
repo_id stringlengths 15 89 | file_path stringlengths 27 180 | content stringlengths 1 2.23M | __index_level_0__ int64 0 0 |
|---|---|---|---|
hf_public_repos | hf_public_repos/datasets/CODE_OF_CONDUCT.md | # Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of... | 0 |
hf_public_repos | hf_public_repos/datasets/dvc.yaml | stages:
benchmark_array_xd:
cmd: python ./benchmarks/benchmark_array_xd.py
deps:
- ./benchmarks/benchmark_array_xd.py
metrics:
- ./benchmarks/results/benchmark_array_xd.json:
cache: false
benchmark_indices_mapping:
cmd: python ./benchmarks/benchmark_indices_mapping.py
deps:
... | 0 |
hf_public_repos | hf_public_repos/datasets/.pre-commit-config.yaml | repos:
- repo: https://github.com/charliermarsh/ruff-pre-commit # https://github.com/charliermarsh/ruff#usage
rev: 'v0.1.5'
hooks:
# Run the linter.
- id: ruff
args: [ --fix ]
# Run the formatter.
- id: ruff-format
| 0 |
hf_public_repos | hf_public_repos/datasets/setup.cfg | [metadata]
license_files = LICENSE
[tool:pytest]
# Test fails if a FutureWarning is thrown by `huggingface_hub`
filterwarnings =
error::FutureWarning:huggingface_hub*
markers =
unit: unit test
integration: integration test
| 0 |
hf_public_repos | hf_public_repos/datasets/ADD_NEW_DATASET.md | # How to add one new datasets
Add datasets directly to the 🤗 Hugging Face Hub!
You can share your dataset on https://huggingface.co/datasets directly using your account, see the documentation:
* [Create a dataset and upload files on the website](https://huggingface.co/docs/datasets/upload_dataset)
* [Advanced guide... | 0 |
hf_public_repos | hf_public_repos/datasets/README.md | <p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/datasets-logo-dark.svg">
<source media="(prefers-color-scheme: light)" srcset="https://huggingface.co/datasets/huggingface/documentation-images/raw/main/d... | 0 |
hf_public_repos | hf_public_repos/datasets/pyproject.toml | [tool.black]
line-length = 119
target_version = ['py37']
[tool.ruff]
# Ignored rules:
# "E501" -> line length violation
# "F821" -> undefined named in type annotation (e.g. Literal["something"])
# "C901" -> `function_name` is too complex
ignore = ["E501", "F821", "C901"]
select = ["C", "E", "F", "I", "W"]
line-l... | 0 |
hf_public_repos | hf_public_repos/datasets/CONTRIBUTING.md | # How to contribute to Datasets?
[](CODE_OF_CONDUCT.md)
Datasets is an open source project, so all contributions and suggestions are welcome.
You can contribute in many different ways: giving ideas, answering questions, reporti... | 0 |
hf_public_repos | hf_public_repos/datasets/additional-tests-requirements.txt | unbabel-comet>=1.0.0
git+https://github.com/google-research/bleurt.git
git+https://github.com/ns-moosavi/coval.git
git+https://github.com/hendrycks/math.git
| 0 |
hf_public_repos | hf_public_repos/datasets/setup.py | # Lint as: python3
""" HuggingFace/Datasets is an open library of datasets.
Note:
VERSION needs to be formatted following the MAJOR.MINOR.PATCH convention
(we need to follow this convention to be able to retrieve versioned scripts)
Simple check list for release from AllenNLP repo: https://github.com/allenai/al... | 0 |
hf_public_repos | hf_public_repos/datasets/AUTHORS | # This is the list of HuggingFace Datasets authors for copyright purposes.
#
# This does not necessarily list everyone who has contributed code, since in
# some cases, their employer may be the copyright holder. To see the full list
# of contributors, see the revision history in source control.
Google Inc.
HuggingFac... | 0 |
hf_public_repos | hf_public_repos/datasets/CITATION.cff | cff-version: 1.2.0
message: "If you use this software, please cite it as below."
title: "huggingface/datasets"
authors:
- family-names: Lhoest
given-names: Quentin
- family-names: Villanova del Moral
given-names: Albert
orcid: "https://orcid.org/0000-0003-1727-1045"
- family-names: von Platen
given-names: Patri... | 0 |
hf_public_repos | hf_public_repos/datasets/.zenodo.json | {
"license": "Apache-2.0",
"creators": [
{
"affiliation": "Hugging Face",
"name": "Quentin Lhoest"
},
{
"orcid": "0000-0003-1727-1045",
"affiliation": "Hugging Face",
"name": "Albert Villanova del Moral"
},
{
... | 0 |
hf_public_repos | hf_public_repos/datasets/SECURITY.md | # Security Policy
## Supported Versions
<!--
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_... | 0 |
hf_public_repos | hf_public_repos/datasets/Makefile | .PHONY: quality style test
check_dirs := tests src benchmarks metrics utils
# Check that source code meets quality standards
quality:
ruff check $(check_dirs) setup.py # linter
ruff format --check $(check_dirs) setup.py # formatter
# Format source code automatically
style:
ruff check --fix $(check_dirs) setup.... | 0 |
hf_public_repos | hf_public_repos/datasets/.dvcignore | # Add patterns of files dvc should ignore, which could improve
# the performance. Learn more at
# https://dvc.org/doc/user-guide/dvcignore
| 0 |
hf_public_repos | hf_public_repos/datasets/LICENSE |
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/benchmark_indices_mapping.py | import json
import os
import tempfile
import datasets
from utils import generate_example_dataset, get_duration
SPEED_TEST_N_EXAMPLES = 500_000
RESULTS_BASEPATH, RESULTS_FILENAME = os.path.split(__file__)
RESULTS_FILE_PATH = os.path.join(RESULTS_BASEPATH, "results", RESULTS_FILENAME.replace(".py", ".json"))
@get_d... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/benchmark_getitem_100B.py | import json
import os
from dataclasses import dataclass
import numpy as np
import pyarrow as pa
import datasets
from utils import get_duration
SPEED_TEST_N_EXAMPLES = 100_000_000_000
SPEED_TEST_CHUNK_SIZE = 10_000
RESULTS_BASEPATH, RESULTS_FILENAME = os.path.split(__file__)
RESULTS_FILE_PATH = os.path.join(RESULTS... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/utils.py | import timeit
import numpy as np
import datasets
from datasets.arrow_writer import ArrowWriter
from datasets.features.features import _ArrayXD
def get_duration(func):
def wrapper(*args, **kwargs):
starttime = timeit.default_timer()
_ = func(*args, **kwargs)
delta = timeit.default_timer()... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/benchmark_iterating.py | import json
import os
import tempfile
import datasets
from utils import generate_example_dataset, get_duration
SPEED_TEST_N_EXAMPLES = 50_000
SMALL_TEST = 5_000
RESULTS_BASEPATH, RESULTS_FILENAME = os.path.split(__file__)
RESULTS_FILE_PATH = os.path.join(RESULTS_BASEPATH, "results", RESULTS_FILENAME.replace(".py", ... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/benchmark_array_xd.py | import json
import os
import tempfile
import datasets
from datasets.arrow_writer import ArrowWriter
from datasets.features import Array2D
from utils import generate_examples, get_duration
SHAPE_TEST_1 = (30, 487)
SHAPE_TEST_2 = (36, 1024)
SPEED_TEST_SHAPE = (100, 100)
SPEED_TEST_N_EXAMPLES = 100
DEFAULT_FEATURES = ... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/format.py | import json
import sys
def format_json_to_md(input_json_file, output_md_file):
with open(input_json_file, encoding="utf-8") as f:
results = json.load(f)
output_md = ["<details>", "<summary>Show updated benchmarks!</summary>", " "]
for benchmark_name in sorted(results):
benchmark_res = re... | 0 |
hf_public_repos/datasets | hf_public_repos/datasets/benchmarks/benchmark_map_filter.py | import json
import os
import tempfile
import transformers
import datasets
from utils import generate_example_dataset, get_duration
SPEED_TEST_N_EXAMPLES = 500_000
RESULTS_BASEPATH, RESULTS_FILENAME = os.path.split(__file__)
RESULTS_FILE_PATH = os.path.join(RESULTS_BASEPATH, "results", RESULTS_FILENAME.replace(".py... | 0 |
hf_public_repos/datasets/benchmarks | hf_public_repos/datasets/benchmarks/results/benchmark_array_xd.json | {"write_array2d": 0.14168284999323077, "read_unformated after write_array2d": 0.04353281999647152, "read_formatted_as_numpy after write_array2d": 0.1285462469968479, "read_batch_unformated after write_array2d": 0.023109222995117307, "read_batch_formatted_as_numpy after write_array2d": 0.011352884990628809, "read_col_un... | 0 |
hf_public_repos/datasets/benchmarks | hf_public_repos/datasets/benchmarks/results/benchmark_map_filter.json | {"num examples": 500000, "map identity": 10.19139202599763, "map identity batched": 0.6804238399927272, "map no-op batched": 0.5342009569867514, "map no-op batched numpy": 0.5792830920108827, "map no-op batched pandas": 0.4343639040016569, "map no-op batched pytorch": 0.5403374370071106, "map no-op batched tensorflow":... | 0 |
hf_public_repos/datasets/benchmarks | hf_public_repos/datasets/benchmarks/results/benchmark_getitem_100B.json | {"num examples": 100000000000, "get_first_row": 0.00019991099999927542, "get_last_row": 5.4411000000698095e-05, "get_batch_of_1024_rows": 0.0004897069999998394, "get_batch_of_1024_random_rows": 0.01800621099999944} | 0 |
hf_public_repos/datasets/benchmarks | hf_public_repos/datasets/benchmarks/results/benchmark_iterating.json | {"num examples": 50000, "read 5000": 0.2152090710005723, "read 50000": 2.077654693988734, "read_batch 50000 10": 1.5041199039987987, "read_batch 50000 100": 1.5411947140091797, "read_batch 50000 1000": 1.4684901159926085, "read_formatted numpy 5000": 4.584776938994764, "read_formatted pandas 5000": 3.7457121399929747, ... | 0 |
hf_public_repos/datasets/benchmarks | hf_public_repos/datasets/benchmarks/results/benchmark_indices_mapping.json | {"num examples": 500000, "select": 0.03741131999413483, "sort": 0.7371353159978753, "shuffle": 0.17655655200360343, "train_test_split": 0.29633847798686475, "shard": 0.01452581599005498} | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/ter/README.md | # Metric Card for TER
## Metric Description
TER (Translation Edit Rate, also called Translation Error Rate) is a metric to quantify the edit operations that a hypothesis requires to match a reference translation. We use the implementation that is already present in [sacrebleu](https://github.com/mjpost/sacreBLEU#ter),... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/ter/ter.py | # Copyright 2021 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bleu/README.md | # Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a ma... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bleu/bleu.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/xnli/README.md | # Metric Card for XNLI
## Metric description
The XNLI metric allows to evaluate a model's score on the [XNLI dataset](https://huggingface.co/datasets/xnli), which is a subset of a few thousand examples from the [MNLI dataset](https://huggingface.co/datasets/glue/viewer/mnli) that have been translated into a 14 differ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/xnli/xnli.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/xtreme_s/xtreme_s.py | # Copyright 2022 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/xtreme_s/README.md | # Metric Card for XTREME-S
## Metric Description
The XTREME-S metric aims to evaluate model performance on the Cross-lingual TRansfer Evaluation of Multilingual Encoders for Speech (XTREME-S) benchmark.
This benchmark was designed to evaluate speech representations across languages, tasks, domains and data regimes.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/perplexity/perplexity.py | # Copyright 2022 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/perplexity/README.md | # Metric Card for Perplexity
## Metric Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence. This can be used in two main ways:
1. to evaluate how well the model has learned the distribution of the text it was trained on
- In this cas... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/frugalscore/README.md | # Metric Card for FrugalScore
## Metric Description
FrugalScore is a reference-based metric for Natural Language Generation (NLG) model evaluation. It is based on a distillation approach that allows to learn a fixed, low cost version of any expensive NLG metric, while retaining most of its original performance.
The ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/frugalscore/frugalscore.py | # Copyright 2022 The HuggingFace Datasets Authors and the current metric script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/indic_glue/README.md | # Metric Card for IndicGLUE
## Metric description
This metric is used to compute the evaluation metric for the [IndicGLUE dataset](https://huggingface.co/datasets/indic_glue).
IndicGLUE is a natural language understanding benchmark for Indian languages. It contains a wide variety of tasks and covers 11 major Indian ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/indic_glue/indic_glue.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mse/README.md | # Metric Card for MSE
## Metric Description
Mean Squared Error(MSE) represents the average of the squares of errors -- i.e. the average squared difference between the estimated values and the actual values.
;
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mean_iou/README.md | # Metric Card for Mean IoU
## Metric Description
IoU (Intersection over Union) is the area of overlap between the predicted segmentation and the ground truth divided by the area of union between the predicted segmentation and the ground truth.
For binary (two classes) or multi-class segmentation, the *mean IoU* o... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mean_iou/mean_iou.py | # Copyright 2022 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mahalanobis/README.md | # Metric Card for Mahalanobis Distance
## Metric Description
Mahalonobis distance is the distance between a point and a distribution (as opposed to the distance between two points), making it the multivariate equivalent of the Euclidean distance.
It is often used in multivariate anomaly detection, classification on h... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mahalanobis/mahalanobis.py | # Copyright 2021 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/roc_auc/README.md | # Metric Card for ROC AUC
## Metric Description
This metric computes the area under the curve (AUC) for the Receiver Operating Characteristic Curve (ROC). The return values represent how well the model used is predicting the correct classes, based on the input data. A score of `0.5` means that the model is predicting... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/roc_auc/roc_auc.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/pearsonr/README.md | # Metric Card for Pearson Correlation Coefficient (pearsonr)
## Metric Description
Pearson correlation coefficient and p-value for testing non-correlation.
The Pearson correlation coefficient measures the linear relationship between two datasets. The calculation of the p-value relies on the assumption that each data... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/pearsonr/pearsonr.py | # Copyright 2021 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wiki_split/wiki_split.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wiki_split/README.md | # Metric Card for WikiSplit
## Metric description
WikiSplit is the combination of three metrics: [SARI](https://huggingface.co/metrics/sari), [exact match](https://huggingface.co/metrics/exact_match) and [SacreBLEU](https://huggingface.co/metrics/sacrebleu).
It can be used to evaluate the quality of sentence splitt... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/code_eval/README.md | # Metric Card for Code Eval
## Metric description
The CodeEval metric estimates the pass@k metric for code synthesis.
It implements the evaluation harness for the HumanEval problem solving dataset described in the paper ["Evaluating Large Language Models Trained on Code"](https://arxiv.org/abs/2107.03374).
## How... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/code_eval/execute.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/code_eval/code_eval.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/seqeval/seqeval.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/seqeval/README.md | # Metric Card for seqeval
## Metric description
seqeval is a Python framework for sequence labeling evaluation. seqeval can evaluate the performance of chunking tasks such as named-entity recognition, part-of-speech tagging, semantic role labeling and so on.
## How to use
Seqeval produces labelling scores along ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bertscore/bertscore.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bertscore/README.md | # Metric Card for BERT Score
## Metric description
BERTScore is an automatic evaluation metric for text generation that computes a similarity score for each token in the candidate sentence with each token in the reference sentence. It leverages the pre-trained contextual embeddings from [BERT](https://huggingface.co/... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/spearmanr/spearmanr.py | # Copyright 2021 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/spearmanr/README.md | # Metric Card for Spearman Correlation Coefficient Metric (spearmanr)
## Metric Description
The Spearman rank-order correlation coefficient is a measure of the
relationship between two datasets. Like other correlation coefficients,
this one varies between -1 and +1 with 0 implying no correlation.
Positive correlation... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/meteor/README.md | # Metric Card for METEOR
## Metric description
METEOR (Metric for Evaluation of Translation with Explicit ORdering) is a machine translation evaluation metric, which is calculated based on the harmonic mean of precision and recall, with recall weighted more than precision.
METEOR is based on a generalized concept o... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/meteor/meteor.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/squad/README.md | # Metric Card for SQuAD
## Metric description
This metric wraps the official scoring script for version 1 of the [Stanford Question Answering Dataset (SQuAD)](https://huggingface.co/datasets/squad).
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/squad/evaluate.py | """ Official evaluation script for v1.1 of the SQuAD dataset. """
import argparse
import json
import re
import string
import sys
from collections import Counter
def normalize_answer(s):
"""Lower text and remove punctuation, articles and extra whitespace."""
def remove_articles(text):
return re.sub(r... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/squad/squad.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/sari/README.md | # Metric Card for SARI
## Metric description
SARI (***s**ystem output **a**gainst **r**eferences and against the **i**nput sentence*) is a metric used for evaluating automatic text simplification systems.
The metric compares the predicted simplified sentences against the reference and the source sentences. It expli... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/sari/sari.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/competition_math/competition_math.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/competition_math/README.md | # Metric Card for Competition MATH
## Metric description
This metric is used to assess performance on the [Mathematics Aptitude Test of Heuristics (MATH) dataset](https://huggingface.co/datasets/competition_math).
It first canonicalizes the inputs (e.g., converting `1/2` to `\\frac{1}{2}`) and then computes accurac... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mae/README.md | # Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
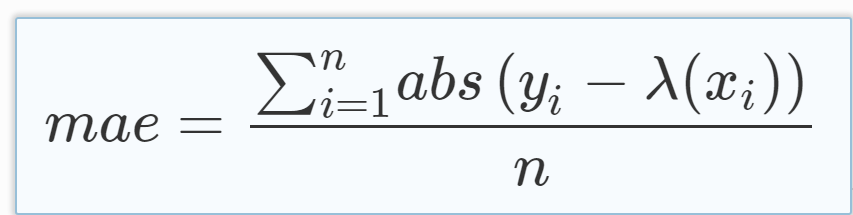
## How to Use
At minimum, this metric re... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/mae/mae.py | # Copyright 2022 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/bleurt/bleurt.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/comet/comet.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/comet/README.md | # Metric Card for COMET
## Metric description
Crosslingual Optimized Metric for Evaluation of Translation (COMET) is an open-source framework used to train Machine Translation metrics that achieve high levels of correlation with different types of human judgments.
## How to use
COMET takes 3 lists of strings as inp... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/rouge/README.md | # Metric Card for ROUGE
## Metric Description
ROUGE, or Recall-Oriented Understudy for Gisting Evaluation, is a set of metrics and a software package used for evaluating automatic summarization and machine translation software in natural language processing. The metrics compare an automatically produced summary or tra... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/rouge/rouge.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/google_bleu/README.md | # Metric Card for Google BLEU (GLEU)
## Metric Description
The BLEU score has some undesirable properties when used for single
sentences, as it was designed to be a corpus measure. The Google BLEU score, also known as GLEU score, is designed to limit these undesirable properties when used for single sentences.
To ca... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/google_bleu/google_bleu.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wer/README.md | # Metric Card for WER
## Metric description
Word error rate (WER) is a common metric of the performance of an automatic speech recognition (ASR) system.
The general difficulty of measuring the performance of ASR systems lies in the fact that the recognized word sequence can have a different length from the reference... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/wer/wer.py | # Copyright 2021 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/f1/README.md | # Metric Card for F1
## Metric Description
The F1 score is the harmonic mean of the precision and recall. It can be computed with the equation:
F1 = 2 * (precision * recall) / (precision + recall)
## How to Use
At minimum, this metric requires predictions and references as input
```python
>>> f1_metric = dataset... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/f1/f1.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/squad_v2/squad_v2.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/squad_v2/README.md | # Metric Card for SQuAD v2
## Metric description
This metric wraps the official scoring script for version 2 of the [Stanford Question Answering Dataset (SQuAD)](https://huggingface.co/datasets/squad_v2).
SQuAD is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia art... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/squad_v2/evaluate.py | """Official evaluation script for SQuAD version 2.0.
In addition to basic functionality, we also compute additional statistics and
plot precision-recall curves if an additional na_prob.json file is provided.
This file is expected to map question ID's to the model's predicted probability
that a question is unanswerable... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/accuracy/accuracy.py | # Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/accuracy/README.md | # Metric Card for Accuracy
## Metric Description
Accuracy is the proportion of correct predictions among the total number of cases processed. It can be computed with:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Where:
TP: True positive
TN: True negative
FP: False positive
FN: False negative
## How to Use
At minim... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/coval/README.md | # Metric Card for COVAL
## Metric description
CoVal is a coreference evaluation tool for the [CoNLL](https://huggingface.co/datasets/conll2003) and [ARRAU](https://catalog.ldc.upenn.edu/LDC2013T22) datasets which implements of the common evaluation metrics including MUC [Vilain et al, 1995](https://aclanthology.org/M... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/coval/coval.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/super_glue/README.md | # Metric Card for SuperGLUE
## Metric description
This metric is used to compute the SuperGLUE evaluation metric associated to each of the subsets of the [SuperGLUE dataset](https://huggingface.co/datasets/super_glue).
SuperGLUE is a new benchmark styled after GLUE with a new set of more difficult language understan... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/super_glue/record_evaluation.py | """
Official evaluation script for ReCoRD v1.0.
(Some functions are adopted from the SQuAD evaluation script.)
"""
import argparse
import json
import re
import string
import sys
from collections import Counter
def normalize_answer(s):
"""Lower text and remove punctuation, articles and extra whitespace."""
... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/super_glue/super_glue.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/cuad/README.md | # Metric Card for CUAD
## Metric description
This metric wraps the official scoring script for version 1 of the [Contract Understanding Atticus Dataset (CUAD)](https://huggingface.co/datasets/cuad), which is a corpus of more than 13,000 labels in 510 commercial legal contracts that have been manually labeled to ident... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/cuad/cuad.py | # Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or ... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/cuad/evaluate.py | """ Official evaluation script for CUAD dataset. """
import argparse
import json
import re
import string
import sys
import numpy as np
IOU_THRESH = 0.5
def get_jaccard(prediction, ground_truth):
remove_tokens = [".", ",", ";", ":"]
for token in remove_tokens:
ground_truth = ground_truth.replace(t... | 0 |
hf_public_repos/datasets/metrics | hf_public_repos/datasets/metrics/sacrebleu/README.md | # Metric Card for SacreBLEU
## Metric Description
SacreBLEU provides hassle-free computation of shareable, comparable, and reproducible BLEU scores. Inspired by Rico Sennrich's `multi-bleu-detok.perl`, it produces the official Workshop on Machine Translation (WMT) scores but works with plain text. It also knows all t... | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.