---
license: apache-2.0
pipeline_tag: image-text-to-text
tags:
- minicpm-v
- multimodal
---
> **This repository hosts the bitsandbytes (NF4, 4-bit) quantized version of [MiniCPM-V 4.6 Thinking](https://huggingface.co/openbmb/MiniCPM-V-4.6-Thinking).** For the original BF16 weights and the full model card, please refer to [openbmb/MiniCPM-V-4.6-Thinking](https://huggingface.co/openbmb/MiniCPM-V-4.6-Thinking).
A Pocket-Sized MLLM for Ultra-Efficient Image and Video Understanding on Your Phone
[GitHub](https://github.com/OpenBMB/MiniCPM-o) | [CookBook](https://github.com/OpenSQZ/MiniCPM-V-CookBook) | [Demo](https://huggingface.co/spaces/openbmb/MiniCPM-V-4.6-Thinking-BNB-Demo) |
[Feishu (Lark)](https://raw.githubusercontent.com/openbmb/MiniCPM-V/main/assets/feishu_qrcode.png)
## MiniCPM-V 4.6 Thinking
**MiniCPM-V 4.6 Thinking** is the long chain-of-thought reasoning variant of [MiniCPM-V 4.6](https://huggingface.co/openbmb/MiniCPM-V-4.6). It generates an explicit reasoning trace before producing the final answer, substantially boosting performance on complex multimodal reasoning, math, and OCR-heavy tasks, while keeping the same edge-friendly architecture (SigLIP2-400M vision encoder + Qwen3.5-0.8B LLM) and the mixed 4x/16x visual token compression of MiniCPM-V 4.6.
### Evaluation
**Overall Performance (Thinking)**
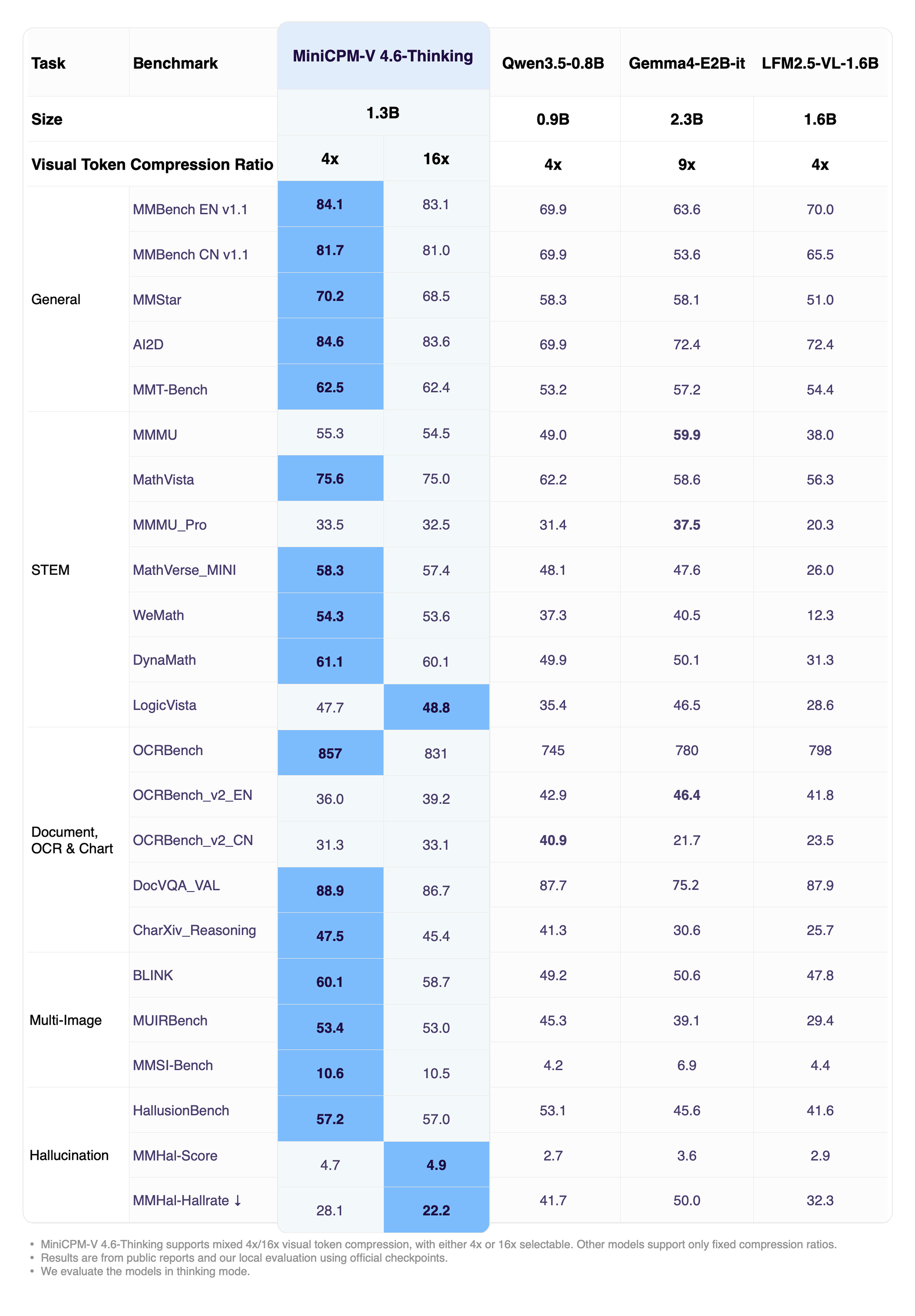
Click to view MiniCPM-V 4.6 (Instruct) performance.
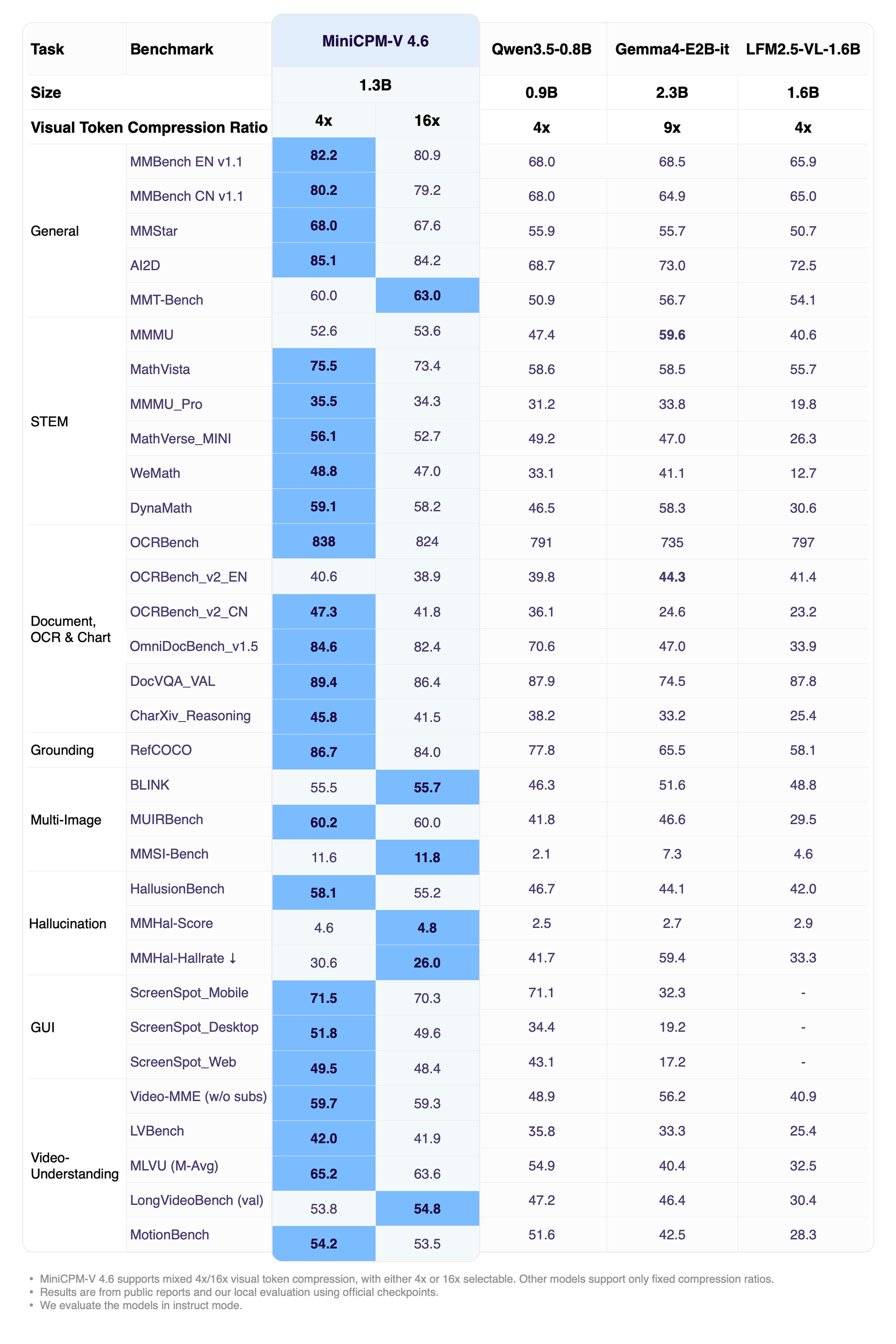
Click to view MiniCPM-V 4.6 inference efficiency results.
**High-Concurrency Throughput**
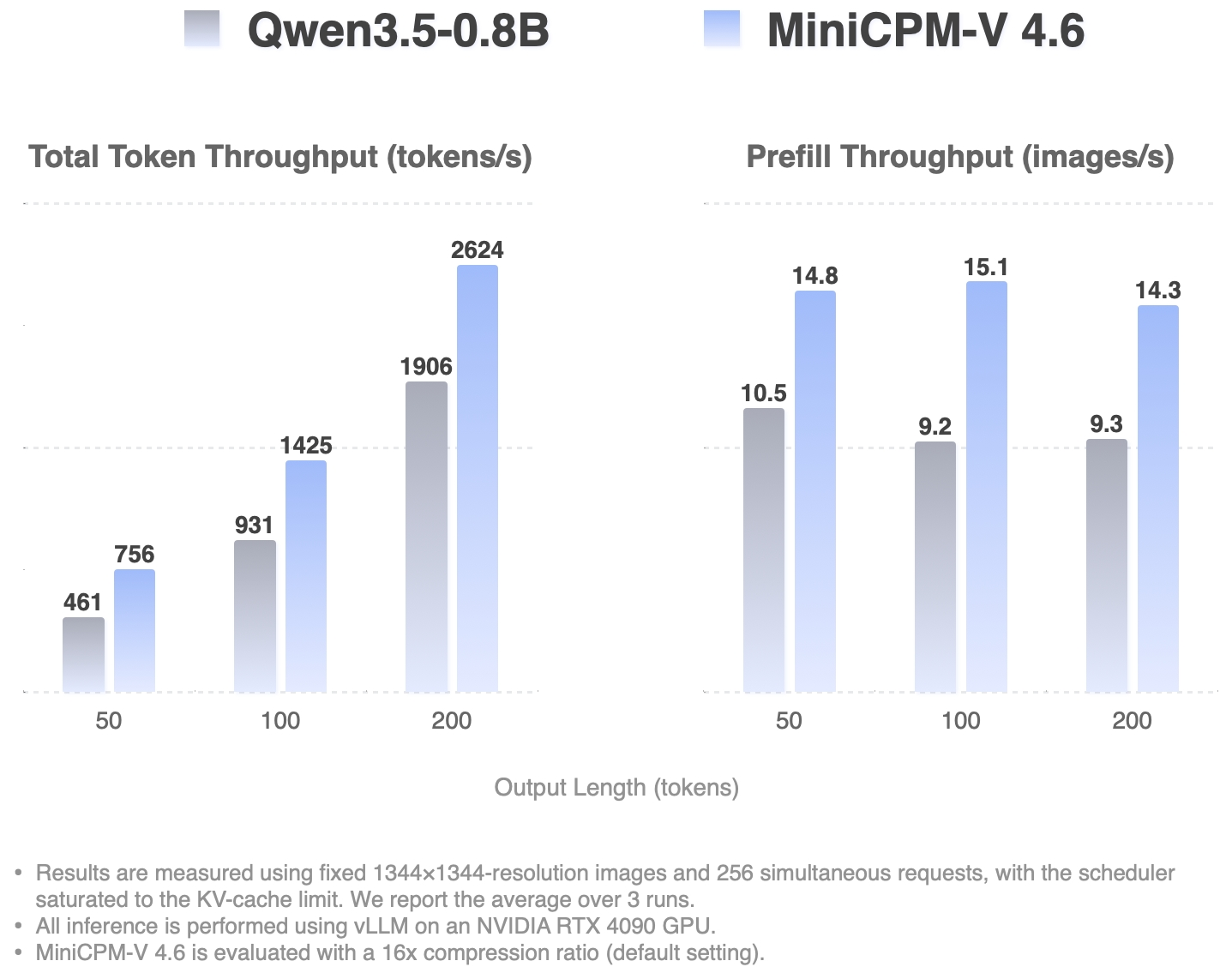
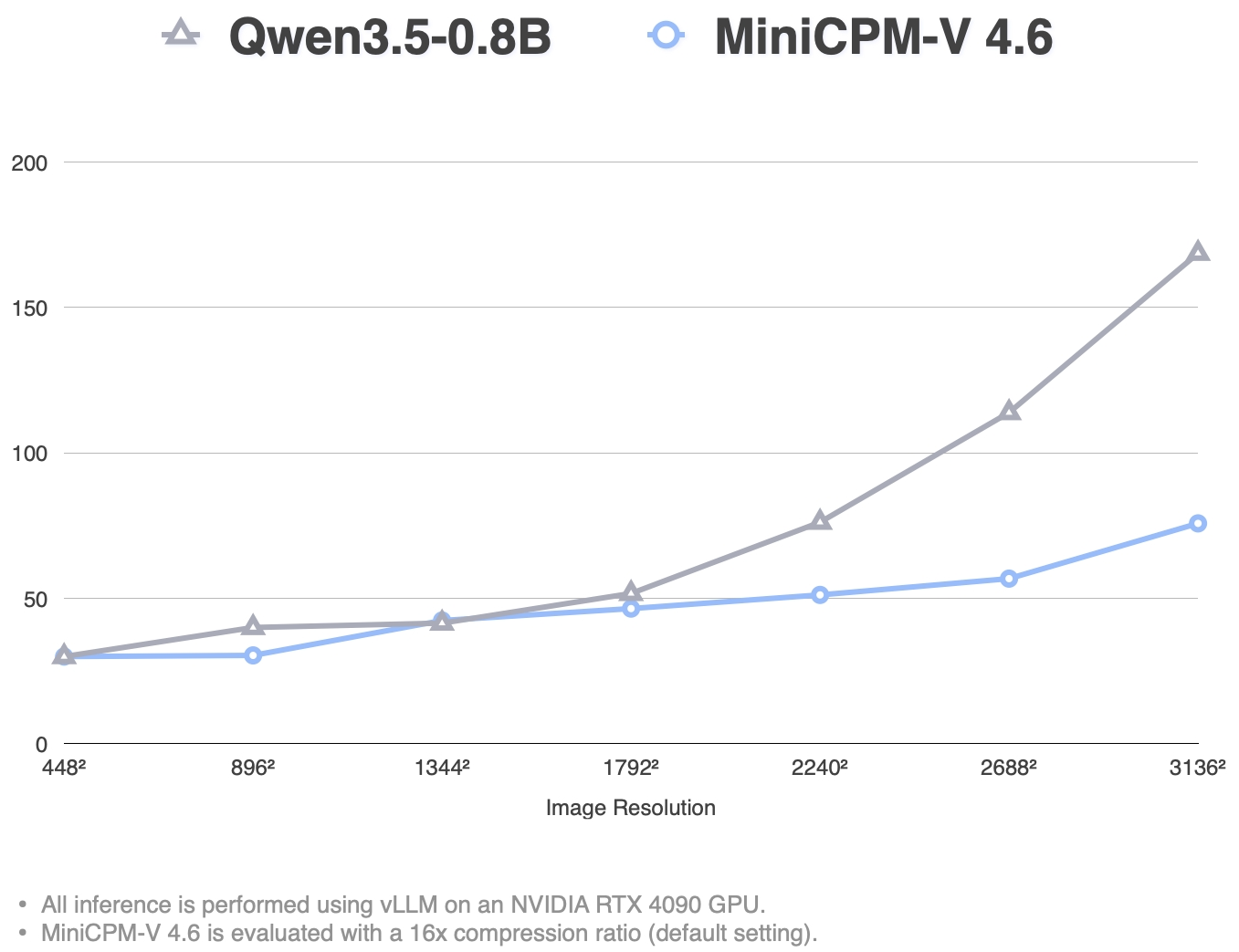
**Single Request TTFT (ms)**
### Examples
#### Overall
MiniCPM-V 4.6 can be deployed across three mainstream end-side platforms — **iOS, Android and HarmonyOS**. The clips below are raw screen recordings on phone devices without edition.
iPhone
iPhone 17 Pro Max |
Android
Redmi K70 |
HarmonyOS
HUAWEI nova 14 |
 |
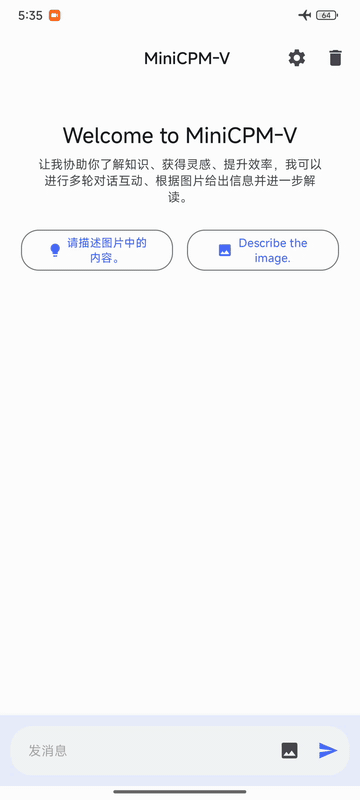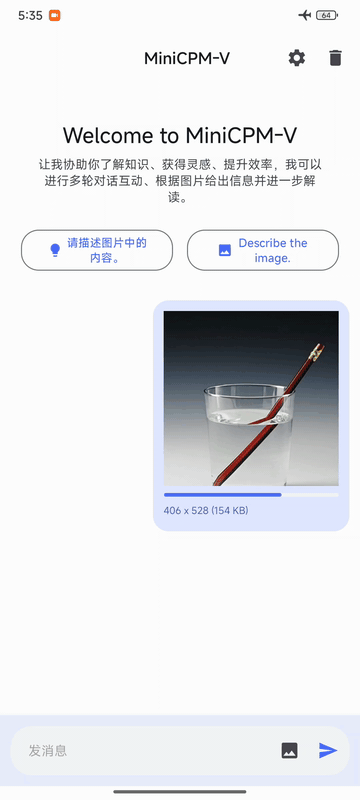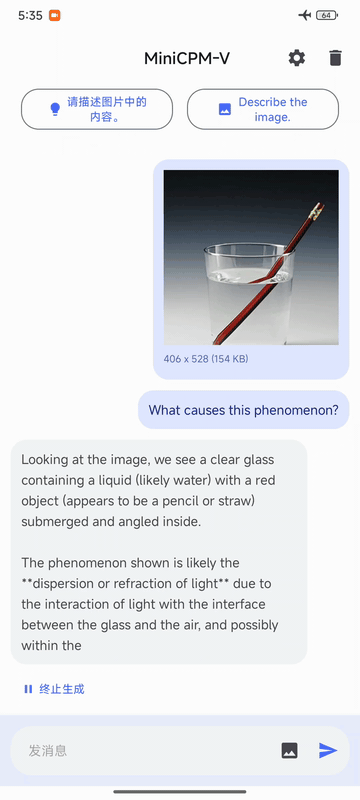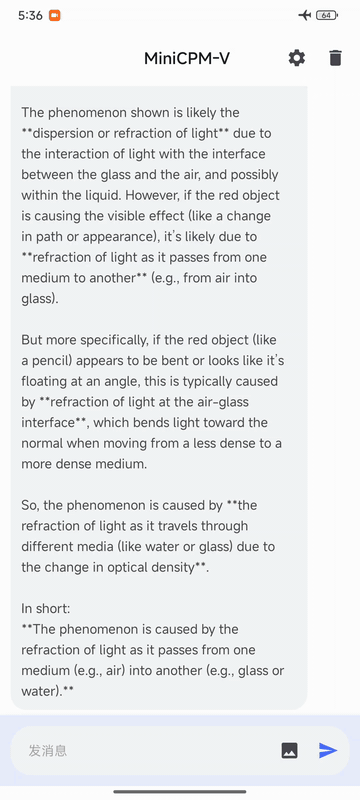 |
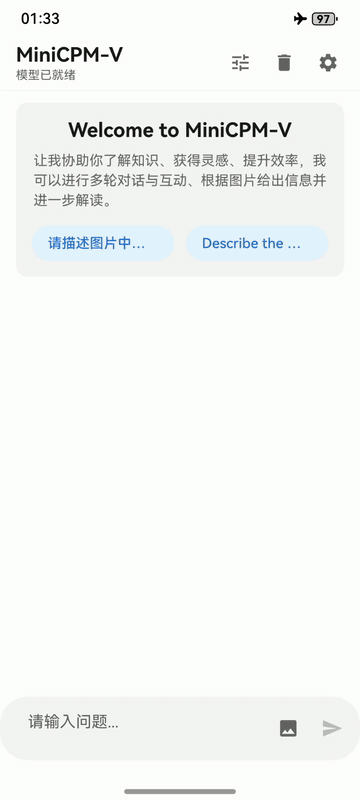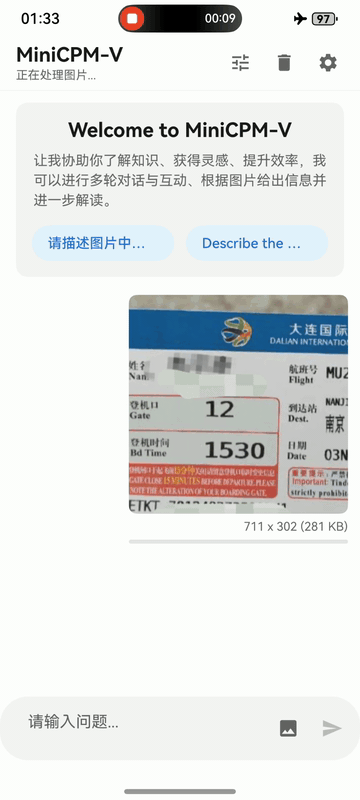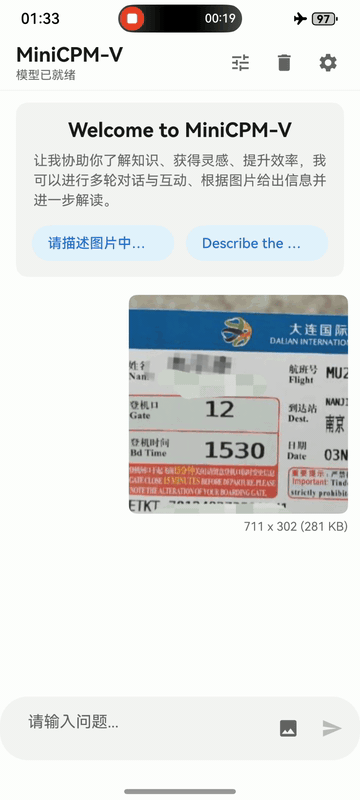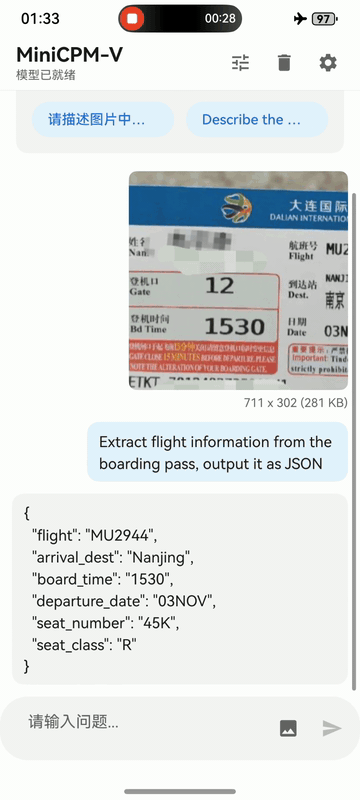 |
### Usages
#### Inference with Transformers
##### Installation
```bash
pip install "transformers[torch]>=5.7.0" torchvision torchcodec
```
> **Note on CUDA compatibility:** `torchcodec` (used for video decoding) may have compatibility issues with certain CUDA versions. For example, `torch>=2.11` bundles CUDA 13.1 by default, while environments with CUDA 12.x may encounter errors such as `RuntimeError: Could not load libtorchcodec`. Two workarounds:
>
> 1. **Replace `torchcodec` with `PyAV`** — supports both image and video inference without CUDA version constraints:
> ```bash
> pip install "transformers[torch]>=5.7.0" torchvision av
> ```
> 2. **Pin the CUDA version** when installing torch to match your environment (e.g. CUDA 12.8):
> ```bash
> pip install "transformers>=5.7.0" torchvision torchcodec --index-url https://download.pytorch.org/whl/cu128
> ```
##### Load Model
```python
from transformers import AutoModelForImageTextToText, AutoProcessor
model_id = "openbmb/MiniCPM-V-4.6-Thinking-BNB"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForImageTextToText.from_pretrained(
model_id, torch_dtype="auto", device_map="auto"
)
# Flash Attention 2 is recommended for better acceleration and memory saving,
# especially in multi-image and video scenarios.
# model = AutoModelForImageTextToText.from_pretrained(
# model_id,
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
```
##### Image Inference
```python
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"},
{"type": "text", "text": "What causes this phenomenon?"},
],
}
]
downsample_mode = "16x" # Using `downsample_mode="4x"` for Finer Detail
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_dict=True, return_tensors="pt",
downsample_mode=downsample_mode,
max_slice_nums=36,
).to(model.device)
generated_ids = model.generate(**inputs, downsample_mode=downsample_mode, max_new_tokens=512)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
```
##### Video Inference
```python
messages = [
{
"role": "user",
"content": [
{"type": "video", "url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/football.mp4"},
{"type": "text", "text": "Describe this video in detail. Follow the timeline and focus on on-screen text, interface changes, main actions, and scene changes."},
],
}
]
downsample_mode = "16x" # Using `downsample_mode="4x"` for Finer Detail
inputs = processor.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True,
return_dict=True, return_tensors="pt",
downsample_mode=downsample_mode,
max_num_frames=128,
stack_frames=1,
max_slice_nums=1,
use_image_id=False,
).to(model.device)
generated_ids = model.generate(**inputs, downsample_mode=downsample_mode, max_new_tokens=2048)
generated_ids_trimmed = [
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text[0])
```
##### Advanced Parameters
You can customize image/video processing by passing additional parameters to `apply_chat_template`:
| Parameter | Default | Applies to | Description |
|-----------|---------|------------|-------------|
| `downsample_mode` | `"16x"` | Image & Video | Visual token downsampling. `"16x"` merges tokens for efficiency; `"4x"` keeps 4× more tokens for finer detail. Must also be passed to `generate()`. |
| `max_slice_nums` | `9` | Image & Video | Maximum number of slices when splitting a high-resolution image. Higher values preserve more detail for large images. Recommended: `36` for image, `1` for video. |
| `max_num_frames` | `128` | Video only | Maximum number of main frames sampled from the video. |
| `stack_frames` | `1` | Video only | Total sample points per second. `1` = main frame only (no stacking). `N` (N>1) = 1 main frame + N−1 sub-frames per second; the sub-frames are composited into a grid image and interleaved with main frames. Recommended: `3` or `5`. |
| `use_image_id` | `True` | Image & Video | Whether to prepend `N` tags before each image/frame placeholder. Recommended: `True` for image, `False` for video. |
> **Note:** `downsample_mode` must be passed to **both** `apply_chat_template` (for correct placeholder count) and `generate` (for the vision encoder). All other parameters only need to be passed to `apply_chat_template`.
##### Serving with `transformers serve`
Hugging Face Transformers includes a lightweight OpenAI-compatible server for quick testing and moderate-load deployment.
```bash
pip install "transformers[serving]>=5.7.0"
```
Start the server:
```bash
transformers serve openbmb/MiniCPM-V-4.6-Thinking-BNB --port 8000 --host 0.0.0.0 --continuous-batching
```
Send a request:
```bash
curl -s http://localhost:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "openbmb/MiniCPM-V-4.6-Thinking-BNB",
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"}},
{"type": "text", "text": "What causes this phenomenon?"}
]
}]
}'
```
#### Handling Escaped Newlines in Model Outputs
In some cases, the model might output escaped newline characters `\n` as string literals instead of actual newlines. To render the text correctly, especially in UI layers, you can use the following utility function. This function carefully replaces literal `\n` with real newlines while protecting scenarios where `\n` has specific semantic meaning.
**Utility Function:**
```python
import re
_PATTERN = re.compile(
r'(```[\s\S]*?```' # fenced code blocks
r'|`[^`]+`' # inline code
r'|\$\$[\s\S]*?\$\$' # display math
r'|\$[^$]+\$' # inline math
r'|\\\([\s\S]*?\\\)' # \(...\)
r'|\\\[[\s\S]*?\\\]' # \[...\]
r')'
r'|(? str:
"""
Lightweight post-processing: Converts literal '\\n' to actual newlines,
while protecting code blocks, inline code, and LaTeX commands.
"""
if not isinstance(text, str) or "\\" not in text:
return text
return _PATTERN.sub(lambda m: m.group(1) or '\n', text)
```
#### Deploy MiniCPM-V 4.6 on iOS, Android, and HarmonyOS Platforms
We have adapted MiniCPM-V 4.6 for deployment on **iOS, Android, and HarmonyOS** platforms, with **all edge adaptation code fully open-sourced**. Developers can reproduce the on-device experience in just a few steps. Visit our [edge deployment repository](https://github.com/OpenBMB/MiniCPM-V-edge-demo) for platform-specific build guides, or go to the [download page](https://github.com/OpenBMB/MiniCPM-V-edge-demo/blob/main/DOWNLOAD.md) to try pre-built apps directly.
#### Use MiniCPM-V 4.6 in Other Inference and Training Frameworks
MiniCPM-V 4.6 supports multiple inference and training frameworks. Below are quick-start commands for each. For full details, see our [Cookbook](https://github.com/OpenSQZ/MiniCPM-V-CookBook).
vLLM — Full Guide
```bash
vllm serve openbmb/MiniCPM-V-4.6-Thinking-BNB \
--port 8000 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--default-chat-template-kwargs '{"enable_thinking": true}'
```
> **Note:** `--enable-auto-tool-choice` and `--tool-call-parser qwen3_coder` enable tool/function calling support. If you don't need tool use, you can omit these flags and simply run `vllm serve openbmb/MiniCPM-V-4.6-Thinking-BNB`.
```bash
curl -s http://localhost:8000/v1/chat/completions -H 'Content-Type: application/json' -d '{
"model": "openbmb/MiniCPM-V-4.6-Thinking-BNB",
"messages": [{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"}},
{"type": "text", "text": "What causes this phenomenon?"}
]}]
}'
```
Tool calling example:
```bash
curl -s http://localhost:8000/v1/chat/completions -H 'Content-Type: application/json' -d '{
"model": "openbmb/MiniCPM-V-4.6-Thinking-BNB",
"messages": [{"role": "user", "content": [
{"type": "text", "text": "北京的天气"}
]}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City name"}
},
"required": ["location"]
}
}
}]
}'
```
SGLang — Full Guide
```bash
python -m sglang.launch_server --model openbmb/MiniCPM-V-4.6-Thinking-BNB --port 30000
```
```bash
curl -s http://localhost:30000/v1/chat/completions -H 'Content-Type: application/json' -d '{
"model": "openbmb/MiniCPM-V-4.6-Thinking-BNB",
"messages": [{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"}},
{"type": "text", "text": "What causes this phenomenon?"}
]}]
}'
```
llama.cpp — Full Guide
```bash
llama-server -m MiniCPM-V-4.6-Q4_K_M.gguf --port 8080
```
```bash
curl -s http://localhost:8080/v1/chat/completions -H 'Content-Type: application/json' -d '{
"model": "MiniCPM-V-4.6",
"messages": [{"role": "user", "content": [
{"type": "image_url", "image_url": {"url": "https://huggingface.co/datasets/openbmb/DemoCase/resolve/main/refract.png"}},
{"type": "text", "text": "What causes this phenomenon?"}
]}]
}'
```
Ollama — Full Guide
```bash
ollama run minicpm-v-4.6-thinking
```
In the interactive session, paste an image path or URL directly to chat with the model.
LLaMA-Factory (Fine-tuning) — Full Guide
```bash
llamafactory-cli train examples/train_lora/minicpmv4_6_lora_sft.yaml
```
ms-swift (Fine-tuning) — Full Guide
```bash
swift sft --model_type minicpm-v-4_6 --dataset
```
## License
#### Model License
* The MiniCPM-o/V model weights and code are open-sourced under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM-V/blob/main/LICENSE) license.
#### Statement
* As MLLMs, MiniCPM-o/V models generate content by learning a large number of multimodal corpora, but they cannot comprehend, express personal opinions, or make value judgements. Anything generated by MiniCPM-o/V models does not represent the views and positions of the model developers
* We will not be liable for any problems arising from the use of MiniCPM-o/V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination, or misuse of the model.
## Technical Reports and Key Techniques Papers
👏 Welcome to explore key techniques of MiniCPM-o/V and other multimodal projects of our team:
**Technical Reports:** [MiniCPM-o 4.5](https://huggingface.co/papers/2604.27393) | [MiniCPM-V 4.5](https://arxiv.org/abs/2509.18154) | [MiniCPM-o 2.6](https://openbmb.notion.site/MiniCPM-o-2-6-A-GPT-4o-Level-MLLM-for-Vision-Speech-and-Multimodal-Live-Streaming-on-Your-Phone-185ede1b7a558042b5d5e45e6b237da9) | [MiniCPM-Llama3-V 2.5](https://arxiv.org/abs/2408.01800) | [MiniCPM-V 2.0](https://openbmb.vercel.app/minicpm-v-2)
**Other Multimodal Projects:** [VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLPR](https://github.com/OpenBMB/RLPR) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
## Citation
If you find our model/code/paper helpful, please consider citing our papers 📝 and staring us ⭐️!
```bib
@misc{cui2026minicpmo45realtimefullduplex,
title={MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction},
author={Junbo Cui and Bokai Xu and Chongyi Wang and Tianyu Yu and Weiyue Sun and Yingjing Xu and Tianran Wang and Zhihui He and Wenshuo Ma and Tianchi Cai and others},
year={2026},
url={https://arxiv.org/abs/2604.27393},
}
@proceedings{yu2025minicpmv45cookingefficient,
title={MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe},
author={Tianyu Yu and Zefan Wang and Chongyi Wang and Fuwei Huang and Wenshuo Ma and Zhihui He and Tianchi Cai and Weize Chen and Yuxiang Huang and Yuanqian Zhao and others},
year={2025},
url={https://arxiv.org/abs/2509.18154},
}
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={arXiv preprint arXiv:2408.01800},
year={2024}
}
```