Nucleus-Image: Scaling Text-to-Image with Sparse Mixture of Experts




🌐 Website | 🤗 Model | 🖥️ GitHub | 📑 Tech Report
TL;DR
We are releasing Nucleus-Image, a 17B-parameter text-to-image diffusion model that activates only ~2B parameters per forward pass through sparse mixture-of-experts. It matches or beats Qwen-Image, GPT Image 1, Seedream 3.0, and Imagen 4 on GenEval (0.87), DPG-Bench (88.79), and OneIG-Bench (0.522). All from pre-training alone, with no DPO, RL, or human preference tuning. Weights, training code, and dataset recipe are open, making Nucleus-Image the first fully open-source MoE diffusion model at this quality tier.

Why MoE for diffusion?
The dominant scaling recipe for text-to-image diffusion has been "make the dense DiT bigger." That works, but every extra billion dense parameters shows up as inference latency on every denoising step and there are dozens of denoising steps per image.
Sparse MoE decouples capacity from compute. Nucleus-Image packs 17B parameters into 64 routed experts per MoE layer, but any given image token only touches ~2 of them. The model has the knowledge of a much larger network and the serving cost of a much smaller one. The open question was whether MoE actually works for diffusion the way it does for LLMs and what it takes to make it stable. This release is our answer to that question, with the training recipe and weights to back it up.
What's new under the hood
1. Decoupled routing: the fix that makes MoE diffusion stable
The single most important architectural finding in this work is that naively reusing LLM-style MoE routing in a diffusion transformer silently breaks it.
DiT blocks apply adaptive modulation x_mod = x_norm * (1 + s(t)), where s(t) depends on the diffusion timestep. At convergence, the norm of x_mod at t=0.01 differs from t=0.99 by an order of magnitude. If you feed x_mod to the router (the default), router logits end up dominated by the timestep scale rather than the token content i.e. every token at a given timestep gets routed to the same handful of experts. Expert-choice routing collapses into timestep-choice routing, and the expert specialization you paid for disappears.
We fix this with a clean separation:
- The router sees the unmodulated representation concatenated with the timestep embedding:
[x_norm ‖ t_emb]. Content decides routing; timestep is an additive channel, not a multiplicative one. - The experts see the fully modulated representation
x_mod, keeping full conditioning expressivity for the actual computation.
Route by content and timestep; compute with conditioning.
This turned out to be load-bearing: with coupled routing, training is unstable and experts homogenize. With decoupled routing, experts cleanly specialize by spatial and semantic identity across the denoising trajectory.
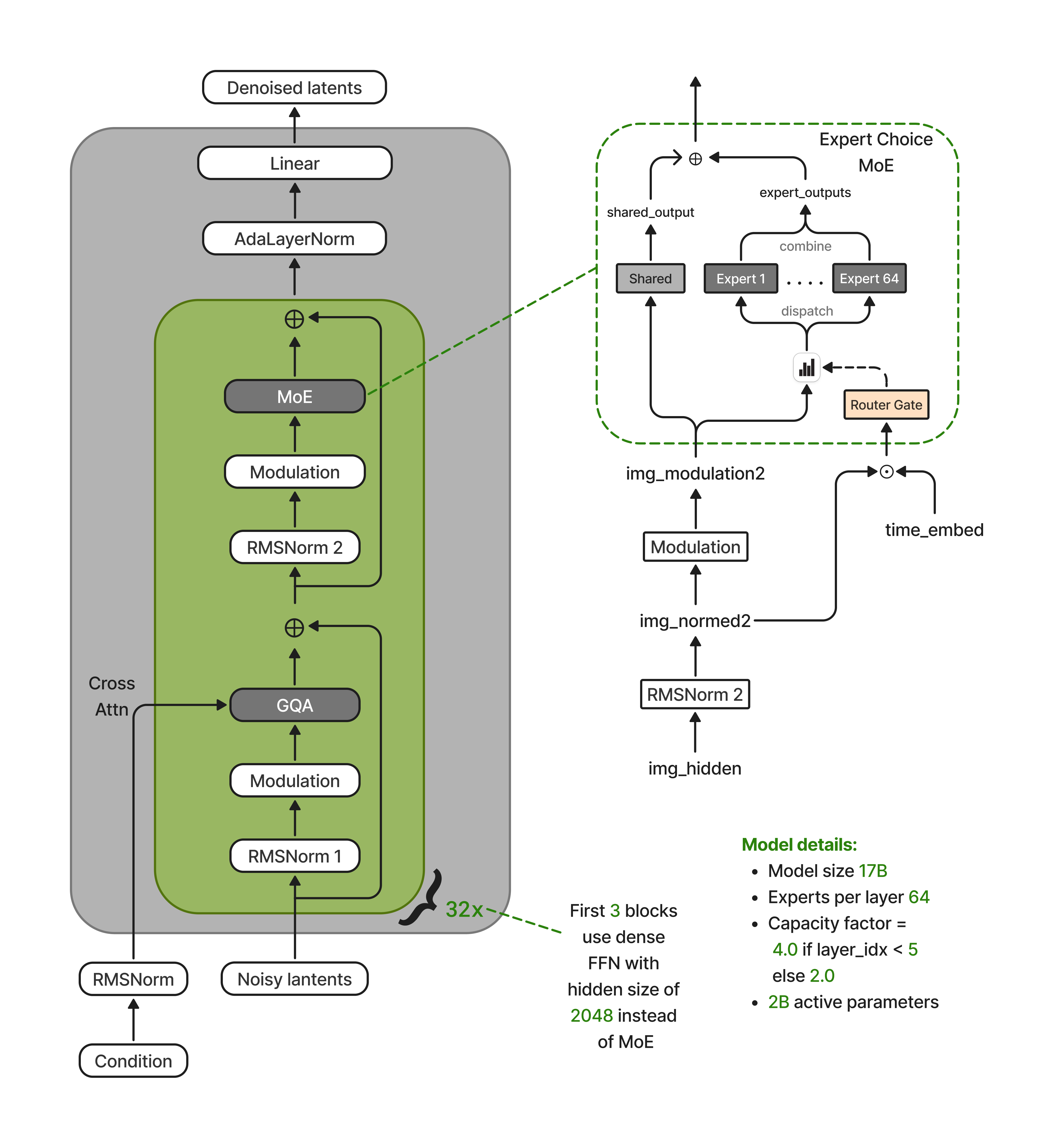
2. Text tokens as KV-only citizens
Dual-stream architectures (Flux, SD3) let text tokens participate as first-class citizens in every transformer sublayer. We went the other way: text tokens never enter the MoE backbone. They contribute only keys and values to joint attention. They don't generate queries, don't pass through MLPs or experts, and don't receive timestep modulation.
Two things fall out of this for free:
- No MoE routing overhead for text. Routing operates purely on image tokens, which simplifies load balancing and kernel scheduling.
- Full text KV caching across denoising steps. Because text-side activations have zero timestep dependence, every per-layer text K/V tensor can be computed once at the start of sampling and reused across all ~50 denoising steps.
This caching is natively integrated in diffusers. You can enable it with a one-line TextKVCacheConfig and your inference loop speeds up with no code changes.
3. Progressive sparsification tied to resolution
MoE experts need enough tokens per step to produce a stable gradient. Since text is off the MoE path, the MoE sequence length is just the image tokens. Which at 256² resolution is only 256 tokens split across 64 experts.
We therefore couple the expert capacity factor to the resolution curriculum:
| Stage | Base resolution | Batch size | Capacity factor |
|---|---|---|---|
| 1 | 256 | 4,096 | 8.0 (uniform) |
| 2 | 512 | 1,024 | 4.0 (uniform) |
| 3 | 1024 | 256 | 4.0 / 2.0 (per-layer) |
Low resolutions need dense expert participation (high CF) for stable gradients; high resolutions can sparsify aggressively because each forward pass already supplies plenty of tokens per expert. As a bonus, early layers keep a higher capacity factor than later layers. Thus, early layers benefit from broader token-expert mixing, later ones can specialize narrowly.
4. Muon + Warmup-Stable-Merge: no EMA, no decay commitment
Diffusion training has leaned on two expensive crutches: EMA shadow weights (a full second copy of the model, doubling weight memory) and fixed LR decay schedules (forcing you to commit up front to when the run ends).
We drop both. The optimizer is Muon for attention and expert FFN matrices, with an AdamW group for the parameters that don't orthogonalize well (patch embed, modulation projections, output head, and router gates). Learning rate follows a Warmup-Stable-Merge (WSM) schedule: warm up, hold a flat LR forever, and produce the release model by weight-averaging the last N checkpoints with inverse-square-root weights after training.
Why this works: online EMA is mathematically equivalent to a geometric weighted average of past checkpoints. Once you make that equivalence explicit, you can do the averaging offline i.e. no shadow copy during training, no commitment to a decay horizon, and you can extend or continue the run at any time by just merging a new window. On GenEval (1024², 50 steps, CFG 8.0), the merged checkpoint with N=16 gains +3.2 points over the unmerged checkpoint.
5. Custom Triton kernels + expert parallelism
On 64× H100 (8 nodes), we place exactly one expert per GPU. Forward and backward passes use PyTorch's all-to-all collectives for token routing, with a GPU-resident Triton token-permutation kernel (adapted from TorchTitan) that avoids any host synchronization. Fused Triton kernels for gated residual + LayerNorm + modulation eliminate the memory-bandwidth overhead of the repeated modulation patterns, and we use Flash Attention 3 and the Liger kernels for attention and SwiGLU.
Data: 700M images, 1.5B captions, curriculum-sampled
We built the training corpus through multi-stage filtering, perceptual deduplication, aesthetic scoring, and a multi-granularity captioning pipeline that stores short, medium, and detailed captions per image with explicit provenance. Each image gets two orthogonal labels: a static quality tier (A1–A5) and an episodic curriculum bucket (B1–B8). Training then progressively shifts sampling mass toward higher quality and later buckets while maintaining a small allocation to earlier ones for diversity.
One practical trick worth highlighting: we train with multi-aspect-ratio bucketing from step zero at every resolution stage, rather than starting on square crops and introducing aspect-ratio variation later. The model sees 16:9, 9:16, 3:4, and other layouts from the very first gradient update.
Results
All scores below are from the base model (no RL, no DPO, no preference tuning), at 1024×1024, 50 inference steps, CFG 8.0.
| Benchmark | Nucleus-Image | Notes |
|---|---|---|
| GenEval | 0.87 | Matches Qwen-Image; leads all models on spatial position (0.85) |
| DPG-Bench | 88.79 | #1 overall; leads entity (93.08), attribute (92.20), other (93.62) |
| OneIG-Bench | 0.522 | Beats Imagen 4 (0.515) and Recraft V3 (0.502); strong style (0.430) |
The spatial-position result on GenEval (0.85) is notable — strong dense baselines like SD3.5 Large and FLUX.1 Dev score 0.34 and 0.22 respectively on the same category. Spatial layout understanding appears to be one of the capabilities that MoE expert specialization captures particularly well.



Try it in three lines
import torch
from diffusers import DiffusionPipeline, TextKVCacheConfig
pipe = DiffusionPipeline.from_pretrained(
"NucleusAI/NucleusMoE-Image", torch_dtype=torch.bfloat16
).to("cuda")
pipe.transformer.enable_cache(TextKVCacheConfig()) # cache text KV across steps
image = pipe(
prompt="A weathered lighthouse on a rocky coastline at golden hour, "
"waves crashing against the rocks, seagulls overhead, "
"dramatic amber-and-violet clouds",
width=1344, height=768,
num_inference_steps=50, guidance_scale=8.0,
generator=torch.Generator(device="cuda").manual_seed(42),
).images[0]
image.save("nucleus_output.png")
Supported aspect ratios out of the box: 1:1 (1024²), 16:9, 9:16, 4:3, 3:4, 3:2, 2:3.
What we are releasing
- Model weights (Apache 2.0):
NucleusAI/NucleusMoE-Image - Training code: github.com/WithNucleusAI/Nucleus-Image
- Dataset recipe and curation pipeline: Coming Soon
- Technical report: PDF
This base model is the raw output of pre-training. It has not been sharpened by DPO, reinforcement learning from human preferences, or any form of post-training distillation. We think it is the right starting point for the community to build on, and we are excited to see what people do with a genuinely open MoE diffusion base.
What's next
Post-training is the obvious next axis: preference optimization typically adds several points on every benchmark, and MoE base models are well-positioned to absorb those gains without inflating inference cost. We are also working on higher-resolution variants, controllable generation, and further inference optimizations stacking on top of the text-KV-cache machinery.
If you build on Nucleus-Image, we would love to hear about it. Reach out on the model page or GitHub.
Citation
@misc{nucleusimage2026,
title = {Nucleus-Image: Sparse MoE for Image Generation},
author = {Nucleus AI Team},
year = {2026},
eprint = {XXXX.XXXXX},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}