---
license: mit
datasets:
- Sylvest/LIBERO-plus
---
## 🌌 CorridorVLA
This repository provides the official implementation of **CorridorVLA**.
> **Direct spatial constraints for Vision-Language-Action models via sparse physical anchors**
[](https://arxiv.org/abs/2604.21241)
[](https://github.com/lidc54/corridorVLA)
[](#)
---
## 🔍 TL;DR
* Explore an alternative to common visual-style spatial guidance (e.g., predicting future images/videos) using **text-style physical anchors**
* Predict sparse **end-effector Δ-positions**
* Use them to impose an **explicit corridor constraint** on action generation
* Achieves **83.21% success rate on LIBERO-Plus**
---
## 🧠 Motivation
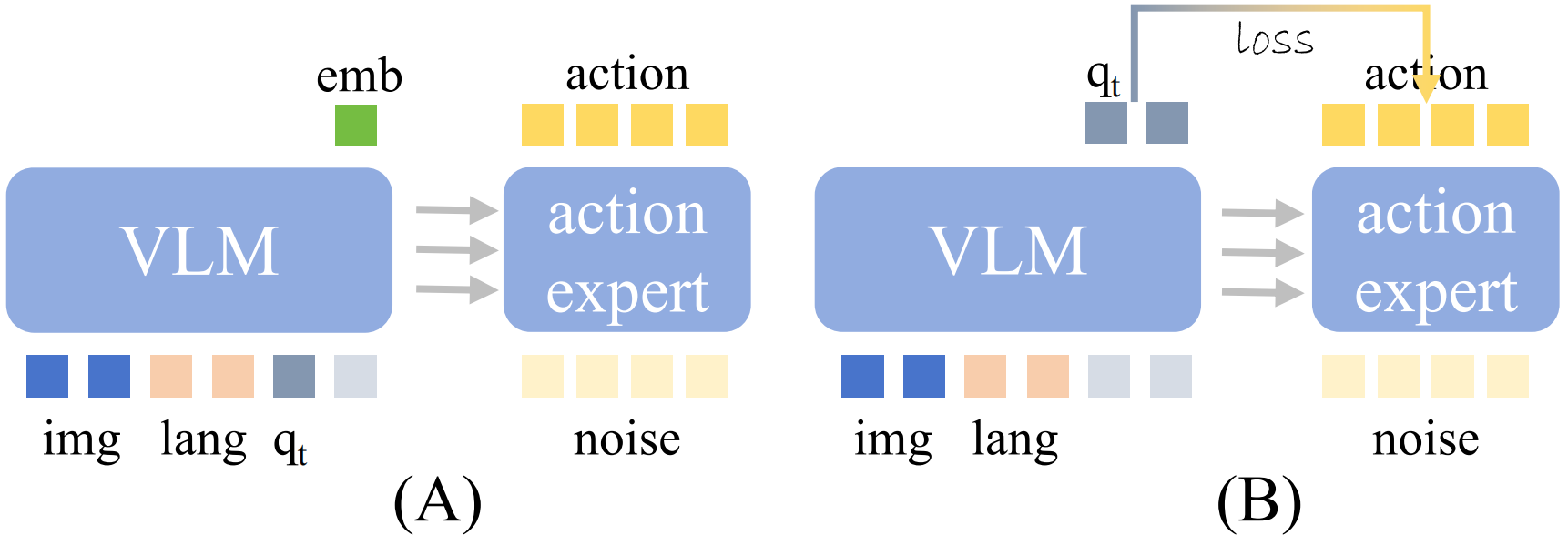
### Existing VLA paradigm
* Spatial guidance is encoded as visual-style tokens or latent features
* Action generation is influenced indirectly through the backbone features
### CorridorVLA
* Predict **compact physical quantities** (spatial anchors)
* Apply them as **direct constraints in the loss**
* No need for heavy visual intermediate representations
---
## 🏗️ Method Overview
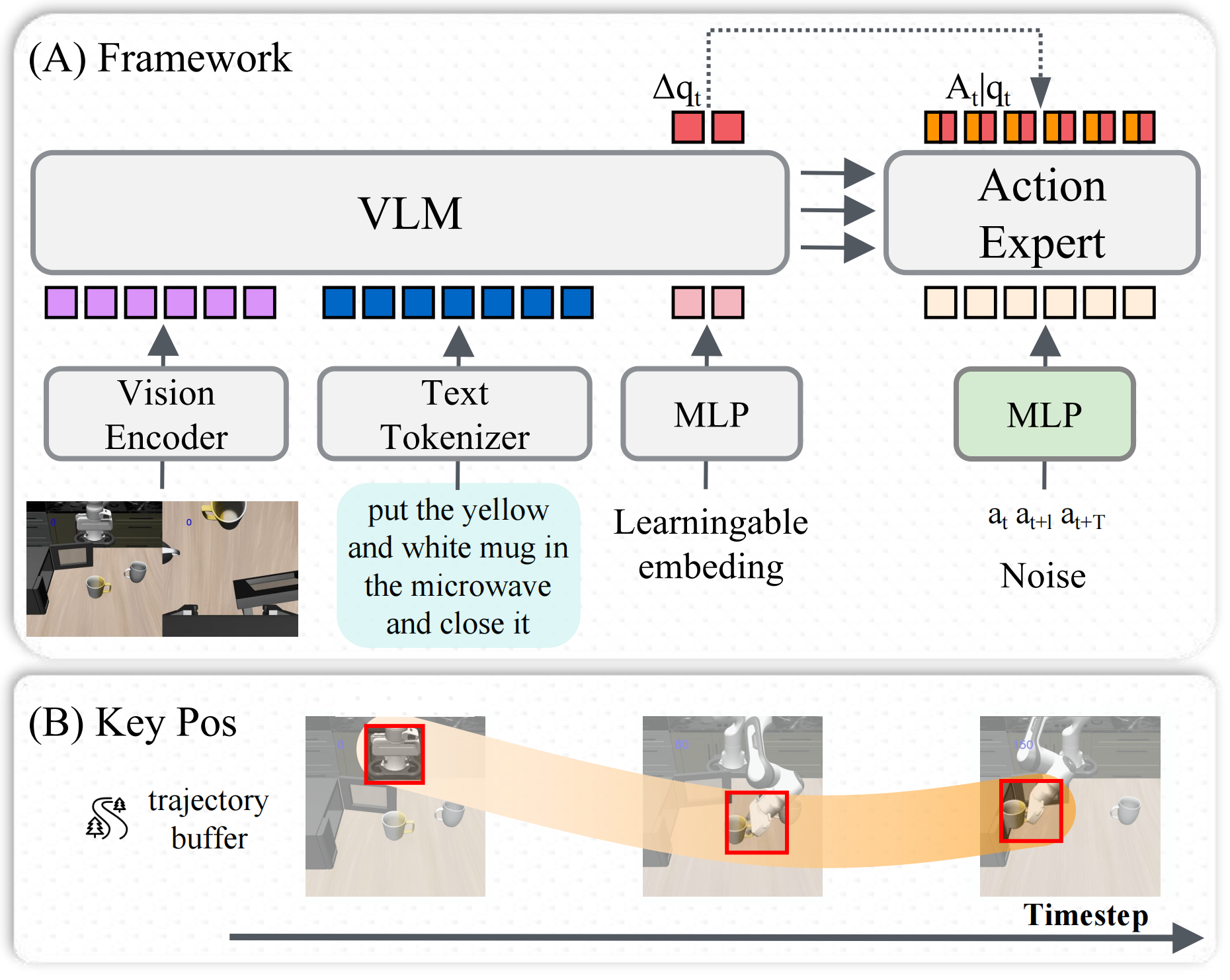
### Key components
**(1) Sparse Anchor Prediction**
* Predict $K$ future **Δ-position anchors**
* Represent trajectory structure in a compact form
**(2) Action Augmentation**
* Concatenate state-related physical quantities (e.g., Δ-positions) to the action vector
* Enable joint prediction of state and action, providing implicit alignment between state space and action space
**(3) Corridor Loss**
* Defines a tolerance region over the predicted trajectory
* Penalizes deviations outside the region while allowing smooth convergence within it
👉 Behaves like a **structured smooth-L1 in trajectory space**
---
## 📊 Results
### LIBERO-Plus (GR00T-based)
| Variant | Description | AVG |
|--------|----------------------------------|------|
| base | | 75.23 |
| c1 | query=3 | 77.25 |
| c2 | + extra data | 77.25 |
| c3 | + Δpos anchors | 79.21 |
| **c4** | + corridor loss (**CorridorVLA**) | **83.21** |
📈 Improvement:
* +7.98% over baselines
* Largest gain from **explicit spatial constraint**
---
## ⚙️ Implementation
* Built on **[StarVLA](https://github.com/starVLA/starVLA/commit/e1e6457c6cd124248f5ce7b2d3d40fb74f48c6fc)**
* Minimal changes:
* few prediction slots
* loss terms
* No heavy architecture redesign
---
## 📌 Key Insights
* Spatial guidance can be:
* **explicit (loss-level)** instead of implicit (feature-level)
* Physical quantities are:
* more **action-aligned**
* more **interpretable**
* Simple constraints can:
* significantly improve **stability**
* reduce **unstructured exploration**
---
## 📖 Citation
If you find this work useful, please cite:
```bibtex
@article{corridorvla2025,
title={CorridorVLA: Explicit Spatial Constraints for Generative Action Heads via Sparse Anchors},
author={Dachong Li and ZhuangZhuang Chen and Jin Zhang and Jianqiang Li},
year={2026},
eprint={2604.21241},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2604.21241}
}