
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .gitattributes +1 -0
- README.md +5 -3
- data/surgicalthinker_rl.json +3 -0
- env.sh +12 -0
- model/EasyR1/.github/CODE_OF_CONDUCT.md +128 -0
- model/EasyR1/.github/CONTRIBUTING.md +64 -0
- model/EasyR1/.github/requirements-test.txt +11 -0
- model/EasyR1/.github/workflows/tests.yml +64 -0
- model/EasyR1/.pre-commit-config.yaml +22 -0
- model/EasyR1/Dockerfile +68 -0
- model/EasyR1/Dockerfile.legacy +68 -0
- model/EasyR1/LICENSE +201 -0
- model/EasyR1/Makefile +24 -0
- model/EasyR1/README.md +236 -0
- model/EasyR1/assets/baselines.md +51 -0
- model/EasyR1/assets/easyr1_grpo.png +3 -0
- model/EasyR1/assets/qwen2_5_vl_7b_geo.png +3 -0
- model/EasyR1/examples/README.md +190 -0
- model/EasyR1/examples/baselines/qwen2_5_vl_3b_clevr.sh +19 -0
- model/EasyR1/examples/baselines/qwen2_5_vl_3b_geoqa8k.sh +19 -0
- model/EasyR1/examples/config_d_grpo.yaml +109 -0
- model/EasyR1/examples/config_ema_grpo.yaml +108 -0
- model/EasyR1/examples/config_ema_grpo_64.yaml +109 -0
- model/EasyR1/examples/config_grpo.yaml +108 -0
- model/EasyR1/examples/format_prompt/dapo.jinja +1 -0
- model/EasyR1/examples/format_prompt/math.jinja +1 -0
- model/EasyR1/examples/format_prompt/r1v.jinja +1 -0
- model/EasyR1/examples/qwen2_5_7b_math_grpo.sh +9 -0
- model/EasyR1/examples/qwen2_5_vl_32b_geo3k_grpo.sh +16 -0
- model/EasyR1/examples/qwen2_5_vl_3b_geo3k_grpo.sh +14 -0
- model/EasyR1/examples/qwen2_5_vl_7b_geo3k_dapo.sh +18 -0
- model/EasyR1/examples/qwen2_5_vl_7b_geo3k_grpo.sh +13 -0
- model/EasyR1/examples/qwen2_5_vl_7b_geo3k_reinforce.sh +17 -0
- model/EasyR1/examples/qwen2_5_vl_7b_geo3k_swanlab.sh +14 -0
- model/EasyR1/examples/qwen2_5_vl_7b_multi_image.sh +16 -0
- model/EasyR1/examples/qwen3_14b_dapo17k_dapo.sh +41 -0
- model/EasyR1/examples/qwen3_4b_math_grpo.sh +11 -0
- model/EasyR1/examples/qwen3_vl_30b_geo3k_grpo.sh +16 -0
- model/EasyR1/examples/runtime_env.yaml +10 -0
- model/EasyR1/local_scripts/run_onethinker_rl.sh +52 -0
- model/EasyR1/local_scripts/run_surgicalthinker_rl_d-grpo.sh +63 -0
- model/EasyR1/local_scripts/run_surgicalthinker_rl_ema-grpo.sh +63 -0
- model/EasyR1/local_scripts/run_surgicalthinker_rl_grpo.sh +63 -0
- model/EasyR1/pyproject.toml +39 -0
- model/EasyR1/requirements.txt +20 -0
- model/EasyR1/scripts/model_merger.py +186 -0
- model/EasyR1/setup.py +61 -0
- model/EasyR1/tests/check_license.py +39 -0
- model/EasyR1/tests/test_checkpoint.py +50 -0
- model/EasyR1/tests/test_dataproto.py +183 -0
.gitattributes
CHANGED
|
@@ -58,3 +58,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 58 |
# Video files - compressed
|
| 59 |
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 60 |
*.webm filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 58 |
# Video files - compressed
|
| 59 |
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 60 |
*.webm filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
data/surgicalthinker_rl.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,5 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
| 1 |
+
将data/下的文件放在之前data/Medical下
|
| 2 |
+
|
| 3 |
+
将model/下的EasyR1替换原来的project/OneThinker/EasyR1
|
| 4 |
+
|
| 5 |
+
bash env.sh 安装环境
|
data/surgicalthinker_rl.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d84c106ab9ae519a94d59ef4efdc5c8844f631a800ff3567245490f54671c9f3
|
| 3 |
+
size 259793690
|
env.sh
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cd ../OneThinker/EasyR1
|
| 2 |
+
|
| 3 |
+
conda create -n easyr1 python=3.11
|
| 4 |
+
conda activate easyr1
|
| 5 |
+
cd EasyR1
|
| 6 |
+
pip install torch==2.8.0
|
| 7 |
+
pip install torchvision==0.23.0
|
| 8 |
+
pip install transformers==4.57.6
|
| 9 |
+
pip install vllm==0.11.0
|
| 10 |
+
pip install qwen_vl_utils==0.0.14
|
| 11 |
+
pip install flash-attn==2.8.3 --no-build-isolation --no-cache-dir
|
| 12 |
+
pip install -e .
|
model/EasyR1/.github/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributor Covenant Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
We as members, contributors, and leaders pledge to make participation in our
|
| 6 |
+
community a harassment-free experience for everyone, regardless of age, body
|
| 7 |
+
size, visible or invisible disability, ethnicity, sex characteristics, gender
|
| 8 |
+
identity and expression, level of experience, education, socio-economic status,
|
| 9 |
+
nationality, personal appearance, race, religion, or sexual identity
|
| 10 |
+
and orientation.
|
| 11 |
+
|
| 12 |
+
We pledge to act and interact in ways that contribute to an open, welcoming,
|
| 13 |
+
diverse, inclusive, and healthy community.
|
| 14 |
+
|
| 15 |
+
## Our Standards
|
| 16 |
+
|
| 17 |
+
Examples of behavior that contributes to a positive environment for our
|
| 18 |
+
community include:
|
| 19 |
+
|
| 20 |
+
* Demonstrating empathy and kindness toward other people
|
| 21 |
+
* Being respectful of differing opinions, viewpoints, and experiences
|
| 22 |
+
* Giving and gracefully accepting constructive feedback
|
| 23 |
+
* Accepting responsibility and apologizing to those affected by our mistakes,
|
| 24 |
+
and learning from the experience
|
| 25 |
+
* Focusing on what is best not just for us as individuals, but for the
|
| 26 |
+
overall community
|
| 27 |
+
|
| 28 |
+
Examples of unacceptable behavior include:
|
| 29 |
+
|
| 30 |
+
* The use of sexualized language or imagery, and sexual attention or
|
| 31 |
+
advances of any kind
|
| 32 |
+
* Trolling, insulting or derogatory comments, and personal or political attacks
|
| 33 |
+
* Public or private harassment
|
| 34 |
+
* Publishing others' private information, such as a physical or email
|
| 35 |
+
address, without their explicit permission
|
| 36 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 37 |
+
professional setting
|
| 38 |
+
|
| 39 |
+
## Enforcement Responsibilities
|
| 40 |
+
|
| 41 |
+
Community leaders are responsible for clarifying and enforcing our standards of
|
| 42 |
+
acceptable behavior and will take appropriate and fair corrective action in
|
| 43 |
+
response to any behavior that they deem inappropriate, threatening, offensive,
|
| 44 |
+
or harmful.
|
| 45 |
+
|
| 46 |
+
Community leaders have the right and responsibility to remove, edit, or reject
|
| 47 |
+
comments, commits, code, wiki edits, issues, and other contributions that are
|
| 48 |
+
not aligned to this Code of Conduct, and will communicate reasons for moderation
|
| 49 |
+
decisions when appropriate.
|
| 50 |
+
|
| 51 |
+
## Scope
|
| 52 |
+
|
| 53 |
+
This Code of Conduct applies within all community spaces, and also applies when
|
| 54 |
+
an individual is officially representing the community in public spaces.
|
| 55 |
+
Examples of representing our community include using an official e-mail address,
|
| 56 |
+
posting via an official social media account, or acting as an appointed
|
| 57 |
+
representative at an online or offline event.
|
| 58 |
+
|
| 59 |
+
## Enforcement
|
| 60 |
+
|
| 61 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 62 |
+
reported to the community leaders responsible for enforcement at
|
| 63 |
+
`hoshihiyouga AT gmail DOT com`.
|
| 64 |
+
All complaints will be reviewed and investigated promptly and fairly.
|
| 65 |
+
|
| 66 |
+
All community leaders are obligated to respect the privacy and security of the
|
| 67 |
+
reporter of any incident.
|
| 68 |
+
|
| 69 |
+
## Enforcement Guidelines
|
| 70 |
+
|
| 71 |
+
Community leaders will follow these Community Impact Guidelines in determining
|
| 72 |
+
the consequences for any action they deem in violation of this Code of Conduct:
|
| 73 |
+
|
| 74 |
+
### 1. Correction
|
| 75 |
+
|
| 76 |
+
**Community Impact**: Use of inappropriate language or other behavior deemed
|
| 77 |
+
unprofessional or unwelcome in the community.
|
| 78 |
+
|
| 79 |
+
**Consequence**: A private, written warning from community leaders, providing
|
| 80 |
+
clarity around the nature of the violation and an explanation of why the
|
| 81 |
+
behavior was inappropriate. A public apology may be requested.
|
| 82 |
+
|
| 83 |
+
### 2. Warning
|
| 84 |
+
|
| 85 |
+
**Community Impact**: A violation through a single incident or series
|
| 86 |
+
of actions.
|
| 87 |
+
|
| 88 |
+
**Consequence**: A warning with consequences for continued behavior. No
|
| 89 |
+
interaction with the people involved, including unsolicited interaction with
|
| 90 |
+
those enforcing the Code of Conduct, for a specified period of time. This
|
| 91 |
+
includes avoiding interactions in community spaces as well as external channels
|
| 92 |
+
like social media. Violating these terms may lead to a temporary or
|
| 93 |
+
permanent ban.
|
| 94 |
+
|
| 95 |
+
### 3. Temporary Ban
|
| 96 |
+
|
| 97 |
+
**Community Impact**: A serious violation of community standards, including
|
| 98 |
+
sustained inappropriate behavior.
|
| 99 |
+
|
| 100 |
+
**Consequence**: A temporary ban from any sort of interaction or public
|
| 101 |
+
communication with the community for a specified period of time. No public or
|
| 102 |
+
private interaction with the people involved, including unsolicited interaction
|
| 103 |
+
with those enforcing the Code of Conduct, is allowed during this period.
|
| 104 |
+
Violating these terms may lead to a permanent ban.
|
| 105 |
+
|
| 106 |
+
### 4. Permanent Ban
|
| 107 |
+
|
| 108 |
+
**Community Impact**: Demonstrating a pattern of violation of community
|
| 109 |
+
standards, including sustained inappropriate behavior, harassment of an
|
| 110 |
+
individual, or aggression toward or disparagement of classes of individuals.
|
| 111 |
+
|
| 112 |
+
**Consequence**: A permanent ban from any sort of public interaction within
|
| 113 |
+
the community.
|
| 114 |
+
|
| 115 |
+
## Attribution
|
| 116 |
+
|
| 117 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
| 118 |
+
version 2.0, available at
|
| 119 |
+
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
| 120 |
+
|
| 121 |
+
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
| 122 |
+
enforcement ladder](https://github.com/mozilla/diversity).
|
| 123 |
+
|
| 124 |
+
[homepage]: https://www.contributor-covenant.org
|
| 125 |
+
|
| 126 |
+
For answers to common questions about this code of conduct, see the FAQ at
|
| 127 |
+
https://www.contributor-covenant.org/faq. Translations are available at
|
| 128 |
+
https://www.contributor-covenant.org/translations.
|
model/EasyR1/.github/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributing to EasyR1
|
| 2 |
+
|
| 3 |
+
Everyone is welcome to contribute, and we value everybody's contribution. Code contributions are not the only way to help the community. Answering questions, helping others, and improving the documentation are also immensely valuable.
|
| 4 |
+
|
| 5 |
+
It also helps us if you spread the word! Reference the library in blog posts about the awesome projects it made possible, shout out on Twitter every time it has helped you, or simply ⭐️ the repository to say thank you.
|
| 6 |
+
|
| 7 |
+
However you choose to contribute, please be mindful and respect our [code of conduct](CODE_OF_CONDUCT.md).
|
| 8 |
+
|
| 9 |
+
**This guide was heavily inspired by [transformers guide to contributing](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md).**
|
| 10 |
+
|
| 11 |
+
## Ways to contribute
|
| 12 |
+
|
| 13 |
+
There are several ways you can contribute to EasyR1:
|
| 14 |
+
|
| 15 |
+
* Fix outstanding issues with the existing code.
|
| 16 |
+
* Submit issues related to bugs or desired new features.
|
| 17 |
+
* Contribute to the examples or to the documentation.
|
| 18 |
+
|
| 19 |
+
### Style guide
|
| 20 |
+
|
| 21 |
+
EasyR1 follows the [Google Python Style Guide](https://google.github.io/styleguide/pyguide.html), check it for details.
|
| 22 |
+
|
| 23 |
+
### Create a Pull Request
|
| 24 |
+
|
| 25 |
+
1. Fork the [repository](https://github.com/hiyouga/EasyR1) by clicking on the [Fork](https://github.com/hiyouga/EasyR1/fork) button on the repository's page. This creates a copy of the code under your GitHub user account.
|
| 26 |
+
|
| 27 |
+
2. Clone your fork to your local disk, and add the base repository as a remote:
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
git clone git@github.com:[username]/EasyR1.git
|
| 31 |
+
cd EasyR1
|
| 32 |
+
git remote add upstream https://github.com/hiyouga/EasyR1.git
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
3. Create a new branch to hold your development changes:
|
| 36 |
+
|
| 37 |
+
```bash
|
| 38 |
+
git checkout -b dev_your_branch
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
4. Set up a development environment by running the following command in a virtual environment:
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
pip install -e ".[dev]"
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
5. Check code before commit:
|
| 48 |
+
|
| 49 |
+
```bash
|
| 50 |
+
make commit
|
| 51 |
+
make style && make quality
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
6. Submit changes:
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
git add .
|
| 58 |
+
git commit -m "commit message"
|
| 59 |
+
git fetch upstream
|
| 60 |
+
git rebase upstream/main
|
| 61 |
+
git push -u origin dev_your_branch
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
7. Create a merge request from your branch `dev_your_branch` at [origin repo](https://github.com/hiyouga/EasyR1).
|
model/EasyR1/.github/requirements-test.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
codetiming
|
| 2 |
+
datasets
|
| 3 |
+
pillow
|
| 4 |
+
pytest
|
| 5 |
+
qwen-vl-utils
|
| 6 |
+
ray[default]
|
| 7 |
+
ruff
|
| 8 |
+
tensordict
|
| 9 |
+
torch
|
| 10 |
+
torchvision
|
| 11 |
+
transformers>=4.54.0,<=4.57.0
|
model/EasyR1/.github/workflows/tests.yml
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: tests
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
workflow_dispatch:
|
| 5 |
+
push:
|
| 6 |
+
branches:
|
| 7 |
+
- "main"
|
| 8 |
+
paths:
|
| 9 |
+
- "**/*.py"
|
| 10 |
+
- "**/requirements*.txt"
|
| 11 |
+
- ".github/workflows/*.yml"
|
| 12 |
+
pull_request:
|
| 13 |
+
branches:
|
| 14 |
+
- "main"
|
| 15 |
+
paths:
|
| 16 |
+
- "**/*.py"
|
| 17 |
+
- "**/requirements*.txt"
|
| 18 |
+
- ".github/workflows/*.yml"
|
| 19 |
+
|
| 20 |
+
jobs:
|
| 21 |
+
tests:
|
| 22 |
+
strategy:
|
| 23 |
+
fail-fast: false
|
| 24 |
+
matrix:
|
| 25 |
+
python-version:
|
| 26 |
+
- "3.11"
|
| 27 |
+
os:
|
| 28 |
+
- "ubuntu-latest"
|
| 29 |
+
|
| 30 |
+
runs-on: ${{ matrix.os }}
|
| 31 |
+
|
| 32 |
+
concurrency:
|
| 33 |
+
group: ${{ github.workflow }}-${{ github.ref }}-${{ matrix.os }}-${{ matrix.python-version }}
|
| 34 |
+
cancel-in-progress: ${{ github.ref != 'refs/heads/main' }}
|
| 35 |
+
|
| 36 |
+
steps:
|
| 37 |
+
- name: Checkout
|
| 38 |
+
uses: actions/checkout@v4
|
| 39 |
+
|
| 40 |
+
- name: Set up Python
|
| 41 |
+
uses: actions/setup-python@v5
|
| 42 |
+
with:
|
| 43 |
+
python-version: ${{ matrix.python-version }}
|
| 44 |
+
cache: "pip"
|
| 45 |
+
cache-dependency-path: "**/requirements*.txt"
|
| 46 |
+
|
| 47 |
+
- name: Install dependencies
|
| 48 |
+
run: |
|
| 49 |
+
python -m pip install --upgrade pip
|
| 50 |
+
python -m pip install torch torchvision --index-url https://download.pytorch.org/whl/cpu
|
| 51 |
+
python -m pip install -r .github/requirements-test.txt
|
| 52 |
+
python -m pip install --no-deps .
|
| 53 |
+
|
| 54 |
+
- name: Check quality
|
| 55 |
+
run: |
|
| 56 |
+
make style && make quality
|
| 57 |
+
|
| 58 |
+
- name: Check license
|
| 59 |
+
run: |
|
| 60 |
+
make license
|
| 61 |
+
|
| 62 |
+
- name: Test with pytest
|
| 63 |
+
run: |
|
| 64 |
+
make test
|
model/EasyR1/.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
repos:
|
| 2 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 3 |
+
rev: v5.0.0
|
| 4 |
+
hooks:
|
| 5 |
+
- id: check-ast
|
| 6 |
+
- id: check-added-large-files
|
| 7 |
+
args: ['--maxkb=25000']
|
| 8 |
+
- id: check-merge-conflict
|
| 9 |
+
- id: check-yaml
|
| 10 |
+
- id: debug-statements
|
| 11 |
+
- id: end-of-file-fixer
|
| 12 |
+
- id: requirements-txt-fixer
|
| 13 |
+
- id: trailing-whitespace
|
| 14 |
+
args: [--markdown-linebreak-ext=md]
|
| 15 |
+
- id: no-commit-to-branch
|
| 16 |
+
args: ['--branch', 'main']
|
| 17 |
+
|
| 18 |
+
- repo: https://github.com/asottile/pyupgrade
|
| 19 |
+
rev: v3.17.0
|
| 20 |
+
hooks:
|
| 21 |
+
- id: pyupgrade
|
| 22 |
+
args: [--py38-plus]
|
model/EasyR1/Dockerfile
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Start from the NVIDIA official image (ubuntu-24.04 + cuda-12.9 + python-3.12)
|
| 2 |
+
# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-25-05.html
|
| 3 |
+
FROM nvcr.io/nvidia/pytorch:25.05-py3
|
| 4 |
+
|
| 5 |
+
# Define environments
|
| 6 |
+
ENV MAX_JOBS=32
|
| 7 |
+
ENV VLLM_WORKER_MULTIPROC_METHOD=spawn
|
| 8 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 9 |
+
ENV NODE_OPTIONS=""
|
| 10 |
+
ENV PIP_ROOT_USER_ACTION=ignore
|
| 11 |
+
ENV HF_HUB_ENABLE_HF_TRANSFER="1"
|
| 12 |
+
|
| 13 |
+
# Define installation arguments
|
| 14 |
+
ARG APT_SOURCE=https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
|
| 15 |
+
ARG PIP_INDEX=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
|
| 16 |
+
|
| 17 |
+
# Set apt source
|
| 18 |
+
RUN cp /etc/apt/sources.list /etc/apt/sources.list.bak && \
|
| 19 |
+
{ \
|
| 20 |
+
echo "deb ${APT_SOURCE} jammy main restricted universe multiverse"; \
|
| 21 |
+
echo "deb ${APT_SOURCE} jammy-updates main restricted universe multiverse"; \
|
| 22 |
+
echo "deb ${APT_SOURCE} jammy-backports main restricted universe multiverse"; \
|
| 23 |
+
echo "deb ${APT_SOURCE} jammy-security main restricted universe multiverse"; \
|
| 24 |
+
} > /etc/apt/sources.list
|
| 25 |
+
|
| 26 |
+
# Install systemctl
|
| 27 |
+
RUN apt-get update && \
|
| 28 |
+
apt-get install -y -o Dpkg::Options::="--force-confdef" systemd && \
|
| 29 |
+
apt-get clean
|
| 30 |
+
|
| 31 |
+
# Install tini
|
| 32 |
+
RUN apt-get update && \
|
| 33 |
+
apt-get install -y tini && \
|
| 34 |
+
apt-get clean
|
| 35 |
+
|
| 36 |
+
# Change pip source
|
| 37 |
+
RUN pip config set global.index-url "${PIP_INDEX}" && \
|
| 38 |
+
pip config set global.extra-index-url "${PIP_INDEX}" && \
|
| 39 |
+
python -m pip install --upgrade pip
|
| 40 |
+
|
| 41 |
+
# Uninstall nv-pytorch fork
|
| 42 |
+
RUN pip uninstall -y torch torchvision torchaudio \
|
| 43 |
+
pytorch-quantization pytorch-triton torch-tensorrt \
|
| 44 |
+
transformer-engine flash-attn apex megatron-core \
|
| 45 |
+
xgboost opencv grpcio
|
| 46 |
+
|
| 47 |
+
# Remove nv file
|
| 48 |
+
RUN rm -rf /workspace
|
| 49 |
+
|
| 50 |
+
# Fix cv2
|
| 51 |
+
RUN rm -rf /usr/local/lib/python3.10/dist-packages/cv2
|
| 52 |
+
|
| 53 |
+
# Install torch-2.8.0+cu128 + vllm-0.11.0
|
| 54 |
+
RUN pip install --no-cache-dir "vllm==0.11.0" "torch==2.8.0" "torchvision==0.23.0" "torchaudio==2.8.0" tensordict torchdata \
|
| 55 |
+
"transformers[hf_xet]>=4.51.0" accelerate datasets peft hf-transfer \
|
| 56 |
+
"numpy<2.0.0" "pyarrow>=15.0.0" "grpcio>=1.62.1" "optree>=0.13.0" pandas \
|
| 57 |
+
ray[default] codetiming hydra-core pylatexenc qwen-vl-utils wandb liger-kernel mathruler \
|
| 58 |
+
pytest yapf py-spy pre-commit ruff
|
| 59 |
+
|
| 60 |
+
# Install flash-attn-2.8.3
|
| 61 |
+
RUN ABI_FLAG=$(python -c "import torch; print('TRUE' if torch._C._GLIBCXX_USE_CXX11_ABI else 'FALSE')") && \
|
| 62 |
+
URL="https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.3/flash_attn-2.8.3+cu12torch2.8cxx11abi${ABI_FLAG}-cp312-cp312-linux_x86_64.whl" && \
|
| 63 |
+
wget -nv -P /opt/tiger "${URL}" && \
|
| 64 |
+
pip install --no-cache-dir "/opt/tiger/$(basename ${URL})"
|
| 65 |
+
|
| 66 |
+
# Reset pip config
|
| 67 |
+
RUN pip config unset global.index-url && \
|
| 68 |
+
pip config unset global.extra-index-url
|
model/EasyR1/Dockerfile.legacy
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Start from the NVIDIA official image (ubuntu-22.04 + cuda-12.6 + python-3.10)
|
| 2 |
+
# https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-24-08.html
|
| 3 |
+
FROM nvcr.io/nvidia/pytorch:24.08-py3
|
| 4 |
+
|
| 5 |
+
# Define environments
|
| 6 |
+
ENV MAX_JOBS=32
|
| 7 |
+
ENV VLLM_WORKER_MULTIPROC_METHOD=spawn
|
| 8 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 9 |
+
ENV NODE_OPTIONS=""
|
| 10 |
+
ENV PIP_ROOT_USER_ACTION=ignore
|
| 11 |
+
ENV HF_HUB_ENABLE_HF_TRANSFER="1"
|
| 12 |
+
|
| 13 |
+
# Define installation arguments
|
| 14 |
+
ARG APT_SOURCE=https://mirrors.tuna.tsinghua.edu.cn/ubuntu/
|
| 15 |
+
ARG PIP_INDEX=https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
|
| 16 |
+
|
| 17 |
+
# Set apt source
|
| 18 |
+
RUN cp /etc/apt/sources.list /etc/apt/sources.list.bak && \
|
| 19 |
+
{ \
|
| 20 |
+
echo "deb ${APT_SOURCE} jammy main restricted universe multiverse"; \
|
| 21 |
+
echo "deb ${APT_SOURCE} jammy-updates main restricted universe multiverse"; \
|
| 22 |
+
echo "deb ${APT_SOURCE} jammy-backports main restricted universe multiverse"; \
|
| 23 |
+
echo "deb ${APT_SOURCE} jammy-security main restricted universe multiverse"; \
|
| 24 |
+
} > /etc/apt/sources.list
|
| 25 |
+
|
| 26 |
+
# Install systemctl
|
| 27 |
+
RUN apt-get update && \
|
| 28 |
+
apt-get install -y -o Dpkg::Options::="--force-confdef" systemd && \
|
| 29 |
+
apt-get clean
|
| 30 |
+
|
| 31 |
+
# Install tini
|
| 32 |
+
RUN apt-get update && \
|
| 33 |
+
apt-get install -y tini && \
|
| 34 |
+
apt-get clean
|
| 35 |
+
|
| 36 |
+
# Change pip source
|
| 37 |
+
RUN pip config set global.index-url "${PIP_INDEX}" && \
|
| 38 |
+
pip config set global.extra-index-url "${PIP_INDEX}" && \
|
| 39 |
+
python -m pip install --upgrade pip
|
| 40 |
+
|
| 41 |
+
# Uninstall nv-pytorch fork
|
| 42 |
+
RUN pip uninstall -y torch torchvision torchaudio \
|
| 43 |
+
pytorch-quantization pytorch-triton torch-tensorrt \
|
| 44 |
+
transformer-engine flash-attn apex megatron-core \
|
| 45 |
+
xgboost opencv grpcio
|
| 46 |
+
|
| 47 |
+
# Remove nv file
|
| 48 |
+
RUN rm -rf /workspace
|
| 49 |
+
|
| 50 |
+
# Fix cv2
|
| 51 |
+
RUN rm -rf /usr/local/lib/python3.10/dist-packages/cv2
|
| 52 |
+
|
| 53 |
+
# Install torch-2.7.1+cu126 + vllm-0.10.0
|
| 54 |
+
RUN pip install --no-cache-dir "vllm==0.10.0" "torch==2.7.1" "torchvision==0.22.1" "torchaudio==2.7.1" tensordict torchdata \
|
| 55 |
+
"transformers[hf_xet]>=4.51.0" accelerate datasets peft hf-transfer \
|
| 56 |
+
"numpy<2.0.0" "pyarrow>=15.0.0" "grpcio>=1.62.1" "optree>=0.13.0" pandas \
|
| 57 |
+
ray[default] codetiming hydra-core pylatexenc qwen-vl-utils wandb liger-kernel mathruler \
|
| 58 |
+
pytest yapf py-spy pyext pre-commit ruff
|
| 59 |
+
|
| 60 |
+
# Install flash-attn-2.8.2
|
| 61 |
+
RUN ABI_FLAG=$(python -c "import torch; print('TRUE' if torch._C._GLIBCXX_USE_CXX11_ABI else 'FALSE')") && \
|
| 62 |
+
URL="https://github.com/Dao-AILab/flash-attention/releases/download/v2.8.2/flash_attn-2.8.2+cu12torch2.7cxx11abi${ABI_FLAG}-cp310-cp310-linux_x86_64.whl" && \
|
| 63 |
+
wget -nv -P /opt/tiger "${URL}" && \
|
| 64 |
+
pip install --no-cache-dir "/opt/tiger/$(basename ${URL})"
|
| 65 |
+
|
| 66 |
+
# Reset pip config
|
| 67 |
+
RUN pip config unset global.index-url && \
|
| 68 |
+
pip config unset global.extra-index-url
|
model/EasyR1/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
model/EasyR1/Makefile
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.PHONY: build commit license quality style test
|
| 2 |
+
|
| 3 |
+
check_dirs := examples scripts tests verl setup.py
|
| 4 |
+
|
| 5 |
+
build:
|
| 6 |
+
python3 setup.py sdist bdist_wheel
|
| 7 |
+
|
| 8 |
+
commit:
|
| 9 |
+
pre-commit install
|
| 10 |
+
pre-commit run --all-files
|
| 11 |
+
|
| 12 |
+
license:
|
| 13 |
+
python3 tests/check_license.py $(check_dirs)
|
| 14 |
+
|
| 15 |
+
quality:
|
| 16 |
+
ruff check $(check_dirs)
|
| 17 |
+
ruff format --check $(check_dirs)
|
| 18 |
+
|
| 19 |
+
style:
|
| 20 |
+
ruff check $(check_dirs) --fix
|
| 21 |
+
ruff format $(check_dirs)
|
| 22 |
+
|
| 23 |
+
test:
|
| 24 |
+
pytest -vv tests/
|
model/EasyR1/README.md
ADDED
|
@@ -0,0 +1,236 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework
|
| 2 |
+
|
| 3 |
+
[](https://github.com/hiyouga/EasyR1/stargazers)
|
| 4 |
+
[](https://twitter.com/llamafactory_ai)
|
| 5 |
+
[](https://hub.docker.com/r/hiyouga/verl/tags)
|
| 6 |
+
|
| 7 |
+
### Used by [Amazon Web Services](https://aws.amazon.com/cn/blogs/china/building-llm-model-hub-based-on-llamafactory-and-easyr1/)
|
| 8 |
+
|
| 9 |
+
This project is a clean fork of the original [veRL](https://github.com/volcengine/verl) project to support vision language models, we thank all the authors for providing such a high-performance RL training framework.
|
| 10 |
+
|
| 11 |
+
EasyR1 is efficient and scalable due to the design of **[HybirdEngine](https://arxiv.org/abs/2409.19256)** and the latest release of **[vLLM](https://github.com/vllm-project/vllm)**'s SPMD mode.
|
| 12 |
+
|
| 13 |
+
## Features
|
| 14 |
+
|
| 15 |
+
- Supported models
|
| 16 |
+
- Llama3/Qwen2/Qwen2.5/Qwen3 language models
|
| 17 |
+
- Qwen2-VL/Qwen2.5-VL/Qwen3-VL vision language models
|
| 18 |
+
- DeepSeek-R1 distill models
|
| 19 |
+
|
| 20 |
+
- Supported algorithms
|
| 21 |
+
- GRPO
|
| 22 |
+
- DAPO
|
| 23 |
+
- Reinforce++
|
| 24 |
+
- ReMax
|
| 25 |
+
- RLOO
|
| 26 |
+
|
| 27 |
+
- Supported datasets
|
| 28 |
+
- Any text, vision-text dataset in a [specific format](#custom-dataset)
|
| 29 |
+
|
| 30 |
+
- Supported tricks
|
| 31 |
+
- Padding-free training
|
| 32 |
+
- Resuming from the latest/best checkpoint
|
| 33 |
+
- Wandb & SwanLab & Mlflow & Tensorboard tracking
|
| 34 |
+
|
| 35 |
+
## Requirements
|
| 36 |
+
|
| 37 |
+
### Software Requirements
|
| 38 |
+
|
| 39 |
+
- Python 3.9+
|
| 40 |
+
- transformers>=4.54.0
|
| 41 |
+
- flash-attn>=2.4.3
|
| 42 |
+
- vllm>=0.8.3
|
| 43 |
+
|
| 44 |
+
We provide a [Dockerfile](./Dockerfile) to easily build environments.
|
| 45 |
+
|
| 46 |
+
We recommend using the [pre-built docker image](https://hub.docker.com/r/hiyouga/verl) in EasyR1.
|
| 47 |
+
|
| 48 |
+
```bash
|
| 49 |
+
docker pull hiyouga/verl:ngc-th2.8.0-cu12.9-vllm0.11.0
|
| 50 |
+
docker run -it --ipc=host --gpus=all hiyouga/verl:ngc-th2.8.0-cu12.9-vllm0.11.0
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
If your environment does not support Docker, you can consider using **Apptainer**:
|
| 54 |
+
|
| 55 |
+
```bash
|
| 56 |
+
apptainer pull easyr1.sif docker://hiyouga/verl:ngc-th2.8.0-cu12.9-vllm0.11.0
|
| 57 |
+
apptainer shell --nv --cleanenv --bind /mnt/your_dir:/mnt/your_dir easyr1.sif
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
Use `USE_MODELSCOPE_HUB=1` to download models from the ModelScope hub.
|
| 61 |
+
|
| 62 |
+
### Hardware Requirements
|
| 63 |
+
|
| 64 |
+
\* *estimated*
|
| 65 |
+
|
| 66 |
+
| Method | Bits | 1.5B | 3B | 7B | 32B | 72B |
|
| 67 |
+
| ------------------------ | ---- | ------ | ------ | ------ | ------- | ------- |
|
| 68 |
+
| GRPO Full Fine-Tuning | AMP | 2*24GB | 4*40GB | 8*40GB | 16*80GB | 32*80GB |
|
| 69 |
+
| GRPO Full Fine-Tuning | BF16 | 1*24GB | 1*40GB | 4*40GB | 8*80GB | 16*80GB |
|
| 70 |
+
|
| 71 |
+
> [!NOTE]
|
| 72 |
+
> Use `worker.actor.fsdp.torch_dtype=bf16` and `worker.actor.optim.strategy=adamw_bf16` to enable bf16 training.
|
| 73 |
+
>
|
| 74 |
+
> We are working hard to reduce the VRAM in RL training, LoRA support will be integrated in next updates.
|
| 75 |
+
|
| 76 |
+
## Tutorial: Run Qwen2.5-VL GRPO on [Geometry3K](https://huggingface.co/datasets/hiyouga/geometry3k) Dataset in Just 3 Steps
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
### Installation
|
| 81 |
+
|
| 82 |
+
```bash
|
| 83 |
+
git clone https://github.com/hiyouga/EasyR1.git
|
| 84 |
+
cd EasyR1
|
| 85 |
+
pip install -e .
|
| 86 |
+
```
|
| 87 |
+
|
| 88 |
+
### GRPO Training
|
| 89 |
+
|
| 90 |
+
```bash
|
| 91 |
+
bash examples/qwen2_5_vl_7b_geo3k_grpo.sh
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
### Merge Checkpoint in Hugging Face Format
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
python3 scripts/model_merger.py --local_dir checkpoints/easy_r1/exp_name/global_step_1/actor
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
> [!TIP]
|
| 101 |
+
> If you encounter issues with connecting to Hugging Face, consider using `export HF_ENDPOINT=https://hf-mirror.com`.
|
| 102 |
+
>
|
| 103 |
+
> If you want to use SwanLab logger, consider using `bash examples/qwen2_5_vl_7b_geo3k_swanlab.sh`.
|
| 104 |
+
|
| 105 |
+
## Custom Dataset
|
| 106 |
+
|
| 107 |
+
Please refer to the example datasets to prepare your own dataset.
|
| 108 |
+
|
| 109 |
+
- Text dataset: https://huggingface.co/datasets/hiyouga/math12k
|
| 110 |
+
- Image-text dataset: https://huggingface.co/datasets/hiyouga/geometry3k
|
| 111 |
+
- Multi-image-text dataset: https://huggingface.co/datasets/hiyouga/journeybench-multi-image-vqa
|
| 112 |
+
- Text-image mixed dataset: https://huggingface.co/datasets/hiyouga/rl-mixed-dataset
|
| 113 |
+
|
| 114 |
+
## How to Understand GRPO in EasyR1
|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
|
| 118 |
+
- To learn about the GRPO algorithm, you can refer to [Hugging Face's blog](https://huggingface.co/docs/trl/v0.16.1/en/grpo_trainer).
|
| 119 |
+
|
| 120 |
+
## How to Run 70B+ Model in Multi-node Environment
|
| 121 |
+
|
| 122 |
+
1. Start the Ray head node.
|
| 123 |
+
|
| 124 |
+
```bash
|
| 125 |
+
ray start --head --port=6379 --dashboard-host=0.0.0.0
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
2. Start the Ray worker node and connect to the head node.
|
| 129 |
+
|
| 130 |
+
```bash
|
| 131 |
+
ray start --address=<head_node_ip>:6379
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
3. Check the Ray resource pool.
|
| 135 |
+
|
| 136 |
+
```bash
|
| 137 |
+
ray status
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
4. Run training script on the Ray head node only.
|
| 141 |
+
|
| 142 |
+
```bash
|
| 143 |
+
bash examples/qwen2_5_vl_7b_geo3k_grpo.sh
|
| 144 |
+
```
|
| 145 |
+
|
| 146 |
+
See the **[veRL's official doc](https://verl.readthedocs.io/en/latest/start/multinode.html)** for more details about multi-node training and Ray debugger.
|
| 147 |
+
|
| 148 |
+
## Other Baselines
|
| 149 |
+
|
| 150 |
+
We also reproduced the following two baselines of the [R1-V](https://github.com/deep-agent/R1-V) project.
|
| 151 |
+
- [CLEVR-70k-Counting](examples/baselines/qwen2_5_vl_3b_clevr.sh): Train the Qwen2.5-VL-3B-Instruct model on counting problem.
|
| 152 |
+
- [GeoQA-8k](examples/baselines/qwen2_5_vl_3b_geoqa8k.sh): Train the Qwen2.5-VL-3B-Instruct model on GeoQA problem.
|
| 153 |
+
|
| 154 |
+
## Performance Baselines
|
| 155 |
+
|
| 156 |
+
See [baselines.md](assets/baselines.md).
|
| 157 |
+
|
| 158 |
+
## Awesome Work using EasyR1
|
| 159 |
+
|
| 160 |
+
- **MMR1**: Enhancing Multimodal Reasoning with Variance-Aware Sampling and Open Resources. [![[code]](https://img.shields.io/github/stars/LengSicong/MMR1)](https://github.com/LengSicong/MMR1) [![[arxiv]](https://img.shields.io/badge/arxiv-2509.21268-blue)](https://arxiv.org/abs/2509.21268)
|
| 161 |
+
- **Vision-R1**: Incentivizing Reasoning Capability in Multimodal Large Language Models. [![[code]](https://img.shields.io/github/stars/Osilly/Vision-R1)](https://github.com/Osilly/Vision-R1) [![[arxiv]](https://img.shields.io/badge/arxiv-2503.06749-blue)](https://arxiv.org/abs/2503.06749)
|
| 162 |
+
- **Seg-Zero**: Reasoning-Chain Guided Segmentation via Cognitive Reinforcement. [![[code]](https://img.shields.io/github/stars/dvlab-research/Seg-Zero)](https://github.com/dvlab-research/Seg-Zero) [![[arxiv]](https://img.shields.io/badge/arxiv-2503.06520-blue)](https://arxiv.org/abs/2503.06520)
|
| 163 |
+
- **MetaSpatial**: Reinforcing 3D Spatial Reasoning in VLMs for the Metaverse. [![[code]](https://img.shields.io/github/stars/PzySeere/MetaSpatial)](https://github.com/PzySeere/MetaSpatial) [![[arxiv]](https://img.shields.io/badge/arxiv-2503.18470-blue)](https://arxiv.org/abs/2503.18470)
|
| 164 |
+
- **Temporal-R1**: Envolving Temporal Reasoning Capability into LMMs via Temporal Consistent Reward. [![[code]](https://img.shields.io/github/stars/appletea233/Temporal-R1)](https://github.com/appletea233/Temporal-R1)
|
| 165 |
+
- **NoisyRollout**: Reinforcing Visual Reasoning with Data Augmentation. [![[code]](https://img.shields.io/github/stars/John-AI-Lab/NoisyRollout)](https://github.com/John-AI-Lab/NoisyRollout) [![[arxiv]](https://img.shields.io/badge/arxiv-2504.13055-blue)](https://arxiv.org/pdf/2504.13055)
|
| 166 |
+
- **GUI-R1**: A Generalist R1-Style Vision-Language Action Model For GUI Agents. [![[code]](https://img.shields.io/github/stars/ritzz-ai/GUI-R1)](https://github.com/ritzz-ai/GUI-R1) [![[arxiv]](https://img.shields.io/badge/arxiv-2504.10458-blue)](https://arxiv.org/abs/2504.10458)
|
| 167 |
+
- **R1-Track**: Direct Application of MLLMs to Visual Object Tracking via Reinforcement Learning. [![[code]](https://img.shields.io/github/stars/Wangbiao2/R1-Track)](https://github.com/Wangbiao2/R1-Track)
|
| 168 |
+
- **VisionReasoner**: Unified Visual Perception and Reasoning via Reinforcement Learning. [![[code]](https://img.shields.io/github/stars/dvlab-research/VisionReasoner)](https://github.com/dvlab-research/VisionReasoner) [![[arxiv]](https://img.shields.io/badge/arxiv-2505.12081-blue)](https://arxiv.org/abs/2505.12081)
|
| 169 |
+
- **MM-UPT**: Unsupervised Post-Training for Multi-Modal LLM Reasoning via GRPO. [![[code]](https://img.shields.io/github/stars/waltonfuture/MM-UPT)](https://github.com/waltonfuture/MM-UPT) [![[arxiv]](https://img.shields.io/badge/arxiv-2505.22453-blue)](https://arxiv.org/pdf/2505.22453)
|
| 170 |
+
- **RL-with-Cold-Start**: Advancing Multimodal Reasoning via Reinforcement Learning with Cold Start. [![[code]](https://img.shields.io/github/stars/waltonfuture/RL-with-Cold-Start)](https://github.com/waltonfuture/RL-with-Cold-Start) [![[arxiv]](https://img.shields.io/badge/arxiv-2505.22334-blue)](https://arxiv.org/pdf/2505.22334)
|
| 171 |
+
- **ViGoRL**: Grounded Reinforcement Learning for Visual Reasoning. [![[code]](https://img.shields.io/github/stars/Gabesarch/grounded-rl)](https://github.com/Gabesarch/grounded-rl) [![[arxiv]](https://img.shields.io/badge/arxiv-2505.22334-blue)](https://arxiv.org/abs/2505.23678)
|
| 172 |
+
- **Revisual-R1**: Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning. [![[code]](https://img.shields.io/github/stars/CSfufu/Revisual-R1)](https://github.com/CSfufu/Revisual-R1) [![[arxiv]](https://img.shields.io/badge/arxiv-2506.04207-blue)](https://arxiv.org/abs/2506.04207)
|
| 173 |
+
- **SophiaVL-R1**: Reinforcing MLLMs Reasoning with Thinking Reward. [![[code]](https://img.shields.io/github/stars/kxfan2002/SophiaVL-R1)](https://github.com/kxfan2002/SophiaVL-R1) [![[arxiv]](https://img.shields.io/badge/arxiv-2505.17018-blue)](https://arxiv.org/abs/2505.17018)
|
| 174 |
+
- **Vision-Matters**: Simple Visual Perturbations Can Boost Multimodal Math Reasoning. [![[code]](https://img.shields.io/github/stars/YutingLi0606/Vision-Matters)](https://github.com/YutingLi0606/Vision-Matters) [![[arxiv]](https://img.shields.io/badge/arxiv-2506.09736-blue)](https://arxiv.org/abs/2506.09736)
|
| 175 |
+
- **VTool-R1**: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use. [![[code]](https://img.shields.io/github/stars/VTOOL-R1/vtool-r1)](https://github.com/VTOOL-R1/vtool-r1) [![[arxiv]](https://img.shields.io/badge/arxiv-2505.19255-blue)](https://arxiv.org/abs/2505.19255)
|
| 176 |
+
- **Long-RL**: Scaling RL to Long Sequences. [![[code]](https://img.shields.io/github/stars/NVlabs/Long-RL)](https://github.com/NVlabs/Long-RL) [![[arxiv]](https://img.shields.io/badge/arxiv-2507.07966-blue)](https://arxiv.org/abs/2507.07966)
|
| 177 |
+
- **EditGRPO**: Reinforcement Learning with Post-Rollout Edits for Clinically Accurate Chest X-Ray Report Generation. [![[code]](https://img.shields.io/github/stars/taokz/EditGRPO)](https://github.com/taokz/EditGRPO)
|
| 178 |
+
|
| 179 |
+
## TODO
|
| 180 |
+
|
| 181 |
+
- Support LoRA (high priority).
|
| 182 |
+
- Support ulysses parallelism for VLMs (middle priority).
|
| 183 |
+
- Support more VLM architectures.
|
| 184 |
+
|
| 185 |
+
> [!NOTE]
|
| 186 |
+
> We will not provide scripts for supervised fine-tuning and inference in this project. If you have such requirements, we recommend using [LLaMA-Factory](https://github.com/hiyouga/LLaMA-Factory).
|
| 187 |
+
|
| 188 |
+
### Known bugs
|
| 189 |
+
|
| 190 |
+
These features are temporarily disabled for now, we plan to fix them one-by-one in the future updates.
|
| 191 |
+
|
| 192 |
+
- Vision language models are not compatible with ulysses parallelism yet.
|
| 193 |
+
|
| 194 |
+
## Discussion Group
|
| 195 |
+
|
| 196 |
+
👋 Join our [WeChat group](https://github.com/hiyouga/llamafactory-community/blob/main/wechat/easyr1.jpg).
|
| 197 |
+
|
| 198 |
+
## FAQs
|
| 199 |
+
|
| 200 |
+
> ValueError: Image features and image tokens do not match: tokens: 8192, features 9800
|
| 201 |
+
|
| 202 |
+
Increase the `data.max_prompt_length` or reduce the `data.max_pixels`.
|
| 203 |
+
|
| 204 |
+
> RuntimeError: CUDA Error: out of memory at /workspace/csrc/cumem_allocator.cpp:62
|
| 205 |
+
|
| 206 |
+
Reduce the `worker.rollout.gpu_memory_utilization` and enable `worker.actor.offload.offload_params`.
|
| 207 |
+
|
| 208 |
+
> RuntimeError: 0 active drivers ([]). There should only be one.
|
| 209 |
+
|
| 210 |
+
Uninstall `deepspeed` from the current python environment.
|
| 211 |
+
|
| 212 |
+
## Citation
|
| 213 |
+
|
| 214 |
+
Core contributors: [Yaowei Zheng](https://github.com/hiyouga), [Junting Lu](https://github.com/AL-377), [Shenzhi Wang](https://github.com/Shenzhi-Wang), [Zhangchi Feng](https://github.com/BUAADreamer), [Dongdong Kuang](https://github.com/Kuangdd01) and Yuwen Xiong
|
| 215 |
+
|
| 216 |
+
We also thank Guangming Sheng and Chi Zhang for helpful discussions.
|
| 217 |
+
|
| 218 |
+
```bibtex
|
| 219 |
+
@misc{zheng2025easyr1,
|
| 220 |
+
title = {EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework},
|
| 221 |
+
author = {Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, Yuwen Xiong},
|
| 222 |
+
howpublished = {\url{https://github.com/hiyouga/EasyR1}},
|
| 223 |
+
year = {2025}
|
| 224 |
+
}
|
| 225 |
+
```
|
| 226 |
+
|
| 227 |
+
We recommend to also cite the original work.
|
| 228 |
+
|
| 229 |
+
```bibtex
|
| 230 |
+
@article{sheng2024hybridflow,
|
| 231 |
+
title = {HybridFlow: A Flexible and Efficient RLHF Framework},
|
| 232 |
+
author = {Guangming Sheng and Chi Zhang and Zilingfeng Ye and Xibin Wu and Wang Zhang and Ru Zhang and Yanghua Peng and Haibin Lin and Chuan Wu},
|
| 233 |
+
year = {2024},
|
| 234 |
+
journal = {arXiv preprint arXiv: 2409.19256}
|
| 235 |
+
}
|
| 236 |
+
```
|
model/EasyR1/assets/baselines.md
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Baselines
|
| 2 |
+
|
| 3 |
+
Environment: [hiyouga/verl:ngc-th2.7.1-cu12.6-vllm0.10.0](https://hub.docker.com/layers/hiyouga/verl/ngc-th2.7.1-cu12.6-vllm0.10.0/images/sha256-cfc8c1ce3ea52dee0444f3e58e900d0b1d3b6b315deaf5f58c44b5fbb52fa989)
|
| 4 |
+
|
| 5 |
+
EasyR1 version: [v0.3.2](https://github.com/hiyouga/EasyR1/tree/v0.3.2)
|
| 6 |
+
|
| 7 |
+
Welcome to contribute new data points!
|
| 8 |
+
|
| 9 |
+
## Algorithm Baselines
|
| 10 |
+
|
| 11 |
+
### [Qwen2.5-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on [Math12k](https://huggingface.co/datasets/hiyouga/math12k)
|
| 12 |
+
|
| 13 |
+
| Size | Algorithm | Bits | LR | KL | Test Accuracy |
|
| 14 |
+
| ---- | ----------- | ---- | ---- | ---- | -------------------- |
|
| 15 |
+
| 7B | GRPO | AMP | 1e-6 | 1e-2 | 0.75 -> 0.77 (+0.02) |
|
| 16 |
+
|
| 17 |
+
### [Qwen2.5-VL-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) on [Geometry3k](https://huggingface.co/datasets/hiyouga/geometry3k)
|
| 18 |
+
|
| 19 |
+
| Size | Algorithm | Bits | LR | KL | Test Accuracy |
|
| 20 |
+
| ---- | ----------- | ---- | ---- | ---- | -------------------- |
|
| 21 |
+
| 7B | GRPO | AMP | 1e-6 | 1e-2 | 0.37 -> 0.48 (+0.11) |
|
| 22 |
+
| 7B | GRPO | BF16 | 1e-6 | 1e-2 | 0.37 -> 0.48 (+0.11) |
|
| 23 |
+
| 7B | DAPO | AMP | 1e-6 | 1e-2 | 0.37 -> 0.50 (+0.13) |
|
| 24 |
+
| 3B | GRPO | AMP | 1e-6 | 1e-2 | 0.24 -> 0.38 (+0.14) |
|
| 25 |
+
| 32B | GRPO | BF16 | 1e-6 | 1e-2 | 0.50 -> 0.56 (+0.06) |
|
| 26 |
+
|
| 27 |
+
> [!NOTE]
|
| 28 |
+
> The hyper-parameters not listed are all the same as the default values.
|
| 29 |
+
|
| 30 |
+
## Performance Baselines
|
| 31 |
+
|
| 32 |
+
### [Qwen2.5-VL-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) on [Geometry3k](https://huggingface.co/datasets/hiyouga/geometry3k)
|
| 33 |
+
|
| 34 |
+
| Size | GPU Type | Bits | Batch Size | vLLM TP | Peak Mem | Peak VRAM | Throughput | Sec per step | Actor MFU |
|
| 35 |
+
| ---- | ------------- | ---- | ---------- | ------- | -------- | --------- | ----------- | ------------ | --------- |
|
| 36 |
+
| 3B | 8 * H100 80GB | AMP | 1 / 2 | 2 | 120GB | 54GB | 1800 (+600) | 120s | 8.1% |
|
| 37 |
+
| 7B | 8 * H100 80GB | AMP | 1 / 2 | 2 | 120GB | 68GB | 1600 (+400) | 145s | 16.0% |
|
| 38 |
+
| 7B | 8 * H100 80GB | AMP | 4 / 8 | 2 | 200GB | 72GB | 2000 (+600) | 120s | 23.2% |
|
| 39 |
+
| 7B | 8 * L20 48GB | AMP | 1 / 2 | 2 | 120GB | 42GB | 410 (+0) | 580s | 26.5% |
|
| 40 |
+
| 7B | 8 * H100 80GB | BF16 | 1 / 2 | 2 | 120GB | 58GB | 1600 (+320) | 145s | 16.0% |
|
| 41 |
+
| 32B | 8 * H100 80GB | BF16 | 1 / 2 | 8 | 260GB | 72GB | 620 (+260) | 530s | 25.8% |
|
| 42 |
+
|
| 43 |
+
- Batch Size: micro_batch_size_per_device_for_update / micro_batch_size_per_device_for_experience
|
| 44 |
+
- vLLM TP: rollout.tensor_parallel_size
|
| 45 |
+
- Peak Mem: Peak CPU memory usage
|
| 46 |
+
- Peak VRAM: Peak GPU memory usage
|
| 47 |
+
- Throughput: Number of tokens per second per GPU by one training step (including the improvement compared to the [previous version](https://github.com/hiyouga/EasyR1/blob/v0.3.1/assets/baselines.md))
|
| 48 |
+
- Sec per step: Average time per step in seconds
|
| 49 |
+
|
| 50 |
+
> [!NOTE]
|
| 51 |
+
> The hyper-parameters not listed are all the same as the default values.
|
model/EasyR1/assets/easyr1_grpo.png
ADDED

|
Git LFS Details
|
model/EasyR1/assets/qwen2_5_vl_7b_geo.png
ADDED

|
Git LFS Details
|
model/EasyR1/examples/README.md
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: image-text-to-text
|
| 4 |
+
---
|
| 5 |
+
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
|
| 6 |
+
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
| 7 |
+
</a>
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Qwen3-VL-4B-Instruct
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
Meet Qwen3-VL — the most powerful vision-language model in the Qwen series to date.
|
| 14 |
+
|
| 15 |
+
This generation delivers comprehensive upgrades across the board: superior text understanding & generation, deeper visual perception & reasoning, extended context length, enhanced spatial and video dynamics comprehension, and stronger agent interaction capabilities.
|
| 16 |
+
|
| 17 |
+
Available in Dense and MoE architectures that scale from edge to cloud, with Instruct and reasoning‑enhanced Thinking editions for flexible, on‑demand deployment.
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
#### Key Enhancements:
|
| 21 |
+
|
| 22 |
+
* **Visual Agent**: Operates PC/mobile GUIs—recognizes elements, understands functions, invokes tools, completes tasks.
|
| 23 |
+
|
| 24 |
+
* **Visual Coding Boost**: Generates Draw.io/HTML/CSS/JS from images/videos.
|
| 25 |
+
|
| 26 |
+
* **Advanced Spatial Perception**: Judges object positions, viewpoints, and occlusions; provides stronger 2D grounding and enables 3D grounding for spatial reasoning and embodied AI.
|
| 27 |
+
|
| 28 |
+
* **Long Context & Video Understanding**: Native 256K context, expandable to 1M; handles books and hours-long video with full recall and second-level indexing.
|
| 29 |
+
|
| 30 |
+
* **Enhanced Multimodal Reasoning**: Excels in STEM/Math—causal analysis and logical, evidence-based answers.
|
| 31 |
+
|
| 32 |
+
* **Upgraded Visual Recognition**: Broader, higher-quality pretraining is able to “recognize everything”—celebrities, anime, products, landmarks, flora/fauna, etc.
|
| 33 |
+
|
| 34 |
+
* **Expanded OCR**: Supports 32 languages (up from 19); robust in low light, blur, and tilt; better with rare/ancient characters and jargon; improved long-document structure parsing.
|
| 35 |
+
|
| 36 |
+
* **Text Understanding on par with pure LLMs**: Seamless text–vision fusion for lossless, unified comprehension.
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
#### Model Architecture Updates:
|
| 40 |
+
|
| 41 |
+
<p align="center">
|
| 42 |
+
<img src="https://qianwen-res.oss-accelerate.aliyuncs.com/Qwen3-VL/qwen3vl_arc.jpg" width="80%"/>
|
| 43 |
+
<p>
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
1. **Interleaved-MRoPE**: Full‑frequency allocation over time, width, and height via robust positional embeddings, enhancing long‑horizon video reasoning.
|
| 47 |
+
|
| 48 |
+
2. **DeepStack**: Fuses multi‑level ViT features to capture fine‑grained details and sharpen image–text alignment.
|
| 49 |
+
|
| 50 |
+
3. **Text–Timestamp Alignment:** Moves beyond T‑RoPE to precise, timestamp‑grounded event localization for stronger video temporal modeling.
|
| 51 |
+
|
| 52 |
+
This is the weight repository for Qwen3-VL-4B-Instruct.
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
---
|
| 56 |
+
|
| 57 |
+
## Model Performance
|
| 58 |
+
|
| 59 |
+
**Multimodal performance**
|
| 60 |
+
|
| 61 |
+
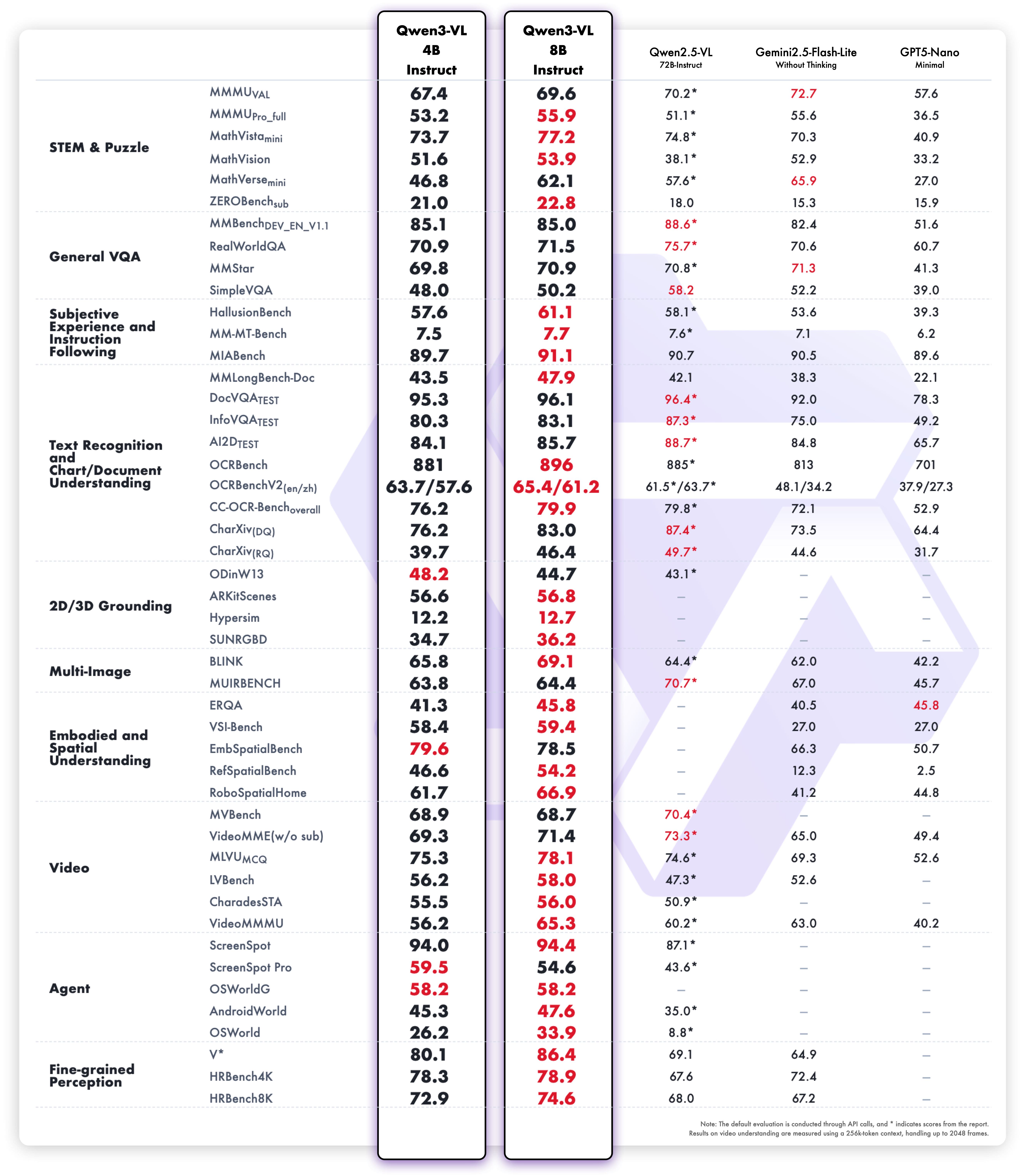
|
| 62 |
+
|
| 63 |
+
**Pure text performance**
|
| 64 |
+
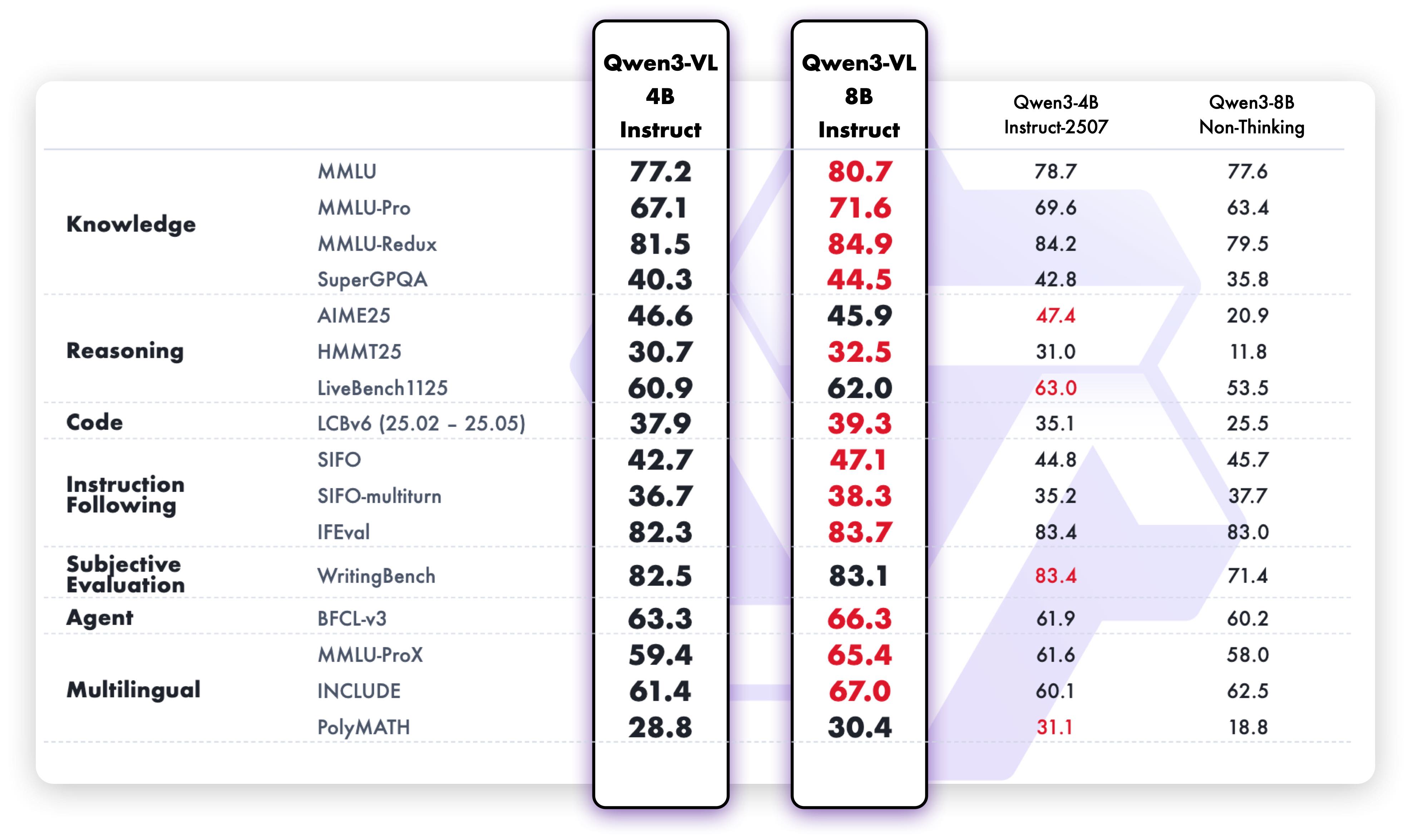
|
| 65 |
+
|
| 66 |
+
## Quickstart
|
| 67 |
+
|
| 68 |
+
Below, we provide simple examples to show how to use Qwen3-VL with 🤖 ModelScope and 🤗 Transformers.
|
| 69 |
+
|
| 70 |
+
The code of Qwen3-VL has been in the latest Hugging Face transformers and we advise you to build from source with command:
|
| 71 |
+
```
|
| 72 |
+
pip install git+https://github.com/huggingface/transformers
|
| 73 |
+
# pip install transformers==4.57.0 # currently, V4.57.0 is not released
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
### Using 🤗 Transformers to Chat
|
| 77 |
+
|
| 78 |
+
Here we show a code snippet to show how to use the chat model with `transformers`:
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
from transformers import Qwen3VLForConditionalGeneration, AutoProcessor
|
| 82 |
+
|
| 83 |
+
# default: Load the model on the available device(s)
|
| 84 |
+
model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 85 |
+
"Qwen/Qwen3-VL-4B-Instruct", dtype="auto", device_map="auto"
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
| 89 |
+
# model = Qwen3VLForConditionalGeneration.from_pretrained(
|
| 90 |
+
# "Qwen/Qwen3-VL-4B-Instruct",
|
| 91 |
+
# dtype=torch.bfloat16,
|
| 92 |
+
# attn_implementation="flash_attention_2",
|
| 93 |
+
# device_map="auto",
|
| 94 |
+
# )
|
| 95 |
+
|
| 96 |
+
processor = AutoProcessor.from_pretrained("Qwen/Qwen/Qwen3-VL-4B-Instruct")
|
| 97 |
+
|
| 98 |
+
messages = [
|
| 99 |
+
{
|
| 100 |
+
"role": "user",
|
| 101 |
+
"content": [
|
| 102 |
+
{
|
| 103 |
+
"type": "image",
|
| 104 |
+
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
|
| 105 |
+
},
|
| 106 |
+
{"type": "text", "text": "Describe this image."},
|
| 107 |
+
],
|
| 108 |
+
}
|
| 109 |
+
]
|
| 110 |
+
|
| 111 |
+
# Preparation for inference
|
| 112 |
+
inputs = processor.apply_chat_template(
|
| 113 |
+
messages,
|
| 114 |
+
tokenize=True,
|
| 115 |
+
add_generation_prompt=True,
|
| 116 |
+
return_dict=True,
|
| 117 |
+
return_tensors="pt"
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
# Inference: Generation of the output
|
| 121 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 122 |
+
generated_ids_trimmed = [
|
| 123 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 124 |
+
]
|
| 125 |
+
output_text = processor.batch_decode(
|
| 126 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 127 |
+
)
|
| 128 |
+
print(output_text)
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
### Generation Hyperparameters
|
| 132 |
+
#### VL
|
| 133 |
+
```bash
|
| 134 |
+
export greedy='false'
|
| 135 |
+
export top_p=0.8
|
| 136 |
+
export top_k=20
|
| 137 |
+
export temperature=0.7
|
| 138 |
+
export repetition_penalty=1.0
|
| 139 |
+
export presence_penalty=1.5
|
| 140 |
+
export out_seq_length=16384
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
#### Text
|
| 144 |
+
```bash
|
| 145 |
+
export greedy='false'
|
| 146 |
+
export top_p=1.0
|
| 147 |
+
export top_k=40
|
| 148 |
+
export repetition_penalty=1.0
|
| 149 |
+
export presence_penalty=2.0
|
| 150 |
+
export temperature=1.0
|
| 151 |
+
export out_seq_length=32768
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
## Citation
|
| 156 |
+
|
| 157 |
+
If you find our work helpful, feel free to give us a cite.
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
@misc{qwen3technicalreport,
|
| 161 |
+
title={Qwen3 Technical Report},
|
| 162 |
+
author={Qwen Team},
|
| 163 |
+
year={2025},
|
| 164 |
+
eprint={2505.09388},
|
| 165 |
+
archivePrefix={arXiv},
|
| 166 |
+
primaryClass={cs.CL},
|
| 167 |
+
url={https://arxiv.org/abs/2505.09388},
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
@article{Qwen2.5-VL,
|
| 171 |
+
title={Qwen2.5-VL Technical Report},
|
| 172 |
+
author={Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Zesen and Zhang, Hang and Yang, Zhibo and Xu, Haiyang and Lin, Junyang},
|
| 173 |
+
journal={arXiv preprint arXiv:2502.13923},
|
| 174 |
+
year={2025}
|
| 175 |
+
}
|
| 176 |
+
|
| 177 |
+
@article{Qwen2VL,
|
| 178 |
+
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
|
| 179 |
+
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
|
| 180 |
+
journal={arXiv preprint arXiv:2409.12191},
|
| 181 |
+
year={2024}
|
| 182 |
+
}
|
| 183 |
+
|
| 184 |
+
@article{Qwen-VL,
|
| 185 |
+
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
|
| 186 |
+
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
|
| 187 |
+
journal={arXiv preprint arXiv:2308.12966},
|
| 188 |
+
year={2023}
|
| 189 |
+
}
|
| 190 |
+
```
|
model/EasyR1/examples/baselines/qwen2_5_vl_3b_clevr.sh
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
export PYTHONUNBUFFERED=1
|
| 6 |
+
|
| 7 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-3B-Instruct # replace it with your local file path
|
| 8 |
+
|
| 9 |
+
python3 -m verl.trainer.main \
|
| 10 |
+
config=examples/config.yaml \
|
| 11 |
+
data.train_files=BUAADreamer/clevr_count_70k@train \
|
| 12 |
+
data.val_files=BUAADreamer/clevr_count_70k@test \
|
| 13 |
+
data.format_prompt=./examples/format_prompt/r1v.jinja \
|
| 14 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 15 |
+
worker.rollout.tensor_parallel_size=1 \
|
| 16 |
+
worker.reward.reward_type=sequential \
|
| 17 |
+
worker.reward.reward_function=./examples/reward_function/r1v.py:compute_score \
|
| 18 |
+
trainer.experiment_name=qwen2_5_vl_3b_clevr \
|
| 19 |
+
trainer.n_gpus_per_node=2
|
model/EasyR1/examples/baselines/qwen2_5_vl_3b_geoqa8k.sh
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
export PYTHONUNBUFFERED=1
|
| 6 |
+
|
| 7 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-3B-Instruct # replace it with your local file path
|
| 8 |
+
|
| 9 |
+
python3 -m verl.trainer.main \
|
| 10 |
+
config=examples/config.yaml \
|
| 11 |
+
data.train_files=leonardPKU/GEOQA_8K_R1V@train \
|
| 12 |
+
data.val_files=leonardPKU/GEOQA_8K_R1V@test \
|
| 13 |
+
data.format_prompt=./examples/format_prompt/r1v.jinja \
|
| 14 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 15 |
+
worker.rollout.tensor_parallel_size=1 \
|
| 16 |
+
worker.reward.reward_type=sequential \
|
| 17 |
+
worker.reward.reward_function=./examples/reward_function/r1v.py:compute_score \
|
| 18 |
+
trainer.experiment_name=qwen2_5_vl_3b_geoqa8k \
|
| 19 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/config_d_grpo.yaml
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data:
|
| 2 |
+
train_files: ""
|
| 3 |
+
val_files: ""
|
| 4 |
+
prompt_key: problem
|
| 5 |
+
answer_key: answer
|
| 6 |
+
image_key: images
|
| 7 |
+
video_key: videos
|
| 8 |
+
image_dir: null
|
| 9 |
+
video_fps: 2.0
|
| 10 |
+
max_prompt_length: 16384
|
| 11 |
+
max_response_length: 4096
|
| 12 |
+
rollout_batch_size: 512 # equivalent to verl's data.train_batch_size
|
| 13 |
+
mini_rollout_batch_size: null # equivalent to verl's data.gen_batch_size
|
| 14 |
+
val_batch_size: 1024
|
| 15 |
+
format_prompt: “”
|
| 16 |
+
override_chat_template: null
|
| 17 |
+
shuffle: true
|
| 18 |
+
seed: 1
|
| 19 |
+
min_pixels: 3136
|
| 20 |
+
max_pixels: 1048576
|
| 21 |
+
resize_size: 336
|
| 22 |
+
filter_overlong_prompts: false
|
| 23 |
+
|
| 24 |
+
algorithm:
|
| 25 |
+
adv_estimator: ema_grpo
|
| 26 |
+
disable_kl: true
|
| 27 |
+
use_kl_loss: true
|
| 28 |
+
kl_penalty: low_var_kl
|
| 29 |
+
kl_coef: 1.0e-2
|
| 30 |
+
online_filtering: true # dapo filter groups
|
| 31 |
+
filter_key: accuracy
|
| 32 |
+
filter_low: 0.01
|
| 33 |
+
filter_high: 0.99
|
| 34 |
+
|
| 35 |
+
worker:
|
| 36 |
+
actor:
|
| 37 |
+
global_batch_size: 128 # equivalent to verl's actor.ppo_mini_batch_size
|
| 38 |
+
micro_batch_size_per_device_for_update: 1 # equivalent to verl's actor.ppo_micro_batch_size_per_gpu
|
| 39 |
+
micro_batch_size_per_device_for_experience: 2 # equivalent to verl's rollout.log_prob_micro_batch_size_per_gpu
|
| 40 |
+
max_grad_norm: 1.0
|
| 41 |
+
padding_free: true
|
| 42 |
+
dynamic_batching: true
|
| 43 |
+
ulysses_size: 1
|
| 44 |
+
model:
|
| 45 |
+
model_path: Qwen/Qwen2.5-7B-Instruct
|
| 46 |
+
enable_gradient_checkpointing: true
|
| 47 |
+
trust_remote_code: false
|
| 48 |
+
freeze_vision_tower: true
|
| 49 |
+
optim:
|
| 50 |
+
lr: 5.0e-6
|
| 51 |
+
weight_decay: 1.0e-2
|
| 52 |
+
strategy: adamw # {adamw, adamw_bf16}
|
| 53 |
+
lr_warmup_ratio: 0.0
|
| 54 |
+
fsdp:
|
| 55 |
+
enable_full_shard: true
|
| 56 |
+
enable_cpu_offload: false
|
| 57 |
+
enable_rank0_init: true
|
| 58 |
+
offload:
|
| 59 |
+
offload_params: false # true: more CPU memory; false: more GPU memory
|
| 60 |
+
offload_optimizer: false # true: more CPU memory; false: more GPU memory
|
| 61 |
+
|
| 62 |
+
rollout:
|
| 63 |
+
n: 8
|
| 64 |
+
temperature: 1.0
|
| 65 |
+
top_p: 1.0
|
| 66 |
+
limit_images: 0
|
| 67 |
+
gpu_memory_utilization: 0.5
|
| 68 |
+
enforce_eager: false
|
| 69 |
+
enable_chunked_prefill: false
|
| 70 |
+
tensor_parallel_size: 2
|
| 71 |
+
disable_tqdm: true
|
| 72 |
+
max_num_batched_tokens: 20480
|
| 73 |
+
val_override_config:
|
| 74 |
+
temperature: 0.7
|
| 75 |
+
top_p: 0.95
|
| 76 |
+
n: 1
|
| 77 |
+
|
| 78 |
+
ref:
|
| 79 |
+
fsdp:
|
| 80 |
+
enable_full_shard: true
|
| 81 |
+
enable_cpu_offload: false # true: more CPU memory; false: more GPU memory
|
| 82 |
+
enable_rank0_init: true
|
| 83 |
+
offload:
|
| 84 |
+
offload_params: false
|
| 85 |
+
|
| 86 |
+
reward:
|
| 87 |
+
reward_type: batch
|
| 88 |
+
reward_function: EasyR1/verl/reward_function/onethinker_reward.py:compute_score
|
| 89 |
+
|
| 90 |
+
trainer:
|
| 91 |
+
total_epochs: 1
|
| 92 |
+
max_steps: null
|
| 93 |
+
project_name: easy_r1
|
| 94 |
+
experiment_name: qwen2_5_7b_math_grpo
|
| 95 |
+
logger: ["file", "wandb"]
|
| 96 |
+
# logger: ["file"]
|
| 97 |
+
nnodes: 8
|
| 98 |
+
n_gpus_per_node: 8
|
| 99 |
+
max_try_make_batch: 20 # -1 means no limit
|
| 100 |
+
val_freq: -1 # -1 to disable
|
| 101 |
+
val_before_train: false
|
| 102 |
+
val_only: false
|
| 103 |
+
val_generations_to_log: 3
|
| 104 |
+
save_freq: 200 # -1 to disable
|
| 105 |
+
save_limit: 100000 # -1 to disable
|
| 106 |
+
save_model_only: false
|
| 107 |
+
save_checkpoint_path: checkpoints/qwen3-8b-rl
|
| 108 |
+
load_checkpoint_path: null
|
| 109 |
+
find_last_checkpoint: true
|
model/EasyR1/examples/config_ema_grpo.yaml
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data:
|
| 2 |
+
train_files: ""
|
| 3 |
+
val_files: ""
|
| 4 |
+
prompt_key: problem
|
| 5 |
+
answer_key: answer
|
| 6 |
+
image_key: images
|
| 7 |
+
video_key: videos
|
| 8 |
+
image_dir: null
|
| 9 |
+
video_fps: 2.0
|
| 10 |
+
max_prompt_length: 16384
|
| 11 |
+
max_response_length: 4096
|
| 12 |
+
rollout_batch_size: 128
|
| 13 |
+
mini_rollout_batch_size: null
|
| 14 |
+
val_batch_size: 1024
|
| 15 |
+
format_prompt: ""
|
| 16 |
+
override_chat_template: null
|
| 17 |
+
shuffle: true
|
| 18 |
+
seed: 1
|
| 19 |
+
min_pixels: 3136
|
| 20 |
+
max_pixels: 1048576
|
| 21 |
+
resize_size: 336
|
| 22 |
+
filter_overlong_prompts: false
|
| 23 |
+
|
| 24 |
+
algorithm:
|
| 25 |
+
adv_estimator: ema_grpo
|
| 26 |
+
disable_kl: true
|
| 27 |
+
use_kl_loss: true
|
| 28 |
+
kl_penalty: low_var_kl
|
| 29 |
+
kl_coef: 1.0e-2
|
| 30 |
+
online_filtering: false
|
| 31 |
+
filter_key: accuracy
|
| 32 |
+
filter_low: 0.0
|
| 33 |
+
filter_high: 1.0
|
| 34 |
+
|
| 35 |
+
worker:
|
| 36 |
+
actor:
|
| 37 |
+
global_batch_size: 32
|
| 38 |
+
micro_batch_size_per_device_for_update: 1
|
| 39 |
+
micro_batch_size_per_device_for_experience: 1
|
| 40 |
+
max_grad_norm: 1.0
|
| 41 |
+
padding_free: true
|
| 42 |
+
dynamic_batching: true
|
| 43 |
+
ulysses_size: 1
|
| 44 |
+
model:
|
| 45 |
+
model_path: ""
|
| 46 |
+
enable_gradient_checkpointing: true
|
| 47 |
+
trust_remote_code: false
|
| 48 |
+
freeze_vision_tower: true
|
| 49 |
+
optim:
|
| 50 |
+
lr: 5.0e-6
|
| 51 |
+
weight_decay: 1.0e-2
|
| 52 |
+
strategy: adamw
|
| 53 |
+
lr_warmup_ratio: 0.0
|
| 54 |
+
fsdp:
|
| 55 |
+
enable_full_shard: true
|
| 56 |
+
enable_cpu_offload: false
|
| 57 |
+
enable_rank0_init: true
|
| 58 |
+
offload:
|
| 59 |
+
offload_params: false
|
| 60 |
+
offload_optimizer: false
|
| 61 |
+
|
| 62 |
+
rollout:
|
| 63 |
+
n: 8
|
| 64 |
+
temperature: 1.0
|
| 65 |
+
top_p: 1.0
|
| 66 |
+
limit_images: 0
|
| 67 |
+
gpu_memory_utilization: 0.7
|
| 68 |
+
enforce_eager: false
|
| 69 |
+
enable_chunked_prefill: false
|
| 70 |
+
tensor_parallel_size: 4
|
| 71 |
+
disable_tqdm: true
|
| 72 |
+
max_num_batched_tokens: 20480
|
| 73 |
+
val_override_config:
|
| 74 |
+
temperature: 0.7
|
| 75 |
+
top_p: 0.95
|
| 76 |
+
n: 1
|
| 77 |
+
|
| 78 |
+
ref:
|
| 79 |
+
fsdp:
|
| 80 |
+
enable_full_shard: true
|
| 81 |
+
enable_cpu_offload: false
|
| 82 |
+
enable_rank0_init: true
|
| 83 |
+
offload:
|
| 84 |
+
offload_params: false
|
| 85 |
+
|
| 86 |
+
reward:
|
| 87 |
+
reward_type: batch
|
| 88 |
+
reward_function: EasyR1/verl/reward_function/onethinker_reward.py:compute_score
|
| 89 |
+
|
| 90 |
+
trainer:
|
| 91 |
+
total_epochs: 1
|
| 92 |
+
max_steps: null
|
| 93 |
+
project_name: easy_r1
|
| 94 |
+
experiment_name: ""
|
| 95 |
+
logger: ["file", "wandb"]
|
| 96 |
+
nnodes: 1
|
| 97 |
+
n_gpus_per_node: 2
|
| 98 |
+
max_try_make_batch: 20
|
| 99 |
+
val_freq: -1
|
| 100 |
+
val_before_train: false
|
| 101 |
+
val_only: false
|
| 102 |
+
val_generations_to_log: 3
|
| 103 |
+
save_freq: 200
|
| 104 |
+
save_limit: 100000
|
| 105 |
+
save_model_only: false
|
| 106 |
+
save_checkpoint_path: ""
|
| 107 |
+
load_checkpoint_path: null
|
| 108 |
+
find_last_checkpoint: false
|
model/EasyR1/examples/config_ema_grpo_64.yaml
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data:
|
| 2 |
+
train_files: hiyouga/math12k@train
|
| 3 |
+
val_files: ""
|
| 4 |
+
prompt_key: problem
|
| 5 |
+
answer_key: answer
|
| 6 |
+
image_key: images
|
| 7 |
+
video_key: videos
|
| 8 |
+
image_dir: null
|
| 9 |
+
video_fps: 2.0
|
| 10 |
+
max_prompt_length: 16384
|
| 11 |
+
max_response_length: 4096
|
| 12 |
+
rollout_batch_size: 512 # equivalent to verl's data.train_batch_size
|
| 13 |
+
mini_rollout_batch_size: null # equivalent to verl's data.gen_batch_size
|
| 14 |
+
val_batch_size: 1024
|
| 15 |
+
format_prompt: “”
|
| 16 |
+
override_chat_template: null
|
| 17 |
+
shuffle: true
|
| 18 |
+
seed: 1
|
| 19 |
+
min_pixels: 3136
|
| 20 |
+
max_pixels: 1048576
|
| 21 |
+
resize_size: 336
|
| 22 |
+
filter_overlong_prompts: false
|
| 23 |
+
|
| 24 |
+
algorithm:
|
| 25 |
+
adv_estimator: ema_grpo
|
| 26 |
+
disable_kl: true
|
| 27 |
+
use_kl_loss: true
|
| 28 |
+
kl_penalty: low_var_kl
|
| 29 |
+
kl_coef: 1.0e-2
|
| 30 |
+
online_filtering: true # dapo filter groups
|
| 31 |
+
filter_key: accuracy
|
| 32 |
+
filter_low: 0.01
|
| 33 |
+
filter_high: 0.99
|
| 34 |
+
|
| 35 |
+
worker:
|
| 36 |
+
actor:
|
| 37 |
+
global_batch_size: 128 # equivalent to verl's actor.ppo_mini_batch_size
|
| 38 |
+
micro_batch_size_per_device_for_update: 1 # equivalent to verl's actor.ppo_micro_batch_size_per_gpu
|
| 39 |
+
micro_batch_size_per_device_for_experience: 2 # equivalent to verl's rollout.log_prob_micro_batch_size_per_gpu
|
| 40 |
+
max_grad_norm: 1.0
|
| 41 |
+
padding_free: true
|
| 42 |
+
dynamic_batching: true
|
| 43 |
+
ulysses_size: 1
|
| 44 |
+
model:
|
| 45 |
+
model_path: Qwen/Qwen2.5-7B-Instruct
|
| 46 |
+
enable_gradient_checkpointing: true
|
| 47 |
+
trust_remote_code: false
|
| 48 |
+
freeze_vision_tower: true
|
| 49 |
+
optim:
|
| 50 |
+
lr: 5.0e-6
|
| 51 |
+
weight_decay: 1.0e-2
|
| 52 |
+
strategy: adamw # {adamw, adamw_bf16}
|
| 53 |
+
lr_warmup_ratio: 0.0
|
| 54 |
+
fsdp:
|
| 55 |
+
enable_full_shard: true
|
| 56 |
+
enable_cpu_offload: false
|
| 57 |
+
enable_rank0_init: true
|
| 58 |
+
offload:
|
| 59 |
+
offload_params: false # true: more CPU memory; false: more GPU memory
|
| 60 |
+
offload_optimizer: false # true: more CPU memory; false: more GPU memory
|
| 61 |
+
|
| 62 |
+
rollout:
|
| 63 |
+
n: 8
|
| 64 |
+
temperature: 1.0
|
| 65 |
+
top_p: 1.0
|
| 66 |
+
limit_images: 0
|
| 67 |
+
gpu_memory_utilization: 0.5
|
| 68 |
+
enforce_eager: false
|
| 69 |
+
enable_chunked_prefill: false
|
| 70 |
+
tensor_parallel_size: 2
|
| 71 |
+
disable_tqdm: true
|
| 72 |
+
max_num_batched_tokens: 20480
|
| 73 |
+
val_override_config:
|
| 74 |
+
temperature: 0.7
|
| 75 |
+
top_p: 0.95
|
| 76 |
+
n: 1
|
| 77 |
+
|
| 78 |
+
ref:
|
| 79 |
+
fsdp:
|
| 80 |
+
enable_full_shard: true
|
| 81 |
+
enable_cpu_offload: false # true: more CPU memory; false: more GPU memory
|
| 82 |
+
enable_rank0_init: true
|
| 83 |
+
offload:
|
| 84 |
+
offload_params: false
|
| 85 |
+
|
| 86 |
+
reward:
|
| 87 |
+
reward_type: batch
|
| 88 |
+
reward_function: EasyR1/verl/reward_function/onethinker_reward.py:compute_score
|
| 89 |
+
|
| 90 |
+
trainer:
|
| 91 |
+
total_epochs: 1
|
| 92 |
+
max_steps: null
|
| 93 |
+
project_name: easy_r1
|
| 94 |
+
experiment_name: qwen2_5_7b_math_grpo
|
| 95 |
+
logger: ["file", "wandb"]
|
| 96 |
+
# logger: ["file"]
|
| 97 |
+
nnodes: 8
|
| 98 |
+
n_gpus_per_node: 8
|
| 99 |
+
max_try_make_batch: 20 # -1 means no limit
|
| 100 |
+
val_freq: -1 # -1 to disable
|
| 101 |
+
val_before_train: false
|
| 102 |
+
val_only: false
|
| 103 |
+
val_generations_to_log: 3
|
| 104 |
+
save_freq: 200 # -1 to disable
|
| 105 |
+
save_limit: 100000 # -1 to disable
|
| 106 |
+
save_model_only: false
|
| 107 |
+
save_checkpoint_path: checkpoints/qwen3-8b-rl
|
| 108 |
+
load_checkpoint_path: null
|
| 109 |
+
find_last_checkpoint: true
|
model/EasyR1/examples/config_grpo.yaml
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data:
|
| 2 |
+
train_files: ""
|
| 3 |
+
val_files: ""
|
| 4 |
+
prompt_key: problem
|
| 5 |
+
answer_key: answer
|
| 6 |
+
image_key: images
|
| 7 |
+
video_key: videos
|
| 8 |
+
image_dir: null
|
| 9 |
+
video_fps: 2.0
|
| 10 |
+
max_prompt_length: 16384
|
| 11 |
+
max_response_length: 4096
|
| 12 |
+
rollout_batch_size: 128
|
| 13 |
+
mini_rollout_batch_size: null
|
| 14 |
+
val_batch_size: 1024
|
| 15 |
+
format_prompt: ""
|
| 16 |
+
override_chat_template: null
|
| 17 |
+
shuffle: true
|
| 18 |
+
seed: 1
|
| 19 |
+
min_pixels: 3136
|
| 20 |
+
max_pixels: 1048576
|
| 21 |
+
resize_size: 336
|
| 22 |
+
filter_overlong_prompts: false
|
| 23 |
+
|
| 24 |
+
algorithm:
|
| 25 |
+
adv_estimator: grpo
|
| 26 |
+
disable_kl: true
|
| 27 |
+
use_kl_loss: true
|
| 28 |
+
kl_penalty: low_var_kl
|
| 29 |
+
kl_coef: 1.0e-2
|
| 30 |
+
online_filtering: false
|
| 31 |
+
filter_key: accuracy
|
| 32 |
+
filter_low: 0.0
|
| 33 |
+
filter_high: 1.0
|
| 34 |
+
|
| 35 |
+
worker:
|
| 36 |
+
actor:
|
| 37 |
+
global_batch_size: 32
|
| 38 |
+
micro_batch_size_per_device_for_update: 1
|
| 39 |
+
micro_batch_size_per_device_for_experience: 1
|
| 40 |
+
max_grad_norm: 1.0
|
| 41 |
+
padding_free: true
|
| 42 |
+
dynamic_batching: true
|
| 43 |
+
ulysses_size: 1
|
| 44 |
+
model:
|
| 45 |
+
model_path: ""
|
| 46 |
+
enable_gradient_checkpointing: true
|
| 47 |
+
trust_remote_code: false
|
| 48 |
+
freeze_vision_tower: true
|
| 49 |
+
optim:
|
| 50 |
+
lr: 5.0e-6
|
| 51 |
+
weight_decay: 1.0e-2
|
| 52 |
+
strategy: adamw
|
| 53 |
+
lr_warmup_ratio: 0.0
|
| 54 |
+
fsdp:
|
| 55 |
+
enable_full_shard: true
|
| 56 |
+
enable_cpu_offload: false
|
| 57 |
+
enable_rank0_init: true
|
| 58 |
+
offload:
|
| 59 |
+
offload_params: false
|
| 60 |
+
offload_optimizer: false
|
| 61 |
+
|
| 62 |
+
rollout:
|
| 63 |
+
n: 8
|
| 64 |
+
temperature: 1.0
|
| 65 |
+
top_p: 1.0
|
| 66 |
+
limit_images: 0
|
| 67 |
+
gpu_memory_utilization: 0.7
|
| 68 |
+
enforce_eager: false
|
| 69 |
+
enable_chunked_prefill: false
|
| 70 |
+
tensor_parallel_size: 4
|
| 71 |
+
disable_tqdm: true
|
| 72 |
+
max_num_batched_tokens: 20480
|
| 73 |
+
val_override_config:
|
| 74 |
+
temperature: 0.7
|
| 75 |
+
top_p: 0.95
|
| 76 |
+
n: 1
|
| 77 |
+
|
| 78 |
+
ref:
|
| 79 |
+
fsdp:
|
| 80 |
+
enable_full_shard: true
|
| 81 |
+
enable_cpu_offload: false
|
| 82 |
+
enable_rank0_init: true
|
| 83 |
+
offload:
|
| 84 |
+
offload_params: false
|
| 85 |
+
|
| 86 |
+
reward:
|
| 87 |
+
reward_type: batch
|
| 88 |
+
reward_function: EasyR1/verl/reward_function/onethinker_reward.py:compute_score
|
| 89 |
+
|
| 90 |
+
trainer:
|
| 91 |
+
total_epochs: 1
|
| 92 |
+
max_steps: null
|
| 93 |
+
project_name: easy_r1
|
| 94 |
+
experiment_name: ""
|
| 95 |
+
logger: ["file", "wandb"]
|
| 96 |
+
nnodes: 1
|
| 97 |
+
n_gpus_per_node: 2
|
| 98 |
+
max_try_make_batch: 20
|
| 99 |
+
val_freq: -1
|
| 100 |
+
val_before_train: false
|
| 101 |
+
val_only: false
|
| 102 |
+
val_generations_to_log: 3
|
| 103 |
+
save_freq: 1
|
| 104 |
+
save_limit: 100000
|
| 105 |
+
save_model_only: false
|
| 106 |
+
save_checkpoint_path: ""
|
| 107 |
+
load_checkpoint_path: null
|
| 108 |
+
find_last_checkpoint: false
|
model/EasyR1/examples/format_prompt/dapo.jinja
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Solve the following math problem step by step. The last line of your response should be of the form Answer: $Answer (without quotes) where $Answer is the answer to the problem.\n\n{{ content | trim }}\n\nRemember to put your answer on its own line after "Answer:".
|
model/EasyR1/examples/format_prompt/math.jinja
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{{ content | trim }} You FIRST think about the reasoning process as an internal monologue and then provide the final answer. The reasoning process MUST BE enclosed within <think> </think> tags. The final answer MUST BE put in \boxed{}.
|
model/EasyR1/examples/format_prompt/r1v.jinja
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{{ content | trim }} A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think><answer> answer here </answer>
|
model/EasyR1/examples/qwen2_5_7b_math_grpo.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-7B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
worker.actor.model.model_path=${MODEL_PATH}
|
model/EasyR1/examples/qwen2_5_vl_32b_geo3k_grpo.sh
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-32B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 12 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 13 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 14 |
+
worker.rollout.tensor_parallel_size=8 \
|
| 15 |
+
trainer.experiment_name=qwen2_5_vl_32b_geo_grpo \
|
| 16 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen2_5_vl_3b_geo3k_grpo.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-3B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 12 |
+
worker.rollout.tensor_parallel_size=1 \
|
| 13 |
+
trainer.experiment_name=qwen2_5_vl_3b_geo_grpo \
|
| 14 |
+
trainer.n_gpus_per_node=2
|
model/EasyR1/examples/qwen2_5_vl_7b_geo3k_dapo.sh
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-7B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
data.mini_rollout_batch_size=128 \
|
| 12 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 13 |
+
worker.actor.clip_ratio_low=0.2 \
|
| 14 |
+
worker.actor.clip_ratio_high=0.28 \
|
| 15 |
+
algorithm.disable_kl=True \
|
| 16 |
+
algorithm.online_filtering=True \
|
| 17 |
+
trainer.experiment_name=qwen2_5_vl_7b_geo_dapo \
|
| 18 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen2_5_vl_7b_geo3k_grpo.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-7B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 12 |
+
trainer.experiment_name=qwen2_5_vl_7b_geo_grpo \
|
| 13 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen2_5_vl_7b_geo3k_reinforce.sh
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-7B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 12 |
+
algorithm.adv_estimator=reinforce_plus_plus \
|
| 13 |
+
algorithm.use_kl_loss=false \
|
| 14 |
+
algorithm.kl_penalty=kl \
|
| 15 |
+
algorithm.kl_coef=1.0e-3 \
|
| 16 |
+
trainer.experiment_name=qwen2_5_vl_7b_geo_reinforce_pp \
|
| 17 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen2_5_vl_7b_geo3k_swanlab.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-7B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 12 |
+
trainer.experiment_name=qwen2_5_vl_7b_geo_grpo \
|
| 13 |
+
trainer.logger=['console','swanlab'] \
|
| 14 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen2_5_vl_7b_multi_image.sh
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# REMINDER: this script uses test data split and should ONLY be used for debugging. DO NOT use for training.
|
| 3 |
+
|
| 4 |
+
set -x
|
| 5 |
+
|
| 6 |
+
MODEL_PATH=Qwen/Qwen2.5-VL-7B-Instruct # replace it with your local file path
|
| 7 |
+
|
| 8 |
+
python3 -m verl.trainer.main \
|
| 9 |
+
config=examples/config.yaml \
|
| 10 |
+
data.train_files=hiyouga/journeybench-multi-image-vqa@train \
|
| 11 |
+
data.val_files=hiyouga/journeybench-multi-image-vqa@test \
|
| 12 |
+
data.rollout_batch_size=256 \
|
| 13 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 14 |
+
worker.rollout.limit_images=2 \
|
| 15 |
+
trainer.experiment_name=qwen2_5_vl_7b_multi_image \
|
| 16 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen3_14b_dapo17k_dapo.sh
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen3-14B-Base # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=Saigyouji-Yuyuko1000/dapo17k@train \
|
| 10 |
+
data.val_files=Saigyouji-Yuyuko1000/dapo17k@test \
|
| 11 |
+
data.format_prompt=./examples/format_prompt/dapo.jinja \
|
| 12 |
+
data.max_prompt_length=2048 \
|
| 13 |
+
data.max_response_length=20480 \
|
| 14 |
+
data.rollout_batch_size=512 \
|
| 15 |
+
data.mini_rollout_batch_size=256 \
|
| 16 |
+
worker.actor.ulysses_size=8 \
|
| 17 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 18 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 19 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 20 |
+
worker.actor.optim.weight_decay=0.1 \
|
| 21 |
+
worker.actor.optim.lr_warmup_steps=10 \
|
| 22 |
+
worker.actor.global_batch_size=32 \
|
| 23 |
+
worker.actor.clip_ratio_low=0.2 \
|
| 24 |
+
worker.actor.clip_ratio_high=0.28 \
|
| 25 |
+
worker.actor.clip_ratio_dual=10.0 \
|
| 26 |
+
worker.rollout.n=16 \
|
| 27 |
+
worker.rollout.max_num_batched_tokens=22528 \
|
| 28 |
+
worker.rollout.val_override_config='{"n":16,"temperature":1.0,"top_p":0.7}' \
|
| 29 |
+
worker.rollout.gpu_memory_utilization=0.8 \
|
| 30 |
+
worker.rollout.tensor_parallel_size=4 \
|
| 31 |
+
worker.reward.reward_function=./examples/reward_function/dapo.py:compute_score \
|
| 32 |
+
worker.reward.reward_function_kwargs='{"max_response_length":20480,"overlong_buffer_length":4096,"overlong_penalty_factor":1.0}' \
|
| 33 |
+
algorithm.disable_kl=True \
|
| 34 |
+
algorithm.online_filtering=True \
|
| 35 |
+
algorithm.filter_key=accuracy_normalized \
|
| 36 |
+
algorithm.filter_low=0.01 \
|
| 37 |
+
algorithm.filter_high=0.99 \
|
| 38 |
+
trainer.total_epochs=10 \
|
| 39 |
+
trainer.max_try_make_batch=10 \
|
| 40 |
+
trainer.experiment_name=qwen3_14b_dapo17k_dapo \
|
| 41 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/qwen3_4b_math_grpo.sh
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen3-4B # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.max_response_length=4096 \
|
| 10 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 11 |
+
trainer.experiment_name=qwen3_4b_math_grpo
|
model/EasyR1/examples/qwen3_vl_30b_geo3k_grpo.sh
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
MODEL_PATH=Qwen/Qwen3-VL-30B-A3B-Instruct # replace it with your local file path
|
| 6 |
+
|
| 7 |
+
python3 -m verl.trainer.main \
|
| 8 |
+
config=examples/config.yaml \
|
| 9 |
+
data.train_files=hiyouga/geometry3k@train \
|
| 10 |
+
data.val_files=hiyouga/geometry3k@test \
|
| 11 |
+
worker.actor.model.model_path=${MODEL_PATH} \
|
| 12 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 13 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 14 |
+
worker.rollout.tensor_parallel_size=8 \
|
| 15 |
+
trainer.experiment_name=qwen3_vl_30b_geo_grpo \
|
| 16 |
+
trainer.n_gpus_per_node=8
|
model/EasyR1/examples/runtime_env.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
working_dir: ./
|
| 2 |
+
excludes: ["/.git/"]
|
| 3 |
+
env_vars:
|
| 4 |
+
TOKENIZERS_PARALLELISM: "true"
|
| 5 |
+
NCCL_DEBUG: "WARN"
|
| 6 |
+
VLLM_LOGGING_LEVEL: "WARN"
|
| 7 |
+
TORCH_NCCL_AVOID_RECORD_STREAMS: "1"
|
| 8 |
+
PYTORCH_CUDA_ALLOC_CONF: "expandable_segments:False"
|
| 9 |
+
CUDA_DEVICE_MAX_CONNECTIONS: "1"
|
| 10 |
+
VLLM_ALLREDUCE_USE_SYMM_MEM: "0"
|
model/EasyR1/local_scripts/run_onethinker_rl.sh
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
#!/usr/bin/env bash
|
| 3 |
+
set -x
|
| 4 |
+
|
| 5 |
+
export DECORD_EOF_RETRY_MAX=2048001
|
| 6 |
+
export WANDB_API_KEY=<YOUR_KEY>
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
project_name='EasyR1-onethinker-rl'
|
| 10 |
+
exp_name='qwen3_vl_onethinker-rl'
|
| 11 |
+
|
| 12 |
+
MODEL_PATH=<SFT_Model>
|
| 13 |
+
TRAIN_FILE="onethinker_rl_train.json"
|
| 14 |
+
TEST_FILE="onethinker_rl_train.json"
|
| 15 |
+
IMAGE_DIR=<Train_Data_Path>
|
| 16 |
+
|
| 17 |
+
ROLLOUT_BS=128
|
| 18 |
+
GLOBAL_BS=32
|
| 19 |
+
MB_PER_UPDATE=1
|
| 20 |
+
MB_PER_EXP=1
|
| 21 |
+
TP_SIZE=4
|
| 22 |
+
N_GPUS_PER_NODE=8
|
| 23 |
+
NNODES=4
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
python3 -m verl.trainer.main \
|
| 28 |
+
config=EasyR1/examples/config_ema_grpo_64.yaml \
|
| 29 |
+
data.train_files="${TRAIN_FILE}" \
|
| 30 |
+
data.val_files="${TEST_FILE}" \
|
| 31 |
+
data.image_dir="${IMAGE_DIR}" \
|
| 32 |
+
data.rollout_batch_size="${ROLLOUT_BS}" \
|
| 33 |
+
worker.actor.global_batch_size="${GLOBAL_BS}" \
|
| 34 |
+
worker.actor.micro_batch_size_per_device_for_update="${MB_PER_UPDATE}" \
|
| 35 |
+
worker.actor.micro_batch_size_per_device_for_experience="${MB_PER_EXP}" \
|
| 36 |
+
worker.actor.model.model_path="${MODEL_PATH}" \
|
| 37 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 38 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 39 |
+
worker.actor.optim.lr=2e-6 \
|
| 40 |
+
worker.rollout.tensor_parallel_size="${TP_SIZE}" \
|
| 41 |
+
algorithm.filter_low=0.01 \
|
| 42 |
+
algorithm.filter_high=0.99 \
|
| 43 |
+
algorithm.online_filtering=true \
|
| 44 |
+
algorithm.filter_key=accuracy \
|
| 45 |
+
trainer.project_name="${project_name}" \
|
| 46 |
+
trainer.experiment_name="${exp_name}" \
|
| 47 |
+
trainer.n_gpus_per_node="${N_GPUS_PER_NODE}" \
|
| 48 |
+
trainer.nnodes="${NNODES}" \
|
| 49 |
+
trainer.save_freq=100 \
|
| 50 |
+
trainer.save_checkpoint_path=EasyR1/checkpoints
|
| 51 |
+
|
| 52 |
+
|
model/EasyR1/local_scripts/run_surgicalthinker_rl_d-grpo.sh
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
set -x
|
| 3 |
+
|
| 4 |
+
export DECORD_EOF_RETRY_MAX=2048001
|
| 5 |
+
export WANDB_API_KEY=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
|
| 6 |
+
|
| 7 |
+
# NCCL settings to fix timeout
|
| 8 |
+
export NCCL_P2P_DISABLE=1
|
| 9 |
+
export NCCL_TIMEOUT=1800 # 30 minutes timeout
|
| 10 |
+
export NCCL_ASYNC_ERROR_HANDLING=1
|
| 11 |
+
export NCCL_DEBUG=WARN # Set to INFO for more debug output
|
| 12 |
+
export NCCL_BLOCKING_WAIT=0
|
| 13 |
+
|
| 14 |
+
# PyTorch distributed settings
|
| 15 |
+
export TORCH_DISTRIBUTED_DEBUG=OFF # Set to DETAIL for more debug info
|
| 16 |
+
export TORCH_NCCL_BLOCKING_WAIT=0
|
| 17 |
+
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
project_name='EasyR1'
|
| 21 |
+
exp_name='surgicalthinker_onethinker_d-grpo'
|
| 22 |
+
|
| 23 |
+
MODEL_PATH="/home/cgv/extend_data/wp/project/OneThinker/models/OneThinker/SurgicalThinker-SFT"
|
| 24 |
+
TRAIN_FILE="/home/cgv/extend_data/wp/data/Medical/surgicalthinker_rl_subset.json"
|
| 25 |
+
TEST_FILE="/home/cgv/extend_data/wp/data/Medical/surgicalthinker_rl_subset.json"
|
| 26 |
+
IMAGE_DIR="/home/cgv/extend_data/wp/data/Medical"
|
| 27 |
+
|
| 28 |
+
ROLLOUT_BS=8
|
| 29 |
+
GLOBAL_BS=8
|
| 30 |
+
MB_PER_UPDATE=1
|
| 31 |
+
MB_PER_EXP=1
|
| 32 |
+
TP_SIZE=4
|
| 33 |
+
N_GPUS_PER_NODE=8
|
| 34 |
+
NNODES=1
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
python3 -m verl.trainer.main \
|
| 39 |
+
config=EasyR1/examples/config_ema_grpo.yaml \
|
| 40 |
+
data.train_files="${TRAIN_FILE}" \
|
| 41 |
+
data.val_files="${TEST_FILE}" \
|
| 42 |
+
data.image_dir="${IMAGE_DIR}" \
|
| 43 |
+
data.rollout_batch_size="${ROLLOUT_BS}" \
|
| 44 |
+
worker.actor.global_batch_size="${GLOBAL_BS}" \
|
| 45 |
+
worker.actor.micro_batch_size_per_device_for_update="${MB_PER_UPDATE}" \
|
| 46 |
+
worker.actor.micro_batch_size_per_device_for_experience="${MB_PER_EXP}" \
|
| 47 |
+
worker.actor.model.model_path="${MODEL_PATH}" \
|
| 48 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 49 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 50 |
+
worker.actor.optim.lr=2e-6 \
|
| 51 |
+
worker.rollout.tensor_parallel_size="${TP_SIZE}" \
|
| 52 |
+
algorithm.filter_low=0.0 \
|
| 53 |
+
algorithm.filter_high=1.0 \
|
| 54 |
+
algorithm.online_filtering=false \
|
| 55 |
+
algorithm.filter_key=accuracy \
|
| 56 |
+
trainer.project_name="${project_name}" \
|
| 57 |
+
trainer.experiment_name="${exp_name}" \
|
| 58 |
+
trainer.n_gpus_per_node="${N_GPUS_PER_NODE}" \
|
| 59 |
+
trainer.nnodes="${NNODES}" \
|
| 60 |
+
trainer.save_freq=100 \
|
| 61 |
+
trainer.save_checkpoint_path=EasyR1/checkpoints
|
| 62 |
+
|
| 63 |
+
|
model/EasyR1/local_scripts/run_surgicalthinker_rl_ema-grpo.sh
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
set -x
|
| 3 |
+
|
| 4 |
+
export DECORD_EOF_RETRY_MAX=2048001
|
| 5 |
+
export WANDB_API_KEY=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
|
| 6 |
+
|
| 7 |
+
# NCCL settings to fix timeout
|
| 8 |
+
export NCCL_P2P_DISABLE=1
|
| 9 |
+
export NCCL_TIMEOUT=1800 # 30 minutes timeout
|
| 10 |
+
export NCCL_ASYNC_ERROR_HANDLING=1
|
| 11 |
+
export NCCL_DEBUG=WARN # Set to INFO for more debug output
|
| 12 |
+
export NCCL_BLOCKING_WAIT=0
|
| 13 |
+
|
| 14 |
+
# PyTorch distributed settings
|
| 15 |
+
export TORCH_DISTRIBUTED_DEBUG=OFF # Set to DETAIL for more debug info
|
| 16 |
+
export TORCH_NCCL_BLOCKING_WAIT=0
|
| 17 |
+
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
project_name='EasyR1'
|
| 21 |
+
exp_name='surgicalthinker_onethinker_rl_ema_grpo'
|
| 22 |
+
|
| 23 |
+
MODEL_PATH="WangYe007/OneThinker_SurgicalThinker-SFT"
|
| 24 |
+
TRAIN_FILE="../../data/Medical/surgicalthinker_rl.json"
|
| 25 |
+
TEST_FILE="../../data/Medical/surgicalthinker_rl.json"
|
| 26 |
+
IMAGE_DIR="../../data/Medical"
|
| 27 |
+
|
| 28 |
+
ROLLOUT_BS=128
|
| 29 |
+
GLOBAL_BS=32
|
| 30 |
+
MB_PER_UPDATE=1
|
| 31 |
+
MB_PER_EXP=1
|
| 32 |
+
TP_SIZE=4
|
| 33 |
+
N_GPUS_PER_NODE=8
|
| 34 |
+
NNODES=1
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
python3 -m verl.trainer.main \
|
| 39 |
+
config=EasyR1/examples/config_ema_grpo.yaml \
|
| 40 |
+
data.train_files="${TRAIN_FILE}" \
|
| 41 |
+
data.val_files="${TEST_FILE}" \
|
| 42 |
+
data.image_dir="${IMAGE_DIR}" \
|
| 43 |
+
data.rollout_batch_size="${ROLLOUT_BS}" \
|
| 44 |
+
worker.actor.global_batch_size="${GLOBAL_BS}" \
|
| 45 |
+
worker.actor.micro_batch_size_per_device_for_update="${MB_PER_UPDATE}" \
|
| 46 |
+
worker.actor.micro_batch_size_per_device_for_experience="${MB_PER_EXP}" \
|
| 47 |
+
worker.actor.model.model_path="${MODEL_PATH}" \
|
| 48 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 49 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 50 |
+
worker.actor.optim.lr=2e-6 \
|
| 51 |
+
worker.rollout.tensor_parallel_size="${TP_SIZE}" \
|
| 52 |
+
algorithm.filter_low=0.0 \
|
| 53 |
+
algorithm.filter_high=1.0 \
|
| 54 |
+
algorithm.online_filtering=false \
|
| 55 |
+
algorithm.filter_key=accuracy \
|
| 56 |
+
trainer.project_name="${project_name}" \
|
| 57 |
+
trainer.experiment_name="${exp_name}" \
|
| 58 |
+
trainer.n_gpus_per_node="${N_GPUS_PER_NODE}" \
|
| 59 |
+
trainer.nnodes="${NNODES}" \
|
| 60 |
+
trainer.save_freq=50 \
|
| 61 |
+
trainer.save_checkpoint_path=EasyR1/checkpoints/ema_grpo
|
| 62 |
+
|
| 63 |
+
|
model/EasyR1/local_scripts/run_surgicalthinker_rl_grpo.sh
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env bash
|
| 2 |
+
set -x
|
| 3 |
+
|
| 4 |
+
export DECORD_EOF_RETRY_MAX=2048001
|
| 5 |
+
export WANDB_API_KEY=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
|
| 6 |
+
|
| 7 |
+
# NCCL settings to fix timeout
|
| 8 |
+
export NCCL_P2P_DISABLE=1
|
| 9 |
+
export NCCL_TIMEOUT=1800 # 30 minutes timeout
|
| 10 |
+
export NCCL_ASYNC_ERROR_HANDLING=1
|
| 11 |
+
export NCCL_DEBUG=WARN # Set to INFO for more debug output
|
| 12 |
+
export NCCL_BLOCKING_WAIT=0
|
| 13 |
+
|
| 14 |
+
# PyTorch distributed settings
|
| 15 |
+
export TORCH_DISTRIBUTED_DEBUG=OFF # Set to DETAIL for more debug info
|
| 16 |
+
export TORCH_NCCL_BLOCKING_WAIT=0
|
| 17 |
+
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
project_name='EasyR1'
|
| 21 |
+
exp_name='surgicalthinker_onethinker_grpo'
|
| 22 |
+
|
| 23 |
+
MODEL_PATH="WangYe007/OneThinker_SurgicalThinker-SFT"
|
| 24 |
+
TRAIN_FILE="../../data/Medical/surgicalthinker_rl.json"
|
| 25 |
+
TEST_FILE="../../data/Medical/surgicalthinker_rl.json"
|
| 26 |
+
IMAGE_DIR="../../data/Medical"
|
| 27 |
+
|
| 28 |
+
ROLLOUT_BS=128
|
| 29 |
+
GLOBAL_BS=32
|
| 30 |
+
MB_PER_UPDATE=1
|
| 31 |
+
MB_PER_EXP=1
|
| 32 |
+
TP_SIZE=4
|
| 33 |
+
N_GPUS_PER_NODE=8
|
| 34 |
+
NNODES=1
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
python3 -m verl.trainer.main \
|
| 39 |
+
config=EasyR1/examples/config_grpo.yaml \
|
| 40 |
+
data.train_files="${TRAIN_FILE}" \
|
| 41 |
+
data.val_files="${TEST_FILE}" \
|
| 42 |
+
data.image_dir="${IMAGE_DIR}" \
|
| 43 |
+
data.rollout_batch_size="${ROLLOUT_BS}" \
|
| 44 |
+
worker.actor.global_batch_size="${GLOBAL_BS}" \
|
| 45 |
+
worker.actor.micro_batch_size_per_device_for_update="${MB_PER_UPDATE}" \
|
| 46 |
+
worker.actor.micro_batch_size_per_device_for_experience="${MB_PER_EXP}" \
|
| 47 |
+
worker.actor.model.model_path="${MODEL_PATH}" \
|
| 48 |
+
worker.actor.fsdp.torch_dtype=bf16 \
|
| 49 |
+
worker.actor.optim.strategy=adamw_bf16 \
|
| 50 |
+
worker.actor.optim.lr=2e-6 \
|
| 51 |
+
worker.rollout.tensor_parallel_size="${TP_SIZE}" \
|
| 52 |
+
algorithm.filter_low=0.0 \
|
| 53 |
+
algorithm.filter_high=1.0 \
|
| 54 |
+
algorithm.online_filtering=false \
|
| 55 |
+
algorithm.filter_key=accuracy \
|
| 56 |
+
trainer.project_name="${project_name}" \
|
| 57 |
+
trainer.experiment_name="${exp_name}" \
|
| 58 |
+
trainer.n_gpus_per_node="${N_GPUS_PER_NODE}" \
|
| 59 |
+
trainer.nnodes="${NNODES}" \
|
| 60 |
+
trainer.save_freq=50 \
|
| 61 |
+
trainer.save_checkpoint_path=EasyR1/checkpoints/grpo
|
| 62 |
+
|
| 63 |
+
|
model/EasyR1/pyproject.toml
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["setuptools>=61.0"]
|
| 3 |
+
build-backend = "setuptools.build_meta"
|
| 4 |
+
|
| 5 |
+
[project]
|
| 6 |
+
name = "verl"
|
| 7 |
+
dynamic = [
|
| 8 |
+
"version",
|
| 9 |
+
"dependencies",
|
| 10 |
+
"optional-dependencies",
|
| 11 |
+
"requires-python",
|
| 12 |
+
"authors",
|
| 13 |
+
"description",
|
| 14 |
+
"readme",
|
| 15 |
+
"license"
|
| 16 |
+
]
|
| 17 |
+
|
| 18 |
+
[tool.ruff]
|
| 19 |
+
target-version = "py39"
|
| 20 |
+
line-length = 119
|
| 21 |
+
indent-width = 4
|
| 22 |
+
|
| 23 |
+
[tool.ruff.lint]
|
| 24 |
+
ignore = ["C901", "E501", "E741", "W605", "C408"]
|
| 25 |
+
select = ["C", "E", "F", "I", "W", "RUF022"]
|
| 26 |
+
|
| 27 |
+
[tool.ruff.lint.per-file-ignores]
|
| 28 |
+
"__init__.py" = ["E402", "F401", "F403", "F811"]
|
| 29 |
+
|
| 30 |
+
[tool.ruff.lint.isort]
|
| 31 |
+
lines-after-imports = 2
|
| 32 |
+
known-first-party = ["verl"]
|
| 33 |
+
known-third-party = ["torch", "transformers", "wandb"]
|
| 34 |
+
|
| 35 |
+
[tool.ruff.format]
|
| 36 |
+
quote-style = "double"
|
| 37 |
+
indent-style = "space"
|
| 38 |
+
skip-magic-trailing-comma = false
|
| 39 |
+
line-ending = "auto"
|
model/EasyR1/requirements.txt
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
codetiming
|
| 3 |
+
datasets
|
| 4 |
+
# flash-attn>=2.4.3
|
| 5 |
+
liger-kernel
|
| 6 |
+
mathruler
|
| 7 |
+
numpy
|
| 8 |
+
omegaconf
|
| 9 |
+
pandas
|
| 10 |
+
peft
|
| 11 |
+
pillow
|
| 12 |
+
pyarrow>=15.0.0
|
| 13 |
+
pylatexenc
|
| 14 |
+
qwen-vl-utils
|
| 15 |
+
ray[default]
|
| 16 |
+
tensordict
|
| 17 |
+
torchdata
|
| 18 |
+
# transformers>=4.54.0,<=4.57.0
|
| 19 |
+
# vllm>=0.8.0
|
| 20 |
+
wandb
|
model/EasyR1/scripts/model_merger.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import argparse
|
| 16 |
+
import os
|
| 17 |
+
import re
|
| 18 |
+
from concurrent.futures import ThreadPoolExecutor
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
import torch
|
| 22 |
+
from torch.distributed._tensor import DTensor, Placement, Shard
|
| 23 |
+
from transformers import (
|
| 24 |
+
AutoConfig,
|
| 25 |
+
AutoModelForCausalLM,
|
| 26 |
+
AutoModelForImageTextToText,
|
| 27 |
+
AutoModelForTokenClassification,
|
| 28 |
+
PretrainedConfig,
|
| 29 |
+
PreTrainedModel,
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def merge_by_placement(tensors: list[torch.Tensor], placement: Placement):
|
| 34 |
+
if placement.is_replicate():
|
| 35 |
+
return tensors[0]
|
| 36 |
+
elif placement.is_partial():
|
| 37 |
+
raise NotImplementedError("Partial placement is not supported yet")
|
| 38 |
+
elif placement.is_shard():
|
| 39 |
+
return torch.cat(tensors, dim=placement.dim).contiguous()
|
| 40 |
+
else:
|
| 41 |
+
raise ValueError(f"Unsupported placement: {placement}")
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def upload_model_to_huggingface(local_path: str, remote_path: str):
|
| 45 |
+
# Push to hugging face
|
| 46 |
+
from huggingface_hub import HfApi
|
| 47 |
+
|
| 48 |
+
api = HfApi()
|
| 49 |
+
api.create_repo(repo_id=remote_path, private=False, exist_ok=True)
|
| 50 |
+
api.upload_folder(repo_id=remote_path, folder_path=local_path, repo_type="model")
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
if __name__ == "__main__":
|
| 54 |
+
parser = argparse.ArgumentParser()
|
| 55 |
+
parser.add_argument("--local_dir", required=True, type=str, help="The path for your saved model")
|
| 56 |
+
parser.add_argument("--hf_upload_path", default=False, type=str, help="The path of the huggingface repo to upload")
|
| 57 |
+
args = parser.parse_args()
|
| 58 |
+
local_dir: str = args.local_dir
|
| 59 |
+
|
| 60 |
+
assert not local_dir.endswith("huggingface"), "The local_dir should not end with huggingface."
|
| 61 |
+
|
| 62 |
+
# copy rank zero to find the shape of (dp, fsdp)
|
| 63 |
+
rank = 0
|
| 64 |
+
world_size = 0
|
| 65 |
+
for filename in os.listdir(local_dir):
|
| 66 |
+
match = re.match(r"model_world_size_(\d+)_rank_0\.pt", filename)
|
| 67 |
+
if match:
|
| 68 |
+
world_size = match.group(1)
|
| 69 |
+
break
|
| 70 |
+
|
| 71 |
+
assert world_size, "No model file with the proper format."
|
| 72 |
+
|
| 73 |
+
rank0_weight_path = os.path.join(local_dir, f"model_world_size_{world_size}_rank_{rank}.pt")
|
| 74 |
+
state_dict = torch.load(rank0_weight_path, map_location="cpu", weights_only=False)
|
| 75 |
+
pivot_key = sorted(state_dict.keys())[0]
|
| 76 |
+
weight = state_dict[pivot_key]
|
| 77 |
+
if isinstance(weight, DTensor):
|
| 78 |
+
# get sharding info
|
| 79 |
+
device_mesh = weight.device_mesh
|
| 80 |
+
mesh = device_mesh.mesh
|
| 81 |
+
mesh_dim_names = device_mesh.mesh_dim_names
|
| 82 |
+
else:
|
| 83 |
+
# for non-DTensor
|
| 84 |
+
mesh = np.array([int(world_size)], dtype=np.int64)
|
| 85 |
+
mesh_dim_names = ("fsdp",)
|
| 86 |
+
|
| 87 |
+
print(f"Got device mesh {mesh}, mesh_dim_names {mesh_dim_names}")
|
| 88 |
+
|
| 89 |
+
assert mesh_dim_names in (("fsdp",), ("ddp", "fsdp")), f"Unsupported mesh_dim_names {mesh_dim_names}."
|
| 90 |
+
|
| 91 |
+
if "tp" in mesh_dim_names:
|
| 92 |
+
# fsdp * tp
|
| 93 |
+
total_shards = mesh.shape[-1] * mesh.shape[-2]
|
| 94 |
+
mesh_shape = (mesh.shape[-2], mesh.shape[-1])
|
| 95 |
+
else:
|
| 96 |
+
# fsdp
|
| 97 |
+
total_shards = mesh.shape[-1]
|
| 98 |
+
mesh_shape = (mesh.shape[-1],)
|
| 99 |
+
|
| 100 |
+
print(f"Processing {total_shards} model shards in total.")
|
| 101 |
+
model_state_dict_lst = []
|
| 102 |
+
model_state_dict_lst.append(state_dict)
|
| 103 |
+
model_state_dict_lst.extend([""] * (total_shards - 1))
|
| 104 |
+
|
| 105 |
+
def process_one_shard(rank, model_state_dict_lst):
|
| 106 |
+
model_path = os.path.join(local_dir, f"model_world_size_{world_size}_rank_{rank}.pt")
|
| 107 |
+
state_dict = torch.load(model_path, map_location="cpu", weights_only=False)
|
| 108 |
+
model_state_dict_lst[rank] = state_dict
|
| 109 |
+
return state_dict
|
| 110 |
+
|
| 111 |
+
with ThreadPoolExecutor(max_workers=min(32, os.cpu_count())) as executor:
|
| 112 |
+
for rank in range(1, total_shards):
|
| 113 |
+
executor.submit(process_one_shard, rank, model_state_dict_lst)
|
| 114 |
+
|
| 115 |
+
state_dict: dict[str, list[torch.Tensor]] = {}
|
| 116 |
+
param_placements: dict[str, list[Placement]] = {}
|
| 117 |
+
keys = set(model_state_dict_lst[0].keys())
|
| 118 |
+
for key in keys:
|
| 119 |
+
state_dict[key] = []
|
| 120 |
+
for model_state_dict in model_state_dict_lst:
|
| 121 |
+
try:
|
| 122 |
+
tensor = model_state_dict.pop(key)
|
| 123 |
+
except Exception:
|
| 124 |
+
print(f"Cannot find key {key} in rank {rank}.")
|
| 125 |
+
|
| 126 |
+
if isinstance(tensor, DTensor):
|
| 127 |
+
state_dict[key].append(tensor._local_tensor.bfloat16())
|
| 128 |
+
placements = tuple(tensor.placements)
|
| 129 |
+
# replicated placement at ddp dimension can be discarded
|
| 130 |
+
if mesh_dim_names[0] == "ddp":
|
| 131 |
+
placements = placements[1:]
|
| 132 |
+
|
| 133 |
+
if key not in param_placements:
|
| 134 |
+
param_placements[key] = placements
|
| 135 |
+
else:
|
| 136 |
+
assert param_placements[key] == placements
|
| 137 |
+
else:
|
| 138 |
+
state_dict[key].append(tensor.bfloat16())
|
| 139 |
+
|
| 140 |
+
del model_state_dict_lst
|
| 141 |
+
|
| 142 |
+
for key in sorted(state_dict):
|
| 143 |
+
if not isinstance(state_dict[key], list):
|
| 144 |
+
print(f"No need to merge key {key}")
|
| 145 |
+
continue
|
| 146 |
+
|
| 147 |
+
if key in param_placements:
|
| 148 |
+
# merge shards
|
| 149 |
+
placements: tuple[Shard] = param_placements[key]
|
| 150 |
+
if len(mesh_shape) == 1:
|
| 151 |
+
# 1-D list, FSDP without TP
|
| 152 |
+
assert len(placements) == 1
|
| 153 |
+
shards = state_dict[key]
|
| 154 |
+
state_dict[key] = merge_by_placement(shards, placements[0])
|
| 155 |
+
else:
|
| 156 |
+
# 2-D list, FSDP + TP
|
| 157 |
+
raise NotImplementedError("FSDP + TP is not supported yet.")
|
| 158 |
+
else:
|
| 159 |
+
state_dict[key] = torch.cat(state_dict[key], dim=0)
|
| 160 |
+
|
| 161 |
+
print("Merge completed.")
|
| 162 |
+
hf_path = os.path.join(local_dir, "huggingface")
|
| 163 |
+
config: PretrainedConfig = AutoConfig.from_pretrained(hf_path)
|
| 164 |
+
architectures: list[str] = getattr(config, "architectures", ["Unknown"])
|
| 165 |
+
|
| 166 |
+
if "ForTokenClassification" in architectures[0]:
|
| 167 |
+
AutoClass = AutoModelForTokenClassification
|
| 168 |
+
elif "ForConditionalGeneration" in architectures[0]:
|
| 169 |
+
AutoClass = AutoModelForImageTextToText
|
| 170 |
+
elif "ForCausalLM" in architectures[0]:
|
| 171 |
+
AutoClass = AutoModelForCausalLM
|
| 172 |
+
else:
|
| 173 |
+
raise NotImplementedError(f"Unknown architecture {architectures}.")
|
| 174 |
+
|
| 175 |
+
with torch.device("meta"):
|
| 176 |
+
model: PreTrainedModel = AutoClass.from_config(config, torch_dtype=torch.bfloat16)
|
| 177 |
+
|
| 178 |
+
assert isinstance(model, PreTrainedModel)
|
| 179 |
+
model.to_empty(device="cpu")
|
| 180 |
+
|
| 181 |
+
print(f"Saving model to {hf_path}...")
|
| 182 |
+
model.save_pretrained(hf_path, state_dict=state_dict)
|
| 183 |
+
del state_dict, model
|
| 184 |
+
|
| 185 |
+
if args.hf_upload_path:
|
| 186 |
+
upload_model_to_huggingface(hf_path, args.hf_upload_path)
|
model/EasyR1/setup.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import os
|
| 16 |
+
import re
|
| 17 |
+
|
| 18 |
+
from setuptools import find_packages, setup
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def get_version() -> str:
|
| 22 |
+
with open(os.path.join("verl", "__init__.py"), encoding="utf-8") as f:
|
| 23 |
+
file_content = f.read()
|
| 24 |
+
pattern = r"__version__\W*=\W*\"([^\"]+)\""
|
| 25 |
+
(version,) = re.findall(pattern, file_content)
|
| 26 |
+
return version
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_requires() -> list[str]:
|
| 30 |
+
with open("requirements.txt", encoding="utf-8") as f:
|
| 31 |
+
file_content = f.read()
|
| 32 |
+
lines = [line.strip() for line in file_content.strip().split("\n") if not line.startswith("#")]
|
| 33 |
+
return lines
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
extra_require = {
|
| 37 |
+
"dev": ["pre-commit", "ruff"],
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def main():
|
| 42 |
+
setup(
|
| 43 |
+
name="verl",
|
| 44 |
+
version=get_version(),
|
| 45 |
+
description="An Efficient, Scalable, Multi-Modality RL Training Framework based on veRL",
|
| 46 |
+
long_description=open("README.md", encoding="utf-8").read(),
|
| 47 |
+
long_description_content_type="text/markdown",
|
| 48 |
+
author="verl",
|
| 49 |
+
author_email="zhangchi.usc1992@bytedance.com, gmsheng@connect.hku.hk, hiyouga@buaa.edu.cn",
|
| 50 |
+
license="Apache 2.0 License",
|
| 51 |
+
url="https://github.com/volcengine/verl",
|
| 52 |
+
package_dir={"": "."},
|
| 53 |
+
packages=find_packages(where="."),
|
| 54 |
+
python_requires=">=3.9.0",
|
| 55 |
+
install_requires=get_requires(),
|
| 56 |
+
extras_require=extra_require,
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
if __name__ == "__main__":
|
| 61 |
+
main()
|
model/EasyR1/tests/check_license.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import sys
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
KEYWORDS = ("Copyright", "2024", "Bytedance")
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def main():
|
| 23 |
+
path_list: list[Path] = []
|
| 24 |
+
for check_dir in sys.argv[1:]:
|
| 25 |
+
path_list.extend(Path(check_dir).glob("**/*.py"))
|
| 26 |
+
|
| 27 |
+
for path in path_list:
|
| 28 |
+
with open(path.absolute(), encoding="utf-8") as f:
|
| 29 |
+
file_content = f.read().strip().split("\n")
|
| 30 |
+
license = "\n".join(file_content[:5])
|
| 31 |
+
if not license:
|
| 32 |
+
continue
|
| 33 |
+
|
| 34 |
+
print(f"Check license: {path}")
|
| 35 |
+
assert all(keyword in license for keyword in KEYWORDS), f"File {path} does not contain license."
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
if __name__ == "__main__":
|
| 39 |
+
main()
|
model/EasyR1/tests/test_checkpoint.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import json
|
| 17 |
+
import os
|
| 18 |
+
import shutil
|
| 19 |
+
import uuid
|
| 20 |
+
|
| 21 |
+
import pytest
|
| 22 |
+
|
| 23 |
+
from verl.utils.checkpoint import CHECKPOINT_TRACKER, find_latest_ckpt, remove_obsolete_ckpt
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
@pytest.fixture
|
| 27 |
+
def save_checkpoint_path():
|
| 28 |
+
ckpt_dir = os.path.join("checkpoints", str(uuid.uuid4()))
|
| 29 |
+
os.makedirs(ckpt_dir, exist_ok=True)
|
| 30 |
+
yield ckpt_dir
|
| 31 |
+
shutil.rmtree(ckpt_dir, ignore_errors=True)
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def test_find_latest_ckpt(save_checkpoint_path):
|
| 35 |
+
with open(os.path.join(save_checkpoint_path, CHECKPOINT_TRACKER), "w") as f:
|
| 36 |
+
json.dump({"last_global_step": 10}, f, ensure_ascii=False, indent=2)
|
| 37 |
+
|
| 38 |
+
assert find_latest_ckpt(save_checkpoint_path)[0] is None
|
| 39 |
+
os.makedirs(os.path.join(save_checkpoint_path, "global_step_10"), exist_ok=True)
|
| 40 |
+
assert find_latest_ckpt(save_checkpoint_path)[0] == os.path.join(save_checkpoint_path, "global_step_10")
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def test_remove_obsolete_ckpt(save_checkpoint_path):
|
| 44 |
+
for step in range(5, 30, 5):
|
| 45 |
+
os.makedirs(os.path.join(save_checkpoint_path, f"global_step_{step}"), exist_ok=True)
|
| 46 |
+
|
| 47 |
+
remove_obsolete_ckpt(save_checkpoint_path, global_step=30, best_global_step=10, save_limit=3)
|
| 48 |
+
for step in range(5, 30, 5):
|
| 49 |
+
is_exist = step in [10, 25]
|
| 50 |
+
assert os.path.exists(os.path.join(save_checkpoint_path, f"global_step_{step}")) == is_exist
|
model/EasyR1/tests/test_dataproto.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import os
|
| 17 |
+
from typing import Any, Optional
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import pytest
|
| 21 |
+
import torch
|
| 22 |
+
|
| 23 |
+
from verl.protocol import DataProto, pad_dataproto_to_divisor, unpad_dataproto
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def _get_data_proto(
|
| 27 |
+
tensors: Optional[dict[str, list[Any]]] = None,
|
| 28 |
+
non_tensors: Optional[dict[str, list[Any]]] = None,
|
| 29 |
+
meta_info: Optional[dict[str, Any]] = None,
|
| 30 |
+
) -> DataProto:
|
| 31 |
+
if tensors is None and non_tensors is None:
|
| 32 |
+
tensors = {"obs": [1, 2, 3, 4, 5, 6]}
|
| 33 |
+
non_tensors = {"labels": ["a", "b", "c", "d", "e", "f"]}
|
| 34 |
+
|
| 35 |
+
if tensors is not None:
|
| 36 |
+
tensors = {k: torch.tensor(v) if not isinstance(v, torch.Tensor) else v for k, v in tensors.items()}
|
| 37 |
+
|
| 38 |
+
if non_tensors is not None:
|
| 39 |
+
non_tensors = {
|
| 40 |
+
k: np.array(v, dtype=object) if not isinstance(v, np.ndarray) else v for k, v in non_tensors.items()
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
meta_info = meta_info or {"info": "test_info"}
|
| 44 |
+
return DataProto.from_dict(tensors=tensors, non_tensors=non_tensors, meta_info=meta_info)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def _assert_equal(data1: DataProto, data2: Optional[DataProto] = None):
|
| 48 |
+
data2 = data2 or _get_data_proto()
|
| 49 |
+
if data1.batch is not None:
|
| 50 |
+
assert data1.batch.keys() == data2.batch.keys()
|
| 51 |
+
for key in data1.batch.keys():
|
| 52 |
+
assert torch.all(data1.batch[key] == data2.batch[key])
|
| 53 |
+
else:
|
| 54 |
+
assert data2.batch is None
|
| 55 |
+
|
| 56 |
+
if data1.non_tensor_batch is not None:
|
| 57 |
+
assert data1.non_tensor_batch.keys() == data2.non_tensor_batch.keys()
|
| 58 |
+
for key in data1.non_tensor_batch.keys():
|
| 59 |
+
assert np.all(data1.non_tensor_batch[key] == data2.non_tensor_batch[key])
|
| 60 |
+
else:
|
| 61 |
+
assert data2.non_tensor_batch is None
|
| 62 |
+
|
| 63 |
+
assert data1.meta_info == data2.meta_info
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def test_tensor_dict_constructor():
|
| 67 |
+
obs = torch.randn(100, 10)
|
| 68 |
+
act = torch.randn(100, 10, 3)
|
| 69 |
+
data = DataProto.from_dict(tensors={"obs": obs, "act": act})
|
| 70 |
+
assert len(data) == 100
|
| 71 |
+
|
| 72 |
+
with pytest.raises(AssertionError):
|
| 73 |
+
data = DataProto.from_dict(tensors={"obs": obs, "act": act}, num_batch_dims=2)
|
| 74 |
+
|
| 75 |
+
with pytest.raises(AssertionError):
|
| 76 |
+
data = DataProto.from_dict(tensors={"obs": obs, "act": act}, num_batch_dims=3)
|
| 77 |
+
|
| 78 |
+
labels = np.array(["a", "b", "c"], dtype=object)
|
| 79 |
+
data = DataProto.from_dict(non_tensors={"labels": labels})
|
| 80 |
+
assert len(data) == 3
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def test_getitem():
|
| 84 |
+
data = _get_data_proto()
|
| 85 |
+
assert data[0].batch["obs"] == torch.tensor(1)
|
| 86 |
+
assert data[0].non_tensor_batch["labels"] == "a"
|
| 87 |
+
_assert_equal(data[1:3], _get_data_proto({"obs": [2, 3]}, {"labels": ["b", "c"]}))
|
| 88 |
+
_assert_equal(data[[0, 2]], _get_data_proto({"obs": [1, 3]}, {"labels": ["a", "c"]}))
|
| 89 |
+
_assert_equal(data[torch.tensor([1])], _get_data_proto({"obs": [2]}, {"labels": ["b"]}))
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def test_select_pop():
|
| 93 |
+
obs = torch.randn(100, 10)
|
| 94 |
+
act = torch.randn(100, 3)
|
| 95 |
+
dataset = _get_data_proto(tensors={"obs": obs, "act": act}, meta_info={"p": 1, "q": 2})
|
| 96 |
+
selected_dataset = dataset.select(batch_keys=["obs"], meta_info_keys=["p"])
|
| 97 |
+
|
| 98 |
+
assert selected_dataset.batch.keys() == {"obs"}
|
| 99 |
+
assert selected_dataset.meta_info.keys() == {"p"}
|
| 100 |
+
assert dataset.batch.keys() == {"obs", "act"}
|
| 101 |
+
assert dataset.meta_info.keys() == {"p", "q"}
|
| 102 |
+
|
| 103 |
+
popped_dataset = dataset.pop(batch_keys=["obs"], meta_info_keys=["p"])
|
| 104 |
+
assert popped_dataset.batch.keys() == {"obs"}
|
| 105 |
+
assert popped_dataset.meta_info.keys() == {"p"}
|
| 106 |
+
assert dataset.batch.keys() == {"act"}
|
| 107 |
+
assert dataset.meta_info.keys() == {"q"}
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def test_chunk_concat_split():
|
| 111 |
+
data = _get_data_proto()
|
| 112 |
+
with pytest.raises(AssertionError):
|
| 113 |
+
data.chunk(5)
|
| 114 |
+
|
| 115 |
+
chunked_data = data.chunk(2)
|
| 116 |
+
|
| 117 |
+
assert len(chunked_data) == 2
|
| 118 |
+
expected_data = _get_data_proto({"obs": [1, 2, 3]}, {"labels": ["a", "b", "c"]})
|
| 119 |
+
_assert_equal(chunked_data[0], expected_data)
|
| 120 |
+
|
| 121 |
+
concat_data = DataProto.concat(chunked_data)
|
| 122 |
+
_assert_equal(concat_data, data)
|
| 123 |
+
|
| 124 |
+
splitted_data = data.split(2)
|
| 125 |
+
assert len(splitted_data) == 3
|
| 126 |
+
expected_data = _get_data_proto({"obs": [1, 2]}, {"labels": ["a", "b"]})
|
| 127 |
+
_assert_equal(splitted_data[0], expected_data)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def test_reorder():
|
| 131 |
+
data = _get_data_proto()
|
| 132 |
+
data.reorder(torch.tensor([3, 4, 2, 0, 1, 5]))
|
| 133 |
+
expected_data = _get_data_proto({"obs": [4, 5, 3, 1, 2, 6]}, {"labels": ["d", "e", "c", "a", "b", "f"]})
|
| 134 |
+
_assert_equal(data, expected_data)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
@pytest.mark.parametrize("interleave", [True, False])
|
| 138 |
+
def test_repeat(interleave: bool):
|
| 139 |
+
data = _get_data_proto({"obs": [1, 2]}, {"labels": ["a", "b"]})
|
| 140 |
+
repeated_data = data.repeat(repeat_times=2, interleave=interleave)
|
| 141 |
+
expected_tensors = {"obs": [1, 1, 2, 2] if interleave else [1, 2, 1, 2]}
|
| 142 |
+
expected_non_tensors = {"labels": ["a", "a", "b", "b"] if interleave else ["a", "b", "a", "b"]}
|
| 143 |
+
_assert_equal(repeated_data, _get_data_proto(expected_tensors, expected_non_tensors))
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
@pytest.mark.parametrize("size_divisor", [2, 3])
|
| 147 |
+
def test_dataproto_pad_unpad(size_divisor: int):
|
| 148 |
+
data = _get_data_proto({"obs": [1, 2, 3]}, {"labels": ["a", "b", "c"]})
|
| 149 |
+
# test size_divisor=2
|
| 150 |
+
padded_data, pad_size = pad_dataproto_to_divisor(data, size_divisor=size_divisor)
|
| 151 |
+
unpadded_data = unpad_dataproto(padded_data, pad_size=pad_size)
|
| 152 |
+
|
| 153 |
+
if size_divisor == 2:
|
| 154 |
+
assert pad_size == 1
|
| 155 |
+
expected_tensors = {"obs": [1, 2, 3, 1]}
|
| 156 |
+
expected_non_tensors = {"labels": ["a", "b", "c", "a"]}
|
| 157 |
+
expected_data = _get_data_proto(expected_tensors, expected_non_tensors)
|
| 158 |
+
else:
|
| 159 |
+
assert pad_size == 0
|
| 160 |
+
expected_data = data
|
| 161 |
+
|
| 162 |
+
_assert_equal(padded_data, expected_data)
|
| 163 |
+
_assert_equal(unpadded_data, data)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def test_data_proto_save_load():
|
| 167 |
+
data = _get_data_proto()
|
| 168 |
+
data.save_to_disk("test_data.pt")
|
| 169 |
+
loaded_data = DataProto.load_from_disk("test_data.pt")
|
| 170 |
+
os.remove("test_data.pt")
|
| 171 |
+
_assert_equal(data, loaded_data)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def test_union_tensor_dict():
|
| 175 |
+
obs = torch.randn(100, 10)
|
| 176 |
+
data1 = _get_data_proto({"obs": obs, "act": torch.randn(100, 3)})
|
| 177 |
+
data2 = _get_data_proto({"obs": obs, "rew": torch.randn(100)})
|
| 178 |
+
data1.union(data2)
|
| 179 |
+
|
| 180 |
+
data1 = _get_data_proto({"obs": obs, "act": torch.randn(100, 3)})
|
| 181 |
+
data2 = _get_data_proto({"obs": obs + 1, "rew": torch.randn(100)})
|
| 182 |
+
with pytest.raises(ValueError):
|
| 183 |
+
data1.union(data2)
|