---
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- long-context
- procedural-generation
- benchmark
- evaluation
pretty_name: 'LongProc: Long Procedural Generation Benchmark'
configs:
- config_name: countdown_0.5k
data_files:
- split: test
path: countdown_0.5k/test-*
- config_name: countdown_2k
data_files:
- split: test
path: countdown_2k/test-*
- config_name: countdown_8k
data_files:
- split: test
path: countdown_8k/test-*
- config_name: html_to_tsv_0.5k
data_files:
- split: test
path: html_to_tsv_0.5k/test-*
- config_name: html_to_tsv_2k
data_files:
- split: test
path: html_to_tsv_2k/test-*
- config_name: html_to_tsv_8k
data_files:
- split: test
path: html_to_tsv_8k/test-*
- config_name: path_traversal_0.5k
data_files:
- split: test
path: path_traversal_0.5k/test-*
- config_name: path_traversal_2k
data_files:
- split: test
path: path_traversal_2k/test-*
- config_name: path_traversal_8k
data_files:
- split: test
path: path_traversal_8k/test-*
- config_name: pseudo_to_code_0.5k
data_files:
- split: test
path: pseudo_to_code_0.5k/test-*
- config_name: pseudo_to_code_2k
data_files:
- split: test
path: pseudo_to_code_2k/test-*
- config_name: tom_tracking_0.5k
data_files:
- split: test
path: tom_tracking_0.5k/test-*
- config_name: tom_tracking_2k
data_files:
- split: test
path: tom_tracking_2k/test-*
- config_name: tom_tracking_8k
data_files:
- split: test
path: tom_tracking_8k/test-*
- config_name: travel_planning_2k
data_files:
- split: test
path: travel_planning_2k/test-*
- config_name: travel_planning_8k
data_files:
- split: test
path: travel_planning_8k/test-*
- config_name: travel_planning_icl_examples
data_files:
- split: test
path: travel_planning_icl_examples/test-*
dataset_info:
- config_name: countdown_0.5k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 3548952
num_examples: 200
download_size: 408756
dataset_size: 3548952
- config_name: countdown_2k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 4299610
num_examples: 200
download_size: 557786
dataset_size: 4299610
- config_name: countdown_8k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 6816325
num_examples: 200
download_size: 1012154
dataset_size: 6816325
- config_name: html_to_tsv_0.5k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 11123701
num_examples: 100
download_size: 2455321
dataset_size: 11123701
- config_name: html_to_tsv_2k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 32637641
num_examples: 189
download_size: 7035053
dataset_size: 32637641
- config_name: html_to_tsv_8k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 34465586
num_examples: 120
download_size: 7111617
dataset_size: 34465586
- config_name: path_traversal_0.5k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 2430029
num_examples: 200
download_size: 498807
dataset_size: 2430029
- config_name: path_traversal_2k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 7881106
num_examples: 200
download_size: 1868730
dataset_size: 7881106
- config_name: path_traversal_8k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 22492022
num_examples: 200
download_size: 5715549
dataset_size: 22492022
- config_name: pseudo_to_code_0.5k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 1127287
num_examples: 199
download_size: 410927
dataset_size: 1127287
- config_name: pseudo_to_code_2k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 2315410
num_examples: 200
download_size: 471798
dataset_size: 2315410
- config_name: tom_tracking_0.5k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 2425744
num_examples: 200
download_size: 311014
dataset_size: 2425744
- config_name: tom_tracking_2k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 4333995
num_examples: 200
download_size: 561712
dataset_size: 4333995
- config_name: tom_tracking_8k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 11996935
num_examples: 200
download_size: 1479326
dataset_size: 11996935
- config_name: travel_planning_2k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 23775247
num_examples: 769
download_size: 3407254
dataset_size: 23775247
- config_name: travel_planning_8k
features:
- name: id
dtype: string
- name: input_prompt
dtype: string
- name: reference_output
dtype: string
- name: metadata
dtype: string
splits:
- name: test
num_bytes: 11798420
num_examples: 239
download_size: 1833210
dataset_size: 11798420
---
# LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation



**LongProc** (**Long Proc**edural Generation) is a benchmark for evaluating long-context LLMs through long procedural generation tasks that require models to follow specified procedures and produce structured outputs. LongProc was accepted at [COLM 2025](https://colmweb.org/).
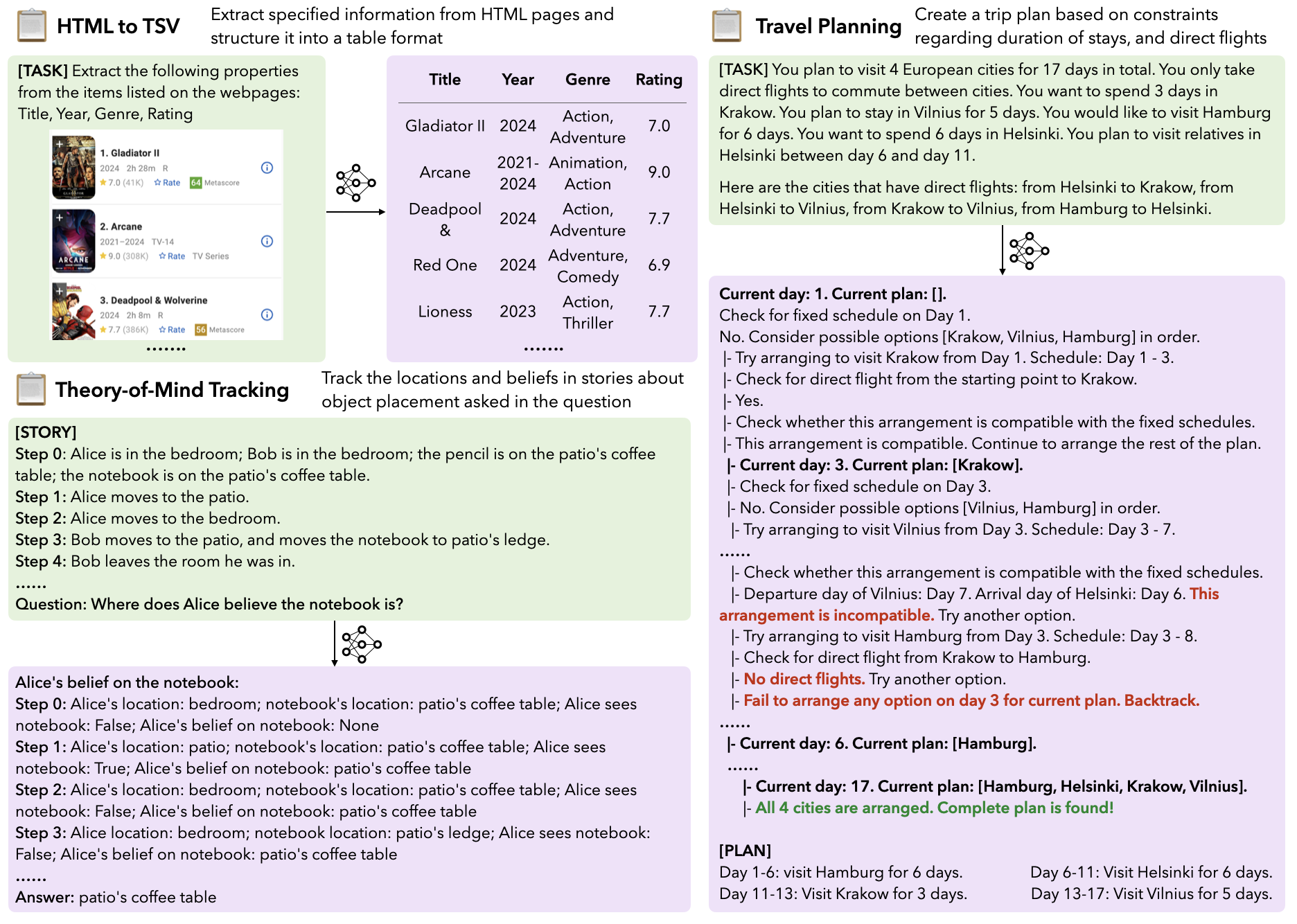
## Dataset Overview
LongProc consists of **6 tasks**, each at up to 3 difficulty levels based on the expected output length (~0.5K, ~2K, ~8K tokens). The dataset is organized into **17 subsets** (configs), each containing a single `test` split.
| Task | Description | Configs | Total Examples |
|------|-------------|---------|---------------|
| **HTML to TSV** | Extract information from HTML pages into structured TSV tables | `html_to_tsv_0.5k`, `html_to_tsv_2k`, `html_to_tsv_8k` | 100 + 189 + 120 = 409 |
| **Pseudocode to Code** | Translate line-by-line pseudocode into C++ code | `pseudo_to_code_0.5k`, `pseudo_to_code_2k` | 199 + 200 = 399 |
| **Path Traversal** | Trace a route between cities in a directed graph where each city has one outgoing edge | `path_traversal_0.5k`, `path_traversal_2k`, `path_traversal_8k` | 200 + 200 + 200 = 600 |
| **Theory-of-Mind Tracking** | Track object locations and agent beliefs through multi-step stories | `tom_tracking_0.5k`, `tom_tracking_2k`, `tom_tracking_8k` | 200 + 200 + 200 = 600 |
| **Countdown** | Search to combine numbers with arithmetic operations to reach a target | `countdown_0.5k`, `countdown_2k`, `countdown_8k` | 200 + 200 + 200 = 600 |
| **Travel Planning** | Search to construct a trip plan satisfying duration and flight constraints | `travel_planning_2k`, `travel_planning_8k`, `travel_planning_icl_examples` | 769 + 239 + 4 = 1012 |
## Loading the Dataset
```python
from datasets import load_dataset
# Load a specific task + difficulty
ds = load_dataset("PrincetonPli/LongProc", "countdown_0.5k", split="test")
print(ds)
# Dataset({
# features: ['nums', 'target', 'solution', 'search_steps', 'demonstration', 'solution_text', 'num_search_tokens'],
# num_rows: 200
# })
# Load another config
ds = load_dataset("PrincetonPli/LongProc", "html_to_tsv_2k", split="test")
print(ds[0].keys())
# dict_keys(['task_id', 'website_id', 'task_topic', 'task_description', 'gt', 'tsv_header', 'filtering_instruction', 'html_content'])
```
## Data Fields
### html_to_tsv
| Field | Type | Description |
|-------|------|-------------|
| `task_id` | string | Unique identifier for the task instance |
| `website_id` | string | Identifier for the source website |
| `task_topic` | string | Topic of the webpage (e.g., "electronics", "books") |
| `task_description` | string | Description of what properties to extract |
| `gt` | string | Ground truth TSV output |
| `tsv_header` | string | Header row for the TSV output |
| `filtering_instruction` | string | Additional instructions for filtering rows |
| `html_content` | string | Full HTML content of the webpage (inlined) |
### pseudo_to_code
| Field | Type | Description |
|-------|------|-------------|
| `problem_id` | string | Unique problem identifier |
| `pseudocode_lines` | list[string] | Pseudocode description, line by line |
| `code_lines` | list[string] | Ground truth C++ code lines |
| `testcases` | list | Test cases for validation |
### path_traversal
| Field | Type | Description |
|-------|------|-------------|
| `context_nl` | string | Natural language description of the city graph |
| `question_repr` | list[string] | Source and destination cities |
| `answer_nl` | string | Ground truth route in natural language |
### tom_tracking
| Field | Type | Description |
|-------|------|-------------|
| `story_components` | string | Components of the story (agents, objects, rooms, containers) |
| `story` | string | The multi-step story |
| `question` | string | Question about an agent's belief about an object's location |
| `solution` | string | Step-by-step solution trace |
| `answer` | list[string] | Final answer(s) |
### countdown
| Field | Type | Description |
|-------|------|-------------|
| `nums` | list[int] | Four input numbers |
| `target` | int | Target number to reach |
| `solution` | list[string] | Sequence of equations forming the solution |
| `search_steps` | float | Number of search steps in the ground truth trace |
| `demonstration` | string | In-context demonstration of the search procedure |
| `solution_text` | string | Full solution text including the search procedure |
| `num_search_tokens` | int | Number of tokens in the search procedure |
### travel_planning
| Field | Type | Description |
|-------|------|-------------|
| `id` | string | Unique problem identifier |
| `ground_truth_cities` | string | Ordered list of cities in the ground truth plan |
| `ground_truth_durations` | string | Duration of stay for each city |
| `num_cities` | int | Number of cities to visit |
| `total_days` | int | Total number of trip days |
| `constraints` | list[object] | Constraints with city, type, start/end days, num_days |
| `connected_cities` | list[list[string]] | Direct flight connections between cities |
| `original_question_text` | string | Original problem statement |
| `disambig_question_text` | string | Disambiguated problem statement |
| `ground_truth_plan` | string | Complete ground truth trip plan |
| `estimated_output_tokens` | int | Estimated output length in tokens (not present in ICL examples) |
The `travel_planning_icl_examples` config contains 4 in-context learning examples that share the same schema but without `estimated_output_tokens`.
## Prompt Templates
The prompt templates below are used to construct the input prompts for each task. Placeholders in `{braces}` are filled from the corresponding data fields.
HTML to TSV
```
[TASK]
Your task is to extract specific information from an HTML webpage and output the extracted
information in a tsv file. You will be first given an HTML webpage. Then, you should follow
the specific instruction provided later and output the tsv file following the format provided
in the instruction.
[INPUT WEBPAGE]
```html
{html_content}
```
[TARGET INFORMATION]
Based on the HTML webpage above about {task_topic}, extract the following properties from
the items listed on the webpage: {task_description}{filtering_instruction}
[OUTPUT FORMAT]
Structure your output in TSV format such that each row of your output corresponds to the
aforementioned properties of an item and each property is separated from each other by a
tab "\t". Your output should be in the following format:
```tsv
{tsv_header}
{Your TSV output}
```
[IMPORTANT NOTES]
- Make sure that you have read through all items listed on the webpage and followed the
same order as they appear on the webpage.
- If you are asked to only extract some rows that satisfy specific conditions, ONLY extract
those rows that satisfy the conditions and do NOT include other irrelevant rows in your output.
- If a property of an item is blank, not applicable, or not parseable, please set the property
to "N/A" for the item.
- If a property spans multiple lines, please extract all the lines and replace the newline
character with a space character.
- If a property consists of a list of items, please replace the newline character with a space
character and separate the items with a comma ",".
- If there are any special characters, numerical values of a specific format, or any unusual
formatting in the property, please keep them as they are. If the property comes with a unit,
please keep the unit as well in the property.
- Do not include html tags in the extracted information. Only include the text.
- Do not provide any additional information in your output other than the tsv.
Now, extract the information from the HTML webpage above and follow the output format above
in your answer.
```
Pseudocode to Code
```
[TASK]:
You will be given lines of pseudocode, your task is to write the corresponding C++ code.
The pseudocode will provide detailed description of the c++ code line by line. The pseudocode
is garanteed to be correct and complete.
[INSTRUCTION]:
The following libraries are already included in the code.
```cpp
#include
#include
#include
#include
#include
#include
#include
#include
#include
Path Traversal
```
[TASK]
In a completely hypothetical world, there are a number of cities. Each city has a one-way
connection to only one other city via a specific transit method (bus, train, plane, or ferry).
Your task is to provide a route from a city to another city. You should follow the specific
instruction provided later and output the route following the format provided in the instruction.
[IMPORTANT NOTES]
- All connections are one-way. If city A is connected to city B, you can travel from A to B,
but not the other way around.
- Because each city is connected to only one other city, so there's only one possible route.
To find the route, you can simply start from the starting city, identify the next city it's
connected to, and repeat the process until you reach the destination city.
- Please follow the exact format specified below when outputting the route.
[OUTPUT FORMAT]
Please mark the route with and tags. The route should be in the following
format, where one line is one step of the route:
From , take a to .
...
From , take a to .
[EXAMPLE]
...
[PROBLEM]
{context_nl}
Now find the route from {src_city} to {dst_city} based on the information above.
```
Where `{src_city}` and `{dst_city}` come from the `question_repr` field.
Theory-of-Mind Tracking
```
[TASK]
You'll see a story about object placement. Each story involves four components: Agents,
Objects, Rooms, and Containers. Given a question about an (agent, object) pair, your task
is to track the locations and beliefs in stories about object placement asked in the question.
[APPROACH]
You will solve the problem by tracking the location of the agent, location of the object,
and the agent's belief of the object.
1. Initial Setup: set up agent's starting location, object's starting location, agent's
initial belief on the object's location. Note that if an agent does not see an object
at the start, their belief on the object is None.
2. Then, track step-by-step:
- If a step involves that the agent moves to another room, leaves a room, or enters a
room, you should update the agent's location.
- If a step involves the object of interest moving, you should update the object's location.
- To keep track of the agent's belief on the object: If the agent and the object are in
the same room, the agent can see the object, so the agent's belief will reflect the
true location of the object. If the agent cannot see the object, the agent's belief
will remain unchanged until the agent sees the object again.
3. Format your output exactly as shown in example answers below.
[EXAMPLE STORY / QUESTION / ANSWER]
...
[PROBLEM]
Read the following story and answer the question.
[STORY]
{story}
[QUESTION]
{question}
[YOUR ANSWER]
```
Countdown
```
[TASK]
You will be given four numbers and a target number, your task is to find a way to use all
four numbers exactly once, along with the basic operations (+, -, *, /), to reach the
target number.
[RULES]
- You can use each number exactly once.
- You can use the four basic operations (+, -, *, /).
- The intermediate results must be integers (no decimals allowed).
- The intermediate results must be positive.
- The intermediate results will not exceed 2000.
[APPROACH]
We will solve the problem by searching. Starting from a given set of four numbers, we will
follow this search process...
[EXAMPLES]
{demonstration}
[Problem]
Numbers: {nums}
Target: {target}
```
The `{demonstration}` field is provided per-example and contains worked examples of the search procedure. `{nums}` comes from joining the `nums` list.
Travel Planning
```
TASK:
Your task is to create a trip plan based on given constraints regarding cities to visit,
duration of stays for each city, and available direct flight connections.
REQUIREMENTS AND NOTES:
- You will arrange a trip plan for visiting several cities for a specified total number of days.
- You will be informed about how long we will stay in each city. Some cities have fixed
schedules because of pre-planned events. You have to follow the fixed schedules for those
cities. Cities without fixed schedules need to be arranged according to the constraints.
- Only direct flights may be used to travel between cities.
- When calculating the duration of a stay in a city, count both arrival and departure days
as full days.
APPROACH:
We will solve the problem by searching...
EXAMPLES:
{demonstration}
YOUR TASK:
{problem}
```
The `{demonstration}` is constructed from the `travel_planning_icl_examples` config. `{problem}` comes from `disambig_question_text` (or `original_question_text`).
## Running Evaluation
We recommend using the [LongProc GitHub repository](https://github.com/princeton-nlp/LongProc) for data loading and evaluation:
```python
from longproc.longproc_data import load_longproc_data
data, eval_fn = load_longproc_data("countdown_0.5k")
# data: list of dicts with 'input_prompt', 'reference_output', 'item'
# eval_fn: task-specific evaluation function
```
For large-scale evaluation, we recommend the [HELMET](https://github.com/princeton-nlp/HELMET) framework with the [LongProc Addon](https://github.com/princeton-nlp/HELMET/blob/longproc/longproc_addon/README.md).
## Citation
```bibtex
@inproceedings{ye25longproc,
title={LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation},
author={Ye, Xi and Yin, Fangcong and He, Yinghui and Zhang, Joie and Yen, Howard and Gao, Tianyu and Durrett, Greg and Chen, Danqi},
journal={Conference on Language Modeling},
year={2025}
}
```
LongProc adapts several existing datasets. Please also cite the original sources:
```bibtex
@article{arborist,
author = {Li, Xiang and Zhou, Xiangyu and Dong, Rui and Zhang, Yihong and Wang, Xinyu},
title = {Efficient Bottom-Up Synthesis for Programs with Local Variables},
year = {2024},
journal = {Proc. ACM Program. Lang.},
volume = {8},
number = {POPL},
}
@inproceedings{spoc,
author = {Kulal, Sumith and Pasupat, Panupong and Chandra, Kartik and Lee, Mina and Padon, Oded and Aiken, Alex and Liang, Percy S},
booktitle = {Proceedings of the Conference on Advances in Neural Information Processing Systems (NeurIPS)},
title = {{SPoC: Search-based Pseudocode to Code}},
}
@inproceedings{gandhi2024stream,
title={{Stream of Search (SoS): Learning to Search in Language}},
author={Kanishk Gandhi and Denise H J Lee and Gabriel Grand and Muxin Liu and Winson Cheng and Archit Sharma and Noah Goodman},
booktitle={First Conference on Language Modeling},
year={2024},
}
@article{natplan,
title={{NATURAL PLAN: Benchmarking LLMs on Natural Language Planning}},
author={Zheng, Huaixiu Steven and Mishra, Swaroop and Zhang, Hugh and Chen, Xinyun and Chen, Minmin and Nova, Azade and Hou, Le and Cheng, Heng-Tze and Le, Quoc V and Chi, Ed H and others},
journal={arXiv preprint arXiv:2406.04520},
year={2024}
}
```
## Contact
For questions, feel free to open issues on the [GitHub repository](https://github.com/princeton-nlp/LongProc) or email `xi.ye@princeton.edu`.