# 开源盘古-R-7B-Diffusion
中文 | [English](README_EN.md)
## 1. 简介
openPangu-R-7B-Diffusion 是一种基于扩散机制的新型语言模型,采用了前文因果块扩散(context-causal block diffusion)技术,采用稠密结构,参数量为 7B(不含词表Embedding)。openPangu-R-7B-Diffusion在openPangu-Embedded-7B预训练模型基础上进行续训,依次进行了700B 8k序列长度的预训练,100B 32k序列长度的退火,和10 epoch的10B慢思考SFT。模型训练推理全流程基于昇腾NPU。
- openPangu-7B-Diffusion-Base:预训练模型,上下文长度为8k。
- openPangu-R-7B-Diffusion:慢思考SFT模型,上下文长度为32k。
### 主要特点:
#### 推理
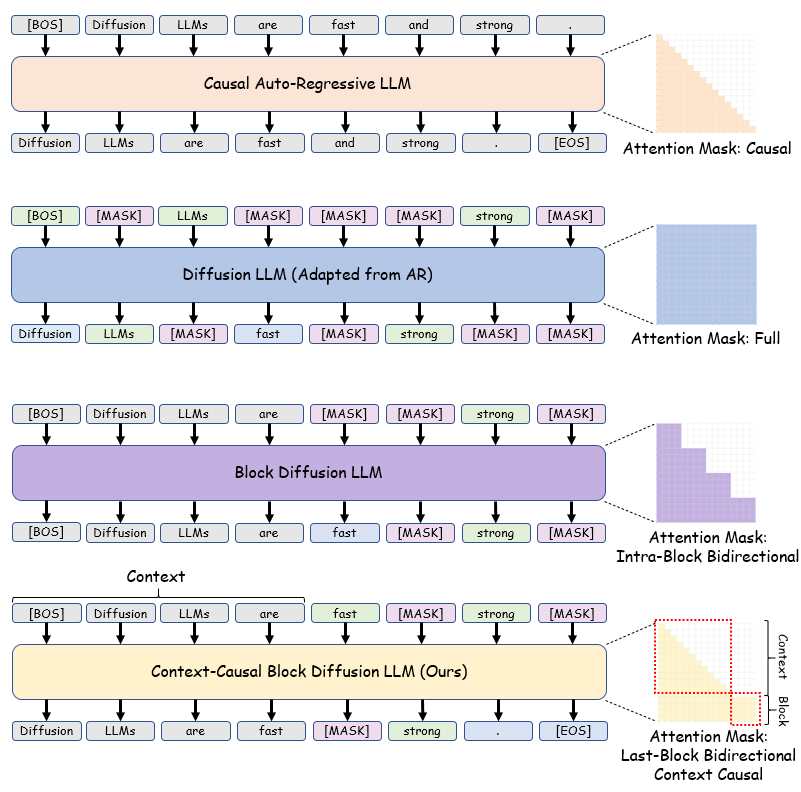
openPangu-R-7B-Diffusion采用**前文因果块扩散解码**,逐块进行扩散解码。解码过程中块内为全注意力,前文为因果注意力。当块内的token全部完成解码时,将整块token存入前文KV缓存,缓存采用因果注意力掩码,同时解码下一个block的首token。
- 支持变长推理和KV缓存。
- 灵活的上下文长度,不受块长度的限制。
- 支持自回归和块扩散两种解码方式。
- 使用confidence threshold采样,相比标准自回归解码,吞吐量最高可提升2.5倍。
- 类似于Fast dLLMv2在block内设置small block,可实现吞吐和效果的权衡,通常在small block长为4或8时表现最优。
#### 训练

openPangu-R-7B-Diffusion训练时将带掩码语料块与不带掩码的context拼接。对掩码语料块预测掩码部分token,对不带掩码的context部分进行自回归训练。
- 保留与自回归模型相同的前文因果注意力掩码(causal attention mask)形状,快速从自回归模型适配到BlockDiffusion模型。
- BlockDiffusion的块扩散训练,只利用了带掩码的语料块进行训练,无掩码的context部分信息被浪费。得益于前文因果(context-causal)的设计,openPangu-R-7B-Diffusion能够同时对context进行自回归训练,提升训练效率。
- 与全注意力扩散模型相比,每个batch参与训练的token数更稳定,确保长序列训练能够平稳进行。

## 2. 模型架构
| | openPangu-R-7B-Diffusion |
| :----------------------------: | :--------------------: |
| **Architecture** | Dense |
| **Parameters (Non-Embedding)** | 7B |
| **Number of Layers** | 34 |
| **Hidden Dimension** | 12800 |
| **Attention Mechanism** | GQA |
| **Number of Attention Heads** | 32 for Q,8 for KV |
| **Vocabulary Size** | 153k |
| **Context Length (Natively)** | 32k |
| **Continued training Tokens** | 800B |
## 3. 测评结果
| Benchmark | 测评指标 | Dream-v0-Instruct-7B | Fast-dLLMv2 | LLaDA2.0-mini-preview (16BA1B) | SDAR-8B | openPangu-R-7B-Diffusion |
| :-------: | :-----------: | :------------------: | :----------: |:------------------------------:| :----------: | :----------------------: |
| **通用能力** | | | | | | |
| MMLU | Acc | 67.00 | 66.60 | 72.49 | 78.60 | **81.66** |
| MMLU-Pro | Acc | 43.30 | 44.42* | 49.22 | 56.90 | **71.26** |
| CMMLU | Acc | 58.82 | 59.67* | 67.53 | 75.70 | **76.43** |
| CEval | Acc | 57.98 | 66.76* | 66.54 | **72.72*** | 70.81 |
| IFEval | Prompt Strict | **62.50** | 61.40 | **62.50** | 61.40 | 60.81 |
| **数学能力** | | | | | | |
| GSM8K | Acc | 81.00 | 83.70 | 89.01 | 91.30 | **91.89** |
| MATH | Acc | 39.20 | 61.60 | 73.50 | 78.60 | **84.26** |
| **代码能力** | | | | | | |
| MBPP | Pass@1 | 58.80 | 57.10 | 77.75 | 72.00 | **84.05** |
| HumanEval | Pass@1 | 55.50 | 63.40 | 80.49 | 78.70 | **87.80** |
| **Avg** | | 58.22 | 62.74 | 70.95 | 73.99 | **78.77** |
**注:** 对于编程基准测试(MBPP和HumanEval),我们使用采样设置`alg="entropy", num_small_blocks=32, top_p=0.8, temperature=1`。对于其他基准测试,我们使用`alg="entropy", num_small_blocks=8, top_p=1, temperature=0`。所有评估生成长度为28k个token。上表中标有*的数据官方没有报告,指标是用官方代码自行测出。
## 4. 部署和使用
### 4.1 环境准备
##### 硬件规格
Atlas 800T A2 (64GB),驱动与固件安装包获取请参照 [[Atlas 800T A2](https://www.hiascend.com/hardware/firmware-drivers/community?product=4&model=26&cann=8.2.RC1.alpha003&driver=Ascend+HDK+25.0.RC1)]。
##### 软件环境
- 操作系统:Linux(推荐 openEuler>=24.03)
- CANN==8.1.RC1,安装准备及流程请参照 [[CANN Install]](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/82RC1alpha002/softwareinst/instg/instg_0001.html?Mode=PmIns&OS=Ubuntu&Software=cannToolKit)
- python==3.10
- torch==2.6.0
- torch-npu==2.6.0
- transformers==4.53.2
以上软件配套经过验证,理论可以支持更高版本,如有疑问,可以提交 issue。
### 4.2 推理样例
下述内容提供 openPangu-R-7B-Diffusion 在 `transformers` 框架上进行推理的一个简单示例:
> 运行前请修改 generate.py,添加模型路径。
```bash
cd inference
python generate.py
```
与基准测试不同,为了实现最佳吞吐量,采样参数应设置为 `alg="confidence_threshold", threshold=0.9, num_small_blocks=1`,并根据设备选择合适的batch size。
## 5. 模型许可证
除文件中对开源许可证另有约定外,openPangu-R-7B-Diffusion 模型根据 OPENPANGU MODEL LICENSE AGREEMENT VERSION 1.0 授权,旨在允许使用并促进人工智能技术的进一步发展。有关详细信息,请参阅模型存储库根目录中的 [LICENSE](LICENSE) 文件。
## 6. 免责声明
由于 openPangu-R-7B-Diffusion(“模型”)所依赖的技术固有的技术限制,以及人工智能生成的内容是由盘古自动生成的,华为无法对以下事项做出任何保证:
- 尽管该模型的输出由 AI 算法生成,但不能排除某些信息可能存在缺陷、不合理或引起不适的可能性,生成的内容不代表华为的态度或立场;
- 无法保证该模型 100% 准确、可靠、功能齐全、及时、安全、无错误、不间断、持续稳定或无任何故障;
- 该模型的输出内容不构成任何建议或决策,也不保证生成的内容的真实性、完整性、准确性、及时性、合法性、功能性或实用性。生成的内容不能替代医疗、法律等领域的专业人士回答您的问题。生成的内容仅供参考,不代表华为的任何态度、立场或观点。您需要根据实际情况做出独立判断,华为不承担任何责任。
## 7. 反馈
如果有任何意见和建议,请提交issue或联系 openPangu@huawei.com。