


Squashing commit
Browse filesCo-authored-by: mishig <mishig@users.noreply.huggingface.co>
This view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +59 -0
- 1403/1403.4682.md +47 -0
- 1404/1404.5997.md +47 -0
- 1406/1406.5388.md +47 -0
- 1411/1411.4166.md +47 -0
- 1506/1506.07285.md +47 -0
- 1506/1506.08909.md +47 -0
- 1511/1511.04143.md +283 -0
- 1512/1512.03385.md +47 -0
- 1602/1602.00370.md +47 -0
- 1603/1603.05027.md +47 -0
- 1610/1610.00291.md +204 -0
- 1702/1702.04066.md +47 -0
- 1703/1703.06870.md +47 -0
- 1704/1704.04086.md +47 -0
- 1706/1706.03762.md +373 -0
- 1707/1707.06347.md +47 -0
- 1708/1708.02002.md +47 -0
- 1708/1708.09230.md +239 -0
- 1709/1709.07330.md +47 -0
- 1710/1710.03208.md +47 -0
- 1711/1711.10925.md +47 -0
- 1712/1712.07629.md +47 -0
- 1801/1801.01681.md +47 -0
- 1801/1801.04381.md +47 -0
- 1802/1802.00810.md +0 -0
- 1803/1803.03635.md +0 -0
- 1803/1803.06535.md +47 -0
- 1803/1803.10963.md +47 -0
- 1803/1803.11485.md +47 -0
- 1804/1804.02767.md +47 -0
- 1804/1804.03287.md +47 -0
- 1804/1804.04637.md +47 -0
- 1806/1806.02639.md +47 -0
- 1807/1807.03418.md +321 -0
- 1807/1807.03819.md +568 -0
- 1807/1807.10221.md +47 -0
- 1809/1809.03327.md +47 -0
- 1810/1810.04805.md +47 -0
- 1810/1810.09305.md +47 -0
- 1810/1810.12440.md +47 -0
- 1901/1901.00212.md +47 -0
- 1901/1901.03735.md +47 -0
- 1901/1901.10995.md +47 -0
- 1902/1902.05605.md +737 -0
- 1902/1902.06634.md +286 -0
- 1903/1903.03273.md +47 -0
- 1904/1904.06472.md +47 -0
- 1904/1904.07272.md +0 -0
- 1904/1904.09751.md +47 -0
.gitattributes
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.lz4 filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.mds filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
# Audio files - uncompressed
|
| 39 |
+
*.pcm filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
*.sam filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
*.raw filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
# Audio files - compressed
|
| 43 |
+
*.aac filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
*.flac filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
*.mp3 filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
*.ogg filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
*.wav filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
# Image files - uncompressed
|
| 49 |
+
*.bmp filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
*.gif filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
*.tiff filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
# Image files - compressed
|
| 54 |
+
*.jpg filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
*.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
*.webp filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
# Video files - compressed
|
| 58 |
+
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
*.webm filter=lfs diff=lfs merge=lfs -text
|
1403/1403.4682.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1403.4682
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1403.4682#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1403.4682'
|
| 27 |
+
=======================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1404/1404.5997.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1404.5997
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1404.5997#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1404.5997'
|
| 27 |
+
=======================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1406/1406.5388.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1406.5388
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1406.5388#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1406.5388'
|
| 27 |
+
=======================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1411/1411.4166.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1411.4166
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1411.4166#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1411.4166'
|
| 27 |
+
=======================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1506/1506.07285.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1506.07285
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1506.07285#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1506.07285'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1506/1506.08909.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1506.08909
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1506.08909#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1506.08909'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1511/1511.04143.md
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Deep Reinforcement Learning in Parameterized Action Space
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1511.04143
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Matthew Hausknecht
|
| 7 |
+
|
| 8 |
+
Department of Computer Science
|
| 9 |
+
|
| 10 |
+
University of Texas at Austin
|
| 11 |
+
|
| 12 |
+
mhauskn@cs.utexas.edu
|
| 13 |
+
|
| 14 |
+
&Peter Stone
|
| 15 |
+
|
| 16 |
+
Department of Computer Science
|
| 17 |
+
|
| 18 |
+
University of Texas at Austin
|
| 19 |
+
|
| 20 |
+
pstone@cs.utexas.edu
|
| 21 |
+
|
| 22 |
+
###### Abstract
|
| 23 |
+
|
| 24 |
+
Recent work has shown that deep neural networks are capable of approximating both value functions and policies in reinforcement learning domains featuring continuous state and action spaces. However, to the best of our knowledge no previous work has succeeded at using deep neural networks in structured (parameterized) continuous action spaces. To fill this gap, this paper focuses on learning within the domain of simulated RoboCup soccer, which features a small set of discrete action types, each of which is parameterized with continuous variables. The best learned agents can score goals more reliably than the 2012 RoboCup champion agent. As such, this paper represents a successful extension of deep reinforcement learning to the class of parameterized action space MDPs.
|
| 25 |
+
|
| 26 |
+
1 Introduction
|
| 27 |
+
--------------
|
| 28 |
+
|
| 29 |
+
This paper extends the Deep Deterministic Policy Gradients (DDPG) algorithm (Lillicrap et al., [2015](https://arxiv.org/html/1511.04143v5#bib.bib8)) into a parameterized action space. We document a modification to the published version of the DDPG algorithm: namely bounding action space gradients. We found this modification necessary for stable learning in this domain and will likely be valuable for future practitioners attempting to learn in continuous, bounded action spaces.
|
| 30 |
+
|
| 31 |
+
We demonstrate reliable learning, from scratch, of RoboCup soccer policies capable of goal scoring. These policies operate on a low-level continuous state space and a parameterized-continuous action space. Using a single reward function, the agents learn to locate and approach the ball, dribble to the goal, and score on an empty goal. The best learned agent proves more reliable at scoring goals, though slower, than the hand-coded 2012 RoboCup champion.
|
| 32 |
+
|
| 33 |
+
RoboCup 2D Half-Field-Offense (HFO) is a research platform for exploring single agent learning, multi-agent learning, and adhoc teamwork. HFO features a low-level continuous state space and parameterized-continuous action space. Specifically, the parameterized action space requires the agent to first select the type of action it wishes to perform from a discrete list of high level actions and then specify the continuous parameters to accompany that action. This parameterization introduces structure not found in a purely continuous action space.
|
| 34 |
+
|
| 35 |
+
The rest of this paper is organized as follows: the HFO domain is presented in Section [2](https://arxiv.org/html/1511.04143v5#S2 "2 Half Field Offense Domain ‣ Deep Reinforcement Learning in Parameterized Action Space"). Section [3](https://arxiv.org/html/1511.04143v5#S3 "3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") presents background on deep continuous reinforcement learning including detailed actor and critic updates. Section [5](https://arxiv.org/html/1511.04143v5#S5 "5 Bounded Parameter Space Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") presents a method of bounding action space gradients. Section [6](https://arxiv.org/html/1511.04143v5#S6 "6 Results ‣ Deep Reinforcement Learning in Parameterized Action Space") covers experiments and results. Finally, related work is presented in Section [8](https://arxiv.org/html/1511.04143v5#S8 "8 Related Work ‣ Deep Reinforcement Learning in Parameterized Action Space") followed by conclusions.
|
| 36 |
+
|
| 37 |
+
2 Half Field Offense Domain
|
| 38 |
+
---------------------------
|
| 39 |
+
|
| 40 |
+
RoboCup is an international robot soccer competition that promotes research in AI and robotics. Within RoboCup, the 2D simulation league works with an abstraction of soccer wherein the players, the ball, and the field are all 2-dimensional objects. However, for the researcher looking to quickly prototype and evaluate different algorithms, the full soccer task presents a cumbersome prospect: full games are lengthy, have high variance in their outcome, and demand specialized handling of rules such as free kicks and offsides.
|
| 41 |
+
|
| 42 |
+
The Half Field Offense domain abstracts away the difficulties of full RoboCup and exposes the experimenter only to core decision-making logic, and to focus on the most challenging part of a RoboCup 2D game: scoring and defending goals. In HFO, each agent receives its own state sensations and must independently select its own actions. HFO is naturally characterized as an episodic multi-agent POMDP because of the sequential partial observations and actions on the part of the agents and the well-defined episodes which culminate in either a goal being scored or the ball leaving the play area. To begin each episode, the agent and ball are positioned randomly on the offensive half of the field. The episode ends when a goal is scored, the ball leaves the field, or 500 timesteps pass. The following subsections introduce the low-level state and action space used by agents in this domain.
|
| 43 |
+
|
| 44 |
+
### 2.1 State Space
|
| 45 |
+
|
| 46 |
+
The agent uses a low-level, egocentric viewpoint encoded using 58 continuously-valued features. These features are derived through Helios-Agent2D’s (Akiyama, [2010](https://arxiv.org/html/1511.04143v5#bib.bib1)) world model and provide angles and distances to various on-field objects of importance such as the ball, the goal, and the other players. Figure [1](https://arxiv.org/html/1511.04143v5#S2.F1 "Figure 1 ‣ 2.1 State Space ‣ 2 Half Field Offense Domain ‣ Deep Reinforcement Learning in Parameterized Action Space") depicts the perceptions of the agent. The most relevant features include: Agent’s position, velocity, and orientation, and stamina; Indicator if the agent is able to kick; Angles and distances to the following objects: Ball, Goal, Field-Corners, Penalty-Box-Corners, Teammates, and Opponents. A full list of state features may be found at [https://github.com/mhauskn/HFO/blob/master/doc/manual.pdf](https://github.com/mhauskn/HFO/blob/master/doc/manual.pdf).
|
| 47 |
+
|
| 48 |
+

|
| 49 |
+
|
| 50 |
+
(a) State Space
|
| 51 |
+
|
| 52 |
+

|
| 53 |
+
|
| 54 |
+
(b) Helios Champion
|
| 55 |
+
|
| 56 |
+
Figure 1: Left: HFO State Representation uses a low-level, egocentric viewpoint providing features such as distances and angles to objects of interest like the ball, goal posts, corners of the field, and opponents. Right: Helios handcoded policy scores on a goalie. This 2012 champion agent forms a natural (albeit difficult) baseline of comparison.
|
| 57 |
+
|
| 58 |
+
### 2.2 Action Space
|
| 59 |
+
|
| 60 |
+
Half Field Offense features a low-level, parameterized action space. There are four mutually-exclusive discrete actions: Dash, Turn, Tackle, and Kick. At each timestep the agent must select one of these four to execute. Each action has 1-2 continuously-valued parameters which must also be specified. An agent must select both the discrete action it wishes to execute as well as the continuously valued parameters required by that action. The full set of parameterized actions is:
|
| 61 |
+
|
| 62 |
+
Dash(power, direction): Moves in the indicated direction with a scalar power in [0,100]0 100[0,100][ 0 , 100 ]. Movement is faster forward than sideways or backwards. Turn(direction): Turns to indicated direction. Tackle(direction): Contests the ball by moving in the indicated direction. This action is only useful when playing against an opponent. Kick(power, direction): Kicks the ball in the indicated direction with a scalar power in [0,100]0 100[0,100][ 0 , 100 ]. All directions are parameterized in the range of [−180,180]180 180[-180,180][ - 180 , 180 ] degrees.
|
| 63 |
+
|
| 64 |
+
### 2.3 Reward Signal
|
| 65 |
+
|
| 66 |
+
True rewards in the HFO domain come from winning full games. However, such a reward signal is far too sparse for learning agents to gain traction. Instead we introduce a hand-crafted reward signal with four components: Move To Ball Reward provides a scalar reward proportional to the change in distance between the agent and the ball d(a,b)𝑑 𝑎 𝑏 d(a,b)italic_d ( italic_a , italic_b ). An additional reward 𝕀 kick superscript 𝕀 𝑘 𝑖 𝑐 𝑘\mathbb{I}^{kick}blackboard_I start_POSTSUPERSCRIPT italic_k italic_i italic_c italic_k end_POSTSUPERSCRIPT of 1 is given the first time each episode the agent is close enough to kick the ball. Kick To Goal Reward is proportional to the change in distance between the ball and the center of the goal d(b,g)𝑑 𝑏 𝑔 d(b,g)italic_d ( italic_b , italic_g ). An additional reward is given for scoring a goal 𝕀 goal superscript 𝕀 𝑔 𝑜 𝑎 𝑙\mathbb{I}^{goal}blackboard_I start_POSTSUPERSCRIPT italic_g italic_o italic_a italic_l end_POSTSUPERSCRIPT. A weighted sum of these components results in a single reward that first guides the agent close enough to kick the ball, then rewards for kicking towards goal, and finally for scoring. It was necessary to provide a higher gain for the kick-to-goal component of the reward because immediately following each kick, the move-to-ball component produces negative rewards as the ball moves away from the agent. The overall reward is as follows:
|
| 67 |
+
|
| 68 |
+
r t=d t−1(a,b)−d t(a,b)+𝕀 t kick+3(d t−1(b,g)−d t(b,g))+5𝕀 t goal subscript 𝑟 𝑡 subscript 𝑑 𝑡 1 𝑎 𝑏 subscript 𝑑 𝑡 𝑎 𝑏 subscript superscript 𝕀 𝑘 𝑖 𝑐 𝑘 𝑡 3 subscript 𝑑 𝑡 1 𝑏 𝑔 subscript 𝑑 𝑡 𝑏 𝑔 5 subscript superscript 𝕀 𝑔 𝑜 𝑎 𝑙 𝑡 r_{t}=d_{t-1}(a,b)-d_{t}(a,b)+\mathbb{I}^{kick}_{t}+3\big{(}d_{t-1}(b,g)-d_{t}% (b,g)\big{)}+5\mathbb{I}^{goal}_{t}italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = italic_d start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ( italic_a , italic_b ) - italic_d start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_a , italic_b ) + blackboard_I start_POSTSUPERSCRIPT italic_k italic_i italic_c italic_k end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT + 3 ( italic_d start_POSTSUBSCRIPT italic_t - 1 end_POSTSUBSCRIPT ( italic_b , italic_g ) - italic_d start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ( italic_b , italic_g ) ) + 5 blackboard_I start_POSTSUPERSCRIPT italic_g italic_o italic_a italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT(1)
|
| 69 |
+
|
| 70 |
+
It is disappointing that reward engineering is necessary. However, the exploration task proves far too difficult to ever gain traction on a reward that consists only of scoring goals, because acting randomly is exceedingly unlikely to yield even a single goal in any reasonable amount of time. An interesting direction for future work is to find better ways of exploring large state spaces. One recent approach in this direction, Stadie et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib16)) assigned exploration bonuses based on a model of system dynamics.
|
| 71 |
+
|
| 72 |
+
3 Background: Deep Reinforcement Learning
|
| 73 |
+
-----------------------------------------
|
| 74 |
+
|
| 75 |
+
Deep neural networks are adept general purpose function approximators that have been most widely used in supervised learning tasks. Recently, however they have been applied to reinforcement learning problems, giving rise to the field of deep reinforcement learning. This field seeks to combine the advances in deep neural networks with reinforcement learning algorithms to create agents capable of acting intelligently in complex environments. This section presents background in deep reinforcement learning in continuous action spaces. The notation closely follows that of Lillicrap et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib8)).
|
| 76 |
+
|
| 77 |
+
Deep, model-free RL in discrete action spaces can be performed using the Deep Q-Learning method introduced by Mnih et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib11)) which employs a single deep network to estimate the value function of each discrete action and, when acting, selects the maximally valued output for a given state input. Several variants of DQN have been explored. Narasimhan et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib12)) used decaying traces, Hausknecht & Stone ([2015](https://arxiv.org/html/1511.04143v5#bib.bib4)) investigated LSTM recurrency, and van Hasselt et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib19)) explored double Q-Learning. These networks work well in continuous state spaces but do not function in continuous action spaces because the output nodes of the network, while continuous, are trained to output Q-Value estimates rather than continuous actions.
|
| 78 |
+
|
| 79 |
+
An Actor/Critic architecture (Sutton & Barto, [1998](https://arxiv.org/html/1511.04143v5#bib.bib17)) provides one solution to this problem by decoupling the value learning and the action selection. Represented using two deep neural networks, the actor network outputs continuous actions while the critic estimates the value function. The actor network μ 𝜇\mu italic_μ, parameterized by θ μ superscript 𝜃 𝜇\theta^{\mu}italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT, takes as input a state s 𝑠 s italic_s and outputs a continuous action a 𝑎 a italic_a. The critic network Q 𝑄 Q italic_Q, parameterized by θ Q superscript 𝜃 𝑄\theta^{Q}italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT, takes as input a state s 𝑠 s italic_s and action a 𝑎 a italic_a and outputs a scalar Q-Value Q(s,a)𝑄 𝑠 𝑎 Q(s,a)italic_Q ( italic_s , italic_a ). Figure [2](https://arxiv.org/html/1511.04143v5#S3.F2 "Figure 2 ‣ 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") shows Critic and Actor networks.
|
| 80 |
+
|
| 81 |
+
Updates to the critic network are largely unchanged from the standard temporal difference update used originally in Q-Learning (Watkins & Dayan, [1992](https://arxiv.org/html/1511.04143v5#bib.bib20)) and later by DQN:
|
| 82 |
+
|
| 83 |
+
Q(s,a)=Q(s,a)+α(r+γmax a′Q(s′,a′)−Q(s,a))𝑄 𝑠 𝑎 𝑄 𝑠 𝑎 𝛼 𝑟 𝛾 subscript superscript 𝑎′𝑄 superscript 𝑠′superscript 𝑎′𝑄 𝑠 𝑎 Q(s,a)=Q(s,a)+\alpha\big{(}r+\gamma\max_{a^{\prime}}Q(s^{\prime},a^{\prime})-Q% (s,a)\big{)}italic_Q ( italic_s , italic_a ) = italic_Q ( italic_s , italic_a ) + italic_α ( italic_r + italic_γ roman_max start_POSTSUBSCRIPT italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_Q ( italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ) - italic_Q ( italic_s , italic_a ) )(2)
|
| 84 |
+
|
| 85 |
+
Adapting this equation to the neural network setting described above results in minimizing a loss function defined as follows:
|
| 86 |
+
|
| 87 |
+
L Q(s,a|θ Q)=(Q(s,a|θ Q)−(r+γmax a′Q(s′,a′|θ Q)))2 subscript 𝐿 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 superscript 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 𝑟 𝛾 subscript superscript 𝑎′𝑄 superscript 𝑠′conditional superscript 𝑎′superscript 𝜃 𝑄 2 L_{Q}(s,a|\theta^{Q})=\Big{(}Q(s,a|\theta^{Q})-\big{(}r+\gamma\max_{a^{\prime}% }Q(s^{\prime},a^{\prime}|\theta^{Q})\big{)}\Big{)}^{2}italic_L start_POSTSUBSCRIPT italic_Q end_POSTSUBSCRIPT ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) = ( italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) - ( italic_r + italic_γ roman_max start_POSTSUBSCRIPT italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_Q ( italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) ) ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT(3)
|
| 88 |
+
|
| 89 |
+
However, in continuous action spaces, this equation is no longer tractable as it involves maximizing over next-state actions a′superscript 𝑎′a^{\prime}italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT. Instead we ask the actor network to provide a next-state action a′=μ(s′|θ μ)superscript 𝑎′𝜇 conditional superscript 𝑠′superscript 𝜃 𝜇 a^{\prime}=\mu(s^{\prime}|\theta^{\mu})italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT = italic_μ ( italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT | italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT ). This yields a critic loss with the following form:
|
| 90 |
+
|
| 91 |
+
L Q(s,a|θ Q)=(Q(s,a|θ Q)−(r+γQ(s′,μ(s′|θ μ)′|θ Q)))2 subscript 𝐿 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 superscript 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 𝑟 𝛾 𝑄 superscript 𝑠′conditional 𝜇 superscript conditional superscript 𝑠′superscript 𝜃 𝜇′superscript 𝜃 𝑄 2 L_{Q}(s,a|\theta^{Q})=\Big{(}Q(s,a|\theta^{Q})-\big{(}r+\gamma Q(s^{\prime},% \mu(s^{\prime}|\theta^{\mu})^{\prime}|\theta^{Q})\big{)}\Big{)}^{2}italic_L start_POSTSUBSCRIPT italic_Q end_POSTSUBSCRIPT ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) = ( italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) - ( italic_r + italic_γ italic_Q ( italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT , italic_μ ( italic_s start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT | italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT ) start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) ) ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT(4)
|
| 92 |
+
|
| 93 |
+
The value function of the critic can be learned by gradient descent on this loss function with respect to θ Q superscript 𝜃 𝑄\theta^{Q}italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT. However, the accuracy of this value function is highly influenced by the quality of the actor’s policy, since the actor determines the next-state action a′superscript 𝑎′a^{\prime}italic_a start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT in the update target.
|
| 94 |
+
|
| 95 |
+
The critic’s knowledge of action values is then harnessed to learn a better policy for the actor. Given a sample state, the goal of the actor is to minimize the difference between its current output a 𝑎 a italic_a and the optimal action in that state a∗superscript 𝑎 a^{*}italic_a start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT.
|
| 96 |
+
|
| 97 |
+
L μ(s|θ μ)=(a−a∗)2=(μ(s|θ Q)−a∗)2 subscript 𝐿 𝜇 conditional 𝑠 superscript 𝜃 𝜇 superscript 𝑎 superscript 𝑎 2 superscript 𝜇 conditional 𝑠 superscript 𝜃 𝑄 superscript 𝑎 2 L_{\mu}(s|\theta^{\mu})=\big{(}a-a^{*}\big{)}^{2}=\big{(}\mu(s|\theta^{Q})-a^{% *}\big{)}^{2}italic_L start_POSTSUBSCRIPT italic_μ end_POSTSUBSCRIPT ( italic_s | italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT ) = ( italic_a - italic_a start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT = ( italic_μ ( italic_s | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) - italic_a start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT(5)
|
| 98 |
+
|
| 99 |
+
The critic may be used to provide estimates of the quality of different actions but naively estimating a∗superscript 𝑎 a^{*}italic_a start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT would involve maximizing the critic’s output over all possible actions: a∗≈argmax aQ(s,a|θ Q)superscript 𝑎 subscript arg max 𝑎 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 a^{*}\approx\operatorname*{arg\,max}_{a}Q(s,a|\theta^{Q})italic_a start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT ≈ start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ). Instead of seeking a global maximum, the critic network can provide gradients which indicate directions of change, in action space, that lead to higher estimated Q-Values: ∇a Q(s,a|θ Q)subscript∇𝑎 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄\nabla_{a}Q(s,a|\theta^{Q})∇ start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ). To obtain these gradients requires a single backward pass over the critic network, much faster than solving an optimization problem in continuous action space. Note that these gradients are not the common gradients with respect to parameters. Instead these are gradients with respect to inputs, first used in this way by NFQCA (Hafner & Riedmiller, [2011](https://arxiv.org/html/1511.04143v5#bib.bib3)). To update the actor network, these gradients are placed at the actor’s output layer (in lieu of targets) and then back-propagated through the network. For a given state, the actor is run forward to produce an action that the critic evaluates, and the resulting gradients may be used to update the actor:
|
| 100 |
+
|
| 101 |
+
∇θ μ μ(s)=∇a Q(s,a|θ Q)∇θ μ μ(s|θ μ)subscript∇superscript 𝜃 𝜇 𝜇 𝑠 subscript∇𝑎 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 subscript∇superscript 𝜃 𝜇 𝜇 conditional 𝑠 superscript 𝜃 𝜇\nabla_{\theta^{\mu}}\mu(s)=\nabla_{a}Q(s,a|\theta^{Q})\nabla_{\theta^{\mu}}% \mu(s|\theta^{\mu})∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_μ ( italic_s ) = ∇ start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) ∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_μ ( italic_s | italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT )(6)
|
| 102 |
+
|
| 103 |
+
Alternatively one may think about these updates as simply interlinking the actor and critic networks: On the forward pass, the actor’s output is passed forward into the critic and evaluated. Next, the estimated Q-Value is backpropagated through the critic, producing gradients ∇a Q subscript∇𝑎 𝑄\nabla_{a}Q∇ start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT italic_Q that indicate how the action should change in order to increase the Q-Value. On the backwards pass, these gradients flow from the critic through the actor. An update is then performed only over the actor’s parameters. Figure [2](https://arxiv.org/html/1511.04143v5#S3.F2 "Figure 2 ‣ 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") shows an example of this update.
|
| 104 |
+
|
| 105 |
+

|
| 106 |
+
|
| 107 |
+

|
| 108 |
+
|
| 109 |
+
Figure 2: Actor-Critic architecture (left): actor and critic networks may be interlinked, allowing activations to flow forwards from the actor to the critic and gradients to flow backwards from the critic to the actor. The gradients coming from the critic indicate directions of improvement in the continuous action space and are used to train the actor network without explicit targets. Actor Update (right): Backwards pass generates critic gradients ∇a Q(s,a|θ Q)subscript∇𝑎 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄\nabla_{a}Q(s,a|\theta^{Q})∇ start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) w.r.t. the action. These gradients are back-propagated through the actor resulting in gradients w.r.t. parameters ∇θ μ subscript∇superscript 𝜃 𝜇\nabla_{\theta^{\mu}}∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT which are used to update the actor. Critic gradients w.r.t. parameters ∇θ Q subscript∇superscript 𝜃 𝑄\nabla_{\theta^{Q}}∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT end_POSTSUBSCRIPT are ignored during the actor update.
|
| 110 |
+
|
| 111 |
+
### 3.1 Stable Updates
|
| 112 |
+
|
| 113 |
+
Updates to the critic rely on the assumption that the actor’s policy is a good proxy for the optimal policy. Updates to the actor rest on the assumption that the critic’s gradients, or suggested directions for policy improvement, are valid when tested in the environment. It should come as no surprise that several techniques are necessary to make this learning process stable and convergent.
|
| 114 |
+
|
| 115 |
+
Because the critic’s policy Q(s,a|θ Q)𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄 Q(s,a|\theta^{Q})italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) influences both the actor and critic updates, errors in the critic’s policy can create destructive feedback resulting in divergence of the actor, critic, or both. To resolve this problem Mnih et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib11)) introduce a Target-Q-Network Q′superscript 𝑄′Q^{\prime}italic_Q start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT, a replica of the critic network that changes on a slower time scale than the critic. This target network is used to generate next state targets for the critic update (Equation [4](https://arxiv.org/html/1511.04143v5#S3.E4 "In 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space")). Similarly a Target-Actor-Network μ′superscript 𝜇′\mu^{\prime}italic_μ start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT combats quick changes in the actor’s policy.
|
| 116 |
+
|
| 117 |
+
The second stabilizing influence is a replay memory 𝒟 𝒟\mathcal{D}caligraphic_D, a FIFO queue consisting of the agent’s latest experiences (typically one million). Updating from mini-batches of experience sampled uniformly from this memory reduces bias compared to updating exclusively from the most recent experiences.
|
| 118 |
+
|
| 119 |
+
Employing these two techniques the critic loss in Equation [4](https://arxiv.org/html/1511.04143v5#S3.E4 "In 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") and actor update in Equation [5](https://arxiv.org/html/1511.04143v5#S3.E5 "In 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") can be stably re-expressed as follows:
|
| 120 |
+
|
| 121 |
+
L Q(θ Q)=𝔼(s t,a t,r t,s t+1)∼𝒟[(Q(s t,a t)−(r t+γQ′(s t+1,μ′(s t+1))))2]subscript 𝐿 𝑄 superscript 𝜃 𝑄 subscript 𝔼 similar-to subscript 𝑠 𝑡 subscript 𝑎 𝑡 subscript 𝑟 𝑡 subscript 𝑠 𝑡 1 𝒟 delimited-[]superscript 𝑄 subscript 𝑠 𝑡 subscript 𝑎 𝑡 subscript 𝑟 𝑡 𝛾 superscript 𝑄′subscript 𝑠 𝑡 1 superscript 𝜇′subscript 𝑠 𝑡 1 2 L_{Q}(\theta^{Q})=\mathbb{E}_{(s_{t},a_{t},r_{t},s_{t+1})\sim\mathcal{D}}\bigg% {[}\Big{(}Q(s_{t},a_{t})-\big{(}r_{t}+\gamma Q^{\prime}(s_{t+1},\mu^{\prime}(s% _{t+1}))\big{)}\Big{)}^{2}\bigg{]}italic_L start_POSTSUBSCRIPT italic_Q end_POSTSUBSCRIPT ( italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) = blackboard_E start_POSTSUBSCRIPT ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_s start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT ) ∼ caligraphic_D end_POSTSUBSCRIPT [ ( italic_Q ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) - ( italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT + italic_γ italic_Q start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ( italic_s start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT , italic_μ start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT ( italic_s start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT ) ) ) ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT ](7)
|
| 122 |
+
|
| 123 |
+
∇θ μ μ=𝔼 s t∼𝒟[∇a Q(s t,a|θ Q)∇θ μ μ(s t)|a=μ(s t)]subscript∇superscript 𝜃 𝜇 𝜇 subscript 𝔼 similar-to subscript 𝑠 𝑡 𝒟 delimited-[]evaluated-at subscript∇𝑎 𝑄 subscript 𝑠 𝑡 conditional 𝑎 superscript 𝜃 𝑄 subscript∇superscript 𝜃 𝜇 𝜇 subscript 𝑠 𝑡 𝑎 𝜇 subscript 𝑠 𝑡\nabla_{\theta^{\mu}}\mu=\mathbb{E}_{s_{t}\sim\mathcal{D}}\bigg{[}\nabla_{a}Q(% s_{t},a|\theta^{Q})\nabla_{\theta^{\mu}}\mu(s_{t})|_{a=\mu(s_{t})}\bigg{]}∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_μ = blackboard_E start_POSTSUBSCRIPT italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ∼ caligraphic_D end_POSTSUBSCRIPT [ ∇ start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT italic_Q ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) ∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_μ ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) | start_POSTSUBSCRIPT italic_a = italic_μ ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT ) end_POSTSUBSCRIPT ](8)
|
| 124 |
+
|
| 125 |
+
Finally, these updates are applied to the respective networks, where α 𝛼\alpha italic_α is a per-parameter step size determined by the gradient descent algorithm. Additionally, the target-actor and target-critic networks are updated to smoothly track the actor and critic using a factor τ≪1 much-less-than 𝜏 1\tau\ll 1 italic_τ ≪ 1:
|
| 126 |
+
|
| 127 |
+
θ Q=θ Q+α∇θ Q L Q(θ Q)θ μ=θ μ+α∇θ μ μ θ Q′=τθ Q+(1−τ)θ Q′θ μ′=τθ μ+(1−τ)θ μ′superscript 𝜃 𝑄 superscript 𝜃 𝑄 𝛼 subscript∇superscript 𝜃 𝑄 subscript 𝐿 𝑄 superscript 𝜃 𝑄 superscript 𝜃 𝜇 superscript 𝜃 𝜇 𝛼 subscript∇superscript 𝜃 𝜇 𝜇 superscript 𝜃 superscript 𝑄′𝜏 superscript 𝜃 𝑄 1 𝜏 superscript 𝜃 superscript 𝑄′superscript 𝜃 superscript 𝜇′𝜏 superscript 𝜃 𝜇 1 𝜏 superscript 𝜃 superscript 𝜇′\begin{split}&\theta^{Q}=\theta^{Q}+\alpha\nabla_{\theta^{Q}}L_{Q}(\theta^{Q})% \\ &\theta^{\mu}=\theta^{\mu}+\alpha\nabla_{\theta^{\mu}}\mu\\ &\theta^{Q^{\prime}}=\tau\theta^{Q}+(1-\tau)\theta^{Q^{\prime}}\\ &\theta^{\mu^{\prime}}=\tau\theta^{\mu}+(1-\tau)\theta^{\mu^{\prime}}\end{split}start_ROW start_CELL end_CELL start_CELL italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT = italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT + italic_α ∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_L start_POSTSUBSCRIPT italic_Q end_POSTSUBSCRIPT ( italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ) end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT = italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT + italic_α ∇ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_μ end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL italic_θ start_POSTSUPERSCRIPT italic_Q start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT = italic_τ italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT + ( 1 - italic_τ ) italic_θ start_POSTSUPERSCRIPT italic_Q start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT end_CELL end_ROW start_ROW start_CELL end_CELL start_CELL italic_θ start_POSTSUPERSCRIPT italic_μ start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT = italic_τ italic_θ start_POSTSUPERSCRIPT italic_μ end_POSTSUPERSCRIPT + ( 1 - italic_τ ) italic_θ start_POSTSUPERSCRIPT italic_μ start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT end_CELL end_ROW(9)
|
| 128 |
+
|
| 129 |
+
One final component is an adaptive learning rate method such as ADADELTA (Zeiler, [2012](https://arxiv.org/html/1511.04143v5#bib.bib21)), RMSPROP (Tieleman & Hinton, [2012](https://arxiv.org/html/1511.04143v5#bib.bib18)), or ADAM (Kingma & Ba, [2014](https://arxiv.org/html/1511.04143v5#bib.bib6)).
|
| 130 |
+
|
| 131 |
+
### 3.2 Network Architecture
|
| 132 |
+
|
| 133 |
+
Shown in Figure [2](https://arxiv.org/html/1511.04143v5#S3.F2 "Figure 2 ‣ 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space"), both the actor and critic employ the same architecture: The 58 state inputs are processed by four fully connected layers consisting of 1024-512-256-128 units respectively. Each fully connected layer is followed by a rectified linear (ReLU) activation function with negative slope 10−2 superscript 10 2 10^{-2}10 start_POSTSUPERSCRIPT - 2 end_POSTSUPERSCRIPT. Weights of the fully connected layers use Gaussian initialization with a standard deviation of 10−2 superscript 10 2 10^{-2}10 start_POSTSUPERSCRIPT - 2 end_POSTSUPERSCRIPT. Connected to the final inner product layer are two linear output layers: one for the four discrete actions and another for the six parameters accompanying these actions. In addition to the 58 state features, the critic also takes as input the four discrete actions and six action parameters. It outputs a single scalar Q-value. We use the ADAM solver with both actor and critic learning rate set to 10−3 superscript 10 3 10^{-3}10 start_POSTSUPERSCRIPT - 3 end_POSTSUPERSCRIPT. Target networks track the actor and critic using a τ=10−4 𝜏 superscript 10 4\tau=10^{-4}italic_τ = 10 start_POSTSUPERSCRIPT - 4 end_POSTSUPERSCRIPT. Complete source code for our agent is available at [https://github.com/mhauskn/dqn-hfo](https://github.com/mhauskn/dqn-hfo) and for the HFO domain at [https://github.com/mhauskn/HFO/](https://github.com/mhauskn/HFO/). Having introduced the background of deep reinforcement learning in continuous action space, we now present the parameterized action space.
|
| 134 |
+
|
| 135 |
+
4 Parameterized Action Space Architecture
|
| 136 |
+
-----------------------------------------
|
| 137 |
+
|
| 138 |
+
Following notation in (Masson & Konidaris, [2015](https://arxiv.org/html/1511.04143v5#bib.bib10)), a Parameterized Action Space Markov Decision Process (PAMDP) is defined by a set of discrete actions A d={a 1,a 2,…,a k}subscript 𝐴 𝑑 subscript 𝑎 1 subscript 𝑎 2…subscript 𝑎 𝑘 A_{d}=\{a_{1},a_{2},\dots,a_{k}\}italic_A start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT = { italic_a start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , italic_a start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT , … , italic_a start_POSTSUBSCRIPT italic_k end_POSTSUBSCRIPT }. Each discrete action a∈A d 𝑎 subscript 𝐴 𝑑 a\in A_{d}italic_a ∈ italic_A start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT features m a subscript 𝑚 𝑎 m_{a}italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT continuous parameters {p 1 a,…,p m a a}∈ℝ m a subscript superscript 𝑝 𝑎 1…subscript superscript 𝑝 𝑎 subscript 𝑚 𝑎 superscript ℝ subscript 𝑚 𝑎\{p^{a}_{1},\dots,p^{a}_{m_{a}}\}\in\mathbb{R}^{m_{a}}{ italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT end_POSTSUBSCRIPT } ∈ blackboard_R start_POSTSUPERSCRIPT italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT end_POSTSUPERSCRIPT. Actions are represented by tuples (a,p 1 a,…,p m a a)𝑎 subscript superscript 𝑝 𝑎 1…subscript superscript 𝑝 𝑎 subscript 𝑚 𝑎(a,p^{a}_{1},\dots,p^{a}_{m_{a}})( italic_a , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT end_POSTSUBSCRIPT ). Thus the overall action space A=∪a∈A d(a,p 1 a,…,p m a a)𝐴 subscript 𝑎 subscript 𝐴 𝑑 𝑎 subscript superscript 𝑝 𝑎 1…subscript superscript 𝑝 𝑎 subscript 𝑚 𝑎 A=\cup_{a\in A_{d}}(a,p^{a}_{1},\dots,p^{a}_{m_{a}})italic_A = ∪ start_POSTSUBSCRIPT italic_a ∈ italic_A start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT end_POSTSUBSCRIPT ( italic_a , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT end_POSTSUBSCRIPT ).
|
| 139 |
+
|
| 140 |
+
In Half Field Offense, the complete parameterized action space (Section [2.2](https://arxiv.org/html/1511.04143v5#S2.SS2 "2.2 Action Space ‣ 2 Half Field Offense Domain ‣ Deep Reinforcement Learning in Parameterized Action Space")) is A=(Dash,p 1 dash,p 2 dash)∪(Turn,p 3 turn)∪(Tackle,p 4 tackle)∪(Kick,p 5 kick,p 6 kick)𝐴 Dash superscript subscript 𝑝 1 dash superscript subscript 𝑝 2 dash Turn superscript subscript 𝑝 3 turn Tackle superscript subscript 𝑝 4 tackle Kick superscript subscript 𝑝 5 kick superscript subscript 𝑝 6 kick A=(\textrm{Dash},p_{1}^{\textrm{dash}},p_{2}^{\textrm{dash}})\cup(\textrm{Turn% },p_{3}^{\textrm{turn}})\cup(\textrm{Tackle},p_{4}^{\textrm{tackle}})\cup(% \textrm{Kick},p_{5}^{\textrm{kick}},p_{6}^{\textrm{kick}})italic_A = ( Dash , italic_p start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT dash end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT dash end_POSTSUPERSCRIPT ) ∪ ( Turn , italic_p start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT turn end_POSTSUPERSCRIPT ) ∪ ( Tackle , italic_p start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT tackle end_POSTSUPERSCRIPT ) ∪ ( Kick , italic_p start_POSTSUBSCRIPT 5 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT kick end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 6 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT kick end_POSTSUPERSCRIPT ). The actor network in Figure [2](https://arxiv.org/html/1511.04143v5#S3.F2 "Figure 2 ‣ 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space") factors the action space into one output layer for discrete actions (Dash,Turn,Tackle,Kick)Dash Turn Tackle Kick(\textrm{Dash},\textrm{Turn},\textrm{Tackle},\textrm{Kick})( Dash , Turn , Tackle , Kick ) and another for all six continuous parameters (p 1 dash,p 2 dash,p 3 turn,p 4 tackle,p 5 kick,p 6 kick)superscript subscript 𝑝 1 dash superscript subscript 𝑝 2 dash superscript subscript 𝑝 3 turn superscript subscript 𝑝 4 tackle superscript subscript 𝑝 5 kick superscript subscript 𝑝 6 kick(p_{1}^{\textrm{dash}},p_{2}^{\textrm{dash}},p_{3}^{\textrm{turn}},p_{4}^{% \textrm{tackle}},p_{5}^{\textrm{kick}},p_{6}^{\textrm{kick}})( italic_p start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT dash end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT dash end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 3 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT turn end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 4 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT tackle end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 5 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT kick end_POSTSUPERSCRIPT , italic_p start_POSTSUBSCRIPT 6 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT kick end_POSTSUPERSCRIPT ).
|
| 141 |
+
|
| 142 |
+
### 4.1 Action Selection and Exploration
|
| 143 |
+
|
| 144 |
+
Using the factored action space, deterministic action selection proceeds as follows: At each timestep, the actor network outputs values for each of the four discrete actions as well as six continuous parameters. The discrete action is chosen to be the maximally valued output a=max(Dash,Turn,Tackle,Kick)𝑎 Dash Turn Tackle Kick a=\max(\textrm{Dash},\textrm{Turn},\textrm{Tackle},\textrm{Kick})italic_a = roman_max ( Dash , Turn , Tackle , Kick ) and paired with associated parameters from the parameter output layer (a,p 1 a,…,p m a a)𝑎 subscript superscript 𝑝 𝑎 1…subscript superscript 𝑝 𝑎 subscript 𝑚 𝑎(a,p^{a}_{1},\dots,p^{a}_{m_{a}})( italic_a , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT end_POSTSUBSCRIPT ). Thus the actor network simultaneously chooses which discrete action to execute and how to parameterize that action.
|
| 145 |
+
|
| 146 |
+
During training, the critic network receives, as input, the values of the output nodes of all four discrete actions and all six action parameters. We do not indicate to the critic which discrete action was actually applied in the HFO environment or which continuous parameters are associated with that discrete action. Similarly, when updating the actor, the critic provides gradients for all four discrete actions and all six continuous parameters. While it may seem that the critic is lacking crucial information about the structure of the action space, our experimental results in Section [6](https://arxiv.org/html/1511.04143v5#S6 "6 Results ‣ Deep Reinforcement Learning in Parameterized Action Space") demonstrate that the critic learns to provide gradients to the correct parameters of each discrete action.
|
| 147 |
+
|
| 148 |
+
Exploration in continuous action space differs from discrete space. We adapt ϵ italic-ϵ\epsilon italic_ϵ-greedy exploration to parameterized action space: with probability ϵ italic-ϵ\epsilon italic_ϵ, a random discrete action a∈A d 𝑎 subscript 𝐴 𝑑 a\in A_{d}italic_a ∈ italic_A start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT is selected and the associated continuous parameters {p 1 a,…,p m a a}subscript superscript 𝑝 𝑎 1…subscript superscript 𝑝 𝑎 subscript 𝑚 𝑎\{p^{a}_{1},\dots,p^{a}_{m_{a}}\}{ italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT , … , italic_p start_POSTSUPERSCRIPT italic_a end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_m start_POSTSUBSCRIPT italic_a end_POSTSUBSCRIPT end_POSTSUBSCRIPT } are sampled using a uniform random distribution. Experimentally, we anneal ϵ italic-ϵ\epsilon italic_ϵ from 1.0 to 0.1 over the first 10,000 10 000 10,000 10 , 000 updates. Lillicrap et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib8)) demonstrate that Ornstein-Uhlenbeck exploration is also successful in continuous action space.
|
| 149 |
+
|
| 150 |
+
5 Bounded Parameter Space Learning
|
| 151 |
+
----------------------------------
|
| 152 |
+
|
| 153 |
+
The Half Field Offense domain bounds the range of each continuous parameter. Parameters indicating direction (e.g. Turn and Kick direction) are bounded in [−180,180]180 180[-180,180][ - 180 , 180 ] and parameters for power (e.g. Kick and Dash power) are bounded in [0,100]0 100[0,100][ 0 , 100 ]. Without enforcing these bounds, after a few hundred updates, we observed continuous parameters routinely exceeding the bounds. If updates were permitted to continue, parameters would quickly trend towards astronomically large values. This problem stems from the critic providing gradients that encourage the actor network to continue increasing a parameter that already exceeds bounds. We explore three approaches for preserving parameters in their intended ranges:
|
| 154 |
+
|
| 155 |
+
Zeroing Gradients: Perhaps the simplest approach is to examine the critic’s gradients for each parameter and zero the gradients that suggest increasing/decreasing the value of a parameter that is already at the upper/lower limit of its range:
|
| 156 |
+
|
| 157 |
+
∇p={∇p if p min<p<p max 0 otherwise subscript∇𝑝 cases subscript∇𝑝 if p min<p<p max 0 otherwise\nabla_{p}=\begin{cases}\nabla_{p}&\text{if $p_{\min}<p<p_{\max}$}\\ 0&\text{otherwise}\end{cases}∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT = { start_ROW start_CELL ∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT end_CELL start_CELL if italic_p start_POSTSUBSCRIPT roman_min end_POSTSUBSCRIPT < italic_p < italic_p start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT end_CELL end_ROW start_ROW start_CELL 0 end_CELL start_CELL otherwise end_CELL end_ROW(10)
|
| 158 |
+
|
| 159 |
+
Where ∇p subscript∇𝑝\nabla_{p}∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT indicates the critic’s gradient with respect to parameter p 𝑝 p italic_p, (e.g. ∇p Q(s t,a|θ Q)subscript∇𝑝 𝑄 subscript 𝑠 𝑡 conditional 𝑎 superscript 𝜃 𝑄\nabla_{p}Q(s_{t},a|\theta^{Q})∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT italic_Q ( italic_s start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT )) and p min,p max,p subscript 𝑝 subscript 𝑝 𝑝 p_{\min},p_{\max},p italic_p start_POSTSUBSCRIPT roman_min end_POSTSUBSCRIPT , italic_p start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT , italic_p indicate respectively the minimum bound, maximum bound, and current activation of that parameter.
|
| 160 |
+
|
| 161 |
+
Squashing Gradients: A squashing function such as the hyperbolic tangent (tanh) is used to bound the activation of each parameter. Subsequently, the parameters are re-scaled into their intended ranges. This approach has the advantage of not requiring manual gradient tinkering, but presents issues if the squashing function saturates.
|
| 162 |
+
|
| 163 |
+
Inverting Gradients: This approach captures the best aspects of the zeroing and squashing gradients, while minimizing the drawbacks. Gradients are downscaled as the parameter approaches the boundaries of its range and are inverted if the parameter exceeds the value range. This approach actively keeps parameters within bounds while avoiding problems of saturation. For example, if the critic continually recommends increasing a parameter, it will converge to the parameter’s upper bound. If the critic then decides to decrease that parameter, it will decrease immediately. In contrast, a squashing function would be saturated at the upper bound of the range and require many updates to decrease. Mathematically, the inverted gradient approach may be expressed as follows:
|
| 164 |
+
|
| 165 |
+
∇p=∇p⋅{(p max−p)/(p max−p min)if∇p suggests increasing p(p−p min)/(p max−p min)otherwise subscript∇𝑝⋅subscript∇𝑝 cases subscript 𝑝 𝑝 subscript 𝑝 subscript 𝑝 if∇p suggests increasing p 𝑝 subscript 𝑝 subscript 𝑝 subscript 𝑝 otherwise\nabla_{p}=\nabla_{p}\cdot\begin{cases}(p_{\max}-p)/(p_{\max}-p_{\min})&\text{% if $\nabla_{p}$ suggests increasing $p$}\\ (p-p_{\min})/(p_{\max}-p_{\min})&\text{otherwise}\end{cases}∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT = ∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT ⋅ { start_ROW start_CELL ( italic_p start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT - italic_p ) / ( italic_p start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT - italic_p start_POSTSUBSCRIPT roman_min end_POSTSUBSCRIPT ) end_CELL start_CELL if ∇ start_POSTSUBSCRIPT italic_p end_POSTSUBSCRIPT suggests increasing italic_p end_CELL end_ROW start_ROW start_CELL ( italic_p - italic_p start_POSTSUBSCRIPT roman_min end_POSTSUBSCRIPT ) / ( italic_p start_POSTSUBSCRIPT roman_max end_POSTSUBSCRIPT - italic_p start_POSTSUBSCRIPT roman_min end_POSTSUBSCRIPT ) end_CELL start_CELL otherwise end_CELL end_ROW(11)
|
| 166 |
+
|
| 167 |
+
It should be noted that these approaches are not specific to HFO or parameterized action space. Any domain featuring a bounded-continuous action space will require a similar approach for enforcing bounds. All three approaches are empirically evaluated the next section.
|
| 168 |
+
|
| 169 |
+
6 Results
|
| 170 |
+
---------
|
| 171 |
+
|
| 172 |
+
We evaluate the zeroing, squashing, and inverting gradient approaches in the parameterized HFO domain on the task of approaching the ball and scoring a goal. For each approach, we independently train two agents. All agents are trained for 3 million iterations, approximately 20,000 episodes of play. Training each agent took three days on a NVidia Titan-X GPU.
|
| 173 |
+
|
| 174 |
+
Of the three approaches, only the inverting gradient shows robust learning. Indeed both inverting gradient agents learned to reliably approach the ball and score goals. None of the other four agents using the squashing or zeroing gradients were able to reliably approach the ball or score.
|
| 175 |
+
|
| 176 |
+
Further analysis of the squashing gradient approach reveals that parameters stayed within their bounds, but squashing functions quickly became saturated. The resulting agents take the same discrete action with the same maximum/minimum parameters each timestep. Given the observed proclivity of the critic’s gradients to push parameters towards ever larger/small values, it is no surprise that squashing function quickly become saturated and never recover.
|
| 177 |
+
|
| 178 |
+
Further analysis of the zeroing gradient approach reveals two problems: 1) parameters still overflow their bounds and 2) instability: While the gradient zeroing approach negates any direct attempts to increase a parameter p 𝑝 p italic_p beyond its bounds, we hypothesize the first problem stems from gradients applied to other parameters p i≠p subscript 𝑝 𝑖 𝑝 p_{i}\neq p italic_p start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ≠ italic_p which inadvertently allow parameter p 𝑝 p italic_p to overflow. Empirically, we observed learned networks attempting to dash with a power of 120, more than the maximum of 100. It is reasonable for a critic network to encourage the actor to dash faster.
|
| 179 |
+
|
| 180 |
+
Unstable learning was observed in one of the two zeroing gradient agents. This instability is well captured in the Q-Values and critic losses shown in Figure [3](https://arxiv.org/html/1511.04143v5#S6.F3 "Figure 3 ‣ 6 Results ‣ Deep Reinforcement Learning in Parameterized Action Space"). It’s not clear why this agent became unstable, but the remaining stable agent showed clear results of not learning.
|
| 181 |
+
|
| 182 |
+
These results highlight the necessity of non-saturating functions that effectively enforce action bounds. The approach of inverting gradients was observed to respect parameter boundaries (observed dash power reaches 98.8 out of 100) without saturating. As a result, the critic was able to effectively shape the actor’s policy. Further evaluation of the reliability and quality of the inverting-gradient policies is presented in the next section.
|
| 183 |
+
|
| 184 |
+

|
| 185 |
+
|
| 186 |
+

|
| 187 |
+
|
| 188 |
+

|
| 189 |
+
|
| 190 |
+

|
| 191 |
+
|
| 192 |
+

|
| 193 |
+
|
| 194 |
+

|
| 195 |
+
|
| 196 |
+

|
| 197 |
+
|
| 198 |
+
(a) Inverting Gradients
|
| 199 |
+
|
| 200 |
+

|
| 201 |
+
|
| 202 |
+
(b) Zeroing Gradients
|
| 203 |
+
|
| 204 |
+

|
| 205 |
+
|
| 206 |
+
(c) Squashing Gradients
|
| 207 |
+
|
| 208 |
+
Figure 3: Analysis of gradient bounding strategies: The left/middle/right columns respectively correspond to the inverting/zeroing/squashing gradients approaches to handling bounded continuous actions. First row depicts learning curves showing overall task performance: Only the inverting gradient approach succeeds in learning the soccer task. Second row shows average Q-Values produced by the critic throughout the entire learning process: Inverting gradient approach shows smoothly increasing Q-Values. The zeroing approach shows astronomically high Q-Values indicating instability in the critic. The squashing approach shows stable Q-Values that accurately reflect the actor’s performance. Third row shows the average loss experienced during a critic update (Equation [7](https://arxiv.org/html/1511.04143v5#S3.E7 "In 3.1 Stable Updates ‣ 3 Background: Deep Reinforcement Learning ‣ Deep Reinforcement Learning in Parameterized Action Space")): As more reward is experienced critic loss is expected to rise as past actions are seen as increasingly sub-optimal. Inverting gradients shows growing critic loss with outliers accounting for the rapid increase nearing the right edge of the graph. Zeroing gradients approach shows unstably large loss. Squashing gradients never discovers much reward and loss stays near zero.
|
| 209 |
+
|
| 210 |
+
7 Soccer Evaluation
|
| 211 |
+
-------------------
|
| 212 |
+
|
| 213 |
+
We further evaluate the inverting gradient agents by comparing them to an expert agent independently created by the Helios RoboCup-2D team. This agent won the 2012 RoboCup-2D world championship and source code was subsequently released (Akiyama, [2010](https://arxiv.org/html/1511.04143v5#bib.bib1)). Thus, this hand-coded policy represents an extremely competent player and a high performance bar.
|
| 214 |
+
|
| 215 |
+
As an additional baseline we compare to a SARSA learning agent. State-Action-Reward-State-Action (SARSA) is an algorithm for model-free on-policy Reinforcement Learning Sutton & Barto ([1998](https://arxiv.org/html/1511.04143v5#bib.bib17)). The SARSA agent learns in a simplified version of HFO featuring high-level discrete actions for moving, dribbling, and shooting the ball. As input it is given continuous features that including the distance and angle to the goal center. Tile coding Sutton & Barto ([1998](https://arxiv.org/html/1511.04143v5#bib.bib17)) is used to discretize the state space. Experiences collected by playing the game are then used to bootstrap a value function.
|
| 216 |
+
|
| 217 |
+
To show that the deep reinforcement learning process is reliable, in additional to the previous two inverting-gradient agents we independently train another five inverting-gradient agents, for a total of seven agents DDPG 1-7. All seven agents learned to score goals. Comparing against the Helios’ champion agent, each of the learned agents is evaluated for 100 episodes on how quickly and reliably it can score.
|
| 218 |
+
|
| 219 |
+
Six of seven DDPG agents outperform the SARSA baseline, and remarkably, three of the seven DDPG agents score more reliably than Helios’ champion agent. Occasional failures of the Helios agent result from noise in the action space, which occasionally causes missed kicks. In contrast, DDPG agents learn to take extra time to score each goal, and become more accurate as a result. This extra time is reasonable considering DDPG is rewarded only for scoring and experiences no real pressure to score more quickly. We are encouraged to see that deep reinforcement learning can produce agents competitive with and even exceeding an expert handcoded agent.
|
| 220 |
+
|
| 221 |
+

|
| 222 |
+
|
| 223 |
+
(a) Learning Curve
|
| 224 |
+
|
| 225 |
+
(b) Evaluation Performance
|
| 226 |
+
|
| 227 |
+
Figure 4: Left: Scatter plot of learning curves of DDPG-agents with Lowess curve. Three distinct phases of learning may be seen: the agents first get small rewards for approaching the ball (episode 1500), then learn to kick the ball towards the goal (episodes 2,000 - 8,000), and start scoring goals around episode 10,000. Right: DDPG-agents score nearly as reliably as expert baseline, but take longer to do so. A video of DDPG 1’s policy may be viewed at [%****␣dqn-hfo.tex␣Line␣725␣****https://youtu.be/Ln0Cl-jE_40](https://arxiv.org/html/1511.04143v5/%****%20dqn-hfo.tex%20Line%20725%20****https://youtu.be/Ln0Cl-jE_40).
|
| 228 |
+
|
| 229 |
+
8 Related Work
|
| 230 |
+
--------------
|
| 231 |
+
|
| 232 |
+
RoboCup 2D soccer has a rich history of learning. In one of the earliest examples, Andre & Teller ([1999](https://arxiv.org/html/1511.04143v5#bib.bib2)) used Genetic Programming to evolve policies for RoboCup 2D Soccer. By using a sequence of reward functions, they first encourage the players to approach the ball, kick the ball, score a goal, and finally to win the game. Similarly, our work features players whose policies are entirely trained and have no hand-coded components. Our work differs by using a gradient-based learning method paired with using reinforcement learning rather than evolution.
|
| 233 |
+
|
| 234 |
+
Masson & Konidaris ([2015](https://arxiv.org/html/1511.04143v5#bib.bib10)) present a parameterized-action MDP formulation and approaches for model-free reinforcement learning in such environments. The core of this approach uses a parameterized policy for choosing which discrete action to select and another policy for selecting continuous parameters for that action. Given a fixed policy for parameter selection, they use Q-Learning to optimize the policy discrete action selection. Next, they fix the policy for discrete action selection and use a policy search method to optimize the parameter selection. Alternating these two learning phases yields convergence to either a local or global optimum depending on whether the policy search procedure can guarantee optimality. In contrast, our approach to learning in parameterized action space features a parameterized actor that learns both discrete actions and parameters and a parameterized critic that learns only the action-value function. Instead of relying on an external policy search procedure, we are able to directly query the critic for gradients. Finally, we parameterize our policies using deep neural networks rather than linear function approximation. Deep networks offer no theoretical convergence guarantees, but have a strong record of empirical success.
|
| 235 |
+
|
| 236 |
+
Experimentally, Masson & Konidaris ([2015](https://arxiv.org/html/1511.04143v5#bib.bib10)) examine a simplified abstraction of RoboCup 2D soccer which co-locates the agent and ball at the start of every trial and features a smaller action space consisting only of parameterized kick actions. However, they do examine the more difficult task of scoring on a keeper. Since their domain is hand-crafted and closed-source, it’s hard to estimate how difficult their task is compared to the goal scoring task in our paper.
|
| 237 |
+
|
| 238 |
+
Competitive RoboCup agents are primarily handcoded but may feature components that are learned or optimized. MacAlpine et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib9)) employed the layered-learning framework to incrementally learn a series of interdependent behaviors. Perhaps the best example of comprehensively integrating learning is the Brainstormers who, in competition, use a neural network to make a large portion of decisions spanning low level skills through high level strategy (Riedmiller et al., [2009](https://arxiv.org/html/1511.04143v5#bib.bib14); Riedmiller & Gabel, [2007](https://arxiv.org/html/1511.04143v5#bib.bib15)). However their work was done prior to the advent of deep reinforcement learning, and thus required more constrained, focused training environments for each of their skills. In contrast, our study learns to approach the ball, kick towards the goal, and score, all within the context of a single, monolithic policy.
|
| 239 |
+
|
| 240 |
+
Deep learning methods have proven useful in various control domains. As previously mentioned DQN (Mnih et al., [2015](https://arxiv.org/html/1511.04143v5#bib.bib11)) and DDPG (Lillicrap et al., [2015](https://arxiv.org/html/1511.04143v5#bib.bib8)) provide great starting points for learning in discrete and continuous action spaces. Additionally, Levine et al. ([2015](https://arxiv.org/html/1511.04143v5#bib.bib7)) demonstrates the ability of deep learning paired with guided policy search to learn manipulation policies on a physical robot. The high requirement for data (in the form of experience) is a hurdle for applying deep reinforcement learning directly onto robotic platforms. Our work differs by examining an action space with latent structure and parameterized-continuous actions.
|
| 241 |
+
|
| 242 |
+
9 Future Work
|
| 243 |
+
-------------
|
| 244 |
+
|
| 245 |
+
The harder task of scoring on a goalie is left for future work. Additionally, the RoboCup domain presents many opportunities for multi-agent collaboration both in an adhoc-teamwork setting (in which a single learning agent must collaborate with unknown teammates) and true multi-agent settings (in which multiple learning agents must collaborate). Challenges in multi-agent learning in the RoboCup domain have been examined by prior work (Kalyanakrishnan et al., [2007](https://arxiv.org/html/1511.04143v5#bib.bib5)) and solutions may translate into the deep reinforcement learning settings as well. Progress in this direction could eventually result in a team of deep reinforcement learning soccer players.
|
| 246 |
+
|
| 247 |
+
Another interesting possibility is utilizing the critic’s gradients with respect to state inputs ∇s Q(s,a|θ Q)subscript∇𝑠 𝑄 𝑠 conditional 𝑎 superscript 𝜃 𝑄\nabla_{s}Q(s,a|\theta^{Q})∇ start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPT italic_Q ( italic_s , italic_a | italic_θ start_POSTSUPERSCRIPT italic_Q end_POSTSUPERSCRIPT ). These gradients indicate directions of improvement in state space. An agent with a forward model may be able to exploit these gradients to transition into states which the critic finds more favorable. Recent developments in model-based deep reinforcement learning (Oh et al., [2015](https://arxiv.org/html/1511.04143v5#bib.bib13)) show that detailed next state models are possible.
|
| 248 |
+
|
| 249 |
+
10 Conclusion
|
| 250 |
+
-------------
|
| 251 |
+
|
| 252 |
+
This paper has presented an agent trained exclusively with deep reinforcement learning which learns from scratch how to approach the ball, kick the ball to goal, and score. The best learned agent scores goals more reliably than a handcoded expert policy. Our work does not address more challenging tasks such as scoring on a goalie or cooperating with a team, but still represents a step towards fully learning complex RoboCup agents. More generally we have demonstrated the capability of deep reinforcement learning in parameterized action space.
|
| 253 |
+
|
| 254 |
+
To make this possible, we extended the DDPG algorithm (Lillicrap et al., [2015](https://arxiv.org/html/1511.04143v5#bib.bib8)), by presenting an analyzing a novel approach for bounding the action space gradients suggested by the Critic. This extension is not specific to the HFO domain and will likely prove useful for any continuous, bounded action space.
|
| 255 |
+
|
| 256 |
+
#### Acknowledgments
|
| 257 |
+
|
| 258 |
+
The authors wish to thank Yilun Chen. This work has taken place in the Learning Agents Research Group (LARG) at the Artificial Intelligence Laboratory, The University of Texas at Austin. LARG research is supported in part by grants from the National Science Foundation (CNS-1330072, CNS-1305287), ONR (21C184-01), AFRL (FA8750-14-1-0070), AFOSR (FA9550-14-1-0087), and Yujin Robot. Additional support from the Texas Advanced Computing Center, and Nvidia Corporation.
|
| 259 |
+
|
| 260 |
+
References
|
| 261 |
+
----------
|
| 262 |
+
|
| 263 |
+
* Akiyama (2010) Akiyama, Hidehisa. Agent2d base code, 2010.
|
| 264 |
+
* Andre & Teller (1999) Andre, David and Teller, Astro. Evolving Team Darwin United. _Lecture Notes in Computer Science_, 1604:346, 1999. ISSN 0302-9743. URL [http://link.springer-ny.com/link/service/series/0558/bibs/1604/16040346.htm;http://link.springer-ny.com/link/service/series/0558/papers/1604/16040346.pdf](http://link.springer-ny.com/link/service/series/0558/bibs/1604/16040346.htm;http://link.springer-ny.com/link/service/series/0558/papers/1604/16040346.pdf).
|
| 265 |
+
* Hafner & Riedmiller (2011) Hafner, Roland and Riedmiller, Martin. Reinforcement learning in feedback control. _Machine Learning_, 84(1-2):137–169, 2011. ISSN 0885-6125. doi: 10.1007/s10994-011-5235-x. URL [http://dx.doi.org/10.1007/s10994-011-5235-x](http://dx.doi.org/10.1007/s10994-011-5235-x).
|
| 266 |
+
* Hausknecht & Stone (2015) Hausknecht, Matthew J. and Stone, Peter. Deep recurrent q-learning for partially observable mdps. _CoRR_, abs/1507.06527, 2015. URL [http://arxiv.org/abs/1507.06527](http://arxiv.org/abs/1507.06527).
|
| 267 |
+
* Kalyanakrishnan et al. (2007) Kalyanakrishnan, Shivaram, Liu, Yaxin, and Stone, Peter. Half field offense in RoboCup soccer: A multiagent reinforcement learning case study. In Lakemeyer, Gerhard, Sklar, Elizabeth, Sorenti, Domenico, and Takahashi, Tomoichi (eds.), _RoboCup-2006: Robot Soccer World Cup X_, volume 4434 of _Lecture Notes in Artificial Intelligence_, pp. 72–85. Springer Verlag, Berlin, 2007. ISBN 978-3-540-74023-0.
|
| 268 |
+
* Kingma & Ba (2014) Kingma, Diederik P. and Ba, Jimmy. Adam: A method for stochastic optimization. _CoRR_, abs/1412.6980, 2014. URL [http://arxiv.org/abs/1412.6980](http://arxiv.org/abs/1412.6980).
|
| 269 |
+
* Levine et al. (2015) Levine, Sergey, Finn, Chelsea, Darrell, Trevor, and Abbeel, Pieter. End-to-end training of deep visuomotor policies. _CoRR_, abs/1504.00702, 2015. URL [http://arxiv.org/abs/1504.00702](http://arxiv.org/abs/1504.00702).
|
| 270 |
+
* Lillicrap et al. (2015) Lillicrap, T.P., Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. _ArXiv e-prints_, September 2015.
|
| 271 |
+
* MacAlpine et al. (2015) MacAlpine, Patrick, Depinet, Mike, and Stone, Peter. UT Austin Villa 2014: RoboCup 3D simulation league champion via overlapping layered learning. In _Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence (AAAI)_, January 2015.
|
| 272 |
+
* Masson & Konidaris (2015) Masson, Warwick and Konidaris, George. Reinforcement learning with parameterized actions. _CoRR_, abs/1509.01644, 2015. URL [http://arxiv.org/abs/1509.01644](http://arxiv.org/abs/1509.01644).
|
| 273 |
+
* Mnih et al. (2015) Mnih, Volodymyr, Kavukcuoglu, Koray, Silver, David, Rusu, Andrei A., Veness, Joel, Bellemare, Marc G., Graves, Alex, Riedmiller, Martin, Fidjeland, Andreas K., Ostrovski, Georg, Petersen, Stig, Beattie, Charles, Sadik, Amir, Antonoglou, Ioannis, King, Helen, Kumaran, Dharshan, Wierstra, Daan, Legg, Shane, and Hassabis, Demis. Human-level control through deep reinforcement learning. _Nature_, 518(7540):529–533, February 2015. ISSN 0028-0836. doi: 10.1038/nature14236. URL [http://dx.doi.org/10.1038/nature14236](http://dx.doi.org/10.1038/nature14236).
|
| 274 |
+
* Narasimhan et al. (2015) Narasimhan, Karthik, Kulkarni, Tejas, and Barzilay, Regina. Language understanding for text-based games using deep reinforcement learning. _CoRR_, abs/1506.08941, 2015. URL [http://arxiv.org/abs/1506.08941](http://arxiv.org/abs/1506.08941).
|
| 275 |
+
* Oh et al. (2015) Oh, Junhyuk, Guo, Xiaoxiao, Lee, Honglak, Lewis, Richard L., and Singh, Satinder P. Action-conditional video prediction using deep networks in atari games. _CoRR_, abs/1507.08750, 2015. URL [http://arxiv.org/abs/1507.08750](http://arxiv.org/abs/1507.08750).
|
| 276 |
+
* Riedmiller et al. (2009) Riedmiller, Martin, Gabel, Thomas, Hafner, Roland, and Lange, Sascha. Reinforcement learning for robot soccer. _Autonomous Robots_, 27(1):55–73, 2009. ISSN 0929-5593. doi: 10.1007/s10514-009-9120-4. URL [http://dx.doi.org/10.1007/s10514-009-9120-4](http://dx.doi.org/10.1007/s10514-009-9120-4).
|
| 277 |
+
* Riedmiller & Gabel (2007) Riedmiller, Martin A. and Gabel, Thomas. On experiences in a complex and competitive gaming domain: Reinforcement learning meets robocup. In _CIG_, pp. 17–23. IEEE, 2007. ISBN 1-4244-0709-5. URL [http://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp?punumber=4219012](http://ieeexplore.ieee.org/xpl/mostRecentIssue.jsp?punumber=4219012).
|
| 278 |
+
* Stadie et al. (2015) Stadie, Bradly C., Levine, Sergey, and Abbeel, Pieter. Incentivizing exploration in reinforcement learning with deep predictive models. _CoRR_, abs/1507.00814, 2015. URL [http://arxiv.org/abs/1507.00814](http://arxiv.org/abs/1507.00814).
|
| 279 |
+
* Sutton & Barto (1998) Sutton, Richard S. and Barto, Andrew G. _Reinforcement Learning: An Introduction_. MIT Press, 1998. ISBN 0262193981. URL [http://www.cs.ualberta.ca/%7Esutton/book/ebook/the-book.html](http://www.cs.ualberta.ca/%7Esutton/book/ebook/the-book.html).
|
| 280 |
+
* Tieleman & Hinton (2012) Tieleman, T. and Hinton, G. Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012.
|
| 281 |
+
* van Hasselt et al. (2015) van Hasselt, Hado, Guez, Arthur, and Silver, David. Deep reinforcement learning with double q-learning. _CoRR_, abs/1509.06461, 2015. URL [http://arxiv.org/abs/1509.06461](http://arxiv.org/abs/1509.06461).
|
| 282 |
+
* Watkins & Dayan (1992) Watkins, Christopher J. C.H. and Dayan, Peter. Q-learning. _Machine Learning_, 8(3-4):279–292, 1992. doi: 10.1023/A:1022676722315. URL [http://jmvidal.cse.sc.edu/library/watkins92a.pdf](http://jmvidal.cse.sc.edu/library/watkins92a.pdf).
|
| 283 |
+
* Zeiler (2012) Zeiler, Matthew D. ADADELTA: An adaptive learning rate method. _CoRR_, abs/1212.5701, 2012. URL [http://arxiv.org/abs/1212.5701](http://arxiv.org/abs/1212.5701).
|
1512/1512.03385.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1512.03385
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1512.03385#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1512.03385'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1602/1602.00370.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1602.00370
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1602.00370#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1602.00370'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1603/1603.05027.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1603.05027
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1603.05027#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1603.05027'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1610/1610.00291.md
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Feature Perceptual Loss for Variational Autoencoder
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1610.00291
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Ke Sun
|
| 7 |
+
|
| 8 |
+
University of Nottingham, Ningbo, China
|
| 9 |
+
|
| 10 |
+
ke.sun@nottingham.edu.cn Linlin Shen
|
| 11 |
+
|
| 12 |
+
Shenzhen University, Shenzhen, China
|
| 13 |
+
|
| 14 |
+
llshen@szu.edu.cn Guoping Qiu
|
| 15 |
+
|
| 16 |
+
University of Nottingham, Ningbo, China
|
| 17 |
+
|
| 18 |
+
guoping.qiu@nottingham.edu.cn
|
| 19 |
+
|
| 20 |
+
###### Abstract
|
| 21 |
+
|
| 22 |
+
We consider unsupervised learning problem to generate images like Variational Autoencoder (VAE) and Generative Adversarial Network (GAN), which are two popular generative models around this problem. Recent works on style transfer have shown that higher quality images can be generated by optimizing feature perceptual loss, which is based on pretrained deep convolutional neural network (CNN). We propose to train VAE by using feature perceptual loss to measure the similarity between the input and generated images instead of pixel-by-pixel loss. Testing on face image dataset, our model can produce better qualitative results than other models. Moreover, our experiments demonstrate that the learned latent representation in our model has powerful capability to capture the conceptual and semantic information of natural images, and achieve state-of-the-art performance in facial attribute prediction.
|
| 23 |
+
|
| 24 |
+
1 Introduction
|
| 25 |
+
--------------
|
| 26 |
+
|
| 27 |
+
Deep Convolutional Neural Networks (CNNs) have been used to achieve state-of-the-art performances in many supervised computer vision tasks such as image classification [[13](https://arxiv.org/html/1610.00291v2#bib.bib13), [28](https://arxiv.org/html/1610.00291v2#bib.bib28)], retrieval [[1](https://arxiv.org/html/1610.00291v2#bib.bib1)], detection [[5](https://arxiv.org/html/1610.00291v2#bib.bib5), sermanet2013overfeat], and captioning [[9](https://arxiv.org/html/1610.00291v2#bib.bib9), vinyals2015show]. Deep CNNs-based generative models, a branch of unsupervised learning techniques in machine learning, have become a hot research topic in computer vision area in recent years. A generative model trained with a given dataset can be used to generate data like the samples in the dataset, learn the internal essence of the dataset and ”store” all the information in the limited parameters that are significantly smaller than the training dataset.
|
| 28 |
+
|
| 29 |
+
Variational Autoencoder (VAE) [[12](https://arxiv.org/html/1610.00291v2#bib.bib12), [24](https://arxiv.org/html/1610.00291v2#bib.bib24)] has become a popular generative model, allowing us to formalize this problem in the framework of probabilistic graphical models with latent variables. By default, pixel-by-pixel measurement like L2 loss, or logistic regression loss is used to measure the difference between reconstructed and original images. Such measurements are easily implemented and effective for deep neural network training. However, the generated images are not clear and tend to be very blurry when compared to natural images. This is because the pixel-by-pixel loss is not good enough to capture the visual perceptual difference between two images and it is not the way how humans look at the world. For example, the same image offsetted by a few pixels has little visual perceptual difference for humans, but it could have very high pixel-by-pixel loss.
|
| 30 |
+
|
| 31 |
+
In this paper, we try to improve the standard (plain) VAE by replacing the pixel-by-pixel loss with feature perceptual loss which is the difference between high level features of images extracted from hidden layer in pretrained deep convolutional neural networks such as AlexNet [[13](https://arxiv.org/html/1610.00291v2#bib.bib13)] and VGGNet [[28](https://arxiv.org/html/1610.00291v2#bib.bib28)] trained on ImageNet [[26](https://arxiv.org/html/1610.00291v2#bib.bib26)]. The high-level feature-based loss has been successfully applied to deep neural network visualization [[27](https://arxiv.org/html/1610.00291v2#bib.bib27), [31](https://arxiv.org/html/1610.00291v2#bib.bib31)], texture synthesis and style transfer [[4](https://arxiv.org/html/1610.00291v2#bib.bib4), [3](https://arxiv.org/html/1610.00291v2#bib.bib3)], demonstrating superiority over pixel-by-pixel loss. We also explore the conceptual representation capability of the learned latent space, and use it for facial attribute prediction.
|
| 32 |
+
|
| 33 |
+
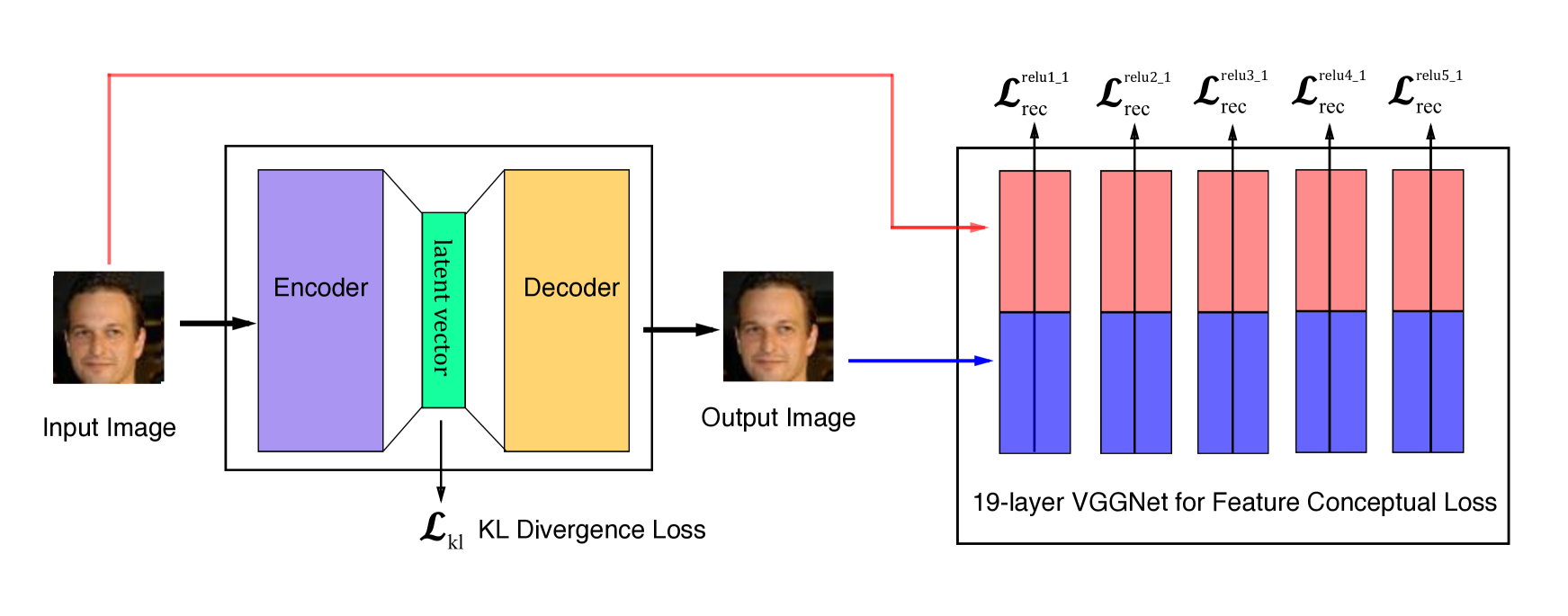
|
| 34 |
+
|
| 35 |
+
Figure 1: Model Overview. The left is a deep CNN-based Variational Autoencoder, and the right is a pretrained deep CNN used to compute feature perceptual loss.
|
| 36 |
+
|
| 37 |
+
2 Related Work
|
| 38 |
+
--------------
|
| 39 |
+
|
| 40 |
+
Variational Autoencoder (VAE). A VAE [[12](https://arxiv.org/html/1610.00291v2#bib.bib12)] helps us to do two things. Firstly it allows us to encode an image x 𝑥 x italic_x to a small dimension latent vector z=Encoder(x)∼q(z|x)𝑧 𝐸 𝑛 𝑐 𝑜 𝑑 𝑒 𝑟 𝑥 similar-to 𝑞 conditional 𝑧 𝑥 z=Encoder(x)\sim q(z|x)italic_z = italic_E italic_n italic_c italic_o italic_d italic_e italic_r ( italic_x ) ∼ italic_q ( italic_z | italic_x ) with an encoder network, and then an decoder network is used to decode the latent vector z 𝑧 z italic_z back to an image that will be as similar as the original image x¯=Decoder(z)∼p(x|z)¯𝑥 𝐷 𝑒 𝑐 𝑜 𝑑 𝑒 𝑟 𝑧 similar-to 𝑝 conditional 𝑥 𝑧\bar{x}=Decoder(z)\sim p(x|z)over¯ start_ARG italic_x end_ARG = italic_D italic_e italic_c italic_o italic_d italic_e italic_r ( italic_z ) ∼ italic_p ( italic_x | italic_z ). That is to say, we need to maximize marginal log-likelihood of each observation (pixel) in x, and the VAE reconstruction loss ℒ rec subscript ℒ 𝑟 𝑒 𝑐\mathcal{L}_{rec}caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT is negative expected log-likelihood of observations in x. Another important property of VAE is able to control the distribution of latent vector z 𝑧 z italic_z, which has characteristic of being independent unit Gaussian random variables, i.e., z∼𝒩(0,I)similar-to 𝑧 𝒩 0 𝐼 z\sim\mathcal{N}(0,I)italic_z ∼ caligraphic_N ( 0 , italic_I ). Moreover, the difference between the distribution of q(z|x)𝑞 conditional 𝑧 𝑥 q(z|x)italic_q ( italic_z | italic_x ) and the distribution of a Gaussian distribution (called KL Divergence) can be quantified and minimized using gradient descent algorithm [[12](https://arxiv.org/html/1610.00291v2#bib.bib12)]. Therefore, VAE models can be trained by optimizing the sum of the reconstruction loss (ℒ rec subscript ℒ 𝑟 𝑒 𝑐\mathcal{L}_{rec}caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT) and KL divergence loss (ℒ kl subscript ℒ 𝑘 𝑙\mathcal{L}_{kl}caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT) using gradient descent.
|
| 41 |
+
|
| 42 |
+
ℒ rec=−𝔼 q(z|x)[logp(x|z)]subscript ℒ 𝑟 𝑒 𝑐 subscript 𝔼 𝑞 conditional 𝑧 𝑥 delimited-[]𝑝 conditional 𝑥 𝑧\mathcal{L}_{rec}=-\mathbb{E}_{q(z|x)}[\log p(x|z)]caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT = - blackboard_E start_POSTSUBSCRIPT italic_q ( italic_z | italic_x ) end_POSTSUBSCRIPT [ roman_log italic_p ( italic_x | italic_z ) ]
|
| 43 |
+
|
| 44 |
+
ℒ kl=D kl(q(z|x)||p(z))\mathcal{L}_{kl}=D_{kl}(q(z|x)||p(z))caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT = italic_D start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT ( italic_q ( italic_z | italic_x ) | | italic_p ( italic_z ) )
|
| 45 |
+
|
| 46 |
+
ℒ vae=ℒ rec+ℒ kl subscript ℒ 𝑣 𝑎 𝑒 subscript ℒ 𝑟 𝑒 𝑐 subscript ℒ 𝑘 𝑙\mathcal{L}_{vae}=\mathcal{L}_{rec}+\mathcal{L}_{kl}caligraphic_L start_POSTSUBSCRIPT italic_v italic_a italic_e end_POSTSUBSCRIPT = caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT + caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT
|
| 47 |
+
|
| 48 |
+
Several methods have been proposed to improve the performance of VAE. [[11](https://arxiv.org/html/1610.00291v2#bib.bib11)] extends the variational auto-encoders to semi-supervised learning with class labels, [[30](https://arxiv.org/html/1610.00291v2#bib.bib30)] proposes a variety of attribute-conditioned deep variational auto-encoders, and demonstrates that they are capable of generating realistic faces with diverse appearance, Deep Recurrent Attentive Writer (DRAW) [[7](https://arxiv.org/html/1610.00291v2#bib.bib7)] combines spatial attention mechanism with a sequential variational auto-encoding framework that allows iterative generation of images. Considering the shortcoming of pixel-by-pixel loss, [[25](https://arxiv.org/html/1610.00291v2#bib.bib25)] replaces pixel-by-pixel loss with multi-scale structural-similarity score (MS-SSIM) and demonstrates that it can better measure human perceptual judgments of image quality. [[15](https://arxiv.org/html/1610.00291v2#bib.bib15)] proposes to enhence the objective function with discriminative regularization. Another approach [[16](https://arxiv.org/html/1610.00291v2#bib.bib16)] tries to combine VAE and generative adversarial network (GAN) [[23](https://arxiv.org/html/1610.00291v2#bib.bib23), [6](https://arxiv.org/html/1610.00291v2#bib.bib6)], and use the learned feature representation in the GAN discriminator as basis for the VAE reconstruction objective.
|
| 49 |
+
|
| 50 |
+
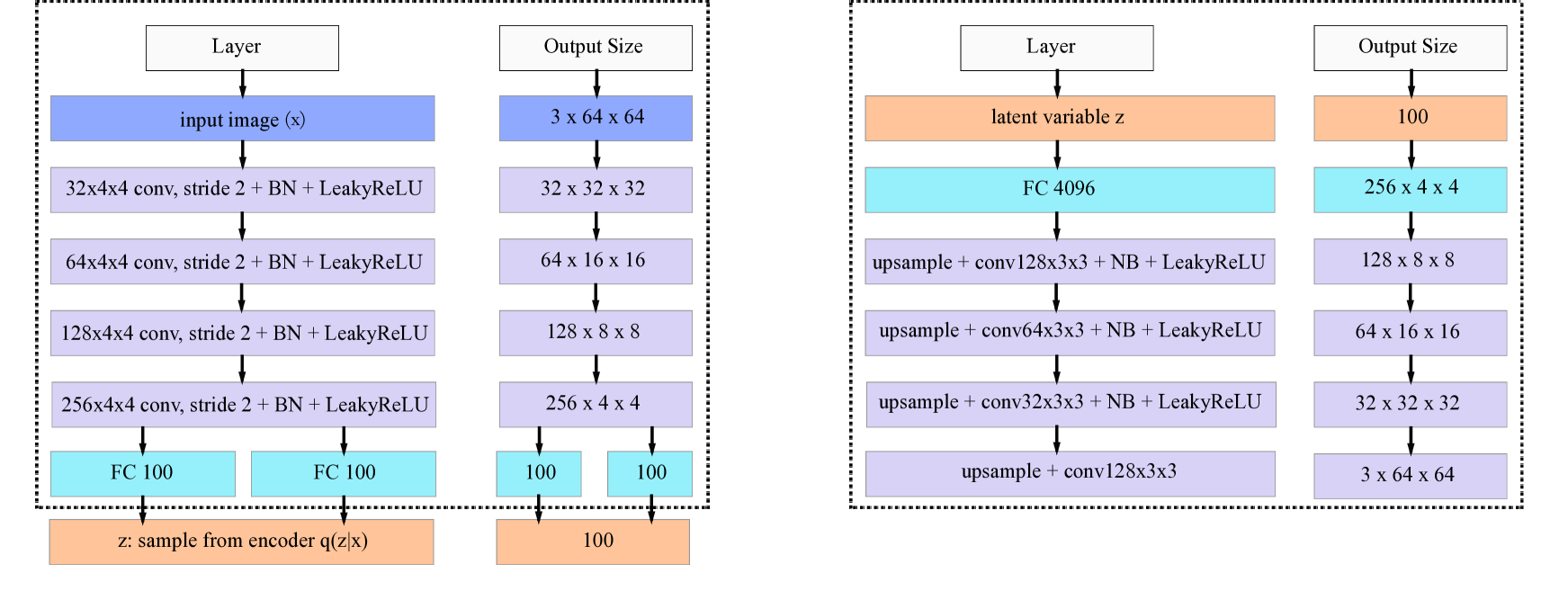
|
| 51 |
+
|
| 52 |
+
Figure 2: Autoencoder network architecture. The left is encoder network, and the right is decoder network.
|
| 53 |
+
|
| 54 |
+
high-level feature perceptual loss. Several recent papers successfully generate images by optimizing perceptual loss, which is based on the high-level features extracted from pretrained deep convolutional neural networks. Neural style transfer [[4](https://arxiv.org/html/1610.00291v2#bib.bib4)] and texture synthesis [[3](https://arxiv.org/html/1610.00291v2#bib.bib3)] tries to jointly minimize high-level feature reconstruction loss and style reconstruction loss by optimization. Additionally images can be also generated by maximizing classification scores or individual features [[27](https://arxiv.org/html/1610.00291v2#bib.bib27), [31](https://arxiv.org/html/1610.00291v2#bib.bib31)]. Other works try to train a feed-forward network for real-time style transfer [[8](https://arxiv.org/html/1610.00291v2#bib.bib8), [29](https://arxiv.org/html/1610.00291v2#bib.bib29), [17](https://arxiv.org/html/1610.00291v2#bib.bib17)] and super-resolution [[8](https://arxiv.org/html/1610.00291v2#bib.bib8)] based on feature perceptual loss. In this paper, we train a deep convolutional variational autoencoder (CVAE) for image generation by replacing pixel-by-pixel reconstruction loss with high-level feature perceptual loss based on pre-trained network.
|
| 55 |
+
|
| 56 |
+
3 Method
|
| 57 |
+
--------
|
| 58 |
+
|
| 59 |
+
Our system consists two main components as shown in Figure [1](https://arxiv.org/html/1610.00291v2#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Feature Perceptual Loss for Variational Autoencoder"): an autoencoder network including an encoder network(E(x)𝐸 𝑥 E(x)italic_E ( italic_x )) and a decoder network(D(z)𝐷 𝑧 D(z)italic_D ( italic_z )), and a loss network (Φ Φ\Phi roman_Φ) that is a pretrained deep convolutional neural network to define feature perceptual loss. An input image x 𝑥 x italic_x is encoded as a latent vector z=E(x)𝑧 𝐸 𝑥 z=E(x)italic_z = italic_E ( italic_x ), which will be decoded (x¯=D(z)¯𝑥 𝐷 𝑧\bar{x}=D(z)over¯ start_ARG italic_x end_ARG = italic_D ( italic_z )) back to image space. After training, new image can be generated by decoder network with a given vector z 𝑧 z italic_z. In order to train a VAE, we need two loss functions, one is KL divergence loss (ℒ kl=D kl(q(z|x)||p(z))\mathcal{L}_{kl}=D_{kl}(q(z|x)||p(z))caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT = italic_D start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT ( italic_q ( italic_z | italic_x ) | | italic_p ( italic_z ) )) [[12](https://arxiv.org/html/1610.00291v2#bib.bib12)] which is used to make sure that the latent vector z 𝑧 z italic_z is an independent unit Gaussian random variable. The other is feature reconstruction loss. Instead of direct comparing the input image and the generated image in the pixel space, we pass both of them to a pre-trained deep convolutional neural network Φ Φ\Phi roman_Φ respectively and then measure the difference between hidden layer representation, i.e., ℒ rec=ℒ 1+ℒ 2+…+ℒ l subscript ℒ 𝑟 𝑒 𝑐 superscript ℒ 1 superscript ℒ 2…superscript ℒ 𝑙\mathcal{L}_{rec}=\mathcal{L}^{1}+\mathcal{L}^{2}+...+\mathcal{L}^{l}caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT = caligraphic_L start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT + caligraphic_L start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT + … + caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT, where ℒ l superscript ℒ 𝑙\mathcal{L}^{l}caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT represents the feature loss at the l th superscript 𝑙 𝑡 ℎ l^{th}italic_l start_POSTSUPERSCRIPT italic_t italic_h end_POSTSUPERSCRIPT hidden layer. Thus, we use the high-level feature loss to better measure perceptual and semantic differences between the two images, this is because the pretrained network on image classification has already incorporated perceptual and semantic information we desire for. During the training, the pretrained loss network is fixed and just for high-level feature extraction, and KL divergence loss ℒ kl subscript ℒ 𝑘 𝑙\mathcal{L}_{kl}caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT is just used to update encoder network while the reconstruction feature loss ℒ rec subscript ℒ 𝑟 𝑒 𝑐\mathcal{L}_{rec}caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT is responsible for updating parameters of both encoder and decoder.
|
| 60 |
+
|
| 61 |
+
### 3.1 Variational Autoencoder Network Architecture
|
| 62 |
+
|
| 63 |
+
Both encoder and decoder network are based on deep convolutional neural network (CNN) like AlexNet [[13](https://arxiv.org/html/1610.00291v2#bib.bib13)] and VGGNet [[28](https://arxiv.org/html/1610.00291v2#bib.bib28)]. We construct 4 convolutional layers in encoder network with 4 x 4 kernels, and the stride is fixed to be 2 to achieve spatial downsampling instead of using deterministic spatial functions such as maxpooling. Each convolutional layer is followed by a batch normalization layer and a LeakyReLU activation layer. Then two fully-connected output layers (for mean and variance) are added to encoder, and will be used to compute the KL divergence loss and sample latent variable z 𝑧 z italic_z (see [[12](https://arxiv.org/html/1610.00291v2#bib.bib12), Joost2015] for details). For decoder, we use 4 convolutional layers with 3 x 3 kernels and set stride to be 1, and replace standard zero-padding with replication padding, i.e., feature map of an input is padded with the replication of the input boundary. For upsampling we use nearest neighbor method by scale of 2 instead of fractional-strided convolutions used by other works [[19](https://arxiv.org/html/1610.00291v2#bib.bib19), [23](https://arxiv.org/html/1610.00291v2#bib.bib23)]. We also use batch normalization to help stabilize training and use LeakyReLU as activation function. The details of autoencoder network architecture is shown in Figure [2](https://arxiv.org/html/1610.00291v2#S2.F2 "Figure 2 ‣ 2 Related Work ‣ Feature Perceptual Loss for Variational Autoencoder").
|
| 64 |
+
|
| 65 |
+
### 3.2 Feature Perceptual Loss
|
| 66 |
+
|
| 67 |
+
Feature perceptual loss of two images is defined as the difference between the hidden features in a pretrained deep convolutional neural network Φ Φ\Phi roman_Φ. Similar to [[4](https://arxiv.org/html/1610.00291v2#bib.bib4)], we use VGGNet [[28](https://arxiv.org/html/1610.00291v2#bib.bib28)] as the loss network in our experiment, which is trained for classification problem on ImageNet dataset. The core idea of feature perceptual loss is to seek the similarity between the hidden representation of two images, and the input images tend to be similar from perceptual and semantic aspect if the difference of hidden representation is small. Specifically, let Φ(x)l Φ superscript 𝑥 𝑙\Phi(x)^{l}roman_Φ ( italic_x ) start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT denote the representation of a l th superscript 𝑙 𝑡 ℎ l^{th}italic_l start_POSTSUPERSCRIPT italic_t italic_h end_POSTSUPERSCRIPT hidden layer when input image x 𝑥 x italic_x is fed to network Φ Φ\Phi roman_Φ. Mathematically Φ(x)l Φ superscript 𝑥 𝑙\Phi(x)^{l}roman_Φ ( italic_x ) start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT is a 3D volume block array of shape [C l superscript 𝐶 𝑙 C^{l}italic_C start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT x W l superscript 𝑊 𝑙 W^{l}italic_W start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT x H l superscript 𝐻 𝑙 H^{l}italic_H start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT], where C l superscript 𝐶 𝑙 C^{l}italic_C start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT is the number of filters, W l superscript 𝑊 𝑙 W^{l}italic_W start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT and H l superscript 𝐻 𝑙 H^{l}italic_H start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT represent the width and height of each feature map for the l th superscript 𝑙 𝑡 ℎ l^{th}italic_l start_POSTSUPERSCRIPT italic_t italic_h end_POSTSUPERSCRIPT layer. The feature perceptual loss for one layer (ℒ rec l subscript superscript ℒ 𝑙 𝑟 𝑒 𝑐\mathcal{L}^{l}_{rec}caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT) between two images x 𝑥 x italic_x and x¯¯𝑥\bar{x}over¯ start_ARG italic_x end_ARG can be simply defined by squared euclidean distance. Actually it is quite like pixel-by-pixel loss for images except that the color channel is not 3 any more.
|
| 68 |
+
|
| 69 |
+
ℒ rec l=1 2C lW lH l∑c=1 C l∑w=1 W l∑h=1 H l(Φ(x)c,w,h l−Φ(x¯)c,w,h l)2 subscript superscript ℒ 𝑙 𝑟 𝑒 𝑐 1 2 superscript 𝐶 𝑙 superscript 𝑊 𝑙 superscript 𝐻 𝑙 superscript subscript 𝑐 1 superscript 𝐶 𝑙 superscript subscript 𝑤 1 superscript 𝑊 𝑙 superscript subscript ℎ 1 superscript 𝐻 𝑙 superscript Φ subscript superscript 𝑥 𝑙 𝑐 𝑤 ℎ Φ subscript superscript¯𝑥 𝑙 𝑐 𝑤 ℎ 2\mathcal{L}^{l}_{rec}=\frac{1}{2C^{l}W^{l}H^{l}}\sum_{c=1}^{C^{l}}\sum_{w=1}^{% W^{l}}\sum_{h=1}^{H^{l}}(\Phi(x)^{l}_{c,w,h}-\Phi(\bar{x})^{l}_{c,w,h})^{2}caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT = divide start_ARG 1 end_ARG start_ARG 2 italic_C start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT italic_W start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT italic_H start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_ARG ∑ start_POSTSUBSCRIPT italic_c = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_C start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_w = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_W start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ∑ start_POSTSUBSCRIPT italic_h = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_H start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT end_POSTSUPERSCRIPT ( roman_Φ ( italic_x ) start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_c , italic_w , italic_h end_POSTSUBSCRIPT - roman_Φ ( over¯ start_ARG italic_x end_ARG ) start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_c , italic_w , italic_h end_POSTSUBSCRIPT ) start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT
|
| 70 |
+
|
| 71 |
+
By optimization to reconstruct images from noise, [[4](https://arxiv.org/html/1610.00291v2#bib.bib4), [8](https://arxiv.org/html/1610.00291v2#bib.bib8)] show that reconstruction from lower layers is almost perfect. While using higher layers, pixel information such as color and shape are changed although overall spatial structures can be preserved. In our paper, our reconstruction loss is defined as the total loss at different layers of VGG Network, i.e., ℒ rec=∑l ℒ rec l subscript ℒ 𝑟 𝑒 𝑐 subscript 𝑙 subscript superscript ℒ 𝑙 𝑟 𝑒 𝑐\mathcal{L}_{rec}=\sum_{l}\mathcal{L}^{l}_{rec}caligraphic_L start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT = ∑ start_POSTSUBSCRIPT italic_l end_POSTSUBSCRIPT caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT. Additionally we adopt the KL divergence loss ℒ kl subscript ℒ 𝑘 𝑙\mathcal{L}_{kl}caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT[[12](https://arxiv.org/html/1610.00291v2#bib.bib12)] to regularize the encoder network to control the distribution of latent variable z 𝑧 z italic_z. To train VAE, we jointly minimize the KL divergence loss ℒ kl subscript ℒ 𝑘 𝑙\mathcal{L}_{kl}caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT and feature perceptual loss ℒ rec l subscript superscript ℒ 𝑙 𝑟 𝑒 𝑐\mathcal{L}^{l}_{rec}caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT for different layers, i.e.,
|
| 72 |
+
|
| 73 |
+
ℒ total=αℒ kl+β∑i l(ℒ rec l)subscript ℒ 𝑡 𝑜 𝑡 𝑎 𝑙 𝛼 subscript ℒ 𝑘 𝑙 𝛽 superscript subscript 𝑖 𝑙 subscript superscript ℒ 𝑙 𝑟 𝑒 𝑐\mathcal{L}_{total}=\alpha\mathcal{L}_{kl}+\beta\sum_{i}^{l}(\mathcal{L}^{l}_{% rec})caligraphic_L start_POSTSUBSCRIPT italic_t italic_o italic_t italic_a italic_l end_POSTSUBSCRIPT = italic_α caligraphic_L start_POSTSUBSCRIPT italic_k italic_l end_POSTSUBSCRIPT + italic_β ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT ( caligraphic_L start_POSTSUPERSCRIPT italic_l end_POSTSUPERSCRIPT start_POSTSUBSCRIPT italic_r italic_e italic_c end_POSTSUBSCRIPT )
|
| 74 |
+
|
| 75 |
+
where α 𝛼\alpha italic_α and β 𝛽\beta italic_β are weighted parameters for KL Divergence and image reconstruction. It is quite similar to style transfer [[4](https://arxiv.org/html/1610.00291v2#bib.bib4)] if we treat KL Divergence as style reconstruction.
|
| 76 |
+
|
| 77 |
+
4 Experiments
|
| 78 |
+
-------------
|
| 79 |
+
|
| 80 |
+
In this paper, we perform experiments on face images to test our method. Specifically we compare the performance of our model trained by high-level feature perceptual loss with other generative models. Furthermore, we also investigate the latent space to seek semantic relationship between different latent representation and apply it to facial attribute prediction.
|
| 81 |
+
|
| 82 |
+
### 4.1 Training Details
|
| 83 |
+
|
| 84 |
+
Our model is trained on CelebFaces Attributes (CelebA) Dataset [[18](https://arxiv.org/html/1610.00291v2#bib.bib18)]. CelebA is a large-scale face attributes dataset with 202,599 number of face images, and 5 landmark locations, 40 binary attributes annotations per image. We build the training dataset by cropping and scaling the alignment images to 64 x 64 pixels like [[16](https://arxiv.org/html/1610.00291v2#bib.bib16), [23](https://arxiv.org/html/1610.00291v2#bib.bib23)]. We train our model with a batch size of 64 for 5 epochs over the training dataset and use Adam method for optimization [[10](https://arxiv.org/html/1610.00291v2#bib.bib10)] with initial learning rate of 0.0005, which is decreased by 0.5 for the following epochs. The 19-layer VGGNet [[28](https://arxiv.org/html/1610.00291v2#bib.bib28)] is chosen as loss network Φ Φ\Phi roman_Φ to construct feature perceptual loss for image reconstruction. We experiment with different layer combinations to construct feature perceptual loss and report the results by using layers relu1_2, relu2_1, relu3_1. In addition, the dimension of latent vector z 𝑧 z italic_z is set to be 100, and the loss weighted parameters α 𝛼\alpha italic_α and β 𝛽\beta italic_β are 1 and 0.8 respectively. Our implementation is built on deep learning framework Torch [[2](https://arxiv.org/html/1610.00291v2#bib.bib2)] and style transfer implementation [Johnson2015].
|
| 85 |
+
|
| 86 |
+
### 4.2 Qualitative Results for Image Generation
|
| 87 |
+
|
| 88 |
+
In this paper, we also train additional two generative models for comparison. One is the plain Variational Autoencoder (PVAE), which has the same architecture as our proposed model, but trained with pixel-by-pixel loss in the image space. The other is Deep Convolutional Generative Adversarial Networks (DCGAN) consisting of a generator and a discriminator network [[23](https://arxiv.org/html/1610.00291v2#bib.bib23)], which has shown the ability to generate high quality images from a noise vector. DCGAN is trained with open source code [[23](https://arxiv.org/html/1610.00291v2#bib.bib23)] in Torch. The comparison is divided into two parts: arbitrary face images generated by decoder based on latent vector z 𝑧 z italic_z drawn from 𝒩(0,1)𝒩 0 1\mathcal{N}(0,1)caligraphic_N ( 0 , 1 ), and face image reconstruction.
|
| 89 |
+
|
| 90 |
+

|
| 91 |
+
|
| 92 |
+
Figure 3: Generated fake face images from 100-dimension latent vector z∼𝒩(0,1)similar-to 𝑧 𝒩 0 1 z\sim\mathcal{N}(0,1)italic_z ∼ caligraphic_N ( 0 , 1 ) from different models. The first part is generated from decoder network of plain variational autoencoder (PVAE) trained with pixel-based loss [[12](https://arxiv.org/html/1610.00291v2#bib.bib12)], the second part is generated from generator network of DCGAN [[23](https://arxiv.org/html/1610.00291v2#bib.bib23)], and the third part is our method trained with feature perceptual loss.
|
| 93 |
+
|
| 94 |
+
In the first part, random face images (shown in Figure [3](https://arxiv.org/html/1610.00291v2#S4.F3 "Figure 3 ‣ 4.2 Qualitative Results for Image Generation ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder")) are generated by three models from latent vector z 𝑧 z italic_z drawn from 𝒩(0,1)𝒩 0 1\mathcal{N}(0,1)caligraphic_N ( 0 , 1 ). We can see that the generated face images by plain VAE tend to very blurry, even though overall spatial face structure can be preserved. It is very hard for plain VAE to generate clear facial parts such as eyes and noses, this is because it tries to minimize the reconstruction difference between two images with pixel-by-pixel loss. The pixel-based loss is problematic due to no semantic and perceptual information contained. DCGAN can generate clean and sharp face images containing clearer facial textures, however it has the facial distortion problem and sometimes generates weird faces. Our method based on feature perceptual loss can achieve better results, generating faces of different genders, ages and races with clear noses and eyes. What’s more, face images with sunglasses and white clean teeth can be also randomly generated. One problem found in our method is that the generated hair tends to be blurry in most samples, and we think it is because of the subtle texture of human hair.
|
| 95 |
+
|
| 96 |
+

|
| 97 |
+
|
| 98 |
+
Figure 4: Image reconstruction from different models. The first row is input image, the second row is generated from decoder network of plain variational autoencoder (PVAE) trained with pixel-based loss [[12](https://arxiv.org/html/1610.00291v2#bib.bib12)], and the last row is our method trained with feature perceptual loss.
|
| 99 |
+
|
| 100 |
+
We also compare the reconstruction results (shown in Figure [4](https://arxiv.org/html/1610.00291v2#S4.F4 "Figure 4 ‣ 4.2 Qualitative Results for Image Generation ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder")) between plain VAE and our method, and DCGAN is not compared because of no input image in their model. We can get similar conclusion as above between two methods. Even though the reconstruction is not perfect and the generated face images tend to be blurry when compared to input images, our method is much better than plain VAE.
|
| 101 |
+
|
| 102 |
+
### 4.3 Investigating Learned Latent Space
|
| 103 |
+
|
| 104 |
+
#### 4.3.1 Linear interpolation of latent space
|
| 105 |
+
|
| 106 |
+
In order to get a better understanding of what our model has learned, we investigate the property of the z 𝑧 z italic_z representation in the latent space from our encoder network, and the relationship between the different learned latent vectors.
|
| 107 |
+
|
| 108 |
+
As shown in Figure [5](https://arxiv.org/html/1610.00291v2#S4.F5 "Figure 5 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder"), we investigate the generated images from two latent vectors denoted as z left subscript 𝑧 𝑙 𝑒 𝑓 𝑡 z_{left}italic_z start_POSTSUBSCRIPT italic_l italic_e italic_f italic_t end_POSTSUBSCRIPT and z right subscript 𝑧 𝑟 𝑖 𝑔 ℎ 𝑡 z_{right}italic_z start_POSTSUBSCRIPT italic_r italic_i italic_g italic_h italic_t end_POSTSUBSCRIPT. The interpolation is defined by linear transformation z=(1−α)z left+αz right 𝑧 1 𝛼 subscript 𝑧 𝑙 𝑒 𝑓 𝑡 𝛼 subscript 𝑧 𝑟 𝑖 𝑔 ℎ 𝑡 z=(1-\alpha)z_{left}+\alpha z_{right}italic_z = ( 1 - italic_α ) italic_z start_POSTSUBSCRIPT italic_l italic_e italic_f italic_t end_POSTSUBSCRIPT + italic_α italic_z start_POSTSUBSCRIPT italic_r italic_i italic_g italic_h italic_t end_POSTSUBSCRIPT, where α=0,0.1,…,1 𝛼 0 0.1…1\alpha=0,0.1,\dots,1 italic_α = 0 , 0.1 , … , 1, and then z 𝑧 z italic_z is fed to decoder network to generate new face images. In this paper, we provide three examples for latent vector z 𝑧 z italic_z encoded from input images and one example for z 𝑧 z italic_z randomly drawn from 𝒩(0,1)𝒩 0 1\mathcal{N}(0,1)caligraphic_N ( 0 , 1 ). From the first row in Figure [5](https://arxiv.org/html/1610.00291v2#S4.F5 "Figure 5 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder"), we can see the smooth transitions between vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Woman without smiling and short hair”) and vector 𝑣 𝑒 𝑐 𝑡 ��� 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Woman with smiling and long hair”). Little by little the hair become longer, the distance between lips become larger and teeth is shown in the end for smiling, and pose turns from looking slightly left to looking front. Additionally we provide examples of transitions between vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Man without sunglass”) and vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Man with sunglass”), and vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Man”) and vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Woman”).
|
| 109 |
+
|
| 110 |
+

|
| 111 |
+
|
| 112 |
+
Figure 5: Linear interpolation for latent vector. Each row is the interpolation from left latent vector z left subscript 𝑧 𝑙 𝑒 𝑓 𝑡 z_{left}italic_z start_POSTSUBSCRIPT italic_l italic_e italic_f italic_t end_POSTSUBSCRIPT to right latent vector z right subscript 𝑧 𝑟 𝑖 𝑔 ℎ 𝑡 z_{right}italic_z start_POSTSUBSCRIPT italic_r italic_i italic_g italic_h italic_t end_POSTSUBSCRIPT. e.g. (1−α)z left+αz right 1 𝛼 subscript 𝑧 𝑙 𝑒 𝑓 𝑡 𝛼 subscript 𝑧 𝑟 𝑖 𝑔 ℎ 𝑡(1-\alpha)z_{left}+\alpha z_{right}( 1 - italic_α ) italic_z start_POSTSUBSCRIPT italic_l italic_e italic_f italic_t end_POSTSUBSCRIPT + italic_α italic_z start_POSTSUBSCRIPT italic_r italic_i italic_g italic_h italic_t end_POSTSUBSCRIPT. The first row is transitions from a non-smiling woman to a smiling woman, the second row is transitions from a man without sunglass to a man with sunglass, the third row is transitions from a man to a woman, and the last row is transitions between two fake faces decoded from z∼𝒩(0,1)similar-to 𝑧 𝒩 0 1 z\sim\mathcal{N}(0,1)italic_z ∼ caligraphic_N ( 0 , 1 ).
|
| 113 |
+
|
| 114 |
+

|
| 115 |
+
|
| 116 |
+
Figure 6: Vector arithmetic for visual attributes. Each row is the generated faces from latent vector z left subscript 𝑧 𝑙 𝑒 𝑓 𝑡 z_{left}italic_z start_POSTSUBSCRIPT italic_l italic_e italic_f italic_t end_POSTSUBSCRIPT by adding or subtracting an attribute-specific vector. e.g. z left subscript 𝑧 𝑙 𝑒 𝑓 𝑡 z_{left}italic_z start_POSTSUBSCRIPT italic_l italic_e italic_f italic_t end_POSTSUBSCRIPT + α 𝛼\alpha italic_α z smiling subscript 𝑧 𝑠 𝑚 𝑖 𝑙 𝑖 𝑛 𝑔 z_{smiling}italic_z start_POSTSUBSCRIPT italic_s italic_m italic_i italic_l italic_i italic_n italic_g end_POSTSUBSCRIPT, where α=0,0.1,…,1 𝛼 0 0.1…1\alpha=0,0.1,\dots,1 italic_α = 0 , 0.1 , … , 1. The first row is the transitions by adding a smiling vector with a linear factor α 𝛼\alpha italic_α from left to right, the second row is the transitions by subtracting a smiling vector, the third and fourth row are the results by adding a sunglass vector to latent representation for a man and women, and the last row shows results by the subtracting a sunglass vector.
|
| 117 |
+
|
| 118 |
+
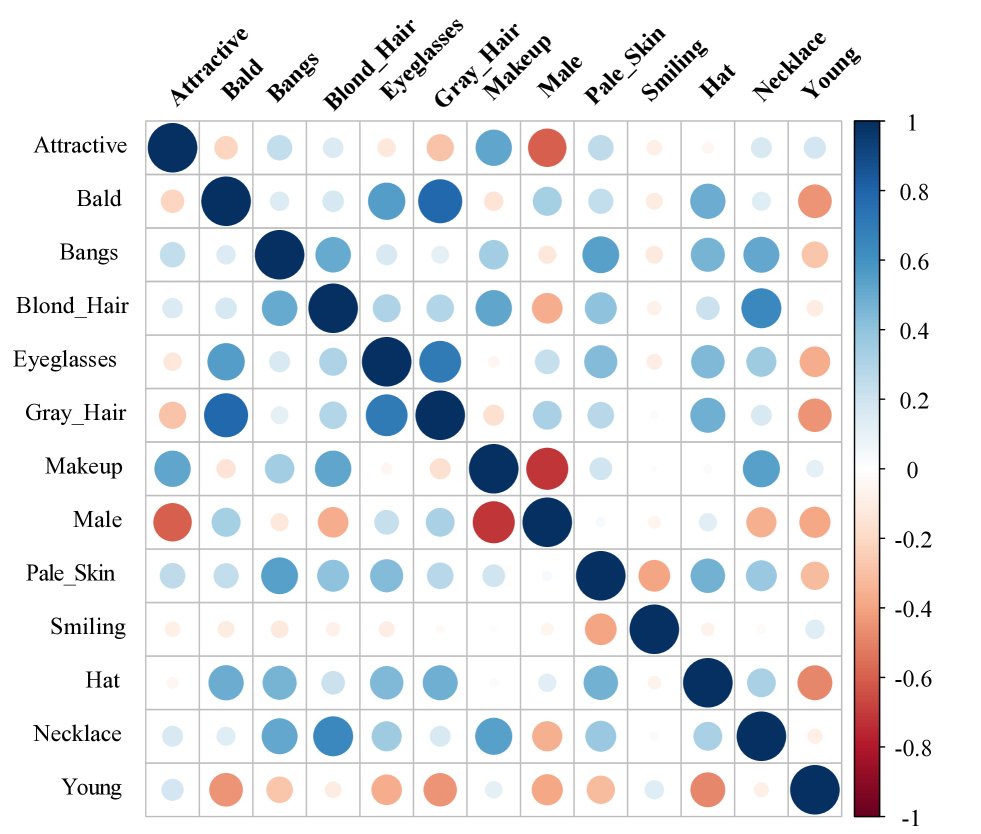
|
| 119 |
+
|
| 120 |
+
Figure 7: Diagram for the correlation between selected facial attribute-specific vectors. The blue indicates positive correlation, while red represents negative correlation, and the color shades and sizes of the circle represent the strength the correlation.
|
| 121 |
+
|
| 122 |
+

|
| 123 |
+
|
| 124 |
+
Figure 8: Visualization of 400 x 400 face images by latent vectors with t-SNE algorithm [[20](https://arxiv.org/html/1610.00291v2#bib.bib20)]
|
| 125 |
+
|
| 126 |
+
Method 5 Shadow Arch. Eyebrows Attractive Bags Un. Eyes Bald Bangs Big Lips Big Nose Black Hair Blond Hair Blurry Brown Hair Bushy Eyebrows Chubby Double Chin Eyeglasses Goatee Gray Hair Heavy Makeup H. Cheekbones Male
|
| 127 |
+
FaceTracer 85 76 78 76 89 88 64 74 70 80 81 60 80 86 88 98 93 90 85 84 91
|
| 128 |
+
PANDA-w 82 73 77 71 92 89 61 70 74 81 77 69 76 82 85 94 86 88 84 80 93
|
| 129 |
+
PANDA-l 88 78 81 79 96 92 67 75 85 93 86 77 86 86 88 98 93 94 90 86 97
|
| 130 |
+
LNets+ANet 91 79 81 79 98 95 68 78 88 95 84 80 90 91 92 99 95 97 90 87 98
|
| 131 |
+
VAE-Z 89 77 75 81 98 91 76 79 83 92 95 80 87 94 95 96 94 96 85 81 90
|
| 132 |
+
VGG-FC 83 71 68 73 97 81 51 77 78 88 94 67 81 93 93 95 93 94 79 64 84
|
| 133 |
+
Method Mouth S. O.Mustache Narrow Eyes No Beard Oval Face Pale Skin Pointy Nose Reced. Hairline Rosy Cheeks Sideburns Smiling Straight Hair Wavy Hair Wear. Earrings Wear. Hat Wear. Lipstick Wear. Necklace Wear. Necktie Young Average
|
| 134 |
+
FaceTracer 87 91 82 90 64 83 68 76 84 94 89 63 73 73 89 89 68 86 80 81.13
|
| 135 |
+
PANDA-w 82 83 79 87 62 84 65 82 81 90 89 67 76 72 91 88 67 88 77 79.85
|
| 136 |
+
PANDA-l 93 93 84 93 65 91 71 85 87 93 92 69 77 78 96 93 67 91 84 85.43
|
| 137 |
+
LNets+ANet 92 95 81 95 66 91 72 89 90 96 92 73 80 82 99 93 71 93 87 87.30
|
| 138 |
+
VAE-Z 80 96 89 88 73 96 73 92 94 95 87 79 74 82 96 88 88 93 81 86.95
|
| 139 |
+
VGG-FC 60 93 87 84 66 96 58 86 93 85 65 68 70 49 98 82 87 89 74 79.85
|
| 140 |
+
|
| 141 |
+
Table 1: Performance comparison of 40 facial attributes prediction. The accuracies of FaceTracer [[14](https://arxiv.org/html/1610.00291v2#bib.bib14)], PANDA-w [[32](https://arxiv.org/html/1610.00291v2#bib.bib32)], PANDA-l [[32](https://arxiv.org/html/1610.00291v2#bib.bib32)], and LNets+ANet [[18](https://arxiv.org/html/1610.00291v2#bib.bib18)] are collected from [[18](https://arxiv.org/html/1610.00291v2#bib.bib18)]. PANDA-l, VAE-Z and VGG-FC use the truth landmarks to get the face part.
|
| 142 |
+
|
| 143 |
+
#### 4.3.2 Facial attributes manipulation
|
| 144 |
+
|
| 145 |
+
The experiments above demonstrate interesting smooth transition’s property between two learned latent vectors. In this part, instead of manipulating the overall face images, we seek to find a way to control a specific attribute of face images. In previous works, [[21](https://arxiv.org/html/1610.00291v2#bib.bib21)] shows that vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”King”) - vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Man”) + vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Woman”) generates a vector whose nearest neighbor was the vector 𝑣 𝑒 𝑐 𝑡 𝑜 𝑟 vector italic_v italic_e italic_c italic_t italic_o italic_r(”Queen”) when evaluating learned representation of words. [[23](https://arxiv.org/html/1610.00291v2#bib.bib23)] demonstrates that visual concepts such as face pose and gender could be manipulated by simple vector arithmetic. In this paper, we investigate two facial attributes wearing sunglass and smiling. We randomly choose 1000 face images with sunglass and 1000 without sunglass respectively from the CelebA dataset [[18](https://arxiv.org/html/1610.00291v2#bib.bib18)], finally the two type of images are fed to our encoder network to compute the latent vectors, and the mean latent vectors are calculated for each type respectively, denoted as z pos_sunglass subscript 𝑧 𝑝 𝑜 𝑠 _ 𝑠 𝑢 𝑛 𝑔 𝑙 𝑎 𝑠 𝑠 z_{pos\_sunglass}italic_z start_POSTSUBSCRIPT italic_p italic_o italic_s _ italic_s italic_u italic_n italic_g italic_l italic_a italic_s italic_s end_POSTSUBSCRIPT and z neg_sunglass subscript 𝑧 𝑛 𝑒 𝑔 _ 𝑠 𝑢 𝑛 𝑔 𝑙 𝑎 𝑠 𝑠 z_{neg\_sunglass}italic_z start_POSTSUBSCRIPT italic_n italic_e italic_g _ italic_s italic_u italic_n italic_g italic_l italic_a italic_s italic_s end_POSTSUBSCRIPT. We then define the difference z pos_sunglass−z neg_sunglass subscript 𝑧 𝑝 𝑜 𝑠 _ 𝑠 𝑢 𝑛 𝑔 𝑙 𝑎 𝑠 𝑠 subscript 𝑧 𝑛 𝑒 𝑔 _ 𝑠 𝑢 𝑛 𝑔 𝑙 𝑎 𝑠 𝑠 z_{pos\_sunglass}-z_{neg\_sunglass}italic_z start_POSTSUBSCRIPT italic_p italic_o italic_s _ italic_s italic_u italic_n italic_g italic_l italic_a italic_s italic_s end_POSTSUBSCRIPT - italic_z start_POSTSUBSCRIPT italic_n italic_e italic_g _ italic_s italic_u italic_n italic_g italic_l italic_a italic_s italic_s end_POSTSUBSCRIPT as sunglass-specific latent vector z sunglass subscript 𝑧 𝑠 𝑢 𝑛 𝑔 𝑙 𝑎 𝑠 𝑠 z_{sunglass}italic_z start_POSTSUBSCRIPT italic_s italic_u italic_n italic_g italic_l italic_a italic_s italic_s end_POSTSUBSCRIPT. In the same way, we calculate the smiling-specific latent vector z smiling subscript 𝑧 𝑠 𝑚 𝑖 𝑙 𝑖 𝑛 𝑔 z_{smiling}italic_z start_POSTSUBSCRIPT italic_s italic_m italic_i italic_l italic_i italic_n italic_g end_POSTSUBSCRIPT. Then we apply the two attribute-specific vectors to different latent vectors z 𝑧 z italic_z by simple vector arithmetic, for instance, z 𝑧 z italic_z + α 𝛼\alpha italic_α z smiling subscript 𝑧 𝑠 𝑚 𝑖 𝑙 𝑖 𝑛 𝑔 z_{smiling}italic_z start_POSTSUBSCRIPT italic_s italic_m italic_i italic_l italic_i italic_n italic_g end_POSTSUBSCRIPT. From Figure [6](https://arxiv.org/html/1610.00291v2#S4.F6 "Figure 6 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder"), by adding a smiling vector to the latent vector of a non-smiling man, we can observe the smooth transitions from non-smiling face to smiling face (the first row). What’s more, the smiling appearance becomes more obvious when the factor α 𝛼\alpha italic_α is bigger, while other facial attributes are able to remain unchanged. The other way round, when the latent vector of smiling woman is subtracted by the smiling vector, the smiling face can be translated to not smiling by only changing the shape of mouth (the second row in Figure [6](https://arxiv.org/html/1610.00291v2#S4.F6 "Figure 6 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder")). Moreover, we could add or wipe out a sunglass by playing with the calculated sunglass vector.
|
| 146 |
+
|
| 147 |
+
#### 4.3.3 Correlation between attribute-specific vectors
|
| 148 |
+
|
| 149 |
+
Considering the conceptual relationship between different facial attributes in natural images, for instance, bald and gray hair are often related old people, we selected 13 of 40 attributes from CelebA dataset and calculate the attribute-specific vector respectively (the calculation is the same as calculating sunglass-specific vector above). We then visualize the correlation as shown in Figure [7](https://arxiv.org/html/1610.00291v2#S4.F7 "Figure 7 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder"), and the results are well consistent with human interpretation. We can see that Attractive 𝐴 𝑡 𝑡 𝑟 𝑎 𝑐 𝑡 𝑖 𝑣 𝑒 Attractive italic_A italic_t italic_t italic_r italic_a italic_c italic_t italic_i italic_v italic_e has a strong positive correlation with Makeup 𝑀 𝑎 𝑘 𝑒 𝑢 𝑝 Makeup italic_M italic_a italic_k italic_e italic_u italic_p, and a negative correlation with Male 𝑀 𝑎 𝑙 𝑒 Male italic_M italic_a italic_l italic_e and GrayHair 𝐺 𝑟 𝑎 𝑦 𝐻 𝑎 𝑖 𝑟 Gray\>Hair italic_G italic_r italic_a italic_y italic_H italic_a italic_i italic_r. It makes sense that female is generally considered more attractive than male and uses a lot of makeup. Similarly, Bald 𝐵 𝑎 𝑙 𝑑 Bald italic_B italic_a italic_l italic_d has a positive correlation with GrayHair 𝐺 𝑟 𝑎 𝑦 𝐻 𝑎 𝑖 𝑟 Gray\>Hair italic_G italic_r italic_a italic_y italic_H italic_a italic_i italic_r and Eyeglasses 𝐸 𝑦 𝑒 𝑔 𝑙 𝑎 𝑠 𝑠 𝑒 𝑠 Eyeglasses italic_E italic_y italic_e italic_g italic_l italic_a italic_s italic_s italic_e italic_s, and a negative correlation with Young 𝑌 𝑜 𝑢 𝑛 𝑔 Young italic_Y italic_o italic_u italic_n italic_g. Additionally, Smiling 𝑆 𝑚 𝑖 𝑙 𝑖 𝑛 𝑔 Smiling italic_S italic_m italic_i italic_l italic_i italic_n italic_g seems to have no correlation with most of other attributes and only have a weak negative correlation with PaleSkin 𝑃 𝑎 𝑙 𝑒 𝑆 𝑘 𝑖 𝑛 Pale\>Skin italic_P italic_a italic_l italic_e italic_S italic_k italic_i italic_n. It could be explained that Smiling 𝑆 𝑚 𝑖 𝑙 𝑖 𝑛 𝑔 Smiling italic_S italic_m italic_i italic_l italic_i italic_n italic_g is a very common human facial expression and it could have a good match with many other attributes.
|
| 150 |
+
|
| 151 |
+
#### 4.3.4 Visualization of latent vectors
|
| 152 |
+
|
| 153 |
+
Considering that the latent vectors are nothing but the encoding representation of the natural face images, we think that it may be interesting to visualize the natural images based on the similarity of the latent representation in an unsupervised way. Specifically we randomly choose 1600 face images from CelebA dataset and extract the corresponding 100-dimensional latent vectors, which are then reduced to 2-dimensional embedding by using t-SNE algorithm [[20](https://arxiv.org/html/1610.00291v2#bib.bib20)]. t-SNE can arrange images that have a similar high-dimensional code (L2 distance) nearby in the embedding space. The visualization of 400 x 400 images is shown in Figure [8](https://arxiv.org/html/1610.00291v2#S4.F8 "Figure 8 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder"), and we can discover that images with similar background (black or white) tend to be clustered as a group, and female with smiling can be clustered together (green rectangle in Figure [8](https://arxiv.org/html/1610.00291v2#S4.F8 "Figure 8 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder")). What’s more, the face pose information can also be captured even no pose annotations in the dataset. The face images in the upper left (blue rectangle) tend to look left and samples in the lower left (red rectangle) tend to look right, while in other area tend to look front.
|
| 154 |
+
|
| 155 |
+
#### 4.3.5 Facial attribute prediction
|
| 156 |
+
|
| 157 |
+
In the end, we evaluate our model by applying latent vector to facial attribute prediction, which is a very challenging problem due to complex face variations. Similar to [[18](https://arxiv.org/html/1610.00291v2#bib.bib18)], 20,000 images from CelebA dataset are selected for testing and the rest for training. Firstly we use ground truth landmark points to crop out the face parts of the original images like PANDA-l [[32](https://arxiv.org/html/1610.00291v2#bib.bib32)], and the cropped face images are fed to our encoder network to extract latent vectors, which are then used to train standard Linear SVM [[22](https://arxiv.org/html/1610.00291v2#bib.bib22)] classifiers. As a result, we train 40 binary classifiers for each attribute in CelebA dataset respectively. As a baseline, we also train different Linear SVM classifiers with 4096-dimensional deep features extracted from the last fully connected layer of pretrained VGGNet [[28](https://arxiv.org/html/1610.00291v2#bib.bib28)]. We then compare our method with other state-of-the-art methods. The average of prediction accuracies of FaceTracer [[14](https://arxiv.org/html/1610.00291v2#bib.bib14)], PANDA-w [[32](https://arxiv.org/html/1610.00291v2#bib.bib32)], PANDA-l [[32](https://arxiv.org/html/1610.00291v2#bib.bib32)], and LNets+ANet [[18](https://arxiv.org/html/1610.00291v2#bib.bib18)] are 81.13, 79.85, 85.43 and 87.30 percent respectively. Our method with latent vector of VAE (VAE-Z) and VGG last layer features (VGG-FC) are 86.95 and 79.85 respectively. From Table [1](https://arxiv.org/html/1610.00291v2#S4.T1 "Table 1 ‣ 4.3.1 Linear interpolation of latent space ‣ 4.3 Investigating Learned Latent Space ‣ 4 Experiments ‣ Feature Perceptual Loss for Variational Autoencoder"), we can see that our method is comparable to the LNets+ANet and outperforms other methods. Our method can do a better job to predict Wearing_Necklace 𝑊 𝑒 𝑎 𝑟 𝑖 𝑛 𝑔 _ 𝑁 𝑒 𝑐 𝑘 𝑙 𝑎 𝑐 𝑒 Wearing\_Necklace italic_W italic_e italic_a italic_r italic_i italic_n italic_g _ italic_N italic_e italic_c italic_k italic_l italic_a italic_c italic_e, Receding_Hairline 𝑅 𝑒 𝑐 𝑒 𝑑 𝑖 𝑛 𝑔 _ 𝐻 𝑎 𝑖 𝑟 𝑙 𝑖 𝑛 𝑒 Receding\_Hairline italic_R italic_e italic_c italic_e italic_d italic_i italic_n italic_g _ italic_H italic_a italic_i italic_r italic_l italic_i italic_n italic_e and Pale_Skin 𝑃 𝑎 𝑙 𝑒 _ 𝑆 𝑘 𝑖 𝑛 Pale\_Skin italic_P italic_a italic_l italic_e _ italic_S italic_k italic_i italic_n. In addition, we notice that all the methods can achieve a good performance to predict Bald 𝐵 𝑎 𝑙 𝑑 Bald italic_B italic_a italic_l italic_d, Wearing_Hat 𝑊 𝑒 𝑎 𝑟 𝑖 𝑛 𝑔 _ 𝐻 𝑎 𝑡 Wearing\_Hat italic_W italic_e italic_a italic_r italic_i italic_n italic_g _ italic_H italic_a italic_t and Eyeglasses 𝐸 𝑦 𝑒 𝑔 𝑙 𝑎 𝑠 𝑠 𝑒 𝑠 Eyeglasses italic_E italic_y italic_e italic_g italic_l italic_a italic_s italic_s italic_e italic_s, while they are very difficult to correctly predict attributes like Big_Lips 𝐵 𝑖 𝑔 _ 𝐿 𝑖 𝑝 𝑠 Big\_Lips italic_B italic_i italic_g _ italic_L italic_i italic_p italic_s and Oval_Face 𝑂 𝑣 𝑎 𝑙 _ 𝐹 𝑎 𝑐 𝑒 Oval\_Face italic_O italic_v italic_a italic_l _ italic_F italic_a italic_c italic_e. The reason we think is that attributes like whether wearing hat and eyeglasses or not are much more obvious in natural face images, than attributes whether having big lips and Oval face or not, and the extracted features are not able to capture such subtle differences. Future work is needed to find a way to extract better features which can also capture tiny variation of facial attributes.
|
| 158 |
+
|
| 159 |
+
### 4.4 Discussion
|
| 160 |
+
|
| 161 |
+
For (variational) autoencoder models, one essential part is to define a reconstruction loss to measure the similar between input image and generated image. The plain VAE adopts the pixel-by-pixel distance, which is problematic and the generated images tend to be very blurry. Inspired by the state-of-the-art works on style transfer and texture synthesis [[4](https://arxiv.org/html/1610.00291v2#bib.bib4), [8](https://arxiv.org/html/1610.00291v2#bib.bib8), [29](https://arxiv.org/html/1610.00291v2#bib.bib29)], we measure the reconstruction loss in VAE by feature perceptual loss based on pretrained deep convolutional neural networks (CNNs). Our experiments above have shown that feature perceptual loss can be used to improve the performance of VAE to generate high quality images. One explanation is that the hidden representation in a pretrained deep CNN could capture conceptual and semantic information of a given image since it has the ability to do classification, which is a human understanding task. Another benefit of using deep CNNs is that we can combine different level of hidden representation, which can provide more constraints for the reconstruction. Actually we could explore different combinations even add weights to different level representation to generate weird but interesting images. However, the feature perceptual loss is not perfect, the trained model fails to generate clear hair texture in our experiments even though it can do a good job for eyes, noses and mouths generation. For further work, trying to construct better reconstruction loss to measure the similarity of the output images and ground-truth images is essential for this problem. One possibility is to combine feature perceptual loss with generative adversarial networks(GAN).
|
| 162 |
+
|
| 163 |
+
The more interesting part of VAE is the linear structure in the learned latent space. Different images generated by decoder can be smoothly transformed to each other by simply linear combination of their latent vectors. Additionally attribute-specific latent vectors could be also calculated by encoding the annotated images and used to manipulate the related attribute of a given image while keeping other attributes unchanged, what’s more, the correlation between attribute-specific vectors is well consistent with human understanding. Our experiments shows that the learned latent space of VAE can learn powerful representation of conceptual and semantic information of natural images, and it could be used for other applications like face attribute prediction.
|
| 164 |
+
|
| 165 |
+
5 Conclusion
|
| 166 |
+
------------
|
| 167 |
+
|
| 168 |
+
In this paper, we try to improve the performance of image generation of VAE by combining feature perceptual loss based on pretrained deep CNNs to measure the similar of two images. We apply our model on face images and achieve comparable and better performance compared to different generative models (plain VAE and GAN). In addition, we fully explore the learned latent representation in our model and demonstrates it has powerful capability to capture the conceptual and semantic information of natural images. We also achieved state-of-the-art performance of facial attribute prediction based on the learned latent representation.
|
| 169 |
+
|
| 170 |
+
References
|
| 171 |
+
----------
|
| 172 |
+
|
| 173 |
+
* [1] A.Babenko, A.Slesarev, A.Chigorin, and V.Lempitsky. Neural codes for image retrieval. In Computer Vision–ECCV 2014, pages 584–599. Springer, 2014.
|
| 174 |
+
* [2] R.Collobert, K.Kavukcuoglu, and C.Farabet. Torch7: A matlab-like environment for machine learning. In BigLearn, NIPS Workshop, number EPFL-CONF-192376, 2011.
|
| 175 |
+
* [3] L.Gatys, A.S. Ecker, and M.Bethge. Texture synthesis using convolutional neural networks. In Advances in Neural Information Processing Systems, pages 262–270, 2015.
|
| 176 |
+
* [4] L.A. Gatys, A.S. Ecker, and M.Bethge. A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576, 2015.
|
| 177 |
+
* [5]R.Girshick, J.Donahue, T.Darrell, and J.Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 580–587, 2014.
|
| 178 |
+
* [6] I.Goodfellow, J.Pouget-Abadie, M.Mirza, B.Xu, D.Warde-Farley, S.Ozair, A.Courville, and Y.Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, pages 2672–2680, 2014.
|
| 179 |
+
* [7] K.Gregor, I.Danihelka, A.Graves, D.J. Rezende, and D.Wierstra. Draw: A recurrent neural network for image generation. arXiv preprint arXiv:1502.04623, 2015.
|
| 180 |
+
* [8] J.Johnson, A.Alahi, and L.Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. arXiv preprint arXiv:1603.08155, 2016.
|
| 181 |
+
* [9] A.Karpathy and L.Fei-Fei. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3128–3137, 2015.
|
| 182 |
+
* [10] D.Kingma and J.Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
|
| 183 |
+
* [11] D.P. Kingma, S.Mohamed, D.J. Rezende, and M.Welling. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems, pages 3581–3589, 2014.
|
| 184 |
+
* [12] D.P. Kingma and M.Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
|
| 185 |
+
* [13] A.Krizhevsky, I.Sutskever, and G.E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
|
| 186 |
+
* [14] N.Kumar, P.Belhumeur, and S.Nayar. Facetracer: A search engine for large collections of images with faces. In European conference on computer vision, pages 340–353. Springer, 2008.
|
| 187 |
+
* [15] A.Lamb, V.Dumoulin, and A.Courville. Discriminative regularization for generative models. arXiv preprint arXiv:1602.03220, 2016.
|
| 188 |
+
* [16] A.B.L. Larsen, S.K. Sønderby, and O.Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.
|
| 189 |
+
* [17] C.Li and M.Wand. Combining markov random fields and convolutional neural networks for image synthesis. arXiv preprint arXiv:1601.04589, 2016.
|
| 190 |
+
* [18]Z.Liu, P.Luo, X.Wang, and X.Tang. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, pages 3730–3738, 2015.
|
| 191 |
+
* [19] J.Long, E.Shelhamer, and T.Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3431–3440, 2015.
|
| 192 |
+
* [20] L.v.d. Maaten and G.Hinton. Visualizing data using t-sne. Journal of Machine Learning Research, 9(Nov):2579–2605, 2008.
|
| 193 |
+
* [21] T.Mikolov and J.Dean. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 2013.
|
| 194 |
+
* [22] F.Pedregosa, G.Varoquaux, A.Gramfort, V.Michel, B.Thirion, O.Grisel, M.Blondel, P.Prettenhofer, R.Weiss, V.Dubourg, J.Vanderplas, A.Passos, D.Cournapeau, M.Brucher, M.Perrot, and E.Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
|
| 195 |
+
* [23] A.Radford, L.Metz, and S.Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
|
| 196 |
+
* [24] D.J. Rezende, S.Mohamed, and D.Wierstra. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), pages 1278–1286, 2014.
|
| 197 |
+
* [25] K.Ridgeway, J.Snell, B.Roads, R.Zemel, and M.Mozer. Learning to generate images with perceptual similarity metrics. arXiv preprint arXiv:1511.06409, 2015.
|
| 198 |
+
* [26] O.Russakovsky, J.Deng, H.Su, J.Krause, S.Satheesh, S.Ma, Z.Huang, A.Karpathy, A.Khosla, M.Bernstein, A.C. Berg, and L.Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
|
| 199 |
+
* [27] K.Simonyan, A.Vedaldi, and A.Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034, 2013.
|
| 200 |
+
* [28] K.Simonyan and A.Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
|
| 201 |
+
* [29] D.Ulyanov, V.Lebedev, A.Vedaldi, and V.Lempitsky. Texture networks: Feed-forward synthesis of textures and stylized images. arXiv preprint arXiv:1603.03417, 2016.
|
| 202 |
+
* [30] X.Yan, J.Yang, K.Sohn, and H.Lee. Attribute2image: Conditional image generation from visual attributes. arXiv preprint arXiv:1512.00570, 2015.
|
| 203 |
+
* [31] J.Yosinski, J.Clune, A.Nguyen, T.Fuchs, and H.Lipson. Understanding neural networks through deep visualization. arXiv preprint arXiv:1506.06579, 2015.
|
| 204 |
+
* [32] N.Zhang, M.Paluri, M.Ranzato, T.Darrell, and L.Bourdev. Panda: Pose aligned networks for deep attribute modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1637–1644, 2014.
|
1702/1702.04066.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1702.04066
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1702.04066#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1702.04066'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1703/1703.06870.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1703.06870
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1703.06870#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1703.06870'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1704/1704.04086.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1704.04086
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1704.04086#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1704.04086'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1706/1706.03762.md
ADDED
|
@@ -0,0 +1,373 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Attention Is All You Need
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1706.03762
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Provided proper attribution is provided, Google hereby grants permission to reproduce the tables and figures in this paper solely for use in journalistic or scholarly works.
|
| 7 |
+
|
| 8 |
+
Ashish Vaswani
|
| 9 |
+
|
| 10 |
+
Google Brain
|
| 11 |
+
|
| 12 |
+
avaswani@google.com
|
| 13 |
+
|
| 14 |
+
&Noam Shazeer 1 1 footnotemark: 1
|
| 15 |
+
|
| 16 |
+
Google Brain
|
| 17 |
+
|
| 18 |
+
noam@google.com
|
| 19 |
+
|
| 20 |
+
&Niki Parmar 1 1 footnotemark: 1
|
| 21 |
+
|
| 22 |
+
Google Research
|
| 23 |
+
|
| 24 |
+
nikip@google.com
|
| 25 |
+
|
| 26 |
+
&Jakob Uszkoreit 1 1 footnotemark: 1
|
| 27 |
+
|
| 28 |
+
Google Research
|
| 29 |
+
|
| 30 |
+
usz@google.com
|
| 31 |
+
|
| 32 |
+
&Llion Jones 1 1 footnotemark: 1
|
| 33 |
+
|
| 34 |
+
Google Research
|
| 35 |
+
|
| 36 |
+
llion@google.com
|
| 37 |
+
|
| 38 |
+
&Aidan N. Gomez 1 1 footnotemark: 1
|
| 39 |
+
|
| 40 |
+
University of Toronto
|
| 41 |
+
|
| 42 |
+
aidan@cs.toronto.edu&Łukasz Kaiser 1 1 footnotemark: 1
|
| 43 |
+
|
| 44 |
+
Google Brain
|
| 45 |
+
|
| 46 |
+
lukaszkaiser@google.com
|
| 47 |
+
|
| 48 |
+
&Illia Polosukhin 1 1 footnotemark: 1
|
| 49 |
+
|
| 50 |
+
illia.polosukhin@gmail.com
|
| 51 |
+
|
| 52 |
+
Equal contribution. Listing order is random. Jakob proposed replacing RNNs with self-attention and started the effort to evaluate this idea. Ashish, with Illia, designed and implemented the first Transformer models and has been crucially involved in every aspect of this work. Noam proposed scaled dot-product attention, multi-head attention and the parameter-free position representation and became the other person involved in nearly every detail. Niki designed, implemented, tuned and evaluated countless model variants in our original codebase and tensor2tensor. Llion also experimented with novel model variants, was responsible for our initial codebase, and efficient inference and visualizations. Lukasz and Aidan spent countless long days designing various parts of and implementing tensor2tensor, replacing our earlier codebase, greatly improving results and massively accelerating our research. Work performed while at Google Brain.Work performed while at Google Research.
|
| 53 |
+
|
| 54 |
+
###### Abstract
|
| 55 |
+
|
| 56 |
+
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks that include an encoder and a decoder. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data.
|
| 57 |
+
|
| 58 |
+
1 Introduction
|
| 59 |
+
--------------
|
| 60 |
+
|
| 61 |
+
Recurrent neural networks, long short-term memory [[13](https://arxiv.org/html/1706.03762v7#bib.bib13)] and gated recurrent [[7](https://arxiv.org/html/1706.03762v7#bib.bib7)] neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation [[35](https://arxiv.org/html/1706.03762v7#bib.bib35), [2](https://arxiv.org/html/1706.03762v7#bib.bib2), [5](https://arxiv.org/html/1706.03762v7#bib.bib5)]. Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures [[38](https://arxiv.org/html/1706.03762v7#bib.bib38), [24](https://arxiv.org/html/1706.03762v7#bib.bib24), [15](https://arxiv.org/html/1706.03762v7#bib.bib15)].
|
| 62 |
+
|
| 63 |
+
Recurrent models typically factor computation along the symbol positions of the input and output sequences. Aligning the positions to steps in computation time, they generate a sequence of hidden states h t h_{t}, as a function of the previous hidden state h t−1 h_{t-1} and the input for position t t. This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples. Recent work has achieved significant improvements in computational efficiency through factorization tricks [[21](https://arxiv.org/html/1706.03762v7#bib.bib21)] and conditional computation [[32](https://arxiv.org/html/1706.03762v7#bib.bib32)], while also improving model performance in case of the latter. The fundamental constraint of sequential computation, however, remains.
|
| 64 |
+
|
| 65 |
+
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences [[2](https://arxiv.org/html/1706.03762v7#bib.bib2), [19](https://arxiv.org/html/1706.03762v7#bib.bib19)]. In all but a few cases [[27](https://arxiv.org/html/1706.03762v7#bib.bib27)], however, such attention mechanisms are used in conjunction with a recurrent network.
|
| 66 |
+
|
| 67 |
+
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
|
| 68 |
+
|
| 69 |
+
2 Background
|
| 70 |
+
------------
|
| 71 |
+
|
| 72 |
+
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU [[16](https://arxiv.org/html/1706.03762v7#bib.bib16)], ByteNet [[18](https://arxiv.org/html/1706.03762v7#bib.bib18)] and ConvS2S [[9](https://arxiv.org/html/1706.03762v7#bib.bib9)], all of which use convolutional neural networks as basic building block, computing hidden representations in parallel for all input and output positions. In these models, the number of operations required to relate signals from two arbitrary input or output positions grows in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes it more difficult to learn dependencies between distant positions [[12](https://arxiv.org/html/1706.03762v7#bib.bib12)]. In the Transformer this is reduced to a constant number of operations, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section[3.2](https://arxiv.org/html/1706.03762v7#S3.SS2 "3.2 Attention ‣ 3 Model Architecture ‣ Attention Is All You Need").
|
| 73 |
+
|
| 74 |
+
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment and learning task-independent sentence representations [[4](https://arxiv.org/html/1706.03762v7#bib.bib4), [27](https://arxiv.org/html/1706.03762v7#bib.bib27), [28](https://arxiv.org/html/1706.03762v7#bib.bib28), [22](https://arxiv.org/html/1706.03762v7#bib.bib22)].
|
| 75 |
+
|
| 76 |
+
End-to-end memory networks are based on a recurrent attention mechanism instead of sequence-aligned recurrence and have been shown to perform well on simple-language question answering and language modeling tasks [[34](https://arxiv.org/html/1706.03762v7#bib.bib34)].
|
| 77 |
+
|
| 78 |
+
To the best of our knowledge, however, the Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence-aligned RNNs or convolution. In the following sections, we will describe the Transformer, motivate self-attention and discuss its advantages over models such as [[17](https://arxiv.org/html/1706.03762v7#bib.bib17), [18](https://arxiv.org/html/1706.03762v7#bib.bib18)] and [[9](https://arxiv.org/html/1706.03762v7#bib.bib9)].
|
| 79 |
+
|
| 80 |
+
3 Model Architecture
|
| 81 |
+
--------------------
|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
| 85 |
+
Figure 1: The Transformer - model architecture.
|
| 86 |
+
|
| 87 |
+
Most competitive neural sequence transduction models have an encoder-decoder structure [[5](https://arxiv.org/html/1706.03762v7#bib.bib5), [2](https://arxiv.org/html/1706.03762v7#bib.bib2), [35](https://arxiv.org/html/1706.03762v7#bib.bib35)]. Here, the encoder maps an input sequence of symbol representations (x 1,…,x n)(x_{1},...,x_{n}) to a sequence of continuous representations 𝐳=(z 1,…,z n)\mathbf{z}=(z_{1},...,z_{n}). Given 𝐳\mathbf{z}, the decoder then generates an output sequence (y 1,…,y m)(y_{1},...,y_{m}) of symbols one element at a time. At each step the model is auto-regressive [[10](https://arxiv.org/html/1706.03762v7#bib.bib10)], consuming the previously generated symbols as additional input when generating the next.
|
| 88 |
+
|
| 89 |
+
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure[1](https://arxiv.org/html/1706.03762v7#S3.F1 "Figure 1 ‣ 3 Model Architecture ‣ Attention Is All You Need"), respectively.
|
| 90 |
+
|
| 91 |
+
### 3.1 Encoder and Decoder Stacks
|
| 92 |
+
|
| 93 |
+
##### Encoder:
|
| 94 |
+
|
| 95 |
+
The encoder is composed of a stack of N=6 N=6 identical layers. Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection [[11](https://arxiv.org/html/1706.03762v7#bib.bib11)] around each of the two sub-layers, followed by layer normalization [[1](https://arxiv.org/html/1706.03762v7#bib.bib1)]. That is, the output of each sub-layer is LayerNorm(x+Sublayer(x))\mathrm{LayerNorm}(x+\mathrm{Sublayer}(x)), where Sublayer(x)\mathrm{Sublayer}(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension d model=512 d_{\text{model}}=512.
|
| 96 |
+
|
| 97 |
+
##### Decoder:
|
| 98 |
+
|
| 99 |
+
The decoder is also composed of a stack of N=6 N=6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i i can depend only on the known outputs at positions less than i i.
|
| 100 |
+
|
| 101 |
+
### 3.2 Attention
|
| 102 |
+
|
| 103 |
+
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key.
|
| 104 |
+
|
| 105 |
+
#### 3.2.1 Scaled Dot-Product Attention
|
| 106 |
+
|
| 107 |
+
We call our particular attention "Scaled Dot-Product Attention" (Figure[2](https://arxiv.org/html/1706.03762v7#S3.F2 "Figure 2 ‣ 3.2.2 Multi-Head Attention ‣ 3.2 Attention ‣ 3 Model Architecture ‣ Attention Is All You Need")). The input consists of queries and keys of dimension d k d_{k}, and values of dimension d v d_{v}. We compute the dot products of the query with all keys, divide each by d k\sqrt{d_{k}}, and apply a softmax function to obtain the weights on the values.
|
| 108 |
+
|
| 109 |
+
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q Q. The keys and values are also packed together into matrices K K and V V. We compute the matrix of outputs as:
|
| 110 |
+
|
| 111 |
+
Attention(Q,K,V)=softmax(QK T d k)V\mathrm{Attention}(Q,K,V)=\mathrm{softmax}(\frac{QK^{T}}{\sqrt{d_{k}}})V(1)
|
| 112 |
+
|
| 113 |
+
The two most commonly used attention functions are additive attention [[2](https://arxiv.org/html/1706.03762v7#bib.bib2)], and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of 1 d k\frac{1}{\sqrt{d_{k}}}. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
|
| 114 |
+
|
| 115 |
+
While for small values of d k d_{k} the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of d k d_{k}[[3](https://arxiv.org/html/1706.03762v7#bib.bib3)]. We suspect that for large values of d k d_{k}, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients 1 1 1 To illustrate why the dot products get large, assume that the components of q q and k k are independent random variables with mean 0 and variance 1 1. Then their dot product, q⋅k=∑i=1 d k q ik i q\cdot k=\sum_{i=1}^{d_{k}}q_{i}k_{i}, has mean 0 and variance d k d_{k}.. To counteract this effect, we scale the dot products by 1 d k\frac{1}{\sqrt{d_{k}}}.
|
| 116 |
+
|
| 117 |
+
#### 3.2.2 Multi-Head Attention
|
| 118 |
+
|
| 119 |
+
Scaled Dot-Product Attention
|
| 120 |
+
|
| 121 |
+

|
| 122 |
+
|
| 123 |
+
Multi-Head Attention
|
| 124 |
+
|
| 125 |
+

|
| 126 |
+
|
| 127 |
+
Figure 2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.
|
| 128 |
+
|
| 129 |
+
Instead of performing a single attention function with d model d_{\text{model}}-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h h times with different, learned linear projections to d k d_{k}, d k d_{k} and d v d_{v} dimensions, respectively. On each of these projected versions of queries, keys and values we then perform the attention function in parallel, yielding d v d_{v}-dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in Figure[2](https://arxiv.org/html/1706.03762v7#S3.F2 "Figure 2 ‣ 3.2.2 Multi-Head Attention ‣ 3.2 Attention ‣ 3 Model Architecture ‣ Attention Is All You Need").
|
| 130 |
+
|
| 131 |
+
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
|
| 132 |
+
|
| 133 |
+
MultiHead(Q,K,V)\displaystyle\mathrm{MultiHead}(Q,K,V)=Concat(head 1,…,head h)W O\displaystyle=\mathrm{Concat}(\mathrm{head_{1}},...,\mathrm{head_{h}})W^{O}
|
| 134 |
+
wherehead i\displaystyle\text{where}~\mathrm{head_{i}}=Attention(QW i Q,KW i K,VW i V)\displaystyle=\mathrm{Attention}(QW^{Q}_{i},KW^{K}_{i},VW^{V}_{i})
|
| 135 |
+
|
| 136 |
+
Where the projections are parameter matrices W i Q∈ℝ d model×d k W^{Q}_{i}\in\mathbb{R}^{d_{\text{model}}\times d_{k}}, W i K∈ℝ d model×d k W^{K}_{i}\in\mathbb{R}^{d_{\text{model}}\times d_{k}}, W i V∈ℝ d model×d v W^{V}_{i}\in\mathbb{R}^{d_{\text{model}}\times d_{v}} and W O∈ℝ hd v×d model W^{O}\in\mathbb{R}^{hd_{v}\times d_{\text{model}}}.
|
| 137 |
+
|
| 138 |
+
In this work we employ h=8 h=8 parallel attention layers, or heads. For each of these we use d k=d v=d model/h=64 d_{k}=d_{v}=d_{\text{model}}/h=64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
|
| 139 |
+
|
| 140 |
+
#### 3.2.3 Applications of Attention in our Model
|
| 141 |
+
|
| 142 |
+
The Transformer uses multi-head attention in three different ways:
|
| 143 |
+
|
| 144 |
+
* •In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [[38](https://arxiv.org/html/1706.03762v7#bib.bib38), [2](https://arxiv.org/html/1706.03762v7#bib.bib2), [9](https://arxiv.org/html/1706.03762v7#bib.bib9)].
|
| 145 |
+
* •The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
|
| 146 |
+
* •Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to −∞-\infty) all values in the input of the softmax which correspond to illegal connections. See Figure[2](https://arxiv.org/html/1706.03762v7#S3.F2 "Figure 2 ‣ 3.2.2 Multi-Head Attention ‣ 3.2 Attention ‣ 3 Model Architecture ‣ Attention Is All You Need").
|
| 147 |
+
|
| 148 |
+
### 3.3 Position-wise Feed-Forward Networks
|
| 149 |
+
|
| 150 |
+
In addition to attention sub-layers, each of the layers in our encoder and decoder contains a fully connected feed-forward network, which is applied to each position separately and identically. This consists of two linear transformations with a ReLU activation in between.
|
| 151 |
+
|
| 152 |
+
FFN(x)=max(0,xW 1+b 1)W 2+b 2\mathrm{FFN}(x)=\max(0,xW_{1}+b_{1})W_{2}+b_{2}(2)
|
| 153 |
+
|
| 154 |
+
While the linear transformations are the same across different positions, they use different parameters from layer to layer. Another way of describing this is as two convolutions with kernel size 1. The dimensionality of input and output is d model=512 d_{\text{model}}=512, and the inner-layer has dimensionality d ff=2048 d_{ff}=2048.
|
| 155 |
+
|
| 156 |
+
### 3.4 Embeddings and Softmax
|
| 157 |
+
|
| 158 |
+
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension d model d_{\text{model}}. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [[30](https://arxiv.org/html/1706.03762v7#bib.bib30)]. In the embedding layers, we multiply those weights by d model\sqrt{d_{\text{model}}}.
|
| 159 |
+
|
| 160 |
+
### 3.5 Positional Encoding
|
| 161 |
+
|
| 162 |
+
Since our model contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, we must inject some information about the relative or absolute position of the tokens in the sequence. To this end, we add "positional encodings" to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension d model d_{\text{model}} as the embeddings, so that the two can be summed. There are many choices of positional encodings, learned and fixed [[9](https://arxiv.org/html/1706.03762v7#bib.bib9)].
|
| 163 |
+
|
| 164 |
+
In this work, we use sine and cosine functions of different frequencies:
|
| 165 |
+
|
| 166 |
+
PE(pos,2i)=sin(pos/10000 2i/d model)\displaystyle PE_{(pos,2i)}=sin(pos/10000^{2i/d_{\text{model}}})
|
| 167 |
+
PE(pos,2i+1)=cos(pos/10000 2i/d model)\displaystyle PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{\text{model}}})
|
| 168 |
+
|
| 169 |
+
where pos pos is the position and i i is the dimension. That is, each dimension of the positional encoding corresponds to a sinusoid. The wavelengths form a geometric progression from 2π 2\pi to 10000⋅2π 10000\cdot 2\pi. We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k k, PE pos+k PE_{pos+k} can be represented as a linear function of PE pos PE_{pos}.
|
| 170 |
+
|
| 171 |
+
We also experimented with using learned positional embeddings [[9](https://arxiv.org/html/1706.03762v7#bib.bib9)] instead, and found that the two versions produced nearly identical results (see Table[3](https://arxiv.org/html/1706.03762v7#S6.T3 "Table 3 ‣ 6.2 Model Variations ‣ 6 Results ‣ Attention Is All You Need") row (E)). We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
|
| 172 |
+
|
| 173 |
+
4 Why Self-Attention
|
| 174 |
+
--------------------
|
| 175 |
+
|
| 176 |
+
In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations (x 1,…,x n)(x_{1},...,x_{n}) to another sequence of equal length (z 1,…,z n)(z_{1},...,z_{n}), with x i,z i∈ℝ d x_{i},z_{i}\in\mathbb{R}^{d}, such as a hidden layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we consider three desiderata.
|
| 177 |
+
|
| 178 |
+
One is the total computational complexity per layer. Another is the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required.
|
| 179 |
+
|
| 180 |
+
The third is the path length between long-range dependencies in the network. Learning long-range dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the ability to learn such dependencies is the length of the paths forward and backward signals have to traverse in the network. The shorter these paths between any combination of positions in the input and output sequences, the easier it is to learn long-range dependencies [[12](https://arxiv.org/html/1706.03762v7#bib.bib12)]. Hence we also compare the maximum path length between any two input and output positions in networks composed of the different layer types.
|
| 181 |
+
|
| 182 |
+
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. n n is the sequence length, d d is the representation dimension, k k is the kernel size of convolutions and r r the size of the neighborhood in restricted self-attention.
|
| 183 |
+
|
| 184 |
+
As noted in Table [1](https://arxiv.org/html/1706.03762v7#S4.T1 "Table 1 ‣ 4 Why Self-Attention ‣ Attention Is All You Need"), a self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires O(n)O(n) sequential operations. In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n n is smaller than the representation dimensionality d d, which is most often the case with sentence representations used by state-of-the-art models in machine translations, such as word-piece [[38](https://arxiv.org/html/1706.03762v7#bib.bib38)] and byte-pair [[31](https://arxiv.org/html/1706.03762v7#bib.bib31)] representations. To improve computational performance for tasks involving very long sequences, self-attention could be restricted to considering only a neighborhood of size r r in the input sequence centered around the respective output position. This would increase the maximum path length to O(n/r)O(n/r). We plan to investigate this approach further in future work.
|
| 185 |
+
|
| 186 |
+
A single convolutional layer with kernel width k<n k<n does not connect all pairs of input and output positions. Doing so requires a stack of O(n/k)O(n/k) convolutional layers in the case of contiguous kernels, or O(log k(n))O(log_{k}(n)) in the case of dilated convolutions [[18](https://arxiv.org/html/1706.03762v7#bib.bib18)], increasing the length of the longest paths between any two positions in the network. Convolutional layers are generally more expensive than recurrent layers, by a factor of k k. Separable convolutions [[6](https://arxiv.org/html/1706.03762v7#bib.bib6)], however, decrease the complexity considerably, to O(k⋅n⋅d+n⋅d 2)O(k\cdot n\cdot d+n\cdot d^{2}). Even with k=n k=n, however, the complexity of a separable convolution is equal to the combination of a self-attention layer and a point-wise feed-forward layer, the approach we take in our model.
|
| 187 |
+
|
| 188 |
+
As side benefit, self-attention could yield more interpretable models. We inspect attention distributions from our models and present and discuss examples in the appendix. Not only do individual attention heads clearly learn to perform different tasks, many appear to exhibit behavior related to the syntactic and semantic structure of the sentences.
|
| 189 |
+
|
| 190 |
+
5 Training
|
| 191 |
+
----------
|
| 192 |
+
|
| 193 |
+
This section describes the training regime for our models.
|
| 194 |
+
|
| 195 |
+
### 5.1 Training Data and Batching
|
| 196 |
+
|
| 197 |
+
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding [[3](https://arxiv.org/html/1706.03762v7#bib.bib3)], which has a shared source-target vocabulary of about 37000 tokens. For English-French, we used the significantly larger WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary [[38](https://arxiv.org/html/1706.03762v7#bib.bib38)]. Sentence pairs were batched together by approximate sequence length. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
|
| 198 |
+
|
| 199 |
+
### 5.2 Hardware and Schedule
|
| 200 |
+
|
| 201 |
+
We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper, each training step took about 0.4 seconds. We trained the base models for a total of 100,000 steps or 12 hours. For our big models,(described on the bottom line of table [3](https://arxiv.org/html/1706.03762v7#S6.T3 "Table 3 ‣ 6.2 Model Variations ‣ 6 Results ‣ Attention Is All You Need")), step time was 1.0 seconds. The big models were trained for 300,000 steps (3.5 days).
|
| 202 |
+
|
| 203 |
+
### 5.3 Optimizer
|
| 204 |
+
|
| 205 |
+
We used the Adam optimizer[[20](https://arxiv.org/html/1706.03762v7#bib.bib20)] with β 1=0.9\beta_{1}=0.9, β 2=0.98\beta_{2}=0.98 and ϵ=10−9\epsilon=10^{-9}. We varied the learning rate over the course of training, according to the formula:
|
| 206 |
+
|
| 207 |
+
lrate=d model−0.5⋅min(step_num−0.5,step_num⋅warmup_steps−1.5)lrate=d_{\text{model}}^{-0.5}\cdot\min({step\_num}^{-0.5},{step\_num}\cdot{warmup\_steps}^{-1.5})(3)
|
| 208 |
+
|
| 209 |
+
This corresponds to increasing the learning rate linearly for the first warmup_steps warmup\_steps training steps, and decreasing it thereafter proportionally to the inverse square root of the step number. We used warmup_steps=4000 warmup\_steps=4000.
|
| 210 |
+
|
| 211 |
+
### 5.4 Regularization
|
| 212 |
+
|
| 213 |
+
We employ three types of regularization during training:
|
| 214 |
+
|
| 215 |
+
##### Residual Dropout
|
| 216 |
+
|
| 217 |
+
We apply dropout [[33](https://arxiv.org/html/1706.03762v7#bib.bib33)] to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of P drop=0.1 P_{drop}=0.1.
|
| 218 |
+
|
| 219 |
+
##### Label Smoothing
|
| 220 |
+
|
| 221 |
+
During training, we employed label smoothing of value ϵ ls=0.1\epsilon_{ls}=0.1[[36](https://arxiv.org/html/1706.03762v7#bib.bib36)]. This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score.
|
| 222 |
+
|
| 223 |
+
6 Results
|
| 224 |
+
---------
|
| 225 |
+
|
| 226 |
+
### 6.1 Machine Translation
|
| 227 |
+
|
| 228 |
+
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
|
| 229 |
+
|
| 230 |
+
On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) in Table[2](https://arxiv.org/html/1706.03762v7#S6.T2 "Table 2 ‣ 6.1 Machine Translation ‣ 6 Results ‣ Attention Is All You Need")) outperforms the best previously reported models (including ensembles) by more than 2.0 2.0 BLEU, establishing a new state-of-the-art BLEU score of 28.4 28.4. The configuration of this model is listed in the bottom line of Table[3](https://arxiv.org/html/1706.03762v7#S6.T3 "Table 3 ‣ 6.2 Model Variations ‣ 6 Results ‣ Attention Is All You Need"). Training took 3.5 3.5 days on 8 8 P100 GPUs. Even our base model surpasses all previously published models and ensembles, at a fraction of the training cost of any of the competitive models.
|
| 231 |
+
|
| 232 |
+
On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of 41.0 41.0, outperforming all of the previously published single models, at less than 1/4 1/4 the training cost of the previous state-of-the-art model. The Transformer (big) model trained for English-to-French used dropout rate P drop=0.1 P_{drop}=0.1, instead of 0.3 0.3.
|
| 233 |
+
|
| 234 |
+
For the base models, we used a single model obtained by averaging the last 5 checkpoints, which were written at 10-minute intervals. For the big models, we averaged the last 20 checkpoints. We used beam search with a beam size of 4 4 and length penalty α=0.6\alpha=0.6[[38](https://arxiv.org/html/1706.03762v7#bib.bib38)]. These hyperparameters were chosen after experimentation on the development set. We set the maximum output length during inference to input length + 50 50, but terminate early when possible [[38](https://arxiv.org/html/1706.03762v7#bib.bib38)].
|
| 235 |
+
|
| 236 |
+
Table [2](https://arxiv.org/html/1706.03762v7#S6.T2 "Table 2 ‣ 6.1 Machine Translation ‣ 6 Results ‣ Attention Is All You Need") summarizes our results and compares our translation quality and training costs to other model architectures from the literature. We estimate the number of floating point operations used to train a model by multiplying the training time, the number of GPUs used, and an estimate of the sustained single-precision floating-point capacity of each GPU 2 2 2 We used values of 2.8, 3.7, 6.0 and 9.5 TFLOPS for K80, K40, M40 and P100, respectively..
|
| 237 |
+
|
| 238 |
+
### 6.2 Model Variations
|
| 239 |
+
|
| 240 |
+
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
|
| 241 |
+
|
| 242 |
+
N N d model d_{\text{model}}d ff d_{\text{ff}}h h d k d_{k}d v d_{v}P drop P_{drop}ϵ ls\epsilon_{ls}train PPL BLEU params
|
| 243 |
+
steps(dev)(dev)×10 6\times 10^{6}
|
| 244 |
+
base 6 512 2048 8 64 64 0.1 0.1 100K 4.92 25.8 65
|
| 245 |
+
(A)1 512 512 5.29 24.9
|
| 246 |
+
4 128 128 5.00 25.5
|
| 247 |
+
16 32 32 4.91 25.8
|
| 248 |
+
32 16 16 5.01 25.4
|
| 249 |
+
(B)16 5.16 25.1 58
|
| 250 |
+
32 5.01 25.4 60
|
| 251 |
+
(C)2 6.11 23.7 36
|
| 252 |
+
4 5.19 25.3 50
|
| 253 |
+
8 4.88 25.5 80
|
| 254 |
+
256 32 32 5.75 24.5 28
|
| 255 |
+
1024 128 128 4.66 26.0 168
|
| 256 |
+
1024 5.12 25.4 53
|
| 257 |
+
4096 4.75 26.2 90
|
| 258 |
+
(D)0.0 5.77 24.6
|
| 259 |
+
0.2 4.95 25.5
|
| 260 |
+
0.0 4.67 25.3
|
| 261 |
+
0.2 5.47 25.7
|
| 262 |
+
(E)positional embedding instead of sinusoids 4.92 25.7
|
| 263 |
+
big 6 1024 4096 16 0.3 300K 4.33 26.4 213
|
| 264 |
+
|
| 265 |
+
To evaluate the importance of different components of the Transformer, we varied our base model in different ways, measuring the change in performance on English-to-German translation on the development set, newstest2013. We used beam search as described in the previous section, but no checkpoint averaging. We present these results in Table[3](https://arxiv.org/html/1706.03762v7#S6.T3 "Table 3 ‣ 6.2 Model Variations ‣ 6 Results ‣ Attention Is All You Need").
|
| 266 |
+
|
| 267 |
+
In Table[3](https://arxiv.org/html/1706.03762v7#S6.T3 "Table 3 ‣ 6.2 Model Variations ‣ 6 Results ‣ Attention Is All You Need") rows (A), we vary the number of attention heads and the attention key and value dimensions, keeping the amount of computation constant, as described in Section [3.2.2](https://arxiv.org/html/1706.03762v7#S3.SS2.SSS2 "3.2.2 Multi-Head Attention ‣ 3.2 Attention ‣ 3 Model Architecture ‣ Attention Is All You Need"). While single-head attention is 0.9 BLEU worse than the best setting, quality also drops off with too many heads.
|
| 268 |
+
|
| 269 |
+
In Table[3](https://arxiv.org/html/1706.03762v7#S6.T3 "Table 3 ‣ 6.2 Model Variations ‣ 6 Results ‣ Attention Is All You Need") rows (B), we observe that reducing the attention key size d k d_{k} hurts model quality. This suggests that determining compatibility is not easy and that a more sophisticated compatibility function than dot product may be beneficial. We further observe in rows (C) and (D) that, as expected, bigger models are better, and dropout is very helpful in avoiding over-fitting. In row (E) we replace our sinusoidal positional encoding with learned positional embeddings [[9](https://arxiv.org/html/1706.03762v7#bib.bib9)], and observe nearly identical results to the base model.
|
| 270 |
+
|
| 271 |
+
### 6.3 English Constituency Parsing
|
| 272 |
+
|
| 273 |
+
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)
|
| 274 |
+
|
| 275 |
+
Parser Training WSJ 23 F1
|
| 276 |
+
Vinyals & Kaiser el al. (2014) [[37](https://arxiv.org/html/1706.03762v7#bib.bib37)]WSJ only, discriminative 88.3
|
| 277 |
+
Petrov et al. (2006) [[29](https://arxiv.org/html/1706.03762v7#bib.bib29)]WSJ only, discriminative 90.4
|
| 278 |
+
Zhu et al. (2013) [[40](https://arxiv.org/html/1706.03762v7#bib.bib40)]WSJ only, discriminative 90.4
|
| 279 |
+
Dyer et al. (2016) [[8](https://arxiv.org/html/1706.03762v7#bib.bib8)]WSJ only, discriminative 91.7
|
| 280 |
+
Transformer (4 layers)WSJ only, discriminative 91.3
|
| 281 |
+
Zhu et al. (2013) [[40](https://arxiv.org/html/1706.03762v7#bib.bib40)]semi-supervised 91.3
|
| 282 |
+
Huang & Harper (2009) [[14](https://arxiv.org/html/1706.03762v7#bib.bib14)]semi-supervised 91.3
|
| 283 |
+
McClosky et al. (2006) [[26](https://arxiv.org/html/1706.03762v7#bib.bib26)]semi-supervised 92.1
|
| 284 |
+
Vinyals & Kaiser el al. (2014) [[37](https://arxiv.org/html/1706.03762v7#bib.bib37)]semi-supervised 92.1
|
| 285 |
+
Transformer (4 layers)semi-supervised 92.7
|
| 286 |
+
Luong et al. (2015) [[23](https://arxiv.org/html/1706.03762v7#bib.bib23)]multi-task 93.0
|
| 287 |
+
Dyer et al. (2016) [[8](https://arxiv.org/html/1706.03762v7#bib.bib8)]generative 93.3
|
| 288 |
+
|
| 289 |
+
To evaluate if the Transformer can generalize to other tasks we performed experiments on English constituency parsing. This task presents specific challenges: the output is subject to strong structural constraints and is significantly longer than the input. Furthermore, RNN sequence-to-sequence models have not been able to attain state-of-the-art results in small-data regimes [[37](https://arxiv.org/html/1706.03762v7#bib.bib37)].
|
| 290 |
+
|
| 291 |
+
We trained a 4-layer transformer with d model=1024 d_{model}=1024 on the Wall Street Journal (WSJ) portion of the Penn Treebank [[25](https://arxiv.org/html/1706.03762v7#bib.bib25)], about 40K training sentences. We also trained it in a semi-supervised setting, using the larger high-confidence and BerkleyParser corpora from with approximately 17M sentences [[37](https://arxiv.org/html/1706.03762v7#bib.bib37)]. We used a vocabulary of 16K tokens for the WSJ only setting and a vocabulary of 32K tokens for the semi-supervised setting.
|
| 292 |
+
|
| 293 |
+
We performed only a small number of experiments to select the dropout, both attention and residual (section[5.4](https://arxiv.org/html/1706.03762v7#S5.SS4 "5.4 Regularization ‣ 5 Training ‣ Attention Is All You Need")), learning rates and beam size on the Section 22 development set, all other parameters remained unchanged from the English-to-German base translation model. During inference, we increased the maximum output length to input length + 300 300. We used a beam size of 21 21 and α=0.3\alpha=0.3 for both WSJ only and the semi-supervised setting.
|
| 294 |
+
|
| 295 |
+
Our results in Table[4](https://arxiv.org/html/1706.03762v7#S6.T4 "Table 4 ‣ 6.3 English Constituency Parsing ‣ 6 Results ‣ Attention Is All You Need") show that despite the lack of task-specific tuning our model performs surprisingly well, yielding better results than all previously reported models with the exception of the Recurrent Neural Network Grammar [[8](https://arxiv.org/html/1706.03762v7#bib.bib8)].
|
| 296 |
+
|
| 297 |
+
In contrast to RNN sequence-to-sequence models [[37](https://arxiv.org/html/1706.03762v7#bib.bib37)], the Transformer outperforms the BerkeleyParser [[29](https://arxiv.org/html/1706.03762v7#bib.bib29)] even when training only on the WSJ training set of 40K sentences.
|
| 298 |
+
|
| 299 |
+
7 Conclusion
|
| 300 |
+
------------
|
| 301 |
+
|
| 302 |
+
In this work, we presented the Transformer, the first sequence transduction model based entirely on attention, replacing the recurrent layers most commonly used in encoder-decoder architectures with multi-headed self-attention.
|
| 303 |
+
|
| 304 |
+
For translation tasks, the Transformer can be trained significantly faster than architectures based on recurrent or convolutional layers. On both WMT 2014 English-to-German and WMT 2014 English-to-French translation tasks, we achieve a new state of the art. In the former task our best model outperforms even all previously reported ensembles.
|
| 305 |
+
|
| 306 |
+
We are excited about the future of attention-based models and plan to apply them to other tasks. We plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video. Making generation less sequential is another research goals of ours.
|
| 307 |
+
|
| 308 |
+
##### Acknowledgements
|
| 309 |
+
|
| 310 |
+
We are grateful to Nal Kalchbrenner and Stephan Gouws for their fruitful comments, corrections and inspiration.
|
| 311 |
+
|
| 312 |
+
References
|
| 313 |
+
----------
|
| 314 |
+
|
| 315 |
+
* [1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
|
| 316 |
+
* [2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473, 2014.
|
| 317 |
+
* [3] Denny Britz, Anna Goldie, Minh-Thang Luong, and Quoc V. Le. Massive exploration of neural machine translation architectures. CoRR, abs/1703.03906, 2017.
|
| 318 |
+
* [4] Jianpeng Cheng, Li Dong, and Mirella Lapata. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733, 2016.
|
| 319 |
+
* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. CoRR, abs/1406.1078, 2014.
|
| 320 |
+
* [6] Francois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint arXiv:1610.02357, 2016.
|
| 321 |
+
* [7] Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. CoRR, abs/1412.3555, 2014.
|
| 322 |
+
* [8] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. Recurrent neural network grammars. In Proc. of NAACL, 2016.
|
| 323 |
+
* [9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
|
| 324 |
+
* [10] Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013.
|
| 325 |
+
* [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
|
| 326 |
+
* [12] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, 2001.
|
| 327 |
+
* [13] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
|
| 328 |
+
* [14] Zhongqiang Huang and Mary Harper. Self-training PCFG grammars with latent annotations across languages. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 832–841. ACL, August 2009.
|
| 329 |
+
* [15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
|
| 330 |
+
* [16] Łukasz Kaiser and Samy Bengio. Can active memory replace attention? In Advances in Neural Information Processing Systems, (NIPS), 2016.
|
| 331 |
+
* [17] Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. In International Conference on Learning Representations (ICLR), 2016.
|
| 332 |
+
* [18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2, 2017.
|
| 333 |
+
* [19] Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. Structured attention networks. In International Conference on Learning Representations, 2017.
|
| 334 |
+
* [20] Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
|
| 335 |
+
* [21] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint arXiv:1703.10722, 2017.
|
| 336 |
+
* [22] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
|
| 337 |
+
* [23] Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. Multi-task sequence to sequence learning. arXiv preprint arXiv:1511.06114, 2015.
|
| 338 |
+
* [24] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
|
| 339 |
+
* [25] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
|
| 340 |
+
* [26] David McClosky, Eugene Charniak, and Mark Johnson. Effective self-training for parsing. In Proceedings of the Human Language Technology Conference of the NAACL, Main Conference, pages 152–159. ACL, June 2006.
|
| 341 |
+
* [27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. In Empirical Methods in Natural Language Processing, 2016.
|
| 342 |
+
* [28] Romain Paulus, Caiming Xiong, and Richard Socher. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304, 2017.
|
| 343 |
+
* [29] Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein. Learning accurate, compact, and interpretable tree annotation. In Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, pages 433–440. ACL, July 2006.
|
| 344 |
+
* [30] Ofir Press and Lior Wolf. Using the output embedding to improve language models. arXiv preprint arXiv:1608.05859, 2016.
|
| 345 |
+
* [31] Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. arXiv preprint arXiv:1508.07909, 2015.
|
| 346 |
+
* [32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
|
| 347 |
+
* [33] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1):1929–1958, 2014.
|
| 348 |
+
* [34] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In C.Cortes, N.D. Lawrence, D.D. Lee, M.Sugiyama, and R.Garnett, editors, Advances in Neural Information Processing Systems 28, pages 2440–2448. Curran Associates, Inc., 2015.
|
| 349 |
+
* [35] Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems, pages 3104–3112, 2014.
|
| 350 |
+
* [36] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. CoRR, abs/1512.00567, 2015.
|
| 351 |
+
* [37] Vinyals & Kaiser, Koo, Petrov, Sutskever, and Hinton. Grammar as a foreign language. In Advances in Neural Information Processing Systems, 2015.
|
| 352 |
+
* [38] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, 2016.
|
| 353 |
+
* [39] Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu. Deep recurrent models with fast-forward connections for neural machine translation. CoRR, abs/1606.04199, 2016.
|
| 354 |
+
* [40] Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu. Fast and accurate shift-reduce constituent parsing. In Proceedings of the 51st Annual Meeting of the ACL (Volume 1: Long Papers), pages 434–443. ACL, August 2013.
|
| 355 |
+
|
| 356 |
+
Attention Visualizations
|
| 357 |
+
------------------------
|
| 358 |
+
|
| 359 |
+

|
| 360 |
+
|
| 361 |
+
Figure 3: An example of the attention mechanism following long-distance dependencies in the encoder self-attention in layer 5 of 6. Many of the attention heads attend to a distant dependency of the verb ‘making’, completing the phrase ‘making…more difficult’. Attentions here shown only for the word ‘making’. Different colors represent different heads. Best viewed in color.
|
| 362 |
+
|
| 363 |
+

|
| 364 |
+
|
| 365 |
+
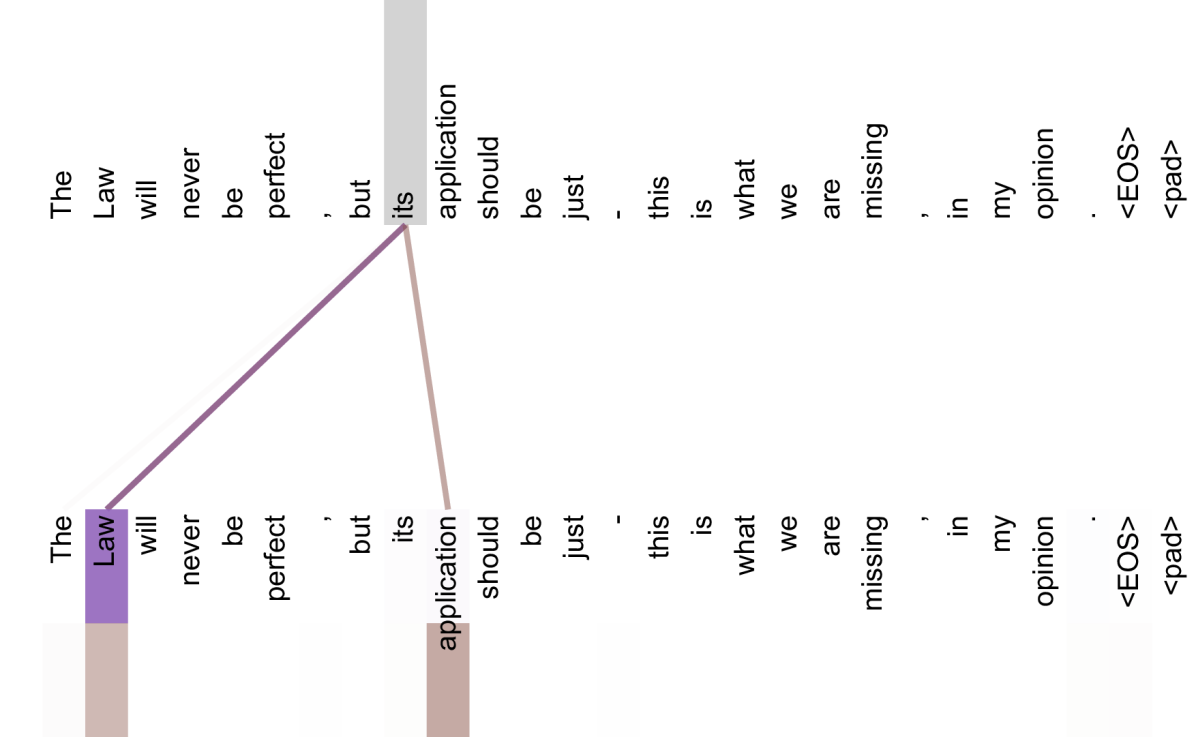
|
| 366 |
+
|
| 367 |
+
Figure 4: Two attention heads, also in layer 5 of 6, apparently involved in anaphora resolution. Top: Full attentions for head 5. Bottom: Isolated attentions from just the word ‘its’ for attention heads 5 and 6. Note that the attentions are very sharp for this word.
|
| 368 |
+
|
| 369 |
+

|
| 370 |
+
|
| 371 |
+

|
| 372 |
+
|
| 373 |
+
Figure 5: Many of the attention heads exhibit behaviour that seems related to the structure of the sentence. We give two such examples above, from two different heads from the encoder self-attention at layer 5 of 6. The heads clearly learned to perform different tasks.
|
1707/1707.06347.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1707.06347
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1707.06347#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1707.06347'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1708/1708.02002.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1708.02002
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1708.02002#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1708.02002'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1708/1708.09230.md
ADDED
|
@@ -0,0 +1,239 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: TANKER: Distributed Architecture for Named Entity Recognition and Disambiguation
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1708.09230
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
[arXiv:1708.09230v3](http://arxiv.org/abs/1708.09230v3) [cs.CL] 25 Oct 2017
|
| 7 |
+
|
| 8 |
+
ABSTRACT
|
| 9 |
+
--------
|
| 10 |
+
|
| 11 |
+
Named Entity Recognition and Disambiguation (NERD) systems have recently been widely researched to deal with the significant growth of the Web. NERD systems are crucial for several Natural Language Processing (NLP) tasks such as summarization, understanding, and machine translation. However, there is no standard interface specification, i.e. these systems may vary significantly either for exporting their outputs or for processing the inputs. Thus, when a given company desires to implement more than one NERD system, the process is quite exhaustive and prone to failure. In addition, industrial solutions demand critical requirements, e.g., large-scale processing, completeness, versatility, and licenses. Commonly, these requirements impose a limitation, making good NERD models to be ignored by companies. This paper presents TANKER, a distributed architecture which aims to overcome scalability, reliability and failure tolerance limitations related to industrial needs by combining NERD systems. To this end, TANKER relies on a micro-services oriented architecture, which enables agile development and delivery of complex enterprise applications. In addition, TANKER provides a standardized API which makes possible to combine several NERD systems at once.
|
| 12 |
+
|
| 13 |
+
INTRODUCTION
|
| 14 |
+
------------
|
| 15 |
+
|
| 16 |
+
The Internet has been growing at an explosive rate for several years, which make harder to handle the big amount of information diffused in diverse formats, such as text, audio and, video. Currently, the Web produces more than 2.5 exabytes of data per day[1](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn1)[](http://arxiv.org/html/1708.09230v3/ "Footnote 1: http://www.northeastern.edu/levelblog/2016/05/13/how-much-data-produced-every-day/"). Therefore, the challenge of indexing, formatting, and making the information available to the users has arisen every day, which makes a critical scenario. In order to deal with such variety of contents, refined NLP techniques are required.
|
| 17 |
+
|
| 18 |
+
One of the most important NLP techniques is Named Entity Recognition and Disambiguation (NERD). The task aims at recognizing the entities and their types in raw texts and also link them to distinct Knowledge Base (KB)s[[8]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490759706). In addition, NERD systems enable the processing of unstructured texts to provide useful data for information retrieval, information extraction, machine translation, question answering systems and automatic summarization tools.
|
| 19 |
+
|
| 20 |
+
Although NERD approaches have been widely researched nowadays and shown good precision, they still present inefficient time-performance algorithms and poor versatility. In an industrial environment, a given newspaper company which desires to annotate their news can deal with different subjects in the same document. It makes the use of distinctive NERD systems and KBs harder. On the other hand, financial companies handle very large documents and the current NERD tools do not deliver the response in a reasonable time (e.g., they may take almost half day to deliver the results from a big data set[2](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn2)[](http://arxiv.org/html/1708.09230v3/ "Footnote 2: See the average time in http://gerbil.aksw.org/gerbil/experiment?id=201701260017")). For instance, DBpedia Spotlight[[6]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490759726) is able to process only 120 queries per minute[3](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn3)[](http://arxiv.org/html/1708.09230v3/ "Footnote 3: https://github.com/dbpedia-spotlight/dbpedia-spotlight/wiki/User's-manual") and also retrieves information only from DBpedia[[5]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490759734), which is not enough for enterprise companies who deal with large documents and different subjects. Therefore, the main lack is scalability which becomes a key factor for academic solutions to be adopted by the industrial environment.
|
| 21 |
+
|
| 22 |
+
Early efforts have focused on algorithms and evaluations, resulting in stand-alone applications that aimed to solve problems in specific domains. For example, Rizzo et al. [[10]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490759749) and Bordino et al. [[2]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490759761) proposed the combination of NERD systems for industrial solutions, but they did not focus on scalability. Thus, it becomes difficult to use them in real cases. Moreover, the systems must be checked whether there is any limitation for using in distributed environments regarding their licenses.
|
| 23 |
+
|
| 24 |
+
To this end, we present TANKER, an approach to address the aforementioned gaps by combining NERD solutions through a micro-services architecture. TANKER is a REST based service that decreases drawbacks especially with regards to integration, licensing, outdated technologies and availability/scalability. The main contributions intended with our work are:
|
| 25 |
+
|
| 26 |
+
* _Scalability_: TANKER allows to start new service instances by language and domain in response to rising demand with a round-robin distribution strategy.
|
| 27 |
+
|
| 28 |
+
* _Fault tolerance_: using a client-side IPC library, a request can be handled for _N_ configured available servers
|
| 29 |
+
|
| 30 |
+
* _Completeness_: under the same request, TANKER can query one-to-many services to provide better results.
|
| 31 |
+
|
| 32 |
+
The paper is structured as follows: In the next section, we present the related works. [Section 3](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760383) presents the TANKER architecture in details and explains how TANKER addresses the gaps pertaining to industrial solutions. In [Section 4](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760402) we present the primary implementation of TANKER. Finally, we give an outlook on further directions and possibilities for TANKER in [Section 5](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760415).
|
| 33 |
+
|
| 34 |
+
RELATED WORK
|
| 35 |
+
------------
|
| 36 |
+
|
| 37 |
+
To the best of our knowledge, there is no work proposing a distributed architecture based on micro-services, especially focusing on its infrastructure and scalability. However, there are two works which had proposed distinct architectures for combining NERD systems without relying on machine learning (ML) algorithms. They are as follows:
|
| 38 |
+
|
| 39 |
+
* _NERD framework_: In 2012, proposed a generic framework which groups either commercial and research approaches among several entity recognition tools. The Named Entity Recognition (NER) tools are made available via Web APIs and they use a hybrid approach for presenting the different outputs of each NER tool via a unique response. Thus, providing users the opportunity to easily query each of these services through the same setup and compare their outputs. In addition, NERD is tailored for entity recognition of Twitter streams and has a public web API[4](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn4)[](http://arxiv.org/html/1708.09230v3/ "Footnote 4: http://nerd.eurocom.fr").
|
| 40 |
+
|
| 41 |
+
* _HERMES framework_: The authors proposed a novel NLP framework dubbed HERMES which focuses on addressing the performance at the infrastructure layer. HERMES provides an Entity Recognition and Disambiguation service, enhanced with three features (topic extraction, topic labeling and topic explanation). It uses Apache Kafka[5](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn5)[](http://arxiv.org/html/1708.09230v3/ "Footnote 5: http://kafka.apache.org")to deal with message queues. However, their implementation comprises of asynchronous modules which does not consider the response time. This implies several challenges for developers, as it is hard to deal with different kinds of failure in asynchronous scenarios. Although Hermes architecture is based on modules, there is no web service or API provided by this solution.
|
| 42 |
+
|
| 43 |
+
In terms of components, i.e. NER, Entity Linking (EL) and NERD models, there are a plenty of available tools that could be integrated in our architecture. However, for the sake of space, we only introduce the approaches which are included in TANKER.
|
| 44 |
+
|
| 45 |
+
* _NER - Stanford NER_ _[6](http://arxiv.org/html/1708.09230v3/TANKER\_Distributed\_Architecture\_for\_Named\_EntityRecognition\_and\_Disambiguation.html#ftn6)[](http://arxiv.org/html/1708.09230v3/ "Footnote 6: https://nlp.stanford.edu/software/CRF-NER.shtml")_[[4]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760481)is a Java implementation of a NER system. It labels sequences of words in a text which are the names of things, such as person and company names, or gene and protein names. It comes with well-engineered feature extractors for Named Entity Recognition, and many options for defining feature extractors. Stanford NER implements Conditional Random Fields (CRF) sequence models to perform NER tasks in pre-existing training sets, and one can also train a new model.
|
| 46 |
+
|
| 47 |
+
* _NED – AGDISTIS_ _[7](http://arxiv.org/html/1708.09230v3/TANKER\_Distributed\_Architecture\_for\_Named\_EntityRecognition\_and\_Disambiguation.html#ftn7)[](http://arxiv.org/html/1708.09230v3/ "Footnote 7: http://aksw.org/Projects/AGDISTIS.html")_[[11]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760498)is an open source named entity disambiguation framework. Its early version can link entities by combining the HITS algorithm with label expansion strategies and string similarity measures. The newer version of it includes a new algorithm called MAG[[7]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760509). MAG is a multilingual and deterministic algorithm which disambiguates entities from a given knowledge base by using HITS and PageRank along with an in-depth context search based on TF-IDF statistics. Based on this combination, it can efficiently detect the correct URIs for a given set of named entities within an input text. Furthermore, AGDISTIS is agnostic of the underlying knowledge base.
|
| 48 |
+
|
| 49 |
+
* _NERD_ - One of the first semantic approaches published in 2011, _DBpedia Spotlight_[8](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn8)[](http://arxiv.org/html/1708.09230v3/ "Footnote 8: http://www.dbpedia-spotlight.org/")[[6]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490759726) is a tool which combines NER and NED approaches for automatically annotating mentions of DBpedia resources[[3]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760525) in texts. In addition, Spotlight contains programmatic inter-faces based on a vector-space representation of entities and cosine similarity for phrase spotting, i.e., recognition of phrases to be annotated. Moreover, it can export the results in various output formats such as XML, JSON/JSON-LD, RDF, NIF, and N3.
|
| 50 |
+
|
| 51 |
+
TANKER was designed with portability and efficiency in mind. It was also designed to be customizable and extensible w.r.t. its user interface, functionality and the integration of underlying components. The overall architecture of TANKER is shown in TANKER is built using a microservice architecture [[9]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760546). Microservices have been getting a lot of attention and popularity in the recent years[9](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn9)[](http://arxiv.org/html/1708.09230v3/ "Footnote 9: https://www.oreilly.com/ideas/the-evolution-of-scalable-microservices") because of its significant benefits, especially w.r.t enabling the agile development, improving scalability, reliability and failure tolerance.
|
| 52 |
+
|
| 53 |
+
TANKER does not depend on any specific NERD service and is generic enough to be connected to any replacement microservice that abides by given service specification. This allows for simple configuration as well as adds a way to extend the functionality of the system - by adding or removing the microservices we can easily tailor the final user experience.
|
| 54 |
+
|
| 55 |
+
Additionally, microservices enforces a modularity level which is much faster to develop, and easier to understand and maintain. This architecture enables the development of each server independently by letting the architects free to choose appropriate technologies for different kind of problems. Thus, being possible to combine different programming languages in one single solution. The other components of TANKER are described in the sequence.
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
**Figure 1.**Overview of TANKER architecture
|
| 60 |
+
|
| 61 |
+
Scalability and Fault tolerance
|
| 62 |
+
-------------------------------
|
| 63 |
+
|
| 64 |
+
Scalability is the capability to handle a growing amount of processes within a computational system in a graceful manner, providing minimal interruptions to ongoing operations. This feature is mandatory for enterprise systems in addition to fault-tolerance, scaling up mode and some others, to deliver a good user experience at a minimum cost.
|
| 65 |
+
|
| 66 |
+
Most of NERD solutions are usually developed under synchronous or asynchronous requests. Both requests wait for a response, however, the synchronous might block the user interaction while the asynchronous does not. Commonly, distributed applications consider services interactions to decide which one will be used in its ecosystem. For instance, in synchronous requests, HTTP REST or Thrift[10](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn10)[](http://arxiv.org/html/1708.09230v3/ "Footnote 10: https://thrift.apache.org/")are adopted, on the other hand, the Advanced Message Queuing Protocol[11](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn11)[](http://arxiv.org/html/1708.09230v3/ "Footnote 11: https://www.amqp.org/")is used for asynchronous.
|
| 67 |
+
|
| 68 |
+
These request types infer on Inter-Process Communication (IPC) mechanisms. IPC software is a central piece of the architecture to ensure that microservices will scale and have fault-tolerance. This component is usually designed to be highly configurable and supports running in hybrid environments that are multi-region and multi-zone. To this end, TANKER supports synchronous interactions relying on Ribbon framework[12](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn12)[](http://arxiv.org/html/1708.09230v3/ "Footnote 12: https://github.com/Netflix/ribbon")as our IPC. Ribbon framework offers client-side software load balancing algorithms and a good set of configuration options such as connection timeouts and retry algorithms that fills in our requirements for NERD environments.
|
| 69 |
+
|
| 70 |
+
Configuration
|
| 71 |
+
-------------
|
| 72 |
+
|
| 73 |
+
The configuration of TANKER aims to reduce the complexity of management processes by using cloud services. Therefore, TANKER is based on Spring Cloud Config[13](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn13)[13](http://arxiv.org/html/1708.09230v3/ "Footnote 13: http://cloud.spring.io/spring-cloud-static/spring-cloud.html") which offers a client-side application for exposing configuration of a distributed system. It is integrated with Spring ecosystem, but it can also be used with any application running in any programming language. This service uses the human-readable data serialization language (YAML[14](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn14)[](http://arxiv.org/html/1708.09230v3/ "Footnote 14: http://yaml.org/")), a widely spread format to describe services parameters and exposes all of them under a REST/API (see Listing 1).
|
| 74 |
+
|
| 75 |
+
```
|
| 76 |
+
spring:
|
| 77 |
+
profiles: eureka primary
|
| 78 |
+
cloud:
|
| 79 |
+
config:
|
| 80 |
+
uri: http://localhost:8001
|
| 81 |
+
eureka:
|
| 82 |
+
instance:
|
| 83 |
+
preferIpAddress: true
|
| 84 |
+
enableSelfPreservation: false
|
| 85 |
+
client:
|
| 86 |
+
name: eureka
|
| 87 |
+
. . .
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
**Listing 1.**YAML example
|
| 91 |
+
|
| 92 |
+
Moreover, the delivered configuration through agnostic technologies will reinforce TANKER architecture pliability, by allowing approaches written in non-JVM technologies to reuse parameters and quickly integrate to the IPC.
|
| 93 |
+
|
| 94 |
+
Service Registry
|
| 95 |
+
----------------
|
| 96 |
+
|
| 97 |
+
Distributed systems need to localize the network address of each service. Services assign network locations dynamically. Moreover, the set of services instances also changes periodically because of auto-scaling, failures, and upgrades. This reinforces the need to have an elaborated service framework that uses a discovery pattern.
|
| 98 |
+
|
| 99 |
+
There are two service registry patterns: client-side discovery and service-side discovery. In client-side discovery pattern, clients query the service registry to select an available resource and perform a request. In the server-side discovery pattern, clients make a request via router, which queries the service registry and forward the request to an available instance [[1]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760595).
|
| 100 |
+
|
| 101 |
+
TANKER uses Eureka[15](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#ftn15)[](http://arxiv.org/html/1708.09230v3/ "Footnote 15: https://github.com/Netflix/eureka") for service discovery. Eureka is a REST server-side discovery service that locates services for load balancing and fail over of middle-tier servers.
|
| 102 |
+
|
| 103 |
+
Completeness
|
| 104 |
+
------------
|
| 105 |
+
|
| 106 |
+
TANKER architecture offers a pluggable platform that al-lows the whole community interconnect a set of services and approaches, making it available into a powerful standardized API. To this end, TANKER comprises of scaffoldtechnique. This technique provides a basis configuration that allows a quick development by using parameters from our setup services and by connecting to our service registry infrastructure.
|
| 107 |
+
|
| 108 |
+
PROTOTYPE
|
| 109 |
+
---------
|
| 110 |
+
|
| 111 |
+
On the primary version, we support both recognition and linking of named entities using DBpedia as a knowledge base. We chose DBpedia as primary KB for our prototype because the most of NERD approaches can handle it. Also, we intend to evaluate TANKER in GERBIL which comprises of many datasets using DBpedia as a KB. Therefore, we include DBpedia Spotlight and Stanford NER for carrying out the recognition part and AGDISTIS framework to disambiguate the recognized entities (see [Figure 2](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490760820)).
|
| 112 |
+
|
| 113 |
+

|
| 114 |
+
|
| 115 |
+
**Figure 2.**Prototype schema with integrated services
|
| 116 |
+
|
| 117 |
+
The described tools will be available into the TANKER infrastructure, under three endpoints: annotate, disambiguate and recognition.
|
| 118 |
+
|
| 119 |
+
* _Annotate_. This parameter performs both name entity recognition and disambiguation (for an example, see Listing 2). TANKER can deliver both the types of entities and their resources links
|
| 120 |
+
|
| 121 |
+
* _Disambiguate_. Once the entities are already recognized in texts, this parameter only disambiguates them.
|
| 122 |
+
|
| 123 |
+
* _Recognition_. This parameter is only able to recognize the types of entities.
|
| 124 |
+
|
| 125 |
+
```
|
| 126 |
+
{
|
| 127 |
+
text: Angela met Obama in New York
|
| 128 |
+
resources: [
|
| 129 |
+
{
|
| 130 |
+
surface-form: New York,
|
| 131 |
+
offset: 20:28,
|
| 132 |
+
score: 0.96,
|
| 133 |
+
type: dbo:Location,
|
| 134 |
+
origin-tool: Spotlight
|
| 135 |
+
{disambiguate: [
|
| 136 |
+
{
|
| 137 |
+
uri: dbr:New_York,
|
| 138 |
+
types: dbo:Location,
|
| 139 |
+
surface-form: New York,
|
| 140 |
+
offset: 20:28,
|
| 141 |
+
similarity-score: 0.86,
|
| 142 |
+
percentage-second-rank: 2,
|
| 143 |
+
origin-tool: SpotLight
|
| 144 |
+
}
|
| 145 |
+
{
|
| 146 |
+
uri: dbr:New_York_City,
|
| 147 |
+
types: dbo:Location,
|
| 148 |
+
surface-form: New York,
|
| 149 |
+
offset: 20:28,
|
| 150 |
+
similarity-score: 0.92,
|
| 151 |
+
percentage-second-rank: 1,
|
| 152 |
+
origin-tool: AGDISTIS
|
| 153 |
+
}]}
|
| 154 |
+
...
|
| 155 |
+
}
|
| 156 |
+
```
|
| 157 |
+
|
| 158 |
+
**Listing 2.**Annotating New York as entity.
|
| 159 |
+
|
| 160 |
+
When a client performs a request, all the available tools in the service discovery will be queried, and their results will be consolidated in the response. As you can see in the Listing 2, the entity New York got different resources from the disambiguation tools, but TANKER provides both and rank them according to their scores to let the user chooses. TANKER initially supports content-negotiation for JSON, JSON-LD, NIF, and N3. Our prototye can be found at [https://github.com/orgs/tanker-nerd/](https://github.com/orgs/tanker-nerd/).
|
| 161 |
+
|
| 162 |
+
Challenges
|
| 163 |
+
----------
|
| 164 |
+
|
| 165 |
+
After the deployment of our first prototype we identified three challenges to be addressed. First, to rank the response when the tools diverge the results from a same entity even more when one of the tools does not provide any score. Second, to combine different KBs at once in a reasonable response time. Finally, to manage the outcomes and configurations of experiments. To bridge this gap, we plan to integrate the MEX vocabulary [[14]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490857138) and stored the configurations of experiments and respective outcomes in the WASOTA repository [[13]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490857127).
|
| 166 |
+
|
| 167 |
+
SUMMARY
|
| 168 |
+
-------
|
| 169 |
+
|
| 170 |
+
We presented TANKER, a distributed architecture for combining NERD systems. In a preliminary overview, our approach is able to deal with a large-scale processing and high number of requests. In addition, TANKER responds to the queries in an appropriate response time thus addressing the aforementioned gaps. As an immediate work, we intend to integrate more NERD systems in order to improve the fault tolerance and evaluate TANKER using GERBIL[[12]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#_Ref490775154) to see the real performance of it compared to other NERD systems. As a future work, we plan to include a KB management service for enabling TANKER to process different KBs altogether. Furthermore, in order to facilitate data management and follow best practices in terms of reproducibility of experiments, we will integrate TAKER within state of the art ML vocabularies and metadata repositories.
|
| 171 |
+
|
| 172 |
+
ACKNOWLEDGEMENTS
|
| 173 |
+
----------------
|
| 174 |
+
|
| 175 |
+
This paper’s research activities were funded by grants from the FP7 & H2020 EU projects ALIGNED (GA-644055) and from the project Smart Data Web BMWi project (GA-01MD15010B) and CNPq foundation (scholarships 201808/2015-3 and 206971/2014-1).
|
| 176 |
+
|
| 177 |
+
REFERENCES
|
| 178 |
+
----------
|
| 179 |
+
|
| 180 |
+
1. K. Bakshi. Microservices-based software architecture and approaches. In 2017 IEEE Aerospace Conference, pages 1-8, March 2017.
|
| 181 |
+
|
| 182 |
+
2. Bordino, A. Ferretti, M. Firrincieli, F. Gullo, M. Paris, S. Pascolutti, and G. Sabena. Advancing nlp via a distributed-messaging approach. In Big Data (Big Data), 2016 IEEE International Conference on, pages 1561-1568. IEEE, 2016.
|
| 183 |
+
|
| 184 |
+
3. J. Daiber, M. Jakob, C. Hokamp, and P. N. Mendes. Improving efficiency and accuracy in multilingual entity extraction. In Proceedings of the 9th International Conference on Semantic Systems, I-SEMANTICS '13, pages 121-124, New York, NY, USA, 2013. ACM.
|
| 185 |
+
|
| 186 |
+
4. J. R. Finkel, T. Grenager, and C. Manning. Incorporating non-local information into information extraction systems by gibbs sampling. In ACL, 2005.
|
| 187 |
+
|
| 188 |
+
5. J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, S. Hellmann, M. Morsey, P. van Kleef, S. Auer, and C. Bizer. DBpedia - a large-scale, multilingual knowledge base extracted from wikipedia. SWJ, 2014.
|
| 189 |
+
|
| 190 |
+
6. P. N. Mendes, M. Jakob, A. Garcia-Silva, and Bizer. DBpedia Spotlight: Shedding Light on the Web of Documents. In 7th International Conference on Semantic Systems (I-Semantics), 2011.
|
| 191 |
+
|
| 192 |
+
7. D. Moussallem, R. Usbeck, M. Röder, and A. C. N. Ngomo. MAG: A Multilingual, Knowledge-base Agnostic and Deterministic Entity Linking Approach. arXiv preprint arXiv:1707.05288, 2017.
|
| 193 |
+
|
| 194 |
+
8. D. Nadeau and S. Sekine. A survey of named entity recognition and classification. Lingvisticae Investigationes, 30:3-26, 2007.
|
| 195 |
+
|
| 196 |
+
9. S. Newman. Building microservices. " O'Reilly Media, Inc., USA, 2015.
|
| 197 |
+
|
| 198 |
+
10. G. Rizzo and R. Troncy. Nerd: a framework for unifying named entity recognition and disambiguation extraction tools. In Proceedings of the Demonstrations at the 13th Conference of the European Chapter of the Association for Computational Linguistics, pages 73{76. Association for Computational Linguistics, 2012.
|
| 199 |
+
|
| 200 |
+
11. R. Usbeck, A. N. Ngomo, M. Roder,• D. Gerber, S. A. Coelho, S. Auer, and A. Both. AGDISTIS - graph-based disambiguation of named entities using linked data. In P. Mika, T. Tudorache, A. Bernstein, Welty, C. A. Knoblock, D. Vrandecic, P. T. Groth, F. Noy, K. Janowicz, and C. A. Goble, editors, The Semantic Web - ISWC 2014 - 13th International Semantic Web Conference, Riva del Garda, Italy, October 19-23, 2014. Proceedings, Part I, volume 8796 of Lecture Notes in Computer Science, pages 457-471. Springer, 2014.
|
| 201 |
+
|
| 202 |
+
12. R. Usbeck, M. Roder,• A. N. Ngomo, C. Baron, Both, M. Brummer,• D. Ceccarelli, M. Cornolti, D. Cherix, B. Eickmann, P. Ferragina, C. Lemke, A. Moro, R. Navigli, F. Piccinno, G. Rizzo, H. Sack, R. Speck, R. Troncy, J. Waitelonis, and L. Wesemann. GERBIL: general entity annotator benchmarking framework. In A. Gangemi, S. Leonardi, and A. Panconesi, editors, Proceedings of the 24 th International Conference on World Wide Web, WWW 2015, Florence, Italy, May 18-22, 2015, pages 1133-1143. ACM, 2015.
|
| 203 |
+
|
| 204 |
+
13. Neto, C. B., Esteves, D., Soru, T., Moussallem, D., Valdestilhas, A., & Marx, E. (2016). WASOTA: What Are the States Of The Art?. In SEMANTiCS (Posters, Demos, SuCCESS).
|
| 205 |
+
|
| 206 |
+
14. Esteves, D., Moussallem, D., Neto, C. B., Soru, T., Usbeck, R., Ackermann, M., & Lehmann, J. (2015, September). MEX vocabulary: a lightweight interchange format for machine learning experiments. In Proceedings of the 11th International Conference on Semantic Systems (pp. 169-176). ACM.
|
| 207 |
+
|
| 208 |
+
Footnotes
|
| 209 |
+
---------
|
| 210 |
+
|
| 211 |
+
[http://www.northeastern.edu/levelblog/2016/05/13/how-much-data-produced-every-day/](http://www.northeastern.edu/levelblog/2016/05/13/how-much-data-produced-every-day/)[[back]](http://arxiv.org/html/1708.09230v3/#fn_pointer_ftn1)
|
| 212 |
+
|
| 213 |
+
See the average time in [http://gerbil.aksw.org/gerbil/experiment?id=201701260017](http://gerbil.aksw.org/gerbil/experiment?id=201701260017)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn2)
|
| 214 |
+
|
| 215 |
+
[https://github.com/dbpedia-spotlight/dbpedia-spotlight/wiki/User's-manual](https://github.com/dbpedia-spotlight/dbpedia-spotlight/wiki/User's-manual)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn3)
|
| 216 |
+
|
| 217 |
+
[http://nerd.eurocom.fr](http://nerd.eurocom.fr/)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn4)
|
| 218 |
+
|
| 219 |
+
[http://kafka.apache.org](http://kafka.apache.org/)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn5)
|
| 220 |
+
|
| 221 |
+
[https://nlp.stanford.edu/software/CRF-NER.shtml](https://nlp.stanford.edu/software/CRF-NER.shtml)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn6)
|
| 222 |
+
|
| 223 |
+
[http://aksw.org/Projects/AGDISTIS.html](http://aksw.org/Projects/AGDISTIS.html)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn7)
|
| 224 |
+
|
| 225 |
+
[http://www.dbpedia-spotlight.org/](http://www.dbpedia-spotlight.org/)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn8)
|
| 226 |
+
|
| 227 |
+
[https://www.oreilly.com/ideas/the-evolution-of-scalable-microservices](https://www.oreilly.com/ideas/the-evolution-of-scalable-microservices)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn9)
|
| 228 |
+
|
| 229 |
+
[https://thrift.apache.org/](https://thrift.apache.org/)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn10)
|
| 230 |
+
|
| 231 |
+
[https://www.amqp.org/](https://www.amqp.org/)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn11)
|
| 232 |
+
|
| 233 |
+
[https://github.com/Netflix/ribbon](https://github.com/Netflix/ribbon)[[back]](file:///TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn12)
|
| 234 |
+
|
| 235 |
+
[http://cloud.spring.io/spring-cloud-static/spring-cloud.html](http://cloud.spring.io/spring-cloud-static/spring-cloud.html)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn13)
|
| 236 |
+
|
| 237 |
+
[http://yaml.org/](http://yaml.org/)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn14)
|
| 238 |
+
|
| 239 |
+
[https://github.com/Netflix/eureka](https://github.com/Netflix/eureka)[[back]](http://arxiv.org/html/1708.09230v3/TANKER_Distributed_Architecture_for_Named_EntityRecognition_and_Disambiguation.html#fn_pointer_ftn15)
|
1709/1709.07330.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1709.07330
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1709.07330#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1709.07330'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1710/1710.03208.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1710.03208
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1710.03208#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1710.03208'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1711/1711.10925.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1711.10925
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1711.10925#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1711.10925'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1712/1712.07629.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1712.07629
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1712.07629#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1712.07629'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1801/1801.01681.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1801.01681
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1801.01681#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1801.01681'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1801/1801.04381.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1801.04381
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1801.04381#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1801.04381'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1802/1802.00810.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
1803/1803.03635.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
1803/1803.06535.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1803.06535
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1803.06535#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1803.06535'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1803/1803.10963.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1803.10963
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1803.10963#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1803.10963'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1803/1803.11485.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1803.11485
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1803.11485#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1803.11485'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1804/1804.02767.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1804.02767
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1804.02767#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1804.02767'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1804/1804.03287.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1804.03287
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1804.03287#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1804.03287'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1804/1804.04637.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1804.04637
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1804.04637#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1804.04637'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1806/1806.02639.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1806.02639
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1806.02639#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1806.02639'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1807/1807.03418.md
ADDED
|
@@ -0,0 +1,321 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1807.03418
|
| 4 |
+
|
| 5 |
+
Published Time: Tue, 28 Nov 2023 02:14:15 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Johanna Vielhaben*{}^{*}start_FLOATSUPERSCRIPT * end_FLOATSUPERSCRIPT Marcel Ackermann Klaus-Robert Müller Sebastian Lapuschkin**absent{}^{**}start_FLOATSUPERSCRIPT * * end_FLOATSUPERSCRIPT Wojciech Samek**absent{}^{**}start_FLOATSUPERSCRIPT * * end_FLOATSUPERSCRIPT Department of Artificial Intelligence, Fraunhofer Heinrich-Hertz-Institute, Berlin, Germany Department of Electrical Engineering and Computer Science, Technische Universität Berlin, Berlin, Germany Department of Brain and Cognitive Engineering, Korea University, Seoul, Korea Max Planck Institute for Informatics, Saarbrücken, Germany BIFOLD – Berlin Institute for the Foundations of Learning and Data, Berlin, Germany
|
| 9 |
+
|
| 10 |
+
###### Abstract
|
| 11 |
+
|
| 12 |
+
Explainable Artificial Intelligence (XAI) is targeted at understanding how models perform feature selection and derive their classification decisions. This paper explores post-hoc explanations for deep neural networks in the audio domain. Notably, we present a novel Open Source audio dataset consisting of 30,000 audio samples of English spoken digits which we use for classification tasks on spoken digits and speakers’ biological sex. We use the popular XAI technique Layer-wise Relevance Propagation (LRP) to identify relevant features for two neural network architectures that process either waveform or spectrogram representations of the data. Based on the relevance scores obtained from LRP, hypotheses about the neural networks’ feature selection are derived and subsequently tested through systematic manipulations of the input data. Further, we take a step beyond visual explanations and introduce audible heatmaps. We demonstrate the superior interpretability of audible explanations over visual ones in a human user study.
|
| 13 |
+
|
| 14 |
+
###### keywords:
|
| 15 |
+
|
| 16 |
+
Deep Learning, Neural Networks, Interpretability, Explainable Artificial Intelligence, Audio Classification, Speech Recognition
|
| 17 |
+
|
| 18 |
+
††journal: Journal of the Franklin Institute
|
| 19 |
+
1 Introduction
|
| 20 |
+
--------------
|
| 21 |
+
|
| 22 |
+
Deep neural networks, owing to their intricate and non-linear hierarchical architecture, are widely regarded as black boxes with regard to the complex connection between input data and the resultant network output. This lack of transparency not only poses a significant challenge for researchers and engineers engaged in the utilization of these models but also renders them entirely unsuitable for domains where understanding and verification of predictions are indispensable, such as healthcare applications [caruana2015intelligible](https://arxiv.org/html/1807.03418v3/#bib.bib1).
|
| 23 |
+
|
| 24 |
+
In response, the field of Explainable Artificial Intelligence (XAI) investigates methods to make the classification strategies of complex models comprehensible, including methods introspecting learned features [hinton2006unsupervised](https://arxiv.org/html/1807.03418v3/#bib.bib2); [erhan2009visualizing](https://arxiv.org/html/1807.03418v3/#bib.bib3) and methods explaining model decisions [baehrens2010explain](https://arxiv.org/html/1807.03418v3/#bib.bib4); [bach2015pixel](https://arxiv.org/html/1807.03418v3/#bib.bib5); [fong2017interpretable](https://arxiv.org/html/1807.03418v3/#bib.bib6); [MonPR17](https://arxiv.org/html/1807.03418v3/#bib.bib7); [samek2021explaining](https://arxiv.org/html/1807.03418v3/#bib.bib8). The latter methods were initially successful in the realm of image classifiers and have more recently been adapted for other domains, such as natural language processing [ArrWASSA17](https://arxiv.org/html/1807.03418v3/#bib.bib9), physiological signals [StuJNM16](https://arxiv.org/html/1807.03418v3/#bib.bib10); [Strodthoff2018DetectingAI](https://arxiv.org/html/1807.03418v3/#bib.bib11), medical imaging [THOMAS2022972](https://arxiv.org/html/1807.03418v3/#bib.bib12); [klauschen2024pathology](https://arxiv.org/html/1807.03418v3/#bib.bib13), and physics [schutt2017quantum](https://arxiv.org/html/1807.03418v3/#bib.bib14); [bluecher2020ft](https://arxiv.org/html/1807.03418v3/#bib.bib15).
|
| 25 |
+
|
| 26 |
+
This paper explores deep neural network interpretation in the audio domain. As in the visual domain, neural networks have fostered progress in audio processing [lee2009unsupervised](https://arxiv.org/html/1807.03418v3/#bib.bib16); [hinton2012deep](https://arxiv.org/html/1807.03418v3/#bib.bib17); [2016arXiv161000087D](https://arxiv.org/html/1807.03418v3/#bib.bib18), particularly in automatic speech recognition (ASR) [rabiner1993fundamentals](https://arxiv.org/html/1807.03418v3/#bib.bib19); [anusuya2010speech](https://arxiv.org/html/1807.03418v3/#bib.bib20). While large corpora of annotated speech data are available (e.g.[godfrey1992switchboard](https://arxiv.org/html/1807.03418v3/#bib.bib21); [garofolo1993darpa](https://arxiv.org/html/1807.03418v3/#bib.bib22); [panayotov2015librispeech](https://arxiv.org/html/1807.03418v3/#bib.bib23)), this paper introduces a simple publicly available dataset of spoken digits in English. The purpose of this dataset is to serve as a basic classification benchmark for evaluating novel model architectures and XAI algorithms in the audio domain. Drawing inspiration from the influential MNIST dataset of handwritten digits [lecun1998mnist](https://arxiv.org/html/1807.03418v3/#bib.bib24) that has played a pivotal role in computer vision, we have named our novel dataset _AudioMNIST_ to highlight its conceptual similarity. AudioMNIST allows for several different classification tasks of which we explore spoken digit recognition and recognition of speakers’ sex. In this work, we train two neural networks for each task on two different audio representations. Specifically, we train one model on the time-frequency spectrogram representations of the audio recordings and another one directly on the raw waveform representation. We then use a popular post-hoc XAI method called layer-wise relevance propagation (LRP) [bach2015pixel](https://arxiv.org/html/1807.03418v3/#bib.bib5) to inspect the which features in the input are influential for the final model prediction. From these we can derive insights about the model’s high-level classification strategies and demonstrate that the spectrogram-based sex classification is mainly based on differences in lower frequency ranges and that models trained on raw waveforms focus on a rather small fraction of the input data. Further, we explore explanation formats beyond visualization of relevance heatmaps that indicate the impact of each timepoint in the raw waveform or time-frequency component in the spectrogram representation towards the model prediction. Notably, we introduce audible heatmaps and demonstrate their superior interpretability over visual explanations in the audio domain in a human user-study.
|
| 27 |
+
|
| 28 |
+
The structure of the paper is as follows: In Section[2](https://arxiv.org/html/1807.03418v3/#S2 "2 Explainable AI in the audio domain ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"), we outline the audio representations used for neural network models, examine LRP as an approach for explaining classifier decisions, and introduce audible explanations generated from LRP relevances while contrasting them with visual explanations. Moving to Section[3](https://arxiv.org/html/1807.03418v3/#S3 "3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"), we present the AudioMNIST dataset and delve into the visual explanations derived from LRP. Subsequently, we evaluate the interpretability of these visual explanations compared to audible explanations for practitioners in a human user study.
|
| 29 |
+
|
| 30 |
+
2 Explainable AI in the audio domain
|
| 31 |
+
------------------------------------
|
| 32 |
+
|
| 33 |
+
In this section, we provide an overview of audio representations utilized in the neural network models for audio. We also explore LRP as a method for explaining the output of these models. Finally, we present audible explanations generated from LRP relevances and compare them to visual explanations.
|
| 34 |
+
|
| 35 |
+
### 2.1 Audio representations for NN models
|
| 36 |
+
|
| 37 |
+
In the realm of audio signal processing, the raw waveform and the spectrogram serve as fundamental representation formats for neural network-based models. These formats bear striking similarities to images in computer vision, exhibiting translation invariance and sparse unstructured data in either 1-dimensional or 2-dimensional form. Consequently, conventional convolutional neural networks (CNNs) used in computer vision can be trained on these audio signals [2016arXiv160909430H](https://arxiv.org/html/1807.03418v3/#bib.bib25); [2016arXiv161000087D](https://arxiv.org/html/1807.03418v3/#bib.bib18).
|
| 38 |
+
|
| 39 |
+
#### Waveform
|
| 40 |
+
|
| 41 |
+
Straightforwardly, an audio signal in the time domain is represented by a waveform 𝒙∈ℝ L 𝒙 superscript ℝ 𝐿\boldsymbol{x}\in\mathbb{R}^{L}bold_italic_x ∈ blackboard_R start_POSTSUPERSCRIPT italic_L end_POSTSUPERSCRIPT which contains the amplitude values x t subscript 𝑥 𝑡 x_{t}italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT of the signal over time. The time steps between the signal values are determined by the sampling frequency f S subscript 𝑓 𝑆 f_{S}italic_f start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT, and the duration of the signal is L f S 𝐿 subscript 𝑓 𝑆\frac{L}{f_{S}}divide start_ARG italic_L end_ARG start_ARG italic_f start_POSTSUBSCRIPT italic_S end_POSTSUBSCRIPT end_ARG.
|
| 42 |
+
|
| 43 |
+
#### Spectrogram
|
| 44 |
+
|
| 45 |
+
Alternatively, we can represent the audio signal in the time-frequency domain. Short Time Discrete Fourier Transform (STDFT) transforms the raw waveform 𝒙 𝒙\boldsymbol{x}bold_italic_x to its representation 𝒀 𝒀\boldsymbol{Y}bold_italic_Y in time-frequency domain, and is defined as,
|
| 46 |
+
|
| 47 |
+
Y k,m=∑n=0 N−1 x n+mH⋅w n⋅e−iπkn N.subscript 𝑌 𝑘 𝑚 superscript subscript 𝑛 0 𝑁 1⋅subscript 𝑥 𝑛 𝑚 𝐻 subscript 𝑤 𝑛 superscript 𝑒 𝑖 𝜋 𝑘 𝑛 𝑁 Y_{k,m}=\sum_{n=0}^{N-1}x_{n+mH}\cdot w_{n}\cdot e^{-\frac{i\pi kn}{N}}\,.italic_Y start_POSTSUBSCRIPT italic_k , italic_m end_POSTSUBSCRIPT = ∑ start_POSTSUBSCRIPT italic_n = 0 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_N - 1 end_POSTSUPERSCRIPT italic_x start_POSTSUBSCRIPT italic_n + italic_m italic_H end_POSTSUBSCRIPT ⋅ italic_w start_POSTSUBSCRIPT italic_n end_POSTSUBSCRIPT ⋅ italic_e start_POSTSUPERSCRIPT - divide start_ARG italic_i italic_π italic_k italic_n end_ARG start_ARG italic_N end_ARG end_POSTSUPERSCRIPT .(1)
|
| 48 |
+
|
| 49 |
+
The STDFT calculates a Discrete Fourier Transform for overlapping windowed parts of the signal. The window function w 𝑤 w italic_w has a length of M 𝑀 M italic_M and a hop size of H 𝐻 H italic_H. The resulting spectrogram 𝒀∈ℂ(K+1)×M 𝒀 superscript ℂ 𝐾 1 𝑀\boldsymbol{Y}\in\mathbb{C}^{(K+1)\times M}bold_italic_Y ∈ blackboard_C start_POSTSUPERSCRIPT ( italic_K + 1 ) × italic_M end_POSTSUPERSCRIPT contains complex-valued time-frequency components in K+1 𝐾 1 K+1 italic_K + 1 frequency bins k 𝑘 k italic_k and M 𝑀 M italic_M time bins m 𝑚 m italic_m, where K=N 2 𝐾 𝑁 2 K=\frac{N}{2}italic_K = divide start_ARG italic_N end_ARG start_ARG 2 end_ARG and M=L−N H 𝑀 𝐿 𝑁 𝐻 M=\frac{L-N}{H}italic_M = divide start_ARG italic_L - italic_N end_ARG start_ARG italic_H end_ARG. Usually, the phase information is disregarded, and only the amplitude of the complex spectrogram 𝒀 magn∈ℝ K+1×M subscript 𝒀 magn superscript ℝ 𝐾 1 𝑀\boldsymbol{Y}_{\text{magn}}\in\mathbb{R}^{K+1\times M}bold_italic_Y start_POSTSUBSCRIPT magn end_POSTSUBSCRIPT ∈ blackboard_R start_POSTSUPERSCRIPT italic_K + 1 × italic_M end_POSTSUPERSCRIPT is considered for training classifiers.
|
| 50 |
+
|
| 51 |
+
### 2.2 Post-hoc explainability via
|
| 52 |
+
|
| 53 |
+
Layer-wise Relevance Propagation
|
| 54 |
+
|
| 55 |
+
CNNs for audio processing are inherently black-box models. In order to understand their inner workings and classfication strategies, we can emply post-hoc explanation methods, see [samek2021explaining](https://arxiv.org/html/1807.03418v3/#bib.bib8); [SamXAI19](https://arxiv.org/html/1807.03418v3/#bib.bib26) for a recent overview of current approaches. Here, we focus on a popular method called _Layer-wise Relevance Propagation_ (LRP) [bach2015pixel](https://arxiv.org/html/1807.03418v3/#bib.bib5), which has been successfully applied to time series data in previous studies [StuJNM16](https://arxiv.org/html/1807.03418v3/#bib.bib10); [strodthoff_ecg_xai](https://arxiv.org/html/1807.03418v3/#bib.bib27); [Strodthoff2018DetectingAI](https://arxiv.org/html/1807.03418v3/#bib.bib11); [gait_2022](https://arxiv.org/html/1807.03418v3/#bib.bib28). LRP allows for a decomposition of a learned non-linear predictor output f(𝒙)𝑓 𝒙 f(\boldsymbol{x})italic_f ( bold_italic_x ) into relevance values R i subscript 𝑅 𝑖 R_{i}italic_R start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT that are associated with the components i 𝑖 i italic_i of input 𝒙 𝒙\boldsymbol{x}bold_italic_x. Starting with the output, LRP performs per-neuron decompositions in a top-down manner by iterating over all layers of the network and propagating relevance scores R i subscript 𝑅 𝑖 R_{i}italic_R start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT from neurons of hidden layers step-by-step towards the input. Each R i subscript 𝑅 𝑖 R_{i}italic_R start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT describes the contribution an input or hidden variable x i subscript 𝑥 𝑖 x_{i}italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT has made to the final prediction. The core of the method is the redistribution of the relevance value R j subscript 𝑅 𝑗 R_{j}italic_R start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT of an upper layer neuron towards the layer inputs x i subscript 𝑥 𝑖 x_{i}italic_x start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT, in proportion to the contribution of each input to the activation of the output neuron j 𝑗 j italic_j.
|
| 56 |
+
|
| 57 |
+
R i←j=z ij∑i z ijR j subscript 𝑅←𝑖 𝑗 subscript 𝑧 𝑖 𝑗 subscript 𝑖 subscript 𝑧 𝑖 𝑗 subscript 𝑅 𝑗 R_{i\leftarrow j}=\frac{z_{ij}}{\sum_{i}z_{ij}}R_{j}italic_R start_POSTSUBSCRIPT italic_i ← italic_j end_POSTSUBSCRIPT = divide start_ARG italic_z start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT end_ARG start_ARG ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_z start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT end_ARG italic_R start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT(2)
|
| 58 |
+
|
| 59 |
+
The variable z ij subscript 𝑧 𝑖 𝑗 z_{ij}italic_z start_POSTSUBSCRIPT italic_i italic_j end_POSTSUBSCRIPT describes the forward contribution (or pre-activation) sent from input i 𝑖 i italic_i to output j 𝑗 j italic_j. The relevance score R i subscript 𝑅 𝑖 R_{i}italic_R start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT at neuron i 𝑖 i italic_i is then obtained by pooling all incoming relevance quantities R i←j subscript 𝑅←𝑖 𝑗 R_{i\leftarrow j}italic_R start_POSTSUBSCRIPT italic_i ← italic_j end_POSTSUBSCRIPT from neurons j 𝑗 j italic_j to which i 𝑖 i italic_i contributes:
|
| 60 |
+
|
| 61 |
+
R i=∑j R i←j subscript 𝑅 𝑖 subscript 𝑗 subscript 𝑅←𝑖 𝑗 R_{i}=\sum_{j}R_{i\leftarrow j}italic_R start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT = ∑ start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT italic_R start_POSTSUBSCRIPT italic_i ← italic_j end_POSTSUBSCRIPT(3)
|
| 62 |
+
|
| 63 |
+
The initial relevance value equals the activation of the output neuron, for deeper layers it is specified by the choice of redistribution rule depending on the layer’s type and position in the model [lapuschkin2019unmasking](https://arxiv.org/html/1807.03418v3/#bib.bib29); [kohlbrenner2020towards](https://arxiv.org/html/1807.03418v3/#bib.bib30); [samek2021explaining](https://arxiv.org/html/1807.03418v3/#bib.bib8). Implementations of the algorithm are publicly available [LapJMLR16](https://arxiv.org/html/1807.03418v3/#bib.bib31); [Alber2018iNNvestigateNN](https://arxiv.org/html/1807.03418v3/#bib.bib32); [Anders2021SoftwareFD](https://arxiv.org/html/1807.03418v3/#bib.bib33).
|
| 64 |
+
|
| 65 |
+
### 2.3 Explanation formats
|
| 66 |
+
|
| 67 |
+
We can easily employ LRP to deep audio classification models trained on the raw waveform 𝒙 𝒙\boldsymbol{x}bold_italic_x or the spectrogram representation 𝒀 𝒀\boldsymbol{Y}bold_italic_Y to obtain feature relevance scores R t subscript 𝑅 𝑡 R_{t}italic_R start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT or R k,m subscript 𝑅 𝑘 𝑚 R_{k,m}italic_R start_POSTSUBSCRIPT italic_k , italic_m end_POSTSUBSCRIPT for each timepoint or each time-frequency component of the input sample, respectively. The next consideration is how to adequately communicate these scores to users as means of an explanation. In this regard, we propose two explanation formats: the conventional visual approach and an alternative audible approach.
|
| 68 |
+
|
| 69 |
+
#### Visual explanations
|
| 70 |
+
|
| 71 |
+
In order to provide a visual explanation, we follow the common practice of overlaying the input with a heatmap composed of the relevance values [Jeyakumar2020HowCI](https://arxiv.org/html/1807.03418v3/#bib.bib34). For the spectrogram this format is very similar to explanations for natural images. For the raw waveform, we employ color-coded timepoint markers based on their respective relevance scores. The heatmap is designed as a color map centered at zero, as a relevance score of R=0 𝑅 0 R=0 italic_R = 0 indicates a neutral contribution or no impact on the prediction. Positive relevance scores are depicted using red colors, while negative scores are represented by shades of blue.
|
| 72 |
+
|
| 73 |
+
#### Audible explanations
|
| 74 |
+
|
| 75 |
+
In the domain of audio data, the interpretability of visual explanations may be called into question, as the most natural way for humans to perceive and understand audio is through listening. In the study by Schuller et al. [schuller2021soni](https://arxiv.org/html/1807.03418v3/#bib.bib35), a roadmap towards XAI for audio is presented, highlighting the importance of providing audible explanations.
|
| 76 |
+
|
| 77 |
+
Existing XAI methods that provide audible explanation include AudioLIME [haunschmid2020audiolime](https://arxiv.org/html/1807.03418v3/#bib.bib36); [melchiorre2021lemons](https://arxiv.org/html/1807.03418v3/#bib.bib37); [wullenwber2022coughlime](https://arxiv.org/html/1807.03418v3/#bib.bib38). This approach initially performs audio segmentation and source separation to obtain interpretable components. The relevance of these components is then quantified using LIME [ribeiro2016lime](https://arxiv.org/html/1807.03418v3/#bib.bib39) and for the explanation, the top most relevant source segments are played. AudioLIME thus shifts the problem of audible explanations to audio segmentation and source separation. In consequence, the final explanation heavily relies on the separation of the signal into interpretable parts. In certain applications, obtaining such a segmentation may not be readily available or straightforward. We offer an approach that is independent of audio segmentation and source separation algorithms (and thus applicable even in cases where no solutions exists for the specific kind of audio data at hand). This cancels undesired variability of the explanations induced by the specific choice of the source separation algorithm. Instead, we port the basic idea of overlaying input with heatmap to the audible domain, by simply taking the element-wise product between the raw waveform and the heatmap,
|
| 78 |
+
|
| 79 |
+
ReLU(𝑹)⊙𝒙.direct-product ReLU 𝑹 𝒙\text{ReLU}(\boldsymbol{R})\odot\boldsymbol{x}\,.ReLU ( bold_italic_R ) ⊙ bold_italic_x .(4)
|
| 80 |
+
|
| 81 |
+
In each audible explanation, we can only present either positive or negative relevance. Thus, in Eq.[4](https://arxiv.org/html/1807.03418v3/#S2.E4 "4 ‣ Audible explanations ‣ 2.3 Explanation formats ‣ 2 Explainable AI in the audio domain ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"), we mask only the positive relevance. Alternatively, we could do the same for the negative relevance to elucidate what contradicts the prediction. Currently, our computation of audible explanations is limited to the time domain. This is due to the exclusion of phase information in the spectrograms, making it challenging to directly reconstruct the waveform representation, although it is theoretically possible.
|
| 82 |
+
|
| 83 |
+
These audible explanations straightforwardly generalize to relevance scores from novel concept-based XAI methods [vielhaben2023multidimensional](https://arxiv.org/html/1807.03418v3/#bib.bib40); [achtibat2023attribution](https://arxiv.org/html/1807.03418v3/#bib.bib41), which is explored in [parekh2022nmf](https://arxiv.org/html/1807.03418v3/#bib.bib42).
|
| 84 |
+
|
| 85 |
+
3 Results
|
| 86 |
+
---------
|
| 87 |
+
|
| 88 |
+
In this section, we introduce a dataset that can serve as a testbed for the audio AI community. Subsequently, we train two models on distinct input representations, namely the raw waveform and spectrogram. We then proceed to present visual explanations for these models, allowing us to extract high-level classification strategies from the perspective of model developers. Finally, we explore audible explanations and conduct a comparative analysis to assess their interpretability in a human user study, contrasting them with visual explanations and their potential for XAI for end-users.
|
| 89 |
+
|
| 90 |
+
### 3.1 AudioMNIST dataset
|
| 91 |
+
|
| 92 |
+
In the computer vision community, the simple MNIST dataset [lecun1998mnist](https://arxiv.org/html/1807.03418v3/#bib.bib24) is still often employed as an initial testbed for model development. Here, we propose an analogous dataset for the audio community and call it _AudioMNIST_. The AudioMNIST dataset 1 1 1 Published at: [https://github.com/soerenab/AudioMNIST](https://github.com/soerenab/AudioMNIST) consists of 30,000 audio recordings (amounting to a grand total of approx. 9.5 hours of recorded speech) of spoken digits (0-9) in English with 50 repetitions per digit for each of the 60 different speakers. Recordings were collected in quiet offices with a RØDE NT-USB microphone as mono channel signal at a sampling frequency of 48kHz and were saved in 16 bit integer format. In addition to audio recordings, meta information including age (range: 22 - 61 years), sex (12 female / 48 male), origin and accent of all speakers were collected as well. All speakers were informed about the intent of the data collection and have given written declarations of consent for their participation prior to their recording session. The AudioMNIST dataset can be used to benchmark models for different classification tasks of which classification of the spoken digit and the speaker’s sex are explored in this paper.
|
| 93 |
+
|
| 94 |
+
### 3.2 Deep spoken digit classifiers
|
| 95 |
+
|
| 96 |
+
In this section, we implement both a CNN trained on (two-dimensional) spectrogram representations of the audio recordings as well as a CNN for (one-dimensional) raw waveform representations.
|
| 97 |
+
|
| 98 |
+
#### Classification based on spectrograms
|
| 99 |
+
|
| 100 |
+
First, we train a CNN model on the spectrogram representation of the recordings. Its architecture is based on AlexNet [NIPS2012_4824](https://arxiv.org/html/1807.03418v3/#bib.bib43) without normalization layers.
|
| 101 |
+
|
| 102 |
+
To obtain the spectrograms from the audio recordings, first we downsample them to 8kHz and zero-padded to get an 8000-dimensional vector per recording. During zero-padding we augment the data by placing the signal at random positions within the vector. Then, we apply a short-time Fourier transform in Eq.[1](https://arxiv.org/html/1807.03418v3/#S2.E1 "1 ‣ Spectrogram ‣ 2.1 Audio representations for NN models ‣ 2 Explainable AI in the audio domain ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark") using a Hann window of width 455 and with 420 time points overlap to the signal. This results in spectrogram representations of size 228×230 228 230 228\times 230 228 × 230 (frequency×\times×time). Next, the spectrograms are cropped to a size of 227×227 227 227 227\times 227 227 × 227 by discarding the highest frequency bin and the last three time segments. Finally, we convert the amplitude of the cropped spectrograms to decibels and use them as input to the model.
|
| 103 |
+
|
| 104 |
+
#### Classification based on raw waveform representations
|
| 105 |
+
|
| 106 |
+
For classification based on raw waveforms, we use the downsampled and zero-padded signals described in Section[3.2](https://arxiv.org/html/1807.03418v3/#S3.SS2.SSS0.Px1 "Classification based on spectrograms ‣ 3.2 Deep spoken digit classifiers ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark") as input to the neural network directly. Here, we design a custom CNN which we refer to as _AudioNet_. For details of the training protocol of both models and the architecture of AudioNet, we refer to [A](https://arxiv.org/html/1807.03418v3/#A1 "Appendix A Model details ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark").
|
| 107 |
+
|
| 108 |
+
Table 1: Mean accuracy ±plus-or-minus\pm± standard deviation over data splits for AlexNet and AudioNet on the digit and sex classification tasks of AudioMNIST.
|
| 109 |
+
|
| 110 |
+
Model performances are summarized in Table[1](https://arxiv.org/html/1807.03418v3/#S3.T1 "Table 1 ‣ Classification based on raw waveform representations ‣ 3.2 Deep spoken digit classifiers ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark") in terms of means and standard deviations across test folds. Comparisons of model performances may be difficult due to the differences in training parameters and are also not the primary goal of this paper, yet, we note that AlexNet performs consistently superior to AudioNet for both tasks. However, both networks show test set performances well above chance level, i.e., for both tasks the networks discovered discriminant features within the data. The considerably high standard deviation for sex classification of AudioNet originates from a rather consistent misclassification of recordings of a single speaker in one of the test folds.
|
| 111 |
+
|
| 112 |
+
### 3.3 Visual explanations reveal classifier strategies
|
| 113 |
+
|
| 114 |
+
In this section, we visualize LRP relevances for AlexNet and AudioNet. We then derive high-level model classification strategies from the explanations, that we evaluate in sample manipulation experiments.
|
| 115 |
+
|
| 116 |
+
#### Relevance maps for AlexNet
|
| 117 |
+
|
| 118 |
+
We compute LRP relevance scores for the AlexNet digit and sex classifier and show exemplary visual explanations based on these scores in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark").
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
(a) female speaker
|
| 123 |
+
|
| 124 |
+
digit zero
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
(b) female speaker
|
| 129 |
+
|
| 130 |
+
digit one
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
(c) female speaker
|
| 135 |
+
|
| 136 |
+
digit zero
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
(d) male speaker
|
| 141 |
+
|
| 142 |
+
digit zero
|
| 143 |
+
|
| 144 |
+
Figure 1: Visual explanations — spectrograms as input to AlexNet with LRP relevance heatmaps overlayed. Left, LABEL:sub@fig:spectro_0_female_digit and LABEL:sub@fig:spectro_1_female_digit: Digit classification. Right, LABEL:sub@fig:spectro_0_female_gender and LABEL:sub@fig:spectro_0_male_gender: Sex classification. Data in LABEL:sub@fig:spectro_0_female_digit and LABEL:sub@fig:spectro_0_female_gender is identical. Text in italics below the panels indicate the prediction task and explained outcome. In all cases, predictions are correct and the true class is explained by LRP.
|
| 145 |
+
|
| 146 |
+
The spectrogram in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_gender and Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_male_gender correspond to a spoken zero by a female and a male speaker, respectively. AlexNet correctly classifies both speakers’ biological sex. Most of the relevance distributed in the lower frequency range for both classes. Based on the relevant frequency bands it may be hypothesized that sex classification is based on the fundamental frequency and its immediate harmonics which are in fact known discriminant features for sex in speech [traunmuller1995frequency](https://arxiv.org/html/1807.03418v3/#bib.bib44).
|
| 147 |
+
|
| 148 |
+
Spectrograms in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_digit and Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_1_female_digit correspond to spoken digits zero and one from the same female speaker. AlexNet correctly classifies both spoken digits and the LRP scores reveal that different areas of the input data appear to be relevant for its decision. However, it is not possible to derive any deeper insights about the classification strategy of the model based on these visual explanations.
|
| 149 |
+
|
| 150 |
+
The spectrogram in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_gender is identical to that in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_digit, but the former is overlayed with relevance heat-maps from the sex classifier while the latter shows the heatmap from the digit classifier. As a sanity check, we confirm that although the input spectrograms in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_digit and Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_gender are identical, the corresponding relevance distributions differ, highlighting the task-dependent feature selection between the digit in and the sex classifier.
|
| 151 |
+
|
| 152 |
+
#### Relevance maps for AudioNet
|
| 153 |
+
|
| 154 |
+
Next, we compute LRP relevance scores for the AudioNet digit and sex classifier that operates on the raw waveforms. In Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"), we show a visual explanation for an exemplary spoken zero from a male speaker for the sex classifier’s correct prediction _male_. Here, we first show the signal and the relevance scores separately in Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:wave_signal and Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:wave_hm. For the time interval from 0.5−0.55 0.5 0.55 0.5-0.55 0.5 - 0.55 seconds a zoomed-in segment is provided in Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:wave_hm_colored for an actual visual explanation, where timepoints color-coded according to the relevance score. Intuitively plausible, zero relevance falls onto the zero-embedding at the left and right side of the recorded data. Furthermore, from Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:wave_hm_colored it appears that mainly timepoints of large magnitude are relevant for the network’s classification decision.
|
| 155 |
+
|
| 156 |
+

|
| 157 |
+
|
| 158 |
+
(a)
|
| 159 |
+
|
| 160 |
+

|
| 161 |
+
|
| 162 |
+
(b)
|
| 163 |
+
|
| 164 |
+

|
| 165 |
+
|
| 166 |
+
(c)
|
| 167 |
+
|
| 168 |
+
Figure 2: AudioNet correctly classifies the speaker’s sex for the waveform in LABEL:sub@fig:wave_signal with associated relevance scores in LABEL:sub@fig:wave_hm. Positive relevance in favor of class male is colored in red and negative relevance, i.e., relevance in favor of class female, is colored in blue. A selected range of the waveform from LABEL:sub@fig:wave_signal is again visualized in LABEL:sub@fig:wave_hm_colored with single samples color-coded according to their relevance. It appears that mainly samples of large magnitude are relevant for the network’s inference.
|
| 169 |
+
|
| 170 |
+
#### Relevance-guided sample manipulation for AlexNet
|
| 171 |
+
|
| 172 |
+
The relevance maps for the AlexNet sex classifier (Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_female_gender and Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:spectro_0_male_gender) suggest that the sex classifier focuses on differences in the fundamental frequency and subsequent harmonics for feature selection. To investigate this hypothesis the test set was manipulated by up- and down-scaling the frequency-axis of the spectrograms of male and female speakers by a factor of 1.5 1.5 1.5 1.5 and 0.66 0.66 0.66 0.66, respectively. Fundamental frequency and spacing between harmonics in the manipulated spectrograms approximately match the original spectrograms of the respectively opposite sex.
|
| 173 |
+
|
| 174 |
+
After the data has been manipulated as described, the trained network reaches an accuracy of only 20.3%±12.6%plus-or-minus percent 20.3 percent 12.6 20.3\%\pm 12.6\%20.3 % ± 12.6 % across test splits on the manipulated data, which is well-below chance level for this task. In other words, identifying sex features via LRP allowed us to successfully perform transformations on the inputs that target the identified features specifically such that the classifier is approximately 80%percent 80 80\%80 % accurate in predicting the _opposite_ sex.
|
| 175 |
+
|
| 176 |
+
#### Relevance-guided sample manipulation for AudioNet
|
| 177 |
+
|
| 178 |
+
For AudioNet we assess the reliance of the models on features marked as relevant by LRP by an analysis similar to the pixel-flipping (or input perturbation) approach introduced in [bach2015pixel](https://arxiv.org/html/1807.03418v3/#bib.bib5); [samek2017evaluating](https://arxiv.org/html/1807.03418v3/#bib.bib45). Specifically, we employ three different strategies to systematically manipulate a fraction of the input signal by setting selected samples to zero. Firstly, as a baseline, (non-zero) samples of the input signal are selected and flipped at random. Secondly, samples of the input are selected with respect to maximal absolute amplitude, e.g the 10% samples with the highest absolute amplitude are selected, reflecting our (naive) observation from Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:wave_hm_colored. Thirdly, samples are selected according to maximal relevance as attributed by LRP. If the model truly relies on features marked as relevant by LRP, performance should deteriorate for smaller fractions of manipulations in case of LRP-based selection than in case of the other selection strategies.
|
| 179 |
+
|
| 180 |
+

|
| 181 |
+
|
| 182 |
+
(a)
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
(a) Digit Classification
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
(b) Sex Classification
|
| 191 |
+
|
| 192 |
+
Figure 3: Assessment of classifer reliance on relevant timepoints by flipping timepoints to zero in order of their relevance scores. LABEL:sub@fig:perturbation_digit_setzero_digit: Digit classification. LABEL:sub@fig:perturbation_digit_setzero_gender: Sex classification. Signal samples are either selected randomly (blue), based on their absolute amplitude (orange) or their relevance according to LRP (green). The dashed black line shows the chance level for the respective task.
|
| 193 |
+
|
| 194 |
+
Model performances for digit and sex classification on manipulated test sets in relation to the fraction of manipulated samples are displayed in Fig.[3](https://arxiv.org/html/1807.03418v3/#S3.F3 "Figure 3 ‣ Relevance-guided sample manipulation for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"). For both tasks, model performances deteriorate for substantially smaller manipulations for LRP-based sample selection as compared to random selection and for slightly smaller manipulations as compared to amplitude-based selections. The effect becomes most apparent for digit classification where a manipulation of 1% of the signal leads to a deterioration of model accuracy from originally 92.53%percent 92.53 92.53\%92.53 % to 92% (random), 85% (amplitude-based) and 77% (LRP-based). In case of sex classification, the network furthermore shows a remarkable robustness towards random manipulations with classification accuracy only starting to decrease when 60% of the signal has been set to zero, as shown in Fig.[3](https://arxiv.org/html/1807.03418v3/#S3.F3 "Figure 3 ‣ Relevance-guided sample manipulation for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")LABEL:sub@fig:perturbation_digit_setzero_gender. The decline in model performance in both the relevance-based and amplitude-based perturbation procedures supports our hypothesis that the model seems to ground its inference in the high-amplitude parts of the signal. The fact the relevance-based perturbation has a marginally stronger impact on the model however tells us that while our initial hypothesis strikes close to the truth, our interpretation of the model’s reasoning based on visual explanations is not exhaustive.
|
| 195 |
+
|
| 196 |
+
### 3.4 Audible explanations surpass visual for
|
| 197 |
+
|
| 198 |
+
interpretability
|
| 199 |
+
|
| 200 |
+
In the above experiments we investigate the overall model behaviour from a technical point of view, which is a XAI use-case scenario targeted mostly at model developers. However, a purely visual explanation as in Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark") may be insufficient to communicate the model reasoning underlying a single model prediction to the non-expert end user. Specifically, we investigate the question, which explanation format is the most interpretable to humans: audible or visual explanations. Previous work on XAI for audio shows a combination of both [melchiorre2021lemons](https://arxiv.org/html/1807.03418v3/#bib.bib37); [haunschmid2020audiolime](https://arxiv.org/html/1807.03418v3/#bib.bib36). Here, we show either an audible or visual explanation and compare their interpretability in a human user study, where we measure the human-XAI performance.
|
| 201 |
+
|
| 202 |
+
#### Study design
|
| 203 |
+
|
| 204 |
+
To compare the interpretability of audible and visual explanations, we ask the user to predict the model prediction based on the explanation, following the method to evaluate the human-XAI performance as suggested in [Hoffman2018MetricsFE](https://arxiv.org/html/1807.03418v3/#bib.bib46). The outcome is particularly interesting for samples where the model prediction does not match the ground truth label, especially given the high prediction accuracy of the classifier. Our study design is similar yet distinct to the human user study design in [parekh2022nmf](https://arxiv.org/html/1807.03418v3/#bib.bib42), which compares different audible explanations by asking the user for a subjective judgments how well explanation and model prediction relate. To the best of our knowledge, we are the first to conduct a user study that compares the interpretability of audible and visual explanation formats.
|
| 205 |
+
|
| 206 |
+

|
| 207 |
+
|
| 208 |
+
Figure 4: Design of the user study: The user was presented with either a visual or audible explanation. As a baseline we present faux explanations that entail only the signal itself. The user was asked to predict the model prediction based on the explanation.
|
| 209 |
+
|
| 210 |
+
We compute LRP relevance scores for the AudioNet digit classifier trained on the raw waveforms.2 2 2 The user study is based in a reconstruction if the original model in Section[3.2](https://arxiv.org/html/1807.03418v3/#S3.SS2 "3.2 Deep spoken digit classifiers ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"), which originate from an earlier preprint of this work [becker2018earlyaudiomnist](https://arxiv.org/html/1807.03418v3/#bib.bib47). The model weights and the performance of the reconstruction used in this section slightly deviate from those of the original model. We choose the digit task, because of its higher complexity compared to sex classification. Further, we focus on explanations for the waveform model because in this representation, relevance can directly be made audible. In summary, we conduct a comparison between visual explanations which consists of heatmaps overlaying the waveform (as shown in Fig.[1](https://arxiv.org/html/1807.03418v3/#S3.F1 "Figure 1 ‣ Relevance maps for AlexNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark") and Fig.[2](https://arxiv.org/html/1807.03418v3/#S3.F2 "Figure 2 ‣ Relevance maps for AudioNet ‣ 3.3 Visual explanations reveal classifier strategies ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark")), and audible explanations based on Eq.[4](https://arxiv.org/html/1807.03418v3/#S2.E4 "4 ‣ Audible explanations ‣ 2.3 Explanation formats ‣ 2 Explainable AI in the audio domain ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"). As a baseline, we additionally present the user with faux ’explanations’ that entail solely the signal itself. Overall, we present both the modulated or overlayed signal with relevance scores as well as solely the signal, for both the audible and visual explanation formats. The study design is visualized in Fig.[4](https://arxiv.org/html/1807.03418v3/#S3.F4 "Figure 4 ‣ Study design ‣ 3.4 Audible explanations surpass visual for interpretability ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"). We choose 10 random samples where the model prediction is correct and 10 random samples where the model is predicting incorrectly.
|
| 211 |
+
|
| 212 |
+
#### Data acquisition
|
| 213 |
+
|
| 214 |
+
We asked 40 subjects from the authors’ research department to predict the model’s predictions for the 20 randomly chosen samples and all 4 explanation modes described above, thus each subject answers 80 questions. We also collect meta-information about gender (7.5% diverse, 15% female, 77.5%male), previous experience with XAI (50% high - researcher in the field, 42.5% medium - had exposure to XAI, 7.5% low - roughly knows what XAI is, 0% zero - never heard of XAI before) and subjectively assessed hearing capabilities (32.5% very good, 42.5% good, 25% medium, 0% low, 0% very low). Test subjects gave their informed written consent to participate in the study and to the data acquisition and processing. A fast-track self-assessment of the study had resulted in a positive evaluation from the ethics commission of the Fraunhofer Heinrich Hertz Institute.
|
| 215 |
+
|
| 216 |
+
#### Evaluation
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
(a) Incorrect model classification
|
| 221 |
+
|
| 222 |
+

|
| 223 |
+
|
| 224 |
+
(b) Correct model classification
|
| 225 |
+
|
| 226 |
+
Figure 5: LABEL:sub@fig:userstudyresults_incorrect: User performance on incorrectly predicted samples based on the different explanation formats. LABEL:sub@fig:userstudyresults_correct: User performance on correctly predicted samples.
|
| 227 |
+
|
| 228 |
+
In in Fig.[5](https://arxiv.org/html/1807.03418v3/#S3.F5 "Figure 5 ‣ Evaluation ‣ 3.4 Audible explanations surpass visual for interpretability ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"), we show the user’s performance in predicting the model’s predictions based on the explanations, where we report informedness and markedness for the multi-class case [powers2011evaluation](https://arxiv.org/html/1807.03418v3/#bib.bib48). Informedness for each class is defined as TP/P−FP/N 𝑇 𝑃 𝑃 𝐹 𝑃 𝑁 TP/P-FP/N italic_T italic_P / italic_P - italic_F italic_P / italic_N and measures how _informed_ the user is about the positive and negative model predictions for this class based on the explanation. Markedness for each class in TP/(TP+FP)−FN/(TN+FN)𝑇 𝑃 𝑇 𝑃 𝐹 𝑃 𝐹 𝑁 𝑇 𝑁 𝐹 𝑁 TP/(TP+FP)-FN/(TN+FN)italic_T italic_P / ( italic_T italic_P + italic_F italic_P ) - italic_F italic_N / ( italic_T italic_N + italic_F italic_N ) and measures the _trustworthiness_ of the user’s prediction of positive and negative model preditions for this class. Here, _TP, FP, TN, FN_ denote true and false positive and negative predictions, respectively. Values for both metrics range from -1 to +1, where positive values imply that the user is informed correctly by the explanation and their prediction can be trusted and negative values imply that the user is informed incorrectly and that it can be trusted that their prediction is wrong.
|
| 229 |
+
|
| 230 |
+
First, we evaluate the case where the model prediction does not match the true digit, see Fig.[5a](https://arxiv.org/html/1807.03418v3/#S3.F5.sf1 "5a ‣ Figure 5 ‣ Evaluation ‣ 3.4 Audible explanations surpass visual for interpretability ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"). We find that audible explanations show a markedly greater informedness and markedness than their visual counterpart. However, the values of 0.12 and 0.1 indicate that there is still room for improvement in terms of the interpretability of audible explanations. This can be achieved by employing innovative concept-based methods that have demonstrated improved interpretability in computer vision applications [achtibat2023attribution](https://arxiv.org/html/1807.03418v3/#bib.bib41). As expected, the baseline containing only the signal show negative informendess and markedness, as the user is informed incorrectly about the model prediction and it can be trusted that their prediction is wrong.
|
| 231 |
+
|
| 232 |
+
Second, for the samples where the model classified the digits correctly, as expected the user’s prediction performance is higher for all explanation formats than for the incorreclty classified samples, see Fig.[5b](https://arxiv.org/html/1807.03418v3/#S3.F5.sf2 "5b ‣ Figure 5 ‣ Evaluation ‣ 3.4 Audible explanations surpass visual for interpretability ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark"). Further, both informedness and markedness are higher for the audible signal than for the actual audible explanation. This is natural as it is possible that the model’s classification strategy deviates from the user’s classifiaction strategy. To illustrate this, across all digits classes, both informedness and markedness have the lowest value for the samples correctly classified as a ’nine’ by the model with a value of 0.33. Here, 33% users predicted that the model classified the digit as a ’nine’ and 32% predicted that the model classified it as a ’five’. In the explanation, only the common syllable, the ’i’ is audible. Like for the samples incorrectly classified by the model, both informedness and markedness are much lower for the visual explanations than for the audible ones. Interestingly, the comparison between explanation and signal only follows the same trend as for their audible counterparts.
|
| 233 |
+
|
| 234 |
+
We conclude that audible explanations for audio classifiers exhibit a higher level of interpretability compared to visual explanations for human users. This highlights the importance of the presentation of the explanation, beyond the mere computation of raw relevance values. Furthermore, it emphasizes that the optimal format of explanations may vary across different applications. In the context of audio applications, the superior interpretability of audible explanations is expected, considering that listening is the innate way for humans to perceive audio signals. As proposed above, to further improve the interpretability of audible explanations, concept-based approaches [vielhaben2023multidimensional](https://arxiv.org/html/1807.03418v3/#bib.bib40); [achtibat2023attribution](https://arxiv.org/html/1807.03418v3/#bib.bib41), that put the model prediction for a single sample into context with the model reasoning over the entire dataset, could be leveraged and made audible, similar to the work in [parekh2022nmf](https://arxiv.org/html/1807.03418v3/#bib.bib42).
|
| 235 |
+
|
| 236 |
+
4 Conclusion
|
| 237 |
+
------------
|
| 238 |
+
|
| 239 |
+
The need for interpretable model decisions is increasingly evident in various machine learning applications. While existing research has primarily focused on explaining image classifiers, there is a dearth of studies in interpreting audio classification models. To foster open research in this direction we provide a novel Open Source dataset of spoken digits in English as raw waveform recordings. Further, we demonstrated that LRP is a suitable XAI method for explaining neural networks for audio classification. By employing visual explanations based on LRP relevances, we have successfully derived high-level classification strategies from the perspective of model developers. Most notably, we have introduced audible explanations that align with the established framework for explanation presentation in computer vision. Through a user study, we have conclusively shown that audible explanations exhibit superior interpretability compared to visual explanations for the classification of individual audio signals by the model.
|
| 240 |
+
|
| 241 |
+
In future work we aim to apply LRP to more complex audio datasets to gain a deeper insight into classification decisions of deep neural networks in this domain. Further, we aim to improve the interpreatbility of audible explanations, by using concept-based XAI methods as studied in [vielhaben2023multidimensional](https://arxiv.org/html/1807.03418v3/#bib.bib40); [achtibat2023attribution](https://arxiv.org/html/1807.03418v3/#bib.bib41).
|
| 242 |
+
|
| 243 |
+
Acknowledgement
|
| 244 |
+
---------------
|
| 245 |
+
|
| 246 |
+
WS and KRM were supported by the German Ministry for Education and Research (BMBF) under grants 01IS14013A-E, 01GQ1115, 01GQ0850, 01IS18056A,
|
| 247 |
+
|
| 248 |
+
01IS18025A and 01IS18037A. WS, SL and JV received funding from the European Union’s Horizon 2020 research and innovation programme under grant iToBoS (grant no.965221), from the European Union’s Horizon Europe research and innovation programme (EU Horizon Europe) as grant TEMA (grant no.101093003), and the state of Berlin within the innovation support program ProFIT (IBB) as grant BerDiBa (grant no.10174498). WS was further supported by the German Research Foundation (ref.DFG KI-FOR 5363). KRM was also supported by the Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (grant no.2017-0-001779), as well as by the Research Training Group “Differential Equation- and Data-driven Models in Life Sciences and Fluid Dynamics (DAEDALUS)” (GRK 2433) and Grant Math+, EXC 2046/1, Project ID 390685689 both funded by the German Research Foundation (DFG).
|
| 249 |
+
|
| 250 |
+
References
|
| 251 |
+
----------
|
| 252 |
+
|
| 253 |
+
* (1) R.Caruana, Y.Lou, J.Gehrke, P.Koch, M.Sturm, N.Elhadad, Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission, in: 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2015, pp. 1721–1730.
|
| 254 |
+
* (2) G.Hinton, S.Osindero, M.Welling, Y.-W. Teh, Unsupervised discovery of nonlinear structure using contrastive backpropagation, Cognitive Science 30(4) (2006) 725–731.
|
| 255 |
+
* (3) D.Erhan, Y.Bengio, A.Courville, P.Vincent, Visualizing higher-layer features of a deep network, University of Montreal 1341(3) (2009) 1.
|
| 256 |
+
* (4) D.Baehrens, T.Schroeter, S.Harmeling, M.Kawanabe, K.Hansen, K.-R. Müller, How to explain individual classification decisions, Journal of Machine Learning Research 11(Jun) (2010) 1803–1831.
|
| 257 |
+
* (5) S.Bach, A.Binder, G.Montavon, F.Klauschen, K.-R. Müller, W.Samek, On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation, PLOS ONE 10(7) (2015) e0130140.
|
| 258 |
+
* (6) R.C. Fong, A.Vedaldi, Interpretable explanations of black boxes by meaningful perturbation, in: 2017 IEEE International Conference on Computer Vision (ICCV), IEEE, 2017, pp. 3449–3457.
|
| 259 |
+
* (7) G.Montavon, S.Bach, A.Binder, W.Samek, K.-R. Müller, Explaining nonlinear classification decisions with deep taylor decomposition, Pattern Recognition 65 (2017) 211–222.
|
| 260 |
+
* (8) W.Samek, G.Montavon, S.Lapuschkin, C.J. Anders, K.-R. Müller, Explaining deep neural networks and beyond: A review of methods and applications, Proceedings of the IEEE 109(3) (2021) 247–278.
|
| 261 |
+
* (9) L.Arras, G.Montavon, K.-R. Müller, W.Samek, Explaining recurrent neural network predictions in sentiment analysis, in: EMNLP’17 Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA), 2017, pp. 159–168.
|
| 262 |
+
* (10) I.Sturm, S.Lapuschkin, W.Samek, K.-R. Müller, Interpretable deep neural networks for single-trial eeg classification, Journal of Neuroscience Methods 274 (2016) 141–145.
|
| 263 |
+
* (11) N.Strodthoff, C.Strodthoff, Detecting and interpreting myocardial infarction using fully convolutional neural networks, Physiological Measurement 40.
|
| 264 |
+
* (12) A.W. Thomas, C.Ré, R.A. Poldrack, Interpreting mental state decoding with deep learning models, Trends in Cognitive Sciences 26(11) (2022) 972–986.
|
| 265 |
+
* (13) F.Klauschen, J.Dippel, P.Keyl, P.Jurmeister, M.Bockmayr, A.Mock, O.Buchstab, M.Alber, L.Ruff, G.Montavon, K.-R. Müller, Toward explainable artificial intelligence for precision pathology, Annual Review of Pathology: Mechanisms of Disease 19(1) (2024) null.
|
| 266 |
+
* (14) K.T. Schütt, F.Arbabzadah, S.Chmiela, K.-R. Müller, A.Tkatchenko, Quantum-chemical insights from deep tensor neural networks, Nature communications 8 (2017) 13890.
|
| 267 |
+
* (15) S.Blücher, L.Kades, J.M. Pawlowski, N.Strodthoff, J.M. Urban, Towards novel insights in lattice field theory with explainable machine learning, Phys. Rev. D 101 (2020) 094507.
|
| 268 |
+
* (16) H.Lee, P.Pham, Y.Largman, A.Y. Ng, Unsupervised feature learning for audio classification using convolutional deep belief networks, in: Advances in Neural Information Processing Systems (NIPS), 2009, pp. 1096–1104.
|
| 269 |
+
* (17) G.Hinton, L.Deng, D.Yu, G.E. Dahl, A.-r. Mohamed, N.Jaitly, A.Senior, V.Vanhoucke, P.Nguyen, T.N. Sainath, et al., Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, IEEE Signal Processing Magazine 29(6) (2012) 82–97.
|
| 270 |
+
* (18) W.Dai, C.Dai, S.Qu, J.Li, S.Das, Very deep convolutional neural networks for raw waveforms, in: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, March 5-9, 2017, 2017, pp. 421–425.
|
| 271 |
+
* (19) L.R. Rabiner, B.-H. Juang, Fundamentals of speech recognition, Vol.14, PTR Prentice Hall Englewood Cliffs, 1993.
|
| 272 |
+
* (20) M.Anusuya, S.K. Katti, Speech recognition by machine; a review, International Journal of Computer Science and Information Security 6(3) (2009) 181–205.
|
| 273 |
+
* (21) J.J. Godfrey, E.C. Holliman, J.McDaniel, Switchboard: Telephone speech corpus for research and development, in: Acoustics, Speech, and Signal Processing, 1992. ICASSP-92., 1992 IEEE International Conference on, Vol.1, IEEE, 1992, pp. 517–520.
|
| 274 |
+
* (22) J.S. Garofolo, L.F. Lamel, W.M. Fisher, J.G. Fiscus, D.S. Pallett, Darpa timit acoustic-phonetic continous speech corpus cd-rom. nist speech disc 1-1.1, NASA STI/Recon technical report n 93.
|
| 275 |
+
* (23) V.Panayotov, G.Chen, D.Povey, S.Khudanpur, Librispeech: an asr corpus based on public domain audio books, in: Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on, IEEE, 2015, pp. 5206–5210.
|
| 276 |
+
* (24) Y.LeCun, The mnist database of handwritten digits, http://yann.lecun.com/exdb/mnist/.
|
| 277 |
+
* (25) S.Hershey, S.Chaudhuri, D.P.W. Ellis, J.F. Gemmeke, A.Jansen, R.C. Moore, M.Plakal, D.Platt, R.A. Saurous, B.Seybold, M.Slaney, R.J. Weiss, K.W. Wilson, CNN architectures for large-scale audio classification, in: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2017, New Orleans, LA, USA, March 5-9, 2017, 2017, pp. 131–135.
|
| 278 |
+
* (26) W.Samek, G.Montavon, A.Vedaldi, L.K. Hansen, K.-R. Müller (Eds.), Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, Vol. 11700 of Lecture Notes in Computer Science, Springer, Cham, Switzerland, 2019.
|
| 279 |
+
* (27) N.Strodthoff, P.Wagner, T.Schaeffter, W.Samek, Deep learning for ecg analysis: Benchmarks and insights from ptb-xl, IEEE Journal of Biomedical and Health Informatics 25(5) (2021) 1519–1528.
|
| 280 |
+
* (28) D.Slijepcevic, F.Horst, B.Horsak, S.Lapuschkin, A.-M. Raberger, A.Kranzl, W.Samek, C.Breiteneder, W.I. Schöllhorn, M.Zeppelzauer, Explaining machine learning models for clinical gait analysis, ACM Transactions on Computing for Healthcare 3(2) (2022) 1–27.
|
| 281 |
+
* (29) S.Lapuschkin, S.Wäldchen, A.Binder, G.Montavon, W.Samek, K.-R. Müller, Unmasking clever hans predictors and assessing what machines really learn, Nature communications 10(1) (2019) 1096.
|
| 282 |
+
* (30) M.Kohlbrenner, A.Bauer, S.Nakajima, A.Binder, W.Samek, S.Lapuschkin, Towards best practice in explaining neural network decisions with lrp, in: 2020 International Joint Conference on Neural Networks (IJCNN), IEEE, 2020, pp. 1–7.
|
| 283 |
+
* (31) S.Lapuschkin, A.Binder, G.Montavon, K.-R. Müller, W.Samek, The layer-wise relevance propagation toolbox for artificial neural networks, Journal of Machine Learning Research 17(114) (2016) 1–5.
|
| 284 |
+
* (32) M.Alber, S.Lapuschkin, P.Seegerer, M.Hägele, K.T. Schütt, G.Montavon, W.Samek, K.-R. Müller, S.Dähne, P.-J. Kindermans, innvestigate neural networks!, J. Mach. Learn. Res. 20 (2018) 93:1–93:8.
|
| 285 |
+
* (33) C.J. Anders, D.Neumann, W.Samek, K.-R. Müller, S.Lapuschkin, Software for dataset-wide xai: From local explanations to global insights with zennit, corelay, and virelay, ArXiv abs/2106.13200.
|
| 286 |
+
* (34) J.Jeyakumar, J.Noor, Y.-H. Cheng, L.Garcia, M.B. Srivastava, How can i explain this to you? an empirical study of deep neural network explanation methods, in: Neural Information Processing Systems, 2020.
|
| 287 |
+
* (35) B.W. Schuller, T.Virtanen, M.Riveiro, G.Rizos, J.Han, A.Mesaros, K.Drossos, Towards sonification in multimodal and user-friendlyexplainable artificial intelligence, in: Proceedings of the 2021 International Conference on Multimodal Interaction, ICMI ’21, Association for Computing Machinery, New York, NY, USA, 2021, p. 788–792.
|
| 288 |
+
* (36) V.Haunschmid, E.Manilow, G.Widmer, audiolime: Listenable explanations using source separation (2020).
|
| 289 |
+
* (37) A.B. Melchiorre, V.Haunschmid, M.Schedl, G.Widmer, Lemons: Listenable explanations for music recommender systems, in: D.Hiemstra, M.-F. Moens, J.Mothe, R.Perego, M.Potthast, F.Sebastiani (Eds.), Advances in Information Retrieval, Springer International Publishing, Cham, 2021, pp. 531–536.
|
| 290 |
+
* (38) A.Wullenweber, A.Akman, B.W. Schuller, Coughlime: Sonified explanations for the predictions of covid-19 cough classifiers, in: 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), 2022, pp. 1342–1345.
|
| 291 |
+
* (39) M.T. Ribeiro, S.Singh, C.Guestrin, ”why should i trust you?”: Explaining the predictions of any classifier, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, Association for Computing Machinery, New York, NY, USA, 2016, p. 1135–1144.
|
| 292 |
+
* (40) J.Vielhaben, S.Bluecher, N.Strodthoff, Multi-dimensional concept discovery (MCD): A unifying framework with completeness guarantees, Transactions on Machine Learning Research.
|
| 293 |
+
* (41) R.Achtibat, M.Dreyer, I.Eisenbraun, S.Bosse, T.Wiegand, W.Samek, S.Lapuschkin, From attribution maps to human-understandable explanations through concept relevance propagation, Nature Machine Intelligence 5(9) (2023) 1006–1019.
|
| 294 |
+
* (42) J.Parekh, S.Parekh, P.Mozharovskyi, F.d'Alché-Buc, G.Richard, Listen to interpret: Post-hoc interpretability for audio networks with nmf, in: S.Koyejo, S.Mohamed, A.Agarwal, D.Belgrave, K.Cho, A.Oh (Eds.), Advances in Neural Information Processing Systems, Vol.35, Curran Associates, Inc., 2022, pp. 35270–35283.
|
| 295 |
+
* (43) A.Krizhevsky, I.Sutskever, G.E. Hinton, Imagenet classification with deep convolutional neural networks, in: Advances in Neural Information Processing Systems (NIPS), 2012, pp. 1097–1105.
|
| 296 |
+
* (44) H.Traunmüller, A.Eriksson, The frequency range of the voice fundamental in the speech of male and female adults, Unpublished manuscript.
|
| 297 |
+
* (45) W.Samek, A.Binder, G.Montavon, S.Lapuschkin, K.-R. Müller, Evaluating the visualization of what a deep neural network has learned, IEEE Transactions on Neural Networks and Learning Systems 28(11) (2017) 2660–2673.
|
| 298 |
+
* (46) R.R. Hoffman, S.T. Mueller, G.Klein, J.Litman, Metrics for explainable ai: Challenges and prospects, arXiv preprint arXiv:1812.04608.
|
| 299 |
+
* (47) S.Becker, M.Ackermann, S.Lapuschkin, K.Müller, W.Samek, Interpreting and explaining deep neural networks for classification of audio signals, arXiv preprint arXiv:1807.03418v2.
|
| 300 |
+
* (48) D.Powers, Evaluation: From precision, recall and f-measure to roc, informedness, markedness & correlation, Journal of Machine Learning Technologies 2(1) (2011) 37–63.
|
| 301 |
+
|
| 302 |
+
Appendix A Model details
|
| 303 |
+
------------------------
|
| 304 |
+
|
| 305 |
+
We provide some further details on the architecture and training protocols for the audio classification models in Section[3.2](https://arxiv.org/html/1807.03418v3/#S3.SS2 "3.2 Deep spoken digit classifiers ‣ 3 Results ‣ AudioMNIST: Exploring Explainable Artificial Intelligence for Audio Analysis on a Simple Benchmark").
|
| 306 |
+
|
| 307 |
+
#### AudioNet architecture
|
| 308 |
+
|
| 309 |
+
AudioNet consists of 9 weight layers that are organized in series as follows 3 3 3 Layer naming pattern examples: conv3-100 – conv layer with 3x1 sized kernels and 100 output channels. FC-1024 – fully connected layer with 1024 output neurons: conv3-100, maxpool2, conv3-64, maxpool2, conv3-128, maxpool2, conv3-128, maxpool2, conv3-128, maxpool2, conv3-128, maxpool2, FC-1024, FC-512, FC-10 (digit classification) or FC-2 (sex classification). All convolutional layers employ a stride of 1 and are activated via ReLU nonlinearities. Max-pooling layers employ stride 2.
|
| 310 |
+
|
| 311 |
+
#### Dataset splits
|
| 312 |
+
|
| 313 |
+
For digit classification, the dataset was divided by speaker into five disjoint splits each containing data of 12 speakers, i.e., 6,000 spectrograms per split. In a five-fold cross-validation, three of the splits were merged to a training set while the other two splits respectively served as validation and test set. In a final, fold-dependent preprocessing step the element-wise mean of the training set was subtracted from all spectrograms.
|
| 314 |
+
|
| 315 |
+
For sex classification, the dataset was reduced to the 12 female speakers and 12 randomly selected male speakers. These 24 speakers were divided by speaker into four disjoint splits each containing data from three female and three male speakers, i.e., 3,000 spectrograms per split. In a four-fold cross-validation, two of the splits were merged to a training set while the other two splits served as validation and test set. All other preprocessing steps and network training parameters were identical to the task of digit classification.
|
| 316 |
+
|
| 317 |
+
#### Model training
|
| 318 |
+
|
| 319 |
+
For both the sex and digit classification task, AlexNet was trained with Stochastic Gradient Descent for 10,000 optimization steps at a batchsize of 100 spectrograms. The initial learning rate of 0.001 was reduced by a factor of 0.5 every 2,500 optimization steps, momentum was kept constant at 0.9 throughout training and gradients were clipped at a magnitude of 5.
|
| 320 |
+
|
| 321 |
+
In case of digit classification, AudioNet was trained with Stochastic Gradient Descent with a batch size of 100 and constant momentum of 0.9 for 50,000 optimization steps with an initial learning rate of 0.0001 which was lowered every 10,000 steps by a factor of 0.5. In case of sex classification, training consisted of only 10,000 optimization steps where the learning rate is reduced after 5,000 steps.
|
1807/1807.03819.md
ADDED
|
@@ -0,0 +1,568 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Universal Transformers
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1807.03819
|
| 4 |
+
|
| 5 |
+
Published Time: Sat, 16 Aug 2025 00:08:37 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Mostafa Dehghani†∗{}^{*}\dagger Stephan Gouws∗Oriol Vinyals University of Amsterdam DeepMind DeepMind dehghani@uva.nl sgouws@google.com vinyals@google.com Jakob Uszkoreit Łukasz Kaiser Google Brain Google Brain usz@google.com lukaszkaiser@google.com
|
| 9 |
+
|
| 10 |
+
###### Abstract
|
| 11 |
+
|
| 12 |
+
Recurrent neural networks (RNNs) sequentially process data by updating their state with each new data point, and have long been the de facto choice for sequence modeling tasks. However, their inherently sequential computation makes them slow to train. Feed-forward and convolutional architectures have recently been shown to achieve superior results on some sequence modeling tasks such as machine translation, with the added advantage that they concurrently process all inputs in the sequence, leading to easy parallelization and faster training times. Despite these successes, however, popular feed-forward sequence models like the Transformer fail to generalize in many simple tasks that recurrent models handle with ease, e.g.copying strings or even simple logical inference when the string or formula lengths exceed those observed at training time. We propose the Universal Transformer (UT), a parallel-in-time self-attentive recurrent sequence model which can be cast as a generalization of the Transformer model and which addresses these issues. UTs combine the parallelizability and global receptive field of feed-forward sequence models like the Transformer with the recurrent inductive bias of RNNs. We also add a dynamic per-position halting mechanism and find that it improves accuracy on several tasks. In contrast to the standard Transformer, under certain assumptions UTs can be shown to be Turing-complete. Our experiments show that UTs outperform standard Transformers on a wide range of algorithmic and language understanding tasks, including the challenging LAMBADA language modeling task where UTs achieve a new state of the art, and machine translation where UTs achieve a 0.9 BLEU improvement over Transformers on the WMT14 En-De dataset.
|
| 13 |
+
|
| 14 |
+
††footnotetext: ∗ Equal contribution, alphabetically by last name.††footnotetext: † Work performed while at Google Brain.
|
| 15 |
+
1 Introduction
|
| 16 |
+
--------------
|
| 17 |
+
|
| 18 |
+
Convolutional and fully-attentional feed-forward architectures like the Transformer have recently emerged as viable alternatives to recurrent neural networks (RNNs) for a range of sequence modeling tasks, notably machine translation(Gehring et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib9); Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31)). These parallel-in-time architectures address a significant shortcoming of RNNs, namely their inherently sequential computation which prevents parallelization across elements of the input sequence, whilst still addressing the vanishing gradients problem as the sequence length gets longer(Hochreiter et al., [2003](https://arxiv.org/html/1807.03819v3#bib.bib16)). The Transformer model in particular relies entirely on a self-attention mechanism (Parikh et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib24); Lin et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib21)) to compute a series of context-informed vector-space representations of the symbols in its input and output, which are then used to predict distributions over subsequent symbols as the model predicts the output sequence symbol-by-symbol. Not only is this mechanism straightforward to parallelize, but as each symbol’s representation is also directly informed by all other symbols’ representations, this results in an effectively global receptive field across the whole sequence. This stands in contrast to e.g.convolutional architectures which typically only have a limited receptive field.
|
| 19 |
+
|
| 20 |
+
Notably, however, the Transformer with its fixed stack of distinct layers foregoes RNNs’ inductive bias towards learning iterative or recursive transformations. Our experiments indicate that this inductive bias may be crucial for several algorithmic and language understanding tasks of varying complexity: in contrast to models such as the Neural Turing Machine(Graves et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib13)), the Neural GPU(Kaiser & Sutskever, [2016](https://arxiv.org/html/1807.03819v3#bib.bib18)) or Stack RNNs(Joulin & Mikolov, [2015](https://arxiv.org/html/1807.03819v3#bib.bib17)), the Transformer does not generalize well to input lengths not encountered during training.
|
| 21 |
+
|
| 22 |
+

|
| 23 |
+
|
| 24 |
+
Figure 1: The Universal Transformer repeatedly refines a series of vector representations for each position of the sequence in parallel, by combining information from different positions using self-attention (see Eqn[2](https://arxiv.org/html/1807.03819v3#S2.E2 "In 2.1 The Universal Transformer ‣ 2 Model Description ‣ Universal Transformers")) and applying a recurrent transition function (see Eqn[4](https://arxiv.org/html/1807.03819v3#S2.E4 "In 2.1 The Universal Transformer ‣ 2 Model Description ‣ Universal Transformers")) across all time steps 1≤t≤T 1\leq t\leq T. We show this process over two recurrent time-steps. Arrows denote dependencies between operations. Initially, h 0 h^{0} is initialized with the embedding for each symbol in the sequence. h i t h^{t}_{i} represents the representation for input symbol 1≤i≤m 1\leq i\leq m at recurrent time-step t t. With dynamic halting, T T is dynamically determined for each position (Section[2.2](https://arxiv.org/html/1807.03819v3#S2.SS2 "2.2 Dynamic Halting ‣ 2 Model Description ‣ Universal Transformers")).
|
| 25 |
+
|
| 26 |
+
In this paper, we introduce the _Universal Transformer (UT)_, a parallel-in-time recurrent self-attentive sequence model which can be cast as a generalization of the Transformer model, yielding increased theoretical capabilities and improved results on a wide range of challenging sequence-to-sequence tasks. UTs combine the parallelizability and global receptive field of feed-forward sequence models like the Transformer with the recurrent inductive bias of RNNs, which seems to be better suited to a range of algorithmic and natural language understanding sequence-to-sequence problems. As the name implies, and in contrast to the standard Transformer, under certain assumptions UTs can be shown to be Turing-complete (or “computationally universal”, as shown in Section[4](https://arxiv.org/html/1807.03819v3#S4 "4 Discussion ‣ Universal Transformers")).
|
| 27 |
+
|
| 28 |
+
In each recurrent step, the Universal Transformer iteratively refines its representations for all symbols in the sequence in parallel using a self-attention mechanism(Parikh et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib24); Lin et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib21)), followed by a transformation (shared across all positions and time-steps) consisting of a depth-wise separable convolution (Chollet, [2016](https://arxiv.org/html/1807.03819v3#bib.bib5); Kaiser et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib19)) or a position-wise fully-connected layer (see Fig[1](https://arxiv.org/html/1807.03819v3#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Universal Transformers")). We also add a dynamic per-position halting mechanism (Graves, [2016](https://arxiv.org/html/1807.03819v3#bib.bib12)), allowing the model to choose the required number of refinement steps _for each symbol_ dynamically, and show for the first time that such a conditional computation mechanism can in fact improve accuracy on several smaller, structured algorithmic and linguistic inference tasks (although it marginally degraded results on MT).
|
| 29 |
+
|
| 30 |
+
Our strong experimental results show that UTs outperform Transformers and LSTMs across a wide range of tasks. The added recurrence yields improved results in machine translation where UTs outperform the standard Transformer. In experiments on several algorithmic tasks and the bAbI language understanding task, UTs also consistently and significantly improve over LSTMs and the standard Transformer. Furthermore, on the challenging LAMBADA text understanding data set UTs with dynamic halting achieve a new state of the art.
|
| 31 |
+
|
| 32 |
+
2 Model Description
|
| 33 |
+
-------------------
|
| 34 |
+
|
| 35 |
+
### 2.1 The Universal Transformer
|
| 36 |
+
|
| 37 |
+
The Universal Transformer (UT; see Fig.[2](https://arxiv.org/html/1807.03819v3#S2.F2 "Figure 2 ‣ 2.1 The Universal Transformer ‣ 2 Model Description ‣ Universal Transformers")) is based on the popular encoder-decoder architecture commonly used in most neural sequence-to-sequence models (Sutskever et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib29); Cho et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib4); Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31)). Both the encoder and decoder of the UT operate by applying a recurrent neural network to the representations of each of the positions of the input and output sequence, respectively. However, in contrast to most applications of recurrent neural networks to sequential data, the UT does not recur over positions in the sequence, but over consecutive revisions of the vector representations of each position (i.e., over “depth”). In other words, the UT is not computationally bound by the number of symbols in the sequence, but only by the number of revisions made to each symbol’s representation.
|
| 38 |
+
|
| 39 |
+
In each recurrent time-step, the representation of every position is concurrently (in parallel) revised in two sub-steps: first, using a self-attention mechanism to exchange information across all positions in the sequence, thereby generating a vector representation for each position that is informed by the representations of all other positions at the previous time-step. Then, by applying a transition function (shared across position and time) to the outputs of the self-attention mechanism, independently at each position. As the recurrent transition function can be applied any number of times, this implies that UTs can have variable depth (number of per-symbol processing steps). Crucially, this is in contrast to most popular neural sequence models, including the Transformer(Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31)) or deep RNNs, which have constant depth as a result of applying a _fixed stack_ of layers. We now describe the encoder and decoder in more detail.
|
| 40 |
+
|
| 41 |
+
Encoder: Given an input sequence of length m m, we start with a matrix whose rows are initialized as the d d-dimensional embeddings of the symbols at each position of the sequence H 0∈ℝ m×d H^{0}\in\mathbb{R}^{m\times d}. The UT then iteratively computes representations H t H^{t} at step t t for all m m positions in parallel by applying the multi-headed dot-product self-attention mechanism from Vaswani et al. ([2017](https://arxiv.org/html/1807.03819v3#bib.bib31)), followed by a recurrent transition function. We also add residual connections around each of these function blocks and apply dropout and layer normalization (Srivastava et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib27); Ba et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib2)) (see Fig.[2](https://arxiv.org/html/1807.03819v3#S2.F2 "Figure 2 ‣ 2.1 The Universal Transformer ‣ 2 Model Description ‣ Universal Transformers") for a simplified diagram, and Fig.[4](https://arxiv.org/html/1807.03819v3#A1.F4 "Figure 4 ‣ Appendix A Detailed Schema of the Universal Transformer ‣ Universal Transformers") in the Appendix[A](https://arxiv.org/html/1807.03819v3#A1 "Appendix A Detailed Schema of the Universal Transformer ‣ Universal Transformers") for the complete model.).
|
| 42 |
+
|
| 43 |
+
More specifically, we use the scaled dot-product attention which combines queries Q Q, keys K K and values V V as follows
|
| 44 |
+
|
| 45 |
+
Attention(Q,K,V)=softmax(QK T d)V,\textsc{Attention}(Q,K,V)=\textsc{softmax}\left(\frac{QK^{T}}{\sqrt{d}}\right)V,(1)
|
| 46 |
+
|
| 47 |
+
where d d is the number of columns of Q Q, K K and V V. We use the multi-head version with k k heads, as introduced in (Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31)),
|
| 48 |
+
|
| 49 |
+
MultiHeadSelfAttention(H t)\displaystyle\textsc{MultiHeadSelfAttention}(H^{t})=Concat(head 1,…,head k)W O\displaystyle=\textsc{Concat}(\mathrm{head_{1}},...,\mathrm{head_{k}})W^{O}(2)
|
| 50 |
+
wherehead i\displaystyle\text{where}~\mathrm{head_{i}}=Attention(H tW i Q,H tW i K,H tW i V)\displaystyle=\textsc{Attention}(H^{t}W^{Q}_{i},H^{t}W^{K}_{i},H^{t}W^{V}_{i})(3)
|
| 51 |
+
|
| 52 |
+
and we map the state H t H^{t} to queries, keys and values with affine projections using learned parameter matrices W Q∈ℝ d×d/k W^{Q}\in\mathbb{R}^{d\times d/k}, W K∈ℝ d×d/k W^{K}\in\mathbb{R}^{d\times d/k}, W V∈ℝ d×d/k W^{V}\in\mathbb{R}^{d\times d/k} and W O∈ℝ d×d W^{O}\in\mathbb{R}^{d\times d}.
|
| 53 |
+
|
| 54 |
+
At step t t, the UT then computes revised representations H t∈ℝ m×d H^{t}\in\mathbb{R}^{m\times d} for all m m input positions as follows
|
| 55 |
+
|
| 56 |
+
H t\displaystyle H^{t}=LayerNorm(A t+Transition(A t))\displaystyle=\textsc{LayerNorm}(A^{t}+\textsc{Transition}(A^{t}))(4)
|
| 57 |
+
whereA t\displaystyle\mathrm{where}~A^{t}=LayerNorm((H t−1+P t)+MultiHeadSelfAttention(H t−1+P t)),\displaystyle=\textsc{LayerNorm}((H^{t-1}+P^{t})+\textsc{MultiHeadSelfAttention}(H^{t-1}+P^{t})),(5)
|
| 58 |
+
|
| 59 |
+
where LayerNorm() is defined in Ba et al. ([2016](https://arxiv.org/html/1807.03819v3#bib.bib2)), and Transition() and P t P^{t} are discussed below.
|
| 60 |
+
|
| 61 |
+
Depending on the task, we use one of two different transition functions: either a separable convolution(Chollet, [2016](https://arxiv.org/html/1807.03819v3#bib.bib5)) or a fully-connected neural network that consists of a single rectified-linear activation function between two affine transformations, applied position-wise, i.e. individually to each row of A t A^{t}.
|
| 62 |
+
|
| 63 |
+
P t∈ℝ m×d P^{t}\in\mathbb{R}^{m\times d} above are fixed, constant, two-dimensional (position, time) _coordinate embeddings_, obtained by computing the sinusoidal position embedding vectors as defined in (Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31)) for the positions 1≤i≤m 1\leq i\leq m and the time-step 1≤t≤T 1\leq t\leq T separately for each vector-dimension 1≤j≤d 1\leq j\leq d, and summing:
|
| 64 |
+
|
| 65 |
+
P i,2j t\displaystyle P^{t}_{i,2j}=sin(i/10000 2j/d)+sin(t/10000 2j/d)\displaystyle=\sin(i/10000^{2j/d})+\sin(t/10000^{2j/d})(6)
|
| 66 |
+
P i,2j+1 t\displaystyle P^{t}_{i,2j+1}=cos(i/10000 2j/d)+cos(t/10000 2j/d).\displaystyle=\cos(i/10000^{2j/d})+\cos(t/10000^{2j/d}).(7)
|
| 67 |
+
|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
Figure 2: The recurrent blocks of the Universal Transformer encoder and decoder. This diagram omits position and time-step encodings as well as dropout, residual connections and layer normalization. A complete version can be found in Appendix[A](https://arxiv.org/html/1807.03819v3#A1 "Appendix A Detailed Schema of the Universal Transformer ‣ Universal Transformers"). The Universal Transformer with dynamic halting determines the number of steps T T for each position individually using ACT(Graves, [2016](https://arxiv.org/html/1807.03819v3#bib.bib12)).
|
| 71 |
+
|
| 72 |
+
After T T steps (each updating all positions of the input sequence in parallel), the final output of the Universal Transformer encoder is a matrix of d d-dimensional vector representations H T∈ℝ m×d H^{T}\in\mathbb{R}^{m\times d} for the m m symbols of the input sequence.
|
| 73 |
+
|
| 74 |
+
Decoder: The decoder shares the same basic recurrent structure of the encoder. However, after the self-attention function, the decoder additionally also attends to the final encoder representation H T H^{T} of each position in the input sequence using the same multihead dot-product attention function from Equation [2](https://arxiv.org/html/1807.03819v3#S2.E2 "In 2.1 The Universal Transformer ‣ 2 Model Description ‣ Universal Transformers"), but with queries Q Q obtained from projecting the decoder representations, and keys and values (K K and V V) obtained from projecting the encoder representations (this process is akin to standard attention (Bahdanau et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib3))).
|
| 75 |
+
|
| 76 |
+
Like the Transformer model, the UT is autoregressive (Graves, [2013](https://arxiv.org/html/1807.03819v3#bib.bib11)). Trained using teacher-forcing, at generation time it produces its output one symbol at a time, with the decoder consuming the previously produced output positions. During training, the decoder input is the target output, shifted to the right by one position. The decoder self-attention distributions are further masked so that the model can only attend to positions to the left of any predicted symbol. Finally, the per-symbol target distributions are obtained by applying an affine transformation O∈ℝ d×V O\in\mathbb{R}^{d\times V} from the final decoder state to the output vocabulary size V V, followed by a softmax which yields an (m×V)(m\times V)-dimensional output matrix normalized over its rows:
|
| 77 |
+
|
| 78 |
+
p(y pos|y[1:pos−1],H T)=softmax(OH T)p\left(y_{pos}|y_{[1:pos-1]},H^{T}\right)=\textsc{softmax}(OH^{T})(8)
|
| 79 |
+
|
| 80 |
+
To generate from the model, the encoder is run once for the conditioning input sequence. Then the decoder is run repeatedly, consuming all already-generated symbols, while generating one additional distribution over the vocabulary for the symbol at the next output position per iteration. We then typically sample or select the highest probability symbol as the next symbol.
|
| 81 |
+
|
| 82 |
+
### 2.2 Dynamic Halting
|
| 83 |
+
|
| 84 |
+
In sequence processing systems, certain symbols (e.g.some words or phonemes) are usually more ambiguous than others. It is therefore reasonable to allocate more processing resources to these more ambiguous symbols. Adaptive Computation Time (ACT) (Graves, [2016](https://arxiv.org/html/1807.03819v3#bib.bib12)) is a mechanism for dynamically modulating the number of computational steps needed to process each input symbol (called the “ponder time”) in standard recurrent neural networks based on a scalar _halting probability_ predicted by the model at each step.
|
| 85 |
+
|
| 86 |
+
Inspired by the interpretation of Universal Transformers as applying self-attentive RNNs in parallel to all positions in the sequence, we also add a dynamic ACT halting mechanism to each position (i.e.to each per-symbol self-attentive RNN; see Appendix[C](https://arxiv.org/html/1807.03819v3#A3 "Appendix C UT with Dynamic Halting ‣ Universal Transformers") for more details). Once the per-symbol recurrent block halts, its state is simply copied to the next step until all blocks halt, or we reach a maximum number of steps. The final output of the encoder is then the final layer of representations produced in this way.
|
| 87 |
+
|
| 88 |
+
3 Experiments and Analysis
|
| 89 |
+
--------------------------
|
| 90 |
+
|
| 91 |
+
We evaluated the Universal Transformer on a range of algorithmic and language understanding tasks, as well as on machine translation. We describe these tasks and datasets in more detail in Appendix[D](https://arxiv.org/html/1807.03819v3#A4 "Appendix D Description of some of the Tasks/Datasets ‣ Universal Transformers").
|
| 92 |
+
|
| 93 |
+
### 3.1 bAbI Question-Answering
|
| 94 |
+
|
| 95 |
+
The bAbi question answering dataset(Weston et al., [2015](https://arxiv.org/html/1807.03819v3#bib.bib33)) consists of 20 different tasks, where the goal is to answer a question given a number of English sentences that encode potentially multiple supporting facts. The goal is to measure various forms of language understanding by requiring a certain type of reasoning over the linguistic facts presented in each story. A standard Transformer does not achieve good results on this task 2 2 2 We experimented with different hyper-parameters and different network sizes, but it always overfits.. However, we have designed a model based on the Universal Transformer which achieves state-of-the-art results on this task.
|
| 96 |
+
|
| 97 |
+
To encode the input, similar to Henaff et al. ([2016](https://arxiv.org/html/1807.03819v3#bib.bib15)), we first encode each fact in the story by applying a learned multiplicative positional mask to each word’s embedding, and summing up all embeddings. We embed the question in the same way, and then feed the (Universal) Transformer with these embeddings of the facts and questions.
|
| 98 |
+
|
| 99 |
+
As originally proposed, models can either be trained on each task separately (“train single”) or jointly on all tasks (“train joint”). Table[1](https://arxiv.org/html/1807.03819v3#S3.T1 "Table 1 ‣ 3.1 bAbI Question-Answering ‣ 3 Experiments and Analysis ‣ Universal Transformers") summarizes our results. We conducted 10 runs with different initializations and picked the best model based on performance on the validation set, similar to previous work. Both the UT and UT with dynamic halting achieve state-of-the-art results on all tasks in terms of average error and number of failed tasks 3 3 3 Defined as >5%>5\% error., in both the 10K and 1K training regime (see Appendix[E](https://arxiv.org/html/1807.03819v3#A5 "Appendix E bAbI Detailed Results ‣ Universal Transformers") for breakdown by task).
|
| 100 |
+
|
| 101 |
+
Model 10K examples 1K examples
|
| 102 |
+
train single train joint train single train joint
|
| 103 |
+
Previous best results:
|
| 104 |
+
QRNet(Seo et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib26))0.3 (0/20)---
|
| 105 |
+
Sparse DNC(Rae et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib25))-2.9 (1/20)--
|
| 106 |
+
GA+MAGE Dhingra et al. ([2017](https://arxiv.org/html/1807.03819v3#bib.bib7))--8.7 (5/20)-
|
| 107 |
+
MemN2N Sukhbaatar et al. ([2015](https://arxiv.org/html/1807.03819v3#bib.bib28))---12.4 (11/20)
|
| 108 |
+
Our Results:
|
| 109 |
+
Transformer(Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31))15.2 (10/20)22.1 (12/20)21.8 (5/20)26.8 (14/20)
|
| 110 |
+
Universal Transformer (this work)0.23 (0/20)0.47 (0/20)5.31 (5/20)8.50 (8/20)
|
| 111 |
+
UT w/ dynamic halting (this work)0.21 (0/20)0.29 (0/20)4.55 (3/20)7.78 (5/20)
|
| 112 |
+
|
| 113 |
+
Table 1: Average error and number of failed tasks (>5%>5\% error) out of 20 (in parentheses; lower is better in both cases) on the bAbI dataset under the different training/evaluation setups. We indicate state-of-the-art where available for each, or ‘-’ otherwise.
|
| 114 |
+
|
| 115 |
+

|
| 116 |
+
|
| 117 |
+
Figure 3: Ponder time of UT with dynamic halting for encoding facts in a story and question in a bAbI task requiring three supporting facts.
|
| 118 |
+
|
| 119 |
+
To understand the working of the model better, we analyzed both the attention distributions and the average ACT ponder times for this task (see Appendix[F](https://arxiv.org/html/1807.03819v3#A6 "Appendix F bAbI Attention Visualization ‣ Universal Transformers") for details). First, we observe that the attention distributions start out very uniform, but get progressively sharper in later steps around the correct supporting facts that are required to answer each question, which is indeed very similar to how humans would solve the task. Second, with dynamic halting we observe that the average ponder time (i.e.depth of the per-symbol recurrent processing chain) over all positions in all samples in the test data for tasks requiring three supporting facts is higher (3.8±2.2 3.8\raisebox{0.86108pt}{$\scriptstyle\pm$}2.2) than for tasks requiring only two (3.1±1.1 3.1\raisebox{0.86108pt}{$\scriptstyle\pm$}1.1), which is in turn higher than for tasks requiring only one supporting fact (2.3±0.8 2.3\raisebox{0.86108pt}{$\scriptstyle\pm$}0.8). This indicates that the model adjusts the number of processing steps with the number of supporting facts required to answer the questions. Finally, we observe that the histogram of ponder times at different positions is more uniform in tasks requiring only one supporting fact compared to two and three, and likewise for tasks requiring two compared to three. Especially for tasks requiring three supporting facts, many positions halt at step 1 or 2 already and only a few get transformed for more steps (see for example Fig[3](https://arxiv.org/html/1807.03819v3#S3.F3 "Figure 3 ‣ 3.1 bAbI Question-Answering ‣ 3 Experiments and Analysis ‣ Universal Transformers")). This is particularly interesting as the length of stories is indeed much higher in this setting, with more irrelevant facts which the model seems to successfully learn to ignore in this way.
|
| 120 |
+
|
| 121 |
+
Similar to dynamic memory networks(Kumar et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib20)), there is an iterative attention process in UTs that allows the model to condition its attention over memory on the result of previous iterations. Appendix[F](https://arxiv.org/html/1807.03819v3#A6 "Appendix F bAbI Attention Visualization ‣ Universal Transformers") presents some examples illustrating that there is a notion of temporal states in UT, where the model updates its states (memory) in each step based on the output of previous steps, and this chain of updates can also be viewed as steps in a multi-hop reasoning process.
|
| 122 |
+
|
| 123 |
+
### 3.2 Subject-Verb Agreement
|
| 124 |
+
|
| 125 |
+
Next, we consider the task of predicting number-agreement between subjects and verbs in English sentences(Linzen et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib22)). This task acts as a proxy for measuring the ability of a model to capture hierarchical (dependency) structure in natural language sentences. We use the dataset provided by(Linzen et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib22)) and follow their experimental protocol of solving the task using a language modeling training setup, i.e.a next word prediction objective, followed by calculating the ranking accuracy of the target verb at test time. We evaluated our model on subsets of the test data with different task difficulty, measured in terms of _agreement attractors_ – the number of intervening nouns with the opposite number from the subject (meant to confuse the model). For example, given the sentence _The keys to the cabinet_ 4 4 4 _Cabinet_ (singular) is an agreement attractor in this case., the objective during training is to predict the verb _are_ (plural). At test time, we then evaluate the ranking accuracy of the agreement attractors: i.e. the goal is to rank _are_ higher than _is_ in this case.
|
| 126 |
+
|
| 127 |
+
Model Number of attractors
|
| 128 |
+
0 1 2 3 4 5 Total
|
| 129 |
+
Previous best results(Yogatama et al., [2018](https://arxiv.org/html/1807.03819v3#bib.bib34)):
|
| 130 |
+
Best Stack-RNN _0.994_ 0.979 0.965 0.935 0.916 0.880 0.992
|
| 131 |
+
Best LSTM 0.993 0.972 0.950 0.922 0.900 0.842 0.991
|
| 132 |
+
Best Attention 0.994 0.977 0.959 0.929 0.907 0.842 0.992
|
| 133 |
+
Our results:
|
| 134 |
+
Transformer 0.973 0.941 0.932 0.917 0.901 0.883 0.962
|
| 135 |
+
Universal Transformer 0.993 0.971 0.969 0.940 0.921 0.892 0.992
|
| 136 |
+
UT w/ ACT 0.994 0.969 0.967 0.944 0.932 0.907 0.992
|
| 137 |
+
Δ\Delta (UT w/ ACT - Best)0-0.008 0.002 0.009 0.016 0.027-
|
| 138 |
+
|
| 139 |
+
Table 2: Accuracy on the subject-verb agreement number prediction task (higher is better).
|
| 140 |
+
|
| 141 |
+
Our results are summarized in Table[2](https://arxiv.org/html/1807.03819v3#S3.T2 "Table 2 ‣ 3.2 Subject-Verb Agreement ‣ 3 Experiments and Analysis ‣ Universal Transformers"). The best LSTM with attention from the literature achieves 99.18% on this task(Yogatama et al., [2018](https://arxiv.org/html/1807.03819v3#bib.bib34)), outperforming a vanilla Transformer(Tran et al., [2018](https://arxiv.org/html/1807.03819v3#bib.bib30)). UTs significantly outperform standard Transformers, and achieve an _average_ result comparable to the current state of the art (99.2%). However, we see that UTs (and particularly with dynamic halting) perform progressively better than all other models as the number of attractors increases (see the last row, Δ\Delta).
|
| 142 |
+
|
| 143 |
+
### 3.3 LAMBADA Language Modeling
|
| 144 |
+
|
| 145 |
+
The LAMBADA task(Paperno et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib23)) is a language modeling task consisting of predicting a missing target word given a broader context of 4-5 preceding sentences. The dataset was specifically designed so that humans are able to accurately predict the target word when shown the full context, but not when only shown the target sentence in which it appears. It therefore goes beyond language modeling, and tests the ability of a model to incorporate broader discourse and longer term context when predicting the target word.
|
| 146 |
+
|
| 147 |
+
The task is evaluated in two settings: as _language modeling_ (the standard setup) and as _reading comprehension_. In the former (more challenging) case, a model is simply trained for next-word prediction on the training data, and evaluated on the target words at test time (i.e.the model is trained to predict all words, not specifically challenging target words). In the latter setting, introduced by Chu et al.Chu et al. ([2017](https://arxiv.org/html/1807.03819v3#bib.bib6)), the target sentence (minus the last word) is used as query for selecting the target word from the context sentences. Note that the target word appears in the context 81% of the time, making this setup much simpler. However the task is impossible in the remaining 19% of the cases.
|
| 148 |
+
|
| 149 |
+
Table 3: LAMBADA language modeling (LM) perplexity (lower better) with accuracy in parentheses (higher better), and Reading Comprehension (RC) accuracy results (higher better). ‘-’ indicates no reported results in that setting.
|
| 150 |
+
|
| 151 |
+
The results are shown in Table[3](https://arxiv.org/html/1807.03819v3#S3.T3 "Table 3 ‣ 3.3 LAMBADA Language Modeling ‣ 3 Experiments and Analysis ‣ Universal Transformers"). Universal Transformer achieves state-of-the-art results in both the language modeling and reading comprehension setup, outperforming both LSTMs and vanilla Transformers. Note that the control set was constructed similar to the LAMBADA development and test sets, but without filtering them in any way, so achieving good results on this set shows a model’s strength in standard language modeling.
|
| 152 |
+
|
| 153 |
+
Our best fixed UT results used 6 steps. However, the average number of steps that the best UT with dynamic halting took on the test data over all positions and examples was 8.2±2.1 8.2\raisebox{0.86108pt}{$\scriptstyle\pm$}2.1. In order to see if the dynamic model did better simply because it took more steps, we trained two fixed UT models with 8 and 9 steps respectively (see last two rows). Interestingly, these two models achieve better results compared to the model with 6 steps, but _do not outperform the UT with dynamic halting_. This leads us to believe that dynamic halting may act as a useful regularizer for the model via incentivizing a smaller numbers of steps for some of the input symbols, while allowing more computation for others.
|
| 154 |
+
|
| 155 |
+
### 3.4 Algorithmic Tasks
|
| 156 |
+
|
| 157 |
+
We trained UTs on three algorithmic tasks, namely Copy, Reverse, and (integer) Addition, all on strings composed of decimal symbols (‘0’-‘9’). In all the experiments, we train the models on sequences of length 40 and evaluated on sequences of length 400(Kaiser & Sutskever, [2016](https://arxiv.org/html/1807.03819v3#bib.bib18)). We train UTs using positions starting with randomized offsets to further encourage the model to learn position-relative transformations. Results are shown in Table[4](https://arxiv.org/html/1807.03819v3#S3.T4 "Table 4 ‣ 3.4 Algorithmic Tasks ‣ 3 Experiments and Analysis ‣ Universal Transformers"). The UT outperforms both LSTM and vanilla Transformer by a wide margin on all three tasks. The Neural GPU reports perfect results on this task(Kaiser & Sutskever, [2016](https://arxiv.org/html/1807.03819v3#bib.bib18)), however we note that this result required a special curriculum-based training protocol which was not used for other models.
|
| 158 |
+
|
| 159 |
+
Table 4: Accuracy (higher better) on the algorithmic tasks. ∗Note that the Neural GPU was trained with a special curriculum to obtain the perfect result, while other models are trained without any curriculum.
|
| 160 |
+
|
| 161 |
+
### 3.5 Learning to Execute (LTE)
|
| 162 |
+
|
| 163 |
+
As another class of sequence-to-sequence learning problems, we also evaluate UTs on tasks indicating the ability of a model to learn to execute computer programs, as proposed in(Zaremba & Sutskever, [2015](https://arxiv.org/html/1807.03819v3#bib.bib35)). These tasks include program evaluation tasks (program, control, and addition), and memorization tasks (copy, double, and reverse).
|
| 164 |
+
|
| 165 |
+
Table 5: Character-level (_char-acc_) and sequence-level accuracy (_seq-acc_) results on the Memorization LTE tasks, with maximum length of 55.
|
| 166 |
+
|
| 167 |
+
Table 6: Character-level (_char-acc_) and sequence-level accuracy (_seq-acc_) results on the Program Evaluation LTE tasks with maximum nesting of 2 and length of 5.
|
| 168 |
+
|
| 169 |
+
We use the mix-strategy discussed in(Zaremba & Sutskever, [2015](https://arxiv.org/html/1807.03819v3#bib.bib35)) to generate the datasets. Unlike(Zaremba & Sutskever, [2015](https://arxiv.org/html/1807.03819v3#bib.bib35)), we do not use any curriculum learning strategy during training and we make no use of target sequences at test time. Tables[5](https://arxiv.org/html/1807.03819v3#S3.T5 "Table 5 ‣ 3.5 Learning to Execute (LTE) ‣ 3 Experiments and Analysis ‣ Universal Transformers") and [6](https://arxiv.org/html/1807.03819v3#S3.T6 "Table 6 ‣ 3.5 Learning to Execute (LTE) ‣ 3 Experiments and Analysis ‣ Universal Transformers") present the performance of an LSTM model, Transformer, and Universal Transformer on the program evaluation and memorization tasks, respectively. UT achieves perfect scores in all the memorization tasks and also outperforms both LSTMs and Transformers in all program evaluation tasks by a wide margin.
|
| 170 |
+
|
| 171 |
+
### 3.6 Machine Translation
|
| 172 |
+
|
| 173 |
+
We trained a UT on the WMT 2014 English-German translation task using the same setup as reported in (Vaswani et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib31)) in order to evaluate its performance on a large-scale sequence-to-sequence task. Results are summarized in Table[7](https://arxiv.org/html/1807.03819v3#S3.T7 "Table 7 ‣ 3.6 Machine Translation ‣ 3 Experiments and Analysis ‣ Universal Transformers"). The UT with a fully-connected recurrent transition function (instead of separable convolution) and without ACT improves by 0.9 BLEU over a Transformer and 0.5 BLEU over a Weighted Transformer with approximately the same number of parameters (Ahmed et al., [2017](https://arxiv.org/html/1807.03819v3#bib.bib1)).
|
| 174 |
+
|
| 175 |
+
Table 7: Machine translation results on the WMT14 En-De translation task trained on 8xP100 GPUs in comparable training setups. All _base_ results have the same number of parameters.
|
| 176 |
+
|
| 177 |
+
4 Discussion
|
| 178 |
+
------------
|
| 179 |
+
|
| 180 |
+
When running for a fixed number of steps, the Universal Transformer is equivalent to a multi-layer Transformer with tied parameters across all its layers. This is partly similar to the Recursive Transformer, which ties the weights of its self-attention layers across depth(Gulcehre et al., [2018](https://arxiv.org/html/1807.03819v3#bib.bib14))5 5 5 Note that in UT both the self-attention and transition weights are tied across layers.. However, as the per-symbol recurrent transition functions can be applied any number of times, another and possibly more informative way of characterizing the UT is as a block of parallel RNNs (one for each symbol, with shared parameters) evolving per-symbol hidden states concurrently, generated at each step by attending to the sequence of hidden states at the previous step. In this way, it is related to architectures such as the Neural GPU (Kaiser & Sutskever, [2016](https://arxiv.org/html/1807.03819v3#bib.bib18)) and the Neural Turing Machine (Graves et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib13)). UTs thereby retain the attractive computational efficiency of the original feed-forward Transformer model, but with the added recurrent inductive bias of RNNs. Furthermore, using a dynamic halting mechanism, UTs can choose the number of processing steps based on the input data.
|
| 181 |
+
|
| 182 |
+
The connection between the Universal Transformer and other sequence models is apparent from the architecture: if we limited the recurrent steps to one, it would be a Transformer. But it is more interesting to consider the relationship between the Universal Transformer and RNNs and other networks where recurrence happens over the time dimension. Superficially these models may seem closely related since they are recurrent as well. But there is a crucial difference: time-recurrent models like RNNs cannot access memory in the recurrent steps. This makes them computationally more similar to automata, since the only memory available in the recurrent part is a fixed-size state vector. UTs on the other hand can attend to the whole previous layer, allowing it to access memory in the recurrent step.
|
| 183 |
+
|
| 184 |
+
Given sufficient memory the Universal Transformer is computationally universal – i.e.it belongs to the class of models that can be used to simulate any Turing machine, thereby addressing a shortcoming of the standard Transformer model 6 6 6 Appendix[B](https://arxiv.org/html/1807.03819v3#A2 "Appendix B On the Computational Power of UT vs Transformer ‣ Universal Transformers") illustrates how UT is computationally more powerful than the standard Transformer.. In addition to being theoretically appealing, our results show that this added expressivity also leads to improved accuracy on several challenging sequence modeling tasks. This closes the gap between practical sequence models competitive on large-scale tasks such as machine translation, and computationally universal models such as the Neural Turing Machine or the Neural GPU (Graves et al., [2014](https://arxiv.org/html/1807.03819v3#bib.bib13); Kaiser & Sutskever, [2016](https://arxiv.org/html/1807.03819v3#bib.bib18)), which can be trained using gradient descent to perform algorithmic tasks.
|
| 185 |
+
|
| 186 |
+
To show this, we can reduce a Neural GPU to a Universal Transformer. Ignoring the decoder and parameterizing the self-attention module, i.e. self-attention with the residual connection, to be the identity function, we assume the transition function to be a convolution. If we now set the total number of recurrent steps T T to be equal to the input length, we obtain exactly a Neural GPU. Note that the last step is where the Universal Transformer crucially differs from the vanilla Transformer whose depth cannot scale dynamically with the size of the input. A similar relationship exists between the Universal Transformer and the Neural Turing Machine, whose single read/write operations per step can be expressed by the global, parallel representation revisions of the Universal Transformer. In contrast to these models, however, which only perform well on algorithmic tasks, the Universal Transformer also achieves competitive results on realistic natural language tasks such as LAMBADA and machine translation.
|
| 187 |
+
|
| 188 |
+
Another related model architecture is that of end-to-end Memory Networks (Sukhbaatar et al., [2015](https://arxiv.org/html/1807.03819v3#bib.bib28)). In contrast to end-to-end memory networks, however, the Universal Transformer uses memory corresponding to states aligned to individual positions of its inputs or outputs. Furthermore, the Universal Transformer follows the encoder-decoder configuration and achieves competitive performance in large-scale sequence-to-sequence tasks.
|
| 189 |
+
|
| 190 |
+
5 Conclusion
|
| 191 |
+
------------
|
| 192 |
+
|
| 193 |
+
This paper introduces the Universal Transformer, a generalization of the Transformer model that extends its theoretical capabilities and produces state-of-the-art results on a wide range of challenging sequence modeling tasks, such as language understanding but also a variety of algorithmic tasks, thereby addressing a key shortcoming of the standard Transformer. The Universal Transformer combines the following key properties into one model:
|
| 194 |
+
|
| 195 |
+
Weight sharing: Following intuitions behind weight sharing found in CNNs and RNNs, we extend the Transformer with a simple form of weight sharing that strikes an effective balance between inductive bias and model expressivity, which we show extensively on both small and large-scale experiments.
|
| 196 |
+
|
| 197 |
+
Conditional computation: In our goal to build a computationally universal machine, we equipped the Universal Transformer with the ability to halt or continue computation through a recently introduced mechanism, which shows stronger results compared to the fixed-depth Universal Transformer.
|
| 198 |
+
|
| 199 |
+
We are enthusiastic about the recent developments on parallel-in-time sequence models. By adding computational capacity and recurrence in processing depth, we hope that further improvements beyond the basic Universal Transformer presented here will help us build learning algorithms that are both more powerful, data efficient, and generalize beyond the current state-of-the-art.
|
| 200 |
+
|
| 201 |
+
#### Acknowledgements
|
| 202 |
+
|
| 203 |
+
We are grateful to Ashish Vaswani, Douglas Eck, and David Dohan for their fruitful comments and inspiration.
|
| 204 |
+
|
| 205 |
+
References
|
| 206 |
+
----------
|
| 207 |
+
|
| 208 |
+
* Ahmed et al. (2017) Karim Ahmed, Nitish Shirish Keskar, and Richard Socher. Weighted transformer network for machine translation. _arXiv preprint arXiv:1711.02132_, 2017.
|
| 209 |
+
* Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. _arXiv preprint arXiv:1607.06450_, 2016. URL [http://arxiv.org/abs/1607.06450](http://arxiv.org/abs/1607.06450).
|
| 210 |
+
* Bahdanau et al. (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. _CoRR_, abs/1409.0473, 2014. URL [http://arxiv.org/abs/1409.0473](http://arxiv.org/abs/1409.0473).
|
| 211 |
+
* Cho et al. (2014) Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014. URL [http://arxiv.org/abs/1406.1078](http://arxiv.org/abs/1406.1078).
|
| 212 |
+
* Chollet (2016) Francois Chollet. Xception: Deep learning with depthwise separable convolutions. _arXiv preprint arXiv:1610.02357_, 2016.
|
| 213 |
+
* Chu et al. (2017) Zewei Chu, Hai Wang, Kevin Gimpel, and David McAllester. Broad context language modeling as reading comprehension. In _Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers_, volume 2, pp. 52–57, 2017.
|
| 214 |
+
* Dhingra et al. (2017) Bhuwan Dhingra, Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Linguistic knowledge as memory for recurrent neural networks. _arXiv preprint arXiv:1703.02620_, 2017.
|
| 215 |
+
* Dhingra et al. (2018) Bhuwan Dhingra, Qiao Jin, Zhilin Yang, William W Cohen, and Ruslan Salakhutdinov. Neural models for reasoning over multiple mentions using coreference. _arXiv preprint arXiv:1804.05922_, 2018.
|
| 216 |
+
* Gehring et al. (2017) Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. _CoRR_, abs/1705.03122, 2017. URL [http://arxiv.org/abs/1705.03122](http://arxiv.org/abs/1705.03122).
|
| 217 |
+
* Grave et al. (2016) Edouard Grave, Armand Joulin, and Nicolas Usunier. Improving neural language models with a continuous cache. _arXiv preprint arXiv:1612.04426_, 2016.
|
| 218 |
+
* Graves (2013) Alex Graves. Generating sequences with recurrent neural networks. _CoRR_, abs/1308.0850, 2013. URL [http://arxiv.org/abs/1308.0850](http://arxiv.org/abs/1308.0850).
|
| 219 |
+
* Graves (2016) Alex Graves. Adaptive computation time for recurrent neural networks. _arXiv preprint arXiv:1603.08983_, 2016.
|
| 220 |
+
* Graves et al. (2014) Alex Graves, Greg Wayne, and Ivo Danihelka. Neural turing machines. _CoRR_, abs/1410.5401, 2014. URL [http://arxiv.org/abs/1410.5401](http://arxiv.org/abs/1410.5401).
|
| 221 |
+
* Gulcehre et al. (2018) Caglar Gulcehre, Misha Denil, Mateusz Malinowski, Ali Razavi, Razvan Pascanu, Karl Moritz Hermann, Peter Battaglia, Victor Bapst, David Raposo, Adam Santoro, et al. Hyperbolic attention networks. _arXiv preprint arXiv:1805.09786_, 2018.
|
| 222 |
+
* Henaff et al. (2016) Mikael Henaff, Jason Weston, Arthur Szlam, Antoine Bordes, and Yann LeCun. Tracking the world state with recurrent entity networks. _arXiv preprint arXiv:1612.03969_, 2016.
|
| 223 |
+
* Hochreiter et al. (2003) Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies. _A Field Guide to Dynamical Recurrent Neural Networks_, 2003.
|
| 224 |
+
* Joulin & Mikolov (2015) A.Joulin and T.Mikolov. Inferring algorithmic patterns with stack-augmented recurrent nets. In _Advances in Neural Information Processing Systems, (NIPS)_, 2015.
|
| 225 |
+
* Kaiser & Sutskever (2016) Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. In _International Conference on Learning Representations (ICLR)_, 2016. URL [https://arxiv.org/abs/1511.08228](https://arxiv.org/abs/1511.08228).
|
| 226 |
+
* Kaiser et al. (2017) Łukasz Kaiser, Aidan N. Gomez, and Francois Chollet. Depthwise separable convolutions for neural machine translation. _CoRR_, abs/1706.03059, 2017. URL [http://arxiv.org/abs/1706.03059](http://arxiv.org/abs/1706.03059).
|
| 227 |
+
* Kumar et al. (2016) Ankit Kumar, Ozan Irsoy, Peter Ondruska, Mohit Iyyer, James Bradbury, Ishaan Gulrajani, Victor Zhong, Romain Paulus, and Richard Socher. Ask me anything: Dynamic memory networks for natural language processing. In _International Conference on Machine Learning_, pp.1378–1387, 2016.
|
| 228 |
+
* Lin et al. (2017) Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. A structured self-attentive sentence embedding. _arXiv preprint arXiv:1703.03130_, 2017.
|
| 229 |
+
* Linzen et al. (2016) Tal Linzen, Emmanuel Dupoux, and Yoav Goldberg. Assessing the ability of lstms to learn syntax-sensitive dependencies. _Transactions of the Association of Computational Linguistics_, 4(1):521–535, 2016.
|
| 230 |
+
* Paperno et al. (2016) Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Ngoc Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernandez. The lambada dataset: Word prediction requiring a broad discourse context. In _Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)_, volume 1, pp.1525–1534, 2016.
|
| 231 |
+
* Parikh et al. (2016) Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention model. In _Empirical Methods in Natural Language Processing_, 2016. URL [https://arxiv.org/pdf/1606.01933.pdf](https://arxiv.org/pdf/1606.01933.pdf).
|
| 232 |
+
* Rae et al. (2016) Jack Rae, Jonathan J Hunt, Ivo Danihelka, Timothy Harley, Andrew W Senior, Gregory Wayne, Alex Graves, and Tim Lillicrap. Scaling memory-augmented neural networks with sparse reads and writes. In _Advances in Neural Information Processing Systems_, pp.3621–3629, 2016.
|
| 233 |
+
* Seo et al. (2016) Minjoon Seo, Sewon Min, Ali Farhadi, and Hannaneh Hajishirzi. Query-reduction networks for question answering. _arXiv preprint arXiv:1606.04582_, 2016.
|
| 234 |
+
* Srivastava et al. (2014) Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. _Journal of Machine Learning Research_, 15(1):1929–1958, 2014.
|
| 235 |
+
* Sukhbaatar et al. (2015) Sainbayar Sukhbaatar, arthur szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In C.Cortes, N.D. Lawrence, D.D. Lee, M.Sugiyama, and R.Garnett (eds.), _Advances in Neural Information Processing Systems 28_, pp.2440–2448. Curran Associates, Inc., 2015. URL [http://papers.nips.cc/paper/5846-end-to-end-memory-networks.pdf](http://papers.nips.cc/paper/5846-end-to-end-memory-networks.pdf).
|
| 236 |
+
* Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. Sequence to sequence learning with neural networks. In _Advances in Neural Information Processing Systems_, pp.3104–3112, 2014. URL [http://arxiv.org/abs/1409.3215](http://arxiv.org/abs/1409.3215).
|
| 237 |
+
* Tran et al. (2018) Ke Tran, Arianna Bisazza, and Christof Monz. The importance of being recurrent for modeling hierarchical structure. In _Proceedings of NAACL’18_, 2018.
|
| 238 |
+
* Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. _CoRR_, 2017. URL [http://arxiv.org/abs/1706.03762](http://arxiv.org/abs/1706.03762).
|
| 239 |
+
* Vaswani et al. (2018) Ashish Vaswani, Samy Bengio, Eugene Brevdo, Francois Chollet, Aidan N. Gomez, Stephan Gouws, Llion Jones, Łukasz Kaiser, Nal Kalchbrenner, Niki Parmar, Ryan Sepassi, Noam Shazeer, and Jakob Uszkoreit. Tensor2tensor for neural machine translation. _CoRR_, abs/1803.07416, 2018.
|
| 240 |
+
* Weston et al. (2015) Jason Weston, Antoine Bordes, Sumit Chopra, Alexander M Rush, Bart van Merriënboer, Armand Joulin, and Tomas Mikolov. Towards ai-complete question answering: A set of prerequisite toy tasks. _arXiv preprint arXiv:1502.05698_, 2015.
|
| 241 |
+
* Yogatama et al. (2018) Dani Yogatama, Yishu Miao, Gabor Melis, Wang Ling, Adhiguna Kuncoro, Chris Dyer, and Phil Blunsom. Memory architectures in recurrent neural network language models. In _International Conference on Learning Representations_, 2018. URL [https://openreview.net/forum?id=SkFqf0lAZ](https://openreview.net/forum?id=SkFqf0lAZ).
|
| 242 |
+
* Zaremba & Sutskever (2015) Wojciech Zaremba and Ilya Sutskever. Learning to execute. _CoRR_, abs/1410.4615, 2015. URL [http://arxiv.org/abs/1410.4615](http://arxiv.org/abs/1410.4615).
|
| 243 |
+
|
| 244 |
+
Appendix A Detailed Schema of the Universal Transformer
|
| 245 |
+
-------------------------------------------------------
|
| 246 |
+
|
| 247 |
+

|
| 248 |
+
|
| 249 |
+
Figure 4: The Universal Transformer with position and step embeddings as well as dropout and layer normalization.
|
| 250 |
+
|
| 251 |
+
Appendix B On the Computational Power of UT vs Transformer
|
| 252 |
+
----------------------------------------------------------
|
| 253 |
+
|
| 254 |
+
With respect to their computational power, the key difference between the Transformer and the Universal Transformer lies in the number of sequential steps of computation (i.e.in depth). While a standard Transformer executes a total number of operations that scales with the input size, the number of sequential operations is constant, independent of the input size and determined solely by the number of layers. Assuming finite precision, this property implies that the standard Transformer cannot be computationally universal. When choosing a number of steps as a function of the input length, however, the Universal Transformer does not suffer from this limitation. Note that this holds independently of whether or not adaptive computation time is employed but does assume a non-constant, even if possibly deterministic, number of steps. Varying the number of steps dynamically after training is enabled by sharing weights across sequential computation steps in the Universal Transformer.
|
| 255 |
+
|
| 256 |
+
An intuitive example are functions whose execution requires the sequential processing of each input element. In this case, for any given choice of depth T T, one can construct an input sequence of length N>T N>T that cannot be processed correctly by a standard Transformer. With an appropriate, input-length dependent choice of sequential steps, however, a Universal Transformer, RNNs or Neural GPUs can execute such a function.
|
| 257 |
+
|
| 258 |
+
![Image 5: [Uncaptioned image]](https://arxiv.org/html/1807.03819v3/x4.png)
|
| 259 |
+
|
| 260 |
+
Appendix C UT with Dynamic Halting
|
| 261 |
+
----------------------------------
|
| 262 |
+
|
| 263 |
+
We implement the dynamic halting based on ACT(Graves, [2016](https://arxiv.org/html/1807.03819v3#bib.bib12)) as follows in TensorFlow. In each step of the UT with dynamic halting, we are given the halting probabilities, remainders, number of updates up to that point, and the previous state (all initialized as zeros), as well as a scalar threshold between 0 and 1 (a hyper-parameter). We then compute the new state for each position and calculate the new per-position halting probabilities based on the state for each position. The UT then decides to halt for some positions that crossed the threshold, and updates the state of other positions until the model halts for all positions or reaches a predefined maximum number of steps:
|
| 264 |
+
|
| 265 |
+
1
|
| 266 |
+
|
| 267 |
+
2
|
| 268 |
+
|
| 269 |
+
3 def should_continue(u0,u1,halting_probability,u2,n_updates,u3):
|
| 270 |
+
|
| 271 |
+
4 return tf.reduce_any(
|
| 272 |
+
|
| 273 |
+
5 tf.logical_and(
|
| 274 |
+
|
| 275 |
+
6 tf.less(halting_probability,threshold),
|
| 276 |
+
|
| 277 |
+
7 tf.less(n_updates,max_steps)))
|
| 278 |
+
|
| 279 |
+
8
|
| 280 |
+
|
| 281 |
+
9(_,_,_,remainder,n_updates,new_state)=tf.while_loop(
|
| 282 |
+
|
| 283 |
+
10 should_continue,ut_with_dynamic_halting,(state,
|
| 284 |
+
|
| 285 |
+
11 step,halting_probability,remainders,n_updates,previous_state))
|
| 286 |
+
|
| 287 |
+
Listing 1: UT with dynamic halting.
|
| 288 |
+
|
| 289 |
+
The following shows the computations in each step:
|
| 290 |
+
|
| 291 |
+
1 def ut_with_dynamic_halting(state,step,halting_probability,
|
| 292 |
+
|
| 293 |
+
2 remainders,n_updates,previous_state):
|
| 294 |
+
|
| 295 |
+
3
|
| 296 |
+
|
| 297 |
+
4 p=common_layers.dense(state,1,activation=tf.nn.sigmoid,
|
| 298 |
+
|
| 299 |
+
5 use_bias=True)
|
| 300 |
+
|
| 301 |
+
6
|
| 302 |
+
|
| 303 |
+
7 still_running=tf.cast(
|
| 304 |
+
|
| 305 |
+
8 tf.less(halting_probability,1.0),tf.float32)
|
| 306 |
+
|
| 307 |
+
9
|
| 308 |
+
|
| 309 |
+
10 new_halted=tf.cast(
|
| 310 |
+
|
| 311 |
+
11 tf.greater(halting_probability+p*still_running,threshold),
|
| 312 |
+
|
| 313 |
+
12 tf.float32)*still_running
|
| 314 |
+
|
| 315 |
+
13
|
| 316 |
+
|
| 317 |
+
14 still_running=tf.cast(
|
| 318 |
+
|
| 319 |
+
15 tf.less_equal(halting_probability+p*still_running,
|
| 320 |
+
|
| 321 |
+
16 threshold),tf.float32)*still_running
|
| 322 |
+
|
| 323 |
+
17
|
| 324 |
+
|
| 325 |
+
18
|
| 326 |
+
|
| 327 |
+
19 halting_probability+=p*still_running
|
| 328 |
+
|
| 329 |
+
20
|
| 330 |
+
|
| 331 |
+
21 remainders+=new_halted*(1-halting_probability)
|
| 332 |
+
|
| 333 |
+
22
|
| 334 |
+
|
| 335 |
+
23 halting_probability+=new_halted*remainders
|
| 336 |
+
|
| 337 |
+
24
|
| 338 |
+
|
| 339 |
+
25 n_updates+=still_running+new_halted
|
| 340 |
+
|
| 341 |
+
26
|
| 342 |
+
|
| 343 |
+
27
|
| 344 |
+
|
| 345 |
+
28
|
| 346 |
+
|
| 347 |
+
29
|
| 348 |
+
|
| 349 |
+
30 update_weights=tf.expand_dims(p*still_running+
|
| 350 |
+
|
| 351 |
+
31 new_halted*remainders,-1)
|
| 352 |
+
|
| 353 |
+
32
|
| 354 |
+
|
| 355 |
+
33 transformed_state=transition_function(self_attention(state))
|
| 356 |
+
|
| 357 |
+
34
|
| 358 |
+
|
| 359 |
+
35 new_state=((transformed_state*update_weights)+
|
| 360 |
+
|
| 361 |
+
36(previous_state*(1-update_weights)))
|
| 362 |
+
|
| 363 |
+
37 step+=1
|
| 364 |
+
|
| 365 |
+
38 return(transformed_state,step,halting_probability,
|
| 366 |
+
|
| 367 |
+
39 remainders,n_updates,new_state)
|
| 368 |
+
|
| 369 |
+
Listing 2: Computations in each step of the UT with dynamic halting.
|
| 370 |
+
|
| 371 |
+
Appendix D Description of some of the Tasks/Datasets
|
| 372 |
+
----------------------------------------------------
|
| 373 |
+
|
| 374 |
+
Here, we provide some additional details on the bAbI, subject-verb agreement, LAMBADA language modeling, and learning to execute (LTE) tasks.
|
| 375 |
+
|
| 376 |
+
### D.1 bAbI Question-Answering
|
| 377 |
+
|
| 378 |
+
The bAbi question answering dataset(Weston et al., [2015](https://arxiv.org/html/1807.03819v3#bib.bib33)) consists of 20 different synthetic tasks 7 7 7[https://research.fb.com/downloads/babi](https://research.fb.com/downloads/babi). The aim is that each task tests a unique aspect of language understanding and reasoning, including the ability of: reasoning from supporting facts in a story, answering true/false type questions, counting, understanding negation and indefinite knowledge, understanding coreferences, time reasoning, positional and size reasoning, path-finding, and understanding motivations (to see examples for each of these tasks, please refer to Table 1 in (Weston et al., [2015](https://arxiv.org/html/1807.03819v3#bib.bib33))).
|
| 379 |
+
|
| 380 |
+
There are two versions of the dataset, one with 1k training examples and the other with 10k examples. It is important for a model to be data-efficient to achieve good results using only the 1k training examples. Moreover, the original idea is that a single model should be evaluated across all the tasks (not tuning per task), which is the _train joint_ setup in Table[1](https://arxiv.org/html/1807.03819v3#S3.T1 "Table 1 ‣ 3.1 bAbI Question-Answering ‣ 3 Experiments and Analysis ‣ Universal Transformers"), and the tables presented in Appendix[E](https://arxiv.org/html/1807.03819v3#A5 "Appendix E bAbI Detailed Results ‣ Universal Transformers").
|
| 381 |
+
|
| 382 |
+
### D.2 Subject-Verb Agreement
|
| 383 |
+
|
| 384 |
+
Subject-verb agreement is the task of predicting number agreement between subject and verb in English sentences. Succeeding in this task is a strong indicator that a model can learn to approximate syntactic structure and therefore it was proposed by Linzen et al. ([2016](https://arxiv.org/html/1807.03819v3#bib.bib22)) as proxy for assessing the ability of different models to capture hierarchical structure in natural language.
|
| 385 |
+
|
| 386 |
+
Two experimental setups were proposed by Linzen et al. ([2016](https://arxiv.org/html/1807.03819v3#bib.bib22)) for training a model on this task: 1) training with a language modeling objective, i.e., next word prediction, and 2) as binary classification, i.e. predicting the number of the verb given the sentence. In this paper, we use the language modeling objective, meaning that we provide the model with an implicit supervision and evaluate based on the ranking accuracy of the correct form of the verb compared to the incorrect form of the verb.
|
| 387 |
+
|
| 388 |
+
In this task, in order to have different levels of difficulty, “agreement attractors” are used, i.e.one or more intervening nouns with the opposite number from the subject with the goal of confusing the model. In this case, the model needs to correctly identify the head of the syntactic subject that corresponds to a given verb and ignore the intervening attractors in order to predict the correct form of that verb. Here are some examples for this task in which subjects and the corresponding verbs are in boldface and agreement attractors are underlined:
|
| 389 |
+
|
| 390 |
+
### D.3 LAMBADA Language Modeling
|
| 391 |
+
|
| 392 |
+
The LAMBADA task(Paperno et al., [2016](https://arxiv.org/html/1807.03819v3#bib.bib23)) is a broad context language modeling task. In this task, given a narrative passage, the goal is to predict the last word (target word) of the last sentence (target sentence) in the passage. These passages are specifically selected in a way that human subjects are easily able to guess their last word if they are exposed to a long passage, but not if they only see the target sentence preceding the target word 8 8 8[http://clic.cimec.unitn.it/lambada/appendix_onefile.pdf](http://clic.cimec.unitn.it/lambada/appendix_onefile.pdf). Here is a sample from the dataset:
|
| 393 |
+
|
| 394 |
+
The LAMBADA task consists in predicting the target word given the whole passage (i.e., the context plus the target sentence). A “control set” is also provided which was constructed by randomly sampling passages of the same shape and size as the ones used to build LAMBADA, but without filtering them in any way. The control set is used to evaluate the models at standard language modeling before testing on the LAMBADA task, and therefore to ensure that low performance on the latter cannot be attributed simply to poor language modeling.
|
| 395 |
+
|
| 396 |
+
The task is evaluated in two settings: as _language modeling_ (the standard setup) and as _reading comprehension_. In the former (more challenging) case, a model is simply trained for the next word prediction on the training data, and evaluated on the target words at test time (i.e.the model is trained to predict all words, not specifically challenging target words). In this paper, we report the results of the Universal Transformer in both setups.
|
| 397 |
+
|
| 398 |
+
### D.4 Learning to Execute (LTE)
|
| 399 |
+
|
| 400 |
+
LTE is a set of tasks indicating the ability of a model to learn to execute computer programs and was proposed by Zaremba & Sutskever ([2015](https://arxiv.org/html/1807.03819v3#bib.bib35)). These tasks include two subsets: 1) program evaluation tasks (program, control, and addition) that are designed to assess the ability of models for understanding numerical operations, if-statements, variable assignments, the compositionality of operations, and more, as well as 2) memorization tasks (copy, double, and reverse).
|
| 401 |
+
|
| 402 |
+
The difficulty of the program evaluation tasks is parameterized by their length and nesting. The length parameter is the number of digits in the integers that appear in the programs (so the integers are chosen uniformly from [1, _length_]), and the nesting parameter is the number of times we are allowed to combine the operations with each other. Higher values of nesting yield programs with deeper parse trees. For instance, here is a program that is generated with length = 4 and nesting = 3.
|
| 403 |
+
|
| 404 |
+
Appendix E bAbI Detailed Results
|
| 405 |
+
--------------------------------
|
| 406 |
+
|
| 407 |
+
Appendix F bAbI Attention Visualization
|
| 408 |
+
---------------------------------------
|
| 409 |
+
|
| 410 |
+
We present a visualization of the attention distributions on bAbI tasks for a couple of examples. The visualization of attention weights is over different time steps based on different heads over all the facts in the story and a question. Different color bars on the left side indicate attention weights based on different heads (4 heads in total).
|
| 411 |
+
|
| 412 |
+
| An example from tasks 1: | (requiring one supportive fact to solve) |
|
| 413 |
+
| --- |
|
| 414 |
+
| Story: | |
|
| 415 |
+
| | John travelled to the hallway. |
|
| 416 |
+
| | Mary journeyed to the bathroom. |
|
| 417 |
+
| | Daniel went back to the bathroom. |
|
| 418 |
+
| | John moved to the bedroom |
|
| 419 |
+
| Question: | |
|
| 420 |
+
| | Where is Mary? |
|
| 421 |
+
| Model’s output: | |
|
| 422 |
+
| | bathroom |
|
| 423 |
+
|
| 424 |
+

|
| 425 |
+
|
| 426 |
+
(a) Step 1
|
| 427 |
+
|
| 428 |
+

|
| 429 |
+
|
| 430 |
+
(b) Step 2
|
| 431 |
+
|
| 432 |
+

|
| 433 |
+
|
| 434 |
+
(c) Step 3
|
| 435 |
+
|
| 436 |
+

|
| 437 |
+
|
| 438 |
+
(d) Step 4
|
| 439 |
+
|
| 440 |
+
Figure 5: Visualization of the attention distributions, when encoding the question: _“Where is Mary?”_.
|
| 441 |
+
|
| 442 |
+
| An example from tasks 2: | (requiring two supportive facts to solve) |
|
| 443 |
+
| --- |
|
| 444 |
+
| Story: | |
|
| 445 |
+
| | Sandra journeyed to the hallway. |
|
| 446 |
+
| | Mary went to the bathroom. |
|
| 447 |
+
| | Mary took the apple there. |
|
| 448 |
+
| | Mary dropped the apple. |
|
| 449 |
+
| Question: | |
|
| 450 |
+
| | Where is the apple? |
|
| 451 |
+
| Model’s output: | |
|
| 452 |
+
| | bathroom |
|
| 453 |
+
|
| 454 |
+

|
| 455 |
+
|
| 456 |
+
(a) Step 1
|
| 457 |
+
|
| 458 |
+

|
| 459 |
+
|
| 460 |
+
(b) Step 2
|
| 461 |
+
|
| 462 |
+

|
| 463 |
+
|
| 464 |
+
(c) Step 3
|
| 465 |
+
|
| 466 |
+

|
| 467 |
+
|
| 468 |
+
(d) Step 4
|
| 469 |
+
|
| 470 |
+
Figure 6: Visualization of the attention distributions, when encoding the question: _“Where is the apple?”_.
|
| 471 |
+
|
| 472 |
+
| An example from tasks 2: | (requiring two supportive facts to solve) |
|
| 473 |
+
| --- |
|
| 474 |
+
| Story: | |
|
| 475 |
+
| | John went to the hallway. |
|
| 476 |
+
| | John went back to the bathroom. |
|
| 477 |
+
| | John grabbed the milk there. |
|
| 478 |
+
| | Sandra went back to the office. |
|
| 479 |
+
| | Sandra journeyed to the kitchen. |
|
| 480 |
+
| | Sandra got the apple there. |
|
| 481 |
+
| | Sandra dropped the apple there. |
|
| 482 |
+
| | John dropped the milk. |
|
| 483 |
+
| Question: | |
|
| 484 |
+
| | Where is the milk? |
|
| 485 |
+
| Model’s output: | |
|
| 486 |
+
| | bathroom |
|
| 487 |
+
|
| 488 |
+

|
| 489 |
+
|
| 490 |
+
(a) Step 1
|
| 491 |
+
|
| 492 |
+

|
| 493 |
+
|
| 494 |
+
(b) Step 2
|
| 495 |
+
|
| 496 |
+

|
| 497 |
+
|
| 498 |
+
(c) Step 3
|
| 499 |
+
|
| 500 |
+

|
| 501 |
+
|
| 502 |
+
(d) Step 4
|
| 503 |
+
|
| 504 |
+
Figure 7: Visualization of the attention distributions, when encoding the question: _“Where is the milk?”_.
|
| 505 |
+
|
| 506 |
+
| An example from tasks 3: | (requiring three supportive facts to solve) |
|
| 507 |
+
| --- |
|
| 508 |
+
| Story: | |
|
| 509 |
+
| Mary got the milk. | |
|
| 510 |
+
| | John moved to the bedroom. |
|
| 511 |
+
| | Daniel journeyed to the office. |
|
| 512 |
+
| | John grabbed the apple there. |
|
| 513 |
+
| | John got the football. |
|
| 514 |
+
| | John journeyed to the garden. |
|
| 515 |
+
| | Mary left the milk. |
|
| 516 |
+
| | John left the football. |
|
| 517 |
+
| | Daniel moved to the garden. |
|
| 518 |
+
| | Daniel grabbed the football. |
|
| 519 |
+
| | Mary moved to the hallway. |
|
| 520 |
+
| | Mary went to the kitchen. |
|
| 521 |
+
| | John put down the apple there. |
|
| 522 |
+
| | John picked up the apple. |
|
| 523 |
+
| | Sandra moved to the hallway. |
|
| 524 |
+
| | Daniel left the football there. |
|
| 525 |
+
| | Daniel took the football. |
|
| 526 |
+
| | John travelled to the kitchen. |
|
| 527 |
+
| | Daniel dropped the football. |
|
| 528 |
+
| | John dropped the apple. |
|
| 529 |
+
| | John grabbed the apple. |
|
| 530 |
+
| | John went to the office. |
|
| 531 |
+
| | Sandra went back to the bedroom. |
|
| 532 |
+
| | Sandra took the milk. |
|
| 533 |
+
| | John journeyed to the bathroom. |
|
| 534 |
+
| | John travelled to the office. |
|
| 535 |
+
| | Sandra left the milk. |
|
| 536 |
+
| | Mary went to the bedroom. |
|
| 537 |
+
| | Mary moved to the office. |
|
| 538 |
+
| | John travelled to the hallway. |
|
| 539 |
+
| | Sandra moved to the garden. |
|
| 540 |
+
| | Mary moved to the kitchen. |
|
| 541 |
+
| | Daniel took the football. |
|
| 542 |
+
| | Mary journeyed to the bedroom. |
|
| 543 |
+
| | Mary grabbed the milk there. |
|
| 544 |
+
| | Mary discarded the milk. |
|
| 545 |
+
| | John went to the garden. |
|
| 546 |
+
| | John discarded the apple there. |
|
| 547 |
+
| Question: | |
|
| 548 |
+
| | Where was the apple before the bathroom? |
|
| 549 |
+
| Model’s output: | |
|
| 550 |
+
| | office |
|
| 551 |
+
|
| 552 |
+

|
| 553 |
+
|
| 554 |
+
(a) Step 1
|
| 555 |
+
|
| 556 |
+

|
| 557 |
+
|
| 558 |
+
(b) Step 2
|
| 559 |
+
|
| 560 |
+

|
| 561 |
+
|
| 562 |
+
(a) Step 3
|
| 563 |
+
|
| 564 |
+

|
| 565 |
+
|
| 566 |
+
(b) Step 4
|
| 567 |
+
|
| 568 |
+
Figure 9: Visualization of the attention distributions, when encoding the question: _“Where was the apple before the bathroom?”_.
|
1807/1807.10221.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1807.10221
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1807.10221#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1807.10221'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1809/1809.03327.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1809.03327
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1809.03327#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1809.03327'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1810/1810.04805.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1810.04805
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1810.04805#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1810.04805'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1810/1810.09305.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1810.09305
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1810.09305#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1810.09305'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1810/1810.12440.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1810.12440
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1810.12440#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1810.12440'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1901/1901.00212.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1901.00212
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1901.00212#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1901.00212'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1901/1901.03735.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1901.03735
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1901.03735#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1901.03735'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1901/1901.10995.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1901.10995
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1901.10995#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1901.10995'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1902/1902.05605.md
ADDED
|
@@ -0,0 +1,737 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1902.05605
|
| 4 |
+
|
| 5 |
+
Markdown Content:
|
| 6 |
+
Back to arXiv
|
| 7 |
+
|
| 8 |
+
This is experimental HTML to improve accessibility. We invite you to report rendering errors.
|
| 9 |
+
Use Alt+Y to toggle on accessible reporting links and Alt+Shift+Y to toggle off.
|
| 10 |
+
Learn more about this project and help improve conversions.
|
| 11 |
+
|
| 12 |
+
Why HTML?
|
| 13 |
+
Report Issue
|
| 14 |
+
Back to Abstract
|
| 15 |
+
Download PDF
|
| 16 |
+
Abstract
|
| 17 |
+
1Introduction
|
| 18 |
+
2Background
|
| 19 |
+
3The Cross
|
| 20 |
+
𝑄
|
| 21 |
+
Algorithm
|
| 22 |
+
License: arXiv.org perpetual non-exclusive license
|
| 23 |
+
arXiv:1902.05605v4 [cs.LG] 25 Mar 2024
|
| 24 |
+
Cross
|
| 25 |
+
𝑄
|
| 26 |
+
: Batch Normalization in Deep Reinforcement Learning for Greater Sample Efficiency and Simplicity
|
| 27 |
+
Aditya Bhatt * 1,4 Daniel Palenicek * 1,2 Boris Belousov 1,4 Max Argus 3
|
| 28 |
+
Artemij Amiranashvili 3 Thomas Brox 3 Jan Peters 1,2,4,5
|
| 29 |
+
*Equal contribution 1Intelligent Autonomous Systems, TU Darmstadt 2Hessian.AI 3University of Freiburg
|
| 30 |
+
4German Research Center for AI (DFKI) 5Centre for Cognitive Science, TU Darmstadt
|
| 31 |
+
aditya.bhatt@dfki.de, daniel.palenicek@tu-darmstadt.de
|
| 32 |
+
Abstract
|
| 33 |
+
|
| 34 |
+
Sample efficiency is a crucial problem in deep reinforcement learning. Recent algorithms, such as REDQ and DroQ, found a way to improve the sample efficiency by increasing the update-to-data (UTD) ratio to 20 gradient update steps on the critic per environment sample. However, this comes at the expense of a greatly increased computational cost. To reduce this computational burden, we introduce Cross
|
| 35 |
+
𝑄
|
| 36 |
+
: A lightweight algorithm for continuous control tasks that makes careful use of Batch Normalization and removes target networks to surpass the current state-of-the-art in sample efficiency while maintaining a low UTD ratio of
|
| 37 |
+
1
|
| 38 |
+
. Notably, Cross
|
| 39 |
+
𝑄
|
| 40 |
+
does not rely on advanced bias-reduction schemes used in current methods. Cross
|
| 41 |
+
𝑄
|
| 42 |
+
’s contributions are threefold: (1) it matches or surpasses current state-of-the-art methods in terms of sample efficiency, (2) it substantially reduces the computational cost compared to REDQ and DroQ, (3) it is easy to implement, requiring just a few lines of code on top of SAC.
|
| 43 |
+
|
| 44 |
+
1Introduction
|
| 45 |
+
Figure 1:Cross
|
| 46 |
+
𝑄
|
| 47 |
+
training performance aggregated over environments. Cross
|
| 48 |
+
𝑄
|
| 49 |
+
is more sample efficient (top) while being significantly more computationally efficient (bottom) in terms of the gradient steps, thanks to a low UTD
|
| 50 |
+
=
|
| 51 |
+
1
|
| 52 |
+
. Following agarwal2021rliable, we normalize performance by the maximum of REDQ in each environment.
|
| 53 |
+
|
| 54 |
+
Sample efficiency is a crucial concern when applying Deep Reinforcement Learning (Deep RL) methods on real physical systems. One of the first successful applications of Deep RL to a challenging problem of quadruped locomotion was achieved using Soft Actor-Critic (SAC, haarnoja2018sac), allowing a robot dog to learn to walk within
|
| 55 |
+
2
|
| 56 |
+
h of experience (haarnoja2018soft). Subsequently, it was noted that the critic in SAC may be underfitted, as only a single gradient update step on the network parameters is performed for each environment step. Therefore, Randomized Ensembled Double Q-Learning (REDQ, chen2021redq) was proposed, which increased this number of gradient steps, termed update-to-data (UTD) ratio. In addition, Dropout Q functions (DroQ, hiraoka2021droq) improved the computational efficiency of REDQ while maintaining the same sample efficiency by replacing its ensemble of critics with dropout. This enabled learning quadruped locomotion in a mere
|
| 57 |
+
20
|
| 58 |
+
min (smith2022walk). Thus, REDQ and DroQ represent the state-of-the-art in terms of sample efficiency in Deep RL for continuous control.
|
| 59 |
+
|
| 60 |
+
Importantly, both REDQ and DroQ showed that naively increasing the UTD ratio of SAC does not perform well due to the critic networks’ Q value estimation bias. Therefore, ensembling techniques were introduced for bias reduction (explicit ensemble in REDQ and implicit ensemble via dropout in DroQ), which allowed increasing the UTD to
|
| 61 |
+
20
|
| 62 |
+
critic updates per environment step. Higher UTD ratios improve sample efficiency by paying the price of increased computational cost, which manifests in higher wallclock time and energy consumption. It is, therefore, desirable to seek alternative methods that achieve the same or better sample efficiency at a lower computational cost, e.g., by using lower UTDs.
|
| 63 |
+
|
| 64 |
+
It turns out that even UTD
|
| 65 |
+
=
|
| 66 |
+
1
|
| 67 |
+
can perform surprisingly well if other algorithmic components are adjusted appropriately. In this paper, we introduce Cross
|
| 68 |
+
𝑄
|
| 69 |
+
, a lightweight algorithm that achieves superior performance by removing much of the algorithmic design complexity that was added over the years, culminating in the current state-of-the-art methods. First, it removes target networks, an ingredient widely believed to slow down training in exchange for stability (mnih2015dqn; lillicrap2016ddpg; Kim2019DeepMellowRT; fan2020theoretical). Second, we find that Batch Normalization variants (ioffe2015batchnorm; ioffe2017batchRenorm), when applied in a particular manner, effectively stabilize training and significantly improve sample efficiency. This contradicts others’ observations that it hurts the learning performance in Deep RL, e.g. hiraoka2021droq. Third, Cross
|
| 70 |
+
𝑄
|
| 71 |
+
uses wider critic layers, motivated by prior research on the ease of optimization of wider networks (ota2021widenets). In addition to the first two improvements, wider networks enable even higher returns.
|
| 72 |
+
|
| 73 |
+
Contributions.
|
| 74 |
+
|
| 75 |
+
(1) We present the Cross
|
| 76 |
+
𝑄
|
| 77 |
+
algorithm, which matches or surpasses the current state-of-the-art for model-free off-policy RL for continuous control environments with state observations in sample efficiency while being multiple times more computationally efficient; (2) By removing target networks, we are able to successfully accelerate off-policy Deep RL with BatchNorm; (3) We provide empirical investigations and hypotheses for Cross
|
| 78 |
+
𝑄
|
| 79 |
+
’s success. Cross
|
| 80 |
+
𝑄
|
| 81 |
+
’s changes mainly pertain to the deep network architecture of SAC; therefore, our study is chiefly empirical: through a series of ablations, we isolate and study the contributions of each part. We find that Cross
|
| 82 |
+
𝑄
|
| 83 |
+
matches or surpasses the state-of-the-art algorithms in sample efficiency while being up to
|
| 84 |
+
4
|
| 85 |
+
×
|
| 86 |
+
faster in terms of wallclock time without requiring critic ensembles, target networks, or high UTD ratios. We provide the Cross
|
| 87 |
+
𝑄
|
| 88 |
+
source code at github.com/adityab/CrossQ.
|
| 89 |
+
|
| 90 |
+
2Background
|
| 91 |
+
2.1Off-policy Reinforcement Learning and Soft Actor-Critic
|
| 92 |
+
|
| 93 |
+
We consider a discrete-time Markov Decision Process (MDP, puterman2014mdp), defined by the tuple
|
| 94 |
+
⟨
|
| 95 |
+
𝒮
|
| 96 |
+
,
|
| 97 |
+
𝒜
|
| 98 |
+
,
|
| 99 |
+
𝒫
|
| 100 |
+
,
|
| 101 |
+
ℛ
|
| 102 |
+
,
|
| 103 |
+
𝜌
|
| 104 |
+
,
|
| 105 |
+
𝛾
|
| 106 |
+
⟩
|
| 107 |
+
with state space
|
| 108 |
+
𝒮
|
| 109 |
+
, action space
|
| 110 |
+
𝒜
|
| 111 |
+
, transition probability
|
| 112 |
+
𝒔
|
| 113 |
+
𝑡
|
| 114 |
+
+
|
| 115 |
+
1
|
| 116 |
+
∼
|
| 117 |
+
𝒫
|
| 118 |
+
(
|
| 119 |
+
⋅
|
| 120 |
+
|
|
| 121 |
+
𝒔
|
| 122 |
+
𝑡
|
| 123 |
+
,
|
| 124 |
+
𝒂
|
| 125 |
+
𝑡
|
| 126 |
+
)
|
| 127 |
+
, reward function
|
| 128 |
+
𝑟
|
| 129 |
+
𝑡
|
| 130 |
+
=
|
| 131 |
+
ℛ
|
| 132 |
+
|
| 133 |
+
(
|
| 134 |
+
𝒔
|
| 135 |
+
𝑡
|
| 136 |
+
,
|
| 137 |
+
𝒂
|
| 138 |
+
𝑡
|
| 139 |
+
)
|
| 140 |
+
, initial state distribution
|
| 141 |
+
𝒔
|
| 142 |
+
0
|
| 143 |
+
∼
|
| 144 |
+
𝜌
|
| 145 |
+
and discount factor
|
| 146 |
+
𝛾
|
| 147 |
+
∈
|
| 148 |
+
[
|
| 149 |
+
0
|
| 150 |
+
,
|
| 151 |
+
1
|
| 152 |
+
)
|
| 153 |
+
. RL describes the problem of an agent learning an optimal policy
|
| 154 |
+
𝜋
|
| 155 |
+
for a given MDP. At each time step
|
| 156 |
+
𝑡
|
| 157 |
+
, the agent receives a state
|
| 158 |
+
𝒔
|
| 159 |
+
𝑡
|
| 160 |
+
and interacts with the environment according to its policy
|
| 161 |
+
𝜋
|
| 162 |
+
. We focus on the Maximum Entropy RL setting (ziebart2008maxent), where the agent’s objective is to find the optimal policy
|
| 163 |
+
𝜋
|
| 164 |
+
∗
|
| 165 |
+
, which maximizes the expected cumulative reward while keeping the entropy
|
| 166 |
+
ℋ
|
| 167 |
+
high;
|
| 168 |
+
arg
|
| 169 |
+
|
| 170 |
+
max
|
| 171 |
+
𝜋
|
| 172 |
+
∗
|
| 173 |
+
𝔼
|
| 174 |
+
𝒔
|
| 175 |
+
0
|
| 176 |
+
∼
|
| 177 |
+
𝜌
|
| 178 |
+
[
|
| 179 |
+
∑
|
| 180 |
+
𝑡
|
| 181 |
+
=
|
| 182 |
+
0
|
| 183 |
+
∞
|
| 184 |
+
𝛾
|
| 185 |
+
𝑡
|
| 186 |
+
(
|
| 187 |
+
𝑟
|
| 188 |
+
𝑡
|
| 189 |
+
−
|
| 190 |
+
𝛼
|
| 191 |
+
ℋ
|
| 192 |
+
(
|
| 193 |
+
𝜋
|
| 194 |
+
(
|
| 195 |
+
⋅
|
| 196 |
+
|
|
| 197 |
+
𝒔
|
| 198 |
+
𝑡
|
| 199 |
+
)
|
| 200 |
+
)
|
| 201 |
+
)
|
| 202 |
+
]
|
| 203 |
+
.
|
| 204 |
+
The action-value function is defined by
|
| 205 |
+
𝑄
|
| 206 |
+
|
| 207 |
+
(
|
| 208 |
+
𝒔
|
| 209 |
+
,
|
| 210 |
+
𝒂
|
| 211 |
+
)
|
| 212 |
+
=
|
| 213 |
+
𝔼
|
| 214 |
+
𝜋
|
| 215 |
+
,
|
| 216 |
+
𝒫
|
| 217 |
+
|
| 218 |
+
[
|
| 219 |
+
∑
|
| 220 |
+
𝑡
|
| 221 |
+
=
|
| 222 |
+
0
|
| 223 |
+
∞
|
| 224 |
+
𝛾
|
| 225 |
+
𝑡
|
| 226 |
+
|
| 227 |
+
(
|
| 228 |
+
𝑟
|
| 229 |
+
𝑡
|
| 230 |
+
−
|
| 231 |
+
𝛼
|
| 232 |
+
|
| 233 |
+
log
|
| 234 |
+
|
| 235 |
+
𝜋
|
| 236 |
+
|
| 237 |
+
(
|
| 238 |
+
𝒂
|
| 239 |
+
𝑡
|
| 240 |
+
|
|
| 241 |
+
𝒔
|
| 242 |
+
𝑡
|
| 243 |
+
)
|
| 244 |
+
)
|
| 245 |
+
|
|
| 246 |
+
𝒔
|
| 247 |
+
0
|
| 248 |
+
=
|
| 249 |
+
𝒔
|
| 250 |
+
,
|
| 251 |
+
𝒂
|
| 252 |
+
0
|
| 253 |
+
=
|
| 254 |
+
𝒂
|
| 255 |
+
]
|
| 256 |
+
and describes the expected reward when taking action
|
| 257 |
+
𝒂
|
| 258 |
+
in state
|
| 259 |
+
𝒔
|
| 260 |
+
. Soft Actor-Critic (SAC, (haarnoja2018sac)) is a popular algorithm that solves the MaxEnt RL problem. SAC parametrizes the Q function and policy as neural networks and trains two independent versions of the Q function, using the minimum of their estimates to compute the regression targets for Temporal Difference (TD) learning. This clipped double-Q trick, originally proposed by fujimoto2018td3 in TD3, helps in reducing the potentially destabilizing overestimation bias inherent in approximate Q-learning (hasselt2010double).
|
| 261 |
+
|
| 262 |
+
2.2High update-to-data Ratios, REDQ, and DroQ
|
| 263 |
+
|
| 264 |
+
Despite its popularity among practitioners and as a foundation for other more complex algorithms, SAC leaves much room for improvement in terms of sample efficiency. Notably, SAC performs exactly one gradient-based optimization step per environment interaction. SAC’s UTD
|
| 265 |
+
=
|
| 266 |
+
1
|
| 267 |
+
setting is analogous to simply training for fewer epochs in supervised learning. Therefore, in recent years, gains in sample efficiency within RL have been achieved through increasing the UTD ratio (janner2019mbpo; chen2021redq; hiraoka2021droq; nikishin2022primacy). Different algorithms, however, substantially vary in their approaches to achieving high UTD ratios. janner2019mbpo uses a model to generate synthetic data, which allows for more overall gradient steps. nikishin2022primacy adopt a simpler approach: they increase the number of gradient steps while periodically resetting the policy and critic networks to fight premature convergence to local minima. We now briefly outline the two high-UTD methods to which we compare Cross
|
| 268 |
+
𝑄
|
| 269 |
+
.
|
| 270 |
+
|
| 271 |
+
REDQ.
|
| 272 |
+
|
| 273 |
+
chen2021redq find that merely raising SAC’s UTD ratio hurts performance. They attribute this to the accumulation of the learned Q functions’ estimation bias over multiple update steps—despite the clipped double-Q trick—which destabilizes learning. To remedy this bias more strongly, they increase the number of Q networks from two to an ensemble of 10. Their method, called REDQ, permits stable training at high UTD ratios up to 20.
|
| 274 |
+
|
| 275 |
+
DroQ.
|
| 276 |
+
|
| 277 |
+
hiraoka2021droq note that REDQ’s ensemble size, along with its high UTD ratio, makes training computationally expensive. They instead propose using a smaller ensemble of Q functions equipped with Dropout (srivastava2014dropout), along with Layer Normalization (ba2016layernorm) to stabilize training in response to the noise introduced by Dropout. Called DroQ, their method is computationally cheaper than REDQ, yet still expensive due to its UTD ratio of 20.
|
| 278 |
+
|
| 279 |
+
3The Cross
|
| 280 |
+
𝑄
|
| 281 |
+
Algorithm
|
| 282 |
+
1def critic_loss(Q_params, policy_params, obs, acts, rews, next_obs):
|
| 283 |
+
2 next_acts, next_logpi = policy.apply(policy_params, obs)
|
| 284 |
+
3
|
| 285 |
+
4 # Concatenated forward pass
|
| 286 |
+
5 all_q, new_Q_params = Q.apply(Q_params,
|
| 287 |
+
6 jnp.concatenate([obs, next_obs]),
|
| 288 |
+
7 jnp.concatenate([acts, next_acts])
|
| 289 |
+
8 )
|
| 290 |
+
9 # Split all_q predictions and stop gradient on next_q
|
| 291 |
+
10 q, next_q = jnp.split(all_q, 2)
|
| 292 |
+
11 next_q = jnp.min(next_q, axis=0) # min over double Q function
|
| 293 |
+
12 next_q = jax.lax.stop_gradient(next_q - alpha * next_logpi)
|
| 294 |
+
13 return jnp.mean((q - (rews + gamma * next_q))**2), new_Q_params\end{lstlisting}
|
| 295 |
+
14 \vspace{-1.1em}
|
| 296 |
+
15 \caption{\textbf{\CrossQ{} critic loss in JAX.} The \CrossQ{} critic loss is easy to implement on top of an existing SAC implementation. One just adds the batch normalization layers into the critic network and removes the target network. As we are now left with only the critic network, one can simply concatenate observations and next observations, as well as actions and next actions along the batch dimension, perform a joint forward pass, and split up the batches afterward.
|
| 297 |
+
16 Combining two forward passes into one grants a small speed-up thanks to requiring only one CUDA call instead of two.
|
| 298 |
+
17 }
|
| 299 |
+
18 \label{fig:crossq_python_code}
|
| 300 |
+
19\end{figure}
|
| 301 |
+
20In this paper, we challenge this current trend of high UTD ratios and demonstrate that we can achieve competitive sample efficiency at a much lower computational cost with a UTD~$=1$ method.
|
| 302 |
+
21\CrossQ{} is our new state-of-the-art off-policy actor-critic algorithm.
|
| 303 |
+
22Based on SAC, it uses purely network-architectural
|
| 304 |
+
23engineering insights from deep learning to accelerate training.
|
| 305 |
+
24As a result, it \xcancel{crosses out} much of the algorithmic design complexity that was added over the years and which led to the current state-of-the-art methods. In doing so, we present a much simpler yet more efficient algorithm.
|
| 306 |
+
25In the following paragraphs, we introduce the three design choices that constitute \CrossQ{}.
|
| 307 |
+
26
|
| 308 |
+
27\subsection{Design Choice 1: Removing Target Networks}
|
| 309 |
+
28\citet{mnih2015dqn} originally introduced target networks to stabilize the training of value-based off-policy RL methods, and today, most algorithms require them~\citep{lillicrap2016ddpg,fujimoto2018td3,haarnoja2018sac}. SAC updates the critics’ target networks with Polyak Averaging
|
| 310 |
+
29\begin{align}
|
| 311 |
+
30\label{eq:taget_polyak}
|
| 312 |
+
31 \textstyle \vtheta^\circ \leftarrow (1-\tau) \vtheta^\circ + \tau \vtheta,
|
| 313 |
+
32\end{align}
|
| 314 |
+
33where $\vtheta^\circ$ are the target network parameters, and $\vtheta$ are those of the trained critic. Here $\tau$ is the \textit{target network smoothing coefficient}; with a high $\tau=1$ (equivalent to cutting out the target network), SAC training can diverge, leading to explosive growth in $\vtheta$ and the $Q$ predictions.
|
| 315 |
+
34Target networks stabilize training by explicitly delaying value function updates, arguably slowing down online learning~\citep{plappert2018multi, Kim2019DeepMellowRT,morales2020grokking}.
|
| 316 |
+
35
|
| 317 |
+
36Recently,~\citet{yang2021overcoming} found that critics with Random Fourier Features can be trained without target networks, suggesting that the choice of layer activations affects the stability of training. Our experiments in Section~\ref{sec:ablation} uncover an even simpler possibility: using bounded activation functions or feature normalizers is sufficient to prevent critic divergence in the absence of target networks, whereas the common choice of \texttt{relu} without normalization diverges. While others have used normalizers in Deep RL before, we are the first to identify that they make target networks redundant. Our next design choice exploits this insight to obtain an even greater boost.
|
| 318 |
+
37
|
| 319 |
+
38\subsection{Design Choice 2: Using Batch Normalization}
|
| 320 |
+
39\label{sec:design_choice_BN}
|
| 321 |
+
40\begin{figure}[t]
|
| 322 |
+
41\begin{tabular}{@{\hspace{2cm}}l@{\hspace{1cm}}l}
|
| 323 |
+
42 \multicolumn{1}{c}{SAC:} & \multicolumn{1}{c}{\CrossQ{} (Ours):} \\[8pt]
|
| 324 |
+
43
|
| 325 |
+
44 {$\!\begin{aligned}
|
| 326 |
+
45 {\color{magenta}Q_\vtheta}(\mS_t,\mA_t) &= \vq_t \\
|
| 327 |
+
46 {\color{magenta}Q_{\vtheta^\circ}}(\mS_{t+1},\mA_{t+1}) &= {\color{purple}\vq_{t+1}^\circ}
|
| 328 |
+
47 \end{aligned}$} &
|
| 329 |
+
48 {$\!\begin{aligned}
|
| 330 |
+
49 {\color{cyan}Q_\vtheta}\left(
|
| 331 |
+
50 \begin{bmatrix}
|
| 332 |
+
51 \begin{aligned}
|
| 333 |
+
52 &\mS_t \\
|
| 334 |
+
53 &\mS_{t+1}
|
| 335 |
+
54 \end{aligned}
|
| 336 |
+
55 \end{bmatrix},
|
| 337 |
+
56 \begin{bmatrix}
|
| 338 |
+
57 \begin{aligned}
|
| 339 |
+
58 &\mA_t \\
|
| 340 |
+
59 &\mA_{t+1}
|
| 341 |
+
60 \end{aligned}
|
| 342 |
+
61 \end{bmatrix}
|
| 343 |
+
62 \right) =
|
| 344 |
+
63 \begin{bmatrix}
|
| 345 |
+
64 \begin{aligned}
|
| 346 |
+
65 &\vq_t \\
|
| 347 |
+
66 &\vq_{t+1}
|
| 348 |
+
67 \end{aligned}
|
| 349 |
+
68 \end{bmatrix}
|
| 350 |
+
69 \end{aligned}$} \\[15pt]
|
| 351 |
+
70 {$\!\begin{aligned}
|
| 352 |
+
71 \gL_{\color{magenta}\vtheta} &= (\vq_t - \vr_t - \gamma\, {\color{purple}\vq^\circ_{t+1}})^2
|
| 353 |
+
72 \end{aligned}$} &
|
| 354 |
+
73 {$\!\begin{aligned}
|
| 355 |
+
74 \gL_{\color{cyan}\vtheta} &= (\vq_t - \vr_t - \gamma\,|\vq_{t+1}|_{\mathtt{sg}})^2
|
| 356 |
+
75 \end{aligned}$}
|
| 357 |
+
76\end{tabular}
|
| 358 |
+
77\caption{SAC \textcolor{magenta}{without BatchNorm in the critic} ${\color{magenta}Q_\vtheta}$ (left) requires \textcolor{purple}{target $Q$ values $\vq_{t+1}^\circ$} to stabilize learning.
|
| 359 |
+
78\CrossQ{} \textcolor{cyan}{with BatchNorm in the critic} ${\color{cyan}Q_\vtheta}$ (right) removes the need for target networks and allows for a joint forward pass of both current and future values.
|
| 360 |
+
79Batches are sampled from the replay buffer $\gB$: $\mS_t, \mA_t, \vr_t, \mS_{t+1}\sim \gB$ and $\mA_{t+1}\sim \pi_\phi(\mS_{t+1})$ from the current policy.
|
| 361 |
+
80$|\cdot|_{\mathtt{sg}}$ denotes the \texttt{stop-gradient} operation.
|
| 362 |
+
81}
|
| 363 |
+
82\label{fig:jointForwardPass}
|
| 364 |
+
83\end{figure}
|
| 365 |
+
84
|
| 366 |
+
85\begin{wrapfigure}[18]{r}{0.3\textwidth}
|
| 367 |
+
86 \centering
|
| 368 |
+
87 \vspace{-5.3em}
|
| 369 |
+
88 \includegraphics[width=0.27\textwidth]{fig/action_densities.pdf}
|
| 370 |
+
89 \vspace{-1.4em}
|
| 371 |
+
90 \caption{\textbf{Replay buffer and current policy actions are distributed differently.} Darker colors denote higher density. Estimated from a batch of $10^4$ transitions $(\va,\vs’)\sim\mathcal{B};$ $\va’\sim\pi_\phi(\vs’)$, after $3\times10^5$ training steps on \texttt{Walker2d}; $a_4$ and $a_5$ are random action dimensions.}
|
| 372 |
+
91 \label{ref:action_densities}
|
| 373 |
+
92\end{wrapfigure}
|
| 374 |
+
93
|
| 375 |
+
94BatchNorm has not yet seen wide adoption in value-based off-policy RL methods, despite its success and widespread use in supervised learning~\citep{he2016resnet, santurkar2018howbatchnorm}, attempts at doing so have fared poorly. \citet{lillicrap2016ddpg} use BatchNorm layers on the state-only representation layers in the DDPG critic but find that it does not help significantly. Others use BatchNorm in decoupled feature extractors for Deep RL networks~\citep{ota2020can, ota2021widenets}, but not in critic networks. \citet{hiraoka2021droq} report that using BatchNorm in critics causes training to fail in DroQ.
|
| 376 |
+
95
|
| 377 |
+
96\hspace{0em}\textbf{We find using BatchNorm \emph{carefully}, when \emph{additionally} removing target networks, performs surprisingly well, trains stably, and is, in fact, algorithmically simpler than current methods.}
|
| 378 |
+
97
|
| 379 |
+
98First, we explain why BatchNorm needs to be used \emph{carefully}.
|
| 380 |
+
99Within the critic loss $[Q_\vtheta(\mS,\mA) - (\vr + \gamma Q_{\vtheta^\circ}(\mS’,\mA’))]^2$, predictions are made for two differently distributed batches of state-action pairs; $(\mS,\mA)$ and $(\mS’,\mA’)$, where $\mA’\sim\pi_\phi(\mS’)$ is sampled from the \textit{current policy}, while $\mA$ originates from old behavior policies.
|
| 381 |
+
100
|
| 382 |
+
101Just like the target network, the BatchNorm parameters are updated by Polyak Averaging from the live network~(Equation~\ref{eq:taget_polyak}).
|
| 383 |
+
102The BatchNorm running statistics of the live network, which were estimated from batches of $(\vs,\va)$ pairs, will clearly not have \textit{seen} samples $(\vs’,\pi_\phi(\vs’))$ and will further not match their statistics.
|
| 384 |
+
103In other words, the state-action inputs evaluated by the target network will be out-of-distribution, given its mismatched BatchNorm running statistics.
|
| 385 |
+
104It is well known that the prediction quality of BatchNorm-equipped networks degrades in the face of such test-time distribution shifts~\citep{pham2022continual, lim2023ttn}.
|
| 386 |
+
105
|
| 387 |
+
106Removing the target network provides an \textit{elegant} solution.
|
| 388 |
+
107With the target network removed, we can concatenate both batches and feed them through the $Q$ network in a single forward pass, as illustrated in Figure~\ref{fig:jointForwardPass} and shown in code in Figure~\ref{fig:crossq_python_code}. This simple trick ensures that BatchNorm’s normalization moments arise from the union of both batches, corresponding to a $50/50$ mixture of their respective distributions. Such normalization layers \textit{do not} perceive the $(\vs’,\pi_\phi(\vs’))$ batch as being out-of-distribution. This small change to SAC allows the safe use of BatchNorm and greatly accelerates training.
|
| 389 |
+
108We are not the only ones to identify this way of using BatchNorm to tackle the distribution mismatch; other works in supervised learning, e.g.,
|
| 390 |
+
109Test-Time Adaptation \citep{lim2023ttn}, EvalNorm \citep{singh2019evalnorm}, and \textit{Four Things Everyone Should Know to Improve Batch Normalization} \citep{Summers2020Four} also use mixed moments to bridge this gap.
|
| 391 |
+
110
|
| 392 |
+
111
|
| 393 |
+
112
|
| 394 |
+
113In practice, \CrossQ{}’s actor and critic networks use Batch Renormalization~(\texttt{BRN},~\citet{ioffe2017batchRenorm}), an improved version of the original \texttt{BN}~\citep{ioffe2015batchnorm} that is robust to long-term training instabilities originating from minibatch noise. \texttt{BRN} performs batch normalization using the less noisy \textit{running statistics} after a warm-up period, instead of noisy minibatch estimates as in \texttt{BN}. In the rest of this paper, all discussions with ‘‘BatchNorm’’ apply equally to both versions unless explicitly disambiguated by \texttt{BN} or \texttt{BRN}.
|
| 395 |
+
114
|
| 396 |
+
115\subsection{Design Choice 3: Wider Critic Networks}
|
| 397 |
+
116Following \citet{ota2021widenets}, we find that wider critic network layers in \CrossQ{} lead to even faster learning.
|
| 398 |
+
117As we show in our ablations in Section~\ref{sec:ablation}, most performance gains originate from the first two design choices; however, wider critic networks further boost the performance, helping to match or outperform REDQ and DroQ sample efficiency.
|
| 399 |
+
118
|
| 400 |
+
119We want to stress again that \textbf{\CrossQ{}}, a UTD $=1$ method, \textbf{\textit{does not use bias-reducing ensembles, high UTD ratios or target networks}}. Despite this, it achieves its competitive sample efficiency at a fraction of the compute cost of REDQ and DroQ (see Figures~\ref{ref:sample_efficiency} and~\ref{ref:compute_efficiency}). Note that our proposed changes can just as well be combined with other off-policy TD-learning methods, such as TD3, as shown in our experiments in Section~\ref{sec:sample_efficiency}.
|
| 401 |
+
120
|
| 402 |
+
121\section{Experiments and Analysis}
|
| 403 |
+
122\begin{figure}[t]
|
| 404 |
+
123 \centering
|
| 405 |
+
124 \includegraphics[width=\textwidth]{fig/camera_ready_sample_efficiency.pdf}
|
| 406 |
+
125 \vspace{-2em}
|
| 407 |
+
126 \caption{\textbf{\CrossQ{} sample efficiency.}
|
| 408 |
+
127 Compared to REDQ and DroQ (UTD $=20$) \CrossQ{} (UTD $=1$) performs either comparably, better, or---for the more challenging \texttt{Humanoid} tasks---substantially better. These results directly transfer to TD3 as the base algorithm in \CrossQ{} (TD3). We plot \textit{interquartile mean} (IQM) and $70\%$ quantile interval of the episodic returns over $10$ seeds.
|
| 409 |
+
128 }
|
| 410 |
+
129 \vspace{-1em}
|
| 411 |
+
130 \label{ref:sample_efficiency}
|
| 412 |
+
131\end{figure}
|
| 413 |
+
132We conduct experiments to provide empirical evidence for \CrossQ{}’s performance,
|
| 414 |
+
133and investigate:
|
| 415 |
+
134\vspace{-0.5em}
|
| 416 |
+
135\begin{enumerate}[noitemsep]
|
| 417 |
+
136 \item Sample efficiency of \CrossQ{} compared to REDQ and DroQ;%
|
| 418 |
+
137 \item Computational efficiency in terms of wallclock time and performed gradient step;%
|
| 419 |
+
138 \item Effects of the proposed design choices on the performance via Q function bias evaluations;
|
| 420 |
+
139\end{enumerate}
|
| 421 |
+
140\vspace{-0.5em}
|
| 422 |
+
141And conduct further ablation studies for the above design choices. We evaluate across a wide range of continuous-control \texttt{MuJoCo}~\citep{todorov2012mujoco} environments, with $10$ random seeds each. Following~\citet{janner2019mbpo,chen2021redq} and~\citet{hiraoka2021droq}, we evaluate on the same four \texttt{Hopper}, \texttt{Walker2d}, \texttt{Ant}, and \texttt{Humanoid} tasks, as well as two additional tasks: \texttt{HalfCheetah} and the more challenging \texttt{HumanoidStandup} from Gymnasium~\citep{towers2023gymnasium}.
|
| 423 |
+
142We adapted the JAX version of stable-baselines~\citep{stable-baselines3} for our experiments.
|
| 424 |
+
143
|
| 425 |
+
144
|
| 426 |
+
145\subsection{Sample Efficiency of \CrossQ{}}
|
| 427 |
+
146\label{sec:sample_efficiency}
|
| 428 |
+
147Figure~\ref{ref:sample_efficiency} compares our proposed \CrossQ{} algorithm with REDQ, DroQ, SAC and TD3 in terms of their sample efficiency, i.e., average episode return at a given number of environment interactions. As a proof of concept, we also present \CrossQ{}~(TD3), a version of \CrossQ{} which uses TD3 instead of SAC as the base algorithm.
|
| 429 |
+
148We perform periodic evaluations during training to obtain the episodic reward. From these, we report the mean and standard deviations over $10$ random seeds.
|
| 430 |
+
149All subsequent experiments in this paper follow the same protocol.
|
| 431 |
+
150
|
| 432 |
+
151This experiment shows that \CrossQ{} matches or outperforms the best baseline in all the presented environments except on \texttt{Ant}, where REDQ performs better in the early training stage, but \CrossQ{} eventually matches it.
|
| 433 |
+
152On \texttt{Hopper}, \texttt{Walker}, and \texttt{HalfCheetah}, the learning curves of \CrossQ{} and REDQ overlap, and there is no significant difference.
|
| 434 |
+
153On the harder \texttt{Humanoid} and \texttt{HumanoidStandup} tasks, \CrossQ{} and \CrossQ{}~(TD3) both substantially surpass all baselines.
|
| 435 |
+
154
|
| 436 |
+
155\subsection{Computational Efficiency of \CrossQ{}}
|
| 437 |
+
156\label{sec:computational_efficiency}
|
| 438 |
+
157\begin{figure}[t]
|
| 439 |
+
158 \centering
|
| 440 |
+
159 \includegraphics[width=\textwidth]{fig/camera_ready_runtime_wallclock.pdf}
|
| 441 |
+
160 \vspace{-2em}
|
| 442 |
+
161 \caption{\textbf{Computational efficiency.} \CrossQ{} trains an order of magnitude faster, taking only $5\%$ of the gradient steps, substantially saving on wallclock time.
|
| 443 |
+
162 The dashed horizontal lines are visual aids to better compare the final performance after training for $5\times10^6$ environment steps. We plot IQM and $70\%$ quantile interval over $10$ seeds. Appendix~\ref{sec:wallclock} provides a table of wallclock times.}
|
| 444 |
+
163 \label{ref:compute_efficiency}
|
| 445 |
+
164 \vspace{-1em}
|
| 446 |
+
165\end{figure}
|
| 447 |
+
166
|
| 448 |
+
167Figure~\ref{ref:compute_efficiency} compares the computational efficiency of \CrossQ{} to the baselines.
|
| 449 |
+
168This metric is where \CrossQ{} makes the biggest leap forward. \CrossQ{} requires $20\times$ fewer gradient steps than REDQ and DroQ, which results in roughly $4\times$ faster wallclock speeds (Table~\ref{tab:computation_times}).
|
| 450 |
+
169Especially on the more challenging \texttt{Humanoid} and \texttt{HumanoidStandup} tasks the speedup is the most pronounced.
|
| 451 |
+
170In our view, this is a noteworthy feature.
|
| 452 |
+
171On the one hand, it opens the possibility of training agents in a truly online and data-efficient manner, such as in real-time robot learning.
|
| 453 |
+
172On the other hand, with large computing budgets \CrossQ{} can allow the training of even larger models for longer than what is currently feasible, because of its computational efficiency stemming from its low UTD~$=1$.
|
| 454 |
+
173
|
| 455 |
+
174
|
| 456 |
+
175\subsection{Evaluating $Q$ Function Estimation Bias}
|
| 457 |
+
176\label{sec:q_bias}
|
| 458 |
+
177All methods we consider in this paper are based on SAC and, thus, include the clipped double-Q trick to reduce Q function overestimation bias~\citep{fujimoto2018td3}. \citet{chen2021redq} and \citet{hiraoka2021droq} stress the importance of keeping this bias even lower to achieve their high performances and intentionally design REDQ and DroQ to additionally reduce bias with explicit and implicit ensembling. In contrast, \CrossQ{} outperforms both baselines without any ensembling. Could \CrossQ{}’s high performance be attributed to implicitly reducing the bias as a side effect of our design choices? Using the same evaluation protocol as~\citet{chen2021redq}, we compare the normalized Q prediction biases in Figure~\ref{fig:q_bias_2envs}. Due to space constraints, here we show \texttt{Hopper} and \texttt{Ant} and place the rest of the environments in Figure~\ref{fig:q_bias} in the Appendix.
|
| 459 |
+
178
|
| 460 |
+
179We find that REDQ and DroQ indeed have lower bias than SAC and significantly lower bias than SAC with UTD $=20$. The results for \CrossQ{} are mixed: while its bias trend exhibits a lower mean and variance than SAC, in some environments, its bias is higher than DroQ, and in others, it is lower or comparable. REDQ achieves comparable or worse returns than CrossQ while maintaining the least bias. As \CrossQ{} performs better \textit{despite} having---perhaps paradoxically---generally higher Q estimation bias, we conclude that the relationship between performance and estimation bias is complex, and one does not seem to have clear implications on the other.
|
| 461 |
+
180
|
| 462 |
+
181\begin{figure}[t]
|
| 463 |
+
182\label{fig:q_bias_2envs}
|
| 464 |
+
183 \centering
|
| 465 |
+
184 \includegraphics[width=\textwidth]{fig/camera_ready_Q_bias_2envs.pdf}
|
| 466 |
+
185 \vspace{-2em}
|
| 467 |
+
186 \caption{\textbf{$Q$ estimation bias does not reliably influence learning performance}. Following the analysis of~\citet{chen2021redq}, we plot the IQM and $70\%$ quantile interval of the normalized Q function bias. REDQ generally has the least bias over $10$ seeds. \CrossQ{} matches or outperforms DroQ, REDQ and SAC while showing more Q function bias in all environments. The full set of environments is shown in Fig.~\ref{fig:q_bias} in the Appendix.}
|
| 468 |
+
187 \label{fig:q_bias}
|
| 469 |
+
188 \vspace{-1em}
|
| 470 |
+
189\end{figure}
|
| 471 |
+
190
|
| 472 |
+
191\subsection{Ablations}
|
| 473 |
+
192\label{sec:ablation}
|
| 474 |
+
193We conduct ablation studies to better understand the impact of different design choices in \CrossQ{}.
|
| 475 |
+
194
|
| 476 |
+
195\subsubsection{\small{Disentangling the Effects of Target Networks and BatchNorm}}
|
| 477 |
+
196\label{sec:bounded_activations}
|
| 478 |
+
197\begin{figure}[t]
|
| 479 |
+
198 \centering
|
| 480 |
+
199 \includegraphics[width=\textwidth]{fig/camera_ready_crossQ_ablation_bounded_activations.pdf}
|
| 481 |
+
200 \vspace{-2em}
|
| 482 |
+
201 \caption{\textbf{The effects of target networks and BatchNorm on sample efficiency.} All SAC variants in this experiment use critics with $\mathrm{tanh}$ activations, since they allow divergence-free training without target networks, enabling this comparison. This ablation uses the original BatchNorm (\texttt{BN}, \citet{ioffe2015batchnorm}). Removing target networks (\texttt{-TN}) provides only small improvements over the SAC baseline with target nets. BatchNorm with target nets (\texttt{+BN}, green) is unstable. Using BatchNorm after removing target nets (\texttt{-TN+BN})---the configuration most similar to \CrossQ{}---performs best. We plots IQM return and $70\%$ quantile intervals over $10$ seeds.}
|
| 483 |
+
202 \vspace{-1em}
|
| 484 |
+
203\label{fig:bounded_activations}
|
| 485 |
+
204\end{figure}
|
| 486 |
+
205
|
| 487 |
+
206\CrossQ{} changes SAC in three ways; of these, two explicitly aim to accelerate optimization: the removal of target networks, and the introduction of BatchNorm. Unfortunately, SAC without target networks diverges; therefore, to study the contribution of the first change, we need a way to compare SAC---divergence-free---\textit{with and without target networks}. Fortunately, we find that such a way exists: according to our supplementary experiments in Appendix~\ref{sec:diverse_activations}, simply using bounded activation functions in the critic appears to prevent divergence. This is a purely empirical observation and an in-depth study regarding the influence of activations and normalizers on the stability of Deep RL is beyond the scope of this paper. In this specific ablation, we use \texttt{tanh} activations instead of \texttt{relu}, solely as a tool to make the intended comparison possible.
|
| 488 |
+
207
|
| 489 |
+
208Figure~\ref{fig:bounded_activations} shows the results of our experiment. The performance of SAC without target networks supports the common intuition that target networks indeed slow down learning to a small extent. We find that the combination of BatchNorm and Target Networks performs inconsistently, failing to learn anything in half of the environments. Lastly, the configuration of BatchNorm without target networks---and the closest to \CrossQ{}---achieves the best aggregate performance, with the boost being significantly bigger than that from removing target networks alone.
|
| 490 |
+
209In summary, even though removing target networks may slightly improve performance in some environments, it is the combination of removing target networks and adding BatchNorm that accelerates learning the most.
|
| 491 |
+
210
|
| 492 |
+
211\subsubsection{Ablating the Different Design Choices and Hyperparameters}
|
| 493 |
+
212\begin{wrapfigure}[20]{tr}{0.45\textwidth}
|
| 494 |
+
213 \vspace{-1.5em}
|
| 495 |
+
214 \centering
|
| 496 |
+
215 \includegraphics[width=0.45\textwidth]{fig/camera_ready_crossQ_ablation_alternative_IQM.pdf}
|
| 497 |
+
216 \vspace{-2.45em}
|
| 498 |
+
217 \caption{\textbf{Ablations on \CrossQ{} and SAC.}
|
| 499 |
+
218 Loss in IQM return in percent---relative to \CrossQ{}---at $1$M environment interactions. Aggregated over all environments and six seeds each, with $95\%$ bootstrapped confidence intervals~\citep{agarwal2021rliable}.
|
| 500 |
+
219 Left shows \CrossQ{} ablations; Right shows effects of adding parts on top of SAC.
|
| 501 |
+
220 Figure~\ref{fig:crossq_ablations} in Appendix shows individual training curves.
|
| 502 |
+
221 }
|
| 503 |
+
222 \vspace{-1em}
|
| 504 |
+
223\label{fig:bar_ablations}
|
| 505 |
+
224\end{wrapfigure}
|
| 506 |
+
225
|
| 507 |
+
226In this subsection, we examine the contributions of the different \CrossQ{} design choices to show their importance.
|
| 508 |
+
227Figure~\ref{fig:bar_ablations} shows aggregated ablations of these components and various hyperparameters, while Figure~\ref{fig:batchnorm_ablations} ablates the BatchNorm layer itself.
|
| 509 |
+
228
|
| 510 |
+
229\paragraph{Hyperparameters.}
|
| 511 |
+
230\CrossQ{} uses the best hyperparameters obtained from a series of grid searches. Of these, only three are different from SAC’s default values.
|
| 512 |
+
231First, we find that \textcolor{fgreen}{reducing the~$\beta_1$ momentum} for the Adam optimizer~\citep{Kingma2014AdamAM} from $0.9$ to $0.5$ as well the \textcolor{fdarkblue}{\textit{policy delay} of $3$} have the smallest impact on the performance. However, since fewer actor gradient steps reduce compute, this setting is favorable.
|
| 513 |
+
232Second, \textcolor{fmagenta}{reducing the critic network’s width to 256}---the same small size as SAC---reduces performance and yet still significantly outperforms SAC.
|
| 514 |
+
233This suggests that practitioners may be able to make use of a larger compute budget, i.e., train efficiently across a range of different network sizes, by scaling up layer widths according to the available hardware resources.
|
| 515 |
+
234Third, as expected, \textcolor{fpink}{removing the \texttt{BRN} layers} proves to be detrimental and results in the worst overall performance.
|
| 516 |
+
235A natural question that comes to mind is whether other normalization strategies in the critic, such as Layer Normalization (LayerNorm,~\citet{ba2016layernorm}), would also give the same results. However, in our ablation, we find that \textcolor{foccer}{replacing BatchNorm with LayerNorm} degrades \CrossQ{}’s performance significantly, roughly to the level of the SAC baseline.
|
| 517 |
+
236Lastly, SAC does not benefit from simply \textcolor{fyellow}{widening critic layers to $2048$}.
|
| 518 |
+
237And \textcolor{fblue}{naively adding \texttt{BRN} to SAC while keeping the target networks} proves detrimental. This finding is in line with our diagnosis of mismatched statistics being detrimental to the training.
|
| 519 |
+
238
|
| 520 |
+
239
|
| 521 |
+
240\begin{figure}[t]
|
| 522 |
+
241 \centering
|
| 523 |
+
242 \includegraphics[width=\textwidth]{fig/camera_ready_crossQ_ablation_BRN.pdf}
|
| 524 |
+
243 \vspace{-2em}
|
| 525 |
+
244 \caption{\textbf{Comparing BatchNorm hyperparameters.} All variants have comparably strong and stable curves early in the training.
|
| 526 |
+
245 Omitting normalization in the actor (\texttt{BRN} critic only) does not significantly affect \CrossQ{}. Using the original Batch Normalization (\texttt{BN}, with moving-average momentum $0.99$) is prone to sudden performance collapses during longer training runs. Using \texttt{BRN} permits stabler training, which improves with higher momentums; \CrossQ{}’s default $0.99$~(black) and higher show no collapses.
|
| 527 |
+
246 We plot IQM return and $70\%$ quantile intervals over five seeds.}
|
| 528 |
+
247 \vspace{-1em}
|
| 529 |
+
248\label{fig:batchnorm_ablations}
|
| 530 |
+
249\end{figure}
|
| 531 |
+
250
|
| 532 |
+
251\paragraph{Batch Normalization Layers.}
|
| 533 |
+
252
|
| 534 |
+
253In Figure \ref{fig:batchnorm_ablations}, we ablate
|
| 535 |
+
254the BatchNorm versions (\texttt{BN}~\citep{ioffe2015batchnorm} and \texttt{BRN}~\citep{ioffe2017batchRenorm}) and their internal moving-average momentums. Compared to \CrossQ{}’s optimal combination---\texttt{BRN} with momentum $0.99$---all variants have similar sample efficiency in the early stages of training (1M steps). When using \texttt{BN}, we sometimes observe sudden performance collapses later in training; we attribute these to \texttt{BN}’s unique approach of using noisy \textit{minibatch estimates} of normalization moments. \texttt{BRN}’s improved approach of using the less noisy \textit{moving-averages} makes these collapses less likely; further noise-reduction via higher momentums eliminates these collapses entirely. Additionally, we find that using BatchNorm only in the critic (instead of both the actor and the critic) is sufficient to drive the strong performance of \CrossQ{}; however, including it in both networks performs slightly better.
|
| 536 |
+
255
|
| 537 |
+
256
|
| 538 |
+
257\section{Conclusion \& Future Work}
|
| 539 |
+
258We introduced \CrossQ{}, a new off-policy RL algorithm that matches or exceeds the performance of REDQ and DroQ---the current state-of-the-art on continuous control environments with state observations---in terms of sample efficiency while being multiple times more computationally efficient.
|
| 540 |
+
259To the best of our knowledge, \CrossQ{} is the first method to successfully use BatchNorm to greatly accelerate off-policy actor-critic RL.
|
| 541 |
+
260Through benchmarks and ablations, we confirmed that target networks do indeed slow down training and showed a way to remove them without sacrificing training stability.
|
| 542 |
+
261We also showed that BatchNorm has the same accelerating effect on training in Deep RL as it does in supervised deep learning.
|
| 543 |
+
262The combined effect of removing target networks and adding BatchNorm is what makes \CrossQ{} so efficient.
|
| 544 |
+
263We investigated the relationship between the Q estimation bias and the learning performance of \CrossQ{}, but did not identify a straightforward dependence. This indicates that the relationship between the Q estimation bias and the agent performance is more complex than previously thought.
|
| 545 |
+
264
|
| 546 |
+
265In future work, it would be interesting to analyze the Q estimation bias more extensively, similar to~\citet{li2022efficient}.
|
| 547 |
+
266Furthermore, a deeper theoretical analysis of the used BatchNorm approach in the context of RL would be valuable, akin to the works in supervised learning, e.g.,~\citet{Summers2020Four}.
|
| 548 |
+
267Although the wider critic networks do provide an additional performance boost, they increase the computation cost, which could potentially be reduced.
|
| 549 |
+
268Finally, while our work focuses on the standard continuous control benchmarking environments, a logical extension would be applying \CrossQ{} to a real robot system and using visual observations in addition to the robot state.
|
| 550 |
+
269Techniques from image-based RL, such as state augmentation~\citep{laskin2020rad,yarats2021drqv2} and auxiliary losses~\citep{schwarzer2020spr,he2022a2ls}, also aim to learn efficiently from limited data. We believe some of these ideas could potentially be applied to CrossQ.
|
| 551 |
+
270
|
| 552 |
+
271\subsubsection*{Acknowledgments}
|
| 553 |
+
272We acknowledge the grant ‘‘Einrichtung eines Labors des Deutschen Forschungszentrum f\"ur K\"unstliche Intelligenz (DFKI)
|
| 554 |
+
273an der Technischen Universit\"at Darmstadt" of the Hessisches Ministerium f\"ur Wissenschaft und Kunst.
|
| 555 |
+
274This research was also supported by the Research Clusters “The Adaptive Mind” and “Third Wave of AI”, funded by the Excellence Program of the Hessian Ministry of Higher Education, Science, Research and the Arts, Hessian.AI and by the German Research Foundation (DFG): 417962828.
|
| 556 |
+
275
|
| 557 |
+
276
|
| 558 |
+
277\bibliography{iclr2024_conference}
|
| 559 |
+
278\bibliographystyle{iclr2024_conference}
|
| 560 |
+
279
|
| 561 |
+
280\newpage
|
| 562 |
+
281\appendix
|
| 563 |
+
282\section{Appendix}
|
| 564 |
+
283\subsection{DeepMind Control Suite Experiments}
|
| 565 |
+
284Figure~\ref{fig:sample_efficiency_dmc} presents an additional set of experiments performed on the DeepMind Control Suite~\citep{tassa2018dm_control}.
|
| 566 |
+
285The experiments shown here are an extension to the experiments shown in Figure~\ref{ref:sample_efficiency} in the main paper and have been moved to the Appendix due to space constraints.
|
| 567 |
+
286For the presented tasks, we lowered the learning rate to $8\times10^{-4}$ for all algorithms, and set the \CrossQ{} policy delay to 1. All other hyperparameters remained the same as for the main paper.
|
| 568 |
+
287\begin{figure}[h]
|
| 569 |
+
288 \centering
|
| 570 |
+
289 \includegraphics[width=\textwidth]{fig/camera_ready_dmc.pdf}
|
| 571 |
+
290 \caption{\textbf{Sample efficiency of \CrossQ{} on DeepMind Control.} The experiments here were each performed on $5$ different random seeds. \CrossQ{}’s good sample efficiency transfers well to the presented tasks from the DeepMind Control Suite.}
|
| 572 |
+
291 \label{fig:sample_efficiency_dmc}
|
| 573 |
+
292\end{figure}
|
| 574 |
+
293\newpage
|
| 575 |
+
294\subsection{Hyperparameters}
|
| 576 |
+
295
|
| 577 |
+
296Experiment hyperparameters, used in the main paper. We adapted most hyperparameters that are commonly used in other works~\citep{haarnoja2018soft,chen2021redq,hiraoka2021droq}. \\ The Moving-Average \textit{Momentum} corresponds to $1$ minus the Moving-Average \textit{Update Rate} as defined in both BatchNorm papers~\citep{ioffe2015batchnorm, ioffe2017batchRenorm}.
|
| 578 |
+
297
|
| 579 |
+
298\begin{table}[h]
|
| 580 |
+
299\centering
|
| 581 |
+
300\caption{Learning Hyperparameters}
|
| 582 |
+
301\label{tab:hyperparameters}
|
| 583 |
+
302\begin{tabular}{l|c|c|c|c}
|
| 584 |
+
303\toprule
|
| 585 |
+
304\textbf{Parameter} & SAC & REDQ & DroQ & \CrossQ{} (ours)\\
|
| 586 |
+
305\midrule\midrule
|
| 587 |
+
306Discount Factor ($\gamma$) & \multicolumn{4}{c}{$0.99$} \\ \midrule
|
| 588 |
+
307Learning Rate (Actor \& Critic) & \multicolumn{4}{c}{$0.001$} \\ \midrule
|
| 589 |
+
308Replay Buffer Size & \multicolumn{4}{c}{$10^6$} \\\midrule
|
| 590 |
+
309Batch Size & \multicolumn{4}{c}{$256$} \\\midrule
|
| 591 |
+
310Activation Function & \multicolumn{4}{c}{\texttt{relu}} \\\midrule
|
| 592 |
+
311Layer Normalization & \multicolumn{2}{c|}{No} & Yes & No \\\midrule
|
| 593 |
+
312Dropout Rate & \multicolumn{2}{c|}{\texttt{N/A}} & $0.01$ & \texttt{N/A} \\\midrule
|
| 594 |
+
313BatchNorm / Version & \multicolumn{3}{c|}{\texttt{N/A}} & \texttt{BRN}
|
| 595 |
+
314\\\midrule
|
| 596 |
+
315BatchNorm / Moving-Average Momentum & \multicolumn{3}{c|}{\texttt{N/A}} &$0.99$
|
| 597 |
+
316\\\midrule
|
| 598 |
+
317BatchNorm / \texttt{BRN} Warm-up Steps & \multicolumn{3}{c|}{\texttt{N/A}} & $10^5$
|
| 599 |
+
318\\\midrule
|
| 600 |
+
319Critic Width & \multicolumn{3}{c|}{$256$} & $2048$ \\\midrule
|
| 601 |
+
320Target Update Rate ($\tau$) & \multicolumn{3}{c|}{$0.005$} & \texttt{N/A} \\\midrule
|
| 602 |
+
321Adam $\beta_1$ & \multicolumn{3}{c|}{$0.9$} & $0.5$ \\\midrule
|
| 603 |
+
322Update-To-Data ratio (UTD) & $1$ & \multicolumn{2}{c|}{$20$} & $1$ \\ \midrule
|
| 604 |
+
323Policy Delay & $1$ & \multicolumn{2}{c|}{$20$} & $3$ \\\midrule
|
| 605 |
+
324Number of Critics & $2$ & \multicolumn{1}{c}{$10$} & \multicolumn{2}{|c}{$2$} \\
|
| 606 |
+
325\bottomrule
|
| 607 |
+
326\end{tabular}
|
| 608 |
+
327\end{table}
|
| 609 |
+
328
|
| 610 |
+
329
|
| 611 |
+
330\subsection{Wallclock Time Measurement}
|
| 612 |
+
331\label{sec:wallclock}
|
| 613 |
+
332Wallclock times were measured by timing and averaging over four seeds each and represent \textit{pure training times}, without the overhead of synchronous evaluation and logging, until reaching $5\times10^6$ environment steps. The times are recorded on an \texttt{Nvidia RTX 3090 Turbo} with an \texttt{AMD EPYC 7453} CPU.
|
| 614 |
+
333
|
| 615 |
+
334\begin{table}[b]
|
| 616 |
+
335 \centering
|
| 617 |
+
336 \vspace{-1.5em}
|
| 618 |
+
337 \caption{\textbf{Wallclock times.} Evaluated for \CrossQ{} and baselines across environments in hours and recorded on an \texttt{RTX 3090}, the details of the measurement procedure are described in Appendix~\ref{sec:computational_efficiency}.
|
| 619 |
+
338 Comparing \CrossQ{} with \CrossQ{} (Small) and SAC, it is apparent that using wider critic networks does come with a performance penalty.
|
| 620 |
+
339 However, compared to REDQ and DroQ, one clearly sees the substantial improvement in Wallclock time of \CrossQ{} over those baselines.
|
| 621 |
+
340 }
|
| 622 |
+
341 \vspace{.8em}
|
| 623 |
+
342 \begin{tabular}{ lccccc }
|
| 624 |
+
343 \toprule
|
| 625 |
+
344 & \multicolumn{5}{c}{Wallclock Time [hours]} \\
|
| 626 |
+
345 & SAC & \CrossQ{} (small) & \textbf{\CrossQ{} (ours)} & REDQ & DroQ \\
|
| 627 |
+
346 \midrule
|
| 628 |
+
347 \texttt{HumanoidStandup-v4} & 1.5 & 2.1 & 2.2 & 8.7 & 7.5 \\
|
| 629 |
+
348 \texttt{Walker2d-v4} & 0.9 & 0.9 & 1.1 & 4.0 & 4.1 \\
|
| 630 |
+
349 \texttt{Ant-v4} & 0.9 & 1.2 & 1.5 & 4.7 & 4.7 \\
|
| 631 |
+
350 \texttt{HalfCheetah-v4} & 0.8 & 1.2 & 1.5 & 4.1 & 4.4 \\
|
| 632 |
+
351 \texttt{Hopper-v4} & 1.0 & 1.1 & 1.3 & 4.1 & 4.2 \\
|
| 633 |
+
352 \bottomrule
|
| 634 |
+
353 \end{tabular}
|
| 635 |
+
354 \label{tab:computation_times}
|
| 636 |
+
355\end{table}
|
| 637 |
+
356
|
| 638 |
+
357\newpage
|
| 639 |
+
358
|
| 640 |
+
359\subsection{Evolving Action Distributions}
|
| 641 |
+
360\begin{figure}[h]
|
| 642 |
+
361 \centering
|
| 643 |
+
362 \includegraphics[width=\textwidth]{fig/moving-densities.pdf}
|
| 644 |
+
363 \caption{\textbf{Replay and policy action distributions are different, and evolve during training.} We train an agent for $300,000$ steps on \texttt{Walker2d}. We take snapshots of the replay buffer $\mathcal{B}$ and policy $\pi_\mathbf{\phi}$ every $60,000$ steps. For each snapshot (one column), we sample a large batch of $10,000$ transitions $(\vs, \va, \vs’, \va’=\pi_\mathbf{\phi}(\vs’))$ and use this to compute a visually interpretable 2D kernel density estimate of the distributions of $\va$ (\textcolor{blue}{blue}) and $\va’$ (\textcolor{red}{red}), as seen through the action-space dimensions $4$ and $5$. The cross denotes the mean, and the dashed ellipse is one standard deviation wide for each of the two dimensions.
|
| 645 |
+
364 We observe that the distributions as well as the means and standard deviations of the off-policy and on-policy actions are visibly and persistently different throughout the training run, and keep drifting as the training progresses. This discrepancy implies that BatchNorm must be used with care in off-policy TD learning.}
|
| 646 |
+
365 \label{fig:evolving_action_densities}
|
| 647 |
+
366\end{figure}
|
| 648 |
+
367
|
| 649 |
+
368
|
| 650 |
+
369\newpage
|
| 651 |
+
370\subsubsection{Ablating the Different Design Choices and Hyperparameters}
|
| 652 |
+
371
|
| 653 |
+
372Figure \ref{fig:crossq_ablations} depicts in detail the \CrossQ{} and SAC ablations, previously shown in aggregate form by Figure \ref{fig:bar_ablations}.
|
| 654 |
+
373
|
| 655 |
+
374\begin{figure}[h]
|
| 656 |
+
375 \centering
|
| 657 |
+
376 \includegraphics[width=\textwidth]{fig/camera_ready_crossQ_ablation.pdf}
|
| 658 |
+
377 \vspace{-2em}
|
| 659 |
+
378 \caption{\textbf{\CrossQ{} ablation study.} We ablate across different hyperparameter settings and architectural configurations.
|
| 660 |
+
379 Using the same network width as SAC, \textcolor{fmagenta}{\CrossQ{} (small)} shows weaker performance, yet is still competitive with \CrossQ{} in four out of six environments. At the same time, \textcolor{fyellow}{SAC with a wider critic} does not work better. Using the default Adam momentum \textcolor{fgreen}{$\beta_1=0.9$} instead of $0.5$ degrades performance in some environments. Using a \textcolor{fblue}{policy delay of $1$} instead of $3$ has a very small effect, except on $\texttt{Ant}$. Using \textcolor{foccer}{LayerNorm} instead of BatchNorm results in slower learning; it also trains stably without target networks. \textcolor{fpink}{Removing BatchNorm} results in failure of training due to divergence. \textcolor{cyan}{Adding BatchNorm to SAC} and reusing the live critic’s normalization moments in the target network fails to train. Training \textcolor{fred}{without double Q} networks (single critic) harms performance.
|
| 661 |
+
380 \label{fig:crossq_ablations}}
|
| 662 |
+
381 \vspace{-1em}
|
| 663 |
+
382\end{figure}
|
| 664 |
+
383
|
| 665 |
+
384\newpage
|
| 666 |
+
385\subsection{REDQ and DroQ Ablations}
|
| 667 |
+
386Figures~\ref{fig:redq_hyperparameter_ablation} and~\ref{fig:droq_hyperparameter_ablation} show REDQ and DroQ ablations on $5$ seeds each. They show both baselines with the \CrossQ{} hyperparameters: wider critic networks as well as $\beta_1=0.5$.
|
| 668 |
+
387Neither baseline benefits from the added changes. In most cases, the performance is unchanged, while in some cases, it deteriorates.
|
| 669 |
+
388The dashed black line shows \CrossQ{} as a reference.
|
| 670 |
+
389
|
| 671 |
+
390\begin{figure}[h]
|
| 672 |
+
391 \centering
|
| 673 |
+
392 \vspace{-1em}
|
| 674 |
+
393 \includegraphics[width=\textwidth]{fig/camera_ready_redq_ablations.pdf}
|
| 675 |
+
394 \vspace{-2em}
|
| 676 |
+
395 \caption{\textbf{REDQ ablation.} Showing performance for different combinations of the \CrossQ{} hyperparameters. The changes in hyperparameters do not help REDQ to get better performance. In fact, in some cases, they even hurt the performance.}
|
| 677 |
+
396 \label{fig:redq_hyperparameter_ablation}
|
| 678 |
+
397\end{figure}
|
| 679 |
+
398
|
| 680 |
+
399\begin{figure}[h]
|
| 681 |
+
400 \centering
|
| 682 |
+
401 \vspace{-1em}
|
| 683 |
+
402 \includegraphics[width=\textwidth]{fig/camera_ready_droq_ablations.pdf}
|
| 684 |
+
403 \vspace{-2em}
|
| 685 |
+
404 \caption{\textbf{DroQ ablation.} The changes in hyperparameters do not help DroQ to get better performance overall. In \texttt{Hopper} and \texttt{Ant}, performance rises to the \CrossQ{} performance, however, on the \texttt{Humanoid}, it hurts performance.}
|
| 686 |
+
405 \label{fig:droq_hyperparameter_ablation}
|
| 687 |
+
406\end{figure}
|
| 688 |
+
407
|
| 689 |
+
408\newpage
|
| 690 |
+
409\subsection{Effect of Activations and Normalizers on Learning Stability}
|
| 691 |
+
410\label{sec:diverse_activations}
|
| 692 |
+
411Figure~\ref{fig:bounded_activations} depicts a small exploratory experiment in which we remove target networks from SAC, and train it with different activation functions and feature normalizers. We do this only to explore whether the boundedness of activations has an influence on training stability. We learn from this experiment that SAC with $\mathrm{tanh}$ activations trains without divergence, allowing us to conduct the study in Section~\ref{sec:bounded_activations}. We also observe that at least two feature normalization schemes (on top of the unbounded relu activations) permit divergence-free optimization.
|
| 693 |
+
412
|
| 694 |
+
413For vectors $\vx$, $\mathrm{relu\_over\_max}(\vx)$ denotes a simple normalization scheme using an underlying unbounded activation: $\mathrm{relu}(\vx)/\mathrm{max}(\vx)$, with the maximum computed over the entire feature vector. $\mathrm{layernormed\_relu}$ simply denotes LayerNorm applied \textit{after} the $\mathrm{relu}$ activations. Both of these schemes prevent divergence. Using LayerNorm \textit{before} the $\mathrm{relu}$ activations also prevent divergence, and is already explored in the ablations in Figure~\ref{fig:crossq_ablations}. None of these normalizers perform as strongly as BatchNorm.
|
| 695 |
+
414
|
| 696 |
+
415A thorough theoretical or experimental study of how activations and normalizers affect the stability of Deep RL is beyond the scope of this paper. We hope, however, that our observations help inform future research directions for those interested in this topic.
|
| 697 |
+
416
|
| 698 |
+
417\begin{figure}[h]
|
| 699 |
+
418 \centering
|
| 700 |
+
419 \includegraphics[width=\textwidth]{fig/camera_ready_sac_activations.pdf}
|
| 701 |
+
420 \caption{\textbf{(In)stability of SAC without target networks.} Observed through the Q estimation bias. In this small-scale experiment, we run SAC with unbounded ($\mathrm{relu, glu, elu}$) and bounded ($\mathrm{tanh, relu6, sin}$) activation functions, as well as ‘‘indirectly" bounded activations through the use of two custom normalizers other than BatchNorm ($\mathrm{relu\_over\_max, layernormed\_relu}$). SAC variants with unbounded activations appear highly unstable in most environments, whereas the variants with bounded activations (as well as the normalizers) do not diverge, maintaining relatively low bias.
|
| 702 |
+
421 }
|
| 703 |
+
422 \label{fig:diverse_activations}
|
| 704 |
+
423\end{figure}
|
| 705 |
+
424
|
| 706 |
+
425\newpage
|
| 707 |
+
426\subsection{Normalized $Q$ Bias Plots}
|
| 708 |
+
427\label{app:q_bias}
|
| 709 |
+
428
|
| 710 |
+
429Figure~\ref{fig:q_bias} shows the results of the Q function bias analysis for all environments.
|
| 711 |
+
430
|
| 712 |
+
431\begin{figure}[h]
|
| 713 |
+
432 \centering
|
| 714 |
+
433 \includegraphics[width=\textwidth]{fig/camera_ready_Q_bias.pdf}
|
| 715 |
+
434 \caption{\textbf{Q estimation bias.} Mean and standard deviation of the normalized Q function bias, computed as described by~\citet{chen2021redq}.
|
| 716 |
+
435 As in the main paper, we do not find a straightforward connection between normalized Q function bias and learning performance.
|
| 717 |
+
436 \CrossQ{} generally shows the same or larger Q estimation bias compared to REDQ but matches or outperforms REDQ in learning speed, especially on the challenging \texttt{Humanoid} tasks.
|
| 718 |
+
437 }
|
| 719 |
+
438 \label{fig:q_bias}
|
| 720 |
+
439\end{figure}
|
| 721 |
+
440
|
| 722 |
+
441\end{document}’
|
| 723 |
+
Report Issue
|
| 724 |
+
Report Issue for Selection
|
| 725 |
+
Generated by L A T E xml
|
| 726 |
+
Instructions for reporting errors
|
| 727 |
+
|
| 728 |
+
We are continuing to improve HTML versions of papers, and your feedback helps enhance accessibility and mobile support. To report errors in the HTML that will help us improve conversion and rendering, choose any of the methods listed below:
|
| 729 |
+
|
| 730 |
+
Click the "Report Issue" button.
|
| 731 |
+
Open a report feedback form via keyboard, use "Ctrl + ?".
|
| 732 |
+
Make a text selection and click the "Report Issue for Selection" button near your cursor.
|
| 733 |
+
You can use Alt+Y to toggle on and Alt+Shift+Y to toggle off accessible reporting links at each section.
|
| 734 |
+
|
| 735 |
+
Our team has already identified the following issues. We appreciate your time reviewing and reporting rendering errors we may not have found yet. Your efforts will help us improve the HTML versions for all readers, because disability should not be a barrier to accessing research. Thank you for your continued support in championing open access for all.
|
| 736 |
+
|
| 737 |
+
Have a free development cycle? Help support accessibility at arXiv! Our collaborators at LaTeXML maintain a list of packages that need conversion, and welcome developer contributions.
|
1902/1902.06634.md
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: Contextual Encoder-Decoder Network for Visual Saliency Prediction
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1902.06634
|
| 4 |
+
|
| 5 |
+
Published Time: Mon, 08 Apr 2024 00:33:30 GMT
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
Mario Senden Kurt Driessens Rainer Goebel Department of Cognitive Neuroscience, Faculty of Psychology and Neuroscience,
|
| 9 |
+
|
| 10 |
+
Maastricht University, Maastricht, The Netherlands Maastricht Brain Imaging Centre, Faculty of Psychology and Neuroscience,
|
| 11 |
+
|
| 12 |
+
Maastricht University, Maastricht, The Netherlands Department of Data Science and Knowledge Engineering, Faculty of Science and Engineering,
|
| 13 |
+
|
| 14 |
+
Maastricht University, Maastricht, The Netherlands Department of Neuroimaging and Neuromodeling, Netherlands Institute for Neuroscience,
|
| 15 |
+
|
| 16 |
+
Royal Netherlands Academy of Arts and Sciences (KNAW), Amsterdam, The Netherlands
|
| 17 |
+
|
| 18 |
+
###### Abstract
|
| 19 |
+
|
| 20 |
+
Predicting salient regions in natural images requires the detection of objects that are present in a scene. To develop robust representations for this challenging task, high-level visual features at multiple spatial scales must be extracted and augmented with contextual information. However, existing models aimed at explaining human fixation maps do not incorporate such a mechanism explicitly. Here we propose an approach based on a convolutional neural network pre-trained on a large-scale image classification task. The architecture forms an encoder-decoder structure and includes a module with multiple convolutional layers at different dilation rates to capture multi-scale features in parallel. Moreover, we combine the resulting representations with global scene information for accurately predicting visual saliency. Our model achieves competitive and consistent results across multiple evaluation metrics on two public saliency benchmarks and we demonstrate the effectiveness of the suggested approach on five datasets and selected examples. Compared to state of the art approaches, the network is based on a lightweight image classification backbone and hence presents a suitable choice for applications with limited computational resources, such as (virtual) robotic systems, to estimate human fixations across complex natural scenes. Our TensorFlow implementation is openly available at [https://github.com/alexanderkroner/saliency](https://github.com/alexanderkroner/saliency).
|
| 21 |
+
|
| 22 |
+
1 Introduction
|
| 23 |
+
--------------
|
| 24 |
+
|
| 25 |
+
Humans demonstrate a remarkable ability to obtain relevant information from complex visual scenes Jonides et al. ([1982](https://arxiv.org/html/1902.06634v4#bib.bib1)); Irwin ([1991](https://arxiv.org/html/1902.06634v4#bib.bib2)). Overt attention is the mechanism that governs the processing of stimuli by directing gaze towards a spatial location within the visual field Posner ([1980](https://arxiv.org/html/1902.06634v4#bib.bib3)). This sequential selection ensures that the eyes sample prioritized aspects from all available information to reduce the cost of cortical computation Lennie ([2003](https://arxiv.org/html/1902.06634v4#bib.bib4)). In addition, only a small central region of the retina, known as the fovea, transforms incoming light into neural responses with high spatial resolution, whereas acuity decreases rapidly towards the periphery Cowey and Rolls ([1974](https://arxiv.org/html/1902.06634v4#bib.bib5)); Berkley et al. ([1975](https://arxiv.org/html/1902.06634v4#bib.bib6)). Given the limited number of photoreceptors in the eye, this arrangement allows to optimally process visual signals from its environment Cheung et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib7)). The function of fixations is thus to resolve the trade-off between coverage and sampling resolution of the whole visual field Gegenfurtner ([2016](https://arxiv.org/html/1902.06634v4#bib.bib8)).
|
| 26 |
+
|
| 27 |
+

|
| 28 |
+
|
| 29 |
+
Figure 1: A visualization of four natural images with the corresponding empirical fixation maps, our model predictions, and estimated maps based on the work by Itti et al. ([1998](https://arxiv.org/html/1902.06634v4#bib.bib9)). The network proposed in this study was not trained on the stimuli shown here and thus exhibits its generalization ability to unseen instances. All image examples demonstrate a qualitative agreement of our model with the ground truth data, assigning high saliency to regions that contain semantic information, such as a door (a), flower (b), face (c), or text (d). On the contrary, the approach by Itti et al. ([1998](https://arxiv.org/html/1902.06634v4#bib.bib9)) detected low-level feature contrasts and wrongly predicted high values at object boundaries rather than their center.
|
| 30 |
+
|
| 31 |
+
The spatial allocation of attention when viewing natural images is commonly represented in the form of topographic saliency maps that depict which parts of a scene attract fixations reliably. Identifying the underlying properties of these regions would allow us to predict human fixation patterns and gain a deeper understanding of the processes that lead to the observed behavior. In computer vision, this challenging problem has originally been approached using models rooted in Feature Integration Theory Treisman and Gelade ([1980](https://arxiv.org/html/1902.06634v4#bib.bib10)). The theory suggests that early visual features must first be registered in parallel before serial shifts of overt attention combine them into unitary object-based representations. This two-stage account of visual processing has emphasized the role of stimulus properties for explaining human gaze. In consequence, the development of feature-driven models has been considered sufficient to enable the prediction of fixation patterns under task-free viewing conditions. Koch and Ullman ([1985](https://arxiv.org/html/1902.06634v4#bib.bib11)) have introduced the notion of a central saliency map which integrates low-level information and serves as the basis for eye movements. This has resulted in a first model implementation by Itti et al. ([1998](https://arxiv.org/html/1902.06634v4#bib.bib9)) that influenced later work on biologically-inspired architectures.
|
| 32 |
+
|
| 33 |
+
With the advent of deep neural network solutions for visual tasks such as image classification Krizhevsky et al. ([2012](https://arxiv.org/html/1902.06634v4#bib.bib12)), saliency modeling has also undergone a paradigm shift from manual feature engineering towards automatic representation learning. In this work, we leveraged the capability of convolutional neural networks (CNNs) to extract relevant features from raw images and decode them towards a distribution of saliency across arbitrary scenes. Compared to the seminal work by Itti et al. ([1998](https://arxiv.org/html/1902.06634v4#bib.bib9)), this approach allows predictions to be based on semantic information instead of low-level feature contrasts (see Figure[1](https://arxiv.org/html/1902.06634v4#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")). This choice was motivated by studies demonstrating the importance of high-level image content for attentional selection in natural images Einhäuser et al. ([2008](https://arxiv.org/html/1902.06634v4#bib.bib13)); Nuthmann and Henderson ([2010](https://arxiv.org/html/1902.06634v4#bib.bib14)).
|
| 34 |
+
|
| 35 |
+
Furthermore, it is expected that complex representations at multiple spatial scales are necessary for accurate predictions of human fixation patterns. We therefore incorporated a contextual module that samples multi-scale information and augments it with global scene features. The contribution of the contextual module to the overall performance was assessed and final results were compared to previous work on two public saliency benchmarks. We achieved predictive accuracy on unseen test instances at the level of current state of the art approaches, while utilizing a computationally less expensive network backbone with roughly one order of magnitude fewer processing layers. This makes our model suitable for applications in (virtual) robotic environments, as demonstrated by Bornet et al. ([2019](https://arxiv.org/html/1902.06634v4#bib.bib15)), and we developed a webcam-based interface for saliency prediction in the browser with only moderate hardware requirements (see [https://storage.googleapis.com/msi-net/demo/index.html](https://storage.googleapis.com/msi-net/demo/index.html)).
|
| 36 |
+
|
| 37 |
+
2 Related Work
|
| 38 |
+
--------------
|
| 39 |
+
|
| 40 |
+
Early approaches towards computational models of visual attention were defined in terms of different theoretical frameworks, including Bayesian Zhang et al. ([2008](https://arxiv.org/html/1902.06634v4#bib.bib16)) and graph-based formulations Harel et al. ([2006](https://arxiv.org/html/1902.06634v4#bib.bib17)). The former was based on the notion of self-information derived from a probability distribution over linear visual features as acquired from natural scenes. The latter framed saliency as the dissimilarity between nodes in a fully-connected directed graph that represents all image locations in a feature map. Hou and Zhang ([2007](https://arxiv.org/html/1902.06634v4#bib.bib18)) have instead proposed an approach where images were transformed to the log spectrum and saliency emerged from the spectral residual after removing statistically redundant components. A mechanism inspired more by biological than mathematical principles was first implemented and described in the seminal work by Itti et al. ([1998](https://arxiv.org/html/1902.06634v4#bib.bib9)). Their model captures center-surround differences at multiple spatial scales with respect to three basic feature channels: color, intensity, and orientation. After normalization of activity levels, the output is fed into a common saliency map depicting local conspicuity in static scenes. This standard cognitive architecture has since been augmented with additional feature channels that capture semantic image content, such as faces and text Cerf et al. ([2009](https://arxiv.org/html/1902.06634v4#bib.bib19)).
|
| 41 |
+
|
| 42 |
+
With the large-scale acquisition of eye tracking measurements under natural viewing conditions, data-driven machine learning techniques became more practicable. Judd et al. ([2009](https://arxiv.org/html/1902.06634v4#bib.bib20)) introduced a model based on support vector machines to estimate fixation densities from a set of low-, mid-, and high-level visual features. While this approach still relied on a hypothesis specifying which image properties would successfully contribute to the prediction of saliency, it marked the beginning of a progression from manual engineering to automatic learning of features. This development has ultimately led to applying deep neural networks with emergent representations for the estimation of human fixation patterns. Vig et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib21)) were the first to train an ensemble of shallow CNNs to derive saliency maps from natural images in an end-to-end fashion, but failed to capture object information due to limited network depth.
|
| 43 |
+
|
| 44 |
+
Later attempts addressed that shortcoming by taking advantage of classification architectures pre-trained on the ImageNet database Deng et al. ([2009](https://arxiv.org/html/1902.06634v4#bib.bib22)). This choice was motivated by the finding that features extracted from CNNs generalize well to other visual tasks Donahue et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib23)). Consequently, DeepGaze I Kümmerer et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib24)) and II Kümmerer et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib25)) employed a pre-trained classification model to read out salient image locations from a small subset of encoding layers. This is similar to the network by Cornia et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib26)) which utilizes the output at three stages of the hierarchy. Oyama and Yamanaka ([2018](https://arxiv.org/html/1902.06634v4#bib.bib27)) demonstrated that classification performance of pre-trained architectures strongly correlates with the accuracy of saliency predictions, highlighting the importance of object information. Related approaches also focused on the potential benefits of incorporating activation from both coarse and fine image resolutions Huang et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib28)), and recurrent connections to capture long-range spatial dependencies in convolutional feature maps Cornia et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib29)); Liu and Han ([2018](https://arxiv.org/html/1902.06634v4#bib.bib30)). Our model explicitly combines semantic representations at multiple spatial scales to include contextual information in the predictive process. For a more complete account of existing saliency architectures, we refer the interested reader to a comprehensive review by Borji ([2018](https://arxiv.org/html/1902.06634v4#bib.bib31)).
|
| 45 |
+
|
| 46 |
+
3 Methods
|
| 47 |
+
---------
|
| 48 |
+
|
| 49 |
+
We propose a new CNN architecture with modules adapted from the semantic segmentation literature to predict fixation density maps of the same image resolution as the input. Our approach is based on a large body of research regarding saliency models that leverage object-specific features and functionally replicate human behavior under free-viewing conditions. In the following sections, we describe our contributions to this challenging task.
|
| 50 |
+
|
| 51 |
+
### 3.1 Architecture
|
| 52 |
+
|
| 53 |
+
Image-to-image learning problems require the preservation of spatial features throughout the whole processing stream. As a consequence, our network does not include any fully-connected layers and reduces the number of downsampling operations inherent to classification models. We adapted the popular VGG16 architecture Simonyan and Zisserman ([2014](https://arxiv.org/html/1902.06634v4#bib.bib32)) as an image encoder by reusing the pre-trained convolutional layers to extract increasingly complex features along its hierarchy. Striding in the last two pooling layers was removed, which yields spatial representations at 1/8 1 8\nicefrac{{1}}{{8}}/ start_ARG 1 end_ARG start_ARG 8 end_ARG of their original input size. All subsequent convolutional encoding layers were then dilated at a rate of 2 by expanding their kernel, and thereby increased the receptive field to compensate for the higher resolution Yu and Koltun ([2015](https://arxiv.org/html/1902.06634v4#bib.bib33)). This modification still allowed us to initialize the model with pre-trained weights since the number of trainable parameters remained unchanged. Prior work has shown the effectiveness of this approach in the context of saliency prediction problems Cornia et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib29)); Liu and Han ([2018](https://arxiv.org/html/1902.06634v4#bib.bib30)).
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
Figure 2: An illustration of the modules that constitute our encoder-decoder architecture. The VGG16 backbone was modified to account for the requirements of dense prediction tasks by omitting feature downsampling in the last two max-pooling layers. Multi-level activations were then forwarded to the ASPP module, which captured information at different spatial scales in parallel. Finally, the input image dimensions were restored via the decoder network. Subscripts beneath convolutional layers denote the corresponding number of feature maps.
|
| 58 |
+
|
| 59 |
+
For related visual tasks such as semantic segmentation, information distributed over convolutional layers at different levels of the hierarchy can aid the preservation of fine spatial details Hariharan et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib34)); Long et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib35)). The prediction of fixation density maps does not require accurate class boundaries but still benefits from combined mid- to high-level feature responses Kümmerer et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib24), [2016](https://arxiv.org/html/1902.06634v4#bib.bib25)); Cornia et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib26)). Hence, we adapted the multi-level design proposed by Cornia et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib26)) and concatenated the output from layers 10, 14, and 18 into a common tensor with 1,280 activation maps.
|
| 60 |
+
|
| 61 |
+
This representation constitutes the input to an Atrous Spatial Pyramid Pooling (ASPP) module Chen et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib36)). It utilizes several convolutional layers with different dilation factors in parallel to capture multi-scale image information. Additionally, we incorporated scene content via global average pooling over the final encoder output, as motivated by the study of Torralba et al. ([2006](https://arxiv.org/html/1902.06634v4#bib.bib37)) who stated that contextual information plays an important role for the allocation of attention. Our implementation of the ASPP architecture thus closely follows the modifications proposed by Chen et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib38)). These authors augmented multi-scale information with global context and demonstrated performance improvements on semantic segmentation tasks.
|
| 62 |
+
|
| 63 |
+
In this work, we laid out three convolutional layers with kernel sizes of 3×3 3 3 3\times 3 3 × 3 and dilation rates of 4, 8, and 12 in parallel, together with a 1×1 1 1 1\times 1 1 × 1 convolutional layer that could not learn new spatial dependencies but nonlinearly combined existing feature maps. Image-level context was represented as the output after global average pooling (i.e. after averaging the entries of a tensor across both spatial dimensions to a single value) and then brought to the same resolution as all other representations via bilinear upsampling, followed by another point-wise convolutional operation. Each of the five branches in the module contains 256 filters, which resulted in an aggregated tensor of 1,280 feature maps. Finally, the combined output was forwarded to a 1×1 1 1 1\times 1 1 × 1 convolutional layer with 256 channels that contained the resulting multi-scale responses.
|
| 64 |
+
|
| 65 |
+
To restore the original image resolution, extracted features were processed by a series of convolutional and upsampling layers. Previous work on saliency prediction has commonly utilized bilinear interpolation for that task Cornia et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib29)); Liu and Han ([2018](https://arxiv.org/html/1902.06634v4#bib.bib30)), but we argue that a carefully chosen decoder architecture, similar to the model by Pan et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib39)), results in better approximations. Here we employed three upsampling blocks consisting of a bilinear scaling operation, which doubled the number of rows and columns, and a subsequent convolutional layer with kernel size 3×3 3 3 3\times 3 3 × 3. This setup has previously been shown to prevent checkerboard artifacts in the upsampled image space in contrast to deconvolution Odena et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib40)). Besides an increase of resolution throughout the decoder, the amount of channels was halved in each block to yield 32 feature maps. Our last network layer transformed activations into a continuous saliency distribution by applying a final 3×3 3 3 3\times 3 3 × 3 convolution. The outputs of all but the last linear layer were modified via rectified linear units. Figure[2](https://arxiv.org/html/1902.06634v4#S3.F2 "Figure 2 ‣ 3.1 Architecture ‣ 3 Methods ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") visualizes the overall architecture design as described in this section.
|
| 66 |
+
|
| 67 |
+
### 3.2 Training
|
| 68 |
+
|
| 69 |
+
Weight values from the ASPP module and decoder were initialized according to the Xavier method by Glorot and Bengio ([2010](https://arxiv.org/html/1902.06634v4#bib.bib41)). It specifies parameter values as samples drawn from a uniform distribution with zero mean and a variance depending on the total number of incoming and outgoing connections. Such initialization schemes are demonstrably important for training deep neural networks successfully from scratch Sutskever et al. ([2013](https://arxiv.org/html/1902.06634v4#bib.bib42)). The encoding layers were based on the VGG16 architecture pre-trained on both ImageNet Deng et al. ([2009](https://arxiv.org/html/1902.06634v4#bib.bib22)) and Places2 Zhou et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib43)) data towards object and scene classification respectively.
|
| 70 |
+
|
| 71 |
+
We normalized the model output such that all values are non-negative with unit sum. The estimation of saliency maps can hence be regarded as a probability distribution prediction task as formulated by Jetley et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib44)). To determine the difference between an estimated and a target distribution, the Kullback-Leibler (KL) divergence is an appropriate measure rooted in information theory to quantify the statistical distance D 𝐷 D italic_D. This can be defined as follows:
|
| 72 |
+
|
| 73 |
+
D KL(P∥Q)=∑i Q iln(ϵ+Q i ϵ+P i)subscript 𝐷 𝐾 𝐿 conditional 𝑃 𝑄 subscript 𝑖 subscript 𝑄 𝑖 italic-ϵ subscript 𝑄 𝑖 italic-ϵ subscript 𝑃 𝑖 D_{KL}(P\;\|\;Q)=\sum\limits_{i}Q_{i}\ln(\epsilon+\frac{Q_{i}}{\epsilon+P_{i}})italic_D start_POSTSUBSCRIPT italic_K italic_L end_POSTSUBSCRIPT ( italic_P ∥ italic_Q ) = ∑ start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT italic_Q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT roman_ln ( italic_ϵ + divide start_ARG italic_Q start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_ARG start_ARG italic_ϵ + italic_P start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT end_ARG )(1)
|
| 74 |
+
|
| 75 |
+
Here, Q 𝑄 Q italic_Q represents the target distribution, P 𝑃 P italic_P its approximation, i 𝑖 i italic_i each pixel index, and ϵ italic-ϵ\epsilon italic_ϵ a regularization constant. Equation ([1](https://arxiv.org/html/1902.06634v4#S3.E1 "1 ‣ 3.2 Training ‣ 3 Methods ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")) served as the loss function which was gradually minimized via the Adam optimization algorithm Kingma and Ba ([2014](https://arxiv.org/html/1902.06634v4#bib.bib45)). We defined an upper learning rate of 10−6 superscript 10 6 10^{-6}10 start_POSTSUPERSCRIPT - 6 end_POSTSUPERSCRIPT and modified the weights in an online fashion due to a general inefficiency of batch training according to Wilson and Martinez ([2003](https://arxiv.org/html/1902.06634v4#bib.bib46)). Based on this general setup, we trained our network for 10 epochs and used the best-performing checkpoint for inference.
|
| 76 |
+
|
| 77 |
+
4 Experiments
|
| 78 |
+
-------------
|
| 79 |
+
|
| 80 |
+
The proposed encoder-decoder model was evaluated on five publicly available eye tracking datasets that yielded qualitative and quantitative results. First, we provide a brief description of the images and empirical measurements utilized in this study. Second, the different metrics commonly used to assess the predictive performance of saliency models are summarized. Finally, we report the contribution of our architecture design choices and benchmark the overall results against baselines and related work in computer vision.
|
| 81 |
+
|
| 82 |
+
### 4.1 Datasets
|
| 83 |
+
|
| 84 |
+
A prerequisite for the successful application of deep learning techniques is a wealth of annotated data. Fortunately, the growing interest in developing and evaluating fixation models has lead to the release of large-scale eye tracking datasets such as MIT1003 Judd et al. ([2009](https://arxiv.org/html/1902.06634v4#bib.bib20)), CAT2000 Borji and Itti ([2015](https://arxiv.org/html/1902.06634v4#bib.bib47)), DUT-OMRON Yang et al. ([2013](https://arxiv.org/html/1902.06634v4#bib.bib48)), PASCAL-S Li et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib49)), and OSIE Xu et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib50)). The costly acquisition of measurements, however, is a limiting factor for the number of stimuli. New data collection methodologies have emerged that leverage webcam-based eye movements Xu et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib51)) or mouse movements Jiang et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib52)) instead via crowdsourcing platforms. The latter approach resulted in the SALICON dataset, which consists of 10,000 training and 5,000 validation instances serving as a proxy for empirical gaze measurements. Due to its large size, we first trained our model on SALICON before fine-tuning the learned weights towards fixation predictions on either of the other datasets with the same optimization parameters. This widely adopted procedure has been shown to improve the accuracy of eye movement estimations despite some disagreement between data originating from gaze and mouse tracking experiments Tavakoli et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib53)).
|
| 85 |
+
|
| 86 |
+
The images presented during the acquisition of saliency maps in all aforementioned datasets are largely based on natural scenes. Stimuli of CAT2000 additionally fall into predefined categories such as Action, Fractal, Object, or Social. Together with the corresponding fixation patterns, they constituted the input and desired output to our network architecture. In detail, we rescaled and padded all images from the SALICON and OSIE datasets to 240×320 240 320 240\times 320 240 × 320 pixels, the MIT1003, DUT-OMRON, and PASCAL-S datasets to 360×360 360 360 360\times 360 360 × 360 pixels, and the CAT2000 dataset to 216×384 216 384 216\times 384 216 × 384 pixels, such that the original aspect ratios were preserved. For the latter five eye tracking sets we defined 80% of the samples as training data and the remainder as validation examples with a minimum of 200 instances. The correct saliency distributions on test set images of MIT1003 and CAT2000 are held out and predictions must hence be submitted online for evaluation.
|
| 87 |
+
|
| 88 |
+
### 4.2 Metrics
|
| 89 |
+
|
| 90 |
+
Various measures are used in the literature and by benchmarks to evaluate the performance of fixation models. In practice, results are typically reported for all of them to include different notions about saliency and allow a fair comparison of model predictions Kümmerer et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib54)); Riche et al. ([2013](https://arxiv.org/html/1902.06634v4#bib.bib55)). A set of nine metrics is commonly selected: Kullback-Leibler divergence (KLD), Pearson’s correlation coefficient (CC), histogram intersection (SIM), Earth Mover’s distance (EMD), information gain (IG), normalized scanpath saliency (NSS), and three variants of area under ROC curve (AUC-Judd, AUC-Borji, shuffled AUC). The former four are location-based metrics, which require ground truth maps as binary fixation matrices. By contrast, the remaining metrics quantify saliency approximations after convolving gaze locations with a Gaussian kernel and representing the target output as a probability distribution. We refer readers to an overview by Bylinskii et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib56)) for more information regarding the implementation details and properties of the stated measures.
|
| 91 |
+
|
| 92 |
+
In this work, we adopted KLD as an objective function and produced fixation density maps as output from our proposed network. This training setup is particularly sensitive to false negative predictions and thus the appropriate choice for applications aimed at salient target detection Bylinskii et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib56)). Defining the problem of saliency prediction in a probabilistic framework also enables fair model ranking on public benchmarks for the MIT1003, CAT2000, and SALICON datasets Kümmerer et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib54)). As a consequence, we evaluated our estimated gaze distributions without applying any metric-specific postprocessing methods.
|
| 93 |
+
|
| 94 |
+
### 4.3 Results
|
| 95 |
+
|
| 96 |
+
A quantitative comparison of results on independent test datasets was carried out to characterize how well our proposed network generalizes to unseen images. Here, we were mainly interested in estimating human eye movements and regarded mouse tracking measurements merely as a substitute for attention. The final outcome for the 2017 release of the SALICON dataset is therefore not reported in this work but our model results can be viewed on the public leaderboard 1 1 1[https://competitions.codalab.org/competitions/17136](https://competitions.codalab.org/competitions/17136) under the user name akroner.
|
| 97 |
+
|
| 98 |
+
AUC-J
|
| 99 |
+
|
| 100 |
+
↑↑\uparrow↑SIM
|
| 101 |
+
|
| 102 |
+
↑↑\uparrow↑EMD
|
| 103 |
+
|
| 104 |
+
↓↓\downarrow↓AUC-B
|
| 105 |
+
|
| 106 |
+
↑↑\uparrow↑sAUC
|
| 107 |
+
|
| 108 |
+
↑↑\uparrow↑CC
|
| 109 |
+
|
| 110 |
+
↑↑\uparrow↑NSS
|
| 111 |
+
|
| 112 |
+
↑↑\uparrow↑KLD
|
| 113 |
+
|
| 114 |
+
↓↓\downarrow↓
|
| 115 |
+
DenseSal (Oyama and Yamanaka, [2018](https://arxiv.org/html/1902.06634v4#bib.bib27))0.87 0.67 1.99 0.81 0.72 0.79 2.25 0.48
|
| 116 |
+
DPNSal (Oyama and Yamanaka, [2018](https://arxiv.org/html/1902.06634v4#bib.bib27))0.87 0.69 2.05 0.80 0.74 0.82 2.41 0.91
|
| 117 |
+
SALICON (Huang et al., [2015](https://arxiv.org/html/1902.06634v4#bib.bib28))††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.87 0.60 2.62 0.85 0.74 0.74 2.12 0.54
|
| 118 |
+
DSCLRCN (Liu and Han, [2018](https://arxiv.org/html/1902.06634v4#bib.bib30))0.87 0.68 2.17 0.79 0.72 0.80 2.35 0.95
|
| 119 |
+
DeepFix (Kruthiventi et al., [2017](https://arxiv.org/html/1902.06634v4#bib.bib57))††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.87 0.67 2.04 0.80 0.71 0.78 2.26 0.63
|
| 120 |
+
EML-NET (Jia, [2018](https://arxiv.org/html/1902.06634v4#bib.bib58))0.88 0.68 1.84 0.77 0.70 0.79 2.47 0.84
|
| 121 |
+
DeepGaze II (Kümmerer et al., [2016](https://arxiv.org/html/1902.06634v4#bib.bib25))0.88 0.46 3.98 0.86 0.72 0.52 1.29 0.96
|
| 122 |
+
SAM-VGG (Cornia et al., [2018](https://arxiv.org/html/1902.06634v4#bib.bib29))††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.87 0.67 2.14 0.78 0.71 0.77 2.30 1.13
|
| 123 |
+
ML-Net (Cornia et al., [2016](https://arxiv.org/html/1902.06634v4#bib.bib26))††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.85 0.59 2.63 0.75 0.70 0.67 2.05 1.10
|
| 124 |
+
SAM-ResNet (Cornia et al., [2018](https://arxiv.org/html/1902.06634v4#bib.bib29))0.87 0.68 2.15 0.78 0.70 0.78 2.34 1.27
|
| 125 |
+
DeepGaze I (Kümmerer et al., [2014](https://arxiv.org/html/1902.06634v4#bib.bib24))0.84 0.39 4.97 0.83 0.66 0.48 1.22 1.23
|
| 126 |
+
Judd (Judd et al., [2009](https://arxiv.org/html/1902.06634v4#bib.bib20))0.81 0.42 4.45 0.80 0.60 0.47 1.18 1.12
|
| 127 |
+
eDN (Vig et al., [2014](https://arxiv.org/html/1902.06634v4#bib.bib21))0.82 0.41 4.56 0.81 0.62 0.45 1.14 1.14
|
| 128 |
+
GBVS (Harel et al., [2006](https://arxiv.org/html/1902.06634v4#bib.bib17))0.81 0.48 3.51 0.80 0.63 0.48 1.24 0.87
|
| 129 |
+
Itti (Itti et al., [1998](https://arxiv.org/html/1902.06634v4#bib.bib9))0.75 0.44 4.26 0.74 0.63 0.37 0.97 1.03
|
| 130 |
+
SUN (Zhang et al., [2008](https://arxiv.org/html/1902.06634v4#bib.bib16))0.67 0.38 5.10 0.66 0.61 0.25 0.68 1.27
|
| 131 |
+
Ours†normal-†{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.87 0.68 1.99 0.82 0.72 0.79 2.27 0.66
|
| 132 |
+
|
| 133 |
+
Table 1: Quantitative results of our model for the MIT300 test set in the context of prior work. The first line separates deep learning approaches with architectures pre-trained on image classification (the superscript ††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT represents models with a VGG16 backbone) from shallow networks and other machine learning methods. Entries between the second and the third line are models based on theoretical considerations and define a baseline rather than competitive performance. Arrows indicate whether the metrics assess similarity ↑↑\uparrow↑ or dissimilarity ↓↓\downarrow↓ between predictions and targets. The best results are marked in bold and models are sorted in descending order of their cumulative rank across a subset of weakly correlated evaluation measures within each group.
|
| 134 |
+
|
| 135 |
+
AUC-J
|
| 136 |
+
|
| 137 |
+
↑↑\uparrow↑SIM
|
| 138 |
+
|
| 139 |
+
↑↑\uparrow↑EMD
|
| 140 |
+
|
| 141 |
+
↓↓\downarrow↓AUC-B
|
| 142 |
+
|
| 143 |
+
↑↑\uparrow↑sAUC
|
| 144 |
+
|
| 145 |
+
↑↑\uparrow↑CC
|
| 146 |
+
|
| 147 |
+
↑↑\uparrow↑NSS
|
| 148 |
+
|
| 149 |
+
↑↑\uparrow↑KLD
|
| 150 |
+
|
| 151 |
+
↓↓\downarrow↓
|
| 152 |
+
SAM-VGG (Cornia et al., [2018](https://arxiv.org/html/1902.06634v4#bib.bib29))††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.88 0.76 1.07 0.79 0.58 0.89 2.38 0.54
|
| 153 |
+
SAM-ResNet (Cornia et al., [2018](https://arxiv.org/html/1902.06634v4#bib.bib29))0.88 0.77 1.04 0.80 0.58 0.89 2.38 0.56
|
| 154 |
+
DeepFix (Kruthiventi et al., [2017](https://arxiv.org/html/1902.06634v4#bib.bib57))††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.87 0.74 1.15 0.81 0.58 0.87 2.28 0.37
|
| 155 |
+
EML-NET (Jia, [2018](https://arxiv.org/html/1902.06634v4#bib.bib58))0.87 0.75 1.05 0.79 0.59 0.88 2.38 0.96
|
| 156 |
+
Judd (Judd et al., [2009](https://arxiv.org/html/1902.06634v4#bib.bib20))0.84 0.46 3.60 0.84 0.56 0.54 1.30 0.94
|
| 157 |
+
eDN (Vig et al., [2014](https://arxiv.org/html/1902.06634v4#bib.bib21))0.85 0.52 2.64 0.84 0.55 0.54 1.30 0.97
|
| 158 |
+
Itti (Itti et al., [1998](https://arxiv.org/html/1902.06634v4#bib.bib9))0.77 0.48 3.44 0.76 0.59 0.42 1.06 0.92
|
| 159 |
+
GBVS (Harel et al., [2006](https://arxiv.org/html/1902.06634v4#bib.bib17))0.80 0.51 2.99 0.79 0.58 0.50 1.23 0.80
|
| 160 |
+
SUN (Zhang et al., [2008](https://arxiv.org/html/1902.06634v4#bib.bib16))0.70 0.43 3.42 0.69 0.57 0.30 0.77 2.22
|
| 161 |
+
Ours†normal-†{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT 0.88 0.75 1.07 0.82 0.59 0.87 2.30 0.36
|
| 162 |
+
|
| 163 |
+
Table 2: Quantitative results of our model for the CAT2000 test set in the context of prior work. The first line separates deep learning approaches with architectures pre-trained on image classification (the superscript ††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT represents models with a VGG16 backbone) from shallow networks and other machine learning methods. Entries between the second and third lines are models based on theoretical considerations and define a baseline rather than competitive performance. Arrows indicate whether the metrics assess similarity ↑↑\uparrow↑ or dissimilarity ↓↓\downarrow↓ between predictions and targets. The best results are marked in bold and models are sorted in descending order of their cumulative rank across a subset of weakly correlated evaluation measures within each group.
|
| 164 |
+
|
| 165 |
+
To assess the predictive performance for eye tracking measurements, the MIT saliency benchmark Bylinskii et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib59)) is commonly used to compare model results on two test datasets with respect to prior work. Final scores can then be submitted on a public leaderboard to allow fair model ranking on eight evaluation metrics. Table[1](https://arxiv.org/html/1902.06634v4#S4.T1 "Table 1 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") summarizes our results on the test dataset of MIT1003, namely MIT300 Judd et al. ([2012](https://arxiv.org/html/1902.06634v4#bib.bib60)), in the context of previous approaches. The evaluation shows that our model only marginally failed to achieve state-of-the-art performance on any of the individual metrics. When computing the cumulative rank (i.e. the sum of ranks according to the standard competition ranking procedure) on a subset of weakly correlated measures (sAUC, CC, KLD)Riche et al. ([2013](https://arxiv.org/html/1902.06634v4#bib.bib55)); Bylinskii et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib56)), we ranked third behind the two architectures DenseSal and DPNSal from Oyama and Yamanaka ([2018](https://arxiv.org/html/1902.06634v4#bib.bib27)). However, their approaches were based on a pre-trained Densely Connected Convolutional Network with 161 layers Huang et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib61)) and Dual Path Network with 131 layers Chen et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib62)) respectively, both of which are computationally far more expensive than the VGG16 model used in this work (see Table 5 by Oyama and Yamanaka ([2018](https://arxiv.org/html/1902.06634v4#bib.bib27)) for a comparison of the computational efficiency). Furthermore, DenseSal and DPNSal implemented a multi-path design where two images of different resolutions are simultaneously fed to the network, which substantially reduces the execution speed compared to single-stream architectures. Among all entries of the MIT300 benchmark with a VGG16 backbone Cornia et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib26)); Huang et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib28)); Cornia et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib29)); Kruthiventi et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib57)), our model clearly achieved the highest performance.
|
| 166 |
+
|
| 167 |
+
Table 3: The number of trainable parameters for all deep learning models listed in Table[1](https://arxiv.org/html/1902.06634v4#S4.T1 "Table 1 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") that are competing in the MIT300 saliency benchmark. Entries of prior work are sorted according to increasing network complexity and the superscript ††{}^{\dagger}start_FLOATSUPERSCRIPT † end_FLOATSUPERSCRIPT represents pre-trained models with a VGG16 backbone.
|
| 168 |
+
|
| 169 |
+
Table 4: The results after evaluating our model with respect to its computational efficiency. We tested five versions trained on different eye tracking datasets, each receiving input images of their preferred sizes in pixels(px). After running each network on 10,000 test set instances from the ImageNet database for 10 times, we averaged the inference speed and described the results in frames per second(FPS). All settings demonstrated consistent outcomes with a standard deviation of less than 1 FPS. The minimal GPU memory utilization was measured with TensorFlow in megabytes(MB) and included the requirements for initializing a testing session. Finally, we estimated the floating point operations per second(FLOPS) at a scale of 9 orders of magnitude.
|
| 170 |
+
|
| 171 |
+
Table 5: Details regarding the hardware and software specifications used throughout our evaluation of computational efficiency. The system ran under the Debian 9 operating system and we minimized usage of the computer during the experiments to avoid interference with measurements of inference speed.
|
| 172 |
+
|
| 173 |
+
We further evaluated the model complexity of all relevant deep learning approaches listed in Table[1](https://arxiv.org/html/1902.06634v4#S4.T1 "Table 1 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction"). The number of trainable parameters was computed based on either the official code repository or a replication of the described architectures. In case a reimplementation was not possible, we faithfully estimated a lower bound given the pre-trained classification network. Table[3](https://arxiv.org/html/1902.06634v4#S4.T3 "Table 3 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") summarizes the findings and shows that our model compares favorably to the best-performing approaches. While the number of parameters provides an indication about the computational efficiency of an algorithm, more measures are needed. Therefore, we recorded the inference speed and GPU memory consumption of our model and calculated the number of computations (see Table[4](https://arxiv.org/html/1902.06634v4#S4.T4 "Table 4 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")) for our given hardware and software specifications (see Table[5](https://arxiv.org/html/1902.06634v4#S4.T5 "Table 5 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")). The results highlight that our approach achieves fast inference speed combined with a low GPU memory footprint, and thus enables applications to systems constrained by computational resources.
|
| 174 |
+
|
| 175 |
+
Table[2](https://arxiv.org/html/1902.06634v4#S4.T2 "Table 2 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") demonstrates that we obtained state-of-the-art scores for the CAT2000 test dataset regarding the AUC-J, sAUC, and KLD evaluation metrics, and competitive results on the remaining measures. The cumulative rank (as computed above) suggests that our model outperformed all previous approaches, including the ones based on a pre-trained VGG16 classification network(Cornia et al., [2018](https://arxiv.org/html/1902.06634v4#bib.bib29); Kruthiventi et al., [2017](https://arxiv.org/html/1902.06634v4#bib.bib57)). Our final evaluation results for both the MIT300 and CAT2000 datasets can be viewed on the MIT saliency benchmark under the model name MSI-Net, representing our multi-scale information network. Qualitatively, the proposed architecture successfully captures semantically meaningful image features such as faces and text towards the prediction of saliency, as can be seen in Figure[1](https://arxiv.org/html/1902.06634v4#S1.F1 "Figure 1 ‣ 1 Introduction ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction"). Unfortunately, a visual comparison with the results from prior work was not possible since most models are not openly available.
|
| 176 |
+
|
| 177 |
+
Table 6: A summary of the quantitative results for the models with ⊕direct-sum\oplus⊕ and without ⊖symmetric-difference\ominus⊖ an ASPP module. The evaluation was carried out on five eye tracking datasets respectively. Each network was independently trained 10 times resulting in a distribution of values characterized by the mean μ 𝜇\mu italic_μ and standard deviation σ 𝜎\sigma italic_σ. The star * denotes a significant increase of performance between the two conditions according to a one sided paired t-test. Arrows indicate whether the metrics assess similarity ↑↑\uparrow↑ or dissimilarity ↓↓\downarrow↓ between predictions and targets. The best results are marked in bold.
|
| 178 |
+
|
| 179 |
+
To quantify the contribution of multi-scale contextual information to the overall performance, we conducted a model ablation analysis. A baseline architecture without the ASPP module was constructed by replacing the five parallel convolutional layers with a single 3×3 3 3 3\times 3 3 × 3 convolutional operation that resulted in 1,280 activation maps. This representation was then forwarded to a 1×1 1 1 1\times 1 1 × 1 convolutional layer with 256 channels. While the total number of feature maps stayed constant, the amount of trainable parameters increased in this ablation setting. Table[6](https://arxiv.org/html/1902.06634v4#S4.T6 "Table 6 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") summarizes the results according to validation instances of five eye tracking datasets for the model with and without an ASPP module. It can be seen that our multi-scale architecture reached significantly higher performance (one tailed paired t-test) on most metrics and is therefore able to leverage the information captured by convolutional layers with different receptive field sizes. An ablation analysis of the multi-level component adapted from Cornia et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib26)) can be viewed in the[A](https://arxiv.org/html/1902.06634v4#A1 "Appendix A Feature Concatenation Ablation Analysis ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction").
|
| 180 |
+
|
| 181 |
+

|
| 182 |
+
|
| 183 |
+
Figure 3: A visualization of four example images from the CAT2000 validation set with the corresponding fixation heat maps, our best model predictions, and estimated maps based on the ablated network. The qualitative results indicate that multi-scale information augmented with global context enables a more accurate estimation of salient image regions.
|
| 184 |
+
|
| 185 |
+
Table 7: A list of the four image categories from the CAT2000 validation set that showed the largest average improvement by the ASPP architecture based on the cumulative rank across a subset of weakly correlated evaluation measures. Arrows indicate whether the metrics assess similarity ↑↑\uparrow↑ or dissimilarity ↓↓\downarrow↓ between predictions and targets. Results that improved on the respective metric are marked in green, whereas results that impaired performance are marked in red.
|
| 186 |
+
|
| 187 |
+
The categorical organization of the CAT2000 database also allowed us to quantify the improvements by the ASPP module with respect to individual image classes. Table[7](https://arxiv.org/html/1902.06634v4#S4.T7 "Table 7 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") lists the four categories that benefited the most from multi-scale information across the subset of evaluation metrics on the validation set: Noisy, Satellite, Cartoon, Pattern. To understand the measured changes in predictive performance, it is instructive to inspect qualitative results of one representative example for each image category (see Figure[3](https://arxiv.org/html/1902.06634v4#S4.F3 "Figure 3 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")). The visualizations demonstrate that large receptive fields allow the reweighting of relative importance assigned to image locations (Noisy, Satellite, Cartoon), detection of a central fixation bias (Noisy, Satellite, Cartoon), and allocation of saliency to a low-level color contrast that pops out from an array of distractors (Pattern).
|
| 188 |
+
|
| 189 |
+

|
| 190 |
+
|
| 191 |
+
Figure 4: A visualization of four example images from the CAT2000 validation set with the corresponding eye movement patterns and our model predictions. The stimuli demonstrate cases with a qualitative disagreement between the estimated saliency maps and ground truth data. Here, our model failed to capture an occluded face (a), small text (b), direction of gaze (c), and low-level feature contrast (d).
|
| 192 |
+
|
| 193 |
+
5 Discussion
|
| 194 |
+
------------
|
| 195 |
+
|
| 196 |
+
Our proposed encoder-decoder model clearly demonstrated competitive performance on two datasets towards visual saliency prediction. The ASPP module incorporated multi-scale information and global context based on semantic feature representations, which significantly improved the results both qualitatively and quantitatively on five eye tracking datasets. This suggests that convolutional layers with large receptive fields at different dilation factors can enable a more holistic estimation of salient image regions in complex scenes. Moreover, our approach is computationally lightweight compared to prior state-of-the-art approaches and could thus be implemented in (virtual) robotic systems that require computational efficiency. It also outperformed all other networks defined with a pre-trained VGG16 backbone as calculated by the cumulative rank on a subset of evaluation metrics to resolve some of the inconsistencies in ranking models by a single measure or a set of correlated ones Riche et al. ([2013](https://arxiv.org/html/1902.06634v4#bib.bib55)); Bylinskii et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib56)).
|
| 197 |
+
|
| 198 |
+
Further improvements of benchmark results could potentially be achieved by a number of additions to the processing pipeline. Our model demonstrates a learned preference for predicting fixations in central regions of images, but we expect performance gains from modeling the central bias in scene viewing explicitly Kümmerer et al. ([2014](https://arxiv.org/html/1902.06634v4#bib.bib24), [2016](https://arxiv.org/html/1902.06634v4#bib.bib25)); Cornia et al. ([2016](https://arxiv.org/html/1902.06634v4#bib.bib26), [2018](https://arxiv.org/html/1902.06634v4#bib.bib29)); Kruthiventi et al. ([2017](https://arxiv.org/html/1902.06634v4#bib.bib57)). Additionally, Bylinskii et al. ([2015](https://arxiv.org/html/1902.06634v4#bib.bib59)) summarized open problems for correctly assigning saliency in natural images, such as robustness in detecting semantic features, implied gaze and motion, and importance weighting of multiple salient regions. While the latter was addressed in this study, Figure[4](https://arxiv.org/html/1902.06634v4#S4.F4 "Figure 4 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") indicates that the remaining obstacles still persist for our proposed model.
|
| 199 |
+
|
| 200 |
+
Overcoming these issues requires a higher-level scene understanding that models object interactions and predicts implicit gaze and motion cues from static images. Robust object recognition could however be achieved through more recent classification networks as feature extractors Oyama and Yamanaka ([2018](https://arxiv.org/html/1902.06634v4#bib.bib27)) at the cost of added computational complexity. However, this study does not investigate whether the benefits of the proposed modifications generalize to other pre-trained architectures. That would constitute an interesting avenue for future research. To detect salient items in search array stimuli (see Figure[4](https://arxiv.org/html/1902.06634v4#S4.F4 "Figure 4 ‣ 4.3 Results ‣ 4 Experiments ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")d), a mechanism that additionally captures low-level feature contrasts might explain the empirical data better. Besides architectural changes, data augmentation in the context of saliency prediction tasks demonstrated its efficiency to improve the robustness of deep neural networks according to Che et al. ([2018](https://arxiv.org/html/1902.06634v4#bib.bib63)). These authors stated that visual transformations such as mirroring or inversion revealed a low impact on human gaze during scene viewing and could hence form an addition to future work on saliency models.
|
| 201 |
+
|
| 202 |
+
Declaration of Competing Interest
|
| 203 |
+
---------------------------------
|
| 204 |
+
|
| 205 |
+
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
|
| 206 |
+
|
| 207 |
+
Acknowledgement
|
| 208 |
+
---------------
|
| 209 |
+
|
| 210 |
+
This study has received funding from the European Union’s Horizon 2020 Framework Programme for Research and Innovation under the Specific Grant Agreement Nos. 720270 (Human Brain Project SGA1) and 785907 (Human Brain Project SGA2). Furthermore, we gratefully acknowledge the support of NVIDIA Corporation with the donation of a Titan X Pascal GPU used for this research.
|
| 211 |
+
|
| 212 |
+
References
|
| 213 |
+
----------
|
| 214 |
+
|
| 215 |
+
* Jonides et al. (1982) J.Jonides, D.E. Irwin, S.Yantis, Integrating visual information from successive fixations, Science 215 (1982) 192–194.
|
| 216 |
+
* Irwin (1991) D.E. Irwin, Information integration across saccadic eye movements, Cognitive Psychology 23 (1991) 420–456.
|
| 217 |
+
* Posner (1980) M.I. Posner, Orienting of attention, Quarterly Journal of Experimental Psychology 32 (1980) 3–25.
|
| 218 |
+
* Lennie (2003) P.Lennie, The cost of cortical computation, Current Biology 13 (2003) 493–497.
|
| 219 |
+
* Cowey and Rolls (1974) A.Cowey, E.Rolls, Human cortical magnification factor and its relation to visual acuity, Experimental Brain Research 21 (1974) 447–454.
|
| 220 |
+
* Berkley et al. (1975) M.A. Berkley, F.Kitterle, D.W. Watkins, Grating visibility as a function of orientation and retinal eccentricity, Vision Research 15 (1975) 239–244.
|
| 221 |
+
* Cheung et al. (2016) B.Cheung, E.Weiss, B.Olshausen, Emergence of foveal image sampling from learning to attend in visual scenes, arXiv preprint arXiv:1611.09430 (2016).
|
| 222 |
+
* Gegenfurtner (2016) K.R. Gegenfurtner, The interaction between vision and eye movements, Perception 45 (2016) 1333–1357.
|
| 223 |
+
* Itti et al. (1998) L.Itti, C.Koch, E.Niebur, A model of saliency-based visual attention for rapid scene analysis, IEEE Transactions on Pattern Analysis and Machine Intelligence 20 (1998) 1254–1259.
|
| 224 |
+
* Treisman and Gelade (1980) A.M. Treisman, G.Gelade, A feature-integration theory of attention, Cognitive Psychology 12 (1980) 97–136.
|
| 225 |
+
* Koch and Ullman (1985) C.Koch, S.Ullman, Shifts in selective visual attention: Towards the underlying neural circuitry, Human Neurobiology 4 (1985) 219–227.
|
| 226 |
+
* Krizhevsky et al. (2012) A.Krizhevsky, I.Sutskever, G.E. Hinton, ImageNet classification with deep convolutional neural networks, Advances in Neural Information Processing Systems 25 (2012) 1097–1105.
|
| 227 |
+
* Einhäuser et al. (2008) W.Einhäuser, M.Spain, P.Perona, Objects predict fixations better than early saliency, Journal of Vision 8 (2008) 18.
|
| 228 |
+
* Nuthmann and Henderson (2010) A.Nuthmann, J.M. Henderson, Object-based attentional selection in scene viewing, Journal of Vision 10 (2010) 20.
|
| 229 |
+
* Bornet et al. (2019) A.Bornet, J.Kaiser, A.Kroner, E.Falotico, A.Ambrosano, K.Cantero, M.H. Herzog, G.Francis, Running large-scale simulations on the Neurorobotics Platform to understand vision – the case of visual crowding, Frontiers in Neurorobotics 13 (2019) 33.
|
| 230 |
+
* Zhang et al. (2008) L.Zhang, M.H. Tong, T.K. Marks, H.Shan, G.W. Cottrell, SUN: A Bayesian framework for saliency using natural statistics, Journal of Vision 8 (2008) 32.
|
| 231 |
+
* Harel et al. (2006) J.Harel, C.Koch, P.Perona, Graph-based visual saliency, Advances in Neural Information Processing Systems 19 (2006) 545–552.
|
| 232 |
+
* Hou and Zhang (2007) X.Hou, L.Zhang, Saliency detection: A spectral residual approach, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2007) 1–8.
|
| 233 |
+
* Cerf et al. (2009) M.Cerf, E.P. Frady, C.Koch, Faces and text attract gaze independent of the task: Experimental data and computer model, Journal of Vision 9 (2009) 10.
|
| 234 |
+
* Judd et al. (2009) T.Judd, K.Ehinger, F.Durand, A.Torralba, Learning to predict where humans look, Proceedings of the International Conference on Computer Vision (2009) 2106–2113.
|
| 235 |
+
* Vig et al. (2014) E.Vig, M.Dorr, D.Cox, Large-scale optimization of hierarchical features for saliency prediction in natural images, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2014) 2798–2805.
|
| 236 |
+
* Deng et al. (2009) J.Deng, W.Dong, R.Socher, L.-J. Li, K.Li, L.Fei-Fei, ImageNet: A large-scale hierarchical image database, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2009) 248–255.
|
| 237 |
+
* Donahue et al. (2014) J.Donahue, Y.Jia, O.Vinyals, J.Hoffman, N.Zhang, E.Tzeng, T.Darrell, DeCAF: A deep convolutional activation feature for generic visual recognition, Proceedings of the International Conference on Machine Learning (2014) 647–655.
|
| 238 |
+
* Kümmerer et al. (2014) M.Kümmerer, L.Theis, M.Bethge, DeepGaze I: Boosting saliency prediction with feature maps trained on ImageNet, arXiv preprint arXiv:1411.1045 (2014).
|
| 239 |
+
* Kümmerer et al. (2016) M.Kümmerer, T.S. Wallis, M.Bethge, DeepGaze II: Reading fixations from deep features trained on object recognition, arXiv preprint arXiv:1610.01563 (2016).
|
| 240 |
+
* Cornia et al. (2016) M.Cornia, L.Baraldi, G.Serra, R.Cucchiara, A deep multi-level network for saliency prediction, Proceedings of the International Conference on Pattern Recognition (2016) 3488–3493.
|
| 241 |
+
* Oyama and Yamanaka (2018) T.Oyama, T.Yamanaka, Influence of image classification accuracy on saliency map estimation, arXiv preprint arXiv:1807.10657 (2018).
|
| 242 |
+
* Huang et al. (2015) X.Huang, C.Shen, X.Boix, Q.Zhao, SALICON: Reducing the semantic gap in saliency prediction by adapting deep neural networks, Proceedings of the International Conference on Computer Vision (2015) 262–270.
|
| 243 |
+
* Cornia et al. (2018) M.Cornia, L.Baraldi, G.Serra, R.Cucchiara, Predicting human eye fixations via an LSTM-based saliency attentive model, IEEE Transactions on Image Processing 27 (2018) 5142–5154.
|
| 244 |
+
* Liu and Han (2018) N.Liu, J.Han, A deep spatial contextual long-term recurrent convolutional network for saliency detection, IEEE Transactions on Image Processing 27 (2018) 3264–3274.
|
| 245 |
+
* Borji (2018) A.Borji, Saliency prediction in the deep learning era: An empirical investigation, arXiv preprint arXiv:1810.03716 (2018).
|
| 246 |
+
* Simonyan and Zisserman (2014) K.Simonyan, A.Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv preprint arXiv:1409.1556 (2014).
|
| 247 |
+
* Yu and Koltun (2015) F.Yu, V.Koltun, Multi-scale context aggregation by dilated convolutions, arXiv preprint arXiv:1511.07122 (2015).
|
| 248 |
+
* Hariharan et al. (2015) B.Hariharan, P.Arbeláez, R.Girshick, J.Malik, Hypercolumns for object segmentation and fine-grained localization, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015) 447–456.
|
| 249 |
+
* Long et al. (2015) J.Long, E.Shelhamer, T.Darrell, Fully convolutional networks for semantic segmentation, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015) 3431–3440.
|
| 250 |
+
* Chen et al. (2018) L.-C. Chen, G.Papandreou, I.Kokkinos, K.Murphy, A.L. Yuille, DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs, IEEE Transactions on Pattern Analysis and Machine Intelligence 40 (2018) 834–848.
|
| 251 |
+
* Torralba et al. (2006) A.Torralba, A.Oliva, M.S. Castelhano, J.M. Henderson, Contextual guidance of eye movements and attention in real-world scenes: The role of global features in object search, Psychological Review 113 (2006) 766.
|
| 252 |
+
* Chen et al. (2017) L.-C. Chen, G.Papandreou, F.Schroff, H.Adam, Rethinking atrous convolution for semantic image segmentation, arXiv preprint arXiv:1706.05587 (2017).
|
| 253 |
+
* Pan et al. (2017) J.Pan, C.C. Ferrer, K.McGuinness, N.E. O’Connor, J.Torres, E.Sayrol, X.Giro-i Nieto, SalGAN: Visual saliency prediction with generative adversarial networks, arXiv preprint arXiv:1701.01081 (2017).
|
| 254 |
+
* Odena et al. (2016) A.Odena, V.Dumoulin, C.Olah, Deconvolution and checkerboard artifacts, Distill 1 (2016) e3.
|
| 255 |
+
* Glorot and Bengio (2010) X.Glorot, Y.Bengio, Understanding the difficulty of training deep feedforward neural networks, Proceedings of the International Conference on Artificial Intelligence and Statistics (2010) 249–256.
|
| 256 |
+
* Sutskever et al. (2013) I.Sutskever, J.Martens, G.Dahl, G.Hinton, On the importance of initialization and momentum in deep learning, Proceedings of the International Conference on Machine Learning (2013) 1139–1147.
|
| 257 |
+
* Zhou et al. (2017) B.Zhou, A.Lapedriza, A.Khosla, A.Oliva, A.Torralba, Places: A 10 million image database for scene recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 40 (2017) 1452–1464.
|
| 258 |
+
* Jetley et al. (2016) S.Jetley, N.Murray, E.Vig, End-to-end saliency mapping via probability distribution prediction, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016) 5753–5761.
|
| 259 |
+
* Kingma and Ba (2014) D.P. Kingma, J.Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
|
| 260 |
+
* Wilson and Martinez (2003) D.R. Wilson, T.R. Martinez, The general inefficiency of batch training for gradient descent learning, Neural Networks 16 (2003) 1429–1451.
|
| 261 |
+
* Borji and Itti (2015) A.Borji, L.Itti, CAT2000: A large scale fixation dataset for boosting saliency research, arXiv preprint arXiv:1505.03581 (2015).
|
| 262 |
+
* Yang et al. (2013) C.Yang, L.Zhang, H.Lu, X.Ruan, M.-H. Yang, Saliency detection via graph-based manifold ranking, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2013) 3166–3173.
|
| 263 |
+
* Li et al. (2014) Y.Li, X.Hou, C.Koch, J.M. Rehg, A.L. Yuille, The secrets of salient object segmentation, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2014) 280–287.
|
| 264 |
+
* Xu et al. (2014) J.Xu, M.Jiang, S.Wang, M.S. Kankanhalli, Q.Zhao, Predicting human gaze beyond pixels, Journal of Vision 14 (2014) 28.
|
| 265 |
+
* Xu et al. (2015) P.Xu, K.A. Ehinger, Y.Zhang, A.Finkelstein, S.R. Kulkarni, J.Xiao, TurkerGaze: Crowdsourcing saliency with webcam based eye tracking, arXiv preprint arXiv:1504.06755 (2015).
|
| 266 |
+
* Jiang et al. (2015) M.Jiang, S.Huang, J.Duan, Q.Zhao, SALICON: Saliency in context, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2015) 1072–1080.
|
| 267 |
+
* Tavakoli et al. (2017) H.R. Tavakoli, F.Ahmed, A.Borji, J.Laaksonen, Saliency revisited: Analysis of mouse movements versus fixations, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017) 6354–6362.
|
| 268 |
+
* Kümmerer et al. (2018) M.Kümmerer, T.Wallis, M.Bethge, Saliency benchmarking made easy: Separating models, maps and metrics, Proceedings of the European Conference on Computer Vision (2018) 770–787.
|
| 269 |
+
* Riche et al. (2013) N.Riche, M.Duvinage, M.Mancas, B.Gosselin, T.Dutoit, Saliency and human fixations: State-of-the-art and study of comparison metrics, Proceedings of the International Conference on Computer Vision (2013) 1153–1160.
|
| 270 |
+
* Bylinskii et al. (2018) Z.Bylinskii, T.Judd, A.Oliva, A.Torralba, F.Durand, What do different evaluation metrics tell us about saliency models?, IEEE Transactions on Pattern Analysis and Machine Intelligence 41 (2018) 740–757.
|
| 271 |
+
* Kruthiventi et al. (2017) S.S. Kruthiventi, K.Ayush, R.V. Babu, DeepFix: A fully convolutional neural network for predicting human eye fixations, IEEE Transactions on Image Processing 26 (2017) 4446–4456.
|
| 272 |
+
* Jia (2018) S.Jia, EML-NET: An expandable multi-layer network for saliency prediction, arXiv preprint arXiv:1805.01047 (2018).
|
| 273 |
+
* Bylinskii et al. (2015) Z.Bylinskii, T.Judd, A.Borji, L.Itti, F.Durand, A.Oliva, A.Torralba, MIT saliency benchmark, http://saliency.mit.edu/, 2015.
|
| 274 |
+
* Judd et al. (2012) T.Judd, F.Durand, A.Torralba, A benchmark of computational models of saliency to predict human fixations, 2012.
|
| 275 |
+
* Huang et al. (2017) G.Huang, Z.Liu, L.Van Der Maaten, K.Q. Weinberger, Densely connected convolutional networks, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2017) 2261–2269.
|
| 276 |
+
* Chen et al. (2017) Y.Chen, J.Li, H.Xiao, X.Jin, S.Yan, J.Feng, Dual path networks, Advances in Neural Information Processing Systems 30 (2017) 4467–4475.
|
| 277 |
+
* Che et al. (2018) Z.Che, A.Borji, G.Zhai, X.Min, Invariance analysis of saliency models versus human gaze during scene free viewing, arXiv preprint arXiv:1810.04456 (2018).
|
| 278 |
+
|
| 279 |
+
Appendix A Feature Concatenation Ablation Analysis
|
| 280 |
+
--------------------------------------------------
|
| 281 |
+
|
| 282 |
+
Table 8: A summary of the quantitative results for the models with ⊕direct-sum\oplus⊕ and without ⊖symmetric-difference\ominus⊖ the concatenation of encoder features. The evaluation was carried out on five eye tracking datasets respectively. Each network was independently trained 10 times resulting in a distribution of values characterized by the mean μ 𝜇\mu italic_μ and standard deviation σ 𝜎\sigma italic_σ. The star * denotes a significant increase of performance between the two conditions according to a one sided paired t-test. Arrows indicate whether the metrics assess similarity ↑↑\uparrow↑ or dissimilarity ↓↓\downarrow↓ between predictions and targets. The best results are marked in bold.
|
| 283 |
+
|
| 284 |
+
Table 9: A list of the image categories from the CAT2000 validation set that either showed the largest average improvement (first two entries) or impairment (last two entries) by the multi-level design based on the cumulative rank across a subset of weakly correlated evaluation measures. Arrows indicate whether the metrics assess similarity ↑↑\uparrow↑ or dissimilarity↓↓\downarrow↓ between predictions and targets. Results that improved on the respective metric are marked in green, whereas results that impaired performance are marked in red.
|
| 285 |
+
|
| 286 |
+
In this experimental setting, we removed the concatenation operation from the network architecture and compared the model performance of the ablated version to the one including a multi-level design (see Table[8](https://arxiv.org/html/1902.06634v4#A1.T8 "Table 8 ‣ Appendix A Feature Concatenation Ablation Analysis ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction")). While models trained on the CAT2000 dataset did not consistently benefit from the aggregation of features at different stages of the encoder, all other cases demonstrated a mostly significant improvement according to the majority of metric scores. Table[9](https://arxiv.org/html/1902.06634v4#A1.T9 "Table 9 ‣ Appendix A Feature Concatenation Ablation Analysis ‣ Contextual Encoder-Decoder Network for Visual Saliency Prediction") indicates that predictions on natural image categories (Action, Social) leveraged the multi-level information for better performance, whereas adverse results were achieved on artificial and simplified stimuli (Fractal, Pattern). In conclusion, the feature concatenation design might only be recommendable for training models on datasets that mostly consist of complex natural images, such as MIT1003, DUT-OMRON, PASCAL-S, or OSIE.
|
1903/1903.03273.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1903.03273
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1903.03273#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1903.03273'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1904/1904.06472.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1904.06472
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1904.06472#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1904.06472'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|
1904/1904.07272.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
1904/1904.09751.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Title: | arXiv e-print repository
|
| 2 |
+
|
| 3 |
+
URL Source: https://arxiv.org/html/1904.09751
|
| 4 |
+
|
| 5 |
+
Warning: Target URL returned error 404: Not Found
|
| 6 |
+
|
| 7 |
+
Markdown Content:
|
| 8 |
+
| arXiv e-print repository
|
| 9 |
+
===============
|
| 10 |
+
[Skip to main content](https://arxiv.org/html/1904.09751#main-container)
|
| 11 |
+
|
| 12 |
+
[](https://cornell.edu/)
|
| 13 |
+
|
| 14 |
+
We gratefully acknowledge support from
|
| 15 |
+
|
| 16 |
+
the Simons Foundation, [member institutions](https://info.arxiv.org/about/ourmembers.html), and all contributors. [Donate](https://info.arxiv.org/about/donate.html)
|
| 17 |
+
|
| 18 |
+
[](https://arxiv.org/)
|
| 19 |
+
|
| 20 |
+
[Help](https://info.arxiv.org/help) | [Advanced Search](https://arxiv.org/search/advanced)
|
| 21 |
+
|
| 22 |
+
Search
|
| 23 |
+
|
| 24 |
+
[Login](https://arxiv.org/login)
|
| 25 |
+
|
| 26 |
+
No HTML for '1904.09751'
|
| 27 |
+
========================
|
| 28 |
+
|
| 29 |
+
HTML is not available for the source.
|
| 30 |
+
|
| 31 |
+
This could be due to the source files not being HTML, LaTeX, or a conversion failure.
|
| 32 |
+
|
| 33 |
+
If you are an author, learn how you can help [HTML conversions for your papers](https://info.arxiv.org/about/accessibility_html_error_messages.html).
|
| 34 |
+
|
| 35 |
+
* [About](https://info.arxiv.org/about)
|
| 36 |
+
* [Help](https://info.arxiv.org/help)
|
| 37 |
+
|
| 38 |
+
* [Contact](https://info.arxiv.org/help/contact.html)
|
| 39 |
+
* [Subscribe](https://info.arxiv.org/help/subscribe)
|
| 40 |
+
|
| 41 |
+
* [Copyright](https://info.arxiv.org/help/license/index.html)
|
| 42 |
+
* [Privacy Policy](https://info.arxiv.org/help/policies/privacy_policy.html)
|
| 43 |
+
|
| 44 |
+
* [Web Accessibility Assistance](https://info.arxiv.org/help/web_accessibility.html)
|
| 45 |
+
* [arXiv Operational Status](https://status.arxiv.org/)
|
| 46 |
+
|
| 47 |
+
Get status notifications via [email](https://subscribe.sorryapp.com/24846f03/email/new) or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)
|