---
license: apache-2.0
library_name: transformers
base_model: DAMO-NLP-SG/VideoLLaMA3-7B
tags:
- multimodal
- video-llm
- video-understanding
- video-grounding
- spatio-temporal-grounding
- temporal-grounding
- referring-expression-comprehension
- grounding
- reasoning
- custom_code
- pytorch
---
# DeViL-7B
**Official checkpoint for "Detector-Empowered Video Large Language Model for Efficient Spatio-Temporal Grounding"**
[Paper](https://arxiv.org/abs/2512.06673) | [Code](https://github.com/gaostar123/DeViL)
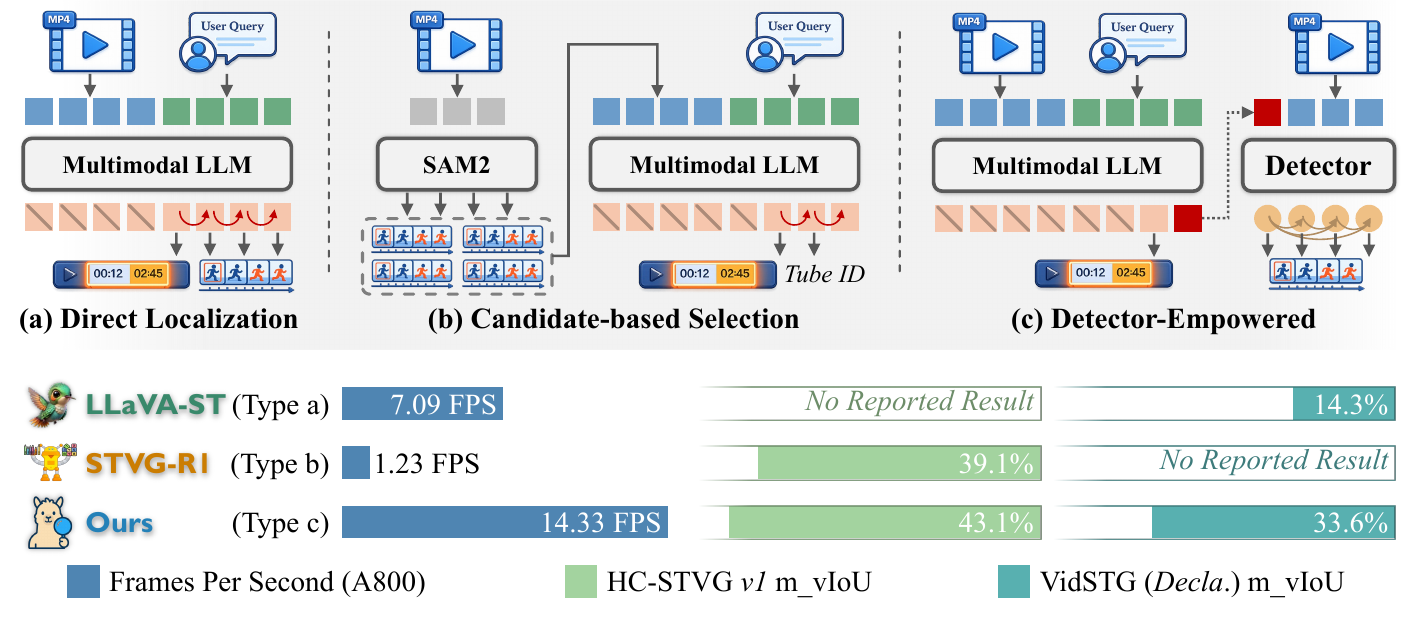
## Overview
DeViL is a detector-empowered video large language model designed for efficient spatio-temporal video grounding (STVG) and grounded video reasoning. Instead of relying on long autoregressive coordinate decoding or expensive candidate construction, DeViL offloads dense spatial grounding to a fully parallel detector. It distills the user query into a detector-compatible reference-semantic token and uses temporal consistency regularization to maintain object coherence across frames.
This repository hosts the official DeViL-7B checkpoint released by the authors.
## Highlights
- Detector-empowered grounding for efficient spatio-temporal localization
- Strong performance reported in the paper: 43.1 m_vIoU on HC-STVG and 14.33 FPS
- Preserves the backbone MLLM's general video understanding and reasoning ability
- Supports both image and video inputs in the official demo pipeline
## Links
- Paper: https://arxiv.org/abs/2512.06673
- Code: https://github.com/gaostar123/DeViL