |
+
torch.cuda.empty_cache()
|
| 104 |
+
|
| 105 |
+
# Create a unique folder name
|
| 106 |
+
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
|
| 107 |
+
target_dir = f"input_images_{timestamp}"
|
| 108 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 109 |
+
|
| 110 |
+
# Clean up if somehow that folder already exists
|
| 111 |
+
if os.path.exists(target_dir):
|
| 112 |
+
shutil.rmtree(target_dir)
|
| 113 |
+
os.makedirs(target_dir)
|
| 114 |
+
os.makedirs(target_dir_images)
|
| 115 |
+
|
| 116 |
+
image_paths = []
|
| 117 |
+
|
| 118 |
+
# --- Handle images ---
|
| 119 |
+
if input_images is not None:
|
| 120 |
+
for file_data in input_images:
|
| 121 |
+
if isinstance(file_data, dict) and "name" in file_data:
|
| 122 |
+
file_path = file_data["name"]
|
| 123 |
+
else:
|
| 124 |
+
file_path = file_data
|
| 125 |
+
dst_path = os.path.join(target_dir_images, os.path.basename(file_path))
|
| 126 |
+
shutil.copy(file_path, dst_path)
|
| 127 |
+
image_paths.append(dst_path)
|
| 128 |
+
|
| 129 |
+
# --- Handle video ---
|
| 130 |
+
if input_video is not None:
|
| 131 |
+
if isinstance(input_video, dict) and "name" in input_video:
|
| 132 |
+
video_path = input_video["name"]
|
| 133 |
+
else:
|
| 134 |
+
video_path = input_video
|
| 135 |
+
|
| 136 |
+
vs = cv2.VideoCapture(video_path)
|
| 137 |
+
fps = vs.get(cv2.CAP_PROP_FPS)
|
| 138 |
+
frame_interval = int(fps * 1) # 1 frame/sec
|
| 139 |
+
|
| 140 |
+
count = 0
|
| 141 |
+
video_frame_num = 0
|
| 142 |
+
while True:
|
| 143 |
+
gotit, frame = vs.read()
|
| 144 |
+
if not gotit:
|
| 145 |
+
break
|
| 146 |
+
count += 1
|
| 147 |
+
if count % frame_interval == 0:
|
| 148 |
+
image_path = os.path.join(target_dir_images, f"{video_frame_num:06}.png")
|
| 149 |
+
cv2.imwrite(image_path, frame)
|
| 150 |
+
image_paths.append(image_path)
|
| 151 |
+
video_frame_num += 1
|
| 152 |
+
|
| 153 |
+
# Sort final images for gallery
|
| 154 |
+
image_paths = sorted(image_paths)
|
| 155 |
+
|
| 156 |
+
end_time = time.time()
|
| 157 |
+
print(f"Files copied to {target_dir_images}; took {end_time - start_time:.3f} seconds")
|
| 158 |
+
return target_dir, image_paths
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
# -------------------------------------------------------------------------
|
| 162 |
+
# 3) Update gallery on upload
|
| 163 |
+
# -------------------------------------------------------------------------
|
| 164 |
+
def update_gallery_on_upload(input_video, input_images):
|
| 165 |
+
"""
|
| 166 |
+
Whenever user uploads or changes files, immediately handle them
|
| 167 |
+
and show in the gallery. Return (target_dir, image_paths).
|
| 168 |
+
If nothing is uploaded, returns "None" and empty list.
|
| 169 |
+
"""
|
| 170 |
+
if not input_video and not input_images:
|
| 171 |
+
return None, None, None, None
|
| 172 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 173 |
+
return None, target_dir, image_paths, "Upload complete. Click 'Reconstruct' to begin 3D processing."
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
# -------------------------------------------------------------------------
|
| 177 |
+
# 4) Reconstruction: uses the target_dir plus any viz parameters
|
| 178 |
+
# -------------------------------------------------------------------------
|
| 179 |
+
def gradio_demo(
|
| 180 |
+
target_dir,
|
| 181 |
+
conf_thres=3.0,
|
| 182 |
+
frame_filter="All",
|
| 183 |
+
mask_black_bg=False,
|
| 184 |
+
mask_white_bg=False,
|
| 185 |
+
show_cam=True,
|
| 186 |
+
mask_sky=False,
|
| 187 |
+
prediction_mode="Pointmap Regression",
|
| 188 |
+
):
|
| 189 |
+
"""
|
| 190 |
+
Perform reconstruction using the already-created target_dir/images.
|
| 191 |
+
"""
|
| 192 |
+
if not os.path.isdir(target_dir) or target_dir == "None":
|
| 193 |
+
return None, "No valid target directory found. Please upload first.", None, None
|
| 194 |
+
|
| 195 |
+
start_time = time.time()
|
| 196 |
+
gc.collect()
|
| 197 |
+
torch.cuda.empty_cache()
|
| 198 |
+
|
| 199 |
+
# Prepare frame_filter dropdown
|
| 200 |
+
target_dir_images = os.path.join(target_dir, "images")
|
| 201 |
+
all_files = sorted(os.listdir(target_dir_images)) if os.path.isdir(target_dir_images) else []
|
| 202 |
+
all_files = [f"{i}: {filename}" for i, filename in enumerate(all_files)]
|
| 203 |
+
frame_filter_choices = ["All"] + all_files
|
| 204 |
+
|
| 205 |
+
print("Running run_model...")
|
| 206 |
+
with torch.no_grad():
|
| 207 |
+
predictions = run_model(target_dir, model)
|
| 208 |
+
|
| 209 |
+
# Save predictions
|
| 210 |
+
prediction_save_path = os.path.join(target_dir, "predictions.npz")
|
| 211 |
+
np.savez(prediction_save_path, **predictions)
|
| 212 |
+
|
| 213 |
+
# Handle None frame_filter
|
| 214 |
+
if frame_filter is None:
|
| 215 |
+
frame_filter = "All"
|
| 216 |
+
|
| 217 |
+
# Build a GLB file name
|
| 218 |
+
glbfile = os.path.join(
|
| 219 |
+
target_dir,
|
| 220 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 221 |
+
)
|
| 222 |
+
|
| 223 |
+
# Convert predictions to GLB
|
| 224 |
+
glbscene = predictions_to_glb(
|
| 225 |
+
predictions,
|
| 226 |
+
conf_thres=conf_thres,
|
| 227 |
+
filter_by_frames=frame_filter,
|
| 228 |
+
mask_black_bg=mask_black_bg,
|
| 229 |
+
mask_white_bg=mask_white_bg,
|
| 230 |
+
show_cam=show_cam,
|
| 231 |
+
mask_sky=mask_sky,
|
| 232 |
+
target_dir=target_dir,
|
| 233 |
+
prediction_mode=prediction_mode,
|
| 234 |
+
)
|
| 235 |
+
glbscene.export(file_obj=glbfile)
|
| 236 |
+
|
| 237 |
+
# Cleanup
|
| 238 |
+
del predictions
|
| 239 |
+
gc.collect()
|
| 240 |
+
torch.cuda.empty_cache()
|
| 241 |
+
|
| 242 |
+
end_time = time.time()
|
| 243 |
+
print(f"Total time: {end_time - start_time:.2f} seconds (including IO)")
|
| 244 |
+
log_msg = f"Reconstruction Success ({len(all_files)} frames). Waiting for visualization."
|
| 245 |
+
|
| 246 |
+
return glbfile, log_msg, gr.Dropdown(choices=frame_filter_choices, value=frame_filter, interactive=True)
|
| 247 |
+
|
| 248 |
+
|
| 249 |
+
# -------------------------------------------------------------------------
|
| 250 |
+
# 5) Helper functions for UI resets + re-visualization
|
| 251 |
+
# -------------------------------------------------------------------------
|
| 252 |
+
def clear_fields():
|
| 253 |
+
"""
|
| 254 |
+
Clears the 3D viewer, the stored target_dir, and empties the gallery.
|
| 255 |
+
"""
|
| 256 |
+
return None
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
def update_log():
|
| 260 |
+
"""
|
| 261 |
+
Display a quick log message while waiting.
|
| 262 |
+
"""
|
| 263 |
+
return "Loading and Reconstructing..."
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
def update_visualization(
|
| 267 |
+
target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode, is_example
|
| 268 |
+
):
|
| 269 |
+
"""
|
| 270 |
+
Reload saved predictions from npz, create (or reuse) the GLB for new parameters,
|
| 271 |
+
and return it for the 3D viewer. If is_example == "True", skip.
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
# If it's an example click, skip as requested
|
| 275 |
+
if is_example == "True":
|
| 276 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 277 |
+
|
| 278 |
+
if not target_dir or target_dir == "None" or not os.path.isdir(target_dir):
|
| 279 |
+
return None, "No reconstruction available. Please click the Reconstruct button first."
|
| 280 |
+
|
| 281 |
+
predictions_path = os.path.join(target_dir, "predictions.npz")
|
| 282 |
+
if not os.path.exists(predictions_path):
|
| 283 |
+
return None, f"No reconstruction available at {predictions_path}. Please run 'Reconstruct' first."
|
| 284 |
+
|
| 285 |
+
key_list = [
|
| 286 |
+
"pose_enc",
|
| 287 |
+
"depth",
|
| 288 |
+
"depth_conf",
|
| 289 |
+
"world_points",
|
| 290 |
+
"world_points_conf",
|
| 291 |
+
"images",
|
| 292 |
+
"extrinsic",
|
| 293 |
+
"intrinsic",
|
| 294 |
+
"world_points_from_depth",
|
| 295 |
+
]
|
| 296 |
+
|
| 297 |
+
loaded = np.load(predictions_path)
|
| 298 |
+
predictions = {key: np.array(loaded[key]) for key in key_list}
|
| 299 |
+
|
| 300 |
+
glbfile = os.path.join(
|
| 301 |
+
target_dir,
|
| 302 |
+
f"glbscene_{conf_thres}_{frame_filter.replace('.', '_').replace(':', '').replace(' ', '_')}_maskb{mask_black_bg}_maskw{mask_white_bg}_cam{show_cam}_sky{mask_sky}_pred{prediction_mode.replace(' ', '_')}.glb",
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
if not os.path.exists(glbfile):
|
| 306 |
+
glbscene = predictions_to_glb(
|
| 307 |
+
predictions,
|
| 308 |
+
conf_thres=conf_thres,
|
| 309 |
+
filter_by_frames=frame_filter,
|
| 310 |
+
mask_black_bg=mask_black_bg,
|
| 311 |
+
mask_white_bg=mask_white_bg,
|
| 312 |
+
show_cam=show_cam,
|
| 313 |
+
mask_sky=mask_sky,
|
| 314 |
+
target_dir=target_dir,
|
| 315 |
+
prediction_mode=prediction_mode,
|
| 316 |
+
)
|
| 317 |
+
glbscene.export(file_obj=glbfile)
|
| 318 |
+
|
| 319 |
+
return glbfile, "Updating Visualization"
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
# -------------------------------------------------------------------------
|
| 323 |
+
# Example images
|
| 324 |
+
# -------------------------------------------------------------------------
|
| 325 |
+
|
| 326 |
+
great_wall_video = "examples/videos/great_wall.mp4"
|
| 327 |
+
colosseum_video = "examples/videos/Colosseum.mp4"
|
| 328 |
+
room_video = "examples/videos/room.mp4"
|
| 329 |
+
kitchen_video = "examples/videos/kitchen.mp4"
|
| 330 |
+
fern_video = "examples/videos/fern.mp4"
|
| 331 |
+
single_cartoon_video = "examples/videos/single_cartoon.mp4"
|
| 332 |
+
single_oil_painting_video = "examples/videos/single_oil_painting.mp4"
|
| 333 |
+
pyramid_video = "examples/videos/pyramid.mp4"
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
# -------------------------------------------------------------------------
|
| 337 |
+
# 6) Build Gradio UI
|
| 338 |
+
# -------------------------------------------------------------------------
|
| 339 |
+
theme = gr.themes.Ocean()
|
| 340 |
+
theme.set(
|
| 341 |
+
checkbox_label_background_fill_selected="*button_primary_background_fill",
|
| 342 |
+
checkbox_label_text_color_selected="*button_primary_text_color",
|
| 343 |
+
)
|
| 344 |
+
|
| 345 |
+
with gr.Blocks(
|
| 346 |
+
theme=theme,
|
| 347 |
+
css="""
|
| 348 |
+
.custom-log * {
|
| 349 |
+
font-style: italic;
|
| 350 |
+
font-size: 22px !important;
|
| 351 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 352 |
+
-webkit-background-clip: text;
|
| 353 |
+
background-clip: text;
|
| 354 |
+
font-weight: bold !important;
|
| 355 |
+
color: transparent !important;
|
| 356 |
+
text-align: center !important;
|
| 357 |
+
}
|
| 358 |
+
|
| 359 |
+
.example-log * {
|
| 360 |
+
font-style: italic;
|
| 361 |
+
font-size: 16px !important;
|
| 362 |
+
background-image: linear-gradient(120deg, #0ea5e9 0%, #6ee7b7 60%, #34d399 100%);
|
| 363 |
+
-webkit-background-clip: text;
|
| 364 |
+
background-clip: text;
|
| 365 |
+
color: transparent !important;
|
| 366 |
+
}
|
| 367 |
+
|
| 368 |
+
#my_radio .wrap {
|
| 369 |
+
display: flex;
|
| 370 |
+
flex-wrap: nowrap;
|
| 371 |
+
justify-content: center;
|
| 372 |
+
align-items: center;
|
| 373 |
+
}
|
| 374 |
+
|
| 375 |
+
#my_radio .wrap label {
|
| 376 |
+
display: flex;
|
| 377 |
+
width: 50%;
|
| 378 |
+
justify-content: center;
|
| 379 |
+
align-items: center;
|
| 380 |
+
margin: 0;
|
| 381 |
+
padding: 10px 0;
|
| 382 |
+
box-sizing: border-box;
|
| 383 |
+
}
|
| 384 |
+
""",
|
| 385 |
+
) as demo:
|
| 386 |
+
# Instead of gr.State, we use a hidden Textbox:
|
| 387 |
+
is_example = gr.Textbox(label="is_example", visible=False, value="None")
|
| 388 |
+
num_images = gr.Textbox(label="num_images", visible=False, value="None")
|
| 389 |
+
|
| 390 |
+
gr.HTML(
|
| 391 |
+
"""
|
| 392 |
+
<h1>🏛️ VGGT: Visual Geometry Grounded Transformer</h1>
|
| 393 |
+
<p>
|
| 394 |
+
<a href="https://github.com/facebookresearch/vggt">🐙 GitHub Repository</a> |
|
| 395 |
+
<a href="#">Project Page</a>
|
| 396 |
+
</p>
|
| 397 |
+
|
| 398 |
+
<div style="font-size: 16px; line-height: 1.5;">
|
| 399 |
+
<p>Upload a video or a set of images to create a 3D reconstruction of a scene or object. VGGT takes these images and generates a 3D point cloud, along with estimated camera poses.</p>
|
| 400 |
+
|
| 401 |
+
<h3>Getting Started:</h3>
|
| 402 |
+
<ol>
|
| 403 |
+
<li><strong>Upload Your Data:</strong> Use the "Upload Video" or "Upload Images" buttons on the left to provide your input. Videos will be automatically split into individual frames (one frame per second).</li>
|
| 404 |
+
<li><strong>Preview:</strong> Your uploaded images will appear in the gallery on the left.</li>
|
| 405 |
+
<li><strong>Reconstruct:</strong> Click the "Reconstruct" button to start the 3D reconstruction process.</li>
|
| 406 |
+
<li><strong>Visualize:</strong> The 3D reconstruction will appear in the viewer on the right. You can rotate, pan, and zoom to explore the model, and download the GLB file. Note the visualization of 3D points may be slow for a large number of input images.</li>
|
| 407 |
+
<li>
|
| 408 |
+
<strong>Adjust Visualization (Optional):</strong>
|
| 409 |
+
After reconstruction, you can fine-tune the visualization using the options below
|
| 410 |
+
<details style="display:inline;">
|
| 411 |
+
<summary style="display:inline;">(<strong>click to expand</strong>):</summary>
|
| 412 |
+
<ul>
|
| 413 |
+
<li><em>Confidence Threshold:</em> Adjust the filtering of points based on confidence.</li>
|
| 414 |
+
<li><em>Show Points from Frame:</em> Select specific frames to display in the point cloud.</li>
|
| 415 |
+
<li><em>Show Camera:</em> Toggle the display of estimated camera positions.</li>
|
| 416 |
+
<li><em>Filter Sky / Filter Black Background:</em> Remove sky or black-background points.</li>
|
| 417 |
+
<li><em>Select a Prediction Mode:</em> Choose between "Depthmap and Camera Branch" or "Pointmap Branch."</li>
|
| 418 |
+
</ul>
|
| 419 |
+
</details>
|
| 420 |
+
</li>
|
| 421 |
+
</ol>
|
| 422 |
+
<p><strong style="color: #0ea5e9;">Please note:</strong> <span style="color: #0ea5e9; font-weight: bold;">VGGT typically reconstructs a scene in less than 1 second. However, visualizing 3D points may take tens of seconds due to third-party rendering, which are independent of VGGT's processing time. </span></p>
|
| 423 |
+
</div>
|
| 424 |
+
"""
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
target_dir_output = gr.Textbox(label="Target Dir", visible=False, value="None")
|
| 428 |
+
|
| 429 |
+
with gr.Row():
|
| 430 |
+
with gr.Column(scale=2):
|
| 431 |
+
input_video = gr.Video(label="Upload Video", interactive=True)
|
| 432 |
+
input_images = gr.File(file_count="multiple", label="Upload Images", interactive=True)
|
| 433 |
+
|
| 434 |
+
image_gallery = gr.Gallery(
|
| 435 |
+
label="Preview",
|
| 436 |
+
columns=4,
|
| 437 |
+
height="300px",
|
| 438 |
+
show_download_button=True,
|
| 439 |
+
object_fit="contain",
|
| 440 |
+
preview=True,
|
| 441 |
+
)
|
| 442 |
+
|
| 443 |
+
with gr.Column(scale=4):
|
| 444 |
+
with gr.Column():
|
| 445 |
+
gr.Markdown("**3D Reconstruction (Point Cloud and Camera Poses)**")
|
| 446 |
+
log_output = gr.Markdown(
|
| 447 |
+
"Please upload a video or images, then click Reconstruct.", elem_classes=["custom-log"]
|
| 448 |
+
)
|
| 449 |
+
reconstruction_output = gr.Model3D(height=520, zoom_speed=0.5, pan_speed=0.5)
|
| 450 |
+
|
| 451 |
+
with gr.Row():
|
| 452 |
+
submit_btn = gr.Button("Reconstruct", scale=1, variant="primary")
|
| 453 |
+
clear_btn = gr.ClearButton(
|
| 454 |
+
[input_video, input_images, reconstruction_output, log_output, target_dir_output, image_gallery],
|
| 455 |
+
scale=1,
|
| 456 |
+
)
|
| 457 |
+
|
| 458 |
+
with gr.Row():
|
| 459 |
+
prediction_mode = gr.Radio(
|
| 460 |
+
["Depthmap and Camera Branch", "Pointmap Branch"],
|
| 461 |
+
label="Select a Prediction Mode",
|
| 462 |
+
value="Depthmap and Camera Branch",
|
| 463 |
+
scale=1,
|
| 464 |
+
elem_id="my_radio",
|
| 465 |
+
)
|
| 466 |
+
|
| 467 |
+
with gr.Row():
|
| 468 |
+
conf_thres = gr.Slider(minimum=0, maximum=100, value=50, step=0.1, label="Confidence Threshold (%)")
|
| 469 |
+
frame_filter = gr.Dropdown(choices=["All"], value="All", label="Show Points from Frame")
|
| 470 |
+
with gr.Column():
|
| 471 |
+
show_cam = gr.Checkbox(label="Show Camera", value=True)
|
| 472 |
+
mask_sky = gr.Checkbox(label="Filter Sky", value=False)
|
| 473 |
+
mask_black_bg = gr.Checkbox(label="Filter Black Background", value=False)
|
| 474 |
+
mask_white_bg = gr.Checkbox(label="Filter White Background", value=False)
|
| 475 |
+
|
| 476 |
+
# ---------------------- Examples section ----------------------
|
| 477 |
+
examples = [
|
| 478 |
+
[colosseum_video, "22", None, 20.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 479 |
+
[pyramid_video, "30", None, 35.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 480 |
+
[single_cartoon_video, "1", None, 15.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 481 |
+
[single_oil_painting_video, "1", None, 20.0, False, False, True, True, "Depthmap and Camera Branch", "True"],
|
| 482 |
+
[room_video, "8", None, 5.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 483 |
+
[kitchen_video, "25", None, 50.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 484 |
+
[fern_video, "20", None, 45.0, False, False, True, False, "Depthmap and Camera Branch", "True"],
|
| 485 |
+
]
|
| 486 |
+
|
| 487 |
+
def example_pipeline(
|
| 488 |
+
input_video,
|
| 489 |
+
num_images_str,
|
| 490 |
+
input_images,
|
| 491 |
+
conf_thres,
|
| 492 |
+
mask_black_bg,
|
| 493 |
+
mask_white_bg,
|
| 494 |
+
show_cam,
|
| 495 |
+
mask_sky,
|
| 496 |
+
prediction_mode,
|
| 497 |
+
is_example_str,
|
| 498 |
+
):
|
| 499 |
+
"""
|
| 500 |
+
1) Copy example images to new target_dir
|
| 501 |
+
2) Reconstruct
|
| 502 |
+
3) Return model3D + logs + new_dir + updated dropdown + gallery
|
| 503 |
+
We do NOT return is_example. It's just an input.
|
| 504 |
+
"""
|
| 505 |
+
target_dir, image_paths = handle_uploads(input_video, input_images)
|
| 506 |
+
# Always use "All" for frame_filter in examples
|
| 507 |
+
frame_filter = "All"
|
| 508 |
+
glbfile, log_msg, dropdown = gradio_demo(
|
| 509 |
+
target_dir, conf_thres, frame_filter, mask_black_bg, mask_white_bg, show_cam, mask_sky, prediction_mode
|
| 510 |
+
)
|
| 511 |
+
return glbfile, log_msg, target_dir, dropdown, image_paths
|
| 512 |
+
|
| 513 |
+
gr.Markdown("Click any row to load an example.", elem_classes=["example-log"])
|
| 514 |
+
|
| 515 |
+
gr.Examples(
|
| 516 |
+
examples=examples,
|
| 517 |
+
inputs=[
|
| 518 |
+
input_video,
|
| 519 |
+
num_images,
|
| 520 |
+
input_images,
|
| 521 |
+
conf_thres,
|
| 522 |
+
mask_black_bg,
|
| 523 |
+
mask_white_bg,
|
| 524 |
+
show_cam,
|
| 525 |
+
mask_sky,
|
| 526 |
+
prediction_mode,
|
| 527 |
+
is_example,
|
| 528 |
+
],
|
| 529 |
+
outputs=[reconstruction_output, log_output, target_dir_output, frame_filter, image_gallery],
|
| 530 |
+
fn=example_pipeline,
|
| 531 |
+
cache_examples=False,
|
| 532 |
+
examples_per_page=50,
|
| 533 |
+
)
|
| 534 |
+
|
| 535 |
+
# -------------------------------------------------------------------------
|
| 536 |
+
# "Reconstruct" button logic:
|
| 537 |
+
# - Clear fields
|
| 538 |
+
# - Update log
|
| 539 |
+
# - gradio_demo(...) with the existing target_dir
|
| 540 |
+
# - Then set is_example = "False"
|
| 541 |
+
# -------------------------------------------------------------------------
|
| 542 |
+
submit_btn.click(fn=clear_fields, inputs=[], outputs=[reconstruction_output]).then(
|
| 543 |
+
fn=update_log, inputs=[], outputs=[log_output]
|
| 544 |
+
).then(
|
| 545 |
+
fn=gradio_demo,
|
| 546 |
+
inputs=[
|
| 547 |
+
target_dir_output,
|
| 548 |
+
conf_thres,
|
| 549 |
+
frame_filter,
|
| 550 |
+
mask_black_bg,
|
| 551 |
+
mask_white_bg,
|
| 552 |
+
show_cam,
|
| 553 |
+
mask_sky,
|
| 554 |
+
prediction_mode,
|
| 555 |
+
],
|
| 556 |
+
outputs=[reconstruction_output, log_output, frame_filter],
|
| 557 |
+
).then(
|
| 558 |
+
fn=lambda: "False", inputs=[], outputs=[is_example] # set is_example to "False"
|
| 559 |
+
)
|
| 560 |
+
|
| 561 |
+
# -------------------------------------------------------------------------
|
| 562 |
+
# Real-time Visualization Updates
|
| 563 |
+
# -------------------------------------------------------------------------
|
| 564 |
+
conf_thres.change(
|
| 565 |
+
update_visualization,
|
| 566 |
+
[
|
| 567 |
+
target_dir_output,
|
| 568 |
+
conf_thres,
|
| 569 |
+
frame_filter,
|
| 570 |
+
mask_black_bg,
|
| 571 |
+
mask_white_bg,
|
| 572 |
+
show_cam,
|
| 573 |
+
mask_sky,
|
| 574 |
+
prediction_mode,
|
| 575 |
+
is_example,
|
| 576 |
+
],
|
| 577 |
+
[reconstruction_output, log_output],
|
| 578 |
+
)
|
| 579 |
+
frame_filter.change(
|
| 580 |
+
update_visualization,
|
| 581 |
+
[
|
| 582 |
+
target_dir_output,
|
| 583 |
+
conf_thres,
|
| 584 |
+
frame_filter,
|
| 585 |
+
mask_black_bg,
|
| 586 |
+
mask_white_bg,
|
| 587 |
+
show_cam,
|
| 588 |
+
mask_sky,
|
| 589 |
+
prediction_mode,
|
| 590 |
+
is_example,
|
| 591 |
+
],
|
| 592 |
+
[reconstruction_output, log_output],
|
| 593 |
+
)
|
| 594 |
+
mask_black_bg.change(
|
| 595 |
+
update_visualization,
|
| 596 |
+
[
|
| 597 |
+
target_dir_output,
|
| 598 |
+
conf_thres,
|
| 599 |
+
frame_filter,
|
| 600 |
+
mask_black_bg,
|
| 601 |
+
mask_white_bg,
|
| 602 |
+
show_cam,
|
| 603 |
+
mask_sky,
|
| 604 |
+
prediction_mode,
|
| 605 |
+
is_example,
|
| 606 |
+
],
|
| 607 |
+
[reconstruction_output, log_output],
|
| 608 |
+
)
|
| 609 |
+
mask_white_bg.change(
|
| 610 |
+
update_visualization,
|
| 611 |
+
[
|
| 612 |
+
target_dir_output,
|
| 613 |
+
conf_thres,
|
| 614 |
+
frame_filter,
|
| 615 |
+
mask_black_bg,
|
| 616 |
+
mask_white_bg,
|
| 617 |
+
show_cam,
|
| 618 |
+
mask_sky,
|
| 619 |
+
prediction_mode,
|
| 620 |
+
is_example,
|
| 621 |
+
],
|
| 622 |
+
[reconstruction_output, log_output],
|
| 623 |
+
)
|
| 624 |
+
show_cam.change(
|
| 625 |
+
update_visualization,
|
| 626 |
+
[
|
| 627 |
+
target_dir_output,
|
| 628 |
+
conf_thres,
|
| 629 |
+
frame_filter,
|
| 630 |
+
mask_black_bg,
|
| 631 |
+
mask_white_bg,
|
| 632 |
+
show_cam,
|
| 633 |
+
mask_sky,
|
| 634 |
+
prediction_mode,
|
| 635 |
+
is_example,
|
| 636 |
+
],
|
| 637 |
+
[reconstruction_output, log_output],
|
| 638 |
+
)
|
| 639 |
+
mask_sky.change(
|
| 640 |
+
update_visualization,
|
| 641 |
+
[
|
| 642 |
+
target_dir_output,
|
| 643 |
+
conf_thres,
|
| 644 |
+
frame_filter,
|
| 645 |
+
mask_black_bg,
|
| 646 |
+
mask_white_bg,
|
| 647 |
+
show_cam,
|
| 648 |
+
mask_sky,
|
| 649 |
+
prediction_mode,
|
| 650 |
+
is_example,
|
| 651 |
+
],
|
| 652 |
+
[reconstruction_output, log_output],
|
| 653 |
+
)
|
| 654 |
+
prediction_mode.change(
|
| 655 |
+
update_visualization,
|
| 656 |
+
[
|
| 657 |
+
target_dir_output,
|
| 658 |
+
conf_thres,
|
| 659 |
+
frame_filter,
|
| 660 |
+
mask_black_bg,
|
| 661 |
+
mask_white_bg,
|
| 662 |
+
show_cam,
|
| 663 |
+
mask_sky,
|
| 664 |
+
prediction_mode,
|
| 665 |
+
is_example,
|
| 666 |
+
],
|
| 667 |
+
[reconstruction_output, log_output],
|
| 668 |
+
)
|
| 669 |
+
|
| 670 |
+
# -------------------------------------------------------------------------
|
| 671 |
+
# Auto-update gallery whenever user uploads or changes their files
|
| 672 |
+
# -------------------------------------------------------------------------
|
| 673 |
+
input_video.change(
|
| 674 |
+
fn=update_gallery_on_upload,
|
| 675 |
+
inputs=[input_video, input_images],
|
| 676 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 677 |
+
)
|
| 678 |
+
input_images.change(
|
| 679 |
+
fn=update_gallery_on_upload,
|
| 680 |
+
inputs=[input_video, input_images],
|
| 681 |
+
outputs=[reconstruction_output, target_dir_output, image_gallery, log_output],
|
| 682 |
+
)
|
| 683 |
+
|
| 684 |
+
demo.queue(max_size=20).launch(show_error=True, share=True)
|
vggt-low-vram/demo_viser.py
ADDED
|
@@ -0,0 +1,400 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import os
|
| 8 |
+
import glob
|
| 9 |
+
import time
|
| 10 |
+
import threading
|
| 11 |
+
import argparse
|
| 12 |
+
from typing import List, Optional
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import torch
|
| 16 |
+
from tqdm.auto import tqdm
|
| 17 |
+
import viser
|
| 18 |
+
import viser.transforms as viser_tf
|
| 19 |
+
import cv2
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
try:
|
| 23 |
+
import onnxruntime
|
| 24 |
+
except ImportError:
|
| 25 |
+
print("onnxruntime not found. Sky segmentation may not work.")
|
| 26 |
+
|
| 27 |
+
from visual_util import segment_sky, download_file_from_url
|
| 28 |
+
from vggt.models.vggt import VGGT
|
| 29 |
+
from vggt.utils.load_fn import load_and_preprocess_images
|
| 30 |
+
from vggt.utils.geometry import closed_form_inverse_se3, unproject_depth_map_to_point_map
|
| 31 |
+
from vggt.utils.pose_enc import pose_encoding_to_extri_intri
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def viser_wrapper(
|
| 35 |
+
pred_dict: dict,
|
| 36 |
+
port: int = 8080,
|
| 37 |
+
init_conf_threshold: float = 50.0, # represents percentage (e.g., 50 means filter lowest 50%)
|
| 38 |
+
use_point_map: bool = False,
|
| 39 |
+
background_mode: bool = False,
|
| 40 |
+
mask_sky: bool = False,
|
| 41 |
+
image_folder: str = None,
|
| 42 |
+
):
|
| 43 |
+
"""
|
| 44 |
+
Visualize predicted 3D points and camera poses with viser.
|
| 45 |
+
|
| 46 |
+
Args:
|
| 47 |
+
pred_dict (dict):
|
| 48 |
+
{
|
| 49 |
+
"images": (S, 3, H, W) - Input images,
|
| 50 |
+
"world_points": (S, H, W, 3),
|
| 51 |
+
"world_points_conf": (S, H, W),
|
| 52 |
+
"depth": (S, H, W, 1),
|
| 53 |
+
"depth_conf": (S, H, W),
|
| 54 |
+
"extrinsic": (S, 3, 4),
|
| 55 |
+
"intrinsic": (S, 3, 3),
|
| 56 |
+
}
|
| 57 |
+
port (int): Port number for the viser server.
|
| 58 |
+
init_conf_threshold (float): Initial percentage of low-confidence points to filter out.
|
| 59 |
+
use_point_map (bool): Whether to visualize world_points or use depth-based points.
|
| 60 |
+
background_mode (bool): Whether to run the server in background thread.
|
| 61 |
+
mask_sky (bool): Whether to apply sky segmentation to filter out sky points.
|
| 62 |
+
image_folder (str): Path to the folder containing input images.
|
| 63 |
+
"""
|
| 64 |
+
print(f"Starting viser server on port {port}")
|
| 65 |
+
|
| 66 |
+
server = viser.ViserServer(host="0.0.0.0", port=port)
|
| 67 |
+
server.gui.configure_theme(titlebar_content=None, control_layout="collapsible")
|
| 68 |
+
|
| 69 |
+
# Unpack prediction dict
|
| 70 |
+
images = pred_dict["images"] # (S, 3, H, W)
|
| 71 |
+
world_points_map = pred_dict["world_points"] # (S, H, W, 3)
|
| 72 |
+
conf_map = pred_dict["world_points_conf"] # (S, H, W)
|
| 73 |
+
|
| 74 |
+
depth_map = pred_dict["depth"] # (S, H, W, 1)
|
| 75 |
+
depth_conf = pred_dict["depth_conf"] # (S, H, W)
|
| 76 |
+
|
| 77 |
+
extrinsics_cam = pred_dict["extrinsic"] # (S, 3, 4)
|
| 78 |
+
intrinsics_cam = pred_dict["intrinsic"] # (S, 3, 3)
|
| 79 |
+
|
| 80 |
+
# Compute world points from depth if not using the precomputed point map
|
| 81 |
+
if not use_point_map:
|
| 82 |
+
world_points = unproject_depth_map_to_point_map(depth_map, extrinsics_cam, intrinsics_cam)
|
| 83 |
+
conf = depth_conf
|
| 84 |
+
else:
|
| 85 |
+
world_points = world_points_map
|
| 86 |
+
conf = conf_map
|
| 87 |
+
|
| 88 |
+
# Apply sky segmentation if enabled
|
| 89 |
+
if mask_sky and image_folder is not None:
|
| 90 |
+
conf = apply_sky_segmentation(conf, image_folder)
|
| 91 |
+
|
| 92 |
+
# Convert images from (S, 3, H, W) to (S, H, W, 3)
|
| 93 |
+
# Then flatten everything for the point cloud
|
| 94 |
+
colors = images.transpose(0, 2, 3, 1) # now (S, H, W, 3)
|
| 95 |
+
S, H, W, _ = world_points.shape
|
| 96 |
+
|
| 97 |
+
# Flatten
|
| 98 |
+
points = world_points.reshape(-1, 3)
|
| 99 |
+
colors_flat = (colors.reshape(-1, 3) * 255).astype(np.uint8)
|
| 100 |
+
conf_flat = conf.reshape(-1)
|
| 101 |
+
|
| 102 |
+
cam_to_world_mat = closed_form_inverse_se3(extrinsics_cam) # shape (S, 4, 4) typically
|
| 103 |
+
# For convenience, we store only (3,4) portion
|
| 104 |
+
cam_to_world = cam_to_world_mat[:, :3, :]
|
| 105 |
+
|
| 106 |
+
# Compute scene center and recenter
|
| 107 |
+
scene_center = np.mean(points, axis=0)
|
| 108 |
+
points_centered = points - scene_center
|
| 109 |
+
cam_to_world[..., -1] -= scene_center
|
| 110 |
+
|
| 111 |
+
# Store frame indices so we can filter by frame
|
| 112 |
+
frame_indices = np.repeat(np.arange(S), H * W)
|
| 113 |
+
|
| 114 |
+
# Build the viser GUI
|
| 115 |
+
gui_show_frames = server.gui.add_checkbox("Show Cameras", initial_value=True)
|
| 116 |
+
|
| 117 |
+
# Now the slider represents percentage of points to filter out
|
| 118 |
+
gui_points_conf = server.gui.add_slider(
|
| 119 |
+
"Confidence Percent", min=0, max=100, step=0.1, initial_value=init_conf_threshold
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
gui_frame_selector = server.gui.add_dropdown(
|
| 123 |
+
"Show Points from Frames", options=["All"] + [str(i) for i in range(S)], initial_value="All"
|
| 124 |
+
)
|
| 125 |
+
|
| 126 |
+
# Create the main point cloud handle
|
| 127 |
+
# Compute the threshold value as the given percentile
|
| 128 |
+
init_threshold_val = np.percentile(conf_flat, init_conf_threshold)
|
| 129 |
+
init_conf_mask = (conf_flat >= init_threshold_val) & (conf_flat > 0.1)
|
| 130 |
+
point_cloud = server.scene.add_point_cloud(
|
| 131 |
+
name="viser_pcd",
|
| 132 |
+
points=points_centered[init_conf_mask],
|
| 133 |
+
colors=colors_flat[init_conf_mask],
|
| 134 |
+
point_size=0.001,
|
| 135 |
+
point_shape="circle",
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
# We will store references to frames & frustums so we can toggle visibility
|
| 139 |
+
frames: List[viser.FrameHandle] = []
|
| 140 |
+
frustums: List[viser.CameraFrustumHandle] = []
|
| 141 |
+
|
| 142 |
+
def visualize_frames(extrinsics: np.ndarray, images_: np.ndarray) -> None:
|
| 143 |
+
"""
|
| 144 |
+
Add camera frames and frustums to the scene.
|
| 145 |
+
extrinsics: (S, 3, 4)
|
| 146 |
+
images_: (S, 3, H, W)
|
| 147 |
+
"""
|
| 148 |
+
# Clear any existing frames or frustums
|
| 149 |
+
for f in frames:
|
| 150 |
+
f.remove()
|
| 151 |
+
frames.clear()
|
| 152 |
+
for fr in frustums:
|
| 153 |
+
fr.remove()
|
| 154 |
+
frustums.clear()
|
| 155 |
+
|
| 156 |
+
# Optionally attach a callback that sets the viewpoint to the chosen camera
|
| 157 |
+
def attach_callback(frustum: viser.CameraFrustumHandle, frame: viser.FrameHandle) -> None:
|
| 158 |
+
@frustum.on_click
|
| 159 |
+
def _(_) -> None:
|
| 160 |
+
for client in server.get_clients().values():
|
| 161 |
+
client.camera.wxyz = frame.wxyz
|
| 162 |
+
client.camera.position = frame.position
|
| 163 |
+
|
| 164 |
+
img_ids = range(S)
|
| 165 |
+
for img_id in tqdm(img_ids):
|
| 166 |
+
cam2world_3x4 = extrinsics[img_id]
|
| 167 |
+
T_world_camera = viser_tf.SE3.from_matrix(cam2world_3x4)
|
| 168 |
+
|
| 169 |
+
# Add a small frame axis
|
| 170 |
+
frame_axis = server.scene.add_frame(
|
| 171 |
+
f"frame_{img_id}",
|
| 172 |
+
wxyz=T_world_camera.rotation().wxyz,
|
| 173 |
+
position=T_world_camera.translation(),
|
| 174 |
+
axes_length=0.05,
|
| 175 |
+
axes_radius=0.002,
|
| 176 |
+
origin_radius=0.002,
|
| 177 |
+
)
|
| 178 |
+
frames.append(frame_axis)
|
| 179 |
+
|
| 180 |
+
# Convert the image for the frustum
|
| 181 |
+
img = images_[img_id] # shape (3, H, W)
|
| 182 |
+
img = (img.transpose(1, 2, 0) * 255).astype(np.uint8)
|
| 183 |
+
h, w = img.shape[:2]
|
| 184 |
+
|
| 185 |
+
# If you want correct FOV from intrinsics, do something like:
|
| 186 |
+
# fx = intrinsics_cam[img_id, 0, 0]
|
| 187 |
+
# fov = 2 * np.arctan2(h/2, fx)
|
| 188 |
+
# For demonstration, we pick a simple approximate FOV:
|
| 189 |
+
fy = 1.1 * h
|
| 190 |
+
fov = 2 * np.arctan2(h / 2, fy)
|
| 191 |
+
|
| 192 |
+
# Add the frustum
|
| 193 |
+
frustum_cam = server.scene.add_camera_frustum(
|
| 194 |
+
f"frame_{img_id}/frustum", fov=fov, aspect=w / h, scale=0.05, image=img, line_width=1.0
|
| 195 |
+
)
|
| 196 |
+
frustums.append(frustum_cam)
|
| 197 |
+
attach_callback(frustum_cam, frame_axis)
|
| 198 |
+
|
| 199 |
+
def update_point_cloud() -> None:
|
| 200 |
+
"""Update the point cloud based on current GUI selections."""
|
| 201 |
+
# Here we compute the threshold value based on the current percentage
|
| 202 |
+
current_percentage = gui_points_conf.value
|
| 203 |
+
threshold_val = np.percentile(conf_flat, current_percentage)
|
| 204 |
+
|
| 205 |
+
print(f"Threshold absolute value: {threshold_val}, percentage: {current_percentage}%")
|
| 206 |
+
|
| 207 |
+
conf_mask = (conf_flat >= threshold_val) & (conf_flat > 1e-5)
|
| 208 |
+
|
| 209 |
+
if gui_frame_selector.value == "All":
|
| 210 |
+
frame_mask = np.ones_like(conf_mask, dtype=bool)
|
| 211 |
+
else:
|
| 212 |
+
selected_idx = int(gui_frame_selector.value)
|
| 213 |
+
frame_mask = frame_indices == selected_idx
|
| 214 |
+
|
| 215 |
+
combined_mask = conf_mask & frame_mask
|
| 216 |
+
point_cloud.points = points_centered[combined_mask]
|
| 217 |
+
point_cloud.colors = colors_flat[combined_mask]
|
| 218 |
+
|
| 219 |
+
@gui_points_conf.on_update
|
| 220 |
+
def _(_) -> None:
|
| 221 |
+
update_point_cloud()
|
| 222 |
+
|
| 223 |
+
@gui_frame_selector.on_update
|
| 224 |
+
def _(_) -> None:
|
| 225 |
+
update_point_cloud()
|
| 226 |
+
|
| 227 |
+
@gui_show_frames.on_update
|
| 228 |
+
def _(_) -> None:
|
| 229 |
+
"""Toggle visibility of camera frames and frustums."""
|
| 230 |
+
for f in frames:
|
| 231 |
+
f.visible = gui_show_frames.value
|
| 232 |
+
for fr in frustums:
|
| 233 |
+
fr.visible = gui_show_frames.value
|
| 234 |
+
|
| 235 |
+
# Add the camera frames to the scene
|
| 236 |
+
visualize_frames(cam_to_world, images)
|
| 237 |
+
|
| 238 |
+
print("Starting viser server...")
|
| 239 |
+
# If background_mode is True, spawn a daemon thread so the main thread can continue.
|
| 240 |
+
if background_mode:
|
| 241 |
+
|
| 242 |
+
def server_loop():
|
| 243 |
+
while True:
|
| 244 |
+
time.sleep(0.001)
|
| 245 |
+
|
| 246 |
+
thread = threading.Thread(target=server_loop, daemon=True)
|
| 247 |
+
thread.start()
|
| 248 |
+
else:
|
| 249 |
+
while True:
|
| 250 |
+
time.sleep(0.01)
|
| 251 |
+
|
| 252 |
+
return server
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
# Helper functions for sky segmentation
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def apply_sky_segmentation(conf: np.ndarray, image_folder: str) -> np.ndarray:
|
| 259 |
+
"""
|
| 260 |
+
Apply sky segmentation to confidence scores.
|
| 261 |
+
|
| 262 |
+
Args:
|
| 263 |
+
conf (np.ndarray): Confidence scores with shape (S, H, W)
|
| 264 |
+
image_folder (str): Path to the folder containing input images
|
| 265 |
+
|
| 266 |
+
Returns:
|
| 267 |
+
np.ndarray: Updated confidence scores with sky regions masked out
|
| 268 |
+
"""
|
| 269 |
+
S, H, W = conf.shape
|
| 270 |
+
sky_masks_dir = image_folder.rstrip("/") + "_sky_masks"
|
| 271 |
+
os.makedirs(sky_masks_dir, exist_ok=True)
|
| 272 |
+
|
| 273 |
+
# Download skyseg.onnx if it doesn't exist
|
| 274 |
+
if not os.path.exists("skyseg.onnx"):
|
| 275 |
+
print("Downloading skyseg.onnx...")
|
| 276 |
+
download_file_from_url("https://huggingface.co/JianyuanWang/skyseg/resolve/main/skyseg.onnx", "skyseg.onnx")
|
| 277 |
+
|
| 278 |
+
skyseg_session = onnxruntime.InferenceSession("skyseg.onnx")
|
| 279 |
+
image_files = sorted(glob.glob(os.path.join(image_folder, "*")))
|
| 280 |
+
sky_mask_list = []
|
| 281 |
+
|
| 282 |
+
print("Generating sky masks...")
|
| 283 |
+
for i, image_path in enumerate(tqdm(image_files[:S])): # Limit to the number of images in the batch
|
| 284 |
+
image_name = os.path.basename(image_path)
|
| 285 |
+
mask_filepath = os.path.join(sky_masks_dir, image_name)
|
| 286 |
+
|
| 287 |
+
if os.path.exists(mask_filepath):
|
| 288 |
+
sky_mask = cv2.imread(mask_filepath, cv2.IMREAD_GRAYSCALE)
|
| 289 |
+
else:
|
| 290 |
+
sky_mask = segment_sky(image_path, skyseg_session, mask_filepath)
|
| 291 |
+
|
| 292 |
+
# Resize mask to match H×W if needed
|
| 293 |
+
if sky_mask.shape[0] != H or sky_mask.shape[1] != W:
|
| 294 |
+
sky_mask = cv2.resize(sky_mask, (W, H))
|
| 295 |
+
|
| 296 |
+
sky_mask_list.append(sky_mask)
|
| 297 |
+
|
| 298 |
+
# Convert list to numpy array with shape S×H×W
|
| 299 |
+
sky_mask_array = np.array(sky_mask_list)
|
| 300 |
+
# Apply sky mask to confidence scores
|
| 301 |
+
sky_mask_binary = (sky_mask_array > 0.1).astype(np.float32)
|
| 302 |
+
conf = conf * sky_mask_binary
|
| 303 |
+
|
| 304 |
+
print("Sky segmentation applied successfully")
|
| 305 |
+
return conf
|
| 306 |
+
|
| 307 |
+
|
| 308 |
+
parser = argparse.ArgumentParser(description="VGGT demo with viser for 3D visualization")
|
| 309 |
+
parser.add_argument(
|
| 310 |
+
"--image_folder", type=str, default="examples/kitchen/images/", help="Path to folder containing images"
|
| 311 |
+
)
|
| 312 |
+
parser.add_argument("--use_point_map", action="store_true", help="Use point map instead of depth-based points")
|
| 313 |
+
parser.add_argument("--background_mode", action="store_true", help="Run the viser server in background mode")
|
| 314 |
+
parser.add_argument("--port", type=int, default=8080, help="Port number for the viser server")
|
| 315 |
+
parser.add_argument(
|
| 316 |
+
"--conf_threshold", type=float, default=25.0, help="Initial percentage of low-confidence points to filter out"
|
| 317 |
+
)
|
| 318 |
+
parser.add_argument("--mask_sky", action="store_true", help="Apply sky segmentation to filter out sky points")
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
def main():
|
| 322 |
+
"""
|
| 323 |
+
Main function for the VGGT demo with viser for 3D visualization.
|
| 324 |
+
|
| 325 |
+
This function:
|
| 326 |
+
1. Loads the VGGT model
|
| 327 |
+
2. Processes input images from the specified folder
|
| 328 |
+
3. Runs inference to generate 3D points and camera poses
|
| 329 |
+
4. Optionally applies sky segmentation to filter out sky points
|
| 330 |
+
5. Visualizes the results using viser
|
| 331 |
+
|
| 332 |
+
Command-line arguments:
|
| 333 |
+
--image_folder: Path to folder containing input images
|
| 334 |
+
--use_point_map: Use point map instead of depth-based points
|
| 335 |
+
--background_mode: Run the viser server in background mode
|
| 336 |
+
--port: Port number for the viser server
|
| 337 |
+
--conf_threshold: Initial percentage of low-confidence points to filter out
|
| 338 |
+
--mask_sky: Apply sky segmentation to filter out sky points
|
| 339 |
+
"""
|
| 340 |
+
args = parser.parse_args()
|
| 341 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 342 |
+
dtype = torch.bfloat16 if torch.cuda.get_device_capability()[0] >= 8 else torch.float16
|
| 343 |
+
print(f"Using device: {device}")
|
| 344 |
+
|
| 345 |
+
print("Initializing and loading VGGT model...")
|
| 346 |
+
# model = VGGT.from_pretrained("facebook/VGGT-1B")
|
| 347 |
+
|
| 348 |
+
model = VGGT()
|
| 349 |
+
_URL = "https://huggingface.co/facebook/VGGT-1B/resolve/main/model.pt"
|
| 350 |
+
model.load_state_dict(torch.hub.load_state_dict_from_url(_URL))
|
| 351 |
+
|
| 352 |
+
model.eval()
|
| 353 |
+
model = model.to(dtype=dtype, device=device)
|
| 354 |
+
|
| 355 |
+
# Use the provided image folder path
|
| 356 |
+
print(f"Loading images from {args.image_folder}...")
|
| 357 |
+
image_names = glob.glob(os.path.join(args.image_folder, "*"))
|
| 358 |
+
print(f"Found {len(image_names)} images")
|
| 359 |
+
|
| 360 |
+
images = load_and_preprocess_images(image_names).to(dtype=dtype, device=device)
|
| 361 |
+
print(f"Preprocessed images shape: {images.shape}")
|
| 362 |
+
|
| 363 |
+
print("Running inference...")
|
| 364 |
+
with torch.no_grad():
|
| 365 |
+
predictions = model(images, verbose=True)
|
| 366 |
+
|
| 367 |
+
print("Converting pose encoding to extrinsic and intrinsic matrices...")
|
| 368 |
+
extrinsic, intrinsic = pose_encoding_to_extri_intri(predictions["pose_enc"], images.shape[-2:])
|
| 369 |
+
predictions["extrinsic"] = extrinsic
|
| 370 |
+
predictions["intrinsic"] = intrinsic
|
| 371 |
+
|
| 372 |
+
print("Processing model outputs...")
|
| 373 |
+
for key in predictions.keys():
|
| 374 |
+
if isinstance(predictions[key], torch.Tensor):
|
| 375 |
+
predictions[key] = predictions[key].cpu().numpy().squeeze(0) # remove batch dimension and convert to numpy
|
| 376 |
+
|
| 377 |
+
if args.use_point_map:
|
| 378 |
+
print("Visualizing 3D points from point map")
|
| 379 |
+
else:
|
| 380 |
+
print("Visualizing 3D points by unprojecting depth map by cameras")
|
| 381 |
+
|
| 382 |
+
if args.mask_sky:
|
| 383 |
+
print("Sky segmentation enabled - will filter out sky points")
|
| 384 |
+
|
| 385 |
+
print("Starting viser visualization...")
|
| 386 |
+
|
| 387 |
+
viser_server = viser_wrapper(
|
| 388 |
+
predictions,
|
| 389 |
+
port=args.port,
|
| 390 |
+
init_conf_threshold=args.conf_threshold,
|
| 391 |
+
use_point_map=args.use_point_map,
|
| 392 |
+
background_mode=args.background_mode,
|
| 393 |
+
mask_sky=args.mask_sky,
|
| 394 |
+
image_folder=args.image_folder,
|
| 395 |
+
)
|
| 396 |
+
print("Visualization complete")
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
if __name__ == "__main__":
|
| 400 |
+
main()
|
vggt-low-vram/docs/package.md
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Alternative Installation Methods
|
| 2 |
+
|
| 3 |
+
This document explains how to install VGGT as a package using different package managers.
|
| 4 |
+
|
| 5 |
+
## Prerequisites
|
| 6 |
+
|
| 7 |
+
Before installing VGGT as a package, you need to install PyTorch and torchvision. We don't list these as dependencies to avoid CUDA version mismatches. Install them first, with an example as:
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
# install pytorch 2.3.1 with cuda 12.1
|
| 11 |
+
pip install torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu121
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
## Installation Options
|
| 15 |
+
|
| 16 |
+
### Install with pip
|
| 17 |
+
|
| 18 |
+
The simplest way to install VGGT is using pip:
|
| 19 |
+
|
| 20 |
+
```bash
|
| 21 |
+
pip install -e .
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
### Install and run with pixi
|
| 25 |
+
|
| 26 |
+
[Pixi](https://pixi.sh) is a package management tool for creating reproducible environments.
|
| 27 |
+
|
| 28 |
+
1. First, [download and install pixi](https://pixi.sh/latest/get_started/)
|
| 29 |
+
2. Then run:
|
| 30 |
+
|
| 31 |
+
```bash
|
| 32 |
+
pixi run -e python demo_gradio.py
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
### Install and run with uv
|
| 36 |
+
|
| 37 |
+
[uv](https://docs.astral.sh/uv/) is a fast Python package installer and resolver.
|
| 38 |
+
|
| 39 |
+
1. First, [install uv](https://docs.astral.sh/uv/getting-started/installation/)
|
| 40 |
+
2. Then run:
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
uv run --extra demo demo_gradio.py
|
| 44 |
+
```
|
| 45 |
+
|
vggt-low-vram/examples/kitchen/images/00.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/01.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/02.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/03.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/04.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/05.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/06.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/07.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/08.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/09.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/10.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/11.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/12.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/13.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/14.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/15.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/16.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/17.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/18.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/19.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/20.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/21.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/22.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/23.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/kitchen/images/24.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/llff_fern/images/000.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/llff_fern/images/001.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/llff_fern/images/002.png
ADDED

|
Git LFS Details
|
vggt-low-vram/examples/llff_fern/images/003.png
ADDED

|
Git LFS Details
|